早稲田大学大学院情報生産システム研究科
博 博 博
博 士 士 士 士 論 論 論 論 文 文 文 文
論 論 論
論 文 文 文 文 題 題 題 題 目 目 目 目
サーボシステムの高性能化に向けた サーボシステムの高性能化に向けた サーボシステムの高性能化に向けた サーボシステムの高性能化に向けた 制御演算およびセンサ信号処理
制御演算およびセンサ信号処理 制御演算およびセンサ信号処理
制御演算およびセンサ信号処理 LSI LSI LSI LSI アーキテクチャの研究 アーキテクチャの研究 アーキテクチャの研究 アーキテクチャの研究 Studies on LSI Architecture
Studies on LSI Architecture Studies on LSI Architecture Studies on LSI Architecture
for Control Operation and Sensor Signal Processing for Control Operation and Sensor Signal Processing for Control Operation and Sensor Signal Processing for Control Operation and Sensor Signal Processing
Toward a High Performance Servo System Toward a High Performance Servo System Toward a High Performance Servo System Toward a High Performance Servo System
申 請 者 柏木 喜孝
Yoshitaka Kashiwagi
情報生産システム工学専攻 新機能 LSI 研究
2009年5月
目次目次 目次目次
第1章 第1章 第1章
第1章 序論序論序論序論... 9999
1.1 研究の背景... 9
1.2 研究の目的... 14
1.2.1 サーボドライバ... 14
1.2.2 エンコーダ... 15
1.3 本論文の構成... 15
第2章 第2章 第2章 第2章 制御演算用 制御演算用制御演算用 ASIP制御演算用ASIPASIP(ASIP((( Application Specific Instruction set ProcessorApplication Specific Instruction set Processor)Application Specific Instruction set ProcessorApplication Specific Instruction set Processor))) RT RT RT RT----COPCOPCOPCOP ( ( ( ( RealTimeRealTimeRealTime-RealTime---Control Operation ProcessorControl Operation ProcessorControl Operation Processor)Control Operation Processor)))... 17...171717 2.1 はじめに... 17
2.2 制御演算用アーキテクチャ... 20
2.2.1 ブロック線図を表現するアーキテクチャ... 20
2.2.2 速度オブザーバによる検証... 24
2.2.3 RT-COP 用コンパイラ... 27
2.3 制御演算用命令セット... 29
2.3.1 RT-COP の VLIW(Very Long Instruction Word)命令フォーマット ... 29
2.3.2 RT-COP の基本演算命令... 32
2.3.2.1 サーボ制御演算のハードウェア化... 32
2.3.2.2 基本演算命令... 34
2.3.3 RT-COP の基本演算ブロック... 35
2.4 スカラエクスパンジョン... 37
2.5 RT-COP の試作と評価... 39
2.5.1 RT-COP の試作... 39
2.5.2 RT-COP 評価基板... 40
2.5.3 RT-COP 評価... 41
2.5.3.1 RT-COP の演算性能... 41
2.5.3.2 発振限界... 42
2.5.3.3 位置決め整定時間... 43
2.6 おわりに... 45
第3章 第3章 第3章 第3章 ハードウェアタスクエンジンおよびそれを実装したセンサ信号処理ハードウェアタスクエンジンおよびそれを実装したセンサ信号処理ハードウェアタスクエンジンおよびそれを実装したセンサ信号処理 SoCハードウェアタスクエンジンおよびそれを実装したセンサ信号処理SoCSoCSoC ( ( ( ( System on a ChipSystem on a ChipSystem on a Chip)System on a Chip)))... 47474747 3.1 はじめに... 47
3.2 ハードウェアタスクの実現... 50
3.2.1 ハードウェアタスクエンジンの概念... 50
3.2.2 ハードウェアタスクエンジンを実現するアーキテクチャ... 51
3.2.2.1 ハードウェアタスクのシーケンス変更... 52
3.2.2.2 再構成を行うデータパス... 57
3.2.2.3 再構成レジスタ... 58
3.2.2.4 ワークレジスタ... 58
3.2.2.5 ハードウェアタスクの起動管理... 59
3.3 データパスの再構成... 60
3.3.1 RCEXE(ReConfigurable EXEcution unit)の基本アーキテクチャ60 3.3.1.1 PE(Processing Element)のアーキテクチャ... 63
3.3.1.2 接続のアーキテクチャ... 64
3.3.2 RCEXE を用いた演算の実現... 65
3.3.2.1 FFT(Fast Fourie Transform)の実現... 65
3.3.2.2 PI(Proportional plus Integral)制御の実現... 66
3.3.2.3 線形サーチの実現... 68
3.3.3 再構成データの作成... 69
3.4 センサ信号処理向けの SoC のアーキテクチャ... 71
3.4.2.2 磁気式エンコーダシステムへの適応検討... 75
3.4.2.3 磁気式エンコーダ向けハードウェアタスクエンジン... 76
3.5 ハードウェアタスクエンジンおよびセンサ信号処理 SoC の試作および評価 ... 80
3.5.1 センサ信号処理 SoC の試作... 80
3.5.2 センサ信号処理 SoC 評価用基板... 82
3.5.3 ハードウェアタスクエンジンおよびセンサ信号処理 SoC の評価.... 84
3.5.3.1 ハードウェアタスクの評価... 84
3.5.3.2 RCEXE の再構成時間... 88
3.5.3.3 RCFSM(ReConfigurable Finite State Machine unit)の動作 ... 90
3.5.3.4 RCEXE での演算時間... 91
3.5.3.5 温度上昇... 92
3.6 おわりに... 93
第4章 第4章 第4章 第4章 結論結論結論結論... 95959595 4.1 まとめ... 95
4.1.1 サーボドライバ... 95
4.1.2 エンコーダ... 96
4.2 今後の課題... 97
謝辞謝辞
謝辞謝辞... 98989898
業績リスト 業績リスト 業績リスト
業績リスト... 99...999999
参考文献参考文献
参考文献参考文献... 101...101101101
図目次図目次 図目次図目次
図 1 サーボシステムの構成... 9
図 2 サーボシステムのブロック図... 10
図 3 サーボ制御のブロック線図... 20
図 4 RT-COP(RealTime-Control Operation Processor)ブロック図... 21
図 5 基本演算ブロックの並列度検証... 23
図 6 速度オブザーバ... 24
図 7 基本演算ブロックの並列性... 25
図 8 RT-COP VLIW(Very Long Instruction Word)命令フォーマット... 29
図 9 機能コードの作用... 30
図 10 サーボ制御プログラムのブロック線図... 32
図 11 サーボ制御演算 のハードウェア化のた めの FPGA(Field Programmable Gate Array)評価基板... 33
図 12 サーボ制御演算解析結果... 34
図 13 RT-COP の基本演算ブロックのアーキテクチャ... 36
図 14 スカラエクスパンジョンの動作... 37
図 15 スカラエクスパンジョンの構成... 38
図 16 RT-COP の外形写真... 39
図 17 RT-COP 評価基板... 40
図 18 処理性能比較... 41
図 19 単位クロックあたりの処理性能比較... 42
図 20 位置指令パターン... 42
図 21 発振限界での速度応答... 43
図 22 位置指令パターン... 43
図 26 ハードウェアタスクエンジンブロック図... 52
図 27 RCFSM(ReConfigurable Finite State Machine unit)ブロック図... 53
図 28 RCFSM の複数接続... 54
図 29 ハードウェアタスク構成... 55
図 30 プリフィルタのハードウェアタスク構成... 55
図 31 プリフィルタでの制御信号... 56
図 32 ポストフィルタのハードウェアタスク構成... 56
図 33 ポストフィルタでの制御信号... 56
図 34 動的再構成可能アーキテクチャの基本構成... 57
図 35 ワークレジスタ... 58
図 36 演算処理と RCEXE(ReConfigurable EXEcution unit)の再構成... 60
図 37 RCEXE ブロック図... 61
図 38 PE(Processing Element)ブロック図... 63
図 39 FFT(Fast Fourie Transform) C 言語ソース... 65
図 40 FFT を実現する再構成... 65
図 41 PI(Proportional-plus-Integral)制御 C 言語ソース... 66
図 42 PI 制御を実現する再構成... 67
図 43 線形サーチ C 言語ソース... 68
図 44 線形サーチを実現する再構成... 68
図 45 ソフトウェア開発手順... 69
図 46 センサ信号処理 SoC(System on a Chip)の基本アーキテクチャ... 71
図 47 磁気式エンコーダのシステム概略... 73
図 48 通常処理とハードウェアタスクの対応... 75
図 49 RCEXE の PE 構成(アプリケーションインデックスが 0)... 77
図 50 RCEXE の PE 構成(アプリケーションインデックスが 1)... 77
図 51 センサ信号処理 SoC ブロック図... 80
図 52 センサ信号処理 SoC 評価基板... 82
図 53 センサ信号処理 SoC 評価環境... 83
図 54 ハードウェアタスク実行時間... 85
図 55 ハードウェアタスク実行時間... 86
図 56 割り込みからの起動遅れ時間... 86
図 57 再構成時間... 88
図 58 RCEXE の連続再構成... 89
図 59 RCFSM 再構成 1... 90
図 60 RCFSM 再構成 2... 90
図 61 RCFSM 再構成 3... 90
図 62 RCFSM 動作... 91
図 63 演算時間... 91
図 64 温度上昇... 92
表目次表目次 表目次表目次
表 1 機能コード... 35
表 2 RT-COP 諸元... 39
表 3 RT-COP 評価基板仕様... 40
表 4 S(State)命令... 53
表 5 ALU(Arithmetic Logical Unit)機能(PE0PE11PE12)... 78
表 6 ALU 機能(PE13)... 78
表 7 センサ信号処理 SoC(System on a Chip)諸元... 81
表 8 FPGA(Field Programmable Gate Array)リソース使用量... 81
表 9 評価基板仕様... 82
第1章 序論
1.1 研究の背景
サーボシステムは,位置,速度,トルクを制御するために産業用ロボットや工 作機械などで利用されている。サーボシステムとは,“物体の位置,方位,姿勢を 制御量とし,目標値の任意の変化に追従するように構成された制御系”である。
図 1に示すようにサーボシステムは,サーボ制御処理を行うサーボドライバ[1]
およびサーボモータ[2],サーボモータの回転角度を計算するエンコーダ[3]から 構成されている。
図 図図
図 1111 サーボシステムの構成サーボシステムの構成サーボシステムの構成サーボシステムの構成
サーボドライバは,上位コントローラからの指令とエンコーダからのフィード バック信号から,サーボモータへの指令となるモータ電流を生成してサーボモー タを駆動するコントローラである。サーボモータは高速に応答できるように慣性 モーメントが小さく設計され,指令に追従して動く電磁モータ(以降モータと記 述する)である。エンコーダはサーボモータの後部に取り付けられ,回転角度を 生成するセンサである。サーボシステムのブロック図を図 2に示す。サーボドラ イバは,サーボ制御部,電流演算部およびパワー部から構成される。サーボ制御 部は,上位コントローラからの指令信号とエンコーダからのフィードバック信号
サー ボモー タ エンコー ダ 上位コントロー ラ
サー ボドライバ
により位置速度制御を行い,トルク指令を生成する。トルク指令は電流演算部に 入力される。電流演算部は,トルク指令とパワー部の出力から得られる電流フィ ードバックにより,パワー部のゲートドライブ信号を生成する。パワー部はゲー トドライブ信号からサーボモータを駆動するモータ電流を生成する。エンコーダ はセンサ,アナログフロントエンド,角度演算部および通信部から構成される。
サーボモータの動きはセンサにより検出され,センサからの出力はアナログフロ ントエンドでディジタル値に変換された後,最終的に角度演算部でモータ軸の回 転角度が演算される。
図図
図図 2222 サーボシステムのブロック図サーボシステムのブロック図サーボシステムのブロック図サーボシステムのブロック図
誘導電動機が 1800 年代後半に発明されて以来,電気エネルギーを動力に変換す るためにモータは利用されてきた。しかし,1948 年のトランジスタの発明,およ び 1957 年のサイリスタの発明により,電子回路でモータを制御することが可能に なった。例えば,可変速制御が必要な製鉄用圧延機や製紙用機械では,水銀整流 器を利用して直流モータの制御を行っていた。水銀整流器は筐体の大きさに加え,
有害な水銀を利用していることから,水銀整流器はサイリスタに置き換えられて サ ー ボ ド ライバ
サ ー ボ ド ライバ サ ー ボ ド ライバ サ ー ボ ド ライバ
センサ
エ ン コ ー ダ エ ン コ ー ダエ ン コ ー ダ エ ン コ ー ダ
アナログ フロントエンド
角度演算部
パワー部
サーボ制御部 電流演算部
指令信号 主電源
電流フィードバック
システムコントロール処理部 通信部
通信部 サーボモータ
えば油圧サーボであり,得られる動力の大きさと応答性でモータは油圧サーボに たちうちできなかった。しかし,DC サーボモータを利用し,検出器にタコメータ,
そしてサイリスタによる制御を用いたサーボシステムが開発され,油圧サーボと 同等性能が出せるようになった。DC サーボモータはブラシのメンテナスが必要な ため,メンテナンスフリーの要求があった。この要求を満足するため,1980 年代 には AC サーボモータによるサーボシステムが開発された。これ以降は,電子デバ イス,特に CPU(Central Processing Unit)やパワー素子の進展にあわせて,サ ーボシステムの性能および機能が向上してきた。CPU の処理能力は 8 ビットから 32 ビットになり,また CISC(Complex Instruction Set Computer)から RISC
(Reduced Instruction Set Computer)へマイクロアーキテクチャがかわること で, CPU の性能は飛躍的に向上した。このような CPU の性能の向上により,多様 な制御アルゴリズムを実行できるようになったことから,制御性能を向上できた。
一方,パワー素子は,サイリスタに始まり,パワートランジスタを経て,現在で は IGBT(Insulated Gate Bipolar Transistor)が利用されている。パワー素子 の進展により,キャリア周波数を高周波数化できたため,制御性能を向上できた。
これまでサーボシステムは高性能化,および高機能,小形・軽量化,操作性向上 の観点から研究開発が行われてきたが,今後もこの傾向は続いていく。そこで,
これらの観点からサーボシステムの課題をまとめると以下のようになる。
①高性能化
制御対象の高速化や高性能化に対応するために,制御対象に適合させた,多 様な制御アルゴリズムを適用して要求を満たす必要がある。しかし,短い制 御周期の間に,複雑になった制御アルゴリズムを実行しなければならず,サ ーボシステムの高性能化が必要となる。
②高機能化
サーボシステムの適用範囲の広がりに対応するため,基本的な制御アルゴリ ズムだけでなく,制振制御のような多種多様な制御アルゴリズムを用意する 必要がある。これらを,制御対象にあわせて切り替え利用することで,制御 を高機能化することができる。なお,高機能化の前提として,①の高性能化
が必要となる。
③小形・軽量化
家庭用ロボットのアクチュエータなどサーボシステムは狭小な空間への設置 が増加することが考えられる。さらに,サーボシステムは単体で使用される のではなく,複数使用されるので,サーボシステムの小形化および軽量化が 必要となる。
④操作性向上
AC サーボモータのパラメータを自動で行うオートチューニングにより,サー ボシステムはつなげるだけで動作するようになった。しかし,要求仕様が厳 しい場合など,100%自動化できているわけではないので,オートチューニン グ性能の向上が必要となる。
本研究では,機械の高精度化がサーボシステムを利用する理由として一番多い [4]ため,①のサーボシステムの高性能化について取り組むこととする。
サーボシステムは,工作機械,産業ロボット,半導体製造装置,機械加工ライ ンや自動車製造ラインといった産業分野の応用が主体であった。しかし,近年で は,福祉機器,家庭用ロボット,自動車,アミューズメント機器や自動改札等の 非産業分野へとサーボシステムの応用が年々広がってきている。そのため,サー ボシステムは,現在では産業や生活の基盤を支えるために欠かせないシステムと して位置付けられている。このようなサーボシステムの応用範囲の拡大に伴って,
制御対象は多様化し,同時に高速化および高性能化してきており,実時間(リア ルタイム)制御の高速化の要求が年々高まっている。リアルタイム制御の高速化 は,サーボシステムの制御性能の向上に直結するからである。サーボシステムで は高速な CPU や MPU(Micro Processor Unit)等のマイクロプロセッサ(以降統 一して CPU と記述)や DSP(Digital Signal Processor)により処理時間の短縮 を図ることが一般的に行われてきた[5]。つまり,クロックを高周波数化すること
用する必要がある。そのため,サーボ制御演算は複雑化するだけでなく,新しい 制御アルゴリズムが考案されて適用されている[6]。サーボ制御演算は,最終的に パルスを生成する必要があるので,演算処理を整数で行っている。そのサーボド ライバの CPU は,サーボ制御演算以外にもシステムコントロール処理や通信処理 を実行している。このような点を背景にして,サーボドライバの抱える課題を考 察する。サーボ制御演算はブロック線図では並列性を表現できるが,サーボドラ イバは CPU でサーボ制御演算を行っている。そのため,サーボ制御演算の実行が 逐次的であるという問題に対し,サーボ制御演算の高速化のため,並列実行され なければならないという課題が存在する。次に,指令応答性の向上のために利用 されているフィードフォワード制御は,高次元のモデルの利用や,モデル間の違 いを吸収するための柔軟性が必要[7]である。そのため,モデルを利用したサーボ 制御演算がハードウェア化しにくいという問題に対し,そのようなサーボ制御演 算を実行できるハードウェアにしなければならないという課題も存在する。また,
サーボ制御演算が整数で演算されるため,演算後のデータの桁落ちや桁あふれと いった精度管理する必要がある。しかし,そのような命令を CPU が備えていない という問題に対し,精度管理を行える命令を提供しなければならないという課題 も存在する。最後に,指令とサーボ制御演算の結果を制御サイクル毎に与える必 要がある。そのためメモリコピーが発生し演算性能を落とすという問題に対し,
メモリコピーの発生を抑えなければならないという課題も存在する。
サーボシステム全体で実時間制御を高性能化するためには,エンコーダからフ ィードバック情報を高速に得る必要がある。エンコーダをセンサシステムとして みた場合,センサデータの取込み処理,回転角度演算を行う演算処理,コントロ ーラへの通信処理という一連のセンサ信号処理が実行される[8]。このセンサ信号 処理は高いリアルタイム性が要求されるため,高い優先度をもった割り込み処理 で実行される。エンコーダではセンサ信号処理に時間を要していることに加え,
割り込みの発生からセンサ信号処理が起動されるまでにも時間を要している。ま た,エンコーダはサーボモータの後部の密閉された空間に取り付けられる。サー ボシステムの知能化[9]のために温度等のセンサ情報を追加したいという要求が ある。このような点を背景にして,エンコーダの抱える課題を考察する。割り込
みからの起動時間を含む,センサ信号処理に時間を要するので,リアルタイム性 が低いという問題に対し,リアルタイム性を向上させなければならないという課 題が存在する。エンコーダは,密閉された狭い空間に設置しなければならない。
そのため,クロックの高周波数化による高速化では消費電力の増加に伴って発熱 が大きいという問題に対し,発熱を抑えなければならないという課題も存在する。
また,そのような空間に設置する必要から小形化が必要であり,同時に低コスト 化への要求も高い。最後に,サーボシステムを知能化するため,異なるセンサへ のセンサ信号処理に対応しなければならないという問題に対し,多様なセンサ信 号処理アルゴリズムに対応する必要があるという課題も存在する。
サーボモータに関しても,制御性能向上のために高速に応答したいという課題 がある。しかし,サーボモータ単体の取り組みではなく,サーボドライバの高性 能化と合わせて行う必要がある。さらに,機械的な対策が必要なため,本研究で はサーボモータに関して取り扱わないものとした。
1.2 研究の目的
本論文は,サーボシステムの制御性能向上に向けて,サーボドライバおよびエ ンコーダの演算処理を高速化する制御演算およびセンサ信号処理向けの
LSI(Large Scale Integration)アーキテクチャを提案することを目的とする。
1.2.1 サーボドライバ
サーボドライバでは,サーボ制御演算に適したLSIアーキテクチャを提案する。
ハードディスクで用いられるサーボシステム[10] のように,確定した処理を高速 化する場合には,サーボ制御部を専用回路に実装するASIC(Application Specific Integrated Circuit)化は有効である。しかし,本論文では汎用的に用いられる サーボドライバを対象としており,制御対象による処理の変更や,制御性能向上 のため新しい制御演算への対応が重要である。よって,アプリケーションに特化
Instruction set Processor)アーキテクチャを提案する。
1.2.2 エンコーダ
エンコーダでは,エンコーダのセンサ信号処理に適した LSI アーキテクチャを 提案する。エンコーダからフィードバック情報を高速に得るためには,エンコー ダの角度演算部でのセンサ信号処理を高速化すること,かつサーボドライバとエ ンコーダ間の通信を高速化する必要がある。しかし,通信の高速化が有効になる ためには,センサ信号処理の高速化が必要であるため,センサ信号処理を高速に 処理するためのアーキテクチャを本論文では対象とする。センサ信号処理は,入 力デバイスから外界の情報を取得し,それを任意のアルゴリズムで信号処理し,
出力デバイスで情報を外界に発信する。センサ信号処理は高速な処理および,制 御周期に同期した動作に加え,各種センサに対応するためアルゴリズムを変更可 能とすることが必要である。また,消費電力は容量と周波数に比例し電源電圧の 自乗に比例する。温度は消費電力に比例するので,アーキテクチャにより容量と 周波数を低減する必要がある。そのため,エンコーダのセンサ信号処理に適した LSI アーキテクチャとして,温度上昇を抑えながら高速な処理を実現するため,
ハードウェアタスクおよびそれを実装したセンサ信号処理 SoC(System on a Chip)
を提案する。
1.3 本論文の構成
本論文では,第1章 序論でサーボシステムに関して本研究の背景および目的に ついて述べる。第2章 制御演算用 ASIP(Application Specific Instruction set Processor) RT-COP(RealTime-Control Operation Processor)では,サーボ制 御演算に適した LSI アーキテクチャとして,制御演算用 ASIP アーキテクチャであ る RT-COP の提案を行う。サーボ制御演算に適した LSI アーキテクチャの新規性の 説明として,制御演算用アーキテクチャ,制御演算用命令セットおよびスカラエ クスパンジョンの 3 点について述べる。そして,RT-COP の試作と,サーボ制御演 算を行った評価結果について述べる。第3章 ハードウェアタスクエンジンおよび それを実装したセンサ信号処理 SoC(System on a Chip)では,エンコーダのセ
ンサ信号処理に適した LSI アーキテクチャとして,ハードウェアタスクを実現す るハードウェアであるハードウェアタスクエンジン,およびそれを実装したセン サ信号処理 SoC の提案を行う。エンコーダのセンサ信号処理に適した LSI アーキ テクチャの新規性の説明として,ハードウェアタスクの実現,データパスの再構 成およびセンサ信号処理 SoC のアーキテクチャの 3 点について述べる。そして,
実アプリケーションとして磁気式エンコーダを選択し,センサ信号処理 SoC への 適用結果と,FPGA を利用した試作および磁気式エンコーダを動作させた評価結果 について述べる。最後に,第4章 結論で結論と今後の課題を述べる。
第 2 章 制 御 演 算 用 ASIP ( Application Specific Instruction set Processor) RT-COP(RealTime-Control Operation Processor)
2.1 はじめに
本 章 で は サ ー ボ 制 御 演 算 を 最 適 に 実 行 す る 制 御 演 算 用 ASIP で あ る RT-COP
(RealTime-Control Operation Processor)について述べる。RT-COP は並列動作 する,サーボ制御演算用に最適化された演算器を 3 つ備えた VLIW(Very Long Instruction Word)型の制御演算用 ASIP アーキテクチャである。制御演算用 ASIP RT-COP の新規性として制御演算用アーキテクチャ,制御演算用命令セットおよび スカラエクスパンジョンの 3 点について述べる。
制御演算用アーキテクチャにより,伝達要素および命令レベルの並列性を表現 でき,さらにハザード無く乗数や演算結果を利用した制御演算を行うことができ る。そのため,ブロック線図が備える並列性を損なうことなく表現できるので,
ブロック線図の実行を効率的に行える。制御演算用命令セットによりブロック線 図の伝達要素を高速に実行できる。さらに,演算器の機能拡張に対応することで,
精度管理された制御演算を実行できる。次制御サイクルへのデータの受け渡し機 構であるスカラエクスパンジョンは,フィードバック制御でメモリへのコピー発 生を削減できる。そのほか,並列動作する中粒度の演算器は C 言語で記述された 式1行程度を 1 サイクルで実行できる,演算器の実行時間が一定であるため,
RT-COP は実行前に最悪実行時間を確定できるといった特長も備えている。
ハードウェアはアプリケーションに対して専用設計していたが,電卓専用 LSI を汎用化することで CPU が誕生した[11][12]。その後,積和演算器(MAC, Multiply ACcumulator)とアドレス生成器をアーキテクチャに取り入れてディジタル信号処 理を行う DSP[13]が開発された。近年では,ネットワーク機器用にパケット処理 やルーティング処理を効率的に行うアーキテクチャを持ったネットワークプロセ ッサ[14]も登場し,アプリケーション指向の CPU である ASIP が様々提案されてい る。制御演算の設計ではブロック線図と呼ばれる図が用いられ,演算主体の伝達 要素は並列に処理が行われる。そのため,制御演算用アーキテクチャには並列処
理機構をアーキテクチャに含む必要がある。また,処理時間を短縮し,処理時間 の変動を生じさせないために,ハザードなくデータを供給する必要もある。並列 処理機構を備えるアーキテクチャに VLIW があり,ディジタルメディア向け SoC [15],VLIW プロセッサ [16][17]やマルチスレッドプロセッサ MLEP(Multithread Lockstep Execution Processor)[18]がある。ディジタルメディア向け SoC は, メディア処理に向けた VLIW プロセッサを搭載した SoC である。メディア処理向け に画素演算処理用の演算器を備え,処理の高速化を図られる。しかし,キャッシ ュをアーキテクチャに含んでいるので最悪実行時間の予測が困難である。ミシガ ン大学での VLIW プロセッサは制御回路をクラスタに分散して備える VLIW プロセ ッサで,構成はマルチプロセッサとあまり差がない。制御回路をクラスタに分散 してスケーラビリティを備えるが,プログラムカウンタも分散しているのでクラ スタ間の同期にはオーバヘッドが発生する。Catalunya 大学での VLIW プロセッサ はマルチスレッドの実行をクラスタレベルで行う VLIW プロセッサで,スレッドの 選択を動的に行う。マルチスレッド実行をクラスタレベルで実行できるが,スレ ッドの管理をハードウェアで行うのでソフトウェアの動作が分かり難い。MELP は 命令が共有でデータが異なる SIMD(Single Instruction Multiple Data)実行の ための CPU で,並列ループの解法に向いている。同じ命令ストリームの並列ルー プの高速化が可能だが,異なる命令ストリームの並列化には対応できない。ハザ ードなくデータを供給するものとして SKY[19]がある。SKY は複数のスーパースカ ラプロセッサから構成されるマルチ CPU であり,リングバスで接続されている。1 つのプロセッサで処理が行われその結果が次のプロセッサに渡されるので,ハザ ードを生じないが,スレッドは逐次的にしか生成されない。レジスタ値の同期や 通信を行うことができるが,データの同期や通信にオーバヘッドを生じてしまう。
制御演算用アーキテクチャの関連研究を以上まとめたが,ブロック線図の処理内 容を最適に実行する ASIP の提案はなく,制御演算用アーキテクチャで問題を解決 する。
ントプロセッサ[20],暗号プロセッサ[21],MPEG(Moving Picture Experts Group)
プロセッサ[22]や FFT(Fast Fourie Transform)プロセッサ[23]などが報告されて いる。これらが備えているのはフォント展開のための専用回路,剰余系のビット スライス回路,ストリームデータ処理回路やバタフライ演算回路であり,伝達要 素の演算に向いた処理回路とはいえない。また,制御演算は整数で行われるため,
特に乗算において桁落ちや桁あふれを管理して,精度管理するための機構が必要 となる。ディジタルメディア向け SoC[15]では,基本ブロックおよび拡張ブロッ クからなる 2 階層の命令フォーマットを備えている。2 階層の命令フォーマット を利用して VLIW 命令の圧縮に利用しているが,演算器の機能変更などは行わない。
制御演算用命令セットの関連研究を以上まとめたが,制御演算を指向した命令セ ットの提案はなく,制御演算用アーキテクチャで問題を解決する。
制御演算ではフィードバックをかけるのに,制御サイクル分の遅延処理(時間 遅れ要素,Z-1)が多用されている。この遅延処理にはメモリが使われており,制 御サイクル毎にメモリのコピーが発生する。メモリのコピー処理は処理時間のか かる処理であるため,コピーが多数発生すると処理時間を圧迫するようになる。
そのため,データコピーを行うための機構が必要になる。 データコピーを行うた めの機構として転写メモリ[24]がある。転写メモリはハードウェアで制御する交 代バッファであるが,管理するデータは同じであるが読み出しと書き込みで異な るメモリ領域が必要となる。ハードウェアで制御する交代バッファでメモリコピ ーを実行するが,読み書きが異なる領域になるので,同じデータであっても変数 名がかわってしまう。スカラエクスパンジョンの関連研究を以上まとめたが,単 一のメモリ領域で行えるデータコピーの提案はなく,スカラエクスパンジョンで 問題を解決する。
サーボドライバにおいて制御性能向上を達成するため,モーション制御を行う 制御演算の解析を行い,クロックの高周波数化に依存せずに CPU より高い演算性 能を持たせた制御演算用 ASIP アーキテクチャ RT-COP を創出した。
2.2 制御演算用アーキテクチャ
2.2.1 ブロック線図を表現するアーキテクチャ
ブロック線図とは加え合わせ点や引き出し点と伝達要素から構成され,要素の 結合や信号の流れを視覚化した図であり,制御アルゴリズムの設計で利用される。
ブロック線図では並列に伝達要素の実行を表現できる。伝達要素の粒度は,粗粒 度ほどの規模はなく中粒度である。そして,加え合せ点で伝達要素の同期がとら れる。サーボドライバにおけるサーボ制御のブロック線図を図 3に示す。
図 図 図
図 3333 サーボ制御のブロック線図サーボ制御のブロック線図サーボ制御のブロック線図サーボ制御のブロック線図
サーボ制御は電流制御部,速度制御部および位置制御部がループ構造になって いる。内側のループは電流制御部で,トルク指令と電流フィードバックからサー ボモータを駆動するゲートドライブ信号を生成する。最も高速性が要求されるが,
電流制御部は比較的処理が固定化しており ASIC やカスタム LSI で処理されること も多い。その外側に速度指令と速度フィードバックからトルク指令を生成する速 度制御部や,位置指令と位置フィードバックから速度指令を生成する位置制御部
サーボ制御部
位置指令
速度 指令
トルク 指令
電流フィードバック 速度フィードバック 位置フィードバック
位置制御部 速度制御部 電流制御部
+ - +
- +
-
サ ー ボ ド ライバ サ ー ボ ド ライバ サ ー ボ ド ライバ サ ー ボ ド ライバ
位置 検出
速度 検出
サーボ モータ
エンコーダエンコーダエンコーダエンコーダ
PID制御 PI制御
Kp I Ki D Kd Kp
I Ki
部の内部に示すようなブロック線図において,伝達要素をタスクと見た場合には,
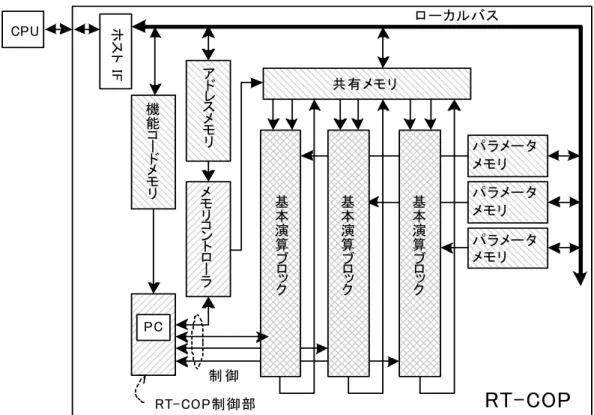
制御演算はタスクレベルの並列性を備えている。しかしながら,CPU は基本的に は逐次動作のため, CPU で制御プログラムを実行した場合にはブロック線図中の 伝達要素は逐次的に処理される。また, MAC 演算器とアドレス演算器を専用に備 えた DSP は,フィルタに代表される信号処理の演算を CPU より高速に演算できる が, CPU と同様に命令処理が逐次的である。CPU や DSP で動作するプログラムを 作成するには,制御演算を逐次処理に書き直す必要がある。そのため,制御演算 用に,制御演算の備える並列性をそのまま実行できるアーキテクチャを備えたハ ードウェアもしくは CPU が望まれる。また,図 3のブロック線図でもその傾向が 現れてい るが, 制御演 算ではゲ インと の乗算 の頻度が 高いと いえる 。そこで , RT-COP[25]は制御演算向けの VLIW アーキテクチャを持つ制御演算用 ASIP アーキ テクチャで,ブロック線図の並列性を損なわず,データをハザード無しに供給で きるアーキテクチャ(図 4)とした。
図図
図図 4444 RTRTRTRT----COPCOPCOPCOP((RealTime((RealTimeRealTime-RealTime---Control Operation ProcessorControl Operation ProcessorControl Operation Processor)Control Operation Processor)))ブロック図ブロック図ブロック図ブロック図
アドレスメモリ
制 御
共有メモリ
パラメー タ メモリ ロ ー カルバス
ホスト IF 基本演算ブロック
RT-COP制御部 PC
メモリコントローラ
パラメー タ メモリ パラメー タ メモリ
基本演算ブロック 基本演算ブロック
機能コードメモリ
RT-COP
CPU
RT-COP は基本演算ブロック,RT-COP 制御部,メモリコントローラ,機能コード メモリ,パラメータメモリ,アドレスメモリ,共有メモリおよびホスト IF から構 成し,データと構成要素の制御は分散して管理する。なお,RT-COP では基本演算 ブロックを利用した演算の単位をサイクルと定義しており,1 サイクルは 8 クロ ックである。
基本演算ブロックの並列動作を RT-COP 制御部で制御し,伝達要素の並列性を表 現する。RT-COP 制御部は,RT-COP の制御演算のシーケンスを制御するコントロー ラで,8 ビットのカウンタで構成した PC(Program Counter)を構成要素に含んで いる。RT-COP では最大 256 サイクルの VLIW 命令を実行でき,機能コードメモリ,
アドレスメモリおよびパラメータメモリはそれぞれ 256 サイクルの VLIW 命令を 分散して格納する。RT-COP 制御部では,RT-COP VLIW 命令を構成する機能コード を記憶するメモリである機能コードメモリの出力を制御に利用する。基本演算ブ ロックは,7 入力 2 出力(図 13参照)の演算器であり,その入出力はワークメモリ である共有メモリと,命令メモリの一部であるパラメータメモリに接続されてお り,並列動作の制御は RT-COP 制御部で行われる。
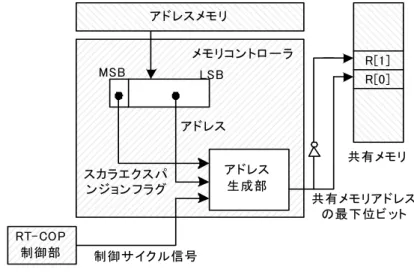
基本演算ブロックとの間のアクセスをスケジュールし共有メモリを伝達要素の 接続をハザードなしに実行する。メモリコントローラは,アドレスメモリを利用 して共有メモリへの入出力の制御を行う。メモリコントローラは,共有メモリが 同時に 3 入力もしくは同時に 3 出力できるように制御し,基本演算ブロックでの 制御演算においてデータハザードによるストールを発生させない。共有メモリは 128 ロングワード(512 バイト)の容量で,基本演算ブロックが制御演算を行うた めの指令データの格納やワークメモリとして使用される。共有メモリは 3 入力 3 出力の 6 ポートのメモリで構成し,3 つの基本演算ブロックを接続するバスの役 割もあわせ持ち,共有メモリへの入出力はスケジューリングを行うことで,入力 と出力を同時発生させないアーキテクチャでハザードをなくした。アドレスメモ
する。パラメータメモリは,RT-COP VLIW 命令を構成するパラメータを格納する。
パラメータは,基本演算ブロックの動作を確定するためのオペコードと,ゲイン として利用する乗数で構成される。乗数は,基本演算ブロックにハザード無く供 給できる。
RT-COP と HOST CPU との通信はホスト IF を通して行う。ローカルバスは,共有 メモリ,機能コードメモリ,アドレスメモリおよびパラメータメモリにそれぞれ 接続されているので,これらのメモリはホストプロセッサから,ホスト CPU との インターフェース回路であるホスト IF を通してアクセス可能である。
RT-COP では,基本演算ブロックの個数を決定するため,個数に対する制御プロ グラムの実行時間を机上計算で求め,これをもとにして基本演算ブロックの個数 と演算性能を見積もった。基本演算ブロックが 3 個まではリニアに性能が向上す るが,それ以上では性能向上にあまり寄与しなくなるという結果を得た。次に,
基本演算ブロックの個数とゲート数の見積もり(図 5)を行い,性能とコストの 最もバランスのとれた 3 並列を最終的な構成とした。
図図図
図 5555 基本演算ブロックの並列度検証基本演算ブロックの並列度検証基本演算ブロックの並列度検証 基本演算ブロックの並列度検証
1.67 μs
個 3.34
1 2 3 4 5 6 7 8 9
5.01 6.68 8.35 10.02
演算器
演算時間
2 0 4 0 6 0 万ゲート
ゲート数
5 0
3 0
1 0
ゲート数 演算時間
2.2.2 速度オブザーバによる検証
制御プログラムに速度オブザーバ(図 6)を利用して RT-COP の評価を行った。
オブザーバとは,状態を直接観測できない時にその状態を推測する手段で,状態 方程式に基づく制御系の解析および設計理論である現代制御理論で利用される。
フィードフォワード制御は,指令応答性の向上のため利用されているが,高次元 のモデルに対応するため複雑であり,モデルの違いを吸収する柔軟性が必要なの で,専用回路としてハードウェア化しにくい制御演算である。
図 図図
図 6666 速度オブザーバ速度オブザーバ速度オブザーバ 速度オブザーバ
図 6のブロック線図からわかるように,オブザーバ部,位置制御部およびフィ ードフォワード制御部の 3 つの伝達要素は並列処理が可能であり,RT-COP による 並列性の検証を机上で実施した。これを図 7に示す。
トルク指令
位置指令位置フィードバックトルク指令 フィードフォワード制御部 位置制御部オブザーバ部 速度制御部 トルクフィルタ部
+ ++
図 図図
図 7777 基本演算ブロックの並列性基本演算ブロックの並列性基本演算ブロックの並列性基本演算ブロックの並列性 基本演算ブロック
サイクル 1 2 3 4 5 6 7 8 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 8 1 9 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2 7 2 8 2 9 3 0 3 1 3 2 3 3 3 4 3 5 3 6 3 7 3 8 3 9
A)
B)
C)
27
24
フィー ドフォワー ド制御
位置制御
オブザー バ
基本演算ブロック 基本演算ブロック
図 7は 3 つの基本演算ブロックの利用状況を視覚化したものであり,縦方向を 時間(サイクル数),横方向は 3 つの基本演算ブロックの利用状況を表現している。
図 7 A)について
各々の伝達要素の中で並列性を検出してプログラム化したものであり,一般 の VLIW コンパイラが生成するコードと等価と考えられる。この場合は有効に 並列処理が行われていない。3 並列はわずか 7.7%,2 並列が 35.9%であり,基本 演算ブロックの利用効率も 50.0%と無駄が多い。48MHz 動作時に1サイクルは 166.67ns かかることから,6.50μs が演算にかかる。
図 7 B)について
各々の伝達要素レベルで並列処理させたプログラムで,図 6のブロック線図 を CPU 上に表現したものといえる。この状態は伝達要素をタスクと見なすと,
タスク レベ ルで並 列化 された もの といえ る。 この場 合, 3 並列 はほ ぼ半分 の 48.0%,2 並列は 22.0%,基本演算ブロックの利用効率も 70.0%とかなり改善で きた。しかし,位置制御にかかる時間は他の 2 つの処理に比べて長いため,位 置制御の並列性を抽出することで基本演算ブロックを有効利用できる。
図 7 C)について
B)の状態から,位置制御のみ伝達要素の中に含まれる並列性も抽出するよう にした。それにより,3 並列は 62.5%,2 並列は 20.0%,基本演算ブロックの利 用効率も 81.9%へと改善でき,演算時間も 4.00μs と A)の 61.5%に圧縮できた。
フィードフォワード部,位置制御およびオブザーバは,演算の結果を次の式で 利用するためデータのハザードが生じるので,命令レベルで並列化を行うと並列 処理の効果を引き出しにくい。RT-COP では,伝達要素を並列実行するためハザー ドに影響されされないことから,アーキテクチャの有効性を確認できた。
2.2.3 RT-COP 用コンパイラ
RT-COP ではブロック線図を表現するために,伝達要素を並列プログラムする必 要がある。また,RT-COP の基本演算ブロックは,通常の CPU の ALU と比較して複 雑な構造をしており,1 サイクルで多くの演算処理を実行できる。そのため,伝 達 要 素 の 並 列 性 を 実 現 し , プ ロ グ ラ ム 開 発 の 利 便 性 を 図 る こ と を 目 的 と し て RT-COP 用 C コンパイラを開発した。
RT-COP 用 C コンパイラは,伝達要素レベルの最適化と命令レベルの最適化を切 り替えて利用することで,ブロック線図で表現した制御演算をオブジェクト化す ることができる。制御演算に基づいて C 言語ソースを記述し RT-COP 用コンパイラ にかけると中間コード(中間コード 1)を生成する。中間コード 1 は命令レベル の並列性を備えておらず,基本演算ブロックを 1 つ利用して逐次的に命令が記述 されている。この中間コードを並列化ツールにかけることで,命令レベルの並列 性を備えた中間コード(中間コード 2)を生成する。中間コード 2 は基本演算ブ ロックを 3 つ利用した,命令レベルの並列性を備えたコードであるが,伝達要素 レベルの並列性は備えていない。この並列化ツールの呼び出しは最適化オプショ ンで制御する。
最適化オプションを与えない場合は,最適化を実行せず,基本演算ブロックを 1 つ利用した中間コードを出力する。最適化オプションに-O1 を与えた場合は,最 適化を実行し,基本演算ブロックを 1 つ利用した中間コードを出力する。ただし,
-O1 では RT-COP のハードウェアに依存した最適化は行わない。最適化オプション に-O2 を与えた場合は,-O1 の最適化は行われず,RT-COP のハードウェアに依存 した最適化を実行し,基本演算ブロックを 3 つ並列に利用した中間コードを出力 する。最適化オプションに-O3 を与えた場合は,最適化オプション-O1 と-O2 の 2 つの最適化を同時に実行し,基本演算ブロックを 3 つ並列に利用した中間コード を出力する。
この中間コードをアセンブラにかけることで最終的にホスト CPU でコンパイル できるホスト用 C 言語ソースが生成される。これは,RT-COP はコプロセッサのた め,実行コードはホスト CPU からダウンロードしなければならないためである。
ホスト用 C ソースコードには配列データの形で RT-COP VLIW 命令のオブジェクト
が記述されている。RT-COP で伝達要素レベルでの並列処理を行いたい場合には,
-O1 でコンパイルを行って生成された中間コードをそのまま利用すればよく,並 列化ツールを利用しない。この中間コードを並列に配置し,マージすることで,
伝達要素レベルの並列化を行うことができるので,図 7の結果を得ることができ る。
2.3 制御演算用命令セット
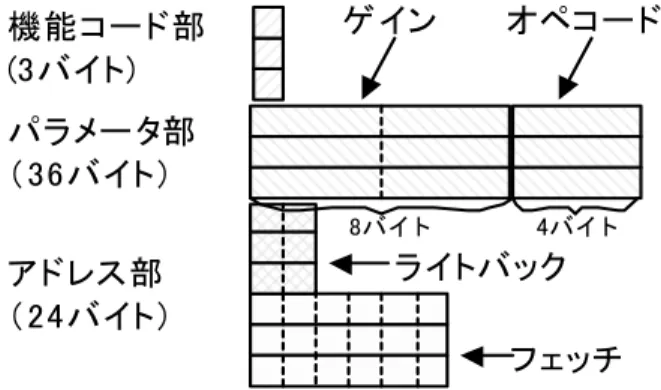
2.3.1 RT-COP の VLIW(Very Long Instruction Word)命令フォーマット サーボ制御を指向した RT-COP VLIW 命令は,命令の部分を機能ごとに分割して 管理するようにした。パラメータ部やアドレス部は演算の内容を決定する。機能 コード部はそれらの上位に位置して並列動作と演算式を決定する。機能コードを 作用させて内部動作を拡張することで,サーボ制御で用いられるデータの精度管 理を実行する。図 8が,制御演算を指向した RT-COP VLIW 命令のフォーマットで ある。
図 図 図
図 88 RT88 RTRTRT----COP COP COP VLIWCOP VLIW(VLIWVLIW(((Very Long Instruction WordVery Long Instruction WordVery Long Instruction Word)Very Long Instruction Word)))命令フォーマット命令フォーマット命令フォーマット 命令フォーマット
RT-COP VLIW 命令は機能コード部,パラメータ部およびアドレス部の 3 つの部 分で構成する。各部は並列に実行される 3 つの基本演算ブロックの命令をパック している。アーキテクチャ的には,機能コードメモリ,アドレスメモリおよびパ ラメータメモリの RT-COP 内にある 3 つのメモリに分散して格納し,それぞれ分散 して制御される。これにはコントローラの簡易化のためと,RT-COP VLIW を構成 する要素の個別変更を容易にするためである。例えば,パラメータ部の乗数はハ ザードを無くすことに加え,制御演算のゲインとして利用しやすいように分割し ている。
機能コード部は複数の機能を兼用させた。まず,基本演算ブロックの並列動作 を決定する。機能コードが定義されている基本演算ブロックを動作させる。次に,
パラメー タ部
(36バイト)
機能コー ド部 (3バイト)
アドレス部
(24バイト)
ライトバック フェッチ ゲ イン オペコー ド
8バイ ト 4バイ ト
基本演算ブロックの演算式を決定する。これは,どの基本演算命令(2.3.2.
2 基本演算命令を参照)を利用するかということと等価である。機能コードは,
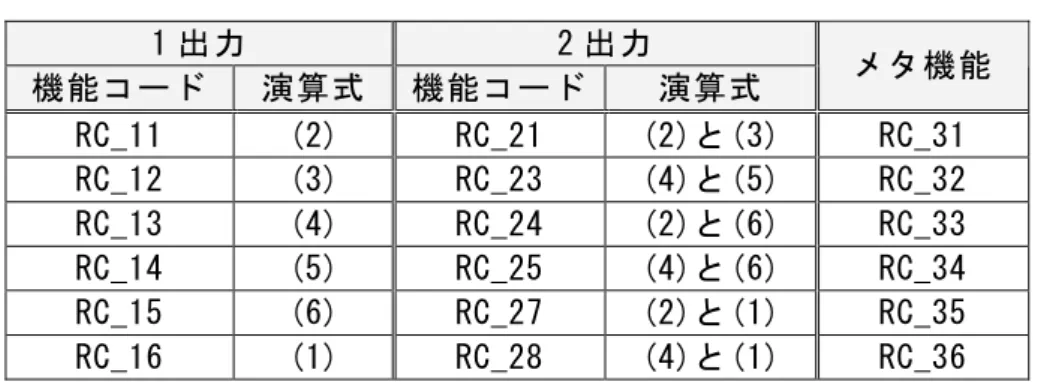
RT-COP の基本演算ブロックを利用して行った演算について,機能コードで出力セ レクタの出力を制御して,どの演算結果を選択するかを決定する。機能コードは 1 出力系と 2 出力系に分類できる。2 出力の機能コード RC_21~RC_28 では,出力 セレクタを制御して 2 つの演算式の結果を得る。そのため,パラメータ部やアド レス部は同じでも,機能コードを変更することで異なる結果を取得できる(図 9)。
図 9の RC_15 の様に A と B を並列に演算して,加算する。B のみを行いたい場合,
あるいは A と B を並列に行い,それぞれ結果を得たい場合,機能コードを RC_13 や RC_23 変更することで簡単に対応できる。
図 図図
図 9999 機能コードの作用機能コードの作用機能コードの作用機能コードの作用
整数演算では,乗算後の桁落ちや桁あふれをチェックし精度管理を行わないと,
制御演算の結果が不連続になり,サーボ制御に致命的なエラーを発生する。乗算 時の精度管理を行わせるため,機能コード RC_31 から RC_36 をメタ機能として実 装した。
パラメータ部は,基本演算ブロックに与える乗数を格納した部分(ゲイン)と,
基本演算ブロック内の演算器等の動作を決定する部分(オペコード)の 2 つの部分 から構成される。このフィールドを作用させることにより,基本演算ブロック内 に実装された個々の演算器の機能を決定できる。このことは,パラメータ部に設
A B
RC_13
RC_15
RC_23 A B B
基本演算命令を参照)の演算結果を,RT-COP VLIW 命令の機能コードで最大 2 個 選択する。RT-COP VLIW 命令のパラメータメモリのオペコードは,対応する ALU やバレルシフタに作用してその機能を決定するために利用される。ALU は加減算 の算術演算,&や|といったビット演算,==や>といった比較演算および制御用の 特殊演算を実行する。制御用の特殊演算には,制御演算でよく利用されるが,丸 め処理のようにソフトウェアで実行した場合には比較的時間がかかる演算を選択 してハードウェアで実装した。バレルシフタではシフトの種類とシフト量が決定 され,演算後の桁あふれや桁落ちを管理する。
アドレス部は, 5 つの入力(フェッチ)データアドレスと 2 つの出力(ライトバ ック)データアドレスを格納している。1 つのアドレスは 8 ビット長である。最上 位のビットはスカラエクスパンジョンフラグとして利用され,残り 7 ビットで共 有メモリのアドレスを指定する。
2.3.2 RT-COP の基本演算命令
2.3.2.1 サーボ制御演算のハードウェア化
RT-COP の基本演算命令抽出に先立って,サーボ制御演算のハードウェア化を行 った。ここで,ハードウェア化とは制御演算の並列性をハードウェアで実現する ことと定義した。図 10のサーボ制御演算は,実験用に用いるためにパラメータを 作用させることで,フィードバック制御や,オブザーバ,フィードフォワード制 御など複数の制御演算を切り替えて利用できるような構造を備えている。このサ ーボ制御プログラムを例題にハードウェア化を実施した。
図 図 図
図 101010 サーボ制御プログラムのブロック線図10 サーボ制御プログラムのブロック線図サーボ制御プログラムのブロック線図 サーボ制御プログラムのブロック線図
サーボ制御演プログラムは指令作成部,フィードバック状態量計算部,制御マト リックス部およびフィルタ処理部から構成されており,指令と検出値からトルク 指令を生成する。このブロック線図では指令作成部とフィードバック状態量計算 部は並列動作が可能である。C 言語で記述するために逐次処理に制御プログラム は書き直されており,200MHz の SH-4 で実行させた時の処理時間は 130.40μs で あった。
C 言語で記述された制御演算を基にして,Verilog HDL でハードウェアに変換し
トルク指令
検出値指令 指令作成部 フィードバック状態量計算部 制御マトリクス部 フィルタ処理部
パラメータ
成し,制御演算で利用されている変数をライフタイム解析することで,制御演算 の並列性を引き出すことを追求した。計算機上でのシミュレーションおよび FPGA を用いたエミュレーションとで,それぞれ演算時間を評価した。FPGA を用いたエ ミュレーションでは FPGA 評価基板(図 11)を作成した。
図 図 図
図 11111111 サーボ制御演算のハードウェア化のためのサーボ制御演算のハードウェア化のためのサーボ制御演算のハードウェア化のためのサーボ制御演算のハードウェア化のための FPGAFPGAFPGAFPGA((((Field Programmable Gate ArrayField Programmable Gate ArrayField Programmable Gate ArrayField Programmable Gate Array))))評評評評 価基板
価基板 価基板 価基板
FPGA に実装した制御演算は,32 ビット固定小数点演算を行うハードウェアとし た。FPGA の動作周波数は 12MHz である。FPGA 評価基板では FPGA として Xilinx 製 XCV800 を 8 個実装しており,そのうち 7 個を利用して制御演算を実装した。そ のため FPGA 間に通信処理が必要となり,FPGA 間の通信処理はオーバヘッドとな った。また, FPGA へ実装する際の制約のために,並列に実行できる部分につい て,逐次処理に一部変更した。
シミュレーションでは 12MHz 動作で演算時簡に 3.90μs 要した。オーバヘッド を除く FPGA での演算時間は 6.80μs で,シミュレーションの 1.7 倍となった。ソ フトウェア処理に比べてクロック周波数を 0.060 倍に低減し,また演算時間も 0.052 倍に短縮することができた。FPGA 間の通信処理によるオーバヘッドは 17.70 μs であり,オーバヘッドを加算した演算時間は 24.50μs である。オーバヘッド を加算した場合でもソフトウェア処理の 0.19 倍に演算時間を低減できることを 確認した。さらに,ソフトウェア処理では制御周期を 500.0μs にしかできなかっ たが,FPGA では制御周期を 62.5μs とソフトウェア処理の 1/8 に短縮することが できた。
2.3.2.2 基本演算命令
制御演算のハードウェア化は,演算時間,制御周期および動作周波数で満足す べき性能を得ることができた。そのため,前節の演算式を解析して,RT-COP の基 本演算ブロックで実現するサーボ制御演算に有効な演算式を決定した。図 12がそ の解析結果である。
図図図
図 12121212 サーボ制御演算サーボ制御演算サーボ制御演算サーボ制御演算 解析結果解析結果解析結果解析結果
(6)式を含みフィードバック要素を加えた(1)式を基本演算命令と名づけ,基本 演算ブロックの演算器配置の基本構成とした。
G S2)) F) E) (((D S1) C)
B)
((((A ⊕ × >> + ⊕ × >> ⊕ (1)
(1)式では ALU(Arithmetic Logical Unit)の演算は⊕ で記述している。C と F はパラメータ部の乗数に相当する。基本演算命令は,(1)式~(6)式の全てを含 む演算式である。基本演算命令と機能コードの関係は表 1である。
B
A ⊕ (2)
E
D⊕ (3)
(4)
(1) (2) (3) (4) (5) (6) (2)
と (3)
(4) と (5) 頻度
演算式の種類 10
20 30 40
表表表
表 1111 機能コード機能コード機能コード機能コード
1 出力 2 出力
機能コード 演算式 機能コード 演算式 メタ機能 RC_11 (2) RC_21 (2)と(3) RC_31 RC_12 (3) RC_23 (4)と(5) RC_32 RC_13 (4) RC_24 (2)と(6) RC_33 RC_14 (5) RC_25 (4)と(6) RC_34 RC_15 (6) RC_27 (2)と(1) RC_35 RC_16 (1) RC_28 (4)と(1) RC_36
2.3.3 RT-COP の基本演算ブロック
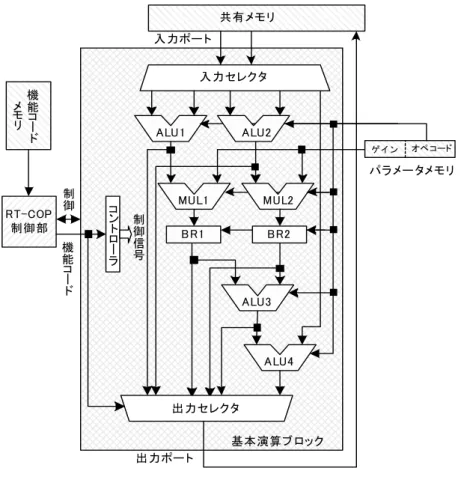
RT-COP の基本演算ブロックは,制御演算の解析結果を基にした基本演算命令を 実行する演算器であり,制御演算を効率的に実行する。メタ機能を実行するため,
演算器の機能を変更する制御信号が,機能コードを用いてコントローラで生成さ れる。伝達要素を表現するため,基本演算ブロックは,一般に用いられる CPU の 機械語レベルの粒度ではなく,C 言語で記述された式レベルの粒度の演算を実行 する。CPU の機械語に換算して,7 個の変数ロード,2 個の変数ストアと 10 個の 算術論理演算からなる 19 個の命令が,1 サイクルに 1 つの基本演算ブロックで実 行できる。制御用の特殊演算を ALU の演算で指定した場合には,さらに多くの命 令を等価的に実行できる。基本演算ブロックのアーキテクチャを図 13に示す。
基本演算ブロックと共有メモリの間には 2 つの 32 ビット幅の入力ポートと 1 つの 32 ビット幅の出力ポートを備えている。そのため,演算に必要な 5 つの入力 データは,入力段に置いた入力セレクタをクロック単位で切り替えながら,基本 演算ブロックに取り込まれる。基本演算ブロックでは,入力データがそろった演 算器から順に演算が実行され,機能コードに適合した演算結果が最大 2 つの生成 される。演算結果は出力段に置いた出力セレクタをクロック単位で切り替えなが ら,基本演算ブロックから出力される。
基本演算ブロックは,それぞれ異なる機能を持つ 4 つの ALU(ALU1~4),乗算 を行う 2 つの乗算器(MUL1,MUL2)および乗算結果の任意量のシフトを行う 2 つ のバレルシフタ(BR1,BR2)から構成され,図 13に示すように演算器間は接続さ れている。ALU1~4 は 32 ビットのデータを元に演算を行い 32 ビットの演算結果