2.6 2 次元プラズマ粒子(PIC)コードの測定評価および宇宙プラズマ5次元ブラソフコード
Vlasov5 の測定評価
名古屋大学宇宙地球環境研究所 梅田 隆行2.6.1 2次元プラズマ粒子(PIC)コードの測定評価
2.6.1.1 はじめに Particle-In-Cell(PIC)法 は、1960 年 代 にプラズマ粒 子 と電 磁 場 との相 互 作 用 のシミュレーシ ョン手 法 として考 案 されて以 来 、様 々な分 野 において幅 広 く用 いられている。オリジナルの PIC 法 は、プラズマ物 理 及 び電 波 科 学 分 野 において開 発 され、格 子 点 (Cell)上 に定 義 された電 磁 場 をマックスウェル方 程 式 により解 き進 め、その電 磁 場 Cell 中 を荷 電 粒 子 が加 減 速 を受 けながら動 きまわることから PIC と名 付 けられた。現 実 空 間 に存 在 する膨 大 な数 の荷 電 粒 子 を有 限 の計 算 機 資 源 で扱 うことは不 可 能 であるため、PIC 法 では、ある程 度 まとまった数 の荷 電 粒 子 の集 団 を 1 つの“超 ”粒 子 (super-particle)として扱 っている。PIC 法 では、ラグランジュ変 数 である粒 子 の 位 置 及 び速 度 と、オイラー変 数 である電 磁 場 がデータ配 列 として混 在 しているため、スカラ型 超 並 列 計 算 機 において高 い性 能 を得 るのは容 易 ではない。そのため、様 々なスカラ型 CPU におけ る性 能 特 性 を理 解 しておく必 要 がある。 2.6.1.2 プログラム概 要 プラズマ粒 子 の運 動 は、以 下 の荷 電 粒 子 の運 動 (ニュートン・ローレンツ)方 程 式 によって記 述 される。 n nv
t
r
=
d
d
(1)(
E
v
B
)
m
q
t
v
n n n n
×
+
=
d
d
(2) また電磁場の時空間発展は以下のマックスウェル方程式によって記述される。t
E
c
J
B
∂
∂
+
=
×
∇
2 01
µ
(3)t
B
E
∂
∂
−
=
×
∇
(4) さらに、荷 電 粒 子 が作 る電 流 を計 算 するために、以 下 の電 荷 の連 続 の式 を用 いる。0
=
⋅
∇
+
∂
∂
J
t
ρ
(5) 運 動 方 程 式 (1) 及 び (2) の 時 間 積 分 が 2 次 精 度 に な る よ う に 、 粒 子 の 位 置 と 速 度 は 互 い に Δt/2 ずれた時 刻 に定 義 される。また粒 子 の位 置 と電 場 を同 じ時 刻 に、粒 子 の速 度 と磁 場 を同 じ時 刻 にすることで、Maxwell 方 程 式 (3)及 び(4)による電 場 の更 新 と磁 場 の更 新 がそれぞれ2次 精 度 になるようにしている。電 磁 場 の各 成 分 (Ex,Ey,Ez,Bx,By,Bz)は、空 間 差 分 が 2 次 精 度 に なるように、Yee 格 子 と呼 ばれる Staggered 格 子 上 に定 義 される。また、電 流 密 度 (Jx,Jy,Jz)は電 場 (Ex,Ey,Ez)と同 じ空 間 格 子 上 かつ粒 子 の速 度 (磁 場 )と同 じ時 刻 に定 義 される。ラグランジュ変 数 で あ る 荷 電 粒 子 の 位 置 及 び 速 度 (x,y,z,vx,vy,vz) と 格 子 状 の オ イ ラ ー 変 数 で あ る 電 磁 場 (Ex,Ey,Ez,Bx,By,Bz)が混 在 していることが、プラズマ PIC コードの特 徴 と言 える。 プラズマ PIC コードのカーネルは3つに大 きく分 けることができる。1つは Maxwell 方 程 式 (3)及 び(4)による電 磁 場 の更 新 で、これには FDTD 法 が用 いられる。電 磁 場 更 新 カーネルの負 荷 が全 体 の計 算 負 荷 で占 める割 合 は 1%未 満 であり、FDTD 法 の性 能 特 性 及 びチューニングについて は、SS 研 マルチコアクラスタ性 能 WG 成 果 報 告 書 を参 照 して頂 き、ここでは割 愛 する。 2 つ目 のカーネルは、式 (3)による荷 電 粒 子 の速 度 計 算 であり、その概 要 をプログラム1に示 す。 粒 子 がどの格 子 の近 くにあるかを計 算 し(2-3 行 目 )、隣 接 格 子 に対 する重 みを計 算 し(4-13 行 目 )、荷 電 粒 子 の位 置 における電 磁 場 の値 を隣 接 格 子 から重 みに基 づいて計 算 し(14-19 行 目 )、 最 後 に荷 電 粒 子 の位 置 における電 磁 場 の値 を用 いて粒 子 を加 速 する(20-22 行 目 )。ここで特 徴 的 なのは、14-19 行 目 が粒 子 の位 置 に対 するリストアクセスになっている点 である。粒 子 番 号 n は 位 置 には全 く依 存 しないため、配 列 のインデックス i,j はランダムとなり、結 果 として 14-19 行 目 の 配 列 へのアクセスはランダムロードとなる。 3 つ目 のカーネルは、式 (5)による電 流 密 度 の計 算 であり、その概 要 をプログラム 2 に示 す。粒 子 がどの格 子 の近 くにあるかを計 算 し(2-3 行 目 )、隣 接 格 子 に対 する重 みを計 算 し(4-13 行 目 )、 荷 電 粒 子 の位 置 における電 流 を重 みに基 づいて隣 接 格 子 へ割 り振 る(14 行 目 -)。電 流 密 度 計 算 カーネルにも速 度 計 算 カーネルと同 様 に粒 子 の位 置 に対 するリストアクセスが存 在 するが、配 列 へのアクセスはランダムロード及 びストアの両 方 となる。また、スレッド間 で同 じインデックスにア クセスする可 能 性 もあるため、配 列 の属 性 は reduction となる。 以 下 では、これら速 度 計 算 カーネルと電 流 密 度 計 算 カーネルの2つについて性 能 測 定 を行 っ た。 2.6.1.3 測 定 環 境 性 能 測 定 には、名 古 屋 大 学 の旧 システムである FX10 と CX400/250 及 び、新 システムである FX100 と CX400/2500 を使 用 した。なお、本 測 定 は単 一 ノードで行 い、MPI を用 いた並 列 性 能 の 測 定 は行 わない。コンパイラオプションは以 下 のとおりである。
CX250/250(インテルコンパイラ): –O3 –ipo –ip –xAVX –openmp
CX250/250(富 士 通 コンパイラ): –Kfast,AVX,openmp
CX250/2550(インテルコンパイラ): –O3 –ipo –ip –xCORE–AVX2 –openmp
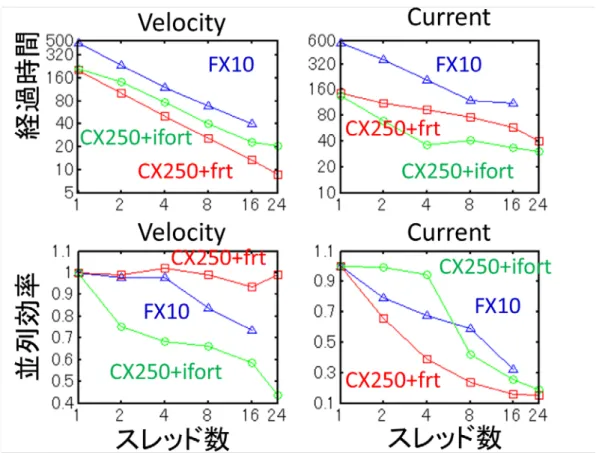
CX250/2550(富 士 通 コンパイラ): –Kfast,CORE–AVX2,openmp FX10/FX100(富 士 通 コンパイラ): –Kfast,visimpact,openmp 2.6.1.4 測 定 結 果 計 算 サイズは 1000x1000 格 子 、144 粒 子 /格 子 とした。これは、約 3GB のメモリ使 用 量 に相 当 する。計 算 ステップ数 は 10 とし、スレッド数 を変 える強 スケーリング測 定 を行 った。 図 1 は、名 大 旧 システムにおけるプラズマ PIC コードのスレッド性 能 を示 す。速 度 計 算 カーネル は、富 士 通 コンパイラを用 いた場 合 は高 いスケーラビリティが得 られているが、インテルコンパイラ を用 いた場 合 はスレッド数 を増 やすにつれて性 能 が低 下 している様 子 が見 られる。一 方 で電 流 密 度 計 算 カーネルは、富 士 通 コンパイラを用 いた場 合 はスレッド数 を増 やすにつれて性 能 が低 下 している様 子 が見 られるが、インテルコンパイラを用 いた場 合 は 4 スレッドまで高 い性 能 を発 揮 するものの、4 スレッドで性 能 が飽 和 する様 子 が見 られた。
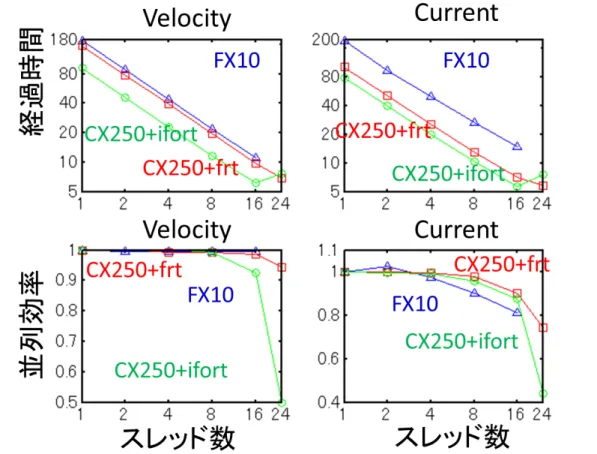
図 2は、名 大 新 システムにおけるプラズマ PIC コードのスレッド性 能 を示 す。速 度 計 算 カーネル は、富 士 通 コンパイラを用 いた場 合 はおおむね 70%以 上 でスケールしており、インテルコンパイラ を用 いた場 合 は若 干 速 度 が向 上 したものの旧 システムとほぼ同 様 の傾 向 を示 した。電 流 密 度 計 算 カ ー ネ ル は 、 富 士 通 コ ン パ イ ラ と イ ン テ ル コ ン パ イ ラ 共 に 旧 シ ス テ ム と ほ ぼ 同 様 の 傾 向 を 示 し た。 次 に、粒 子 のデータが完 全 にソートされ、電 磁 場 データへのアクセスが連 続 的 になった場 合 の 性 能 測 定 を行 った。図 3 は、名 大 旧 システムにおけるプラズマ PIC コードのスレッド性 能 を示 す。 速 度 計 算 カーネルは、富 士 通 コンパイラを用 いた場 合 は 90%以 上 でスケールしており、インテルコ ンパイラを用 いた場 合 でも、16 スレッドまでは 90%以 上 でスケールしたが 24 スレッドの時 に性 能 が 極 端 に低 下 した。電 流 密 度 計 算 カーネルは、富 士 通 コンパイラを用 いた場 合 は 70%以 上 でスケ ールしており、インテルコンパイラを用 いた場 合 でも、16 スレッドまでは 90%近 くでスケールしたが 16 スレッドの時 に性 能 が飽 和 した。 図 4 は、名 大 新 システムにおけるプラズマ PIC コードのスレッド性 能 を示 す。速 度 計 算 カーネル も電 流 密 度 計 算 カーネルも、富 士 通 コンパイラとインテルコンパイラ共 に旧 システムとほぼ同 様 の 傾 向 を示 した。 2.6.1.5 まとめ 本 計 測 で得 られた知 見 は、以 下 のとおりである。 1.富 士 通 コンパイラを用 いた場 合 は、ランダムロードは 70%以 上 でスケールし、連 続 的 なロードは 90%以 上 でスケールする。 2.ランダムストアのスレッド性 能 低 下 は、どちらのコンパイラを用 いても、全 てのシステムにおいて 顕 著 であり、PIC コードにおけるデータの並 び替 えは性 能 面 からは必 須 である。 3.富 士 通 コンパイラを用 いた場 合 は、連 続 的 なロード及 びストアは 70-80% 以 上 で ス ケ ー ル す る。 4.インテルコンパイラを用 いた場 合 は、連 続 的 なロード及 びストアは 90%以 上 でスケールするが、 全 コアを用 いた場 合 のみ極 端 に性 能 が低 下 する。 5.シングルスレッドの性 能 は、インテルコンパイラを用 いた場 合 のほうが高 いが、富 士 通 コンパイ ラを用 いた場 合 ほうがスレッド性 能 が高 いため、結 果 的 にマルチスレッド性 能 は富 士 通 コンパ イラを用 いた場 合 ほうが高 くなる。 6.FX10 と FX100 は似 た傾 向 を示 す。ランダムロード及 びストアは両 者 で性 能 が数 割 しか変 わら ないが、連 続 的 なロードは約 3 倍 、連 続 的 なストアは約 1.7 倍 FX100 のほうが高 速 である。 7.IvyBridge と Haswell は傾 向 を示 す。また両 者 で性 能 はほとんど変 わらない。
プログラム1:速度計算カーネル !$OMP DO 1 DO n=1,Np 2 i = nint(x(n)) 3 j = nint(y(n)) 4 fx1 = ... 5 fx2 = ... 6 fx3 = ... 7 fy1 = ... 8 fy2 = ... 9 fy3 = ... 10 hx1 = ... 11 hx2 = ... 12 hy1 = ... 13 hy2 = ... 14 pex = ...
15 pey = ey(i-1,j-1)*fx1*hy1 + ey(i ,j-1)*fx2*hy1 + ey(i+1,j-1)*fx3*hy1 & + ey(i-1,j )*fx1*hy2 + ey(i ,j )*fx2*hy2 + ey(i+1,j )*fx3*hy2 16 pez = ... 17 pbx = ... 18 pby = ... 19 pbz = ... 20 vx(n) = vx(n) + ... 21 vy(n) = vy(n) + ... 22 vz(n) = vz(n) + ... 23 END DO !$OMP END DO
プログラム 2:電流密度計算カーネル !$OMP DO REDUCTION(+: jx,jy,jz)
1 DO n=1,Np 2 i = nint(x(n)) 3 j = nint(y(n)) 4 fx1 = ... 5 fx2 = ... 6 fx3 = ... 7 fy1 = ... 8 fy2 = ... 9 fy3 = ... 10 hx1 = ... 11 hx2 = ... 12 hy1 = ... 13 hy2 = ... 14 jx(i-1,j-1)=jx(i-1,j-1)+q(n)*vx(n)*hx1*fy1 15 jx(i ,j-1)=jx(i ,j-1)+q(n)*vx(n)*hx2*fy1 16 jx(i-1,j )=jx(i-1,j )+q(n)*vx(n)*hx1*fy2 17 jx(i ,j )=jx(i ,j )+q(n)*vx(n)*hx2*fy2 18 jx(i-1,j+1)=jx(i-1,j+1)+q(n)*vx(n)*hx1*fy3 19 jx(i ,j+1)=jx(i ,j+1)+q(n)*vx(n)*hx2*fy3 :
: :
35 END DO !$OMP END DO
図 1: 名 大 旧 シ ス テ ム に お け る プ ラ ズ マ PIC コ ー ド の ス レ ッ ド 性 能 。 ラ ン ダ ム ア ク セ ス の 場 合
図 2: 名 大 新 シ ス テ ム に お け る プ ラ ズ マ PIC コ ー ド の ス レ ッ ド 性 能 。 ラ ン ダ ム ア ク セ ス の 場 合
図 3: 名 大 旧 シ ス テ ム に お け る プ ラ ズ マ PIC コ ー ド の ス レ ッ ド 性 能 。 粒 子 デ ー タ を ソ ー ト し た 場 合
図 4: 名 大 新 シ ス テ ム に お け る プ ラ ズ マ PIC コ ー ド の ス レ ッ ド 性 能 。 粒 子 デ ー タ を ソ ー ト し た 場 合
2.6.2 宇宙プラズマ5次元ブラソフコード Vlasov5 の測定評価
2.6.2.1 はじめに
希 薄 で無 衝 突 状 態 にある宇 宙 プラズマは、磁 気 流 体 力 学 、イオン運 動 論 、電 子 運 動 論 など の様 々な時 空 間 スケールで物 理 現 象 を記 述 できる。Vlasov コードは、宇 宙 プラズマの第 一 原 理 である Vlasov(無 衝 突 Boltzmann)方 程 式 と Maxwell 方 程 式 により、プラズマ中 の全 ての電 磁 ・ 静 電 波 動 と荷 電 粒 子 の運 動 との相 互 作 用 を解 くシミュレーション手 法 である。Vlasov 方 程 式 は、 位 置 及 び速 度 の関 数 として表 される位 相 空 間 分 布 関 数 の保 存 則 である。現 実 の世 界 では、位 置 及 び速 度 は共 に 3 次 元 であるが、既 存 のコンピュータシステムにおいて 6 次 元 問 題 を扱 うのは 困 難 であるため、本 プロジェクトで用 いる Vlasov5 では実 空 間 (位 置 )を 2 次 元 、速 度 空 間 を 3 次 元 とした 5 次 元 問 題 を扱 う。本 稿 では、前 マルチコアクラスタ性 能 WG 以 降 で行 ったプログラムの 改 良 点 についてまとめる。 2.6.2.2 プログラム概 要
Vlasov コードは、Maxwell 方 程 式 による電 磁 場 の更 新 と Vlasov 方 程 式 による分 布 関 数 の更 新 から成 る。Maxwell 方 程 式 は電 磁 場 の解 析 で広 く用 いられている FDTD(Finite Difference Time Domain)法 により、その時 間 発 展 を解 き進 める。Maxwell 方 程 式 の計 算 負 荷 は Vlasov 方 程 式 の計 算 負 荷 に対 して通 常 0.1%未 満 であるため、今 回 は性 能 評 価 の対 象 外 とした。 Vlasov 方 程 式 による分 布 関 数 の更 新 は、演 算 子 分 離 法 により以 下 のように実 空 間 (位 置 方 向 )の移 流 、電 場 による速 度 空 間 の移 流 及 び磁 場 による速 度 空 間 の回 転 の3つの部 分 に分 解 され、それぞれの式 が①実 空 間 の移 流 (position カーネル)、速 度 空 間 の②移 流 (velocity_e カ ーネル)及 び③回 転 (velocity_b カーネル)に対 応 する。
0
=
∂
∂
+
∂
∂
r
f
v
t
f
s s
(1)0
=
∂
∂
+
∂
∂
v
f
E
m
q
t
f
s s s s
(2)0
)
(
=
∂
∂
×
+
∂
∂
v
f
B
v
m
q
t
f
s s s s
(3) 式 (1)及 び(2)は線 形 移 流 方 程 式 であり、演 算 子 “非 ”分 離 型 の保 存 型 解 法 を用 いる。また式 (3)は回 転 流 方 程 式 であり、back-substitution 法 と呼 ばれる演 算 子 分 離 型 の解 法 を用 いる。ま たこれらの方 程 式 を解 く上 で、物 理 量 の保 存 、解 の無 振 動 性 、正 値 性 の保 証 を満 たす独 自 の 5 次 精 度 保 存 型 無 振 動 スキームを用 いている。 実 空 間 の移 流 (position カーネル)の概 要 をプログラム 1 に、速 度 空 間 の移 流 (velocity_e カー ネル)の概 要 をプログラム 2 に示 す。両 者 は同 じ演 算 手 法 を用 いているが、数 値 流 束 データを格 納 するための一 時 配 列 の容 量 が異 なることが分 かる。分 布 関 数 データの定 義 が、モーメント計 算 (速 度 空 間 の積 分 )を高 速 に行 うために f(vx,vy,vz,x,y)となっており、velocity_e カーネルでは数 値 流 束 データが l,n,m に依 存 するために 3 次 元 であるのに対 して、position カーネルでは数 値 流 束 データが i,j に依 存 するために 5 次 元 になっている。プ ロ グ ラ ム 1: position カ ー ネ ル の 概 要 DO j=1,Ny DO i=1,Nx DO n=1,Nvz DO m=1,Nvy DO l=1,Nvx dfx(l,m,n,i,j)=... !x 方 向 のフラックスの計 算 dfy(l,m,n,i,j)=... !y 方 向 のフラックスの計 算 f(l,m,n,i,j)=f(l,m,n,i,j)-dfx(l,m,n,i,j)+dfx(l,m,n,i-1,j) & -dfy(l,m,n,i,j)+dfy(l,m,n,i,j-1) END DO END DO END DO END DO END DO プ ロ グ ラ ム 2: velocity_e カ ー ネ ル の 概 要 DO j=1,Ny DO i=1,Nx DO n=1,Nvz DO m=1,Nvy DO l=1,Nvx dfx(l,m,n)=... !vx 方 向 のフラックスの計 算 dfy(l,m,n)=... !vy 方 向 のフラックスの計 算 dfz(l,m,n)=... !vz 方 向 のフラックスの計 算 f(l,m,n,i,j)=f(l,m,n,i,j)-dfx(l,m,n)+dfx(l-1,m,n) & -dfy(l,m,n)+dfy(l,m-1,n) & -dfz(l,m,n)+dfz(l,m,n-1) END DO END DO END DO END DO END DO
2.6.2.3 測 定 環 境 性 能 測 定 には、名 古 屋 大 学 の FX100 を使 用 した。なお、本 測 定 は単 一 ノードで行 い、並 列 性 能 の測 定 は行 わない。コンパイラオプションは以 下 のとおりである。 -Kfast,visimpact,openmp,preex,simd=2 –x250 2.6.2.4 配 列 の転 置 Position カーネルで用 いる一 時 配 列 の容 量 を減 らすためには、プログラム3で示 すような速 度 と位 置 を入 れ替 えた配 列 ftmp(x,y,vx,vy,vz)を用 いる必 要 があるが、これには配 列 の転 置 を行 う 必 要 がある。そこで本 プロジェクトでは、配 列 の転 置 について、プログラム4を用 いて性 能 評 価 を 行 った。プログラム4をそのまま 32 スレッドで走 らせると、Nx=166,Ny=86,Nvx=Nvy=Nvz=46 のとき に 1 ステップあたり順 方 向 で 2.6 秒 、逆 方 向 で 2.5 秒 程 度 掛 かる。このプログラムを-Kopenmp を 除 いてコンパイルすると、順 方 向 逆 方 向 共 にソースリストに以 下 のように表 示 される。 <<< INTERCHANGED(nest: 2) do jj=nys-3,nye+3 <<< INTERCHANGED(nest: 4) do ii=nxs-3,nxe+3 <<< INTERCHANGED(nest: 1) do nn=nvzs-3,nvze+3 <<< INTERCHANGED(nest: 3) do mm=nvys-3,nvye+3 し た が っ て 、 n, j, m, i, l の 順 に ル ー プ を 入 れ 替 え た ほ う が 高 速 に な る 。 ま た こ の 場 合 、 COLLAPSE(2)が最 も高 速 であり、このときに 1 ステップあたり順 方 向 で 0.3 秒 、逆 方 向 で 0.23 秒 となり、約 10 分 の 1 に短 縮 された。 プ ロ グ ラ ム 3: 転 置 し た 分 布 関 数 を 用 い た position カ ー ネ ル の 概 要 DO n=1,Nvz DO m=1,Nvy DO l=1,Nvx DO j=1,Ny DO i=1,Nx dfx(i,j)=... !x 方 向 のフラックスの計 算 dfy(i,j)=... !y 方 向 のフラックスの計 算 ftmp(i,j,l,m,n)=ftmp(i,j,l,m,n)-dfx(i,j)+dfx(i-1,j) & -dfy(i,j)+dfy(i,j-1) END DO END DO END DO END DO END DO
プ ロ グ ラ ム 4: 配 列 転 置 !順 方 向 !$OMP DO COLLAPSE(3) do j=1,Ny do i=1,Nx do n=1,Nvz do m=1,Nvy do l=1,Nvx gtmp(i,j,l,m,n)=g(l,m,n,i,j) end do end do end do end do end do !$OMP END DO !逆 方 向 !$OMP DO COLLAPSE(3) do n=1,Nvz do m=1,Nvy do l=1,Nvx do j=1,Ny do i=1,Nx g(l,m,n,i,j)=gtmp(i,j,l,m,n) end do end do end do end do end do !$OMP END DO 2.6.2.5 最 適 化 指 示 子 (OCL) 幾 つかのプログラムパターンについて、ループアンロールの最 適 化 指 示 子 (unroll(n))及 び、ソフトウェアパイプラインの最 適 化 指 示 子 (noswp)について、その有 効 性 を確 かめた。まず、パ ターン1-3の全 ての場 合 において、アンロール回 数 を 10 にするのが概 ね高 速 であることが分 か った。次 に、ソフトウェアパイプラインの最 適 化 指 示 子 (noswp)について有 り無 しの場 合 を比 較 した ところ、ループ内 の配 列 がループの添 え字 を直 接 参 照 している場 合 (パターン1)や、ループ内 の 配 列 がループの添 え字 と単 純 な整 数 演 算 を参 照 している場 合 (パターン 2)は、ソフトウェアパイプ ラインを用 いた(指 示 子 を入 れない)ほうが速 く、ループ内 の配 列 がループの添 え字 と変 数 との演 算 になっている場 合 (パターン 3)は、ソフトウェアパイプラインを用 いない(指 示 子 を入 れた)ほうが 高 速 であることが分 かった。 プ ロ グ ラ ム 5: 最 適 化 指 示 子 確 認 用 の プ ロ グ ラ ム パ タ ー ン !パ タ ー ン 1 : 配 列 の 単 純 参 照 do n=nvzs,nvze do m=nvys-1,nvye !OCL UNROLL(10) do l=nvxs,nvxe vvy(l,m) = vx(l)*bbx+vy(m)*bby+vz(n)*bbz mm0(l,m) = m-floor(vvy(l,m)) mmv(l,m) = sign(1.0d0,vvy(l,m)) end do end do end do
!パ タ ー ン 2 : 配 列 の 参 照 が 単 純 な 演 算 do n=nvzs-1,nvze+1 do m=nvys-1,nvye+1 !OCL UNROLL(10) do l=nvxs-1,nvxe+1 hp2=f(l,mm0(l,m)+2,n,i,j) hp1=f(l,mm0(l,m)+1,n,i,j) hp0=f(l,mm0(l,m) ,n,i,j) hm1=f(l,mm0(l,m)-1,n,i,j) hm2=f(l,mm0(l,m)-2,n,i,j) dfy(l,m)=pic5(hp2,hp1,hp0,hm1,hm2,vvy(l,m)) end do end do end do !パ タ ー ン 3 : 配 列 の 参 照 が 変 数 演 算 do n=nvzs-1,nvze+1 do m=nvys-1,nvye+1 !OCL NOSWP !OCL UNROLL(10) do l=nvxs-1,nvxe+1 hp2=f(l,mm0(l,m)+mmv(l,m)*2,n,i,j) hp1=f(l,mm0(l,m)+mmv(l,m) ,n,i,j) hp0=f(l,mm0(l,m) ,n,i,j) hm1=f(l,mm0(l,m)-mmv(l,m) ,n,i,j) hm2=f(l,mm0(l,m)-mmv(l,m)*2,n,i,j) dfy(l,m)=pic5(hp2,hp1,hp0,hm1,hm2,vvy(l,m)) end do end do end do 以 上 の OCL の最 適 化 により、プログラム全 体 として 1 ステップあたり 17.7 秒 から 15.7 秒 まで 短 縮 された。 2.6.2.6 まとめ 本 性 能 測 定 で得 られた知 見 は以 下 の通 りである。 配 列 の転 置 については、OpenMP のオプションを外 してコンパイルしたときに、コンパイラが最 適 化 した通 りにループを並 び替 えるのが最 も高 速 であることが分 かった。COLLAPSE などの デイレクティブはコンパイラの最 適 化 を阻 害 する場 合 がるため注 意 が必 要 である。
ループアンロールの最 適 化 指 示 子 については、ループ長 が割 り切 れる数 若 しくは、ループ長 を SIMD 数 で割 った値 の約 数 にアンロール回 数 を設 定 するのが概 ね高 速 であることが分 かっ た。
ソフトウェアパイプラインの最 適 化 指 示 子 については、配 列 の添 え字 が変 数 の演 算 で参 照 さ れている場 合 は NOSWP を指 定 したほうが高 速 になる場 合 が多 いことが分 かった。
超次元配列の転置
Copyright 2015 FUJITSU LIMITED 1
転置のソースリスト
26 !$OMP PARALLEL DEFAULT(PRIVATE) &
27 !$OMP SHARED(nxs,nxe,nys,nye,nvxs,nvxe,nvys,nvye,nvzs,nvze,gg,gtmp) 28 !$OMP DO COLLAPSE(3) 29 1 p do jj=nys-3,nye+3 (-1 ~ 84 回転) 30 2 p do ii=nxs-3,nxe+3 (-1 ~ 164回転) 31 3 p do nn=nvzs-3,nvze+3 (-1 ~ 44 回転) 32 4 p do mm=nvys-3,nvye+3 (-1 ~ 44 回転) <<< Loop-information Start >>> <<< [OPTIMIZATION] <<< SIMD(VL: 4) <<< Loop-information End >>> 33 5 p 8v do ll=nvxs-3,nvxe+3 (-1 ~ 44 回転) 34 5 p 8v gtmp(ii,jj,ll,mm,nn)=gg(ll,mm,nn,ii,jj) 35 5 p 8v end do 36 4 p end do 37 3 p end do 38 2 p end do 39 1 p end do 40 !$OMP END DO 41 !$OMP END PARALLEL
45 !$OMP PARALLEL DEFAULT(PRIVATE) &
46 !$OMP SHARED(nxs,nxe,nys,nye,nvxs,nvxe,nvys,nvye,nvzs,nvze,gg,gtmp) 47 !$OMP DO COLLAPSE(3) 48 1 p do nn=nvzs-3,nvze+3 (-1 ~ 44 回転) 49 2 p do mm=nvys-3,nvye+3 (-1 ~ 44 回転) 50 3 p do ll=nvxs-3,nvxe+3 (-1 ~ 44 回転) 51 4 p do jj=nys-3,nye+3 (-1 ~ 84 回転) <<< Loop-information Start >>> <<< [OPTIMIZATION] <<< SIMD(VL: 4) <<< Loop-information End >>> 52 5 p 8v do ii=nxs-3,nxe+3 (-1 ~ 164回転) 53 5 p 8v gg(ll,mm,nn,ii,jj)=gtmp(ii,jj,ll,mm,nn) 54 5 p 8v end do 55 4 p end do 56 3 p end do 57 2 p end do 58 1 p end do 59 !$OMP END DO 60 !$OMP END PARALLEL
swap(順)
swap(逆)
連続アクセス ストライドアクセス 連続アクセス ストライドアクセスループ交換前後のソースリスト
xxx
Copyright 2015 FUJITSU LIMITED
26 !$OMP PARALLEL DEFAULT(PRIVATE) &
27 !$OMP SHARED(nxs,nxe,nys,nye,nvxs,nvxe,nvys,nvye,nvzs,nvze,gg,gtmp) 28 !$OMP DO COLLAPSE(3) 29 1 p do jj=nys-3,nye+3 30 2 p do ii=nxs-3,nxe+3 31 3 p do nn=nvzs-3,nvze+3 32 4 p do mm=nvys-3,nvye+3 33 5 p 8v do ll=nvxs-3,nvxe+3 34 5 p 8v gtmp(ii,jj,ll,mm,nn)=gg(ll,mm,nn,ii,jj) 35 5 p 8v end do 36 4 p end do 37 3 p end do 38 2 p end do 39 1 p end do 40 !$OMP END DO 41 !$OMP END PARALLEL
45 !$OMP PARALLEL DEFAULT(PRIVATE) &
46 !$OMP SHARED(nxs,nxe,nys,nye,nvxs,nvxe,nvys,nvye,nvzs,nvze,gg,gtmp) 47 !$OMP DO COLLAPSE(3) 48 1 p do nn=nvzs-3,nvze+3 49 2 p do mm=nvys-3,nvye+3 50 3 p do ll=nvxs-3,nvxe+3 51 4 p do jj=nys-3,nye+3 52 5 p 8v do ii=nxs-3,nxe+3 53 5 p 8v gg(ll,mm,nn,ii,jj)=gtmp(ii,jj,ll,mm,nn) 54 5 p 8v end do 55 4 p end do 56 3 p end do 57 2 p end do 58 1 p end do 59 !$OMP END DO 60 !$OMP END PARALLEL
26 !$OMP PARALLEL DEFAULT(PRIVATE) &
27 !$OMP SHARED(nxs,nxe,nys,nye,nvxs,nvxe,nvys,nvye,nvzs,nvze,gg,gtmp) 28 !$OMP DO COLLAPSE(2) 29 1 p do nn=nvzs-3,nvze+3 30 2 p do jj=nys-3,nye+3 31 3 p do mm=nvys-3,nvye+3 32 4 p do ii=nxs-3,nxe+3 33 4 !OCL NOUNROLL 34 5 p v do ll=nvxs-3,nvxe+3 35 5 p v gtmp(ii,jj,ll,mm,nn)=gg(ll,mm,nn,ii,jj) 36 5 p v end do 37 4 p end do 38 3 p end do 39 2 p end do 40 1 p end do 41 !$OMP END DO 42 !$OMP END PARALLEL
46 !$OMP PARALLEL DEFAULT(PRIVATE) &
47 !$OMP SHARED(nxs,nxe,nys,nye,nvxs,nvxe,nvys,nvye,nvzs,nvze,gg,gtmp) 48 !$OMP DO COLLAPSE(2) 49 1 p do nn=nvzs-3,nvze+3 50 2 p do jj=nys-3,nye+3 51 3 p do mm=nvys-3,nvye+3 52 4 p do ii=nxs-3,nxe+3 53 5 p v do ll=nvxs-3,nvxe+3 54 5 p v gg(ll,mm,nn,ii,jj)=gtmp(ii,jj,ll,mm,nn) 55 5 p v end do 56 4 p end do 57 3 p end do 58 2 p end do 59 1 p end do 60 !$OMP END DO 61 !$OMP END PARALLEL
ループ交換前
ループ交換後
SWPするため 3 gg ( 3 2 1 5 4 ) ←ネスト数 gtemp ( 4 2 5 3 1 ) ←ネスト数 ( -1, -1, -1, -1, -1 ) キャッシュミス ( -1, -1, -1, -1, -1 ) キャッシュミス ( -1, -1, -1, 0, -1 ) キャッシュミス ( -1, -1, 0, -1, -1 ) キャッシュミス ( -1, -1, -1, 1, -1 ) キャッシュミス ( -1, -1, 1, -1, -1 ) キャッシュミス : : : : ( -1, -1, -1, 164, -1 ) キャッシュミス ( -1, -1, 44, -1, -1 ) キャッシュミス ( -1, -1, -1, -1, 0 ) キャッシュミス ( 0, -1, -1, -1, -1 ) キャッシュヒット ( -1, -1, -1, 0, 0 ) キャッシュミス ( 0, -1, 0, -1, -1 ) キャッシュヒット ( -1, -1, -1, 1, 0 ) キャッシュミス ( 0, -1, 1, -1, -1 ) キャッシュヒット : : : : ( -1, -1, -1, -1, 1 ) キャッシュミス ( 1, -1, 1, -1, -1 ) キャッシュヒット ( -1, -1, -1, 0, 1 ) キャッシュミス ( 1, -1, 0, -1, -1 ) キャッシュヒット ( -1, -1, -1, 1, 1 ) キャッシュミス ( 1, -1, 1, -1, -1 ) キャッシュヒット : : : : gtemp ( 5 4 3 2 1 ) ←ネスト数 gg ( 5 3 1 4 2 ) ←ネスト数 連続アクセス 連続アクセス チューニング前 チューニング後転置
(逆)チューニング前後のキャッシュ効率
L1Dキャッシュとライン数
64KB/コア 1ライン256バイト(32要素) ・ 256ライン
チューニング前後のキャッシュミスとキャッシュヒット
チューニング後は、連続アクセスとなることにより
キャッシュヒット
が増加
連続 アクセス 連続 アクセス転置(逆)チューニング結果
ループ交換によるチューニング
Copyright 2015 FUJITSU LIMITED
L1D ミス率(/ ロード・ストア 数) ロード・ストア数 L1D ミス数 L2 ミス率(/ロー ド・ストア数) L2 ミス数
チューニング前 58.10% 4.38E+08 2.55E+08 51.28% 2.25E+08 チューニング後 4.44% 4.46E+08 1.98E+07 3.39% 1.51E+07
グラフは、32スレッド実行のスレ
ッド0のサイクルアカウンティング
結果
L1Dミス数とL2ミス数が1/10以
下に減少して、性能が向上
チューニング前 チューニング後 5キャッシュ効率のチューニング
キャッシュ利用効率を上げられないか?と言う観点でチューニング
を試した
→ループ交換でキャッシュ利用効率を上げること確認
転置(順)のループ交換チューニングの性能
転置
(逆)のループ交換チューニングの性能
イタレーション回数 ループ交換無し (秒) ループ交換有り (秒) 性能比 (無し/有り) 1 3.093 0.750 4.12 2 2.603 0.291 8.95 3 2.606 0.291 8.96 4 2.602 0.291 8.94 5 2.604 0.291 8.95 イタレーション回数 ループ交換無し (秒) ループ交換有り (秒) 性能比 (無し/有り) 1 2.528 0.234 10.80 2 2.550 0.234 10.90 3 2.531 0.234 10.82 4 2.531 0.234 10.82 5 2.539 0.234 10.85ループアンロール
Copyright 2015 FUJITSU LIMITED 7
主なループの違い
(nvxs=2、nvxe=41)
velocity_e
(42回転) OCL指定あり
ユーザ作成関数
pic5sの中で、fezの符号に応じてhp2~hm2を並び
替えている。
!OCL NOSWP !OCL UNROLL(8) do ll=nvxs-1,nvxe+1 hp2=gg(ll,mm,nn+nv+nv,ii,jj) hp1=gg(ll,mm,nn+nv ,ii,jj) hp0=gg(ll,mm,nn ,ii,jj) hm1=gg(ll,mm,nn-nv ,ii,jj) hm2=gg(ll,mm,nn-nv-nv,ii,jj) t_dgz(ll,mm)=pic5(hp2,hp1,hp0,hm1,hm2,fez) end do !OCL NOSWP !OCL UNROLL(8) do ll=nvxs-1,nvxe+1 hp2=gg(ll,mm,nn+2,ii,jj) hp1=gg(ll,mm,nn+1,ii,jj) hp0=gg(ll,mm,nn ,ii,jj) hm1=gg(ll,mm,nn-1,ii,jj) hm2=gg(ll,mm,nn-2,ii,jj) t_dgz(ll,mm)=pic5s(hp2,hp1,hp0,hm1,hm2,fez) end do
sb
fx
コードの違い
velocity_e
の性能とソース抜粋
タイマー性能結果(単位:秒)
OCL指定している区間4-1,4-2を分析
以降のページで説明
最内ループの回転数は
42回転
区間4-2はsbとfxで同じ
最内のネスト5でタイマーを採取すると
オーバーヘッドが多くなり正しく取れない。
Copyright 2016 FUJITSU LIMITED
do jj=nys-3,nye+3 do ii=nxs-3,nxe+3 処理1 do nn=nvzs-1,nvze+1 do mm=nvys-1,nvye+1 do ll=nvxs-1,nvxe+1 処理2 end do do ll=nvxs-1,nvxe+1 処理3 end do do ll=nvxs-1,nvxe+1 処理4 end do do ll=nvxs-1,nvxe+1 処理5 end do end do do mm=nvys-1,nvye+1 do ll=nvxs-1,nvxe+1 処理6 end do end do end do do nn=nvzs,nvze do mm=nvys,nvye 処理7 end do end do end do end do 4‐1 4‐2 4‐3 !OCL NOSWP !OCL UNROLL(8) !OCL LOOP_NOFUSION !OCL NOSWP !OCL UNROLL(8) !OCL LOOP_NOFUSION !OCL NOSWP !OCL UNROLL(8) !OCL LOOP_NOFUSION !OCL NOSWP !OCL UNROLL(8)
依頼1-1
!OCL NOSWP !OCL UNROLL(8)区間4-1
区間4-2
velocity_e_sb
13.309
6.969
velocity_e_fx
14.036
6.982
9UNROLL数を変更した測定結果
e_sb とe_fxの区間4-1(42回転)の測定結果比較(単位:秒)
UNROLL展開数は、10,5または2が速い
42回転を4(SIMD)×10回転+2回転(余り)となり、
10回転をUNROLLすることで、
2,5,10展開の場合は余りが出ない
ため速い結
果であると考えられる。
区間4-1 -Knoswp-Kunroll=N リスタ e_sb e_fx 1 (nounroll) SIMD 有効SWP 無効 16.541 17.364 2 〃 12.974 13.455 3 〃 14.082 14.198 4 〃 13.713 14.315 5 〃 12.080 13.763 6 〃 14.122 15.072 7 〃 13.509 14.604 8 〃 13.237 13.915 9 〃 12.611 13.878 10 〃 12.175 12.951
UNROLL数を変更した測定結果
e_sb とe_fxの区間4-2(42回転)の測定結果比較(単位:秒)
UNROLL展開数は、6,7,10が速い
SIMDが無効で回転数が42回転であるため、unroll数は割り切れる6,7が高速
であったと考えられる。また、unroll数が10も高速であるが、これは命令の並
列性などのメリットが余りループ(2回転)のデメリットを上回ったと考えられる。
Copyright 2016 FUJITSU LIMITED
区間4-2 -Knoswp
-Kunroll=N リスタ e_sb e_fx 1 (nounroll) SIMD 無効SWP 無効 11.273 11.287 2 〃 8.540 8.583 3 〃 7.544 7.575 4 〃 7.069 7.151 5 〃 7.171 7.219 6 〃 6.885 6.848 7 〃 6.909 6.872 8 〃 7.124 7.152 9 〃 7.318 7.331 10 〃 6.845 6.850 11