「画像の認識・理解シンポジウム (MIRU2009)」 2009 年 7 月
MCMC-based particle filter
を用いた人間の映像注視行動の実時間推定
宮里
洸司
†,††木村
昭悟
†高木
茂
††大和
淳司
†柏野
邦夫
††
日本電信電話(株) NTT コミュニケーション科学基礎研究所、神奈川県厚木市森の里若宮3−1††
国立 沖縄工業高等専門学校 情報通信システム工学科、沖縄県名護市辺野古 905 E-mail:††
[email protected] あらまし 人間は、網膜に映る映像の中から重要と思われる領域を瞬時に判断することで、効率的に情報を獲得して いる。これら人間の高度な視覚機構を計算機上で実現することで、人間と同様に重要性に応じて映像中の情報を能動 的に取捨選択でき、数多くのシステムをより高度化できることが期待される。本報告では、人間の映像注視行動を高 速かつ高精度に模擬するための新しい視覚的注意の計算モデル、及び stream processing に基づく実装方法を提案す る。提案モデルでは、新たにマルコフ連鎖モンテカルロ法に基づくサンプリングと、粒子フィルタに基づく映像注視 行動の事後確率の推定を新たに導入することで、stream processing による並列処理を実現可能とした。大規模視線測 定データベースを用いた人間の注視行動との比較実験により、本提案手法が従来手法と比較して、10 倍以上高速かつ より正確に人間の映像注視行動を推定できることを示す。 キーワード 顕著度、視覚的注意、動的ベイジアンネットワーク、stream processing、マルコフ連鎖モンテカルロ法、 粒子フィルタReal time estimation of human visual attention with MCMC-based
particle filter
Kouji MIYAZATO
†,††, Akisato KIMURA
†, Shigeru TAKAGI
††, Junji YAMATO
†, and Kunio
KASHINO
††
NTT Communication Science Laboratories, NTT Corporation, Japan.††
Department of Information and Communication Systems Engineering, Okinawa National College of Technology, Japan.E-mail:
††
[email protected]Abstract This report proposes a new method for achieving a precise estimation of human visual attention with considerably less execution time. The main contribution of this report is the incorporation of a particle filter with Markov chain Monte-Carlo (MCMC) sampling into a previously proposed stochastic model of saliency-based human visual attention. This enables us to introduce stream processing with such as graphics processing units (GPU) for the acceleration of the estmation. Experimental results indicate that the proposed method can estimate human visual attention more than 10 times faster and more precisely than previous methods.
Key words Saliency-based human visual attention, dynamic Bayesian network, stream processing, Markov chain Monte-Carlo (MCMC), particle filter.
1.
Introduction
人間は、視覚的注意と呼ばれるメカニズムにより、網 膜に写る映像の中から重要と思われる情報を瞬時に判断 して、効率的に情報を獲得している。これら人間の視覚 特性を計算機上で模擬することで、人間と同様に重要性 に応じて映像中の情報を能動的に取捨選択する人工的 な視覚機構が構築され、ロボティクス [1]・アクティブビ ジョン [2]・一般物体認識 [3] ・画像映像検索 [4] など、数 多くのシステムをより高度化できると期待される。 人間の視覚特性に基づく視覚的注意の計算モデルとし て、Koch と Ullman による生理学的モデル [5] を計算機 上に実現した Itti らの計算モデル [6] が最も広く知られて いる。このモデルでは、入力された静止画像から、輝度・ 色彩・エッジ方向などの基本的な画像特徴量の時間的・ 空間的コントラストを抽出して組み合わせることで顕著 度画像 (saliency map) と呼ばれる画像を形成し、この顕 著度画像の画素値である顕著度 (saliency) が最大の箇所に注意が向けられる仕組みを仮定した。Itti らの計算モ デルが提案されて以降、この計算モデルの高度化 [7], [8] や映像への拡張 [9], [10] など、数多くの研究がなされて いる。しかし、これらいずれのモデルも致命的かつ重大 な問題点を内包していた。すなわち、入力される画像・ 映像に対して決定論的に各位置の顕著度が算出され、各 時点において顕著度が最も大きな箇所に注意が向けられ ることを仮定している。しかし、実際には、同じ映像を 見ても視聴する人によってもしくは視聴するタイミング によって視線位置が異なり、モデルの仮定とは矛盾する。 Pangら [11] は、上記の問題を解決するために、人間の視 線移動を確率的な挙動として捉え、動的ベイジアンネッ トワークを用いた視覚的注意のモデルを提案した。Pang らのモデルは、人間の映像注視行動との一致性という観 点において、Itti らのモデルと比較して有意に優れた性 能を示している一方、処理時間が非常に長くなる問題点 があった。実応用への展開を考慮する上で、処理の高速 化は重要な課題の 1 つである。 近年、計算時間が膨大に必要となる一般科学計算を高 速化する目的で、多数のコア(演算単位)を持つハード ウェアを利活用した並列演算を行う動きが各方面で盛ん になっている。これらの動きを後押しする理由として、 以下の 2 点が挙げられる。1) 複数コアを持つ CPU や、 GPU・Cell [12] などに代表される高性能な並列演算デバ イスが一般に入手可能かつ安価になった点、2) OpenMP や CUDA(注 1)に代表される、上記ハードウェア上に所望 の並列演算を手軽に実装するための SDK や API が数多 く開発され、急速に広まった点。これらのハードウェア を用いた並列処理実現のためのプログラミング手法の枠 組は stream processing [13] と呼ばれ、広く知られてい る。この stream processing に基づく実装を導入するこ とで、数多くの一般科学計算に要する処理時間を大幅に 短縮できることが報告されている [14]。しかし、stream processingでは、単純なデータを一度に大量に、かつそ れぞれがほぼ同様の負荷で処理することに特化している ため、その特性と合わない計算に対する速度向上は期待 できない。上記の Pang らの計算モデルには、その一部 に上記特性にそぐわない処理がおり、stream processing には不向きであった。 これらの考察に基づき、本報告では、stream process-ingの導入に適した新しい視覚的注意の計算モデル及び その実装方法を提案する。提案モデルでは、Pang らの計 算モデルに粒子フィルタに基づく注視行動の事後確率推 定を新たに導入することで、計算モデルそのものとして stream processingに適した特性を獲得した。また、粒子 フィルタにおけるサンプル生成方法としてマルコフ連鎖 モンテカルロ法 (Markov chain Monte-Carlo or MCMC) による実装を導入することで、各サンプリングに係る処 理時間を平準化し、並列性を高めた。
(注 1):http://www.nvidia.co.jp/object/cuda home jp.html
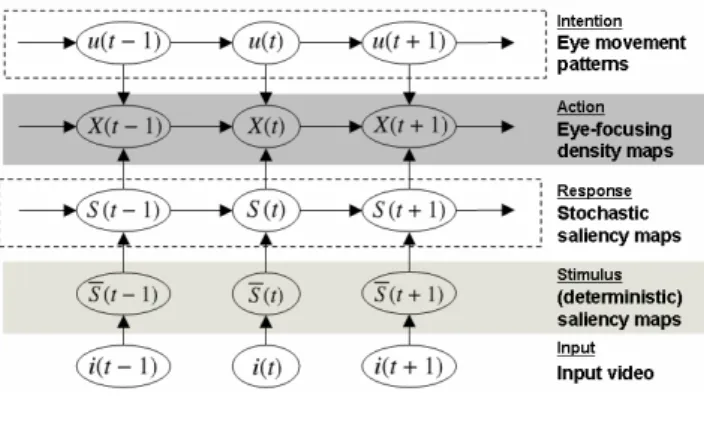
図 1 視覚的注意の計算モデル
Fig. 1 Our stochastic model of human visual attention
本報告の以降の構成は以下の通りである。第 2. 節に て、提案モデルの概要を述べる。第 3. 節から第 5. 節に かけて、提案モデルの詳細とその実装方法について説明 する。特に、第 5. 節では、本提案手法の主張点である、 MCMCサンプリングと粒子フィルタを用いた事後確率 推定の方法とその実装について詳説する。第 6. 節にて、 本提案手法の効果について論じる。特に、提案手法の処 理速度に関する優位性、及び実際の人間の映像注視行動 と比較した際の注視行動の推定精度に関する評価につい て、詳細に議論する。第 7. 章にて、本報告をまとめ、今 後の方向性について述べる。
2.
提案手法の概要
図 2. に、本報告で提案する視覚的注意の計算モデル の構成を示す。提案モデルは、その概略において、Pang らの提案したモデルを踏襲する。本提案モデルは、入力 映像を含む5層の動的ベイジアンネットワークによって 構成される。以下、各層について概説する。 最下層 I = I(1 : T ) ={I(t)}T t=1は、入力映像の各フ レームに対応する。ここで、T は入力映像 I の総フレー ム数、I(t) は入力映像 I の時刻 t におけるフレームを表 現する。以降の説明のため、記号 I を、入力映像を表現 する目的と共に、フレーム内の位置集合を表現するため にも用いる。すなわち、y∈ I と表記したとき、y は入 力映像フレーム内のある位置を示す。 第 2 層 S = S(1 : T ) ={S(t)}T t=1は、顕著度映像と呼 ばれ、その各フレームは、顕著度画像と称する、フレー ム内各位置の顕著性を表現する画像に対応する。顕著度 画像 S(t) = {s(t, y)}y∈I の各画素値は s(t, y) と表記さ れ、これを時刻 t・位置 y における顕著度と呼ぶ。顕著 度は、その時刻・位置における視覚刺激の強さを表現す る量として、直感的には理解される。顕著度画像の抽出 方法については、第 3. 節にて詳説する。 第 3 層 S = S(1 : T ) ={S(t)}T t=1は、確率的顕著度映 像であり、その各フレームは確率的顕著度画像と呼ばれ る。確率的顕著度画像 S(t) ={s(t, y)}y∈Iの各画素値は s(t, y)と表記され、これを時刻 t・位置 y における確率的顕著度と呼ぶ。確率的顕著度は、その時刻・位置にお いて実際に人間が知覚する視覚刺激の強さを表現する量 として直感的には理解され、人間の知覚プロセスにおけ る内部雑音などにより、顕著度に確率的な揺らぎを持っ て獲得されるものと考える。確率的顕著度画像の抽出方 法については、第 4. 節にて詳説する。 最上層 U = u(1 : T ) ={u(t)}T t=1は、視線移動状態変 数の系列であり、各視線移動状態変数 u(t) は映像視聴時 の人間の視線移動に関する戦略を表現する変数として理 解される。 第 4 層 X = x(1 : T ) ={x(t)}T t=1は、推定された視線 位置の系列を表現する確率変数である。実際には、視線 位置確率密度画像と称する、フレーム内各位置の画素値 が当該位置が視線の停留点となり得る確率を示す画像が 各時刻で生成され、この視線位置確率密度画像の系列が 第 4 層をなす。視線位置確率密度画像は、確率的顕著度 画像によって定まる視線移動を伴わない視覚的注意と、 視線移動状態変数によって定まる視線移動戦略の双方を 考慮して決定される。視線位置確率密度画像の抽出方法 については、第 5. 節にて詳説する。 以上の 5 層によって構成される動的ベイジアンネット ワークに基づき、与えられた最下層の入力映像から、第 4層の視線位置確率密度画像系列を推定することが、提 案モデルにおける目的となる。以降の各節において、具 体的な計算モデルの構成及び実装方法について詳説する。
3.
顕著度画像の生成
本節では、入力映像 I から顕著度映像 S を抽出する方 法について述べる。本報告で用いる方法は Pang らのモ デルと同様であり、Itti らの顕著度計算モデル [6] をほぼ そのまま用いる。Itti らの計算モデルでは、入力映像の 各フレーム I(t) から独立に顕著度画像 S(t) を抽出する。 まず、入力映像の各フレーム i(t) からいくつかの基 礎特徴画像を抽出し、それら基礎特徴画像の Gaussian pyramidをそれぞれ構成する。Itti らの方法では、輝度・ 補色差(赤/緑、青/黄)・エッジ方向(0◦、45◦、90◦、 135◦)の計 7 種類の基礎特徴を用いていたが、本報告で は映像を処理対象としていることから、これらに加え動 きに関する情報として optical flow(水平、垂直)を用 い、計 9 種類の基礎特徴とする。 次に、上記の各基礎特徴の Gaussian pyramid を用い て、異なるスケールにある基礎特徴画像の差分を 6 通り のスケールの組み合わせにおいて算出する。この差分画 像は、feature map と呼ばれる。 そして、各 feature map を正規化した後に基礎特徴ご とに加算して、conspicuity map と称する画像を生成す る。この正規化により、feature map 内の局所的なピーク が少数である場合にはそれらが強調され、多数である場 合にはそれらが抑制されることにより、多数のピークを 持つ「顕著ではない」feature map の影響を小さくする。 最後に、各 conspicuity map を上記の方法で正規化し た後に加算することで、顕著度画像を得る。 以上に示す通り、顕著度画像を得る操作は基本的な画 像処理の組み合わせによって構成される。すなわち、こ れらは stream processing に適した処理であり、実際に いくつかの先行研究が Itti らの方法の改良による GPU 実装を扱っている [15]。しかし、本報告の実装では、メ モリ確保やデータ転送の問題から、顕著度画像を抽出す る処理については、CPU 処理として実装している。4.
確率的顕著度画像の生成
本節では、顕著度映像 S から確率的顕著度映像 S を抽 出する方法について述べる。ここでも Pang らのモデル と同様、現時点(時刻 t)の顕著度画像 S(t) 及び 1 時点 前(時刻 t− 1)の確率的顕著度画像 S(t − 1) から現時 点の確率的顕著度画像 S(t) を推定する、以下の線形動的 システムモデルを用いる。 p(s(t, y)|s(t − 1, y)) = N (s(t − 1, y), σs1), p(s(t, y)|s(t, y)) = N (s(t, y), σs2), ここで、σsi (i = 1, 2)は事前の学習によって獲得する ガウス分布の分散を決定するモデルパラメータであり、 N (s, σ) は、平均 s, 分散 σ2のガウス分布である。シス テムの第 1 の関係式は顕著度の時間的連続性を仮定し、 第 2 の関係式は人間の知覚プロセスにおける内部雑音な どにより顕著度が確率的な揺らぎを持って人間に知覚さ れることを示唆する。 以下、上記のモデルに基づいて確率的顕著度画像を推 定する方法について詳説する。説明の簡略化のため、本 節に限って、位置 y を示すインデックスを取り除いた表 記を用いる。例えば、確率的顕著度の表記として、s(t, y) の代わりに s(t) を用いる。 時刻 t− 1 までの顕著度 s(1 : t − 1) を観測とするこれ までの処理により、時刻 t− 1 の確率的顕著度 s(t − 1) の 分布が、以下のように与えられているものとする。 p(s(t− 1)|s(1 : t − 1)) = N (bs(t − 1), σs(t− 1)). このとき、時刻 t の顕著度 s(t) を新たに観測したときの 時刻 t の確率的顕著度 s(t) は、カルマンフィルタに基づ く以下の処理により推定される。 p(s(t)|s(1 : t)) = N (bs(t), σs(t)), bs(t) = σs22 σ2 s1+ σ2s2+ σ2s(t− 1) bs(t − 1) + σ 2 s1+ σ2s(t− 1) σ2 s1+ σs22 + σs2(t− 1) s(t), σs2(t) = σ 2 s2· (σs12 + σs2(t− 1)) σ2 s1+ σ2s2+ σ2s(t− 1) , 以上に示す通り、顕著度画像から確率的顕著度画像を 得る操作は、各ピクセル独立に処理することができるた め、処理としては stream processing に非常に適してい る。しかし、本節の処理は stream processing を用いない場合においても十分高速(3-5msec/frame)であるの で、本報告の実装では CPU 処理としている。
5.
視線位置の推定
5. 1
概 要 本節では、確率的顕著度画像及び視線移動状態変数か ら視線位置を推定する方法について、その概要を述べる。 概要は Pang らのモデルと同様であるが、各部分モデル 及びその実装方法に、stream processing に適した改良を 加えている。この点が、本報告の主な主張点である。 人間の視覚的注意として、以下の 2 種類が独立に存在 することが知られている [16]。(1) “overt shifts of atten-tion”、すなわち当該箇所に視線を移動させることで明示 的に注意を向ける。(2) “covert shifts of attention”、す なわち視線移動を行わずに注意だけを当該箇所に向ける。 上記の知見に基づき、確率的顕著度画像 S(t) 及び視線 移動状態変数 u(t) から視線位置 x(t) を推定する確率モ デルとして、以下の関係式を導入する。 p(x(t), u(t)|p(S(t)), x(t − 1), u(t − 1)) ∝ p(x(t)|p(S(t))) ·p(u(t)|u(t − 1)) · p(x(t)|x(t − 1), u(t)), (1) ここで、∝ は比例関係を表現する関係子である。また、 記号 p(S(t)) によって、第 4. 節で導出した確率的顕著度 画像の確率密度関数の集合を表す簡易表現とする。 p(S(t)) = {p(s(t, y))}y∈I, p(s(t, y)) = p(s(t, y)|s(1 : t, y)) y ∈ I. 式 (1) のモデルは、視線位置を推定するに当たり、確率 的顕著度画像と視線移動状態変数とが独立に作用するこ とを示唆しており、それぞれ covert shifts, overt shifts の自然な確率的モデル化となっている。 視線移動状態変数 u(t) は、映像視聴時の人間の視線移 動に関する戦略を表現する変数として理解できる。本稿 では、以下の2種類の視線移動状態変数を考える。(1) “passive” u(t) = 0: 現在の視線位置位置における視覚情 報を継続して取得すべく、視線位置を大きく動かさない 戦略を採る。(2) “active” u(t) = 1: 現在の視線位置にお ける視覚情報を取得し終えたもしくは不要と判断して、 別の位置へ視線を移動させる戦略を採る。 時刻 t の視線位置の推定は、式 (1) の確率モデルに基 づき、時刻 t までの確率的顕著度画像の確率密度関数 p(S(1 : t))から、視線位置に関する以下の確率密度関数 を求めることで行われる。以降、表記の簡略化のため、 視線位置 x(t) と視線移動状態変数 u(t) の組を視線状態 z(t)と表記する。 p(x(t)|p(S(1 : t))) = ∑ u(t)=0,1 p(z(t)|p(S(1 : t))), (2) p(z(t)|p(S(1 : t))) = ∫ z(t−1) p(z(t− 1)|p(S(1 : t − 1))) ·p(z(t)|p(S(t)), z(t − 1))dz(t − 1). (3) 上記の確率密度値 p(x(t)|p(S(1 : t))) を位置 x(t) の画素 値として保持する画像が、位置 x(t) が視線位置となり える確率を示す画像であるので、これを視線位置確率密 度画像 X(t) とする。上記に示す導出式 (2)(3) はすなわ ち、時刻 t の視線位置確率密度画像が、時刻 t− 1 の視 線状態に関する確率密度を式 (1) の確率モデルを用いて 逐次的に更新し、視線移動状態変数について周辺化する ことで求められることを示している。 式 (2) を解析的に解くことは困難であるので、サンプ リングに基づく方法でこれを近似的に計算する。視線 状態に関する確率密度を、視線状態の N 個のサンプル {zn(t) = (xn(t), un(t))}Nn=1及びサンプルに関連付けら れた重み{wn(t)}Nn=1を用いて、以下のように近似する。 p(z(t)|p(S(1 : t))) ≈ N ∑ n=1 wn(t)· δ(z(t), zn(t)), (4) ここで、δ(·, ·) はクロネッカーのデルタである。 以下、上記の枠組に基づいて視線位置確率密度画像を 推定する方法について詳説する。推定は以下の 2 つのス テップに分割できる。 ( 1 ) 式 (1) 第 1 項 p(x(t)|p(S(t))) の計算、すなわち 確率的顕著度画像のみから視線位置を推定する部分。 ( 2 ) 式 (1) 第 2 項 p(u(t)|u(t − 1)) 及 び 第 3 項 p(x(t)|x(t − 1), u(t)) の計算、すなわち視線移動状態 変数を推定する部分及び視線移動状態変数に基づいて視 線位置を推定する部分。5. 2
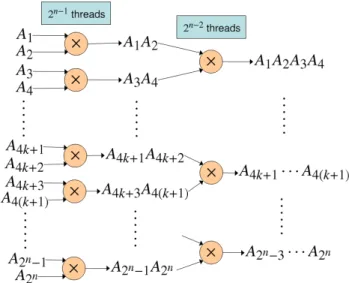
確率的顕著度画像からの推定 本節では、確率的顕著度画像から視線位置を決定する 方法を説明する。この方法の基本的な考え方は、信号検 出理論 [17] と呼ばれる心理物理学的知見に基づく。すな わち、各位置でその確率的顕著度の確率密度関数に従っ て確率的顕著度のサンプル値が 1 つ生成され、そのサン プル値が最大となる位置に注意が向けられる。この知見 に基づくと、視線位置に関する確率密度は、確率的顕著 度画像の確率密度から以下のようにして計算される。 p(x(t)|p(S(t))) = ∫ ∞ −∞ p(s(t, x(t)) = s) ∏ e x|=x(t) P (s(t,ex) <= s)ds, (5) ここで、P (s(t, y) <= s) は、位置 y における確率的顕著 度の確率密度 p(s(t, y)) に対応する確率的顕著度の累積 分布関数である。 Pangらは式 (5) を直接計算していたが、これは多くの 計算量を要する。しかし、この式と等価な以下の表現を 用いると、この計算を並列化でき、計算可能となる。 p(x(t)|p(S(t))) = ∫ ∞ −∞ p(s(t, x(t)) = s) P (s(t, x(t)) <= s) ∏ ex∈I P (s(t,ex) <= s)ds. (6)図 2 2分木による繰り返し積演算及びその並列化 Fig. 2 Tree-based multiplication with a binary tree and its
parallelization まず、式 (6) の積分を、確率的顕著度 s を量子化した 上で加算に置き換える。このとき、式 (6) の後半部分は、 位置 x(t) とは独立に計算できるため、各時刻 t 及び各確 率的顕著度 s においてそれぞれ 1 度計算すれば良い。さ らに、この部分の計算は、図 5. 2 に示す 2 分木による繰 り返し積演算と各段階の並列化により、各確率的顕著度 sについて画素数の対数オーダの時間で計算が可能であ る。一方、式 (6) の前半部分は、各位置 x(t) で独立に計 算できる。最後に、式 (6) の積分の代用としての加算を、 2分木による繰り返し加算と並列化により、量子化精度 の対数オーダの時間で計算を完了できる。
5. 3
視線移動状態変数からの推定 本節では、視線移動状態変数を用いて視線位置を推定 する方法を説明する。図 5. 3 にその概要を示す。 Pangら の モ デ ル [11] で は 、式 (1) の 確 率 モ デ ル を そ の ま ま 用 い て 、時 刻 t − 1 の 視 線 状 態 の サ ン プ ル{zn(t− 1)}Nn=1 から時刻 t の視線状態のサンプル {zn(t)}Nn=1を更新するモデルを用いていた。さらに、こ のサンプリングの実装として、棄却サンプリング法 [18] を用いていた。しかし、棄却サンプリング法は、サンプ リングに要する計算時間がサンプリングを行う確率密度 関数の性質に強く依存する問題がある。そのため、サン プルを更新するために要する処理時間がサンプルごとに 大きく異なってしまい、サンプリング処理を並列化して も速度を向上させることが難しい。 そ こ で 本 報 告 で は 、モ デ ル と 実 装 の 両 面 に お い て stream processingに適する改良を施し、確率密度の近似 精度を保ったまま高速な推定を実現する。 • モデルの改良: 式 (1) に示す確率モデルにおいて、 確率的顕著度画像に依存する部分(第 1 項)と視線移動 状態変数に依存する部分(第 2 項・第 3 項)が独立であ ることに着目し、第 2 項・第 3 項のみでサンプリングを 図 3 視線位置確率密度画像の算出方法(上)Pang らの 提案するモデル (下)提案モデルFig. 3 Strategies for calculating eye focusing density maps (Top) old strategy (Bottom) new strategy
行い、第 1 項でサンプルの重みを更新する枠組を提案す る。この枠組は、式 (1) の確率モデルにおける確率密度 関数の独立性を考慮すると、確率的顕著度画像の確率密 度関数 p(S(t)) を観測として視線状態 z(t) を推定する粒 子フィルタそのものである。 • 実装方法の改良: 式 (1) 第 2 項・第 3 項のサンプ リングに MCMC を用いる。これにより、サンプリング 処理を単純化し、かつその処理に要する時間をほぼ一定 とでき、stream processing を用いた実装を可能とする。 具体的な手順を以下に示す。 ( 1 ) 時刻 t− 1 までの手順により、時刻 t − 1 の視線 状態のサンプル{zn(t− 1) = (xn(t− 1), un(t− 1))}Nn=1 及びその重み{wn(t− 1)}Nn=1が得られていると仮定す る。このとき、時刻 t の視線状態のサンプル{zn(t) = (xn(t), un(t))}Nn=1は、式 (1) のうち視線移動状態変数に 依存する部分(第 2 項・第 3 項)から、Metropolis 法 [19] を用いることにより得られる。 un(t) ∼ p(u(t)|un(t− 1)), (7) xn(t) ∼ p(x(t)|xn(t− 1), un(t)). (8) ここで、∼ は左辺のサンプルを右辺の確率密度関数から 抽出することを示す関係子である。式 (7) の確率分布は、 事前の学習により獲得した 2× 2 遷移確率行列により特 徴付けられる。また、式 (8) の確率密度関数は、Pang ら のモデルと同様、視線移動距離に関するガウス分布であ
る以下の関数を仮定する。 p(x(t)|x(t − 1), u(t)) = L(x(t); x(t − 1), γx,u(t), σx,u(t)), ここで、γxiと σxi (i = 0, 1)は、それぞれ視線移動距離 の平均値及び分散を定めるモデルパラメータである。ま た、L(x; x, γ, σ) は、以下の式で定義される。 L(x; x, γ, σ) ∝ exp { −(∥x − x∥ − γ)2 2σ2 } . ( 2 ) 式 (1) の確率的顕著度画像に依存する部分(第 1項)を用いて、時刻 t の重みを以下の式で更新する。 wn(t) ∝ wn(t− 1) · p(x(t) = xn(t)|p(S(t))). 上式の右辺第 2 項は、5. 2 節ですでに計算されているこ とに注意する。式 (4) に示すように、ここまでの手順に より、視線位置確率密度画像がサンプル{zn(t)}Nn=1及び その重み{wn(t)}Nn=1から得られる。 ( 3 ) 最後に、必要に応じてリサンプリングを行う。 リサンプリングを行うかどうかを決定する基準として、 重みの 2 乗和の逆数 [20] などが一般的に用いられるが、 本報告の実装ではある一定時間間隔でリサンプリングを 実行する。
6.
評 価 実 験
6. 1
実 験 条 件 提案方法の効果を示すために、本手法の基礎となった Pangらのモデル [11]、及びさらにその基礎となった Itti らのモデル [6] と、処理速度及び人間の視線行動との一 致性の双方の観点で比較を行なった。 人間の映像注視行動との一致性を検証するため、Uni-versity of South Californiaが作成元とである CRCNS eye-1データベース(注 2)を使用した。このデータベースに は、映像 100 本(MPEG-1、640× 480 画素、30fps)と、 その映像を視聴した被験者の視線測定データ(各映像 4∼ 6人分、240fps)が含まれている。視線測定に関する詳 細な条件に関しては、データベースのドキュメントを参 照。本実験では、このデータベースの中から、“original experiment”と称する 50 本の映像(総再生時間約 25 分) とそれに対応する視線測定データを用いた。 第 4. 節及び第 5. 3 節に示した各モデルパラメータは、 文献 [11] に記載の方法を用いた事前学習により求めた。 このとき、50 本の映像のうち 40 本をモデル学習に、残 り 10 本を評価に用いる交差検定法を採用した。 人間の映像視聴行動との一致性を評価する尺度として、 本実験では normalized scanpath saliency (NSS) [21] と 呼ばれる尺度を用いた。この尺度は、各モデルの出力映 像(提案モデルの場合には視線位置確率密度画像)のあ るフレームにおいて、ある被験者の視線位置での画素値(注 2):http://crcns.org/data-sets/eye/eye-1
表 1 実験に用いた計算機
Table 1 Platform used in the evaluation
OS Windows Vista Ultimate
Development Microsoft Visual Studio 2008 C++ platform OpenCV 1.1pre & NVIDIA CUDA 2.1
Optimization none
CPU Intel Core2 Quad Q6600 (2.40GHz)
RAM 4.0GB
GPU NVIDIA GeForce8800GT×2 SLI (512MB)
がフレーム内の平均画素値に比べてどの程度大きいかを 測定する尺度として理解できる。正確には、時刻 t にお ける NSS は、以下の式によって定義される。 N SS(t) = 1 Ns Ns ∑ j=1 1 σ(p(x)) { max x(t)∈Rj(t) p(x(t))− p(x) } , ここで、Nsは被験者の数、Rj(t) (j = 1, 2,· · · , Ns)を 第 j 番目の被験者の時刻 t における視線位置を中心とす る半径 30 画素の円形領域、p(x; t) を時刻 t・位置 x に おけるモデルの出力映像フレームの画素値、p(x; t) と σp(x; t)をそれぞれ時刻 t・位置 x におけるモデルの出力 映像フレームの画素値の平均と分散である。 表 1 に実験に用いた計算機の構成を示す。
6. 2
実 験 結 果 図 6. 2 に、各方法の処理時間を比較した結果を示す。 提案方法の比較対象として、Pang らのモデル(左)、第 5. 3節に示した MCMC サンプリングと粒子フィルタに よる推定のみを Pang らのモデルに加えた方法(左から 2番目)、及び Itti らのモデル(右)を用いた。視線位置 確率密度画像を表現するサンプルの数は、Pang らのモ デルにおいては計算時間の制約により 500 個、本提案手 法においては 5000 個とした。第 5. 3 節に示した MCMC サンプリングと粒子フィルタの導入により、サンプル数 の大幅な増加にも関わらず処理速度が大幅に向上してい ることがわかる。第 5. 2 節に示した 2 分木による繰り返 し演算と並列化も処理速度の向上に寄与している。結果 として、提案手法により、Itti らのモデルとほぼ同等、か つほぼリアルタイムでの動作を実現した。 図 6. 2 に、顕著度画像の抽出(左)・確率的顕著度画 像からの視線位置確率密度画像の算出(中)・視線移動 状態変数からの視線位置確率密度画像の算出(右)の各 処理について、処理時間を分析した結果を示す。処理速 度向上の様子を明確に示すために、縦軸に対数軸を採用 していることに注意する。また、確率的顕著度画像の抽 出に要する時間に関しては、いずれの場合もごく短時間 (3-5 msec/frame)であったので省略した。図に示すよう に、MCMC サンプリングと粒子フィルタの導入により、 Pangらのモデルで最も処理時間を要していた、視線移動 状態変数からの視線位置確率密度画像の算出に要する処 理時間が 1/100 以下に削減されていることがわかる。ま図 4 全体の処理時間 [msec/frame] Fig. 4 Total execution time [msec/frame]
図 5 各処理に要する時間 [log msec/frame] Fig. 5 Detailed execution time for each step
図 6 人間の映像注視行動との一致性の比較
Fig. 6 Average NSS score
た、2 分木による繰り返し演算と並列化についても、確 率的顕著度画像からの視線位置確率密度画像の算出に要 する処理時間を 1/10 以下に削減していることがわかる。 図 6. 2 に、人間の映像注視行動との一致性を、先に示 した NSS 尺度にて評価して比較した結果を示す。提案方 法の比較対象として、Pang らのモデルと Itti らのモデ ルを用いた。2 分木による繰り返し演算と並列化の導入 は視線位置確率密度画像の内容に影響を与えないことか ら、MCMC サンプリングと粒子フィルタによる推定の みを Pang らのモデルに加えた方法は、評価値において 本質的に提案モデルと等価であることに注意する。図に 示すように、提案モデルは、いずれの映像においても、 Pangらのモデルとほぼ同様かつ Itti らのモデルよりも 有意に高い NSS 値を示していることがわかる。これは、 提案方法が人間の映像注視行動を高い精度で推定できて いることを示す結果である。 図 6. 2 に、評価用映像およびそれを入力とする各モデ ルの出力結果を示す。ここでは、Itti らのモデルと提案 モデルの結果を比較している。出力結果の映像は添付資 料に収録されている。視認性を向上させるために、提案 モデルの出力に手動で円を付与している。Itti らのモデ ルではフレーム内全域に顕著性の高い領域が散在してい る一方、提案モデルでは視線が向けられる可能性の高い 領域を少量かつ狭い範囲に絞り込むことができている。 すなわち、提案モデルは、より的確に人間の映像注視行 動を推定していることを示す結果である。
7.
ま と め
本報告では、人間の映像注視行動を高速かつ高精度に 推定するための新しい視覚的注意の計算モデル、及びそ の stream processing に基づく実装方法を提案した。提案 モデルでは、粒子フィルタを用いた視線位置推定モデル を導入し、粒子フィルタにおけるサンプリングを MCMC により実装することで、モデル・実装の両面から stream processingに適した処理を実現した。人間の実際の視線 データを元に行なった評価実験により、本報告で提案す る手法が従来の手法と比較して、視線データとの一致性 の観点においてほぼ同等の性能を維持したまま、処理速 度を大幅に向上させたことを確認した。これらの高速化 の結果、本報告で提案する視覚的注意の計算手法を、未 登録物体の検出 [22] や映像認識・検索のフロントエンド として用いることが可能となった。今後の研究では、こ れら応用面への展開を検討する予定である。8.
謝
辞
本研究に対して真摯に御議論いただいた the University of South Californiaの Laurent Itti 博士及び Kyungpook National Universityの Minho Lee 博士に深謝する。ま た、本研究に対し有益な御助言を頂いた NTT コミュニ ケーション科学基礎研究所竹内龍人主幹研究員に深謝す る。筆頭著者は、2008 年 8∼9 月に NTT コミュニケー ション科学基礎研究所に実習生として在籍し、本研究に 寄与した。本実習に対して御支援を頂いた NTT コミュ ニケーション科学基礎研究所 外村佳伸主席研究員所長、 上田修功主席研究員副所長、澤田宏主幹研究員、中沢憲 二主幹研究員部長に感謝する。 文 献[1] N. Ouerhani and H. H¨ugli, “Robot self-localization us-ing visual attention,” Proc. CIRA, pp.309–314, 2005.
図 7 出力結果(上から入力映像、Itti モデル、提案モデル) Fig. 7 Snapshots of results (From top: input, Itti’s model, and proposed model)
[2] T. Xu, Q. M¨uhlbauer, S. Sosnowski, K. K¨uhnlenz, and M. Buss, “Looking at the surprise: Bottom-up attetional control of an active camera system,” Proc. ICARCV, pp.637–642, 2008.
[3] S. Frintrop, A. N¨uchter, H. Surmann, and J. Hertzberg, “Saliency-based object recognition in 3D data,” Proc. IROS, pp.2167–2172, 2004.
[4] S. Li and M. Lee, “An efficient spatiotemporal at-tention model and its application to shot match-ing,” IEEE Trans CSVT, Vol.17, No.10, pp.1383– 1387, 2007.
[5] C. Koch and S. Ullman, “Shifts in selective visual attention: Towards the underlying neural circuitry,” Human Neurobiology, Vol.4, pp.219–227, 1985. [6] L. Itti, C. Koch, and E. Niebur, “A model of
saliency-based visual attention for rapid scene analysis,” IEEE Trans PAMI, Vol.20, No.11, pp.1254–1259, 1998. [7] S. Jeong, S. Ban, and M. Lee, “Stereo saliency
map considering affective factors and selective mo-tion analysis in a dynamic environment,” Neural Net-works, Vol.21, pp.1420–1430, 2008.
[8] D. Gao and N. Vasconcelos, “Decision-theoretic saliency: Computational principles, biological plau-sibility, and implications for neurophysiology and psychophysics,” Neural Computation, Vol.21, No.1, pp.239–271, 2009.
[9] L. Itti and P. Baldi, “A principled approach to detect-ing surprisdetect-ing events in video,” Proc. CVPR, pp.631– 637, 2005.
[10] C. Leung, A. Kimura, T. Takeuchi, J. Yamato, and K. Kashino, “A computational model of saliency de-pletion/recovery phenomena for the salient region ex-traction of videos,” Proc. MIRU, pp.582–587, 2007. [11] D. Pang, A. Kimura, T. Takeuchi, J. Yamato, and
K. Kashino, “A stochastic model of selective visual attention with a dynamic Bayesian network,” Proc. MIRU, pp.1500–1505, 2008.
[12] D. Mallinson and M. DeLoura, “CELL: A new
plat-form for digital entertainment,” Game Developers Conference, 2005.
[13] U. Kapasi, S. Rixner, W. Dally, B. Khailany, J.H. Ahn, P. Mattson, and J. Owens, “Programmable stream processors,” IEEE Computer, Vol.36, No.8, pp.54–62, 2003.
[14] O. Lozano and K. Otsuka, “Real-time visual tracker by stream processing,” Journal of Signal Processing Systems, 2008.
[15] B. Han and B. Zhou, “High speed visual saliency com-putation on GPU,” Proc. ICIP, pp.361–364, 2007. [16] A.R. Hunt and A. Kingstone, “Covert and overt
vol-untary attention: linked or independent?,” Cognitive Brain Research, Vol.18, No.1, pp.102–105, 2003. [17] M.P. Eckstein, J.P. Thomas, J. Palmer, and S.S.
Shi-mozaki, “A signal detection model predicts effects of set size on visual search accuracy for feature, con-junction, triple conjunction and disjunction displays,” Perception and Psychophysics, Vol.62, pp.425–451, 2000.
[18] C.P. Robert and G. Casella, Monte Carlo Statistical Methods (Springer Texts in Statistics), 2nd ed. 2004. corr. 2nd printing ed., Springer, 7 2005.
[19] N. Metropolis, A. Rosenbluth, M. Rosenbluth, A. Teller, and E. Teller, “Equation of state calcula-tions by fast computing machines,” Journal of Chem-ical Physics, Vol.21, pp.1087–1092, 1953.
[20] B. Ristic, S. Arulampalam, and N. Gordon, Beyond the Kalman filter: Particle filters for tracking appli-cations, Artech House Publishers, Boston, 2004. [21] R.J. Peters and L. Itti, “Beyond bottom-up:
Incor-porating task-dependent influences into a computa-tional model of spatial attention,” Proc. CVPR, pp.1– 8, 2007.
[22] K. Fukuchi, K. Miyazato, A. Kimura, S. Takagi, and J. Yamato, “Saliency-based video segmentation with graph cuts and sequentially updated priors,” Proc. ICME, 2009.