レジスタ干渉グラフの分割によるコンパイルの 高速化に関する研究
2008 年 2 月 4 日(月)提出
指導 : 深澤良彰教授
早稲田大学大学院 理工学研究科 情報ネットワーク専攻 学籍番号 : 3606U107-3
山崎 敬史
1 はじめに 1
1.1 レジスタ割り付け . . . . 1
1.2 本論文の流れ . . . . 2
2 グラフ彩色法 3 2.1 生存区間解析 . . . . 3
2.2 レジスタ干渉グラフ . . . . 6
2.3 レジスタ干渉グラフの彩色 . . . . 7
2.4 スピル . . . . 9
2.5 スピルコスト . . . . 10
2.6 グラフ彩色法の問題点 . . . . 12
3 本手法 13 3.1 目的 . . . . 13
3.2 概要 . . . . 13
3.3 アルゴリズム . . . . 15
3.4 レジスタ干渉グラフ作成のオーダー . . . . 17
4 実験1 20 4.1 レジスタ干渉グラフのサイズの比較 . . . . 20
4.1.1 実験方法 . . . . 20
4.1.2 従来手法での実験 . . . . 21
4.1.3 本手法での実験 . . . . 23
4.2 他のプログラムでの実験 . . . . 28
4.3 考察 . . . . 29
5 実験2 32 5.1 実装 . . . . 32
5.2 実験方法 . . . . 32
5.3 実験結果 . . . . 33
5.4 考察 . . . . 34
5.5 結論 . . . . 34
6.2 将来課題 . . . . 36
謝辞 38
参考文献 39
業績 40
1 はじめに
1.1 レジスタ割り付け
プロセッサの方式はRISC方式(Reduced Instruction Set Computer)とCISC
(Complex instruction Set Computer)方式が有名である。RISC方式は命令を最小 限にして設計が容易にする方式で、CISC方式は命令が多岐に広がり高機能な命令 セットを持つ方式である。これらのプロセッサの高速化は動作周波数を高くする ことで達成されてきた。また、同時に複数の命令を実行する並列処理技術として VLIW(Very Long Instruction Word)やスーパースカラといったものがある。
こういった技術によりプロセッサの高速化が成されてきた。しかし、プログラム を高速化するにはプロセッサの高速化だけでなく、様々なアプローチが存在する。
その中には、コンパイラによる最適化が存在し、プログラムの高速な実行には、コ ンパイラによる最適化が必須である。すべてのプログラマがコンパイラの最適化 なしに高速な実行が可能なプログラムを書くことができるのであれば、コンパイ ラによる最適化は必要ではないが、現在の高速なプログラムの実行はコンパイラ の最適化によるものが多い。そして、その最適化の中にはレジスタ割り付けとい うものがある。プロセッサの中でもロード/ストアアーキテクチャは、演算に必 要なデータを全てレジスタに保持する。このレジスタ割り付けとは、中間コード で使用されるすべての仮想レジスタ(プログラム中に出てくる変数の値)をレジ スタへと割り付けることである。レジスタ数が足りないと、レジスタに割り付け られない仮想レジスタはメモリに割り付けられる。この作業をスピルという。メ モリへのアクセスはレジスタへのアクセスに比べて時間がかかるので、プログラ ムの高速な実行には、レジスタの効率的な利用が重要となる。よって、レジスタ 割り付けは重要である。
本手法では、レジスタ干渉グラフを用いたレジスタ割り付けを行う。レジスタ 干渉グラフを用いたレジスタ割り付けは、プログラムの関数ごとにレジスタ干渉 グラフを作成している。レジスタ割り付けを行う時、レジスタ数が不足するとス ピルを行い、再びレジスタ干渉グラフを作成し直す必要があるが、従来手法では、
関数全体に関するレジスタ干渉グラフを作成し直す必要がある。そこで本手法で は、関数を複数のブロックに分割し、そのブロックごとにレジスタ干渉グラフを 作成する。こうすることで、レジスタ数が不足しスピルが発生した際に作成し直 すレジスタ干渉グラフのサイズを縮小し、レジスタ割り付けにかかる時間を短縮 し、コンパイル速度を上げることができる。
1.2 本論文の流れ
まず第2 章で従来手法について説明し、第 3 章で本手法の目的、概要、アルゴ リズムについて説明し、第 4 章で従来手法に比べ本手法がどの程度コンパイル速 度が向上するかの理論値について検証し、第 5章で本手法を実装したコンパイラ を用いた実験を行い、第6 章でまとめと今後の課題について述べていく。
2 グラフ彩色法
レジスタ割り付けを行う手法として、データフロー解析における生存区間解析 の結果を用いるのが一般的である。この生存区間解析の結果を用いたレジスタ割 り付けの古典的な手法として、Chaitinらが発見したグラフ彩色法というものがあ る。このグラフ彩色法では、生存区間解析の結果からレジスタ干渉グラフを作成 し、このレジスタ干渉グラフをレジスタ数色以下で彩色する。そして、この色を実 レジスタに対応付けすることでレジスタ割り付けを行うという手法である[8][3][4]。
この章では、グラフ彩色法について説明していく。
2.1 生存区間解析
グラフ彩色法のレジスタ割り付けでは、まず生存区間解析を行う[1]。中間コー ドのある時点で仮想レジスタの持っている値が、後に使用される可能性があるな ら、その時点でその仮想レジスタは生存していると言い、使用される可能性がな いなら死んでいる、と言う。この仮想レジスタがどの区間において生存している か死んでいるかの解析のことを生存区間解析と言う。
この生存区間解析は、まずそのプログラム中のnode[n]で定義された変数をdef[n]
とし、node[n]で使用された変数をuse[n]とし、前のノードからのエッジをin-edge
、次のノードへのエッジを out-edge とし、すべての out-edge を succ[n] とする。
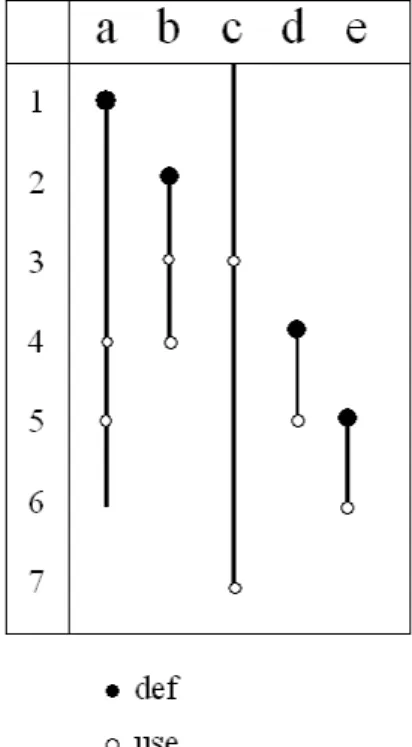
このdef[n]とuse[n]であるが、図4のプログラムを用いた場合、def[1] = [a], use[1]
= [φ], def[2] = [b], use[2] = [φ], def[3] = [c], use[3] = [b,c], def[4] = [d], use[4] = [a,b], def[5] = [e], use[5] = [a,d], def[6] = [φ], use[6] = [e], def[7] = [φ], use[7] = [c],のように表される。そして、次の方程式にそのプログラムを当てはめる事によ り生存区間を求めることができる。
図 1: 生存区間を求める方程式
そして、全ての仮想レジスタについて図1の方程式にあてはめることにより生存 区間解析を行い、その生存区間が少しでも重なっているとその仮想レジスタは異 なるレジスタに割り付けられ、生存区間が全く重なっていなければその仮想レジ スタは同じレジスタに割り付けることができる。図2は、これから行うレジスタ割 り付けに使う簡単なプログラムをコントロールフローグラフで表したものである。
図 2: コントロールフローグラフ
このプログラムの各命令ごとにuse,def されている変数を書き出し、それを先程 の方程式にあてはめることで、各変数の in-edge,out-edge での生存状態を求める ことができる。そして、そのin-edge,out-edgeでの各変数の生存状態を表としてま
てはめ、得られた結果を 1st に書いていき、その結果をまた当てはめていったも のを2nd に書いていき、と、繰り返し方程式に当てはめていく。そして、その結 果が同じものになるまで繰り返していくことで得られた図である。
図 3: 各変数の in-edge,out-edge の生存状態をまとめた表
この図3の n 番目のout-edge の結果と n+1 番目の in-edge の結果を見て、ま た、n+1番目のin-edgeの結果とn+1番目のout-edgeの結果を見ることで各変数 の生存している区間を求めることができる。こうして求めた各変数の生存区間を 直線で表し、各変数の定義された場所と参照された場所を記したものが次の図4で ある。
この図4より、このプログラムでは、変数 a は time = 1 からtime = 6 までの 区間で生存していて、変数bは time = 2 から time = 4 までの区間で生存してい
図 4: 各変数の生存区間
て、変数 cは前のベーシックブロックから time = 7 までの区間で生存していて、
変数d は time = 4 からtime = 5 の区間で生存していて、変数 eは time = 5 か
ら time = 6 の区間で生存していることが分かる。
2.2 レジスタ干渉グラフ
こうして各仮想レジスタの生存区間を求めると、どの仮想レジスタとどの仮想 レジスタが同時に生存しているかがわかる。同時に生存している仮想レジスタは 同じレジスタに割り付ける事はできない。逆に同時に生存していない仮想レジス タは、同じレジスタに割り付ける事ができる。そして、生存区間が重なっている 事を干渉している、という。
そして、各仮想レジスタをノードとし、干渉している仮想レジスタを表すノー
ドをエッジでつないだものをレジスタ干渉グラフという。このレジスタ干渉グラ フを干渉している仮想レジスタを表すノードを異なる色で彩色していく。こうす ることで、エッジでつながれたノード同士は異なる色で塗られ、この色がそれぞ れ仮想レジスタが割り付けられる実レジスタに対応する。こうしてレジスタ干渉 グラフを彩色することで、レジスタ割り付けを行う事ができる。
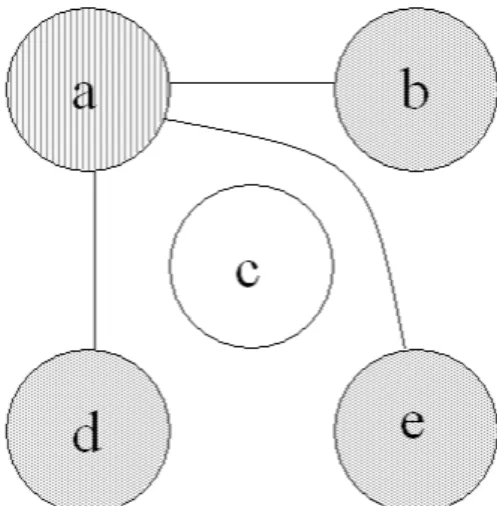
図refLivenessAnalysisをもとにレジスタ干渉グラフを作成する。図4の右の表 より、aは b、c 、d、eすべてと干渉していて、bは a、c と干渉していて、cは a 、b 、c 、d すべてと干渉していて、d は a 、c と干渉していて、e は a、c と 干渉しているので、それぞれの仮想レジスタをあらわすノード間にエッジを張る。
そうしてできたのが、図5である。
図 5: レジスタ干渉グラフの例
2.3 レジスタ干渉グラフの彩色
レジスタ干渉グラフを彩色するにはcoalesceとsimplifyという作業を行う必要 がある。
coalesceは、レジスタ干渉グラフの2つのノードを1つに合併するという作業で
ある。よって、coalesceを行うことによってレジスタ干渉グラフのノード数を減少
させることができるが、むやみにcoalesceを行うとレジスタ干渉グラフの干渉度
(あるノードが干渉しているノードの数)が増えてしまい、彩色時に色数が増えて
しまう可能性がある。そこで、色数を増やさないための条件がある。coalesceでき るものは、干渉していないノード同士で、レジスタ数個未満の干渉を持つノード
同士[9]、共通の干渉しているノードが存在する、ものである。この条件に基づき
coalesceを行い、coalesceができなくなったらsimplifyを行う。
simplifyは、レジスタ干渉グラフからノードを削除し、削除したノードとその
ノードがどのノードを干渉しているかの情報をスタックに積む作業である。ある レジスタ干渉グラフをk 色で彩色したい時に、 k 個未満の干渉を持つノードを削 除してできたレジスタ干渉グラフがk - 1色で彩色できたら、元のレジスタ干渉グ ラフはk 色で彩色することができる。この考えに基づき、レジスタ干渉グラフか ら実レジスタ数未満の干渉を持つノードを削除する。このsimplifyを繰り返して、
レジスタ干渉グラフのノードを全て削除することができれば、レジスタ干渉グラ フはレジスタ数色以下で彩色できることになり、レジスタ割り付けが完了となる。
このレジスタ干渉グラフが k 色で彩色できるかどうかという問題は、NP完全問 題として知られている[4]。simplifyを繰り返してもレジスタ干渉グラフにノード が残ってしまう場合は、レジスタ数色以下でレジスタ干渉グラフを彩色できない ので、レジスタ干渉グラフのノードが表す仮想レジスタを1つメモリに退避する。
そして、仮想レジスタを1つメモリに退避させることで、仮想レジスタの生存区 間情報が変化するので、また生存区間解析をやり直し、レジスタ干渉グラフも作 成し直す必要がある。
この流れをまとめると、レジスタ干渉グラフに対し、coalesceをできなくなるま で行い、次にsimplifyを行う。simplifyができたらcoalesceからやり直す。simplify ができないと仮想レジスタを1つメモリに退避させ、生存区間解析からやり直し、
という流れで実行する。
そして、グラフからノードを全て削除できたら、スタックから1つずつノードを 取り出し、干渉しているものと異なる色を彩色していく。こうすることでレジス タ干渉グラフを彩色することができる。
この法則に従い、レジスタ干渉グラフを彩色した例が図6である。この彩色した 色がそれぞれの実レジスタに対応し、同じ色で塗られたノードに対応する仮想レ ジスタは同じレジスタに割付けられ、異なる色で塗られたノードに対応する仮想 レジスタは異なるレジスタに割り付けられる。この図6では3色で塗られているの で、レジスタを3個使用していることになる。
図 6: 彩色したレジスタ干渉グラフの例
2.4 スピル
レジスタ干渉グラフの彩色の過程で仮想レジスタをメモリに退避させる作業が あった。この、仮想レジスタをメモリに退避させる作業のことをスピル[3]という。
そして、スピルを行うコードをスピルコードという。
レジスタ干渉グラフが k 色で彩色できるかどうかを判定するにはレジスタ干渉 グラフの彩色で述べたcoalesce、simplifyを用いる。まず、simplifyの手順をもう 少し詳細に述べる。レジスタ干渉グラフGを k色で彩色する問題を考える。そし て、レジスタ干渉グラフGの中で、エッジが k 個未満のノードnを見つける。次 にレジスタ干渉グラフ G からノード n とノード n につながるエッジをすべて削 除したレジスタ干渉グラフG’を作成する。こうすることでレジスタ干渉グラフG の彩色問題はレジスタ干渉グラフ G’を彩色する問題に置き換えられる。レジスタ 干渉グラフ G’が k-1 色で塗ることができればレジスタ干渉グラフGは k 色で塗 ることができるので、エッジが k 個未満のノードnとノードn につながるエッジ をすべて削除していった結果、グラフがなくなるか、エッジが k 個以上のノード が残る。グラフがなくなった場合は、ノードを削除した作業の逆順をたどって彩 色することで、もとのグラフは k 色で彩色することができる。エッジが k 個以上 ノードが残った場合は、k 色で彩色できないので、実レジスタ数以下ではレジスタ
割り付けは行えない。そこで、残ったノードが表す仮想レジスタを1つスピルし、
また上記の作業をやり直す。
実際に図5の例で上記の作業を実行してみる。まずレジスタが3個以上あった場 合、エッジが2個以下のノードであるノード b,d,e とそのノードにつながるエッジ を削除することができる。そうすると、残ったノードはa,cのみとなり、このノー ドにつながるエッジはどちらも1個なので、残ったノード a,c も削除することが でき、グラフはなくなったので、3色で彩色することが可能であることがわかる。
また、レジスタが2個しかない場合、エッジが1個以下のノードであるノードと そのノードにつながるエッジを削除するがこの場合、削除できるノードは存在し ない。よってこのグラフは2色では彩色ができないことが分かり、スピルを行う必 要がある。この場合ノード c が表す仮想レジスタをスピルすると、残ったノード
は a,b,d,e となり、ノード b,d,eはエッジが1個なので削除することができる。そ
して、ノード aだけが残るので、ノードa も削除することができる。このように スピルすることで、そのままでは削除できないグラフも削除することができるよ うになる。
このようにスピルすることで、スピルされた仮想レジスタを表すノードはレジ スタ干渉グラフから削除でき、そのノードにつながるエッジも削除することがで きるので、より少ない色数でレジスタ干渉グラフを彩色することができる。k色で 塗り分けられない時は、スピルして、k 色で塗りなおす。それでも k 色で塗れな い時は、k 色で塗り分けられるようになるまで スピルを繰り返す。ここで、図5 の場合でレジスタが2個しかなかった場合を考える。この場合2色では塗ることは できない。よって変数 c をスピルする。そうすると、図7のように変数 c は他の 変数と干渉しなくなり、他の変数を表すノードへのエッジを削除することができ、
レジスタ干渉グラフは2色で塗ることができるようになる。
2.5 スピルコスト
しかし、レジスタに比べメモリの速度性能は低いので、スピルする事でメモリ へのアクセスが増え、またスピルするために余分な命令が増えるので、実行速度 は低下する。よって、スピルはできるだけ少ない方がよく、また頻繁に使用される レジスタをスピルするのは効率が悪い。よってどの仮想レジスタをスピルするべ きかを選択することが重要になってくる。そこで、Chaitinは、スピルコストとい う低い値を示す程スピルした際にスピルコードが少なくてすむような値を定めた。
スピルする際は、このスピルコストが低い仮想レジスタからスピルしていく。
図 7: c をスピルした場合のレジスタ干渉グラフ
スピルコストは次の式から求めていく。ただし、すべての命令が1マシンサイク ルで実行され、かつループ内の命令実行時間は同命令のループ外命令実行時間の 10倍である、と仮定している。この条件下で、ノードn のスピルコストを次の図 8から求める。
図 8: スピルコストを求める方程式
スピルする際は、このスピルコストをすべての仮想レジスタについて求め、ス ピルコストの低い仮想レジスタからスピルし、レジスタ割り付けを行う。
2.6 グラフ彩色法の問題点
従来のグラフ彩色法[5][6][7]では、プログラムの関数ごとにレジスタ干渉グラフ を作成している。そのため、スピルが発生した際、作成し直すレジスタ干渉グラ フのサイズが大きくなっている。スピルされる仮想レジスタの生存区間が非常に 短かったとしても関数全体のレジスタ干渉グラフを作成し直さなければならない。
更に、何度もスピルが発生すると、そのスピルの回数分だけ関数全体のレジスタ 干渉グラフを作成し直さなければならない。これは非常に無駄な作業であり、コ ンパイル速度の低下を引き起こす原因となる。
3 本手法
3.1 目的
グラフ彩色法の問題点でも述べたように、従来のグラフ彩色法では、プログラ ムの関数ごとに対してレジスタ干渉グラフを作成している。この方法では、スピ ルが発生した際に関数全体のレジスタ干渉グラフを作成し直す必要があり、コン パイルに時間がかかってしまう。スピルされる仮想レジスタの生存区間が短い場 合や、何度もスピルが発生した時は非常に無駄な作業となっている。よって本研 究では、プログラムの関数を複数に分割し、そのブロックごとにレジスタ干渉グ ラフを作成する。こうすることで、スピルが発生した際に作成し直すレジスタ干 渉グラフのサイズを小さくし、コンパイル速度を高速にする。
3.2 概要
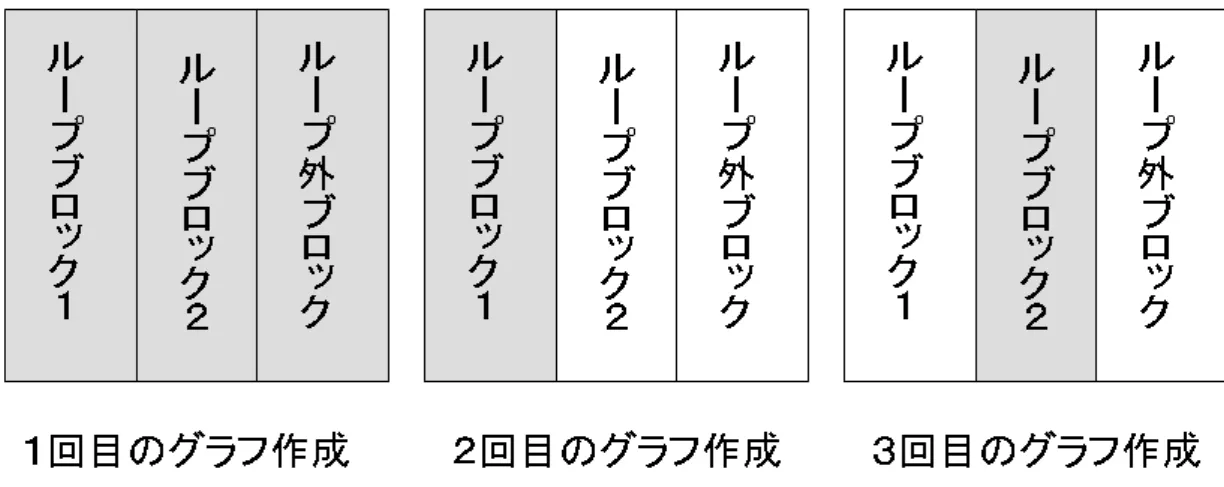
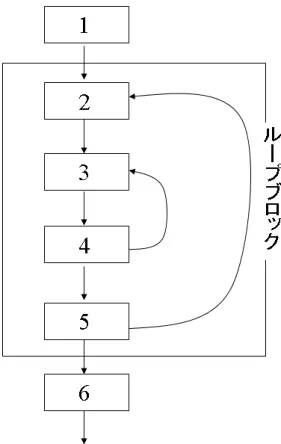
まず本手法では、プログラムの関数を複数に分割する。その分割する基準はプ ログラムのループとする。ループには多重ループも存在するが、本手法では、そ のループ全てには着目せず最も外側のループだけに着目し、最も外側のループに よって関数を分割する。ループのブロックをループブロックとして、複数のループ ブロックを作成する。そして、ループブロックに属さない部分を全てまとめて一 つのループ外ブロックとする。図9はベーシックブロック番号1〜6からなる関数 をループブロックとループ外ブロックに分割した例である。
図9では、ベーシックブロック2〜5がループとなっており、そのループ内でさら にベーシックブロック3、4がループとなっている。本手法では、最も外側のルー プにのみ着目するので、ここでは、ベーシックブロック2〜5がループブロックと なる。そして、ループブロックに属さなかったベーシックブロック1と6がループ 外ブロックとして1つのブロックとなる。そして本手法では、このブロックごとに レジスタ干渉グラフを作成する。これにより、スピルが発生した際、作成し直す必 要があるブロックだけを作成し直すことができ、関数全体を作成し直す必要がな くなる。よって、レジスタ割り付けにかかる時間が短くなり、コンパイル速度を向 上させることができる。
また、ループブロックを作成することによって、ループブロックの始めから終 わりまでブロックを貫いて生存しているにも関わらず、そのループブロックで一 度も参照されない仮想レジスタが存在することがある。このような仮想レジスタ をスルーしている仮想レジスタと呼ぶことにする。スルーしている仮想レジスタ
図 9: 関数をブロックに分割する例
は、そのブロックにおいて参照されないので、レジスタに割り付けられている必 要はない。さらに、スルーしている仮想レジスタがレジスタに割り付けられるこ とで、そのブロックで参照される仮想レジスタがスピルされる可能性が出てくる。
よって、本手法では、スルーしている仮想レジスタはレジスタ干渉グラフから除 去して、レジスタに割り付けないようにする。スルーしている仮想レジスタの例 を図10に示す。
図10をあるループブロックだけの生存区間解析の結果を切り取ったものとして 考えると、図10では、仮想レジスタc はブロックの始めから終わりまで生存して いて、一度も参照されていないのでスルーしている仮想レジスタである。図10を 見て分かるように、スルーしている仮想レジスタは、一度も参照されていないに も関わらず、全ての仮想レジスタと干渉している。よって、スルーしている仮想レ ジスタをレジスタ干渉グラフから除去することは、確実にレジスタ干渉グラフの
図 10: スルーしている仮想レジスタの例
干渉度を減らすことができ、非常に有効であると考えられる。このように、スルー している仮想レジスタをレジスタ干渉グラフから除去することで、ループブロッ クの仮想レジスタ数と干渉度を減少させることができ、レジスタ干渉グラフのサ イズを小さくすることができ、よりコンパイル速度を向上させることができる。
3.3 アルゴリズム
本手法を実現するにあたり、COINSコンパイラ[11]を用いた。COINSとは、新 しいコンパイラ方式を容易に実験、評価できるような共通インフラストラクチャ (COINS: A compiler infra structure)である。その基本は、高水準中間表現(HIR:
High level intermediate representation) と低水準中間表現(LIR: Low level inter- mediate representation) からなり、ソース言語からHIRへの変換部、HIRでの各 種最適化部、HIRからLIRへの変換部、LIRでの各種最適化部、LIRからマシン 語への変換部を適当に組み合せることによってコンパイラを実現出来る。
COINSでは、従来のグラフ彩色法によるレジスタ割り付けを行っている。よっ て、まず関数のループ情報を取り出し、最も外側のループのみを識別し、そのルー プに含まれるベーシックブロックをループブロックとした。こうして、ループが 複数ある場合は、複数のループブロックを作成し、ループブロックに含まれなかっ たベーシックブロックの全てをループ外ブロックとして1つのブロックとした。
しかし、1つの関数を複数のブロックに分けてレジスタ干渉グラフを作成したた め、今まではなかった問題も発生した。複数のブロックにまたがって生存してい る仮想レジスタがブロックごとに異なるレジスタに割り付けられる可能性がある。
これに関して、図11を見てみる。
図 11: 複数のブロックにまたがって生存する仮想レジスタの例
この図は、ベーシックブロック番号1〜7までが存在している関数である。ベー シックブロック番号2〜4がループブロックで、ベーシックブロック番号1と5〜
7がループ外ブロックである。ここで、仮想レジスタ a と c はループブロックと ループ外ブロックにまたがって生存している。従来手法なら、この関数に対してレ ジスタ干渉グラフ1個を作成するので、スピルされない限り a も c も1つずつレ ジスタに割り付けられる。しかし、本手法だとa や c はループブロックで割り付 けられるレジスタとループ外ブロックで割り付けられるレジスタが同じになると
で、本手法では、こういった複数のブロックにまたがって生存している仮想レジス タを1つのレジスタに割り付けていることは困難である。よってブロックの前後に MOVE 命令を挿入することにした。こうすることで、ブロックごとに異なるレジ スタに割り付けられても、複数のブロックにまたがって生存している仮想レジス タの値を受け渡すことを可能にした。
また、本手法を実現するためにスルーしている仮想レジスタを見つけ出す必要 がある。スルーしている仮想レジスタは、あるループブロックの始めと終わりで 生存していて、かつそのループブロックで1度も参照されないものである。これを 見つけ出すには、ループブロックの終わりは調べる必要はなく、ループブロックの 始めで生存していて、そのループブロックで1度も参照されないものを見つけるだ けでよい。ループブロックで1度も参照されていないのにループブロックの始めで 生存いるということは、ループブロックの終わりでも生存していることは自明だ からである。こうして、スルーしている仮想レジスタを見つけ出すことができる。
スルーしている仮想レジスタを見つけ出すことはできたので、この仮想レジスタ をレジスタ干渉グラフに含めないようにすることで、レジスタ干渉グラフの仮想 レジスタ数と干渉度を下げることができる。
3.4 レジスタ干渉グラフ作成のオーダー
COINSコンパイラにおいて、レジスタ干渉グラフを作成オーダーは、関数の命
令数と仮想レジスタの数の積である。これはレジスタ干渉グラフの仮想レジスタ がそれぞれ干渉している仮想レジスタの数の合計と同じであり、また、レジスタ 干渉グラフのエッジの数の2倍と同じである。しかし実際は、レジスタ数不足に よりスピルが発生することがある。スピルが発生するとレジスタ干渉グラフを作 り直す必要があるので、オーダーは関数の命令数と仮想レジスタの数とスピルの 回数の3つの積となる。ここで、本手法はブロックごとにレジスタ干渉グラフを 作成しているので、スピルが発生したブロックのみを作成し直すだけでよいので、
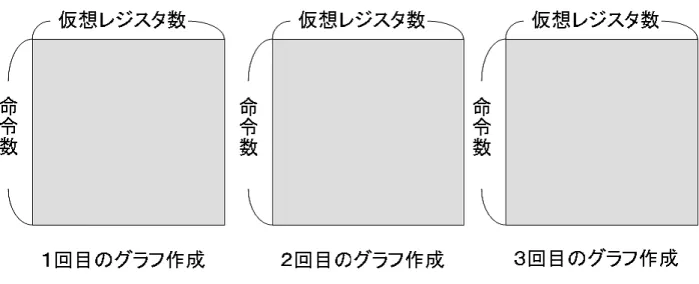
従来手法よりも高速にコンパイルすることができる。レジスタ干渉グラフの作成 のオーダーを図にしたものを図12と図13に示す。どちらも2回スピルが発生した 例を想定している。
図12はスピルが2回発生しているので、関数全体のレジスタ干渉グラフを合計 3回作成している。よって、レジスタ干渉グラフの作成にかかる時間は色のついた 部分の面積で表される。
図13はループブロック1とループブロック2でそれぞれ1回ずつ、合計2回ス ピルが発生している。1回目のレジスタ干渉グラフの作成では、関数全体のレジス
図 12: 従来手法のレジスタ干渉グラフ作成のオーダー
タ干渉グラフを作成しているが、2回目のレジスタ干渉グラフ作成では、ループブ ロック1のレジスタ干渉グラフのみの作成ですんでいる。また、3回目のレジスタ 干渉グラフでも、ループブロック2のレジスタ干渉グラフのみの作成ですんでい る。よって、本手法ではレジスタ干渉グラフの作成にかかる時間は図13の色のつ いた部分の面積で表される。
スピルが発生した際に、スピルが発生したブロックのレジスタ干渉グラフのみ を作成し直すことができるので、本手法は従来手法に比べ高速にコンパイルでき ることが分かる。
図 13: 本手法のレジスタ干渉グラフ作成のオーダー
4 実験 1
本章では、本手法を適用した際に、どの程度コンパイルが高速になるかの理論 値を求める。レジスタ干渉グラフの作成からレジスタ干渉グラフの彩色までのに かかる時間を計算し、理論上どれくらい高速になるのかを実験する。理論上のコ ンパイル速度を求めるために従来手法と本手法それぞれにおいて、作られるレジ スタ干渉グラフのサイズの合計を比較する。
4.1 レジスタ干渉グラフのサイズの比較
本手法をバブルソートを行うプログラムに対して適用した際、どの程度コンパ イルが高速になるかを実験した。
4.1.1 実験方法
COINSコンパイラ(Ver.1.4.2.2)を用いて、バブルソートのプログラムをコンパ
イルし、そのプログラムの中間表現の情報を用い、生存区間解析を行った。この 生存区間解析の結果から、レジスタ干渉グラフを作成した。この時、従来手法の ように関数ごとにレジスタ干渉グラフを作成したものと、本手法を用いたループ を基準として関数を分割し、そのブロックごとにレジスタ干渉グラフを作成した ものの2通りでレジスタ干渉グラフを作成した。このレジスタ干渉グラフに対し て、coalesce、simplify、スピルを行い、レジスタ干渉グラフのノードに対して彩 色する直前までの工程において、どの程度時間がかかるかを計測した。また、環 境としてレジスタ数を4つと仮定する。レジスタ干渉グラフを作成するオーダー は、命令数と仮想レジスタの積であり、それは、各仮想レジスタが干渉している仮 想レジスタの数で表される。そして、この各仮想レジスタが干渉している仮想レ ジスタの数をレジスタ干渉グラフのサイズと呼ぶことにする。また、スピルが発 生すると、スピルされた仮想レジスタを表すノードを削除したレジスタ干渉グラ フを作成する。よって、本実験では、レジスタ干渉グラフが彩色されるまでに作 成された全てのレジスタ干渉グラフのサイズの合計を求めることによって、従来 手法と本手法のコンパイル速度を比較する。
4.1.2 従来手法での実験
まず、従来手法で実験を行った。バブルソートのプログラムをCOINSコンパイ ラでコンパイルを行い、プログラムの中間表現の情報から生存区間解析を行った。
その結果が、図14である。
図 14: 生存区間解析の結果
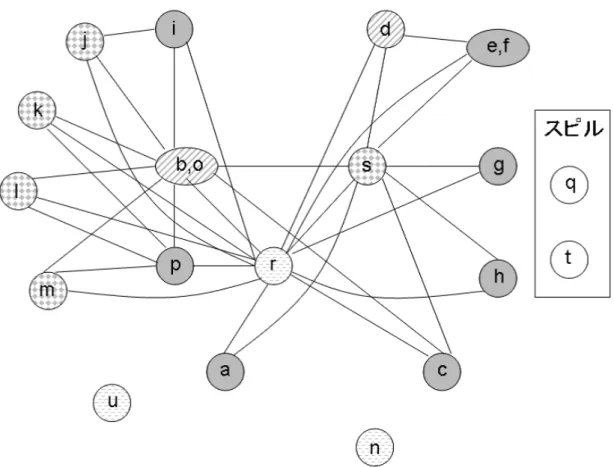
図14から分かるように、実験で用いたバブルソートのプログラムはa〜uの21 個の仮想レジスタが使われている。また、図14のdefとは、その仮想レジスタが 定義された場所を示しており、useは、その仮想レジスタが参照されている場所を 示すものである。そして、仮想レジスタごとの線は、その仮想レジスタが生存し ている区間を示している。この生存区間を見ることによって、どの仮想レジスタ
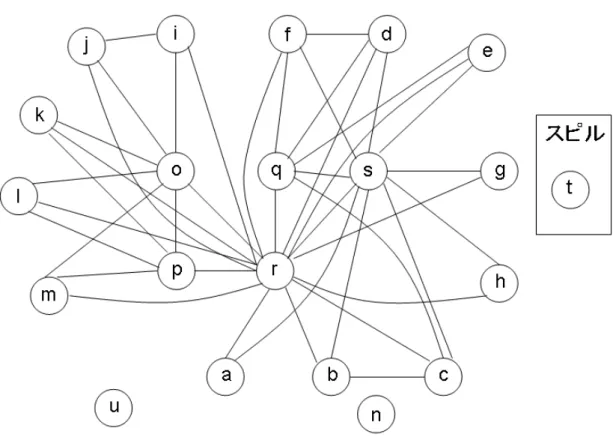
がどの仮想レジスタと干渉しているかが分かる。よって、生存区間解析の結果か らレジスタ干渉グラフを作成することができる。作成されたレジスタ干渉グラフ を図15に示す。
図 15: 従来手法でのレジスタ干渉グラフ
このレジスタ干渉グラフのサイズは122である。このレジスタ干渉グラフに対 して、レジスタ数が4つでは coalesce、simplifyを行っても全てのノードを削除す ることはできなく、仮想レジスタ t をスピルすることになる。仮想レジスタ t を スピルしたレジスタ干渉グラフは、図16となる。
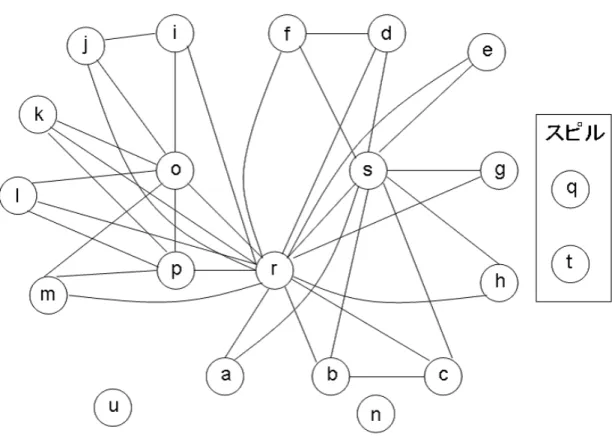
このレジスタ干渉グラフのサイズは84である。そして、このグラフに対しても スピルを行う必要がある。ここでは、仮想レジスタ q がスピルされる。仮想レジ
図 16: tをスピルしたレジスタ干渉グラフ
このレジスタ干渉グラフのサイズは72である。このレジスタ干渉グラフに対し、
coalesce、simplifyを行うと、全てのノードを削除することができ、4色でグラフを
彩色できることになる。
この3つのレジスタ干渉グラフの合計のサイズは、278となり、これが従来手法 でのレジスタ干渉グラフ作成の時間となる。また、彩色したレジスタ干渉グラフ を図18に示す。
4.1.3 本手法での実験
本手法を適用した実験では、まずプログラムの関数をループを基準としてルー プブロックとループ外ブロックに分割する必要がある。プログラムの中間表現の
図 17: t,qをスピルしたレジスタ干渉グラフ
情報により、バブルソートのプログラムのコントロールフローグラフを作成した。
このコントロールフローグラフから各ループが求まるので、ここからループブロッ クを作成する。このコントロールフローグラフを図19に示す。
ベーシックブロック番号2など、存在しないベーシックブロック番号があるが、
それはコンパイル時の最適化により削除されたものである。図19から分かるよう に、この実験で用いたバブルソートのプログラムは、ベーシックブロック番号3〜
8と、10 〜 17、13 〜 16の3つのループが存在する。しかし、ベーシックブロッ
ク番号13〜 16は、10〜 17のループ内に存在している。本手法では、最も外側 のループのみに着目するので、ベーシックブロック番号 13 〜 16のループに関し ては着目しない。よって、バブルソートのプログラムは、ベーシックブロック番号 3 〜 8をループブロック 1、ベーシックブロック番号 10〜 17をループブロック
図 18: 彩色したレジスタ干渉グラフ
2、残りのベーシックブロック番号1、18〜 21をループ外ブロックとした、3つ のブロックに分割することができる。よって、本手法では、このループブロック1
、ループブロック2 、ループ外ブロックごとにレジスタ干渉グラフを作成する。
関数をブロックごとに分割したことに伴い、生存区間解析の結果もこのブロック ごとに分けておく。ブロックごとに分けた生存区間解析の結果を図20に示す。
ここで、さらに本手法ではスルーしている仮想レジスタをレジスタ干渉グラフ に含めないので、スルーしている仮想レジスタを見つける必要がある。まず、ルー プブロック1に関して、ブロックの始めで生存している仮想レジスタは、rとsと t である。仮想レジスタ s と t はループブロック 1 で参照されているが、仮想レ ジスタr は 1度も参照されていない。よって、ループブロック 1では、仮想レジ スタr がスルーしている仮想レジスタであることが分かる。次にループブロック
図 19: コントロールフローグラフ
2であるが、ブロックの始めで生存している仮想レジスタは、rと tである。仮想 レジスタr はループブロック 2で参照されているが、仮想レジスタt は 1度も参 照されていない。よって、ループブロック2 では、仮想レジスタ t がスルーして いる仮想レジスタであることが分かる。
これらの結果から、各ブロックに対してレジスタ干渉グラフを作成することが できる。ループブロック1 では仮想レジスタ r を、ループブロックでは仮想レジ スタt を含めずにレジスタ干渉グラフを作成した。その結果が、図21である。
図21の通り、本手法では 3 つのレジスタ干渉グラフが作成された。レジスタ干 渉グラフのサイズは、ループブロック 1 が 50 、ループブロック 2 が 34 、ルー プ外ブロックが 2 である。よって、レジスタ干渉グラフのサイズの合計は86と なる。しかし、ループブロック1 のレジスタ干渉グラフはレジスタ数が4 つでは
図 20: 本手法での生存区間解析の結果
coalesce、simplifyを行っても全てのノードを削除することはできなく、仮想レジ
スタ k をスピルすることになる。仮想レジスタ k をスピルしたレジスタ干渉グラ フは図22となる。
このレジスタ干渉グラフのサイズは 30 である。このレジスタ干渉グラフに対 し、coalesce、simplifyを行うと、全てのノードを削除することができ、4色でグラ フを彩色できることになる。また、彩色したレジスタ干渉グラフを図23に示す。
よって、本手法のレジスタ干渉グラフの合計のサイズは 116 となり、従来手法 のレジスタ干渉グラフの合計サイズの 278 よりも小さくなった。以上の結果を図 24にまとめる。
図 21: 本手法でのレジスタ干渉グラフ
このレジスタ干渉グラフのサイズがレジスタ干渉グラフの作成にかかる時間に なるので、本手法の方が従来手法よりコンパイルが速くなることが分かる。
4.2 他のプログラムでの実験
また、本手法の有効性を示すため、他のプログラムにおいても実験を行った。整 数要素の行列の掛け算を行うプログラムと再帰的に配列上の値の入れ替えを行う プログラムである。これらのプログラムに対し、バブルソートで行った方法と同 じ手法で実験を行った。行列の掛け算を行うプログラムに従来手法と本手法を適 用した結果を図25に示す。
従来手法 458、本手法 254 と行列の掛け算を行うプログラムにおいても、本手
法の方が従来手法よりも速くなった。続いて、順列生成を行うプログラムに従来 手法と本手法を適用したの結果を図26に示す。
こちらは、従来手法 176、本手法 175とほとんど変わらない結果となった。
図 22: kをスピルしたレジスタ干渉グラフ
4.3 考察
バブルソートのプログラムと行列の掛け算を行うプログラムにおいては、本手 法を用いることにより、コンパイル速度は飛躍的に向上した。しかし、配列上の値 の入れ替えを行うプログラムにおいては、従来手法とほとんど同じコンパイル速 度となった。この原因を追究する。
図24と図25を見ると、複数のブロックのレジスタ干渉グラフがある程度のサイ ズを持っている。しかし、図26を見るとループブロック 1のレジスタ干渉グラフ が全体のほとんどのサイズを占めていて、ループ外ブロックのレジスタ干渉グラ フのサイズは全体からして微々たるサイズである。本手法で関数を複数のブロック に分割しても、このように一つのブロックのレジスタ干渉グラフにほとんどの干 渉情報が集まってしまうと本手法のメリットがなくなってしまう。
よって、本手法は、1 つのブロックに干渉情報が集まっているプログラムに対し てはメリットがなく、複数のブロックに干渉情報が分散しているものに対して有効 性を発揮することが分かる。
図 23: 彩色したレジスタ干渉グラフ
図 24: バブルソートの結果
図 25: 行列の掛け算を行うプログラムの結果
図 26: 順列生成を行うプログラムの結果
5 実験 2
本研究の有効性を調べるために、本手法を実装したコンパイルを用いて実験を 行った。
5.1 実装
本手法を実装するにあたり、COINSコンパイラ(Ver.1.4.2.2)を改良することで、
本手法のシステムを構築した。基本的なレジスタ割り付けのアルゴリズムはCOINS コンパイラと同じで、ループブロックを作成し、ループブロックをスルーしてい る仮想レジスタを除き、そのブロックごとにレジスタ干渉グラフを作成するもの である。
5.2 実験方法
本手法を実装したコンパイラと従来手法としてCOINSコンパイラ(Ver.1.4.2.2) を用いて、実験1で用いたバブルソートのプログラム、行列の積を求めるプログ ラム、順列生成を行うプログラムの三つに加え、スタンフォードのベンチマーク プログラムをコンパイルした。本手法では、ループブロック作成時間とレジスタ 干渉グラフの作成から仮想レジスタを実レジスタへ割り付ける直前までの時間の 合計を求めた。COINSコンパイラでは、レジスタ干渉グラフの作成から仮想レジ スタを実レジスタに割り付ける直前までの時間を求めた。この 2 つの時間を比較 することで、従来手法と本手法のコンパイル速度を比較する。
ここで実験環境を図27に示す。
図 27: 実験環境
5.3 実験結果
従来手法、本手法共に4つのプログラムを20回ずつコンパイルし、その平均の 時間を求めた。その平均時間をグラフ、表にしたものが図28である。
図 28: 実験結果
図28のようにバブルソートのプログラムでは約6 %、行列の積を求めるプログ ラムでは約 14%、スタンフォードのベンチマークプログラムでは約 18%コンパ イル速度は向上した。しかし、順列生成を行うプログラムにおいては、約17%コ ンパイル速度が低下してしまった。
5.4 考察
バブルソートのプログラムと行列の積を求めるプログラムにおいては、レジスタ 干渉グラフのサイズの比較の結果同様、従来手法よりも本手法の方がコンパイル 速度は向上した。しかし、レジスタ干渉グラフのサイズの比較の結果では、では約 50%コンパイル速度が速くなったのに対し、この実験においてはそこまでのコン パイル速度の向上は見られなかった。これは、本手法では、関数をブロックに分け る作業を追加したり、スルーしている仮想レジスタを除去する作業など、COINS コンパイラが行っていない作業をしているためと考えられる。レジスタ干渉グラ フのサイズの比較は行っていないが、スタンフォードのベンチマークプログラム においても本手法の方がコンパイル速度は上昇した。また、順列生成を行うプロ グラムにおいては、COINSコンパイラよりも本手法の方がコンパイル速度は低下 してしまった。これは、レジスタ干渉グラフのサイズの比較の結果でも、従来手 法と本手法のグラフサイズはほとんど同じであった。このため、ループブロック を作成したり、スルーしている仮想レジスタを除去する作業を行っているため、本 手法の方が遅くなったと考えられる。また、本実験においては、どのプログラム に関してもスピルが発生したが、スピルが発生しないプログラムを想定すると本 手法を用いるとコンパイル速度は低下すると考えられる。それは、本手法は関数 を複数のブロックに分割し、そのブロックごとにレジスタ干渉グラフを作成する ことで、スピルが発生した時に作成し直すレジスタ干渉グラフのサイズを小さく することで、コンパイル速度を向上させるからである。
5.5 結論
実験結果、考察により、本手法は従来手法に比べて常に速くなるわけではなく、
遅くなる場合もあることが分かる。
本手法は 1 つのブロックに干渉情報が集まっているプログラムには有効ではな い。1つのブロックに干渉情報が集まっているプログラムでは、本手法で作成され るレジスタ干渉グラフは、従来手法で作られるレジスタ干渉グラフとほぼ同様の サイズになってしまい、関数をブロックに分割しているメリットがなくなってしま う。具体的には、1つのループで関数全体のほとんどの作業をしているプログラム や、ループ内でほとんど仮想レジスタを使用しないプログラムなどである。また、
関数を複数のブロックに分割する作業やスルーしている仮想レジスタを除去する 作業を行っているため、そのようなプログラムに対して本手法を適用すると、従
来手法よりコンパイル速度が低下してしまう。また、スピルが発生しないプログ ラムにおいてもコンパイル速度は低下してしまう。
本手法は、複数のブロックに干渉情報が分散されているプログラムで、スピル が発生するプログラムに対して有効である。
6 おわりに
以上の結果をもとに、まとめと今後の課題について述べる。
6.1 まとめ
グラフ彩色法を用いたレジスタ割り付けは、プログラムの関数ごとにレジスタ 干渉グラフを作成している。そのため、スピルが発生した際に関数全体に関する レジスタ干渉グラフを作成し直す必要がある。スピルされる仮想レジスタがその 関数の一部でしか生存していなくても関数全体のレジスタ干渉グラフを作成し直 している。よって、スピルが発生した際に作成し直すレジスタ干渉グラフのサイズ が大きくなっており、これが高速なコンパイルへの妨げになると考えた。よって、
本論文では、ループを基準としてプログラムの関数を複数のブロックに分割し、そ のブロックごとにレジスタ干渉グラフを作成した。こうすることで、スピルが発生 した際に、スピルが発生したブロックのレジスタ干渉グラフだけを作成し直すこ とができ、他のブロックのレジスタ干渉グラフは作成し直す必要がなくなる。ま た、ループブロックを作成することにより、ループブロックをスルーしている仮 想レジスタが存在するようになった。このスルーしている仮想レジスタはレジス タに割り付けている必要はないので、スルーしている仮想レジスタをレジスタ干 渉グラフから除去した。これにより、レジスタ干渉グラフのサイズを小さくなり、
またスピルによるレジスタ干渉グラフの作成し直す回数も減少させることができ た。よって、作成し直すレジスタ干渉グラフのサイズを小さくし、レジスタ干渉 グラフの作成時間を短くすることができ、コンパイルを高速化することができる。
しかし、本手法はどのような状況においても有効なわけではなく、本手法を適 用することによりコンパイル速度が低下することもある。本手法が有効なプログ ラムは、仮想レジスタの干渉情報が複数のブロックに分散しているようなプログ ラムである。逆に 1 つのブロックに干渉情報が集中しているようなプログラムで は、本手法を適用するとコンパイル速度が低下してしまう。
6.2 将来課題
本手法を適用することで、複数のブロックに干渉情報が分散しているプログラ ムのコンパイル速度は向上したが、1つのブロックに干渉情報が集中しているプロ グラムではコンパイル速度は低下してしまった。よって、今後はループブロックよ
りも効果的な分割方法について検討し、より高速なコンパイルが可能なコンパイ ラについて検討していく予定である。
謝辞
本研究を進めるにあたり、数々のご指導を頂いた深澤良彰教授、本当に多くの御 指導・御助言を賜った、日本IBM(株)東京基礎研究所の小松秀昭氏、古関聰氏 に深く感謝致します。
また、研究に際して非常に多くのアドバイスをいただいた最適化班の片岡さん、
中林君、本当にありがとうございました。
最後になりましたが、大学4年間、修士2年間まで何不自由なく勉学をさせてい ただいた両親に深く感謝いたします。本当にありがとうございました。
参考文献
[1] andrew w.appel:modern compiler implementation in java
[2] G.J.Chaitin,M.A.Auslander,A.K.Chandra.J.Cocke,M.E.Hopkins,and P.W..Markstein:”Register allocation via coloring”,Language,6:47-57,1981 [3] G.J.Chaitin.Register Allocation and spilling via graph coloring.In Proceedings
of the ACM SIGPLAN 1982 Symposium on Compiler Construction,pages 201- 207,1982
[4] R.Sethi. Complete register allocation problems. SIAM Journal on Computing,4(3):226-248,1975
[5] D.Callahan and B.Koblenz:”Register allocation via hierarchical graph color- ing”,In Proceedings of the ACM SIGPLAN 1992 Conference on Programming Language Design and Implementation,pages 192-203,1991
[6] T.A.Proebsting and C.N.Fischer:Probabilistic register allocation”,In Proceed- ings of the ACM SIGPLAN 1992 Conference on Programming Language Design and Implementation,pages 300-310,1992
[7] A.Koseki,H.Komatsu,and T.Nakatani:”Preference-directed graph coloring”,In Proceedings of the ACM SIGPLAN 1992 Conference on Programming Lan- guage Design andImplimentation,pages 33-44,2002
[8] G.J.Chaitin,M.A.Auslander,A.K.Chandra,J.Clcke,M.E.Hopkins,and
P.W.Markstein.Register allocation via coloring.Computer Languages,6:47- 57,1981
[9] P.Briggs,K.D.Cooper,K.Kennedy,and L.Torczon.Coloring heutistics for regis- ter allocation.In Proceedings Language Design and Implementation,pages 275- 284,1989.
[10] 中田育男:”コンパイラの構成と最適化”,朝倉書店,1999 [11] http://www.coins-project.org/
業績
山崎 敬史,中林 淳一郎,片岡 正樹,古関 聰,小松 秀昭,深澤 良彰.”レジスタ干渉グ ラフの分割による高速化手法に関する研究”,情報処理学会第70回全国大会,March 13-15,(2008)
![図 6: 彩色したレジスタ干渉グラフの例 2.4 スピル レジスタ干渉グラフの彩色の過程で仮想レジスタをメモリに退避させる作業が あった。この、仮想レジスタをメモリに退避させる作業のことをスピル [3] という。 そして、スピルを行うコードをスピルコードという。 レジスタ干渉グラフが k 色で彩色できるかどうかを判定するにはレジスタ干渉 グラフの彩色で述べた coalesce、simplify を用いる。まず、simplify の手順をもう 少し詳細に述べる。レジスタ干渉グラフ G を k 色で彩色する問題](https://thumb-ap.123doks.com/thumbv2/123deta/9785850.1869106/12.892.323.572.233.490/レジスタレジスタレジスタレジスタスピルコードレジスタレジスタ.webp)
![図 10: スルーしている仮想レジスタの例 干渉度を減らすことができ、非常に有効であると考えられる。このように、スルー している仮想レジスタをレジスタ干渉グラフから除去することで、ループブロッ クの仮想レジスタ数と干渉度を減少させることができ、レジスタ干渉グラフのサ イズを小さくすることができ、よりコンパイル速度を向上させることができる。 3.3 アルゴリズム 本手法を実現するにあたり、COINS コンパイラ [11] を用いた。 COINS とは、新 しいコンパイラ方式を容易に実験、評価できるような共通イ](https://thumb-ap.123doks.com/thumbv2/123deta/9785850.1869106/18.892.345.541.215.568/ループブロッコンパイルアルゴリズムコンパイラコンパイラ.webp)