欠測のある連続量経時データに対する
統計手法について
Ver2.0
2016
年
4
月
日本製薬工業協会
医薬品評価委員会 データサイエンス部会
2013
年度 タスクフォース
2
2014
年度 タスクフォース
4
欠測のあるデータの解析チーム
目 次
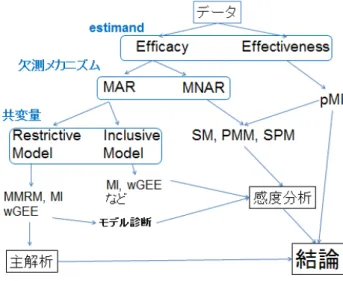
第 I 部 欠測のあるデータの解析の基礎と基本的な手法のまとめ
7
第 1 章 はじめに 8 1.1 本報告書の目的と背景 . . . . 8 1.2 本報告書の構成 . . . . 8 1.3 注意事項 . . . . 9 1.3.1 本報告書の前提知識 . . . . 9 1.3.2 本報告書の対象となるデータ . . . . 9 1.3.3 用語・記号に関する注意 . . . . 9 1.3.4 略語等一覧 . . . . 10 1.3.5 欠測識別変数 . . . . 10 1.3.6 その他のよく用いる記号 . . . . 11 1.4 その他の注意 . . . . 11 参考文献 . . . . 11 第 2 章 欠測のあるデータの基本事項 ∼欠測メカニズム・尤度・データの紹介∼ 13 2.1 はじめに . . . . 13 2.2 欠測メカニズムの定義と具体例 . . . . 13 2.2.1 欠測とは . . . . 13 2.2.1.1 本報告書で扱う欠測 . . . . 13 2.2.1.2 欠測データと欠測のあるデータ . . . . 13 2.2.1.3 欠測識別変数 . . . . 13 2.2.1.4 本報告書で扱うデータの設定 . . . . 14 2.2.2 欠測のパターンと欠測のメカニズム . . . . 14 2.2.2.1 欠測パターンの分類:単調な欠測 . . . . 14 2.2.2.2 中止の種類と脱落 . . . . 152.2.3 欠測メカニズムの種類 (MCAR, MAR, MNAR) . . . . 15
2.2.3.1 Little and Rubin (2002) の MCAR, MAR, MNAR の定義 . . . . 15
2.2.3.2 NRC(2010) の MCAR,MAR,MNAR の定義 . . . . 16 2.2.4 具体例 . . . . 16 2.2.4.1 MCAR の具体例 . . . . 17 2.2.4.2 MAR の具体例 . . . . 17 2.2.4.3 MNAR の具体例 1 . . . . 18 2.2.4.4 MNAR の具体例 2 . . . . 18 2.2.5 臨床試験における MCAR,MAR,MNAR . . . . 19 2.3 欠測メカニズムに対する注意 . . . . 20 2.3.1 無効な症例が存在する場合の欠測メカニズム . . . . 20 2.3.2 MAR かどうか分からない場合にどう考えるか . . . . 23 2.4 尤度を用いた推測 . . . . 23 2.4.1 尤度の種類 . . . . 24
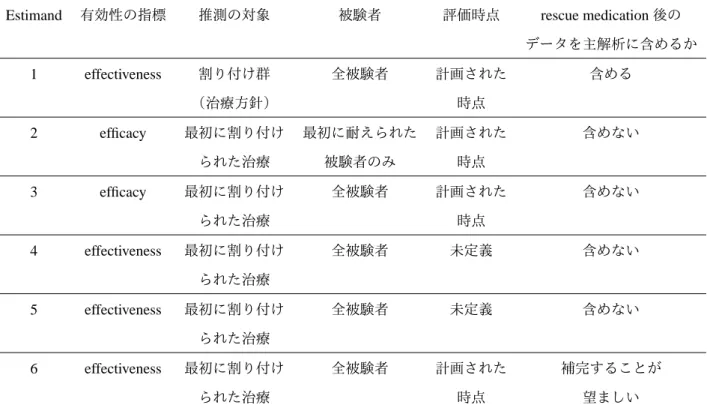
2.4.2 無視できる欠測メカニズム . . . . 24 2.4.2.1 尤度を用いた推測の場合の定義 . . . . 24 2.4.2.2 欠測メカニズムが無視できる場合の統計的推測 . . . . 26 2.5 実際の臨床試験データ . . . . 26 参考文献 . . . . 28 第 3 章 Estimand 30 3.1 はじめに . . . . 30 3.2 Estimand の定義・重要性・注意点 . . . . 30 3.2.1 Estimand とは . . . . 30 3.2.2 Estimand の重要性 . . . . 30 3.2.3 実用上の注意 . . . . 31 3.3 Efficacy と effectiveness . . . . 31 3.4 Mallinckrodt (2013) による 6 つの estimand . . . . 31 3.4.1 Estimand 1 . . . . 31 3.4.2 Estimand 2 . . . . 32 3.4.3 Estimand 3 . . . . 32 3.4.4 Estimand 4, 5 . . . . 32 3.4.5 Estimand 6 . . . . 33
3.5 Mallinckrodt et al. (2014) による 3 つの estimand . . . . 33
3.6 ステークホルダーと estimand . . . . 33
3.7 その他の参考文献など . . . . 34
参考文献 . . . . 34
第 4 章 Complete case 解析,LOCF,及び BOCF に対する論説 36 4.1 はじめに . . . . 36
4.2 Complete case 解析 . . . . 36
4.3 補完に基づくアプローチ . . . . 37
4.3.1 LOCF について . . . . 37
4.3.2 BOCF について . . . . 38
4.3.3 Estimand と LOCF,及び BOCF . . . . 38
4.3.4 その他の補完方法 . . . . 38 4.4 まとめ . . . . 39 参考文献 . . . . 39 第 5 章 Selection Model 40 5.1 はじめに . . . . 40 5.2 SM の一般的定義 . . . . 40 5.2.1 記号の確認 . . . . 40 5.2.2 SM の一般的定義 . . . . 40 5.2.3 SM の対象となる estimand . . . . 41 5.3 MAR を仮定した SM . . . . 41 5.3.1 MAR を仮定した SM その 1(SM の一般論) . . . . 41 5.3.2 MAR を仮定した SM その 2(MMRM) . . . . 42
5.3.3 MNAR (outcome-dependent dropout) を仮定した SM . . . . 45
5.4 SM による感度分析 . . . . 46
5.4.1 アプローチ 1:脱落確率モデルを固定するアプローチ(MNAR を仮定した SM その 1) 46 5.4.2 アプローチ 2:感度パラメータを用いるアプローチ(MNAR を仮定した SM その 2) . . 47
5.5 マクロプログラムについて . . . . 47 5.5.1 アプローチ 1 に対するマクロ(感度パラメータなし) . . . . 48 5.5.2 アプローチ 2 に対するマクロ(感度パラメータあり) . . . . 48 参考文献 . . . . 48 第 6 章 Pattern-Mixture Model 50 6.1 はじめに . . . . 50 6.2 記号の整理と前提事項 . . . . 51 6.3 PMM について . . . . 52 6.4 制約条件について . . . . 53 6.5 制約条件 CCMV,NCMV,ACMV を仮定した PMM . . . . 54 6.5.1 欠測データの分布を特定可能にする制約条件 . . . . 54 6.5.2 CCMV . . . . 55 6.5.3 NCMV . . . . 56 6.5.4 ACMV . . . . 57 6.5.5 制約条件(CCMV,NCMV,ACMV)の利用 . . . . 58 6.5.6 制約条件(CCMV,NCMV,ACMV)を仮定した PMM の実装手順 . . . . 59 6.6 制約条件 (CCMV, NCMV, ACMV) のまとめ . . . . 60 6.7 制約条件 NFMV を仮定した PMM . . . . 61 6.7.1 制約条件 . . . . 61 6.7.2 制約条件 (NFMV) の利用 . . . . 63 6.7.3 制約条件(NFMV)を仮定した PMM の実装手順 . . . . 68 6.7.4 感度分析 . . . . 69 6.7.5 SM と PMM の関係 . . . . 70 6.7.6 マクロプログラム (マクロ %PATTERNMIXTURE) について . . . . 71 6.8 Multiple Imuptation(MI) . . . . 72 6.8.1 Multiple Imuptation の概要 . . . . 72
6.8.2 Multiple Imuptation の正当化(Rubin のルールの原理) . . . . 72
6.8.3 単調回帰による Multiple Imuptation の概要 . . . . 73
6.8.4 Multiple Imputation により得られた複数の推定量の結果統合 . . . . 73
6.9 Marginal treatment effect (周辺治療効果) の推定 . . . . 75
6.10 その他の PMM . . . . 76
6.10.1 対照群のデータを用いた pattern imputation(Controlled imputation) . . . . 76
6.10.2 対照群のデータを用いた pattern imputation の SAS での実行 . . . . 77
6.10.3 対照群のデータを用いた,その他の pattern imputation . . . . 77
6.10.4 Delta adjustment を用いた pattern imputation . . . . 78
6.10.5 中止理由別(AE とその他の理由で区別)の pattern imputation . . . . 79
参考文献 . . . . 80
第 7 章 Shared Parameter Model 82 7.1 はじめに . . . . 82 7.1.1 SPM の一般的な表現 . . . . 82 7.2 モデルの定式化 . . . . 83 7.2.1 応答変数モデル . . . . 83 7.2.2 脱落確率モデル . . . . 84 7.3 パラメータの推定 . . . . 84 7.4 感度分析としての SPM の位置づけ . . . . 85 7.5 マクロ%shared_parameter . . . . 85
参考文献 . . . . 85
第 8 章 その他の手法 87 8.1 はじめに . . . . 87
8.2 Inverse Probability Weighted Complete-Case (IPWCC) Estimator . . . . 88
8.2.1 µ に対する IPWCC 推定量 . . . . 88
8.2.2 IPWCC estimators for Estimating Equations . . . . 90
8.2.3 ブートストラップ法による IPWCC 推定量の分散 . . . . 90
8.3 weighted Generalized Estimating Equation (wGEE) . . . . 91
8.4 Doubly Robust な推定量 (DR) . . . . 93 8.5 8 章のまとめ . . . . 95 参考文献 . . . . 96
第 II 部 MMRM の詳細と感度分析
98
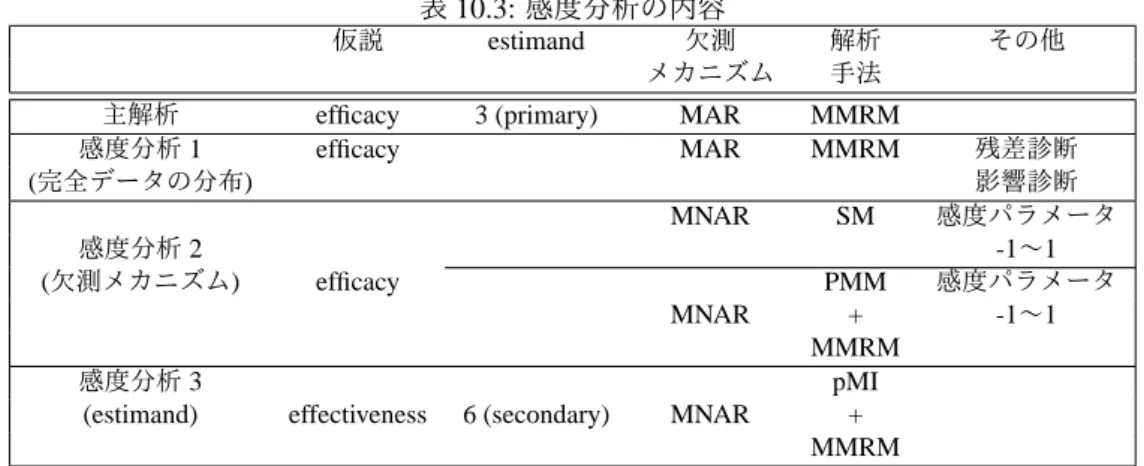
第 9 章 MMRM 99 9.1 はじめに . . . . 99 9.2 MMRM の概念と特徴 . . . 100 9.3 SAS による実装 . . . 101 9.3.1 PROC MIXED ステートメント . . . 102 9.3.2 CLASS ステートメント . . . 102 9.3.3 MODEL ステートメント . . . 103 9.3.4 LSMEANS ステートメント . . . 103 9.3.5 REPEATED ステートメント . . . 103 9.3.6 RANDOM ステートメント . . . 103 9.4 主解析としての MMRM . . . 104 9.5 MMRM に基づく解析の検出力と標本サイズ設計 . . . 104 9.6 おわりに . . . 105 参考文献 . . . 105 第 10 章 感度分析の実行 108 10.1 はじめに . . . 108 10.2 シミュレーションデータと主解析の結果 . . . 109 10.3 完全データの分布に対する感度分析(感度分析 1) . . . 111 10.3.1 共変量の検討 . . . 111 10.3.2 分散共分散構造の検討 . . . 111 10.3.3 残差診断の検討 . . . 112 10.3.4 影響診断の検討 . . . 112 10.4 欠測メカニズムに対する感度分析(感度分析 2) . . . 113 10.4.1 主解析で仮定する欠測メカニズム . . . 11310.4.2 Type (i) ,Type (ii) の仮定と欠測メカニズムに対する感度分析の必要性 . . . 113
10.4.3 SM による感度パラメータを用いた感度分析 . . . 113 10.4.4 PMM による感度パラメータ ∆ を用いた感度分析 . . . 115 10.4.5 SPM による感度分析 . . . 119 10.5 Estimand に対する感度分析(感度分析 3) . . . 120 10.6 感度分析の結果のまとめ . . . 121 参考文献 . . . 121
第 11 章 Estimand ごとの解析手法の使い分け 123 11.1 はじめに . . . 123 11.2 各手法の使い分け . . . 123 11.2.1 Estimand に基づく手法の整理 . . . 123 11.2.2 Estimand 3 . . . 125 11.2.3 Estimand 2 . . . 125 11.2.4 Estimand 1 . . . 125 11.2.5 Estimand 6 . . . 126 11.2.6 Estimand 4 . . . 126 11.2.7 Estimand 5 . . . 126
11.3 Analytic Road Map に関する注意点 . . . 126
参考文献 . . . 127 第 12 章 シミュレーションによる検討 128 12.1 はじめに . . . 128 12.2 シミュレーション 1 . . . 129 12.2.1 性能比較の方法 . . . 129 12.2.2 シミュレーションの設定 . . . 129 12.2.3 データの作成方法 . . . 131 12.2.4 解析方法およびシミュレーションの結果 . . . 133 12.3 シミュレーション 2 . . . 136 12.3.1 性能比較の方法 . . . 136 12.3.2 シミュレーションの設定 . . . 136 12.3.3 データの作成方法 . . . 137 12.3.4 解析方法およびシミュレーションの結果 . . . 140 12.4 まとめ . . . 143 参考文献 . . . 144
更新履歴
Ver 更新年月 更新内容・コメント
1.0 2016 年 1 月 初版(1∼12 章,Appendix A∼C)
2.0 2016 年 4 月 第 2 版(1∼12 章,Appendix 1, Appendix 2)
• 本文の誤植修正
• Appendix A∼C の名称 (Ver1.0 では Appendix) を Appendix 1
に変更
• Appendix 2 を新規作成
• 1∼12 章・Appendix 1・Appendix 2 の電子ファイルを 1 つに
統合
• 1∼12 章・Appendix 1・Appendix 2 に記載された各 Web ペー
第
I
部
欠測のあるデータの解析の基礎と
基本的な手法のまとめ
第
1
章
はじめに
1.1
本報告書の目的と背景
経時的にデータを測定する臨床試験では,計画していた全ての測定時点で適切に測定が行われるとは限らな い.第 III 相の大規模な臨床試験などでは,データの欠測はほとんどの試験で発生している.
特に応答変数が連続変数の比較試験では,これまで主に欠測値を LOCF (Last Observation Carried Forward) で補完した後に共分散分析を用いる,LOCF ANCOVA という手法が主に用いられ,解析結果に対する欠測の 影響の評価も,それほど詳細には検討されてこなかった (Tanaka et al., 2014).しかし近年,欧州では EMA か らガイドライン"Guideline on Missing Data in Confirmatory Clinical Trials"が 2010 年に発行され,米国ではこれ も 2010 年に National Research Council から"The prevention and treatment of missing data in clinical trials"(以下,
NRC (2010) )が出版されたことや,欠測データの取り扱いが原因で「EMA では承認されたが,FDA では承認 されなかった事例」が出てきたこと(JPMA, 2014b)などをきっかけに,データの欠測が解析結果に与える影 響に対して,大変多くの注目が集まっている. データの欠測に対する対応として,最も重要なことは欠測を発生させないことである.試験デザイン,実施 の観点から工夫できる点も様々ある.この観点も含め,主に臨床試験の実施上の観点から,本タスクフォース (医薬品評価委員会 データサイエンス部会 タスクフォース 2(2013 年度))から既に報告書(JPMA, 2014a; 2014b)を発行している. 一方,試験のデザインや実施をどのように工夫をしたとしても,欠測が避けられないことも多い.そのよう な場合に,欠測が解析結果にどのような影響を与えうるか,欠測のあるデータに対してどのような手法を用い ればよいか,等を検討したのが本報告書である.従って,本報告書では主に統計担当者をはじめとする,既存の 統計手法についてはある程度理解されている方を対象に,欠測のあるデータに対する解析手法について述べる. また,NRC (2010) において estimand という用語が強調された.estimand とは,「推定対象」を意味する概念で あり,estimand を明確に特定することにより,治験の目的や評価対象を今まで以上に明確化でき,解析手法の 妥当性の評価や結果の解釈を今まで以上に明晰に行う事ができるようになる,と期待されている.この概念に ついても,NRC (2010) 等を参考に解説を試みた.なお,estimand については,ICH E9 (R1) にて検討が継続中 (2016 年 1 月現在)であり,2014 年に Final Concept Paper が発出されている (ICH Steering Committee, 2014).
また,2015 年 2 月に開催された製薬協主催のシンポジウム(以下,製薬協シンポジウム)では,PMDA から安 藤友紀氏が,FDA から Lisa LaVange 氏が講演を行い,発表資料が製薬協の Web ページで公開されている(安 藤, 2015; LaVange, 2015). また,2014 年より企業・PMDA・アカデミアの統計家により,実務上の統計的課題の議論を行う企画として, データサイエンス・ラウンドテーブル会議が開催されている.欠測のあるデータの解析や estimand の実務への 応用は,過去 3 回で毎回議題となっており,活発な議論が行われた.会議で用いられた資料・議論のまとめは, • 第 1 回(2014 年 2 月):http://www.pmda.go.jp/review-services/reexamine-reevaluate/symposia/0027.html • 第 2 回(2015 年 3 月):https://www.pmda.go.jp/review-services/reexamine-reevaluate/symposia/0007.html • 第 3 回(2016 年 2 月):https://www.pmda.go.jp/review-services/reexamine-reevaluate/symposia/0049.html にて公開されており,今後も引き続き議論のテーマとなる可能性がある.
1.2
本報告書の構成
本報告書の構成は以下の通りである.1. (第 I 部) 欠測のあるデータや estimand に対する基本的考え方や基本的解析手法を整理する.(1∼8 章) 2. (第 II 部) LOCF ANCOVA の代わりに主解析としてよく用いられるようになってきた MMRM (Mixed Model for Repeated Measures) について解説すると共に,これを主解析として選択した場合にどのような
感度分析が考えられるか,を整理する.また,手法間の比較のシミュレーションも行う.(9∼12 章) 3. (Appendix) 基本事項として線形混合モデル (LMM) の解説,本文中で省略した理論の詳細の解説,公開さ れているマクロについての解説を行う.(Appendix A∼C) なお,本報告書では「欧米で批判が強まってきている」という理由から,安易に LOCF ANCOVA を主解析 とすること自体を否定するものではない.また,LOCF ANCOVA の代替手法としての MMRM の使用について も,無批判に勧めるものではない.Estimand や欠測のあるデータに対する解析手法とその特徴について理解を 深め,読者が自身の状況に照らし合わせて主体的に解析方法を選択することを支援するのが,本報告書の目的 である. 以下,本報告書における基本的注意を述べる.
1.3
注意事項
1.3.1
本報告書の前提知識
本報告書では,線形モデル (Linear Model, LM) についての知識(ANCOVA 含む)は前提とするが,線形混合 モデル(Linear Mixed Model, LMM)については前提としない.LMM については Appendix A で解説する.
1.3.2
本報告書の対象となるデータ
本報告書では,応答変数が連続量の場合のみを扱う.解析手法としては頻度論に基づいた手法のみを扱う.
また,本報告書では欠測を防ぐ方法については触れない.「欠測は存在する」という前提のもとで,解析方法の
検討を行う.欠測を防ぐ方法については,NRC (2010),JPMA (2014a) や,解析担当者の実践例として Hughes
et al. (2012) などを参照のこと.また,2015 年 2 月に開催された製薬協シンポジウムの資料として,竹ノ内 (2015),松岡ら (2015) がある.なお,欠測データの割合が増えることによって,主解析の結果がどのような ものであっても議論の余地が残ることが懸念される.そのため,欠測を減らす試験デザイン,試験の実施を工 夫することは,極めて重要である.
1.3.3
用語・記号に関する注意
欠測のあるデータの解析についての文献を読む際,非常に悩ましいのは,「言葉の意味や言葉遣いが文献ごとに異なる」ことがよくある点である.たとえば,Missing At Random ではない欠測のメカニズムを"Missing Not
At Random (MNAR)"と呼ぶ文献もあれば,"Not Missing At Random (NMAR)"と呼ぶ文献もある.また,日本
語の用語としては sensitivity analysis の訳を「感度分析」と呼ぶか「感度解析」と呼ぶか,という点もある.本 報告書ではそれぞれ"MNAR"と「感度分析」を用いる1.さらに,本報告書の主題の 1 つである MMRM(9 章 参照)については,「明示的に変量効果がモデルに組み込まれていない(ことが多い)」という点から"Mixed"の 名前をつけて呼ぶべきではない,という指摘もある.本報告書では慣用に従い MMRM という用語を用いるが, 今後どのような呼称を用いるか,についても引き続き検討が必要である. このように複数の用いられ方をする用語について,本報告書では極力説明を加える,異なる定義を列挙する, などを心がけている.一意的に定義しないものもあるが,本報告書内で限定しすぎた場合,他の文献で異なる 定義がなされていた際に理解を妨げる可能性があることを懸念し,このような対応とした. 1なお,日本語の「感度分析」と「感度解析」の違いとしては,「『感度分析』は統計解析だけでなく,より広範な分析を含む」という考 え方もあるようである.
一方,本報告書では他の文献から引用を行う場合,あまりに本報告書内での一貫性を損う場合,文献と全く 同じ記号ではなく,本報告書で定めた記号を用いたものもある.参考文献を参照される際,注意されたい.
1.3.4
略語等一覧
以下,本報告書で用いる略語等の一覧を示す.なお,たとえば選択モデル (SM) については,SeM という略 称で用いられている文献もある,など文献間で統一されていない部分も多いため,注意されたい. 表 1.1: 本報告書で用いる用語一覧 本報告書での表記 日本語名 英語名ANCOVA 共分散分析 ANalysis of COVAriance AR(1) 1 次自己回帰 AutoRegressive(1)
CS Compound Symmetry
iid 独立同分布 independent and identically distributed
LM 線形モデル Linear Model
LMM 線形混合モデル Linear Mixed Model
LOCF Last Observation Carried Forward
MAR Missing At Random
MI 多重補完法 Multiple Imputation
MMRM Mixed Model for Repeated Measures MNAR Missing Not At Random
PMM パターン混合モデル Pattern-Mixture Model
pMI placebo Multiple Imputation REML 制限付き最尤法(制約付き最尤法) REstricted Maximum Likelihood
SM 選択モデル Selection Model
SPM Shared Paremeter Model
1.3.5
欠測識別変数
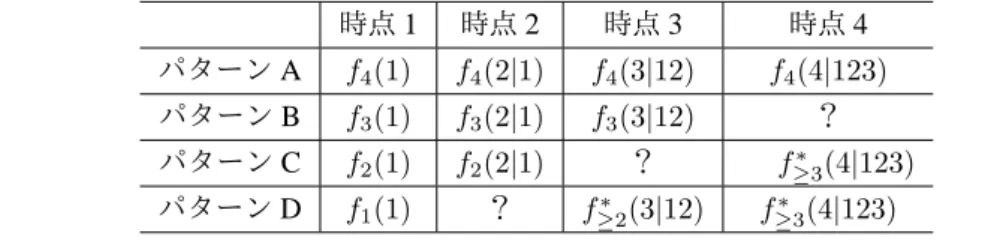
本報告書の対象は 1 被験者に対して複数回の測定が計画される経時データである.以下,i を被験者の添え 字,j を時点の添え字とする.なお,j 時点,とは j 番目の時点,という意味である.つまり,j = 1, 2, 3 がそ れぞれ 1 週目,2 週目,3 週目などとは限らず,j = 1:1 週目,j = 2:2 週目,j = 3:4 週目,などもありうる. また,i = 1,· · · , N; j = 1, · · · , n とし,1 被験者あたりの計画された測定時点数 n は被験者全員で共通とする. 被験者 i の j 時点のデータが欠測しているか,観測されたか,を示す変数には(本質的には同じ)2 種類の 変数が考えられる. • 欠測したとき 1,観測されたとき 0 となる変数 Mij • 観測されたとき 1,欠測したとき 0 となる変数 Rijである.これらを被験者 i についてまとめたベクトルを,それぞれ Mi, Riとおく2.また,「(被験者 i の観測 データ数)+1」を Diとおく.式で表すと Di= n ∑ j=1 Rij+ 1 となる.Diは「ある時点までデータが常に観測されて,その後脱落する」3場合に,最初の欠測時点(ただし, 完了例の場合は「計画された測定時点 +1」)を意味する. これらの記号は,実際に文献ごとに記載が異なることがみられるため,読者は他の文献を読まれる際に注意 されたい.
1.3.6
その他のよく用いる記号
本報告書でよく用いる記号として,以下の n 次元ベクトルを定義する. 1n = 1 1 .. . 1 つまり,全ての成分が 1 であるベクトルである.1.4
その他の注意
• 本報告書では,SAS プログラムの例や使い方等にも触れる.特に断らない限り,SAS のバージョンは 9.2,9.3 もしくは 9.4 である.なお,9.4 で Proc MI に pMI が実装される,などしており,今後もバー ジョンアップに従い,新たな機能が追加されることが想定される. • 本報告書は可能な限り章ごとに独立して読み進められるように,一部の基本的内容は複数の章で重複し て記載している. • 本報告書では, NRC (2010) をよく引用するが,この文献は慣習上「NAS レポート」「NRC レポート」 と呼ばれることがある.• 主に欠測メカニズムが MNAR である場合の解析の際,Missingdata.org.uk (http://missingdata.org.uk/) に
て公開されている SAS マクロ ( (http://missingdata.lshtm.ac.uk/index.php?view=category&id=61%3Amnar-methods&option=com_content&Itemid=137 ) を使用している.本報告書で使用しているマクロの使用法 については,本報告書の本文各章または Appendix C で述べる.
参考文献
[1] 安藤友紀. (2015). PMDA における経験、現状と将来展望. 日本製薬工業協会 データサイエンス部会シン ポジウム,臨床試験の欠測データの取り扱いに関する最近の展開と今後の課題について―NAS レポート、 2たとえば,全 4 時点で 3 時点目まで観測,4 時点目のデータが欠測している場合 Mi= Mi1 Mi2 Mi3 Mi4 = 0 0 0 1 , Ri= Ri1 Ri2 Ri3 Ri4 = 1 1 1 0 である. 3このような欠測を「単調な欠測」と呼ぶ.EMA ガイドライン、estimand と解析方法の概説―
(http://www.jpma.or.jp/information/evaluation/symposium/pdf/20150213/20150213_4.pdf). [2] European Medicines Agency (2010). Guideline on missing data in confirmatory clinical trials.
(http://www.ema.europa.eu/docs/en_GB/document_library/Scientific_guideline/2010/09/WC500096793.pdf) [3] Hughes, S., Harris, J., Flack, N., and Cuffe, R. L. (2012). The statistician’s role in the prevention of missing data.
Pharmaceutical statistics, 11(5), 410-416.
[4] ICH Steering Committee (2014). Final Concept Paper E9(R1): Addendum to Statistical Principles for Clinical Trials dated 22 October 2014.
[5] JPMA (2014a). 臨床試験の欠測データの取り扱いに関する最近の展開と今後の課題について- NAS レポー
ト,EMA ガイドライン,estimand と解析方法の概説 -. 日本製薬工業協会. (http://www.jpma.or.jp/information/evaluation/allotment/pdf/data_140704_1.pdf). [6] JPMA (2014b). 臨床試験の欠測データの取り扱いに関する最近の展開と今後の課題について- NAS レポー ト,EMA ガイドライン,estimand と解析方法の概説 - 付録審査資料で欠測データが議論された事例. 日本 製薬工業協会. (http://www.jpma.or.jp/information/evaluation/allotment/pdf/data_140704_2.pdf).
[7] LaVange, L. (2015). Missing Data Issues in Regulatory Clinical Trials. 日本製薬工業協会 データサイエンス部
会シンポジウム,臨床試験の欠測データの取り扱いに関する最近の展開と今後の課題について―NAS レ ポート、EMA ガイドライン、estimand と解析方法の概説―
(http://www.jpma.or.jp/information/evaluation/symposium/pdf/20150213/20150213_3.pdf)
[8] 松岡伸篤,高木弘毅,土川克,棚橋昌也,吉田早織,鵜飼裕之 (2015). 事例紹介 2. 日本製薬工業協会 デー
タサイエンス部会シンポジウム,臨床試験の欠測データの取り扱いに関する最近の展開と今後の課題につ いて―NAS レポート、EMA ガイドライン、estimand と解析方法の概説―
(http://www.jpma.or.jp/information/evaluation/symposium/pdf/20150213/20150213_9.pdf)
[9] National Research Council. (2010). The prevention and treatment of missing data in clinical trials. National Academy Press.
[10] 竹ノ内一雅 (2015). 事前の計画と報告,欠測予防. 日本製薬工業協会 データサイエンス部会シンポジウム,
臨床試験の欠測データの取り扱いに関する最近の展開と今後の課題について―NAS レポート、EMA ガイ ドライン、estimand と解析方法の概説―
(http://www.jpma.or.jp/information/evaluation/symposium/pdf/20150213/20150213_8.pdf)
[11] Tanaka, S., Fukinbara, S., Tsuchiya, S., Suganami, H., & Ito, Y. M. (2014). Current Practice in Japan for the Prevention and Treatment of Missing Data in Confirmatory Clinical Trials A Survey of Japanese and Foreign Pharmaceutical Manufacturers. Therapeutic Innovation & Regulatory Science, 48(6), 717-723.
第
2
章
欠測のあるデータの基本事項
∼欠測メカニズム・尤度・データの
紹介∼
2.1
はじめに
本章の目的は以下の通りである. • 欠測のあるデータに関する基本的な用語を整理する. • 欠測メカニズムについて解説する. • 尤度を導入する. • 本報告書で対象とするタイプの臨床試験のデータの構造や注意点について述べる.2.2
欠測メカニズムの定義と具体例
2.2.1
欠測とは
2.2.1.1 本報告書で扱う欠測 NRC (2010) の 1 章 (p8) では,欠測データ (missing data) の定義を「応答変数のうち,解析上意味があるが, 収集されなかったデータを指す.たとえば,ある時点で被験者が死亡した場合,その後の QOL データには解 析上意味がないため,これを欠測データ (missing outcome) と呼ぶべきではない」としている. 本報告書では,死亡後のデータの扱い等は扱わず,投与中止・試験中止した症例も全て生存しており,デー タの取得ができなかっただけとする. なお,現実的には,応答変数・共変量等様々なデータの欠測が考えられるが,本報告書では特に応答変数の 欠測に注目する.そのため,単に「欠測」と書いた場合には,応答変数の欠測を意味することとする. 2.2.1.2 欠測データと欠測のあるデータ 本報告書では「欠測データ」と「欠測のあるデータ」を区別する.それぞれ定義は以下の通りである. • 欠測データ:欠測したデータ(観測されていないデータ) • 欠測のあるデータ:測定を予定していた全データのうち,一部が欠測データである データセット つまり,本報告書で扱うのは「『欠測データ』の解析」ではなく,「『欠測のあるデータ』の解析」である. 2.2.1.3 欠測識別変数 Rijを,被験者 i の j 時点の応答変数が観測されているときに 1,欠測しているときに 0 をとる変数とする. このような変数を欠測識別変数と呼ぶ1. 1「はじめに」でも述べたが,M ijを「観測を 0」「欠測を 1」と定義して欠測識別変数とする場合や,Rijを「観測を 0」「欠測を 1」 とする場合など,文献によって定義が様々のため,文献ごとに確認が必要である.2.2.1.4 本報告書で扱うデータの設定 本報告書の主な対象となる臨床試験は,被験者ごとに複数の時点で応答変数の測定が計画されている,2 群 比較試験である.また,プロトコールで計画された 1 時点(以下,計画された最終時点2)での群間差を主な興 味の対象とする3.計画された最終時点の群間差が主な興味の対象となるものの,それまでの時点のデータも治 験薬の有効性に対して十分な情報を持っていると考えられる.そのため,すべての時点のデータを含めたモデ ル化を行った上で,計画された最終時点の群間差を検討することを試みる. • i:被験者番号 (i = 1, · · · , N) • j:時点 (j = 1, · · · , n) • Yij:被験者 i の症例の時点 j での応答変数の値 • Yi:被験者 i の応答変数全てのベクトル(観測データ,欠測データ両方含む) • Yo i:被験者 i の応答変数のうち,観測データを全て集めたベクトル • Ym i :被験者 i の応答変数のうち,欠測データを全て集めたベクトル • Ri:被験者 i の欠測識別変数を全て集めたベクトル ここで,欠測しているデータは手に入らないため,我々の手に入るデータは (Yo i, Ri) である.たとえば,計画 していた測定時点が 4 時点で,3 時点までしか観測されていない場合,被験者 i の各データは Yi= Yi1 Yi2 Yi3 Yi4 , Yoi = Yi1 Yi2 Yi3 , Ymi = ( Yi4 ) , Ri= 1 1 1 0 であり,観測されるデータは (Yo i, Ri) である.以上を受けて,
• 完全データ (full data4):(Y i, Ri) • 観測データ (observed data):(Yo i, Ri) と呼ぶこととする.なお,時点 4 の Yi4は欠測しているが,Ri4は「Yi4が欠測している」という情報から 0 と なる.つまり,Ri4は欠測しない.
2.2.2
欠測のパターンと欠測のメカニズム
Little and Rubin (2002) に従い,欠測のパターンと欠測のメカニズムを区別しておく.
• 欠測のパターン:どのデータが観測されて,どのデータが欠測しているか.Riの 0, 1 の並びで表現さ れる.たとえば,Ri= (1, 1, 1, 0)′と Ri= (1, 0, 0, 1)′は異なる欠測のパターンである. • 欠測メカニズム:欠測識別変数とデータの関係. つまり,欠測確率がどういうデータに(どのように)依 存しているか. 詳細は,以下で検討していく. 2.2.2.1 欠測パターンの分類:単調な欠測 欠測の パターン の重要な区分として,以下の 2 つがある. 2「実際に測定された最後の時点(欠測していない最後のデータがとられた時点)」という意味ではない点に注意が必要である. 3たとえば 12 週間有効性評価を行うが,主要評価時点は 8 週目であるような試験は想定していない. 4日本語の「完全データ」は"complete data"(欠測のないデータ)の訳として用いられることも多いため,注意が必要である.
• 被験者の脱落 (dropout5) のように,応答変数が 1 度欠測した際,その後のデータが全て欠測となるよう な場合,単調な欠測(monotone missing) と呼ぶ.たとえば,Ri = (1, 1, 1, 0)′, (1, 1, 0, 0)′, (1, 0, 0, 0) の ように,一旦 Rijが 0 となった後は常に 0 になる場合である. • ある測定時点のみ来院できなかった,という場合のように,一旦欠測した後に,データが 1 時点でも観 測された場合,非単調な欠測(non-monotone missing) と呼ぶ.たとえば,Ri = (1, 1, 0, 1)′, (1, 0, 1, 0) な ど,一旦 Rijが 0 となった後に,再度 1 となることがある場合である. 本報告書では,特に断らない限り単調な欠測を扱う. 2.2.2.2 中止の種類と脱落 中止の区分として,治験薬の投与中止と治験の中止がある.試験の目的や,3 章で述べる estimand 次第では, 治験薬投与中止後にもデータの収集を続ける必要が生じることもあり得るため,この区分は治験計画・実施・ 解析・結果の解釈を行う上で極めて重要である.
2.2.3
欠測メカニズムの種類 (MCAR, MAR, MNAR)
次に,欠測 メカニズム を考える.欠測のあるデータの解析に対して,(Yi, Ri) の同時密度関数を以下のよ うに分解することを考える. f (Yi, Ri| θ, ψ) = f(Yi| θ) · f(Ri| Yi, ψ) ここで,f (Ri| Yi, ψ) は,欠測識別変数 Riに対する応答変数 Yiの影響を示しており,この関数が欠測メカ ニズムを規定していると考えてよい.以下,この関数に対するモデルを脱落確率モデル(脱落モデル)と呼び, 具体例を用いつつ検討を行う.なお,θ は応答変数の分布のパラメータ,ψ は欠測識別変数の分布のパラメー タである.
2.2.3.1 Little and Rubin (2002) の MCAR, MAR, MNAR の定義
欠測メカニズムとして,特によく用いられる区分として MCAR (Missing Completely At Random),MAR
(Missing At Random),MNAR (Missing Not At Random) の 3 種類がある.Little and Rubin (2002) では,(本質的
に)以下のように定義されている6.
(MCAR) : f (Ri| Yi, ψ) = f (Ri| ψ) (MAR) : f (Ri| Yi, ψ) = f (Ri| Yio, ψ) (MNAR) : f (Ri| Yi, ψ) ̸= f(Ri| Yio, ψ)
(2.1)
なお,一般に MAR は MCAR を含むが,MNAR は MAR を含まない7,とすることが多い.しかし,本報告書
の 6 章を含む Pattern-Mixture Model の文脈などで,「MNAR は MAR を含んだ一般的な欠測メカニズム」とし て定義されることもある.適宜注意すること.
上記記法はよく用いられているものの,以下の 2 点で本報告書で用いるには不十分な点が残る.
• 共変量の影響が明示的に示されていない(周辺化されている) • 変量効果の影響が明示的に示されていない(周辺化されている)
5withdrawal,attrition という言葉が用いられることもある.
6厳密には,Little and Rubin (2002) では MNAR ではなく NMAR(Not Missing At Random) という用語が用いられていたり,R
iではな
く Miが用いられていたりする.本報告書では,後の記載と統一をとるため,上記の記号を用いる.
そこで,本報告書では Little (2008) をもとに,共変量 Xi,変量効果 biを含めた以下の記法も定義する. (MCAR) : f (Ri| Xi, Yi, bi, ψ) = f (Ri| Xi, ψ) (MAR) : f (Ri| Xi, Yi, bi, ψ) = f (Ri| Xi, Yio, ψ) (MNAR) : f (Ri| Xi, Yi, bi, ψ) ̸= f(Ri| Xi, Yio, ψ) (2.2) 2.2.3.2 NRC(2010) の MCAR,MAR,MNAR の定義 次に,NRC (2010) での定義を考える.まず,以下の 2 種類の変数を考える. • デザイン変数 X: 治験薬の投与群,ベースライン時点で取られるデータであり,主解析の際に使用される変数.全症例に 対して観測される8. • 補助変数 V: 脱落確率モデルに対する推論に役立つものであり,一般に主解析には使用されない.被験者ごとの特徴 を表す変数であり,投与前のものも投与後のものもあり得,全データが観測されるとは限らない.たと えば,コンプライアンスや有害事象に関する情報など. ここで,MCAR の定義は f (Ri| Xi, Vi, Yi) = f (Ri) (2.3) であり9,MAR の定義は f (Ri| Xi, Vi, Yi) = f (Ri| Xi, Voi, Y o i) である.なお,Vo i は Viのうち観測されたデータである.MNAR は,MAR でない場合と定義している.
2.2.4
具体例
抽象的な説明だけでは分かりにくいため,MCAR,MAR,MNAR の各メカニズムの具体例をみていくこと とする.これらの例は,シミュレーションで欠測のあるデータを発生させる際に,どのような関数を用いて各 データの欠測確率を決定すればよいか,を考える際などの参考となる.なお,簡単のため欠測確率は共変量や 変量効果に依存しない場合を考える.つまり,上で複数の定義を考えたが,共通部分である (2.1) を扱う10.再 掲しておくと,以下の通りである. (MCAR) : f (Ri| Yi, ψ) = f (Ri| ψ) (MAR) : f (Ri| Yi, ψ) = f (Ri| Yio, ψ) (MNAR) : f (Ri| Yi, ψ) ̸= f(Ri| Yio, ψ) 以下,3 時点での測定を計画している試験を考える.被験者ごとの応答変数ベクトルは Yi= (Yi1, Yi2, Yi3)′, 被験者ごとの欠測識別変数ベクトルは Ri= (Ri1, Ri2, Ri3)′である.なお,以下の例が上記の MCAR,MAR, MNAR の定義を満たすことの確認は,Appendix B で行う. 8ベースライン時点のデータの欠測は本報告書では扱わない. 9式 (2.2) の MCAR との違いは共変量に依存するかどうかである.式 (2.2) では共変量に依存してよいので,たとえば群ごとに別々の メカニズムを考えることとなるが,式 (2.3) の定義では両群合わせて周辺化したモデルで考えることとなる.10また,以下の例は厳密には Seaman et al. (2013) の everywhere MCAR,everywhere MAR である.これらの概念は本報告書のレベルを
2.2.4.1 MCAR の具体例 最初に MCAR の例を考える.単調な欠測であり,時点 1(j = 1) の応答変数 Yi1は必ず観測され,その後の データは「1 つ前のデータが観測されていれば,応答変数 Yiの値によらず次のデータが欠測する確率が 0.1」 となるようにする.つまり, f (Ri1= 0| Yi) = 0 (2.4) f (Ri2 = 0| Yi, Ri1= 0) = 1 f (Ri2 = 0| Yi, Ri1= 1) = 0.1 (2.5) f (Ri3 = 0| Yi, Ri1= 0, Ri2= 0) = 1 f (Ri3 = 0| Yi, Ri1= 1, Ri2= 0) = 1 f (Ri3 = 0| Yi, Ri1= 1, Ri2= 1) = 0.1 (2.6) とおく.被験者 i の時点 j に関して Ri1=· · · = Rij = 0 ならば,Ri,j+1= 0 となる確率が 1 になる,という部 分が単調な欠測であることを示している.また,同様に「一度欠測した場合にその後必ず 0 になる」ことから f (Ri3= 0| Yi, Ri1 = 0, Ri2= 1) = 1 f (Ri3= 1| Yi, Ri1 = 0, Ri2= 1) = 0 とおくこととする. 2.2.4.2 MAR の具体例 次に,MAR の具体例をみる.条件付き分布としては,単調な欠測となる以下のものを考える.時点 j の応答 変数 Yijが観測されたとき,時点 (j + 1) の応答変数 Yi,j+1が観測される確率が,Yijの関数で表され,Yi,j−1
以前や Yi,j+1の値には依存しない,とする. f (Ri1= 0| Yi) = 0 (2.7) f (Ri2= 0| Yi, Ri1= 0) = 1 logitf (Ri2= 0| Yi, Ri1= 1) = 0.2 + 0.5Yi1 (2.8) f (Ri3= 0| Yi, Ri1= 0, Ri2 = 0) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2 = 0) = 1 logitf (Ri3= 0| Yi, Ri1= 1, Ri2 = 1) = 0.2 + 0.5Yi2 (2.9) ここで, logitf (x) = log ( f (x) 1− f(x) ) ⇐⇒ exp (logitf(x)) = f (x) 1− f(x) ⇐⇒ f(x) = exp(logitf (x)) 1 + exp(logitf (x)) である.したがって,式 (2.8),(2.9) の確率 1 でない式を変形すると,それぞれ logitf (Ri2= 0| Yi, Ri1= 1) = 0.2 + 0.5Yi1 ⇐⇒ f(Ri2= 0| Yi1, Ri1= 1) = exp(0.2 + 0.5Yi1) 1 + exp (0.2 + 0.5Yi1)
と, logitf (Ri3 = 0| Yi, Ri1= 1, Ri2= 1) = 0.2 + 0.5Yi2 ⇐⇒ f(Ri3= 0| Yi1, Ri1 = 1, Ri2= 1) = exp(0.2 + 0.5Yi2) 1 + exp (0.2 + 0.5Yi2) となる.さらに,単調性をもとに f (Ri3= 0| Yi, Ri1 = 0, Ri2= 1) = 1 f (Ri3= 1| Yi, Ri1 = 0, Ri2= 1) = 0 とおく.これは MAR となっている. 2.2.4.3 MNAR の具体例 1 次に,MNAR の具体例をみる.2 つの例を考える.1 つ目は単調な欠測を仮定したものである. f (Ri1= 0| Yi) = 0 (2.10) f (Ri2= 0| Yi, Ri1= 0) = 1
logitf (Ri2= 0| Yi, Ri1= 1) = 0.2 + 0.1Yi1+ 0.3Yi2
(2.11) f (Ri3= 0| Yi, Ri1= 0, Ri2= 0) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2= 0) = 1
logitf (Ri3= 0| Yi, Ri1= 1, Ri2= 1) = 0.2 + 0.1Yi2+ 0.3Yi3
(2.12) 書き直すと, f (Ri1= 0| Yi) = 0 f (Ri2= 0| Yi, Ri1= 0) = 1 f (Ri2= 0| Yi, Ri1= 1) =
exp(0.2 + 0.1Yi1+ 0.3Yi2) 1 + exp(0.2 + 0.1Yi1+ 0.3Yi2) f (Ri3= 0| Yi, Ri1= 0, Ri2= 0) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2= 0) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2= 1) =
exp(0.2 + 0.1Yi2+ 0.3Yi3) 1 + exp(0.2 + 0.1Yi2+ 0.3Yi3) となる.さらに単調性をもとに f (Ri3= 0| Yi, Ri1= 0, Ri2= 1) = 1 f (Ri3= 1| Yi, Ri1= 0, Ri2= 1) = 0 とおくと,これは MNAR となっている. 2.2.4.4 MNAR の具体例 2 最後に,MNAR の 2 つ目の例を考える.先にみた MAR の例から,「単調な欠測」という条件を取り除いてみ る.つまり,前のデータが欠測しているかどうかに関わらず,欠測確率を一定とするのである11. f (Ri1= 0| Yi) = 0 11この例は医学的解釈が難しいが,このようなものを数理的に考えておくことは「現在よく用いているものだけが全てではないこと」 「少しイレギュラーなことが起きた場合にどのようになるか」を認識するために重要であるため,記載することとする.
logitf (Ri2= 0| Yi, Ri1= 0) = 0.2 + 0.5Yi1 logitf (Ri2= 0| Yi, Ri1= 1) = 0.2 + 0.5Yi1 logitf (Ri3= 0| Yi, Ri1= 0, Ri2 = 0) = 0.2 + 0.5Yi2 logitf (Ri3= 0| Yi, Ri1= 1, Ri2 = 0) = 0.2 + 0.5Yi2 logitf (Ri3= 0| Yi, Ri1= 0, Ri2 = 1) = 0.2 + 0.5Yi2 logitf (Ri3= 0| Yi, Ri1= 1, Ri2 = 1) = 0.2 + 0.5Yi2 とする.書き直すと, f (Ri1= 0| Yi) = 0 logitf (Ri2= 0| Ri1Yi) = 0.2 + 0.5Yi1 logitf (Ri3= 0| Ri1, Ri2, Yi) = 0.2 + 0.5Yi2 ⇐⇒ f (Ri1= 0| Yi) = 0 f (Ri2= 0| Ri1, Yi) = exp(0.2 + 0.5Yi1) 1 + exp(0.2 + 0.5Yi1) f (Ri3= 0| Ri1, Ri2, Yi) = exp(0.2 + 0.5Yi2) 1 + exp(0.2 + 0.5Yi2) となる.このとき,MNAR である.
2.2.5
臨床試験における MCAR,MAR,MNAR
次に,臨床試験においてどのような欠測が MCAR,MAR,MNAR となるかを考える.本報告書では単調な 欠測を考えるため,脱落(治験中止)に注目する.まず,治験全体で考えるのではなく,1 症例ごとに欠測し た理由を考えていくと分かりやすい.たとえば以下のような理由が考えられる. • MCAR:転居など,主要評価項目・有害事象の発現等とは全く無関係な治験中止 • MAR:原疾患の悪化,有害事象の発現等と関係しうる理由による欠測の場合などのうち,特に,試験 を中止した時点で悪化しているデータが十分にある,もしくは,検査結果を見た上で中止を判断した場 合12. • MNAR:主要評価項目・有害事象の発現等と関係し得る理由による欠測であり,来院間隔が広く欠測の 原因となったデータが得られていない場合など.欠測が発現した段階で,欠測を説明しきれるだけの十 分なデータが得られていない場合. 脱落(治験中止)による欠測のメカニズムが MCAR,MAR,MNAR のどれに該当するか,は疾患の特性・プ ロトコールの状況・組み入れられた被験者の状態等で異なり,試験ごとに個別の検討が必要である.欠測メカ ニズムによって,得られた推定量の妥当性が変わることがありうるため,中止理由の情報を集めておくことは, 当該試験の解析のみならず,類似の薬剤・疾患の治験を計画する際にも,大変重要な情報となる13. また,症例毎の欠測メカニズムと試験全体の欠測メカニズムを考えると,原理的には • 全中止例のうち,全例 MCAR ならば,試験全体で MCAR.• 全中止例のうち,1 例以上 MAR が存在し,残りの全症例が MCAR ならば,試験全体では MAR. • 全中止例のうち,1 例以上 MNAR が存在すれば試験全体では MNAR. である.ここで重要な点は以下の 2 点である. • MAR か MNAR かの判断には Ymが必要になるため,観測されたデータ (Yo , X, R) からは MAR か MNAR かは判断できない. 12中止時検査で情報を十分に収集することで,MAR に近づけることができるとも考えられる.MAR になる,という保証はない点には 注意が必要である. 13なお,「正確な」中止理由を収集できるか,という点も極めて重要であるため,この点も工夫できると望ましい.
• MAR と MNAR では,MAR の解析の方が特定すべき項目も少なく,格段に容易に実行できる.そのた
め,可能な限りデザイン・モデルの工夫をすることで MAR に近づけたい. これらを考慮して,以下のような検討方法・考え方が提案されている.
• 十分に計画された上で適切に実施され,十分な情報が収集された試験では,MAR を仮定した解析を主
解析とすることが妥当な場合は比較的多い (Mallinckrodt et al., 2008).
• MAR を仮定した解析が妥当でなくなるのは,MNAR となる症例の影響である.そのため,MNAR の症
例が特定できれば有益である.症例が(ある程度であれ)特定できれば,その症例を除外した解析も行 い,結果の頑健性をみることもできる.Verbeke and Molenberghs(2000) などでは,Local Influence とい う方法を用いて,脱落確率モデルが正しいと仮定したもとで,MNAR が疑われる症例を特定する方法を 検討している.
2.3
欠測メカニズムに対する注意
欠測メカニズムは,正確に概念を把握することが極めて難しい.そこで,以下の架空の状況について検討を 加えることで,欠測メカニズムに対する理解を深めていく.目的は,データから欠測メカニズムが判断できそ うかどうか,を考えることである.2.3.1
無効な症例が存在する場合の欠測メカニズム
症例全体のうち一部の症例が無効14となりうる状況で,一部の症例が中止する場合,どういう欠測メカニズ ムがあり得るか,を検討する.以下のシミュレーションデータを考える.応答変数は,値が小さい方が改善を 示すとする.最初に,中止した症例の中止後のデータも含めた「全データ」を図 2.1 に示す. 14応答変数の値が,一旦は改善したとしても長期的にはベースライン近くになることを,「無効」と呼ぶこととする.応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 全 デ ー タ ( 欠 測 デ ー タ 含 む ) 図 2.1: 全データ 次に,全データに対して MCAR の欠測がある場合の観測データを図 2.2 に示す. 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 観 測 デ ー タ ( M C A R ) 図 2.2: 観測データ(MCAR) この観測データを,完了例・中止例に分けたものが以下の図 2.3, 2.4 である. 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 完 了 例 ( M C A R ) 図 2.3: 完了例のデータ(MCAR) 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 中 止 例 ( M C A R ) 図 2.4: 中止例のデータ(MCAR) 以下,「改善症例」とは,「中止例は中止後の欠測データも含めて,結果的に改善している症例」を指すことと し,「無効症例」も同様とする.すなわち,観測データでは無効化していなくても,その後の欠測データで無効 化していれば「無効症例」と呼ぶこととする. いま,欠測メカニズムが MCAR であるので,完了例・中止例のそれぞれの中で「改善症例」「無効症例」の 割合は同じとなるはずである.一方で,一見中止例には「無効症例」が存在しないように見える.しかし,図 2.1 と図 2.3 を比較すると,図 2.3 の方が「無効症例」が少ないため,「無効症例」の一部は中止していることが 分かる15.このように,MCAR の完了例(図 2.3)・中止例(図 2.4)のプロットを全体として比較しても,「改 善症例」・「無効症例」の割合が「同じように見える」とは限らない.中止例の中止後のデータも全て取得して プロットすれば,同じように見えるはずである.逆に言うと,観測データから一見して完了例・中止例の振る 15すなわち,観測データでは無効化していないが,欠測後に無効化している症例が存在する,ということである.
舞いが異なるからといって,MCAR の可能性が否定できるわけではない.一方で,中止例に「無効症例」が多 く,完了例に「無効症例」が全く存在しない場合は,「完了例は無効化していないことが確定している」ため, MCAR を否定する根拠となりうる. 次に,全データは MCAR と同じ状況(図 2.1)で,MAR による欠測がある場合の観測データが図 2.5 である. 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 観 測 デ ー タ ( M A R ) 図 2.5: 観測データ(MAR) これを完了例・中止例に分けたものが図 2.6,2.7 である. 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 完 了 例 ( M A R ) 図 2.6: 完了例のデータ(MAR) 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 中 止 例 ( M A R ) 図 2.7: 中止例のデータ(MAR)
最後に,MNAR による欠測を考えた場合の観測データが図 2.8 である. 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 観 測 デ ー タ ( M N A R ) 図 2.8: 観測データ(MNAR) 完了例と中止例に分けたものが図 2.9,2.10 である. 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 完 了 例 ( M N A R ) 図 2.9: 完了例のデータ(MNAR) 応 答 変 数 9 1 2 1 5 1 8 2 1 2 4 2 7 時 点 0 1 2 3 4 中 止 例 ( M N A R ) 図 2.10: 中止例のデータ(MNAR) 図 2.6,2.7 と図 2.9,2.10 を比較すると,MAR と MNAR を目で見て峻別することは大変難しい,という状 況が起こりうることが分かる.
2.3.2
MAR かどうか分からない場合にどう考えるか
本章で重要な点は,「MAR かどうかが正確に判断できないときに,具体的にどのような手法がとれるか」と いうことである.ここで極めて重要な点は,「MAR のときに一致推定量となる」という主張は「MAR でないと きには必ずバイアスの入った推定量になる」ことを意味しない16,ということである.そこで,「MAR を仮定 した方法を主解析とし,MNAR を仮定した感度分析を行う.感度分析の結果も含めて,推定値が妥当な範囲内 であれば,主解析の結果は頑健であると考える」のが現実的な考え方の 1 つであろう. 一方,過去の類薬の試験データなどから MAR でないことに十分な証拠等がある場合は,MNAR を仮定した モデルで主解析を行う必要があると考えられる.2.4
尤度を用いた推測
次に,尤度を用いた推測を考える. 16MAR であることは推定量が一致性をもつための十分条件であり,必要条件ではない,ということである.2.4.1
尤度の種類
まず最初に,Molenberghs and Kenward (2007) に従い,尤度を定義する.最も興味のある対象は,応答変数
Yi= (Yio, Ymi )′の分布であるが17,応答変数が欠測した場合でも,欠測識別変数 Riの値は全て手に入る.通
常,Riの値は Yiの値と独立ではないため18,Riの値は Yiの分布に関する情報を持っているものと考えら
れる.
これより,Yiだけでなく,Riも合わせた完全データ (full-data19)(Yi, Ri)′の同時分布をもとにした尤度関数
を定義することに意味があると考えられる.まず,(Yi, Ri) の同時密度関数を用いて,完全データの尤度 (full data likelihood) L∗(θ, ψ| Yi)∝ N ∏ i=1 f (Yi, Ri| Xi, θ, ψ) = N ∏ i=1 f (Yoi, Yim, Ri| Xi, θ, ψ) を考える.しかし,完全データの尤度は欠測データ Ym i も含むため,Y m i の部分にデータを代入することがで きず,これを θ, ψ で微分して最尤推定等を行うことができない.そこで,Ym i を確率変数と考え,積分消去し
たもの20が観測データの尤度(observed data likelihood)
L(θ, ψ| Yoi)∝ ∫ L∗(θ, ψ| Yi)dYim ∝ ∫ ∏N i=1 f (Yi, Ri| Xi, θ, ψ)dYmi = N ∏ i=1 ∫ f (Yoi, Yim, Ri| Xi, θ, ψ)dYim である21.この尤度に対して観測データ (Yo i, Ri) を代入すると,未知の値はパラメータ θ, ψ のみとなるため, 最尤法等の推測を行うことができる.したがって,尤度を用いた推測では基本的に観測データの尤度を用いる.
2.4.2
無視できる欠測メカニズム
2.4.2.1 尤度を用いた推測の場合の定義Little and Rubin (2002) に従い,尤度を用いた推測を行う際,以下の 2 条件を満たす場合,欠測メカニズムが
無視できる (missing-data mechanism is ignorable) と呼ぶ.
(i)欠測のメカニズムが MAR である. (ii)応答変数のパラメータ θ と脱落確率モデルのパラメータ ψ が分離している. なお,無視可能,と呼ばれることもある. 以下,パラメータが分離している,という用語について述べる.θ と ψ が分離している,とは「(θ, ψ) のパ ラメータ空間 Ωθ,ψが,θ のパラメータ空間 Ωθと ψ のパラメータ空間 Ωψの直積で表されること」である.こ れは,大まかに述べると「θ の各パラメータと ψ の各パラメータに重複がない」ということである. 具体例を用いて,もう少し詳しく検討する.先で見たように,完全データの尤度を条件付き確率を用いて書 き下すと, f (Yi, Ri| Xi, θ, ψ) = f (Yi| Xi, θ)· f(Ri| Xi, ψ) 17ベクトル Y iを厳密に記載すれば Yi= ((Yoi)′, (Ymi )′)′のようになるが,極端に煩雑なため以下本文のような記載とする. 18これが(ある意味で)独立であることは MCAR の定義であるため,MCAR でなければ(その意味で)独立ではないことは定義から 明らかである. 19「完全データ」という用語は,"complete-data"(欠測のないデータ)の訳語として用いられることも多いため,注意が必要である. 20つまり,観測データ (Yo i, Ri) の周辺尤度である.
と表現できる.この段階では,θ と ψ に共通のパラメータがあるかどうかは規定されていない.たとえば,応 答変数の分布を f (Yi| Xi, θ) = 1 √ (2πσ2)3exp ( − 1 2σ2(Yi− µ) ′(Y i− µ) ) と仮定する (µ = (µ1, µ2, µ3)′).このとき,θ = (µ1, µ2, µ3, σ2)′である.次に,f (Ri,| Yi, ψ) を定義するため に,先の MAR の具体例に類似した以下のものを用いる. f (Ri1= 0| Yi, ψ) = 0 f (Ri2= 0| Yi, Ri1= 0, ψ) = 1 f (Ri2= 0| Yi, Ri1= 1, ψ) = exp(ψ1+ ψ2Yi1) 1 + exp (ψ1+ ψ2Yi1) f (Ri3= 0| Yi, Ri1= 0, Ri2= 0, ψ) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2= 0, ψ) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2= 1, ψ) = exp(ψ1+ ψ2Yi2) 1 + exp (ψ1+ ψ2Yi2) このとき,ψ = (ψ1, ψ2)′である.パラメータ間にこれ以上の関係がなければ,パラメータ θ とパラメータ ψ は関係がない22.このような場合を「分離している」と呼ぶ. 次に,上の脱落に対して,「応答変数 Yijの値自体よりも,Yijから平均を引いて標準偏差で割った値に依存 する方が正しい」と考えたとする23.このとき,応答変数のパラメータは上と同じく θ = (µ1, µ 2, µ3, σ2)′であ る.一方,脱落確率モデルのパラメータを eψ とおき,f (Ri| Yi, eψ) を考えると, f (Ri1= 0| Yi, eψ) = 0 f (Ri2= 0| Yi, Ri1= 0, eψ) = 1 f (Ri2= 0| Yi, Ri1= 1, eψ) = exp ( ψ1+ ψ2· Yi1− µ1 σ ) 1 + exp ( ψ1+ ψ2· Yi1− µ1 σ ) 22このとき, Ωθ= µ1 µ2 µ3 σ2 ∈ R 4 µ1, µ2, µ3∈ R, σ2> 0 =R3× R>0 Ωψ= { ( ψ1 ψ2 ) ∈ R2 ψ1, ψ2∈ R } =R2 となる.一方, Ω(θ,ψ)= µ1 µ2 µ3 σ2 ψ1 ψ2 ∈ R4 µ1, µ2, µ3∈ R, σ2> 0, ψ1, ψ2∈ R = (R3× R>0)× R2 となる.したがって, Ω(θ,ψ)= Ωθ× Ωψ となる. 23つまり,時点ごとの系統的な改善は除外した上で,時点ごとの平均からのずれ具合(をばらつきで補正したもの)が欠測確率に影響 を与えている,とするモデルである.
f (Ri3= 0| Yi, Ri1= 0, Ri2= 0, eψ) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2= 0, eψ) = 1 f (Ri3= 0| Yi, Ri1= 1, Ri2= 1, eψ) = exp ( ψ1+ ψ2· Yi2− µ2 σ ) 1 + exp ( ψ1+ ψ2· Yi2− µ2 σ ) と表せる.このとき, eψ = (ψ1, ψ2, µ1, µ2, σ)′となり, eψ の成分に θ = (µ1, µ2, µ3, σ2) と重複するパラメータ (µ1, µ2) や,θ の成分 (σ2) の関数で表されるパラメータ σ がでてくる.このような場合,パラメータ θ と eψ は 分離していない24,という. パラメータが分離している場合,θ は f (Ri| Yi) の分布に現れないため,条件が整えば f (Ri| Yi) の式に依 存しない推測が可能であるが,パラメータが分離していない場合は,観測データの対数尤度を θ で微分する際 に f (Ri| Yi) の項が残ってしまうため,この分布のモデル化が避けられない. 2.4.2.2 欠測メカニズムが無視できる場合の統計的推測 式の計算の詳細は 5 章の Selection Model の解説の際に述べることとし,本節では推定量のもつ統計的性質に ついて概要を述べる. まず,応答変数のみの分布 f (Yo i, Ymi | θ) について,欠測データ Yimを積分消去した尤度 L(θ| Yio) = ∫ f (Yio, Ymi | θ)dYim を考える.このとき,欠測メカニズムが無視できるならば,以下の性質が成り立つ. • θ について,尤度 L(θ | Yo i) に基づく推定・検定が,観測データの尤度 L(θ, ψ| Yoi) に基づくものと同じ つまり,欠測メカニズムが無視できるならば,欠測識別変数 Riを全く考慮せずに推定した推定量が,Riを考 慮した推定量と同等の性能を持つ,ということである.従って,たとえば観測データの尤度 L(θ, ψ| Yo i) に基 づく最尤推定量が一致性を持つならば,尤度 L(θ| Yo i) に基づく最尤推定量も一致性をもつ,ということであ
る.詳細は 5 章や Little and Rubin (2002),岩崎 (2002) 等参照のこと.
2.5
実際の臨床試験データ
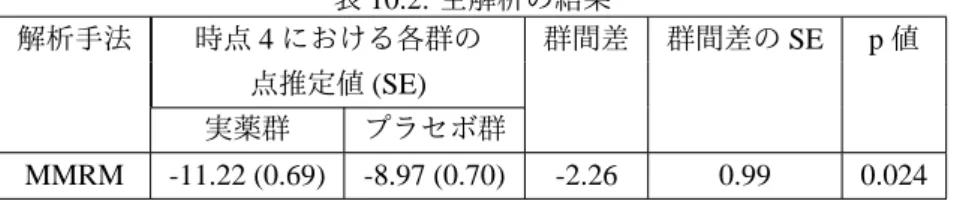
本節では,本報告書のシミュレーションデータ作成の際に参考にした,脊椎損傷後の慢性中枢神経障害性疼痛 の治療に対してプレガバリン (以下 PGB) を 12 週間投与する多施設共同,無作為化,二重盲検,並行群間比較 試験について紹介する(プレガバリン審査資料 http://www.pmda.go.jp/drugs/2013/P201300010/index.html).主 要有効性評価項目は,12 週時の疼痛スコアのベースラインからの変化量である.PGB 群及びプラセボ群 (PLB 群) の経時推移を表 2.1,図 2.11 に示す. 24厳密には,Ω θ=R3× R>0, Ωψe=R4× R>0である.一方, ( θ e ψ ) = µ1 µ2 µ3 σ2 ψ1 ψ2 µ1 µ2 σ に対するパラメータ空間は Ω(θ, eψ)= x1 x2 x3 x4 x5 x6 x7 x8 x9 ∈ R9 x1= x7, x2= x8, x4= x29, x4, x9> 0 であり,明らかに Ω (θ, eψ)̸= Ωθ× Ωψeである.表 2.1: 疼痛スコアのベースラインからの変化量の経時的推移 Visit PLB 群 (N = 67) PGB 群 (N = 69) 被験者数 平均値 SD 被験者数 平均値 SD ベースライン 67 6.73 1.45 69 6.54 1.25 1 週 67 -0.23 1.06 69 -1.42 1.58 2 週 64 -0.29 1.14 67 -1.50 1.51 3 週 62 -0.52 1.18 63 -1.97 1.62 4 週 51 -0.65 1.41 62 -1.89 1.67 5 週 47 -0.51 1.02 55 -2.06 1.66 6 週 47 -0.71 1.07 55 -2.01 1.80 7 週 44 -0.62 1.36 56 -1.89 1.83 8 週 45 -0.59 1.64 55 -1.83 1.85 9 週 40 -0.86 1.48 52 -2.01 1.90 10 週 36 -0.81 1.58 51 -1.93 1.95 11 週 36 -0.70 1.60 49 -2.07 2.09 12 週 34 -0.56 1.53 46 -1.93 2.03 1 5 1 0.5 0 BL 1 2 3 4 5 6 7 8 9 10 11 12 2.5 2 1.5 PLB PGB 図 2.11: 疼痛スコアのベースラインからの変化量の経時推移図 両群で中止被験者が多数発生しており,12 週完了した被験者数は,PGB 群で 46 名 (66.7%) ,PLB 群では 34 名 (50.7%) となっている.また,各群における中止理由の内訳は表 2.2 の通りであり,群によりその中止理由 の構成が異なっており,PGB 群では,有害事象が理由で中止した被験者が多く,PLB 群では効果不十分で中止 した被験者が多い.中止被験者数の構成が両群で異なっているため,発生した欠測が,解析結果の解釈に影響 を及ぼすことが予想される.本試験では,主解析として,ベースラインからの変化量 (欠測値は LOCF により 補完) を応答変数とし,ベースラインなどを共変量とした共分散分析を実施している.解析結果は,PLB 群と の群間差 [95%CI] は−1.533 (95%CI: [−2.150, −0.916]) であり,プラセボに対して統計学的に有意な鎮痛効果 が認められている (表 2.3).

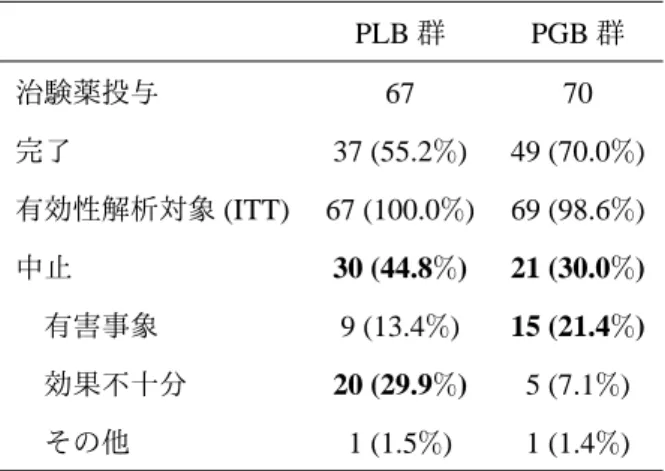

![[書評] Praveen Jha ed., Progressive fiscal policy in India](data:image/gif;base64,R0lGODlhAQABAIAAAP///wAAACH5BAEAAAAALAAAAAABAAEAAAICRAEAOw==)