人間らしい振る舞いを自動獲得するゲームAIに関す
る研究
著者
藤井 叙人
学位名
博士(工学)
学位授与機関
関西学院大学
学位授与番号
34504甲第597号
URL
http://hdl.handle.net/10236/00025139
博士論文
人間らしい振る舞いを自動獲得する
ゲーム
AI
に関する研究
2016
年
3
月
藤井 叙人
関西学院大学大学院
理工学研究科 人間システム工学専攻
概要
ビデオゲームにおけるエージェント(ゲーム AI が制御するキャラクタ)の振る 舞いの自動獲得において,「人間の熟達者に勝利する」という長年の目標が達成さ れつつある.「強さを追求したゲーム AI」は,人智を凌駕するコンピュータの実現 に多大な功績を残している.一方で,これらのゲーム AI が獲得したエージェント の振る舞いは過度に最適化されているため,人間プレイヤにとって機械的に映る という問題が浮き彫りになっている.ゲーム情報学領域における次のステップとし ては,「人間らしい知性を再現すること」,すなわち,十分に強くなったゲーム AI に如何にして「人間らしさ」を持たせるか,ゲーム AI と一緒に遊んだ人間プレイ ヤを如何にして「楽しませる」かが重要なテーマの一つとなっている.特にビデオ ゲーム業界では,プレイフィール(プレイ時の感覚や印象)を決定づける要因の一 つであるゲーム AI (COM:Computer Player あるいは NPC:Non-Player Character とも呼称される)の存在を無視することはできない.ユーザ数の増加,ひいては, 売上の増加には,人間らしいゲーム AI,人間プレイヤを楽しませるゲーム AI の実 装が欠かせない.そのため,市販ビデオゲームでは,プログラマの経験に基づく 綿密な作り込みと,数多くのデバッグプレイを繰り返すことにより,プレイヤの レベルにあわせた難易度の調整を含めたゲーム AI の振る舞いのデザインがなされ てきたが,その作業は極めて煩雑であり,リアリティを追求すると開発コストが 膨大とならざるをえない.人間らしく振る舞うエージェントを機械学習により自 動獲得するゲーム AI の試みもいくつか報告されているが,「人間らしさ」は個人性 が強い項目であることも影響して,人間らしいと思われる振る舞いの定義をどう するか,及び,人間らしさをどう評価するかという課題に直面している. 本研究では,人間らしい振る舞いを表出するエージェントを,開発者のヒュー リスティックに頼って実現するのではなく,機械学習手法により自動的に獲得する ゲーム AI の開発を目標とした.人間らしく振る舞うゲーム AI の構成要素を検討し た上で,構成要素の一つである,人間プレイヤに戦略レベルで適応するゲーム AI と,生物学的制約に基づく人間的なゲーム AI の実現手法を提案した.まずは,戦 略型ビデオ TCG を対象に,戦略を自動学習する戦略学習機構としてゲーム AI を 実装した.戦略学習における困難性として,部分観測に起因した巨大な状態空間 が挙げられるが,サンプリング手法や,ゲームの特徴を考慮した次元圧縮により克服した.戦略学習機構の評価として,ルールベース戦略を相手に学習実験を実 施し,戦略学習機構が様々な戦略への適応できていること,魔法や罠などの特殊 効果に起因する新たなルールの追加にも対応できていることを示した.次に,ア クションゲームの “Infinite Mario Bros.” を学習対象とし,『人間の生物学的制約』を 導入した機械学習及び経路探索により,人間らしい振る舞いを表出するゲーム AI を実装した.人間の生物学的制約としては「身体的な制約:“ゆらぎ”,“遅れ”,“ 疲れ”」,「生き延びるために必要な欲求:“訓練と挑戦のバランス”」と定義し,獲 得されたエージェントの振る舞いが人間らしいかどうかを主観評価実験により検 証した.実験結果から,生物学的制約を導入したゲーム AI は,人間プレイヤより も人間らしいと評定されることが確認できた.しかしながら,エンタテインメン ト系システムの主観評価実験では,ユーザのシステムに対する経験や知識,実験 手順が結果に大きく影響するため,実験の信頼性を確保することが非常に難しい. そこで,本研究では,ユーザ統制や実験手法による主観評価実験の信頼性確保を 最終目的とし,その足掛かりとして,エンタテインメント性を公正に評価するた めに考慮すべき統制視点について議論した.具体的な実験計画として,アクショ ンゲームの “ヨッシーアイランド” のプレイ動画視聴における主観評価実験を実施 し,その評定結果と発話プロトコル分析から,実験参加者間の評定結果の差異,及 び,実験参加者内での評価基準の変化が生じる例を示した.
目 次
第 1 章 序論 1 1.1 強いゲーム AI を追求した研究 . . . . 3 1.1.1 教師あり学習によるゲーム AI . . . . 3 1.1.2 教師なし学習によるゲーム AI . . . . 3 1.2 ゲーム AI 領域の今後の発展 . . . . 4 1.3 人間らしいゲーム AI を実装した研究 . . . . 7 1.3.1 強くない人間プレイヤのトレースによるゲーム AI . . . . 7 1.3.2 ヒューリスティックなパラメータ調整によるゲーム AI . . . 8 1.4 人間らしく振る舞うゲーム AI の構成要素の検討 . . . . 9 1.5 エンタテインメント系システムにおける評価実験の問題点 . . . 10 1.6 従来研究における人間らしさの評価方法と問題点 . . . 11 1.7 研究目的と論文構成 . . . 13 第 2 章 人間プレイヤに適応するゲーム AI の自律的構成 15 2.1 戦略型ビデオ TCG における戦略獲得の意義 . . . 15 2.2 トレーディングカードゲーム(TCG)の概要 . . . 16 2.3 問題設定 . . . 17 2.3.1 代表的な TCG のルール . . . 18 2.3.2 戦略型ビデオ TCG のルール設定 . . . 19 2.3.3 戦略学習法の検討 . . . . 22 2.4 学習機構の実装 . . . 23 2.4.1 最適行動選択 . . . 23 2.4.2 最適組み合わせ選択 . . . 27 2.4.3 状態異常攻撃の学習 . . . 29 2.4.4 罠効果の学習 . . . 30 2.5 シミュレーション実験 . . . 30 2.5.1 Rule-based のルール . . . . 31 2.5.2 様々な戦略への適応性 . . . 32 2.5.3 新たなルールの追加への適応性 . . . 342.5.4 内部の学習状況 . . . 34 2.6 考察 . . . 36 2.7 まとめ . . . 37 第 3 章 生物学的制約に基づく人間的なゲーム AI の自律的構成 39 3.1 人間の生物学的制約の定義 . . . 39 3.2 振る舞いの獲得 . . . 41 3.2.1 生物学的制約を導入した Q 学習 . . . 41 3.2.2 生物学的制約を導入した A*探索 . . . 42
3.2.3 “Infinite Mario Bros.” の仕様 . . . 42
3.2.4 “Infinite Mario Bros.” での振る舞い獲得 . . . 44
3.3 獲得された振る舞いの比較 . . . 47 3.4 主観評価実験 . . . 48 3.4.1 実験計画 . . . . 48 3.4.2 分析手法と結果 . . . 50 3.5 考察 . . . 51 3.6 まとめ . . . 54 第 4 章 主観評価実験におけるユーザ統制の検討 57 4.1 従来研究における具体例 . . . 57 4.1.1 キャラクタの振る舞いに関する事例 . . . . 57 4.1.2 テレビゲーム実施時の脳活動に関する事例 . . . 58 4.2 実験計画段階で考慮すべき統制視点 . . . 59 4.3 主観評価実験の実施 . . . 60 4.3.1 実験手続き . . . 61 4.3.2 実験結果 . . . . 63 4.3.3 熟練度と知識量による影響 . . . . 63 4.3.4 実験刺激の提示順序の影響 . . . . 64 4.3.5 評価基準,評価軸の変更による影響 . . . . 66 4.3.6 考察 . . . 68 4.4 まとめ . . . 68 第 5 章 総合考察 69 5.1 提案したゲーム AI の汎用性 . . . 69 5.2 ゲーム AI における人間らしさのあり方 . . . 70 第 6 章 結論 73
参考文献 75
関連発表論文 81
受賞 85
図 目 次
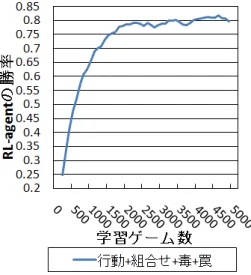
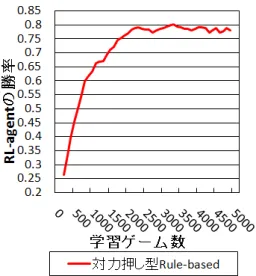
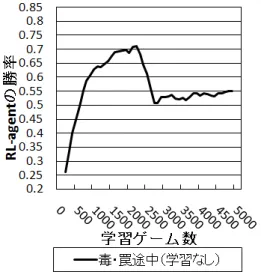
1.1 本論文の構成 . . . 13 2.1 最適行動学習機構 . . . 23 2.2 RL-agent の勝率 . . . 32 2.3 RL-agent の勝率 (対 力押し型) . . . 33 2.4 RL-agent の勝率 (対 堅実型) . . . 33 2.5 途中で毒と罠を追加(毒と罠の学習あり) . . . 34 2.6 途中で毒と罠を追加(毒と罠の学習なし) . . . 35 2.7 行動予測器の正解率 . . . 35 2.8 属性相性学習器の正解率 . . . 363.1 “Infinite Mario Bros.” のゲーム画面 . . . . 43
3.2 次元圧縮された観測情報 . . . 45 3.3 導入なし(左列)と導入あり(右列)での振る舞いの比較 . . . 55 3.4 人間らしさに関する相対的嗜好度 . . . 55 3.5 人間らしさに関する相対的嗜好度.速さと相関ありの実験参加者 5 名を除いた 15 名での分析結果. . . . 56 4.1 ヨッシーアイランドのゲーム画面 . . . 60 4.2 実験参加者 8 名の評定の平均 . . . 64
表 目 次
2.1 各モンスターのパラメータ . . . 21 2.2 モンスターの属性表 . . . 21 3.1 行動の種類とキー入力の組合せ . . . 46 3.2 振る舞いを比較する Q 学習エージェント . . . 47 3.3 プレイ動画のラベルと内容 . . . 49 4.1 チェック項目の一部 . . . 62 4.2 評定に用いたプレイ動画 . . . 63 4.3 個人毎の評定結果(上手さ) . . . 65 4.4 評定結果の変更回数 . . . 65 4.5 個人毎の評定結果(人間らしさ) . . . 67 4.6 人間らしさの評定と動画時間との相関係数 R の遷移 . . . 67第
1
章 序論
1949 年にクロード・シャノンが発表した「チェスのためのコンピュータプログラ ミング [1]」,1950 年にアラン・チューリングが問題提起した「チューリングテス ト(機械が知的かどうか判定するためのテスト)[2]」を皮切りに,人工知能領域 では現在に至るまでに多くの研究成果が報告されている.人工知能領域の根幹的 な興味は現在においても当時と変わらず,「複雑な思考ゲームにおいて人間の熟達 者に勝利すること(人智への挑戦)」と,「コンピュータやヒューマノイドロボット において人間らしい知性を再現すること(知性の創発)」であり,世界中の研究者 が精力的な研究活動を展開している.近年では,ゲーム木探索手法の発展や,マル チコア CPU やクラスタ PC といった計算速度の向上に伴い,ついに「人間の熟達 者に勝利する」という人工知能領域の長年の目標の一つを達成しつつある.1993 年にはチェッカーにおいて,1997 年にはオセロにおいて,コンピュータプログラ ムは世界チャンピオンに勝利を収めている.チェスにおいても,1997 年に IBM が 手がけたチェス専用スーパーコンピュータ Deep Blue が世界チャンピオンを打ち 負かしている.また,2013 年 3 月に最強のコンピュータ将棋プログラムが現役の プロ棋士に史上初の勝利を収め,2014 年 8 月にはコンピュータ将棋の実力がトッ ププロ棋士に追い付いているという分析結果 [3] が出たことから,2015 年 10 月に コンピュータ将棋プロジェクト(トッププロ棋士に勝利することが目的)の終了 が宣言されている.これら「強さを追求したゲーム AI」は,人智を凌駕するコン ピュータの実現というグランドチャレンジの達成に多大な功績を残している.一方 で,これらのゲーム AI が獲得したエージェントの振る舞いは過度に最適化されて いるため,人間プレイヤにとって機械的に映るという問題が浮き彫りになってい る.ゲーム情報学領域における次のステップとしては,「人間らしい知性を再現す ること」,すなわち,十分に強くなったゲーム AI に如何にして「人間らしさ」を 持たせるか,ゲーム AI と一緒に遊んだ人間プレイヤを如何にして「楽しませる」 かが重要なテーマの一つとなっている. ビデオゲームの分野に目を向けると,ゲーム AI(COM:Computer Player ある いは NPC:Non-Player Character とも呼称される)への人間らしさの実装に余念が 無いことが覗える.家庭用ゲームに代表されるゲームコンテンツ市場は,年々躍第 1 章 序論 進を続けており(2014 年の国内市場規模:前年比 4.17%増の 1 兆 1925 億円 [4]), ビデオゲームにおけるプレイフィール(プレイ時の感覚や印象)を決定づける要 因として,ゲーム内に登場するコンピュータ担当のエージェント(本論文ではゲー ム AI が制御するキャラクタをエージェントと表記する)の存在を無視することは できないためである.ユーザ数の増加,ひいては,売上の増加には,人間らしい ゲーム AI,人間プレイヤを楽しませるゲーム AI の実装が欠かせない.そのため, 市販ビデオゲームでは,プログラマの経験に基づく綿密な作り込みと,数多くの デバッグプレイを繰り返すことにより,プレイヤのレベルにあわせた難易度の調 整を含めたゲーム AI の振る舞いのデザインがなされてきたが,その作業は極めて 煩雑であり,リアリティを追求すると開発コストが膨大とならざるをえない. 人間らしいゲーム AI を機械学習により自動獲得する試みもいくつか報告されて いる.強くない人間プレイヤのトレースによる教師あり学習手法 [5, 6, 7],強い ゲーム AI の学習パラメータにヒューリスティックを導入する手法 [8, 9, 10] が提案 されており,人間らしいゲーム AI の実現に向けた先駆け研究といえる.しかし, 人間らしいと思われる振る舞いを開発者が恣意的に定義しなければならず,その 作業は困難を極める.また,人間らしい AI の人間らしさをどう評価するかという 問題にも直面している.チューリングテストに準じた主観評価を実施するのが一 般的ではあるが,「人間らしさ」や「楽しさ」といった個人個人の捉え方が異なる 項目については,評価者を精緻に統制しない限り信頼性の高い評価結果は得られ ない. 本論文では,ビデオゲームを対象として,「人間らしい」振る舞いを機械学習に より自動的に獲得するゲーム AI を提案する.人間らしく振る舞うゲーム AI の構 成要素を検討した上で,構成要素の一つとなる,人間プレイヤに戦略レベルで適応 するゲーム AI と,生物学的制約に基づく人間的なゲーム AI の実現手法を述べる. また,ゲーム AI の人間らしさを評価する際の主観評価実験における,実験結果の 妥当性や再現性を確保するためのユーザ統制及び実験手法についても議論する. 以下,本章では,ゲーム AI 研究の背景を交えながら,強さを追求したゲーム AI の研究事例を述べる.次に,ゲーム AI 領域の今後の発展について検討し,そのう ちの 1 つである「人間らしいゲーム AI の実現」を目指した研究事例を紹介する. 本研究で扱う人間らしいゲーム AI の構成要素を示した後,人間らしさを評価する 上での問題点について議論する.また,その問題点を踏まえて,従来研究におけ る主観評価実験の具体例を述べる.最後に,本研究の目的と本論文の構成につい て述べる.
1.1 強いゲーム AI を追求した研究
1.1
強いゲーム
AI
を追求した研究
エージェントの強い振る舞いを自動的に獲得する手法として,教師データを入 力とする教師あり学習の手法と,ゲーム木探索や試行錯誤による教師なし学習の 手法とに大別される.本節では,それぞれの手法を採用して強いゲーム AI を実現 した研究事例を紹介する.1.1.1
教師あり学習によるゲーム
AI
教師ありの機械学習手法は,入力データに対して出力されるべきデータが明確 であり,かつ,学習の際に大量の教師データを用意できる場合に有効な学習手法 である.事前に与えられた大量のデータセットを教師データとして用い,最適な 結果を出力するためのルールを学習する. 教師あり学習によるアプローチの代表的な研究事例として,保木は,コンピュー タ将棋プログラムである Bonanza を構築している [11].Bonanza は,プロ棋士の棋 譜 6 万局のデータを教師とし,将棋の局面における評価関数を自動学習すること で,従来手法よりも良い振る舞いを得ることに成功している.この手法は Bonanza メソッドと呼ばれ,多くのコンピュータ将棋プログラムで採用されている画期的 な手法である [12, 13].将棋のように,強い人間プレイヤの膨大な棋譜データが用 意できる場合には,教師あり学習による振る舞い獲得は有効である.コンピュー タ将棋プログラムは,2013 年 3 月に現役のトッププロ棋士に史上初の勝利を納め, 以降,2013 年,2014 年とトッププロ棋士に勝ち越している.2015 年は,「プロ棋 士側に事前にコンピュータ将棋プログラムを貸し出す」というルールを活かした プロ棋士側の勝ち越しとなったが,プロ棋士といえど対コンピュータ将棋プログ ラムの戦略を十分に準備しなければコンピュータに勝てないことが明らかとなっ た [14, 15].1.1.2
教師なし学習によるゲーム
AI
教師なしの機械学習手法は,入力データに対して出力すべき結果があらかじめ 決まっていない場合,または,大量の教師データを用意することが困難な場合に 有効な学習手法である.シミュレーションで与えられた大量の入力データを用い て学習を繰り返し,ある目的関数を最適にするような結果を出力する.教師なし 学習の代表的な手法として,経路探索と強化学習が挙げられる. 経路探索は,ゲーム木におけるスタートからゴールまでの,最小コストとなる 経路を探索する手法である.経路探索によるアプローチの代表的な研究として,第 1 章 序論
Baumgarten は,2009 年の Mario AI Competition において,A*アルゴリズムに基
づいたゲーム AI を構築している [16].Mario AI Competition とは,“Infinite Mario
Bros.” (ランダムに生成されるステージを制限時間内に攻略する,「スーパーマリ オワールド」のようなアクションゲーム)を対象としたゲーム AI の評価コンテス ト [17] である.Baumgarten のゲーム AI はマリオや敵の動きを事前に解析し,A* アルゴリズムを用いた経路探索によって,ステージをほぼ最適解で攻略すること が可能であり,評価コンテストで見事優勝を収めている. 強化学習は,自身の振る舞いの試行錯誤を繰り返すことで最適な振る舞いを獲 得する手法である.強化学習によるアプローチの代表的な研究として,Tsay らは, 2009 年の Mario AI Competition において,Q 学習に基づいたゲーム AI を構築して いる [18]. Tsay らのゲーム AI は,敵を倒すこと,アイテムをとること,穴を飛び 越えること,敵を避けることに対して報酬を与えることで,マリオの振る舞いの 自動獲得に成功しており,評価コンテストで 4 位(強化学習ゲーム AI では 1 位) の成績を収めている.また,Fujita らは,カードゲームの Hearts を題材とし,Q 学 習に基づいたゲーム AI を構築している [19, 20, 21, 22].トランプを 52 枚用いる ため巨大な状態空間となること,相手の所持するカードは観測できないため部分 観測状況となること,4 人対戦のマルチエージェントゲームであることの 3 つを, Hearts における戦略学習の困難性と考察している.その上で,困難性の解決手法 として,パーティクルフィルタによるサンプリング,相手の行動予測器,現在の局 面を評価するための状態価値関数,ゲームの特徴に基づく次元圧縮を提案し,困 難性の解決を図っている.計算機実験として,提案手法に基づく学習エージェン トと,ルールベースエージェント 3 体とを対戦させた結果,約 2,000 ゲーム学習後 にはルールベースエージェントよりも強い戦略を,約 4,000 ゲーム学習後には,人 間の熟達者よりも優れた戦略を得ることに成功している.藤田らは,提案手法に よる戦略学習が Hearts だけではなく,他の部分観測カードゲームへも応用が可能 であり,問題に依存した様々な状況に対しても適用することができると検討して いる.
1.2
ゲーム
AI
領域の今後の発展
前節で述べたとおり,チェスや将棋などの確定完全情報ゲーム(偶然の要素が なく,ゲーム局面の全ての情報を観測可能なゲーム)や,合法手が比較的少ない Hearts のような確定 “不” 完全情報ゲーム(偶然の要素はないが,ゲーム局面の一 部の情報しか観測できないゲーム)では,強いゲーム AI は人間の熟達者よりも優 れた戦略を得ることができている.スーパーマリオワールドも,マリオや敵の動 きは一定のアルゴリズムに従っており,ゲーム画面の全ての情報を観測できると1.2 ゲーム AI 領域の今後の発展 いう意味で,リアルタイムな操作を要求される確定完全情報ゲームに分類できる. 将来的には,マルチコア CPU やクラスタ PC の利用による計算資源の増大や,処 理速度の向上がさらに加速し,様々なゲームにおいて,人智を凌駕するコンピュー タの実現が達成されると考えられる.ゲーム AI 領域では今後の発展として以下の 4 つの課題が取り組まれている. 1. より複雑で難しいゲームを対象とした強いゲーム AI の開発 2. 強いゲーム AI をツールとして利用する方法の検討 3. 人間特有の駆け引きや騙し合いを伴う心理ゲームを対象としたゲーム AI の 開発 4. 強さだけでなく,人間らしさや自然さを表出するゲーム AI の開発 1 つめは,将棋やマリオよりも複雑で難しいゲームを対象とした強いゲーム AI の開発である.囲碁 [23, 24, 25],ターン制戦略ゲーム [26, 27],麻雀 [28],リアル タイムストラテジーゲーム(RTS)[29, 30] などを学習対象に,多数の研究成果が 報告されている.囲碁はチェスや将棋と同じく確定完全情報ゲームであるが,状 態空間が非常に大きく(チェスが 10 の 120 乗,将棋が 10 の 220 乗であるが囲碁は 10 の 360 乗以上),かつ,大局観(全体の形の善し悪しの見極めのこと)が必要 とされるゲームである.囲碁のゲーム局面は黒石・白石しかなく,将棋の駒のよ うな能力差がないため,形勢の判断が非常に難しく,強いゲーム AI の構築は困難 を極める.2016 年 1 月 28 日にはグーグルの研究グループが開発したコンピュータ 囲碁「AlphaGo」が人間のプロ棋士に勝利したことが発表され [31],今後ますます 活発な研究が行われるゲームと言える.ターン制戦略ゲームも確定完全情報ゲー ムではあるが,歩兵,戦車,戦闘機といった各駒のパラメータが複雑であり,さら に,1ターンに複数の駒を動かせる,駒間に有利不利が設定されているなど,将棋 や囲碁とはルールが大きく異なっている.麻雀や RTS は不確定不完全情報ゲーム であり,強いゲーム AI の構築には,偶然の要素の考慮や相手の駒の予測が必要と なる.特に RTS は状態空間が 10 の 1600 乗とも言われており,不確定不完全情報 ゲームであることも相まって,強いゲーム AI の獲得が非常に困難なゲームの一つ である.ターン制戦略ゲーム,麻雀,RTS では,ゲーム状態空間の大きさやゲー ムルールの複雑さに起因する解決困難な課題が多々あり,人間の熟達者を超える 戦略の自動獲得には至っていないのが現状である. 2 つめは,強いゲーム AI をツールとして利用する方法の検討である.チェスや 将棋では,プロプレイヤがコンピュータで指し手を調べながら対局するアドバン スドチェス・将棋の大会が行われており,当然人間プレイヤはコンピュータを使 用しながら対局した方がミス無く戦えることが分かっている.また,プロ棋士と
第 1 章 序論 コンピュータ将棋の対局でも,プロ棋士は対コンピュータ将棋プログラムの戦略 を用意することでコンピュータに勝った事例もあり,強いゲーム AI が人間プレイ ヤをより成長させる可能性が示唆されている.しかし,強いゲーム AI が,どのよ うな人間プレイヤにどのような情報をどのタイミングで提示するべきかは難しい 問題であり,今後の課題として取り組まれている. 3 つめは,人間特有の駆け引きや騙し合いを伴う心理ゲームを対象としたゲーム AI の開発である.特に,多人数不完全情報ゲームである「人狼」を扱った研究が 多く報告されている [32, 33, 34].人狼は,ゲーム内での自然言語によるプレイヤ 同士の会話が重要な役割を果たしており,嘘をついて騙す,嘘を見抜く,自分が相 手にどう見られているか推察する,相手と交渉して説得するといった高度な駆け 引きが必要となるゲームである.自然言語による自然な会話に加え,嘘や交渉と いった高度な知能を持ったコンピュータの実現難易度は非常に高い. 4 つめは,強さだけでなく,人間らしさや自然さを表出するゲーム AI の開発で ある.機械学習手法を用いて獲得されたゲーム AI は,人間の熟達者を超えるほど の戦略を獲得できる一方,きわめて最適であるが故に,人間にとっては機械的と 感じる振る舞いを表出してしまう,という問題が浮き彫りになっている.そのた め,ゲーム AI 領域では,今後の最重要課題の一つとして,人間らしいゲーム AI の構築に注目が集まっている. 本論文では,4 つめの,人間らしさや自然さを表出するゲーム AI の開発を目指 す.人間の能力を遥かに上回る反応速度や操作精度を持った強いゲーム AI が,人 間プレイヤにとってのゲームの面白さを損なう要因になることは想像に難くない. 例えば,FPS(First Person Shooter:一人称視点シューティング)ゲームにおいて, 自分が姿を見せた瞬間に超高速で狙いを定めて射撃してくる敵キャラクタや,格闘 ゲームにおいて,自分の攻撃に対して超反応で防御をして難易度の高いコンボ攻 撃で反撃してくる敵キャラクタなどは,人間にとっては実現不可能であるが,ゲー ム AI にとっては非常に容易なことである.このような敵キャラクタの存在は,人 間プレイヤに不公平感を与える要因となり,プレイヤのモチベーションを削ぐこ とにつながる.強さを追求する上では最適な振る舞いであっても,人間プレイヤの 相手や人間プレイヤの代替としては最適であるとは言いがたい.人間プレイヤの 代替となる人間らしいゲーム AI には,人間プレイヤが犯しがちな失敗をする [10], 人間プレイヤにありがちな戦略をとる [35],相手の力量に合わせて自然な手加減 をする [7, 9],相手プレイヤの戦略に合わせて戦略を切り替える,人間プレイヤと 同等の身体的制約をもっている,といったような能力が要求される. 以降,1.3 節では,人間らしいゲーム AI を実装した研究事例を紹介し,1.4 節で は,人間らしいゲーム AI の構成要素として挙げた能力のなかでも,相手プレイヤ の戦略に合わせて戦略を切り替える,人間プレイヤと同等の身体的制約を持つ,の
1.3 人間らしいゲーム AI を実装した研究 二つに焦点を当て議論する.
1.3
人間らしいゲーム
AI
を実装した研究
機械学習手法によって獲得された強すぎる(最適すぎる)ゲーム AI の問題を解 決する方法として,強くない人間プレイヤのプレイログを教師データとして学習 を進める手法と,人間らしい特徴を分析し際立たせるように機械学習のパラメー タを開発者が調整する手法が挙げられる.本節では,それぞれの手法を採用して 人間らしいゲーム AI の実現を目指した研究事例について紹介する.1.3.1
強くない人間プレイヤのトレースによるゲーム
AI
強くない人間プレイヤのプレイログを教師データとした代表的な研究例を 3 つ 紹介する.Polceanu ら,Schrum らは,2012 年の The 2K BotPrize 2012 において,大会史
上初となる,人間よりも人間らしいと評価されるゲーム AI の構成に成功している
[36, 5].The 2K BotPrize とは,FPS(一人称視点シューティングゲーム)の “Unreal Tournament 2004” を対象とした,ゲーム AI の人間らしさを競う評価コンテストで ある.Polceanu らの提案手法では,リアルタイムに他のプレイヤの行動を記録し, そのプレイヤの行動を部分的に再現することによって,人間らしく振る舞うゲー ム AI を実現している.また,Schrum らの提案手法では,人間プレイヤの振る舞 いをトレースしたデータベースを基に,人間らしいと思われる振る舞いを決定論 的に定義し,ニューラルネットにおける制約として適用している.人間プレイヤ は最適な行動をとるよりも特定の敵を粘り強く追跡する傾向がある,とした上で, 積極的に他のプレイヤへの悪意(恨み)を持つゲーム AI として実装している.本 コンテストの評価の結果,対戦相手の人間プレイヤからそれぞれ 52.2%,51.9%の 割合で「人間らしい」と評価されるゲーム AI の振る舞いが獲得できている.人間 プレイヤが他のプレイヤから「人間らしい」と評価された割合の平均は 41.4%で あり,Polceanu ら,Schrum らのゲーム AI は人間プレイヤよりも人間らしいこと が示されている.
Ortega らは,“Infinite Mario Bros.” を学習対象に,人間プレイヤの操作ログを教
師としてキャラクタの通った軌跡をトレースするよう学習するゲーム AI を,教師 あり学習手法で実現している [6].トレース精度の評価の結果,大半の箇所は,人 間プレイヤが操作したキャラクタの振る舞いを正確にトレースできている.しか し,部分的に見ると人間プレイヤが操作したキャラクタと異なる振る舞いをして
第 1 章 序論 しまう箇所もある.人間プレイヤの動画と比較する主観評価実験も実施している が,人間プレイヤより人間らしいという評価には至っていない. 仲道らは,コンピュータ将棋を学習対象とし,アマチュアプレイヤの棋譜のみ を用いて評価関数を学習させることで,将棋 AI の棋力を自然に弱く調整すること に成功している [7].Bonanza[11] ベースの将棋 AI に,将棋初級者レベルのみ,及 び,中級者レベルのみの棋譜を教師データとして与えて学習を進め,さらに,同 程度の強さになるように合法手の探索の深さを調整している.獲得された将棋 AI の棋譜の人間らしさは,大学将棋部のアマチュア学生(上級者レベル)とプロ棋 士(熟達者レベル)を実験参加者とした主観評価実験によって検討している.実 験の結果,提案手法により獲得された将棋 AI は,プロ棋士は人間プレイヤか将棋 AI かの区別がつくが,アマチュアでは人間プレイヤと区別がつかないことが示さ れている.
1.3.2
ヒューリスティックなパラメータ調整によるゲーム
AI
人間らしい特徴を分析し際立たせるように機械学習のパラメータを調整するこ とを目指した研究例を 3 つ紹介する. 杵渕らは,コンピュータ将棋を学習対象に,プロ棋士の棋譜に多く出現する指 し手順を抽出し,将棋 AI の指し手選択時にその手順を選択しやすく調整すること で,プロ棋士が指しがちな自然な手の流れを再現する将棋 AI を提案している [8]. 人間同士の対局の棋譜とコンピュータ同士の対局の棋譜を,将棋の手順の構成に 重要な 4 つの特徴量により分析し,人間プレイヤは選択しがちだがコンピュータは 採用しない手順を抽出している.将棋 AI の実装は,Bonanza[11] をベースに,抽 出された手順を重視して指し手を選択するような評価関数を追加している.主観 評価実験では,将棋の上級者から熟達者レベルの実験参加者に手の流れの自然さ を評価させており,その結果,人間にとってより自然だと感じられる指し手を生 成できていることが示されている. 池田らは,コンピュータ囲碁を対象に,既存の強いゲーム AI に意図的に人間ら しいミスをさせることで,手加減と思われない程度の「強くなさ」を実現するため の初期的検討を実施している [9].うまく手加減を行い相手に楽しんでもらうため の「接待碁 AI」に必要な要素技術として,形勢の誘導,不自然な着手の排除,多 様な戦略などを挙げている.モンテカルロ法 [23] による囲碁 AI をベースとして, 現在の局面における予測勝率と候補手の選択確率を用いた形勢の制御,また,楽 観派や悲観派といったプレイスタイルによる獲得戦略の分析をしており,ゲーム の難易度調整における一アプローチを提案している. 伊藤らは,人間はゲームをプレイするときには必ずミスを犯すものとし,ゲー1.4 人間らしく振る舞うゲーム AI の構成要素の検討 ムにおけるヒューマンエラー(ミス)の分類と,その認知的なメカニズムのモデ ルを提案している [10].ヒューマンエラーのモデルとして,人間の生物学的制約, 個人の技量不足,無意識的なエラー,意識的なエラーがあると考察している.ま た,将棋を題材とした主観評価実験において,将棋上級者レベルの人間プレイヤ の発話プロトコルを分析することで,そのモデルの妥当性を検討している.最後 に,コンピュータ将棋 AI にヒューマンエラーを導入するための方法論についても 議論している. 上記の手法は,人間らしいゲーム AI の実現に向けて,非常に有効な成果を上げ られている.しかし,人間らしいと思われる振る舞いを開発者が恣意的に定義し たものであり,振る舞い獲得における作業負荷はむしろ増大しているという問題 もある.
1.4
人間らしく振る舞うゲーム
AI
の構成要素の検討
1.2 節でも述べたとおり,「人間らしいゲーム AI」には様々な構成要素が考えら れる.前節で述べた従来研究では,人間プレイヤが選択しがちな行動や戦術をト レースすることにより,また,人間が犯してしまいがちな戦術的ミスをわざと再 現することにより,ゲーム AI の人間らしさを実現している.本研究では,機械学 習手法を用いて,人間らしく振る舞うゲーム AI を自動的に獲得することを目指す が,人間らしさの実現方法としては,相手の戦略への適応とルール変更時の対応, 及び,人間プレイヤのような生物学的制約の実装を目標とする. 前者について,人間プレイヤは,ゲームのルールに準じて行動を選択するだけ でなく,様々な相手戦略に対しても臨機応変に適応できる.相手が攻撃重視の戦 略であれば自分は防御重視の戦略を採用したり,相手が戦力増強を図っていれば 自分も同様に戦力増強に努めるといった,戦略レベルでのやりとりがゲームの楽 しみの一つでもある.また,人間プレイヤは,ルールに変更や追加が生じても柔 軟に対応できる.アップデートによってゲームの仕様が変更されたり,新たなキャ ラクタが追加されたとしても,それらを踏襲した最適戦略を考えることも楽しみ につながる.しかしながら,従来研究では,行動のトレースやミスの再現といっ た,戦術レベルの人間らしさしか考慮されていない. 後者について,人間プレイヤがゲームをする際には必ず,人間が生得的・遺伝 的にもつ特徴や性質から生じる生物学的制約の影響を受けているはずである.従 来研究では,生物学的制約を無視しているために,機械的と感じる振る舞いが表 出していると考えられる.コントローラ操作の反応速度が速すぎる,コントロー ラのボタンの入力が正確すぎる,常に一定の行動のみを正確に繰り返すといった, 人間プレイヤでは実現不可能な振る舞いが表出するケースもある.また,難易度調第 1 章 序論 整を重視しすぎると,ゲームの途中から急に弱くなる,あからさまなコントロー ラ操作のミスをするといった,プレイスタイルの統一性が崩壊した振る舞いが表 出するケースもある.これらの振る舞いは,「相手がいんちきをしているのでは」, 「本当に自分の力で勝ったのか」という疑念を生むため,人間プレイヤのゲームへ のモチベーションを削ぐ要因といえる. 機械学習手法を用いて獲得されたゲーム AI の振る舞いについては,その振る舞 いの性質を証明するための評価実験が必要となる.しかし,本研究において評価 すべき対象は「人間らしさ」や「自然さ」といった,人間の主観に頼らざるを得 ない項目である.次節では,エンタテインメント系システムにおける評価実験の 問題点について議論する.
1.5
エンタテインメント系システムにおける評価実験の
問題点
工学系の研究においてシステムを開発した際,その有用性や信頼性を示す評価 実験は必要不可欠である.HCI 系の研究領域においては,システムのユーザが人 間であることから,人間を対象とした主観評価実験が実施されてきた [37, 38].主 観評価実験の中でも,「使いやすさ」や「見やすさ」といった知覚に関連した事項 では,実験参加者による評価の差異(ぶれ)は少なく,ある程度妥当な実験結果 が得られると考えられる.これに対し,エンタテインメント系システム(EC 系シ ステム)において定量化したい評価項目である「楽しさ」や「人間らしさ」といっ た認知に関連した事項は,かなり個人性が強く,その概念に対する個人の捉え方 を統制することは困難である. このような問題意識から,これまでにも,皮膚電気活動や脳血流といった生理 指標に着目した研究 [39, 40, 41, 42] や,センサやカメラを用いてユーザのシステ ム使用状況を物理的に評価する研究 [43, 44] が行われてきた.これらの研究では, システムのエンタテインメント性を,客観的,定量的に評価することができてい るといえる.しかし,実験計画に起因して,得られた知見が必ずしも一般性を主 張できるものでなかったり,さらには,追試をすること自体が困難であるような 事案が少なからず見受けられる. そのような状況を踏まえ,EC 系システムの評価実験において考慮していくべき 事項,特に,実験参加者の経験・知識の把握や統制に関して議論をする必要があ る.本研究では,安定した評価実験を行なうにあたって考慮すべき統制視点の検 討も実施する.次節では,従来研究における人間らしさの評価方法を紹介した後, 実験参加者の経験や知識の量が実験結果に影響を及ぼしている可能性を指摘する.1.6 従来研究における人間らしさの評価方法と問題点
1.6
従来研究における人間らしさの評価方法と問題点
人間らしい AI の実現を目指す上で避けては通れない課題として,獲得された ゲーム AI の人間らしさをどう評価するかという問題がある.人間らしさの評価に は,1950 年にアラン・チューリングが考案した実験手法である「チューリングテ スト [2]」を土台とした主観評価実験が執り行われるのが一般的である.チューリ ングテストとは,ある機械が(人間と同等に)知的であるか,あるいは,人工知 能であるかを判定するためのテストである.実験参加者は,隔離された部屋にい る別の人間及び機械と,キーボードとディスプレイによる文字のみの会話を行う. その際,人間も機械も人間らしくみえるように対応する.5 分間の会話の後に,会 話の相手が人間であったか機械であったかを判定する.30%以上の実験参加者が, 話し相手が人間であったか機械であったかの判別をできなかった場合,その機械 はチューリングテストに合格したことになる. チューリングテスト合格に向けた取り組みは,1966 年に Weizenbaum によって 開発された,精神療法医による心理セラピーをシミュレートした自然言語処理プ ログラムの ELIZA[45] や,1972 年に Colby によって発表された,統合失調症患者 をシミュレートした会話ボットの PARRY[46] が有名である.2014 年 6 月には,「質 問が無作為に出題される 5 分間の会話」という難易度の高いチューリングテスト において,ロシアのスーパーコンピュータが 33%の審査員ら(30 人中 10 人)の目 を欺き,史上初めての合格者となった.このチャットボットは Veselov らによって 開発され,「ウクライナ在住の 13 歳の少年で,婦人科医の父親を持ち,ペットとし てモルモットを飼っている,Eugene Goostman(ユージーン・グーツマン)君」と いう設定であった.英語は第二言語である 13 歳の少年という設定のため,会話に おいて英語の文法上の間違いがあったとしても仕方ないと審査員らに解釈させた ことが,チューリングテスト合格につながる鍵であった.また,最も重要な機能 の 1 つに「タイプミスの修正」機能があり,Goostman は話し相手のスペルミスや タイプミスを自動で予測修正して,会話の意味を理解しようと努め,適切と思わ れる返答をすることができた. 1.3 節で紹介した,人間らしいゲーム AI の研究例における人間らしさの評価方 法も,チューリングテストをベースとした主観評価実験が実施されている. Polceanu ら,Schrum らが開発した FPS(一人称視点シューティングゲーム)の ゲーム AI[36, 5] は,ゲーム AI の人間らしさを競う評価コンテストである The 2KBotPrize 2012 のレギュレーションに則って評価されている.The 2K BotPrize 2012
の評価フェーズでは,人間とゲーム AI が混ざってチーム対戦を行う.審査員は 2 ∼3 ラウンドの対戦の後,仲間の戦闘員が人間であったか機械であったかを判定す る.各人間プレイヤ,各ゲーム AI は審査員に合計 25 回ジャッジされ,人間である と判断された割合を人間性得点として算出する.ただし,全ての審査員が信頼の
第 1 章 序論 おける審査員である保証がないため,判定の正答率(人間プレイヤは人間,ゲー ム AI は機械と正しく判定した割合)を各審査員の信頼度と定義し,人間性得点の 算出には審査員の信頼度による重み付けがされている.The 2K BotPrize 2014 の評 価フェーズでは,さらに,三人称評価として,インターネット上で審査員を募り, 人間プレイヤ及びゲーム AI の対戦のプレイ動画を見せて人間か機械かを判定させ る評価も実施されている.The 2K BotPrize 2014 では,Polceanu らの開発したゲー ム AI が人間プレイヤに次ぐ 2 位という結果で優勝している. 上記の評価実験は,チューリングテストのルールに従った正しい評価方法であ るといえるが,実験参加者(審査員)の統制がなされているかという視点から見 た場合,評価実験自体の再現性や信頼性が確保されているのか疑問が残る.チャッ トボットの Goostman の例では,審査員の年齢が 40 歳代か Goostman と同じ 10 歳 代かで評価結果に差異が生じる可能性がある.また,審査員が習慣的にチャット をしているかチャットを全くしたことがないかでも結果が異なるだろう.The 2K BotPrize の例では,審査員の FPS ゲームの経験によって,評価が大きく異なるこ とが容易に予想される.実際に,操作に不慣れで怪しい挙動をしてしまう人間プ レイヤは人間らしくない,と評価された事実も報告されている. 対象とするゲームにおける実験参加者の経験によって,評価結果に差異が生じ る例はいくつか報告されている.仲道らのコンピュータ将棋 AI[7] の人間らしさの 主観評価実験では,大学将棋部のアマチュア学生(上級者レベル)とプロ棋士(熟 達者レベル)を実験参加者とし,提示された棋譜の人間らしさを 5 段階で評価さ せている.実験の結果,提案手法により獲得された将棋 AI は,プロ棋士は人間プ レイヤか将棋 AI かの区別がつくが,アマチュアでは人間プレイヤと区別がつかな いと結論付けられている.しかし,棋譜ごとにプロ棋士とアマチュアの評価の差 異を分析したところ,アマチュアは人間らしいと評価するが,プロ棋士は AI らし いと評価する棋譜が 20 局中 5 局存在することを報告している.アンケートやイン タビューから,悪手の理由付けや指し手の一貫性を説明できる場合に人間らしい と判断される傾向にあるが,特にプロ棋士はミスの許容度合いが狭く(細かい悪 手にも気づき)多くの悪手を指摘して AI らしいと判断することが示されている. 八田原らは,テレビゲームにおける熟達度に焦点を当て,シューティングゲー ムを実施している際のプレイヤの脳活動を,熟達者,中級者,初心者の 3 種類の条 件で計測している [41, 42].実験の結果,「熟達者が熟達しているゲームタイトル」 を実施時に,中級者と初心者は前頭前野の脳活動が低下する一方で,熟達者は上 昇するという状況が観測されている.また,熟達者に「熟達したジャンルの初め て実施するゲーム」「経験の浅いジャンルのゲーム」もプレイさせたところ,前頭 前野の脳活動が低下することが確認されている.実験参加者の経験の差異は,人 間の脳活動自体に違いを生じさせていることが示されている.
1.7 研究目的と論文構成 実験参加者の統制は,ゲーム AI の人間らしさの評価に留まらず,「楽しさ」など の人間の認知によって惹起する項目を評定する際には考慮すべき問題である.し かしながら,エンタテインメント系システム(EC 系システム)における主観評価 実験ではないがしろに扱われていることが多く,実験参加者の統制手法の策定が 急がれる.
1.7
研究目的と論文構成
本研究では,ビデオゲームを対象として,「人間らしい」振る舞いを機械学習に より自動的に獲得する手法の提案を行い,関連してエンタテインメント系システ ムの評価に関連した議論を行う.本論文は,本章を含め 6 章からなり,その構成を 図 1.7 に示す.1 章 序論
2章 人間プレイヤに適応する ゲーム AI 3章 人間と同様の生物学的制約をもつ ゲーム AI4章 主観評価実験におけるユーザ統制の検討
5章 総合考察
6章 結論
( 以下,オリジナル ) 図 1.1: 本論文の構成 強さを追求したゲーム AI は様々なゲームにおいて人間の熟達者を超えつつある が,その振る舞いは極めて最適であるが故に人間にとっては機械的であり,一緒 に遊ぶ人間プレイヤのモチベーションを削ぐ要因となっている.そのため,ゲー ム AI 領域では,強いゲーム AI の次のステップとして,人間らしさや自然さを表 出するゲーム AI の構築に注目が集まっている.人間らしく振る舞うゲーム AI の 1 つとして,第 2 章では,相手の戦略への適応とルール変更時の対応が可能なゲーム AI を提案する.市販ビデオ TCG(トレーディングカードゲーム)の戦略獲得を目 標とし,強化学習法を用いて自動的に戦略を獲得する手法を提案する.戦略学習第 1 章 序論 における困難性として,部分観測に起因した巨大な状態空間が挙げられるが,サ ンプリング手法や,ゲームの特徴を考慮した次元圧縮により克服する.また,戦 略学習機構によって得た戦略を,ルールベースの戦略と対戦させ,相手戦略への 適応性と,ルールが追加された際の追従性を評価する. 人間らしく振る舞うゲーム AI のもう 1 つのアプローチとして,第 3 章では,生 物学的制約に基づく人間的なゲーム AI の実装を目指す.『人間の生物学的制約』の 条件下での機械学習により,人間らしいゲーム AI の振る舞いを自動的に獲得する 手法について提案する.人間の生物学的制約とは,人間が生得的に持つ性質から生 じる制約や欲求を指す.人間の行動制御における制約 [47, 48] や自己実現理論 [49] から着想を得て,本研究では,人間の生物学的制約を「身体的な制約:“ゆらぎ”, “遅れ”,“疲れ”」「生き延びるために必要な欲求:“訓練と挑戦のバランス”」と定 義する.人間の生物学的制約を機械学習の枠組みに導入することで,ゲーム AI の 持つ「人間には実現不可能な(機械的な)」振る舞いを抑制し,「人間らしさ」を与 えることを可能とする.また,人間の生物学的制約は開発者のヒューリスティック に依存しないため,汎用的な振る舞い獲得の手法として構築が可能である.振る 舞い獲得の対象としては,アクションゲームの “Infinite Mario Bros.” を採用し,自 動的に獲得された振る舞いが人間らしいかどうかを主観評価実験により検証する. 「楽しさ」や「人間らしさ」といった人間の主観に頼った評価実験においては, 実験参加者の経験や知識の量が実験結果に影響を及ぼす可能性がある.第 4 章で は,ゲーム AI の人間らしさを評価する際の主観評価実験における,実験結果の妥 当性や再現性を確保するためのユーザ統制及び実験手法について議論する.筆者 のこれまでの研究事例の中で,実験参加者による評価の差異が観測された事例に ついて紹介し,その解釈を試みる.続いて,安定した評価実験を行なうにあたって 考慮すべき統制視点について議論し,その視点を踏襲した具体的な主観評価実験 として,アクションゲームのプレイ動画視聴における「上手さ」と「人間らしさ」 の評定実験を実施する.最後に,その評定結果と発話プロトコル分析から,実験 参加者間の評定結果の差異,及び,実験参加者内での評価基準の差異が生じる具 体例を述べる. 第 5 章では,2 章∼4 章を総括した総合考察として,本論文で提案したゲーム AI の汎用性と,ゲーム AI における人間らしさのあり方について議論する. 最後に,第 6 章で,本論文のまとめと,今後の展望について述べる.
第
2
章 人間プレイヤに適応するゲー
ム
AI
の自律的構成
本章では,人間らしく振る舞うゲーム AI を構成するための一つの要素である, “人間プレイヤに適応するゲーム AI” の自動獲得について述べる.1.4 節でも述べ たとおり,人間プレイヤは,ゲームのルールに準じて行動を選択するだけでなく, 様々な相手戦略に対しても臨機応変に適応でき,また,ルールに変更や追加が生 じても柔軟に対応できる.一方で,コンピュータに臨機応変さや柔軟さを学習さ せることは困難を極める.以降,本章では,ニューラルネットによる強化学習を 用いて,戦略的な思考を必要とするゲームにおける戦略の自動獲得手法を提案す る.学習対象としては,戦略型ビデオ TCG(トレーディングカードゲーム)を採 用する.戦略型ビデオ TCG は,戦略に基づいた行動選択により勝敗が左右し,か つ,学習の際の探索空間が巨大となる,ゲーム局面が部分的にしか観測できない といった,戦略学習の困難性を持ち合わせており,ゲーム情報学の分野で取り組 まれつつある問題設定といえる.また,自動獲得されたゲーム AI の戦略について は,コンピュータによるシミュレーション実験を実施し,様々な相手戦略に対す る適応性,及び,新たなルールの追加への適応性を検討する.2.1
戦略型ビデオ
TCG
における戦略獲得の意義
藤田らが提案したサンプリング手法や戦略学習手法 [19, 20, 21, 22] に基づき,戦 略型ビデオ TCG における戦略を自動学習する戦略学習機構について検討する.藤 田らは,トランプゲームの “Hearts”を対象とし,部分観測状況に起因する巨大な 状態空間の問題を解決した上で,人間の熟達者よりも優れた戦略を得ることに成 功している.しかし,戦略型ビデオ TCG を扱う場合には,部分観測状況に起因す る巨大な状態空間の問題に加えて,カードを準備する段階でのカードの組み合わ せ,「魔法」などの特殊効果,「罠」などのある条件で発動する効果など,TCG に欠 かせないゲームの要素が多々存在する. 本章の戦略学習機構は,あらゆる TCG に適応できる戦略獲得機構の実現を目指第 2 章 人間プレイヤに適応するゲーム AI の自律的構成 す.戦略学習における困難性として,部分観測に起因した巨大な状態空間が挙げ られるが,サンプリング手法や,ゲームの特徴を考慮した次元圧縮により克服す る.ゲーム AI の最適行動学習だけでなく,TCG 特有の要素である “最適なカード 組み合わせ”や “魔法や罠などの特殊効果”に関しても,それぞれの課題を検討し学 習機構を実装する.戦略学習機構の評価として,ルールベース戦略を相手に学習 実験を実施し,戦略学習機構が正常に動作していることを示す.また,戦略学習機 構の “様々な戦略への適応性”と,魔法や罠などの特殊効果に起因する “新たなルー ルの追加への適応性”について確認する.戦略学習機構により,プレイヤの様々な 戦略に適応する,プレイヤの成長と共に強くなる,新たなルールの追加に臨機応 変に対応する,といったゲーム AI の戦略を自動的に得ることができる. 戦略学習機構開発の意義として,以下の 4 つが挙げられる. 1. 市販の戦略型ビデオ TCG におけるゲーム AI の戦略を,自動的に学習するフ レームワークを構築すること. 2. サンプリング手法や,ゲームの特徴を考慮した次元圧縮により,戦略学習機 構の実装上の課題を解決すること. 3. TCG 特有の要素である “最適なカード組み合わせ” や “魔法や罠などの特殊 効果” に関して,それぞれの課題を検討し学習機構を実装すること. 4. 戦略学習機構によって得た戦略を,ルールベースの戦略と対戦させることで, 様々な戦略や新たなルールの追加への適応性を確認すること.
2.2
トレーディングカードゲーム(
TCG
)の概要
市販 TCG は,1993 年のマジック・ザ・ギャザリング以降,現在までに 100 タイ トル以上発売されている.1999 年に発売された遊☆戯☆王をきっかけに,社会現 象と言われるほど TCG は流行している.TCG はゲームの性質上,市販ビデオ TCG としても発売されることも多い.遊☆戯☆王もその例にもれず,市販 TCG を基に して,1999 年に市販ビデオ TCG として発売されている.また,市販ビデオゲーム を TCG 化した例として,1996 年にポケモンカードゲームが発売されている.ポケ モンカードゲームとは,1996 年に市販ビデオゲームとして発売されたポケットモ ンスター (ポケモン) を再現した TCG である.TCG は,いまや,子どもから大人ま で幅広く遊ばれているゲームであるといえる.TCG の人気は売り上げデータから も読み取れる.遊☆戯☆王は,2011 年 3 月時点で 251 億枚以上を売り上げ,世界 一売れた TCG としてギネスに登録されているほどである.ポケモンに関しては,2.3 問題設定 2011 年時点で 2 億 3 千万本以上を売り上げており,世界一売れたロールプレイン グゲーム (RPG) として同様にギネスに登録されている. ここで,市販 TCG の一般的なルールについて簡単に述べる.TCG は,各プレ イヤが集めたカードの中から,複数枚を組み合わせたカードのセット (デッキ) を 作って持ち寄り,2 人で対戦を行うゲームである.対戦の一般的なルールは以下の ようなものである. 1. デッキからカードを引き,交互にカードを出す. 2. カードに書かれたモンスターや,特殊効果で相手を攻撃する. 3. 自分のモンスターが全部やられる,あるいは,プレイヤの体力 (HP) が 0 に なると勝敗が決まる. プレイヤは,自分の戦術に応じたデッキの作成,モンスターを出す順番,特殊効 果を使用するタイミングなど,相手に勝つための戦略を組み立てて楽しむことに なる. 市販ビデオ TCG においてプレイヤはゲーム AI と対戦することができ,ゲーム AI に勝つための戦略を組み立てることが面白い要素の一つである.しかし,「ゲー ム AI が強すぎて勝てない」「ゲーム AI の戦略は単調なので絶対に勝てる」とプレ イヤが感じることは多々ある.プレイヤの興味を持続させるためには,プレイヤ の要求に合わせたゲーム AI の強さの設定が必要不可欠である.現在ではゲーム製 作者による作り込みによって,ゲーム AI の戦略は実現されているが,これは非常 に煩雑であり時間がかかるという問題点がある.プレイヤとゲーム製作者,両者 の要求を満たすためには,プレイヤの戦略を学習してゲーム AI の戦略パラメータ を自動的に決定する機構を用意し,プレイヤの戦略に順応するゲーム AI を実現す る必要がある.
2.3
問題設定
まず,ポケモンと遊☆戯☆王のルールの概略を述べる.次に,2.2 節で述べた TCG の一般的なルールや,ポケモン,遊☆戯☆王のルールを基に,本章で扱う戦 略型ビデオ TCG のルールを設定する.最後に,戦略型ビデオ TCG において,戦 略学習機構を実装する上での困難性を考察し,問題解決のための手法を提案する.第 2 章 人間プレイヤに適応するゲーム AI の自律的構成
2.3.1
代表的な
TCG
のルール
代表的な TCG の例として,ポケモンと遊☆戯☆王のルールについて大まかに述 べる.ポケモンの一般的なルールは以下のようになる.各モンスターには固有の パラメータが設定されている(属性,レベル,体力,攻撃力,特殊攻撃力,防御 力,特殊防御力,素早さ).属性間には相性が存在し,相性によって相手に与えら れるダメージの量が増減する. 1. プレイヤ,ゲーム AI は数百体のモンスターの中から,6 体選択する.ただし, 最終的によく選ばれる(一般的に強いとされる)モンスターは 20∼30 体程 度である. 2. 選択した 6 体から,戦闘状態とするモンスター 1 体を選択する.残り 5 体を 待機状態とする.(互いに,戦闘状態のモンスターしか観測できない.) 3. 戦闘状態のモンスターに対して,たたかう,入れ替えを指示する. 4. 戦闘状態のモンスターが,相手の戦闘状態のモンスターに対して,指示され た行動を行う.たたかう,の場合はモンスターがもつ技の中から,使用する技 を選択する.技には,相手にダメージを与える,属性相性を考慮したダメー ジを与える,相手を毒状態にする,などが存在する.入れ替えの場合は,現 在の戦闘状態のモンスターを待機状態とし,代わりに待機状態のモンスター の中から戦闘状態にするモンスター 1 体を選択する. 5. 攻撃され,モンスターの体力が 0 になれば,そのモンスターは戦闘不能と する. 6. どちらかのモンスターが 6 体とも戦闘不能になるまで,3,4,5 を繰り返す (以下,3,4,5 をまとめて 1 ターンと呼ぶ). 次に,遊☆戯☆王の一般的なルールを以下に述べる.遊☆戯☆王には,モンス ターカード,魔法カード,罠カードが存在する.モンスターカードには攻撃力と防 御力が設定されている.魔法カードには,相手のモンスターの足止め,攻撃力強 化,防御力強化などがある.また,罠カードには,魔法反射,攻撃の無効化,モ ンスターの復活などがある. 1. プレイヤ,ゲーム AI は数千枚のカードの中から,モンスターカード,魔法 カード,罠カードを混ぜた 40∼60 枚程度のデッキを作成する. 2. 自分のデッキからカードを 5 枚引く.(互いに,相手のカードは観測できな2.3 問題設定 3. 自分に順番が回ってきたら,デッキからカードを 1 枚引く. 4. 自分の手札にモンスターカードがあれば,モンスターを召喚できる.同時に, 魔法カードの使用や,罠カードの設置も可能である.罠カードは,設置して おけば任意のタイミングで発動できる. 5. 召喚したモンスターによって,相手のモンスターを攻撃できる.自分のモン スターの攻撃力が,相手のモンスターの攻撃力よりも高ければ,相手のモン スターを倒すことができる.さらに,相手のライフポイントを,攻撃力の差 の量だけ減らすことができる.相手にモンスターがいない場合,相手のライ フポイントを,自分のモンスターの攻撃力と同じ量だけ減らすことができる. また,相手のモンスターの攻撃を,自分のモンスターを用いて防御すること もできる. 6. どちらかのライフポイントが 0 になるまで,3,4,5 を繰り返す.
2.3.2
戦略型ビデオ
TCG
のルール設定
本章で用いる戦略型ビデオ TCG は,プレイヤ対ゲーム AI の対戦型ゲームとし, ポケモンや遊☆戯☆王のルールを基にして以下のように設定する (各カードには 1 体のモンスターが設定されている).ポケモンの戦略的要素である,属性の相性, 特殊な技,モンスターの入れ替え,また,遊☆戯☆王の戦略的要素である,魔法 カード,罠カードなどを扱えるようにルールを決定している. 1. プレイヤ,ゲーム AI は 15 体のモンスターの中から,3 体選択する. 2. 選択した 3 体から,戦闘状態とするモンスター 1 体を選択する.残り 2 体を 待機状態とする.(互いに,戦闘状態のモンスターしか観測できない.) 3. 戦闘状態のモンスターに対して,攻撃,特殊攻撃,状態異常攻撃,罠設置, 入れ替えを指示する. 4. プレイヤ,ゲーム AI の戦闘状態のモンスターが,相手の戦闘状態のモンス ターに対して,指示された行動を行う.攻撃,特殊攻撃の場合は相手の戦闘 状態のモンスターにダメージを与えることになる.状態異常攻撃の場合は, 相手の戦闘状態のモンスターにダメージを与えると同時に,特殊効果を相 手モンスターに与える.罠設置の場合は,ある条件を満たしたときに罠を発 動できるようになる.入れ替えの場合は,現在の戦闘状態のモンスターを待 機状態とし,代わりに待機状態のモンスターの中から戦闘状態にするモンス ター 1 体を選択する.第 2 章 人間プレイヤに適応するゲーム AI の自律的構成 5. 攻撃され,モンスターの体力が 0 になれば,そのモンスターは戦闘不能と する. 6. どちらかのモンスターが 3 体とも戦闘不能になるまで,3,4,5 を繰り返す (以下,3,4,5 をまとめて 1 ターンと呼ぶ). 各モンスターには,体力,攻撃力,防御力,特殊攻撃力,特殊防御力,素早さの 6 つのパラメータが存在する.各パラメータは以下のように定義し,各モンスター のパラメータを表 2.3.2 に示す.また,攻撃,特殊攻撃,状態異常攻撃のダメージ は,ポケモンと同様の計算式を用いている.特殊攻撃に関しては,計算式の結果 に属性倍率を掛けた値である. 体力 相手モンスターに攻撃された際のダメージは,体力から減算される.また, 体力が 0 になったモンスターは戦闘不能状態になる. 攻撃力 相手に “攻撃”または “状態異常攻撃”をする際に,攻撃力が高いほど多くの ダメージを与えられる. 防御力 相手に “攻撃”または “状態異常攻撃”をされた際に,防御力が高いほど受け るダメージは少なくなる. 特殊攻撃力 相手に “特殊攻撃”をする際に,特殊攻撃力が高いほど多くのダメージを与え られる. 特殊防御力 相手に “特殊攻撃”をされた際に,特殊防御力が高いほど受けるダメージは少 なくなる. 素早さ 自分の戦闘状態のモンスターと,相手の戦闘状態のモンスターにおいて,素 早さの高い方のモンスターから行動できる. 戦略的な要素を付け加えるため,各モンスターには属性を設定する (表 2.3.2,ノ はノーマル属性を表す).モンスターの特殊攻撃のみに,属性によるダメージ倍率 が反映される.属性の相性は,相互補完的に設定されているため,現在戦闘状態
2.3 問題設定 表 2.1: 各モンスターのパラメータ 表 2.2: モンスターの属性表 の相手モンスターに対して有利に戦えるモンスターを,手持ちのモンスター 3 体 の中から選択する必要がある. 「魔法」などの特殊効果の一例として毒攻撃(状態異常攻撃)を設定する.毒 攻撃は 1 ゲーム中で 1 回のみ使えるとし,毒攻撃をされたモンスターは毒状態と なる.毒状態のモンスターは,自分が行動する際に最大体力の 1/8 のダメージを受 ける.つまり,毒攻撃をするタイミングと,毒攻撃の対象とする相手モンスター を決定する必要性が生じる. 「罠」など,ある条件で発動する効果の一例として魔法反射を設定する.魔法 反射の罠設置は 1 ゲーム中で 1 回のみ使えるとし,罠の有効期間は設置してから 3 ターン(自分の順番が 3 回まわってくるまで)とした.魔法反射の罠が有効な間 に,相手モンスターが魔法(状態異常攻撃)を使った場合,自分のモンスターが 受けるダメージを無効化し,すべて相手モンスターに反射する.つまり,罠の有 効期間の間に,相手モンスターが魔法(状態異常攻撃)を使うかどうか推測した 上で,罠を設置するかどうか決定する必要性が生じる. 本章で用いる戦略型ビデオ TCG は,自分のターンにとるべき行動の選択,カー ドを準備する段階でのカードの組み合わせの決定,「魔法」などの特殊効果,「罠」