NAIST-IS-MT1351095
修士論文
難読化の特徴を用いた
ドライブバイダウンロード攻撃検知手法の設計と実装
藤原 寛高
2015年3月11日 奈良先端科学技術大学院大学 情報科学研究科 情報科学専攻本論文は奈良先端科学技術大学院大学情報科学研究科に 修士(工学)授与の要件として提出した修士論文である. 藤原 寛高 審査委員: 山口 英 教授 (主指導教員) 藤川 和利 教授 (副指導教員) 安本 慶一 教授 (副指導教員) 門林 雄基 准教授 (副指導教員) 楫 勇一 准教授 (副指導教員) 猪俣 敦夫 准教授 (副指導教員)
難読化の特徴を用いた
ドライブバイダウンロード攻撃検知手法の設計と実装
∗藤原 寛高
内容梗概 ドライブバイダウンロード攻撃はユーザを悪性のウェブサイトへ誘導し、ウェブ ブラウザやそのプラグインの脆弱性を悪用してユーザの端末にマルウェアを感染さ せる攻撃である。本研究ではドライブバイダウンロード攻撃検知手法の提案と評価 を行う.提案手法では難読化の特徴である文字列の変化に着目し,JavaScriptの難 読化されたドメイン情報を用いてドライブバイダウンロード攻撃の検知を行う.ブ ラウザプラグインを用いた実装の結果では,難読化されたリダイレクト通信の検知 率は100%であり,正規のウェブサイトを用いた誤検知率は53%であった. キーワード ドライブバイダウンロード攻撃, 難読化, JavaScript ∗奈良先端科学技術大学院大学 情報科学研究科 情報科学専攻 修士論文, NAIST-IS-MT1351095, 2015年3月11日.A Design and Implementation of a detection
method against
Drive-by Download Attacks
using obfuscation features
∗Hirotaka Fujiwara
Abstract
Drive-by download attacks usually redirect a user to a malicious webpage where vulnerabilities in a browser or in browser plugins are exploited in order to force the download of a malware. This research presents and evaluates a detec-tion method against drive-by download attacks. The proposed method focusces on the transformation of strings that is the characteristics of the obfuscation. The proposed method employs obfuscated domain information of JavaScript as a trigger to detect drive-by download attack. The browser plug-in implemena-tion of the proposed method was able to detect obfuscated redirecimplemena-tion correctly with 100% true positives, while it showed 53% false positives against legitimate sites.
Keywords:
Drive-by Download Attack, Obfuscation, JavaScript
∗Master’s Thesis, Department of Information Science, Graduate School of Information Science,
目次
目次 iii 図目次 vi 表目次 viii 1章 はじめに 1 1.1 背景 . . . 1 1.2 攻撃検知システムに対する検知回避技術 . . . 2 1.3 研究目的 . . . 3 1.4 論文構成 . . . 4 2章 関連研究 5 2.1 ドライブバイダウンロード攻撃とは . . . 5 2.1.1 ドライブバイダウンロード攻撃の仕組み . . . 6 2.2 既存のドライブバイダウンロード攻撃検知手法 . . . 9 2.2.1 シグネチャを用いた検知 . . . 9 2.2.2 サンドボックスを利用した動的解析 . . . 11 2.2.3 ウェブクローリングを用いたブラックリスト検知 . . . 12 2.3 難読化 . . . 13 2.3.1 難読化の目的 . . . 13 2.3.2 難読化の種類 . . . 13 2.3.3 難読化による問題点 . . . 153章 難読化の調査および分類 17 3.1 良性と悪性の難読化の定義 . . . 17 3.2 データセットについて . . . 17 3.3 難読化の調査 . . . 18 3.3.1 静的解析による調査 . . . 19 3.3.2 1行の長さと区切り文字に注目した分析 . . . 20 3.3.3 1行の長さの割合に注目した分析 . . . 23 3.4 調査結果を用いた決定木による分類 . . . 25 3.5 ランダムおよびデータ難読化の特徴調査 . . . 26 3.5.1 文字の割合に関する調査 . . . 26 3.5.2 頻度分布を利用した調査 . . . 28 3.6 難読化分類における考察 . . . 32 4章 難読化の特徴を利用した攻撃検知手法の提案 34 4.1 検知手法の概要 . . . 34 4.2 検知手法の動作 . . . 36 4.3 提案手法のメリットとデメリット . . . 38 4.4 実装方式 . . . 41 4.4.1 ブラウザプラグイン型 . . . 41 4.4.2 プロキシ型 . . . 42 5章 提案手法の実装と評価 43 5.1 Chrome Extensionを用いた実装 . . . 43 5.1.1 実装環境 . . . 43
5.1.2 Google Chrome Extension . . . 44
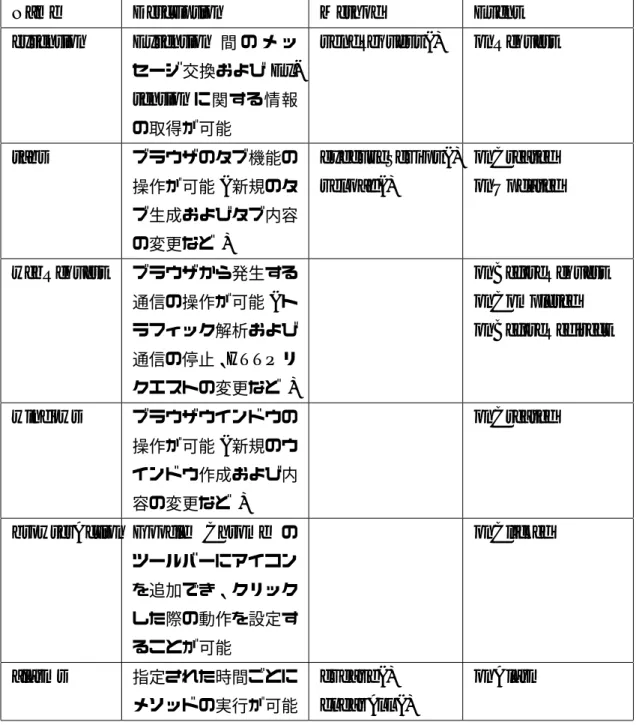
5.1.3 Chrome Platform APIs . . . 46
5.1.4 jQuery . . . 49
5.1.5 Chrome Extensionの動作 . . . 49
5.1.6 Chrome Extension実装におけるタイミング対策 . . . 53
5.1.7 ホワイトリストによる誤検知対策 . . . 55
5.1.9 クローラの構築 . . . 55 5.2 評価手法 . . . 56 5.2.1 評価環境 . . . 56 5.2.2 評価用データセットの構成 . . . 57 5.3 評価結果とまとめ . . . 61 5.4 考察 . . . 61 6章 おわりに 63 6.1 まとめ . . . 63 6.1.1 難読化の調査 . . . 63 6.1.2 提案手法 . . . 63 6.2 今後の課題 . . . 64 謝辞 66 参考文献 66
図目次
2.1 ドライブバイダウンロード攻撃の流れ . . . 7 2.2 シグネチャ検知と難読化 . . . 10 2.3 サンドボックスとクローキング . . . 12 2.4 オリジナルコード . . . 14 2.5 ランダム難読化 . . . 14 2.6 データ難読化 . . . 15 2.7 エンコード難読化 . . . 16 3.1 1行の長さと区切り文字の数 . . . 20 3.2 データセットごとのプロット(D3M2011-2012) . . . 21 3.3 データセットごとのプロット(D3M2013-2014) . . . 22 3.4 データセットごとのプロット(Malwr.com) . . . 22 3.5 データセットごとのプロット(Legitimate Site) . . . 23 3.6 1行の長さと比率 . . . 24 3.7 文字列の長さを利用した難読化の分類 . . . 25 3.8 使用されている文字の割合 . . . 27 3.9 その他における記号の割合 . . . 28 3.10 頻度分布生成フロー . . . 29 3.11 例) ノイズ除去フロー . . . 30 4.1 正規サイトと改ざんサイトから得られるコードの違い . . . 35 4.2 提案システム . . . 374.3 対クローキング . . . 38
4.4 動的なURL生成 . . . 41
5.1 Chrome Extension 構成 . . . 44
5.2 Chrome Extension フローチャート Content Scripts . . . 50
5.3 Chrome Extension フローチャート Background . . . 51
5.4 Chrome Extension シーケンス図 . . . 52
5.5 Chrome ブラウザ シーケンス図 . . . 53
5.6 タイミング対応 Chrome Extension シーケンス図 . . . 54
5.7 Chrome Extension 攻撃検知時の視覚化 . . . 56
表目次
1.1 既存の検知手法と対策 . . . 2 3.1 データセットごとのファイル数および行数 . . . 19 3.2 決定木を用いた各行の分類結果 . . . 26 3.3 各文字の使用数 . . . 27 3.4 ノイズ除去前後におけるデータセットの単語数 . . . 31 3.5 ノイズ除去前後におけるデータセットの単語数 追加検証 . . . 32 3.6 追加検証で利用したウェブサイト . . . 32 3.7 確認された良性および悪性の難読化 . . . 33 4.1 既存の検知手法と回避技術の検知可否 . . . 39 5.1 Chrome Extension 実装環境 . . . 43 5.2 検証環境 . . . 445.3 今回使用したJavaScript APIs(Chrome Platform APIs) . . . 47
5.4 webRequestにおけるファイルタイプ . . . 48 5.5 評価環境 . . . 57 5.6 難読化の組み合わせリスト . . . 58 5.7 誘導経路 . . . 60 5.8 提案手法による難読化サイト検知数 . . . 61 5.9 提案手法による誤検知数 . . . 61
1
章 はじめに
1.1
背景
インターネットバンキングやオンラインショッピングといった様々なウェブサー ビスの提供が行われるようになり、それらのサービスではウェブアプリケーション と呼ばれるインターネットを利用したアプリケーションを利用することで、様々な サービスを受けることが可能となった。ウェブアプリケーションは様々なプログラ ミング言語を利用して構築されており、クライアントサイドのブラウザ上で動作 するJavaScriptやサーバサイドで動作するPHPやJava、Ruby、Pythonといっ たプログラミング言語が利用されている。ウェブアプリケーションの普及が進み、 様々なプログラミング言語が利用できるようになったことで、ウェブアプリケー ションを標的とし、ウェブサイトを訪れることでマルウェアに感染するウェブ感染 型マルウェア(ドライブバイダウンロード攻撃)が増加している[1][2]。 ドライブバイダウンロード攻撃は悪性のウェブサイトへアクセスすることでマル ウェアに感染する攻撃である。この攻撃は改ざんされた正規のウェブサイトや広 告サイトによって悪性のウェブサイトへ誘導され、誘導先でブラウザやActiveX、Java Flash Playerといったプラグインの脆弱性を悪用されることで、端末がマル ウェアに感染する危険性がある。また、正規のウェブサイトが改ざんや正規のウェ ブサイトで利用されている広告に攻撃を仕掛けられることで、多くの被害が発生す る危険性も存在している。ドライブバイダウンロード攻撃の検知手法として、攻撃 コードの特徴を利用したシグネチャベース手法[7]、サンドボックスを用いて動的 に解析する手法[10]、事前に悪性のサイトを取得してブラックリストに登録する手 法[5]が存在している。シグネチャベースの検知手法はアンチウイルスソフトウェ
アや侵入検知システム(IDS : Intrusion Detection System)、侵入防止システム
(IPS : Intrusion Prevention System)といったシステムで利用されており、通信 やファイルから攻撃コードの特徴を検知することが可能である。動的解析手法では サンドボックスやハニーポットを利用して、安全性を考慮した仮想環境などで攻撃 コードやマルウェアを実行し、動作の検証を行い良性と悪性の判定を行う。事前に ブラックリストに登録する手法では、ウェブクローラを用いて悪性と思われるサイ トにサンドボックスやハニーポットでアクセスし、悪性と判定された際にブラック
リストに登録することで、悪性のウェブサイトへのアクセスを阻むものである。以 上のような検知手法が存在しているが、これらの検知手法を回避する技術も存在 している。検知を回避する技術として、難読化、クローキング、短期消滅サイトと いったものが存在しており、攻撃の検知が困難になっている。そのため、既存の検 知手法とは異なった新しい検知手法が必要である。 本研究では攻撃検知システムを回避する手法を逆に利用することで、攻撃検知に 利用する手法を提案し、評価を行った。また、良性と悪性の難読化について調査を 行い、調査結果から難読化の分類のための決定木を作成し、分類と評価を行った。 評価の結果から良性と悪性の難読化の特徴を利用して、難読化の特徴を利用した攻 撃検知についての提案と評価を行う。
1.2
攻撃検知システムに対する検知回避技術
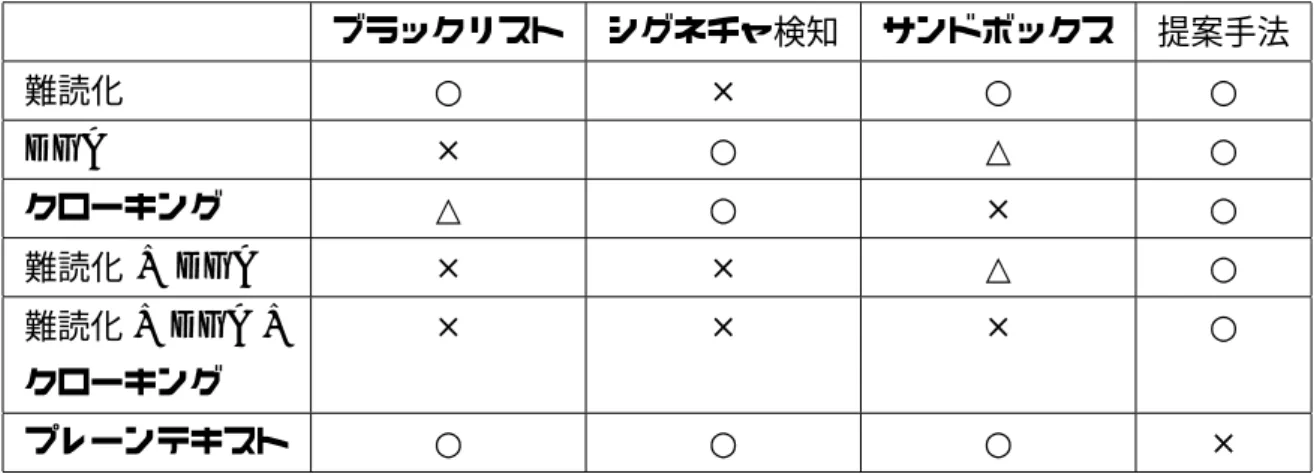
表1.1 既存の検知手法と対策 検知手法 対策 シグネチャ(IDS/IPS、アンチウイルス) 難読化 動的解析 (サンドボックス、ハニーポット) クローキング、スリープ ブラックリスト 短期消滅サイト ウェブ感染型攻撃の検知回避技術には難読化、クローキング、短期消滅サイトが 存在する。表1.1は攻撃検知手法とその回避手法の対応を表にまとめたものであ る。シグネチャベースの検知手法には、本研究で取り扱う難読化を利用することで 検知が可能となっている。難読化の詳細については2.3節で取り扱う。シグネチャ 検知では、ソースコードや通信内容から事前に登録された攻撃の特徴でパターン マッチを行い、攻撃の検知を行っている。しかし、シグネチャ検知の問題点として 攻撃者がシグネチャを容易に変更可能なことがあげられる。難読化はシグネチャが 容易に変更できることに着目し、ウェブ感染型では攻撃コードを難読化すること で、異なる文字列に置換してシグネチャの変更を行う。また、難読化は何重にもか けることが可能となっており、難読化の回数によってシグネチャの変更が簡単に行えることもあり、難読化を用いられることでシグネチャを利用した検知は困難とな る。次に、動的解析には仮想環境を用いて、安全な環境でマルウェアや攻撃コード を実行し、検証するサンドボックスやハニーポットが存在している。現在のセキュ リティ製品として用いられているサンドボックスでは、ユーザのメールに添付され たファイルやダウンロードされる実行ファイルをサンドボックス環境で実行し、シ ステムコールの呼び出し回数やプロセスの監視といった手法で攻撃の検知を行う。 しかし、このような動的解析を回避する手法にクローキングが存在する。クローキ ングは実行環境の情報などを収集し、攻撃対象とするアプリケーションのインス トール情報やバージョン情報といった攻撃対象の調査を目的としたものを指す。
1.3
研究目的
ドライブバイダウンロード攻撃の既存の検知手法であるシグネチャベースの検知 手法や動的解析では難読化やクローキングといった検知を回避する技術の進歩によ り、検知が困難になっている。今後も検知回避技術は進歩していくと考えられ、既 存の手法とは異なった視点の新しい検知手法が必要となっている。 本研究ではシグネチャを変更して攻撃検知を回避する JavaScriptの難読化に着 目し、検知回避のための難読化を逆手に取ることで攻撃を検知する手法についての 新たに提案し、評価する。ドライブバイダウンロード攻撃の特徴である悪性のウェ ブサイトへアクセスする際にJavaScriptによって発生するリダイレクトのドメイ ン情報と攻撃検知を回避するために利用される難読化によって隠されるリダイレク ト先のドメイン情報を用いることで、ドライブバイダウンロード攻撃の検知および マルウェア感染の防止を目指す。また、本提案を既存の検知手法と組み合わせることで、回避技術の無効化を目的とする。本研究ではGoogle Chrome Extensionを
利用して提案手法の実装を行い、評価を行った。また、良性および悪性のウェブサ イトで利用されている難読化の特徴についての調査を行い、その特徴から難読化の 分類についても評価した。
1.4
論文構成
本論文では、第2章でドライブバイダウンロード攻撃の仕組みや既存のドライブ バイダウンロード攻撃検知手法について解説を行い、本研究で取り扱う攻撃検知手 法の1つである難読化についての解説を行う。第3章では良性と悪性の難読化につ いて調査し、難読化の調査で得られた結果から難読化の特徴を利用して静的解析を 行い、難読化の分類と検討を行った。第4章では難読化の特徴を用いたドライブバ イダウンロード攻撃の検知手法について解説を行う。第5章では4章で提案した 手法のChrome Extensionを用いた実装と評価の結果について示す。第6章では3 章および5章のまとめと今後の課題について記す。2
章 関連研究
本章では本研究を進める上で重要となる知識の説明と関連研究について述べる。 2.1節ではドライブバイダウンロード攻撃の背景とその仕組みについて述べ、2.2節 でドライブバイダウンロード攻撃に関連する既存研究について述べる。また、2.3 節ではドライブバイダウンロード攻撃の検知を回避するために用いられる難読化に ついて述べる。2.1
ドライブバイダウンロード攻撃とは
ドライブバイダウンロード攻撃はユーザを悪性のウェブサイトへ誘導し、ブラウ ザやプラグインの脆弱性を悪用して攻撃コードを実行することで、ユーザの端末を マルウェアに感染させる攻撃である。この攻撃は改ざんされた正規のウェブサイト や広告サイトを利用して、悪性のサイトへ誘導する。ドライブバイダウンロード攻 撃として有名なものに2009年に発見されたGumblarが存在する[8][9]。この攻撃 では攻撃者によって正規のウェブサイトが改ざんされ、難読化されたJavaScriptがウェブサイトに埋め込まれた。この攻撃コードはInternet Explorer やAdobe
Acrobat、Adobe Reader、Adobe Flash Player の脆弱性を悪用して様々なマル ウェアをインストールする。また、この攻撃が脅威とされる理由に広告サイトが挙 げられる。近年多くのウェブサイトで利用されているウェブ広告の機能を利用して 悪性のサイトへ誘導する方法も存在しており、大手や個人のブログといったウェブ サイトで利用されている広告サイトが改ざんされ、ドライブバイダウンロード攻撃 の起点となることで多くのユーザが被害にあう可能性がある。また、TrendMicro ブログ [4]によると 2014 年10 月に Youtube 上で偽広告を利用した攻撃が確認 された。この攻撃では攻撃者が正規の広告枠を利用し、ユーザを悪性のサイトへ 誘導するために利用したと考えられている。悪用された脆弱性はJava、Internet Explorer、Flashであり、アメリカだけで約11万人のユーザが影響を受けたと報 告されている。 悪性のウェブサイトへ誘導するための入り口として利用されるウェブサイトに は、正規のウェブサイトの改ざんと広告サイトを利用した方法が存在している。正
規のウェブサイトを改ざんする方法では攻撃者が正規のウェブサイトの脆弱性を悪 用して、ハッキングやSQLインジェクションを用い、リダイレクトや iframe∗と いった他のサイトへの誘導コードを埋め込むことで改ざんを行う。また、広告サイ トでは正規の広告サイトをハッキングするものや、偽の広告を利用して悪性のウェ ブサイトへ誘導する方法も取られる。悪性のウェブサイトへの誘導の仕組みには複 数の踏み台を経由して悪性のウェブサイトへ誘導するものも存在する。これはハ ニーポットを用いたウェブクローリングによるマルウェア収集やウェブ感染型の攻 撃調査に対して、指定された複数の踏み台サーバを経由しなければ悪性のサイトへ 到達させない仕組みとしても利用される。この手法では公開ブラックリストから ウェブクローリングやハニーポットで悪性のサイトへ直接アクセスしてマルウェア の検体を取得しようとする行為に対して、referrer†機能を利用して指定された踏み 台サーバを経由していないアクセスは偽サイトを表示するといったものである。 この攻撃はウェブブラウザやプラグインといった脆弱性を悪用してユーザの端末 にマルウェアを感染させており、ブラウザやJava、Adobe製品といった様々な脆 弱性を悪用している。脆弱性の悪用では悪性の攻撃コードをブラウザへ読み込ま せ、ウェブブラウザやプラグインの脆弱性を悪用してバッファオーバフローやヒー プスプレーを行い、悪性の実行ファイルのダウンロードし、実行ファイルをユーザ の意思とは関係なく実行する。 2.1.1 ドライブバイダウンロード攻撃の仕組み ドライブバイダウンロード攻撃は改ざんされたウェブサイトから悪性のウェブサ イトに誘導することで、JavaScriptを利用してウェブブラウザなどの脆弱性を悪用 し、ユーザの端末をマルウェアに感染させる。この攻撃は複数のステップで表現す ることが可能であり、既存の研究[3]はドライブバイダウンロード攻撃の流れを分 割し、ドライブバイダウンロード攻撃の動作を明解にしている。本研究では誘導に 利用される踏み台サイトへの通信も含めた、ユーザが利用するブラウザとウェブサ イトとの間で発生する通信に注目している。ドライブバイダウンロード攻撃の通信 ∗Inline Frameの略で、ウェブページ中に他のウェブページの表示が可能になる。 †HTTPヘッダの1つであり、この場合は直前に表示していたページを表す。
の流れには規則的な特徴があり、入り口となる改ざんされたウェブサイトから中継 として踏み台サイトを経由し、脆弱性の悪用して攻撃を行う悪性のウェブサイトへ 誘導され、マルウェアのダウンロードが行われる。ドライブバイダウンロード攻撃 は一連の通信の流れが攻撃の要素となるため、1カ所において通信の妨害やクロー キングによる悪性サイトへの誘導条件を不一致にすることで、攻撃を防ぐことが可 能となる。 本研究ではドライブバイダウンロード攻撃の通信に注目し、ステップの分割を 行った。ドライブバイダウンロード攻撃で発生する通信は大きく分けて通常通信、 リダイレクト通信、マルウェアのダウンロード、マルウェアによる悪性の通信に分 けられる。図2.1は通信に注目して複数のステップに分割したものである。以下で はその説明を行う。
Browser
Malicious
Web
Request
Response
Redirect
Response
File download
Response
Execute JavascriptNormal
Redirect
Malicious
Action
Execute Javascript ① ② ④ ③ 図2.1 ドライブバイダウンロード攻撃の流れ 1. 通常通信 : ユーザがブラウザで改ざんされた正規のウェブサイトもしくは、悪性の広告サイトへアクセスした際に発生する通信であり、ドライブバイダ ウンロードの攻撃の起点となるステップである。ブラウザはウェブサイトか ら改ざんされた htmlやjsファイルを取得し、ブラウザ上でJavaScriptが 実行されることで踏み台サイトや悪性のサイトへのiframe やリダイレクト といった通信が発生する。 2. リダイレクト通信 : ユーザが改ざんされたウェブサイトや広告サイトなど から誘導される際に発生する通信であり、クローキングによる攻撃検知対策 やブラウザの情報収集に利用されるステップとなる。この通信は複数の踏み 台サイトを利用することもあり、複数回の通信が発生する可能性がある。ク ローキングではReferrerを利用した悪性のウェブサイトへの誘導経路の正 当性証明や、ブラウザやプラグインの情報といったブラウザフィンガープリ ントの収集を行うことで、悪用する脆弱性に合わせた攻撃サイトへの誘導を 可能とする。また、悪用する脆弱性が存在しない場合は無害なサイトへ誘導 される。 3. マルウェアのダウンロード : 踏み台サイトを経由して攻撃サイトに誘導さ れた後に脆弱性を悪用した攻撃コードが実行されることで発生する通信で あり、マルウェアのダウンロードおよび実行されるステップである。ブラ ウザ上に悪性のウェブサイトから htmlやjsファイルがダウンロードされ、 JavaScript が実行されることで攻撃コードが実行される。この攻撃コード は難読化処理によってシグネチャベースの検知を回避する機能が含まれてい る。また、攻撃コードが実行されることでマルウェアのダウンロードが開始 され、ダウンロードされたマルウェアが実行されることでユーザの端末がマ ルウェアに感染する。 4. マルウェアによる悪性通信 : マルウェアに感染したユーザの端末からボット ネットへのアクセスやネットワークの情報収集といった通信が発生し、様々 な悪意のある活動が行われるステップである。
2.2
既存のドライブバイダウンロード攻撃検知手法
既存のドライブバイダウンロード攻撃対策にはブラックリストやシグネチャベー ス検知、サンドボックスなどが存在している。ブラックリストは悪性のサイトの URLをリストとして保持し、ウェブサイトへアクセスする際にブラックリストを 参照して悪性のウェブサイトとして登録されているウェブサイトか判断を行う。シ グネチャベース検知では事前に攻撃コードや通信の特徴を解析し、取得しておくこ とで悪性の通信と判断する。この検知方法はアンチウイルスソフトやIDS、IPSな どの一般的なソフトウェアで多く利用されている検知手法である。サンドボックス ではユーザのシステムが保護された環境で実際にコードを実行することで、事前に ブラウザで利用されるコードの安全性確認を行う。これらの攻撃検知手法には回避 技術が存在しており、ブラックリストやシグネチャベース検知といった静的解析で は、短期間に消滅する1日限定サイトおよび、攻撃コードや通信の特徴を難読化を 用いて特徴を変化させることで攻撃検知を回避する方法が存在しており、検知が困 難である。また、サンドボックス環境を用いた動的解析ではクローキング技術を用 いることでサンドボックス環境を検知し、サンドボックス上では実行されないマル ウェアが存在している。 2.2.1 シグネチャを用いた検知 シグネチャを用いた検知はアンチウイルスソフトやIDS、IPSといった数多くの 製品で利用されている検知手法である。アンチウイルスソフトで用いられるシグネ チャ検知では悪性のバイナリコードを収録したシグネチャデータベースとソース コードとのパターンマッチングによって悪性判定を行う。また、悪性の通信検知に はシグネチャパターンを定義したパターンファイルにマッチした通信を悪性の通 信と判断している。これらのシグネチャ検知の特徴として、事前に悪性のパターン ファイルを保持しておき、通信やプログラムといった検知対象と特定の文字列や ビット列においてパターンマッチングを行うことで検知を行っている。 シグネチャを利用した検知方法の欠点として、シグネチャ検知で用いる特徴を難 読化で変化させられることで、事前に定義したパターンファイルにマッチしなくな り、攻撃の検知が不可能な点が挙げられる。図2.2はシグネチャ検知と難読化につSignature Database …7368656c6c636f6465… Signature File 736865 6c6c636f 6465 Match …3663363536373639373 436393664363137343635… …333636333336333533 3633373336333933373334 3336333933363634333633 313337333433363335… Obfuscation Obfuscation 図2.2 シグネチャ検知と難読化 いてであり、難読化される前の状態ではシグネチャデータベース上にシグネチャ ファイルが存在しているが、難読化を施すことでシグネチャが変化し、事前に定義 されたシグネチャのパターンファイルにヒットしなくなる。既存研究[7]ではアン チウイルスソフトで検知されるマルウェアに対して、アンチウイルスソフトを利用 し通常のマルウェアと難読化を施したマルウェアの検知率について評価を行ってい る。評価には20種類のアンチウイルスソフトと著者が保有しているマルウェアの サンプルセットを利用しており、サンプルセットに3パターンの難読化を施して検 証を行っている。難読化を施さない状態での平均検知率は86.85%であったのに対 して、最も単純なコメントや空白、変数名や関数名を変えるランダム難読化では検 知率が55.3%となり、長い文字列を複数に分割など行うデータ難読化においては検 知率が45.7%であった。また、文字列全てをアスキーコードやユニコードに置き換 えるエンコード難読化を施した場合はアンチウイルスソフトで検知が不可能であっ た。このことからもシグネチャ検知ではJavaScriptやJavaといったプログラミン グ言語で用いられる難読化を施されることで、攻撃の検知が困難になることが明ら かである。また、この難読化は図2.2のように、何重にも施すことで簡単にシグネ
チャを変更できることからも攻撃の検知は困難である。 2.2.2 サンドボックスを利用した動的解析 サンドボックスは動的解析を行うものであり、仮想環境などを利用して隔離環境 を作成し、事前にウェブサイトのスクリプトや実行ファイルを実行して悪性判定を 行うものである。セキュリティ関連の会社からもサンドボックス製品が登場してお り、メールに添付されたURLを事前に読み込むことでウェブサイトのスクリプト の確認や添付されたファイルの確認が可能となる。研究を目的としたサンドボック
スとして、Wepawet[11]やCuckoo Sandbox[12]などが存在しており、オンライン
やオープンソースとしてサンドボックス環境を利用することも可能である。 サンドボックスやマルウェア収集を目的としたハニーポットといった動的解析技 術の問題点として、クローキング[17][18]を利用した仮想環境上では動作しないマ ルウェアや悪性のサイトが存在している。クローキングは動的解析などを回避する ことを目的とした手法であり、ユーザや実行環境の情報収集を行う。クローキング によって収集される情報は用途によって異なるがブラウザフィンガープリントや Referrer、動作環境といった情報が収集される。ブラウザフィンガープリントでは ユーザが利用しているウェブブラウザの情報やインストールされているプラグイン の種類やバージョン情報などを取得することで、ユーザが利用しているブラウザの 脆弱性を知ることが可能となる。また、Referrerを利用したクローキングでは経由 してきたウェブサイトを調べることで、指定したルートを通ってウェブサイトにア クセスしてきたかの確認が可能となる。悪性のウェブサイトではブラウザフィン ガープリントやreferrerを利用して、ユーザのブラウザやプラグインの情報を収集 し、ユーザの環境に適した攻撃や一時的に悪性のウェブサイトを無害に見せること も可能となる。 図2.3はクローキングを用いたサンドボックス回避が行われた場合の図である。 サンドボックス上でダウンロードされた攻撃コードを含んだhtmlファイルやマル ウェアの実行ファイルが実行されるが、クローキングによってサンドボックス環境 と判定された場合にサンドボックス上では実行されず、ユーザのブラウザ上で実行 される仕組みとなっている。
SandBox
Malicious
Attack code not Execute (Cloaking) Browser Attack code Execute.EXE not Execute
(Cloaking) .EXE Execute
図2.3 サンドボックスとクローキング 2.2.3 ウェブクローリングを用いたブラックリスト検知 ウェブクローリングはハニーポットなどを利用してウェブを巡回し、ウェブに関 する情報を収集する方法である。ドライブバイダウンロード攻撃検知ではこのウェ ブクローリングを利用して、悪性のウェブサイトにアクセスを行い、マルウェアや 通信ログといった情報を収集してブラックリストに活用する提案[5]がされている。 この手法ではハニーポットを利用して事前に悪性のウェブサイトと思われるウェブ サイトにアクセスし、悪性のウェブサイトを発見してブラックリストに追加すると いったものである。ウェブクローリングを利用してブラックリストを常に更新す ることで、ドライブバイダウンロード攻撃の被害を抑えることが可能となる。しか し、ブラックリストを用いた検知手法の問題点として、インターネット上に短期間 で消滅するウェブサイトを利用した、1日限定サイト[16]が上げられる。この1日 限定サイトは短期間で出現と消滅を繰り返すウェブサイトのことで、ブラックリス ト対策として用いられる。また、DGA (ドメインジェネレーションアルゴリズム) を用いた手法が存在する。DGA はドメイン名を特定のアルゴリズムを用いて作成 する手法で、特定のシード値や関数を利用してドメイン名を生成する。このDGA を用いることでブラックリストの回避が可能となる。このようにブラックリストを 用いた手法では1日限定サイトやDGAを用いられることで容易に検知を回避され る可能性がある。
2.3
難読化
本節ではウェブページで難読化が利用される目的と複雑な難読化の種類について まとめた。 2.3.1 難読化の目的 難読化はウェブサイトやソフトウェアなどの様々な分野で利用されており、一般 的にはコードのプライバシーや知的財産を守るために難読化の処理が行われる。難 読化はJavaScriptやJavaで利用されており、難読化の処理を行うことでコードの リバースエンジニアリングを困難にし、コードの解読を困難にすることが可能とな る。難読化はほぼ全てのウェブサイトで利用されており、良性の難読化と悪性の難 読化の判断が困難である。 2.3.2 難読化の種類 JavaScriptの難読化手法には複数の方法が存在しており、既存研究[7]ではラン ダム難読化、データ難読化、エンコード難読化に分類されている。データ難読化お よびエンコード難読化には難読化手法が複数存在しており、それらの特徴によって 分類を行っている。図2.4はオリジナルのコードとなっており、自ら定義した関数 に引数を与えることで、引数の値がアラートで表示されるものである。このオリジ ナルコードに対して各難読化を施した例が図2.5, 図2.6,図2.7となる。 ランダム難読化 ランダム難読化は関数名や変数名を変更することで、関数や変数の動作をわかり づらくすることが可能となる。また、コメントや空白を追加することでシグネチャ を変化させることも可能である。図2.5では関数名と変数名を意味のない別の文字 列へ変化させている。<script>
function myAlert(txt){
alert(txt);
}
var string=“Hello World!!”;
myAlert(string);
</script>
図2.4 オリジナルコード<script>
function _cd(ab){
alert(ab);
}
var ok=“Hello World!!”;
_cd(ok);
</script>
図2.5 ランダム難読化 データ難読化 データ難読化は意味のある文字列を分割し、関数や文字列の結合といった手法で 意味のある文字列に戻す方法となる。データ難読化には様々な分割方法が存在して おり、図2.6はデータ難読化の中で用いられる手法の1つである。図2.6は意味の ある文字列を複数の変数に分割して格納し、文字列の加算 (+) を利用して順番に 文字列の結合を行い、eval()‡やdocument.write()§といった関数を利用するこ とでhtml内に書き込みを行っている。その他の手法に分割した文字列を変数に格 納せずに文字列の加算のみを行うものや結合に用いる関数を定義しておき、関数を 使って文字列の結合を行うものが存在している。 エンコード難読化 エンコード難読化では意味のない文字列を意味のある文字列に変更する難読化手 法であり、文字列の変更には複数の手法が存在している。文字列をASCIIコードや Unicodeへ置き換えてデコードにunescape()¶を用いる手法やデコード用の関数 を定義しておき関数を利用してデコードするものも存在しており、図2.7はオリジ ナルのコードをASCIIコードに変換したものである。ASCIIに変換した文字列を ‡JavaScriptの関数であり、引数の値を実行し評価を行う。 §JavaScriptの関数であり、htmlのドキュメントに引数の値を書き出すことが可能である。 ¶JavaScriptの関数であり、文字列のデコードを行う。<script>
var co = “ert(txt)“;
var pg = “ello World!“;
var am = “functi“;
var qf = “tring=\“H“;
var jl = “ing)“;
var ne = “xt);}var s“;
var rh = “!\”;myA“;
var wb = “on myAl“;
var ik = “lert(str“;
var sd = “{alert(t“;
document.write(am+wb+co+sd+ne+qf+pg+rh+ik+jl);
</script>
図2.6 データ難読化 unescape()を用いてデコードし、document.write()でhtmlへの書き込みを行っ ている。デコード関数を定義する方法ではcharAt()∥やString.replace()∗∗と いった文字列を操作するJavaScriptの関数を利用して、文字列の置換や並び替え によって意味のある文字列を作成する。 2.3.3 難読化による問題点 難読化の利用には大きな問題点がある。悪性のウェブサイトでは難読化を用いて 攻撃検知技術を回避しているのに対して、良性のウェブサイトでは知的財産やコー ドのプライバシーを守るために利用されている。良性と悪性のウェブサイトの両方 で難読化は利用されており、難読化の手法も似たものが利用されている。このこと ∥JavaScriptの関数であり、指定された位置の文字を得られる。 ∗∗JavaScriptの関数であり、条件にマッチした文字列を指定した文字列に置き換える。<script>
document.write(unescape(%66%75%6e%63%74%69%6f%6e
%20%6d%79%41%6c%65%72%74%28%74%78%74%29%7b
%61%6c%65%72%74%28%74%78%74%29%3b%7d
%76%61%72%20%73%74%72%69%6e%67%3d%e2%80%9c
%48%65%6c%6c%6f%20%57%6f%72%6c
%64%21%21%e2%80%9d%3b%6d%79%41%6c
%65%72%74%28%73%74%72%69%6e%67%29%3b));
</script>
図2.7 エンコード難読化 からも難読化には良性と悪性の区別が存在せず、難読化の手法による良性と悪性の 判別は困難なことが挙げられる。悪性と良性の難読化の分類が可能であれば、難読 化手法による悪性判定が可能となる。3
章 難読化の調査および分類
本章では良性と悪性の難読化について静的解析で調査を行い、調査結果から難読 化の分類を行う決定木を作成し、決定木の評価を行った。3.1節では正規のウェブ サイトで利用されている難読化および悪性のウェブサイトで利用されている難読化 についての定義を行った。3.2節では調査に利用したデータセットについて述べ、 3.3節では静的解析を行った際の難読化の調査結果を記す。3.4節では3.3節で得ら れた結果から難読化の分類を行う決定木を作成し、難読化の分類を行った。3.5節 では3.4節の分類結果では判定が困難であった難読化についての調査を行った。3.1
良性と悪性の難読化の定義
難読化には良性と悪性の難読化が存在しており、両者が難読化を施す目的は異 なっていると考えられる。良性の難読化ではコードの処理性能向上やコードのプラ イバシーや知的財産を守ることを目的として可読性を失くすための難読化が施され ている。それに対して、悪性の難読化ではシステムやソフトウェアの脆弱性を攻撃 するために検知システムを回避することを目的に利用されていると考えられる。こ れは攻撃コードに難読化を施すことでシグネチャが変化し、シグネチャを用いた攻 撃の検知が困難になるためである。これは図2.4で利用されているalert() がラ ンダム難読化を施した図2.5では確認できるのに対して、データ難読化を施した図 2.6やエンコード難読化を施した図 2.7 では確認できないことがわかる。このよう に良性と悪性の難読化では目的の違いから利用されている難読化の種類が異なり、 良性の難読化では利用している関数やドメインやファイル名といったものが静的解 析で判別できるのに対して、悪性の難読化では判別できないようにしていると考え られる。3.2
データセットについて
前節で定義した難読化の調査のため、正規のウェブサイトおよび悪性のウェブサ イトのhtmlファイルおよびjsファイルを用意した。正規のウェブサイトとして、Alexaインターネット[13]のグローバル トップサイトに掲載されているウェブサ
イトを抽出した。データの取得環境はMac OSX 10.9のGoogle Chromeを使用
し、Google ChromeのデベロッパーツールからGoogle Chrome上に読み込まれた
トップページおよび読み込まれたJavaScriptファイルを調査の対象とした。また、 悪性のウェブサイトとして、MWS (マルウェア対策研究人材育成ワークショップ) データセット2014[14]の中で提供されている D3Mデータセットの 2011年から 2014年までのものを利用し、pcapファイルからhtmlファイルおよびjsファイル を復元し、検証に利用した。D3Mデータセットはドライブバイダウンロード攻撃 に関する通信を記録したデータセットであり、NTT研究所が作成したMarionetto を利用して公開ブラックリストを巡回した際に得られた通信データが提供されてい
る。D3Mデータセットとは別にMalwr.com[15]のRecent Analysisから解析結果
で悪性と判定されたhtmlファイルを取得して調査の対象とした。Malwr.comはフ リーのオンラインマルウェア解析サービスであり、ユーザがファイルをアップロー ドすることで解析結果を得ることができ、他のユーザと解析結果および検体ファイ ルの共有が可能となっている。 データセットの解析環境にはマルウェアの解析やリバースエンジニアリングツー ルが含まれている Ubuntu のディストリビュートであるREMnux を利用した。 REMnux上でPythonを用いて文字列の解析や分類を行った。また、解析には各 データセットからスクリプトタグ部分を抽出して利用した。 表3.1は各データセットから得られたファイル数および、各データセットの全て のファイルの行数を合計したものとファイルからスクリプトタグを抽出した際の行 数である。良性と悪性のファイル数および行数がほとんど同じなのに対して、スク リプトの行数は悪性のウェブサイトの方が多いことがわかる。
3.3
難読化の調査
正規のウェブサイトおよび悪性のウェブサイトを調査した結果として、以下の特 徴を得ることができた。良性の難読化では主にランダム難読化とデータ難読化が 利用されており、エンコード難読化は利用されていないことが確認できた。また、 コードの可読性を維持するための改行やインデントといったものが利用されていな表3.1 データセットごとのファイル数および行数
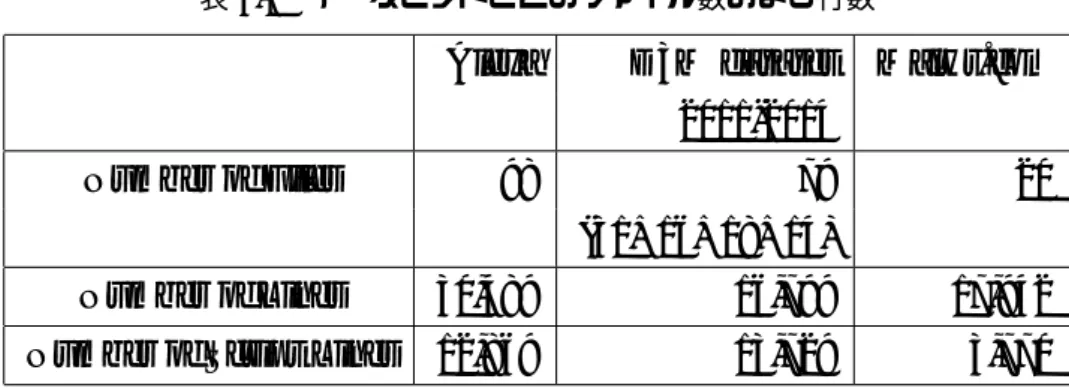
Alexa D3M dataset Malwr.com 2011-2014
Number of Files 98 79 20 (31+16+18+14)
Number of Lines 30,489 16,799 17,942 Number of Script Lines 12,869 13,729 3,770
いウェブサイトが多く見られた。次に、悪性の難読化ではランダム難読化、データ 難読化、エンコード難読化が利用されいることを確認した。また、悪性の難読化の 多くはエンコード難読化が施されており、攻撃コードの本体がエンコード難読化に よって隠されていると考えられる。一部の難読化ではエンコード難読化後にデータ 難読化が施されている複数の難読化を組み合わせたケースも確認された。 一行が2000文字以上の行について調査すると正規のウェブサイトではインデン トや改行といった可読性を維持する方法が用いられていないことが多いのに対し て、悪性のウェブサイトではエンコード難読化を施したものがほとんどであった。 3.3.1 静的解析による調査 良性の難読化で利用されている難読化の種類の調査として、Alexaインターネッ トのトップ 100 サイトからトップページとなるソースコードおよび、関連する ソースコードを取得し、全てのファイルで利用されている難読化についての調査を 行った。 結果として、正規のウェブサイトではエンコード難読化の利用を確認することが できなかった。正規のウェブサイトで利用されている難読化には、主にランダム難 読化と改行やインデントを用いない可読性を失くすための難読化が多くもちいられ ており、ソースコードの解読が困難ではあるが不可能なものは存在していなかった。 また、難読化を利用していない正規のウェブサイトも存在しており、全てのウェブ サイトで難読化が利用されているわけではなかったが、難読化を利用しているウェ
ブサイトがほとんどであった。 3.3.2 1行の長さと区切り文字に注目した分析 良性の難読化で用いられる可読性を失くす難読化やエンコード難読化に見られる 1行あたりの文字列の長さに着目し、調査を行った。両者で異なる点として、良性 の難読化では改行を使用していないことで1行の文字列が長くなっているのに対し て、エンコード難読化では攻撃コード全体を1行の文字列に置き換えているため、 1行の長さと区切り文字の数で特徴が出ると考えられる。JavaScriptでは区切り文 字にカンマやセミコロンといった記号が用いられており、1行あたりの文字列の長 さと区切り文字の数に注目した結果が図3.1となる。横軸が 1行あたりの文字列の 長さであり、縦軸は区切り文字となるカンマとセミコロンの合計となる。 !" !#"" !$""" !$#"" !%""" !%#"" !&""" !&#"" !'""" !" !%"""" !'"""" !("""" !)"""" !$""""" * + ,-./! 0 1! 2! 3 !! 4 5.*678!01!97/:*69!;!5:*. 5.6:7:,<7. =&>%"$$ =&>%"$% =&>%"$& =&>%"$' ><?@/AB0,
①
②
③
図3.1 1行の長さと区切り文字の数 図3.1ではグループ分けを行い、グループごとの内容の確認した。図3.1から正 規のウェブサイトで用いられている1行の文字列の長さと区切り文字の数は一定の 割合で増加しており、改行やインデントといった可読性を失くす難読化を用いられているものがほとんどであった。また、その他に見られた難読化はランダム難読化 およびデータ難読化であった。一方で悪性のデータセットは図3.1の(1)や(2)の ように1行の長さに対して区切り文字がほとんど存在していないものや、正規の 難読化に比べて区切り文字の数が多いものが存在している。図3.1の(1)ではエン コード難読化を用いているものや(2)では区切り文字を用いて文字列のreplace() を用いた手法がほとんどであった。 これらの結果についてクラスタリング手法を用いてクラスタリングを行ったが全 ての結果が同じとなり、良い結果は得られなかった。利用したクラスタリング手法 はR言語で実装されているward法、k-means法、完全連結法、重心法について試 したが全て同じ結果となり、今回のデータを利用したクラスタリングでは有効な結 果を得ることが不可能であった。 以下の図3.2、図3.3、図3.4、図3.5は各データセットごとのグラフである。表 示している範囲が異なっており、左側の図は区切り文字は4000個以下および文字 列の長さは11万字以下となっている。右側の図は区切り文字は100個以下となり、 文字列の長さは1000字以下となっている。 !" !#"" !$""" !$#"" !%""" !%#"" !&""" !&#"" !'""" !" !%"""" !'"""" !("""" !)"""" !$""""" * + ,-./! 0 1! 2! 3 !! 4 56*.!7.*89: ;<=,>76?60+@=A&,%"$$<7.*;!+@6*8!$B' ;<=,>76?60+@=A&,%"$%<7.*;!+@6*8!$B' !"# !$# !%# !&# !'# !(# !)# !*# !+# !"## !# !"## !$## !%## !&## !'## !(## !)## !*## !+## !"### , -./ 01! 2 3! 4! 5 !! 6 78,0!90,:;< =>?.@98A82-B?C%.$#"">90,=!-B8,:!"D& =>?.@98A82-B?C%.$#"$>90,=!-B8,:!"D& 図3.2 データセットごとのプロット(D3M2011-2012)
!" !#"" !$""" !$#"" !%""" !%#"" !&""" !&#"" !'""" !" !%"""" !'"""" !("""" !)"""" !$""""" * + ,-./! 0 1! 2! 3 !! 4 56*.!7.*89: ;<=,>76?60+@=A&,%"$&<7.*;!+@6*8!$B' ;<=,>76?60+@=A&,%"$'<7.*;!+@6*8!$B' !"# !$# !%# !&# !'# !(# !)# !*# !+# !"## !# !"## !$## !%## !&## !'## !(## !)## !*## !+## !"### , -./ 01! 2 3! 4! 5 !! 6 78,0!90,:;< =>?.@98A82-B?C%.$#"%>90,=!-B8,:!"D& =>?.@98A82-B?C%.$#"&>90,=!-B8,:!"D& 図3.3 データセットごとのプロット(D3M2013-2014) !" !#"" !$""" !$#"" !%""" !%#"" !&""" !&#"" !'""" !" !%"""" !'"""" !("""" !)"""" !$""""" * + ,-./! 0 1! 2! 3 !! 4 56*.!7.*89: ;<=,>76?60+@=,>7A/<7.*;!+@6*8!$B' !"# !$# !%# !&# !'# !(# !)# !*# !+# !"## !# !"## !$## !%## !&## !'## !(## !)## !*## !+## !"### , -./ 01! 2 3! 4! 5 !! 6 78,0!90,:;< =>?.@98A82-B?.@9C1>90,=!-B8,:!"D& 図3.4 データセットごとのプロット(Malwr.com)
!" !#"" !$""" !$#"" !%""" !%#"" !&""" !&#"" !'""" !" !%"""" !'"""" !("""" !)"""" !$""""" * + ,-./! 0 1! 2! 3 !! 4 56*.!7.*89: ;<=7.8696,>9.=7.869<7.*;!+?6*8!$@' !"# !$# !%# !&# !'# !(# !)# !*# !+# !"## !# !"## !$## !%## !&## !'## !(## !)## !*## !+## !"### , -./ 01! 2 3! 4! 5 !! 6 78,0!90,:;< =>?90:8;8.@;0?90:8;>90,=!-A8,:!"B& 図3.5 データセットごとのプロット(Legitimate Site) 各グラフの調査として、1行が0-100文字の行では難読化のほどこされていない 通常のコードが書かれており、1行が100文字以上において、各難読化が施された ケースが見られた。また、1行が500文字前後において、図3.3や図 3.5のような 特徴的な結果が見られた。これはデータ難読化のようなものが利用され、一定の文 字列の長さに達した段階で文字列を分割していると考えられる。 3.3.3 1行の長さの割合に注目した分析 次に、各データの1 行の長さとその数についての調査を行った。図3.6は1行 の長さを0、100、600、2000で区切り、各範囲をパーセントで表示したものであ る。図3.6の左側5つが1年ごとのD3MのデータセットおよびMalwr.comの悪 性データセットであり、legitは正規のウェブサイトの合計である。右側の10個は 今回の調査で利用した正規のウェブサイトである。各区切りの基準として、前節の 調査結果から1行の長さが0-100文字の行では難読化が行われていない通常の短い コードが多く存在して、長さが100-600文字の行では通常のコードにしては長く、 エンコード難読化が施された長さではないと考えられることからデータ難読化が用 いられている可能性がある。また、600文字以上ではエンコード難読化が用いられ ている可能性もあり、データ難読化が文字列の分割を行うことから2000文字以上 にはデータ難読化は存在していないと考えられる。文字列の長さが100文字以上は 良性のウェブサイトで用いられる難読化と考えられる。 図3.6から正規のウェブサイトでは1行の長さが600文字以上の行が約12%存
在しているのに対して、悪性のウェブサイトでは約1-3%となった。この結果から 悪性のウェブサイトでは正規のウェブサイトで利用される可読性を失くすための難 読化をあまり利用していないと考えられる。また、図3.6からも各データセットに おいて、難読化手法の違いがグラフに表れていると考えられる。図3.6のliveが悪 性のデータセットと同じ傾向を示しており、確認を行った結果、難読化が利用され ていないことが確認できた。 図3.6の結果を元に1行の長さと難読化について確認を行った。悪性のウェブサ イトにおいて、1行が600文字以上あるものの多くは難読化で利用される文字列や 難読化に関係するものであり、2000文字を超えるもののほとんどがエンコード難読 化で利用される文字列であった。また、正規のウェブサイトの文字列の長さが100 文字以上のものは改行やインデントのない圧縮されたJavaScriptの利用や動的な htmlを生成するための文字列が多く見られた。 !" !#" !$" !%" !&" !'" !(" !)" !*" !+" !#"" ## #$ #% #& ,-./ 0 .12 34 4/ 34 - ,-5 6 -37 8 16 -9 :6 2 ; ; 2 .1 .3< 1 / 3=3 9-> 48 6 1 $"""? (""?$""" #""?("" "?#"" 図3.6 1行の長さと比率
3.4
調査結果を用いた決定木による分類
前節の結果から静的解析による難読化の分類として、決定木の作成を行った。図 3.7は作成した決定木であり、分類基準として1 行あたりの文字列の長さとカン マやセミコロンといった区切り文字を利用した。また、動的にhtml を生成する JavaScriptがエンコード難読化に混ざることが予想されるため、誤検知を回避する ために動的なhtml生成で用いられるdivやコロン、httpといった文字列を利用し て誤検知の回避を行った。 A A : Length of Line B : total ( , & ; ) C : total (div & http & :)0 < A < 100 100 < A < 2000 A/B < 200 2000 < A A A / B Encode randam & data normal 100-400 400 < A A < 400 A / B 200 < A / B B : C B < C C < B A/B < 10 10 < A/B < 95 95 < A/B B:C B < C C < B Start 図3.7 文字列の長さを利用した難読化の分類 決定木を用いて分類を行った結果が表3.2である。結果から決定木を用いてエン コード難読化の分類は可能であったが、見落としが8件、誤検知が10件確認され た。見落としの4件に関しては分類パラメータを変更することでエンコード難読化
の分類は可能であるが、残りの4件に関してはエンコード難読化とデータ難読化 が組み合わされたものが存在しており、エンコード難読化としての分類は困難であ ると考えられる。また、ランダムおよびデータ難読化と分類されたものは正しいこ とが確認できた。良性の難読化ではエンコード難読化と分類されたものには動的な htmlを作成するための要素となるコードが記載されており、この結果からも良性 の難読化ではエンコード難読化が用いられていないことがわかる。また、悪性の難 読化においても1行の文字列の長さが0-100に分類される文字列が多いことから、 可読性を失くすための難読化が用いられているものは少ないことがわかる。 表3.2 決定木を用いた各行の分類結果 Legitimate Malicious Normal 0-100 4,859 16,566 Normal 100-400 2,328 600 Random & Data 5,672 275 Encode 10 58
3.5
ランダムおよびデータ難読化の特徴調査
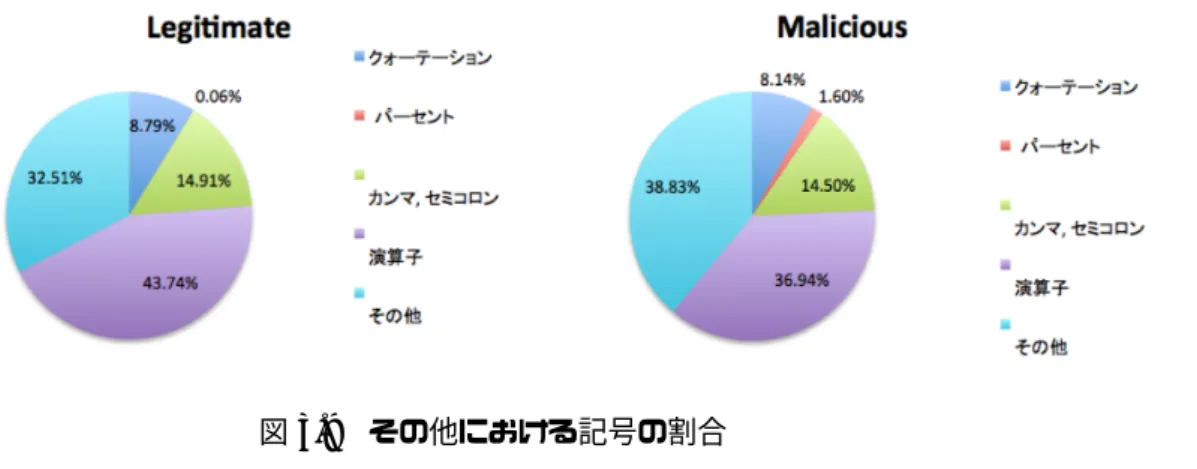
決定木を用いて分類した際にランダムおよびデータ難読化と判定された行につい て、使用されている文字の割合や頻度分布を用いた特徴の調査を行った。 3.5.1 文字の割合に関する調査 ランダムおよびデータ難読化と分類されたデータにおける文字の使用率を調査し た。分類方法の基準として、英字および数字とその他に分類を行った。分類結果は 表3.3 および図3.8 となる。分類結果として総文字数に10倍ほどの差があるが、 図3.8からもわかるように悪性の難読化において、数字の利用率が高いことがわか る。これはASCIIコードやUnicodeといったものが悪性の難読化で頻繁に使用さ れている可能性が考えられる。また、その他に関して図3.9は区切り文字や演算子といった記号に分けて解析を行ったが使用率は同じであった。良性に比べて、悪性 の難読化で数字の使用率が高いことがわかる。これはエンコード難読化でASCII コードやUnicodeといった手法で数字が利用されていることが考えられるが、図 3.9から ASCIIコードで用いられる %といった記号の使用率が良性と悪性の難読 化で変わらないため、数字はエンコード難読化のみで利用されているとは断定でき ず、その他の用途でも利用されていると考えられる。 表3.3 各文字の使用数 Legitimate Malicious Letter 3,185,888 203,521 Number 119,782 78,427 Other 1,570,242 138,352 !"#$%&' (#%!&' $(#()&' !"#$%&'(") *+,+-' ./01+-' 234+-' !"#!$%& '"#((%& )$#*$%& !"#$%$&'() +,-,.& /012,.& 345,.& 図3.8 使用されている文字の割合
図3.9 その他における記号の割合 3.5.2 頻度分布を利用した調査 3.4節で得られた結果からランダムおよびデータ難読化と分類されたデータのノ イズ除去を行った後にPythonのnltkライブラリを利用して頻度分布を使った調 査を行った。図3.10は頻度分布を出力するまでのフローを表しており、図3.8お よび図3.9から良性と悪性の難読化において、記号の利用率に差異はないと考えら れるため、ノイズ除去には表3.3でotherと分類した記号をスペースに置き換え、 置き換えの際に生成される複数のスペースを1つにまとめたものを頻度分布のデー タとして用いた。また、頻度分布の結果から、良性のデータセットから得られた JavaScriptやActiveXといった関数などのウェブページ上で意味のある文字列お よび、nltkで用意されている英語の語彙をまとめたコーパスから難読化されたコー ドとマッチする可能性のあるofやnoといった文字列の長さが2以下のものを除去 し、英語の語彙コーパスで文字列長が3以上のものをまとめて、ノイズ除去用コー パスを作成した。次に検証用データから作成したノイズ除去用コーパスを利用し て意味のある文字列を除去し、頻度分布による出力および、残った文字列の調査を 行った。ノイズ除去で利用した意味のある文字列の単語数は約12万5千語であり、 これらに部分一致した単語はノイズとして除去した。図3.11は例文を使ったノイ ズ除去のフローを表している。
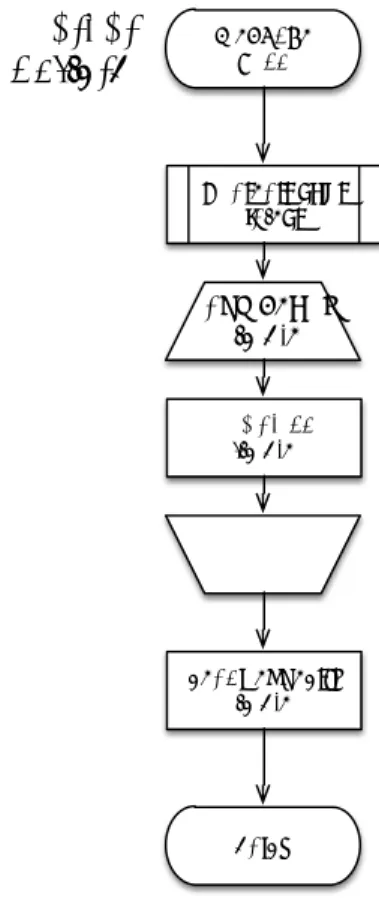
ノイズ除去
Start 記号をスペースに 置き換える 無駄なスペースの 除去 特定文字列の 除去 頻度分布の出力 End 図3.10 頻度分布生成フローfunction gud(){var qklvoan = 64; for( var cfld=0; cfld<140; cfld++){qklvoan++};return qklvoan;}
function gud var qklvoan 64 for var cfld 0 cfld 140 cfld qklvoan return qklvoan
function gud var qklvoan 64 for var cfld 0 cfld 140 cfld qklvoan return qklvoan
function gud var qklvoan 64 for var cfld 0 cfld 140 cfld qklvoan return qklvoan
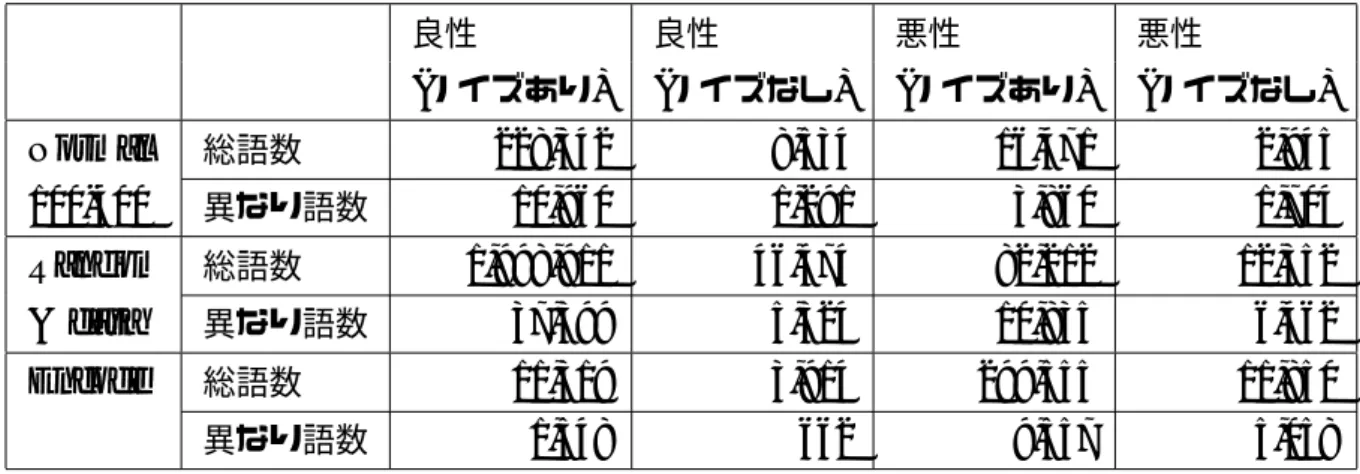
記号をスペースへ変換 意味ある文字列の削除 複数のスペースをまとめる 図3.11 例) ノイズ除去フロー 表3.4は悪性と良性の難読化について、ノイズ除去の有無による単語の総数およ び異なり語数∗の総数となる。検証対象とした良性の難読化には 3.3節の難読化調
査で用意した良性のデータセットとは別に新たにAlexa global topsiteからGoogle
Chromeで閲覧した際に得られるトップページおよび関連するJavaScript ファイ ルを10サイト分取得した。同じJavaScriptが複数回取得されるものに関しては、 1つのファイルのみ取得し、総ファイル数を悪性のデータセットと同数にした。 表3.4の結果からランダムおよびデータ難読化に分類されたものにおいて、悪性 の難読化は解読できる意味のある文字列の除去を行うことで、総単語数で意味の理 解が困難な単語が約15.0%に減少するのに対して、良性では約 2.3%となってい る。また、異なり語の数で見ても悪性では除去された意味のある単語が半分にも満 たないのに対して、良性では約14.2%と大幅に低下する。異なり語数がノイズあり からノイズなしへの単語数の変化が、悪性では半分にもならないものが多く、これ ∗ ユニークな単語であり、単語の出現回数が複数回であっても1とカウントする。
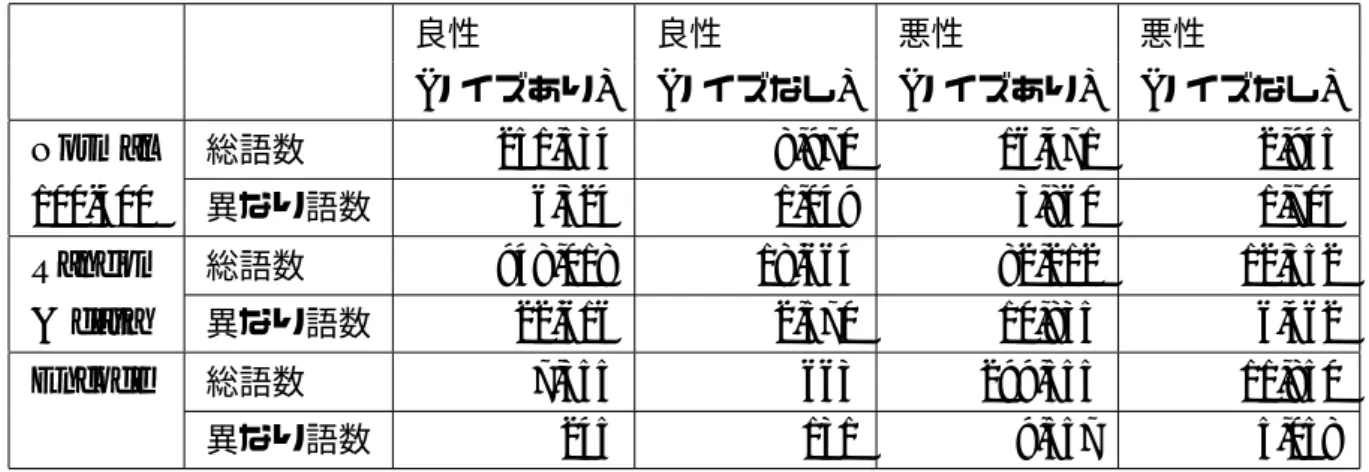
表3.4 ノイズ除去前後におけるデータセットの単語数 良性 良性 悪性 悪性 (ノイズあり) (ノイズなし) (ノイズあり) (ノイズなし) Normal 総語数 228,342 8,534 16,471 2,945 100-400 異なり語数 10,960 1,291 3,860 1,704 Random 総語数 1,998,911 46,474 82,212 12,352 & data 異なり語数 37,399 5,324 10,835 6,462 Encode 総語数 11,319 3,914 299,555 11,850 異なり語数 1,548 662 9,557 5,058 らと決定木を組み合わせて指標とすることで、良性と悪性の判断が可能になると考 えられる。 また、表3.4は英語圏の正規のウェブサイトから収集した結果であるため、英単語 のコーパスを使用した場合に日本語のウェブサイトと比較して、ノイズ除去率が高 いことが考えられる。そのため、日本語を用いる正規のウェブサイトのJavaScript を収集し、再評価した結果が表3.5となる。再評価に利用したウェブサイトは表 3.6である。 再評価の結果として、日本語のウェブサイトは英語のウェブサイトと似た傾向が 得られた。エンコード難読化で悪性と似た傾向が見られるが、これはノイズ除去前 の異なり語の数が極端に少ないことが原因と考えられる。英語と日本語のノイズ除 去率が変わらない要因として、日本語のウェブサイトのJavaScriptコードで、日本 語の使用率が結果に影響を及ぼさない範囲である可能性が高い。その結果、ノイズ 除去率が英語と日本語のサイトで変わらない結果が得られたと考えられる。
表3.5 ノイズ除去前後におけるデータセットの単語数 追加検証 良性 良性 悪性 悪性 (ノイズあり) (ノイズなし) (ノイズあり) (ノイズなし) Normal 総語数 251,534 8,970 16,471 2,945 100-400 異なり語数 6,324 1,049 3,860 1,704 Random 総語数 948,018 18,664 82,212 12,352 & data 異なり語数 22,616 2,570 10,835 6,462 Encode 総語数 7,355 663 299,555 11,850 異なり語数 245 131 9,557 5,058 表3.6 追加検証で利用したウェブサイト
Yahoo.co.jp amazon.co.jp youtube.com rakuten.co.jp twitter.com livedoor.com ameblo.jp goo.ne.jp naver.jp tabelog.com
3.6
難読化分類における考察
難読化の調査結果が表3.7となり、悪性の難読化では全ての種類の難読化が使用 されるのに対して、良性の難読化ではエンコード難読化を利用していないことが確 認できた。また、良性の難読化ではインデントや改行を使用していない難読化が使 用されていることが確認できた。この難読化はGoogle で提供されているClosure Compiler[24]などが利用されていると考えられる。 一方で、良性の難読化では1行の中に意味のある文字列として認識できる単語が 悪性の難読化に比べて多いことが考えられる。そのため、意味のある文字列をノイ ズとして除去した際の除去率を要素として、決定木に反映することで、決定木によ る良性と悪性および難読化の種類の分類が可能と考えられる。決定木を用いた難読 化の分類が可能と考える理由として、決定木でエンコード難読化と分類された良性 と悪性の文字列の違いである。エンコード難読化と分類されたデータを調査したと ころ、悪性のエンコード難読化はASCIIコードで記述されたものがほとんどであり、ノイズ除去を行っても意味のある単語と判断されない。それに対して、良性で エンコード難読化と分類された行はhtmlの構成情報を書き込まれたものがほとん どであり、ノイズ除去を行うことで、ほとんどの意味のある文字列がノイズとして 除去されることが予想できる。そのため、ノイズとして除去された単語の割合を指 標として決定木に反映することは有用だと考えられる。また、同様に1行あたりの 文字列の長さが100-400のものに関してもデータ難読化が混じっている可能性が高 いが、文字列が切り離されているために意味のある単語として除去されない可能性 が高く、良性に比べてノイズとして除去される単語数が少ないことが考えられる。 今回の調査において、問題となった点がスクリプトの処理時間である。意味のあ る文字列をノイズとしたノイズ除去の作業において、1つの単語を調査する場合に 約14.5万語の部分一致の確認を行うため、1単語あたりの処理時間が長く、現状で は実用性に欠ける点が今後の課題となる。 表3.7 確認された良性および悪性の難読化 難読化 ランダム データ エンコード インデントおよび改行なし 良性 ○ ○ × ○ 悪性 ○ ○ ○ △
![図 2.3 サンドボックスとクローキング 2.2.3 ウェブクローリングを用いたブラックリスト検知 ウェブクローリングはハニーポットなどを利用してウェブを巡回し、ウェブに関 する情報を収集する方法である。ドライブバイダウンロード攻撃検知ではこのウェ ブクローリングを利用して、悪性のウェブサイトにアクセスを行い、マルウェアや 通信ログといった情報を収集してブラックリストに活用する提案 [5] がされている。 この手法ではハニーポットを利用して事前に悪性のウェブサイトと思われるウェブ サイトにアクセスし、悪性の](https://thumb-ap.123doks.com/thumbv2/123deta/7045031.789188/22.892.152.743.188.432/ウェブクローリングウェブクローリングドライブバイダウンロード.webp)