2019 ( 令和元 ) 年度 修士論文
多次元時系列データに対する評価指標構築のため の視覚的分析フレームワークに関する研究
Study on Visual Analytics Framework for Formulating Evaluation Metrics of Multi-dimensional Time-series Data
2020 ( 令和 2) 年 2 月 21 日提出
首都大学東京
システムデザイン学部 システムデザイン研究科 情報科学域
18860615 高見 玲
指導教員 高間 康史 教授
要旨
本論文では , 多次元時系列データに対する評価指標構築を支援するための , 視覚的分析フレームワークを 提案する .
計算機の処理能力の増大や情報技術の進展に伴い , 医療 , スポーツ , ビジネスインテリジェンスなどの多 様な分野において , 多次元かつ時系列的な性質を持つデータが収集され , 経営における意思決定などに活用 されている . 多次元時系列データに基づく意思決定のために , 外れ値の検出や , 類似パターンのクラスタリ ングなどが行われる . 収集されたデータをそれらのタスクに活用するために , 評価指標の定義が必要である . 本論文では , データの評価指標を ユーザの主観的な価値 ( 基準 ) に対するデータの適合度合いを判断する ための , 解釈可能かつ定量的な目安の表現方法 ” として定義する . 評価指標の具体例として , 外れ値の決定基 準やクラスタリングに用いる距離関数の決定基準 , プロ野球におけるセイバーメトリクス , 企業組織におけ る達成目標などが存在する . 分類タスクなどに用いられる教師あり学習においても , 評価指標は重要な役割 を持つ . 教師あり学習における訓練データのラベル ( 目的変数 ) は人間によるアノテーションを通じて獲得 されるが , 評価指標を用いない場合 , それらは個人ごとに異なる主観的基準に基づき決定されてしまう . 高 品質な訓練データを獲得するためには , 解釈可能かつ定量的な評価指標に従い , アノテーションを行う必要 がある . 加えて , 時系列データは季節などの時期により傾向が異なる場合があるため , 時点毎の特性の違い を考慮した評価指標を構築する必要がある .
適切な評価指標の決定には , データ分析に主体的に関与しながら分析方針を客観的・定量的に定義し , データの価値を引き出す分析者の存在が必須となる . また , 全てのデータに対して有効な評価指標は存在せ ず , その性質によって適切な評価指標は異なる . そのため , 評価指標は必然的に対象ドメインについて詳細 な知識を持つ専門家により決定される必要がある . しかし , 多次元データを分析対象とする場合 , それらを 高次元のまま分析し , 理解することは困難なため , 対象データの複雑性を解消するためのサンプリングや次 元削減などの前処理が必須となる . このとき , ドメイン専門家はデータに関する知識を持つが , データに適 用される前処理に関する知識を持つとは限らない点が問題となる .
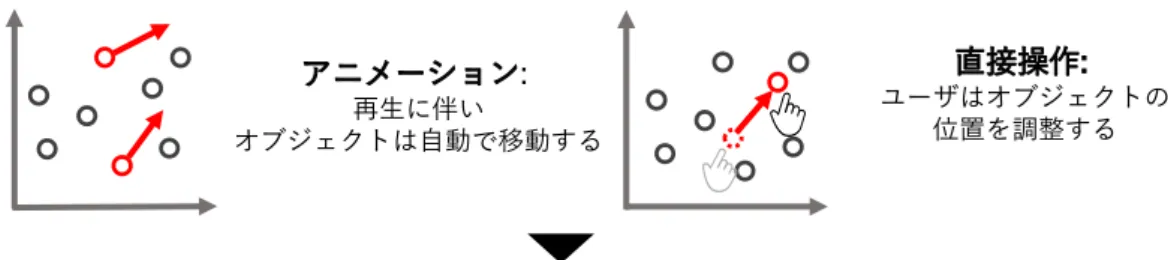
分析対象データの可視化に基づき , 分析作業やデータへの理解を支援する視覚的分析が研究されている . さらに , 前処理アルゴリズムやモデルに関する知識がなくても適切なパラメータ調整を可能とするために , 可視化結果自体に対する直接操作に込められた分析者の意図をシステムが推測し , パラメータに即時反映
する semantic interaction のコンセプトが提案されている . 評価指標の構築も , 多次元データの各属性間の
関係や個々の属性の把握 , 指標の有効性検証を必要とする . そのため , 視覚的分析や semantic interaction が 有効と考えるが , これらを対象とした先行研究は少ない . さらに , 多次元時系列データに適用するためには , データの時間的傾向を考慮した , 新たなインタラクションフレームワークを構築する必要がある .
本論文では , semantic interaction に基づく次元削減アルゴリズムのパラメータ調整を通じて , 多次元時系
列データの評価指標を構築する作業を支援するための視覚的分析フレームワークを提案する . 対象データ
は次元削減アルゴリズムに基づき , 時点毎に 2 次元平面に散布図として可視化され , アニメーションを用い
て時間的特性が表現される . 提案フレームワークでは , 多次元時系列データに対する評価指標を時点ごとに
各属性の重み付き線形結合として表現する . 散布図の各軸も同様に各属性の重み付き線形結合として表現
することで , 評価指標の構築と散布図上でのオブジェクトの移動を対応づける . Semantic interaction のコン
セプトに基づき , 分析者の操作を , 特定オブジェクトを強調する大局的な移動とオブジェクト間の位置関係
を調整する局所的な移動として定義する . 分析者は多次元時系列データに対する自身の知識や意図を反映
するように散布図上のオブジェクト配置を調整し , システムはその結果を各軸に対応した属性の線形結合に
還元する . 分析者はオブジェクト配置を調整する過程で どの時点について , どの属性を強調すべきか ” の
ような指標に関するアイデアを獲得すると同時に , 指標構築のたたき台となる各属性の重みを獲得できる .
提案フレームワークの有効性を検証するために , 主成分分析に対する適用結果を可視化するプロトタイ プインタフェースの設計と実装を行った . 本インタフェースは散布図ビューと詳細ビューの 2 つの画面か ら構成される . 前者は , 散布図を用いた対象データの可視化と , パラメータ調整機能を提供する . 後者は , 線 グラフや平行座標などの複数の可視化手法を組み合わせて , 散布図上のオブジェクトに関する詳細な情報 を提示する . 本インタフェースでは , (1) 各時点におけるデータの空間的座標を表現するノード , (2) ノード の時間的変化を可視化する軌跡表現 , (3) ノードや軌跡の集合を表現する凸包の 3 つの可視化オブジェクト を用いて , 時系列データを可視化する . 各オブジェクトの直接操作を通して , 多次元時系列データの傾向の 探索的な分析と , 分析結果に基づく評価指標の構築を支援する . ユーザ実験に基づき提案フレームワークの 有効性を定量的・定性的側面から検証する .
本論文は全 7 章から構成される . 第 1 章では , 序論として本論文の研究背景と概要を示す . 第 2 章では , 評
価指標の定義を明確化し , 情報可視化や視覚的分析に関する先行研究や , その応用例を述べる . また , 時系列
データや多次元データの可視化や , 評価指標の構築支援に関する先行研究を示す . 第 3 章では , 時系列デー
タに対する指標構築支援のために解決すべき問題点や , 提案フレームワークの要件について考察する . その
結果に基づき , 提案フレークワークの詳細と主成分分析に対する適用例を示す . 第 4 章では , 提案フレーム
ワークに基づくプロトタイプインタフェースの設計と実装に関する詳細を述べる . 第 5 章では , 提案フレー
ムワークおよびインタフェースの , 指標構築プロセスにおける定性的な有効性の検証を目的として行った ,
実データを用いたケーススタディの結果を示す . 第 6 章では , 第 5 章で得られた知見より設計したユーザ実
験の結果を示し , 提案フレームワークおよびインタフェースの有効性を定量的および定性的な側面から検
証する . 第 7 章では , 本論文の内容をまとめ , 今後の展望と研究課題を示す .
Abstract
This thesis proposes a visual analytics framework for formulating evaluation metrics of multi-dimensional
time-series data. Multi-dimensional time-series data has been collected and utilized in various domains. Eval-
uation metrics are expected to play an important role in utilizing those data, such as hypothesis generation and
labeling training data used in machine learning. However, it is a di ffi cult task for domain experts to formulate
metrics especially for multi-dimensional time-series data because of their complexity related to dimensional-
ity and temporal tendency. To support the process of formulating metrics, the proposed framework represents
metrics as a linear combination of data attributes and provides a means for adjusting it through interactive
visual analytics. Following the proposed framework, a prototype interface is implemented, which visualizes
target data using an animated scatter plot. Through this interface, several visualized objects can be directly
manipulated: a node and a trajectory of an instance, and a convex hull as the group of nodes and trajecto-
ries. To adjust parameters for formulating evaluation metrics, linear combinations of attributes are adjusted
in accordance with the direct manipulation of visualized objects by users. The e ff ectiveness of the proposed
framework is demonstrated through case studies of the prototype interface to real-world data. Also, the e ff ec-
tiveness of the framework and the interface is verified by two user experiments based on hypotheses obtained
from the case studies.
目次
1 序論 1
2 関連研究 4
2.1 情報可視化と視覚的分析 . . . . 4
2.2 多次元データの可視化 . . . . 10
2.3 時系列データの可視化 . . . . 18
2.4 ドメイン知識に基づく評価指標構築 . . . . 24
3 多次元時系列データに対する評価指標構築のための視覚的分析フレームワーク 29 3.1 時系列データに対する評価指標構築のための要件 . . . . 29
3.2 時系列データの直接操作に基づく視覚的分析における問題点 . . . . 30
3.3 提案フレームワークの要件 . . . . 33
3.4 提案フレームワークの概要 . . . . 33
3.5 対象データの表現方法 . . . . 34
3.6 分析パラメータ . . . . 36
3.7 投影に対する直接操作 . . . . 37
3.8 PCA に対する提案フレームワークの適用 . . . . 39
3.9 スケーラビリティへの対処 . . . . 41
4 プロトタイプインタフェース 43 4.1 インタフェースのシステム概要 . . . . 43
4.2 探索モード . . . . 45
4.3 インタフェースの設計原則 . . . . 45
4.4 提案インタフェースの構成 . . . . 47
4.5 散布図ビュー . . . . 48
4.6 詳細ビュー . . . . 51
4.7 操作対象 . . . . 53
4.8 パラメータに対する操作 . . . . 57
4.9 ナビゲーションボタン . . . . 61
4.10 探索履歴の可視化 . . . . 66
5 ケーススタディ 68 5.1 QS 世界大学ランキング . . . . 68
5.2 世界幸福度調査 . . . . 72
5.3 MLB データセット . . . . 76
6 評価実験 81 6.1 ケーススタディに基づく要件定義 . . . . 81
6.2 共通の実験環境 . . . . 82
6.3 評価実験 1: 類似オブジェクト探索に関する有効性検証 . . . . 82
6.4 評価実験 2: パラメータ調整機能の有効性検証 . . . . 89
6.5 評価実験 1 の結果と考察 . . . . 95 6.6 評価実験 2 の結果と考察 . . . 118
7 結論 136
謝辞 138
参考文献 139
発表文献 146
1 序論
計算機の処理能力の増大や情報技術の進展に伴い , 医療やセキュリティ , スポーツ , ビジネスイ ンテリジェンスなどの多様な分野で多次元かつ時系列な性質を持つデータが収集されている . 収 集されたデータは , 産業界における経営指針の決定や商品の売り上げ予測 [53] など , 多様なドメ インで活用されている . 収集された多次元時系列データの解釈や , それに基づく意思決定を行うた めに , 外れ値の検出や類似パターンのクラスタリング , 将来の動向予測のような , 多くの計算機技 術を活用した手法が適用される . その際 , 多くのタスクにおいて評価指標を定義する必要がある . 本論文では , データの評価指標を ユーザの主観的な価値 ( 基準 ) に対するデータの適合度合いを 判断するための , 解釈可能かつ定量的な目安の表現方法 ” として定義する . これに該当する評価指 標の例として , 外れ値の判定基準やクラスタリング時の距離関数の種類を決定する基準などが存 在する . 加えて , プロ野球リーグにおける選手の活躍度合いを評価するための指標 ( セイバーメト リクス ) [3] や , 企業組織における KPI (Key Performance Indicator) [10] のような定性的な意思決 定に活用されるものも存在する .
分類問題のような教師あり学習に関しても , 評価指標は必要となる . パターンごとの訓練データ のラベル ( 目的変数 ) は , 人間によるアノテーションを通じて獲得されるが , 評価指標を用いない 場合 , ラベルは個人ごとに異なる主観的基準に基づき決定されてしまうため , 学習の精度が低下す る問題が考えられる . 質の高い訓練データを獲得するためには , 解釈可能かつ定量的な評価指標に 基づき , アノテーションを行う必要がある . 特に , 時系列データは季節や曜日のように , 時期ごと に異なる時間的特性を持つ . それらを適切に活用するためには , 時点毎の特性の違いを考慮した評 価指標を構築する必要がある .
評価指標は任意の対象データを適切に定量化できる必要があり , 主観や特定データへの適合の みに基づき定義された評価指標は確証バイアス [88] をもたらす . このようなバイアスは , 他の利 用者にとって解釈が難しくなったり , 特定のデータへの過適合の問題を引き起こしうると考える . 適切な評価指標を定義し , データを活用するためにはデータ分析に主体的に関与しながら分析方 針を客観的・定量的に定義し , データの価値を引き出す分析者の存在が必須となる [101]. 計算 機技術の利用に基づき指標構築を支援する手法として , 機械学習アルゴリズムなどにより自動的 に算出されたものを活用する手法も考えられるが , モデルの予測精度の面では有効だが , 解釈可 能性に関して問題がある . そのため , 結果に対するドメイン専門家による分析と検証が必要とな る [18].
多次元時系列データを元データのまま理解し , 指標形成のための予備的分析を行うことはドメ イン専門家にとっても困難な作業である . 一般に , 多次元時系列データの複雑性を解消するために はサンプリングやセグメンテーション次元削減などの前処理が適用される [11]. ドメイン専門家 はデータに対する詳細な知識を持つが , データの前処理手法などに関する詳細な知識を持つとは 限らない .
複雑なデータの傾向に関する知識形成を支援するために , 対象データの可視化に基づく視覚的
分析 (visual analytics) が研究されてきた [43]. さらに , 前処理アルゴリズムやモデルに関する知
識を持たないドメイン専門家によるパラメータ調整を支援するために , 可視化されたオブジェク
ト自体への直接操作に込められたユーザの意図を推測した上で , 次元削減アルゴリズムなどの
モデルのパラメータを修正し , 結果を可視化としてユーザに即時フィードバックする semantic
interaction のコンセプトが提案されている [25]. 評価指標の構築においても , 多次元時系列データ を対象とした知識形成プロセスを通じて各属性の特性や関係を把握する必要がある . また , 単一の 指標だけでなく , 代替案の比較検討も必要となるため , 視覚的分析や semantic interaction のコン セプトは有効だと考えるが , これらを指標形成タスクに適用した研究は少ない . 特に , 多次元時系 列データを対象とする場合 , データが持つ周期性のような時間的傾向を考慮すべきであるため , 新 たなインタラクションフレームワークを構築する必要がある .
本論文では , semantic interaction に基づく次元削減結果アルゴリズムのパラメータ調整を通じ て , 多次元時系列データに対する評価指標を構築する作業を支援するための視覚的分析フレーム ワークを提案する . 次元削減アルゴリズムを適用した結果に基づき , 対象データは 2 次元平面に 散布図として時点ごとに可視化される . データの時間的特性はアニメーションを用いて表現さ れる . 提案フレームワークでは , 多次元時系列データの評価指標を時点ごとにデータの各属性の 重み付き線形結合として表現する . 多次元データの 2 次元平面への投影にも , 主成分分析 (PCA:
Principal Component Analysis) などを用いることで , 各属性の寄与度の線形結合として各軸を表
現する . このように , 両者を各属性の強調度合いとして統一的に表現することで , 評価指標の構築 と散布図上でのオブジェクトの移動を対応づける .
提案フレームワークでは , 上述のように各属性の強調度合いとしてドメイン知識を反映する .
Semantic interaction のコンセプトに基づき , 可視化オブジェクトに対する分析者の直接操作を , 特
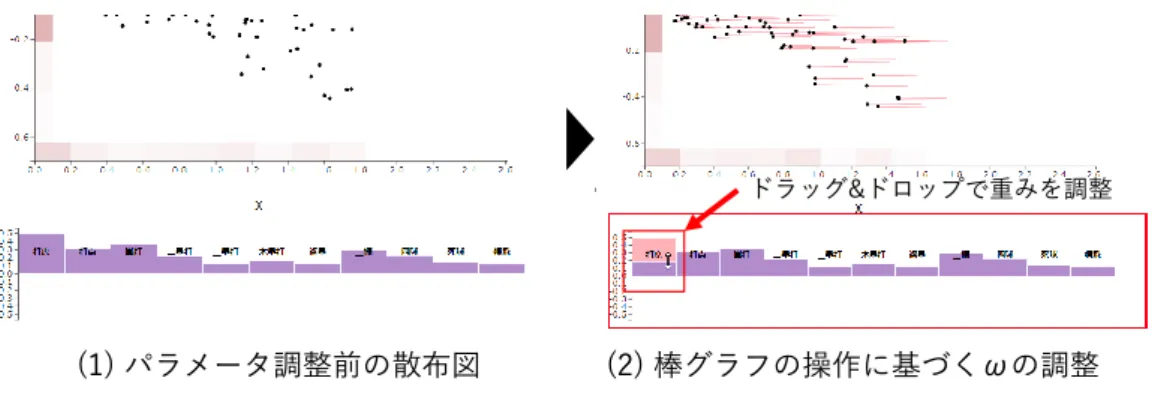
定オブジェクトを暗黙的に強調する大局的な移動と , オブジェクト間の明示的な位置関係の指定 による局所的な移動の 2 種類として定義する . 両操作は , 別々のパラメータの調整としてシステ ム側に解釈される . 大局的な移動によって調整されるパラメータは , 各属性の強調度合いに対応す る . 局所的な移動に対応するパラメータは個々のデータに対する強調を表現し , 分析者の意図に応 じて各属性の強調度合いに還元できる . これらのパラメータを指標の更新に活用することで , 散布 図に対するユーザ意図の柔軟な表現を実現する . 例えば , 散布図上のオブジェクトをドメイン知識 に一致するように移動すると , 局所的な移動に対応するパラメータが調整される . これにより , 分 析者は散布図上のオブジェクト配置を調整しながら , どの時点について , どの属性を強調すべき か ” のような , 指標の構築に必要なアイデアを漸進的に獲得できる . 同時に , ドメイン知識に適合す る投影を獲得した時点で , 各属性の強調度合いを指標構築のためのたたき台として活用できる . ま た , データの時間的な特性を考慮した , 時点ごとのパラメータ調整によって多次元時系列データに 対する指標構築を支援する .
提案フレームワークの有効性を実証するため , 主成分分析を用いた多次元時系列データの次元 削減結果を可視化するプロトタイプインタフェースを設計・実装した . 本インタフェースは散布 図ビューと詳細ビューの 2 つの画面から構成される . 前者は , 時間的変化をアニメーションで表 現する 2 次元散布図を用いて対象データを可視化し , 各属性の強調度合いを散布図の各軸に棒グ ラフとして提示する . 散布図ビューにおいて , 分析者は可視化オブジェクトの直接操作を行いなが ら , データの分布や時間的変化 , 投影アルゴリズムに関する洞察を形成できる . それに基づき , 指 標構築を目的とした各属性の強調度合いの修正や , その結果の検証を行える . 詳細ビューは , 線グ ラフや平行座標のような複数の可視化手法を組み合わせ , 散布図上のオブジェクトに関する詳細 情報を提示する . これにより , 散布図ビューで得られた視覚的傾向に関する仮説検証を支援する .
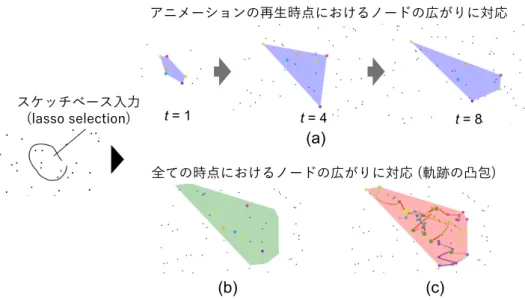
本インタフェースでは , (1) 特定の時点におけるデータの空間的座標を表現するノード , (2) ノー
ドの時間的変化を可視化する軌跡表現 , (3) ノードや軌跡の集合を表現する凸包 の 3 つの可視化 オブジェクトを用いて , 多次元時系列データを可視化する . また , 各オブジェクトに対して , 分析 作業やパラメータ調整を支援するためのインタラクションを提供する . 分析者は各オブジェクト を使い分けながら , 特定の時点についてのみ , 傾向を強調したい ” や , データグループ全体につ いて , それらを他のグループと区別するようにパラメータを調整したい ” のような , 多彩な要求に 基づきデータの探索的分析と評価指標を構築できる . 指標の構築支援に関しては , オブジェクトへ のラベリング , 検索 , パラメータの入出力 , 探索履歴の可視化などの機能も提供する .
提案フレームワークおよびプロトタイプインタフェースの有効性を検証するため , 実データを
用いた外部協力者による定性的なケーススタディを実施した . また , ケーススタディで得られた仮
説を定量的に検証するために , 20 代の工学系大学生および大学院生を中心とした 2 つの評価実験
を行った . 1 つ目の実験では , 類似データの探索効率に関するプロトタイプインタフェースの有効
性を検証する . 提案システムの機能を限定した , 凸包 , 軌跡に関する機能のみを有するベースライ
ンインタフェースと比較し , 探索時間などの観点から有効性を検証する . 2 つ目の実験では , 提案
フレームワークの各パラメータ調整手法の有効性を検証する . 比較対象として , 各パラメータ調整
手法の一部を無効化した複数のベースラインインタフェースを用意し , タスクの達成効率やパラ
メータの調整回数などを比較する . 実験結果に基づき , 提案フレームワークとプロトタイプインタ
フェースの視覚的分析における有効性や , 多次元時系列データに対する指標形成プロセスにおけ
る有効性を議論する .
2 関連研究
本章では , 情報可視化と視覚的分析 , 多次元データの可視化 . 時系列データの可視化の側面から , 関連研究を述べる . また , 提案フレームワークが対象とする評価指標の定義を明確化し , 指標構築 の支援に関する先行研究を示す .
2.1 情報可視化と視覚的分析
センサログやテキストストリーム , ビジネス , スポーツ , 医療などの多様なドメインにおいて , データの種類 , 容量 , 頻度が膨大なデータが蓄積されている . データを解釈したり , 意思決定を行 うためには , 人間がデータ分析を行う必要がある . しかし , 分析対象となるデータ量が大きい場合 , 表計算ツールなどを用いて , 元データを直接分析することは困難になる . 加えて , データが時間的 な特徴を持つ場合には , 分析者は時点間の傾向の違いを考慮しながら分析を行う必要がある . 特 に , 従来の表計算ソフトなどによる多次元時系列データの分析作業は , データ構造の複雑性など の要因から各データドメインの専門家にとって困難である . そのため , 情報可視化技術を用いた 分析タスクの支援が行われる . 可視化 (Visualization) は , グラフやヒストグラムなどの視覚的な 表現を用いて , 分析者に情報を提示する手法である . 可視化技術の活用により , 人間の知覚能力 を活用した多面的なデータの観測や , 直感的な視覚的傾向の把握に基づくデータからの知識獲得 が行える [52]. 可視化技術は , 情報可視化 (Information Visualization) と科学的可視化 (Scientific
Visualization) の 2 つに大別される . 前者は , 株式市場の変動のような , 空間座標上に直接マッピン
グできない抽象的なデータを扱う . 後者は , 現実世界の地理空間などに直接マッピング可能なデー タを対象とする [52]. 本論文では , 前者による抽象的データの可視化を通したデータ分析の支援 を対象とする .
2.1.1 視覚的分析
一般に , データの分析者であるドメイン専門家は分析対象については豊富な知識を持つが , 必ず しもデータ分析手法の専門家ではない . データの分析方針が明確に定義されている場合 , 機械学習 アルゴリズムなどの適用は意思決定などのタスクにおいて大きな効果を得られるが , そうでない 場合には , データの特性を深く理解するところから始め , 分析方針や適用するアルゴリズムの選定 に関する仮説形成を行う必要がある [43]. 対象データに対する明確な分析方針に基づき行われる 分析を確証的分析 (CDA: Confirmatory Data Analysis) と呼ぶのに対して , 未知データに対する分 析方針などの仮説や知識の獲得を目的として行われるものを探索的分析 (EDA: Exploratory Data
Analysis) と呼ぶ [52] [101]. 分析者は探索的分析を通して , データを多様な観点から観測し , それ
らの構造や特性を理解しながら仮説形成を行う . 前述の情報可視化技術は対象データを直感的に 表現できるため , 探索的分析と親和性が高い [101].
情報可視化技術を適用する際に , データが大規模な場合や , 複数の属性を持つ場合には , 前処 理に基づくデータ量・属性数の削減や , 可視化による複数オブジェクトの集約表示が必要とな
る [50]. この場合 , 単一のビューに表示される可視化結果のみから全体の傾向と個々のデータの
特性を同時に把握しづらくなる . また , 単一の可視化表現だけでは多面的なデータ探索は困難であ
る . これらの問題に対処するため , データの可視化結果の提示とズーム操作などのインタラクショ
ンを組み合わせて , 分析者がドメイン知識に基づきデータを解釈し , 洞察を獲得するプロセスを支 援する視覚的分析 (visual analytics) が研究されている [43].
視覚的分析は , 特に企業における意思決定を支援するために , 蓄積されるデータに対する分析や 加工操作を提供する BI (Business Intelligence) の分野で用いられてきた . 可視化や視覚的分析を 利用した BI ツールとして , Tableau Software 社の Tableau
*1や , TIBCO Software 社の Spotfire
*2, Microsoft 社の Power BI
*3などが存在する .
Shneiderman は , 情報可視化の対象となるデータ形式の特性として , データの次元数 , 時系列性 ,
木構造 , ネットワーク構造を挙げている [84]. また , 可視化された情報に対する人間の探索過程と して , データの大局的な流れを傍観しながら必要な要素のみを切り出し , 具体的なデータを探索す る手順を想定し , 以下の visual information seeking mantra を提唱している [84].
Overview first, zoom and, filter, then details-on-demand.”
Keim らはこの考えをインタラクティブ情報探索や視覚的分析に拡張し , 以下に示す visual
analytics mantra を提唱している . これは , 最初にデータベースを概観し , 興味深い箇所に着目して
可視化を適用 , ズームやフィルタリング操作を用いて表示データ数を制御し , 最終的に具体的な データを探索するというプロセスを表している [43].
Analyze first, show the important, zoom, filter and analyze further details on demand.”
Yi らは , 視覚的分析においてデータから洞察を形成したり , 複数の可視化表現を比較する際に は , 静的な可視化手法とインタラクションを組み合わせることが重要であるとしている . また , 情 報可視化や視覚的分析インタフェースにおいて一般的に用いられるインタラクションを , 可視化 表現を介したデータ表現への操作 , もしくはデータの調整として定義し , ユーザの分析行動に基づ き以下の 7 種類に分類している [97].
• Select: 興味のあるオブジェクトの選択
• Explore: 探索対象外のオブジェクトの表示 , 探索
• Reconfigure: 異なった配置の提示
• Encode: 対象オブジェクトの視覚的表現の変更
• Abstract / Elaborate: データの詳細度の変更
• Filter: 特定の条件に従うデータの提示
• Connect: 対象オブジェクトの関連オブジェクトの提示
2.1.2 混合主導型システム
機械学習やデータマイニング技術はその進歩に伴い多様なドメインで活用されている . 中でも , パターン認識技術は既知のデータに対する分類タスクなどにおいて質の高い結果を残している . 一方で . 人間は訓練データの付与など , 未知のデータに対する探索的な推論に関して優れた能力を 持つ . 対象タスクの複雑化に伴い , 近年では機械学習などのアルゴリズムに対する人間の介在に関
*1https://www.tableau.com/ja-jp/products/
*2https://www.tibco.com/products/tibco-spotfire
*3https://docs.microsoft.com/ja-jp/power-bi/
![図 4. 提案フレームワークにおけるパラメータと可視化の対応例 3.7 投影に対する直接操作 データオブジェクトの移動によるドメイン知識の反映は , 投影アルゴリズムに対する暗黙的な フィードバックに基づくオブジェクト間の類似性を再定義するタスクとして解釈できる [12]](https://thumb-ap.123doks.com/thumbv2/123deta/10131562.1965450/43.892.132.765.136.328/フレームワークデータオブジェクトアルゴリズムフィードバック.webp)

![表 3. ケーススタディで用いたデータセットの一覧 データセット名称 説明箇所 データ数 属性数 時点数 世界幸福度調査 5.1 96 6 9 QS 世界大学ランキング 5.2 320 6 6 MLB 野手成績データ 5.3 198 11 12 している世界の大学に関するランキングである [68]](https://thumb-ap.123doks.com/thumbv2/123deta/10131562.1965450/75.892.226.662.166.269/ケーススタディデータセットデータセットランキングランキング.webp)
![表 4. パラメータ調整前後の X 軸における各属性の強調度合いと , 調査報告における回帰 係数の比較 強調度合い・係数値 人口あたり GDP 社会的支援 健康寿命 自由度 寛容さ 腐敗の認識 調整前 0.0359 -0.0256 -0.0226 0.137 0.963 -0.228 調整後 -0.189 0.622 0.345 0.415 0.136 -0.812 差分 ( 調整後 - 調整前 ) -0.225 0.648 0.368 0.278 -0.827 -0.583 順位への影響 [34] 0.](https://thumb-ap.123doks.com/thumbv2/123deta/10131562.1965450/81.892.125.770.283.409/パラメータ調整前後おける各属度合いおけるあたり自由度調整後.webp)