博士論文
聴覚障害者のためのリアルタイム字幕
システムにおける話者顔情報と誤認識
字幕の呈示方法に関する研究
黒木 速人
2012 年 3 月
目次
第 1 章
序論
···1
1.1
情報保障という考え方 ···1
1.2
文字による情報保障と音声-文字変換システムへの期待 ···3
1.3
音声同時字幕システムの開発と対遠隔地運用の必要性 ···4
1.4
内容理解を向上させるためのノンバーバル情報の活用の可能性 ···5
1.5
本研究の目的···6
1.6
本論文の構成···6
参考文献 ···8
第 2 章
従来研究と本研究の位置付け
···11
2.1
はじめに ···11
2.2
聴覚障害者に対する情報保障手段 ···11
2.2.1
音自体を伝える情報保障手段 ···12
2.2.1.1 FM 補聴システム・赤外線補聴システム···12
2.2.1.2 磁気誘導ループ···13
2.2.2
音を別の伝達媒体に変換して伝える情報保障手段···14
2.2.2.1 手話通訳 ···14
2.2.2.2 文字通訳 ···15
2.3
音声認識技術の仕組み ···20
2.3.1
音声認識技術の歴史···21
2.3.2
音声認識技術の概要···21
2.3.3
音声特徴量の分析 ···23
2.3.5
サーチ···24
2.4
現在の音声認識技術の課題···24
2.5
音声認識技術を用いたリアルタイム音声-文字変換の取り組み···25
2.5.1
NHK(直接話者認識方式)によるニュース字幕···25
2.5.2
NHK(リスピーク方式)による生放送字幕 ···26
2.5.3
Julius を用いた直接話者認識による講義保障···28
2.5.4
その他の取り組み ···29
2.5.4.1 Liberated Learning Project ···29
2.5.4.2 JOIN-Project (Joint project Of IBM-Nagano university)···29
2.5.4.3 愛媛大学 ···29
2.6
まとめと本研究の位置付け···30
参考文献 ···32
第 3 章
遠隔型音声同時字幕システムの構築・運用・評価
···37
3.1
はじめに ···37
3.2
音声同時字幕システムの基本構成 ···38
3.2.1 ローカルシステムにおける実運用試験···40
3.2.1.1 精度 ···41
3.2.1.2 所要時間 ···43
3.2.2 ローカルシステムにおける実運用試験の結果 ···43
3.2.2.1 精度 ···43
3.2.2.2 所要時間 ···44
3.3
遠隔型音声同時字幕システム···44
3.3.1 ネットワークシステムにおける実運用試験···46
3.3.1.1 精度 ···46
3.3.1.2 所要時間 ···47
3.3.2 ネットワークシステムにおける実運用試験の結果···48
3.3.2.1 精度 ···48
3.3.2.2 所要時間 ···48
3.4
実運用試験結果の考察 ···49
3.4.1 精度 ···49
3.4.2 所要時間···52
3.4.3 実用的観点からの考察···53
3.5
まとめ ···55
参考文献 ···56
第 4 章 不完全文の内容理解向上を目的とした顔映像の呈示方法
··59
4.1
はじめに ···59
4.2
顔映像の呈示部位に関する実験···60
4.2.1 実験方法···60
4.2.2 実験結果···67
4.2.3 考察 ···70
4.3
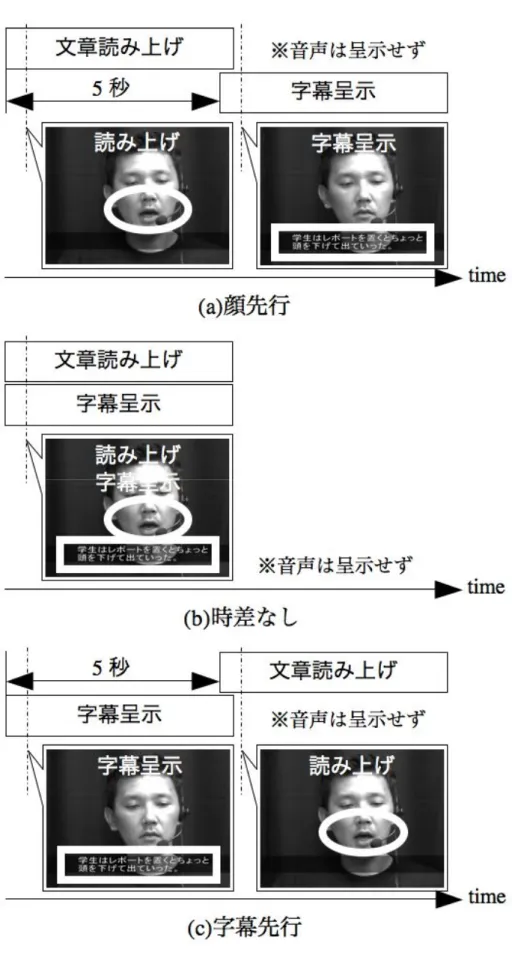
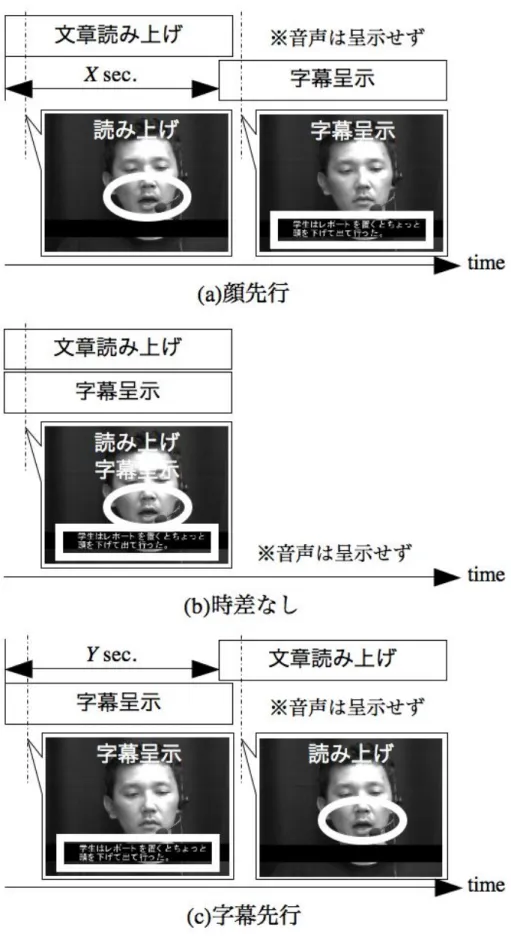
不完全文と顔映像の呈示タイミングに関する定性実験 ···72
4.3.1 実験方法···72
4.3.2 実験結果···74
4.3.3 考察 ···76
4.4
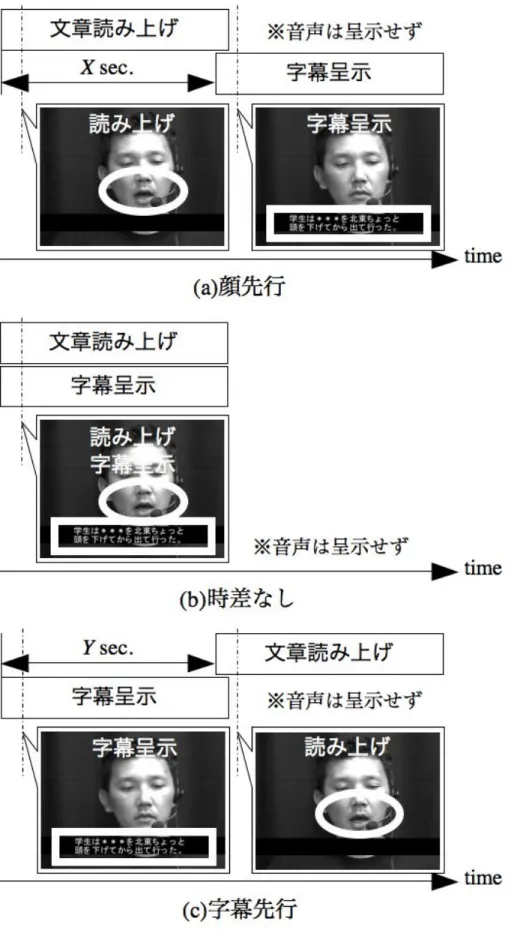
不完全文と顔映像の呈示タイミングに関する定量実験 ···77
4.4.1 実験方法···77
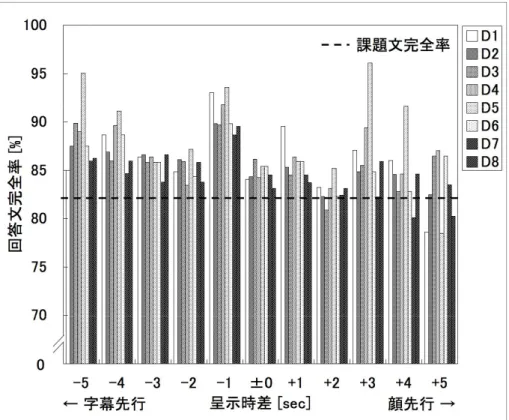
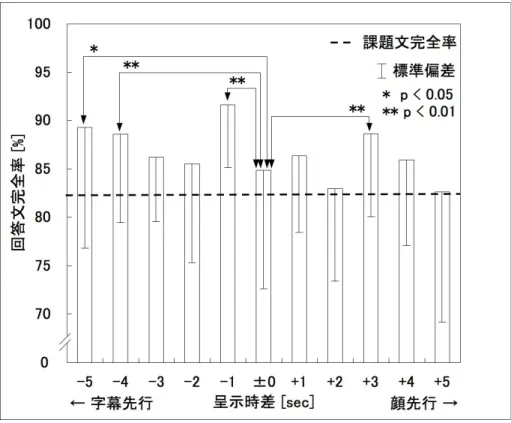
4.4.2 実験結果···82
4.4.3. 考察 ···87
4.4.3.1 複数情報呈示における呈示時差に関する従来研究 ···90
4.5
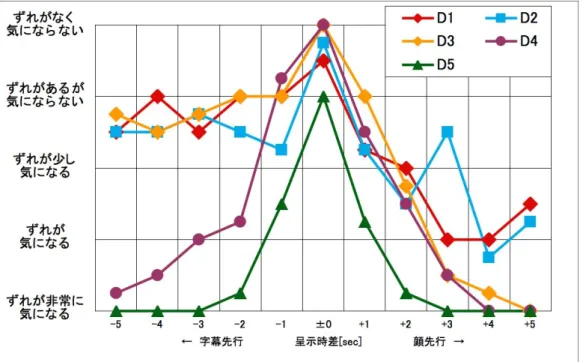
呈示時差の主観的許容に関する実験 ···91
4.5.1 実験方法···91
4.5.2 実験結果···94
4.5.3 考察 ···96
4.6
まとめ ···98
参考文献 ···100
第 5 章
結論
···103
5.1
本研究の結論···103
5.2
今後の展望 ···105
謝辞
···108付録 A
顔映像の呈示部位に関する定量実験 回答票···109
付録 B
不完全文と顔映像の呈示タイミングに関する定量実験 回答票 ···113
第 1 章
序論
1.1 情報保障という考え方
近年,国際会議,各種講演会,大学講義などの場面において,情報取得の障害とな る聴覚・視覚障害者に対する情報保障への考え方や取り組みが,一部の人達だけで行わ れる特別な取り組みではなく,社会一般でごく当たり前のものであると言う認識がよう やくなされるようになってきた.障害者は生来もしくは後天的に,その障害に起因する 情報を得られない,もしくは,得にくい状態にあると言える訳であるが,情報保障とは, それら障害により得られない,または,得にくい情報を「保障」すると言う考え方であ る.この背景には,1982 年(昭和 57 年)に国連で計画された「国連障害者の十年」を 初めとし,アメリカで 1990(平成 2 年)に制定された ADA 法[1]などの,障害者の人権 や社会参加に対する「権利」獲得の動向があげられる.特に ADA 法は,障害者に関す る雇用,移動等の公共サービスなどの社会活動における差別禁止を規定した法律として 知られ,アメリカではこの法律の制定により,バリアフリー関連の整備が急速に進んだ と言うことができる.日本においては,1993(平成 5 年)改定の障害者基本法[2],日 本の障害者施策の方向性を定めた障害者基本計画[3](2002 年(平成 14 年))や,視聴 覚障害者向け放送普及行政の指針[4],[5](2007 年(平成 19 年))などの動向があげられ, 「情報保障」と言う名前のとおり,会議・講義など,その場でやり取りされている「情 報」を「保障」すると言う,障害者が持つ「権利」に対して,ようやく健常者と同等に 保障する必要があると言う認識がされるようになって来たと言えよう. 情報保障を実現する手段としては,保障される対象となる障害者の障害の内容や障 害の程度により様々である.例えば,視覚障害者に対しては点字化・墨字拡大化した配 付資料を事前に用意したり,聴覚障害者に対してはその場でやり取りされている発言内第 1 章 序論 容などの音に関する情報を伝達するための手話通訳者や要約筆記者を配置したりする 必要がある.一般に,視覚障害者に対する情報保障は,配付資料等の配布物に対する保 障が多く,その場でやり取りされる言葉に指示語を避けるなどの注意をすれば,情報保 障手段としては「事前」に行うものが多い.また,聴覚障害者に対する情報保障は,そ の場でやり取りされる音と言う揮発で刻一刻と変化する情報に対する保障であるため, 情報保障手段としては「リアルタイム」に行うものが多い.どのような情報保障手段が 最適であるかは,被情報保障者の障害,その程度,生い立ち(障害背景)などにより様々 であり,一概には何が良いとは言えず,その場面に応じた対応手段で何が適切かを考慮 して提供する必要がある. 聴覚障害者に対して情報保障を行う場合,音自体から何らかの手がかりを積極的に 取得しようとする聴覚障害者に対する,音自体をなるべく雑音なくクリアに伝える方法 と,音自体からは何らかの手がかりを余り頼りにしない聴覚障害者に対する,音情報を 手話や文字言語(書記日本語)などの別の伝達媒体に変換して伝える方法に別けること ができる.これらの方法は単独で用いることもあれば,組み合わせで用いることもあり, 被情報保障者(聴覚障害者)が普段どのようなコミュニケーション様式(モード)を用 いているか等に応じて対応を考える必要がある. 音自体をなるべくクリアに伝達する方法には,発話者の音声をマイクで取得し,伝 送路で音を劣化させることなく,聴覚障害者に伝える方法が一般的である.これを実現 する方法としては,FM や近赤外線を用いた補聴システムなどがある.工学的な仕組み は基本的に同じである. 音情報を別の伝達媒体に変換して聴覚障害者に伝える方法として,最初に挙げられ るものとして手話通訳があろう[6].手話通訳とは,話者の話した内容を日本手話(場 合によっては日本語対応手話)により通訳を行う作業である.手話を習得しているろう 者に対して,話者が話した内容をリアルタイムに,かつ言語的なダイレクトさを持って 内容伝達できる点で,大きなメリットがある.しかしながら,聴覚障害者(ろう者,難 聴者,中途失聴者)の全てが手話を習得もしくは熟練しているとは限らず,難聴者,中 途失聴者や健聴者にとっては第二言語と言う意味で新たな言語の習得には困難が伴い, 聴覚障害者,健聴者の誰もが直ぐに使える情報保障手段であるとは言えない.また,手 話通訳において,内容の厳密性を保った情報保障をする際に,表現する者(情報保障者 (手話通訳者))と,それ読み取る者(被情報保障者(聴覚障害者))ともに高度な手話 言語技術を身につけていることが要求される. 一方,話者の話した内容を文字言語により表現する情報保障手段として文字通訳が ある.文字通訳には,音声を文字化させるための手技や方法論により,要約筆記(ノー トテイク)とパソコン要約筆記に別けることができる.要約筆記は手書き文字により内
第 1 章 序論 容をノートに記述(ノートテイク)し,パソコン要約筆記はキーボード入力により音声 を文字化させる.いずれも程度の差違はあるが,ある程度「要約」した内容を聴覚障害 者に伝える.これら文字通訳は,使用する文字言語(書記日本語)を習得している限り 有効な手段となり得るため,聴覚に障害を負った者の誰でも特別な訓練なく用いること のできる情報保障手段と言うことができよう.
1.2 文字による情報保障と音声-文字変換システムへの期待
高等教育支援では,初等,中等教育とは教育内容が大きく異なり,講義等において 伝達する内容の厳密性が非常に重要となる.そのため聴覚障害学生に対して,「厳密性」 を確保した情報保障手段が必要となる.内容伝達の「厳密性」を確保した情報保障手段 なると,手話通訳か文字通訳を用いる必要がある.しかしながら先述の通り,手話にお いては,通訳における訳出内容の厳密性と,厳密性を維持した内容の読み取りには,手 話通訳者側の訳出,聴覚障害者側の読み取りの双方において優れた手話言語力が要求さ れる.一方,文字通訳を情報保障手段に用いた場合,話者が話した内容をそのまま文字 化させることができると言う意味(異言語間の言語変換をしないと言う意味)において, 厳密性を維持したまま内容を伝えることが可能である.もちろん聴覚障害者の中には書 記日本語による「記述」や「読み取り」を不得意とする者もいるが,高等教育支援の現 場においては大学入試試験を突破する日本語能力を持つことが前提となるため,書記日 本語の記述,読解においては概ね問題の生じないレベルと行って良い.しかしながら, 文字通訳である要約筆記やパソコン要約筆記は,音声を文字化させるための手技,手法 の入力限界により,全ての音声を文字化させることができず,内容をある程度「要約」 せざるを得ない状況が生じる.言うまでもなく,内容が要約されればされるほど,内容 の厳密性は失われることになる.また,音声を文字化させる際の入力限界を克服するた めに,新しい入力装置を用いた方法などが開発されているが,いずれも特殊な入力装置 を用いているため,入力者に高い熟練度を要し,誰もが手軽に扱えるものではない. 一方,近年の PC(パーソナルコンピュータ)に関するハードウェアとしての処理能 力の発達とソフトウェアの情報処理技術の発達が相まって,音声認識技術の活用は身近 なものとなった.音声認識装置が持つ利点である,「音声入力による簡便さ(喋ること ができる人であれば誰でも音声入力者としての可能性を持つ)」や「文字化までのリア ルタイム性の高さ」を聴覚障害者の情報保障手段に積極的に活用しようとする取り組み がいくつかなされてきている[7],[8],[9].音声認識装置を用いることで,喋ることができ る人であれば誰でも音声入力者としてのポテンシャルを持つことから,話者の話した内 容を要約せず,高等教育で必要とされる厳密性を維持したまま,誰でも比較的簡便に音第 1 章 序論 声-文字変換できる可能性が出てきたと言える.
1.3 音声同時字幕システムの開発と対遠隔地運用の必要性
しかしながら,音声認識技術に関する現在の技術レベルでは,話者が代わる不特定 話者の認識や,話し言葉のようなルーズな文法構造に対する認識,未知語の認識などは 非常に難しく,音声認識装置を用いたとしても,いかなる状況においても支障なく音声 を文字化させることができる訳ではない[10].一方,自然発話である話し言葉に良く見 られるような[11],語の省略,倒置,フィラー(冗長語,不要語)が追加された文,多 少の誤りや未知語が含まれる文に対しても,ヒトは文脈,単語の前後関係や,ノンバー バル情報(話者の,表情,口の動き,ジェスチャー等)などから意味を類推して正しい 内容を理解することができる[12],[13].これには,曖昧な文であっても,様々な認知情 報から最終的に正しい内容を理解するヒトの優れた能力が大きく関与している. この様な背景のもと,音声を文字化させることの有効性に着目し,音声認識技術の 持つ利点とヒトの持つ認知特性を生かして音声-文字変換を行う,新しいタイプのシス テムを研究・開発している[14],[15].このシステムでは,ヒトと機械が得意とする領域 を生かし,逆にそれぞれが不得意とする領域を補う形で協調することで,最終的なパフ ォーマンスを向上させると言うコンセプトに基づいてシステムを構成している.現在ま でに,システムの字幕生成過程おける設計として,音声認識装置の弱点である不特定話 者認識,話し言葉認識,未知語処理を克服するために,復唱者による音声認識方式[16] と字幕修正者による音声認識結果修正方式[17]を同時に採用し,テストを兼ねた実運用 を通して,システム改良を行ってきた. 運用の当初においては,会場内部に運用スタッフとシステム機材の全てを持ち込む ローカル運用が主であったが,会場に全てを持ち込むのには,人員のスケジュール調整 はもちろん,会場までのスタッフの移動や機材の運搬,会場における機材の設営・撤収 が伴い,コスト高になることは容易に想像できる.そのため,実運用の初期段階から対 遠隔地運用を視野に入れた実運用試験を行う必要性が生じた.さらに,対遠隔地運用の ためにシステムをネットワーク化し,問題なく運用することができれば,復唱者・修正 者などがネットワーク上どこに存在しても運用することは理論上可能であるため,「誰 がどこにいても」稼働できる運用形態としての可能性が開けることになる.このことは, 車椅子利用者や視覚障害者などの移動困難な者にとっても対して,新たな職域を開拓す る可能性を開くことを意味する.そればかりか,障害者による障害者の支援と言った, 支援の新たな形態を開拓することになる.第 1 章 序論
1.4 内容理解を向上させるためのノンバーバル情報の活用の可能性
前節で述べたとおり,本システムではヒトと機械を協調させることによりシステム パフォーマンスを向上させると言うコンセプトに基づき,字幕生成過程において復唱者 による音声認識方式と字幕修正者による音声認識結果修正方式を同時に採用し,音声認 識装置単体がもつ弱点を克服する工夫をシステムに対し施してきた.しかしながら,こ の様に様々な設計をしても,最終的に得られる字幕の精度を 100%にさせることは困難 であった[15],[18].また,音声-字幕変換における処理時間は零でないために,真に リ アルタイム な字幕を提供できる訳ではなく,処理時間分の時間ずれ(時差)が 生 の 情報に対して生じることになる.現時点での実績では,字幕精度は日本語音声-日本語 字幕変換において最高で約 97%であり,処理時間は英語音声-英語字幕変換において最 速で約 4 秒と言う結果となっている[15].もちろん言うまでもなく,システムにこれだ けの成績を達成させるためには,それ相応のコストが要求される.この様に,現状の技 術と方法論を用いるだけでは字幕精度と処理時間に関して自ずと限界が生じるため,よ り高いパフォーマンスを要求する場合には,精度と処理時間に関するシステム上の限界 を踏まえた上で,システム全体としてのコントロール方法を改めて検討しておく必要が ある. もちろん言うまでもなく,字幕精度の向上や処理時間の短縮を達成するための基礎 技術に関する改善や改良は不可欠である.しかし,本システムのコンセプトである「ヒ トの能力の把握と活用」のコンセプトに立ち戻り,ヒトが内容理解をする際に字幕(文 字)であるバーバル情報以外でどのような情報を参照しているかを明らかにし,それら の知見を基に呈示された情報の内容理解を向上させるために活用することは重要であ ろう.バーバル情報以外の,内容理解を促進させることのできる情報とは,ヒトが 生 のコミュニケーションにおいて内容理解に用いている情報ではあるが,音声-字幕変換 過程を経ることにより(文字という離散記号化させることにより)欠落してしまう情報 であると言うことができる(本論文では,この,文字などの離散的な記号で一意に表現 できる情報以外の情報を「ノンバーバル情報」とする).これらバーバル情報やノンバ ーバル情報を混在させて呈示する際,適切な形で呈示しないと逆にヒトの内容理解を阻 害する恐れがある[19],[20],[21].つまり,これらバーバル・ノンバーバル情報の呈示に 関して適切な方法を探求する必要があると言える.これらの探求をすることで得られる, 情報の最適呈示方法,パソコン要約筆記など,文字により情報呈示を行う他の全ての文 字呈示方法に対しても有効な知見になる可能性があると言える.第 1 章 序論
1.5 本研究の目的
以上述べてきたとおり,本論文では,ヒトと機械が得意とする領域で協調し最終的 なシステムパフォーマンスを向上させると言うコンセプトに基づいて設計した音声同 時字幕システムにおいて,現在までの実運用試験を通して明らかになってきた課題を解 決し,システムのパフォーマンスを更に向上させるための方法に関して論ずる.具体的 には,いま一度システムコンセプトに立ち戻り,字幕生成過程のみならず字幕呈示過程 においてもヒトの能力を活用し,現状の復唱音声認識方式においても誤認識結果が生じ, 文としては完全でない不完全文となるバーバル情報と,音声-字幕変換と言う,音声を 離散的な文字記号に変換することで欠落してしまう話者の発話時におけるノンバーバ ル情報を,ヒトの内容理解を促進させる形で呈示する方法を模索する. 同時に,将来的なシステム運用を考慮し,対遠隔地運用のためにシステムをネット ワーク化した実運用試験を実施し,その結果とローカル運用における結果を比較評価し, 将来的な対遠隔地運用の可能性を探る.この対遠隔地運用は,車椅子利用者や視覚障害 者などの移動困難者による運用参加だけでなく,障害者による障害者支援システムの運 用の可能性も秘めると言えよう.1.6 本論文の構成
本論文は 5 章より構成される.以下,各章の概要を記す. 第 1 章「序論」では,ここまで述べてきたとおり,本研究に関わる背景と本研究の 目的および本論文の構成について示している. 第 2 章「従来研究と本研究の位置付け」では,聴覚障害者に対して行われる一般的 な情報保障手段に関して概略および分類し,それら情報保障手段の中で比較的新しい技 術として期待されている音声-字幕変換技術に関する従来技術と本研究との位置付けに 関して論ずる. 第 3 章「遠隔型音声同時字幕システムの構築・運用・評価」では,音声同時字幕シ ステムに関して概略し,システムの実運用的な視点から,将来的に主流となる対遠隔地 運用のためのネットワークシステムの構築と,それを用いた実運用試験の結果とその評 価に関して論ずる.まず評価の基準となるローカルシステムに関して評価を行い,次に ネットワークシステムの評価を行う.最後に,ローカルシステムとネットワークシステ ムの結果を比較評価し,対遠隔地運用の可能性に関して論ずる. 第 4 章「不完全文の内容理解向上を目的とした顔映像の呈示方法」では,音声同時 字幕システムを基盤とし,システム性能を更に発展させるために,バーバル情報として第 1 章 序論 誤認識結果を含む不完全文とノンバーバル情報として顔情報の複数情報を,内容理解の 阻害なく促進させるための情報呈示方法に関して論ずる. 従来システムでは字幕生成過程において,第 3 章で述べたような方式を考案・採用し たが,字幕精度と変換時間の関係はトレードオフであり,最終的に呈示される字幕には 誤認識が避けられない.また一方,音声を文字などの離散記号として変換する際,どう しても話者の発話情報などのノンバーバル情報が失われてしまう.欠落するノンバーバ ル情報を字幕呈示過程において適した条件で呈示することで,誤認識字幕を含む字幕に おいても最終的な内容理解を向上させるための情報呈示方法に関する評価検証結果に 関して論ずる. 第 5 章「結言」では,本研究における様々な実験を要約し,本論文の結論と,本研 究で得た知見に対して今後の展望等に関して論ずる.
参考文献
[1] Americans with Disabilities Act http://www.ada.gov/(2012.3.1 現在) [2] 内閣府: 障害者基本法, 2011 改定. http://www8.cao.go.jp/shougai/suishin/kihonhou/s45-84.html(2012.3.1 現在) [3] 内閣府: 障害者基本計画, 2002. http://www8.cao.go.jp/shougai/suishin/kihonkeikaku.html(2012.3.1 現在) http://www8.cao.go.jp/shougai/suishin/kihonkeikaku.pdf(2012.3.1 現在) [4] 総務省: 視聴覚障害者向け放送普及行政の指針の概要, 2007. http://www.soumu.go.jp/main_content/000030361.pdf(2012.3.1 現在) [5] 総務省: 「デジタル放送時代の視聴覚障害者向け放送に関する研究会」報告書, 2007. http://www.soumu.go.jp/main_sosiki/joho_tsusin/policyreports/chousa/digi_hoso_sikakusy ogai/index.html(2012.3.1 現在) [6] 白澤麻弓, 徳田克己, 斎藤佐和(監): 聴覚障害学生サポートハンドブック, 日本医療 企画, 2002. [7] 安藤彰男, 今井亨, 小林彰夫, 本間真一, 後藤淳, 清山信正, 三島剛, 小早川剛, 佐 藤庄衛, 尾上和穂, 世木寛之, 今井篤, 松井淳, 中村章, 田中英輝, 都築徹, 宮坂栄 一, 磯野春雄: “音声認識を利用した放送用ニュース字幕制作システム”, 信学論 (D-II), Vol.J84-D-II, No.6, pp.877-887, 2001.
[8] 小林正幸, 西川俊, 石原保志: “聴覚障害者のための音声認識技術を活用したリアル タイム字幕挿入システム(1)”, 信学技報, ET99-89, pp.41-48, 2000. [9] 立入哉, 井上かおり, 宮武由佳: “音声認識を利用した聴覚障害学生学習保障システ ムについて”, 信学技報, ET-2003-8, pp.43-48, 2003. [10] 安藤彰男: リアルタイム音声認識, (社)電子情報通信学会(編), (社)電子情報通信学 会, 2003. [11] 田窪行則, 前川喜久雄, 窪園晴夫, 本多清志, 白川克彦, 中川聖一: 言語の科学 2 音
第 1 章 参考文献
声, 岩波書店, 2004.
[12] Q. Summerfield: “Lipreading and audio-visual speech perception,” Phil. Trans. R. Soc. Lond. B, Vol.335, pp.71-78, 1992.
[13] K.W. Grant, B.E. Walden, and P.F. Seitz: “Auditory-visual speech recognition by hearing-impaired subjects: Consonant recognition, sentence recognition, and auditory-visual integration,” J. Acoust. Soc. Am., Vol.103, No.5, pp.2677-2690, 1998. [14] 加藤士雄, 井野秀一, 伊福部達 他: “聴覚障害者の国際会議参加支援を目的とした 音声字幕変換システムの設計”, ヒューマンインタフェースシンポジウム 2002 論文 集, pp.463-466, 2002. [15] 黒木速人, 井野秀一, 中野聡子, 堀耕太郎, 伊福部達: “聴覚障害者のための音声同 時字幕システムの遠隔地運用の結果とその評価”, ヒューマンインタフェース学会 論文誌, Vol.8, No.2, pp.255-262, 2006. [16] 井野秀一: “情報バリアフリーと VR-聴覚障害者のコミュニケーション支援技術-”, 日本バーチャルリアリティ学会誌, Vol.8, No.2, pp.70-75, 2003. [17] 加藤士雄, 井野秀一, 伊福部達: “国際会議における聴覚障害者支援を目的とした 音声字幕変換システムの設計”, ヒューマンインタフェース学会研究報告集, Vol.4, No.4, pp.65-70, 2002. [18] 黒木速人, 井野秀一, 中野聡子, 堀耕太郎, 伊福部達: “聴覚障害者の国際会議参加 支援のための遠隔型音声字幕化システム-札幌-横浜間におけるシステム運用とその 評価-”, ヒューマンインタフェースシンポジウム 2003 論文集, pp.729-732, 2003. [19] H. McGurk and J. MacDonald: “Hearing lips and seeing voices,” Nature, Vol.264,
pp.746-748, 1976.
[20] D. Burnham, J. Robert-Rives and R. Ellison: “Why captions have to be on time,” Proc. of AVSP’98, pp.153-156, Terrigal, Sydney, South Wales, Australia, Dec.4-6.1998.
[21] 加藤謙二郎, 妹尾宏, 磯部忠: “ハイビジョンにおける字幕(クローズドキャプショ ン)提示条件の検討”, テレビジョン学会技術報告, Vol.19, No.10, pp.19-24, 1995.
第 2 章
従来研究と本研究の位置付け
2.1 はじめに
本章では,一般的に用いられている情報保障手段に関して概略し,音声認識技術を 用いた新しい情報保障手段の研究・開発に対する代表的な取り組みを紹介するとともに, それらの研究と本研究の位置付けに関して論ずる.2.2 聴覚障害者に対する情報保障手段
第 1 章で述べたとおり,聴覚障害者に対する情報保障手段としては,分類の方法は 様々あるが,本論文では,「音情報自体をなるべく雑音なくクリアに伝える方法」と, 「音情報を別の感覚情報媒体に変換して伝える方法」に別けることとする.主に前者は, 音自体から何らかの手がかりを積極的に取得しようとする聴覚障害者に対する情報保 障手段であり,後者は音情報自体よりもむしろ,例えば文字などの,音情報から変換さ れた別の感覚情報媒体を頼りにする聴覚障害者に対する情報保障手段と言える.ある聴 覚障害者に対して,これらの手段を単独で用いれば情報保障は完了されるという程単純 ではなく,これらの手段を単独で用いることもあれば,組み合わせで用いることもあり, 被情報保障者である聴覚障害者の障害の程度や,情報保障場面に応じて対応手段を考え る必要が生じる. その一方,音声認識技術を用いた情報保障手段は,話者の発言内容を基本的に全文 文字化できるため,高等教育支援で求められる厳密性を維持した情報保障手段としての 可能性を秘めている.その可能性を模索する目的で,音声認識技術を情報保障手段とし て用いようとする,いくつかの取り組みがなされている.第 2 章 従来研究と本研究の位置付け 筆者は音声認識技術を直接発話者の音声に対して認識させる方法は採用せず,音声 認識技術に対し復唱音声認識方式と認識結果修正方式を採用した音声同時字幕システ ムを開発し,実運用試験を通して課題を解決してきた.
2.2.1 音自体を伝える情報保障手段
音情報自体をなるべく雑音なくクリアに伝える情報保障手段としては,基本として は,発話者の音声など,音源からの音を直接マイクで雑音少なく取得し,同時に聴覚障 害者までに伝達する伝送経路においても音を劣化させることなく伝える手段を用いる ことが基本となる.伝送路や伝送方式などの区別で,色々な種類が方式・手段が存在す る.FM 補聴システム,赤外線補聴システム,磁気誘導ループなどが代表的な手段であ る. 以下に,音自体を伝える情報保障手段の代表例である,FM 補聴システム(赤外線補 聴システム),磁気誘導ループに関して概説する.2.2.1.1 FM 補聴システム・赤外線補聴システム
FM 補聴システムとは,FM 電波を使用して音声信号を送受信するためのシステムで, FM 送信器・受信器で構成される.話者(話し手)は FM 送信器に繋がれたマイクに対 して音声を入力し,聴覚障害者側では FM 受信器により音声信号を受信する.FM 受信 器には,箱形単体のもの,耳かけ単体のもの,補聴器のインタフェースに接続するアダ プタタイプなどがある(図 2.1(a)).受信器に単体のものを使用する場合,イヤホンを介 して聴覚障害者の耳に直接音を伝える場合もあれば,タイループや M リンクと呼ばれ る電磁誘導コイルを介して誘導コイル付き補聴器に伝える場合もある(図 2.1(b)). FM 補聴システムは搬送波に電波を用いているため,混信や雑音に弱い面があり,最 近では搬送波に近赤外線を用いているものもある.ただしその場合,伝送手段に近赤外 線を用いるため,伝送路の経路上に光を遮る障害物があると,伝送できないので注意が 必要である.また近年,携帯電話など Bluetooth 規格に対応した機器が増えてきたこと もあり,Bluetooth を用いて携帯電話の音を受信するための Bluetooth アダプタも販売さ れている.これにより,携帯電話の音声をよりクリアに取得することができるようにな る.第 2 章 従来研究と本研究の位置付け (a) FM 受信器用アダプタを用いる場合 (b) タイループを用いる場合 図 2.1 FM 補聴システム(リオン(株)ホームページより改編)
2.2.1.2 磁気誘導ループ
磁気誘導ループとは,電磁誘導の原理を用いて補聴器に直接音声信号を伝達するた めの装置である(図 2.2).話者はマイクを介して音声信号を装置に入力し,磁界を発生 するループコイルを介して,補聴器に音声信号が電磁誘導で伝達される.受信するため の補聴器には,誘導コイル(テレホンコイル)機能付き補聴器である必要があり,ルー プコイルにて音声を受信する際,受信モードを「T(テレホンコイル)」もしくは「MT (マイク・テレホンコイル)」にする必要がある.ループコイルには常設式と移動式(簡 易設置式)のものがあり,常設式はループコイルを該当する部屋の床下に埋設する方式 で,安定した磁界を得るためや漏洩磁界を遮断する設計を施工時に施すため,安定した 音声信号を得ることができる.一方,移動式はコードリールなどを用いて,設営する場第 2 章 従来研究と本研究の位置付け に応じてループコイルを敷設する方式であり,移動ができる点と,出力に余裕がある限 りループコイルのエリアを自由に設定できる点がメリットである. 磁気誘導ループは FM 補聴システム同様,一度に多数の聴覚障害者に対して音声信 号を伝達することが可能であることに加え,聴覚障害者がテレホンコイル付き補聴器を 使用してさえいれば,受信側には特別な機材が不要である点が大きなメリットである. しかしながら,音声の伝送方式がアナログ伝送であるため音声の劣化が生じてしまう点 や,そもそも聴覚障害者が電話ハンドセットを用いて電話をする機会の減少に伴い,T モードが標準で備わっていなくオプション装備とする補聴器が増えてきていることか らも,将来的に主流の方式であるとは言い難い. 図 2.2 磁気誘導ループ((株)ソナールホームページより)
2.2.2 音を別の伝達媒体に変換して伝える情報保障手段
音情報を別の情報媒体に変換して伝える情報保障手段としては,手話通訳,文字通 訳(要約筆記(ノートテイク)やパソコン要約筆記(パソコンテイク))などがある. これら別の感覚情報媒体への変換を伴う情報保障手段は,重要となるのは別の感覚情報 媒体への変換機能を機械もしくは人のどちらが担うかの点である.残念ながら機械によ る伝達媒体の変換,つまり自動翻訳はまだ研究途上である.本項で紹介する情報保障手 段はいずれも人力,つまり人による伝達媒体の変換方法に関して紹介する.人を介した 伝達媒体の変換はつまり通訳であり,実際,手話通訳,文字通訳と呼ばれる.これらの 手段に関して概説する.2.2.2.1 手話通訳
手話通訳は,話者が話す内容を手話通訳者が手話言語に通訳変換して呈示する方法第 2 章 従来研究と本研究の位置付け である.話者が話す内容をリアルタイムに表出できること,手話を第一言語とする先天 ろう者などが内容理解する場合に有利となる.日本で用いられる手話には,日本手話と 日本語対応手話に分けられ,それぞれ異なる言語体系を持つ.日本手話は,日本語の語 順とは異なる独特の文法体系を持つ.日本語対応手話は,手話単語を日本語の文法体系 に当てはめた表現の仕方をする.日本手話は,主にろう者が第一言語として獲得する言 語である.つまりろう者の言葉である.独特の言語体系を持つために,後天的な聴覚障 害者,難聴者,健聴者など,日本語を第一言語として獲得した者にはとっては新たな言 語として習得する必要が生じるため,受障時期において年齢が進んでいる場合など,修 得に困難を来すことがある.第二言語として修得できたとしてもネイティブに近い形で 修得するには更なる困難を要す.そのため,日本手話を正確に表出・読み取りできる者 は限られ,厳密な言い回しとなると更なる困難さが要求されると言える. 図 2.3 手話通訳の様子 (話者は中央壇上,手話通訳者は左手(日本手話)と右手(アメリカ手話))
2.2.2.2 文字通訳
文字通訳は文字言語(書記日本語)を媒体とした情報保障手段であり,話者が話し た内容(や,その場で発生した環境音などの音に関する情報)を要約筆記者が文字にし て聴覚障害者に伝える手段である.手話を第一言語としない中途失聴者に対してや,手 話を第一言語とするろう者に対しても手話通訳と組み合わせて用いることもある. 文字通訳には音声を文字にする方法により更に大きく 3 つに分けることができる.第 2 章 従来研究と本研究の位置付け 手書き文字をノートに記述していく方法と,パソコンのキーボード入力によりパソコン 画面に文字を呈示していく方法,それ以外の機器を用いる方法に分けることができる. 手書きによる方法は「要約筆記」や「ノートテイク」と呼ばれる.パソコンを用いる方 法は「パソコン要約筆記」,「パソコンテイク(パソコンノートテイク)」,「パソコン通 訳」などと呼ばれる.音声を文字化する際の要約度や表出速度に大きな違いがあるため, 文字化するための思想や方法論も異なっていると言える. ・要約筆記 要約筆記は,要約筆記者が手書きで音情報を文字化し呈示する方法である.手書 きであるため,人の話速に対して自ずと文字化できる情報量に限界が生じる.その ため文字通り内容を「要約」する必要が出てくる.要約の程度や方法論に関しては, 厚生労働省の「要約筆記奉仕員養成プログラム」を受講して学ぶことが一般的であ るが,この講習だけで実作業に十分耐えうるだけの技能を身につけられる訳ではな いので,情報保障者の経験により差が現れることがある.人の話速を 300∼350 文字 /分とすると,筆記できる文字数を 50∼70 文字/分であると言われているため,話す 内容の約 15∼20%が伝達されると言える.連続作業による作業効率低下を回避する ために通常 2 人 1 組で作業に臨み,時間ごとに人が交代することで効率低下を防ぐ ことが一般的である.要約筆記は,紙と筆記具があれば情報保障が可能であるとい う,手軽さと言う点で大きなメリットがある.要約筆記者が書いた文字を特定の聴 覚障害者だけに提供する場合もあれば,複数の聴覚障害者に提供するために OHC や書画カメラを用いる場合もある. ・パソコン要約筆記 パソコン要約筆記は,パソコン要約筆記者のキーボード入力により音情報を文字 化するため,要約筆記と比較すると文字化できる情報量は多くなる.もともと手書 きによる要約筆記の伝達情報量の限界は以前から知られていたため,キーボード入 力であるワードプロセッサが登場した当時から本手法は試みられてきた経緯がある. 以前はワードプロセッサ上の原稿画面上に入力される文字をそのまま聴覚障害者に 呈示させることで情報保障手段として用いることも試みられた.その後,パソコン 自体と Ethernet 通信の普及に伴い,複数のパソコンの通信を用いて呈示する情報保 障文章を作成する方法が,2000 年頃からほぼ標準的な情報保障手段として用いられ るようになった(図 2.4).この背景には「IPtalk[1]」や「まあちゃん[2]」と言った パソコン要約筆記に特化した入力・通信・表示ソフトがフリーで入手できることも 大きな一因であると言える.キーボードによる入力文字数を 1 人あたり 80∼120 文 字/分とすると,話す内容の 25∼40%が伝達されると言える.1 人あたりのキーボー ド入力の限界を補うために,2 人で連係して文を作成する「連係入力」により文字
第 2 章 従来研究と本研究の位置付け 変換量を多くする方法が一般的に使われる.また要約筆記同様,連続作業による効 率の低下を回避するために,複数組で臨み,入力する組を交代して効率低下を防ぐ 方法により実施する.パソコン要約筆記は,要約筆記と比較して多くの文字量を伝 達できることが最大のメリットである. 日本におけるパソコン要約筆記と同様の方法が,アメリカでは NTID が開発した C-Print[3]として存在する.C-Print は音声を文字化させるためのソフトウェアであり, C-Print Pro バージョンは音声認識ソフトによる入力も可能にしている. 図 2.4 パソコン要約筆記による情報保障の様子(図は 2 人連携入力の様子) ・特殊な入力機器を用いる方法 パソコンのキーボードを用いた日本語入力は,一般的に QWERTY 配列のキーボ ードを用い,ローマ字もしくは仮名字入力方式により 26 ないし 50 個の入力キーを 基本的に 1 ローマ字(1 かな文字)につき 1 キーを対応させ,1 キーずつ打鍵して「仮 名文」を作成し,必要な箇所を仮名-漢字変化することにより「漢字仮名混じり文」 を生成させる.この作業には,仮名文の「入力」と仮名-漢字「変換」の 2 段階の作 業の必要があるために,どうしても時間を要し入力速度に限界が生じさせてしまう. その他の入力機器を用いる方法は,この「入力」と「変換」の速度限界を克服する ために,現在までに様々な方法が試みられてきた.いずれの方法もキー数を少なく した入力装置を用いる手法が主流と言える.入力には,基本入力である登録されて いない語を入力するか,短縮入力である機器に登録されている語(単語や言い回し) を入力するかにより異なるが,基本的には複数キーを組み合わせて同時に打鍵する ことで,「仮名文」もしくは一気に「漢字仮名混じり文」を入力できるのが特徴であ
第 2 章 従来研究と本研究の位置付け る.入力するための複数キーの組み合わせを習得することが必要になるため,入力 者に対するキー打鍵技能の養成が必要になり,誰でも直ぐに入力できる訳ではない. また,入力者の熟練度による差は大きく,高速入力には熟練度の高い入力者を複数 人揃える必要があり,高速入力にはより困難が伴う.さらに,商用サービスとして 運用されているケースがほとんどあるため,サービス対価は自ずと高価になる.こ こでは代表的な 2 方式を紹介する. 1 つ目は「はやとくん」と呼ばれるシステム[4]である.裁判における速記録を作 成するための約 22∼24 個のキーを持つステノタイプ(stenotype[5],日本語版ステノ タイプをソクタイプと呼ぶこともある)を入力装置に用い,ステノタイプが出力す る速記記号データをパソコンにて自動反訳させることで「仮名文」を作成し,その 結果を「変換」させることで「漢字仮名混じり文」を生成するシステムである(図 2.5).ステノタイプにて入力する役割の人と,「仮名文」を変換する役割の人の 2 人 1 組を基本として,情報保障を行う時間等により複数組で行うことがある.情報保 障目的でのサービス提供は,速記団体等が行っている.ただし,日本では速記者を 養成しない傾向にあるため,供給量は少なくなる手段と言える. 図 2.5 「はやとくん」システムの概要 ステノタイプ 反訳ソフト 呈示字幕
第 2 章 従来研究と本研究の位置付け 2 つ目は「スピードワープロ」と呼ばれるシステム[6]である.入力装置として独 自の約 10 個の文字入力用キーを持つキーボード(ステノワード[7])を用いる.ス テノワードをコンピュータに接続し,変換前の「仮名文」に相当する基の文を入力 する「入力担当」と「変換」役を担当する「校正担当」の 2 人 1 組を基本として, 情報保障を行う内容や時間により組数を調整して行う.このシステムは,第 3 者が 利用できるシステムではなく,スピードワープロ(株)が字幕付与サービスを商用 サービスとして提供している[8],[9].主に放送番組用のリアルタイム字幕付与サー ビスとして用いられている.情報保障目的で用いられることは少ないが,各種行事・ シンポジウムや筑波技術大学の講義などにおいて用いられる例[10],[11]もある.ち なみに,スピードワープロではキー入力者(ステノキャプショナー)の技能に応じ て検定級を設けており,スピードワープロ検定 1 級では,キー入力に関しては 320 文字/分の技能を必要とする[12]. 図 2.6 スピードワープロによる字幕付与の様子(4 人による入力の様子) 裁判速記用のステノタイプを用いて情報保障を行うサービスは,アメリカでは CART(Communication Access Real-time Translation[13])と呼ばれる.先述の「はや とくん」システム同様,コンピュータを用いてリアルタイムに反訳した文字を聴覚 障害者に呈示する方法である.日本語にあるような仮名-漢字変換が不要であるため, 入力者 1 人で字幕作成が行え,ステノタイプと PC をシリアル接続すれば字幕呈示 が可能になる.基本的に,話者が話した内容を要約せずに全てを文字化させる.日 本の速記者の減少傾向とは違い,アメリカでは訴訟社会を反映し,速記者は数多く 存在すると言われる.アメリカでは CART は高品質でリアルタイム性の高い情報保
第 2 章 従来研究と本研究の位置付け 障手段として用いられることが多い. 図 2.7 CART システム ・音声認識技術を用いた方法 以上述べてきたような,いわゆる「人力」により話者の話した内容を文字化させ る方法に対し,近年音声認識技術のもつ「音声入力による簡便さ」や「高速な音声-文字変換」などの技術的なポテンシャルのある手法を情報保障手段として活用しよ うとする取り組みがなされている[14],[15],[16].高速かつリアルタイムに音声-文字 変換が可能であることは,要約せずに話者の話した内容の多くを文字化させること ができることを意味し,商用サービスを用いずコストパフォーマンス高く,多くの 文字量つまり情報量を聴覚障害者に呈示できる可能性を持つ.この様な,音声認識 技術の持つ特長を情報保障の場面に生かすことで,特に伝達内容の厳密性が重要視 される高等教育場面における活用することで,利用価値が大いに発揮されると期待 されている.しかしながら,音声認識技術に関する現在の技術レベルでは,話者が 代わる不特定話者認識や,厳密でない文法構造を持つ話し言葉認識,未知語の認識 は非常に難しい.そこで,筆者を含む研究グループが開発した,現在の音声認識技 術の持つ弱点を克服するために,音声認識技術の持つ利点とヒトの持つ認知特性を 生かして音声-文字変換を行う「復唱方式」により音声認識を行う情報保障手段が注 目されている.
2.3 音声認識技術の仕組み
本節では,音声認識技術を情報保障手段として用いる際,話者の話す内容をそのま ま音声認識装置に入力する直接音声認識方式を用いず,なぜ復唱音声認識方式を採用す第 2 章 従来研究と本研究の位置付け るのかを理解するために,現在用いられている一般的な音声認識技術の仕組みに関して 概略する.
2.3.1 音声認識技術の歴史
世界初の音声認識装置に関する論文は,数字の読み上げに対する音声認識装置[17] に関する論文と言われている.この論文は 1952 年に発表された.その後,音声タイプ ライタと呼ばれる単音節音声認識装置が研究された.単音節音声認識とは,連続する音 節からなる語に対する認識であっても,語の音節を一音節ごとに区切って認識させる音 声認識の方式である[18].例えば「おはようございます」を認識させる場合,「お」「は」 「よ」「う」「ご」「ざ」「い」「ま」「す」と一音節ごとに発声と認識を繰りかえる必要が ある.その後,ヒトの言語理解に関する知識を音声認認識に積極的に取り組むアプロー チがなされていくが,これには 1971 年の APRA(米国防省高等研究計画局)による「音 声理解プロジェクト」の貢献が大きい.1980 年代に入り,連続音声認識装置の研究・ 開発がなされていくが,1984 年の DARPA(米国防総省高等研究計画局; 1972 年に ARPA から DARPA に改称,後 1993 年再び ARPA に改称し,1996 年に DARPA に再改称する) における「Strategic Computing Program」の一環として,大語彙・不特定話者・連続音声 認識システムのプロジェクトが開始された[19].さらに,1991 年から同じく DARPA で 実施された Wall Street Journal の読み上げ音声を対象とした Hub3,1995 年より実施され た Hub4 において, HMM(Hidden Markov Model;隠れマルコフモデル)と n-gram 言 語モデルを用いた統計的手法が大語彙連続音声認識に対して有効であることが示され た[20].日本においては,1996 年より開始された日経新聞読み上げ音声の認識に関する 研究がなされ,1997 年から開始された「日本語ディクテーション基本ソフトウェア」 開発プロジェクトにおいて,Julius 等の音声認識用ソフトウェアが開発され,音声認識 研究のために広く利用されている.これらの研究・開発の成果が今日の音声認識装置の 発展に大きな影響を与えたといえる.2.3.2 音声認識技術の概要
音声認識技術では,音響モデルと言われる,母音や子音などの発音の音素ごとに, 個人個人の音声の音響的な特徴を記述したモデル(モデルとは,出現確率を簡素に記述 した,一種のデータベース)と,言語モデルと言われる,文構成における単語列の規則 性を記述した,言わば発話内容の単語の言語的な連続性を表すモデルの 2 つのモデルと, 発音音素列と単語との関連性を記述した発音辞書を基にして,入力された音声を照合し, 最も出現確率が高いと判断された結果を認識結果として表していく. 音声認識の処理の流れを図 2.8 に示す.第 2 章 従来研究と本研究の位置付け 図 2.8 音声認識処理の流れ まず入力音声の初めの部分を音響分析し,その結果より算出した音響的特徴がどの 音素列の出現確率に近いかを音響モデルを用いて照合する.この処理により,入力音声 がどの音素列で構成されているかを算出することができる.この音素列と発声辞書を照 合させ,算出音素列-単語候補を算出する.同時に,言語モデルからリストアップされ た単語候補と照合する.次に入力される音声に対しても,音響分析・音響モデルとの照 合・発声辞書との照合・言語モデルとの照合を行っていく.照合の際,音響モデルは入 力音声の前後関係,言語モデルは単語候補の前後関係も参照のパラメータとして含め, 独立した入力音声から独立な単語を照合させ,結果算出された独立な単語群を認識結果
第 2 章 従来研究と本研究の位置付け としている訳ではない.入力音声に対し,音響モデルと言語モデルから得られた候補群 とを照合する処理をサーチと言い,このサーチを次から次へと連続的に入力される音声 に対して行って行く処理が連続音声認識である[18],[20].
2.3.3 音声特徴量の分析
入力された音声信号(音声波形)から,音声認識処理で必要な情報を取り出す処理 を音声特徴量の分析(音声分析)という.音声認識処理では,母音の「あ」と「い」な どをうまく区別することが必要とされる.ヒトは発声の際に,口の形などを変化させる ことで,音響的に異なる音声を発声している.したがって,音声認識処理で必要な情報 は,声帯の振動に起因する声の高さではなく,口や鼻から喉までの,声道の形に関する 情報(声道伝達特性)である.観測される音声は,入力である声帯音源をある伝達特性 を持つ声道を介した出力として見ることができる.声帯音源は「パフ音」と呼ばれる一 種のインパルスであるため,観測音声は声道の伝達特性のインパルス応答と見なせる. この様に,観測音声から声帯の伝達特性を分析する手法をケプストラム分析と言い,実 際の音声認識処理では A/D 変換された離散値におけるディジタルフィルタの特性係数 に対する分析を行う. 音響分析では,観測音声から声道特性に関する情報を取り出すことで認識パラメー タを得る.認識パラメータは,観測音声を 20∼25ms の区間に区切った短区間に対して 数十の次元を持つベクトルとして算出される.連続した観測音声に対し,この短区間を 約 10ms ごとに次々に移動・分析をすることで,連続した認識パラメータを得る.上述 の通り,音声認識処理では声の高さの情報は基本的に用いないため,一般にイントネー ションの異なる音声に対しても,イントネーションの違いを無視した音声部分だけが認 識される.2.3.4 HMM(Hidden Markov Model;隠れマルコフモデル)
音響分析により得られた認識パラメータに対し,音響モデルと言語モデルとの照合 を行う.照合の際,ある単独の短区間だけで得られた単独の認識パラメータ群だけを照 合するのではなく,認識パラメータの遷移の様子も照合する.つまり,音響モデルに関 しては音声の時間的な遷移も含めて照合する.このことにより,発声における調音結合 (わたり)や停留を反映することができる,言語モデルは単語候補の連続関係も参照す る.これら状態の時系列パターンを記述したものが HMM(Hidden Markov Model)と呼 ばれる確率統計モデルである.音響モデルで用いられているモデルを特に n-phone と言 い,特に mono-phone,bi-phone,tri-phone(それぞれ,1 次,2 次,3 次のマルコフ連鎖 を示したモデルを示す)が用いられる.言語モデルに関しては n-gram を用いる.言語
第 2 章 従来研究と本研究の位置付け モデルが用いる確率モデルを HMM とせず n-gram とのみ記述している文献もあるが, n-gram も(n-1)次マルコフ連鎖であるため,言語モデルも HMM であると言える[21].
2.3.5 サーチ
サーチとは,音響モデル・言語モデルで得られた単語列候補の中から正解候補を探 索していくこと言う.音声認識では,認識結果として得られる単語列の単語数が未知で あり,認識結果の単語列と各単語と認識パラメータとの対応が未知であるため,音響モ デルと言語モデルが一体になったネットワークを構成し,実際の音声と照合しながら, このネットワークを探索する方法を取る.ネットワーク上の,ある状態をノードと言い, ノード間をつなぐノード変化の経路を木という. 音声認識処理では,入力音声に対応する単語列の探索であるから,登録単語数を M とした場合,理論的には初期状態から最初の深さのノードに M 個のノードが存在し,k 番目の深さでは,Mk個のノードを持つ木の探索問題として定式化できる.探索は時刻 と共に深いノードの方向に進むため,全てノードを系統的に調べるには膨大な処理が必 要になる.また,音響モデルには n-phone,言語モデルには n-gram を利用するため(一 般的には tri-phone 音響モデルと 3-gram 言語モデルまでが用いられる)探索空間はさら に大きくなり,リアルタイム処理をするためには探索を効率化する必要がある.そのた めに,まず,簡易な音響モデルと言語モデルを用いて認識スコアである尤度が高い候補 を N 文(N-ベスト文)算出し,その後,より詳細な音響モデルと言語モデルを用いて N ベスト文のスコアを再計算し認識結果を確定する.2.4 現在の音声認識技術の課題
前節で述べたとおり,現在の音声認識技術は,音響モデルと言語モデルに確率統計 モデルを用いているため,モデルに記述されていない入力に対しては対処できない.こ のことはモデルの学習の重要性を示すと共に,音声認識技術が持つ現状の技術的制約と なる.具体的には以下の場面において,技術的に解決されていない箇所が課題点として 呈することになる. ・ 不特定話者認識 音響モデルは特定の話者音声の音響的特徴をモデル化しているため,登録されて いない話者の認識には対応できない.そのため講演会・会議・大学ゼミにおける 話者交代・質疑・ディスカッションなどの話者が入れ替わる場面での利用は困難 である. ・ 話し言葉(自然発話)認識第 2 章 従来研究と本研究の位置付け 言語モデルはモデルとして,基本的に新聞・雑誌など,単語間の文法的関係がし っかりした文のコーパス(自然言語の文章を構造化し集積したデータベース)を 用いているため,話し言葉である自然発話に対する認識は困難である.大学講義・ 講演会などにおける発話内容に関しても自然発話であるため,文としは文法的な 省略・倒置が生じている話し言葉になっている. ・ 雑音下での認識 音響モデルは音声が入力されることを前提としているため,環境音や話者以外の 音声などの認識対象以外の音は,認識の妨げとなる雑音として扱われる.これら の雑音の除去は,技術的に非常に困難である. ・ 未知語の認識 発音辞書に登録されていない単語に対しては認識できない.音声認識処理では入 力音声に対し,生成確率が高い結果を算出しているため,意味的に近い単語が認 識結果として算出される訳ではないため,未知語に対する誤認識が文全体の意味 を通らなくすることもある.
2.5 音声認識技術を用いたリアルタイム音声-文字変換の取り組み
現在の音声認識技術を単体で,不特定の直接話者認識などの意図で利用しようとし た場合,前節で述べた技術的な制約から,音声認識処理における課題が露呈することに なる.しかしながら,音声認識技術の持つ可能性を積極的に実際的な情報保障サービス に生かそうとする試みがなされている.これらの背景には,音声認識技術の持つ音声-文字変換技術と言う,聴覚障害者にとっては認識困難な音声言語から認識可能な文字言 語への言語変換(言語通訳)に相当する技術に対する潜在的な需要に依るところが大き いと言える. 聴覚障害者に対する情報保障手段として音声認識技術を用いた方法は,認識対象と なる話者の声を直接音声認識システムに取り込むことで認識する直接話者認識方式と, 話者音声をヒトの介在により音声認識システム対して適した形に前処理を施してから 音声認識システムに入力させる方式に分けることができる.後者は特に復唱音声認識方 式とよばれ,話者音声を音声認識システムに復唱入力する人を復唱者と呼ぶ.ここでは, これらの代表的な取り組みに関して紹介する.2.5.1 NHK(直接話者認識方式)によるニュース字幕[20], [22]-[24]
NHK が行っている直接話者音声認識方式は「ダイレクト方式」と呼ばれ,ニュース 番組中のアナウンサーの原稿読み上げ音声を字幕化することを目的に,2000 年 3 月の第 2 章 従来研究と本研究の位置付け 「ニュース 7」で運用が開始された[23],[24].アナウンサーの音声明瞭性,ニュース原 稿の文法構造の良さ,スタジオと言う耐雑音性能の良い環境を生かした音声認識システ ムと言える.アナウンサーの読み上げ音声を音声認識システムで認識した後,認識結果 を確認し,必要があれば修正する方式を採用しており,誤りを発見する発見者 1 名と実 際に修正作業を行う修正者 1 名を 1 組とし,2 組体制で担当を 1 文ごとに振り分けて確 認・修正を行う.音声入力から字幕表示までの遅れ時間は,平均 10 秒である[29].音 声認識エンジンおよび言語モデルは,NHK 技術研究所がニュース番組に特化したもの を作成し,言語モデル・辞書は放送直前に最新のニュース原稿を自動的に取得すること で,毎日学習・更新がされる.NHK ではニュース番組の原稿や音声の蓄積が既に存在 するため,特化した開発を行うための開発資産が揃っている点が,他の開発機関と大き く異なる.また,開発と言った技術的な面と,実運用を行うサービス提供の両面が揃っ ている点も他の開発機関と大きく異なる.この様な背景のもと,ニュース音声認識方式 はある程度の成功を収めた.しかし,ニュース音声認識方式はアナウンサの原稿を読み 上げに対してのみ適用されるシステムであり,収録画像を流す場面やレポータによる実 況などには対応していないため 2006 年頃から次第に運用されなくなり,NHK が提供す るニュース番組の字幕は特殊キーボードの手打ちにて字幕を作成するスピードワープ ロによる字幕提供が大多数となった.直接話者認識方式は,大リーグ野球中継の実況ア ナウンスを日本のスタジオで付ける場合にて,現在でも運用を継続している[29],[30]. 図 2.9 ニュース音声認識システム(直接話者認識方式)[30]
2.5.2 NHK(リスピーク方式)による生放送字幕[20],[25]-[28]
前節で述べた NHK によるニュース音声認識システムは,アナウンサーがスタジオで 原稿を読み上げた音声を直接音声認識するシステムである.先述したとおり,アナウン第 2 章 従来研究と本研究の位置付け サーの音声明瞭性,読み上げ原稿の文法構造の良さなどの特徴により,番組中の音声を 直接認識するシステムの実用が可能になったと言える[20].一方,生放送やスポーツ中 継番組おいては,発話内容が話し言葉(自然発話)であったり,複数の人間が同時に発 言したり,歓声などの背景雑音が混在していたりする場合があり,音声認識処理にとっ て良い条件とは言い難い.これらの理由から,生中継番組の字幕化のために,音声認識 専門のキャスターが番組で発せられた音声の中で必要な音声だけを再発声することで, 高精度な字幕を生成するシステムが開発された[25].字幕化のために番組音声を再発声 する専門のキャスターを NHK ではリスピーカー(re-speaker)と呼び,現役を引退したキ ャスターなど音声明瞭度の高い人員を起用することで,高い字幕精度を確保する工夫を している.リスピーカーは,基本的には番組中の実況アナウンサーや解説者の発話を復 唱し,場合によっては内容を要約して復唱する.要約の理由は,放送字幕は基本的に 1 画面当たり 16 文字 2 行の表示に収める必要があり,複数画面にわたる字幕呈示もある が,長すぎると内容が伝わらなくなることがあるためである.またリスピーカーは,実 況アナウンサーが説明しない拍手や歓声など,場面の様子の補足など,解説の役割を果 たすこともある.音声認識結果を修正する修正者は 1 名で対応している[26],[30].字幕 遅れは,スポーツ番組において 5∼10[秒]と報告されている[29]. 現在,直接話者認識であるダイレクト方式が得意とする,スタジオアナウンサーの 原稿読み上げ,記者による現場リポート,アナウンサーと記者との落ち着いた対談にお ける音声認識をダイレクト方式で行い,復唱認識であるリスピーク方式を使用せざるを 得ない,インタビュー,収録済みビデオ素材,自由発話の多い対談等における音声認識 をリスピーク方式で行う,双方式併用型であるハイブリッド方式の生字幕制作システム を試作している[29],[30].音声認識の入力音声をリスピーカー自身が,番組音声・リス ピーク音声の間を手動で切り替え,認識結果の確認・修正を 1∼2 名の修正者で行う. 図 2.10 生放送字幕システム(リスピーク方式)[30]
第 2 章 従来研究と本研究の位置付け 図 2.11 生放送字幕システム(ハイブリッド方式)[30]