確率モデルによる確率入門
豊泉 洋
1平成
24
年
11
月
26
日
2
目 次
第 1 章 Introduction 5 1.1 なぜ、統計学が? . . . . 7 第 2 章 記述統計 8 2.1 「代表(センター)」の記述 . . . . 8 2.2 ばらつきの記述 . . . . 8 2.3 グラフ . . . . 9 第 3 章 確率の計算規則 10 3.1 確率の解釈 . . . . 10 3.2 サンプリング . . . . 11 3.3 順列と組み合わせ . . . . 11 第 4 章 確率と仮説検定 12 4.1 コイン投げ . . . . 12 4.2 仮説検定 . . . . 12 第 5 章 条件付き確率と確率変数 14 5.1 病気の判定 . . . . 14 5.2 条件付き確率の計算 . . . . 16 5.3 独立 . . . . 16 5.4 Bayesの定理 . . . . 17 第 6 章 確率変数とその周辺 18 6.1 確率変数 . . . . 18 6.2 確率密度、確率分布 . . . . 18 6.3 期待値 . . . . 19 6.4 分散 . . . . 19 6.5 ベルヌーイ試行 . . . . 20 6.6 独立、同一な分布 . . . . 213 第 7 章 幾何分布、2項分布、Poisson 分布 22 7.1 幾何分布 . . . . 22 7.2 2項分布 . . . . 23 7.3 2項分布の応用例 . . . . 24 7.4 Poisson分布 . . . . 24 7.5 Poisson分布の応用例 . . . . 26 7.6 超幾何分布 . . . . 27 第 8 章 正規分布とその仲間たち 28 8.1 一様分布 . . . . 28 8.2 連続確率変数 . . . . 28 8.3 正規分布 . . . . 29 8.4 対数正規分布 . . . . 32 8.5 中心極限定理 . . . . 32 8.6 χ2(カイ二乗分布) . . . 32 8.7 t分布 . . . . 34 8.8 F分布 . . . . 34 第 9 章 2つの確率変数と相関 35 9.1 同時確率分布 . . . . 35 9.2 周辺分布 . . . . 35 9.3 条件付き分布 . . . . 36 9.4 独立 . . . . 36 9.5 共分散、相関係数 . . . . 37 9.6 和の分散 . . . . 37 9.7 ポートフォリオ分析 . . . . 38 第 10 章 統計的推測 40 10.1 平均の推測 . . . . 40 10.2 最尤推定法 . . . . 41 10.3 一致推定量 . . . . 43 10.4 不偏推定量 . . . . 43 10.5 推定量の選び方 . . . . 44 第 11 章 信頼区間 46 11.1 正規分布を使って信頼区間を求める:分散既知の場合 . . 46 11.2 t分布を使って信頼区間を求める:分散未知の場合 . . . . 48
4 11.3 その他の推定における信頼区間 . . . . 51 第 12 章 サンプリング 52 12.1 世論調査 . . . . 52 12.2 支持率の信頼区間 . . . . 53 12.3 サンプリングの方法 . . . . 55 12.4 マーケティングリサーチの手法 . . . . 56 第 13 章 仮説検定 59 13.1 仮説検定の結果と正しさ . . . . 59 13.2 検定統計量 . . . . 60 13.3 平均の検定 . . . . 61 13.4 片側検定 . . . . 63 13.5 検定が意味すること . . . . 65
5
第
1
章
Introduction
ビジネスの定量的な分析にかかせない応用確率論の基礎や、データの 統計処理の基礎を学ぶ。 はじめに、確率変数の概念や基本的な確率分布 のような確率論の基礎、推定および検定、分析など統計データの処理法 を概観する。 最終的には、基本的な確率論を元に、様々な事象について モデル化し、定量的な分析を行う方法を概説する。特に、ファイナンスや 経営判断に用いられるさまざまな確率理論を学ぶことを通して、確率的 な事象の定量的な評価方法を学ぶ。さらに、定量的な評価を通して、意 思決定をする方法について学ぶ。 この講義は輪講形式で行う。Methods & Evaluation
講義形式定期試験 60 %、提出物 40 % (講義テキスト中に出てきた Prob-lemを随時受け付けます。)
Requirements
数学に自信のない学生は、統計学 1 を同時に受講してください。
Text book
Business Statistics (Barron’s Business Review Series)、Douglas Downing (著), Jeff Clark (著) Barrons Educational Series Inc ; 4th 版 (2003/09)
スケジュール
6 第 1 章 Introduction
図 1.1: 教科書:Business Statistics (Barron’s Business Review Series)[1]
2. 確率と仮説検定 3. 確率の計算 4. 条件付き確率と確率変数 5. 確率分布1 6. 確率分布2 7. 同時確率分布と相関 8. 統計的推測 9. 信頼区間 10. サンプリング 11. 仮説検定 12. χ2乗検定 13. 分散分析 14. 単純回帰分析
1.1. なぜ、統計学が? 7
1.1
なぜ、統計学が?
統計学は、未確定・確率的な現象を、データに基づいて客観的に分析 し、他の人たちと合意するための最良の手段である。 Example 1.1(統計学の応用例). いくつかあげると、 1. 新製品のリリース 2. アイスクリームの売れ行き予想 3. 会計監査 4. 新薬 5. 品質管理 6. 大相撲の八百長 7. メジャーリーグ 8. 株式市場 9. 地球温暖化 10. 政策 Problem 1.1. 上の例で、どのように統計学が使えるか?8
第
2
章 記述統計
2.1
「代表(センター)」の記述
データが与えられた場合、そのデータを代表する値を求めるには、次 ように3つの方法がある。
Definition 2.1(average). Given n samples of data, the quantity below is called by “average.” ¯ x =x1+ x2+··· + xn n = ∑n i=1xi n . (2.1)
Definition 2.2 (median). Given n samples of data, the center of the ordered samples is called by “median.”
Definition 2.3(mode). Given n samples of data, the value which is appeared most in the data is called by “mode.”
Problem 2.1. 1. average、median、mode のそれぞれの特徴は? 2. データの「センター」を記述する場合に、どんな注意が必要か? 3. どんな時に、どの記述法が望ましいか?
2.2
ばらつきの記述
データの記述として、センターを記述するだけでは、不十分な場合が よくある。 Problem 2.2. どんな場合にセンターの記述だけでは、不十分であるか? 例を3つあげろ。 データが与えられた場合、そのデータのばらつきを代表する値を求め るのにも、いくつかの方法がある。2.3. グラフ 9 Definition 2.4 (variance). Given n samples of data, the quantity below is called by “variance” of data.
Var(x) =σ2= ∑
n
i=1(xi− ¯x)2
n (2.2)
= ¯x2− ¯x2. (2.3) The sample variance is also defined by
s22= ∑ n i=1(xi− ¯x)2 n− 1 (2.4) Problem 2.3. 式 (2.3) に変形できることを示せ。 分散は、ちらばりを代表する値としては有用だが、欠点がある。x2の オーダーであることである。その大きさは、値が大きくなると、かなり の速さで大きくなる。
Definition 2.5(standard deviation). Given n samples of data, the square-root of the variance Var(x) is called by standard deviation, and given by
σ=√Var(x) (2.5) = √ ¯ x2− ¯x2. (2.6)
2.3
グラフ
コンピュータの力を借りることにより、データの全体像を得ることは、 比較的簡単である。特に、データを以下のようなグラフにより可視化す ることは、データの解析の第一歩と言える。 Example 2.1(グラフ). 例えば、以下のようなグラフが考えられる。 • ヒストグラム • 折れ線ヒストグラム • 累積度数グラフ • 円グラフ • 散布図 Problem 2.4. インターネット上で、ダウンロードできる興味深いデータ を使い、上記のグラフを Excel で実際に出力してみよ。10
第
3
章 確率の計算規則
3.1
確率の解釈
二つの確率の解釈がある。 1. 頻度としての確率の解釈:何度も同じ事象を繰り返し、観測すると その頻度は、確率に近づく。 2. 主観としての確率の解釈:個人がその現象が起こると信じる確率 通常の確率論では、「確率」自体の解釈は触れない。公理的な条件が示 されるだけで、この条件にあてはまれば、どんなものも確率として解釈 される。 Remark 3.1. もうひとつの解釈として、ギャンブラーとしての確率の解釈 がある。たいていの場合、これは、ギャンブラー個人の「直感」に基づく。 Definition 3.1. すべての可能な試行の集合をサンプル空間と呼ぶ。Ω と書 く場合が多い。サンプル空間上のイベントの集合 A に対して、A が起こ る確率を P{A}, (3.1) と書く。 簡単な確率の計算: P{A or B} = P{A ∪ B} = P(A) + P(B)− P(A ∩ B). (3.2) P{A and B} = P{A ∩ B} (3.3) P{ not A} = P{Ac} = 1− P{A}. (3.4)3.2. サンプリング 11
3.2
サンプリング
一度抜き出したものを、もう一度戻して、再び抜き出す場合と、戻さ ずに抜き出す場合では、確率は異なる。 Problem 3.1. あなたは、5枚のセーターを持っている。毎朝、ランダム に一枚のセーターを着る。1週間、同じセーターを着る確率はいくつ?3.3
順列と組み合わせ
簡単な計算をする場合には、順列と組み合わせの考え方が有用である。 n個の中から、 j 個を順番を考慮して選んだ場合、そのオーダーの数を 順列とよび、 nPj= n! (n− j)!, (3.5) となる。n 個の中から、 j 個を順番を考慮せずに選んだ場合、その組み合 わせの数を組み合わせとよび、 ( n j ) =nCj= n! (n− j)! j!, (3.6) となる。 Problem 3.2. 18人のプレイヤーで、野球のチームを二つ作る。ランダム に選手を選んだ時、片方のチームに良い選手が固まってしまう確率を求 めよ。12
第
4
章 確率と仮説検定
4.1
コイン投げ
フェアなコインを n 回投げて、h 回表が出る確率 P{ フェアなコインを n 回投げて、h 回表が出る } = ( n h )( 1 2 )n (4.1) = n! h!(n− h)! ( 1 2 )n (4.2) Problem 4.1. 10回投げて、2回しか表がでない確率を上の式に当ては めて考えよ。 Problem 4.2. 10回投げて、2回しか表がでなかったとすると、このコ インはフェアか?4.2
仮説検定
• 帰無仮説 (null hypothesis):テストすべき本来の仮説 • 対立仮説 (alternative hypothesis):「帰無仮説が間違っている」とい う仮説 この二つの仮説を「対立」させて、データの観測結果から、どちらが 正しいかを判断する。観測結果に応じて、「否定領域」と「肯定領域」が 考えられる。観測結果が「肯定領域」に入っていれば、帰無仮説が採択 される。 しかし、次の2つの種類の誤りが考えられる。 • 第一種の過誤(false positive):テストすべき本来の仮説を誤って、 否定するミス。対立仮説を誤って採用するミス。4.2. 仮説検定 13 • 第二種の過誤(error):本来の仮説が間違っているのに、肯定してし まうミス。帰無仮説を誤って採用するミス。 Problem 4.3. どちらの過誤がより深刻か? Remark 4.1. たいていの場合、第一種の過誤は避けたい。通常は、仮説が 正しいと判断した場合には、さらにその仮説を元に、あらたな実験や観 測を続ける。一方、仮説が否定された場合には、その仮説に関する議論 がストップする。したがって、第一種の過誤が起こらないように、慎重 にデータ処理する必要がある。 通常は、第一種の過誤の確率が 5%や 10%になるように、判定する。 Example 4.1. コインがフェアかどうかテストしたい場合、それぞれの仮 説は、次のようになる。 • 帰無仮説(null hypothesis):このコインはフェアだ。すなわち、p = 1/2. • 対立仮説 (alternative hypothesis):このコインはアンフェアだ。すな わち、p̸= 1/2. Problem 4.4. コインがフェアかどうか、どのようにテストするか? テスト結果対する過誤の種類: • 第一種の過誤(false positive):フェアなコインをフェアでないと判 定する。 • 第二種の過誤(error):アンフェアなコインをフェアと判定する。
14
第
5
章 条件付き確率と確率変数
条件付き確率と確率変数は、実に役に立つ概念である。複雑な確率的 な事象もこの二つの概念を使うことで、手品のように簡単に理解するこ とできる。5.1
病気の判定
病院へ行って検査を受ける。この間の不安感ほど、嫌なものはなかなか ない。1000人に1人かかる命に関わるような病気がある1。すなわち、 P{ 病気にかかる } = 1 1000. (5.1) 自分が病気にかかっているのではと疑って、病院へ行くことになる。病 院では、医師の診察と同時にさまざまな検査がある。血液検査や MRI な どのハイテク技術を組み合わることで、かなりの精度で病気の診断が可 能だ。 しかし、どんなハイテク機器と名医にも誤診はある。この病気の検査 では、どうしても、5% の確率で誤診が起こる。正常なのに、病気である と診断されたり、逆に病気なのに、正常であると判定されることが 5% 程 度あるということだ。 このような現象は、条件付き確率で表すことができる。条件付き確率 は、P{A|B} のように書き表す。B は、条件と呼ばれる部分で、特定の条 件 B が成立したときの確率を考えることを示している。この検査であれ ば、次のように書ける。 P{病気だと判定される | 本当は病気にかかっていない } = 1 20, P{病気でないと判定される | 本当は病気にかかっている } = 1 20. (5.2) 1[3, p.207]より改題5.1. 病気の判定 15 例えば、本当は病気にかかっていない人、100人が病院で検査を受けた 場合に、5人が病気にかかっていると診断されることを表している。条 件付き確率 P{A|B} は、通常の確率を使って次のように定義される。 P{A|B} = P{A ∩ B} P{B} . (5.3) 残念なことに、病院の検査で、病気だと判定されてしまった。医師の 話では、この病気にかかるとかなりリスクの高い手術を受ける必要があ るそうだ。自分の一生に関わる重大な判断の場面だ。ここで、問題にな るのは、果たして、検査の結果でこの病気であると判定された時に、手 術を受けるべきかどうかだ。この判定にも、条件付き確率を使うことが できる。 P{本当は病気にかかっていない | 病気だと判定される }. (5.4) この確率が高ければ、手術を受ける必要はないと考えることができる。ど うやって、この条件付きを計算する? 今までの情報で、十分計算できる。(5.2) と (5.4) はちょうど逆さまの関 係になっていることには、注意しなくてはいけない。
Problem 5.1(False positives2). Answer the followings:
1. Suppose there are illegal acts in one in 10000 companies on the aver-age. You as a accountant audit companies. The auditing contains some uncertainty. There is a 1% chance that a normal company is declared to have some problem. Find the probability that the company declared to have a problem is actually illegal.
2. Suppose you are tested by a disease that strikes 1/1000 population. This test has 5% false positives, that mean even if you are not affected by this disease, you have 5% chance to be diagnosed to be suffered by it. A medical operation will cure the disease, but of course there is a mis-operation. Given that your result is positive, what can you say about your situation?
最初に5の目が出たとする(条件)。すると、次に3の目が出た場合に、 トータルが8となる。この確率は、1/6 である。
16 第 5 章 条件付き確率と確率変数 ところが、最初に出た目が1の場合(条件)、次にどんな目が出ても、 トータルが8になることはない。したがって、この確率は 0 である。 このように、条件をつけた確率(条件付き確率)は、元の確率とは異 なる。
5.2
条件付き確率の計算
Definition 5.1. Bが与えられときの条件付き確率: P{A|B} = P{A ∩ B} P{B} . (5.5) Example 5.1. 最初に5の目が出たとするとした時に、トータルが8にな る条件付き確率を定義に従って、求める。 P{ トータルが8 | 最初に5が出た } =P{(トータルが8) ∩ (最初に5が出た)} P{ 最初に5が出た } =P{ 最初が5で次が3 } P{ 最初に5が出た } =P{ 最初が5 }P{ 次が 3} P{ 最初に5 } = P{ 次が3 } =1 6. Problem 5.2. ロイヤルストレートフラッシュの出る確率を求めよ。また、 既に、手札にハートの A と K がある場合に、ロイヤルストレートフラッ シュの出る確率を求めろ。 Problem 5.3. あなたの会社は、A 社の買収を試みている。この買収が成 功する確率は 0.3 である。もし、この交渉が成功すれば、あなたの会社の 利益が増大する確率は、0.8 だと予想される。 さて、買収の正否のわからない現時点で、あなたの会社の利益が増大 する確率は?5.3
独立
条件付き確率は、特定の条件が、次に起こるイベントの起こる確率に 影響を与える場合の計算の仕方を教えてくれる。 しかし、それがうまく行かない場合もある。5.4. Bayesの定理 17 Problem 5.4. 前に生まれた子供が女の子であることを知っている場合に、 次にその家族に生まれる子供が女の子である確率は? Definition 5.2. イベント A と B が独立であるとは、 P{A|B} = P{A} (5.6) が成り立つことである。 Theorem 5.1(独立). A と B が独立であるとき、 P{A ∩ B} = P{A}P{B}. (5.7) Problem 5.5. Theorem 5.1を証明せよ。
5.4
Bayes
の定理
条件付き確率を計算する上で、とても便利なツールが Bayes の定理で ある。 Theorem 5.2(Bayes). P{B|A} = P{A|B}P{B} P{A|B}P{B} + P{A|Bc}P{Bc}. (5.8) Problem 5.6. Theorem 5.2を証明せよ。18
第
6
章 確率変数とその周辺
6.1
確率変数
確率的な変動で変化するものを数えたり、観測する場合には、確率そ のものを相手にするよりも、確率変数を相手にした方が直感的に把握し やすい。 Definition 6.1. 確率的な変動に応じて、その値が変化する変数を確率変数 と呼ぶ。 Example 6.1. W:テニスという言葉が11時のニュースに出てくる回数。6.2
確率密度、確率分布
Definition 6.2(確率密度). X が離散確率変数の場合、 f (a) = P{X = a}, (6.1) を確率密度と呼ぶ。 Problem 6.1. 3回コインを投げた場合の表が出た回数を X とする。X の 確率密度を求めろ Definition 6.3(確率分布). X が(一般の)確率変数の場合、 F(x) = P{X ≤ x}, (6.2) を確率分布と呼ぶ。また、確率分布を使うと確率密度 f (x) は次のように 表される。 f (x) = dF(x) dx = dP(X≤ x) dx . (6.3) Theorem 6.1. lim x→∞F(x) = 1, (6.4) lim x→−∞F(x) = 0 (6.5)6.3. 期待値 19
6.3
期待値
確率変数の大きさを測るには期待値が便利である。 Definition 6.4(期待値). E[X ] = ∫ xdP{X ≤ x} (6.6) Remark 6.1. Xが離散確率変数の場合には、 E[X ] = ∫ xdP{X ≤ x} =∑
a aP{X = a} (6.7)6.4
分散
同じ期待値であっても、確率的変動の大きさが異なる場合がある。 Example 6.2. 次のような二つの確率変数 U,V を考える。 • 恒等的に 1/2 な確率変数。 U≡ 1/2, (6.8) • ふたつの値をとる確率変数。 V = { 1 with probability 1/2, 0 with probability 1/2. (6.9)Problem 6.2. E[U ] = E[V ] =1/2を確かめろ。
このような場合には、期待値だけでは確率変数の「特性」を測ることが できない。
Definition 6.5(分散). 平均からの変動の大きさを二乗平均したものを分散 と呼ぶ。
20 第 6 章 確率変数とその周辺 Theorem 6.2.
Var[X ] = E[X2]− (E[X])2. (6.11)
Var[aX + b] = a2Var[X ]. (6.12) Remark 6.2. 分散は、X の二乗のオーダーを持つので、使いにくい場合が ある。 Definition 6.6(標準偏差). 分散の平方根を標準偏差と呼ぶ。 σ=√Var[X ]. (6.13) Problem 6.3. Example 6.2の例において各確率変数の分散、標準偏差を求 めろ。 Theorem 6.3. X ,Y が独立な場合には、
E[XY ] = E[X ]E[Y ], (6.14)
Var[X +Y ] = Var[X ] +Var[Y ]. (6.15)
6.5
ベルヌーイ試行
ベルヌーイ確率変数 A は、成功、失敗のような形で表される試行を表す。 Definition 6.7(ベルヌーイ確率変数). A = { 1 with probability p, 0 with probability 1− p. (6.16) Theorem 6.4. E[A] = p, (6.17) Var[A] = p(1− p). (6.18)6.6. 独立、同一な分布 21
6.6
独立、同一な分布
同一の事象を別々な時点で観測したり、同じ母集団の中からサンプル を選んだりした場合に得られる確率の列は、独立、同一な分布を持つ確 率変数として扱うことが多い。 Definition 6.8. X1, X2, . . . , Xn, (6.19) が、独立で P{Xi≤ x} = F(x), (6.20) という同じ確率分布に従うときに、X1, X2, . . . , Xnは独立、同一分布を持つ(i.i.d: independent and identically distributed) と言う。または、分布 X から のランダムサンプルと呼ばれる。 Theorem 6.5. X1, X2, . . . , Xn, (6.21) が独立、同一分布の時、 ¯ X = 1 n n
∑
i=1 Xi, (6.22) でサンプル平均を定義すると E[ ¯X ] = E[X ], (6.23) Var[ ¯X ] =Var[X ] n . (6.24) サンプル平均は、サンプル数を増やすに従って、変動が小さくなり安定 する。22
第
7
章 幾何分布、2項分布、
Poisson
分布
ここでは、離散確率変数の確率分布を詳細に述べる。7.1
幾何分布
幾何分布は、何かが起こるまでの回数を数えるときに使う。 Definition 7.1(幾何分布). 何かかが起こる確率が p である実験を複数回行 い、X 回目で、それが初めて起こったとする。この確率変数 X は幾何確 率変数と呼ばれ、その確率密度は P{X = i} = (1 − p)i−1p, (7.1) となる。 Theorem 7.1. 幾何確率変数 X の期待値: E[X ] = 1 p, (7.2) Var[X ] = 1− p p2 . (7.3) Proof. 一回目に着目する。何かが起こるとその場で終わり、起こらなけ れば同じことを繰り返すので、 X = { 1 with probability p, 1 + X′ with probability 1− p, (7.4) ここで、X′は、X と独立で同一な分布に従う確率変数。したがって、両 辺の期待値をとれば、 E[X ] = p· 1 + (1 − p)E[1 + X], (7.5) さらに両辺を整理すれば、E[X ] = 1/p となる。7.2. 2項分布 23 Problem 7.1. E[X2] = p· 12+ (1− p)E[(1 + X)2], (7.6) であることに注意して、Var[X ] を求めろ。 Problem 7.2. 賞金1万円の当たる確率が 1/100 で、一枚100円宝くじ がある。 1. 当たるまでの回数の確率密度をグラフに描け。また、当たるまでの 回数の期待値は? 2. 所持金が一万円あるが、宝くじに当たるまで買い続けた場合には、 どんなことが起こるか?所持金がなくなるまでに、宝くじに当たる 確率を求めて、説明せよ。
7.2
2項分布
2項分布は、成功/失敗の数を数えるようなときに使う。 Definition 7.2(2項分布). 成功の確率が p である実験を、n 回繰り返した。 成功した数を X とすると、この確率変数 X は2項確率変数と呼ばれ、そ の確率密度は P{X = i} = ( n i ) pi(1− p)n−i, (7.7) となる。 Theorem 7.2. 2項確率変数 X は、独立な Bernouilli 確率変数 Aiを使って、 次のように表すことができる。 X = n∑
i=1 Ai, (7.8) 但し、P{Ai= 1} = p とする。 Theorem 7.3. 2項確率変数 X の期待値と分散: E[X ] = np, (7.9) Var[X ] = np(1− p). (7.10)24 第 7 章 幾何分布、2項分布、Poisson 分布
7.3
2項分布の応用例
Problem 7.3(ランダムな解答). 4択の問題が、20 問ある。ランダムに解 答を選んだときに、80点以上取れる確率を求めよ。 20 40 60 80 100 n 0.05 0.1 0.15 0.2 P_n 図 7.1: ランダムな解答の正解数分布:80 点以上を取る確率は 3.865×10−7 Problem 7.4(航空会社のダブルブッキング). あなたは、航空会社のチケッ ト予約担当です。座席数200の便の予約をマネージメントしています。 経験的に、7%の乗客は無断でキャンセルすることがわかっています。し たがって、予約を200だけしか受け付けないのは、空席のリスクがあ ります。 あなたはダブルブッキングをしようと考えました。ダブルブッキングを して、200人以上の乗客が来てしまうと、空港で大混乱が起こります。 このような確率を 5%以内に押さえるためには、何人まで予約を受付す ることができるでしょうか?7.4
Poisson
分布
ある1分間に高田馬場のスターバックスに来店するお客の数などを表 す場合に、Poisson 分布は使うことができる。 Definition 7.3(Poisson分布). ある一定時間に来店する客の数を N とする。 次のような場合、確率変数 N はパラメータλ の Poisson 確率変数と呼ば7.4. Poisson分布 25 195 200 205 210 215 220 n 0.02 0.04 0.06 0.08 0.1 P_n 図 7.2: 座席数を 215 人まで予約した場合の搭乗希望客数の分布:座席が 足りなくなる確率は 0.456 195 200 205 210 215 220n 0.02 0.04 0.06 0.08 0.1 P_n 図 7.3: 座席数を 208 人まで予約した場合の搭乗希望客数の分布:座席が 足りなくなる確率は 0.019 202 204 206 208 210 212 214 n 0.1 0.2 0.3 0.4 risk 図 7.4: 予約可能座席数と座席が足りなくなるリスクの関係
26 第 7 章 幾何分布、2項分布、Poisson 分布 れる。 P{N = n} =λ n n!e −λ. (7.11) となる。 Theorem 7.4. Poisson確率変数 N の期待値と分散: E[N] =λ, (7.12) Var[N] =λ. (7.13) Theorem 7.5. nが大きく、np が小さいときの2項分布は、平均λ = npの Poisson分布で近似できる。
7.5
Poisson
分布の応用例
Problem 7.5(スターバックスで待たされる). 1分間に平均1人が来店す るスターバックスがあります。この店は、1分間に3人のお客をさばく だけのスタッフが配置されています。偶然、同じ1分間に3人以上のお 客さんが来る場合があります。この場合には、お客さんは、待たなくて いけません。お客さんが待たされる確率は、どのくらいでしょうか? 2 4 6 8 10 n 0.05 0.1 0.15 0.2 0.25 0.3 0.35 P_n 図 7.5: スターバックスに来店する客数の分布:待たされる確率は 0.0189 Problem 7.6(期末テストでの身体的危険性評価). 試験用紙で、一人の学 生が指を切る確率は 0.00002 とする。会計研400人の学生が一斉に試験 を受けた場合に、二人の学生が指が、試験用紙で指を切る確率を求めよ。7.6. 超幾何分布 27
7.6
超幾何分布
Definition 7.4(超幾何分布). M 個のタイプ A と N− M 個のタイプ B の中 から、ランダムに n を重複なしに選んだとき、タイプ A の数を X とする。 このとき、X は超幾何確率変数と呼び、 P{X = i} = (M i )(N−M n−i ) (N n ) . (7.14) Theorem 7.6. 超幾何確率変数 N の期待値と分散: E[N] = nM N , (7.15) Var[N] = n ( M N )( 1−M N )( N− n N− 1 ) . (7.16)28
第
8
章 正規分布とその仲間たち
8.1
一様分布
Definition 8.1. Xが a と b の間で、どの値を取るのも同じ確率のとき、X は [a, b] 上の一様確率変数という。このとき、 P{c ≤ X ≤ d} = d− c b− a, (8.1) ここで、a≤ c ≤ d ≤ b。 Remark 8.1. 連続な確率変数の場合、特定の値をとる確率は0である。す なわち、 P{X = x} = 0. (8.2)8.2
連続確率変数
Definition 8.2. 連続な値をとる確率変数を連続確率変数という。 Example 8.1. 電話帳から無作為に一人の人物をピックアップし、その人 の身長を H とする。H は連続確率変数となる。 Definition 8.3(確率分布関数). 確率変数 X に対して、(累積)確率分布関 数 (Cumulative Distribution Function: CDF or Probability Density Function: PDF)は次のように定義する。F(x) = P{X ≤ x}. (8.3) Theorem 8.1.
P{X > a} = 1 − F(a), (8.4)
8.3. 正規分布 29 Problem 8.1. [a, b]上の一様分布の確率分布関数をグラフに描け。
Definition 8.4(確率密度関数). 確率分布関数 F(x) の導関数を確率密度関 数 (probability density function:pdf) とよぶ。
f (x) = dF(x) dx . (8.6) Problem 8.2. [a, b]上の一様分布の確率密度関数をグラフに描け。 Theorem 8.2. P{a < X ≤ b} = ∫ b a f (x)dx = F(b)− F(a). (8.7) Theorem 8.3. E[X ] = ∫ ∞ −∞x f (x)dx, (8.8) E[X2] = ∫ ∞ −∞x 2f (x)dx, (8.9)
Var[X ] = E[X2]− E[X]2. (8.10) Problem 8.3. [a, b]上の一様確率変数 X の期待値と分散を求めよ。
8.3
正規分布
正規確率変数は、二つのパラメータ(平均µ と分散σ2)で決定される 連続確率変数である。 Definition 8.5(正規分布). 確率変数 X が平均µと分散σ2の正規分布に従 うとき、その確率密度 f (x) は次のようになる。 f (x) = √1 2πσe −[(x−µ)/σ]2/2 . (8.11) このとき、X は、正規分布 N(µ,σ2)に従う確率変数であると言う。 Definition 8.6(標準正規分布). 確率変数 Z が平均µ = 0と分散σ2= 1の 正規分布に従うとき、Z は標準正規分布 N(0, 1) に従うという。標準正規 分布の分布関数を次のように書く。 Φ(x) = P{Z ≤ x}. (8.12)30 第 8 章 正規分布とその仲間たち Theorem 8.4. 正規確率変数は、確率 95% で平均から2標準偏差の範囲内 に入る。 P{µ− 2σ ≤ X ≤µ+ 2σ} ≤ 0.95. (8.13) Theorem 8.5. 平均µと分散σ2の正規確率変数 Y は、標準正規確率変数 Zを使って、次のように表される。 Y =µ+σZ. (8.14) 逆に、正規確率変数は標準確率変数に次のように変換できる。 Z =Y−µ σ . (8.15) Theorem 8.6. 正規分布は、標準正規分布を使って計算できる。 P{X ≤ a} = Φ ( a−µ σ ) . (8.16) Proof. P{X ≤ a} = P { X−µ σ ≤ a−µ σ } = P { Z≤ a−µ σ } =Φ ( a−µ σ ) . Remark 8.2. 昔は、正規分布表を用いて、いろいろな計算をする必要があっ た。しかし、最近は、標準正規分布が Excel の関数でも用意されているの で、これを用いるのが簡単である。 Example 8.2(コンビニの発注量). あるコンビニで売れるおにぎりの売り 上げ X は、平均 400、標準偏差 20 の正規分布に従うことが POS データか ら経験的にわかっている。売れ残りが出る確率を 2.5%にするような発注 量を決めたい。 Theorem 8.5より、 Z = X−µ σ (8.17)
8.3. 正規分布 31 は標準正規分布 N[0, 1] に従う。ここで、標準正規分布の性質より、 P{−2 ≤ Z ≤ 2} ≤ 0.95. (8.18) さらに、 P{Z ≥ 2} + P{−2 ≤ Z ≤ 2} + P{Z ≤ −2} = 1. (8.19) ここで、標準正規分布が原点に対して対称なので、P{Z ≤ 2} = P{Z ≤ −2} より、 P{Z ≥ 2} = 1/2P{−2 ≤ Z ≤ 2} = 0.025. (8.20) 変数を X に戻すと、 0.025 = P{Z ≥ 2} = P { X−µ σ ≥ 2 } = P{X ≥µ+ 2σ} = P{X ≥ 440} したがって発注量を、440 にすれば、売れ残りがでる確率は、0.025%と なる。 Problem 8.4. あなたは、忙しい友達から Sony 株の売却を依頼されまし た。もし、明日12時の Sony 株が 5300 円から 5700 円の間に入っている なら、その場で売却するように依頼されています。今日の株価は、5500 円で、Sony の株価は、平均 5500 円、標準偏差 100 円の正規分布に従う と仮定します。このとき、あなたが、友達の株を売却する確率を Excel を 使って求めなさい。 Theorem 8.7. 独立な正規確率変数の和は、正規確率変数になる。Xiを平 均µiと分散σi2の正規確率変数とする。 X = n
∑
i=1 Xi∼ N ( n∑
i=1 µi, n∑
i=1 σ2 i ) . (8.21)32 第 8 章 正規分布とその仲間たち
8.4
対数正規分布
数理ファイナンスにおいては、正規分布を元にして作ることができる 正規対数分布は、有用である。 Definition 8.7(対数正規分布). log(Y ) が正規分布になるとき、この確率変 数 Y を対数正規分布と呼ぶ。 したがって、正規確率変数 X によって、 Y = eX, (8.22) とあらわすことができる。 Theorem 8.8(対数正規分布の期待値と分散). X が N[µ,σ2]のとき、対数 正規正規確率変数 Y = eX について、 E[Y ] = eµ+σ2/2, (8.23) Var[Y ] = e2µ+2σ2− e2µ+σ2. (8.24) が成立する。 Problem 8.5. E[Y ]が eµではないことは、おかしくないか?8.5
中心極限定理
Theorem 8.9(中心極限定理). どんな確率変数でも、サンプルのサイズが 大きくなれば、サンプル平均は正規分布で近似できる。(Figure 8.1 参照。) Remark 8.3. 中心極限定理のおかげで、たいていの現象の統計量は正規分 布で近似できる。8.6
χ
2(
カイ二乗分布)
χ2確率変数は、後に標本偏差の検定を行なう際に有用である。 Definition 8.8(χ2確率変数). Z を標準正規確率変数とする。Z の二乗をχ2 確率変数という。 χ= Z2 (8.25)8.6. χ2(カイ二乗分布) 33 0.46 0.48 0.5 0.52 0.54 5 10 15 20 25 30
図 8.1: The detailed histgram of the sample average A = 1n∑ni=1Xiwhen n =
10, where Xiis a Bernouilli random variable with E[Xi] = 1/2. The solid line
is the corresponding Normal distribution.
Theorem 8.10. E[χ] = 1, (8.26) Var[χ] = 2. (8.27) Proof. E[χ] = E[Z2] = 1. (8.28) Definition 8.9(自由度 n のχ2確率変数). Ziを独立な標準確率変数とする。 χn= n
∑
i=1 Zi2, (8.29) を自由度 n のχ2確率変数という。 Remark 8.4. なぜ、自由度 n というのか? 独立な標準確率変数 Ziというのは、それぞれ自分が勝手に決めること ができる数かのように扱えるため。 Remark 8.5. 残念ながら、χ2確率変数の確率分布関数を簡単な式で表す ことはできない。 Theorem 8.11. E[χn] = n, (8.30) Var[χn] = 2n. (8.31)34 第 8 章 正規分布とその仲間たち
8.7
t
分布
Definition 8.10(t分布). Z を標準確率変数、Y を自由度 m のχ2確率変数 とする。 T = √Z Y /m, (8.32) を自由度 m の student t 分布という。 Remark 8.6. student t分布は、標本数の少ない場合に、正規分布の代わり に使われる。8.8
F
分布
Definition 8.11(t分布). X 、Y をそれぞれ独立な自由度 m と自由度 n のχ2 確率変数とする。 F = X /m Y /n, (8.33) を自由度 m と n の F 分布という。35
第
9
章 2つの確率変数と相関
9.1
同時確率分布
Definition 9.1 (同時確率分布). 二つの確率変数 X 、Y の関係を知るには、 次のような同時確率分布を考えるのが良い。 F(x, y) = P{X ≤ x,Y ≤ y}. (9.1) また、次のような同時密度も考えることができる。 f (x, y) = d 2 dxdyF(x, y). (9.2) Theorem 9.1. E[XY ] = ∫ ∫ xy f (x, y)dxdy. (9.3) Problem 9.1. さいころで出た目 X とその裏の目 Y の同時確率分布を求 めろ。9.2
周辺分布
Definition 9.2(周辺分布). 関連する二つの確率変数のうち、片方だけを考 えたいときもある。そのときには、次のような周辺分布を用いる。 P{X ≤ x} = FX(x) = F(x,∞). (9.4) また、周辺密度を次のように定義できる。 fX(x) = ∫ ∞ y=∞ f (x, y)dy. (9.5) Problem 9.2. さいころで出た目 X とその裏の目 Y の同時確率分布から、 周辺分布を求めろ。36 第 9 章 2つの確率変数と相関
9.3
条件付き分布
Definition 9.3(条件付き分布). ひとつの確率変数の値(情報)を知ると他 の確率変数の値を知るの役立つ場合がある。このような場合には、条件 付き分布を考えるのが自然である。 P{X ≤ x|Y = y}. (9.6) また、条件付き密度を次のように定義できる。 f (x|Y = y) = f (x, y) fY(y) . (9.7) Problem 9.3. さいころで出た目 X とその裏の目 Y の同時確率分布から、 条件付き密度 f (x|Y = 2), (9.8) を求めろ。9.4
独立
ふたつの確率変数が、影響を及ぼすかどうかをチェックしたい時があ る。そのような場合には、独立性をチェックする。もし、X が Y に影響を 及ばさないなら、 f (x|Y = y) = fX(x). (9.9) (9.7)を使うと、独立な場合には、 f (x, y) = fX(x) fY(y). (9.10) Theorem 9.2. X と Y が独立なとき、9.5. 共分散、相関係数 37
9.5
共分散、相関係数
Definition 9.4. ふたつの確率変数 X と Y の依存性を測るのに、次のよう な共分散を用いる。
Cov(X ,Y ) = E [(X− E[X])(Y − E[Y])] (9.12) = E [XY ]− E[X]E[Y]. (9.13) Problem 9.4. Cov(X ,Y )の定義を用い、その正負が何を意味するか考えよ。 Problem 9.5. さいころで出た目 X とその裏の目 Y の同時確率分布から、 共分散を求めろ。 Definition 9.5. 共分散の正負は重要な指標だが、その大きさを解釈するの は難しい。したがって、次のように変動の大きさで正規化した相関係数 を用いる。 ρ(X ,Y ) =√ Cov(X ,Y ) Var(X )Var(Y ). (9.14) Problem 9.6. 相関係数の定義を用い、ρ(X ,Y )が 1、-1 の時にそれが、何 を意味するのか考えよ。 Problem 9.7. さいころで出た目 X とその裏の目 Y の同時確率分布から、 相関係数を求めろ。
9.6
和の分散
Theorem 9.3. 一般に、相関のある二つの確率変数の和については次が成 り立つ。E[X +Y ] = E[X ] + E[Y ], (9.15)
Var[X +Y ] = Var[X ] +Var[Y ] + 2Cov[X ,Y ]. (9.16)
Remark 9.1. もし、X と Y が負の相関を持っているときには、和の分散は、 分散の和よりも小さくなる。
Problem 9.8. 定義に基づいて、
Var[X +Y ] = Var[X ] +Var[Y ] + 2Cov[X ,Y ]. (9.17) を証明せよ。
38 第 9 章 2つの確率変数と相関
9.7
ポートフォリオ分析
Example 9.1. あなたが、次の株式を所有しているとする。
• Worldwide Fastburgers, Inc
この株式からの年間の利益を W とし、 E[W ] = 1000, (9.18) Var[W ] = 400, (9.19) とする。 ここで、あなたはさらに余剰資金を使って、株式を買い増すことを考 えている。対象となるのは、次の二つの株式である。
• HaveItYourWay Burgers, Inc その年間利益は H で、
E[H] = 1000, (9.20)
Var[H] = 400. (9.21)
• FunGoodTimes Pizza, Inc その年間利益は F で、
E[F] = 1000, (9.22) Var[F] = 400. (9.23) Problem 9.9. 期待値で考えたとき、どちらの株式を買い増すのが良いか? ポートフォリオを考えた場合、ポートフォリオ全体の利益の期待値の 最大化だけではなく、ポートフォリオ全体の利益の分散を最小化するこ とも重要である。 Problem 9.10. ポートフォリオ全体の利益の分散の最小化はなぜ大事か? Theorem 9.3より、ポートフォリオ全体の利益の分散の評価には、共分 散が必要である。ここで、 Cov(W, H) = 380, (9.24) Cov(W, F) =−200, (9.25) とする。
9.7. ポートフォリオ分析 39 Problem 9.11. 株式からの利益の共分散の正負は、実際の経済活動とどの ような関係があると予想されるか?
ポートフォリオ全体の利益の分散は、次のように評価できる。HaveItY-ourWay Burgers, Incを買った場合には、
Var[W + H] = Var[W ] +Var[H] + 2Cov(W, H) (9.26) = 400 + 400 + 2× 380 (9.27) = 1, 560. (9.28) Problem 9.12. FunGoodTimes Pizza, Incを買った場合のポートフォリオ全 体の利益の分散を評価せよ。
Problem 9.13. あなたは、どちらの株を買い増した方が良いか?また、そ の理由は?
40
第
10
章 統計的推測
ここまでは、全ての確率的現象が既知であるとして、問題を取り扱っ てきた。実際には、データの背後にある確率的現象に対して、限定的な 知識しか得られていない場合がある。 以降の章では、統計的推測の手法を使って、データの背後にある確率 的現象を分析する手法を学ぶ。10.1
平均の推測
確率変数 X の期待値µ を推定する。推定するために、同じ対象を n 回 観測し、独立なデータ X1, X2, ..., Xn(ランダムサンプル)を得る。 サンプルデータからのµ の「自然な」推定量 ˆµは、サンプル平均 ¯xで ある。 ˆ µ = ¯x =1 n n∑
i=0 Xi. (10.1) この ¯xのようにサンプルデータを処理して得られる量を統計量という。 Definition 10.1. 特定の一つの値を推定する場合を、点推定と言う。 Example 10.1. サンプルデータが 5, 7, 4, 10, 12, (10.2) の時、µ = E[X ]のサンプルアベレージを使った推定量 ˆµは ˆ µ = ¯x = 1 5(5 + 7 + 4 + 10 + 12) = 7. (10.3) Remark 10.1. 推定量 ˆµ自体も確率変数である。10.2. 最尤推定法 41
10.2
最尤推定法
Definition 10.2(最尤推定量). あるパラメータの真の値が、その推定値だっ たときに、サンプルデータを与える可能性が最大になるとき、その推定 量を最尤推定量と呼ぶ。すなわち、 P{X1= x1, X2= x2, ..., Xn= xn|µ}, (10.4) が最大となるようなµを最尤推定量と呼ぶ。 Remark 10.2. したがって、ある推定量が最尤推定量であることがわかっ た時には、その推定量は、データに一番うまくフィットすると言える。 Example 10.2(株価上昇率の推定). 株価の上昇確率を推定する問題を考え る。株価を10日間観測した。上昇した日を +1、下降した日を 0 とする と、次のようなデータが得られた。 {1,0,0,0,1,0,1,0,0,0}. (10.5) この時に、各観測日の株価の変動が独立として、上昇する確率 p を推定 する。試しに、p = 1/2 と考える。すると、このようなデータの得られる 確率は、 P{X1= 1, X2= 0, . . . , X10= 0} = 1 210 ≈ 0.00097, (10.6) となる。これが適切かどうかわからないので、p をずらしてみる。今度 は、p = 1/3 を試すと、 P{X1= 1, X2= 0, . . . , X10= 0} = 27 310 ≈ 0.00216, (10.7) となり、だいぶ改善される。 Problem 10.1. どんな p で上の確率が最大になるか? 一般には、 P{X1= 1, X2= 0, . . . , X10= 0} = p3(1− p)7 (10.8) であり、これを最大にする p を求めれば良い。ここで、log が単調増加関 数であるので、両辺の log をとった42 第 10 章 統計的推測 が最大になる p を求めれば十分である。p で微分して 0 とおいてみると、 3 p+ −7 1− p= 0, (10.10) よって、p = 3/10 が確率最大となることがわかる。一般に、n 日の観測 データが得られた場合に、 p = 1 n n
∑
i=1 xi (10.11) で株価上昇確率を推定すると、そのデータ (x1, x2, . . . , xn)が出る確率が最 大になる。 Example 10.3. Xが正規分布に従うとき、サンプル平均 ˆ µ = ¯x =1 n n∑
i=0 Xi, (10.12) は平均µ = E[X ]の最尤推定量である。 最尤推定量は、平均以外の推定にも使用できる。 Example 10.4. Xが正規分布に従うとき、サンプル分散 ˆ σ2= 1 n n∑
i=1 (Xi− ¯x)2, (10.13) は分散σ2= Var[X ]の最尤推定量である。 Example 10.5(2項分布). 2項分布 (Definition 7.2 参照)は次のような確 率分布を持つ。 P{X = i} = ( n i ) pi(1− p)n−i, (10.14) ここで、 成功の数 成功の数+失敗の数 (10.15) は、2項分布のパラメータである成功の確率 p の最尤推定量である。10.3. 一致推定量 43
10.3
一致推定量
Definition 10.3. サンプルの数を増やしたとき、その推定値が安定すると きに、その推定量を一致推定量(consistent estimator) と呼ぶ。より厳密に は、サンプル数無限大の極限で、その推定量の分散が0になるとき、一 致推定量という。 Remark 10.3. 一致推定量の場合には、サンプルを増やすと変動がなくな り、推定値が真の値に収束する。 Problem 10.2. 推定量が一致推定量でないときには、どんな問題があるか? Example 10.6. どんな確率分布の場合でも、サンプル平均 ¯xは平均µの一 致推定量である。なぜなら、 Var[ ¯x] = Var [ 1 n n∑
i Xi ] = 1 n2nVar[X ] = 1 nVar[X ]→ 0 as n → 0.10.4
不偏推定量
Definition 10.4. 推定量の期待値が推定するパラメータと一致するとき、 その推定量を不偏推定量(偏りが無い)と呼ぶ。 Problem 10.3. サンプル平均 ¯xが不偏推定量であることを示せ。 Example 10.7. サンプル分散 ˆσ2を考える。データは適当に変換しておき、 E[X ] = 0, (10.16) σ2 = Var[X ] = E[X2]. (10.17) となるようにしておく。 ˆ σ2=1 n n∑
i=0 (Xi− ¯x)2. (10.18)44 第 10 章 統計的推測 すると E[ ˆσ2] = 1 nE [ n
∑
i=0 (Xi− ¯x)2 ] (10.19) = 1 n n∑
i=0 E[Xi2− 2 ¯xXi+ ¯x2 ] (10.20) = (n− 1)σ 2 n . (10.21) ここで、 E[Xi2] =σ2, (10.22) E[ ¯xXi] = 1 nσ 2, (10.23) E[ ¯x2] = 1 nσ 2, (10.24) に注意すれば、 E[ ˆσ2] =(n− 1)σ 2 n . (10.25) したがって、サンプル分散 ˆσ2は不偏推定量ではないことがわかる。一 方、あらたな統計量 ˆs2を考える。 ˆ s2= 1 n− 1 n∑
i=0 (Xi− ¯x)2 (10.26) すると、 E[ ˆs2] =σ2, (10.27) となり、不偏推定量になっていることがわかる。 Example 10.8. 一般に不偏推定量はたくさんありえる。10.5
推定量の選び方
一般に、不偏推定量はたくさんありえるので、不偏であるだけでは、推 定量としては不十分である。一般に、推定量としては、最低でも不偏推 定量であることが望ましい。さらに、一致推定量であれば、サンプルを 増やすことで、良い推定量になる。与えられたデータを増やせない場合 には、その中で、最尤推定量をとるのが良い。10.5. 推定量の選び方 45 Example 10.9. ある商品に関するアンケート調査を考える。この商品の満 足度の期待値µを求めたい。ランダムに抽出した2人に、アンケートをし て、商品の満足度 (X1, X2)のデータを得た。推定値として、サンプル平均 ˆ µ2= X1+ X2 2 (10.28) をとると、不偏推定量であることがわかる。一方、ランダムに抽出する 人数をもっと増やして、1000 人にした場合、 ˆ µ1000= 1 n n
∑
i Xi, (10.29) としても、同じように不偏推定量である。 Problem 10.4. 上の二つの推定量が不偏であることを示せ。 しかし、直感的にも ˆµ1000の方が、望ましい推定量であることがわかる。 これは、分散を比較することで定量的に、明らかにできる。 Problem 10.5. 二つの推定量の分散を比較せよ。46
第
11
章 信頼区間
Chapter 10では、どのような推定量を使うのが適切かを学んだ。しかし、 「その推定量が、真の値にどれくらい近いのか?」 ということが、まだわかっていない。この章では、さまざまな場面を設 定し、この疑問に答える。 Problem 11.1(フロリダの降雨確率). あなたが、フロリダに一日滞在した とする。その日がたまたま雨であったとする。あなたの滞在した日は、ラ ンダムサンプルと言えるから、フロリダの降雨確率は、 雨が降った日数 滞在した日数 = 1, (11.1) という推定量で推定できる。この推定量が真のフロリダの降雨確率とど の程度かけ離れているだろうか? Problem 11.2. ある企業の監査を行なった。10の伝票をチェックしたら、 不正なく処理されていることがわかった。その企業が正当な会計処理を 行なっている確率を 不正のない伝票の数 チェックした伝票の数= 1, (11.2) という推定量で推定できる。この推定は、正しいか?11.1
正規分布を使って信頼区間を求める:分散既
知の場合
データ X1, X2, ..., Xnが正規分布からのランダムサンプルであるとする。 すると、期待値µ= E[X ]の推定量として、サンプル平均 ¯xを使うのは自 然である。 ¯ x = 1 n n∑
i=0 Xi. (11.3)11.1. 正規分布を使って信頼区間を求める:分散既知の場合 47 Theorem 11.1. x¯も正規分布である。 Proof. Theorem 8.7より、独立な正規分布の和は、正規分布なので、 ¯xも 正規分布である。 この定理から、 ¯xの分布がわかった。しかし、我々が知りたいのは、 ¯x がどの程度、真の値µから離れているかである。その距離を c と考える と、我々の目標は、 真の値µが [ ¯x− c, ¯x+ c] に入る確率 を評価することである。もし、この評価ができたとすると、これを逆に 使うことで、 真の値µが [ ¯x− c, ¯x+ c] に入る確率を 95%とするような c を求めることができる。 Definition 11.1 (信頼区間と信頼度). データ X1, X2, ..., Xnを使って、パラ メータµを ¯xで推定するとき、その推定値と真の値の誤差の大きさを信 頼区間 [ ¯x− c, ¯x+ c]、その信頼区間の信頼度を CL とする。 より詳しくは、真の値µ と推定値 ¯xには次の関係が成立する。 P{ ¯x− c <µ < ¯x + c} = CL. (11.4) Theorem 11.2(信頼区間). データ X1, X2, ..., Xnが正規分布からのランダム サンプルであるとき、 P{ ¯x− c <µ < ¯x + c} = 0.95, (11.5) (11.6) を満たす c は、 c = 1.96√ σ n , (11.7) で与えられる。すなわち、信頼度 95%の信頼区間は、 [ ¯x− c, ¯x+ c] = [ ¯ x−1.96√ σ n , ¯x + 1.96σ √ n ] , (11.8) となる。
48 第 11 章 信頼区間 はじめに、次の Lemma を証明しておく。 Lemma 11.1. Z = √x¯−µ σ2/n = √ nx¯−µ σ , (11.9) は、標準正規分布 N[0, 1] に従う。 Proof. ¯xの平均はµ,分散はσ2/nなので、Theorem 8.5 の変形を使えばよ い。
Proof of Theorem 11.3. Lemma 11.1を使うと、
P{ ¯x− c <µ < ¯x + c} = P{−c < ¯x−µ < c} = P{−c √ n σ < √ nx¯−µ σ < c√n σ } = P{−c √ n σ < Z < c√n σ }. ここで、標準正規分布の性質より、 P{−1.95 < Z < 1.95} = 0.95. (11.10) したがって、 c =1.96√ σ n . (11.11) Problem 11.3. 信頼区間の大きさは、何を表しているのか?どんなときに、 信頼区間は小さくなるか?
11.2
t
分布を使って信頼区間を求める:分散未知
の場合
Section 11.1では、推定値と真の値の間の関係を評価する方法として、 信頼区間の求め方を学んだ。すなわち、 c =1.96√ σ n , (11.12)11.2. t分布を使って信頼区間を求める:分散未知の場合 49 を計算すれば良い。 しかし、この計算をするためには、X の分散σ2があらかじめわかって いることが前提となる。 Problem 11.4. 分散σ2はわかっているという前提は、妥当か?どのよう な場合は妥当で、どのような場合は妥当でないのか? 解決策: 1. データからσ2をサンプル分散 ˆσ2で推定する。 2. 推定値 ˆσ2を使って、c を計算する。 Problem 11.5. この解決方法は妥当か? 一般に、データ数が少ない時には、別の方法で精度の評価することが 必要である。Lemma 11.1 の代わりに、次の Lemma を考える。 Lemma 11.2. サンプル分散として、次の不偏推定量を考える。 ˆ s2= 1 n− 1 n
∑
i=0 (Xi− ¯x)2. (11.13) ここで、次の統計量、 T = √ n( ¯x−µ) ˆ s , (11.14) は、自由度 n− 1 の t 分布(Section 8.7 参照)に従う。 Proof. Section 8.7より、独立な標準正規確率変数 Z とχ2確率変数 Y で、 T = √Z Y /m, (11.15) のようにかけるとき、T は t 分布に従うと言える。ここで、(11.14) は次の ように書き換えることができる。 T = √ n( ¯x−µ)/σ ˆ s/σ (11.16) = √ n( ¯x−µ)/σ √ ∑n i=0(Xi− ¯x)2/[(n− 1)σ2] . (11.17)50 第 11 章 信頼区間 分母は Lemma 11.1 より標準正規分布に従うことがわかる。また、 ∑n i=0(Xi− ¯x)2 σ2 , (11.18) は、¯xの分だけ自由度がひとつ減っている自由度 n−1 のχ2分布に従うこ とがわかる(詳細は、例えば [2]P84-P87 参照)。 Lemma 11.2を使ってサンプルが少ない場合の信頼区間を算出する。 Theorem 11.3(データが少ない場合の信頼区間). データ X1, X2, ..., Xnが正 規分布からのランダムサンプルであり、n が少ないとする。 P{ ¯x− c <µ< ¯x + c} = 0.95, (11.19) (11.20) を満たす c は、 c = √a ˆσ n, (11.21) で与えられる。ここで、a は、t 分布から P{−a < T < a} = 0.95, (11.22) から計算された定数である。例えば、n = 7 の場合には、a = 2.306 すな わち、信頼度 95%の信頼区間は、 [ ¯x− c, ¯x+ c] = [ ¯ x−√a ˆσ n, ¯x + a ˆσ √ n ] , (11.23) となる。 Proof. P{ ¯x− c <µ< ¯x + c} = P{−c < ¯x−µ < c} = P{−c √ n ˆ σ < T < c√n ˆ σ }. ここで、t 分布の性質より、 P{−c √ n ˆ σ < T < c√n ˆ σ } (11.24) Remark 11.1. 図 11.1 をみると、正規分布と比較すると、t 分布の方が微妙 に分散が大きくなっていることがわかる。もし、t 分布を使わずに、正規 分布を使った場合には、それだけ推定精度を甘く見積もることになる。
11.3. その他の推定における信頼区間 51 -3 -2 -1 1 2 3 0.1 0.2 0.3 0.4 t!n!7" Normal 図 11.1: 標準正規分布と t 分布の密度関数
11.3
その他の推定における信頼区間
その他にも、 1. 分散を推定する場合 2. 二つの平均の差を推定する場合 などで、信頼区間を評価することができる。詳しくは、教科書 [1] 参照。52
第
12
章 サンプリング
12.1
世論調査
世論調査の方法: • 全数調査:全員に尋ねる。→ 通常コストがかかりすぎる。 • サンプル調査:特定の一部の人に尋ねる。 Problem 12.1. どんなときに、全数調査が行なわれるか?例をあげて答 えよ。 Example 12.1(朝日新聞 12 月 12 日記事より). 朝日新聞の行なった世論調査 (図 12.1 参照。http://www.asahi.com/politics/naikaku/TKY200612110286.html)。 有権者1億人の内閣支持率を2018人のサンプル調査によって、推定 している。 図 12.1: 阿部内閣支持率の推移12.2. 支持率の信頼区間 53 朝日新聞社が9、10の両日実施した全国世論調査(電話) によると、安倍内閣の支持率は47%で前回11月調査の5 3%から低下、初めて5割を割り込んだ。不支持は32%で 前回の21%から上がった。首相の改革に取り組む姿勢が就 任時と比べて「後退している」と見る人が46%で、「維持さ れている」の29%を上回った。「郵政造反議員」11人の自 民党復党を「評価しない」は67%を占めた。復党や道路特 定財源の問題などへの対応が支持率低下に影響したようだ。 (中略) 〈調査方法〉 9、10の両日、全国の有権者を対象に「朝 日RDD」方式で電話調査をした。対象者の選び方は無作為 3段抽出法。有効回答は2018人、回答率は57%。 Problem 12.2. 上のサンプル調査には、どんな欠点があるか?あなたは、 信頼できるか?
12.2
支持率の信頼区間
有権者 N 人の中で、M 人が内閣を支持しているとする。我々は、内閣 支持率 p = M N, (12.1) を知りたい。全数調査はコストがかかるので、n 人の有権者に内閣を支持 するかの調査を行なう。n 人の有権者中、X 人が支持したとすると、推定 される支持率 ˆpは ˆ p = X n, (12.2) で与えられる。もし、サンプリングが妥当であれば、この推定支持率 ˆp は、真の支持率 p に近いと考えられる。 Problem 12.3. どんなサンプリング方法が望ましいか? Lemma 12.1. サンプル調査数 n が大きい時には、支持する人の数 X はパ ラメータ (n, p) の二項分布に従う。さらに、n が十分大きいときには、X は平均 np、分散 np(1− p) の正規分布で近似できる。54 第 12 章 サンプリング Proof. 実際のサンプリング調査では、一度調査した人が、さらに同じ調 査をされることはない。しかし、n が大きければ、実際上、同じ人が再度 調査される可能性は少ない。したがって、X は繰り返し有りで、同一サ ンプルから、条件に適合する数を数えているので、二項分布に従う。二 項分布は、n が大きいときには、正規分布に従う。 Theorem 12.1. n人の有権者中、X 人が支持したとすると、推定される支 持率 ˆ p =X n, (12.3) は確率変数であり、その分布は正規分布 N(p, p(1− p)/n) で近似できる。 Proof. Lemma 12.1より、X は正規確率変数 N(np, np(1− p)) で近似でき る。また、 ˆ p =X n, (12.4) は、X の大きさを変えただけなので、正規確率変数となることがわかる。 ここで、 E[ ˆp] = E [ X n ] = np n = p. (12.5) また、 Var[ ˆp] = Var [ X n ] = 1 n2np(1− p) = p(1− p) n . (12.6) Remark 12.1. 推定値 ˆpは E[ ˆp] = p. (12.7) を満たすので、不偏推定量である。また、サンプル数 n が大きくなると、 推定値 ˆpの分散は、 Var[ ˆp] = p(1− p) n → 0, (12.8) となり、推定値 ˆpは一致推定量であることがわかる。
12.3. サンプリングの方法 55 Theorem 12.2. サンプル数 n が大きいとき、推定量 ˆpの 95%信頼区間は [ ˆ p− 1.96 √ ˆ p(1− ˆp) n , ˆp + 1.96 √ ˆ p(1− ˆp) n ] (12.9) となる。 Proof. Theorem 12.1より、 ˆpは正規分布に従い、その分散は、 σ2 = Var[ ˆp] = p(1ˆ − ˆp) n . (12.10) Theorem 11.3を使えば、その信頼区間が得られる。 Remark 12.2. サンプリングによる支持率の精度は、母集団の大きさには 依らずに、サンプル数のに依存する(教科書 [1] P259 参照)。 Example 12.2. 朝日新聞の調査のように、n = 2018 の場合には、支持率の 推定値 ˆp = 0.47の 95%信頼区間は、 [ ˆ p− 1.96 √ ˆ p(1− ˆp) n , ˆp + 1.96 √ ˆ p(1− ˆp) n ] = [0.448224, 0.491776] , (12.11) となる。
12.3
サンプリングの方法
サンプリングがランダムではない場合には、サンプリングによる調査 は、実際と異なることがある。Example 12.3. 1936年の Literacy Digest によるアメリカ合衆国大統領選 挙の世論調査は、電話帳からランダムに抽出した名前への郵便による調査 だった。この調査は、Roosevelt の負けを予想したが、実際には、Roosevelt の大勝利だった。
Problem 12.4. Literacy Digestの失敗の原因は?
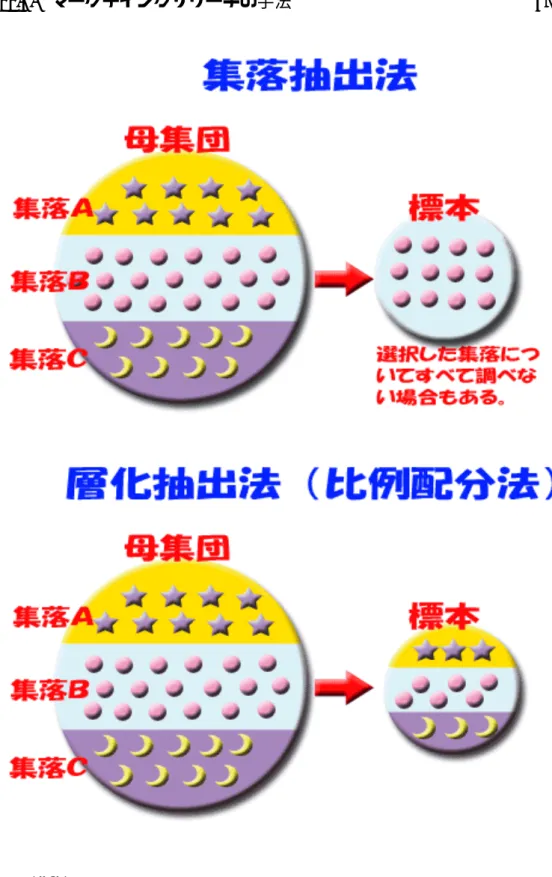
Example 12.4(完全にランダムでないサンプリング手法の例). 高度なサン プリング手法の例。図 12.2 参照。
56 第 12 章 サンプリング 1. クラスターサンプリング:あらかじめ設定されたクラスター毎(例 えば、地域毎)に分ける。クラスターのサンプルをランダムに抽出 する。さらに、このクラスター内で全数を調査する(さらにサンプ ルを抽出する場合もあり)。このことにより、特定のクラスター(地 域内)に集中的にサンプルを確保することができ、コストが削減で きる。 2. 層化サンプリング:いくつかの均一な部分母集団(層化)に分割し、 各部分母集団からサンプルを抽出する。 3. 簡易サンプリング:本来、統計調査の手法としては望ましくないが、 簡単に調査できるので、採用される種々の方法。例:ショッピング モールで、立ち止まった人にアンケート調査をする。 Problem 12.5(テレゴング). テレゴングでの世論調査には、どのような問 題があるか? テレゴング放送メディアタイプ: 視聴者の声をリアルタイム に番組に反映できます。放送メディアタイプは、テレビ、ラジ オなどでサービス番号をPRし、視聴者からの電話のコール数 を集計・通知するサービス。集計データは約5秒ごとに更新さ れ、あらかじめお客さまに設置していただくパソコンから随時 確認することができます。また、集計結果がリアルタイムに通 知されるので、番組内でその結果をオンエアし、トークを展開 することもできます。(http://www.ntt.com/telegong/info02.html より引用)
12.4
マーケティングリサーチの手法
マーケンティングにおいて、アンケート調査を行なうのは、基本であ る。しかし、近年は、 • 世の中に、アンケート調査が溢れている。 • 電話や email でのセールス活動と混同されやすい。 Problem 12.6. アンケート調査において、無回答をどう扱うのが適切か?12.4. マーケティングリサーチの手法 57
図 12.2: ク ラ ス タ ー サ ン プ リ ン グ( 集 落 抽 出 法 )と 層 化 抽 出 法: http://www.pref.saitama.lg.jp/A01/BP00/faq/q11.htmlより
58 第 12 章 サンプリング 図 12.3: テ レ ゴ ン グ 放 送 メ ディア タ イ プ: http://www.ntt.com/telegong/info02.htmlより引用 どんなアンケート手法を使うのか? • 対面:効果的だが、高価。 • 電話 • メール:ひまな時間にやってもらえるが、反応は悪い。 • 自由記述式の質問:有用な情報が得られるが、統計的に分析するの は、むずかしい。 • マーク式の質問:回答はしやすいが、スケースの解釈がむずかしい。 • 答えを導くような質問は避ける。 Problem 12.7. 次の質問は、アンケートとして不適当なのはなぜか? 今日の世界情勢を考えると、日本は防衛予算を増やすべき か? (YES or NO)
![図 1.1: 教科書:Business Statistics (Barron’s Business Review Series)[1]](https://thumb-ap.123doks.com/thumbv2/123deta/7041133.788314/6.892.406.551.196.414/図11教科書BusinessStatisticsBarronsBusinessReviewSeries1.webp)
![図 8.1: The detailed histgram of the sample average A = 1 n ∑ n i=1 X i when n = 10, where X i is a Bernouilli random variable with E[X i ] = 1/2](https://thumb-ap.123doks.com/thumbv2/123deta/7041133.788314/33.892.241.599.194.411/図-detailed-histgram-sample-average-bernouilli-random-variable.webp)