部会資料
新医薬品開発戦略
新たなナレッジマネジメントの潮流
(
Model-Based Drug Development 解説)
平成
24 年 3 月
日 本 製 薬 工 業 協 会
医薬品評価委員会 統計・DM 部会
i 目次 1. MBDD を活用した医薬品開発ビジネスモデルへの展開 ...1 1.1MBDD とは?...1 1.1.1 概説 ...1 1.1.2 モデリングとシミュレーション...3 1.2MBDD 導入により期待される効果...5 1.3MBDD を運用すると医薬品開発ビジネスがどのように変わるか? ...7 1.3.1 医薬品開発における現状の課題...7 1.3.2 医薬品開発の将来展望...10 2. MBDD の理論背景解説 ...12 2.1 はじめに...12 2.2 モデルの解説...13 2.2.1 疾患モデル ...13 2.2.2 薬剤モデル ...14 2.2.3 試験モデル ...16 2.3 統計手法の概説...16 2.3.1 MBDD で用いられる統計モデル...16 2.3.2 モデル内のパラメータの配置による分類...17 2.3.3 モデル内のパラメータの役割による分類...18 2.3.4 応答変数の種類による分類...18 2.3.5 共変量 ...19 2.3.6 パラメータの推定方法...20 2.4 モデルの評価...20 2.4.1 当てはまりのよさ...20 2.4.2 モデルの選択 ...22 2.4.3 モデルのバリデーション...23 2.5 シミュレーション...25 2.5.1 確率的シミュレーションの手順...26 2.5.2 疑似データの生成...27 2.5.3 反復回数 ...28 2.6MBDD 運用手順...28 2.6.1 ナレッジの蓄積...28 2.6.2 疾患モデルの構築...29 2.6.3 薬剤モデルの構築...30 2.6.4 臨床開発戦略と臨床試験シミュレーション...30 2.6.5 試験モデルの構築...31 2.6.6 影響因子の特定...31
ii 2.6.7 不確定要素のためのシナリオ作成...32 2.6.8 臨床試験モデルのチューニング...33 2.6.9 臨床試験シミュレーションの実行...33 2.6.10 感度分析 ...34 2.6.11 最適な試験条件の選択...37 2.7 不確実性の意思決定...37 2.7.1 シナリオの発生確率(もしくは信頼度)が設定可能な場合...38 2.7.2 シナリオの発生確率(もしくは信頼度)が未知の場合...40 2.7.3 不確実性の意思決定における注意点...42 2.8 最近の話題...43 2.8.1 End-of-Phase 2A Meeting...43 2.8.2 アダプティブ・デザイン...44 2.8.3 ベイズ統計学 ...45 3. MBDD 適応事例 ...47 3.1 はじめに...47 3.2 事例紹介...49 3.2.1 事例 1 第 1 相試験からの用法・用量設定(Zosuquidar と抗腫瘍薬の併用)...49 3.2.2 事例 2 POC 試験結果からの後期第 2 相試験デザイン選択(ナラトリプタン) ...54 3.2.3 事例 3 先行薬モデルを利用した第 2 相試験のデザイン(HAE-1) ...60 3.2.4 事例 4 競合他剤との比較による Go/No-Go 判断(Gemcabene) ...62 3.2.5 事例 5 疾患進行モデルの構築(アルツハイマー型認知症)...66 3.2.6 事例 6 疾患進行モデルの構築(非小細胞肺がん)...69 3.2.7 事例 7 特殊集団における用量調整(ブスルファン)...76 3.2.8 事例 8 特殊集団における用量調整(ソタロール)...78 3.2.9 事例 9 特殊集団における用量調整(メロペネム)...79 4. 疾患別モデリング事例 ...82 4.1 ヒト免疫不全症候群(HIV) ...82 4.22 型糖尿病...83 4.3 高血圧...84 4.4 慢性関節リウマチ...84 4.5 悪性腫瘍...85 4.6 鎮痛薬...85 4.7 アルツハイマー型認知症, うつ病...86 5. MBDD に必要な環境と担当者の育成 ...87 5.1MBDD の知識,技術の多様性...87 5.2MBDD に必要な環境...89
iii 5.2.1 MBDD 導入時の注意点...89 5.2.2 組織の考え方 ...90 5.2.3 担当者の構成 ...91 5.2.4 MBDD を用いた医薬品開発の進め方...91 5.2.5 MBDD のタイムライン...92 5.3MBDD の実施...93 5.4 担当者育成...94 5.4.1 育成方針 ...95 5.4.2 数学及び統計知識・技術の必要性...95 5.4.3 臨床薬理等に関する知識・技術の必要性...95 5.4.4 担当者の意識改革...96 5.4.5 ソフトウェア ...96 5.5 アカデミア,学会...97 5.6 ファーマコメトリシャンの今後の課題...97 5.6.1 過去のデータの見直し...98 5.6.2 臨床試験シミュレーション結果の再現...98 5.6.3 モデル作成担当者間での情報共有...98
1
1. MBDD を活用した医薬品開発ビジネスモデルへの展開
1.1 MBDD とは?1.1.1 概説
医薬品開発のさまざまなプロセスにモデリングとシミュレーション(Modeling & Simulation; M&S)を活用した手法あるいはその開発戦略(図 1-1)は,モデルに基づく医薬品開発“Model-Based Drug Development (以下,MBDD)”と称され,近年,欧米を中心に盛んに議論されている1,2,3,4。 MBDD の特徴は,開発過程において継続的に蓄積される情報や開発以前に蓄積された他剤や病態 に関する情報などをモデルに変換し,そのモデルを用いた臨床試験シミュレーションで得られる 定量的な情報を開発戦略と意思決定に役立てるということにある。この定量的な情報を得るため のさまざまな技術や理論体系は,ファーマコメトリクス(Pharmacometrics; PMx)という5。 医薬品開発とモデル構築 探索と検証 各意思決定の時点での継続的な探索/検証/予測 モデリング&シミュレーションの繰り返し実施 非臨床 フェーズ1 フェーズ2a フェーズ2b フェーズ3 フェーズ4 有効性 毒性 PK/PD 忍容性 ヒトでの PK/PD 有効性および安全性 用量/暴露-反応 用量調整 疾患ごとの指標 共変量効果 承認申請 /取得 競合品と比べた 結果,地域差, 疾患ごとの指標 薬剤および疾患に対する確かさ 不確実性 図 1-1 各臨床ステージにおける M&S の活用(1 の論文より一部改変) 従来,非臨床及び臨床でさまざまな知見や情報が得られていても,データの質や条件の違いな どを超えて論理的に結合する定量的な方法がないために,これら知見や情報の結合は主にプロジ ェクト担当者の頭の中で行われていた。しかし,これら非臨床及び臨床のさまざまな知見・情報 は,モデルに転換し同じ土俵に載せることで,それらの蓄積,連携および活用を促進(ナレッジ マネジメント)できるようになる。さらにモデルには確率の要素を含めることができる。複数の 試験デザインから最良のものを選択するような場面において,モデルを用いるとモデルの中に組 み入れられた確率に関する情報をもとに,従来の主観的なメリット・デメリットの評価に加えて, さまざまな試験デザインでの試験成功確率なども推定でき,それに基づき試験デザインの優劣の 比較が数値で行えるようになる(定量的意思決定)。さらに,コンピュータ上での臨床試験シミ ュレーションでは,あらゆる試験デザインについて試行が可能であり,慣例とは異なる新しい優
2 れた試験デザインが立案できる可能性も高まる。必要症例数の削減,試験期間の短縮,開発品の 隠れたポテンシャルを引き出し標準薬との差別化を容易にする,などの利点を有する新規の試験 デザインが多く採用されれば,より効率的に開発を進められる。 また,MBDD では臨床試験の結果に影響しうる数多くの要因について同時に考慮することが可 能である。従来の臨床試験計画立案時においても,さまざまな因子の影響について考慮はされて いるが,複数の因子の相互関係により生じる影響まで考慮することは困難なことが多い。MBDD ではそうした因子の同時発生確率なども織り込んだうえでの意思決定が可能となる。 さらに,MBDD では非臨床及び臨床試験成績から得られたデータや知識(熟練の開発担当者の 開発経験やそれに基づく勘)を,モデルに変換することで“見える化”し,薬物あるいは疾患, その他の臨床試験に関するさまざまな情報に関して何が既知で何が未知かということを適宜明 確にすることができる。開発初期の段階では,その薬物に関して多くの未知情報が存在すること になるが,そうした未知情報も複数のシナリオ(楽観的なケース,現実的なケース,悲観的なケ ース等)を想定してモデル化することができる。複数のシナリオに基づくシミュレーションの結 果を総合的に評価することで,各未知情報の重要度(開発戦略や臨床試験結果への影響度)を明 らかにすることも可能となる(2.6.7 章参照)。このため MBDD では,より重要度の高い未知情報 を優先的に取得する効率的な開発が可能となる(図 1-2)。その未知情報が開発継続・中止を決定 するほど重要度が高い場合には,より早期にその情報を得ることで中止になった場合のコストを 最小化することができる。この場合,従来なら定型的なプロセスの中で必然的にとられていた重 要度の低い(開発戦略や臨床試験結果への影響が小さい)未知情報を取得するための無駄な投資 を回避することにも繋がる。 モデリング&シミュレーション を用いた医薬品開発 モデリング&シミュレーション を用いない従来の医薬品開発 1 2 3 4 データ,情報 知識の蓄積 意思決定 成功 ¾候補化合物の選定 (例:疾患モデル) ¾用量選択 (例:PPK, PK/PD, E-Rモデル) ¾試験デザインの選択 (例:臨床試験のシミュレーション) のための モデリング&シミュレーション 臨床試験の相 ・ m ・ ッ ・ ハ 図 1-2 医薬品開発におけるモデリングとシミュレーションの役割 知識量
3 1.1.2 モデリングとシミュレーション ここでモデリングとシミュレーション(以下,M&S)について簡単に解説する。モデリングと は,数式によって記述された数理モデルを組み立てることであり,シミュレーションとは,物理 的・生態的・社会的等のシステムの挙動を,これとほぼ同じ法則に支配される他のシステムまた はコンピュータの挙動によって模擬することである。他の実験計測で得られたデータを解析して 結果を出すのと同様,経験で得られた情報をもとにさまざまな条件下での数値シミュレーション で仮想集団を発生させ,そのデータを解析し結果を導き出す。 M&S は,すでに様々な分野で活用されており,宇宙開発,航空機開発や飛行トレーニング,車 両,船舶,原子力や化学プラント,経済・金融など,さまざまな場面で使用されている。例とし て,近未来の地球における温度が予測されている国連及び気候変動に関する政府間パネル(IPCC) の温暖化のシミュレーションをここでとりあげる6。温暖化シミュレーションでは,地球の温度に 影響を与える排出物のさまざまな要因を数理モデルに組み込み,気候モデルを構築してシミュレ ーションにより将来の気候の変化を予測している。 医薬品開発におけるモデリングとは,図 1-3 に示すように血中濃度や薬理効果などの観測デー タに,その背景となっている薬物曝露,薬物の体内での挙動や,それらと観測データとの間に経 験的に導かれた関係性を数式として組み入れ,観測データを表現する上で最適なモデルを構築・ 選択することである (具体的な例については 3 章参照)。 図 1-3 モデリングのプロセス シミュレーションは,さまざまな試験の要素(デザイン,症例数や用法・用量など)を変化さ せた場合の試験結果を予測し,最適な試験条件を探索するために用いる。 観測データ 仮説モデル n 仮説モデル 3 仮説モデル 2 仮説モデル 1 最適モデル モデル式 モデルパラメータ モデルの当てはめ 観測条件 投与量 採血時間 体重,併用薬 その他共変量 … 血中濃度 薬理効果 有効性 … PKモデル PK/PDモデル PK/PD/疾患モデル E-Rモデル … 観測データを最もよく 説明できるモデル データ数,投与量, 採血時間,年齢,性別 各共変量
4 図 1-4 シミュレーションのプロセス 他にも例えば,小児における投与設計では,年齢または体重のいずれか(あるいは両方)を考 慮しなければならないが,その最適化にも M&S は有用である(図 1-5)。 図 1-5 小児適応のための M&S のプロセス 予測条件 1 z データ数 z 投与量 z 採血時間 z 年齢,性別 z 各共変量 z … PKモデル PK/PDモデル PK/PD/疾患モデル E-Rモデル 予測条件 2 予測条件 m 最適モデル モデル式 予測データ 1 予測データ 2 予測データ m 最適予測条件 最適な予測条件を選択 予測条件をモデルに適用 場合によってはモンテカルロ法 z 血中濃度 z 薬理効果 z 有効性 z … 血中濃度 データ 基本モデル 年齢依存モデル 体重依存PKモデル 年齢体重依存PKモデル 最適モデル モデル式 成人+ 小児少数例 体重あたり 投与量 年齢区分 投与量 予測 血中濃度 予測 血中濃度 最適投与量 モデリング シミュレーション
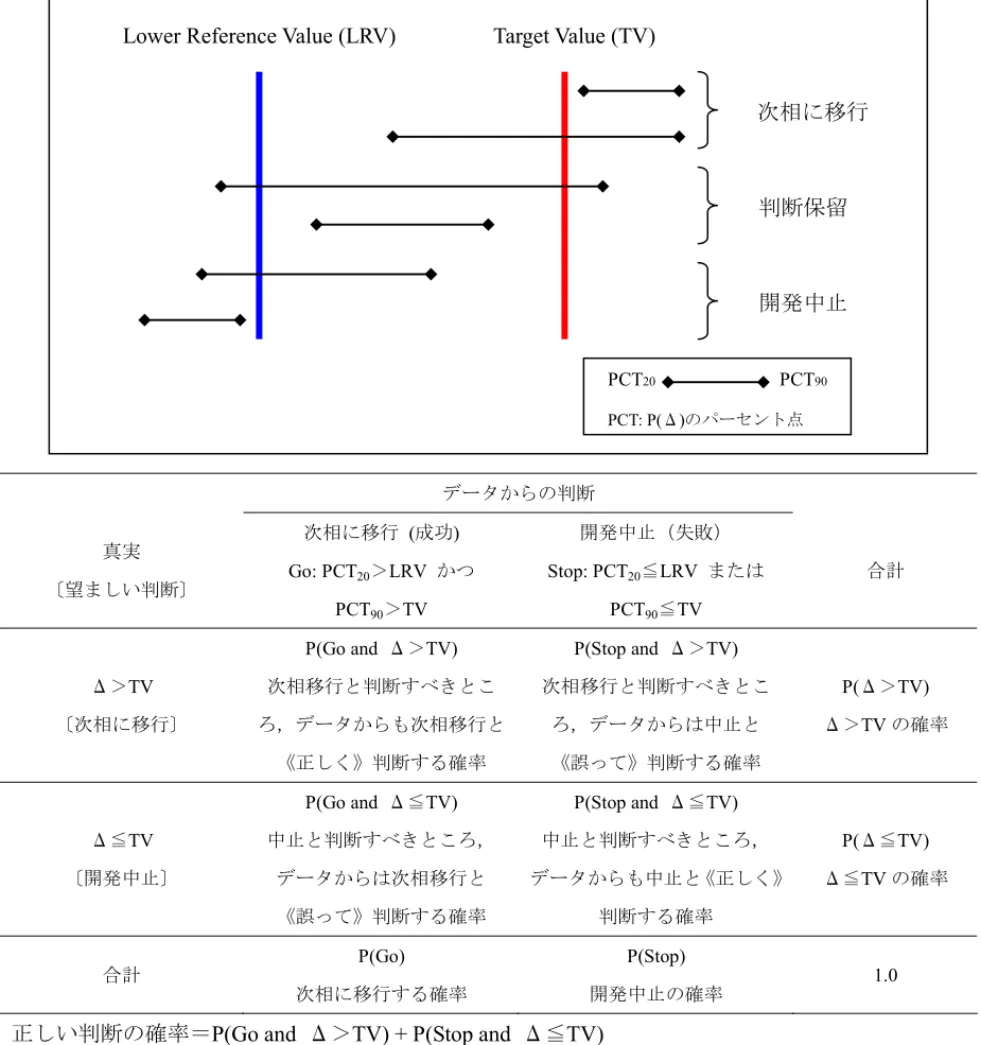
5 1.2 MBDD 導入により期待される効果 MBDD 適応下で実施される M&S の重要な役割として, 1) 臨床開発初期の候補品の絞り込み又は選択のための情報提供 2) 臨床開発における次相移行時の臨床試験デザイン選択のための情報提供 3) ライフサイクルマネジメントにおける適正利用のための情報提供 が挙げられる。より具体的にはMBDD の導入により,以下のようなことが可能となる。 • バイオマーカー等の経時推移のM&S による有効性プロファイルの明確化, 他剤との差別化要素の特定 • 副作用発現データを対象としたM&S による安全性プロファイルの明確化, 副作用対処方法の確立 • 開発上の課題(薬物相互作用,特殊患者集団等)に対する対処方法の確立 また,治験相談においてモデルを共通言語として用いることで,開発戦略の根底にある様々な ナレッジを規制当局に伝えることが可能となり,規制当局のもつナレッジ(様々な開発品に対す る助言・審査の経験)をモデルに反映することも可能となる。その結果,開発成功確率の向上, 開発プロセスの質の向上,開発戦略の最適化によるコスト削減・開発期間の短縮が期待できる7,8。 医薬品開発には複数のステップがあるが,M&S はどのステップにおいても活用できる。第 1 相試験での製剤変更や用量設定,第2 相試験以降で用いるバイオマーカーの検討や用量設定,適 応拡大での用量設定などで活用事例の報告がある(表 1-1)。 表 1-1 開発相毎の MBDD 適応事例 相 試験の 目的 課題 M&S タスク 事例 第1相 薬物動態 (PK),薬力 学(PD)の 特性評価 最初の臨床試験での,PK特性の 特定 線形PK/予測可能か? PK及びPDモデ ルの開発又は 更新 Org25935(中枢神経系の薬剤,グリ シントランスポーター阻害薬,製剤変 更,第1相試験データのPK/PD解析 結果を用いてシミュレーション実施)9 前期 第2相 (POC) 想定する 母集団で の有効性 の提示 目標とする母集団での薬剤の特 性(既存治療との差別化要素)は 何か? 疾患進行と用量 反応の時間経 過を理解するた めの薬剤-疾患 モデルの開発 Maraviroc(非競合的CCR5受容体ア ンダゴニスト,CCR5に対する受容体 占有率が抗ウイルス活性のバイオマ ーカーとなり,患者におけるウイルス 量減少を予測できることを確認する ためシミュレーションを実施)9 前期 第2相 (POC) 既存薬に 対する有 効性の非 劣性の掲 示 既存の治療と同じ位の改善効果 があるか? 後期第2相/3相試験の用量は? 用量反応関係プロファイルは? 開発を続けるメリットはあるか? 用量反応モデ ルの構築とモデ ル情報を活用し た最適な試験デ ザインの探索 CI-1017(M1-ムスカリン酸作用薬, 前臨床データ・第1相試験データ・既 存薬データを用いて臨床試験デザイ ンをシミュレートし,より費用を抑えた 試験を実施.)10
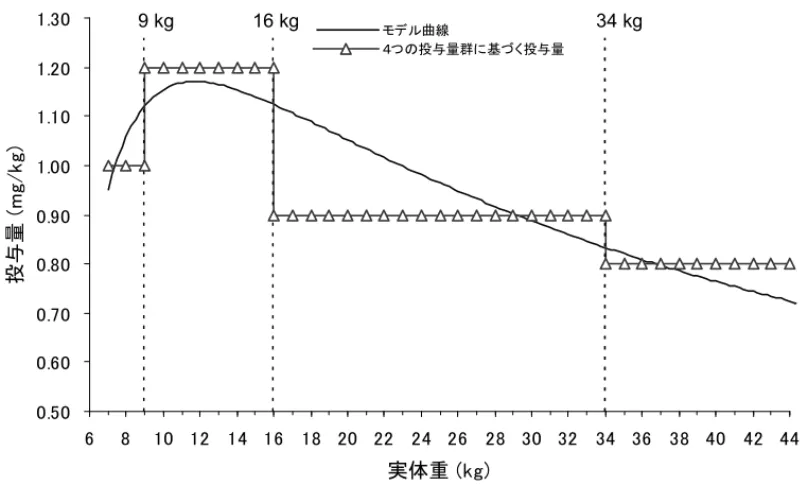
6 表 1-1 開発相毎の MBDD 適応事例(続き) フェーズ 試験の目 的 課題 M&S タスク 事例 前期 第2相 (POC) 想定する 母集団で の有効性 の提示 目標とする患者に対する用量反 応関係は? 有効性確認試験での至適用量 は? 有効か無効か を早期に判断す るため,治験実 施中にモデル 更新 UK-279,276(好中球抑制,適応型第 2相用量反応・POC試験,ベイズ流適 応型用量割付方法,アダプティブ・デ ザインにより,時間と費用を最小化し つつ,効率的に用量反応を調べて, 早期の試験終了を実現.)11 後期 第2相 目標母集 団(適応 症)での最 適利用 目標母集団で有効性を明確に示 すために,どのような試験デザイ ンを立てるべきか? a) 対象(選択/除外基準) b) 投与量,用量群の数 c) 症例数 d) 解析方法 e) 評価時期 所与の仮定や 試験デザインの もとで結果をシ ミュレートし,試 験の成功確率 を評価 CI-1017(試験デザインと用量反応パ ターンの組合せを複数設定し,薬効 や検出力を検討)10 第3相 臨床用量 での安全 性及び有 効性の提 示 臨床用量が患者集団に対して期 待通りの安全性及び有効性を示 すか? 母集団PK/PD モデルの妥当 性確認 Nesiritide(種々の投与量シナリオに ついてシミュレーション。提案した用 法・用量で臨床試験が実施され,試 験成績が一致)12 適応拡大 成人で承 認されたも のを小児 へ適応拡 大 小児についても成人と同じ効果 が得られるか?またその条件 は? 対象集団での 用量-曝露相 関を確立/確認 ブスルファン(国内申請資料;海外第 2相試験データ[小児患者24人]で母 集団PK解析し,体重が共変量と判 明。目標AUCに到達するための投与 量調整のために,CLのモデル式に 基づいて目標AUCの中央値とした場 合の体重・投与量曲線を描画。体重 別用量設定の提案) 13 市販後 臨床現場 への情報 提供 至適用法・用量の検討 母集団PK解析 後,仮想濃度推 移を発生させ T>MICを計算 メロペネム(種々の用法,用量につい てシミュレーション)14
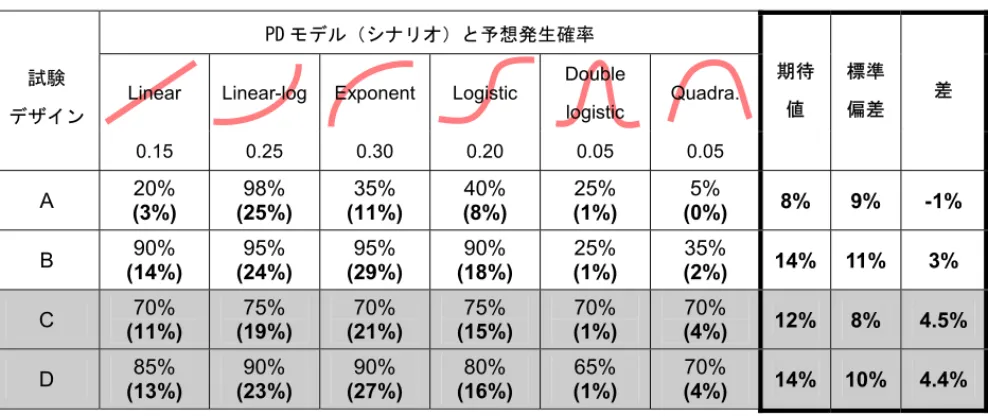
7 中枢系の薬剤である Org25935 では早期(第1相試験終了時点)に,投与方法を最適化するこ とにより有害事象の発現を防ぎつつ有効性を確保できることがM&S により明らかとなった9。ま た,Nesiritide では M&S により至適な用量を推測し,必要最低限の臨床試験結果での承認を得る ことができた12。いずれの例においても,M&S のアウトカムとしての数値を判断のよりどころと している。 MBDD を行うにあたり,開発早期からデータに基づく定量的な判断基準を定め各ステップにつ いて的確な統計的な評価を実施することが,医薬品の開発を科学的かつ効率的に行うために欠か すことができないポイントと言える。有効性や安全性に影響を与える要因を定量的に理解し,モ デリングの過程で補わねばならなかった仮定から,未知の情報が何であるか,現在の作業仮説の 問題は何かを明確にでき,次の試験での選択基準,除外基準をより合目的的に設定することが可 能となり,ひいては開発期間の短縮に繋がる。すなわち,適切なMBDD を実施することにより, 有効である薬がきちんと患者の手元に届くこと,無効(あるいは危険)な薬が適切に排除される ことが従来よりも短期間で可能となる。これは患者にとって重要なことであることはもちろん, 企業としても臨床試験の成功確率を上げ,開発費を抑制できるというメリットになる。 開発候補品の数が限られているメガファーマ以外の多くの企業では,それら数少ない候補品の 開発中止が経営に与える影響が大きい。そうした企業では特に MBDD により開発の成功確率が 高まることに注目すべきである。表 1-1 の例で Org25935 を紹介しているが,これは第1相試験 結果を用いた M&S により,開発の中止を阻止できた例である。第1相試験の結果において有効 性を示す用量と有害事象を示す用量が近接していた。ここでPK/PD 解析結果を元に M&S を行っ たところ,吸収速度を低下させると有効性には影響が無い一方で,有害事象の発現率を低下させ ることが示され,徐放性製剤の開発に繋がった。従来の考え方では開発を断念した可能性が高く, M&S が有効に活用された例である。MBDD に関する公表論文は,「いかに駄目な薬を早期に断念 できたか」というものが多く,候補品を多数保有するメガファーマでなくては有効活用できない, との懸念もあったが,このOrg25935 の例は開発候補品が少ない企業でも MBDD が十分に活用可 能であることを示している。 1.3 MBDD を運用すると医薬品開発ビジネスがどのように変わるか? 1.3.1 医薬品開発における現状の課題 近年,医薬品開発の効率が著しく落ちている事が大きな問題として取り上げられる様になり始 めている。米国においては,その開発費の高騰に反して新薬の上市数が減少の一途をたどってい ることも報告されている15。本邦に於いても同様に,特に第2 相から第 3 相に移行する段階で医 薬品開発の成功確率が落ち込んでいることが確認できる(表 1-2)。
8 表 1-2 医薬品開発の成功確率(16の文献より引用) これらの原因としては様々な要因が考えられるが,特に開発早期での成功確率が低い点から, ここでは初期の医薬品開発の複雑化に注目して考察したい。1980 年代から 90 年代にかけて,製 薬企業はその研究開発力の進歩に伴い多くのブロックバスターを手に入れた。これらの多くは高 血圧・高脂血症・胃潰瘍等の科学的にその疾患メカニズムが明らかな疾患の治療薬だった。それ から年月が経ち,それらの疾患に対するアンメットメディカルニーズが一定程度満たされた中で 2010 年問題を迎える事となった。これらのことから,現在では医薬品企業の主な開発ターゲット 領域はメディカルニーズの未だに充たされていない,癌やアルツハイマー病などの疾患メカニズ ムがはっきりしていない領域へとシフトしてきている17,18。そのため,以前に比べて医薬品開発 の効率が低下していると考えられる。 本項では,このような複雑化した現在の医薬品開発に対して MBDD を活用することでもたら される変化について考察する。図 1-6 のように,MBDD では,その時点で得られている全ての情 報を用いてモデルを構築する。もちろん,このような考え方は従来も開発担当者の経験に基づい て用いられてきたと考えられる。しかし,従来に比べてとりまく環境が複雑化している現在の医 薬品開発に於いては,個人がこれらの情報を活かすことは難しくなってきている。 MBDD ではこれらの情報を一元管理し,モデルという臨床試験のデザイン立案に有用な定量化 された情報として提示することが出来る。つまり,MBDD は既存の利用可能な情報を徹底的に使 うことでその開発計画の精度を常に高め続ける開発手法と言える。当然ながら MBDD で扱うデ ータや情報には従来使われていたデータや情報を全て含んでいるため,MBDD の導入により開発 計画の精度が従来よりも低下するということは理論的にありえない。開発プロセスが改善するこ とはあっても悪化することはありえないのである。但し,MBDD の運用には M&S のために十分 なリソースを投入する必要がある。十分なリソースが投入できなければ従来の開発スケジュール に M&S が追いつかず,その結果として開発の遅延を招き,必ずしも開発効率の向上とならない
9 危険性はある。MBDD の導入が進まない原因の一つがこのリソースに関わる導入コストの問題で あると考えられる。 RDCとの連携により、背景 情報のみならず、血中濃度 や有効性指標などの盲検 データを盲検のままリアルタ イムにモデルに反映すること が可能に。 P1 のデータ (PK) 海外データ (PK-PD,…) 前臨床の情報 ・類薬とのin vitro活性比較 ・システムファーマコロジー 類薬の情報 (PK-PDモデル等) P 2 (実施中)の データ モデルによる情報の Knowledge Base化 病態進行 パターン 1.試験デザインA 2.試験デザインB 3.試験デザインC
臨床試験シミュレーション
領域特有の 脱落パターン 試験デザイン 要素 全て”モデル”に変換蓄積された
情報を統合
図 1-6 MBDD における情報の蓄積とその活用米国医薬品食品局(FDA)では MBDD の企業への導入を推進するため End-of-Phase 2A Meeting を取り入れた19。第2 相及び第 3 相試験のための用量選択は,多くの医薬品開発における課題で あり,安易な用量の選択が試験の失敗を招くことも多い。開発早期における用量選択を改善する ことにより,将来の試験の成功率の上昇が望める。さらには,薬物の曝露-反応,プラセボ効果, 病態モデルを用いた臨床試験シミュレーションを用いることで臨床試験デザインの改善が期待 される。End-of-Phase 2A Meeting では,FDA のファーマコメトリクス担当者(ファーマコメトリ シャン)が企業に対し,臨床試験シミュレーションと定量的にモデル化された事前情報の臨床試 験デザインへの利用,それによる用量-反応関係の精度良い推定と,効果的な用量設定への活用を 促している。 以下に,End-of-Phase 2A Meeting での議論の例を挙げる19。 • 有効性及び安全性への関与が既知のバイオマーカー,代替エンドポイントまたは臨床エ ンドポイントを利用した用量選択 • 動物及びヒトでの薬物の効果に関する定量的情報を反映した用量設定試験のデザイン 及び安全性評価 • 非臨床及び臨床の曝露-反応データの用量反応試験デザインへの反映
10 • 他の試験デザイン戦略(例,並行群間,クロスオーバー,アダプティブデザイン)及び 他の解析手法(例,ベイズ)の対比 • 非臨床及び臨床で得られた遺伝薬理学情報の活用と遺伝要因のPK-PD への影響(用量選 択における遺伝子の影響の定量的評価や以降の臨床試験での安全性及び有効性の評価 への遺伝情報の利用を含む。) • 以降の臨床試験の価値を最大化するための血液・DNA の収集戦略及びその他の試験デザ イン上の工夫に関する議論 • 特殊集団(例,小児)への用量調整のためのPK/PD データの活用に関する議論 このように米国では規制当局が主体となって MBDD の導入を進めており,日本よりも導入コ ストに対する抵抗感は低いと推察される。 但し,日本の規制当局においてもMBDD の利用可能性に関する検討は既に始まっている。2011 年8 月には医薬品医療機器総合機構(PMDA)内に,新薬審査部(統計分野,臨床分野,ADME 分野),信頼性保証部,レギュラトリーサイエンス推進部,審査マネジメント部等のメンバーか らなる新統計プロジェクトが発足され,部門横断的な活動が行われている20。今後のPMDA から の情報発信に期待したい。 1.3.2 医薬品開発の将来展望 以上の点を踏まえた上で,将来の医薬品開発について少し考えてみたい。 最近では,各社の情報を共有し医薬品開発に活かそうとする動きが始まっている。例えば,ア ルツハイマー病の病態解明を目的としたコンソーシアムや21,アジアでの抗癌剤開発を扱うコン ソーシアムが立ち上がっている22。また,一昔前であれば,開発する薬剤の対象患者数は国内の 疫学を用いていたが,今では国際共同開発の潮流に乗り,世界の疫学を想定してビジネスが成立 するようになり始めている。これによって,今までは企業としては開発対象になり得なかった患 者が国内に数十人・数百人しかいないような超希少疾病も医薬品の開発対象として考えられるよ うになってきた。このような超希少疾病に対する医薬品の開発では,今まで以上に情報がない中 での開発が求められると考える。そのような状況下では,全ての情報を徹底的に使うことの出来 る MBDD は強力なツールになると考える。さらに,未承認薬や適応外薬の開発の際に公知申請 が一つの解決手段として考えられているが,その点に於いても,それまでの開発時点の情報や公 知情報を入手したうえでモデルを構築して,その薬剤の効果を説明することで定量的にその薬剤 のプロファイルを論じることが出来ると考える。最終的には,下図のように医薬品開発の各段階 でモデルを見直しつつ,その薬剤の効果の予測に役立つ「成熟されたモデル」を構築し,蓄積し ていくことが期待される。これらの情報を当然の形で個人レベルの実臨床に反映出来るように, 医薬品開発のみならず医薬品そのものの一つの「薬剤モデル」を構築することが求められる時代 が来ることも予想される。近年では,臨床開発の段階で得られる情報には限りがあり,市場に出 てからも医薬品は成長するべきものと認識されつつある。この点からも,上市後においてもその 新しい情報を「薬剤モデル」に組み込むことで,MBDD が医薬品のライフサイクルに真に寄与で きるような時代が来ると考える(図 1-7)。
11
Learning
Confirming
Sample Size Reestimation
Group Sequential Design Seamless POC/P2a
Adaptive Dose Ranging Seamless II/III
Bayesian Dose Finding
Modeling & Simulations
非臨床の情報 バイオマーカー PGx Disease モデル 類薬の情報 有意差の★は 昔の笑話に
良くない薬は
早く安く止める
良い薬は
滅多に
失敗しない
緻密な計画 適度に単純で 予測に役立つ “熟成されたモデル”レジメの選択を
効率よく
事前情報に 基づいたモデル 民族差の検討は モデルで済! 図 1-7 次世代の医薬品開発のイメージ MBDD は Risk-Benefit を定量化した,より科学的な開発手法である。導入に関わる障壁は高い ものの,MBDD はそのコストを補って余りある利益をもたらす,今後の医薬品の開発に必要不可 欠の手段であることをご理解いただければ幸いである。12
2. MBDD の理論背景解説
2.1 はじめに MBDD により定量的かつ効率的な医薬品開発を実施するには,モデリングとシミュレーション (以下,M&S)を反復して実施することが必要になる。各臨床試験の企画段階では,最新の情報 を適用した臨床試験シミュレーションを用いて試験デザインの立案,評価,選択を行う。臨床試 験シミュレーションの具体的な使用例としては,バイオマーカー,代替エンドポイントまたは臨 床エンドポイントを利用した定量的情報に基づいた用量選択,試験デザインの比較などがある。 MBDD の運用手順を概説すると,まず行うべきことは臨床開発に関連するいくつかの情報をモ デル化し,ナレッジとしてPK-PD プロファイル,非臨床薬理データ,類薬の PK-PD 及び有効性・ 安全性プロファイルなどを蓄積することである。このナレッジの蓄積は,その情報の信頼性も考 慮したとき一朝一夕にできるものではなく,MBDD の運用開始当初に目立った成果を挙げること は困難であることが予想される。ある程度のナレッジが蓄積された段階で,次に臨床試験シミュ レーションの目的,意思決定の判定基準を設定し,シミュレーション計画を立案することになる。 臨床試験シミュレーションを実行するためには,その基礎となる3 つのモデル群(疾患モデル: Disease model,薬剤モデル:Drug model,試験モデル:Trial model)を用いて目的に応じた数理モ デルを設計及び構築し,最新の情報に基づく改定を適時行うことになる。一方,モデル化では, 有効性,安全性に関する評価項目などに対する影響因子を選択,定義し,臨床試験モデルの全体 像を特定するため,要因連関図などで整理することも重要である。要因関連図を元に3 つのモデ ル群を組み合わせて臨床試験モデルを作成し,想定される様々な条件(シナリオ)でのシミュレ ーションを実施する。そして,得られた結果を基に,試験デザインの選択,評価などを行い,開 発方針を検討する。また,そのようにしてモデルとして蓄積されたナレッジを組み合わせた臨床 試験シミュレーションの結果や実施された臨床試験の結果が,新たなナレッジを生み出すことな る。 MBDD では,上述のように多くの過程を経るため,その立案,運用には様々な専門知識が必要 となる。ここでの専門知識とは,M&S を実施し,結果を評価するために必要となる薬物動態学, 薬力学,臨床薬理学,医学,及び臨床統計学などを総合したものである。これはファーマコメト リクス(Pharmacometrics; PMx)と定義され5,MBDD を実施するために必須な基礎知識とされて いる。 医薬品開発の成功確率向上や効率化の方策として,アダプティブ・デザイン,ベイズ統計学を 用いた試験デザインも注目を浴びている23。アダプティブ・デザインでは,変更基準,有意性の 判断基準(もしくは試験の成功判断)など多くの基準の設定が必要となり,またベイズ統計学を 用いた試験デザインでは,事前分布の設定や成否の判断基準など,汎用的な頻度論の試験デザイ ンと異なった,いくつかの設定条件が必要となる。さらに,ベイズ統計学とアダプティブ・デザ インを複合する場合も設定すべき条件が当然ながら多くなる。このような複雑な条件設定を必要 とする試験デザインを立案する際には,特に複数のシナリオでの成功確率を定量的に評価できる 臨床試験シミュレーションは有益である。 そこで本章では,MBDD を実施するために必要なファーマコメトリクスの基礎理論として,疾 患モデル,薬剤モデル,試験モデルなどのモデルの概略,統計手法・シミュレーションに関する13 概略を説明し,さらに実務担当者が実際に MBDD を運用する際の目安となるように具体的な MBDD 運用手順について整理する。さらに,MBDD を実施する際には疎隔しがたい話題である End-of-Phase 2A Meeting,アダプティブ・デザイン,ベイズ統計学について 2.8 章で紹介する。 2.2 モデルの解説 MBDD は,疾患モデル,薬剤モデルおよび試験モデルという数学的モデルを用いることにより, 過去の試験情報を臨床試験シミュレーションに含めて実施することができ,医薬品開発における 意思決定に有用と考えられる。モデルの構成(組み合わせ)は,シミュレーションの目的によっ て異なる。例えば,特殊集団での用量調節や投与レジメンの最適化(1 日 1 回 vs. 1 日 2 回投与な ど)のように,主に薬物動態の変動が薬理効果に及ぼす影響を考慮する場合では,薬剤モデルは 有用である。また,服薬期間が長期に渡り,病態の進行を考慮する必要がある場合は,疾患モデ ルを組み込む必要があると考えられる。さらに,複数の試験デザインの比較や試験結果に影響を 与えそうな要因の検出などでは,試験モデルも考慮する必要がある。以下に,疾患モデル,薬剤 モデルおよび試験モデルに含まれる要素を図 2-1 に示し,それぞれ要約する。
疾患モデル
薬剤モデル
試験モデル
バイオロジ― バイオマーカー/ 結果変数 病態の自然推移 プラセボ効果 ファーマコロジー 有効性 安全性 非臨床/健康成人/ 患者 化合物特性 患者集団 脱落 プロトコール逸脱 図 2-1 疾患モデル,薬剤モデルおよび試験モデルの要素(24の論文より改変して引用) 2.2.1 疾患モデル 疾患モデルは,疾患の進行の時間推移を記述するものである。薬物の曝露量に対する薬理効果 の中長期的な評価においては往々にして疾患の進行などによる変化の影響を無視することがで きない。この場合,曝露量と薬理効果の短期的な関係を表現する薬剤モデルに加えて病態の経時 的な変化を表す疾患モデルを考慮する必要がある25,26,27。また,疾患モデルはエンドポイントの最 も効果的な観察時期を推定するうえでも有用である。その概念図を図 2-2 に示す。例えば,症状 は改善されるが,疾患の進行速度に影響しない(Symptomatic Effect)A 薬と,疾患の進行速度を 低下させる(Disease Modifying)B 薬の比較試験を行ったとする。時期 1 で比較した場合は,A 薬の方が,時期2 で比較した場合は B 薬の方が症状の悪化程度は低く,評価時点によって結果が 異なることを示している。14 図 2-2 疾患モデル 時期 1 と時期 2 で薬剤の評価が異なる。 Symptomatic Effect: 症状は改善されるが,疾患の進行速度は変わらない。 Disease Modifying: 疾患の進行速度を変化させる。 疾患モデルには,自然の疾患の進行を示すモデルだけでなくバイオマーカーと代替エンドポイ ント(または真のエンドポイント)との関係を表すモデルやプラセボ効果モデルも含まれる。 疾患の進行はバイオマーカーまたは臨床エンドポイントを指標に評価されるため,疾患モデル で取り扱われるデータは測定値やスコアなど様々である。概念的には無治療での病態進行とプラ セボ効果の影響は分離した形の方が理解しやすいが,現実的には,無治療での臨床データを得る ことは倫理的な面において難しく,特殊なケースを除き,モデル構築はプラセボデータの利用と なる。従って,疾患モデルはプラセボ効果の影響を含めたモデルとなることがほとんどである。 また,プラセボ群は,対象疾患により純粋にプラセボ剤だけの投与ではなく,標準的な治療を基 礎治療として受けていることもあり,複数の試験データを統合して疾患モデルを構築する場合に は注意が必要となる。 モデルは生体システムを反映した機構的なモデルというより経験的なモデルとなることが多 い。モデルには,疾患の経時的変化とプラセボ効果以外に,季節などの影響による周期的な変動 が含められることがある。 FDA は,肥満,パーキンソン病と非小細胞肺癌の病態モデルを構築済みであり,アルツハイマ ー病,HIV,2 型糖尿病などの領域でもモデルの構築を進めている28。 2.2.2 薬剤モデル 薬剤モデルは,投与量や生体内薬物濃度と,薬理効果(バイオマーカーなど)又は臨床エンド ポイント(有効性,安全性に関わるエンドポイント)との関連性を記述するモデルである。ここ では,薬物動態学と薬力学が基礎理論となる。薬物の用法・用量と薬物濃度推移の関係を取り扱 うのが薬物動態学,薬物濃度と薬理作用(有効性,安全性などすべての反応を含む)の関係を取 悪化 時間 病態の進行(Disease Model) Disease Modifying(B 薬) Symptomatic Effect(A 薬) 時期1 時期2 薬剤投与
15 り扱うのが薬力学である。以下に薬剤投与後,血漿中薬物濃度を介して薬理作用が発現するまで の過程についての代表的な概念図の一つを図 2-3 に示す。 図 2-3 薬理作用が発現するまでの過程の概念図 生体内での薬物濃度の時間変化を薬物動態(Pharmacokinetics; PK)と呼び,薬物濃度と薬理効 果との関連性を薬力学(Pharmacodynamics; PD)と呼ぶ。そして,薬物動態を薬力学に結合させ, 短期での薬理効果の時間推移を記述するモデルがPK-PD モデルである。この PK-PD モデルによ り,投与量から薬理作用の経時的変化が予測可能となる。一方,薬理効果の時間推移を考慮せず, 投与量又はPK パラメータ(Cmax,AUC,Cmin,Caveなど)と,薬理効果との関係を記述したモデ ルがExposure-Response(E-R)モデルである29。全身曝露により薬理効果が発揮される場合,薬剤 の曝露量は薬物動態に影響を及ぼす様々な要因により個体間変動,個体内変動を生じるので,投 与量よりPK パラメータを用いるほうが理論的には予測性がよいとされている。 PK モデルは,通常,生体をいくつかの抽象化されたコンパートメントに分け,各コンパート メントでの物質収支式に基づいて構築されたコンパートメントモデル(マルチコンパートメント や非線形消失プロセスなどがある場合も含む)が用いられる。PK-PD モデル(あるいは E-R モデ ル)では,曝露と反応の関係を表す(シグモイド)Emax モデル(及び Linear,log-linear などの派 生モデル),ロジスティック回帰モデルなども用いられ,骨髄抑制モデルはその一事例である。 薬物濃度の変動と薬理効果の発現に時間的ズレ(hysteresis)が存在する場合には,効果コンパー トメントを仮定したモデルや,間接反応モデルなどのように生体内反応を反映した機構的なモデ ルを用いることもある。従来薬剤モデルの構築においては,得られたデータに基づき当該データ を表現可能で,より簡略なモデルの適用が望ましいとされてきた。しかしながら,臨床試験シミ ュレーションを行う場合の薬剤モデルは,その外挿可能性をも考慮し,薬剤の疾患への作用機序 をより重視すべきである30。対照薬のPK-PD 或いは E-R モデルも薬剤モデルに含まれる。薬理効 果だけでなく安全性バイオマーカーや有害事象の発現をモデル化することもある。 ここで,曝露量の指標となる薬物動態パラメータ(例えば,Cmax,AUC)が投与量に比例する 場合に用量比例性(線形性)があるという。薬物動態における「線形」と後述する統計モデルに おける「線形」は異なる定義であることに注意が必要である。 Cp:血漿中薬物濃度,Ce:標的部位薬物濃度 Cp Ce 効果 臨床転帰 投与 薬物動態学 リンク 薬力学 (真のエンドポイント) (代替エンドポイント) Kinetics Dynamics
16 2.2.3 試験モデル
試験プロトコルに依存したデザイン情報を定義する要因(Trial-based input factor),逸脱・服薬 遵守の状況を示す試験実施モデルは臨床試験結果に影響を及ぼす要因として考慮する必要があ り,これらを総じて試験モデルと呼称する。仮想患者を発生させる場合の被験者背景に関する共 変量の分布も試験モデルに含める。このとき,背景因子間の相関(背景因子が正規分布の場合は 分散共分散行列)を考慮しないと仮想被験者が非現実的な被験者背景を持つことになるので注意 が必要である。 2.2.3.1 試験デザインに基づく要因 臨床試験シミュレーションは,複数のシナリオ(試験デザイン)のパフォーマンスを定量的に 評価するための手段である。試験デザインに基づく要因が結果に与える影響を検討する,いわゆ る“What if”シミュレーションは,適切な試験デザイン立案に極めて重要となる。試験デザイン に基づく要因として,並行群間試験やクロスオーバー試験などの直接的なデザインの情報,全被 験者数,処置の数, 各群に割り付けられる被験者の比,観察時点などがあげられる。 2.2.3.2 試験実施モデル 試験実施モデルは,プロトコル逸脱や脱落などによる試験結果への影響を記述するモデルとし て定義され,服薬遵守モデルや脱落モデルなどが含まれる31,32。プロトコル逸脱はその発生が, 前のイベントや時間に依存する時間依存型およびその発生が前のイベントの発生に依存しない 時間非依存型の2 種類に分けて考えることができる。 服薬遵守モデルは服薬率などの低下を考慮するためのモデルである。服薬率低下の表現には確 率モデルであるマルコフモデル(現在の状態が過去のある時点までの状態に依存する確率構造を とるモデル)が適用されることがある。遵守する症例群と遵守しない症例群の存在を考慮する混 合の分布を考えることが適切な場合もある。実際の服薬遵守パターンからリサンプリングしてシ ミュレーションすることも有用である。 脱落モデルは試験実施中の患者脱落による症例数減少を考慮するためのモデルである。特別な 理由のないランダムな脱落は,単純に全体の症例数が減り検出力に影響を与える。この場合,モ デルは時間の関数で表される。疾患や試験条件などによる非ランダムな脱落では,例えば,病態 が改善されなければ脱落率が増える,といった状況が想定され,試験結果に影響を与える因子と なりうる。 2.3 統計手法の概説 2.3.1 MBDD で用いられる統計モデル 本節では,前節で示した各種モデルを,統計モデルとして整理する。統計モデルの構成は,観
17 察可能な説明変数及び応答変数,説明変数と応答変数の構造的関係を示すパラメータ及び誤差か らなる。その概念図を図 2-4 に示す。統計モデルは,モデル内のパラメータの関係や,応答変数 の種類により区分される。 応答変数 説明変数2 説明変数1 説明変数4 説明変数3 説明変数6 説明変数5 b1 b2 b3 b4 b5 b6
ε
観察可能な項目 パラメータ 誤差 図 2-4 統計モデルの概念図 2.3.2 モデル内のパラメータの配置による分類 2.3.2.1 線形モデル(Linear model) 本節で示す線形モデルの「線形」は,前節で示された薬物動態学的な「線形」(投与量に対す る用量比例性)とは異なる。線形モデルは,パラメータと説明変数(例えば血漿中薬物濃度(x)) からなるモデル式が適切な変換を行うことで,線形結合,すなわち和の形で示されるモデルであ る。前節のE-R モデルの 1 例として,血漿中薬物濃度(x)と反応(y)の関係をy
=
a
1x
+
a
2x
2 (a1,a2はパラメータ)で表したモデルは線形モデルであるが,薬物濃度-反応関係をグラフに 示した場合,モデルは曲線で表される33。 2.3.2.2 非線形モデル(Nonlinear model) 統計モデルのうち,適切な変換を行ってもパラメータが線形結合で表されないモデルを非線形 モデルという33。MBDD で用いられる各種モデルは,モデルの理論的背景から非線形モデルとし て表されるものが多い。薬剤モデルである PK モデルのコンパートメントモデルや,E-R モデル のEmax モデルが非線形モデルに当たる。また,各種疾患モデルなども非線形モデルで表されるこ とが多い。18 2.3.3 モデル内のパラメータの役割による分類 2.3.3.1 固定効果モデル 固定効果モデルは,統計モデルに含まれる全てのパラメータが,個体に寄らず一定であること を前提としている。例えば,E-R モデルとして単回帰モデルを想定した場合,切片や傾きのパラ メータが個体に寄らず共通であると想定するモデルとして表される。換言すると,固定効果は, パラメータの値に関連し,応答変数の推定値に直接影響を及ぼす。 2.3.3.2 変量効果モデル 変量効果モデルは,統計モデルに含まれる全てのパラメータが,個体ごとに異なり,個体ごと の違いは確率分布に従うことを想定している。E-R モデルとして単回帰モデルを想定した場合, 切片や傾きのパラメータが個体ごとに異なるが,これは母集団全体の傾きや切片に,ある確率分 布に従う個体の効果を示す確率変数が付与されていることを想定するモデルとして表される。換 言すると,変量効果は,一般的にパラメータの値に関連がなく,分散だけに関連し,応答変数の 分散のみに影響を及ぼす。 2.3.3.3 混合効果モデル 混合効果モデルは,統計モデルに含まれるパラメータの一部が固定効果,残りが変量効果であ ることを想定している。例えば,E-R モデルとして単回帰モデルを想定した場合,切片は個体ご とに異なり,母集団としての切片にある確率分布に従う個体の効果を示す確率変数が付与される が,傾きは個体にかかわらず一定であることを想定するモデルとして表される。線形モデルに変 量効果が含まれるモデルを線形混合効果モデル,非線形モデルに変量効果が含まれるモデルを非 線形混合効果モデルという。どのパラメータに変量効果を設定すべきかについては,パラメータ に対する個体間変動の大きさと元となるデータが持つ情報量を勘案して決定される。変量効果は 正規分布(あるいは対数正規分布)に従うと仮定することが多いが,他の確率分布に従うと仮定 する場合もある。 2.3.4 応答変数の種類による分類 2.3.4.1 応答変数が計量値の場合 応答変数が計量値の場合,誤差は正規分布,対数正規分布などに従い,様々なモデルが用いら れる。例えば,E-R モデルでは, Emaxモデルが例としてあげられる34。 Emaxモデルは式 (1)で表 されるが,パラメータである EC50及び Emaxは,式を変換しても線形結合として表せない非線形 モデルである。
19
[ ]
[ ]
+ε
+ = D D E 50 max EC E (1)E:反応量(応答変数),Emax:最大反応(パラメータ),EC50:50%反応濃度(パラメータ),
[D]:薬物濃度(説明変数),ε:誤差 計量値を応答変数としたモデルの事例として,3.2.1 章に Zosuguidar の PD モデルが示されて いる。 2.3.4.2 応答変数が 2 値の場合 応答変数が 2 値応答の場合,ロジスティック・モデルが汎用的である。2 値応答と説明変数 X のモデルにおいて,値x をとる確率を p(x)とするとロジスティック・モデルは確率 p(x)のロジッ トに対して線形であり,式(2)で示される35,36。2 値応答の場合,応答変数は二項分布やポアソン分 布に従う。
( )
(
)
( )
( )
a a x x p x p x p 1 2 1 log ⎟⎟= + ⎠ ⎞ ⎜⎜ ⎝ ⎛ − = logit (2) 2 値を応答変数としたモデルの事例として,3.2.2 章にスマトリプタンの PK-PD モデルが示さ れている。 2.3.4.3 応答変数が順序カテゴリの場合 応答変数が順序カテゴリの場合,順序性の情報をロジットに直接組み入れることができる。累 積確率(cumulative probability)とは,応答変数 Y がカテゴリ j 以下になる確率であり,第 j 番目 の累積確率は式(3)で示される35,36。(
Y j)
p p j J p ≤ = 1+L+ j, =1,L, J-1 までのロジットは次式で表され累積ロジットと言われる。(
)
(
)
(
(
)
)
1 , , 1 , log 1 log it log 1 1 = − ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ + + + + = ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ ≤ − ≤ = ≤ + J j p p p p j Y p j Y p j Y P J j j L L L (3) ロジスティック・モデルと同様にこの累積ロジットを応答変数として,線形モデルを構築する ことができる。順序カテゴリの場合,応答変数は多項分布に従う。 順序カテゴリを応答変数としたモデルの事例として,3.2.2 章にスマトリプタンの Pain Severity の PD モデルが示されている。 2.3.5 共変量 疾患モデル,薬剤モデル,試験モデルを構築する際には,応答変数に影響を与える共変量20 (Covariate)を考慮する必要がある37。共変量には,性別のように時間に影響されない時間非依 存共変量と,併用薬や臨床検査値のように,時間とともに応答変数への影響が変化する時間依存 共変量がある38。共変量を無視した場合は,共変量の応答変数への影響は誤差に含まれるが,適 切な共変量を選択してモデルへ組み込むことで,共変量の応答変数への影響を誤差と分離するこ とが可能となり,固定効果の推定精度が向上することが期待できる。これらの共変量は臨床試験 モデルのシミュレーションにおいて重要な情報となる。 2.3.6 パラメータの推定方法 線形モデルでは,尤度方程式を解析的に解くことによりパラメータの推定を行うことが可能で あるが,非線形モデルでは,尤度方程式が複雑になるため解析的に解くことが出来ず,反復計算 が必要となる。非線形モデルでは,反復計算を行うための初期値の設定が必要であり,適切な初 期値を設定しないと,反復計算が収束しない場合や,適切なパラメータの推定値が得られない場 合がある39。 複雑なモデルである非線形混合効果モデルでは,最尤法を用いてパラメータの推定が行われる 39。最尤法では,パラメータに対する尤度関数を最大化するものを最尤推定量とする。非線形混 合効果モデルでは,固定効果を推定するため変量効果を多重積分した周辺尤度を用いるが,非線 形混合効果モデルでは多重積分を直接計算できないため,いくつかの数値的な方法により多重積 分を実施している 39,40,41。以下に,主な解析ソフトウェアで利用可能な非線形混合効果モデルの パラメータ推定方法を表 2-1 に示す 37,42。一般に,精度と収束までの所要時間は,Monte Carlo Integration>Adaptive Gaussian Quadrature>Laplacian method>First-order conditional estimation> First-order approximation の順であると言われている37。
表 2-1 各種解析ソフトウェアにおける非線形混合効果モデルのパラメータ推定方法
ソフトウェア名称 非線形混合効果モデルのパラメータ推定方法
NONMEM First-order approximation,First-order conditional estimation method, Laplacian method など
SAS (NLMIXED) First-order approximation,Laplacian method,Monte Carlo Integration, Adaptive Gaussian Quadrature
S-PLUS (nlme) First-order conditional estimation method,Laplacian method,Adaptive Gaussian Quadrature
2.4 モデルの評価 2.4.1 当てはまりのよさ
モデル構築に際しては,データに対する「当てはまりのよさ(Goodness of Fit)」を評価するこ とが必要である。当てはまりのよさを明確に定義することは難しいが,通常は視覚的な方法や定
21 量的な尺度によって評価することが多い。ここでは,MBDD に広く利用できる汎用的な方法を取 り上げる。 2.4.1.1 視覚的な方法 視覚的な方法としては,観測値,モデルによる予測値,残差などを用いて様々な組み合わせの 散布図を作成し,モデルからのズレや系統的な誤差を評価する方法がある43。大きなズレや系統 的なトレンドが見られる場合には,モデルでは説明できていない部分があることが示唆される。 そのような場合には,モデルの形や説明変数の選択を再検討すべきである。 作成する散布図には,以下のようなものがある。 • 予測値 vs 観測値 • 予測値 vs 残差 • 時間 vs 残差 • 共変量 vs 残差 ここでの残差は,観測値と予測値との差である。この他,残差の代わりにバラツキの大きさで 残差を調整した重み付き残差,残差の平方値や絶対値などを用いる場合もある。時間に対するプ ロットは,モデルに時間的な推移が含まれる場合に重要である。残差と共変量のプロットは,特 定の共変量を変化させた場合の残差の系統的なトレンドを見るためのものである。モデルに含ま れている共変量はもちろんのこと,モデルに含まれていない共変量について調べることで系統的 なトレンドが見えてくることがある。 その他,シミュレーションを交えた視覚的な評価方法も存在する。そのひとつである Visual Predictive Check では,まずデータからモデルを作成し,作成したモデルからシミュレーションに より疑似データを生成する。疑似データは必要な測定点について複数作成し(例えば 1,000 個), 中央値やパーセント点により要約する。要約した値を観測値とあわせてプロットして見比べるこ とにより,作成されたモデルが元データの変動を説明できているかを検討することができる。 2.4.1.2 定量的な尺度 当てはまりのよさを評価するための定量的な尺度としては,残差に関連する指標と情報量基準 とよばれる指標が代表的である。 バイアスの小さいモデルでは,測定値とモデルから得られる予測値のズレが小さくなると考え るのが自然であろう。そこで定義される指標が,残差平方和(SSE;Sum of Square Error)である。
∑
= − = N i i i y y 1 2 ) ˆ ( SSE (4) ここで N はデータの個数,y
i,yˆ
iおよびy
i−
yˆ
iはそれぞれi 番目の観測値,予測値および残 差である。すなわち,残差平方和はN 個の残差の 2 乗を足し合わせたものであり,この値が小さ い程,モデルの当てはまりがよいと考えることができる。 ところが,残差平方和はモデルに多くの説明変数を含めるほど小さくなるという性質がある。22
つまり,予測にほとんど寄与しない説明変数であっても,とにかくモデルに含めておけば残差平 方和は小さくなる。一方,説明変数が多ければ多いほどその解釈や応用は困難になることが多い。 そこで,次の平均2 乗誤差(MSE;Mean Square Error)によって当てはまりのよさを評価する場 合もある。 p N− = SSE MSE (5) ここでp はモデルに含まれるパラメータの数である。説明変数を多く含むほど分母が小さくな りMSE は大きくなる。
一方,代表的な情報量基準としては,赤池情報量基準(AIC;Akaike’s Information Criteria)が あり,モデル選択の指標として広く用いられている。L を尤度関数について最大化した値(最大 尤度)とするとき, ) (ln 2 AIC=− L−p (6) となる。モデルがデータに当てはまっているほど,最大対数尤度ln L が大きくなるので AIC は小 さい値となる。直観的には,パラメータ数p による引き算は,説明変数の多さに対するペナルテ ィと理解することができる。AIC には様々な拡張版が存在するが,基本的な考え方は同様である。 通常これらの尺度は,当てはまりがよい程その値が小さくなるように定義されている。ただし, その値自体を解釈することは意味をなさず,例えば10,000 だったら大きいとか 0.01 だったら小 さいという類の絶対的な値に対する解釈は適切でない。これらの指標の主眼は,モデル間の相対 的な比較にある。 2.4.2 モデルの選択 2.4.2.1 モデル選択の考え方 モデルの選択においては,複雑なモデルから得られるバイアスの少なさと,シンプルなモデル から得られる予測の一般化可能性とのバランスが重要である。一般にモデルに多くの説明変数を 含める程,モデルによる予測値と観測値のズレは小さくなっていく。しかしながら,説明変数が 多くなりモデルが複雑になるにつれてモデル構築に用いたデータに当てはまりすぎてしまい,そ れ以外のデータへの一般化が難しくなるという問題が生じる。また,説明変数が多いほど,モデ ルの解釈が困難になる。そもそも,誤差として説明されるべき部分まで説明変数で説明してしま うといった誤りもあり得る。一方,説明変数が少ないシンプルなモデルは,より一般的な状況で の予測に用いやすいが,重要な説明変数を組み込めていないと予測にバイアスが残ることになる。 なお,MBDD では意思決定のための材料をタイムリーに生み出すことが重要である。モデル選 択に過度な時間を費やすよりは,タイムリーにM&S を進め,ナレッジの蓄積を繰り返しながら モデルを成熟していく立場が適していると考えられる。誤ったモデル選択によって誤った判断を 導いてしまうことは大きな損失につながりうるが,一方でモデルの当てはまりを追求することが スピード面での足かせとならないような配慮も必要である。1 つのモデルへの絞り込みが難しい 場合には,複数のモデルで評価を行う感度分析による検討も考慮すべきである。
23 2.4.2.2 モデル選択のアプローチ モデル選択には,情報量基準を用いるアプローチ,検定によるアプローチなどがあるが,これ らの理論的な根幹を成しているのは前節で述べた当てはまりのよさの指標である。 情報量基準を用いるアプローチでは,AIC などの情報量基準を計算してより当てはまりのよい モデル(AIC であれば値の小さなモデル)を選択する。このようなアプローチは以下に述べる検 定によるアプローチに比べて汎用性が高い。M&S のように比較的広い範囲でモデルを検討するよ うな場合には,情報量基準を用いるアプローチのほうが適用しやすいだろう。 検定によるアプローチは,ネストしているモデル同士の比較にのみ用いることができる。2 つ のモデルはネストしているとは,一方のモデルが他方のモデルの特別な場合として表せる関係の ことである。以下,必要な説明変数をすべて含むモデルをフルモデル F,その特定の場合として 表わされるモデルを縮小モデルR とよぶ。 2 つのモデルの当てはまりに差がないという帰無仮説の下で次の統計量は F 分布に従うことが 知られている。 ) p N , p (p F F R F F R F R F F ~ p N SSE p p SSE SSE − − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − ⎟⎟ ⎠ ⎞ ⎜⎜ ⎝ ⎛ − − (7) これにより,当てはまりについての検定を構成することができる。検定が棄却されれば,フル モデルの方が有意に当てはまりがよいと判断する。検定が棄却されなければ,よりシンプルな縮 小モデルでも説明可能と判断する。ただし,非線形モデルにおいては,上記のF 分布は近似的な ものになる。 検定による他の方法として,尤度比検定がある。2 つのモデルの当てはまりに差がないという 帰無仮説の下で,次の統計量がx2分布に従うことから,検定を構成することができる。 ) ( 2 ~ ) ln (ln 2 LR− LF pF−pR − χ (8) 検定によるアプローチの短所は,原則としてネストしたモデル間の比較にしか使うことができ ないことである。モデルの枠組みを固定した状況下での説明変数の選択のような問題には有効だ が,そもそもモデルの型から選択の対象としたい場合には適用が難しい。また,検定を構成する 場合の有意水準の設定や多重性の考慮も悩ましい問題である。 いずれのアプローチを選択した場合でも,統計学的な当てはまりの指標のみを用いてモデルを 選択すると,解釈しづらいモデルや,これまでの知見と相容れないモデルになることがある。こ のようなモデル選択の限界を理解し,総合的な観点からモデルを選択する必要がある。 2.4.3 モデルのバリデーション バリデーションは共通の理解が得られにくい考え方であるが,ここではバリデーションを「モ デル作成に用いられたデータ」以外のデータに対する予測可能性,外挿可能性の評価と定義する。 先に述べた当てはまりのよさの指標等を活用し,「このモデルを予測に使ってもよいのか」とい う問いに対して答えようとするのがバリデーションである。モデルが真実か,ということの検証
24 ではないことに留意が必要である。以下,バリデーションを外的バリデーションと内的バリデー ションに分けて説明する。 2.4.3.1 外的なバリデーション 外的なバリデーションは,モデル作成用データを用いてモデルを作成し,別の評価用データに 対してこのモデルを適用し,当てはまりを評価する方法である。わかりやすく,後述の内的なバ リデーションより説得力があるが,モデル作成用データとは別にモデル評価用データを得ること が現実的でない場合が多い。 2.4.3.2 内的なバリデーション 内的なバリデーションは,1 組のデータで行うバリデーションであり,別途評価用の外部デー タを必要としない。データ分割,クロス・バリデーションおよびブートストラップ法によるアプ ローチがある。 2.4.3.2.1 データ分割 データ分割は,手元のデータをランダムに2 つに分割し,一方のデータでモデルを作成し,他 方のデータでその評価を行うアプローチである。汎用的なアプローチであるが,データを分割す ることによるパラメータ推定精度の低下を考慮する必要がないほど十分なデータ量がある場合 に最適応となる(図 2-5)。 ○●○○○○●…○● (○:モデル作成用データ,●:モデル評価用データ) 図 2-5 データ分割 2.4.3.2.2 クロス・バリデーション クロス・バリデーションは,1 組のデータから繰り返し抽出を行い疑似的なデータセットを反 復的に作成する,リサンプリングに分類される方法である。 クロス・バリデーションでは,前述のデータ分割を反復的に繰り返し行う。まず,N 個のデー タを N-1 個からなるモデル作成用データと残りの 1 個からなるモデル評価用データに分割する。 次に,作成用のデータからモデルのパラメータを推定し,これを評価用のデータに当てはめて誤 差を評価する。これをすべてのデータが1 回ずつ評価用データとなるよう N 回繰り返す。最後に N 回分の誤差の平均を求めることにより,モデルの誤差を推定する(図 2-6)。
25 ●○○○○○○…○○ ○●○○○○○…○○ ○○●○○○○…○○ : ○○○○○○○…●○ ○○○○○○○…○● (○:モデル作成用データ,●:モデル評価用データ) 図 2-6 クロス・バリデーションにおけるデータ分割 2.4.3.2.3 ブートストラップ法 ブートストラップ法は,リサンプリングの代表的な方法である。ブートストラップ法では,N 個のデータからの無作為復元抽出により,M 個のデータからなる疑似データセットを繰り返し作 成する。このデータセットはブートストラップ標本とよばれ,もともとの母集団の分布F を近似 する経験分布関数Fˆに従うことが知られている。近似の精度は,繰り返し回数B が増えるにつれ て高くなる。得られたブートストラップ標本から予測誤差を推定することができる(図 2-7)。 (N=10 の元データ) ①②③④⑤⑥⑦⑧⑨⑩ ▼ (大きさM=10,繰り返し回数 B=5 のブートストラップ標本) 標本1: ①⑥⑦②⑥⑤③⑦⑦⑤ 標本2: ⑨②④⑨③④⑧⑤⑦⑧ 標本3: ⑦①⑦②⑥⑥⑤⑤⑧① 標本4: ②③⑩③③⑤⑤③⑩⑨ 標本5: ④④⑦①⑧④⑦⑧③⑩ 図 2-7 ブートストラップ標本 2.5 シミュレーション シミュレーションは,これまでに得られた知見や仮定を統合して複雑な事象のふるまいを定量 的に探索するための手段として,医薬品開発において広く応用されている。特に MBDD におい ては,M&S が道具立ての柱となっており,シミュレーションを理解して使いこなすことが不可欠 である。 一般に,シミュレーションは,確定的シミュレーションと確率的シミュレーションに分けて考 えることができる。確定的シミュレーションは,確率的な変動を含まないモデルによるシミュレ