論 文
異粒度データ分析のための非負値行列分解に基づく確率モデル
幸島 匡宏
†a)松林 達史
†澤田 宏
†Probabilistic Models Based on Non-Negative Matrix Factorization for Inconsistent Resolution Dataset Analysis
Masahiro KOHJIMA
†a), Tatsushi MATSUBAYASHI
†, and Hiroshi SAWADA
†あらまし 近年,網羅的なデータ収集の困難さや個人情報保護の観点から,ユーザ個人を単位とする粒度の細 かいデータと年代・性別などの属性情報でまとめられたユーザ集団を単位とする粒度の粗いデータといった,異 なる粒度のデータを扱う機会が増えている.本研究では,個人単位・集団単位のデータの組のように,粒度の異 なる複数のデータを組み合わせて分析するための新たな手法を提案する.提案手法は,非負値行列分解に基づく 新たな確率モデルである.このモデルは粒度の粗い方のデータの背後に存在するデータを潜在変数として導入す ることで導かれる.実購買履歴を用いた実験を通して,提案手法は既存手法を上回る性能を示したこと,低解像 度のデータ数が増えるに従い性能向上が達成されることを確認した.更に上記提案手法に基づく拡張手法を導出 することで,提案手法が様々な異粒度データ分析問題を考える際の基盤的アプローチとなりうることを示す.
キーワード 異粒度データ,確率モデル,非負値行列分解,集合行列分解
1.
ま え が き近年データ分析を駆使して成功を収めた企業が注目 を集め,数多くの企業がデータ収集・分析に関する取 り組みを加速させている.多様なデータ収集や分析を 行う取組みが報告される情勢の中,データを網羅的に 収集する困難さや個人情報保護等の観点から,粒度の 異なる複数のデータ,例えば
“
あるユーザがあるお店 を何回訪問したか”
というユーザ個人のデータと“
あ る同一年代のユーザ集団にある商品が計何個購入され た”
というユーザ集団のデータの組を分析する機会が 増えている.本研究では,上記の個人単位・集団単位 のデータの組のように,粒度の異なる複数のデータを 組み合わせて分析するという問題を考える.なお粒度 の細かい方に対応するデータは,より詳細に訪問や購 買などの起こった事象を捉えていることから,以後こ れを高解像度データと呼ぶこととする.同様に粒度の 粗い方のデータを低解像度データと呼ぶ.先ほどの例†日本電信電話株式会社 NTTサービスエボリューション研究所,
横須賀市
NTT Service Evolution Laboratories, NTT Corporation, 1–1 Hikarinooka, Yokosuka-shi, 239–0847 Japan
a) E-mail: [email protected] DOI:10.14923/transinfj.2016DEP0012
では,ユーザ個人のデータが高解像度データ,ユーザ 集団のデータが低解像度データである.
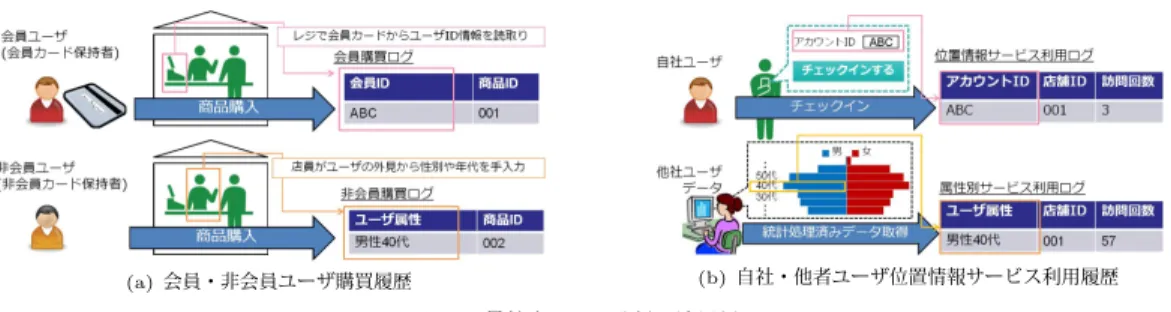
異粒度データ分析が必要となる設定は例えば次の二 つが挙げられる.例の一つ目は小売業で収集される データの分析である
(
図1 (a))
.現在多くの小売店で は会員カードを利用者に発行することで,会員ユーザ の購買履歴を収集している.しかしながら,会員カー ドをもたない利用者も存在することから,網羅的な データ収集は困難であり,購買履歴の一部は会員カー ドの識別情報(ID)
をもたず,店舗スタッフが会計時 に外見から推定して入力した利用者の性別や年代の情 報しか含まない.したがって収集されるデータはユー ザ個人のデータとユーザ集団のデータから成ることと なる.よって,会員ユーザの購買履歴が十分収集され ていないときには,非会員ユーザの購買履歴を利用し 補うという,異粒度データ分析のアプローチが有用と なる.例の二つ目は自社・他社のデータを組み合わせ たデータの分析である(
図1 (b))
.位置情報サービス を提供するfoursquare
(注1)やYelp
(注2)などのソーシャ ルデータでは,個人情報保護の観点からユーザ個人の(注1):http://gnip.com/sources/foursquare/
(注2):http://www.yelp.com/dataset challenge
図1 異粒度データ分析の適用例
Fig. 1 Application examples of inconsistent resolution dataset analysis.
店舗訪問履歴は非公開であり,ユーザ集団の店舗訪問 履歴,例えばある店舗を
“
女性”
が何人訪問している か,という履歴のみが公開されている.したがって,自社でもつ自社サービス利用者の個人のデータと上記 のソーシャルデータを組み合わせて分析する場合,異 粒度データ分析が必要となる.
本研究では,異粒度データ分析のための新たな手法 を提案する(注3).提案する異粒度データ分析手法は,
多様な研究分野でその有効性が確認されている,非負 値行列分解
(NMF: Non-negative Matrix Factoriza- tion) [2]
〜[4]
を拡張することで構築する.まずはじめ に異粒度データ分析の基本的な設定として,(A1)
共 通ユーザ集合,(A2)
独立同分布という二つの仮定が 満たされる状況に注目する.これらの仮定(A1)(A2)
とNMF
の定式化を用いることで,高解像度・低解像 度データを同時に分析する手法,確率的非負値異粒 度集合行列分解( pNimf : probabilistic non-negative inconsistent-resolution matrices factorization)
を提 案する.この手法により,単独のデータのみを利用す る場合よりも正確にデータを分析することが可能とな る.例えば,前述した会員・非会員の購買履歴への適 用では,行列中の欠損値補完の精度を向上させること で,より正確に会員・非会員の商品購入量を予測する ことが可能となる.また,会員と非会員両方の購買傾 向を反映した購買パターンの抽出が可能となる.提案手法
pNimf
は低解像度行列の背後に潜在的に 存在する潜在高解像度データを含めたデータ生成過程 を考えることで導かれる数理的な正当性をもつ手法 である.仮定(A1)
から潜在高解像度データを定義で き,仮定(A2)
より高解像度データと低解像度データ の間に関係性が導入できる.仮定(A1)(A2)
は異粒度 データ分析における全ての問題において成り立つこと(注3):本論文は国際会議予稿論文[1]の内容を発展させたものである.
が想定できるわけではないが,この関係性を用いたア プローチはより一般的な問題を解く際の基盤となりう る.本論文では,上記二つの仮定とは異なる状況,異 なる仮定が必要となる際の提案手法
pNimf
の拡張方 法についても示す.本論文の構成は次のとおりである.
2.
で関連研究,3.
で提案手法について述べる.4.
で提案手法の有効 性を実験的に検証し,5.
で提案手法の拡張例を示す.6.
がまとめである.2.
関 連 研 究非負値行列分解
(NMF) [2], [3]
は入力となる行列を 要素が非負の行列の積へ因子分解する手法である.因 子分解の結果を利用することでソフトクラスタリン グや行列中の欠損値の補完に利用することができる ことが知られている.NMF
は多様な損失関数を取り 扱うことが可能であるため,適切な損失関数を選ぶこ とで映画の評価ログや文書集合,購買履歴など多様 な種類のデータに適用することが可能である[4]
.加 えて,損失関数として一般化カルバック–
ライブラー ダイバージェンスを用いる際にはNMF
は確率的潜 在意味解析(PLSI: probabilistic latent semantic in- dexing) [5]
と呼ばれる潜在的ディリクレ配分法(LDA:
latent Dirichlet allocation) [6]
の基となった情報検索 における著名な手法と等価であることも示されてい る[7]
.これらの事実から,NMF
は機械学習における 核となる技術の一つであると考えられるため,我々はNMF
を拡張することで提案手法の構築を行うことを 考えた.近年,複数のデータを統合して分析する手法として 集合的行列分解
(CMF: Collective Matrix Factoriza-
tion)
または複合行列分解(MMF: Multiple Matrix
Factorization)
などと呼ばれる複数の行列を同時に分 解する技術が提案されている[8]
.NMF
における同種の拡張もなされており
[9], [10]
,Non-negative Multi- ple Matrix Factorization (NMMF)
と呼ばれる技術 が存在する[10]
.これらの手法は複数の行列,すなわ ち複数のデータの情報を組み合わせることで,単一の 行列のみの利用と比べて性能が改善することが報告さ れている.しかしながら,これらの手法はデータ間の 解像度の違いを考慮して設計されてはいない.また,集合的行列分解とは別の文脈で,相本らは行列分解時 に集約データ
(
本論文における低解像度行列に相当)
の 情報を組み合わせる手法の提案を行っている[11]
.し かしながら,その手法は粒度の異なるデータが厳密に 同一のデータを表現している状況に特化したもので あり,異粒度データ分析の基礎手法としては適切では ない.3.
提 案 手 法3. 1
定 式 化この章では,
(A1)
共通ユーザ集合,(A2)
独立同分 布という二つの仮定が満たされる状況における異粒 度データ分析の問題に注目する.これらの仮定の厳密 な説明の前に,まず直感的な説明を与える.あるスー パーマーケットで会員カードを12
月から発行し,そ れ以後はその店舗の全利用者は利用時に会員カードを 提示しなければならなくなったとしよう.すると,11
月の時点では会員カードが存在していないため,図2
に示すように,11
月の購買履歴は低解像度データ,12
月の購買履歴は高解像度データとして表現される.な お,11
月の購買履歴に性別や年代などのユーザ属性 情報が記録されているのは,利用者の会計時に店舗ス タッフが外見から推定して入力していることを想定し図2 観測データと非観測データの例 Fig. 2 Example of observed and unobserved data.
ている.この例においては,仮定
(A1)
は11
月と12
月の全店舗利用者の集合は等しいこと(
何らかの商品 を購入したか否かは問わない)
,仮定(A2)
は11
月と12
月で各ユーザの商品購入確率は一定であるとする こと,に相当する.以後我々はこの購買履歴解析の例 を用いて説明し,記号の定義はこの例に従う.ただし,我々の研究はこの例のみに限られることはなく,より 一般的な状況についても
3. 4
で説明する.記号の定義:
I
,J
,K
をそれぞれユーザ,商品,ユー ザ属性の総数とする.行列X
をその要素x
ijが12
月 におけるユーザi
による商品j
の購入数,行列Y
を その要素y
kjが11
月におけるユーザ属性k
による商 品j
の購入数を表す行列であるとする.行列X
が高 解像度行列,行列Y
が低解像度行列に対応する.こ れに加えてユーザのユーザ属性に関する情報も利用可 能であるとする.会員カードを作る際に性別や年代な どのユーザ属性を入力することは通常要求されるため,この仮定は決して強いものではない.このユーザ属性 情報を行列
V = { v
ik}
i,kI,K=1で表す.要素v
ik∈ { 0, 1 }
は,ユーザi
がユーザ属性k
であるときに1
,そうで なければ0
をとるものである.潜在高解像度行列:続いて,潜在高解像度行列
Z
を 定義する.この行列は提案モデルを構築するにあたり 重要な役割を果たす.行列Z
は,「もしも11
月に会員 カードが発行されていたら」収集されたはずの11
月 の高解像度データを表す行列として定義する.すなわ ち行列Z
は,低解像度データの背後に存在する隠れ た高解像度データを表す.しかしながら,行列Z
に対 応する潜在高解像度データに含まれるユーザは観測不 可能であるため,行列Z
を表現するのに必要な行数 がわからない.そのために仮定(A1)
を利用すること でこの問題を回避する.すなわち仮定(A1)
のフォー マルな定義は次のとおりである.「高解像度行列X
と 潜在高解像度行列Z
におけるユーザ集合は同一であ る」これによって行列Z
の行数は行列X
と等しいI
行とできる.すなわち,各要素z
ijはユーザi
による 商品j
の11
月における購入数を表すとできる.非常 に重要なことに,この定義によって行列Y
とZ
の間 にはY = V
TZ
という関係が導入される.これはy
kj の値は定義から,ユーザ属性k
であるユーザi
の購入 量z
ijを足し合わせたもの,y
kj=
i
v
ikz
ijであるこ とを考えれば明らかである.3. 2
確率モデルこ の 節 で 提 案 す る 確 率 モ デ ル に つ い て 述 べ る .
ユ ー ザ 因 子 行 列 と 商 品 因 子 行 列 を そ れ ぞ れ 行 列
A := {a
ir}
I,Ri,r=1,B := {b
jr}
J,Rj,r=1で定義する.R
は 因子数を表す.各因子行列は,ベクトル(a
i1, · · · , a
iR)
,(b
j1, · · · , b
jR)
がそれぞれユーザi,
商品j
の潜在的な 特徴を表し,購買傾向の観点で類似するユーザまたは商 品が類似するベクトルとなる.加えて,因子行列の積をX ˆ = AB
Tで定義する.行列要素はˆ x
ij=
r
a
irb
jr で与えられる.購買データの分析では,一般的に購買 数をポアソン分布によりモデル化することが多い[12]
. よって本論文では,ポアソン分布を用いた確率モデル の構築を行う.ポアソン分布PO
の密度関数は以下の ように書き下せる.PO(x
ij|ˆ x
ij)
= exp {− x ˆ
ij+ x
ijlog(ˆ x
ij) − log Γ(x
ij+ 1) } .
ポアソン分布を用いたNMF
のモデルでは,行列X
の生成確率を次の式で定義する.p( X|A , B ) =
I,J i,j=1PO (x
ij| x ˆ
ij). (1)
なお,入力行列の要素がユーザの商品に対する評価値 などを表すときには,正規分布を用いたモデル化を行 う場合もあるが,以後の議論は正規分布を用いた確率 モデルでもほぼ同様に成り立つ.
我々は次の三つのステップにより,提案する確率モ デルを構築する.
(Step-1)
行列X
とZ
を生成する確 率分布を定める.前述のようにここではポアソン分布 に従うとする.(Step-2)
仮定(A2)
独立同分布,を利 用する.ここでこの仮定(A2)
の厳密な定義を与える.それは,「行列
X
とZ
の同じ添え字の要素x
ijとz
ij は同一の確率分布(
今回の場合,パラメタx ˆ
ijのポアソ ン分布)
に従い,それらは相互に独立である」というも のである.仮定(A2)
は購買データを得た月には依存 しない因子を得ることを助ける効果がある.(Step-3)
前の章で述べた潜在高解像度行列Z
と低解像度行列Y
の関係(y
kj=
i
v
ikz
ij)
を利用する.これらを全 てまとめると,行列X
,Z
,Y
の生成確率はp( X , Z , Y |A , B , V ) (2)
=
i,j
PO (x
ij| x ˆ
ij) PO (z
ij| x ˆ
ij)
×
k,j
δ
y
kj−
i
v
ikz
ij,
と表現される.ただし,
δ(·)
はデルタ関数である.図
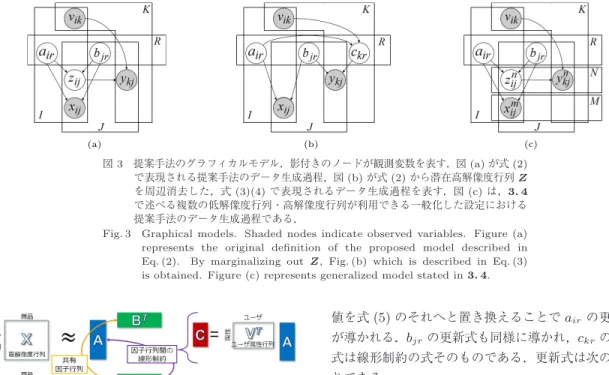
3 (a)
は上記の提案手法におけるデータ生成過程のグラフィカルモデル表現を表す.潜在高解像度行列
Z
を導入することで,全データの生成確率を自然に定義 することができている.しかしながら,行列Z
はI
行J
列というサイズの大きい行列であり,より取り扱い の容易な形式に変換することがパラメタ推定を考える うえでは重要である.ここで鍵となるものが,ポアソン分布の性質「ポア ソン分布に従う確率変数の和はポアソン分布に従う」
というものである.我々のモデルにおいては
z
ijはポ アソン分布に従う確率変数でありy
kjはその和として 定義されている.これを使うと式(2)
より行列Z
を周 辺消去することが可能であり,次のような提案モデル の等価な表現を導くことができる.p( X , Y |A , B , V ) =
p( X , Z , Y |A , B , V )d Z
=
i,j
PO(x
ij|ˆ x
ij)
k,j
PO(y
kj|ˆ y
kj), (3)
where y ˆ
kj=
R r=1c
krb
jrand c
kr=
I i=1v
ika
ir. (4)
図
3 (b)
がこの表現におけるグラフィカルモデルを表す.行列
C := {c
kr}
K,Rk,r=1がユーザ属性の因子行列を 表すとみなすことで,式(3)
は高解像度行列と低解像度 行列を因子行列A
とC
がユーザ属性行列V
を用いた 線形制約C = V
TA
を満たすという条件を課したもと で同時に因子分解した手法であるとみなすことができ る(
図4)
.よって我々はこの提案手法をProbabilistic Non-negative Inconsistent-resolution Matrices Fac- torization ( pNimf )
と呼ぶこととする.なお,因子行 列間の線形制約C = V
TA
を除くと提案手法pNimf
は既存の集合行列分解手法の一つである(NMMF) [10]
と一致する.よって,
pNimf
はNMMF
の拡張手法で あるとみなすこともできる.3. 3
推定アルゴリズム提案手法
pNimf
のパラメタ推定アルゴリズムはNMF
における導出とほぼ同様の手続きにより導くこ とができる.式(3)
に対数をとったものを目的関数,式
(4)
は線形制約であるとみなす.A
,B
,C
が推定 対象となる変数である.アルゴリズムの方針は,目的 関数を直接最大化するのではなく,目的関数の下界の 最大化を通して間接的に最大化を行うというものであ図3 提案手法のグラフィカルモデル.影付きのノードが観測変数を表す.図(a)が式(2) で表現される提案手法のデータ生成過程,図(b)が式(2)から潜在高解像度行列Z を周辺消去した,式(3)(4)で表現されるデータ生成過程を表す.図(c)は,3. 4 で述べる複数の低解像度行列・高解像度行列が利用できる一般化した設定における 提案手法のデータ生成過程である.
Fig. 3 Graphical models. Shaded nodes indicate observed variables. Figure (a) represents the original definition of the proposed model described in Eq. (2). By marginalizing out Z, Fig. (b) which is described in Eq. (3) is obtained. Figure (c) represents generalized model stated in3. 4.
図4 提案モデルの図3 (b)の表現に対応する因子分解形 Fig. 4 Factorization form which corresponds to
Fig. 3 (b).
る.目的関数の下界
F
はイェンセンの不等式を適用す ることで導出することができる.F =
i,j
−
Rr=1
a
irb
jr+ x
ij R r=1s
ijrlog a
irb
jrs
ijr+
k,j
−
Rr=1
c
krb
jr+ y
kj R r=1t
kjrlog c
krb
jrt
kjr,
ただし,
{ s
ijr}
と{ t
kjr}
は補助変数,等号成立条件は 次のとおりである.s
ijr= a
irb
jr Rr=1
a
irb
jr, t
kjr= c
krb
jr Rr=1
c
krb
jr. (5)
下界
F
を微分して0
とおき(
∂a∂Fir
= 0)
,補助変数の値を式
(5)
のそれへと置き換えることでa
irの更新式 が導かれる.b
jrの更新式も同様に導かれ,c
krの更新 式は線形制約の式そのものである.更新式は次のとお りである.a
newir← a
ir jxij
xˆij
b
jr+
k
j
v
ikyyˆkjkj
b
jrj
b
jr+
k
j
v
ikb
jr, (6)
b
newjr← b
jr ixij
xˆij
a
ir+
kykj yˆkj
c
kri
a
ir+
k
c
kr, (7)
c
newkr←
i
v
ika
ir. (8)
なお,本論文では観測データを表す行列中に欠損値が ある場合の扱いは省略したが,通常の
NMF
における 欠損値の取り扱いとほぼ同様に適用可能である.3. 4
一 般 化最後に提案手法
pNimf
がより一般的な異粒度データ 解析の設定においても適用可能であることについて述 べる.3. 1
で我々は高解像度データと低解像度データ がそれぞれ1
ヶ月分の購買履歴であるという例を示し た.しかし,仮定(A1)
と(A2)
が満たされているか ぎり,提案手法は任意の設定に対して適用可能であ る.例えば,複数個の高解像度データと低解像度デー タが利用可能であることを考える.この場合におい てもpNimf
は若干の修正を加えることでそのまま適 用することができる.M
を高解像度データの個数,X
m= { x
mij}
をm
番目の高解像度データを表す行列 であるとする.同様に,N
を低解像度データの個数,Y
n= {y
nkj}
をn
番目の低解像度データを表す行列で あるとする.各m
やn
は必ずしもデータが収集され た日・週・月などの時間に対応する必要はなく,県・国などの場所に対応するものであってもよい.図
3 (a)
で表現されていた提案手法のデータ生成過程を図3 (c)
の示すものへと拡張することで,式(6)(7)
を修正した 次のパラメタ更新式が求まる.a
newir← a
irM
j x¯ij
xˆij
b
jr+N
k
j
v
ikyy¯ˆkjkj
b
jrM
j
b
jr+N
k
j
v
ikb
jr, (9)
b
newjr← b
jrM
i x¯ij
xˆij
a
ir+ N
k y¯kj yˆkj
c
krM
i
a
ir+ N
k
c
kr, (10)
ただし,
x ¯
ij=
M1 Mm=1
x
mij,y ¯
kj=
N1 Nn=1
y
nkjで ある.4.
実 験4. 1
実 験 設 定この章では,人工データと実購買データを用いて提 案手法の有効性を確認する.
人工データ:人工データは,式
(2)
の確率モデルを 用いてサイズがI = 100
,J = 100
,K = 10
である 高解像度行列と低解像度行列を作成した.ユーザ属性 行列V
は,I/K = 10
行ずつ異なる値となるよう,要 素v
ikの値をi/K
の商がk
であるときv
ik= 1
,そ うでなければv
ik= 0
と設定した.データを生成す る際の因子行列A
,B
の値はガンマ分布から生成し たランダムな値を利用した.データ生成の際の因子数R = 5, 10, 20
ごとにガンマ分布のパラメタを調節する ことで,確率モデルから生成される高解像度行列X
のスパースネス(
行列中の値がゼロとなる要素の割合)
の異なるデータを作成した.作成した高解像度行列X
のスパースネスは約50%
,90%
,99%
であり,それら に対応する低解像度行列Y
のスパースネスは約10%
,40%
,80%
である.実購買データ:実購買データには株式会社インテー ジの消費者パネルデータ
“SCI”
を利用する.特に我々 は2013.1.1
から2013.12.31
までの期間の牛乳,コー ヒー菓子類などの日用品項目に関する購買履歴を用い る.これらの項目は各月で繰り返し購買される商品で あることから,仮定(A2)
の独立同分布という仮定は 満たされていると期待できる.このデータにはユーザの年齢と性別の属性情報も含まれている.我々はこの データから,
Two-month
データとFour-month
データ の2
種類の実験用データを作成する.Two-month
は 図2
で示したように11
月と12
月の購買データを用い て作成する.なお作成するうえでは,仮定(A1)
が満 たされるケースを取り扱うため,両方の月で10
回以 上購買を行うユーザの履歴を用い,商品は購買履歴中 に10
回以上現れたものを用いた.作成した行列のサ イズはI = 1589
,J = 3164
,K = 34
となり,行列X
DecとY
Novのスパースネスはそれぞれ,99.15%
,54.4%
となった.この手続きを1
月と2
月のデータに 対しても適用する.得られた行列のサイズとスパース ネスは11
月と12
月のデータから作成したものとほぼ 同様である.Four-month
データの作成も9
月,10
月,11
月,12
月のデータを用いて同様に作成する.12
月 の購買履歴を表す高解像度行列X
Decとそれ以外の各 月の低解像度行列Y
Nov,Y
Oct及びY
Sepを作成し た.得られた行列のサイズはI = 1288
,J = 4842
,K = 34
となった.評価指標:この実験ではテストデータに対する対数 ゆう度を評価尺度として利用する.行列
X
の要素を 学習用データとテスト用データに分割し,学習用の データのみを用いて推定した因子行列を用いて,テス トデータの生成確率を正しく表現できているかを評 価する.テストデータとされた要素は学習時には欠損 要素として扱う.テストデータに対する対数ゆう度は1
|T |
(i,j)∈T
log PO x
ijx ˆ
ijとして定義される.た だし,
T
はテストデータとされた行列要素の添え字全 体を表し,| · |
で集合中の要素数を表す.行列要素中か ら5%
の非ゼロ要素をランダムに抽出することで,学 習・テストデータの組を10
組作成して実験を行った.比 較 手 法:比 較 手 法 に は 次 の 二 つ を 利 用 し た .
(1) NMF [2]
,単一の行列を因子分解する手法.高 解像度行列X
のみを因子分解して学習結果を得る.(2) NMMF [10]
,NMF
を複数の行列を同時に分解で きるよう発展させた拡張手法.X
とY
を同時に因子 分解することで学習結果を得る.内部の行列Y
に関す る重要度を定める重みパラメタには,α = 0.1, 0.5, 1.0
という候補の中でもっとも優れた値を示したα = 1.0
を利用する.4. 2
実 験 結 果まず人工データを用いた実験結果を表
1
に示す.行 列X
のスパースネス50%
,因子数R = 5, 10
におけ る結果に着目すると,3
手法はほぼ同等程度の性能を表1 人工データを用いた実験結果:行列Xのスパース ネスと生成時の因子数Rの異なる各設定における テストデータに対する対数ゆう度を表す.学習時に 利用した因子数は生成時の因子数と同一のものを利 用した.表中の値が平均と標準偏差を表す.平均値 が大きいほど良い.スパースネス99%の設定では平 均と標準偏差ともに10で割った値を示す.
Table 1 Result ofsyntheticdata: test log-likelihood forX determined with different sparseness values. Average and standard deviation are shown. Larger values are better. Scores and standard deviation are divided by ten in the 99% sparseness setting.
Sparseness R NMF NMMF pNimf
X: 50%
Y: 10%
5 −2.77(±0.17)−2.71(±0.10)−2.66(±0.09) 10−2.72(±0.18)−2.54(±0.09)−2.42(±0.04) 20−16.7(±20.1)−3.11(±0.18)−3.09(±0.21) X: 90%
Y: 40%
5 −6.71(±2.13)−4.11(±0.97)−3.48(±0.69) 10−5.26(±0.92)−3.28(±0.45)−2.96(±0.23) 20−21.5(±4.38)−7.57(±1.28)−5.72(±0.48) X: 99%
Y: 80%
5 −5.44(±1.82)−3.62(±1.73)−2.04(±1.12) 10−6.64(±3.52)−7.05(±2.62)−4.59(±1.67) 20−17.0(±32.7)−7.43(±3.37)−6.64(±3.13)
表2 Two-monthデータを用いた実験結果:各因子数R
におけるテストデータに対する対数ゆう度を表す.
表中の値が平均と標準偏差を表す.平均値が大きい ほど良い.
Table 2 Result ofTwo-monthdata: test set log- likelihood varying the number of fac- tors,R. Average and standard devia- tions are presented. Larger values are better.
Data R NMF NMMF pNimf
SCI XFeb&
YJan
10 −13.3±0.63 −7.89±0.38 −7.84±0.17 20 −18.7±1.95 −9.14±0.48 −8.81±0.20 50 −32.7±2.15 −11.8±0.48 −10.4±0.33 SCI
XDec&
YNov
10 −13.9±0.99 −8.24±0.59 −7.83±0.23 20 −14.4±0.73 −8.95±0.37 −8.68±0.27 50 −32.59±2.17 −12.32±0.50 −10.45±0.30
発揮していることが確かめられる.しかし,スパース ネスが更に上がり,
90%
の設定ではNMMF
と提案手 法がNMF
を上回り,更に99%
の設定では提案手法がNMMF
より優れた性能を示している.この結果から,提案手法は入力行列がよりスパースである場合に,既 存手法よりも優れた性能を発揮すると考えられる.
次に実データである
Two-month
データを利用した 結果を表2
に示す.提案手法pNimf
とNMMF
が因 子数の値によらずNMF
を上回る性能を示しているこ とが分かる.この結果は低解像度行列を利用すること が性能向上をもたらすことを示している.加えて,提 案手法の性能はNMMF
よりも優れたものとなってい る.また,その差は因子数の値が大きいときに,より 大きくなり,提案手法が因子数の設定に対してロバス図5 Four-monthデータを用いた実験結果:各低解像度行 列の数N におけるテストデータに対する対数ゆう 度を表す.ヒストグラムの高さとエラーバーが平均 と標準偏差を表す.平均値が大きいほど良い.
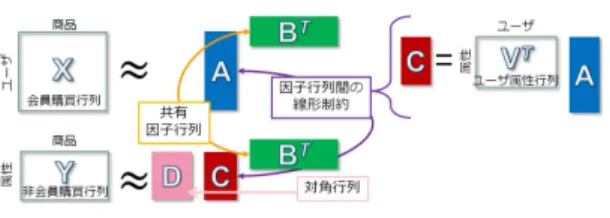
Fig. 5 Result ofFour-monthdata: test set log-likelihood varying the number of low-resolution data,N.
トであることも確認できる.これは提案手法が,因子 行列間の線形制約を導入することによって,行列間の 粒度の違いを考慮しながら因子分解を行うことができ ることに由来する効果であると考えられる(注4).
最後に
Four-month
データを用いて,低解像度行列 の数が性能に与える影響について調べる.提案手法の 因子数R = 10
と設定し,学習時に利用する低解像度 行列の数N
を変えて因子分解を行い評価を行う.図5
にその結果を示す.利用する低解像度行列の数が増え るにつれて提案手法の性能が向上していることが分か る.修正したデータ生成過程により提案手法は複数の 低解像度行列が存在する状況でも適用できることから,各行列の数が異なる状況でも因子分解を行うことが可 能であることが確かめられた.
5.
提案技術の拡張例これまでの章で,二つの仮定
(A1)(A2)
が満たされ る異粒度データ解析問題に注目し,新たな確率モデル を提案・その有効性を検証した.ここで注意しなけれ ばならない点は,高解像度行列と低解像度行列の間に 導入することができる関係性は問題設定に応じて変わ りうるため,提案した確率モデルが異粒度データ解析 の全ての問題に対する妥当なモデリングになるとは限 らない,ということである.しかし,この手法を基礎 に据えた拡張を考えることで,多くの異粒度データ解 析の問題が解決可能になると我々は考えている.そこ で本論文の最後に,提案モデルの拡張によりどのよう に新たな技術を創出することができるかの例を示す.(注4):この結果は,人工データの結果と整合性がとれている.Two- monthデータのスパースネスは(X:99.15%,Y:54.4%)であり,低 解像度行列のスパースネスの値から,人工データの設定(X:99%,Y: 80%)と(X:90%,Y:40%)の中間的な設定に相当する.
5. 1
定 式 化ここでは,会員・非会員購買履歴という異粒度デー タが
3. 1
で示したものとは違ったプロセスで作られ た状況を考える.3. 1
の例では,12
月から会員カー ドが発行・提示が必要とされる状況を考えたため,11
月の利用者と12
月の利用者が同一であるという仮定(A1)
共通ユーザ集合を置くことができた.しかしな がら,コンビニエンスストアなど,非会員ユーザも利 用することが可能な店舗で収集されるデータは,会員 ユーザと非会員ユーザが常に混在し,またそれぞれ異 なるユーザ群に対応するため,これまで用いた仮定(A1)
共通ユーザ集合を利用することは一般には適切 ではない.その理由を図6
を用いて説明する.図
6
は会員と非会員のユーザ群が異なる場合に起こ りうる状況の例である.図(a)(b)
の違いは,会員と非 会員における各属性ごとの人数がほぼ同一であるか,それとも大きく異なるかにある.図
6 (a)
の設定にお いては,3.
で示した提案手法に一定の妥当性がある が,(b)
の設定の場合は妥当性を失う.なぜなら,提 案手法でおいた仮定(A1)(A2)
は,結果的に「各属性 ごとの各商品の総購買量が会員・非会員で同程度であ る」ことを想定している.これは図(a)
の状況ではお おむね適当であるのに対し,図(b)
の設定では明らか に不適当なためである.そこでここでは新たな仮定として,「同一属性の会 員購買履歴と非会員購買履歴はおおよそ比例する」と いう新たな仮定
(A3)
属性購買数比例,を導入したア プローチを考える.会員購買履歴を表す(
高解像度)
図6 会員と非会員のユーザ群が異なる状況の例.(a)の設定では3.で示した提案手法を 適用することは妥当性が保たれる一方,(b)の設定では会員と非会員の属性ごとの 人数の違いから総購買量が大きく異なりうるため,手法の拡張が必要となる.
Fig. 6 An example where a user set of members and that of non-members are different. Proposed method shown in3.can be applied to the case of (a).
However, it is not appropriate in the case of (b) since the purchase volume of members and that of non-members are greatly different.
行列を
X,
非会員購買履歴を表す(
低解像度)
行列をY
と書く.属性k
の会員購買履歴はIi=1
v
ikx
i,非 会員購買履歴はy
kで与えられるから,仮定(A3)
の 比例関係は数式y
k∝
Ii=1
v
ikx
iで表現できる.属 性k
の会員が一定数存在するならば,この仮定を置く ことはきわめて自然であると考えられる.したがって 我々はこの比例関係が因子行列を用いて再構成する行 列X ˆ
,Y ˆ
に成り立つ因子分解形を考える.対角行列D := diag( { d
k}
kK=1)
をその要素d
kが属性k
の比例 定数を表すとすると,比例関係が成り立つにはY ˆ = DV
TX ˆ (11)
が満たされれば良い.行列
X ˆ
の因子分解形にはNMF
と同じX ˆ = AB
Tという形を用いることとし,式(11)
に代入すると,行列Y
の因子分解形は以下とすれば よいことがわかる.Y ˆ = DCB
T, C = V
TA . (12)
これをまとめると,次のような確率モデルを考えれ ば良いことがわかる.p(X, Y |A, B, C, D, V )
=
i,j
PO (x
ij| x ˆ
ij)
k,j
PO (βy
kj| β y ˆ
kj),
where y ˆ
kj=
R r=1d
kc
krb
jrand c
kr=
I i=1v
ika
ir.
ただしβ
は重みパラメタであり,データ量の違いによ図7 拡張した提案モデルの因子分解形 Fig. 7 Factorization form of the extended method.
り非会員データが目的関数で支配的にならないように コントロールするものである.この確率モデルに対応 する行列分解形は図
7
で与えられる.3.
の図4
で示 した行列分解形と比較すると,対角行列D
が新たに 導入されている点が異なり,拡張された定式化である ことがわかる.パラメタ更新アルゴリズムの導出を行 うと,行列要素a
ir,b
jr,c
kr,d
kの更新式は次のよ うに与えられる.a
newir← a
ir jxij
xˆij
b
jr+ β
k
d
kv
ikjykj yˆkj
b
jrj
b
jr+ β
k
d
kv
ikj
b
jr, b
newjr← b
jr ixij
xˆij
a
ir+ β
kykj yˆkj
d
kc
kri
a
ir+ β
k
d
kc
kr, c
newkr←
i
v
ika
ir, d
newk←
j
y
kjr
c
kr(
j
b
jr) .
5. 2
実 験実験には,
4.
と同じく株式会社インテージの“SCI”
データを利用する.ただしデータ作成方法は前回とは 異なり,購買データを月別に分けるのではなく,データ 中のユーザからランダムに抽出した
5%
,10%
,20%
,40%
を会員,残りを非会員として取り扱い,会員購買 履歴より行列X
,非会員購買履歴より行列Y
を作成 する.ここで,解析対象とするユーザ・商品はそれぞ れ50
回以上,30
回以上購買履歴中に存在するユー ザ・商品に限定した.作成したユーザ(
会員と非会員 両方を含む)
と商品の総数はそれぞれ5000
,7000
と なった.比較手法と評価指標は
4.
の実験と同一のものを 利用する.なお,NMMF
と提案手法の重みパラメ タ の 値 は ,会 員 購 買 履 歴 と 非 会 員 購 買 履 歴 を 対 等 に扱うよう人数の比率(
会員数/
非会員数)
を用い,β = 0.05, 0.11, 0.25, 0.66
と設定した.図
8
に実験結果を示す.会員比率によらず提案手法 とNMMF
はNMF
より優れた結果が得られている.図8 各会員ユーザ比率におけるテストデータに対する対 数ゆう度を表す.青,赤,緑色のヒストグラムがそ
れぞれNMF, NMMF,拡張した提案手法の結果を
示す.
Fig. 8 Test set log-likelihood varying the ratio of members and non-members. Blue, red and green histogram represent a result of NMF, NMMF and proposed method.
これは,非会員購買履歴の利用が性能向上に寄与する ことを示すといえる.その寄与の度合いに注目すると,
会員数が十分多い会員比率
40%
のときには効果が小さ く,会員数の少ない会員比率5%
,10%
,20%
のとき に,より大きな性能向上がもたらされていることがわ かる.提案手法とNMMF
の結果を比較すると,会員 比率10%
,20%
,40%
のときにはほぼ同等の結果が得 られている.しかし,会員数の非常に少ない会員比率5%
のときには,提案手法はNMMF
を上回る結果を 示している.ここから,属性間の購買数の比例関係を 明示的に導入することで,会員数が少なくデータが十 分でない場合に,提案手法はより有効に非会員購買履 歴を統合した因子分解が可能であると読み取れる.6.
む す び本論文では,異粒度データ分析のための新たな手法 を提案した.はじめに
(A1)
ユーザ共通,(A2)
独立 同分布という二つの仮定が満たされる状況に着目し,潜在高解像度行列を用いたデータ生成過程を考える ことで,異粒度データ分析のための新たな確率モデル
pNimf
を提案した.更にこの拡張により,上記とは別 の仮定を要する状況で用いる手法が構築可能であるこ とも示した.これらの結果は提案手法が異粒度データ 分析問題を考える際の基盤的アプローチになりうるこ とを示すと考える.残された研究課題には,季節性などを導入すること によるモデルの更なる拡張や,提案技術の性能の理論 的解明が挙げられる.低解像度行列を用いることによ る性能向上の度合いは高解像度行列と低解像度行列の 粒度の違い
(
行数の違い)
の大きさに影響すると考え られ,その理論的解析は今後の課題である.文 献
[1] M. Kohjima, T. Matsubayashi, and H. Sawada,
“Probabilistic non-negative inconsistent-resolution matrices factorization,” Proc. 24th ACM Interna- tional Conference on Information and Knowledge Management, pp.1855–1858, 2015.
[2] D.D. Lee and H.S. Seung, “Learning the parts of ob- jects by non-negative matrix factorization,” Nature, vol.401, no.6755, pp.788–791, 1999.
[3] D.D. Lee and H.S. Seung, “Algorithms for non- negative matrix factorization,” Advances in Neural Information Processing Systems, pp.556–562, 2001.
[4] A. Cichocki, R. Zdunek, A.H. Phan, and S. Amari, Nonnegative matrix and tensor factorizations: Appli- cations to exploratory multi-way data analysis and blind source separation, John Wiley & Sons, 2009.
[5] T. Hofmann, “Probabilistic latent semantic index- ing,” Proc. 22nd Annual International ACM SIGIR Conference on Research and Development in Infor- mation Retrieval, pp.50–57, 1999.
[6] D.M. Blei, A.Y. Ng, and M.I. Jordan, “Latent Dirichlet allocation,” J. Machine Learning Research, vol.3, pp.993–1022, 2003.
[7] C. Ding, T. Li, and W. Peng, “On the equivalence between non-negative matrix factorization and prob- abilistic latent semantic indexing,” Computational Statistics & Data Analysis, vol.52, no.8, pp.3913–
3927, 2008.
[8] A.P. Singh and G.J. Gordon, “Relational learn- ing via collective matrix factorization,” Proc. 14th ACM SIGKDD International Conference on Knowl- edge Discovery and Data Mining, pp.650–658, 2008.
[9] H. Lee and S. Choi, “Group nonnegative matrix factorization for EEG classification,” International Conference on Artificial Intelligence and Statistics, pp.320–327, 2009.
[10] K. Takeuchi, K. Ishiguro, A. Kimura, and H. Sawada,
“Non-negative multiple matrix factorization,” Proc.
23rd International Joint Conference on Artificial In- telligence, pp.1713–1720, 2013.
[11] Y. Aimoto and H. Kashima, “Matrix factoriza- tion with aggregated observations,” Advances in Knowledge Discovery and Data Mining, pp.521–532, Springer, 2013.
[12] 阿部 誠,近藤文代,マーケティングの科学—POSデー タの解析—,朝倉書店,2005.
(平成28年6月27日受付,11月7日再受付,
29年1月6日早期公開)
幸島 匡宏
2009年,東京工業大学工学部情報工学 科卒業.2012年,同大学院総合理工学研究 科知能システム科学専攻修士課程修了.同 年,日本電信電話株式会社入社.以来NTT サービスエボリューション研究所にて,機 械学習の研究に従事.
松林 達史
2000年,京都大学理学部物理学科卒業.
2002年10月より2年半,理化学研究所 非常勤研究員.2005年,東京工業大学大 学院理工学研究科地球惑星科学専攻博士課 程修了.同年,日本電信電話株式会社入社.
以来,NTTコミュニケーション科学基礎 研究所,NTTサービスエボリューション研究所にて,グラフ 可視化及び機械学習の研究開発に従事.博士(理学).情報処理 学会会員.
澤田 宏 (正員)
1991年,京都大学工学部情報工学科卒 業.1993年,同工学研究科情報工学専攻 修士課程修了.2001年,京都大学博士(情 報学). 1993年,日本電信電話株式会社
(NTT)入社.以来,同社コミュニケーショ
ン科学基礎研究所及びサービスエボリュー ション研究所において,VLSI設計技術及び計算機アーキテ クチャ,信号処理技術(音響信号の分離技術),機械学習技術
(多次元データ分析技術)の研究に従事.現在,NTTコミュニ ケーション科学基礎研究所協創情報研究部部長.日本音響学会,
IEEE各会員.