Naoaki YAMANAKA
†and Eiji OKI
††あらまし 本論文は,電話中心のネットワークからビデオやマルチメディアといった高速のサービスをサポー トするネットワークとして発展した超高速パケットネットワークを,アーキテクチャ,トラヒック設計,システ ム化技術,デバイス技術,実装技術として融合し,数々の世界最高速度のパケットネットワークシステムを開発 し,更に実用化を行った主要技術を俯瞰し,著者らの提案技術を述べるとともに今後の技術展開についてまとめ る.パケットネットワークの主要トピックとして,パケットスイッチングシステム,パケット競合制御,マルチ レイヤトラヒックエンジニアリング,及び,プロトコル・相互接続・標準化について述べる.
キーワード パケット,スイッチ,スケジューリング,ネットワーク,シリコン,ガリウムヒ素,光インターコ ネクション,マルチチップモジュール
1.
ま え が きブロードバンドインターネットにおいて,トラヒッ クが集中するバックボーンネットワークでは,パケッ トを宛先ごとに高速に振り分けるパケットスイッチン グシステムが必要となる.また,トラヒック需要の変 動が生じる場合でも,ネットワークの資源を有効に活 用するためには,動的に経路や帯域を制御するネット ワーキング技術の確立が必要である.
筆者らは,ブロードバンドインターネットの基盤と なる超高速パケットネットワーク技術の研究開発に携 わってきた.超高速パケットネットワーク技術は,パ ケット交換,
Asynchronous Transfer Mode (ATM)
,Multi-Protocol Label Switching (MPLS)
,General- ized MPLS (GMPLS)
,フォトニックネットワーク,及び,インターネットに寄与するものである.
本論文は,電話中心のネットワークからビデオや マルチメディアといった高速のサービスをサポートす るネットワークとして発展した超高速パケットネット
†慶應義塾大学大学院理工学研究科,横浜市
Graduate School of Science and Technology, Keio University, 3–14–1 Hiyoshi, Kohoku-ku, Yokohama-shi, 223–8522 Japan
††京都大学大学院情報学研究科,京都市
Graduate School of Informatics, Kyoto University, Yoshida- honmachi, Sakyo-ku, Kyoto-shi, 606–8501 Japan
DOI:10.14923/transcomj.2016SHI0001
ワークを,アーキテクチャ,トラヒック設計,システム 化技術,デバイス技術,実装技術として融合し,数々 の世界最高速度のパケットネットワークシステムを開 発し,更に実用化を行った主要技術を俯瞰し,著者ら の提案技術を述べるとともに今後の技術展開について まとめる.パケットネットワークの主要トピックとし て,パケットスイッチングシステム,パケット競合制 御,マルチレイヤトラヒックエンジニアリング,及び,
プロトコル・相互接続・標準化について述べる.
本論文の構成は,以下のとおりである.
2.
では,パ ケットスイッチングシステムに関するシステム構成と アーキテクチャ,及び,実装技術の進展について述べ る.3.
では,パケット競合制御技術について述べる.パケット競合制御は,システム構成,ハードウェア技 術,及び,実装技術に深く関連するものである.理論 と実用の両面から行われてきたパケット競合制御技術 の進展について解説する.
4.
では,マルチレイヤト ラヒックエンジニアリング技術について述べる.マル チレイヤトラヒックエンジニアリングは,複数のレイ ヤの協調制御により,上位レイヤのサービスを経済的 に提供することができる.5.
では,相互接続性と標 準化について述べる.6.
では,本論文のまとめと今 後の技術の展開を述べる.図1 サービスとシステムアーキテクチャの関係 Fig. 1 Relationship between service and system ar-
chitecture.
2.
パケットスイッチングシステム2. 1
システム構成とアーキテクチャ図
1
にサービスとシステムの関連を示すための構成 図を示した.新しいサービス,例えば,電話にかわり 動画の発信サービスや,データセンタのライブマイグ レーションといったものの登場により,ネットワーク の構成やプロトコル等に影響を与える[1]
.動画の配信であれば,
1: n
接続で保留時間が長く,再送しにくくリアルタイム性も必要かもしれない.一 方,データセンタのマイグレーションであれば,極め てバースト性の高いデータを特定の場所に転送し,リ ソースを専有すべきサービスかもしれない.一方,デバ イスからのボトムアップのインパクトもある.例えば,
電子技術で言えば,シリコン
(Si: silicone)
やガリウム ひ素(GaAs: gallium arsenide)
といったLarge Scale Integration (LSI)
の材料,Complementary Metal- Oxide-Semiconductor (CMOS)
やバイポーラ(bipo- lar)
といった回路技術がそれである.システムアーキ クチャ,システムテクノロジーに対する考察は,1997
年にかなり詳細に行われており[2]
,図2
に示したの は,各種テクノロジーの適用範囲の予想である.当時 の予想と比べると,CMOS
技術の進展は大きかった.これは,消費電力の制限が予想以上に大きく
CMOS
技術の発展のモティベーションになったからである.近年のシリコンフォトニクスのように,大きなインパ クトがあるであろう技術もこのマップに入っている.
図
3
には,システムとその必要スピードが示されて いる.本チャートにおいても,2016
年では,予想を上 回る性能をもったところもある一方,高速デバイスの図2 高速ATMスイッチにおける要素技術[2]
Fig. 2 Key technologies for high-speed ATM switches [2].
図3 高速LSI技術の進展と適用領域[2]
Fig. 3 Progress of high-speed LSI technologies and applications [2].
一部は
CMOS
にとって代わった部分もある.実装技 術についても,熱やサイズの制限を強く受けながら,新しい技術が発達し,システムに大きなインパクトが ある.例えば,光インターコネクションやシリコンの
LSI
技術である.システムの設計者はそれぞれの技術 の可能性を見ながら,拡張性やコストと考慮しながら 設計していく.文献
[3]
は,大規模スイッチに対して,選択すべき アーキテクチャについて調査している.文献[4]
は,ATM
スイッチからIP
ルータに至るまで代表的なパ ケットスイッチング技術について述べている.文献[5]
は,光技術を取り入れたパケットネットワーク技術の 動向を述べている.
2. 2 Synchronous Transfer Mode (STM)
スイッチと銅ポリイミドマルチチップ技術 図4
に1990
年に研究開発した8 × 8
のギガビット空 間分割Synchronous Transfer Mode (STM)
スイッチ図4 銅ポリイミドマルチチップ技術による8×8 STM スイッチ
Fig. 4 8×8 STM based on copper polyimide tech- nology.
の写真を示す
[6]
.本モジュールのキー技術は,シリコ ンバイポーラSuper Self-aligned process Technology
(SST)
デバイス技術,及び銅ポリイミドマルチチップモジュールを用いている点である.シリコンのバイ ポーラ技術は,特に性能の必要となるスーパーコン ピュータのキャッシュや高速光伝送用として開発され た.特徴としては,バイポーラであるため,高速で動 作するだけでなく信号のドライブ能力にも優れ,実装 上も有利である一方,消費電力が大きい欠点もある.
このスイッチング・デバイス技術を初めて通信シス テムのモジュールに適用し,超高密度実装を実現する ため,誘電率が高いポリイミドを絶縁層とし,ロスを 減らすために銅配線を用いたマルチチップモジュール を世界で初めて開発した.銅ポリイミドは高速信号伝 送に優れるが,絶縁体のポリイミドは熱電導性が劣る 等の課題があり,電源を含めての多層化構成を検討し た.詳細は割愛するが,セラミックとポリイミドを組 み合わせた多層のモジュールで,電源はセラミック層 でその上に高速信号用に銅ポリイミドの信号層を多層 化した
(
図5)
.本実装技術を用いて開発した
32 × 32
マルチチップ モジュール(図4
)は,発熱の大きいシリコンLSI
の ため,銅ポリイミド多層配線基板上に,熱電導を向上 させるためのサーマルビアを用いている.更に,モ ジュールレベルでの高速テストを可能とする.LSI
検 査技術として発展した同軸グローブを作り,オンス ピードでのモジュール検査も可能とした.この技術は,Very Large Scale Integration (VLSI)
テスターのオ図5 セラミックとポリイミド多層マルチチップモジュー ルの構成図
Fig. 5 Structure of multi-chip module based on ce- ramic and copper-polyimide multi-layer sub- strate.
図6 Tape Automated Bonding (TAB)による検査性 に優れたチップ
Fig. 6 Chip with Tape Automated Bonding (TAB) enhancing inspectability.
ンスピード評価として発展していった.これらの技術 は,モトローラ,
IBM
といったスーパーコンピュータ メインフレーム技術としてライセンスすることに成 功した.このとき考えるに,LSI
,システム,実装と いった個々の技術が世界一つであったのみではなく,Needs/Applications
をしっかりもち,きわめてタイ トに協力し合いながら開発したのが,成功のポイント であった.図5
に示すように,チップをそのまま基盤 に搭載する技術は明らかに高速性で優れる.一方,組 み立てやメンテナンスは難しくなり,そのため,図6
に示すTape Automated Bonding (TAB)
技術[7]
で 事前にチップにポリイミドのテープを圧着し,高速評図7 Static Random Access Memory (SRAM)を多層 にスタッキングさせる技術
Fig. 7 Stacking Static Random Access Memory (SRAM) technique.
価後にボードに搭載する技術や,更にチップを複数ス タックさせ
[8]
,密度を更に上げる技術(
図7)
を開発 し[9], [10]
,これらをNTT
の実交換機に応用する等,先駆的に技術を開発し,本技術は,
IEEE
の最大級 の国際会議Electronic Components and Technology Conference (ECTC)
で300
件以上の論文から,Best Paper
を3
回受賞し[6], [10], [11]
,IEEE
の論文誌で もBest Transaction Paper Award [12]
を受賞する 等,アカデミックにも実用化でも大きな成果を上げて いった.これらの技術は,その後,通信システムのみ ではなく,サーバーやスーパーコンピュータのメイン フレーム等,多くに発展していった.2. 3
サブテラビットパケットスイッチングシステ ムのクーリングと光インターコネクションの 採用超高速パケットスイッチングシステムの実現は,イ ンターコネクションと発展するパワーとの戦いでもあ る.ここでは,その中でも先駆的に取り組んだヒート パイプによる冷却技術及び光インターコネクション 技術を紹介する.図
8
は,サブテラビットパケット スイッチングシステムのスループットを有するパケッ トスイッチの基本モジュール(40 Gbps
)である[12]
. セラミックと銅ポリイミドのマルチチップモジュール を用いている[13]
.パワーの増加,集中に対応するた めにセラミック側の裏面にはヒートパイプを搭載して 裏面を強風の空冷で冷却している.モジュール4
個 間は,マイクロストリップラインのフレキシブルリ ボンのコネクタで接続している.一方,システムは,複数架で構成されており,そのインターコネクション
は
10Gbps
の新規に開発された小型光インターコネクションモジュール
[14]
で接続される.図9
にモジュー ルの外観を示した[15]
.このように高性能システムは,アーキテクチャ,
VLSI
,モジュール,インターコネク ション冷却といったシステム技術の融合体である.図8 ヒートパイプによる冷却技術を採用した超高速パ ケットスイッチ
Fig. 8 High-speed switch using heat-pipe cooling technique.
図9 光インターコネクションモジュールの外観 Fig. 9 Appearance of optical interconnection mod-
ule.
3.
パケット競合制御技術3. 1
クロスポイントLSI
型スイッチの競合制御3. 1. 1
従来の競合制御の問題点図
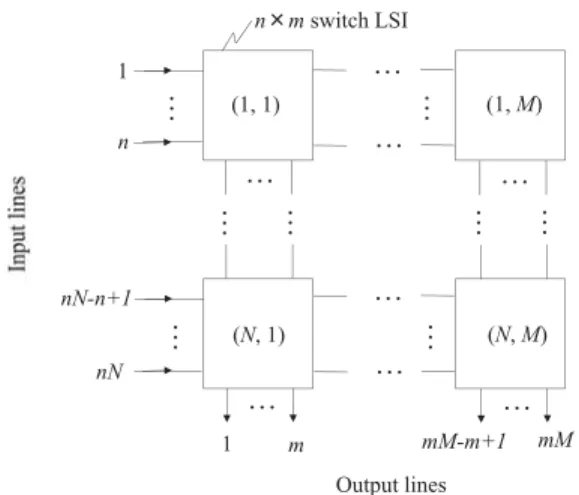
10
に,クロスポイントLSI
型スイッチ構成を示 す.n × m
のスイッチング機能を有するスイッチLSI
がN × M
の格子状に配備されることを考える.ス イッチングシステムとして,nN
本の入力回線とmM
本の出力回線があり,nN × mM
スイッチング機能が 提供される.リングアービトレーションに基づいた従来の競合制 御を図
11
に示す.図11
では,ある一つの出カポート に着目している.従来の競合制御では,セルの出力要 求を出しているスイッチLSI
の出カバッファを制御信 号がリング上で探索し,出力要求を最初に見つけた時 点で,その出力要求を出しているスイッチLSI
の出カ図10 クロスポイントLSI型スイッチアーキテクチャ Fig. 10 Crosspoint-LSI-type switch architecture.
図11 リングアービトレーションに基づいた従来の競合 制御
Fig. 11 Conventional contention control based on ring arbitration.
バッファにセルの出力,許可を与える.次のセル時間 後に,許可を与えたスイッチ
LSI
の次のスイッチLSI
をリングのスタート地点とし,探索を開始する.した がって,探索が最も長い場合,1
セル時間以内に同一 出カポートに属する全てのスイッチLSI
間を制御信号 を転送する必要が生じる.このため,従来のスイッチ では,出力回線速度が,縦に接続されるスイッチLSI
数と,スイッチLSI
間の制御信号の転送時間に制限さ れる.最大出力回線速度は,NTLs で与えられる.ここ で,
N
は縦に接続されるスイッチLSI
数,T
s[s]
はス イッチLSI
間の制御信号の転送遅延(実装の配線遅延図12 スケーラブル分散アービトレーション Fig. 12 Scalable distributed arbitration (SDA).
やデバイス遅延等により依存),
L [bit]
はセル長であ る.ただし,各セル時間にはガードタイムはないと仮 定している.このように,リングアービトレーションを用いた従 来の競合制御では,入カポート数が増加すると,リン グアービトレーションの制御信号の転送時間が大きく なるため,出力回線速度が制限される.したがって,
特殊な実装やデバイスを用いて
T
s[s]
小さくしたり,厳しいタイミング設定をしない限り,スループットを 向上できないという問題があった.
3. 1. 2
分散拡張競合制御開発したスケーラブル分散アービトレーション
(SDA:
scalable distributed arbitration)
のメカニズムにつ いて,図12
を用いて説明する[16]
〜[18]
.SDA
では,各スイッチ
LSI
の出力ポート部に,出カバッファ,中 継バッファ,競合制御部(CNTL: controller)
,及びセ レクタを有している.図12
では,一つの出力ポート に着目している.出カバッファは,セルが蓄積されているとき,
CNTL
にセル出力要求(Req)
を送出する.中継バッファは,上流のスイッチ
LSI
の出カバッファまたは上流のス イッチLSI
の中継バッファから送出されたセルを蓄 積する.中継バッファサイズは,数セル程度である.これは,競合制御時間やスイッチ
LSI
間のセル転送 時間によって決まる.中継バッファは,セルが蓄積されているとき,
CNTL
にReq
を送出する.中継バッ ファにおけるセル損失を防ぐため,中継バッファがフ ルの状態のときは,上流のCNTL
へNack
を送出す る.CNTL
は,出力バッファか中継バッファから少な くとも一つのReq
を受信し,かつ,下流からNack
が 来ない限り,1
セル時間以内にセルを選択し,セレク タを介して,下流の中継バッファに送出する.Req
が 片方の場合は,Req
を送出したバッファのセルを選択 する.Req
を両方から受信した場合は,セル選択則に 従ってセルを選択する.セル選択則は以下のとおりである.セルが出カバッ ファに入力された時点から現時点までの当該セルの遅 延時間を計測し,その遅延時間が大きい方のセルを選 択する.遅延時間が等しかった場合は,第
2
のセル選択 則を採用する.上流から数えてk
番目( k = 1 , · · · , N )
のスイッチLSI
を考える.最上流のスイッチLSI
はk = 1
,最下流のスイッチLSI
はk = N
である.k
番目のスイッチLSI
でセルが競合した場合,出カバッ ファと中継バッファは,それぞれ,1 /k
,( k − 1) /k
の 確率で選択される.k
番目の出力バッファに入力され たセルは,出力回線に送出されるまでにセル競合にお いて選択される確率は,それぞれのスイッチLSI
で選 択される確率の積となり,次式で与えられる.1 k × k
k + 1 × · · · N − 2
N − 1 × N − 1 N = 1
N (1)
ここで,式
(1)
の左辺の第1
項は,k
番目のスイッチLSI
で出カバッファが選択される確率,第2
項は,k +1
番目のスイッチLSI
で中継バッファが選択される確率,最終項は,
N
番のスイッチLSI
で中継バッファが選択 される確率である.式(1)
の右辺は,N
番目のLSI
の 出力バッファが選択される確率1 /N
と一致する.各 スイッチLSI
の出カバッファ間のトラヒックに偏りが なければ,選択確率の公平性は保たれている.SDA
の遅延性能をコンピュータシミュレーション により評価した.クロスポイント型スイッチにおいて,スイッチ
LSI
の出カバッファには,セルはベルヌーイ 過程に従って到着すると仮定した.出力回線への入力 トラヒック負荷は0.95
とした.SDA
は,遅延時間の公平性を保つことができる.図
13
は,縦に接続されるスイッチLSI
数N = 8
に おける遅延時間がd
を超える確率を示している.ここ で,遅延時間は,セルが出カバッファに入力された時 点から出力回線に送出されるまでの時間と定義した.スイッチ
LSI
ごとの遅延時間の公平性を示すために,図13 SDAにおける遅延時間の確率 Fig. 13 Probability of delay time in SDA.
スイッチ
LSI
ごとの遅延時間を示している.SDA
で は,d > 10
のとき,各スイッチLSI
の遅延時間の確率 がほとんど同じであり,従来のスイッチと同様に,遅 延時間の公平性が保たれていることがわかる.更に,SDA
では,d > 50
になると,遅延時間がd
を超える 確率が従来の競合制御と比べて小さくなることがわか る.従来の競合制御では,セルの遅延時間に無関係に リングアービトレーションに基づいてセルを逐次選択 しているのに対し,SDA
では,遅延時間に基づくセ ルの選択則に従って遅延時間の大きいセルを優先的に 選択しているため,遅延時間が大きくなる確率を小さ くすることができる.我々は,図
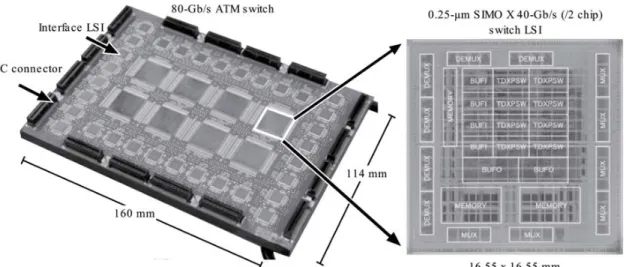
14
に示すSDA
を搭載したATM
スイッ チLSI
,及び,スイッチングモジュールを開発した[19]
. スイッチLSI
は,1
本の回線速度を10 Gbps
とする4 × 2
スイッチング機能を備え,スイッチング方式とし て,タンデムクロスポイント方式[20]
を採用している.スイッチ
LSI
は,0.25- µ m CMOS/SIMOX
技術によ り製造された[21]
.スイッチングモジュールは,8
個 のスイッチLSI
と32
のインタフェースLSI
がマルチ チップ基板上にベアチップで実装されている.スイッ チモジュールは,左辺から8
本の入力信号が入力され,8 × 8
のスイッチング機能により,下辺から8
本の出 力信号が出力され,80 Gbps
のスイッチスループット を有する.スイッチモジュールは,マトリックス状に 配備して,スループットを拡大できるように,上辺は8
本の拡張入力インタフェース,右辺は8
本の拡張出 力インタフェースを有する.スイッチモジュール同士図14 SDAを搭載したスイッチLSI (右)とスイッチモジュール(左) Fig. 14 Switch LSI (right) and switch model (left) adopting SDA.
図15 3段パケットスイッチングネットワークの競合制御 Fig. 15 Contention control in three-stage packet
swiching network.
は,高密度
Flexible Printed Circuit (FPC)
により接 続される.スイッチモジュールの基板材料にアルミナ 基板を用い,層構成は電源層33
層と信号層7
層の合 計40
層であり,約2,000
ネットという高い配線収容 を実現している.本アーキテクチャを中心とする技術 は,本会論文賞[20]
を受賞し,オリジナリティの高い 研究として評価された.3. 2 3
段パケットスイッチングネットワークの競合制御
クロスバースイッチでは,クロスバーの交差点のス イッチングエレメントの数が入出力ポート数の
2
乗 に比例し,かつ,クロスバースイッチをLSI
スイッチ に実装する際に,ピン数の制限によって実装できる入 出力ポート数が制限される.このため,入出力ポート 数を増加していくと,クロスバースイッチではハード ウェアには実装できなくなる場合がある.クロスバースイッチの制限を解消するために,ス イッチをネットワークで接続し,接続されたスイッチ 群を一つのスイッチとして扱う
3
段クロスネットワー クスイッチがClos
により提案された[22]
.IP
ルータ において,1
段目スイッチに入力されたセル(
パケッ ト)
は,適切な2
段目スイッチを選択し,宛先出力回 線を有する3
段目スイッチを目指す.高スループット を得るために,セルの競合を回避する必要があり,セ ル/
パケットがどの2
段目のスイッチを経由するかが 問題となる.ここで,セルの順序逆転を防ぐために,2
段目スイッチには,バッファを備えないスイッチング システムを考える.i SLIP [23]
で採用されたラウンドロビンアービタ とそのポインタの更新方法を応用して,3
段クロス ネットワークスイッチに適用した競合制御方式として,Concurrent Round-Robin Dispatching (CRRD)
方 式がある[24], [25]
.図15
に,CRRD
の構成を示す.1
段目のスイッチには,出力ポートに対応した仮想出 力バッファ(VOQ: virtual output queue)
が配備され ている.入力ポートから1
段目スイッチに入力された セルは,3
段目の出力ポートの宛先に従ってVOQ
に 格納される.CRRD
では,三つのラウンドロビンアー ビタがある.第1
ラウンドロビンアービタは,1
段目 スイッチの出力回線すなわち2
段目スイッチを選択す る.第2
ラウンドロビンアービタは,VOQ
を選択す る.第3
ラウンドロビンアービタは,1
段スイッチを 選択する.2
段目スイッチの選択を考慮したマッチングを決定する場合,
i SILP
と同様に,リクエストフェー ズ,グラントフェーズ,及び,アクセプトフェーズが ある.ラウンドロビンポインタの更新は,マッチング に関わったラウンドロビンアービタのみについて実行 される.したがって,ポインタ値が自動的にずれてい くラウンドロビンポインタの分散化効果により,競合 を回避することができる.CRRD
では,宛先が均等な トラヒックに対しては,100%
のスループットを達成で きることが示されている.CRRD
は,1
セル時間以内 に競合制御を完了する必要がある.この競合制御時間 の制約を緩和するために,競合制御をパイプライン化 する方式が[26]
に紹介されている.パイプライン化さ れた競合制御を採用する場合でも,宛先が均等なトラ ヒックに対しては,100%
のスループットを達成でき ることが確認されている[26]
.また,独立で受け付け 可能な条件を満たし,宛先が均等でないトラヒックに 対しては,最大重みマッチングを採用することにより,100%
のスループットを達成できることが,[27], [28]
に よって証明された.一方,ラウンドロビン選択の代わりにランダム選択 を採用する
Random Dispatching (RD)
方式も提案さ れている[29]
.しかし,Parralel Iterative Matching (PIM) [30]
と同様に,ランダム選択によりリクエスト が競合するため,スイッチ内部を高速化しないと,ス イッチのスループットは,63%
しか達成できない.RD
方式のスループットの理論解析は,文献[25]
によって 示された.4. IP
光ネットワークにおけるマルチレイヤトラヒックエンジニアリング技術
図
16
に示すように,ネットワークは複数のレイヤ から構成される[31]
.光ファイバから構成されるファ イバレイヤの上に,光パスが設定される.1
本の光パス は,光ファイバの中で利用可能な複数の波長から一つ の波長を用いる.パケットパスは,光パスに収容され る.光パスは,複数の光ファイバから構成される.複 数の光パス群は,仮想ネットワークトポロジー(VNT:
virtual network topology)
を構成する[32], [33]
.仮想 ネットワークトポロジー上に,IP
パケットが転送さ れる.バックボーンネットワークでは,
IP
パケットを処 理できるスイッチング能力のインタフェースを有するIP
ルータの機能と,光パスを処理できるスイッチン グ能力のインタフェースを有する光クロスコネクト図16 複数のレイヤから構成させるネットワークとIP光 統合ノード
Fig. 16 Network consisting of multiple layers and IP+optical node.
の機能を備えたノードが存在する.両方のスイッチン グ能力を有するノードを
IP
光統合ノードと呼ぶ[34]
.IP
光統合ノードは,二つのスイッチング能力のインタ フェースを有しているので,IP
トラヒック需要の変動 やネットワークのリソースを考慮しながら,最適な状 態になるように,光パスレイヤのトポロジーをダイナ ミックに変化させることができる.マルチレイヤトラヒックエンジニアリングと呼ばれ る複数のレイヤ(パケットレイヤと光パスレイヤ)の 協調制御により,
IP
サービスを経済的に提供すること ができる.光IP
統合ノード構成を図16
に示してい る.光IP
統合ノードは,IP
パケットやパケットパス を処理するパケットスイッチング部,光パスを処理す る光パススイッチング部,及び,IP
光制御部から構成 されている.IP
光制御部では,ルーチングプロトコ ルにより,パケットレイヤと光パスレイヤのリンク状 態を他のノードからの情報と交換しながら広告する.IP
パケットトラヒックモニタにより,IP
トラヒック 量を観測して,これもリンクステートの一部として広 告する.また,シグナリングにより,必要に応じて,各レイヤのパスが設定される.これらの機能により,
自ノードで,パケットレイヤトポロジーと光パスレイ ヤトポロジーは,絶えず更新されている.光パスレ イヤのトポロジーをどのように変化させ,パケットパ ス,及び光パスの経路をどのように選択するのか等の 判断は,
Path Computation Element (PCE) [35]
〜[37]
により行われる.IP
トラヒック需要の変動により,光パスレイヤのト ポロジーは,ダイナミックに変化して,ネットワーク リソースが有効に活用される.このダイナミックに変 化するトポロジーは,図17
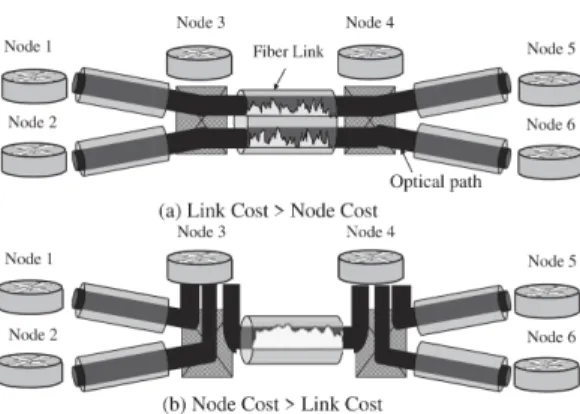
に示すようにノードコス図17 ノードコストとリンクコストのトレードオフ Fig. 17 Tradeoff between node and link costs.
トとリンクコストのトレードオフの関係から,導き出 される.ノード
1
とノード5
,及び,ノード2
とノー ド6
が,それぞれ,IP
レイヤにより通信している状 況を考える.図17 (a)
では,ノード1
とノード5
,及 び,ノード2
とノード6
の間に直接光パスを設定して いる.ノード3
とノード4
は,パケットスイッチング 能力と光パススイッチング能力のインタフェースを有 しているが,光パススイッチング部のみを使用して,IP
パケットとして処理せずに,光パスとして,スイッ チングしている.このメリットとして,対地間に十分 なトラヒックが存在するときは,ノード3
とノード4
のIP
スイッチング処理を回避でき,ノードコストを 削減できる.しかし,トラヒック量が少ないときには,光パスが使用している波長リソースの使用効率が低く なり,少ないトラヒックで,波長を占有するので,リ ンクコストが増加する.一般に,図
17 (a)
において,リンクコスト
>
ノードコストという関係になる.一方,図
17 (b)
では,ノード1
とノード5
,及び,ノード
2
とノード6
の間に直接光パスを設定せずに,ノード
1
とノード2
からのトラヒックをノード3
で 束ねて,ノード3
とノード4
間の波長リソースとして1
波長のみを使用する.ノード4
において束ねたトラ ヒックをそれぞれ,ノード5
とノード6
に対して分離 している.この場合,図17 (a)
とは逆に,ノード3
と ノード4
において,IP
パケットをスイッチング処理 するために,ノードコストが増加する.しかし,対地 間のトラヒック量が少ないときは,ノード3
とノード4
間の波長リソースの帯域使用効率が高くなり,リン クコストが減少する.したがって,図17 (b)
におい て,ノードコスト>
リンクコストという関係になる.図
17 (a)
と(b)
のどちらがネットワークコストを小図18 仮想ネットワークトポロジーの変化によるコスト 削減効果
Fig. 18 Network cost reduction.
さくするのかは,対地間のトラヒック需要及びネット ワークリソースの使用状況を考慮して,決定される.
適切な仮想ネットワークトポロジーを算出する方法 が研究されてきた
[38]
〜[41]
.文献[38], [39]
では,予 想される将来のトラヒック需要が与えられ,使用する リンクの使用率の最大値や上位レイヤのトラヒックの ホップ数が最小となるように,現在の仮想ネットワー クトポロジーを変化させる.文献[40]
は,時間ごとに 変化する将来のトラヒック需要が与えられた場合に,仮想ネットワークトポロジーを最適化する手法を述べ ている.
文献
[41]
は,ネットワークコストをノードコストと リンクコストの和として,対地間のIP
トラヒック需要 に応じて,ネットワークコストを最小にするような仮想 ネットワークトポロジーを算出するモデルを示し,ネッ トワークコストを削減できることを示した.図18
に,仮想ネットワークトポロジーの変化によるコスト削減 効果を示す.トラヒック需要が少ない場合は,図
17 (b)
のように,光パスレイヤは,疎らなトポロジーである.トラヒック需要が増加すると,図
17 (a)
のように,対 地間に直接光パスを設定して,密なトポロジーにダイ ナミックに変化していく.固定的なトポロジーとは,トラヒック需要が変化してもトポロジーが変化してい ないケースである.固定的なトポロジーに対して,ダ イナミックにトポロジーを変化させた場合は,ネット ワークコストを大幅に削減することが可能である.こ のように,レイヤ間協調によるマルチレイヤトラヒッ クエンジニアリングは,ネットワークリソースの有効 な活用を可能にしている.
PCE
をベースとしたマルチ レイヤトラヒックエンジニアリングのフレームワークは
[42]
に述べられており,その適用事例が[43]
〜[45]
で紹介されている.また,ネットワーク最適化に関す る
PCE
のプロトコルが[46]
で記述されている.ネッ トワークリソースの有効利用するための計算手法とし て,数理計画法や発見的手法が用いられる[47], [48]
. 文献[49]
は,予測されたトラヒック需要が与えられ ない場合を想定して,観測されたトラヒックに基づい て,仮想ネットワークトポロジーを制御する方式を述 べている.文献[50]
は,観測されたトラヒックに基づいて,
5.
で述べるGMPLS
プロトコルを用いて,分散的に仮想ネットワークトポロジーを制御する方式の 有効性を示した.
5.
プロトコル・相互接続・標準化5. 1
マルチレイヤ制御とGMPLS
IP
パケットを転送するパケットネットワークにおい ても,コネクションという概念がある.MPLS
におい てはSIM
ヘッダによりパスを作り,パケットをその パス上で転送することにより,高速で且つ,トラヒッ クエンジニアリング(ルートの選択や輻輳制御)で優 れている[51]
.高速パケットシステムの延長線には,光技術との融合がある.つまり,パケットベースでの ネットワークの中で,トラヒックの多いコネクション は光パスへバイパスするものである.
MPLS
で,20
ビットのSIM
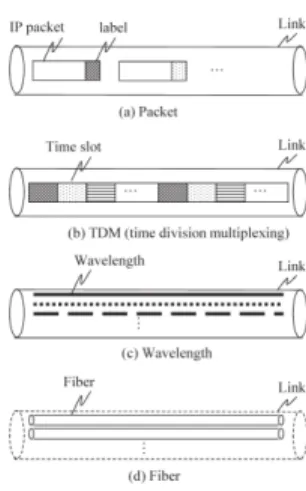
ヘッダをラベルとしているが,それを 更に一般化させて,TDM
のスロットや波長,光ファ イバもラベルとしてパスとして扱うこと(図19
)が研 究された.これがGMPLS
である[52], [53]
.ラベルを抽象化することにより,レイヤの違うネッ トワークを統合して,よりダイナミックに扱える可能 性が出てきた.それは,つまり図
20
に示すようにマ ルチレイヤをダイナミックに連携させることであり,その後の
4.
で述べたマルチレイヤトラヒックエンジ ニアリングへと発展していく.サービスやアプリケー ションを考えると,センサーデータのように,トラヒッ ク密度が低い場合は電気のパケットスイッチは最適で ある.一方,TV
の配信やサーバーのミラーリングと いった接続時間の長いサービスは波長パスのような技 術が適する.GMPLS
は高速パケット通信の波長で,バイパス若しくはオフロード技術を実現するために開 発された.
5. 2
相互接続性と標準化図
21
に一般的なネットワークモデルを示す.ユーザ とネットワークはUser-Network Interface (UNI)
であ図19 一般化されたラベルの概念 Fig. 19 Concept of generalized labels.
り,ユーザとの契約の元となる品質を定義したり,ユー ザが契約違反しないかをチェックしている.一つのキャ リアの範囲をドメインと言うとすると,他のキャリア 間は
External Network-Network Interface (E-NNI)
と定義され,キャリア間のシステムとシステムの間のイ ンタフェースはInternal NNI (I-NNI)
となっている.このインタフェース相互接続性は,グローバルスタン ダードの中で行われていかねばならない
[54], [55]
.標 準化は,グローバルにはInternational Telecommuni- cation Union Telecommunication Standardization Sector (ITU-T)
,Internet Engineering Task Force (IETF)
,Optical Internetworking Forum (OIF)
の3
か所で行われていた[56]
.我々は,例えばIETF
で の活動を強化する為に,NTT
,KDDI
等のキャリアを はじめ多くのベンダー,大学の入ったコンソーシアム,けいはんなオープンラボで相互接続性や標準化を検討 したり,完全に自由なベンダー活動をサポートする仮 想研究所
Photonic Internet Lab (PIL) [57]
を作り,更に中長期的な光ネットワークのストラテジーを作る
Photonic Internet Forum (PIF)
に参画しながら,米 国のIsocore (http://www.isocore.com/)
のファウン ティングメンバーとなり日本と米国と連携しながら,これらのプロトコルの研究,普及を行った
(
図22)
.超 高速パケットネットワークの研究開発,実用化には,部品機材技術,実装技術,システム
/
ネットワーク技 術と標準化をうまく連携させながら行う必要がある.ここでのキーポイントは,標準化作業そのもののみで はなく,事前の検証や相互接続コンソーシアムという 形によるグループ化と人脈を含めた長期的活動が重要
図20 GMPLSによるマルチレイヤネットワーク制御 Fig. 20 Multi-layer network control based on GMPLS.
図21 キャリア間,ベンダ間の接続を許容するインタ フェース
Fig. 21 Interfaces allowing connections between dif- ferent carriers and between different vendors.
図22 相互接続性のグローバル化 Fig. 22 Globalization of inter-operability.
である.
6.
む す び本論文は,電話中心のネットワークからビデオや マルチメディアといった高速のサービスをサポートす るネットワークとして発展した超高速パケットネット ワークを,アーキテクチャ,トラヒック設計,システ ム化技術,デバイス技術,実装技術として融合し,パ ケットネットワークシステムの研究開発を行い,更に 実用化を行った技術について述べた.パケットネット
ワークの主要トピックとして,パケットスイッチング システム,パケット競合制御,マルチレイヤトラヒッ クエンジニアリング,及び,プロトコル・相互接続・
標準化について述べた.
光ネットワークは,距離と帯域の制限を大幅に緩和 した.そして,単なるポイント
–
ポイント間の通信と しては,量的拡大のブレークスルーが得られ,また限 界も見えてきた.更にフレキシビリティを向上させる ためには,簡単なLayer 2
の機能を実現することが更 なる発展になる.そのため,ダイナミックなサーキッ トスイッチや光パケット・バースト技術が最重要であ る.ダイナミックなサーキットスイッチには,超高速 の光スイッチ素子,また,パケット・バーストに関し ては,超高速スイッチに加え,バッファや簡単な光に よる光の制御がブレークスルーになる.バッファは,現在は主に遅延線によるものであるが,スローライト やフォトニック結晶等のサイエンスからの改善も課題 であろう.信号処理に関しては,過去から研究はされ ているが,困難な点も多い.一方,明らかにポジティ ブなインパクトとしては,シリコンフォトニックスで あると考える.シリコンフォトニクスでは,電気回路 の
LSI
で広く使われるシリコン基板上に,光回路設 計技術及び極微細加工技術を用いて,発光素子,光 変調器,及び,受光器などの光デバイスをモノリシッ ク光集積回路として製作し,小型化することができ る[59]
〜[61]
.シリコンフォトニクスの極微細加工に は,半導体産業で高度に発達したプロセス技術を活用 することができる.電気も利用しつつ,光回路デバイ スを製造できるシリコンフォトニクスのポテンシャル は大きい.シリコンフォトニクスは,新エネルギー・産業技術総合開発機構
(New Energy and Industrial
図23 超成熟社会への未来予想 Fig. 23 Future forcast for super mature society.
Tehcnology Development Organization, NEDO)
の プロジェクトで日本は先行しており,既に簡単なトラ ンスミッター等は完成している.この優位性を生かし て,研究開発を行うべきだ.わずか
40
年前は電話サービスしかなかった通信ネッ トワークは,携帯電話やパーソナルコンピュータの進 展,そしてクラウドやWorld Wide Web (www)
の登 場,更にはInternet of Things (IoT)
やMachine to Machine (M2M)
といった今までとは数や頻度も大き く変わり,人工知能やビックデータに支えられた新し いサービスが登場するだろう.図23
にグラフを描い たが,我々の将来はサステーナブルで,人間中心の生 活や精神的にサポートされた超成熟社会[58]
へと向 かっている.情報通信技術,特に光通信の技術は,数 多くの社会的豊かさをクリエーションしてきて,今後 もサステーナブルで,よりエキサイティングな社会へ と発展していくと考える.文 献
[1] E. Oki, N. Yamanaka, and F. Pitcho, “Multiple- availability-level ATM network architecture,” IEEE Commun. Mag., vol.33, no.9, pp.80–88, Sept. 1995.
[2] N. Yamanaka, Y. Doi, H. Fukuda, T. Takenaka, and Z. Yashiro, “Very-high-speed ATM switching system technologies.” NTT Review, vol.1, no.2, pp.16–17, March 1997.
[3] J. Turner and N. Yamanaka, “Architectural choices in large scale ATM switches,” IEICE Trans. Commun., vol.E81-B, no.2, pp.120–137, Feb. 1998.
[4] H.J. Chao, C.H. Lam, and E. Oki, Broadband Packet Switching Technologies: A Practical Guide to ATM Switches and IP Routers, John Wiley & Sons, New York, 2001.
[5] D.J. Blumenthal, J. Barton, N. Beheshti, J.E.
Bowers, E. Burmeister, L.A. Coldren, M. Dummer,
G. Epps, A. Fang, Y. Ganjali, J. Garcia, B. Koch, V.
Lal, E. Lively, J. Mack, M. Ma˘sanovi´c, N. McKeown, K. Nguyen, S.C. Nicholes, H. Park, B. Stamenic, A.
Tauke-Pedretti, H. Poulsen, and M. Sysak, “Inte- grated photonics for low-power packet networking,”
IEEE J. Sel. Top. Quantum Electron., vol.17, no.2, pp.458–471, March/April 2011.
[6] N. Yamanaka, S. Kikuchi, T. Kon, and T.
Ohsaki, “Multichip 1.8-Gb/s high-speed space- division switching module using copper-polyimide multilayer substrate,” IEEE 40th Electronic Com- ponents & Technology Conference (ECTC), vol.1, pp.562–570, May 1990.
[7] T. Kawamura, N. Yamanaka, T. Matsumura, H.
Ichino, C. Yamaguchi, and Y. Kobayashi, “Sub-T bit/s large-capacity ATM MCM switching system de- sign and modules with new low-power Gbit/s I/O circuits,” 1995 IEMT Japan Symposium, pp.44–47, Dec. 1995.
[8] T. Kawamura, N. Yamanaka, and K. Kaizu, “Ad- vanced ATM-layer function MCM-D module for ATM wide-area network,” IEEE 47th Electronic Compo- nents & Technology Conference (ECTC), pp.486–
490, May 1997.
[9] N. Yamanaka, T. Kawamura, and K. Kaizu, “Ad- vanced ATM switching system line interface hard- ware technologies based on MCM-D integrated with ASIC and S-RAMS,” IEEE 1st 1997 IEMT/IMC Symposium, pp.286–289, April 1997.
[10] N. Yamanaka, T. Kawano, K. Kaizu, and A. Harada,
“Advanced ATM switching system hardware technol- ogy using MCM-D, stacking RAM micro-processor module,” IEEE 48th Electronic Components & Tech- nology Conference (ECTC), pp.884–888, May 1998.
[11] N. Yamanaka, K. Endo, K. Genda, H. Fukuda, T. Kishimoto, and S. Sasaki, “320 Gb/s high- speed ATM switching system hardware technolo- gies based on copper-polyimide MCM,” IEEE 44th Electronic Components & Technology Conference (ECTC), pp.776–785, May 1994.
[12] N. Yamanaka, K. Endo, K. Genda, H. Fukuda, T.
Kishimoto, and S. Sasaki, “320 Gb/s high-speed ATM switching system hardware technologies based on copper-polyimide MCM,” IEEE Trans. Compon.
Packag. Manuf. Technol. B, Adv. Packag., vol.18, no.1, pp.83–91, Feb. 1995.
[13] N. Yamanaka, E. Oki, S. Yasukawa, K. Genda, R.
Kawano, and K. Okazaki, “Tbit/s ATM switch- ing system hardware technologies in NTT,” Inter- national Conference on Computer Communication (ICCC ’99), no.1-3-5, Sept. 1999.
[14] 川野龍介,安川正祥,山中直明,“640 Gb/s WDMイン タコネクション用超小型10 Gb/s光モジュール,”エレ クトロニクス実装学会誌,vol.2, no.7, pp.552–555, Jan.
1999.
tration scheme,” IEEE ATM’97 Workshop, pp.28–35, May 1997.
[17] E. Oki, N. Yamanaka, Y. Ohtomo, and K.
Okazaki, “A 10-Gb/s (1.25 Gb/s x8)4x2 0.25-µm CMOS/SIMOX ATM switch based on scalable dis- tributed arbitration,” IEEE J. Solid-State Circuits, vol.34, no.12, pp.1921–1934, Dec. 1999.
[18] E. Oki and N. Yamanaka, “A high-speed ATM switch based on scalable distributed arbitration,” IEICE Trans. Commun., vol.E80-B, no.9, pp.1372–1376, Sept. 1997.
[19] 大木英司,山中直明,岡崎勝彦,川野龍介,大友祐輔,“ス ケーラブル超小型80 Gbit/s ATMスイッチングモジュー ルの開発,”信学論(B),vol.J83-B, no.4, pp.490–500, April 2000.
[20] E. Oki and N. Yamanaka, “A high-speed tandem- crosspoint ATM switch architecture with input and output buffers,” IEICE Trans. Commun., vol.E81-B, no.2, pp.215–223, Feb. 1998.
[21] E. Oki, N. Yamanaka, and Y. Ohtomo, “A 10Gb/s (1.25Gb/s×8) 4×2 CMOS/SIMOX ATM switch,”
IEEE International Solid-State Circuits Conference (ISSCC 1999), TA 9.6, pp.172–173, Feb. 1999.
[22] C. Clos, “A study of non-blocking switching net- works,” Bell Syst. Tech. J., pp.406–424, March 1953.
[23] N. McKeown, “TheiSLIP scheduling algorithm for input-queues switches,” IEEE/ACM Trans. Network- ing, vol.7, no.2, pp.188–200, April 1999.
[24] E. Oki, Z. Jing, R. Rojas-Cessa, and H.J. Chao,
“Concurrent round-robin dispatching scheme in a Clos-network switch,” IEEE International Confer- ence on Communications (ICC) 2001, pp.107–111, June 2001.
[25] E. Oki, Z. Jing, R. Rojas-Cessa, and H.J. Chao,
“Concurrent round-robin-based dispatching schemes for Clos-network switches,” IEEE/ACM Trans.
Netw., vol.10, no.6, pp.830–844, Dec. 2002.
[26] E. Oki, R. Rojas-Cessa, and H.J. Chao, “PCRRD:
A pipeline-based concurrent round-robin dispatch- ing scheme for clos-network switches,” IEEE Inter- national Conference on Communications (ICC) 2002, pp.2121–2125, April 2002.
[27] R. Rojas-Cessa, E. Oki, and H.J. Chao, “Maxi- mum weight matching dispatching scheme in buffered clos-network packet switches,” IEEE IEEE Interna- tional Conference on Communications (ICC) 2004, pp.1075–1079, June 2004.
IEEE Commun. Mag., pp.44–53, Dec. 1997.
[30] T. Anderson, S. Owicki, J. Saxe, and C. Thacker,
“High speed switch scheduling for local area net- works,” ACM Trans. Comput. Syst., vol.11, no.4, pp.319–352, Nov. 1993.
[31] E. Oki, K. Shiomoto, D. Shimazaki, N. Yamanaka, W. Imajuku, and Y. Takigawa, “Dynamic multilayer routing schemes in GMPLS-based IP + optical net- works,” IEEE Commun. Mag., vol.43, no.1, pp.108- 114, Jan. 2005.
[32] R. Ramaswami and K.N. Sivarajan, “Design of log- ical topologies for wavelength-routed optical net- works,” IEEE J. Sel. Areas Commun., vol.14, pp.840–
851, June 1996.
[33] B. Mukherjee, D. Banerjee, S. Ramamurthy, and A.
Mukherjee, “Some principles for designing a wide- area WDM optical network,” IEEE/ACM Trans.
Netw., vol.4, pp.684–696, Oct. 1996.
[34] S. Okamoto, E. Oki, K. Shimano, A. Sahara, and N. Yamanaka, “Demonstration of the highly reliable HIKARI router network based on a newly devel- oped disjoint path selection scheme,” IEEE Commun.
Mag., vol.40, no.11, pp.52–59, Nov. 2002.
[35] A. Farrel, J.P. Vasseur, and J. Ash, “A path com- putation element (PCE)-based architecture,” RFC 4655, Aug. 2006.
[36] J.P. Vasseur, J.L. Le Roux (Editors), A. Ayyangar, E. Oki, A. Atlas, A. Dolganow, Y. Ikejiri, and K.
Kumaki, “Path computation element (PCE) commu- nication protocol (PCEP),” RFC 5440, March 2009.
[37] J. Ash and J.L. Le Roux (Editros), A.K. Atlas, A. Ayyanagr, N. Bitar, I. Bryskin, D. Cheng, D.
Gangisetti, K. Kumaki, E. Oki, and R. Zhang, “Path computation element (PCE) communication protocol Generic requirements,” RFC 4657, Sept. 2006.
[38] J.-F.P. Labourdette, G.W. Hart, and A.S. Acampora,
“Logically rearrangeable multihop lightwave net- works,” IEEE Trans. Commun., vol.39, pp.1223–
1230, Aug. 1991.
[39] D. Banerjee and B. Mukherjee, “Wavelength-routed optical networks: linear formulation, resource bud- geting tradeoffs, and a reconfiguration study,”
IEEE/ACM Trans. Netw., vol.8, pp.598–607, Oct.
2000.
[40] F. Ricciato, S. Salsano, A. Belmonte, and M. Listanti,
“Off-line configuration of a MPLS over WDM net- work under time-varying offered traffic,” Proc. IEEE
INFOCOM, vol.1, pp.57–65, June 2002.
[41] E. Oki, K. Shiomoto, S. Okamoto, W. Imajuku, and N. Yamanaka, “A heuristic multi-layer optimum topology design scheme based on traffic measure- ment for IP+photonic networks,” Proc. Optical Fiber Communication Conference and Exhibit (OFC 2002), pp.104–105, March 2002.
[42] E. Oki, J.L. Le Roux, and A. Farrel, “Framework for PCE-based inter-layer MPLS and GMPLS traffic engineering,” RFC 5623, Sept. 2009.
[43] E. Oki, I. Inoue, and K. Shiomoto, “Path compu- tation element (PCE)-based traffic engineering in MPLS and GMPLS networks,” IEEE Sarnoff Sym- posium (SARNOFF 07), May 2007.
[44] M. Tatipamula, E. Oki, I. Inoue, K. Shiomoto, and Z. Ali, “Framework for PCE based multi-layer service networks,” IEICE Trans. Commun., vol.E90-B, no.8, pp.1903–1911, Aug. 2007.
[45] B. Jabarri, S. Gong, and E. Oki, “On constraints for path computation in multi-layer switched networks,”
IEICE Trans. Commun., vol.E90-B, no.8, pp.1922–
1927, Aug. 2007.
[46] Y. Lee, J.L. Le Roux, D. King, and E. Oki,
“Path computation element communication proto- col (PCECP) requirements and protocol extensions in support of global concurrent optimization,” RFC 5557, July 2009.
[47] E. Oki, Linear Programming and Algorithms for Communication Networks, CRC Press, Boca Raton, 2012.
[48] 大木英司,通信ネットワークのための数理計画法,コロナ 社,東京,2012.
[49] A. Gencata and B. Mukherjee, “Virtual-topology adaptation for WDM mesh networks under dynamic traffic,” Proc. IEEE INFOCOM, vol.1, pp.48–56, June 2002.
[50] K. Shiomoto, E. Oki, W. Imajuku, S. Okamoto, and N. Yamanaka, “Distributed virtual network topol- ogy control mechanism in GMPLS-based multi-region networks,” IEEE J. Sel. Areas Commun., vol.21, no.8, pp.1254–1262, Oct. 2003.
[51] E. Rosen, A. Viswanathan, and R. Callon, “Multipro- tocol label switching architecture,” IETF RFC 3031, Jan. 2001.
[52] E. Mannie, Editor, “Generalized multi-protocol label switching (GMPLS) architecture,” IETF RFC 3945, Oct. 2004.
[53] N. Yamanaka, K. Shiomoto, and E. Oki, GMPLS Technologies, CRC Press, Boca Raton, 2005.
[54] E. Oki, T. Takeda, and A. Farrel, “Extensions to the path computation element communication protocol for route exclusions,” IETF RFC 5521, April 2009.
[55] T. Takeda, E. Oki, Y. Iizawa, I. Nishioka, M. Asaie, K. Kusama, S. Okamoto, and T. Otani, “Inter-carrier PCE-based path computation in Keihanna interoper-
ablity project,” iPOP 2008, June 2008.
[56] 山中直明(編),MPLSとフォトニックGMPLS,電気通 信協会,2003.
[57] N. Yamanaka, “Photonic internet lab.: Breakthrough for leading edge photonic-GMPLS,” IEICE Trans.
Commun., vol.E87-B, no.3, pp.573–578, March 2004.
[58] 山中直明(編),インターネットバックボーンネットワーク,
電気通信協会,2014.
[59] 馬場俊彦,“シリコンフォトニクスによる新世代光集積と インタコネクション,”信学誌,vol.94, no.12, pp.1037–
1040, Dec. 2011.
[60] 硴塚孝明,藤井拓郎,西 英隆,佐藤具就,長谷川浩一,
土澤 泰,山本 剛,山田浩治,松尾慎治,“シリコン基板 上集積横注入薄膜レーザ,” NTT技術ジャーナル,pp.23–
26, Nov. 2015.
[61] 小川憲介,“シリコンフォトニクスをプラットフォームと した高速光変調器,” 光技術コーディネートジャーナル,
vol.35, no.9, pp.99–105, Sept. 2016.
(平成28年11月30日受付,29年3月22日再受付,
6月7日早期公開)
山中 直明 (正員:フェロー)
1981慶大・理工・計測卒.1983同大大 学院修士課程了.同年日本電信電話(株) 武蔵野電気通信研究所入社.以来,将来の Broadband ISDN,高速・広帯域交換方式 の研究開発,ATM網におけるトラヒック マネジメントに関する研究,超高速ATM ノードシステムの研究開発,GMPLS,光バックボーンの研究に 従事.2004慶大・理工・情報・教授,現在に至る.工博.1990, 1994, 1998 IEEE ECTC 40th,IEEE ECTC 44th,及び,
IEEE ECTC 48th Best Paper Award,1995 IEEE CPMT Part-B The Best Transaction Paper Award,同年電気通信 普及財団テレコムシステム技術賞,1998マイクロエレクトロ ニクスシンポジウム最優秀論文賞,1999 IEMT/IMT Best Paper Award,本会論文賞,本会業績賞,2011本会通信ソサ エティ論文賞,IEEE ISAS2011 Best Paper Award, IEEE Globecom 2015 Best Paper Award受賞.IEEE Commu- nication Surveys Broadband Network Area Editor,IEEE Com. Mag. Technical Editor,IEEE ComSoc Board,IEEE ComSoc Asia Pacific Board,本会フォトニックネットワーク 研究会委員長,本会東京支部長,本会編集理事を歴任.Photonic Internet Lab.代表.IEEEフェロー.
(Path Computation Element)のインターネットプロトコル 標準化に従事.2001–2002米国Polytechnic University大 学(Brooklyn, New York)にて客員研究員として,高速ス イッチングルータシステムの研究に従事.2008電通大准教授.
2013同大教授.2017京大教授.工博.本会論文賞,本会業績 賞,本会交換システム研究賞,IEEE Communication Society Asia-Pacific Outstanding Young Researcher Award,電気 通信普及財団テレコムシステム技術賞,IEEE HPSR 2012 Outstanding Paper Award, IEEE HPSR 2014 Best Paper Award Finalist, First Runner-Up, IEEE Globecom 2015 Best Paper Award等を受賞.IEEEフェロー.
![図 3 高速 LSI 技術の進展と適用領域 [2]](https://thumb-ap.123doks.com/thumbv2/123deta/10085171.1486405/2.774.414.700.395.572/図3高速LSI技術の進展と適用領域2.webp)


![Fig. 16 Network consisting of multiple layers and IP+optical node. の機能を備えたノードが存在する.両方のスイッチン グ能力を有するノードを IP 光統合ノードと呼ぶ [34] . IP 光統合ノードは,二つのスイッチング能力のインタ フェースを有しているので, IP トラヒック需要の変動 やネットワークのリソースを考慮しながら,最適な状 態になるように,光パスレイヤのトポロジーをダイナ ミックに変化させることができる. マルチレイヤトラヒッ](https://thumb-ap.123doks.com/thumbv2/123deta/10085171.1486405/8.774.407.705.103.333/スイッチンスイッチングネットワークマルチレイヤトラヒッ.webp)