DEIM Forum 2016 G6-4
メタファー的写像に基づくエンティティ表現の発見
宇都宮
圭
†大島
裕明
†田中
克己
††
京都大学情報学研究科
〒 606–8501 京都市左京区吉田本町
E-mail:
†{
utsunomiya,ohshima,tanaka
}
@dl.kuis.kyoto-u.ac.jp
あらまし あるドメインにおけるエンティティの位置付けを理解するために,別ドメインでの対応するエンティティ
の位置付けを用いた比喩表現が有効な場合がある.本研究では,あるドメインとそのドメインに属するエンティティ
の組が与えられた時,別のドメインにおいて類似の位置関係をもつエンティティを発見する手法を提案する.例えば,
ドメインを「ラグビー」とし,(日本, 南アフリカ) というエンティティ組が与えられた場合,ドメイン「野球」におけ
るエンティティ組 (高校野球, プロ野球) を発見し提示することで,2 国のラグビー代表チームの強さの違いが理解し
やすくなる.提案手法では,与えられたドメインにおけるエンティティ間の関係を表す語を,Web マイニングによっ
て抽出する.これらを,あらかじめ Wikipedia のカテゴリに基づいて取得したドメインにおいて,抽出された関係情
報と類似する関係をもつエンティティの組を取得し提示する.
キーワード メタファー的写像,Web マイニング,言語パターン
1.
は じ め に
本研究は,あるドメインとそのドメインに属するエンティ ティの組が与えられた時,別のドメインにおいて類似の位置関 係をもつエンティティの組を発見する手法を提案する. あるドメインに属する複数のエンティティがあり,それらが 特定の関係をもつことがある.例えば“日本のプロ野球チーム” というドメインにおいて“読売ジャイアンツ(巨人)”と“阪 神タイガース(阪神)”の関係は,その試合が「伝統の一戦」 と称されるほどに際立っている.一方で“スペインのプロサッ カーチーム”というドメインにおいて“レアル・マドリード” と“FCバルセロナ”の関係はその試合が「エル・クラシコ(El Clasico)」と称される関係である. このような関係は,しばしば例えの表現として用いられる. 日本において,スペインなどの海外サッカーに不慣れな人に “レアル・マドリード”と“FCバルセロナ”の関係を説明する 際に,比較的知名度があると思われる日本のプロ野球を用いて 「巨人と阪神のようなものだ」と説明する場合がある. 「2015年のラグビーワールドカップで日本代表が南アフリカ 代表に勝利した」というニュースがあり,現在の日本で他のプ ロスポーツと比較するとやや馴染みの薄いラグビーにおけるこ の健闘に対して,様々な例えがなされた. 「ラグビーにおける日本と南アフリカ」の関係について「サッ カーにおける日本とブラジル」「野球における高校とプロ」「ド ラえもんにおけるのび太とジャイアン」「ドラゴンボールにお けるクリリンとフリーザ」(注 1) のように,様々なドメインに関 係を例える表現がなされたことが伺える. (注 1):以下 4 例本文と同順,2015 年 9 月 20 日 https://twitter.com/haruharu0629/status/645395183123566592 https://twitter.com/ktre 729/status/645385078336389120 https://twitter.com/kskalternative/status/645314677648396288 https://twitter.com/tebasAKii p/status/645397852408037376 ある事柄について知りたいと感じたときに,Web検索はよ く用いられる手段である.検索結果に現れたWebページにア クセスし,一つ一つの内容を確認することは,確実ではあるが 手間がかかる方法である.簡潔な説明を提供する方法には要約 など様々なものがある. 物事を説明する際に,別の物に例えるという方法は,理解を 促したり興味を喚起することを期待して用いられる.例えを 用いた表現には様々な分類があるが,そのひとつに隠喩表現が ある. 隠喩とは,修辞技法のひとつであり,比喩の一種に分類され る.比喩のうち「のようだ」といった句を用いて,比喩である ことを明らかにしているものは直喩,あるいは明喩と呼ばれ, そうでないものが隠喩と呼ばれる.隠喩はまた,暗喩,メタ ファー(metaphor)とも呼ばれる. 修辞技法は,言語表現を豊かにするために用いられる.文章 や演説といった場において,著者や話者の主張がより魅力的で 説得力があるように,読者や聴衆に印象づけることを期待する ために用いられる技術である.我々が普段他人と会話する場に おいても,自分の考えを相手にうまく伝えるために様々な修辞 技法を用いることがある. それらの中でも隠喩は,ある物事のもつ特徴について,より 簡潔に,具体的な対象を挙げることで想起を容易にする効果を 期待して用いられる.効果的な隠喩は,比喩であることを感じ させず,適切に物事の特徴についてイメージを伝達することが でき,慣用句のように用いられる場合もある. 一方で,物事を理解したいときに,簡単な手段でこのような 隠喩などの例えの表現を得ることが難しいという課題がある. 日本語QAサイトであるYahoo!知恵袋(注 2)には,例えにつ いての質問が投稿されている.野球選手や戦国武将で例えるこ (注 2):Yahoo!知恵袋 http://chiebukuro.yahoo.co.jp/図 1 Yahoo!知恵袋の例えに関する QA の例 とを求める質問などを含め,“例えて”及び“例えると”の少な くとも一方を含むQAを検索した結果が88,000件以上(注 3) 存 在する. QAサイトを利用するという手段は,人間の感性やユーモア に基づいた答えが得られる可能性があるという利点がある一方 で,答えを得るのに時間がかかるという問題点がある. また,例えの表現をWeb検索によって発見することは,検 索に慣れていない人にとって難しいと考えられる.「ラグビー 日本 南アフリカ」というキーワードを入力しただけでは,検 索結果に現れるページ内に偶然例えの表現が現れることを期待 するほかない. クエリを修正し「例えると」「まるで のようだ」などの語 を付け加えるといった方法が考えられるが,比喩の表現の記述 のされ方は様々であり,そのような語を直接含むような文書以 外は得ることができない.加えて,このような検索方法では, 同一文書内に例えとして記述されているものしか発見できない といった問題がある. 本研究では,入力されたドメインとそれに属するエンティティ の組から,それらを例えるような別ドメインのエンティティ組 を発見することを目的とする. すなわち「ラグビー」ドメインの「日本」と「南アフリカ」の エンティティ組に対して,出力として「野球」ドメインの「高 校野球」と「プロ野球」や,「サッカー」ドメインの「日本」と 「ブラジル」が得られることを目指す. 2.章では関連研究について述べる.3.章ではこの問題を定式 化する定義を行う.4.章では提案手法について述べる.6.章で はまとめと今後の課題について記す. (注 3):2015 年 9 月 10 日現在
2.
関 連 研 究
Lakoff [1]は,例えられる概念をtarget概念,例える概念をsource概念と呼び,メタファーはsource概念からtarget概念 へのドメインを横断する写像であると定義している. Iwayama et al. [2]はある概念の性質の顕現性について確率 的に定式化する手法を提案し ,source概念からtarget概念へ と移されるべき性質という点からの隠喩理解を行っている. 内海ら[3]は,顕現性に関する計算モデルに文脈との関連性 についての枠組みを取り入れる手法を提案している. 桝井ら[4]は,直喩表現を生成する指標パターンを用いてWeb から断片知識を収集し,クエリ語に対する素描を提示する手法 を提案している. 近村ら[5]は,Webを活用した比喩説明の自動収集と生成に ついての手法を提案している. 青木ら[6]は,比較表現の言語パターンに基づいた,2つのオ ブジェクトの比較観点のWebからの抽出手法を提案している. 加藤ら[7]は,関係を入力として与え,その関係との類似度 に基づいてオブジェクト名を検索する手法を提案している.こ れは,既知であるがクエリ化し難い関係を用いてオブジェクト 名を検索するものである. Ducら[8]は,Webのテキストコーパスから,ワイルドカー ドを用いた手法で語彙パターンのクラスタリングを行うことで, エンティティペア間の関係を決定している.また,その関係に 基づいたペアの相手を発見する検索を行っている. Fangら[9]は,知識ベースに基づいた関係説明の生成手法と, そのランキング手法を提案している. Mikolovら[10]は,ニューラルネットワークの学習に基づい た語のベクトル表現モデルを提案している.この評価において, アナロジー問題を解くことを行っている. これらの手法との違いについて,我々は,ドメインと2つの エンティティの組についての関係を扱う.2つのエンティティが ドメインに属していることは前提でありドメイン内では全ての エンティティについて共通である.関係がもつ特徴のうち「属 する」というのはさほど重要ではないものとして扱われるべき である.
3.
問 題 定 義
以降,ドメインのラベルを表す文字列をx, yで表し,それ ぞれのドメインをDx, Dyで表す,それぞれに属するエンティ ティのある1つはex, eyで表し,特定の1つを表すときex 1, e y i のようにインデックスを付けて表す.また,Name(ex)によっ てexを表す文字列を示す. 本論文では,ドメインDxに属する2つのエンティティex1 と ex2 の組が入力として与えられる.このとき,あるドメインDy に属する2つのエンティティeyi とeyjを組として,入力に与え られた組の関係を表すのにより適している組を発見し出力する. ドメインのラベルyは人手によって,事前に複数の候補が 与えられている.以降,yは与えられた複数のラベルy1,y2, ...,ynのいずれか1つを表すとする.出力はそれぞれのyごスペインのサッカーチーム レアル マドリード FCバルセロナ バレンシアCF 日本の野球チーム 巨人 阪神 中日 写像 写像 写像 図 2 “日本の野球チーム” ドメインのエンティティ“巨人” と “阪神” の組から “スペインのサッカーチーム” ドメインの “レアル・マ ドリード” と “FC バルセロナ” の組への写像 とに対して得られる.それぞれのDyを構成するeyは事前に 人手によって選択条件が与えられるか,直接一覧として与えら れる.|Dy|はドメインのサイズであり,含まれるeyの個数で ある. Dyのエンティティから成るの組の集合をDyで表す.ex1 と ex2の組とそれぞれ対応づけることを考慮すると,これらは次の ように表される. Dy ={(eyi, eyj)|(eiy, eyj)∈ Dy× Dy∧ i |= j}. (1) 以上より,次のように表される. 入力 文字列3つ: x,Name(ex1),Name(ex2). 出力 yそれぞれについて,順序付けられた組(Name(eyi) , Name(eyj))のリスト. “スペインサッカー”をx,“レアル・マドリード”をName(ex 1), “FCバルセロナ”をName(ex2)として入力に与えたとき,yが “日本のプロ野球チーム”である結果には,(“読売ジャイアン ツ”,“阪神タイガース” )のペアが上位に現れるべきである.な ぜなら,一般的に“レアル・マドリード”と“FCバルセロナ” の関係は,“伝統”や“ライバル”といった語で表され,“読売 ジャイアンツ”と“阪神タイガース”の関係も同じような語で 表されるからである. 図2は,“日本の野球チーム”ドメインのエンティティ“巨人” と“阪神”の組から“スペインのサッカーチーム”ドメインの “レアル・マドリード”と“FCバルセロナ”の組への写像を示 す.エンティティを白丸で表し,ドメインとエンティティの関 係を黒丸と白丸の間の矢印で表している.ドメイン-エンティ ティ関係と2つのエンティティ-エンティティ関係の合計3つが 写像される様子を表している. 我々は,以下のような仮定をおく. 仮定1 Dyに含まれる組(ex1, ex2)の特徴は,次の3つの関係 を表す特徴によって表される. (1) Dx とex1 の関係を表す特徴. (2) Dx とex 2 の関係を表す特徴. (3) ex 1 とex2 の関係を表す特徴. (eyi, eyj)の特徴についても同様とする. 仮定2 仮定1の特徴は,各元が単語に対応した特徴ベクトルで 表すことができる.それぞれをV1,V2,V3で表しV1(ex1, ex2) というように用いる. TF-‐IDF行列 Wikipedia Wikipediaからドメイン構成 ドメインの条件設定 (人手で) 入力: ドメインのラベル y1, y2, 各記事に形態素解析 ドメインごとにTF-IDF行列作成 出力: 各組の特徴ベクトル VW 1,2,3 (eyi, eyj) 組の特徴ベクトル作成 エンティティ組作成 特徴ベクトル VW 1,2,3 (eyi, eyj) 出力ドメイン 図 3 出力ドメイン構成手法の概略図 仮定3 Dxの組(ex 1, ex2)とDyの組(e y i, e y j)の類似度は,次の 3つを足し合わせたものである. (1) V1(ex1, ex2)とV1(eyi, e y j)の類似度. (2) V2(ex1, ex2)とV2(e y i, e y j)の類似度. (3) V3(ex 1, ex2)とV3(e y i, e y j)の類似度. 仮定4 2組の類似度が高ければ,一方の組は他方の組を比喩 的に表現するのにより適している. 2 つ の 特 徴 ベ ク ト ル の 類 似 度 を Sim と 表 す こ と と す る .V1(ex1, ex2) とV1(e y i, e y j) の 類 似 度 はSim(V1(ex1, ex2), V1(eyi, eyj))と表される. 2つの組の類似度を,係数w1, w2, w3を用いて,次のように 表す. Similarity((ex1, e x 2), (e y i, e y j)) = w1Sim(V1(ex1, e x 2), V1(eyi, e y j)) + w2Sim(V2(ex1, e x 2), V2(eyi, e y j)) + w3Sim(V3(ex1, e x 2), V3(eyi, e y j)). (2) 我々の目標は,組(ex 1, ex2)が与えられたとき,それぞれの yについてSimilarity((ex 1, ex2), (e y i, e y j))を最大化する組(e y i, eyj)を発見し,(Name(eyi), Name(eyj))を出力することである.
4.
提 案 手 法
4. 1 手法の概略 前もって,4. 2節と4. 3節で出力のためのドメインを構成す る.図3に概略図を示す.4. 2節ではドメインの決定方法を示 す.4. 3節ではTF-IDFによってエンティティ組の特徴ベクト ルを作る. 図4に入力エンティティ組に対する特徴ベクトル作成と組の 類似度計算の概略図を示す.4. 4節では,Webから入力エン ティティ組の特徴を抽出する.4. 5節で入力エンティティ組の 特徴ベクトルを作る.最後に4. 6節で,入力エンティティ組と入力: x, Name(ex 1), Name(ex2) 出力: 組のリスト (Name(ey i), Name(eyj)),
Web
クエリ生成 スニペット収集 形態素解析器で語抽出 特徴ベクトル VS 1,2,3 (ex1, ex2) 特徴ベクトル作成 2組の類似度計算 各語に対するχ2 検定 ソート 特徴ベクトル VW 1,2,3 (eyi, eyj) 図 4 入力エンティティ組に対する特徴ベクトル作成と組の類似度計算 の概略図 出力候補組の類似度を求め,出力する. 4. 2 出力ドメインの構成 出力に用いるドメインDy を,前もって構成する.以下の3 つの理由により,これには日本語版Wikipediaを用いる. 第一に,Wikipediaはカテゴリ構造を導入している.全ての 記事は基本的には1つ以上のカテゴリに属している.(注 4) この 構造は,記事を概念ごとにグループ分けしており,ドメインの 作成に有用である. 第二に,Dyに含まれる組の数の問題がある.これはおよそ |Dy|2 に上る.これだけの組の関係をWeb検索によって求める 場合,|Dy|の大きさによっては相応の検索回数を必要とし,コ ストがかかる. 第三に,我々[11]が,ドメインとエンティティの関係を得る ために提案する手法に必要な検索回数の問題である.手法では, 言語パターンに従って特徴語候補を収集し,それが専門語でな いかを与えられた1つの出力ドメインを用いてWeb検索によっ て確認するものである.これは,ドメインとエンティティの関 係を得るために1エンティティに対して数百回のWeb検索を 必要とする.これを|Dy|回行うのはコストがかかる. yに対して,“日本のプロ野球チーム”や,“NHK紅白歌合 戦出場者”,“日本の都道府県”といったラベルを選択し,ドメ インを構成する.エンティティeyは,Wikipediaの記事とし, Name(ey)は記事のタイトルを用いる.それぞれのラベルに対 して,記事を集めるカテゴリの条件を人手で設定する.“日本の 都道府県”は数が少ないので直接与える.“NHK紅白歌合戦出 場者”ならば「“NHK紅白歌合戦出場者”カテゴリに属し,“一 覧”をカテゴリ名に含むカテゴリに属していない記事」となる. “野球の日本代表選手経験者”は「属するカテゴリのうちどれか が“野球”,“日本”,“代表”,“選手”,“人物”を含み,“一覧” を1つも含まない」となる. 4. 3 出力ドメインの特徴ベクトル 1つの組に対し,特徴を表すベクトルを3つ作成する.2つ (注 4):https://ja.wikipedia.org/wiki/Wikipedia:カテゴリの方針 , 2016 年 2 月 8 日閲覧 はドメインとエンティティの関係を表し,1つはエンティティ とエンティティの関係を表す. その前に,まず2つの特徴ベクトルを作る.これはエンティ ティごとにWikipediaの記事から作られる.これにはそれぞれ のドメインごとにTF-IDFを用いる.tをある語とすると,こ れは次のようになる. TF(t, ey) = eyの記事にtが現れた回数. (3) IDF(t) = log2 |Dy| Dyのうちtが現れるey記事数.(4) TFIDF(t, ey) = TF· IDF. (5) tは数字を除いた日本語の名詞とする.Wikipediaの各記事 から,形態素解析器MeCabを用いて抽出したそれぞれのtに 対し,TF-IDF行列を作成する.これは各行がeyに対応する 記事を表し,各列が語tに対応する.各列のベクトルは長さ1 の単位ベクトルに正規化される. 各列ベクトルの元について,上位のスコアをもつ元に対応す る語が,eyの特徴語であるとみなす.そこで,それを表すバイ ナリベクトルUW(ey)を作成する.これは各語が対応する元 を1,それ以外を0としたベクトルである. 組(eyi, eyj)に対しUW(ey i)とU W(ey j)から組の特徴ベクト ルV1,V2,V3を作る.これらはWikipediaから抽出用いて 作られるので,V1W,V W 2 ,V W 3 と書くこととする.ベクト ルの各元ごとに最大値,最小値をとりベクトルを返す関数をそ れぞれpmax,pminと表すと,これらは, V1W(e y i, e y j) = pmax(U W (eyi)− UW(eyj), 0). (6) V2W(e y i, e y j) = pmax(U W (eyj)− UW(eyi), 0). (7) V3W(e y i, e y j) = pmin(U W (eyi), U W (eyj)). (8) と表される.バイナリベクトルの場合順番に,UW(eyi)のみが 表す語,UW(eyj)のみが表す語,両方が表す語,というように それぞれ対応する. 4. 4 入力エンティティの特徴語取得 ドメインDxおよびそのエンティティ組(ex1,ex2)が与えられ たときに,ドメインとそれぞれのエンティティとの関係を表す語 を取得する.これらはWebを用いる.その理由は,Wikipedia のみを用いる場合,例えばName(ex 1) が“日本”,xが“ラグ ビー”であるとき,Wikipediaの“日本”というタイトルの記 事にはラグビーの記述がないからである. 加藤ら[7]は,Web検索結果のスニペットを用いて,χ2検定 により2つのエンティティの関係を得る手法を提案している. Name(ex1)∧ Name(ex2), (9) Name(ex1)∧ ¬Name(e x 2), (10) ¬Name(ex 1)∧ Name(e x 2). (11) 式 をクエリとして検索した結果に表れる語の出現率を基準に用 いる.ここで出現率とは,全てのスニペットの個数のうち語が 現れたスニペットの個数の割合である.式10と式11をクエリ とした検索結果における語の出現率が基準と有意差があり,か つ基準より大きければ,その語が2つのエンティティの関係を表す語だとみなしている. 我々は ,こ の 手 法 を も と に ,3 つ の 文 字 列 Name(ex 1), Name(ex 2),xから4つのクエリを作成する. x∧ Name(ex1)∧ Name(ex2), (12) x∧ Name(ex1)∧ ¬Name(e x 2), (13) x∧ ¬Name(ex1)∧ Name(e x 2), (14) x∧ ¬Name(ex1)∧ ¬Name(e x 2). (15) それぞれでWeb検索を行い,スニペットを取得する.取得し たスニペットに対して形態素解析器MeCabを用いて,数字を 除く日本語の名詞のみを取得する. 4. 5 入力エンティティ組の特徴ベクトル 1つの組に対して3つの特徴ベクトルV1,V2,V3を作成す る.Web検索によって取得した語をもとに作成するこれらを, VS 1 ,V2S,V3S と書くこととする. Dxとex1の関係を表す特徴ベクトルV S 1 (e x 1, e x 2)を作成する. 抽出された各語についてそれぞれ2つのχ2検定を行う.式13 の検索結果における語の出現率を基準として,式12と式15の 検索結果における出現率がともに有意差があり,かつ基準より 大きければ,その語はDxとex 1 の関係を表しているとみなす. それらの語がV1S(e x 1, e x 2)で該当する元の値を1,それ以外を0 とすることで,バイナリベクトルを作成する. Dxとex2の関係を表す特徴ベクトルV2S(ex1, ex2)を作成する. 式13の代わりに式14の検索結果を基準に用いて,上記の方法 と同様に行うことで,VS 2 (ex1, ex2)を得る. ex1 とe x 2の関係を表す特徴ベクトルV S 3 (e x 1, e x 2)を作成する. 式13と式14の検索結果における語の出現率を基準とした2つ のχ2検定を行う.両方において式12の語の出現率が有意差 があり,かつ基準より大きければ,その語はex 1 とex2の関係を 表しているとみなす.これによりバイナリベクトルV3 2(ex1, ex2) を得る. 4. 6 2組間の類似度計算 組(ex1, ex2)と組(e y i, e y j) の類似度を計算する.ここでは, Jaccard係数を用いる.ベクトルA = (a1, ..., an)とB = (b1, ..., bn)について,Jaccard係数は次のように表される. Jaccard(A, B) = ∑n i=1min(ai, bi) ∑n i=1max(ai, bi) . (16) バイナリベクトルでは,2つのベクトルの両方とも1である元 の個数を,どちらかが1である元の個数で除した値になる.式 2は,Jaccard係数を用いると,次のようになる. Similarity((ex1, e x 2), (e y i, e y j)) = w1Jaccard(V1S(e x 1, e x 2), V W 1 (e y i, e y j)) + w2Jaccard(V2S(e x 1, e x 2), V W 2 (e y i, e y j)) + w3Jaccard(V3S(e x 1, e x 2), V W 3 (e y i, e y j)). (17) これをそれぞれのyについて,全ての組(eyi, e y j)∈ D y につい て求める.Similarityの値が大きい順に,上位数件の組を結果 として出力する. 表 1 出力に用いるドメインの一覧 ドメインのラベル yk k :記事が属するカテゴリ名の条件(もしくは人手) |Dky| 1 野球の日本代表選手経験者:“野球” “日本” “代表” “選 手” “人物” を含み “一覧” を含まない 204 2 サッカーの日本代表選手経験者:“サッカー” “日本” “代表” “選手” “人物” を含み “一覧” を含まない 822 3 NHK紅白歌合戦出場者:“NHK 紅白歌合戦出場者” を含み “一覧” を含まない 686 4 戦国大名:“戦国大名” を含み “一覧” を含まない 499 5 日本のプロ野球チーム:(人手で列挙) 12 6 日本の都道府県:(人手で列挙) 47 7 世界の国:(Wikipedia“国の一覧 (大陸別)” から人手 で列挙) 206
5.
実
験
5. 1 実 験 設 定 Wikipedia日本語版の2015年12月26日付けダンプデー タ(注 5) のうち,記事全体をダンプしたものを用いた.これには 1,598,053件の日本語版記事が含まれている.本文は,ウィキ のマークアップ構文にを用いて記述されている.形態素解析器 に入力する前に,これらのマークアップ記号を取り除いておく.形態素解析器は,IPA辞書を適用したMeCabを用いた.Web
検索は,BingのAPIの結果を用いた. 4. 3節において,UW(ey)を作成するのに,各eyに対応す る文書におけるTF-IDF値が上位50件の単語を用いた. 4. 4節では,検索結果上位50件のスニペットを使用した.ま た,χ2検定は有意水準5%で行った. 式17の係数w1,w2,w3の値は全て1とした. 事前に,7つのドメインを人手で選択し構築した.これらの カテゴリの条件や含まれるエンティティの数を表1に示す. 以上の条件で,以下の5つの入力を与えた.それぞれをドメ イン名x,エンティティ名の組(Name(ex 1), Name(ex2))の順で 記す.さらに,評価を行った際に参考にしたそれぞれの関係の 概略を続けて記す. • サッカー, (FCバルセロナ,レアル・マドリード) -ライバル関係. • ラグビー, (日本,南アフリカ) -強弱の関係. • 芸人, (8.6秒バズーカー,オリエンタルラジオ) -後続者の関係. • 大統領選, (トランプ,サンダース) -対極の関係. • 福岡, (天神,博多) -種類が異なる代表者の関係. 5. 2 結 果 5つのクエリについて,7つのドメインそれぞれで出力され た上位3件について,各入力クエリとともに示した関係を満た しているかを人手によって評価した.合計105件の出力につい て評価し,適合率の平均(Precision@3)を求めたところ,0.171 であった. (注 5):http://dumps.wikimedia.org/jawiki/
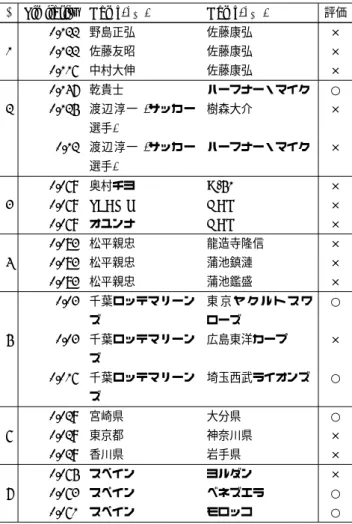
表 2 xが “サッカー”,Name(ex
1)が “FC バルセロナ”,Name(ex2) が “レアル・マドリード” のときの各ドメインにおける上位 3 件 の出力及び評価
k Similarity Name(yk i) Name(yk j) 評価
0.122 野島正弘 佐藤康弘 × 1 0.122 佐藤友昭 佐藤康弘 × 0.116 中村大伸 佐藤康弘 × 0.147 乾貴士 ハーフナー・マイク ○ 2 0.125 渡辺淳一 (サッカー 選手) 樹森大介 × 0.12 渡辺淳一 (サッカー 選手) ハーフナー・マイク × 0.069 奥村チヨ D-51 × 3 0.069 SEAMO KAN × 0.069 オユンナ KAN × 0.083 松平親忠 龍造寺隆信 × 4 0.083 松平親忠 蒲池鎮漣 × 0.083 松平親忠 蒲池鑑盛 × 0.03 千葉ロッテマリーン ズ 東 京 ヤ ク ル ト ス ワ ローズ ○ 5 0.03 千葉ロッテマリーン ズ 広島東洋カープ × 0.016 千葉ロッテマリーン ズ 埼玉西武ライオンズ ○ 0.029 宮崎県 大分県 ○ 6 0.029 東京都 神奈川県 × 0.029 香川県 岩手県 × 0.065 スペイン ヨルダン × 7 0.063 スペイン ベネズエラ ○ 0.061 スペイン モロッコ ○ 結果の具体例を示す.xを“サッカー”,Name(ex 1)を“FC バルセロナ”,Name(ex2)を“レアル・マドリード”として入力 に与えたときの,7つのドメインそれぞれの上位3件の結果を 表2に示す.評価は,適合としたものを○で表している.こ のクエリに対するPrecision@3は0.286であった.中間出力と して得られたVS 1 ,V2S,V3S について表3に示す.同様にx を“ラグビー”,Name(ex1)を“日本”,Name(ex2)を“南アフ リカ”としたときの結果を表4,中間出力を表5に示す.この クエリに対するPrecision@3は0.333であった. 形態素解析により分割されているが表3のVS 3 に得られた, “クラ”,“シコ”や,表5のVS 3 に得られた,“衝撃”,“金星”, “番狂わせ”などは,関係を表すのに適している語だと考えた. これらをスコア付けしたり,V3Wで得られた語とマッチングさ せる必要があると考えられる. 表2,4に,同じエンティティが何件も出力されている.こ れは,4. 3節で原因があると考えられる.半分以上のV3W が 0ベクトルであった.すなわち,2つのエンティティについて TF-IDFの上位50件に共通する単語が存在しなかった.また, 0でないものについても,共通する単語が1つのみであるよう なものが多くみられた.そのため,VW 1 やV2W が大きな影響 を与えたと考えられる. 表 3 xが “サッカー”,Name(ex 1)が “FC バルセロナ”,Name(ex2) が “レアル・マドリード” のとき各 VSが表す特徴語(VSの 元が 1 の値をとる語) VS 1 用, ホームスタジアム, カタルーニャ, プロ, 公式, 所属, 満 載, 応援, フットボール, 本拠地, 各種, 東京, 毎日, クラブ, 名門, スクール, 商品, データ, 付き, メンズ, グッズ, 件. VS 2 マドリード, 強豪, 設立, 横浜, 育成, 校, 機関, 公式, 所属, フランス, レ, フットボール, バスケットボール, 参加, 市, アル, 掲載, ファンデーション, 記, スクール, 付き, 財団, アカデミー, 開催, 出場. VS 2 ガ, 手配, 観戦, バレンシア, 事前, ここ, 杯, 動画, 国王, マ ンチェスター, シコ, 戦, はじめ, 首都, 節, 移動, 最大, 予 約, クラ, ファン, チケット, 安, 格安, リー, 対, エル, チャ ンピオンズ. 表 4 xが “ラグビー”,Name(ex 1)が “日本”,Name(ex2)が “南アフ リカ” のときの各ドメインにおける上位 3 件の出力及び評価 k Similarity Name(yk i) Name(yk j) 評価
0.125 黒須隆 井端弘和 ○ 1 0.107 黒須隆 黒田博樹 ○ 0.104 黒須隆 米村明 × 0.103 京川舞 佐藤寿人 × 2 0.094 井原正巳 大儀見優季 × 0.094 斎藤才三 大儀見優季 × 0.063 Sexy Zone ポケットビスケッツ × 3 0.063 Sexy Zone ゴスペラーズ × 0.063 Sexy Zone CHEMISTRY ×
0.082 南部信義 蠣崎光広 × 4 0.078 南部信義 筒井順政 × 0.074 南部信義 結城明朝 × 0.015 広島東洋カープ 埼玉西武ライオンズ × 5 0.015 広島東洋カープ 千葉ロッテマリーン ズ × 0.015 広島東洋カープ 北海道日本ハムファ イターズ ○ 0.049 佐賀県 愛知県 ○ 6 0.049 山口県 愛知県 ○ 0.049 福岡県 愛知県 × 0.071 バーレーン ニュージーランド ○ 7 0.065 アイルランド ニュージーランド × 0.065 セ ン ト ク リ ス ト フ ァー・ネイビス ニュージーランド ○
6.
まとめと今後の課題
あるドメインとそのドメインに属するエンティティの組が与 えられた時,別のドメインにおいて類似の位置関係をもつエン ティティの組を発見する手法を提案した. 1つの組に対し3つの特徴ベクトルを作り,それぞれを比較 することにより,組の類似度を求めた.入力エンティティ組と あらかじめ用意したドメインにおけるエンティティの組との類 似度を求め,類似度の高い順に出力した. これにより,ユーザが不慣れなドメインについて,エンティ ティ組の関係を,慣れたドメインにおけるエンティティ組の例表 5 xが “ラグビー”,Name(ex 1)が “日本”,Name(ex2)が “南アフ リカ” のとき各 VSが表す特徴語(VSの元が 1 の値をとる語) VS 1 選手権, ニュース, 日程, 日本一, ヤマハ発動機, その他, 速 報, 福岡, 網羅, ラグビーフットボール, 帝京大, 回, パナソ ニック, 協会, コラム, 表, 秩父宮, 満載, 組み合わせ, 総合, 森, 決勝, トップ, 特集, 問い合わせ, 界, 順位. VS 2 愛称, 編集, 新品, ボックス, 楽天, アシックス, ニュージー ランド, カンタベリー, 製, 国, 共和, オーク, スプリング, 商品, コメント, オーストラリア. VS 3 衝撃, 的, 星, ブライトン, 金星, イングランド, 瞬間, 開幕, 時間, 予選, 南ア, 杯, 前半, 撃破, 動画, 優勝, 話題, 日, 次, 候補, 分, 組, 大金, 世界, 試合, 初戦, 前回, ファン, 位, 史 上, 興奮, 代表, 後, 南部, 五郎丸, プール, 開始, 英国, 逆 転, 発表, 歴史, メンバー, 番狂わせ, ランキング, ランク, 開催, 出場, 勝利, ワールドカップ, さ. えによって理解することができる検索を行う,といった応用が 期待できる. 本論文における手法は,ドメインをあらかじめ用意している. これは,出力可能な関係があらかじめ制限されているというこ とでもある.候補を絞り,Web検索を併用することにより,よ り多様な出力が得られると考えられる. 語を直接関係を表す語として用いていることで,専門語がド メインを横断して写像されなかったり,誤って写像されること があり得る.語の上位下位関係や同位語を用いるということが 考えられる.また青木ら[6]やMikolovら[10]は,周辺語を用 いている. 出力候補全ての組に対して計算を行うことは時間がかかる. 出力候補のドメインを,サブドメインなどを用いて構成するこ とにより,あらかじめ候補を絞ることができるという改善が考 えられる.これは,ドメイン内においてエンティティ組の特徴 を抽出する際にも有効にはたらくことが考えられる.
謝
辞
本研究の一部は,文部科学省科学研究費補助金(課題番号 15H01718,24680008)によるものです.ここに記して謝意を 表します. 文 献[1] Lakoff, G., “The contemporary theory of metaphor,” In A. Ortony (Ed.), Metaphor and thought 2nd Edition, Cam-bridge: Cambridge University Press, pp. 202–251, 1993. [2] Iwayama, M., Tokunaga, T., and Tanaka, H. “A Method
of Calculating the Measure of Salience in Understanding Metaphors,” in Proceedings of the Eighth National Confer-ence on Artificial IntelligConfer-ence (AAAI-90), pp. 298-303, 1990. [3] 内海彰, 菅野道夫, “関連性理論を用いた文脈の中の隠喩解釈の 計算モデル,” 情報処理学会論文誌 37(6), pp. 1017-1029, 1996. [4] 桝井文人, ジェプカ・ラファウ, 木村泰知, 福本潤一, 荒木賢治, “WWW活用による語の比喩的素描手法,” 日本知能情報ファジ イ学会誌 Vol.22, No.6, pp. 707-719, 2010. [5] 近村亮一, ジェプカ・ラファウ, 荒木賢治, “Web データを用いた 単語に対する比喩的説明文収集手法,” 日本知能情報ファジィ学会 ファジィ システム シンポジウム 講演論文集 27, pp. 112-115, 2011. [6] 青木伸也, 湯本高行, 新居学, 高橋豐, “Web 上の比較表現を用 いた 2 オブジェクト間の比較観点の発見,” DEWS2008, A7-6, 2008. [7] 加藤誠, 大島裕明, 小山聡, 田中克己, “関係の類似性に基づく Webからのオブジェクト名検索情報処理学会論文誌. データベー ス 2(2), pp. 110-125, 2009. [8] グェン トアン ドゥク, ボレガラ ダヌシカ, 石塚満, “エンティ ティペア間類似性を利用した潜在関係検索,” 情報処理学会論文 誌 Vol.52, No.4, pp. 1790-1802, 2011.
[9] “Fang, L. and Sarma, A. D. and Yu, C. and Bohannon, P.” REX: Explaining Relationships Between Entity Pairs, VLDB Endow Proceedings, Vol. 5, No. 3, pp. 241–252, 2011. [10] Mikolov, Tomas, et al., “Efficient estimation of word repre-sentations in vector space,” arXiv preprint arXiv:1301.3781, 2013.
[11] 宇都宮圭, 大島裕明, 田中克己, “隠喩表現に着目した Web 情報 検索,” 第 7 回データ工学と情報マネジメントに関するフォーラ ム (DEIM Forum 2015), E8-4, 2015.