2007 年度 修士論文
高位レベル設計における fault-secure 設計 に関する研究
指導教授 柳澤 政生 教授
早稲田大学大学院 理工学研究科 情報・ネットワーク専攻
3606U118–1
和田 敏之
目 次
第1章 序論 4
1.1 本論文の背景と目的 . . . . 5
1.2 本論文の概要 . . . . 8
第2章 fault-secure設計 9 2.1 本章の概要 . . . . 10
2.2 fault . . . . 11
2.3 高位レベルにおけるfault-secure設計 . . . . 12
2.4 fault-secure設計の検出力. . . . 16
2.4.1 SPN(Substitution Permutation Network) . . . . 16
2.4.2 検出力の評価実験結果 . . . . 17
2.5 本章のまとめ . . . . 22
第3章 関連研究 23 3.1 本章の概要 . . . . 24
3.2 Anotolaらの手法 . . . . 25
3.2.1 本手法の概要 . . . . 25
3.2.2 実行例 . . . . 25
3.2.3 本手法のまとめ . . . . 28
3.3 Karriらの手法 . . . . 29
3.3.1 本手法の概要 . . . . 29
3.3.2 実行例 . . . . 30
3.3.3 本手法のまとめ . . . . 31
3.4 Wuの手法 . . . . 34
目 次
3.4.1 本手法の概要 . . . . 34
3.4.2 実行例 . . . . 34
3.4.3 本手法のまとめ . . . . 38
3.5 本章のまとめ . . . . 41
第4章 提案手法 43 4.1 本章の概要 . . . . 44
4.2 既存研究の考察 . . . . 45
4.2.1 Antolaらの手法の考察 . . . . 45
4.2.2 Karriらの手法の考察 . . . . 46
4.2.3 Wuらの手法の考察 . . . . 46
4.2.4 3手法の考察と課題点. . . . 47
4.3 新手法提案 . . . . 49
4.4 提案手法の実行例 . . . . 53
4.4.1 Wuらの手法による実行例 . . . . 53
4.4.2 提案手法による実行例 . . . . 53
4.5 提案手法の比較・考察 . . . . 58
4.5.1 サンプル入力結果の考察 . . . . 58
4.5.2 FIR入力結果の考察 . . . . 58
4.5.3 EWF入力結果の考察 . . . . 63
4.5.4 大規模入力結果の考察 . . . . 63
4.6 本章のまとめ . . . . 67
第5章 評価実験 69 5.1 本章の概要 . . . . 70
5.2 最適解との比較 . . . . 71
5.2.1 整数線形計画法 . . . . 71
目 次
5.3.1 FDSの概要 . . . . 75
5.3.2 FDSの流れ . . . . 75
5.3.3 力の算出 . . . . 75
5.3.4 スケジューリング . . . . 77
5.3.5 FDSによる結果と比較考察 . . . . 78
5.4 本章のまとめ . . . . 81
第6章 結論 82
謝辞 85
参考文献 86
第 1 章
序論
第1章 序論
1.1 本論文の背景と目的
VLSIデバイスの集積度は年々向上している.とりわけ近年ではその集積技術の 微細化が進みDeep SubMicron(DSM)からVery Deep SubMicron(VDSM)技術の 時代となっている.VDSM化は集積度の向上による面積削減のみならず,演算速 度の向上,電力消費量の削減をも実現するためその有効性は大きく,今後のVLSI デバイスはVDSMが標準となっていく.
VDSMはデバイスの大きさを小さくし,電源電圧を減らし,動作周波数を大き くすることでこれらの目標を達成している.一方でデバイスの微細化が進むと,宇 宙放射線のような極微小の粒子の影響により誤動作をする可能性が高くなる.こ のような誤動作の影響を総称してSingle Event Effect(SEE)と呼ぶ.
SEEの中には大きく分けて2つの現象がある.1つはデバイス内部のノードの電 荷量が減少し閾値に至っていない少量の宇宙放射線の粒子でも半導体素子のビッ ト反転が起こるために生じる一時的なエラーであるSingle Event Upset(SEU)と 呼ばれるものである.2つめはSingle Event Latch up(SEL)といい宇宙放射線の 影響によりデバイス内で永続的損傷が起こるというものである.これらの現象は デバイスの信頼性低下をもたらすためVDSM化に伴う問題となっている[13, 14].
インバータに1.1に示す6つのNAND素子からなるフリップフロップを28個つな げた回路におけるエラーの発生頻度は動作周波数10MHzにおいて毎秒300回にも 及ぶ[6].
図 1.1: フリップフロップ[6].
第1章 序論 SEEの中でもSEUによりエラーが起きる可能性はデバイスの動作周波数と深 く関係している.図1.2にインバータにD-ラッチが続く単純な回路での動作周波 数とSEUによるエラー発生確率の関係を示す.
図 1.2: SEUによるエラー発生頻度と動作周波数の関係[6].
縦軸がSEUによるエラー発生確率であり,横軸が動作周波数となっている.ま た,実線がこの回路全体のエラー発生確率を示し,点線がこの回路内の順序回路 部,破線が組合せ回路部でのエラー発生確率を示している.このような結果となっ た原因は,組合せ回路と順序回路を含むデバイス内でクロックのセンシティブエッ ジ付近でSEUが起こったとき,順序回路部はエラーを起こすことになるが,組合 せ回路部ではクロックの間隔とSEUの持続時間を比較しクロック間隔が長ければ 組合せ回路でエラーが起きることはないが,2つの値が近くなるとエラーが起き るためである.
本来SEUの持続時間はピコセカンドオーダーであるため,動作周波数がGHz からTHz程度でなければ組合せ回路部でのエラーはほとんど発生せず問題として いなかった.しかし,前述のようにデバイスの動作周波数は大きくなっており無 視できない状況となっているのである.
第1章 序論 このようにデバイスの信頼性低下を克服する手段として,エラー検出機能をデ バイスに持たせるという方法がある.この方法はデバイス内でエラーが起きてい ないかをチェックすることでデバイスの信頼性を高めるというものである.その 中でもデバイスが演算を実行中に逐次的にエラーを検出する逐次的エラー検出機 能をデバイスに持たせる手法,fault-secure設計[2]についての研究が行われてい る.本論文ではその中でも高位レベル設計[9, 12]に関する研究を対象とした既存 研究についての調査に基づき,新たな手法の提案を行う.また,その有効性を検 証し考察することを目的とする.
第1章 序論
1.2 本論文の概要
本論文では,VLSIデバイスの微細化が進む中で問題となっているデバイスの信 頼性低下の解決方法としてデバイス設計時からあらかじめ逐次的エラー検出機能 を組み込むという設計手法であるfault-secure設計について特に高位レベルにおけ るものを扱う.まず,fault-secure設計の定義に触れ,高位合成レベルでの既存研 究と,その課題点を挙げる.次にその課題点を下に提案した新手法を示し,その 有効性を示す.
本論文は6章から構成される.以下にその概要を示す.
第2章「fault-secure設計」では,逐次的エラー検出機能を持ったデバイス設 計手法であるfault-secure設計について示す.まずfaultの定義を示す.次に高位 レベルにおけるfault-secure設計の定義を示す.また,その検出力についても示す.
第3章「関連研究」では,高位レベルにおけるfault-secure設計に関する3つの 既存研究をとりあげる.各節でそれぞれその手法と同一の入力に対する実行例を 示し,その面積オーバヘッド,時間オーバヘッドを示す.
第4章「提案手法」では,まず前章の各既存研究に対して,その手法と行った 実行結果を面積オーバヘッド,時間オーバヘッドに注目し考察する.次に,その 考察から既存手法よりも面積オーバヘッド,時間オーバヘッドを削減するために 新たな手法を示し,既存手法との比較を行う.
第5章「評価実験」では,fault-secure設計の提案手法のさらなる有効性を示す ため,最適解との比較を行い,fault-secure設計におけるヒューリスティックな手 法の必要性を示す.また,一般的なヒューリスティックなアルゴリズムとの比較 考察を行い提案手法の優位性を示す.
第6章「結論」では,本論文全体のまとめをし,高位レベル設計におけるfault- secure設計の今後の指針を示す.
第 2 章
fault-secure 設計
第2章 fault-secure設計
2.1 本章の概要
本章では,近年のVLSIデバイスの微細化にともなう信頼性低下の問題を克服 するために提案されている,設計の高位レベル段階での新しい設計手法である fault-secure設計について説明する.
2.2節では,まずfault-secure設計におけるfaultの定義を示すとともに,近年そ れが問題化している理由を示し,その回避の難しさについて述べる.
2.3節では,高位レベルにおけるfault-secure設計についてその概念を説明し,
面積オーバヘッド,時間オーバヘッドの付加が必須であることを示す.また設計 例として,面積オーバヘッドのみ許容した最も単純な設計例と,面積オーバヘッ ドのみを許容した最も単純な設計例を示す.そして,その問題点を指摘するとと もに,既存研究における基本方針を示す.
2.4節では,文献[22]のSNPを対象としたfault-secure設計の検出力に関する実 験結果を示し,fault-secure設計の有用性を示す.
2.5節では,本章をまとめる.
第2章 fault-secure設計
2.2 fault
fault-secure設計におけるfaultには,デバイス設計段階の欠陥によるエラーは 含んでいない.デバイス設計には何の欠損もなく,製造後でもデバイス内の素子 に欠陥がなかったとする.そのような状態でも演算実行時にデバイス内で不具合 がおきエラーが発生することがある.特に近年ではデバイスの微細化が進みDSM からVDSMの時代となってきており,それに伴う動作周波数の増大,消費電力の 低減は今までのデバイスでは問題としなかったような微量な電流や電圧の変化を も信号ととらえエラーを起こす可能性が上がってきている.例えば,地球上には 宇宙から宇宙放射線が微量ではあるが降り注いでいる.この中の粒子は通常のデ バイス内の素子の閾値にも満たないような微量なエネルギーしか持っていない.
しかし,デバイスの超微細化と消費電力低減のために閾値が下げられているため,
この宇宙放射線の粒子が1つでもデバイスを通過するとデバイスに不具合をおこ し,エラーが発生することがある.この現象を,シングルイベントと言い,現在 のVLSIデバイスではこのシングルイベントにより生じるエラーのための信頼性 低下が無視できない状況になっている.シングルイベントにより引き起こされる デバイス内の不具合には比較的強いエネルギーを持つ宇宙放射線がデバイス内の 素子を壊してしまうSELと呼ばれる現象と,宇宙放射線によりデバイス内の電荷 が励起されビット反転がおきるSEUと呼ばれるものがある.また,シングルイベ ントが原因によるものに限らず,このようにデバイス内で一時的に起き,デバイ スが実行する演算に悪影響を及ぼす全ての状態の総称をfaultととらえている.
つまりfaultとはデバイス設計の不具合により起こるものではないため,全ての
デバイスにより起こりうるといえる.
本論文では以後,SELのようにデバイス自体の予期せぬ故障などが原因で永続 的に起き続けるエラーを総称して永続的なfaultと呼ぶ.また,SEUのように一 時的に起きたエラーを総称して一時的なfaultと呼ぶ.
第2章 fault-secure設計
2.3 高位レベルにおける fault-secure 設計
前節で述べたようにデバイスにおこるfaultにはSEUのように,現在のデバイ ス製造の技術では完全に回避できない問題も含まれている.そのような中でデバ イスの信頼性を上げるためには,エラーを起こさないようにするという方法より も,エラーが起きたことを検出できるようにするという方法が現実的であると言 える.この観点から逐次的エラー検出機能をデバイスに組み込むという設計が提 案されており,その設計手法をfault-secure設計と呼ぶ.
fault-secure設計では,デバイスがある演算を実行するとき,その計算を二度繰
り返す.そしてその結果を比較器を用い比較することでfaultが起きていないか を判断するのである.本論文では以後,fault-secure設計されたデバイスにおける 通常の演算を通常計算,エラー検出用の二度目の演算を再計算と呼ぶ.ここで注 意しなくてはならない点がある.この通常計算と再計算の際に同一の演算を同一 の演算器で行ってはならないという点である.同じ演算を同一の演算器で行うと,
その2回の演算で演算器が受けている永続的なfaultによる影響を受ける可能性が あるので通常計算と再計算では別の演算器を用いることで永続的なエラーの検出 を図るのである.また,入力のデータが既にfaultによるエラーの影響をを受けて いる可能性も考えられるので,通常計算と再計算の入力の比較もしておかなけれ ばならない.
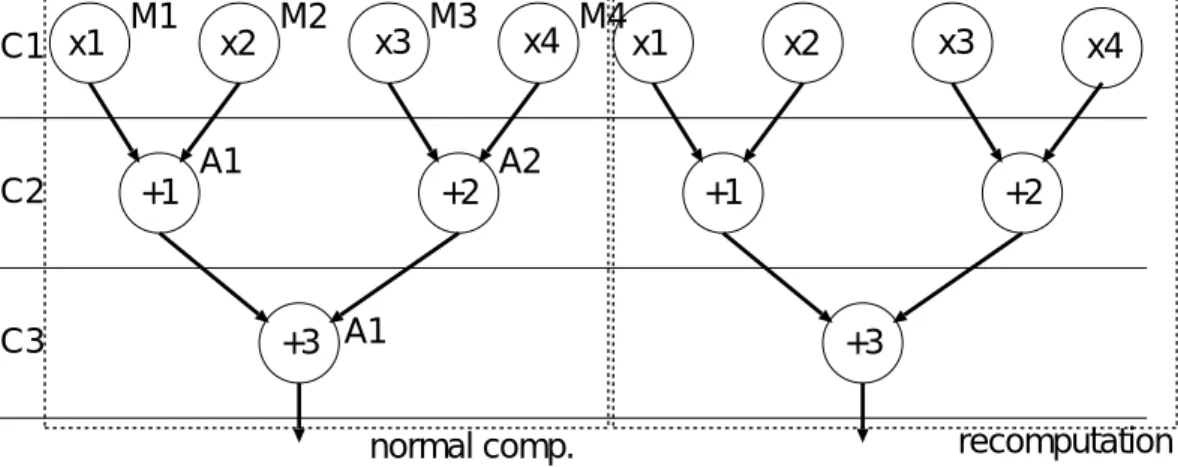
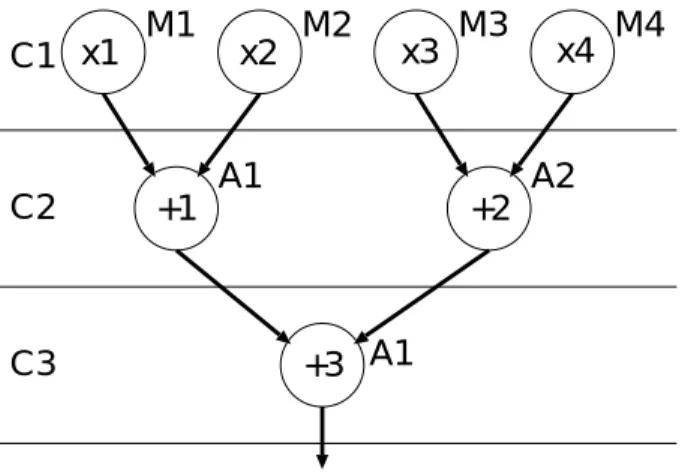
高位レベルにおけるfault-secure設計では本来デバイスで実現すべきControl- Data Flow Graph(CDFG)を入力として,それを通常計算のCDFGと考え,そこ に通常計算と同一のCDFGを用意しスケジューリング,アロケーションしていく という方法をとっている.ここで,入力CDFGとして,図2.1を用いたときの最 も単純なfault-secure設計の例を図2.2に示す.
この単純な設計手法では入力CDFGと同一のCDFGを再計算用として付加し,
さらに,通常計算に用いる演算器とは別に再計算用の演算器を付加している.この
第2章 fault-secure設計
x1 x2 x3 x4
+1 +2
+3 C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
図 2.1: 入力CDFG.
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
M5 M6 M7 M8
A3 A4
A3
x1 x2 x3 x4
+1 +2
+3
normal comp. recomputation
図 2.2: 出力CDFG1.
第2章 fault-secure設計 ている.加えて,比較器が付加されるため面積オーバヘッドは2倍以上となる.こ の設計方針は時間オーバヘッドを許さず,面積オーバヘッドを許容しfault-secure を付加するというものである.
次に別の設計手法によるfault-secure設計例を図2.3に示す.
C1
C2
C3
C4
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
C5
C6
M3 M4 M1 M2
A2 A1
A2
x1 x2 x3 x4
+1 +2
+3 normal comp.
recomputation
図 2.3: 出力CDFG2.
図2.3に示される設計手法は,入力CDFGと同一の再計算用CDFGを付加する 際に,クロックC4以降に付加し,既に通常計算で利用された演算器を同一オペ レーションで同一演算器が利用されないようにアロケーションを行っている.通 常計算では乗算x1,x2,x3,x4にそれぞれ乗算器M1,M2,M3,M4が割 り当てられているのに対し,再計算ではそれぞれのオペレーションに乗算器M3,
M4,M1,M2が割り当てられている.また,加算器に関しても通常計算では加
第2章 fault-secure設計 る.しかし,時間に関しては,入力CDFGが3クロックサイクルで実行している のに対して,fault-secure設計後は6クロックサイクルと2倍の時間オーバヘッド となっている.この設計手法はfault-secure設計において付加が必須である比較器 以外の面積オーバヘッドを許さず,時間オーバヘッドを許容しfault-secure設計を 付加するというものである.
以上2つの簡単なfault-secure設計を演算器数,クロックサイクルという観点で 面積オーバヘッド,時間オーバヘッドについて表2.1に示す.どちらの設計方法に しても,通常計算と再計算の出力を比較する必要があり,必ず比較器1つ分の面 積オーバヘッドが必要となる.
表 2.1: 2つの手法の比較.
乗算器数 加算器数 比較器数 面積OH 時間OH
入力 4 2 0 – –
例1 8 4 1 7 0
例2 4 2 1 1 3
ここで示したこの2つの手法はfault-secure設計を行う上で必ず必要となる時間 オーバヘッド,面積オーバヘッドという観点において正反対のアプローチを用い た手法であるといえる.しかし,このどちらも時間,あるいは面積オーバヘッド が2倍以上となり,現実的であるとは言えない.そこで,CDFGの演算器のアイ ドリングクロックを利用するといった手法により時間オーバヘッド,面積オーバ ヘッドを抑えつつfault-secure設計をする方法が研究されている.高位レベルにお ける研究としては,現在,スケジューリングとアロケーションを行うことにより,
この問題を解決しようという研究が主流である.
第2章 fault-secure設計
2.4 fault-secure 設計の検出力
本節ではWuらの行ったfault-secure設計の検出力を検証した実験結果[22]を紹 介し,fault-secure設計の有効性を示す.
2.4.1 SPN ( Substitution Permutation Network )
文献[22]ではfault-secure設計の設計対象として暗号化技術の中でも特にSPN
(Substitution Permutation Network)[5]という暗号化処理を行う回路に関して行 う.この小節では簡単にSPNの処理について説明する.
SPNはブロック暗号の一種である.通常の暗号が暗号化と復号化に逆の処理を 行うのに対して,この暗号は暗号化と復号化に同一の処理を行う.異なるのは各処 理に用いる鍵が逆となっていることである.これはアーキテクチャの観点から見 て暗号化と復号化のハードウェアを同一のものが利用可能ということであり,面 積の面で非常に有効という特長となっている.
この文献ではSPNの中でも特に64bitの平文を入力とするKHAZAD[3]と128bit の平文を入力とするANUBIS[4]の2つについてfault-secure設計の検出力を調査 している.
両者に共通している点は対合を用いるという点と,大きく3つの処理に分ける ことができる点である.この2つは構造が似ているので比較のしやすさのために 3つのラウンドに分割して用いることとする.この3つのラウンドは
1. 線形拡散 2. 非線形置換 3. キーミキシング
を行うラウンドとなっている.
1の線形拡散は,出力に全ての入力を関連付ける機能である.
2の非線形置換において,1
第2章 fault-secure設計
図 2.4: 排他的論理和.
この処理に関してエラーを回避できないという問題がある.ここで得られた出 力をもとに復号化処理を行うことを考える.仮にこの復号処理の際に,先ほど得 られた出力の最下位ビットの反転が起きたとすると,図2.5に示すような結果とな る.エラーが起き,間違った出力が用いられたにも関わらず,正しい入力が得ら れてしまう.このため,信頼性が低下してしまう.この問題点を解決するために
図 2.5: faultを含む排他的論理和.
KHAZADとANUBISでは図2.6に示されるように,2つの入力を半分に分け,左 半分のビットと右半分のビットを交換して処理を行うという処理が行われている.
2.4.2 検出力の評価実験結果
文献[22]ではKHAZADとANUBISの2種類のSNPを3つのラウンドに分け,
そこにfault-secure設計のCEDを組み込んだ処理プロセスをC言語を用いて実現
第2章 fault-secure設計
図 2.6: ビット交換[22].
第2章 fault-secure設計 しfaultの検出力を調べている.
図2.7において,γは線形拡散処理を,θは非線形置換処理を,σはキーミキ シング処理を示している.
この図をみると,同一モジュールの結果を比較しているため,faultの検出が正 しく行われないように見えるが,実際は暗号化処理により比較されるデータが図
2.4,2.5に示されるように,直接の入力データと,その入力データと固定入力の
排他的論理和により出力されたデータにさらに固定入力との排他的論理和をとっ て元通りにした入力データを比較しているので,一時的なfaultと永続的なfault の両方を検出することができる.
このCEDを組み込んだSNPにランダムに1ビット反転のfaultを含ませた入 力とランダムに複数ビット反転のfaultを含ませた入力を与えることで,一時的
なfaultの検出力を調べている.150万の異なる入力データにおいて実験を行って
いる.
また,永続的なfaultの検出力を調べるために,出力データの一部にランダムな ビット反転のfaultを起こさせた実験も行っている.
実験の結果,1ビットのfaultを含む入力を与えた場合と複数ビットのfaultを 含む入力を与えた場合の結果をそれぞれ表2.2,表2.3に示す.
表 2.2: 1ビットのfaultを含む入力に対する検出力.
処理 一時的fault 永続的fault
線形拡散 99.995% 100%
非線形置換 100% 100%
キーミキシング 100% 100%
表2.2,2.3に示されるように,かなり高い検出力があることがわかる.しかし,
条件によって検出力が100%ではない場合もあるので実験結果をもとに考察を行う.
第2章 fault-secure設計
表 2.3: 複数ビットのfaultを含む入力に対する検出力.
ビット数 一時的fault 永続的fault 2bit 99.996% 99.998%
3bit 99.999% 100%
4bit 99.999% 99.999%
5bit 100% 100%
1ビットのfault入力の考察
表2.2を見ると,ほぼ全て100%の検出力があることがわかる.しかし,線形拡 散の処理に関する一時的なfaultの検出力のみ劣っている.これは,同一ビットに
同じfaultが2クロックサイクル連続して起きる場合が検出できないからである.
たとえば,入力としてC8D3 EEF4 AE2D 2DA1が与えられたとき,これに対 する固定入力との排他的論理和をとった結果が7E05 93BC 87F3 F32Cだとする.
ここで,この入力の最下位3ビット目が反転するfaultが起き,入力がC8D3 EEF4 AE2D 2DA5になったとする.すると,この入力に対する出力は7E05 93BC 87F3 F328となる.この出力をさらに固定入力に対して排他的論理和をとることで入力 に戻し比較するわけであるが,この出力が戻される前にさらに最下位3ビット目 が反転したとする.すると,7E05 93BC 87F3 F32Cと変わり,これは初めのfault が起きなかった場合と同様の値であり,この排他的論理和は,faultが起きたにも 関わらず,正しい動作をしたと認識されてしまうのである.
複数ビットのfault入力の考察
各機能に関しては概ね1ビットの場合と変わらないので表2.3は全体の検出力 となっている.線形拡散に関しては1ビットの場合と同じである.非線形置換に
第2章 fault-secure設計 この文献によるとfault-secure設計による逐次的エラー検出の性能は極めて高 く,その有用性が示されている.
第2章 fault-secure設計
2.5 本章のまとめ
本章では,近年のVLSIデバイスの微細化にともなう信頼性低下の問題を克服 するために提案されている,設計の高位レベル段階での新しい設計手法である fault-secure設計について説明した.
2.2節では,まずfault-secure設計におけるfaultの定義を示すとともに,近年そ れが問題化している理由を示し,その回避の難しさについて述べた.
2.3節では,高位レベルにおけるfault-secure設計についてその概念を説明し,
面積オーバヘッド,時間オーバヘッドの付加が必須であることを示した.また設 計例をとして,面積オーバヘッドのみ許容した最も単純な設計例と,面積オーバ ヘッドのみを許容した最も単純な設計例をしめした.そして,その問題点を指摘 するとともに,既存研究における基本方針を示した.
2.4節では,文献[22]のSNPを対象としたfault-secure設計の検出力に関する実 験結果を示し,fault-secure設計の有用性を示した.
この章ではfaultの定義から,fault-secure設計の概念を説明した.fault-secure 設計を行うことで面積オーバヘッドか時間オーバヘッドが現れることは不可避で ある.この章では最も簡単なfault-secure設計例として面積オーバヘッドのみを許 容した設計例と,時間オーバヘッドのみを許容した設計例を示した.この2つの 例ではどちらもそのオーバヘッドは2倍以上になり現実的な設計方法とは言えな かった.そこで,この問題点を解決するために,デバイス内の演算器のアイドリ ングクロックを利用するためにスケジューリングとアロケーションを行うという 設計方法が研究されていることについて触れた.また,fault-secure設計の検出力 調査に関する文献を紹介し,その有用性を示した.
第 3 章
関連研究
第3章 関連研究
3.1 本章の概要
第2章で説明したように,fault-secure設計を行う上で,入力に対して面積オー バヘッドや時間オーバヘッドが付加することは避けられない.単純にfault-secure 設計を行えば,そのオーバヘッドは2倍近いものとなり,デバイス設計において は非現実的なものとなってしまう.
本章ではそのような面積オーバヘッド,時間オーバヘッドを小さくし,fault-
secure設計を行うための研究された手法についてとりあげる.
3.2節では,Antolaらが文献[1]で提案した,時間オーバヘッドを許容すること で生まれる再計算用CDFGの可動性に注目し,付加する演算器数を少なくするよ うにスケジューリングを行うことで面積オーバヘッドをできるだけ小さくすると いう設計手法についてその実行例を示し説明する.
3.3節では,Karriらが文献[10]で提案した,時間オーバヘッドを許容しないと いう条件で,再計算用CDFGをサブCDFGに分割することで生まれる可動性に 注目し,スケジューリングを行うことで面積オーバヘッドを小さくするという手 法について説明する.
3.4節では,Wuらが文献[23]で提案した,Karriらの手法の発展的手法ともい える,時間オーバヘッドの許容のもとで再計算用CDFGをサブCDFGに分割し,
スケジューリングを行い面積オーバヘッドを小さくするという手法にについて説 明する.
3.5節では,本章をまとめる.
第3章 関連研究
3.2 Anotola らの手法
この節では高位レベルにおけるfault-secure設計に関するAntolaらの手法につ いて説明する.
3.2.1 本手法の概要
本手法ではまず,入力CDFG に通常計算のCDFGのコピーである再計算用 CDFGを付加したCDFGを考える.図2.1の入力に対し再計算用CDFGを付加 したものを図3.1に示す.
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2 x3 x4
+1 +2
+3
normal comp. recomputation
図 3.1: Antolaの設計過程CDFG1.
AntolaらはこのCDFGにおいて,あらかじめ時間オーバヘッドを許容しfault-
secure設計をする方法を提案した.その手法では,この入力CDFGにあらかじめ
時間オーバヘッドを付加することで,CDFG内のオペレーション実行に時間的猶 予を作る.その猶予がうまれることで,CDFG内のオペレーションを実行するク ロックサイクルに幅が生まれる.この時間的幅を可動性と呼んでおり,この可動 性に注目し,面積オーバヘッドを小さくしていく手法となっている.
3.2.2 実行例
実際に,図2.1に示す例を入力として,この手法を実行した例を示す.まず,前 節で示した図3.1のように,入力CDFGをコピーしたものを再計算用CDFGとし て付加する.このCDFGをそのままfault-secure設計のためにアロケーションを
第3章 関連研究 おこなうと,図2.2に示されるように必要となる演算器数が乗算器8,加算器6と なる.そこで,アロケーションをする前に,このCDFGに時間オーバヘッドとし て1クロックサイクルを付加する.そのCDFGを図3.2に示す.
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2 x3 x4
+1 +2
+3
normal comp. recomputation
C4
図 3.2: Antolaの設計過程CDFG2.
この手法では,このCDFGの再計算用部分に対して,その可動性に注目し,必 要となる演算器の数が減少するようにスケジューリングを行うのである.そのス ケジューリング方法は基本的には通常,演算器を減らすために施されるようなス ケジューリング方法と同様で,CDFG内のオペレーションが許される可動性の範 囲内で全てのクロックサイクルになるべく均等に分布するように行う.そのスケ ジューリング結果を図3.3に示す.
ここで,再計算用CDFGについてアロケーションを行っていく.ここでアロケー ションを行う際に,fault-secure設計の定義である,通常計算と再計算の同一のオ ペレーションを同一の演算器で行わないという点に注意し,通常計算とは異なる 演算器を割り当てていく.図3.4にアロケーション結果を示す.これがこの手法の
第3章 関連研究
C1
C2
C3
C4
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2 x3 x4
+1
+3
+2
normal comp.
recomputation
図 3.3: Antolaの設計過程CDFG3.
C1
C2
C3
C4
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2 x3 x4
+1
+3
+2
M1 M2
M3 M4
A2
normal comp.
recomputation
A2
A3
図 3.4: Antolaの手法の設計結果.
第3章 関連研究
表 3.1: Antolaらの手法の比較.
乗算器数 加算器数 比較器数 面積OH 時間OH
入力 4 2 0 – –
例1 8 4 1 7 0
例2 4 2 1 1 3
Antolaの手法 4 3 1 2 1
設計結果となる.
3.2.3 本手法のまとめ
この手法による出力結果と前節,図2.2,2.3に示したfault-secure設計の例との 比較結果を表3.1に示す.
Antolaらの手法は,許容された実行時間ないでできるだけ必要となる演算器の
数を減らすためのスケジューリングおこなうという手法であった.この例ではス ケジューリングの結果,1,2,4クロックサイクル目では通常計算で使用されてい ない演算器を用いることで再計算を行うことができるようになった.しかし,3ク ロックサイクル目には加算のオペレーションが3つ存在するため,ここで加算器 を1つ加える必要があり,面積オーバヘッドとしては1つの演算器が必要となって いる.表3.1からもわかるように,面積オーバヘッド,時間オーバヘッドのどちら も生じるが,それらの値を小さいもので抑えることができている.そのため,第 2章で例示した2つの手法よりは現実的な手法であると言える.
第3章 関連研究
3.3 Karri らの手法
この節では高位レベルにおけるfault-secure設計に関するKarriらの手法につい て説明する.
3.3.1 本手法の概要
前節で挙げたAntolaらの手法は入力CDFGに許容される時間オーバヘッドを 付加した上で,スケジューリングにより面積オーバヘッドを少なく抑えるといっ た手法であった.これに対し,Karriらは時間オーバヘッドを付加せずに面積オー バヘッドを少なくする方法を提案している.
この手法でもAntolaらの手法と同様にCDFGを入力として,そこに同一の CDFGを再計算用CDFGとして付加したものを考える.Antolaらの手法ではさ らに許容される範囲で時間オーバヘッドを付加した上で再計算用CDFGをスケ ジューリングしていった.しかし,Karriらの手法では時間オーバヘッドを付加し ないまま,面積オーバヘッドが小さくなるように再計算用CDFGをスケジューリ ングしていくのである.図2.1に示すCDFGを入力とする場合を考えると,そこ に再計算用CDFGを付加したものは図3.1となる.Karriらの手法ではこのCDFG の再計算部をこのまま演算器数が小さくなるようにスケジューリングしていくの であるが,このCDFGにはどのオペレーションにも可動性がないためこれ以上ス ケジューリングすることは不可能である.そこで,Karriらは,演算器数を減らす ために再計算用CDFGのエッジを選択的に分断し,いくつかの小さなサブCDFG に分けてスケジューリングを行っている.サブCDFGに分割することで,分割さ れたサブCDFGのオペレーションに可動性が生まれスケジューリングが可能とな る.分断されて新たにできたサブCDFGの入力データに関しては通常計算により 計算されたデータを流用することでその問題を解決している.しかし,この方法に は注意しなくてはならない点がある.それは,fault-secure設計においては入力と 出力の比較を行う必要が生じるということである.つまり,1つの再計算用CDFG をいくつかのサブCDFGに分割したことで増えた入力エッジと出力エッジ全てで,
対応する通常計算CDFG内のエッジのデータと比較しエラー検出のためのチェッ クを行わなくてならないということである.そのためにはそのようなエッジでそ
第3章 関連研究 れぞれ比較器が必要となり面積オーバヘッドが増加することにつながる.しかし,
設計対象となるようなVLSIでは加算器や乗算器にと比べ比較器の方が面積が小さ いために,この手法によりある程度比較器が増えたとしても全体的には面積オー バヘッド削減が実現できるのである.
3.3.2 実行例
実際に,図2.1に示す例を入力として,この手法を実行した例を示す.
まず,この入力CDFGに対して同一のCDFGを再計算用CDFGとして付加し,
図3.1としたものを考える.ここで,このCDFGの再計算部ついてサブCDFGに 分割を行うわけであるが,その分割アルゴリズムとしては,グラフ理論の観点か ら文献[19]に示されるmin-cut手法と,文献[24]に示されるアルゴリズムを適用 する.その分割結果を図3.5に示す.
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2 x3 x4
+1 +2
+3
normal comp. recomputation
R1
R2
normal comp.
図 3.5: Karriの設計過程CDFG1.
このように再計算用CDFGを2つのサブCDFG R1,R2に分割すると,サブ
CDFG R1に可動性が生まれ,スケジューリングが可能となる.また,サブCDFG
R2のオペレーション +3の入力エッジが切断されたため,あらたな入力エッジが
第3章 関連研究 にできた入力エッジの入力データをサブCDFG R1の出力から得ることができなく なってしまった.この問題を解決する方法として,Karriらは通常計算のデータを 再計算に流用する方法を提案した.図3.5に示す通常計算CDFGの印のついたエッ ジのデータを入力として用いるのである.同時に,このエッジのデータと,サブ CDFG R1の出力エッジを比較することで,サブCDFG R1のfault-secureを保障 し,かつ,サブCDFG R2の入力データの比較が行われるためにR2のfault-secure も同時に保障されるのである.
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2
x3 x4
+1
+2
+3
normal comp. R1 recomputation R2
normal comp.
図 3.6: Karriの設計過程CDFG2.
この例ではサブCDFG R1のみに可動性が生まれたため,R1のみスケジューリ ングを行っているが,どのサブCDFGもスケジューリングを行うことができる.
最後にfault-secure設計に基づきアロケーションを行い終了する.Karriらの手 法による設計結果を図3.7に示す.
3.3.3 本手法のまとめ
この手法による出力結果と前節,図2.2,2.3に示したfault-secure設計の例との 比較結果を表3.2に示す.
Karriらの手法は,時間オーバヘッドを許さないとうい条件の下,できるだけ必
要となる演算器の数を減らすためにスケジューリングおこなうという手法であっ た.しかし,時間オーバヘッドがないとオペレーションに存在する可動性が非常 に小さく満足にスケジューリングが行えない場合や,例で示したように可動性が 全く存在せず,スケジューリングが行えないケースがある.そこで,Karriらは
第3章 関連研究
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2
x3 x4
+1
+2
+3
normal comp. R1 recomputation R2
normal comp.
M5 M6
M5 M6 A3
A2 A3
図 3.7: Karriの手法の設計結果.
表 3.2: Karriらの手法の比較.
乗算器数 加算器数 比較器数 面積OH 時間OH
入力 4 2 0 – –
例1 8 4 1 7 0
例2 4 2 1 1 3
Karri 6 3 2 5 0
第3章 関連研究 CDFGのエッジを選択的に切断し,いくつかのサブCDFGに分けることで,その サブCDFGに可動性を生み出し,スケジューリング可能にした.その方法により 必要な演算器を減らすためのスケジューリングは行えるようになったが,それと 同時に,分割した全てのサブCDFGにおいてfault-secureを保障するために比較 器を付加する必要も生じた.表3.2を見るとわかるが,他の手法では入力データ がすでに1fault-secureであると仮定し,最終的な出力エッジの比較のみで済むた めに1つの比較器だけでよいが,Karriらの手法では比較器が2つ必要となってい る.だが,Karriらの手法と同じく時間オーバヘッドを許していない第2章で挙げ た例1の手法と比べても,演算器数のオーバヘッドでも勝っておりその有効性がわ かる.また,比較器は他の演算器と比べて面積は小さいため他の演算器数を減ら すために比較器数が増えてもデバイス自体の面積を小さくすることが可能となる.
第3章 関連研究
3.4 Wu の手法
この節では高位レベルにおけるfault-secure設計に関するWuらの手法について 説明する.
3.4.1 本手法の概要
Karriらの手法は時間オーバヘッドを許さず,面積オーバヘッドを2倍以下に
抑えるべくサブCDFGをスケジューリングするという方針の手法であった.しか し,入力CDFGをただコピーしたにすぎない再計算用サブCDFGでは時間オー バヘッドがなければ可動性がなくスケジューリングが行えないために,Karriらは 再計算用CDFGのエッジを選択的に切断しいくつかのサブCDFGに分けること で,可動性を生み出しスケジューリング可能にした.この操作により,全てのサ ブCDFGのfault-secureを保障しなくてはならなくなり,比較するエッジが増え,
比較器の数は増えたが,スケジューリングにより演算器数が減ることと,比較器 の面積が他の演算器の面積と比べ小さいことから面積オーバヘッドを減らすため に効果の高い手法と言えた.
Wuらの手法はこのKarriらの手法の発展的な手法と位置づけられる.Wuらは
このKarriらの手法の特徴とも言える,再計算用CDFGの分割しながらスケジュー
リングを行うという方法を,時間オーバヘッドの許容のもとに行う方法を提案し た.Wuらの手法は基本的な考え方こそKarriらの手法に似ているが,その実行手 順は異なる.Wuらの手法では入力として,CDFGの他に許容される時間オーバ ヘッドと,fault-secure設計のために付加してよい演算器とその数が必要としてい る.そのため,今までの手法が与えられた時間オーバヘッド内で,なるべく小さ な面積オーバヘッドで済ませるかという手法であったのに対し,この手法は,与 えられた演算器数でなるべく小さな時間オーバヘッドで済ませるという手法であ るといえる.
第3章 関連研究 CDFGの他に表3.3に示す演算器数,時間オーバヘッドを入力とした.
表 3.3: Wuの手法の入力.
乗算器数 加算器数 許容される時間OH
4 2 1
まずはじめに,入力CDFGの下に同一のCDFGを再計算用CDFGとして付加 した図3.8を考える.
C1
C2
C3
C4
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
C5
C6
x1 x2 x3 x4
+1 +2
+3 normal comp.
recomputation
図 3.8: Wuの手法の設計過程CDFG1.
次にこのCDFGの再計算部をいくつかのサブCDFGに分割していく.その分
割方法はKarriらの手法と異なる.ここではCDFGを分割する際にスケジューリ
ング後のアロケーションのしやすさを意識した独自の分割手法を用いている.Wu
第3章 関連研究 らの手法では,まず,再計算用CDFGの入力エッジに続くオペレーションを示す 入力ノード,つまり,この例ではx1,x2,x3,x4のいずれかを選ぶ.この 例ではx1を選ぶことにする.選んだこのノードがこれから作るサブCDFGの第 1ノードとなる.そして,選んだノードと出力エッジでつながるノードと,選ん だノードに入力データを与えているノードである隣接ノードをそのサブCDFGに 加える.さらに,サブCDFGに加えられたノードの隣接ノードを加えていく.こ の操作を繰り返し,サブCDFGに含まれていない隣接ノードがなくなれば1つの サブCDFGができあがるのである.その際に,注意すべき点が1つある.Wuら の手法では,その後のアロケーションであらかじめ入力として与えられた演算器 数を越えるようなアロケーションを行うことをしないために,この分割後のスケ ジューリング結果が最悪,分割後のあるサブCDFGとその通常計算サブCDFGと 同一クロックサイクルにスケジューリングされるような結果であった場合に,そ のクロックで演算器が不足するということが起こりうる.そのようなケースを回 避するために,分割段階からサブCDFG内の同一クロックサイクルに含まれる同 種オペレーション数を与えられた演算器数の半分以下とする.x1から始まるサ ブCDFGが完成すると,次に,まだサブCDFGに含まれていない入力ノードを 選択し,同様の操作を行う.全てのノードがサブCDFGに分割されればこの操作 の終わりとなる.その結果を図3.9に示す.
分割後はスケジューリングを行っていく.このスケジューリングは大きなサブ CDFGから順に行っていくこととする.この例ではサブCDFG R1,R2の順に スケジューリングしていくことになる.サブCDFG内のエッジが切断されない範 囲で演算器が空いており,かつ,可能な限り早いクロックサイクルにスケジュー リングを行う.全てのサブCDFGのスケジューリング終了後にその結果が入力と なっている許容される時間オーバヘッドを満たしていればスケジューリング終了 となる.もし,許容される時間オーバヘッドを満たしていなければ,サブCDFG のエッジを切断してもよいとして演算器があいているなるべく早いクロックサイ
第3章 関連研究
C1
C2
C3
C4
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
C5
C6
x1 x2 x3 x4
+1 +2
+3 normal comp.
recomputation R1
R2
図 3.9: Wuの手法の設計過程CDFG2.
第3章 関連研究 この例でのスケジューリング結果を図3.10に示す.この例では最初に分割した サブCDFGをさらに分割することなく時間オーバヘッドを満たすことができた.
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2 x3 x4
+1
+2 +3
normal comp.
recomputation C4
normal comp.
R1 R2
図 3.10: Wuの手法の設計過程CDFG3.
ここにfault-secure設計を満たすようにアロケーションを行い終了する.ここ
で,この例では再計算用サブCDFGのfault-secureを保証するためにサブCDFG
R1,R2の出力にそれぞれ比較器が必要となるため,2つの比較器を加えることに
なる.Wuらの手法による設計結果を図3.11に示す.
3.4.3 本手法のまとめ
この手法による出力結果と前節,図2.2,2.3に示したfault-secure設計の例との 比較結果を表3.4に示す.
Wuらの手法ではあらかじめ使用する演算器数を決めて入力とするために面積 オーバヘッドはその入力に関係する.この例では,乗算器,加算器の付加を許さ
2 CDFG
第3章 関連研究
C1
C2
C3
M1 M2 M3 M4
A1 A2
A1
x1 x2 x3 x4
+1 +2
+3
x1 x2 x3 x4
+1
+2 +3
normal comp.
recomputation C4
normal comp.
R1 R2
M3 M4 M1 M2
A2
A2 A1
図 3.11: Wuの手法の設計結果CDFG.
表 3.4: Wuらの手法の比較.
乗算器数 加算器数 比較器数 面積OH 時間OH
入力 4 2 0 – –
例1 8 4 1 7 0
例2 4 2 1 1 3
Wuの手法 4 2 2 2 1
第3章 関連研究 用CDFGを分割しスケジューリングするという方法をとっていたが,Wuらは,あ らかじめ演算器数を決めておき,その中で時間オーバヘッドを満たすべく再計算 用CDFGを分割していくという違いがあった.
この例ではスケジューリング中にさらにサブCDFGを分割する必要はなかった が,大規模なCDFGや,演算器数を抑えた設計要求の場合には必然的に再分割の 必要があり,比較器の数が増え,面積オーバヘッドが増えるケースがあることも 考えられる.しかし,この手法では演算器数を設計者があらかじめ入力できるこ とを利用し,あまりにも分割が進むようなケースではある程度の演算器数の増加 を許すことで比較器を減らすといった方法もとれる.同様に,入力する演算器数 を変えられることで,面積オーバヘッドと時間オーバヘッドのトレードオフのバ ランスをとりうることが可能となる.このような柔軟性の高さにもこの手法の特 長があると言える.
第3章 関連研究
3.5 本章のまとめ
第2章で説明したように,fault-secure設計を行う上で,入力に対して面積オー バヘッドや時間オーバヘッドが付加することは避けられない.単純にfault-secure 設計を行えば,そのオーバヘッドは2倍近いものとなり,デバイス設計において は非現実的なものとなってしまう.
本章ではそのような面積オーバヘッド,時間オーバヘッドを小さくし,fault-
secure設計を行うための研究された手法についてとりあげた.
3.2節では,Antolaらが文献[1]で提案した,時間オーバヘッドを許容すること で生まれる再計算用CDFGの可動性に注目し,付加する演算器数を少なくするよ うにスケジューリングを行うことで面積オーバヘッドをできるだけ小さくすると いう設計手法についてその実行例を示し説明した.
3.3節では,Karriらが文献[10]で提案した,時間オーバヘッドを許容しないと いう条件で,再計算用CDFGをサブCDFGに分割することで生まれる可動性に 注目し,スケジューリングを行うことで面積オーバヘッドを小さくするという手 法について説明した.
3.4節では,Wuらが文献[23]で提案した,Karriらの手法の発展的手法ともい える,時間オーバヘッドの許容のもとで再計算用CDFGをサブCDFGに分割し,
スケジューリングを行い面積オーバヘッドを小さくするという手法にについて説 明した.
これら3つの手法は全てスケジューリングにより面積オーバヘッドを小さくす るとともに,時間オーバヘッドを小さくしている.
Antolaらは,入力となるCDFGに時間オーバヘッドを付加することで再計算用
CDFGに可動性を生み出しスケジューリング可能とした.
Karriらは,時間オーバヘッドを付加しなかったが,再計算用CDFGをいくつ
かのサブCDFGに分割することでそこに可動性を生み出しスケジューリング可能 とした.サブCDFGに分割することで,サブCDFGの入力データが得られない という問題が生じたが,通常計算のデータを用いるという方法でその問題を回避
第3章 関連研究 した.また,この手法では全てのサブCDFGのfault-secureを保証するために比 較器を多く用いる必要があった.
Wuらは,Karriらの手法を発展させ,あらかじめ指定した演算器数で時間オー バヘッドを許容される範囲で設計すると言う手法を提案した.
第 4 章
提案手法
第4章 提案手法
4.1 本章の概要
本章では,第3章で取り上げた高位レベルにおけるfault-secure設計の3つの 既存研究についてその考察を行い,それぞれの手法の特長となる面積オーバヘッ ド,時間オーバヘッド削減のためのポイントをみつける.また,それぞれの手法 における課題点を挙げる.そして,それらを踏まえた上で今後の高位レベルにお
けるfault-secure設計に関する研究の指針を考察し,面積オーバヘッド,時間オー
バヘッド削減を目指した新手法を提案し既存手法との比較を行う.
4.2節では,第3章で挙げた3つの既存研究についてそれぞれその考察を行う.
その後,3つの手法の比較考察を行い,新手法提案につながる課題点を挙げる.
4.3節では,4.2節での考察結果に基づき,入力CDFGの可動性を考慮した新た な設計手法について述べる.
4.4節では,ある入力例に対する新手法の実行例を示す.また,比較のために同 一入力に対するWuらの手法による実行例も示す.
4.5節では,いくつかの入力例について提案手法と既存手法との面積オーバヘッ ド,時間オーバヘッドの比較を行い,その有効性を示すとともに考察を行う.
4.6節では,本章をまとめる.
第4章 提案手法
4.2 既存研究の考察
第3章で挙げた3つの高位レベルにおけるfault-secure設計に関する研究では,
全ての手法で入力CDFGに同一の再計算用CDFGを付加し,そこに時間オーバ ヘッドを付加したり,CDFGをサブCDFGに分割することで可動性を生み出し,
スケジューリングを行うことで面積オーバヘッドを小さくするという方法をとっ たいた.その結果,いずれの手法でも面積オーバヘッド,時間オーバヘッドが2倍 を下回るような設計が可能となった.表4.1に第2章で挙げた最も単純な2つの設 計例と,3つの手法の面積オーバヘッド,時間オーバヘッドを示す.この表をもと に各手法について考察する.
表 4.1: 既存手法の比較.
乗算器数 加算器数 比較器数 面積OH 時間OH
入力 4 2 0 – –
例1 8 4 1 7 0
例2 4 2 1 1 3
Antolaの手法 4 3 1 2 1
Karriの手法 6 3 2 5 0
Wuの手法 4 2 2 2 1
4.2.1 Antola らの手法の考察
Antolaらの手法では,許容される時間オーバヘッドを与えることで,再計算用
CDFGに可動性を与え,アイドリングサイクルを利用することで付加される演算 器数が小さくなるようにスケジューリングを行った.今回の例では演算器の付加 が1で済むというようにいい結果が得られているが,この手法では,入力で与え られている演算器にアイドリングサイクルがあったとしても,再計算用CDFGが くずれるようなスケジューリングは行わないため,演算器削減量は許容する時間 オーバヘッドが十分でないと小さな値しか期待できない.
第4章 提案手法
4.2.2 Karri らの手法の考察
Karriらの手法では,入力CDFGにそれと同一の再計算用CDFGを付加した
あと,その再計算部をいくつかのサブCDFGに分割することでそれぞれのサブ CDFGに可動性を生み出し,時間オーバヘッドの付加なしで付加される演算器数 を抑えるためのスケジューリングを可能とした.この分割操作により,分割したサ ブCDFGのfault-secureを保証するために,付加する比較器の数が増え面積オー バヘッドが増えうる可能性も考えられる.しかし,同様に時間オーバヘッドを許さ ない最も単純な設計例である例1と比べると,1つの比較器の付加で乗算器2つ,
加算器1つを削減している.この結果から再計算用CDFGの分割は有効な手法で あると考えられる.
この手法ではCDFGの分割が重要な点となっていることはすでに述べた.ここ で,問題となるのがfault-secure設計に向いたCDFG分割手法である.fault-secure 設計では通常計算と再計算内の同一オペレーションで同一の演算器をアロケーショ ンすることが許されていない.そのために,既存のスケジューリング手法とは異 なるスケジューリングを行うことになるために既存の分割手法が最適であるとい うわけではないのである.また,このようにfault-secure設計においてはアロケー ションとスケジューリングを分けて考えることはできないが,この手法では完全 に分けてそれぞれの操作を行っている.
4.2.3 Wu らの手法の考察
Wuらの手法は,Karriらの手法で提案された再計算用CDFGの分割手法をAn- tolaらが提案した時間オーバヘッドによる手法に組み込んだ手法と言える.また,
この手法は入力として,設計対象となるCDFGと許容される時間オーバヘッドの 他に利用できる演算器の種類とその数を与えておき,その演算器数の中で時間オー バヘッドを小さくしていくという手法であった.
この手法とAntolaらの手法を比較すると,1つの比較器を導入することで1つ
第4章 提案手法 により面積削減に成功していることが示されている.ただし,サブCDFGの分割 数が増えるとfault-secureを補償するために全てのサブCDFGの出力を比較する 必要が生じ,そのサブCDFG分の比較器が必要となる点が面積オーバヘッドの増 大という問題点として残っている.
この手法ではKarriらの手法で触れた,サブCDFGの分割手法と,スケジュー リングとアロケーションの融合に関する改良がなされている.第3章でも記した が,この手法ではサブCDFG分割際に,fault-secure設計のアロケーションを踏 まえた分割がなされている.
4.2.4 3 手法の考察と課題点
これら3つの手法は共通して,付加した再計算用CDFGに可動性を与えること で面積オーバヘッドを小さくしている.特にWuらの手法では,時間オーバヘッ ドを与えたことによる可動性と,再計算用CDFGをサブCDFGに分割すること による可動性の2つの可動性があるために,他の手法よりも面積オーバヘッドを 削減することに成功している.
高位レベルにおけるfault-secure設計ではスケジューリングとアロケーション による方法が主になるため,このようにCDFGの可動性に注目する手法が必然と なっている.今後の研究においてもこの可動性をいかに見出すかが重要となると 考えられる.特にfault-secure設計における,通常計算のオペレーションと再計 算の同一オペレーションが同じ演算器を使用してはならないという定義から,既 存のスケジューリング手法ではそれに続くアロケーションに影響を及ぼすことが 考えられる.また,既存の手法では通常計算CDFGが既にアロケーション済みと なっていることも,あとに続く再計算部のスケジューリング,アロケーションに 影響を与えているしたがって,既存手法における方法で再計算部をスケジューリ ング,アロケーションを行うといった設計では十分に面積オーバヘッド,時間オー バヘッドが削減できているとは言えない.
また,既存の研究では用意したCDFGの再計算部にのみ操作を施すに留まっ ている.これは既存の研究が,あらかじめ設計されたデバイスに後から付加的に
fault-secure設計を行うという方針によるものである.しかし,通常計算部を設計
段階からfault-secure設計を行うという方針のもとで設計を行えばCDFGの通常
第4章 提案手法 計算部の可動性をも利用できることからさらに面積オーバヘッド,時間オーバヘッ ドを削減できる可能性が考えられる.
このような点に注目すれば,高位レベルにおけるfault-secure設計の新たな改良 手法を考えることができると言える.
第4章 提案手法
4.3 新手法提案
前節で行った既存手法の考察から,新手法を考える.
高位レベルにおけるfault-secure設計において,その面積オーバヘッド,時間 オーバヘッドにはトレードオフの関係があることが既存研究の結果からも分かっ ている.また,設計対象となるデバイスにより許容される面積オーバヘッド,時 間オーバヘッドは異なるため,Wuらが提案したように,許容される時間オーバ ヘッドと演算器数が入力として与えられる手法が設計側にとって柔軟性があり望 ましいと言える.そこで,Wuらの手法をもとに改良方法を考える.
Wuらの手法が面積オーバヘッドを削減する効率が高い要因の1つは,再計算 部の柔軟なスケジューリングが可能であることだと考えられる.Wuら手法では 時間オーバヘッドを与えたことにより生まれる再計算CDFGの可動性と,再計算 CDFGをサブCDFGに分割することで生まれる可動性の2つを利用している.そ こで,新手法では設計対象となるCDFGにこの2つの他に新たな可動性を生み出 すために,入力となるCDFGに注目する.
既存研究では入力のCDFGについては一切の操作を加えていなかった.これ は設計対象となるデバイスの要求を満たすために入力CDFGはこれ以上のスケ ジューリングが行えないとみなしているからである.つまり,入力となるCDFG にはこれ以上の可動性がないとしているのである.しかし,全ての入力CDFGに ついて可動性がないわけではない.例えば,図4.1に示すCDFGを考える.この CDFGは4クロックサイクルの実行時間で,2つの乗算器 M1,M2と,2つの加
算器 A1,A2により実現されている.このCDFGは同じ実行時間,同じ演算器数
で,図4.2に示すようにも実現可能である.この例では他にも実現可能な例が存 在する.
このように入力CDFGに可動性があり,デバイス設計の要求を満たしうるスケ ジューリングパターンが2つ以上存在するようなCDFGは存在しうる.このよう な場合,この入力CDFGの可動性を利用し,面積オーバヘッド,時間オーバヘッ ドを削減できる可能性があると思われる.
この例において,再計算CDFGをサブCDFGに分割する手法を適用すること を考えると,この入力CDFGをそのスケジューリングの柔軟性を挙げるような形
第4章 提案手法
+1
x1 +3 x2
x3 x4
+4 C1
C2
C3
A1
M2 A1 M1
M2 M1
C4 A1
+2 A2
図 4.1: 新手法の入力CDFG1.
+1 x1
+3 x2
x3
x4
+4 C1
C2
C3
A1 M2
A1 M1
M2
M1
C4 A1
+2 A2
第4章 提案手法 にスケジューリングしておくことが効果的であると思われる.
CDFGのスケジューリング手法には設計対象となるデバイスやソフトウェアを 考慮した様々なものが研究提案されている[7, 8, 11, 15, 16, 21].中でもFDS(Force Directed Scheduling)と呼ばれる高位レベルにおけるスケジューリング手法[17]は,
面積オーバヘッドを減らすための手法として有名である.また,このスケジュー リング手法はAntolaらの提案手法においても用いられている.
本提案手法では通常計算部のスケジューリングに全てのノードを可能な限り早 いステップに割り当てるASAP(As Soon As Possible)スケジューリングの発想を 用いてみる.これは,通常計算部のノードはエッジの分断を行うことができず,可 動度が小さいという点と,再計算部のノードはエッジの分断を許容するため,結 果的にそのノードの可動度が通常計算部における本来の親ノードにあたるノード に依存するためである.可動度が大きいほど柔軟なスケジューリングが可能とな り,結果的に面積オーバヘッド,時間オーバヘッドの削減が期待される.
また,スケジューリングと同様に重要となるアロケーションについても,既存 の手法ではあらかじめ入力となるCDFGはアロケーション済みであった.しかし,
新手法ではこのアロケーションに関してもfault-secure設計を施すことを前提に可 変であると考える.ここで,入力CDFGのアロケーションを変更することに関し ては,既存手法においても,再計算用のCDFGのアロケーションの際に特別な制 限をかけていないことから,問題ないと考えられる.
サブCDFG分割に伴い必要となる比較器についても改良を加える.Wuらの手 法ではサブCDFG分割された出力部分のfault-secureを補償するための比較チェッ クのタイミングは全体の演算の終了後となっている.そのため,比較器の数はサ ブCDFG数と同数が必要となる.しかし,fault-secure設計がデバイスに逐次的 エラー検出機能を組み込むというものであることから,比較チェックのタイミン グは逐次的に行うことが妥当であると言える.比較チェックを逐次的に行い,か つ複数のサブCDFG出力において比較器の共有をすることで付加される比較器数 を削減することが可能となる.
図4.3に本提案手法のチャートを示す.
第4章 提案手法
![図 2.6: ビット交換 [22].](https://thumb-ap.123doks.com/thumbv2/123deta/9785888.1869143/19.892.273.673.190.1064/図26ビット交換22.webp)