e ラーニングにおける効果的なマルチメディア教材の提示方法 についての研究
安藤 雅洋
電気通信大学大学院情報システム学研究科 博士(学術)の学位申請論文
2012 年 3 月
博士論文審査委員会
主査 : 植野 真臣 准教授
委員 : 岡本 敏雄 教授
委員 : 田中 健次 教授
委員 : 田野 俊一 教授
委員 : 佐藤 俊治 准教授
委員 : 鈴木 克明 教授
著作権所有者 安藤 雅洋
2012
Research on effective presentation method of multimedia contents in e-Learning
Masahiro Ando
Abstract
In this paper, we propose a method for supporting the synchronization of auditory and visual content when presenting educational materials in a multimedia/e-learning environment. We base this method on the dual-channel information-processing model and show that improving synchronization between these two types of content can make human learning more efficient.
The dual-channel model assumes the existence of an auditory channel and visual channel as two independent channels for processing auditory and visual information in humans with each having a finite capacity.
Richard Mayer, a leading authority in the research of multimedia materials, defines multimedia as a method for simultaneously presenting words (narration and text) and pictures (illustrations, photos, figures/tables, and animation). Mayer et al. have re- ported on the basis of many experiments that multimedia materials that synchronize the presentation of pictures and animation (visual content) and narration (auditory content) makes for efficient learning based on the dual-channel model. The results of these exper- iments have been double checked by many researchers and their validity confirmed. In the conventional approach to conducting such experiments, an instructor first teaches a group of students while presenting content via a projector and then administers a test.
The results of multiple experiments and tests can then be compared. Such experiments, however, implicitly assume that synchronization between the auditory channel and visual channel can be achieved by simply presenting auditory content and visual content simul- taneously. In general, though, there is no guarantee that auditory and visual content will be synchronized by simply presenting them simultaneously. In e-learning, moreover, the student must learn in an autonomous manner in contrast to the face-to-face format of a traditional class in which a teacher is present. There is consequently a high possi- bility that experimental results will differ between a conventional face-to-face class and an e-learning environment.
ii
In this paper, we propose a pointer-presentation method for e-learning/multimedia materials to support the synchronization of auditory and visual content, and show that auditory and visual synchronization can be improved with this method based on the results of a quantitative evaluation by experiments using an eye-mark recorder. In this way, we also demonstrate the validity of the dual-channel model, which has heretofore been used with implicit assumptions.
The results of comparing the simultaneous presentation of narration with three dif- ferent types of content―text, still images, and animation―have shown that the use of animation results in the best auditory/visual synchronization and a good learning effect regardless of the presence of a pointer. These results show that well-designed animated content can guide a student s gaze point synchronized with narration. At the same time, the cost of creating animated content is usually high and the type of content that can be represented by animation is limited. When using a pointer, however, it has been shown that still images can be synchronized with narration in the same way as animation and that gaze duration and learning effect equivalent to that of animation can be achieved.
In addition to being cheaper to create, still images can represent a wider range of content than animation. It has also been shown, however, that inserting text in still images can result in an overload of visual information making synchronization difficult thereby in- hibiting the learning process. Taking this effect into account, it has been suggested that simultaneously presenting narration and still images without text while using a pointer is the best technique for producing a high learning effect in e-learning.
It has also been reported in the learning sciences that taking notes while studying enhances the learning effect, but the mechanism behind this process has yet to be clar- ified. In this paper, we show that note-taking can improve the learning effect even in e-learning and explain its mechanism in terms of the dual-channel model. Specifically, we use an eye-mark recorder to compare e-learning sessions while taking notes on paper or with a keyboard, pen tablet (graphics pad), or tablet computer and show that under- lining or tracing with the tip of a pen in unison with narration supports auditory/visual synchronization and enables the student to learn without hindering the effectiveness of the multimedia material. We also show that the act of writing when taking notes while listening to narration induces synchronization between auditory and visual information in working memory and promotes recollection. These results suggest that using a tablet computer to take notes in an e-learning environment is the best technique for improving
the learning effect. Furthermore, on comparing note-taking in the cases of text, still images, and animation on a tablet computer, we found that the learning effect is highest when using content consisting of still images with no text.
Thus, while earlier research has reported that combining animation and narration is the most effective method for presenting educational materials in a presentation environ- ment, the above results suggest that simultaneously presenting still images and narration is most effective method in an e-learning environment.
v
eラーニングにおける効果的なマルチメディア教材の提示方法についての研究
安藤 雅洋
概 要
本論では,人間の情報処理モデルの1つである「デュアル・チャンネル・モデル」に基 づき,マルチメディア・eラーニング環境における,聴覚コンテンツと視覚コンテンツの 同期を支援する教材提示方法を提案し,同期の向上により学習が効率化できることを示す.
デュアル・チャンネル・モデルは,人間の聴覚と視覚それぞれ情報処理を行う独立な チャンネル,聴覚チャンネルと視覚チャンネルが存在し,それら二つにそれぞれ決まった 容量があると仮定したモデルである.
マルチメディア教材研究の第一人者,Mayerは,マルチメディアを「語(ナレーショ ン,文章)と図(絵,写真,図表,動画)を同時提示する方法」と定義している.Mayer らは,デュアル・チャンネル・モデルに基づき,多くの実験を行うことで,視覚コンテン ツである図や動画と聴覚コンテンツであるナレーションを同期して提示するマルチメディ ア教材が学習に効果的であると報告している.これらの実験は,多くの研究者によって追 試され,その有効性が確認されている.従来研究での実験方法は,教師が学習者集団にコ ンテンツをプロジェクター提示しながら,説明を行い,そのあとに実施されるテスト結果 の比較を行うというものである.しかし,これらは聴覚コンテンツと視覚コンテンツを同 時に提示しただけで聴覚チャンネルと視覚チャンネルの同期が取れることを暗黙に仮定し ている.一般には聴覚コンテンツと視覚コンテンツを同時に提示しただけでは,その同期 は保障されていない.また,eラーニングでは,教師が存在する対面授業と異なり,自律 的に学習を行わなければならず,従来の対面授業での実験結果とは異なる可能性が高い.
本論では,聴覚コンテンツと視覚コンテンツの同期を支援するため,eラーニング・マ ルチメディア教材におけるポインタ提示法を提案し,実験でアイマークレコーダを用いた 定量的評価の結果,実際に視覚と聴覚の同期が改善されることを示す.さらに,それによ り学習が改善されることを示すことで,これまで暗黙の仮定として扱われてきたデュアル・
チャンネル・モデルの妥当性を示すこともできる.
テキスト,静止画,動画のそれぞれのコンテンツとナレーションを同時提示した場合 を比較した結果,ポインタの有無にかかわらず,動画が最も聴覚と視覚の同期が取れ,学 習効果が良いことが示された.これは,よく設計された動画コンテンツが学習者の注視点
をナレーションに同期して誘導していることを示している.しかし,一般にはこのような 動画コンテンツの制作コストは高く,また,動画で表現できる内容も限られている.一方,
ポインタを用いる場合には,静止画コンテンツが動画と同様に同期を支援し,同等のコン テンツ注視時間を保障すること,同等の学習効果があることが示された.静止画は,制作 コストが低いだけでなく,表現できる内容の範囲も動画に比較して広い.ただし,テキス トを静止画に挿入した場合,視覚情報が多くなりすぎ,同期がとりにくくなり,学習を阻 害することも示された.このような結果より,eラーニングでは,テキストを挿入しない 静止画とナレーションをポインタを用いて同時提示することが最も学習効果を高める手法 であることが示唆された.
また,学習科学の研究では,学習中のメモ書きが学習効果を高めることが報告されて いる.しかし,そのメカニズムは明らかにはされてきていない.本論では,eラーニング においてもメモ書きが学習効果を高めることを示し,そのメカニズムをデュアル・チャン ネル・モデルにより説明した.具体的には,紙媒体,キーボード,ペンタブレット,タブ レットPCによるメモ書きを行いながらのeラーニングを,アイマークレコーダを用いて 比較した結果,ナレーションに合わせて下線を引いたりペン先でなぞることで,聴覚と視 覚の同期が支援され,マルチメディア教材の有効性を阻害することなく学習できることが 示された.また,ナレーションを聞きながらのメモ書きは,書込み行為が作業記憶におけ る聴覚情報と視覚情報の同期を誘発し,記憶を促進することを示した.このような結果よ り,eラーニング環境でのメモ書きでは,タブレットPCの利用が最も学習効果を高める 手法であることが示唆された.また,テキスト,静止画,動画のコンテンツで比較したと ころ,テキストなしの静止画コンテンツでタブレットPCによる学習効果が最も向上する ことが示された.
以上から,プレゼンテーション環境では動画とナレーションが最も効果的な教材提示 法であることが従来研究で報告されているが,eラーニング環境では静止画とナレーショ ンの同時提示が最も効果的な教材提示法であることが示唆された.
vii
目 次
第1章 緒言 1
第2章 デュアル・チャンネル・モデル 8
2.1 デュアル・チャンネル・モデルを構成する3つの認知理論の仮定 . . . . 8
2.2 マルチメディア学習における3つの記憶庫 . . . . 13
2.3 マルチメディア学習における5つの認知処理過程 . . . . 14
2.4 表現の5つの形式 . . . . 16
2.5 マルチメディア教材における3種類の提示資料の処理 . . . . 17
第3章 デュアル・チャンネル・モデルに基づくマルチメディア教材提示法 21 3.1 先行研究からのマルチメディア教材作成原則 . . . . 21
3.2 従来研究の問題点 . . . . 26
第4章 ポインタによる提示コンテンツの認知負荷軽減 31 4.1 はじめに . . . . 31
4.2 マルチメディア教材とデュアル・チャンネル・モデル . . . . 35
4.3 ポインタによる認知資源効率化 . . . . 35
4.4 実験 . . . . 36
4.4.1 実験概要. . . . 36
4.4.2 実験コンテンツ . . . . 37
4.4.3 実験手順. . . . 38
4.5 実験結果 . . . . 41
4.5.1 デュアル・チャンネル・モデルに基づくマルチメディア教材の有効性 41 4.5.2 ポインタによる視覚コンテンツとナレーションの同期性. . . . 42
4.5.3 ポインタによる学習効果 . . . . 45
4.5.4 アンケート結果 . . . . 50
4.6 コンテンツ開発支援システムへの実装. . . . 51
4.7 まとめと今後の課題 . . . . 52
第5章 タブレットPCによる入力環境の認知負荷軽減 56
5.1 はじめに . . . . 56
5.2 デュアル・チャンネル・モデルに基づく書込みの効果 . . . . 57
5.3 マルチメディア教材 . . . . 59
5.4 実験 . . . . 61
5.4.1 実験概要. . . . 61
5.4.2 実験機材. . . . 61
5.4.3 実験手順. . . . 64
5.5 文章入力時の誤記率の比較 . . . . 65
5.6 コンテンツへの注視時間の比較 . . . . 69
5.6.1 コンテンツへの注視時間 . . . . 69
5.7 視覚コンテンツとナレーションの同期性 . . . . 70
5.8 手書き入力による学習効果の評価 . . . . 73
5.8.1 実験後のテスト結果 . . . . 73
5.8.2 メモ書き行為による学習効果 . . . . 74
5.8.3 手書き入力による学習効果の評価 . . . . 75
5.9 メモ書き参照時の記憶テスト. . . . 76
5.10 アンケート結果 . . . . 77
5.11 まとめ . . . . 80
第6章 結言 84 謝辞 88 関連論文 89 付 録A 第4章実験コンテンツ 93 コンテンツ詳細 . . . . 93
テスト問題 . . . . 116
アンケート . . . . 120
付 録B 第5章実験コンテンツ 121 コンテンツ詳細 . . . . 121
テスト問題 . . . . 129
アンケート . . . . 134
ix
図 目 次
2.1 デュアル・チャンネル・モデル . . . . 8
4.1 実験の様子と実験システム . . . . 37
4.2 ポインタ形状 . . . . 38
4.3 コンテンツ画面 . . . . 39
4.4 再生テスト正答率 . . . . 41
4.5 注視点位置座標データ例 . . . . 43
4.6 コンテンツの注視時間の割合. . . . 44
4.7 ポインタ有無における記憶テストの差. . . . 46
4.8 ポインタ有無における理解テストの差. . . . 46
4.9 3日後の記憶保持テスト結果 . . . . 49
4.10 コンテンツ開発支援システム. . . . 52
4.11 ポインタ提示型eラーニング・コンテンツ . . . . 53
5.1 実験の様子 . . . . 62
5.2 コンテンツ画面 . . . . 63
5.3 注視点位置座標データ例 . . . . 71
5.4 テスト結果 . . . . 73
5.5 1週間後の記憶テスト結果例 . . . . 75
5.6 メモ書き参照時のテスト結果. . . . 76
表 目 次
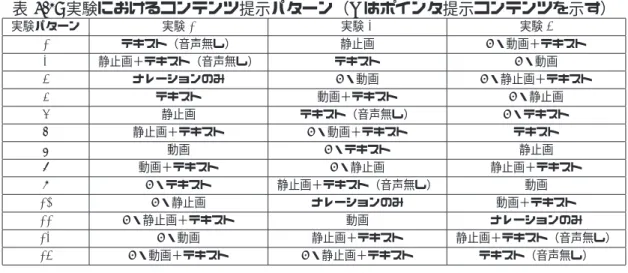
4.1 実験におけるコンテンツ提示パターン. . . . 40
4.2 ポインタと視点との二乗誤差比のF検定 . . . . 43
4.3 ポインタ無しコンテンツ注視時間の多重比較 . . . . 45
4.4 ポインタ無しコンテンツでの記憶テスト結果の多重比較 . . . . 46
4.5 ポインタ無しコンテンツでの理解テスト結果の多重比較 . . . . 47
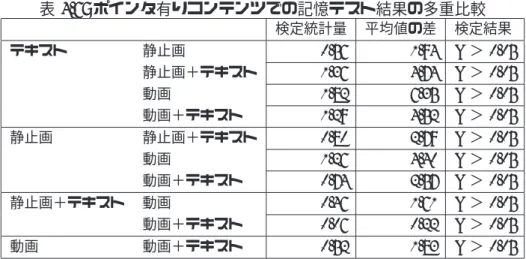
4.6 ポインタ有りコンテンツでの記憶テスト結果の多重比較 . . . . 48
4.7 ポインタ有りコンテンツでの理解テスト結果の多重比較 . . . . 48
4.8 アンケート結果 . . . . 51
4.9 ポインタの必要性に関するアンケート結果 . . . . 51
5.1 実験における書込み方法パターン . . . . 64
5.2 各デバイスの平均書込み数 . . . . 65
5.3 各デバイスの書込み文字数の多重比較. . . . 67
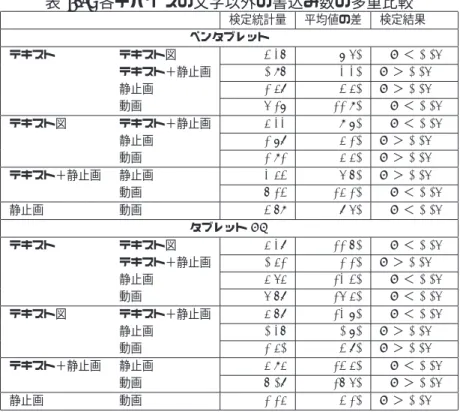
5.4 各デバイスの文字以外の書込み数の多重比較 . . . . 68
5.5 各デバイスでの注視箇所と平均注視時間割合 . . . . 69
5.6 規範データと注視点間の二乗距離の平均 . . . . 70
5.7 コンテンツ再生時間における説明箇所注視時間の割合 . . . . 72
5.8 メモ書き数におけるテスト正答率とメモ書き総数 . . . . 75
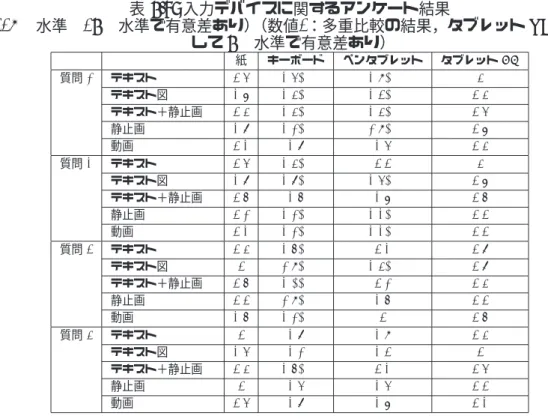
5.9 入力デバイスに関するアンケート結果. . . . 78
5.10 学習中の印象に関するアンケート結果. . . . 79
5.11 入力デバイスの使用経験および対面講義でのメモ書きに関するアンケート 結果 . . . . 80
1
第 1 章 緒言
eラーニングの特徴は,(1)マルチメディア・コンテンツによる教材の提示,(2)ネット ワーク上での複数の学習者間の相互作用を通した学習活動,(3)コンピュータの計算/推 論機能による学習支援,という三つの要素の融合による新しい学習環境下での学習を実現 することである(植野2007).従来から,eラーニングに関しては,(2)と(3)に関する研 究は多く存在するが,(1)のマルチメディア・コンテンツに関する研究は多くはない.一 方,従来からの教育心理学の分野において効果的なコンテンツ開発および学習環境構築手 法は,学習中の認知負荷(Cognitive load)を如何に減少させるかという問題に帰着させ ることが多い.スウェラーら(Sweller & Chandler 1994, Sweller 1999)は,学習中の認 知負荷として,次の2つの分類をあげている.
外的認知負荷(Extraneous cognitive load):作業記憶容量の範囲を無視して,概念 の構築と使用に作業記憶資源を集中させないような,不適当な教授設計によって引 き起こされる認知負荷.すなわち,説明が悪文であったり,字が小さいなど教材の 提示方法が悪いために生じる認知負荷.
本質的な認知負荷(Intrinsic cognitive load):学習内容を理解するための,学習者 が持つ知識や熟達度に応じて決まる認知負荷.すなわち,学習内容の難易度によっ てもたらされる認知負荷.
本質的な認知負荷は,学習者にとって新しい知識の獲得や成長に繋がる必要な認知負荷で あるが,外的認知負荷は学習を阻害する要因となる.外的認知負荷を軽減することが,作 業記憶資源を学習内容の理解へ多く振り分けることへ繋がる.本論では,eラーニングに おけるマルチメディア・コンテンツによる学習中の外的認知負荷を減少させることを目的 とし,以降述べられる認知負荷とは外的認知負荷を意味するものとする.
学習中の認知負荷を表現できる人間の情報処理モデルの1つに「デュアル・チャンネ ル・モデル」がある.デュアル・チャンネル・モデルは,人間の聴覚と視覚それぞれ情報 処理を行う独立なチャンネル,聴覚チャンネルと視覚チャンネルが存在し,それら二つに それぞれ決まった容量があると仮定したモデルである.このモデルでは,一方のチャンネ ルを使っていなくても,もう一方のチャンネルの作業記憶容量が増えるわけではないので,
二つのチャンネルを同時に使うことが効率的な作業記憶容量の利用法であると考える.さ らに二つのチャンネルを通過する情報が同期することにより,二つのチャンネル内の聴覚 情報と視覚情報が相互作用し,情報伝達効率をより強化するというモデルである.情報伝 達効率を高め,認知容量の配分を効率化し意味統合に認知資源を多く使うことで,内容理 解を深めることができ,結果として記憶保持も効率化させると考える.
マルチメディア教材研究の第一人者,Mayerは,マルチメディア(Multimedia)を「言 語(ナレーション,文章)と図(絵,写真,図表,動画)を同時提示する方法」と定義し ている.彼は,デュアル・チャンネル・モデルに基づき,多くの実験を行うことで,視覚 コンテンツである図や動画と聴覚コンテンツであるナレーションを同期して提示するマル チメディア教材が学習に効果的であると報告している.これらの実験は,多くの研究者に よって追試され,その有効性が確認されている.ただし,これらは,教師が学習者集団に コンテンツをプロジェクター提示しながら,説明を行い,そのあとに実施されるテスト結 果の比較を行うというものである.すなわち,聴覚コンテンツと視覚コンテンツを同時に 提示しただけで,聴覚チャンネルと視覚チャンネルの同期が取れることを暗黙に仮定して いる.一般には聴覚コンテンツと視覚コンテンツを同時に提示しただけでは,その同期は 保障されていない.また,eラーニングでは,教師が存在する対面授業と異なり,自律的に 学習を行わなければならず,従来の対面授業での実験結果とは異なる可能性が高い.特に マルチメディア教材では,学習者が時間的,空間的に同期が取れずに聴覚コンテンツが視 覚コンテンツ中のどこを示しているのか学習者に分からないことがある.この場合,デュ アル・チャンネル・モデルにおける聴覚チャンネルと視覚チャンネルの相互作用が生起し ないだけでなく,同期のための探索に認知容量資源が大きく用いられ,結果として内容理 解を著しく損なうことも有り得る.
本論では,マルチメディア・eラーニング環境において,ポインタにより聴覚コンテ ンツと視覚コンテンツの同期を支援する教材提示方法を提案し,実験でアイマークレコー ダを用いた定量的評価を行うことで,視覚と聴覚の同期が改善されることを示す.さらに,
それにより学習が改善されることを示すことで,これまで暗黙の仮定として扱われてきた デュアル・チャンネル・モデルの妥当性を示すこともできる.
一方,学習者は受講中,ただコンテンツを視聴しているだけではない.学習者は何ら かの方法で書込みやノートテイキングを行っている場合がある.近年,学習中における書 込み行為やノートテイキングの有効性が指摘されている.例えば,野崎ら(2006)は読解 場面において,テキストへの自由な書込み行為が文章理解を促し,普段書込みを行わない 学習者に対しても書込みを促すことは有効であることを示している.また,岸ら(2004) は講義で使用する図表を載せたレジュメへ書込みを行わせる講義を行った結果,ノートテ
3
イキングが多いと記憶保持に有効であることを示唆した.
eラーニングにおいても,ノートテイキングやメモ書きにより学習効果を高められるこ とが期待される.しかし,学習中のメモ書きが学習効果を高めるメカニズムは明確にされ てはいない.また,eラーニングの場合,メモ書きに利用する入力デバイスによっては操 作にかかる外的認知負荷のために学習活動を阻害する場合がある.特に,日本語のローマ 字入力のような,キーボード操作で変換作業を伴う言語では,負荷が大きくなることが考 えられる.一方,コンピュータ利用での書込み行為における外的認知負荷の軽減には,ペ ンで紙資料にメモ書きを行うように,画面上に直接書込みができるタブレットPCが有効 であることが知られている.ムハマドら(2008)はコンピュータ利用において,キーボー ド入力よりも手書き入力の作業効率が高く,ペン入力によりユーザの作業に対する集中力 が向上することを実験により示している.
タブレットPCをeラーニングで用いる場合,画面上に直接書込むことができるため,
視覚コンテンツを注視したまま,メモ書きや下線引きが行え,外的認知負荷をもたらさず に学習を進めることができる.また,タブレットPCはナレーションとも同期が取りやす く,ペンと紙資料と同じように,ナレーションに合わせ文章に下線を引いたり,ペン先で なぞる等の行為が注視点を誘導し,デュアル・チャンネル・モデルにおける二つのチャン ネルの同期を支援することが期待される.
以上より本論では,eラーニング環境における外的認知負荷軽減の手法について,教材 提示方法および入力デバイスの観点から提案するため,人間の情報処理モデルの1つであ るデュアル・チャンネル・モデルに基づき,以下の検証実験を行った.
1). 聴覚コンテンツと視覚コンテンツの同期を支援するため,eラーニング・マルチメディ ア教材におけるポインタ提示法を提案し,実際に同期が生起したかどうかをアイマー クレコーダで確認しながら,学習効果を分析した.
2). 紙媒体,キーボード,ペンタブレット,タブレットPCによるメモ書きを行いながら のeラーニングを比較し,実際に同期が生起したかどうかをアイマークレコーダで 確認しながら,学習効果を分析した.
1)の実験の結果,以下の知見を得た.
デュアル・チャンネル・モデルに基づくマルチメディア教材の有効性を追認する分 析を行った結果,視覚コンテンツのみのほうが聴覚コンテンツのみよりテスト結果 が良かったが,それらに静止画コンテンツを加えただけで,テスト結果が逆転する
ことが示された.すなわち,先行研究では暗黙に仮定されてきたデュアル・チャン ネル・モデルの妥当性を示すことができた.
アイマークレコーダを用いて得られた学習者の注視点データより,動画以外で,e ラーニングにおけるポインタ提示によって学習者の視点が有意にコントロールされ,
聴覚チャンネルと視覚チャンネルの同期性が向上することが確認された.
ポインタによる聴覚チャンネルと視覚チャンネルの同期から,深いレベルの理解を 問うテストにおいてポインタの効果が確認された.
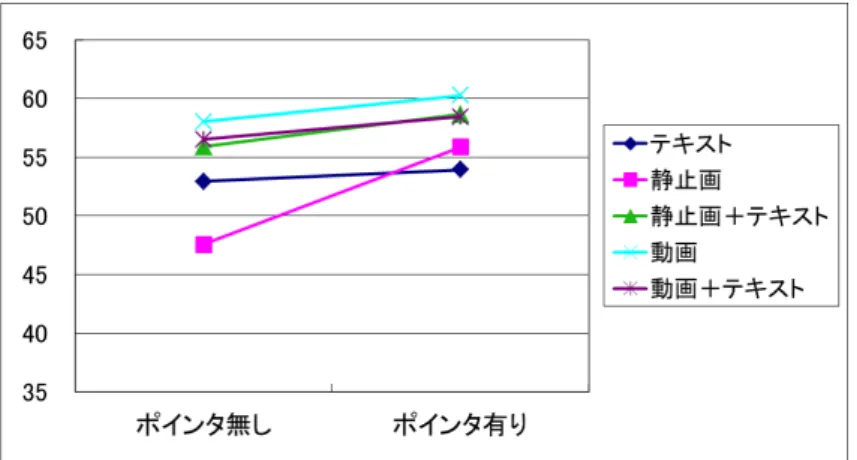
深いレベルの理解を問うテストから,動画を用いたコンテンツ,静止画を用いたコ ンテンツ,テキスト・コンテンツの順に正答率が高くなり,この順序はポインタを導 入しても変化することは無いことが分かった.
3日後にも同一のテストを行った結果から,ポインタの効果は作業記憶だけでなく,
長期記憶での記憶保持にも効果があることが示された.
アンケートを行った結果,マルチメディア教材におけるポインタ提示によって,学習者のコ ンテンツ視聴時の負担が軽減されていると感じていることが示された.結果として,デュ アル・チャンネル・モデルに従い,ポインタにより注視点誘導を行うことで探索による認 知負荷を軽減し,聴覚チャンネルと視覚チャンネルの同期を効率的に行うことができるこ とが示された.その結果,作業記憶内の資源が有効活用でき,内容理解を支援できること も示した.
この研究で,最も重要な知見は以下のとおりである.
従来研究が示してきたことと同様に,ポインタの有無にかかわらず,動画コンテンツ の学習効果が良いことが示された.これは,よく設計された動画コンテンツが学習者の注 視点をナレーションに同期して誘導していることを示している.しかし,一般にはこのよ うな動画コンテンツの制作コストは高く,また,動画で表現できる内容も制限されている.
本論では,ポインタ提示により,静止画コンテンツが動画とほぼ同等にナレーション と同期が取れ,学習効果も高まることを示した.静止画コンテンツは,制作コストが低い だけでなく,表現できる内容も動画と比較して広範囲である.さらに,テキストを静止画 に挿入した場合,聴覚情報が多くなりすぎ,聴覚と視覚の同期がとりにくくなり学習を阻 害することも示した.このような結果より,eラーニングでは,テキストを挿入しない静 止画とナレーションをポインタを用いて同時提示することが最も学習効果を高める手法で あることが示唆された.
2)の実験の結果,以下の知見を得た.
5
キーボードと,手書きでの誤記率を比較した結果,手書きでは書込みにかかる外的 認知負荷が少なく誤記率が低い.
アイマークレコーダを用いた学習者の注視点測定結果から,タブレットPCではデュ アル・チャンネル・モデルにおける聴覚チャンネルと視覚チャンネルの同期を取り やすい.
学習後テストと後日テストの結果から,コンテンツに直接メモを書き込んだ場合,学 習者の理解,記憶保持が高い.
学習者自身のメモ書きを見直しさせた結果,タブレットPCによるメモ書きが,学 習メモとしての正確性が高い.
タブレットPCによるeラーニングでは,ナレーションに合わせて下線を引いたりペン 先でなぞることで,聴覚コンテンツと視覚コンテンツの同期が支援され,マルチメディア 教材の有効性を阻害することなく学習できることが示された.また,ナレーションを聞き ながらのメモ書きは,書込み行為が作業記憶における聴覚情報と視覚情報の同期を誘発し,
記憶を促進することを示した.このような結果より,「ナレーションを聞きながら書く」と いう行為そのものが学習を促進するメカニズムを示唆したことになる.そのため,eラー ニング環境でのメモ書きでは,タブレットPCの利用が最も学習効果を高める手法であり,
効率的なメモ書きを支援できることを示した.また,テキスト,静止画,動画のコンテン ツで比較し,テキストなしの静止画コンテンツでタブレットPCによる学習効果が最も向 上することも示した.
本論文の構成は以下の通りである.
第2章では,本論において,マルチメディア教材およびタブレットPC利用の有効性 の理論的根拠として用いた,人間の情報処理モデルの1つである「デュアルチャンネル・
モデル」について詳述する.
第3章では,「マルチメディア教材に関する先行研究」について述べる.ここでは,デュ アル・チャンネル・モデルに基づく,マルチメディア教材の作成に関する先行研究を紹介 し,本研究の動機と意義について述べる.
第4章では,「ポインタによる提示コンテンツの認知負荷軽減」について述べる.ここ では,デュアル・チャンネル・モデルに基づき,視覚コンテンツ(テキスト,画像)と聴 覚コンテンツ(ナレーション),ポインタを同期して提示するマルチメディア教材が作業 記憶容量の資源配分を効率化させるとともに伝達される情報量を増加させると仮定する.
ポインタの有無での統制実験を,eラーニングでの様々なコンテンツ提示環境((1)ナレー
ション,(2)テキスト(ナレーションの有無),(3)静止画,(4)静止画+テキスト(ナレー ションの有無),(5)動画,(6)動画+テキスト)の下で実施し,アイマークレコーダによ り学習者の注視点を測定するとともに,記憶保持・内容理解テストおよびアンケート調査 を行った.結果,ポインタは表層的な知識獲得には影響しないが,深いレベルの理解には 効果があることが示され,それらの効果はコンテンツの種類によって変化することが示さ れた.
第5章では,「タブレットPCによる入力環境の認知負荷軽減」について述べる.ここ では,eラーニングにおけるタブレットPCの効果について,デュアル・チャンネル・モ デルに基づいて分析を行った.具体的には,eラーニングでの書込みに用いられる入力デ バイスに,紙媒体,キーボード,ペンタブレット,タブレットPCを用意し,アイマーク レコーダで学習者の注視点を測定し,記憶・理解テスト,アンケート調査およびメモ書き の評価により,各デバイスの評価を行った.その結果,タブレットPCを用いたeラーニ ングでは,1)ナレーションと同期してコンテンツに注視しやすく,2)書込みにかかる外的 認知負荷が少なく,3)学習者の理解,記憶保持が高く,4)メモ書きが効率的に行えるため に,学習メモとしての正確性も高いことが示された.
最後に第6章で,本論文の総括を行い,今後の展望を記述する
参考文献
岸俊行,塚田裕恵,野嶋栄一郎(2004)ノートテイキングの有無と事後テストの得点と の関連分析.日本教育工学会論文誌,28(suppl), 265-268
Mayer, R. E. (2001) Multimedia Learning. Cambridge University Press
持田典彦,福添誠,中山実,清水康敬 (1996) 学習テキストの提示方法に関する実験的 研究−要約表示と指示棒による効果を中心として− 日本教育工学会論文誌,19-4, pp189-196
ムハマド ズルキフリー,田野 俊一,岩田 満,橋山 智訓(2008)日本語のメモ書き作業に おける手書き入力の有効性,情報処理学会論文誌Vol.J91-D, No.03:771-783
野崎浩成,吉橋彩奈,梅田恭子,江島撤郎(2006)テキストへの自由な書込み行為が文 章理解に及ぼす影響. 日本教育工学会論文誌,29(Suppl), 49-52
Paivio, A. (1986) Mental representations: A dual coding approach. Oxford, England:
Oxford University Press
7
佐藤弘毅,赤堀侃司 (2005) 電子化黒板に共有された情報への視線集中が学習者の存在感 および学習の情意面に与える影響. 日本教育工学会論文誌,29(4):501-513
清水康敬,柳田修一,吉澤康雄 (1981) OHP提示における指示棒の効果. 日本教育工学 雑誌,6,1, pp.11-17
Sweller, J. (1999) Instructional design in technical areas. ACER PRESS
Sweller, J. and Chandler, P. (1994) Why some material is difficult to learn. Cognition and Instruction., 12:185-233
植野真臣 (2007) 知識社会におけるeラーニング. 培風館. 東京
第 2 章 デュアル・チャンネル・モデル
「デュアル・チャンネル・モデル」は,人間の情報処理を通信路における情報伝達と してモデル化したものである.デュアル・チャンネル・モデルでは,図2.1に示すように 人間の聴覚と視覚それぞれ情報処理を行う独立なチャンネル,聴覚チャンネルと視覚チャ ンネルが存在し,それら二つにそれぞれ決まった容量があり,認知処理を能動的に行って いると仮定している.このモデルでは,一方のチャンネルを使っていなくても,もう一方 のチャンネルの作業記憶容量が増えるわけではないので,二つのチャンネルを同時に使う ことが効率的な作業記憶容量の利用法であると考える.そのため,マルチメディア学習お よびマルチメディア教材の有効性の理論的根拠として用いられる.
本章では,本論の教材提示方法および入力デバイスとしてのタブレットPCの有効性 の理論的根拠として用いる,デュアル・チャンネル・モデルに関連する認知理論,および モデルの処理過程について詳述する.
㖸㖿⊛╓ภൻ
࿑⊛╓ภൻ
䉼䊞䊮䊈䊦 ᬺ⸥ᙘ 㐳ᦼ⸥ᙘ
䊅䊧䊷䉲䊢䊮
࿑
⡬ⷡ
ⷞⷡ
㖸ჿ
↹
⸒⺆⊛䊝䊂䊦
࿑⊛䊝䊂䊦
⺆䈱♽ൻ
࿑䈱♽ൻ
೨⍮⼂
䊙䊦䉼䊜䊂䉞䉝 ឭ␜
ᗧ⛔ว
⺆䈱ㆬᛯ
࿑䈱ㆬᛯ
㖸ჿ ឭ␜
ᗧ⛔ว
図2.1: デュアル・チャンネル・モデル
2.1 デュアル・チャンネル・モデルを構成する 3 つの認知理論の仮定
マルチメディア教材の設計には,人間はどのように学習するかという根本的な概念が 反映される.すなわち,マルチメディア教材の設計は,設計者が持つ人間の認知処理にお
2.1 デュアル・チャンネル・モデルを構成する3つの認知理論の仮定 9
ける概念に左右される.例えば,マルチメディア教材のスクリーン映像が,動き回る多彩 な単語や図(静止画と動画)で溢れているなら,その設計者が持つ人間の学習に関する認 知処理の概念は,学習者の認知処理システムは単独チャンネルで,容量無制限で,受動的 な処理システムであるというものだろう.まず,教材に聴覚コンテンツを利用しないこと は,この設計が,全ての情報がその形式にかかわらず同様に認知システムに入るという,
単独チャンネルの仮定に基づいていることになる.この場合,音声でもテキストでも,た だ情報が示される限り,どの形式が使用されるかは重要ではないことになる.次に,多く の情報を同時提示することは,その設計が,人間は無制限の量の資料を処理できるという,
認知容量無制限の仮定に基づいていることになる.これでは,設計者の仕事は,学習者に ただ情報を提供すれば良いということになってしまう.最後に,多くの分離された数片の 情報を提示することは,その設計が,受動的処理の仮定に基づいていることになる.この 仮定では,人間はその記憶へできるだけ情報を加えるテープレコーダのようなものである.
学習者が提示された情報を組織化して,理解できるように学習者を指導することも必要と しないことになる.
しかし,現在の認知心理学における研究では,人間の精神動作について全く異なる見 方を持っている(Bransford et al 1999, Lambert & McCombs 1998, Mayer 2003).すな わち,いくつかのマルチメディア教材学習における人間の精神動作に関する暗黙の理論は 単一チャンネル,認知容量無制限,受動的な処理活動であったが,現在では以下の3つの 理論が用いられる.
1. 二元経路仮説(Dual-Channel Assumption):聴覚と視覚でそれぞれ情報処 理を行う独立なチャンネル,聴覚チャンネルと視覚チャンネルが存在す る (Clark & Paivio 1991, Paivio 1986)
2. 容量制限仮説(Limited Capacity Assumption):各チャンネルで一度に処理 することができる作業記憶の情報量に制限がある(Baddeley 1986, 1999, Chandler & Sweller 1991)
3. 能動処理仮説(Active Processing Assumption):人間は,情報に注意を向け,
入力された情報からメンタルモデルを構築,整理し,長期記憶の知識と統 合する活動を含む認知処理を能動的に行っている(Mayer 2001, Wittrock 1989)
そして,デュアル・チャンネル・モデルは,以上の3つのマルチメディア学習における認知 理論の仮説に基づきモデル化したものである(Mayer 2001).本節では,デュアル・チャ ンネル・モデルの基礎となる3つの仮説について述べる.
1. 二元経路仮説
二元経路仮説は,人間が聴覚情報と視覚情報でそれぞれ独立の情報処理チャンネル,聴 覚チャンネルと視覚チャンネルを持っているというものである.情報が視覚情報(図,イ ラスト,アニメーション,動画,テキスト)で提示される場合,視覚チャンネルにより処 理される.情報が聴覚情報(ナレーション,音楽)で提示される場合,聴覚チャンネルに より処理される.個別の情報処理チャンネルについての概念は認知心理学において長い歴 史があり,Paivioの二重符号化理論(Clark & Paivio 1991, Paivio 1986)とBaddeleyの 作業記憶モデル(Baddeley 1986, 1999)に関係している.
2つのチャンネルを分類する概念として,プレゼンテーション形式に基づくものと,知 覚形式に基づくものの2通りある.プレゼンテーション形式に基づけば,提示資料が言 語(ナレーションあるいはテキスト)か,非言語的(絵,動画,アニメーションあるいは BGM)かどうかに注目する.この場合,1つのチャンネルが言語資料を処理し,もう一方 のチャンネルが画像資料および非言語的な音を処理する.この概念は,Paivio(1986) の 言語・非言語的システムの相違と一致している.
対して,知覚形式に基づけば,学習者が最初に視覚(絵,動画,アニメーションやテキ スト)か聴覚(ナレーションやBGM)によって提示資料を処理するかどうかに注目する.
この場合,1つのチャンネルは視覚的資料を処理し,もう一方のチャンネルは聴覚資料を 処理する.この概念は,Baddeley(1986, 1999)の視空間スケッチパッドと音韻ループの 相違と一致している.
プレゼンテーション形式(言語的か非言語的か)に基づくと提示資料形式そのものに注 目するが,知覚形式(聴覚的か視覚的か)に基づくと作業記憶中で処理される刺激に注目 する.これらのマルチメディア学習に関する大きな違いは,テキストとBGMの処理にあ る.テキストは,プレゼンテーション形式に基づくと最初に言語チャンネルで処理される が,知覚形式に基づくと最初に視覚チャンネルで処理される.非言語的音楽を含むBGM は,プレゼンテーション形式に基づくと,最初に非言語チャンネルで処理されるが,知覚 形式に基づくと最初に聴覚チャンネルで処理される.
デュアル・チャンネル・モデルでは,マルチメディア学習の認知処理過程において,作 業記憶中の画像ベースと言語ベースのモデルの構築を識別するため,知覚形式に基づくチャ ンネルの概念を採用している.この場合,プレゼンテーション間でも視覚資料(絵,動画,
アニメーション,テキスト)と聴覚資料(ナレーションとBGM)を識別できる.
また,チャンネル間の関係として,1種類の情報は1つのチャンネルを通って入力され るが,もう一方のチャンネルで処理を行うために表現を変えることができる.例えば,視
2.1 デュアル・チャンネル・モデルを構成する3つの認知理論の仮定 11
覚情報としてテキストが提示された場合,始め視覚チャンネルで処理されるが,読み手に よっては精神的に音韻に変換することがあり,これは聴覚チャンネルで処理される.同様 に,視覚情報として機械の動作が提示された場合,始め視覚チャンネルで処理されるが,
精神的に機械動作に対応する音韻的記述を構築することもある.反対に,ある動物につい ての説明や機械の動作についての解説を口述で行った場合,始め聴覚チャンネルで処理さ れるが,これに加えて,対応する動物の姿や機械動作の様子などの視覚的イメージを形成 し,視覚チャンネルで処理することがある.同じ情報に対する2つのチャンネル間の横断
的表現はPaivio(1986)の二重符号化理論で重要な役割をはたしている.
2. 容量制限仮説
容量制限仮説は,各チャンネルで一度に処理することができる情報量に制限があると いうものである.静止画かアニメーションが提示される場合,学習者は,いつでも作業記 憶中にほんの少数の画像を保持することができる.その画像は提示資料の正確なコピーで はなく,提示資料の一部分を反映したものである.ナレーションが提示される場合,学習 者は,作業記憶中にほんの短い幾つかの単語を保持することができる.それらの単語は逐 語的な記録ではなく,提示されたナレーションの一部分を反映したものである.認知容量 制限の概念は心理学において長い歴史があり,現代の例では,Baddeley(1986, 1999)の 作業記憶とChandler and Sweller(1991, Sweller 1999)の認知負荷理論が関係している.
チャンネルがそれぞれ処理容量を制限されると考える場合,各チャンネルでどれだけ の情報を処理することができるだろうか.認知容量を測定する古典的方法として記憶範囲 テスト(Miller 1956, Simon 1980)がある.例えば,数字長テストでは,被験者に毎秒1 桁の割合で数字の一覧(例えば,8-7-5-3-9-6-4)を読ませ,その後,順番にそれらを復唱 させる.間違えず暗唱することができる桁数が,その被験者の記憶範囲となる.あるいは,
毎秒一つの割合で被験者に単純な線画(例えば,月・鉛筆・櫛・りんご・椅子・本・なまこ・
銑)を提示し,その後,提示順にそれらを復唱させる.再び,間違えずに暗唱することが できた数が,その被験者の図情報における記憶範囲となる.記憶範囲には個人差があるも のの,人間はおおむね7±2の項目を覚えている.また,人間は7桁の数字8-7-5-3-9-6-4 を3桁(875)・2桁(39)・2桁(64)の3個のまとまりにグループ化するように一覧中の 要素をチャンキングする技術を学習することができる.この方法で,認知容量は同じまま,
より多くの要素を各まとまりの内に記憶することができる.多くの研究者により聴覚・視 覚的な作業記憶容量をより多く精錬させる方法が開発されたが,その結果は人間の処理容 量は厳しく制限されていること示している(Miyake & Shah 1999).
人間は処理容量における規制によって,どの入力情報に注意を向けるか,選択された
数片の情報間の統合にどの程度取り組むか,および選択された数片の情報と既存の知識と の統合にどの程度取り組むか,を決定しなければならない.メタ認知方略は,これらの限 られた認知資源を割り当てて監視し,調整し,調節するためのテクニックである.これら の方略は,Baddeley(1986, 1999)が中央実行系(認知資源配分制御システム)と呼ぶこ とに関する中心にあり,知性の現代理論(Sternberg 1990)で中心的な役割をはたす.
3. 能動処理仮説
能動処理仮説は,人間はメンタルモデルを構築するために認知処理を能動的に行ってい るというものである.この処理過程には,周囲にある情報や物事に注意を払い,入ってく る情報を整理し,他の知識と統合することも含まれている.つまり,人間はマルチメディ アによるプレゼンテーションを理解しようと努力しているのである.この視点は,人間の 記憶にできるだけ情報を加えようと注力する受動的学習とは異なるものである.
学習者が受入教材を認知処理する場合,学習者が教材を理解できるように支援するこ とを目的とした,能動学習が生じる.能動認知処理の結果は一貫したメンタルモデルの構 築である.したがって,能動学習は,モデル構成のプロセスと見ることができる.メンタ ルモデル(または知識構造)は,提示資料およびそれらの関係の重要な部分を表わす.
能動学習の結果構築される一貫したメンタルモデルには,いくつかの典型的な形がある.
いくつかの基礎知識構造は過程,比較,一般化,列挙および分類を含んでいる(Chambliss
& Calfee 1998, Cook & Mayer 1988).あるシステムがどのように動作するかの説明のよ うな過程構造は因果連鎖として表わされる.2つの理論を比較対照させる場合は,メンタ ルモデルの構造は,数個の寸法に沿って2つの理論を比較する一種のマトリクス構造を構 築する.歴史などの様々な詳細から結果を説明するような一般化構造は分岐木として表わ し,本旨を支援する詳細(枝)から成る.列挙構造はリストとして表わし,アイテムのコ レクションから成る.海洋動物の生物分類システムなどの分類構造は階層として表わし,
セットと部分集合から成る.
マルチメディア教材の理解はこれらの知識構造のうちの1種を構築することを含んで いる.この仮定は,マルチメディア設計のための2つの重要な含意を示唆している.すな わち,1) 提示資料は首尾一貫した構造を持っているべきである,2) 教材はどう構造を構 築するかの指導を学習者に提供するべきである,の2つである.教材が首尾一貫した構造 を欠けば(例えばそれぞれが独立した事象の寄せ集めのような),学習者のモデル構成努 力には成果がない.教材が提示資料を構築する方法に関する指導を欠けば,学習者のモデ ル構成努力が圧倒されるかもしれない.マルチメディア設計は,それらのモデル構成努力 で学習者を支援する試みとして概念化することができる.
2.2 マルチメディア学習における3つの記憶庫 13
能動学習にとって不可欠なプロセスは,適切な資料の選択する,選択された資料を体 系化する,および選択された資料と既存の知識を統合することである(Mayer 1996, 2001,
Wittrock 1989).学習者が提示教材中の言語や図を充当するために注意を払う場合,適切
な資料の選択が生じる.このプロセスは外部から資料を認知体系の作業記憶へもたらすこ とを必要とする.選択された資料の体系化は要素構造の関係を構築することを含んでいる.
このプロセスは認知体系の作業記憶内で起こる.既存の知識に選択された資料を統合する ことは,受入材料や事前知識の適切な部分といった建築用接続部品を間に含んでいる.こ の処理は長期記憶中の知識を活性化しそれを作業記憶へもたらすことを必要とする.
まず,次節からマルチメディア学習で使用される3つの記憶について詳述し,その後,
能動学習に必要な5つのプロセスについて詳述する.
2.2 マルチメディア学習における 3 つの記憶庫
感覚記憶,作業記憶,長期記憶の3つの記憶庫がある.図と言語は,マルチメディア 教材として外部から,視覚および聴覚を通して感覚記憶に入力される.視覚の感覚記憶中 では視覚情報として絵やテキストを,聴覚の感覚記憶中では聴覚情報としてナレーション や他の音を,非常に短時間ではあるが正確に保持することができる.
マルチメディア学習における主な処理は,作業記憶の中で起こる.作業記憶は能動意識 の中に一時的に知識を保持し操作するために使用される.例えば,ある文を読む際に,そ の言葉のうちのいくつかの語だけに専念するだろうし,あるいは図を見る際に心の中に図 中のいくつかだけのイメージを一度に保持するだろう.この種の意識的な処理は作業記憶 の中で起こる.図2.1中における作業記憶の左側は,視覚・聴覚の形式に基づき,作業記憶 に入る資料を表す(言語の音声と図の画像).対して,作業記憶の右側は,作業記憶で図お よび言語の2つの表現形式に基づき構築された知識(言語的モデルと図的モデルおよびそ の間のリンク)を表わす.「音声」から「画像」までの矢印は,音声から視覚的イメージへ の精神の転換を表わす.すなわち,単語「猫」を聞いた場合,さらに猫の精神的なイメー ジを形成するかもしれない.「画像」から「音声」までの矢印は,視覚的イメージから音声 への精神の転換を表わす.すなわち,猫の写真を見た場合,精神的に音韻としての「ねこ」
や猫の鳴き声を想像するかもしれない.マルチメディア学習に必要な主な認知処理は次節 に記述する.
最後に,長期記憶は学習者の知識の倉庫に相当する.作業記憶と異なり,長期記憶は 長期間にわたり大量の知識を保持することができる.しかし,教材に関して考えたりする ためには,積極的に長期記憶中の知識を作業記憶へ送らなければならない.
2.3 マルチメディア学習における 5 つの認知処理過程
マルチメディア学習において,学習者の認知処理は受動的に処理しているのではなく,
能動的に処理している.マルチメディア環境において有益な学習とするためには,学習者 は以下の5つの認知処理過程に従事しなければならない.
1. 聴覚チャンネルの作業記憶中で処理するための適切な言語選択 2. 視覚チャンネルの作業記憶中で処理するための適切な図選択 3. 選択した言語を言語的モデルへ体系化
4. 選択した図を図的モデルへ体系化
5. 言語的・図的表現を互いに,および事前知識との統合
しかし,これらの過程は,必ずこの順番に生じるというわけではない.学習者の処理は様々 な方法である過程から別の過程へ移ることもありうる.成功するマルチメディア学習は,
学習者がこれらの5つの過程を調整し,監視することを必要とする.
1. 適切な言語選択
第1のステップは,教材から耳に入る音の知覚の表現,そして作業記憶内部の単語音 の表現までの知識表現における変化を含んでいる.このステップの入力はナレーションで あり,出力は図2.1中の作業記憶内における精神的な表現としての「音声」である.この 変更を調停する認知過程は適切な言語選択と呼ばれ,聴覚メモリを通り抜けるとき,マル チメディア教材の中で示される言語のいくつかに注意を向けることを伴う.その言語がナ レーションで提示される場合,このプロセスは,聴覚チャンネルで始まる.しかしながら,
その言語がスクリーン上のテキストあるいは印刷物のテキストとして示される場合,この プロセスは,視覚チャンネルで始まり,学習者がテキストを精神的に明瞭に表現すれば,
後で聴覚チャンネルへ移動するかもしれない.
提示教材の一部分だけを選択する必要性は,各チャンネルの認知容量の制限のために 生じる.もし容量が無制限ならば,ナレーションの一部だけに注意を集中する必要はない だろう.最終的に,言語の選択は任意ではない.学習者は,能動的に学習にとってどの言 語が適切か決めなければならない.
2. 適切な図選択
第2のステップは,教材から目に入る視覚刺激(例えば静止画や動画)の知覚の表現,
そして作業記憶内部の図(静止画や動画の一部の視覚的イメージ)の表現までの知識表現
2.3 マルチメディア学習における5つの認知処理過程 15
における変化を含んでいる.このステップの入力は視覚メモリの中に一時的に保持される マルチメディア教材の図部分であり,出力は図2.1中の作業記憶内における精神的な表現 としての「画像」である.この変更の基礎となる認知過程は,適切な図選択と呼ばれ,マ ルチメディア教材中で示された動画または静止画の一部に注意を向けることを伴う.この 過程は視覚チャンネルで始まるが,精神的に進行中の動画を物語ることなどで,情報の一 部を聴覚チャンネルに変換するのは可能である.
提示された図資料の一部だけを選択する必要性は,認知容量の制限から起こる.学習 者が入力される図資料の一部だけに注目しなければならないように,複雑な静止画やアニ メーションをすべて処理することは不可能である.最後に,どの図がマルチメディア教材 の意味理解にとって適切か,学習者が判断しなければならないので,(言語の選択過程のよ うな)図の選択過程は任意ではない.
3. 選択された言語の体系化
学習者は,以前にマルチメディア教材より入力された言語から音声の基礎を形成した.
次のステップは,1つ1つの言語を「言語的モデル」と呼ばれる首尾一貫した表現の知識 構造へ体系化することである.このステップの入力はナレーションから選択された単語音 の基礎であり,出力は学習者が選択した単語や句に関する作業記憶中で構築され首尾一貫 した表現としての言語的モデルである.
この変化にかかわる認識過程は,学習者は数片の言語知識間を接続することで,選択 された言語を組織化することである.このプロセスは,聴覚チャンネルで生じる可能性が 高く,選択過程と同じように容量制限に影響を受けることがある.学習者にはあらゆる接 続を構築する無制限の容量がないので,単純構造を構築することに焦点を合わせなければ ならない.体系化の過程は任意ではないが,因果連鎖構造のようなものを感覚的に作る努 力をやや反映する.精神的に因果連鎖を構築する際に,学習者は選択された言語を組織し ている.
4. 選択された図の体系化
図を体系化する過程は,言語を選択するためのそれに平行する.一旦学習者がマルチ メディア教材より入力された写真から画像の基礎を形成したならば,次のステップは,「図 的モデル」と呼ぶ首尾一貫した表現の知識構造へ体系化することである.このステップの 入力は視覚より入ってきた図資料から選ばれた画像の基礎であり,出力は学習者が選択し た図に関する作業記憶中で構築され首尾一貫した表現としての図的モデルである.
画像から図的モデルまでの変化は,選択された図の体系化と呼ばれる認知過程の適用 を要求する.このプロセスで,学習者は数片の画像知識間を接続する.このプロセスは視 覚チャンネルで生じ,選別過程と同じように容量制限に影響をうけることがある.学習者 は,それらの作業記憶中のイメージ中のあらゆる接続を構築する容量を欠くが,接続の単 純なセットの構築にやや注目するに違いない.学習者は,それらの画像の基礎の中で可能 な,あらゆる接続を構築する無制限の容量がないので,簡単な接続を構築することに焦点 を合わせなければならない.言語の体系化の過程でのように,図を体系化する過程は任意 ではない.むしろ,学習者に理解できる単純構造を因果連鎖のように構築する努力を反映 する.
5. 言語および画像表現の統合
恐らく,マルチメディア学習の最も重大なステップが,言語に基づく表現と画像に基 づく表現の間を接続することを伴う.このステップは,2つの別個の表現(図的モデルおよ び言語的モデル)が,一方のモデルから対応する要素および関係をもう一方のモデルと接 続し,1つの統合モデルへ変更することを含んでいる.このステップの入力は,学習者が これまで構築した図的モデルおよび言語的モデルであり,出力は統合モデル(2つの表現 の接続に基づくモデル)である.さらに,統合モデルは,事前知識との接続を含んでいる.
言語と画像の統合と呼ばれるこの認知過程は,長期記憶からの知識と同様に図的およ び言語的モデルの対応する部分間の接続を構築することを伴う.このプロセスは視覚的・
聴覚的作業記憶に生じ,そして,それらの間の調整を伴う.これは,認知容量の効率的な 使用を要求する,非常に過酷なプロセスである.学習者が視覚的・聴覚的表現の根本的な 構造に焦点を合わせなければならないので,過程は感覚作成の概略を反映する.学習者は,
意味統合の支援のため,長期記憶から事前知識を使用することができる.
マルチメディア学習中,5つの処理過程の各々が,全学習内容に対してまとめて起こる のでは無く,節によって何度も生じる.学習者は,学習内容から断片的に適切な言語およ び図を選び,言語的・図的モデルを構築し,完成したモデルを互いに結び付けて,さらに 同様のプロセスを次の内容へと繰り返し行っている.
2.4 表現の 5 つの形式
言語と図の表現には,処理過程の加工段階に応じて,5つの形式がある.まず第1形 式として,図2.1の左端のマルチメディア提示での言語および図から始まる.次に,提示
2.5 マルチメディア教材における3種類の提示資料の処理 17
された言語および図が学習者の耳および目に刺激を与えることで,第2形式の感覚記憶に おける聴覚情報および視覚情報になる.もし学習者がそれらに注意を向けなければ,知覚 情報は急速に衰える.第3形式は,学習者が作業記憶中で処理するために言語と図のうち のいくつかの情報を選択した時,作業記憶中に保持される音声および画像である.これら は知識を構築するための材料となる.第4形式は,学習者の作業記憶中で構築した言語的 モデルおよび図的モデルである.ここで,学習者はそれまで得た情報を言語的・図的に組 織化し,精神的に統合を行っている.最後に,第5形式は長期記憶中の知識である.学習 者は作業記憶の中で知識構築をするためにその事前知識を使用する.Sweller(1999)はこ の知識を概要(スキーマ)と呼んでいる.新しい知識が作業記憶で構築された後,それは 次の学習を支援するのに使用する事前知識として,長期記憶に格納される.
2.5 マルチメディア教材における 3 種類の提示資料の処理
デュアル・チャンネル・モデルでは,マルチメディア教材に使用される,図情報,音 声情報およびテキストの3種類の提示資料は次のように処理される.
1. 図情報の処理
教材中の絵,写真,動画,アニメーション等の図は,学習者の視覚より視覚情報とし て入力され,視覚メモリに図の簡素な映像が一時的に適用される.以上の処理は学習者の 無意識で起こる.しかし,次に,能動認知処理(学習者が意識的にコントロールする処理)
が始まる.学習者が視覚に入る図に注意を払えば,入って来る図情報内のいくつかが,作 業記憶中で「画像」として表わされる.一旦,作業記憶が画像の断片で一杯になったら,
次の能動的認知処理として,図の体系化(図の組織化)を行い,知識表現として「図的モ デル」を構築する.最後に,能動的認知処理はこの新しい知識表現を理解するために長期 記憶から事前知識を要求し意味統合を行う.さらに,学習者がテキスト中や図情報自体か ら,図の意味や名称に相当する音韻的符号を生成し,言語的モデルを生産していれば,図 的モデルと統合する.
2. 音声情報の処理
ナレーションなどの音声情報は,学習者の聴覚により聴覚情報として入力される.情 報は聴覚メモリに一時的に適用され,次に,能動認知処理が起こる.学習者が聴覚に入る 音に注意を払えば,入って来る音の内のいくつかが,単語音ベースで,図2.1における作 業記憶内の「音声」の包含に選ばれる.単語ベースの言葉は無秩序な破片であるので,次
のステップとして,語の体系化(言葉の組織化)が行われ「言語的モデル」を構築する.
この過程では,語の意味に基づいて表されることによって,その単語は変化する.最後に,
学習者は,あるステップから別のステップへの変遷について説明するのを支援するために 事前知識を使用するかもしれないし,ただ単に提示資料中の図と結び付けるかもしれない し,言葉からその実態や概念をイメージして図的符号を生成し,図的モデルを構築し結び つけるかもしれない.この処理によって生じる学習成果は,作業記憶内の意味統合となる.
3. テキストの処理
上述の通り,図の認知処理は,視覚チャンネルで起こり,ナレーションの認知処理は主 として聴覚チャンネルで起こる.しかしながら,図2.1における作業記憶中の「画像」か ら「音声」までの矢印のように,学習者は視覚的なイメージに対応する音を精神的に作成 することができる.同様に,作業記憶中の「音声」から「画像」までの矢印のように,学 習者が精神的にその言葉に対応するイメージを作成することができる.
マルチメディア教材中のテキストによる言語は視覚的に示される.したがって,それ らは最初に視覚よって処理される.次に,学習者は入って来る言語のうちのいくつかに注 目し,画像の一部として作業記憶へ入れる.その後,学習者はテキスト画像を精神的に発 音すること,すなわち音韻的符号化をすることによって,聴覚チャンネルにその言語を入 れることができる.一旦その言語が聴覚チャンネルで表わされれば,それらは音声情報の ように処理される.
言語資料が視覚チャンネルを通って入るような場合,その内容はシステムによって複 雑なルートを取らなければならず,また,学習者が視覚チャンネルを通して処理している 図情報と注意を競合する可能性がある.
視覚チャンネルおよび聴覚チャンネルでの二つの処理が同時に行われるとき,聴覚チャ ネルと視覚チャネルにおける相互作用が情報伝達効率を高め,認知容量の配分を効率化し 意味統合に認知資源を多く使うことで,内容理解を深めることができ,結果として記憶保 持も効率化させる.
聴覚チャンネルと視覚チャンネルの相互作用を生起させ,結果として認知容量の効率 化を誘発するには,聴覚コンテンツと視覚コンテンツの同期が重要である.
参考文献
Baddeley, A. D. (1986). Working memory. Oxford, England: Oxford University Press.