Title 深層学習を用いた特徴表現に基づく字種非依存型オフライン筆者照合に関する研究( 本文(Fulltext) ) Author(s) 細江, 麻梨子 Report No.(Doctoral Degree) 博士(工学) 工博甲第579号 Issue Date 2020-03-25 Type 博士論文 Version ETD URL http://hdl.handle.net/20.500.12099/79346 ※この資料の著作権は、各資料の著者・学協会・出版社等に帰属します。
博 士 論 文
深層学習を用いた特徴表現に基づく
字種非依存型オフライン筆者照合に関する研究
Research of offline text-independent writer verification
based on feature representation using deep learning
2020 年 3 月
岐阜大学大学院工学研究科
電子情報システム工学専攻
i
論 文 要 旨
2012 年に深層学習を用いた技術が研究分野で注目され,昨今ではその技術を 応用したシステムや製品が社会の発展に大きく貢献している.特に画像認識の 分野では,人の視覚情報処理の過程に着目した Convolutional Neural Network (CNN)を用いた手法が,様々なタスクにおいて従来の Handcrafted な特徴抽出 手法よりも大幅に高い性能を示している.深層学習とは,大量のデータを用いる ことで,人の情報処理過程を模したネットワークモデルを探索的に学習し,デー タの背後に潜む何らかの規則性を見出す技術といえる.そのため,職人芸といわ れるような,判断根拠となる要因の説明が困難な課題について,数値的に解釈す るための新たな試みを可能とすることも深層学習の大きな貢献といえる.本研 究では,犯罪捜査において行われている筆跡鑑定に関する課題に対して,深層学 習技術を応用した解明に挑んだ. 犯罪捜査における筆跡鑑定として,筆者不詳の疑問筆跡と筆者既知の対照筆 跡を比較することで,疑問筆跡が対照筆跡の筆者によって書かれたか否かを調 べる筆者照合が行われている.通常の筆跡鑑定は,疑問筆跡と対照筆跡間の同一 字種を比較して筆者の異同を判断する字種依存型の筆者照合であり,鑑定条件 が資料間での同一字種の存在の有無によって制限されるという問題がある.実 際の犯罪場面においては,疑問筆跡と同内容の対照筆跡が採取不可能である状 況が存在し,字種依存型の筆者照合では,そのような状況下において疑問筆跡と 対照筆跡間で同一字種が存在しない場合には照合不能となる.しかしながら,筆 跡は手の運動制御という物理的要因や学習経験等をもとに生成されることから, 同一人が記載した筆跡は字種に依存しない性質を有すると考えられ,字種非依 存型の筆者照合及び筆者識別についての研究も盛んに行われてきた.字種非依 存型の筆者照合が可能となれば,鑑定資料間で同一字種が存在しない,または少 数しか存在しない状況に対しても筆跡鑑定を行うことができ,鑑定の幅を広げ, 犯罪捜査への貢献は大きい.そこで,本研究では,通常の筆跡鑑定における字種 依存の問題に対して,字種非依存型の筆者照合システムを構築することを目的 とした. 本研究は,異なる字種間に潜む人間の行動的特徴の共通性を解明するサイエ ンスの要素と,精度の高い筆者照合システムを構築するエンジニアリングの要
ii 素を含み,深層学習というテクノロジーにより研究課題に取り組んだ.最初に, 筆跡には字種に依存しない個性的な筆跡特徴が存在することを示す先行研究の 結果を踏まえ,異なる字種同士から筆者照合に有効な個人性を見出すことがで きるか否かというサイエンスに対して,CNN による特徴抽出モデルの構築を試 みた.次に,見出された字種非依存の筆跡特徴について,いかに筆跡鑑定におけ る筆者照合の高精度化につなげるかというエンジニアリングに対しては,Metric Learning により同一人の異字種間の類似性を考慮した特徴空間の学習を行った. ETL-1 Character Database と独自に収集した Hiragana dataset を用いて,提案手法 により字種非依存な筆跡特徴の抽出が可能か否か,Metric Learning による筆者の 類似性に着目した特徴空間が学習可能か否かについて,潜在空間の可視化及び 筆者照合性能から評価した.評価実験を行った結果,字種情報を Encoder と Decoder に付与した Conditional AutoEncoder を用いることで,筆跡画像から字種 に依存しない特徴表現の可能な潜在空間が学習されている状態が確認された. また,潜在空間で表現される字種非依存な筆跡特徴を用いることで,比較する筆 跡間で同一字種が存在しない条件かつ少数字種でしか照合ができない条件であ っても,高精度に筆者照合が可能となる特徴空間が Siamese Network 構造の Metric Learning 手法により学習されていることが確認された.
iii
目次
第1 章 序論 ··· 1 1.1 研究背景 ··· 1 1.2 研究目的 ··· 3 1.3 本論文の構成 ··· 4 第2 章 筆者照合の研究動向 ··· 5 2.1 犯罪捜査における筆跡鑑定と本研究の位置づけ ··· 5 2.2 関連研究 ··· 8 2.2.1 書字行動の運動理論からの調査研究 ··· 9 2.2.2 筆跡の個人性に関する調査研究 ··· 10 2.2.3 照合精度向上に関する研究 ··· 10 2.3 犯罪捜査における筆者照合手法の課題 ··· 11 2.4 まとめ ··· 12 第3 章 Conditional AutoEncoder による筆跡特徴抽出 ··· 13 3.1 関連研究 ··· 14 3.1.1 字種に依存しない筆跡特徴の潜在表現 ··· 14 3.1.2 生成モデルにおける特徴分離手法 ··· 16 3.2 提案手法 ··· 16 3.3 評価実験 ··· 19 3.3.1 実験データセット ··· 193.3.1.1 ETL-1 Character Database(ETL-1) ··· 20
3.3.1.2 Hiragana dataset(平仮名データ) ··· 21 3.3.2 前処理 ··· 22 3.3.3 提案手法との比較モデル ··· 23 3.3.3.1 AutoEncoder の字種ラベル付与の有効性 ··· 23 3.3.3.2 潜在空間の構造化の筆跡特徴抽出への影響 ··· 26 3.3.4 学習方法 ··· 27 3.3.5 評価方法 ··· 28
iv 3.3.5.1 潜在空間の可視化による特徴表現の評価··· 28 3.3.5.2 筆者照合実験からの評価 ··· 32 3.3.5.3 実験パラメータ ··· 36 3.3.6 実験結果と各結果についての考察 ··· 36 3.3.6.1 潜在空間の評価結果 ··· 37 3.3.6.2 筆者照合実験結果 ··· 57 3.4 考察 ··· 74 3.5 まとめ ··· 75 第4 章 Siamese Network による筆者照合 ··· 77 4.1 関連研究 ··· 77 4.2 提案手法 ··· 77
4.2.1 Handwriting Feature Extraction Model (HFEM) ··· 80
4.2.2 Writer Verification Model (WVM) ··· 80
4.2.3 WVM の学習方法 ··· 82 4.3 評価実験 ··· 83 4.3.1 実験条件 ··· 84 4.3.2 評価方法 ··· 85 4.3.3 実験結果 ··· 85 4.3.3.1 HFEM・WVM 構造のモデル比較 ··· 85 4.3.3.2 WVM とユークリッド距離による類似度算出手法の比較 ··· 93 4.3.3.3 照合結果例 ··· 94 4.4 考察 ··· 99 4.5 まとめ ··· 99 第5 章 筆者照合手法の高精度化に向けた検討 ··· 100 5.1 学習データ数と照合性能の関係 ··· 100 5.1.1 実験条件 ··· 100 5.1.2 実験結果 ··· 101 5.2 Metric Learning 手法による照合性能の比較··· 111 5.2.1 比較モデル ··· 113 5.2.2 モデルの学習条件 ··· 116 5.2.3 評価方法 ··· 117
v 5.2.4 実験結果 ··· 117 5.3 考察 ··· 123 5.4 まとめ ··· 125 第6 章 結論と展望 ··· 126 謝辞 ··· 128 参考文献 ··· 129 研究業績一覧 ··· 138
vi
図目次
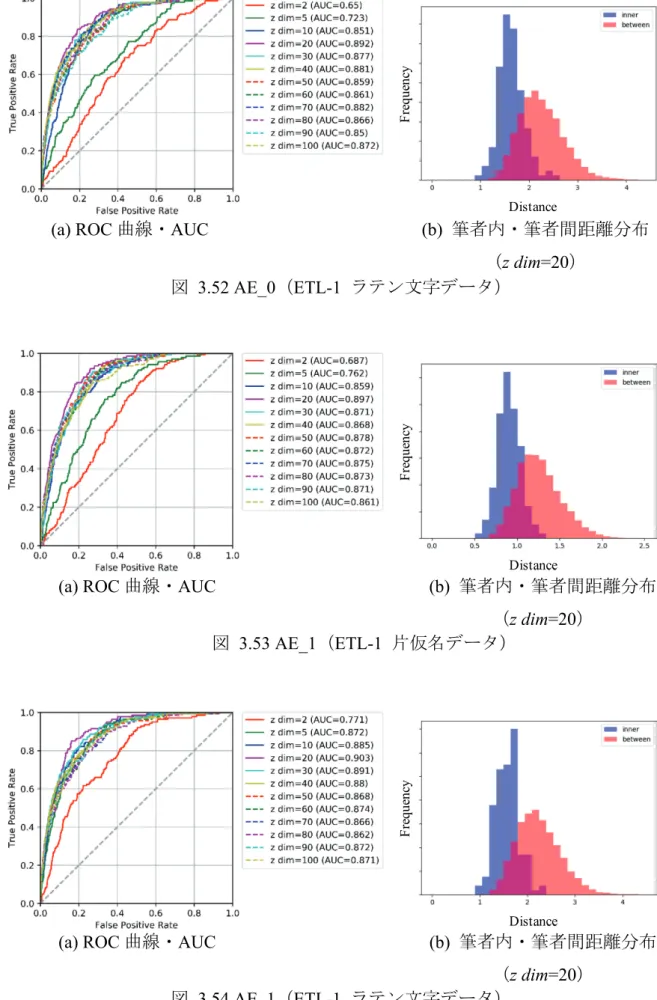
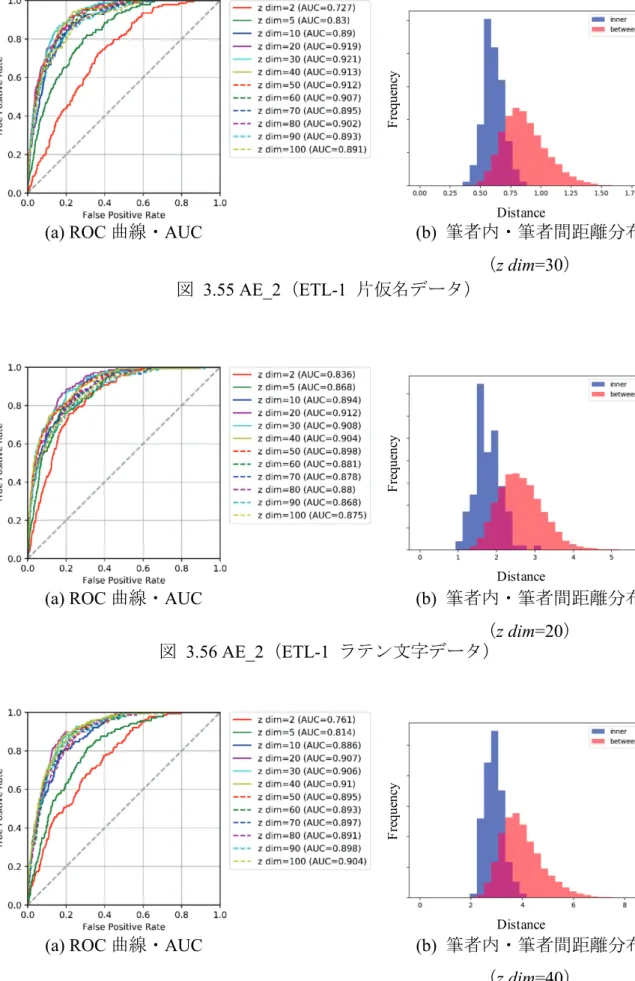
図 1.1 本論文の構成 ··· 4 図 2.1 一般的な筆跡鑑定の流れ(字種依存型筆者照合) ··· 6 図 2.2 筆者照合の分類と本研究の位置づけ ··· 7 図 2.3 登録型筆者照合(筆者依存型) ··· 7 図 2.4 非登録型筆者照合(筆者非依存型) ··· 8 図 3.1 CVAE による潜在空間の学習と特徴表現 ··· 15 図 3.2 提案手法の概要 ··· 17 図 3.3 CAE(AE_2)のネットワーク構造 ··· 18 図 3.4 ETL-1 のサンプル ··· 20 図 3.5 平仮名データのサンプル ··· 21 図 3.6 ETL-1 の前処理 ··· 22 図 3.7 平仮名データの前処理 ··· 23 図 3.8 AE_0 のネットワーク構造 ··· 24 図 3.9 AE_1 のネットワーク構造 ··· 25 図 3.10 VAE_2 のネットワーク構造 ··· 26 図 3.11 潜在変数 z を入力とする生成画像からの潜在空間の可視化 ··· 29 図 3.12 字種情報 y を変化させて画像生成 ··· 30 図 3.13 実際の手書き文字の潜在空間へのマッピング ··· 31 図 3.14 筆者単位で潜在空間にマッピング ··· 32 図 3.15 同一人ペア,他人ペアの作成(m=3 の場合) ··· 34 図 3.16 データ間の類似度計算(比較字種数=m の場合) ··· 36 図 3.17 AE_0 の 2D 潜在空間の可視化 ··· 37 図 3.18 AE_1 の 2D 潜在空間の可視化 ··· 38 図 3.19 AE_2 の 2D 潜在空間の可視化 ··· 38 図 3.20 VAE_2 の 2D 潜在空間の可視化 ··· 39 図 3.21 Input の「ス」の z を用いて画像生成 ··· 40vii 図 3.22 Input の「S」の z を用いて画像生成 ··· 41 図 3.23 AE_0(ETL-1 片仮名データ「ア」) ··· 42 図 3.24 AE_0(ETL-1 片仮名データ「ス」) ··· 43 図 3.25 AE_0(ETL-1 ラテン文字データ「K」) ··· 43 図 3.26 AE_0(ETL-1 ラテン文字データ「S」) ··· 44 図 3.27 AE_1(ETL-1 片仮名データ「ア」) ··· 44 図 3.28 AE_1(ETL-1 片仮名データ「ス」) ··· 45 図 3.29 AE_1(ETL-1 ラテン文字データ「K」) ··· 45 図 3.30 AE_1(ETL-1 ラテン文字データ「S」) ··· 46 図 3.31 AE_2(ETL-1 片仮名データ「ア」) ··· 46 図 3.32 AE_2(ETL-1 片仮名データ「ス」) ··· 47 図 3.33 AE_2(ETL-1 ラテン文字データ「K」) ··· 47 図 3.34 AE_2(ETL-1 ラテン文字データ「S」) ··· 48 図 3.35 VAE_2(ETL-1 片仮名データ「ア」) ··· 48 図 3.36 VAE_2(ETL-1 片仮名データ「ス」) ··· 49 図 3.37 VAE_2(ETL-1 ラテン文字データ「K」) ··· 49 図 3.38 VAE_2(ETL-1 ラテン文字データ「S」) ··· 50 図 3.39 AE_2 の 2D 潜在空間(「ア」のマッピング状況) ··· 51 図 3.40 AE_2 の 2D 潜在空間(「ス」のマッピング状況) ··· 51 図 3.41 AE_2 の 2D 潜在空間(「K」のマッピング状況) ··· 52 図 3.42 AE_2 の 2D 潜在空間(「S」のマッピング状況) ··· 52 図 3.43 AE_0(ETL-1 片仮名データ 46 字種) ··· 53 図 3.44 AE_0(ETL-1 ラテン文字データ 26 字種) ··· 53 図 3.45 AE_1(ETL-1 片仮名データ 46 字種) ··· 54 図 3.46 AE_1(ETL-1 ラテン文字データ 26 字種) ··· 54 図 3.47 AE_2(ETL-1 片仮名データ 46 字種) ··· 55 図 3.48 AE_2(ETL-1 ラテン文字データ 26 字種) ··· 55 図 3.49 VAE_2(ETL-1 片仮名データ 46 字種) ··· 56 図 3.50 VAE_2(ETL-1 ラテン文字データ 26 字種) ··· 56 図 3.51 AE_0(ETL-1 片仮名データ) ··· 57 図 3.52 AE_0(ETL-1 ラテン文字データ) ··· 58
viii 図 3.53 AE_1(ETL-1 片仮名データ) ··· 58 図 3.54 AE_1(ETL-1 ラテン文字データ) ··· 58 図 3.55 AE_2(ETL-1 片仮名データ) ··· 59 図 3.56 AE_2(ETL-1 ラテン文字データ) ··· 59 図 3.57 VAE_2(ETL-1 片仮名データ) ··· 59 図 3.58 VAE_2(ETL-1 ラテン文字データ) ··· 60 図 3.59 ETL-1 片仮名データ実験における AUC のモデル比較 ··· 61 図 3.60 ETL-1 ラテン文字データ実験における AUC のモデル比較 ··· 62 図 3.61 ETL-1 片仮名データ実験における平均 EER ··· 66 図 3.62 ETL-1 片仮名データ実験における平均 AUC ··· 67 図 3.63 ETL-1 ラテン文字データ実験における平均 EER ··· 70 図 3.64 ETL-1 ラテン文字データ実験における平均 AUC ··· 71 図 3.65 平仮名データの 2D 潜在空間の可視化 ··· 72 図 3.66 各筆者の手書き文字の潜在空間へのマッピング ··· 72 図 3.67 平仮名データを用いた各パターンでの最大 AUC ··· 73 図 3.68 平仮名データを用いた単一同一字種条件での最大 AUC ··· 74 図 4.1 各特徴軸(次元)で表現される字形の可視化··· 78 図 4.2 各筆者の手書き文字の 2D 潜在空間へのマッピング ··· 79 図 4.3 Siamese Network を用いた筆者照合の流れ ··· 79 図 4.4 HFEM(AE_2 の Encoder 部分) ··· 80 図 4.5 WVM のネットワーク構造 ··· 80 図 4.6 学習用の同一人ペア,他人ペアの作成例(m=3 の場合) ··· 82 図 4.7 Direct モデルのネットワーク構造 ··· 83 図 4.8 ETL-1 片仮名データ実験における平均 EER ··· 88 図 4.9 ETL-1 片仮名データ実験における平均 AUC ··· 89 図 4.10 ETL-1 ラテン文字データ実験における平均 EER ··· 91 図 4.11 ETL-1 ラテン文字データ実験における平均 AUC ··· 92 図 4.12 類似性評価手法による比較(ETL-1 片仮名データ) ··· 93 図 4.13 類似性評価手法による比較(ETL-1 ラテン文字データ) ··· 93 図 4.14 ETL-1 片仮名データの各パターンの ROC 曲線 ··· 95 図 4.15 ETL-1 片仮名データ 3 字種の照合結果例 ··· 95
ix 図 4.16 ETL-1 片仮名データ 5 字種の照合結果例 ··· 96 図 4.17 ETL-1 片仮名データの各パターンの出力値ヒストグラム ··· 96 図 4.18 ETL-1 ラテン文字データの各パターンの ROC 曲線 ··· 97 図 4.19 ETL-1 ラテン文字データ 3 字種の照合結果例 ··· 97 図 4.20 ETL-1 ラテン文字データ 5 字種の照合結果例 ··· 98 図 4.21 ETL-1 ラテン文字データの各パターンの出力値ヒストグラム ···· 98 図 5.1 ETL-1 の学習データ数(筆者数)を制限した分割 ··· 101 図 5.2 ETL-1 片仮名データ実験における平均 EER ··· 105 図 5.3 ETL-1 片仮名データ実験における平均 AUC ··· 106 図 5.4 ETL-1 ラテン文字データ実験における平均 EER ··· 109 図 5.5 ETL-1 ラテン文字データ実験における平均 AUC ··· 110 図 5.6 Triplet Network による特徴空間の学習 ··· 111 図 5.7 Quadruplet Network による特徴空間の学習 ··· 112 図 5.8 Siamese モデルのネットワーク構造 ··· 113 図 5.9 Triplet モデルのネットワーク構造··· 114 図 5.10 Quadruplet モデルのネットワーク構造 ··· 114 図 5.11 最適化の流れ ··· 115 図 5.12 Siamese_Dist モデルのネットワーク構造 ··· 116 図 5.13 ETL-1 片仮名データ実験における平均 EER ··· 119 図 5.14 ETL-1 片仮名データ実験における平均 AUC ··· 120 図 5.15 ETL-1 ラテン文字データ実験における平均 EER ··· 122 図 5.16 ETL-1 ラテン文字データ実験における平均 AUC ··· 123
x
表目次
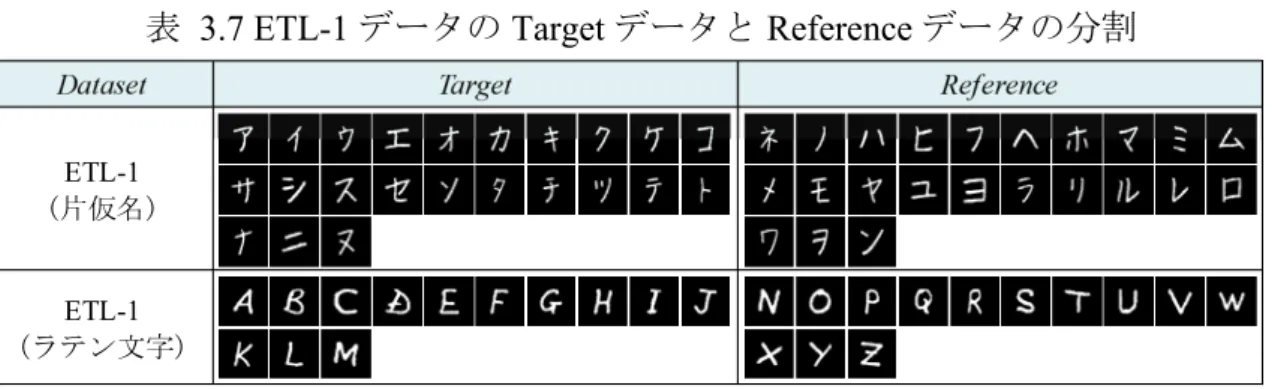
表 3.1 CAE(AE_2)の各層の詳細··· 18 表 3.2 AE_0 の各層の詳細 ··· 24 表 3.3 AE_1 の各層の詳細 ··· 25 表 3.4 VAE_2 の各層の詳細 ··· 26 表 3.5 実験データセットの詳細 ··· 27 表 3.6 データ分割の詳細 ··· 27表 3.7 ETL-1 データの Target データと Reference データの分割 ··· 33
表 3.8 平仮名データの異字種筆者照合実験におけるデータ分割 ··· 34 表 3.9 平仮名データの同一字種筆者照合実験におけるデータ分割 ··· 35 表 3.10 ETL-1 片仮名データ実験における AUC のモデル比較 ··· 61 表 3.11 ETL-1 ラテン文字データ実験における AUC のモデル比較 ··· 61 表 3.12 ETL-1 片仮名データ実験におけるモデル比較 ··· 63 表 3.13 ETL-1 片仮名データ実験におけるモデル比較 ··· 64 表 3.14 ETL-1 片仮名データ実験におけるモデル比較 ··· 65 表 3.15 ETL-1 ラテン文字データ実験におけるモデル比較 ··· 68 表 3.16 ETL-1 ラテン文字データ実験におけるモデル比較 ··· 69 表 3.17 平仮名データを用いた特定パターンでの筆者照合結果 ··· 73 表 3.18 平仮名データを用いた単一同一字種での筆者照合結果 ··· 74 表 4.1 WVM の各層の詳細 ··· 81 表 4.2 Direct モデルの各層の詳細 ··· 84 表 4.3 WVM の学習で用いるペアデータ数(ns-pair=nd-pair) ··· 84 表 4.4 ETL-1 片仮名データ実験におけるモデル比較 ··· 86 表 4.5 ETL-1 片仮名データ実験におけるモデル比較 ··· 87 表 4.6 ETL-1 ラテン文字データ実験におけるモデル比較 ··· 90 表 4.7 平仮名データ実験における筆者照合性能比較(AUC) ··· 94 表 4.8 ETL-1 片仮名データの特定パターンにおける評価結果 ··· 95 表 4.9 ETL-1 ラテン文字データの特定パターンにおける評価結果 ··· 97
xi 表 5.1 ETL-1 片仮名データ実験の結果 ··· 102 表 5.2 ETL-1 片仮名データ実験の結果 ··· 103 表 5.3 ETL-1 片仮名データ実験の結果 ··· 104 表 5.4 ETL-1 ラテン文字データ実験の結果 ··· 107 表 5.5 ETL-1 ラテン文字データ実験の結果 ··· 108 表 5.6 g (z)の各層の詳細 ··· 115 表 5.7 ETL-1 片仮名データ実験におけるモデル比較 ··· 118 表 5.8 ETL-1 ラテン文字データ実験におけるモデル比較 ··· 121
1
第
1章 序論
1.1 研究背景
2012 年に深層学習を用いた技術が研究分野で注目され [1],昨今ではその技 術を応用したシステムや製品が社会の発展に大きく貢献している.特に画像認 識の研究分野では,人の視覚情報処理の過程に着目した Convolutional Neural Network(CNN)を用いた手法が,従来の Handcrafted な特徴抽出手法よりも大幅 に高い性能を示している.深層学習は,大量のデータを用いることで,人の情報 処理過程を模したネットワークモデルを探索的に学習し,データの背後に潜む 何らかの規則性を見出す技術であり,その応用分野は非常に多様である.2012 年 の 大 規 模 な 一 般 物 体 認 識 の コ ン ペ テ ィ シ ョ ン (ImageNet large-Scale Visual Recognition Challenge; ILSVRC)において,画像認識における深層学習の有効性 が示されて以降,音声認識,自然言語処理等の様々な研究分野において横断的に 深層学習技術が応用,研究されてきた [2].また,職人芸といわれるような,判 断根拠となる要因の説明が困難な課題について,数値的に解釈するための新た な試みを可能とすることも深層学習の大きな貢献といえる. 現実社会においては,ある問題に対して推論を重ねていき,最終判断を行う場 面が多く存在する.例えば,人が車両を運転するときには,自己車両の走行状態, 歩行者や障害物等の周辺環境の状態,周囲の車両との位置関係,白線や路面標示, 道路標識等の様々な事象を把握し,状況に合わせて車両を制御するための判断 が行われている.車両の自動運転技術を実現するには,カメラ,レーザー等のセ ンシング技術によってこれらの事象を捉え,自動認識及び判断による車両制御 を行う必要がある [3].また,医療分野における病巣の有無の判断は生命に直結 する非常にナイーブな問題であり,X 線画像や MRI 画像等の医用画像の読影に は,経験豊富な医師による診断が重要となる.コンピュータを用いて画像を定量 的に解析し,医師に判断材料となる情報を提供するコンピュータ支援診断 (Computer-Aided Diagnosis; CAD)の研究,システム開発が行われており [4],2 人による病巣の見落としを低減することにつなげられる技術である. 社会の治安維持に関わる警察活動においても多くの判断が経験を積んだ人々 によって行われてきた.事件の予兆となる端緒の見逃しは,事件の発生につなが り,国民の生命,安全に重大な被害をもたらす.また,犯罪捜査における鑑定業 務は犯罪の立証につながる重要な役割を担う.警察組織において鑑定業務を担 う科学捜査研究所では,犯罪に関連する物や現象について法科学的に鑑定し,事 件の解明につながる情報を鑑定書という書面に記す.作成された鑑定書は,法廷 における刑罰の判断材料,証拠となり得る効力をもち,その後の被告人の人生に 大きく関わる重要なものである.文献 [5]においては,「鑑定人は特別な学識経 験でもって鑑定に臨まなければならない」という鑑定に携わる者の心構えが述 べられている.鑑定人は様々な機器を用いて対象を観察し,それらを総合的に検 討して鑑定結果を導く.鑑定結果は,各種検査の結果について,鑑定人が自身の 知識,経験を踏まえたうえで最終的に判断されるものであり,その判断には経験 的な要素が存在し,鑑定の客観性について問題となることがある [6].また,事 前の事件情報が鑑定結果に及ぼす影響について調査した研究 [7, 8]では,鑑定結 果には影響しないが,結果への鑑定人のもつ確証度に違いがみられることが示 されている. 犯罪捜査における法科学的鑑定の一つである筆跡鑑定では,筆者不詳の疑問 筆跡と筆者既知の対照筆跡を比較することで,疑問筆跡が対照筆跡の筆者によ って書かれたか否かを調べる筆者照合が行われている [9, 10, 11].鑑定人は筆跡 を詳細に観察し,色材の付着状態や紙面の凹みから,その筆跡が記載されたとき の状況を表す動的な特徴を捉え,観察された特徴を総合的に検討することで,筆 跡から筆者の同一性の推定までを行う.筆跡鑑定は,筆跡から個人性をもった特 徴をどのように抽出するのか,どの程度の特徴がみられたら同一人と判断する のかについて,鑑定人の知識,経験に基づく部分が多い分野といえる.そのため, 鑑定の客観性への対応に向けたコンピュータによる自動判定手法が研究として 盛んに行われてきたが,さまざまな筆跡が鑑定対象となる実際の鑑定に則した 手法については検討の余地がある [12, 13, 14, 15, 16].例えば,筆跡鑑定の実務 場面においては,ある筆者から収集可能な筆跡データは少数であるため,少数サ ンプル問題に対応した照合手法を考案する必要がある.また,通常の筆跡鑑定は, 疑問筆跡と対照筆跡間の同一字種を比較して筆者の異同を判断する字種依存型
3 の筆者照合であり,鑑定条件が資料間での同一字種の存在の有無によって制限 されるという問題がある.字種依存の問題及び少数サンプル問題への対処は,鑑 定資料間で同一字種が存在しない,または少数しか存在しない状況に対しても 筆跡鑑定を行うことを可能とし,鑑定の幅を広げ,犯罪捜査に大きく貢献できる 挑戦的課題といえる.
1.2 研究目的
本研究では,通常の筆跡鑑定における字種に依存した筆者照合である問題と 少数サンプル問題に対処し,実際の犯罪捜査への貢献を目的とした字種非依存 型のオフライン筆者照合手法を提案する.目的の実現に向けて,以下の 3 つの 項目について取り組む. (1)字種に依存しない筆跡特徴抽出手法の検討 (2)抽出した筆跡特徴を用いた筆者照合モデルの構築 (3)Metric Learning 手法 [17, 18, 19, 20]による同一人の異字種間の類似性を考 慮した特徴空間の学習による筆者照合性能の高精度化の検討 本研究は,異なる字種間に存在する人間の行動的特徴の共通性を解明すると いうサイエンスの要素と,筆跡特徴から精度の高い筆者照合システムを構築す るというエンジニアリングの要素を含み,深層学習というテクノロジーにより 研究課題に取り組む.最初に,筆跡から字種に依存しない筆跡特徴の抽出手法を 示している字種非依存型の筆者照合及び筆者識別の先行研究 [21, 22, 23, 24]を 踏まえ,少数の異なる字種同士から筆者照合に有効な個人性を見出すことがで きるか否かというサイエンスに対して,CNN による特徴抽出モデルの構築を試 みる.次に,見出された字種非依存の筆跡特徴について,いかに筆跡鑑定におけ る筆者照合の高精度化につなげるかというエンジニアリングに対しては,Metric Learning により同一人の異字種間の類似性を考慮した特徴空間の学習を行う.提 案手法について,手書き文字の大規模データベースである ETL-1 Character Database [25]の片仮名とラテン文字及び独自に収集した Hiragana dataset [26]を用 い,様々な人の手書き文字の分析と考察を踏まえて字種非依存型筆者照合への4 有用性を評価する.
1.3 本論文の構成
本論文は,図 1.1 に示すとおり 6 章から構成される.第 2 章では,筆跡鑑定 の研究動向をバイオメトリクス認証,書字運動理論を含めて概観することによ り,本研究で取り組むオフライン筆者照合の課題と位置づけ明らかにする.加え て,本研究のベースとなる深層学習を筆者照合に応用した関連研究についてま とめる.第 3 章では,Encoder と Decoder に字種情報を付与する Conditional AutoEncoder を用いた字種非依存の筆跡特徴の抽出手法を提案する.第 4 章では, Conditional AutoEncoder により抽出された字種非依存の筆跡特徴について, Siamese Network により筆者の同一性を判定するために有効な特徴空間の学習を 行い,少数の異字種条件での筆者照合手法を提案する.第5 章では,筆者照合手 法の高精度化に向けた検討として,学習データ数と照合性能の関係を調べると ともに,Metric Learning 手法による照合性能の比較を行った.最後に,第 6 章で は,本論文の結論と展望について述べる. 第2章 筆者照合の研究動向 ・犯罪場面における筆跡鑑定 ・本研究の位置づけと関連研究 第3章 Conditional AutoEncoderによる筆跡特徴抽出 ・字種に依存しない筆跡特徴の抽出 ・潜在空間における特徴表現の評価 第4章 Siamese Networkによる筆者照合 ・筆跡特徴の特徴空間への埋め込み ・Siamese Networkによる学習と評価 第5章 筆者照合手法の高精度化に向けた検討 ・学習データ数と照合性能の関係 ・Metric Learning手法の比較 第6章 結論と展望 第1章 序論 ・研究背景と目的 ・本論文の構成 図 1.1 本論文の構成5
第
2章 筆者照合の研究動向
本章では,筆跡鑑定の研究動向をバイオメトリクス認証,書字運動理論を含め て概観することにより,本研究で取り組むオフライン筆者照合課題の位置づけ を明らかにする.加えて,本研究のベースとなる深層学習を筆者照合に応用した 関連研究についてまとめる.2.1 犯罪捜査における筆跡鑑定と本研究の位置づけ
犯罪に関連する物や現象について,科学技術を用いて徹底的に追求し,犯罪の 真実を明らかにすることを目的として,各都道府県警察には科学捜査研究所が 設置されている.犯罪現場から収集される情報は多岐にわたることから,科学捜 査は,それらに対応するための幅広い学問分野によって支えられている [27]. 法医学分野では血液・体液・毛髪・骨・皮膚などを対象として,これらの資料か ら血液型検査やDNA 型鑑定などを行うことで,被疑者の割り出しに繋がる情報 の捜査側への提供,犯罪の証明に寄与する.化学分野では血液からのアルコール 検査,毒物,麻薬,覚せい剤等の薬物や油類,塗膜,繊維片等の資料について機 器分析等の検査,分析及び異同識別を行う.工学分野では画像解析,銃器類等の 鑑定,火災や交通事故等の原因解明を行う.心理学分野では記憶検査の一種であ るポリグラフ検査や犯罪心理に関わる鑑定を行う.文書分野では,筆跡,印章, 印刷物,不明文字,通貨などの鑑定を行う [28].これらの科学捜査は,捜査の決 め手となる犯罪事実を見つけ出し,捜査を方向付けるとともに,犯罪の立証に関 わる重要な役割を担う. 本研究では,文書分野の筆跡鑑定を研究対象とする.犯罪捜査における筆跡鑑 定では,事件の対象となる筆者不詳の疑問筆跡と筆者既知の対照筆跡を比較す ることで,疑問筆跡が対照筆跡の筆者によって書かれたか否かを調べる筆者照 合が行われている.一般的な筆跡鑑定の流れを図 2.1 に示す.鑑定人は筆跡を詳 細に観察し,図形的特徴に加え,色材の付着状態や紙面の凹みから,鑑定対象で6 ある筆跡がどのように記載されたのかを表す動的な特徴を捉える.これらの観 察された特徴を総合的に検討することで,筆跡の類似性をもとに筆者の同一性 の推定までを行う. 通常の筆跡鑑定は,疑問筆跡と対照筆跡間の同一字種を比較して筆者の異同 を判断する字種依存型の筆者照合であり,鑑定条件が資料間での同一字種の存 在の有無によって制限されるという問題がある.また,犯罪場面で鑑定対象とな る筆跡は,ある所定の様式に書かれた署名,住所といったものから,メモ紙等に 乱雑に書かれた犯罪行為に関する内容や文言が書かれたものまで多岐にわたる. 近年ではタブレットPC やスマートフォンの普及に伴い,電子署名が鑑定対象と なる場面もある.ただし,専用の入力機器を必要としない書面によるやり取りが 疑問筆跡(筆者不詳) 対照筆跡(筆者既知) 対照筆跡 疑問筆跡 ①対照筆跡から個人内変動・恒常性・個人性の把握 ②疑問筆跡と対照筆跡間の全体的な傾向及び同一字種を比較対照 筆 者 照 合 比較 検査結果を総合的に検討 図 2.1 一般的な筆跡鑑定の流れ(字種依存型筆者照合)
7 依然として多く,鑑定としてもオフライン筆跡が対象となる場面が多い.また, 鑑定対象となる筆跡は,少数の字種(例えば,名字のみ,1 単語のみ)しか存在 しない場合があり,少数サンプル問題に対処するためには,単一字種を対象とし て筆跡特徴を抽出できることが望ましい.これらの犯罪捜査における筆跡鑑定 の現状を踏まえ,本研究では,図 2.2 に示す字種レベルでの字種非依存型オフラ イン筆者照合を研究の対象とする. 筆者照合モデルの構築にあたって,比較対照する筆者から大量の筆跡サンプ ルを収集・登録するような筆跡データベースの作成は困難であることから,特定 の人物の筆跡をデータベースに登録したうえで,データベース内の全筆者(N 人) “s”
“It’s a sunny day.” “sunny”
【時系列】 ペン先座標 筆圧 ペン仰角 ペン方位角 【画像】 色材の付着状態 筆圧痕 筆者照合 対象領域 データ形式 比較方法 文章 行 単語(署名) 字種 オンライン オフライン 字種依存型 字種非依存型 図 2.2 筆者照合の分類と本研究の位置づけ (青色部分が本研究の対象) 筆跡データ テンプレート 特徴抽出 筆跡データ 特徴抽出 類似性評価 照合結果 ・ ・ ・ 図 2.3 登録型筆者照合(筆者依存型)
8 の筆跡との比較による1 対 N の登録型筆者照合(図 2.3)は現実的ではなく,少 数サンプル条件下での1 対 1 の非登録型筆者照合(図 2.4)に対応した照合手法 が現実的には望ましい.非登録型筆者照合では,多くの人の筆跡を学習データと して全筆者共通の筆者照合モデルを構築することで,新規(未知)の筆者に対す る筆者照合を可能とする.本研究では,ある筆者から収集可能な筆跡データが少 数である点,1 対 N の登録型筆者照合(筆者依存型)が実用的ではない点を考慮 し,筆者非依存型として筆者照合モデルを構築する.
2.2 関連研究
バイオメトリクス認証とは,指紋,虹彩,DNA 型などの生物学的特徴や,歩 容,声紋,筆跡といった行動的特徴を用いることによって個人の認識を行う技術 であり [29],電子機器の使用許可,記憶媒体内の情報へのアクセス認証,建物へ の入退室管理,空港等における入出国管理など幅広い用途で活用されている.本 研究で対象とする筆者照合は,書字行動という人間の行動的特徴に着目したバ イオメトリクス認証の犯罪捜査への応用といえる.筆跡とは書字行動が筆記具 を介して紙面等に残された結果であり,筆跡には運動の個人性が存在すること が調査研究で示されている [15, 30, 31].筆跡に存在する運動の個人性に着目し, 筆跡の特徴が同一であれば,その筆跡が生成されたときの行動的特徴も同一で あり,筆者も同一であると考える筆跡鑑定(筆者照合)が犯罪捜査の一つとして 行われている.人間の行動的特徴を扱う筆者照合は,記載条件や生体固有の変化 による影響を大きく受けるため,生来的な生物学的特徴を扱う手法ほどの高い 学習データ 照合モデル 筆跡データ 筆跡データ 特徴抽出 類似性評価 照合結果 ・ ・ ・ 図 2.4 非登録型筆者照合(筆者非依存型)9 照合精度は得られない.しかしながら,筆者照合は犯罪に関わる行動の所在を明 らかにするための重要な役割を担っており,行動的特徴のもつ変動を踏まえた うえで,いかに照合性能を高めるかという研究が行われてきた. 本研究目的である字種非依存型のオフライン筆者照合にあたり,はじめに字 種に依存しない筆跡特徴の抽出方法を検討する必要がある.そのため,書字行動 を含めた筆者照合に関わる研究として以下の3 つの項目を概観する. (1)書字行動の運動理論からの調査研究 (2)筆跡の個人性に関する調査研究 (3)照合精度向上に関する研究 (1),(2)は,文字を記載するときの行動的特徴には個性が存在することや, 書字行動には記載条件によって変動が生じることを調べるために,実際に書字 行動を測定し,その測定データ及び収集した筆跡を分析するサイエンス領域の 研究にあたる.(3)は,(1),(2)で解明された,筆跡には個人性が存在すると いう前提から,筆者照合の照合精度を向上させるための特徴抽出手法,識別器の 構築手法について考案するエンジニアリング領域の研究にあたる.
2.2.1 書字行動の運動理論からの調査研究
文献 [32]において,人が文字を記載するときの書字行動を,腕に測定機器を 装着することで直接的に計測し,書字形態の多様性の発生要因について分析し ている.筆跡とは,中枢神経と運動神経の複雑な協調作用によって形成されるも のであり,書字行動について分析することで,筆跡から生体運動機能に関する情 報が取得可能であり,運動障害の臨床等への応用も考えられている [33, 34].ま た,文献 [35, 36, 37, 38]においては,既に記載された筆跡の形態と,それが記載 されたときの書字行動を分析することで,筆跡と書字行動の関係性についてモ デル化を行っている. 書字行動とは,生得的特徴ではなく,学習と訓練によって習得される高度に習 熟された運動である.筆跡は,運動制御という物理的要因や学習経験等をもとに 生成される書字行動の結果といえる.同一人により記載される筆跡は,同一の物10 理的要因及び文字認知システムをもとに生成されることから,同一人が記載し た筆跡には字種に依存しない共通の運動特性が存在すると考えられている [39].
2.2.2 筆跡の個人性に関する調査研究
個性的な筆跡特徴は,始筆部,転折部,終筆部等の字画形態,各画線の長さや 位置関係等の字画構成に現れる [40, 41, 42].文献 [15]では,1,500 人の筆跡サン プルを収集,分析することで,筆跡の個人性について検証している.また,筆跡 とは人の行動的特徴が反映され,記載条件によってどの程度変動するのかを把 握することも筆者照合にあたり重要であり,文献 [43]では,薬物やアルコール, 記載するときの体勢,心理的要因,疲労度等が書字行動に影響を与える要因とし て挙げられている.文献 [44, 45] では,酩酊条件における筆跡では,通常の筆 跡と比較して文字が大きく書かれる傾向,文字間隔が広く書かれる傾向が確認 され,酩酊条件で書かれた筆跡から筆者固有の特徴を検出することが困難であ ることが述べられている.文献 [46]では,小学校 2~6 年生の子供の筆跡の経年 変化を追跡調査している.子供の筆跡個性は固定化されておらず,経時変化が大 きいこと,学年が上がっていくにつれて個人差が現れ,個人内において筆跡が固 定化されることが確認されている.文献 [47]では,記載時に用いられる筆記具 によって,筆跡がどのように変化するのかを調査しており,筆圧や線質は筆記具 によって異なるが,同一人の筆跡であれば何らかの共通特徴は存在することが 示されている.ただし,筆跡鑑定にあたっては,できる限り筆記具の影響を排除 するためにも同じ筆記具で対照筆跡を収集することが望ましいと述べられてい る.2.2.3 照合精度向上に関する研究
個性的な筆跡特徴を捉え,精度の高い筆者照合を行うための研究が盛んに行 われてきた [13, 48, 49, 50, 51, 24, 52, 53].特徴抽出には,テクスチャベースで余 白を含めた筆跡の空間的特徴に着目した手法 [23, 54, 55, 56]や局所円弧パター ン特徴 [57],SIFT 特徴量や KAZE 特徴量等により得られる局所的な字画形態の11
方向成分に着目した手法が提案されてきた [58, 59].字種依存型の研究では,比 較する同一字種のパターンの類似性に着目することから,文字認識の分野にお いて提案されている特徴抽出手法である方向特徴や構造特徴に着目したパター ンマッチング問題として扱うものが多い.一方,字種非依存型の筆者照合では Gabor フィルタや Local Binary Pattern 等により求められるテクスチャ特徴を用い た手法が多くみられる [21, 22, 23].文献 [23]では,文章から字種単位で切出し た筆跡画像をブロック状に領域分割し,各ブロック画像に対してテクスチャ解 析をすることで,筆跡の全体的な傾向を捉え,その全体的な傾向は比較対照する 文章が異なっても同一人であれば類似するという考えにより筆者の照合を行っ ている.そのため,字種非依存型の筆者照合を対象とした研究では,大域的な特 徴を捉えるために,ある一定の照合精度を得るためには字種依存型よりも多く の文字数が必要となる.文献 [60]では,少数字種を用いた場合の字種非依存型 の筆者識別に取り組んでおり,30 人の筆者データベースを対象とした筆者依存 型の分類問題であっても,異なる5 字種同士の比較では EER=28.6%,異なる 50 字種同士の比較ではEER=8.3%という結果であり,筆者固有の特徴を少数字種か ら抽出する字種非依存型の筆者照合及び筆者識別が困難な課題であることを示 している. 昨今では,画像認識において従来の特徴抽出手法と比較して高い精度を示し ているCNN を筆者照合に用いた手法も多く提案されている[13, 61, 62, 63, 64]. 文献 [61, 64]では,オフライン筆跡の署名照合に CNN による特徴抽出を用いて いる.文献 [62]では,オンライン筆跡の署名照合について,署名データの筆跡特 徴を潜在空間で表現するためのAutoEncoder と,潜在空間で表現される筆跡特徴 同士を比較するSiamese Network を用いた手法を提案している.深層学習を用い た手法は,変動を多く含む筆跡という対象から,変動を考慮したうえで筆者照合 に有効となる筆跡特徴を抽出し,高い照合性能をもつ筆者照合モデルが構築可 能であることが示されている.
2.3 犯罪捜査における筆者照合手法の課題
実際の犯罪捜査における筆跡鑑定では,疑問筆跡と同内容の対照筆跡が採取 不可能である状況が存在する.例えば,疑問筆跡と同内容の筆跡を対照筆跡とし12 て採取したい筆者が所在不明,死亡もしくは記載拒否する場合や,犯罪に関連す る内容の筆跡は,通常の日記や手帳などの一般的な文章には現れない場合があ る.字種依存型の筆者照合では,そのような状況下において疑問筆跡と対照筆跡 間で同一字種が存在しない場合には照合不能となる.しかしながら,筆跡は手の 運動制御という物理的要因や学習経験等をもとに生成されることから,同一人 が記載した筆跡は字種に依存しない性質を有すると考えられ,字種非依存型の 筆者照合及び筆者識別についての研究も盛んに行われてきた.字種非依存型の 筆者照合が可能となれば,鑑定資料間で同一字種が存在しない,または少数しか 存在しない状況に対しても筆跡鑑定を行うことができ,鑑定の幅を広げ,犯罪捜 査への貢献は大きい.この課題に対処するには,筆跡特徴の個性を字種に依存す ることなく,できるだけ少数の文字から抽出する必要がある.特定の字種につい て多くの筆跡データを収集し,分析を行うことで筆跡特徴を定義した研究 [40, 41]がみられるが,「常用漢字表」(平成 22 年 11 月 30 日内閣告示第 2 号) [65] には,日本において日常的に用いられる漢字使用の目安として2,136 字の漢字が 示されており,26 字種のラテン文字と比較して多くの字種が存在する.日本語 筆跡を対象とする筆者照合については,すべての字種に対して包括的に筆跡特 徴を抽出可能な手法を定義することは困難である.そこで,本研究では定義困難 な筆跡特徴の抽出には深層学習を用いる手法が有効と考え,第 3 章では字種に 依存しない筆跡特徴の抽出にあたり,Conditional AutoEncoder を用いた手法を提 案し,第 4 章においては抽出された筆跡特徴を用いた字種非依存型の筆者照合 モデルの構築を試みる.
2.4 まとめ
本章では,犯罪捜査における筆跡鑑定について述べることで,その課題として 本研究の位置づけを明確にし,課題に対する関連研究をまとめた.第 3 章では 先行研究を踏まえ,字種非依存な筆跡特徴が抽出可能であるか否かを深層学習 による特徴表現から検証する.13
第
3章 Conditional AutoEncoder による筆跡特
徴抽出
本章では,字種非依存型のオフライン筆者照合の実現にあたり,深層学習を用 いたオフライン筆跡からの字種に依存しない筆跡特徴の抽出手法を述べる. 書字行動とは,学習,訓練されることによって習得されるものであり,運動制 御という物理的要因や学習経験等をもとに筆跡は生成されることから,同一人 が記載した筆跡には字種に依存しない書字運動の共通性が存在すると考えられ る.これを根拠として,字種非依存型の筆者照合及び筆者識別に関する研究が盛 んに行われてきた.テクスチャベースの筆者照合においては,多数の字種が含ま れた筆跡を用いることで筆者固有の筆跡特徴が抽出可能であることを示してい る.ただし,実際の犯罪場面で扱う筆跡については,対象となる筆跡サンプルが 大量に収集できない場合が多いため,少数の字種から筆跡特徴を抽出できるこ とが望ましい. 本研究では,書字行動に関わる研究と字種非依存型の筆者照合及び筆者識別 の研究を踏まえ,同一人が記載した筆跡は,異なる字種であっても同じ書字行動 のもとで生成された結果であり,筆跡にも字種に依存することなく一貫した特 徴が存在すると考えた.そこで,筆跡とは字種に依存しない個性的な書き方スタ イルと字種情報から構成されていると仮定し,それらを分離する方法を提案す る.具体的には,AutoEncoder [66](以下,AE)に字種情報を条件付けした Conditional AE(以下,CAE)を用いることで,筆跡画像から字種に依存しない 筆跡特徴の表現が可能な潜在空間の学習を試みた.提案手法について,手書き文 字の大規模データベースである ETL-1 Character Database [25]の片仮名とラテン 文字及び独自に収集したHiragana dataset [26]を用い,手書き文字自体の分析と考 察を踏まえて字種非依存型の筆者照合への有用性を評価した.14
3.1 関連研究
筆者照合に関わる研究としては,字種依存型で署名といった一連の字種が含 まれた筆跡を対象としたものが,オンライン筆跡,オフライン筆跡のいずれにつ いても多くみられる.一方,本研究で対象としたオフライン筆跡から字種レベル で字種非依存の特徴を抽出する筆者照合を扱った研究はあまりみられず,類似 した研究としては文献 [24, 56, 60, 67]が存在する.文献 [67]では,特定の筆者に 依存しない署名照合モデルを全筆者共通の筆者非依存型で構築している点は本 研究と類似するが,比較対象とする筆跡については同一字種の含まれた署名と いう字種依存型である点で本研究の目的とは異なる.また,文献 [24]は字種非 依存型でオフライン筆跡を対象とし,CNN を用いて字種に依存しない特徴を抽 出している点は本研究と類似する.ただし,筆者毎に筆跡特徴を求めて筆者分類 モデルを構築するデータベースの存在を仮定した筆者識別(筆者依存型)問題で ある点で本研究の目的とは異なる.加えて,CNN を用いて抽出される筆者識別 に有効な字種非依存特徴については深く議論されておらず,CNN がどのような 特徴を抽出しているかは不明である.本研究では,字種に依存しない筆跡特徴に ついて,照合精度からの評価だけではなく,学習された潜在空間上でどのように 表現されるのかという検証を含め,説明可能な解釈可能性の高いモデルとして 構築することが,最終的な鑑定への応用を目的とする場合に重要と考える.3.1.1 字種に依存しない筆跡特徴の潜在表現
筆跡画像が,字種情報とそれ以外の字形のスタイルに関わる特徴から構成さ れていると仮定し,字種情報を分離して字形のスタイルを表す特徴空間(潜在空 間)を学習する手法として,Variational AutoEncoder [67](以下,VAE)に字種情 報を条件付けしたConditional VAE [69](以下,CVAE)を用いた手法が提案され ている.文献 [69]で提案されている CVAE の概要を図 3.1 に示す.多くの人が 記載した 0~9 の数字 10 字種の手書き文字が含まれた MNIST(Mixed National Institute of Standards and Technology)データセット [70](訓練用画像 60,000 枚と15 テスト用画像 10,000 枚から成る画像データセットで,画像データと字種情報が 関連付けられているもの)を用い,Encoder の途中と潜在特徴 z を Decoder に入 力する部分にone-hot エンコーディングされた字種情報 y(ある字種に対応する 次元のみを1,それ以外は 0 とするビット列)を付与することで,画像から y を 分離した特徴をz として表現するネットワーク構造となっている.全字種を,各 字種に対応したy により条件付けた Encoder と Decoder を通して,入力画像と出 力画像間の再構成誤差に加えて z と多変量標準正規分布との誤差の両方が小さ くなるように学習を行う(詳細は3.3.3.2 で述べる).z の次元数が少ない場合, いずれの字種についてもできる限り再構成誤差を小さくするには,字種に関わ る情報はy で表現し,z 空間上には字種に依存しない共通のスタイルが表現でき るように学習されることが望ましい.実際にz の次元数を 5 とした CVAE によ り学習し,潜在空間で表現される字形を可視化したところ(詳細は 3.3.5.1 で述 べる),図 3.1 に示すとおり,字種に依存することなく,線分の太さや傾斜の程 度といったスタイルが同様の潜在空間上において表現されることが確認されて いる.
y=[7] y=[4] y=[9]
Input Encoder Decoder z ・・・ Output Character Label y μ σ Sampling z0 z1 z0 z1 z0 z1 図 3.1 CVAE による潜在空間の学習と特徴表現
16
3.1.2 生成モデルにおける特徴分離手法
画像から,その画像を構成している要素となる特徴を抽出する手法には,AE, VAE 以 外 に も Generative Adversarial Network [71] ( GAN ) や Adversarial AutoEncoder [72](AAE)といった敵対的学習(Adversarial training)を用いた手 法が提案されている [73, 74, 75, 76, 77].これらの手法は,画像とその構成要素 と考えられる要因(例えば,筆跡であれば字種といったカテゴリ情報)の関係性 をモデル化する試みといえ,潜在空間上で画像から要因(特徴)を分離するため に工夫された様々なネットワークが提案されている.抽出特徴自体を分類や照 合に用いる研究以外に,学習された特徴空間上で表現される特徴を操作するこ とで,特徴の変化を反映した未知の画像を生成することを目的とした生成モデ ルの研究が盛んに行われている.画像は様々な要因から構成され(例えば,顔画 像の場合では,性別,年齢,表情,髪の色,顔の形,メガネの有無,髭の有無等), 複雑に絡み合った各要因を抽出するために適した特徴抽出手法が明確にできな い場合には,大量のデータから規則性を見出す深層学習により解く方法が適し ており,画像や音声の生成分野においては,深層学習を用いたモデル化の成功例 が多く報告されている.
3.2 提案手法
字種に依存しない筆跡特徴を,照合精度からの評価だけではなく,学習された 潜在空間上でどのように特徴が表現されるのかという検証を含めて説明できる 解釈可能性を含んだモデルとして構築することが,最終的な鑑定への応用を目 的とした場合に重要と考える.そのため,本研究では,特徴抽出モデルをVGGNet [78],GoogLeNet [79],ResNet [80],DenseNet [81],Xception [82]等の深いネット ワーク構造では,各層における処理が不明瞭になると考え,LeNet-5 [83]をベー スとした浅いネットワーク構造とした. 提案手法の概要を図 3.2 に示す.文献 [69]のアイデアを参考に,潜在空間上 で字種に依存しない筆跡特徴を表現し,表現された筆跡特徴が筆者照合に有効 な個人性を有するか否かについて検証を行う.文献 [69]では,特徴抽出のネッ トワークにおいてVAE が用いられている.VAE では,画像は何らかの統計的な17 プロセスを経て生成されていると仮定し,その生成過程を考慮して潜在空間を 求める.本研究では,潜在空間に制約を与えずに学習を行う AE ベースの手法 が,潜在空間の学習に制約を与えるVAE ベースの手法と比較し,大量の学習デ ータの変動を直接的に踏まえた潜在空間の学習ができると考えた.なお,筆跡画 像から字種情報と筆跡特徴を分離するという明確な目的があり,さらに抽出さ れた筆跡特徴についての解釈可能性を踏まえると,敵対的学習のための識別ネ ットワーク(Discriminator)を含めたモデル(GAN,AAE 等)よりも,Discriminator を含まずに処理の説明が容易な AE を用いた手法が本研究には適していると考 えた.
AE の Encoder と Decoder に字種情報を条件付けした Conditional AE(CAE)を 字種非依存な筆跡特徴を抽出するモデルとして構築した.構築したCAE のネッ トワーク構造を図 3.3 及び表 3.1 に示す.なお,以下では本提案モデルを AE の 2 か所に字種情報を付与したモデルとして AE_2 と呼称する. Encoder Decoder z Character Label y Training data zB zq zA B A Unknown 潜在空間 ①全筆者共通の字種非依存特徴抽出モデルを構築 ②抽出特徴を潜在空間にマッピング ③潜在空間で筆者の類似性を評価 図 3.2 提案手法の概要
18
ネットワークの途中にone-hot エンコーディングされた字種情報 y を付与する ことで,筆跡画像から y を分離した筆跡特徴を潜在変数 z として抽出する. Encoder は LeNet-5 の構造をベースとし,Decoder は Encoder の構造をほぼ反転 させてz と y から画像を生成するネットワークである.モデル学習時には,入力 する筆跡画像と,その筆跡画像の字種に対応したy を Encoder と Decoder の両方 y Encoder z Decoder Reconstruction Error Input Output Input Convolution+ReLU Upsampling Batch Normalization Sigmoid Concatenation Dense Max Pooling Convolution Dense+ReLU+L2 Norm Latent Label 図 3.3 CAE(AE_2)のネットワーク構造 Output shape (w, h, channel) or unit size
Input Input width, height , 1
Conv1 Convolution width, height , 4 Activation=ReLU, Kernel=3, Stride=1, Padding=1 MP1 MaxPooling width /2, height /2, 4 Kernel=2, Stride=2
Conv2 Convolution width /2, height /2, 16 Activation=ReLU, Kernel=3, Stride=1, Padding=1 MP2 MaxPooling width /4, height /4, 16 Kernel=2, Stride=2
Flatten Flatten (width /4)×(height /4)×16
Label Input n
Enc-Merge Merge (width /4)×(height /4)×16+n Concatenation
Enc-D1 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Enc-D2 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Enc-D2-BN BatchNormalization
Latent Dense z dim
Dec-Merge Merge z dim +n Concatenation
Dec-D1 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Dec-D2 Dense (width /4)×(height /4)×16 Activation=ReLU, L2 regularization (λ =0.01) Dec-D2-BN BatchNormalization
Reshape Reshape width /4, height /4, 16
US1 UpSampling width /2, height /2, 16
DeConv1 DeConvolution width /2, height /2, 4 Activation=ReLU, Kernel=3, Stride=1, Padding=1 US2 UpSampling width, height , 4
DeConv2 DeConvolution width, height , 1 Kernel=3, Stride=1, Padding=1 Dec-DeConv2-BN BatchNormalization
Output Output width, height , 1 Activation=Sigmoid Encoder Decoder Layer type Layer name Model Parameters 表 3.1 CAE(AE_2)の各層の詳細
19 に入力する.誤差逆伝搬に用いる誤差関数LCAE(I, O)を式(3.1)に示す.式(3.1) 中のN は,入力画像 I と出力画像 O の総画素数を表す.入力画像 I=(i1, i2, …, iN ∈ {0,1})と出力画像 O=(o1, o2, …, oN ∈ [0,1])間の平均絶対誤差を再構成 誤差DREとして算出する.
𝐿𝐿
𝐶𝐶𝐶𝐶𝐶𝐶(𝑰𝑰, 𝑶𝑶) = 𝐷𝐷
𝑅𝑅𝐶𝐶(𝑰𝑰, 𝑶𝑶) = 1𝑁𝑁 �|𝑖𝑖
𝑛𝑛− 𝑜𝑜
𝑛𝑛|
𝑁𝑁 𝑛𝑛=1(3.1)
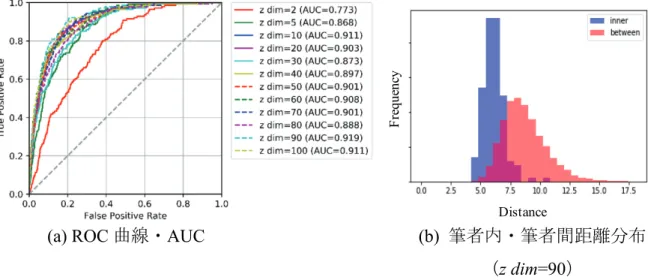
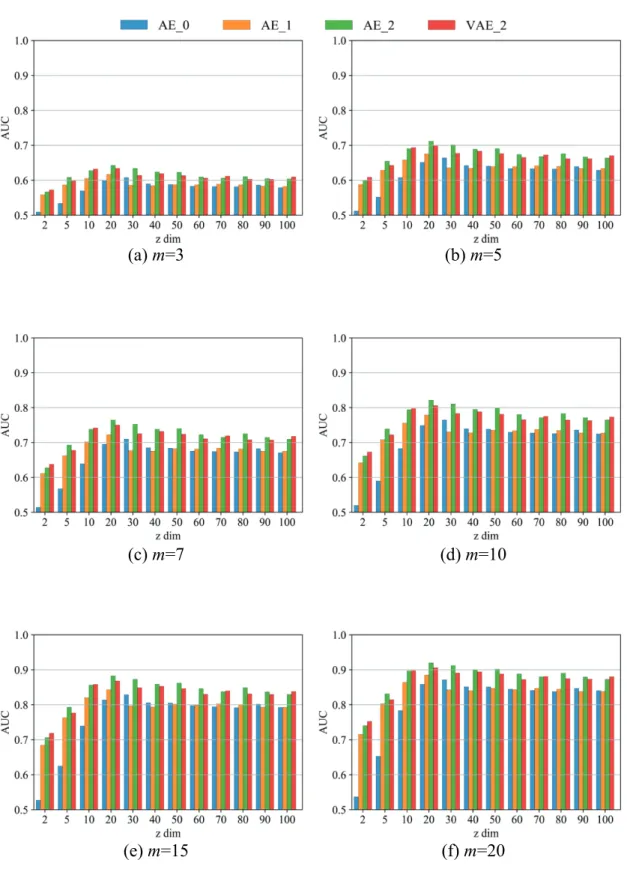
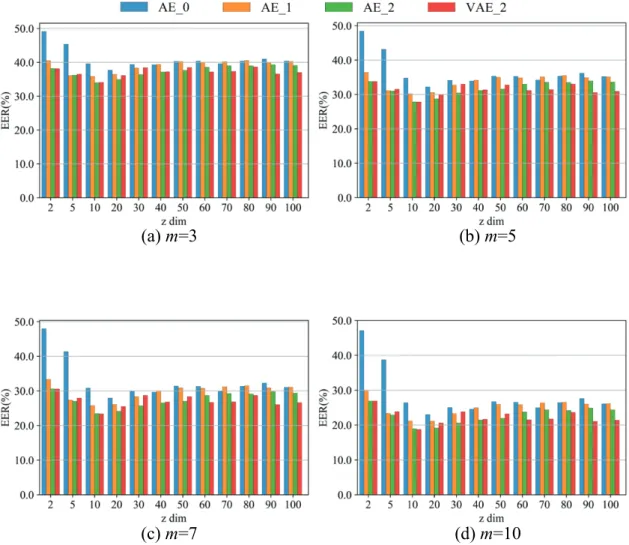
低次元の潜在空間で表現されるz には,y とは分離した筆跡特徴が反映される と考え,AE_2 により学習される潜在空間について,以下の 2 点を検証する. ・潜在空間上で字種非依存な筆跡特徴が表現可能か否か ・筆跡特徴が筆者照合に有効な個人性を捉えられるか否か3.3 評価実験
公開されている手書き文字の大規模データベースである ETL-1 Character Database [25](以下,ETL-1 と呼称)の片仮名とラテン文字及び独自に収集した Hiragana dataset [26](以下,平仮名データと呼称)を用いて,提案手法により字 種に依存しない筆跡特徴が潜在空間上で表現可能であるか否かを検証する.ま た,評価実験にあたり,Encoder と Decoder の両方に字種情報を付与する提案モ デル(AE_2)の筆跡特徴抽出への有効性を確認するために,字種情報の付与条 件を変更したモデルとの比較を行う.同様に,VAE を用いた潜在空間の学習に 制約を与えたモデルとAE ベースの提案手法について比較を行う.3.3.1 実験データセット
実際の筆跡鑑定の現場における多量な字種を含んだ筆跡が収集できない状況 を踏まえると,少数の字種から字種に依存しない筆者固有の特徴を抽出できる ことが望ましい.そのため,少数サンプル問題を考慮した字種単位での特徴抽出 手法としてモデルを学習するためには,字種単位で筆者情報と関連付けられた20
データが必要である.本研究では,その条件を満たした手書き文字データベース としてETL-1 と平仮名データを用いる.
3.3.1.1 ETL-1 Character Database(ETL-1)
ETL Character Database は日本語文字認識のために収集された大規模データベ ースである.1973 年から 1984 年にかけて,電子技術総合研究所(現 独立行政 法人産業技術総合研究所)において,日本電子工業振興協会(現 電子情報技術 産業協会),大学,民間の研究機関の協力をもとに文字認識研究用に収集された ものであり,ETL-1 から ETL-9 の 9 種類のデータとしてまとめられている.本 研究では,筆者情報を含み,字種単位での手書き文字が収められた ETL-1 を用 いて実験を行った. ETL-1 は,1,445 人によって記載された片仮名 51 字種,大 文字のラテン文字26 字種,0~9 までの数字 10 字種及び 12 の記号(「*」,「+」, 「¥」 等)が収められている.各筆者が枠線の印刷された用紙 1 枚の各枠内に 1 つずつ文字を記載したものであり,1 枚のシート上に書かれた文字が同一人で あることが保証されている.各文字はスキャナにより電子化され,字種単位で分 図 3.4 ETL-1 のサンプル (a) 片仮名データ (b) ラテン文字データ
21 割されており,原画像は16 階調の 64×63pixels である.本実験では,図 3.4 に 示す基本的な片仮名46 字種(記載された片仮名 51 字種中,ヤ行の「イ」,「エ」 及びワ行の「ヰ」,「ウ」,「ヱ」を除いたもの)とラテン文字26 字種を用い る.
3.3.1.2 Hiragana dataset(平仮名データ)
ETL-1 は 1 人あたり同一字種を 1 回のみ記載したデータであり,同一字種が 複数回記載される場合の筆跡の恒常性や変動を捉えることはできない.同一字 種内の恒常性及び変動を検討することは,実際の筆跡鑑定の場面を想定すると 重要である.同一字種の恒常性及び変動を把握するためには,同一筆者が 1 字 種あたり複数回記載した筆跡が含まれるデータベースを用いた検証が必要であ る.そのため,本研究では独自に収集した平仮名データを実験に用いる.平仮名 図 3.5 平仮名データのサンプル22 データには,日本語の文章を記載するときに単語間の関係性を表現するための 助詞を含んだ「て,に,は,と,を,の,せ,る,が,い,で,ん」という12 字 種が含まれる.これらの字種の選定には,平仮名全46 字種が複数回記載された 筆跡を収集するためには多くの時間を要することと,あらゆる文章において出 現頻度の高い字種について検証することが現実的に望ましい点を考慮した.一 連の文章を記載するときの筆跡として収集するために,図 3.5 に示す用紙に「手 に鳩を乗せる外伝」という文章を意識して所定の枠内に10 回繰り返して記載を 求めた.約 500 人の実験参加者から筆跡を収集し,字種ごとに筆者と紐づけら れた大規模な平仮名データセットを作成した.
3.3.2 前処理
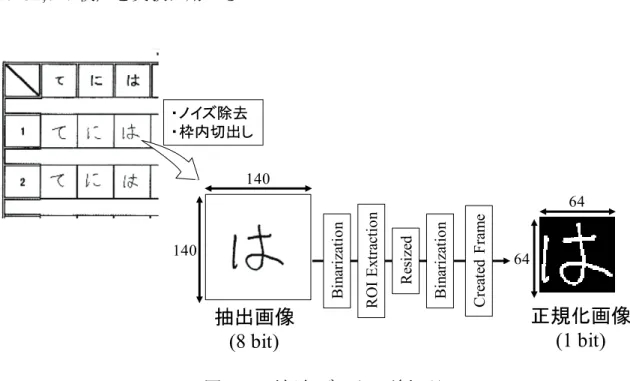
ETL-1 と平仮名データについて,電子化にともなうノイズの除去を行うとと もに,位置と大きさの正規化を行う.所定の枠に対して,どのような大きさで文 字を書くのかという情報にも個性は存在すると考えられるが,本研究では,大き さよりも形態情報を重視した前処理を行う. ETL-1 には,スキャナによる電子化の過程でのノイズの混入や枠を基準とし た自動切出しのエラー,記載者の書き損じ等のデータも存在する.そこで,図 3.6 に示す前処理を行い,2 値化された 128×128pixels の画像を実験に用いる. なお,判読不能文字は実験データから除外した.また,筆者による学習字種数の 偏りが評価実験に影響する可能性を考慮し,片仮名データについては 1 人あた り46 字種が全て揃った 1,364 人分の画像データ(1,364×46=62,744 枚),ラテ ン文字データについては1 人あたり 26 字種が全て揃った 1,406 人分の画像デー タ(1,406×26=36,556 枚)を実験に用いる. 図 3.6 ETL-1 の前処理 64 63 64 64 Ga ussi an B lu r Bin ar iz atio n Re sized RO I Ex tra ctio n Cr ea te d F ram e Bin ar iz atio n原画像
(4 bit)
128 128正規化画像
(1 bit)
23 平仮名データは枠線を基準として切出された 140×140pixels の画像である. 本実験では図 3.7 に示す前処理を行い,2 値化された 64×64pixels の画像を実験 に用いる.筆者による学習字種数の偏りが評価実験に影響する可能性を考慮し, 1 人あたり 12 字種 10 回分の全てが揃った 267 人分の画像データ(267×12× 10=32,040 枚)を実験に用いる.
3.3.3 提案手法との比較モデル
提案手法の字種ラベルの条件付け方法が,字種に依存しない筆跡特徴の抽出 に有効であるか否かを検証するため,AE への字種ラベルの付与方法を変更した 2 つのモデルとの比較を行う.また,潜在空間に制約をつけて学習する VAE と 提案手法であるAE ベースの手法を比較することで,潜在空間を構造化すること による筆跡特徴抽出への影響について調べる.3.3.3.1 AutoEncoder の字種ラベル付与の有効性
AE_2 のように Encoder と Decoder の両方に字種情報を付与する方法が,字種 に依存しない筆跡特徴抽出に有効であるか否かを検証するため,字種情報を付 ・ノイズ除去 ・枠内切出し 140 140
抽出画像
(8 bit)
64 64正規化画像
(1 bit)
Cr ea te d F ram e Bin ar iz atio n Re sized RO I Ex tra ctio n Bin ar iz atio n 図 3.7 平仮名データの前処理24 与しない通常の AutoEncoder と Decoder のみに字種情報を付与するモデルとの 比較を行う. AE_2 と比較する字種ラベルを含まない AutoEncoder として構築したモデル (以下,AE_0 と呼称する)のネットワーク構造を図 3.8 及び表 3.2 に示す.同 様に,AE_2 との比較として構築した Decoder のみに字種ラベルを付与する Encoder z Decoder Reconstruction Error Input Output Input Convolution+ReLU Upsampling Batch Normalization Sigmoid Dense Max Pooling Convolution Dense+ReLU+L2 Norm Latent 図 3.8 AE_0 のネットワーク構造 Output shape (w, h, channel) or unit size
Input Input width, height , 1
Conv1 Convolution width, height , 4 Activation=ReLU, Kernel=3, Stride=1, Padding=1 MP1 MaxPooling width /2, height /2, 4 Kernel=2, Stride=2
Conv2 Convolution width /2, height /2, 16 Activation=ReLU, Kernel=3, Stride=1, Padding=1 MP2 MaxPooling width /4, height /4, 16 Kernel=2, Stride=2
Flatten Flatten (width /4)×(height /4)×16
Enc-D1 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Enc-D2 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Enc-D2-BN BatchNormalization
Latent Dense z dim
Dec-D1 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Dec-D2 Dense (width /4)×(height /4)×16 Activation=ReLU, L2 regularization (λ =0.01) Dec-D2-BN BatchNormalization
Reshape Reshape width /4, height /4, 16
US1 UpSampling width /2, height /2, 16
DeConv1 DeConvolution width /2, height /2, 4 Activation=ReLU, Kernel=3, Stride=1, Padding=1 US2 UpSampling width, height , 4
DeConv2 DeConvolution width, height , 1 Kernel=3, Stride=1, Padding=1 Dec-DeConv2-BN BatchNormalization
Output Output width, height , 1 Activation=Sigmoid Encoder
Decoder
Model Layer name Layer type Parameters
25 AutoEncoder のモデル(以下,AE_1 と呼称する)のネットワーク構造を図 3.9 及 び表 3.3 に示す.AE_0,AE_1 の誤差逆伝搬に用いる誤差関数は,AE_2 と同様 に入力画像と出力画像間の平均絶対誤差を再構成誤差DREとして算出する. y Encoder z Decoder Reconstruction Error Input Output Input Convolution+ReLU Upsampling Batch Normalization Sigmoid Concatenation Dense Max Pooling Convolution Dense+ReLU+L2 Norm Latent Label 図 3.9 AE_1 のネットワーク構造 Output shape (w, h, channel) or unit size
Input Input width, height , 1
Conv1 Convolution width, height , 4 Activation=ReLU, Kernel=3, Stride=1, Padding=1 MP1 MaxPooling width /2, height /2, 4 Kernel=2, Stride=2
Conv2 Convolution width /2, height /2, 16 Activation=ReLU, Kernel=3, Stride=1, Padding=1 MP2 MaxPooling width /4, height /4, 16 Kernel=2, Stride=2
Flatten Flatten (width /4)×(height /4)×16
Enc-D1 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Enc-D2 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Enc-D2-BN BatchNormalization
Latent Dense z dim
Label Input n
Dec-Merge Merge z dim +n Concatenation
Dec-D1 Dense 500 Activation=ReLU, L2 regularization (λ =0.01) Dec-D2 Dense (width /4)×(height /4)×16 Activation=ReLU, L2 regularization (λ =0.01) Dec-D2-BN BatchNormalization
Reshape Reshape width /4, height /4, 16
US1 UpSampling width /2, height /2, 16
DeConv1 DeConvolution width /2, height /2, 4 Activation=ReLU, Kernel=3, Stride=1, Padding=1 US2 UpSampling width, height , 4
DeConv2 DeConvolution width, height , 1 Kernel=3, Stride=1, Padding=1 Dec-DeConv2-BN BatchNormalization
Output Output width, height , 1 Activation=Sigmoid Encoder
Decoder
Parameters Model Layer name Layer type