「画像の認識・理解シンポジウム (MIRU2011)」 2011 年 7 月
読唇のための線形回帰による視点変換
齊藤
剛史
††
九州工業大学大学院情報工学研究院 飯塚市川津 680–4 E-mail:†
[email protected] あらまし 近年,視覚情報を用いて発話内容を認識する読唇に関する研究が盛んに取り組まれている.多くの報告は 正面顔画像に対するアプローチであり,他の視点に対する報告が少ない.実社会で読唇を利用する際,常に正面から 撮影されるとは限らない.そこで本研究では正面以外の既知視点から撮影された画像を入力とし,線形回帰を用いて 目標視点である正面顔画像を生成することにより顔向きを変換する手法に取り組む.手法の有効性を確認にするため, 6台のカメラを用いて 6 視点より発話シーンを撮影した.非正面の視点より撮影された画像から正面の視点を生成し, 変換精度を検証した.その結果,平均輝度値誤差は 7.5 であり,本アプローチの有効性を確認した. キーワード 口形認識,顔向き変換,画像生成,線形回帰1.
は じ め に
カメラ付き携帯端末やスマートフォンなどの普及によ り,様々な場所で携帯端末が利用されている.さらに音 声認識機能を搭載した端末などの高機能化が進んでいる. 音声認識には,周囲の騒音に影響を受ける問題や,発声 するために公共の場で利用が難しい問題がある.前者の 問題に関しては,ノイズにロバストな音声認識技術が随 所で提案されている.一方,後者の問題に関しては音声 認識でなく,映像情報を利用する読唇技術が注目されて いる.また音声情報と映像情報を利用したバイモーダル 認識に関しても様々な手法が提案されている [1]. 読唇の多くの研究は正面顔画像を利用している [1], [2]. 正面顔は個々の人物を特徴づける有用な情報を多く含み, 読唇だけでなく,個人認識,表情認識などでも多く用い られている.しかし,携帯端末,特に携帯電話の利用を 考えた場合,正面顔画像を撮影するためには,口唇が写 るようにユーザが距離を調整しながらカメラを位置させ る必要があり,これは利便性が低下する.また音声情報 を取得するためのマイクは,音声が取得できる範囲であ れば,場所の制限はないものの,これまでの読唇技術で は,正面顔画像を撮影するためにカメラ位置に制限があ る.読唇技術を実利用するためには,正面顔画像を取得 できない状況を想定する必要がある.このような観点の もと,正面顔画像以外に斜め顔画像や横顔画像を用いた アプローチが提案されている [3]∼[9]. 井出ら [3],Iwano ら [4],齊藤と小西 [5] は,横顔画像 を用いた読唇について検討している.Kumar は正面顔画 像と横顔画像を用いて各視点からの単語読唇を検討して いる [6].山口らは,多方向の唇画像を利用した音声認識 に関して,正面,左 30 度,左 60 度の 3 方向から撮影し た発話シーンより,撮影方向の影響による認識精度の影 響について検討している [7].これらの研究では,各視点 から撮影された顔画像を入力とし,各視点に適した認識 手法を提案している.そのため,視点の異なる顔画像が 入力された場合は対応できない問題がある.一方,Lucey らは発話者が正面や横に顔の向きを変える発話シーンに 対する読唇手法を提案している [8].彼らの手法では各フ レームの顔画像を左横顔,正面顔,右横顔のいずれかに 分けている.さらに線形回帰を用いて左右の横顔画像か ら正面の顔を推定する手法を提案している [9]. 本研究では読唇技術を用いた障害者のコミュニケー ション支援システムの開発を目的としている.読唇技術 を実利用するために,正面顔画像以外にも適用可能な手 法として,Lucey らと同様の線形回帰に基づくアプロー チ [9] に着目する.Lucey らは正面顔と左右横顔の 3 視 点を利用している.本論文では,認識に有用な視点の検 討にも取り組むため,より多くの視点として 6 視点の顔 画像を用いる.ある一つの視点を目標視点,その他の視 点を非目標視点に設定し,非目標視点画像から線形回帰 を用いて目標視点画像を生成する視点変換に取り組む. 視点変換に関して,顔や歩容に対する研究が報告され ている.近年,広域監視システムを目的として,監視カ メラから得られる映像を用いた人物認識が注目を集め ている [14]∼[16].監視カメラの設置位置や人物の姿勢 の違いにより,カメラから撮影される人物画像は必ずし も期待する方向から撮影されているとは限らない.その ため,任意の方向から撮影された人物画像を推定する手 法が提案されている.顔に関して,予め用意した顔の 3 次元モデルを用いて,1 枚あるいは 2 枚の画像から 3 次 元顔を復元するアプローチが提案されている [10]∼[12]. これらの研究では撮影した状態,すなわち静止した顔画 像に対する形状復元である.また目の開閉のように人物 による違いがなく,かつ少ない動きであれば 3 次元モデ図1 顔 画 像 ルを変形することも可能である.しかし,口唇は形状だ けでなく動きにおいても人物による違いがある.また動 き量も大きい.そのため,これらのアプローチは読唇に は適していない.また 3 次元モデルを用いないアプロー チとして,Seitz と Dyer は顔画像だけでなく一般物体へ の適用も可能な View Morphing を提案している [13].河 野らは大量の高解像度な顔画像を用いて,入力された低 解像度な顔画像から高解像度な顔画像を推定する Face Hallucinationの枠組みのもと,多数の顔画像を用いて視 点変換を行う View Hallucination を提案している [14]. 一方,歩容に関して,3 次元歩容データに基づく手法 [15] や視点変換モデルを用いる手法 [16] が提案されている. 本論文は,複数カメラより撮影された多視点画像を用 いる.視点変換に関しては顔や歩容に関して幾つかの手 法が提案されているが,最初の試みとして読唇分野にお ける従来手法である Lucey らの手法を適用する.また Luceyらの研究を含めて,これまでの視点変換に対して は定性的な評価しかなされていない.本論文では視点変 換の精度を定量的に評価し,その有効性を検証する. 本論文は以下のように構成されている.まず,2. で線 形回帰を用いた目標視点画像の生成について述べる.3. で提案手法の有効性を確認するための実験について述べ る.最後に 4. で結論と今後の課題について述べる.
2.
目標視点画像の生成
2. 1
位置合わせ 本研究で用いる顔画像例を図 1 に示す.本研究で用い るシーンの詳細は 3. 1 で後述するが,図 1 に示すよう に同じ人物であっても,撮影日時の違いにより,服装や 光源,顔の位置に違いが生じる.次節で説明する目標視 点画像を生成するためには,処理対象画像を同じ位置に 合わせる必要がある.そこで最初に画像の位置合わせを 行う. 位置合わせを行うために,最初に基準となる画像 Iref を用意する.処理対象となる画像を It,Itを (sx, sy)平 行移動した画像を I(sx,sy) t と表記する.このとき, arg min sx,sy Iref− I (sx,sy) t となる (sx, sy)を求めることにより,I (sx,sy) t を推定する. 平行移動によって推定された画像は基準画像とほぼ同reference image target image
shifted image Iref It It(sx, sy) R R R R S S ROI normalized ROI 図2 位置合わせの処理の流れ じ位置に鼻や口唇が写ると仮定できる.そこで,事前に 設定した座標をもとに,平行移動後の画像より,R× R の処理対象領域 ROI を切り出す.さらに R× R の ROI を S× S に縮小して,視点変換に用いる口唇画像を得る. 以上の処理の流れを図 2 に示す.ここで本研究では読唇 を目標としており,読唇に不要と考えられる口唇以外の 部位や服,背景を軽減するため撮影画像をそのまま用い ず,口唇周辺のみの領域を用いる.
2. 2
線形回帰による目標視点画像の生成[9]
ある視点から撮影された N 枚の非目標視点の画像群 を X = {x1,· · · , xN},Xと同期して撮影された N 枚 の目標視点の画像群を T ={[t1, 1]T,· · · , [tN, 1]T} とす る.ただし,xnと tnは M 次元のベクトルとする.こ のとき事前にXとT を用いて T = W X となる変換行列 Wを求める.W を用いることにより,新しくある視点 から撮影された非目標視点の画像xから,真の目標視点 の画像tを得ずとも目標視点の画像 t′を t′ = W xより推 定することが可能となる.ここでW は N 組の学習サン プルを用いて最小二乗法により求めることができる.過 学習を防ぐために誤差関数に正規化項を加えると,次式 で表される誤差を最小化する問題になる [17]. (W T − X)T(W T − X) + λWTW Wは次式で得られる. W = T XT ( XXT + λI )−1 上式により求まるW を用いて目標視点画像を生成する. 非目標視点画像を入力として線形回帰により目標視点画 像を生成するイメージを図 3 に示す.3.
生成画像の評価実験
3. 1
発話シーン 多方向から撮影した画像として (財) ソフトピアジャパ ンが提供するデータベースがある.しかしこの画像は静 止状態であり,本研究で目的とする発話シーンが含まれ ていない.そこで独自に多方向からの発話シーンを撮影T
X
W
x
t
t’
t’ = W x
offline
N images N images 図3 線形回帰による目標視点画像の生成 表1 各発話者の総フレーム数 speaker A B C D E F G H I J F (×103 ) 74.6 70.6 65.7 64.3 62.5 71.4 64.7 63.9 69.0 69.8 した. 発話シーンを撮影するために,図 4 に示すような撮影 ユニットを製作した.ユニット内には 6 台のカメラ C1∼ C6が固定されている.ユニット内に用意した椅子に発話 者を着席させ,6 台のカメラを用いて図 5 に示すような 6視点の発話シーンを同期して撮影した.撮影に用いた6台のカメラは全て Point Grey Research 社製 Flea2 で
ある.C1∼C3 は口と同じ高さ(仰角 θEL= 0◦),C4∼ C6は少し低い位置ある水平板の上に設置したカメラで あり,仰角 θEL= 45◦である.C1 と C4 は顔の正面(方 位角 θAZ = 0◦),C2 と C5 は斜め方向(θAZ = 45◦), C3と C6 は真横(θAZ = 90◦)に位置している. これらの撮影環境において男性 8 人,女性 2 人の 10 人(A∼J)から会話文を想定した日本語短文 50 文の発 話シーンを撮影した.発話シーンは 1 短文ずつ撮影して おり,発話前後は口を閉じている.1 文につき 15 シー ン,1 人あたり 750 シーンを撮影した.撮影時のフレー ムレートは 30fps,画像サイズは 320× 240 画素である. 撮影する際,なるべく同じ姿勢を保つように発話者に指 示を与えた.また口唇とカメラの距離は約 25cm に設定 した.撮影は 1 文ずつであるため,発話中の頭部の動き はほとんど観測されなかった.しかし,2. 1 で述べたよ うに撮影日時が違う場合には位置等にずれが生じた. 表 1 に各発話者の総フレーム数 F を示す.1 人あたり の平均フレーム数は 67.6k である.1 シーンあたりの平 均フレーム数は 90.2 である.
3. 2
位置合わせ 位置合わせに用いる基準画像 Iref は発話者毎に発話 前のフレーム画像を 1 枚ずつ選んだ.撮影画像から切り 出す ROI のサイズは R = 140,また縮小後の画像サイ ズは S = 32 とした. 実験で用いるフレーム画像数は膨大である.そのため backboard C1~C3 C4~C6 C1 C2 C3 C4 C5 C6 backboard C1 C2 C3 C4 C5 C6 C1 C2 C3 C4 C5 C6 図4 発話シーンの撮影環境 (a) C1 (b) C2 (c) C3 (d) C4 (e) C5 (f) C6 図5 撮 影 画 像 位置合わせについて,全てのフレーム画像に対して評価 することは難しい.そこで 3. 4 の口形認識に用いる 6 口 形のフレーム画像に対して,正しく位置が得られたか目 視により確認した.評価画像枚数は 1 人 1 視点につき 270 枚である.10 人の平均成功率を求めたところ,C1∼C6 の各視点においてそれぞれ 99.33%,94.37%,92.15%, 99.96%,98.37%,94.89%であった.成功率が低下した 原因として,本論文で適用した位置合わせは移動のみを 適用しており,回転や拡大・縮小を考慮していないこと が挙げられる.3. 3
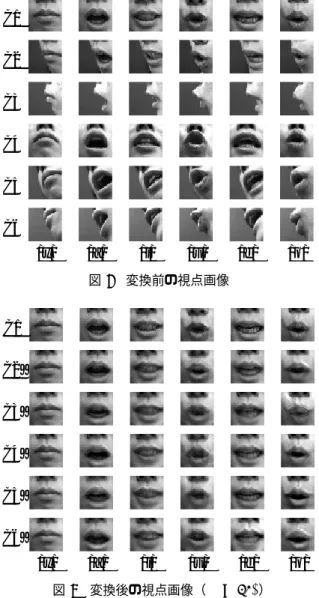
視点変換実験 本実験では,代表的な視点である C1 を目標視点と し,C2∼C6 の視点を非目標視点として,線形回帰に よる目標視点画像を生成した.C2∼C6 に対する生成 画 像 を C2’∼C6’ と 表 記 す る .学 習 サ ン プ ル 数 N を N = {1k, 2k, 3k, 4k, 5k, 10k} の場合において目標視点 画像を生成した.学習サンプルは,全発話シーンよりラ ンダムに N 枚選択した.また M = S× S であり,λ = 1 とした. 3. 4の口形認識で用いる 6 口形において,各視点の変 換前の画像を図 6,N = 10k における変換後の画像を図 7に示す.図 7 より,変換後の画像 C2’∼C6’ は目標視点C1 C2 C3 C4 C5 C6
/x/ /a/ /i/ /u/ /e/ /o/
図6 変換前の視点画像 C1 C2’ C3’ C4’ C5’ C6’
/x/ /a/ /i/ /u/ /e/ /o/
図7 変換後の視点画像(N = 10k) 画像である C1 とほぼ同じ画像が生成されていることが 目視で確認できる. 図 8 に N の違いによる変換結果例を示す.図 8(a) は 閉唇口形/x/,図 8(b) はア口形/a/である.目視による 評価では,/x/の場合は N = 1k,/a/の場合は N <= 3k においてごま塩雑音のようなノイズが観測される.N が 大きくなるに従い,ノイズが低減していることがわかる. 以上のことより視点変換するために N は重要なパラメー タであることがわかる. 視点変換に関する研究の多くは,変換の評価を定性 的に行なっている.変換精度を定量的に評価するため, 目標視点画像 ICT と変換後の視点画像 ICXにおける各 画素の平均輝度値誤差 E を求めた.すなわち座標 (x, y) における ICT と ICX の輝度値をそれぞれ ICT(x, y), ICX(x, y)と表記すると,E は次式で定義する. E = 1 S× S ∑ x ∑ y |ICT(x, y)− ICX(x, y)| すなわち E が小さいほど,目標視点画像と視点変換画像 の差が小さいことを意味する.ただし,本実験では目標 視点画像 ICT は C1 である. C2’ C3’ C4’ C5’ C6’ 1k 2k 3k 4k 5k 10k (a) /x/ C2’ C3’ C4’ C5’ C6’ 1k 2k 3k 4k 5k 10k (b) /a/ 図8 Nの違いによる変換結果 0 5 10 15 20 25 30 35 E 2k 4k 6k 8k 10k 0 C2’ C3’ C4’ C5’ C6’ N 図9 視点変換結果 N を変化させた場合における 10 人の全ての発話シー ンの平均輝度値差の変化を図 9 に示す.学習サンプル数 が増加するに従い誤差 E が小さくなる.N >= 4k で E は ほぼ収束しており,N = 10k の平均輝度値誤差は 7.5 で あった.また視点に着目すると,C2,C4 の誤差が小さ く,C3,C6 の誤差が大きい.これは目標視点 C1 に近い 視点ほど誤差が小さく,遠い視点ほど誤差が大きいため と推測する.また λ に関しては λ = 100 において視点変 換を適用して誤差を計測した.しかし λ = 1 と差がほと んどなかった.そのため,以後の実験においても λ = 1 を用いる.
3. 4
口形認識実験 本論文で検討する視点変換は,読唇への応用を目的と している.読唇は発話時の口形の動き,すなわち時系列 変化から特徴量を求め認識する.一方,視点変換は静止 画像処理である.そこで視点変換の有効性を検証するた め,発話内容の認識でなく,口形認識を実施した.日本 語発話時の代表的な口形は閉唇口形/x/と 5 母音の口形 (/a/,/i/,/u/,/e/,/o/)である.そこで発話シー ンから 6 口形の発話フレーム画像を目視で検出した.各 口形につき 45 枚,6 口形あわせて 270 枚のフレーム画像 を口形認識実験に用いた. 口形認識は以下の手順で実施した.視点変換で用いる 画像に対して 2 次元離散コサイン変換(2D-DCT)を適 用し,DCT 係数を求める.DCT 係数には低次元から高 次元の特徴が含まれている.一般的に高次元より低次元 の係数に重要な情報が含まれる.そこで S× S 個の全て の DCT 係数を用いず,ジグザグスキャンを適用し,低 次 D 個の DCT 係数を特徴量として取得する.得られた 特徴量を入力とし,パターン認識においてよく用いられ ている線形判別分析を適用する.本実験では D = 32 を 用いた. 各視点,各口形における認識結果を図 10 に示す.視点 変換前の画像を用いた平均認識率は,C1,C2,C3,C4, C5,C6 それぞれ 94.9%,90.7%,89.2%,94.0%,91.7%, 89.6%であった.この結果より,正面,すなわち C1 の視 点で最も高い認識率を得られた.またカメラの水平方向 の角度にわけて観察すると,正面から側面に視点が変化 するほど,すなわち C1→C2→C3,C4→C5→C6 の順で 認識率が低下している.一方,C1∼C3 と C4∼C6 のカ メラの仰角に関しては認識率にほとんど差がない. 視点変換により生成された画像を用いた平均認識 率は C2’,C3’,C4’,C5’,C6’ それぞれ 91.5%,88.9%, 93.3%,91.7%,88.1%であった.3. 3 より視点変換の誤 差はほとんどない.そのため視点変換後の認識率は,C1 とほぼ同じ 95%近い認識率を得られることを期待して いた.しかし,視点変換後の画像による認識結果は視点 変換前の画像とほぼ同じであった.この要因を解析する ため,認識に用いた 270 枚のフレーム画像において各 口形の平均変換誤差を算出した.その結果を図 11 に示 す.3. 3 で示した全フレーム画像の平均誤差 7.5 に対し て,270 枚の平均誤差は 12.2 であった.図 11 より,閉 唇口形である/x/の誤差は 6.0 であるが,その他の口形 は 10∼18 の範囲である.3. 1 で述べたとおり,本実験 で用いた発話シーンでは発話前後に口を閉じている.こ のため発話シーンに占める閉唇口形のフレーム数が他の 口形フレーム数より多いため,学習サンプル N に含ま れる閉唇口形が多くなり,口形による変換精度に差が生 じたと考えられる.視点変換誤差が大きかったことによ り,目標視点である正面顔画像に変換されても認識精度 が向上しなかったと推測する. 80 60 40 20 0/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape R e co g n it io n r a te [ % ]100 C1 (a) C1 80 60 40 20 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape R e co g n it io n r a te [ % ]100 C2 C2’ (b) C2,C2’ 80 60 40 20 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape R e co g n it io n r a te [ % ]100 C3 C3’ (c) C3,C3’ 80 60 40 20 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape R e co g n it io n r a te [ % ]100 C4 C4’ (d) C4,C4’ 80 60 40 20 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape R e co g n it io n r a te [ % ]100 C5 C5’ (e) C5,C5’ 80 60 40 20 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape R e co g n it io n r a te [ % ]100 C6 C6’ (f) C6,C6’ 図10 認 識 結 果
3. 5
目標視点と非目標視点の組み合わせ 3. 3と 3. 4 では,目標視点 ICT を C1,非目標視点 ICXを C2∼C6 に設定した実験であった.本実験ではそ の他の ICT に対して議論する. 3. 4で用いた 6 口形,合計 270 枚のフレーム画像を用 いて ICT と ICX を様々に変化させて,30 通りの組み 合わせにおいて視点変換を適用した.各組み合わせにお ける変換誤差を表 2 に示す.表中の数値は,発話者 10 人の 270 枚の視点変換の平均誤差を表している.また ICT = ICXに関しては,変換する必要がないため,組 み合わせから外した. 表 2 より,ICX=C3における平均誤差 14.0 が最も大 きい.この要因は 3. 2 で述べたとおり C3 の位置合わせ 成功率は他の視点よりも低いことが挙げられる.位置合 わせは視点変換の前処理である.前処理の成功率の低さ が変換精度に影響したと考えられる.一方,ICT =C3 における平均誤差 9.8 が最も小さい.図 6 の視点画像を 観測すると,C3 は一様な背景領域が画像の半分以上を 占め,かつ他視点に比べ口の内部が写らず画像に占める 口唇領域が少ないため,誤差が低くなったと推測できる. 表 2 は 6 口形の平均を示しているが,/a/,/i/,/u/,20
15
10
5
0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape E (a) C2’ 20 15 10 5 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape E (b) C3’ 20 15 10 5 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape E (c) C4’ 20 15 10 5 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape E (d) C5’ 20 15 10 5 0
/a/ /i/ /u/ /e/ /o/ /x/ ave Mouth shape E (e) C6’ 図11 各口形の変換結果 表2 目標視点と非目標視点の組み合わせによる変換結果 ICX C1 C2 C3 C4 C5 C6 ave C1 — 10.4 12.9 11.4 12.1 14.1 12.2 C2 11.0 — 12.4 12.1 11.9 13.6 12.2 C3 10.2 9.4 — 9.7 9.5 10.3 9.8 ICT C4 15.1 15.3 16.1 — 12.0 15.7 14.9 C5 13.9 13.2 13.9 10.8 — 12.7 12.9 C6 15.4 14.6 14.6 13.7 12.2 — 14.1 ave 13.1 12.6 14.0 11.6 11.5 13.3 12.7 /e/,/o/,/x/の各口形の平均はそれぞれ 16.0,12.4, 13.0,13.4,14.5,6.7 であった.3. 4 で述べたのと同様 に,閉唇口形の変換誤差が最も少なかった.
4.
お わ り に
本論文では線形回帰を用いて非目標視点画像から目標 視点画像を生成する視点変換に着目し,6 視点から撮影 された発話シーンを用いて,視点変換の有効性を検証し た.また従来の視点変換では定性的な評価しかなされて いないのに対し,本論文では生成画像と目標視点画像の 輝度値誤差を画素単位で計測し定量的に評価を行なった. その結果,発話シーンの全フレームに対しては平均輝度 値差は 7.5 であり,本アプローチが有効であることを確 認した.ただし,発話時の代表的な口形に着目したとこ ろ,誤差にばらつきが生じた.これは学習サンプルの選 び方に依存していることが判明した.今後の課題として, 様々な口形を均等に学習サンプルとして用いることによ る視点変換の精度の検証が挙げられる.また本論文では 線形回帰を用いたが,その他の視点変換手法を適用し, 読唇に有効なアプローチを検証することが挙げられる.謝
辞
本研究の一部は,総務省戦略的情報通信研究開発推進 制度(SCOPE),文部科学省科学研究費補助金(若手研 究(B))によるものである. 文 献[1] I. Matthews, T. F. Cootes, J. A. Bangham, S. Cox, and R Harvey, “Extraction of visual features for lipreading,” IEEE Trans. Pattern Anal. & Mach. In-tell., vol. 24, no. 2, pp. 198–213, 2002.
[2] T. Saitoh, K. Morishita, and R. Konishi, “Analysis of efficient lip reading method for various languages,” Proc. of ICPR2008, 2008, doi: 10.1109/ICPR.2008.4761049.
[3] 井出健,小越康宏,荒木哲郎,“横顔口唇動画像におけ
る注目点追跡による読唇手法の提案,”第20回人工知
能学会全国大会,2006.
[4] K. Iwano, T. Yoshinaga, S. Tamura, and S. Fu-rui, “Audio-visual speech recognition using lip infor-mation extracted from side-face images, EURASIP Journal on Audio, Speech, and Music Processing, vol. 2007, pp. 69–73, 2007, doi:10.1155/2007/64506. [5] T. Saitoh and R.Konishi, “Profile lip reading for vowel
and word recognition,” Proc. of ICPR2010, pp. 1356-1359, 2010, doi: 10.1109/ICPR.2010.335.
[6] K. Kumar, T. Chen, and R. M. Stern, “Profile view lip reading,” Proc. of IEEE International Conference on Acoustics, Speech and Signal Processing, no. 4, pp. 429–432, 2007.
[7] 山口健,山本俊一,駒谷和範,尾形哲也,奥乃博,“多
方向の唇画像を利用した音声認識,”第14回人工知能
学会全国大会,2004.
[8] P. Lucey, S. Sridharan, and D. Dean, “Continu-ous pose-invariance lipreading,” Proc. of Interspeech 2008, pp. 69–73, 2008.
[9] P. Lucey, G. Potamianos, and S. Sridharan, “A uni-fied approach to multi-pose audio-visual ASR,” Proc. of Interspeech 2007, pp. 650–653, 2007.
[10] V. Blanz, P. Grother, P. J. Phillips, and T. Vetter, “Face recognition based on frontal views generated from non-frontal images,” Proc. of CVPR2005, vol. 2, pp. 454–461, 2005.
[11] J. Heo and M. Savvides, “Rapid 3D face modeling using a frontal face and a profile face for accurate 2D pose synthesis,” Proc. of IEEE International Con-ference on Automatic Face and Gesture Recognition, 2011.
[12] I. Kemelmacher-Shlizerman and R. Basri, “3D face re-construction from a single image using a single refer-ence face shape,” IEEE Trans. Pattern Anal. & Mach. Intell., vol. 33, no. 2, pp. 394–405, 2011.
[13] S. M. Seitz and C. R. Dyer, “View morphing,” Proc. of SIGGRAPH1996, pp. 21–30, 1996.
[14] 河野雄紀,高橋友和,出口大輔,井手一郎,村瀬洋,“多 数の顔画像を用いて顔向きの変換を行うView hallucina-tionの提案,”信学技報,PRMU,vol. 109,no. 306, pp. 247–252,2009. [15] 岩下友美,馬場亮輔,小川原光一,倉爪亮,“多次元全 周歩容データベースの構築と歩容による個人識別,” MIRU2010,pp. 1604–1610,2010. [16] 白石明,槇原靖,八木康史,“三次元歩容データによる 任意視点変換モデルを用いた歩容認証,”情処学研報,
vol. 2010-CVIM-175,no. 34,pp. 1–8,2011. [17] C. M. Bishop, Pattern Recognition and Machine
![図 1 顔 画 像 ルを変形することも可能である.しかし,口唇は形状だ けでなく動きにおいても人物による違いがある.また動 き量も大きい.そのため,これらのアプローチは読唇に は適していない.また 3 次元モデルを用いないアプロー チとして,Seitz と Dyer は顔画像だけでなく一般物体へ の適用も可能な View Morphing を提案している [13].河 野らは大量の高解像度な顔画像を用いて,入力された低 解像度な顔画像から高解像度な顔画像を推定する Face Hallucination の枠](https://thumb-ap.123doks.com/thumbv2/123deta/8022500.1740675/2.892.466.822.72.272/しかしにおいによるき量も大きいこれらアプローチアプロー.webp)