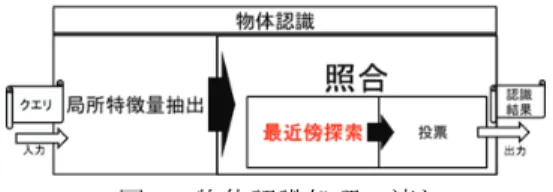
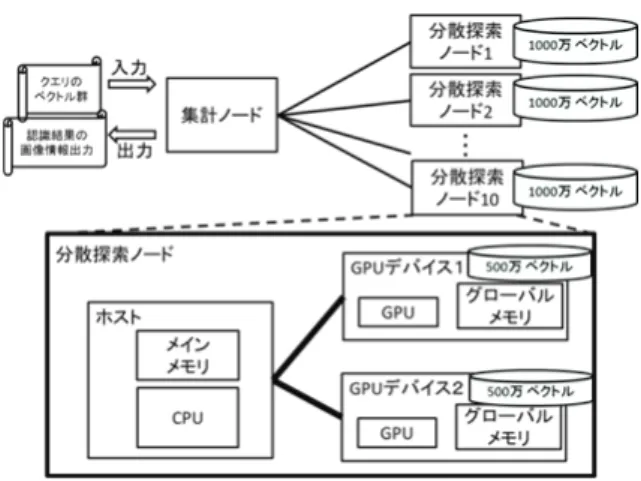
対して,DB ベクトルが 1 億個の場合の最近傍探索処理を 1 秒以内に処理することを目指す. 2. 従来技術と課題 2.1 従来技術 DB 中の画像群が大規模化すると,DB ベクトル群が大規模化する. 大規模化した DB ベクトル群を想定し, クエリベクトル数を 1000 個,DB のベクトル数を
8
0
0
全文
図

+2
関連したドキュメント
CN 割り込みが発生した場合、ユーザーは CN ピンに対応する PORT レジスタを読み出す
を軌道にのせることができた。最後の2年間 では,本学が他大学に比して遅々としていた
今回の授業ではグループワークを個々人が内面化
る、関与していることに伴う、または関与することとなる重大なリスクがある、と合理的に 判断される者を特定したリストを指します 51 。Entity
攻撃者は安定して攻撃を成功させるためにメモリ空間 の固定領域に配置された ROPgadget コードを用いようとす る.2.4 節で示した ASLR が機能している場合は困難とな
断面が変化する個所には伸縮継目を設けるとともに、斜面部においては、継目部受け台とすべり止め
が前スライドの (i)-(iii) を満たすとする.このとき,以下の3つの公理を 満たす整数を に対する degree ( 次数 ) といい, と書く..
新設される危険物の規制に関する規則第 39 条の 3 の 2 には「ガソリンを販売するために容器に詰め 替えること」が規定されています。しかし、令和元年
