ベータ分布を用いた累積プロスペクト理論における確率ウェイト関数についての一考察
29
0
0
全文
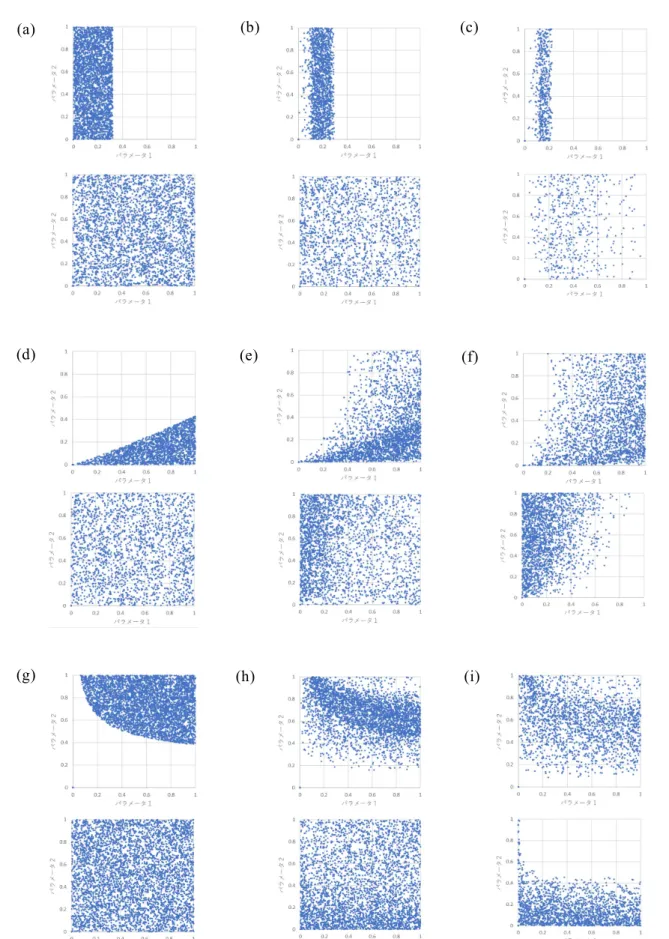
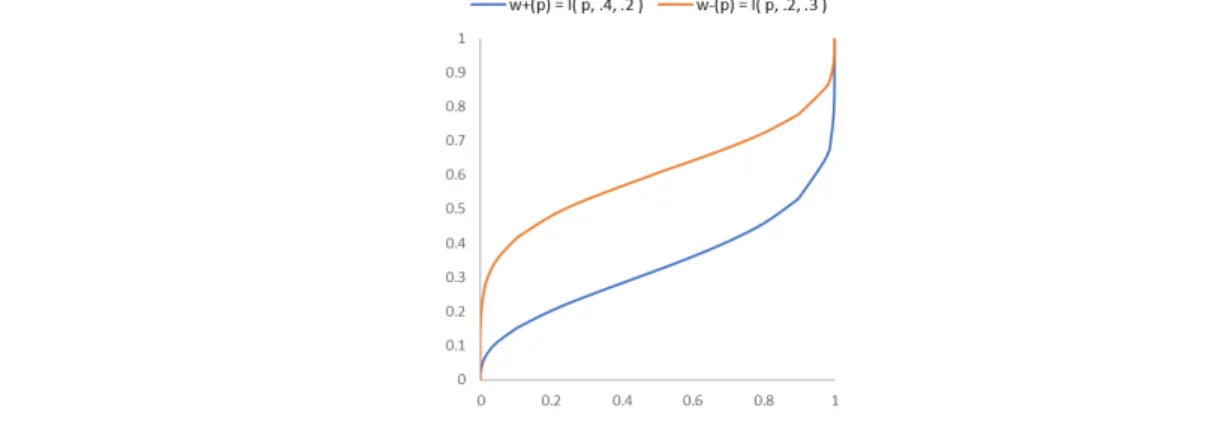
(2) 含め,期待効用理論では予測できない現実の人々の典型的な選択パタンを記述する代 替理論であり,今日の行動経済学ないし広い意味で行動科学と総称される分野におけ る重要な基礎理論の一つになっている.Daniel KahnemanとAmos Tverskyはその改良版 である累積プロスペクト理論(CPT)において,ショケ積分(ランク依存変換)を取り入れた 確率ウェイト関数が組み込んだ(Tversky & Kahneman, 1992; Wakker, 2010).累積プロス ペクト理論では,クジの結果が3種類以上ある場合にも適用できるようにすると同時に,確 率が未知の場合を含む選択問題も扱えるようにして,とくにEllsberg(1957)によって指摘さ れた現実の人々が確率の曖昧なクジを嫌う傾向を記述できる.また感度逓減のモデル化 において,改善されている(Fennema & Wakker, 1997). オリジナルのプロスペクト理論(Kahenman & Tversky, 1979)では,両端で不連続な確 率 ウ ェ イ ト 関 数 の グ ラ フ が , 関 数 形 を 明 示 せ ず に 示 さ れ た が , Tversky&Kahnemann(1992)の累積プロスペクト理論では,次の関数形が明示的に導入 された. 𝑝𝑝𝛾𝛾 𝑤𝑤(𝑝𝑝) = (1) 1 (𝑝𝑝𝛾𝛾 + (1 − 𝑝𝑝)𝛾𝛾 ) �𝛾𝛾 パラメータγが0から1までの値を取り,γ=1のとき確率そのものであり,1より小さくなる ほどバイアスによる歪みが顕著になる.図1aのグラフ形状から分かるように,0や1の付近 での確率の変化に対してより敏感で,それ以外の部分ではほぼ線形である.導関数は偏 りのあるバスタブ(U字)型である.. (a). (b). (c). (d). 図 1 確率ウェイト関数.(a)は,𝑝𝑝𝛾𝛾 /(𝑝𝑝𝛾𝛾 + (1 − 𝑝𝑝)𝛾𝛾 ). 1� 𝛾𝛾 ,γ=0.61. およびγ=0.32.(b)はγ=0.61 の場合とそ. のベータ分布𝐼𝐼𝑝𝑝 (0.4,0.3)による近似.(c)は(b)の微修正,(d)はβ=0.4α上から選んだ. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 2.
(3) 確率ウェイト関数は利得と損失では若干形が変わり,損失側のパラメータは利得側の それよりやや大きくなり,元の線形に近づく. Tversky & Kahnemann(1992)では,確実性 等価の金額の実証データの中央値から利得側のγを0.61と損失側を0.69と推定している. な お (1) は Karmarker(1978) の 関 数 形 𝑝𝑝𝛾𝛾 ⁄𝑝𝑝𝛾𝛾 + (1 − 𝑝𝑝)𝛾𝛾 の 一 般 化 と み な せ る . Quiggin(1982)やYarri(1987)では𝑤𝑤(1/2) = 1/2が仮定されたが,この性質が取り除かれ た.2002年にDaniel Kahnemanがノーベル経済科学賞を実験経済学者のVernon Smithと 共 に 受 賞 し て以 降 , 行 動 経 済 学 が に わか に 注 目 さ れるよ うに な り,2017年 に Richard Thalerが受賞した時点ではすでに経済学において隆盛で,政策応用が各国で進んでい る状況であった.中村(2013は確率ウェイト関数の代表的な関数形をPT・CPTとの関係を 整理し,理論的な矛盾の潜在性,心理学的基盤の考察,関数形を特定しモデルのパラ メータをより精密に調べる必要性を指摘している. 確率ウェイト関数が研究されたきっかけは,期待効用理論の修正であり,Allais(1953), Ellsberg(1961),Strotz(1955)以降,長らく研究されてきた.この文脈については第2節で かいつまんで紹介する.このうち確率ウェイト関数の研究は,とくにAllaisやEllsbergの提 起したリスク選択における意思決定問題への対処に関連する.Strotzの論文は動的選択 における双曲線型時間割引率と自己制御にかんするものであり.意思決定問題の種類 が異なるが,しかし理論的あるいは心理学的な基盤において,両者は潜在的に関連する (Lowenstein & Prelec, 1991; Grant, Kajii, & Polak, 2000; Halevy, 2008; Takahashi, 2011; Takemura & Murakami, 2016;竹村・村上, 2019; 犬童, 2019b). Allais のパラドックスを生じる具体的な CPT モデルは,第 3 節で説明するが,一般に 簡単な条件では書けないため,コンピュータ・シミュレーションの力を借りて計算する.先 行研究では確率ウェイト関数の関数形および参照点を反映した金額シフト付きの CPT を 用いて,具体的に Allais のパラドックスの例題を予測できるモデルパラメータ範囲が視覚 化されている(犬童, 2018a, 2018b).本論文では確率ウェイト関数の関数形をベータ分布 や一 般 化 双 曲線 型割 引に変更することによって CPT モデルの改良を示唆した犬 童 (2019b, 2020)の結果の一部,およびその関連実験を合わせて報告する. ベータ分布の累積分布は,実数部分が0と1の間にある複素数z(0 ≤ 𝑅𝑅𝑅𝑅 𝑧𝑧 ≤ 1)にお いて次のように定義される. Β𝑧𝑧 (𝛼𝛼, 𝛽𝛽) (2) 𝐼𝐼𝑧𝑧 (𝛼𝛼, 𝛽𝛽) = . Β(𝛼𝛼, 𝛽𝛽) 𝑧𝑧. ここでΒ𝑝𝑝 (𝛼𝛼, 𝛽𝛽)は不完全ベータ関数Β𝑧𝑧 (𝛼𝛼, 𝛽𝛽) = ∫0 𝑡𝑡 𝛼𝛼−1 (1 − 𝑡𝑡)𝛽𝛽 𝑑𝑑𝑑𝑑 であり,またΒ(𝛼𝛼, 𝛽𝛽) =. Β1 (𝛼𝛼, 𝛽𝛽)はベータ関数と呼ばれる.𝐼𝐼0 (𝛼𝛼, 𝛽𝛽)=0,𝐼𝐼1−𝑧𝑧 (𝛼𝛼, 𝛽𝛽) = 1 − 𝐼𝐼𝑧𝑧 (𝛽𝛽, 𝛼𝛼)である. 𝐼𝐼𝑧𝑧 (𝛼𝛼, 𝛽𝛽)は,不完全ベータ比,あるいは正則化された不完全ベータ関数(正則ベータ関 数)とも呼ばれる.ベータ分布は,直観的に言うと,連続化した二項分布である.実際,平 均 成 功 率 𝑝𝑝 の ベ ル ヌ ー イ 試 行 𝑛𝑛 回 に お い て 成 功 回 数 𝑘𝑘 以 下 の 確 率 は 𝐼𝐼1−𝑝𝑝 (𝑛𝑛 − 𝑘𝑘, 𝑘𝑘 + 1)=1 − 𝐼𝐼𝑝𝑝 (𝑘𝑘 + 1, 𝑛𝑛 − 𝑘𝑘)である(Wadsworth, 1960 p.52).り,F 分布やt分布はベータ分布. によって簡潔に表すことができる.自由度𝑑𝑑1 , 𝑑𝑑2 の F 分布にしたがう変数𝑥𝑥に対して,𝑧𝑧 = 𝑑𝑑2 𝑥𝑥⁄𝑑𝑑1 (1 − 𝑥𝑥)の累積分布は𝐼𝐼𝑧𝑧 (𝑑𝑑1 ⁄2 , 𝑑𝑑2 ⁄2)であり,また t 分布は𝐼𝐼𝑧𝑧 (1⁄2 , 𝑑𝑑2 ⁄2),つまり 𝑑𝑑1 = 1とした F 分布である(蓑谷, 2010; 四辻, 2019).ベータ分布は経験的ベイズ法の自 然共役事前分布として知られる(Raiffa & Schraifer, 2000).例えばベルヌーイ試行𝑛𝑛回中 ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 3.
(4) 𝑘𝑘回の成功が観察されたときの事後分布は𝐼𝐼𝑧𝑧 (𝛼𝛼 + 𝑘𝑘, 𝛽𝛽 + 𝑛𝑛 − 𝑘𝑘)である.またベータ分布を 多次元に拡張したディリクレ分布は幅広く工学的に応用されている. ところで𝛼𝛼, 𝛽𝛽を0から1の範囲で選ぶと,ベータ分布の累積分布はは逆S字の形状になり, また(𝛼𝛼 − 1)⁄(𝛼𝛼 + 𝛽𝛽 − 2)が反モード(antimode)となる.たとえば,𝐼𝐼𝑧𝑧 (0.5,0.5)は,後述する ように,逆正弦関数であり,𝑧𝑧 = 0.5で不動点となる.. 確率ウェイト関数 𝑤𝑤(𝑝𝑝) = 𝐼𝐼𝑝𝑝 (𝛼𝛼, 𝛽𝛽)とすると,図1bに示されるように,𝛼𝛼 = 0.4,𝛽𝛽 = 0.3とした ベータ分布が,関数形(1)のγ=0.61と似る(ベータ分布との類似は犬童(2020)で報告さ れた.付録A1⑨の図も参照).また標準ケースだけでなく,個別被験者に適合させた確 率ウェイト関数についてもベータ分布を用いて柔軟に近似できる.実際,図1cに示した3 種類のベータ分布は,Takemura & Murakami(2016)や竹村・村上(2019)で報告された個 人の確率ウェイト関数に類似する.さらに,図1dに示されたベータ分布を用いて, Allais のパラドックスを予測すると,オリジナルのCPTを用いた図1aの下側カーブ(γ≤0.32)と比 べ,より自然な逆S字形状が得られる.Allaisのパラドックスの予測モデルの修正について は第3節で詳しく述べる. ちなみに 𝐼𝐼𝑝𝑝 (0.5,0.5),すなわち,𝛼𝛼 = 𝛽𝛽 = 0.5のベータ分布は,n 回ベルヌーイ試行にお けるジェフリーズの事前分布(Jeffreys’ prior) にあたる.また逆正弦(arcsine)分布𝐹𝐹(𝑥𝑥) = 2𝜋𝜋 −1 arcsin�√𝑥𝑥�もこの場合と一致する.同じ関係が 2 次元正規分布(ないしある種のコピ ュラ)における相関係数𝜌𝜌とケンドールの順位相関係数𝜏𝜏との間の関係に表れる.2 系列間 で順序関係が保たれるペア(concordant pairs)の比率を𝑇𝑇とすると,𝜏𝜏 = 2𝑇𝑇 − 1である.ま た 1 次元ブラウン運動(Wiener 過程)によってこのケースはシミュレーション的に近似でき るが,これは逆正弦法則(arcsine law)として知られる(Lévy, 1939).すなわち[-1,1]の一様 乱数の和分が正負のいずれの象限に属するかについての分布である.なお Wiener 過程 では領域境界での粒子の反射が仮定されるが,この過程を緩和しても 𝐼𝐼𝑝𝑝 (0.5,0.5)が再 現される.境界で吸収される(到達した粒子はそこで停止する)と仮定すると,図 1c の 3 形状をいずれも近似することができるが,詳細は別の機会に報告したい. Takemura & Murakami(2016)は,Gonzalez&Wu(1999)で提案された2パラメータの確 率ウェイト関数の推定法を修正して用い,7種類の関数形を推定し,その中でTakahashi (2011)の一般化双曲線割引関数 𝛿𝛿 𝑝𝑝 𝑤𝑤(𝑝𝑝) = � � 𝑝𝑝 + 𝑘𝑘(1 − 𝑝𝑝). (3). が,個別被験者の確率ウェイト関数としてもっともよく適合するとしている. 犬童(2019b)はマッチング法則に基づくヒューリスティクな推論から, 𝑤𝑤(𝑝𝑝) = (1 + 𝑘𝑘𝐷𝐷 𝛾𝛾 )−1 を導き,この関数形の下でAllaisのパラドックスを予測するコンピュータ実験を示している. (2)は𝑤𝑤(𝑝𝑝) = (1 + 𝑘𝑘(𝑝𝑝−1 − 1))−𝛿𝛿 と書き直せるから,明らかに 𝐷𝐷 = 𝑝𝑝−1 − 1 かつ 𝛾𝛾 = 𝛿𝛿 = 1 とした場合である. 図1aに示したγ=0.32は,実は(オリジナルの)CPTでこのあと紹介するAllaisのパラドッ クスとして知られる例題の典型的な回答パタンを再現することができるγの値の上限であ る.図1aから明らかなように,標準的とされた実証値γ=0.61からは大きく外れる.より最近 行われた実証研究では,回答データのヒストグラムから,γ=0.32付近の値はほとんど観 察されない(Takemura & Murakami, 2016).一般化双曲線割引(3)を確率ウェイト関数(1) の代わりに用いても,Allaisのパラドックス,とくにAllaisのCCE例に対して,オリジナルの ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 4.
(5) CPT よ り 自 然 な モ デ ル が 得 ら れ る ( 犬 童 , 2019b ) . 双 曲 線 型 割 引 は マ ッ チ ン グ 法 則 (Herrnstein, Laibson & Rachlin, 2000)から導かれる.つまり選択対象への反応率がその 魅力の相対比率に比例する.また第2パラメータを共有する独立なガンマ分布にしたがう 2変数の相対比率はベータ分布にしたがう(四辻(2019) p.246).それゆえ類推としては, ベータ分布が2つの競合するガンマ分布から生成されたものとみなせるなら,双曲線型割 引とベータ分布が似た記述力を持つ場合があってもおかしくはない.しかし厳密な異同 については未検証であり,事実,本論文で示すように,Allaisパラドックスの予測にかんす る両者の記述力は同等ではない. なお,先行研究ではソフトウェアとして,エクセルと Prolog を使用した(ベータ分布のプ ログラム検証のため R や Python も部分的に使用している).複雑なモデル作成,柔軟な モデル変更,見通しの良い便利なプログラミング,さまざまな条件下で行うシミュレーショ ン実験,およびそのデータの保存と再利用,ソフトウェア間のデータ連携といった煩雑な 作業を遂行し,正確性と可読性,再現性を損なわないための工夫が必要である.本論文 では,Indo(2015, 2019a)で開発された Prolog プログラムなどを再利用し,それらをさらに 拡張して用いた.その基本部分を再現するためのインストラクションを付録とした. 本論文の以降の部分では,第 2 節で期待効用理論の修正について,とくに確率ウェイ ト関数に関連する研究に簡単に言及する.第 3 節では累積プロスペクト理論の定式化に ついて説明する.第 4 節は参照点を考慮した CPT を用いて,Allais パラドックスの例題を 予測する条件について述べ,また予測可能なモデルパラメータを視覚化する(実験 1). 第 5 節はベータ分布と一般化双曲線型割引を,CPT のオリジナルの確率ウェイト関数の 代わりに用いて,3 水準の参照点 0, 50, 100 についてそれぞれ利得側と損失側の確率ウ ェイト関数をペアで生成し,予測可能モデルを比較する(実験 2).第 6 節はベータ分布 を用いて利得側と損失側の一方のパラメータを固定して他方の予測可能モデルを可視 化する(実験 3,実験 4).第 7 節では文献における選択問題における実証的な選択率 のデータを用いて,確率ウェイト関数を交換するなどして修正した CPT など,代替的なモ デル間で適合度を比較する(実験 5~7).最後に第 8 節でまとめとする.. 2 期待効用モデルの修正 以下では,期待効用理論の修正にかんする研究を手短に紹介する.ただし,以下で は本論文に関連する代表的な文献に限定して言及するに止め,網羅的でも厳密でもな いことを予めお断りしておく.日本語で読めるレビューとしては,前述の中村(2013)がある. 経 済 学 とそれが応用される諸分野では,20世紀半ば以降, John von Neumann と Oskar Morgensternの期待効用理論,あるいはその不確実性下への一般化であるSavage の主観的期待効用理論とその公理系が,リスクのある状況での合理的選択の理論として 用 いられてきた.しかし,これらの標 準 的 理 論の初 期 時 点 ですでに,Mourice Allais, Daniel Ellsberg,Harry Markowitzらがそれぞれ提示した例題を通じて,現実の人々の選 択パタンが仮定(公理)に矛盾することがあることは研究者の間では知られていた. 元 々 Allais や Ellsberg が 提 起 し た 問 題 は , 期 待 効 用 理 論 の 独 立 性 公 理 あ る い は Savageの 確 実 性 原 理 といった ,合 理 的 選 択 の 基 本 性 質 の 違 反 と して論 じら れたが , Strotz や Machina が 論 じ た よ う に , そ れ は 動 的 意 思 決 定 の 文 脈 で は , 帰 結 主 義 ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 5.
(6) (consequentialism)の仮定と関連しつつ,時間不整合(動的矛盾)やゲーム理論における 投機的取引の可能性という別の現象となって現れる(Halevy, 2004, 2008).また(末尾)独 立性の違反のさまざまなバリエーションが実証的に知られるようになった(Birnbaum, 2008). Birnbaumらはクジの結果間で確率ウェイトを柔軟に移動できる修正理論(TAX)を提唱し ている.また第3節で述べるように,CPTは参照点の移動に対して必ずしも感応的ではな いのである. 確 率 ウ ェ イ ト 関 数 は 心 理 学 で Edwards(1962) に よ っ て 論 じ ら れ , 経 済 学 で は Handa(1977)やKarmarker(1979)が確率ウェイト関数を用いてAllaisのパラドックスを予測 し た . Handa は 確 率 ウ ェ イ ト の 推 定 に ク ジ の 確 実 性 等 価 を 用 い た . ま た Einhorn & Hoagrth(1985, 1986),Currim & Sarin(1989)によって心理学と経営行動科学の文脈で研 究された.経済学ではQuiggin(1982)が最初期の文献であり,期待効用理論のアノマリー への対処として1980年代後半から1990年代初頭にかけて集中的に研究された(Machina, 1982, 1992).また 修 正 された 期 待 効 用 理 論 の 公 理 系 は , Yaari(1987), Segal(1989), Chew, Karni, & Safra(1987), Schmeidler(1989), Giboa(1987), Luce & Fishburn(1991), Chateauneuf(1991), Schmidt & Zank(1992), Wakker & Tversky(1993)らが発 展 させた (Sugden(2004)も参 照 ).確 率 ウェイト関 数 の 実 証 的 な推 定 法 は,Lattimore, Baker & Witte(1992) , Tversky & Kahneman(1992) , Tversky & Fox (1994) , Prelec(1998) , Birnbaum(2008) , Wu & Gonzalez(1996), Wu & Gonzalez(1999), Wakker & Deneffe(1996), Abdelloui(2000), Bleichrodt and Pinto(2000)などによって考察 された. PrelecはLowensteinと共に,学習心理学におけるマッチング法則に関連する双曲型時間 割引と,確率ウェイト関数の2つの心理学的研究を統合的に発展させた (Takahashi(2011), Takemura & Murakami(2016), 竹村・村上(2019)も参照). オリジナルのプロスペクト理論(Kahneman & Tversky, 1979)の主な狙いは,参照点に依 存する選好のモデル化であった.参照点付きの,つまり金額をシフトしたCPTモデルは, 第 3 世 代 プ ロ ス ペク ト 理 論 と 呼 ば れる こ とも ある (Schmidt, Starmer & Sugden, 2008) . Schmidtらは第3世代プロスペクト理論を用いてそれまでの期待効用理論の修正では予 測できなかった選好逆転現象を記述できると主張した.一方,現実の人々の選択は,第3 世代プロスペクト理論の仮定に反するとの批判もある(Birnbaum, 2018). ショケ積分を用いた期待効用理論の修正や非協力ゲーム理論への応用が地道に続 けられていたが,累積プロスペクト理論に採用されたことにより,行動経済学に関連する 基本的手法の一つとしても知られるようになった.前述のように,確率ウェイト関数はクジ の確 率がショケ容 量 に相 当すると解 釈できる場合に相 当する.ショケ積 分は,容 量 (capacity)についてのChoquetによる数学研究に由来し,信念関数,ファジィ理論,マルコ フ過程,ポテンシャル理論,ゲーム理論との深い結びつきがある.本論文ではショケ積分 自体については詳しく論じない.Phelps(2001), Grabisch (2016)などの文献を参照された い. 前述のように,1990年代までの,期待効用理論の修正の文脈における確率ウェイト関 数の研究は,代表的なアノマリーに対する理論(公理系)の修正という目的が主たる意図 であって,今日の行動経済学における現実の人間行動の予測,およびその政策的な現 実応用にまでは至っていない.現時点でもなお,確率ウェイト関数の研究は,行動経済 学の中心からやや外れて,心理学よりに位置している.しかし関連する隣接領域の広がり ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 6.
(7) から,その潜在的な意義は小さくないと思われる.ちなみに,このジャンルの文献は確率 ウェイト関数を明示せず,非加法的確率(nonadditive probability)と言うテーマで括られる ことがある.本論文では取り上げないが,Dempster-Shafer理論は非加法的確率の下での ベイズの定理の一般化であり,膨大な文献がある.例えば,実験ゲーム理論への先駆的 な応用として,Camerer & Karjalainen(1994)は非協力ゲームにおけるプレイヤー間の信 頼関係の分析に非加法法的確率を応用した.実質的に確率ウェイト関数の下でのゲー ム理論の修正とその行動経済学的な意義を論じたものと言える.. 3 累積プロスペクト理論(CPT) ショケ積分は容量を計算する方法として,容量の限界貢献(ポテンシャル)を累積する. 容 量 (capacity) は , 事 象 E ⊆ S に 対 し て 定 義 さ れ た 実 数 値 関 数 𝑊𝑊: 2𝑆𝑆 → 𝑅𝑅 で , 𝑊𝑊(∅) =. 0,𝑊𝑊(𝑆𝑆) = 1, 𝑋𝑋 ⊆ 𝑌𝑌 → 𝑊𝑊(𝑋𝑋) ≤ 𝑊𝑊(𝑌𝑌)を満たす.累積プロスペクト理論において,決定ウ ェイトπは,利得側と損失側を区別して,それぞれゼロを起点にした容量の限界貢献であ る. 𝜋𝜋𝑖𝑖+ (𝑓𝑓). 𝑛𝑛. 𝑛𝑛. 𝑘𝑘=𝑖𝑖. 𝑘𝑘=𝑖𝑖+1. = 𝑊𝑊 �� 𝐴𝐴𝑘𝑘 � − 𝑊𝑊 � � 𝐴𝐴𝑘𝑘 � , 0 ≤ 𝑖𝑖 < 𝑛𝑛 − 1, 𝜋𝜋𝑛𝑛+ (𝑓𝑓) = 𝑊𝑊(𝐴𝐴𝑛𝑛 ), 𝑖𝑖. 𝑖𝑖−1. (4). − (𝑓𝑓) 𝜋𝜋𝑖𝑖− (𝑓𝑓) = 𝑊𝑊 � � 𝐴𝐴𝑘𝑘 � − 𝑊𝑊 � � 𝐴𝐴𝑘𝑘 � , 1 − 𝑚𝑚 ≤ 𝑖𝑖 < 0, 𝜋𝜋𝑚𝑚 = 𝑊𝑊(𝐴𝐴−𝑚𝑚 ) 𝑘𝑘=−𝑚𝑚. 𝑘𝑘=−𝑚𝑚. リスク下の選択では,各𝐴𝐴𝑖𝑖 の確率𝑃𝑃𝑃𝑃(𝐴𝐴𝑖𝑖 ) = 𝑝𝑝𝑖𝑖 , 𝑖𝑖 = −𝑚𝑚, … , 𝑛𝑛が既知であり,クジ(ない しプロスペクト)は確率分布𝑝𝑝 = (𝑝𝑝−𝑚𝑚 , ⋯ , 𝑝𝑝0 , … , 𝑝𝑝𝑛𝑛 )と同一視し,容量の代わりに確率ウェ イト関数を用いる. ⎧ ⎪. 𝜋𝜋𝑖𝑖+ (𝑝𝑝). 𝑛𝑛. 𝑛𝑛. 𝑘𝑘=𝑖𝑖. 𝑘𝑘=𝑖𝑖+1 𝑖𝑖−1. = 𝑤𝑤 �� 𝑝𝑝𝑘𝑘 � − 𝑤𝑤 � � 𝑝𝑝𝑘𝑘 � , 0 ≤ 𝑖𝑖 < 𝑛𝑛 − 1, 𝜋𝜋𝑛𝑛+ (𝑝𝑝) = 𝑤𝑤(𝑝𝑝𝑛𝑛 ),. (5) ⎨ − − ⎪𝜋𝜋𝑖𝑖 (𝑝𝑝) = 𝑤𝑤 � � 𝑝𝑝𝑘𝑘 � − 𝑤𝑤 � � 𝑝𝑝𝑘𝑘 � , 1 − 𝑚𝑚 ≤ 𝑖𝑖 < 0, 𝜋𝜋−𝑚𝑚 (𝑝𝑝) = 𝑤𝑤(𝑝𝑝−𝑚𝑚 ). 𝑘𝑘=−𝑚𝑚 𝑘𝑘=−𝑚𝑚 ⎩ ク ジ ( な い し プ ロ ス ペ ク ト ) 𝑓𝑓 = (𝑥𝑥, 𝑝𝑝)の 評 価 関 数 𝑉𝑉 は , 原 点 で 屈 折 す る 価 値 関 数 𝑢𝑢(𝑥𝑥) = 𝑥𝑥 𝛼𝛼 , 𝑥𝑥 ≥ 𝑟𝑟; = −𝜆𝜆(−𝑥𝑥)𝛽𝛽 , 𝑥𝑥 < 𝑟𝑟と合わせて,決定ウェイトπを用いて以下のように定 義される. 𝑖𝑖. 0. 𝑛𝑛. 𝑖𝑖=−𝑚𝑚. 𝑖𝑖=0. 𝑉𝑉(𝑓𝑓) = � 𝜋𝜋𝑖𝑖− 𝑢𝑢(𝑥𝑥𝑖𝑖 ) + � 𝜋𝜋𝑖𝑖+ 𝑢𝑢(𝑥𝑥𝑖𝑖 ),. (6). プロスペクトの対f,g間の選好をf≽gのように書き,「fはgより好まれる」と読む.つまり≽は 意思決定者の選好ないし選好順序を表し,「fとgを比べて一つを選べるとすると,fが選ば れる」ことを意味する.数学的には≽は完備的かつ反射的かつ推移的な二項関係であり, f≽gかつg≽fでないとき,f≻gと書くまた無差別f∼g はf≽gかつg≽fのときである.評価関数𝑉𝑉 は直観的に次のような意味において意思決定者の選好を表現する.すなわち, f≽g⇔ V(f)≥V(g) である. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 7.
(8) なお,特殊ケースとして,符号による変化や参照点の影響を無視した(6)は,ショケ期待 効用理論と呼ばれる.ショケ期待効用では,第一階確率支配やさまざまな末尾独立性の 違反を説明できない(Birnbaum, 2008).. 4 Allais のパラドックスを予測する:参照点を考慮した CPT 金額単位を日本円にアレンジしたAllaisのパラドックスを,以下に示そう.. 問 1:. 題 オプション 1: �. ¥500,000,000, 10%; ¥100,000,000, 89%. オプション 2:. 問 題 2. オプション 3:¥500,000,000, 10% オプション 4:¥100,000,000, 11%. ¥10,000,000, 100% それぞれの問題では一つのオプションを選ぶことができる.現実の人々の典型的な回 答パタンは,問題1では確実な金額として提示されたオプション2を選ぶ(確実性効果)が, 問題2では金額のより大きなオプション3を選ぶ(共通結果効果(CCE)).ところが問題2は 89%の1億円を消去した問題1と一致するから,クジの期待効用は,構成成分の金額とそ の確率を掛け合わせて合計したものに等しくなるという期待効用理論の仮定に反するた め,上述のような選択パタンは予測できない. (6)の評価関数を用いて予測モデルの条件を具体的に書くと,次のようになる. 𝑉𝑉1 < 𝑉𝑉2 ⟺ 𝑤𝑤 + (0.1)500𝛼𝛼 + �𝑤𝑤 + (0.99) − 𝑤𝑤 + (0.1)�100𝛼𝛼 < 100𝛼𝛼 , (6a) 𝑉𝑉3 ≥ 𝑉𝑉4 ⟺ 𝑤𝑤 + (0.1)500𝛼𝛼 ≥ 𝑤𝑤 + (0.11)100𝛼𝛼 整理すると次のようになる. 1 − 𝑤𝑤 + (0.99) > 𝑤𝑤 + (0.1)(5𝛼𝛼 − 1) ≥ 𝑤𝑤 + (0.11)(1 − 5−𝛼𝛼 ). (6b) 問題1で確実な金額のオプション2,問題2で金額の大きい方のオプション3をそれぞれ 選ぶパタン(確実性効果+共通結果効果)を予測できる(1)のパラメータγは0.32程度か それより小さくなくてはいけない.(6b)式から分かるように,金額単位は条件(6a)の成立に 影響しない.またこの後すぐ説明するように,金額から参照点を差し引いてCPT評価値を 計算しなおしても,ほとんど影響はない(図2も参照).すなわち,たとえ参照点を金額シフ し て も , 上 記 の Allais パ ラ ド ッ ク ス に 対 す る 予 測 力 は 向 上 し な い ( ち な み に Tversky&Kahnemann(1992)の推定値は 𝛼𝛼 = 𝛽𝛽 = 0.88, 𝜆𝜆 = 2.25である). 次にもう一つのAllaisの例題を示す. 問題 3 オプション 1: 問題 4 オプション 3:¥400,000,000, 20% ¥400,000,000, 80% オプション 4:¥30,000,000, 25%. オプション 2:. ¥300,000,000, 100% 前の例題同様,現実の人々は,問題3は確実な金額であるオプション2を選び,問題4 では確率の大きさよりも金額の大きさを重視してオプション3を選ぶ(確実性効果+共通 比効果(CRE)).しかし問題4は問題3の確率を25%の倍率で縮小したものであり,期待 効用理論に沿って計算したとき,両オプションの大小関係は保たれるため,このような回 答パタンは矛盾なく予測できない. 後の方に示した例題(確実性効果+共通比効果)については,(1)の関数形でγを1よ ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 8.
(9) り若干小さくするだけで予測が成立する.プロスペクト理論の紹介ではこのケースを取り 上 げ て 説 明 し て い る 文 献 が 多 い . ま た オ リ ジ ナ ル の PT を 提 案 し た Kahneman & Tversky(1979)における共通結果効果の数値例は,上述の問題1と2とは異なる.そこで, 以下ではAllaisパラドックスのCPTによる予測を論じるときは,CREではなく,主にCCEの 例題について論じることにする. 参 照 点 に 依 存 し た CPT モ デ ル は , よ り 記 述 力 が 高 い と さ れ る (Schmidt, Starmer & Sugden, 2008).例えば,金額シフト𝑟𝑟 × 106 が1億円以内のときの予測モデルは,次のよう になる. 𝑤𝑤 + (0.1)(500 − 𝑟𝑟)𝛼𝛼 + (𝑤𝑤 + (0.99) − 𝑤𝑤 + (0.1))(100 − 𝑟𝑟)𝛼𝛼 − 𝑤𝑤 − (0.01)𝜆𝜆𝜆𝜆𝛽𝛽 < (100 − 𝑟𝑟)𝛼𝛼 , (7) 𝑤𝑤 + (0.1)(500 − 𝑟𝑟)𝛼𝛼 − 𝑤𝑤 − (0.9)𝜆𝜆𝜆𝜆𝛽𝛽 < 𝑤𝑤 + (0.11)(100 − 𝑟𝑟)𝛼𝛼 − 𝑤𝑤 − (0.89)𝜆𝜆𝜆𝜆𝛽𝛽 . (1)を代入して整理すると次のようになる(犬童(2018) 命題 2). 0.99𝛾𝛾 5𝛼𝛼 0.1𝛾𝛾 0.11𝛾𝛾 1− (8) 1 > 1 ≥ 1 (0.99𝛾𝛾 + 0.01𝛾𝛾 ) �𝛾𝛾 (0.1𝛾𝛾 + 0.9𝛾𝛾 ) �𝛾𝛾 (0.11𝛾𝛾 + 0.89𝛾𝛾 ) �𝛾𝛾 その他の場合は犬童(2018)付録Aにまとめられているが,簡潔な表現は得られない. そこで犬童シミュレーション技法を用い,予測モデルの視覚化を試みよう.犬童(2018a)は Allaisのパラドックスを予測する参照点付きCPTモデルの視覚化し,また実験用Prologプ ログラミングをIndo(2019)において公開しているので,これらを利用することができる. 実験 1 利得側の確率ウェイト関数のパラメータγと参照点𝑟𝑟を同時にランダム生成し, 損失側の確率ウェイト関数のパラメータは 0.69 に固定ないし利得側標準パラメータからの 乖離に応じて比例配分することによって,上記の問題 3 と問題 4 の典型的選択パタンを 予測する CPT モデルを見出す. 実験 1 の結果(CPT モデルの予測可能領域)を図 2 に示す.. (a). (b). (c). 図 2 実験 1.Allais のパラドックスの CPT モデル.横軸は金額シフト(参照点)𝑟𝑟,縦軸は利得側の確率ウ ェイト関数𝑤𝑤(𝑝𝑝) = 𝑝𝑝𝛾𝛾 (𝑝𝑝𝛾𝛾 + (1 − 𝑝𝑝)𝛾𝛾 )−1⁄𝛾𝛾 のパラメータγ.参照点𝑟𝑟と確率ウェイト関数のパラメータγの組を. ランダム発生させた(a は 5 万件,bと c は各 3 万件).図 2a は参照点をより広い区間とした.図 2a と図 2b では損失側パラメータを 0.69 に固定し,図 2c ではγ(1 + ρ),ρ = (0.69 − 0.61)/(1 − 0.61)とした.. 図 2 から分かるように,左図上側のγ≧1.5(非逆 S 字)の領域を無視すると,𝑟𝑟 = 0,す なわち参照点による金額シフトなしでは,γは概ね 0.32 以下でないといけない.また金額 のゼロ点を横軸の参照点𝑟𝑟分シフトしたとしても,可能領域は広がらず,むしろγの上限 値が減少しており,また小さなγの値について予測が失敗する領域が新たに発生してい. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 9.
(10) る(図 2 中央を参照).なお付録 A に図 2b をエクセルで再現する方法を概略した. 本論文では選択問題の予測の成否を,前述の CPT 評価値による選好順序の表現可 能性に基づく 2 値的な判断とする.しかしそれとは異なる考え方もある.すなわち 2 オプ ションの評価値をその魅力と考えて,マッチング法則に準じて評価値の相対比率の関数 として選択確率(ないし反応率)を予測し,実証的な回答比率と適合させる.ロジットモデ ルなどで採用されるこの方法には,前者にはなかった,予測モデルの有用性を連続的な 指標として吟味できる利点がある.ただし,図 2 のような,視覚的な境界がはっきりしなくな る.図 2 では,仮にロジットモデルを採用したとして,境界付近では選択確率が 1/2 に近 いと推論することができる.. 5 確率ウェイト関数変更による CPT の改良 本節では実験 2 として,確率ウェイト関数を変更して参照点シフト付き CPT モデルに代 入し,CCE 例の予測可能領域を視覚化する. 実験 2 利得側の確率ウェイト関数のパラメータ組と,損失側の確率ウェイト関数のパラメ ータ組を同時にランダム生成し,実験 1 と同様に CPT 評価値を計算し,問題 3 と問題 4 の典型的選択パタンを予測する CPT モデルを見出す.確率ウェイト関数の関数形は, (1)Tversky&Kahneman(1992),(2)ベータ分布,(3)一般化双曲線型割引の 3 種類を,そ れぞれ第 3 節で定義した CPT モデルに代入し,また参照点𝑟𝑟は 0, 50, 100 の 3 水準で金 額シフトさせた表 1 に示す計 9 パタンについて調べる. 表 1 実験 2 で用いる確率ウェイト関数の図 2 における記号(利得側および損失側). 確率ウェイト関数. \ 参照点 0. 50. 100. CPT(累積プロスペクト理論). a. d. g. ベータ分布(正則ベータ関数). b. e. h. 一般化双曲線割引(マッチング法則). c. f. i. 以下に実験 2 の結果をまとめる. 1)オリジナルの CPT では,単一パラメータ𝛾𝛾 ≤ 0.32で予測可能である(図 2a).しかし参 照点のシフトはほとんど予測を改善せず,かえって予測可能領域を狭くする(図 2d およ び図 2g).これらは実験 1 の結果と一致する. 2)ベータ分布は参照点を考慮しないとき,図 2b で示される 0≤ 𝛼𝛼 ≤ 1の範囲では,概ね 𝛽𝛽 ≤ 0.4𝛼𝛼の領域内で予測できる.ただし𝛼𝛼 > 146辺りから𝛽𝛽の小さい値は予測できなくなり, 𝛼𝛼 > 155で予測可能領域は消える.参照点を 0~100 の範囲で動かすと,参照点が上昇 するにつれて,傾向として利得側では同上領域が拡散し,また損失側では𝛽𝛽 ≥ 𝛼𝛼の領域 に集まる(図 2e および図 2h).参照点を 500 まで上げると,ほぼ𝛼𝛼 ≤ 0.4𝛽𝛽の領域になる. 3)一般化双曲線割引を用いた場合,参照点なしで 2 パラメータがなす予測可能領域は 双曲線型の境界部分から上方の範囲に広がる(図 2c).しかし参照点が上昇すると,可 能領域は拡散し,損失側は𝑘𝑘が 0 に近い場合を除き,𝛿𝛿 ≤ 0.4に集中する(図 2f および図 2i). ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 10.
(11) (a). (b). (c). (d). (e). (f). (g). (h). (i). 図 3 実験 2.Allais のパラドックス(CCE 例)を予測する修正 CPT モデルの 3 種類の確率ウェイト関数, (1) 𝑝𝑝𝛾𝛾 (𝑝𝑝𝛾𝛾 + (1 − 𝑝𝑝)𝛾𝛾 )−1⁄𝛾𝛾 ,(2) 𝐼𝐼𝑝𝑝 (𝛼𝛼, 𝛽𝛽),(3) (1 + 𝑘𝑘(𝑝𝑝−1 − 1))−𝛿𝛿 .利 得 側 ( 上 ) と 損 失 側 ( 下 ) で ( 𝛾𝛾 ,-) ,. (𝛼𝛼, 𝛽𝛽),(𝑘𝑘, 𝛿𝛿/100)をそれぞれ 1 万組の[0,1]区間一様乱数ペアとして発生させた.参照点は a~c では𝑟𝑟 =. 0, d~f では𝑟𝑟 = 50,g~i では 𝑟𝑟 = 100とした.. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 11.
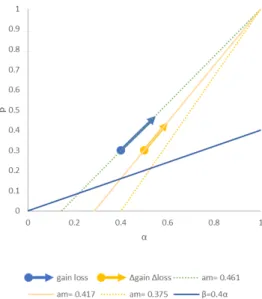
(12) ちなみに,グラフを含 めた詳 しい結 果 は省 力 するが,Prelec(1998)の関 数 形 𝑤𝑤(𝑝𝑝) = exp(−𝑘𝑘(− ln(𝑝𝑝))𝛼𝛼 ))を関数形(1)の代わりに用いた場合, 𝑘𝑘 ≤ 1.5では,(1)と同様に記述 力がなく,境界は𝑘𝑘 = 1.5のとき𝛼𝛼 ≤ 0.11,𝑘𝑘 = 2では𝛼𝛼 ≤ 0.61であり,下方に押しつぶれた グラフ形状になる. 2 パラメータを自由に動かすことによって記述力が改善するが,しか し参照点の移動は貢献せず,わずかのシフトで予測可能領域が消失する.付録で説明 するエクセルシート等を用いて確認することができる.. 6 利得側と損失側のペアリング 実験 2 では Allais パラドックス(CCE 例)を予測可能な CPT の確率ウェイト関数の利得 側と損失側のペアを,ランダムなパラメータの分布として観察したが,図 2 のグラフでは利 得側と損失側のパラメータがそれぞれ独立に描かれており,個別の CPT モデルにおける ペア関係については十分な情報が得られない.そこで実験 3 として,ベータ分布を用い た個別の CPT モデルにおける確率ウェイト関数の利得側と損失側のペア関係を視覚化 する.. 図 4 予測境界の近似𝛽𝛽 = 0.4𝛼𝛼上のベータ分布の反モード 5⁄(7 − 3/(𝛼𝛼 − 1)).. ところで,図 1d に示した 3 種類のグラフは,図 3d の予測可能領域の境界部分𝛽𝛽 = 0.4𝛼𝛼に沿って移動することによってベータ分布を変化させることによって得られたものだっ た.この境界上で得られるベータ分布の反モードは,図 4 に示されるように,𝛼𝛼によって単 調に減少する(図 4 参照). 表 2 Tversky & Kahneman(1992)の確率ウェイト関数のベータ分布による近似. 利得/損失. 金額の大きさ. α. β. 反モード. 利得側. $200 以下. 0.4. 0.3. 0.462. 利得側. $200 より大きい. 0.5. 0.3. 0.417. 損失側. $200 以下. 0.55. 0.47. 0.459. 損失側. $200 より大きい. 0.6. 0.44. 0.417. 興味深いことに金額の大きさによって区別された Tversky & Kahneman(1992)の確率ウ ェイト関数のグラフをベータ分布で近似すると,利得側と損失側とでそれぞれ反モード(α -1)/(α+β-2)が一定となる.この結果は犬童(2020)のポスター報告および事前録画にお いて示唆された.表 2 はそれを再現している. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 12.
(13) 図 5 利得側から損失側への確率ウェイト関数のパラメータの変化と反モード.右上(1,1)に至る点線の線 分は反モード一定のパラメータ組(α,β)の集合を表す.矢線は表 2 にしたがって Tversky&Kanheman(1992)の標準モデルを金額の大きさによって区別して近似した.. 図 5 は表 2 に示したパラメータ組とベータ分布の反モードの関係を視覚的に表現した. 図 2d~f からも予想されうるように,表 2 および図 5 に示した確率ウェイト関数の利得・損 失ペアでは,Allais パラドックスの CCE 例を予測することができない. 次に前の 2 つの実験で用いたシミュレーション実験に若干改良を加えることによって, 利得側(あるいは損失側)の確率ウェイト関数をベータ分布モデルとして特定したとき,そ のペアとなる損失側(あるいは利得側)の予測可能なモデルを領域として視覚化する.. 図 6 ベータ分布(α,β) = (0.35, 0.25)を利得側の確率ウェイト関数とし,参照点 100 として,Allais のパラ ドックスを予測する損失側の確率ウェイト関数のパラメータ.矢線は図 7 のペア.. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 13.
(14) 図 7 参照点 100 として Allais のパラドックスを予測する確率ウェイト関数のペアの一つ.. 実験 3 標準的な CPT の確率ウェイト関数のベータ分布による近似(α,β) =(0.4, 0.3) と図 1c のモデルの一つであるベータ分布(α,β) = (0.3, 0.2)の中間を利得側確率ウェイ ト関数として,Allais のパラドックスを予測できる損失側の確率ウェイト関数のパラメータ組 をシミュレーション実験によって生成する.参照点は 100 とする. 図 6 は実験 3 の結果を示している.図 6 には利得側(0.3, 0.2)から損失側(0.17, 0.35) への矢線を追加し,(α,β) の変化も示してある.興味深いことに,前者は標準モデルと 反モードが近い値である.また参照点 100 のとして,図 1c の下側のグラフ(α,β) = (0.4, 0.2)と上側のグラフ(α,β) = (0.2, 0.3)のペアリングは Allais のパラドックスを予測する (CPT 値は v1 = -4.248, v2 = 0, v3 = -71.963, v4 = 100.130).図 6 からわかるように,このモ デルの弱点は,損失側のパラメータの下では,利得側のパラメータはかなり広範囲に広 がってしまうことである.事実,図 6 で示された損失側の可能領域は,参照点を上げたと きの損失側の可能領域(図 3f)そのものに近づく.また損失側のカーブが利得側に比べ て,より線形に近くなるという Tversky & Kahneman(1992)以来の観察にも反している.そ こで,実験 3 とは逆に損失側のパラメータを固定して,利得側の可能領域を視覚化して みよう. 実験 4 損失側の確率ウェイト関数の近似として,ベータ分布(0.17, 0.35)と(0.3, 0.2)を 固定して,Allais のパラドックスを予測できる利得側のパラメータ組の範囲を調べる.. 図 8 参照点 100 のとき,確率ウェイト関数の損失側のモデルを,図 8 左側は(α,β) = (0.17, 0.35),また 図 8 右側では(α,β) = (0.3, 0.2)として,それぞれ Allais のパラドックスを予測できる確率ウェイト関数のパ ラメータ組ペアの利得側を図示した. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 14.
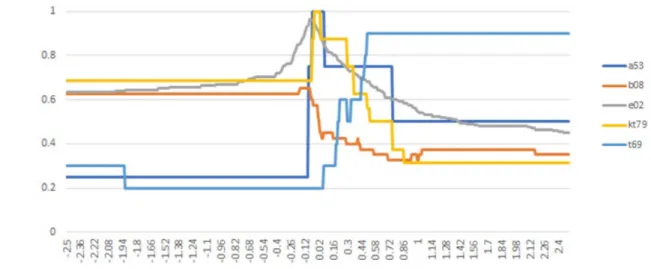
(15) 図 8 左側は損失側をベータ分布(α,β) = (0.17, 0.35)としたときの利得側モデルの予測 可能領域である.また (α,β) = (0.3, 0.2)のとき,標準モデルの損失側はより線形に近い 形状となる.利得側の予測可能領域は図 8 右側のようである.図 8 右側から分かるように, 損失側の確率ウェイト関数がより線形に近い標準的な形状であると仮定するならば,利 得側のモデルは参照点なしの場合(図 3d)を若干非線形に歪めた領域になり,参照点移 動による効果が観察できた.. 7 実証的選択率による諸モデルの比較 文 献 で は 一 般 双 曲 型 割 引 の 記 述 力 が 優 れ て い る と 報 告 さ れ て い る (Takemura & Murakami, 2016).前節までの考察を踏まえると,ベータ分布は一般双曲型割引と同等 かそれ以上の記述力が期待できる.そこで本節では,文献で報告された実証的な選択 率のデータを用いて各種モデルの適合度を比較してみよう. 第 3 節で説明したように,CPT 評価関数は,確率ウェイト関数を容量とみなした価値関 数のショケ積分(4)(5)によって計算される.すなわち,符号を考慮して利得側と損失側そ れぞれ,最善値から最悪値に向かって限界貢献を累計する(これはゲーム理論における Shapley 値とも関係するが詳しくは省く).逆に最悪値点から始めて限界貢献を累計する ことも考えられる.この双対的な CPT は,通常の CPT 値の楽観的なバージョンである. 実験 5 Takahashi(2011)の一般双曲線割引を確率ウェイト関数に代入し,CPT 値𝑓𝑓と 双対 CPT 値𝑔𝑔を線形結合した新しい評価関数(1 − 𝑎𝑎)𝑓𝑓 + 𝑎𝑎𝑎𝑎による予測の実証的な選択 率 との 適 合 を 調 べる.ただし 参 照 点 は 動 か さない.また 価 値 関 数 とそのパラメ ータは Tversky&Kahneman(1992)の標準的な設定とする. 文献に対応する記号 を,a53:Allais(1953),b08:Birnbaum(2008), kt79:Kahneman & Tversky(1979), t69:Tversky(1969), e02: Erev, Roth, Slonim, & Barron (2002)とする.また 実験に用いた文献の選択問題データは,a53:4 問,b08:40 問,e02:200 問,kt79:16 問, t69:10 問の計 270 問である.ただし a53 については Allais(1953)に実証的な選択率のデ ータがないため,犬童(2013)の追試のデータを用いた.. 図 9 楽観的な CPT との線形混合による一般双曲線型割引(20, 0.6)の実証的選択率との適合度. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 15.
(16) 図 9 の横軸は混合係数𝑎𝑎であり,0 のときが元の一般双曲線型割引(20, 0.6)の場合で ある.適合度は,ペア比較(x,y)における実証的な x の選択率 Pr(x)が 50%を超えるとき に x の評価値 v(x)が y の評価値 v(y)より大きい,つまり Pr(x)-0.5 と v(x)-v(y)が同符号 の場合,もしくは実証的な選択率と 50%の差が 5%未満であり,かつ評価値の合計が正 で,かつ相対評価値と 50%の差が 3%未満,つまり 0.03 > v(x)/(v(x)+v(y))-0.5 のとき 1, それ以外を 0 として平均した. 一般双曲線型割引モデル(20, 0.6)は,図 3g で示した予測境界の若干外側に位置す るが,図 9 が示すように𝑎𝑎 =0 付近で,Allais のパラドックスの 4 問とプロスペクト理論が予 測する kt79 の 16 問すべてと適合し,e02 についても 90%を超える.また𝑎𝑎をわずかに負と した場合に e02 や b08 の予測力が若干改善していることに注意する.絶対値の小さい負 の混合係数𝑎𝑎 < 0は,CPT に若干の楽観性が追加されることを意味する.また 𝑎𝑎 > 0で t69 の非推移性のケースの予測力が改善する.末尾独立性の違反などを含む b08 では −0.08 ≥ 𝑎𝑎 ≥ −0.18で 65%が最大である. 次に,文献で観察されたように,損失側の確率ウェイトがより線形に近いと仮定して,よ り線形のグラフに近いベータ分布を用いて,利得側を反モード一定として参照点を動か しながら予測モデルを生成してみよう. 実験 6 利得側を反モード 0.37 としたベータ分布(0.5,β),損失側を ベータ分布(0.6, 0.52)とした場合の修正 CPT を,参照点を 0~500 の範囲で動かして実験する(実験結果 を図 10 として示す).. 図 10 利得側の確率ウェイト関数を反モード 0.37 のベータ分布( 0.5, β),損失側をベータ分布(0.6, 0.52)とした場合の修正 CPT を,参照点を 0~500 の範囲で動かしたときの文献の実証的選択率との適合 度 . a53 : Allais(1953) , b08:Birnbaum(2008), kt79:Kahneman & Tversky(1979), t69:Tversky(1969), e02:Erev et al.(2002).. もし反モードを 0.38 に変えると,a53 は参照点なしでも予測できることに注意する.図 10 から分かるように,利得側のモデルが図 3d の境界付近に位置するためか,参照点の 移動による改善は限定的である.言い換えれば,実証的なパタンと適合する参照点が特 定される.具体的には,この事例では 30~37 の範囲に定まる. 実験 7 さまざまな確率ウェイト関数を CPT に代入し,同上文献データを使って選択率適 合度を比較する(結果を図 11 として示す). ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 16.
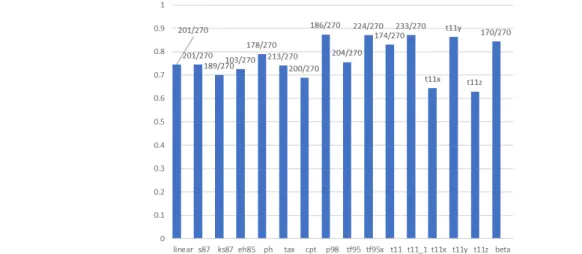
(17) 図 11 さまざまな確率ウェイト関数を代入した CPT の修正版が文献の実証的選択率データと適合する比 率.確率ウェイト関数の種類は,linear:線形,s87:Segal(1987),k87:Karni & Safra(1987), eh85: Einhorn and Hogarth(1985,1986), Currim and Sarin(1989), cpt: Tversky & Kahneman (1992), tax: Birnbaum(2008), tf94: Tversky & Fox (1994), Lattimore, Baker, and Witte(1992), t11, t11_1: Takahashi(2011)でパラメータ 組(20, 0.6), (7, 0.8), t11x~z: 楽観的な CPT バージョンとの線形混合(混合比𝑎𝑎=0, 0.5, -0.08, -1.03). 5 系列目の ph は優先順位ヒューリスティックス(Brandstätter, Gigerenzer, and Hertwig, 2006).ベータ分布は 右端の beta で(α,β)=(1, 0.1).. 実験 7 の結果を示す図 11 では,Prelec の p98(2, 0.57), Tversky&Fox の tf95x(2, 0.57)と並んで Takahashi の一般化双曲線割引(7, 0.8)の適合が高い.楽観混合バージョ ン t11x は,t11 の一般化双曲線割引(20, 0.6)の適合度 83.0%より良い.しかしこれらのモ デルはグラフ形状が J 字型をしており,確率が 1 に近づくまで下方につぶれた形である (付録 A1⑨の図を参照).これらと比較するため,図 11 ではあえて極端なパラメータ値の ベータ分布(α,β)=(1, 0.1)のケースが示されている.このデータセットではオリジナルの cpt は 68.9% と,線 形 モデル(74.4%)に すら劣 っている.した がってベータ 分 布 (α, β)=(0.4, 0.3)についても適合が良くない.このデータセットでは,問題数にばらつきが大 きく,とくに問題数が多い e02 で結果が良好であるモデルに有利になる(線形モデルでも 十分良い).e02 を除いた 70 件のデータセットでは,b08 の占める割合が大きくなり,tax が 77.1%で最も適合し,次いで Prelec 60.0%,一般双曲線型割引 58.6%と続く.tax 以外 のモデルは 60%を超えない.. 8 まとめ 本 論 文 では 累 積 プロ スペクト理 論 (CPT)の 確 率 ウェイト関 数 の 関 数 形 を 修 正 して, Allais のパラドックスをより自然に表現できるように改良を試みた.一般化双曲型割引は, CPT の確率ウェイト関数に代入すると,じゅうらい提案されてきた代替理論と比較して優 れた記述力を持つと考えられる.しかし Tversky & Kahneman のオリジナルの関数形同 様,参照点の移動による予測改善は見られなかった.一方,ベータ分布を用いた場合, 参照点の移動による影響が観察された.またベータ分布を用いた予測モデルから,参照 点の位置を推論できる可能性が示唆された. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 17.
(18) 付録A 本付録では,エクセルを用いて確率ウェイト関数と CPT モデルによる予測を実験する ための簡便な方法を述べる.以下では実験 1 の一部を再現するが,一定の汎用性をもた せてあり,その他の分析にも応用可能である. A1 各種の確率ウェイト関数を定義し,計算する ① エクセルで新しくファイルを開き,シート名「モデル定義」として下図のように入力する. A. ◢. B. C. D. E. F. G. Prm1. Prm2. Prob. formula. 1. index. name. Formula. 2. 1. linear. P. 3. 2. eh85. p+θ*(1-p-p^β). β. 4. 3. tk92. p^γ/(p^ γ+(1-p)^γ)^(1/γ). γ. 5. 4. p98. EXP(-κ*(-LN(p))^α). κ. α. p. 6. 5. tf95. θ*p^δ/(θ*p^δ+(1-p)^δ). θ. δ. p. 7. 6. t11. (1+Κ*((1-p)/p) )^(-α). Κ. α. p. 8. 7. beta. BETA.DIST(p,α,β,TRUE). α. β. p. パラメータと変数の記号. Prm1. Prm2. Prob. p θ. p p. 9 10. ②の数式. ② セル G2 に以下の数式を入力し,G8 まで下向きコピーする. =SUBSTITUTE(SUBSTITUTE(SUBSTITUTE($C2,F2,F$10),D2,D$10),E2,E$10) ③ シート名「モデル計算」を作り下図のように入力する.H1:P1 には 0.1~0.9 を入力する. ◢. A. B. C. D. E. F. G. Prm1. Prm2. 0. 0.01. 0.05. 1. #. 種類. 2. 1. linear. 3. 2. eh85. 0.4. 4. 3. tk92. 0.61. 5. 4. p98. 2. 0.57. 0. 1. 6. 5. tf95. 0.724. 0.61. 0. 1. 7. 6. t11. 20. 0.6. 0. 1. 8. 7. beta. 0.4. 0.3. 0. 1. 0 0.1. 0 0. H I J K L M N O P. Q. R. S. 0.95. 0.99. 1 1. ④の数式を入力し,F2:. 1. T8 にコピー&貼り付け. 1. 9. ④ セル F2 に以下の数式を入力し,F2 を範囲 F2:T8 にコピーして貼り付けする. ="="&SUBSTITUTE(SUBSTITUTE(SUBSTITUTE( モ デ ル 定 義 !$G2,"Prob", F$1),"Prm1","$C"& $A2+1),"Prm2","$D"& $A2+1) 例えば,セル H5 には,「=EXP(-2*(-LN(K5))^0.57)」と表示されていることを確かめる.確 率 0 や 1 での数値エラーに対処するためには,以下のように修正する. ="=IF(""Prob""=0,0,IF(""Prob""=1,1,"&SUBSTITUTE(SUBSTITUTE(SUBSTITUT ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 18.
(19) ⑤ ⑥ ⑦ ⑧. E( モ デ ル 定 義 !$G2,"Prob", F$1),"Prm1","$C"& $A2+1),"Prm2","$D"& $A2+1) &"))" ここなでの結果を,エクセルファイルを「モデル管理.xlsx」として保存する. 「モデル計算」シートを CSV ファイルとして保存し,ファイルを保存せずに閉じる. 「モデル計算.csv」をダブルクリックして開き,「実験1.xlsx」として保存する. 適宜分析を追加する(下図参照).. A2 効用関数ないし価値関数を定義し,計算する A1 で作成した「モデル管理.xlsx」を開き,効用関数(価値関数)を定義するため,「効用 モデル」シートを追加する. ◢. A. B. C. D Prm1. Prm2. E. F. Prm3. Money. 1. #. name. formula. 2. 1. linear. x. 3. 2. power. x^α. Α. x. 4. 3. cara. 1.0 -EXP(-x/(1000*α)). Α. x. 5. 4. tk92. IF(x<0, -λ*(-x)^β, x^α). Α. 6. 5. log. IF( y = 0, 0, IF( y > 0,. G formula 2. x. Β. λ. x y. LN( y ), -LN( -y ) ) 7. 6. ks87. IF( X < -1, X, IF( X <. X. 12, 10 * X + 10, 6.75 * X + 49 ) ) 8 ⑩の数式. 9 10. Prm1. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. Prm2. Prm3. XX. を入力. 19.
(20) ⑨ セル G2 に以下の数式を入力し,G8 まで下向きコピーする. =SUBSTITUTE(SUBSTITUTE(SUBSTITUTE(SUBSTITUTE($C2,G2,G$10) ,D2,D$10),E2,E$10),F2,F$10) ⑩ 「オプション定義」シートを追加し,以下のように入力する. A. B. 1. Option. No. 1. 2. 3. 4. 5. 6. 7. 8. 2. outcome. 1. 500. 100. 500. 100. 400. 300. 400. 300. 3. outcome. 2. 100. 0. 0. 0. 0. 0. 4. outcome. 3. 0. 5. probability. 1. 0.1. 0.1. 0.11. 0.8. 0.2. 0.25. 6. probability. 2. 0.89. 0.9. 0.89. 0.2. 0.8. 0.75. 7. probability. 3. 0.01. ◢. C. D. 1. E. F. G. H. I. 1. J. 8. ⑪ B10:B15 に図のように数値を入力し,C10 に以下の数式を入力して C10:J15 にコピー する. =IF(ISERROR(MATCH($B10,C$2:C$4,0)),0,INDEX(C$5:C$7,MATCH($B1 0,C$2:C$4,0))) 10. Pr($). 500. 11. 400. ⑫の数式を入力し,. 12. 300. C10:J15 にコピー&貼. 13. 200. 14. 100. 15. 0. 16. ⑫ 「パラメータ設定」シートを追加する.B4:B5 に文字列「'=RAND()*500」を入力し,また C4:C5 に「'=RAND()」を入力して D4:I5 にコピーして貼り付けする. ◢. A. 1. B 参照点. C. D. E. 効用関数のパラメータ. F. G. 利得側 Id. R. Prm1. 4. 1. =RAND()*500. =RAND(). 5. 2. =RAND()*500. =RAND(). Prm2. I. 確率ウェイト関数のパラメータ. 2 3. H. Prm3. Prm1. 損失側 Prm2. Prm1. Prm2. ⑬ セル A5 に「=A4+1」と入力し直し,実験するケース数分を行コピーする. ⑭ 「効用計算」シートを追加し,以下のように入力する. 15-1) A~Q 列 1 行 目 に 列 名 を 英 文 字 で入 力 する(「= LEFT( ADDRESS( ROW(), COLUMN(), 4), 1)」を入力してコピーする). 15-2)G 列までを以下のように入力する.ただしセル A5 には「=A4+1」を入力する. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 20.
(21) A. ◢ 1. B. A. 2. C. B. C. 参照点. パラメータ. R. Prm1. D. E. D. F. E. Prm2. Prm3. G. H. F. G. モデル. 効用関数. 効用u. u:formula. 3. Id. 4. 1. 4. 5. 2. 4. H. 6. 15-3)B4 に「="=パラメータ設定!"&B$1&ROW()」を入力し,コピーして B4:E5 に貼付け する. 15-4)G4 に以下の数式を入力し,G5 にコピーする. =SUBSTITUTE(SUBSTITUTE(SUBSTITUTE( INDEX(効用モデル!H:H, F4+1), "Prm1", "$" & C$1 & ROW() ), "Prm2", "$" & D$1 & ROW() ), "Prm3", "$" & E$1 & ROW() ) 15-5)H~Q 列の 3 行目までを図のように入力する(後の計算のため,利得と損失に分け る). H H. I I. J J. K K. L L. 利得側 0. M M. N. O. P. Q. N. O. P. Q. 100. 300. 400. 500. 損失側 100. 300. 400. 500. 0. 15-6)H4 に以下の数式を入力し,L5 まで右向きコピーする. ="="&SUBSTITUTE($G4,"XX","MAX(0,"&H$1&"$3-$"&$B$1&ROW()&")") 15-7)M4 に以下の数式を入力し,Q5 まで右向きコピーする. ="="&SUBSTITUTE($G4,"XX","MIN(0,"&N$1&"$3-$"&$B$1&ROW()&")") 15-8)5 行目(A5:Q5)をコピーして,⑭で作成した個数分,貼付けする. 15-9)「モデル管理.xlsx」を上書き保存する. ⑮ 「モデル管理.xlsx」に追加したシートを以下の手順で「実験 1.xlsx」に反映する. 16-1) 「オプション定義」「パラメータ設定」「効用計算」の各シートをいったん CSV ファイ ルに保存する.これらを書き出したら,ファイルを保存せずに閉じる. 16-2) 先に「実験1.xlsx」を開いておく.⑯で保存した CSV ファイルをそれぞれダブル クリックしてエクセルに読み込む.各シートのタブを右クリックし,「シートの移動または コピー」で「実験1.xlsx」に移動する(モデル管理.xlsx から直接シートをコピーするの ではないことに注意). 16-3) 「モデル管理.xlsx」で,「データ」「クエリと接続」の「リンクの編集」で,リンク元をす べて「モデル管理.xlsx」に変更する.変更したらファイルを上書き保存する. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 21.
(22) A3 CPT 評価値を計算し,実験結果をレビューする ⑯ 「モデル管理.xlsx」に「CPT (1)」シートを追加し,以下のように J 列 5 行目まで入力す る. A. ◢ 1. A. 2. B. C. D. B. C. 参照点. 利得側. R. Prm1. E. D. F. E. G. F. 損失側 Prm2. Prm1. Pr. H. I. J. G. H. I. J. 選択. 関数. 利得. 損失. option. w. w+. w-. 3. Id. 4. 1. 1. 3. 5. 2. 1. 3. 17-1) B4 に「="=パラメータ設定!"&B$1&ROW()」と入力する. 17-2) C4 に「="=パラメータ設定!"&F$1&ROW()」と入力し,F4 まで右向きコピーする. 17-3) I4 に以下の数式を入力する. =SUBSTITUTE(SUBSTITUTE(VLOOKUP(H4, モ デ ル 定 義 !$A$1:$G$8, 7, FALSE), "Prm1", "$"&C$1&ROW()), "Prm2", "$"&D$1&ROW()) 17-4) J4 に以下の数式を入力する. =SUBSTITUTE(SUBSTITUTE(VLOOKUP(H4, モ デ ル 定 義 !$A$1:$G$8, 7, FALSE), "Prm1", "$"&E$1&ROW()), "Prm2", "$"&F$1&ROW()) 17-5)「CPT (1)」シートの K~U 列の 3 行目までを図のように入力する. K. L. K. L. 累積確率. 利得. 0. 100. M M 300. N N 400. O O 500. P P oo. Q. R. Q. R. 累積確率. 損失. 0. 100. S. T. U. S. T. U. 300. 400. 500. 0. 17-6) K4 に以下の数式を入力し,O4 まで右向きコピーする. ="=IF(" & K$1 & "$3<$" & $B$1 & ROW() & ", 0, VLOOKUP(" & K$1 & "$3,オ プ ショ ン定 義 !$B$10:$J$15,1+$" & $G$1 & ROW() & ",FALSE))+" & L$1 & ROW() 17-7) Q4 に以下の数式を入力し,U4 まで右向きコピーする. ="=IF(" & Q$1 & "$3<$" & $B$1 & ROW() & ",VLOOKUP(" & Q$1 & "$3,オプ シ ョ ン 定 義 !$B$10:$J$15,1+$" & $G$1 & ROW() & ",FALSE),0)+" & P$1 & ROW() 17-8)「CPT (1)」シートの V~AE 列の 3 行目までを図のように入力する. V. W. X. Y. Z. V. W. X. Y. Z. ウェイト. 利得. 0. 100. 300. 400. 500. AA. AB. ウェイト. 損失. 0. 100. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. AC. AD. AE. 300. 400. 500. 22.
(23) 17-9)AA1 に「=LEFT(ADDRESS(ROW(),COLUMN(),4),2)」と入力し,AP1 まで右向き コピーする. 17-10) V4 に以下の数式を入力し,Z4 まで右向きコピーする. ="="&SUBSTITUTE($I4,"Prob",K$1&ROW()) 17-11) AA4 に以下の数式を入力し,AE4 まで右向きコピーする. ="="&SUBSTITUTE($J4,"Prob",Q$1&ROW()) 17-12)「CPT (1)」シートの AF~AP 列の 3 行目までを図のように入力する. AF. AG. AF. AG. 決定ウェイト. 利得. 0. 100. AH. AI. AH. AJ. AI. 300. AJ. 400. 500. AK. AL. AK. AL. 決定ウェイト. 損失. 0. 100. AM AM. AN AN. AO AO. AP AP 評価値. 300. 400. 500. cpt. 17-13) AJ4 には「="="&Z$1&ROW()」を入力する.また AF4 に以下の数式を入力し, AJ4 まで右向きコピーする. ="="&V$1&ROW()&"-"&W$1&ROW() 17-14) AK4 には「="="&AA$1&ROW()」を入力する.また AL4 に以下の数式を入力し, AO4 まで右向きコピーする. ="="&AB$1&ROW()&"-"&AA$1&ROW() 17-15) AP4 に以下の数式を入力する. ="=SUMPRODUCT(" & AF$1 & ROW() & ":" & AO$1 & ROW() & ",効用計 算!H" & ROW() & ":Q" & ROW() & ")" 17-16) B4:AP4 をコピーして B5 で貼付けする. 17-17) 「モデル管理.xlsx」を上書き保存する. ⑰ 「実験結果」シートを追加し,5 行目 J 列まで図のように入力する. ◢. A. B. 1. 実験結. 2. CPT値. 3. Id. 4. 1. 5. 2. 1. C. D. E. F. G. 差 2. 3. 4. ⊿1-2. ⊿3-4. H. I. 選好逆. アレ. reversal. cce. J. 18-1) A5 に「=A4+1」と入力する. 18-2) B4 に以下の数式を入力し,E4 まで右向きコピーする. ="='CPT ("&B$2&")'!AP"&ROW() 18-3) F4 に「="=B"&ROW()&"-C"&ROW()」を入力する. 18-4) G4 に「="=D"&ROW()&"-E"&ROW()」を入力する. 18-5) H4 に以下の数式を入力する. ="=NOT(SIGN(F"&ROW()&")=SIGN(G"&ROW()&"))" 18-6) I4 に以下の数式を入力する. ="=AND(B"&ROW()&"<C"&ROW()&","&"NOT(D"&ROW()&"<E"&ROW()&" ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 23.
(24) ))" ⑱ 「CPT (1)」と「実験結果」をそれぞれ CSV に保存し,⑯と同様の手順で,これらを「実 験 1.xlsx」に反映し,リンク元を変更する.また「実験 1.xlsx」で「CPT (1)」を「移動また はコピー」で「コピーを作成する」を 3 回実行し,「CPT (2)」「CPT (3)」「CPT (4)」それぞ れで G 列を 2,3,4 に変える.「実験 1.xlsx」を上書き保存し,また適宜分析を追加する (図参照).. ⑲ ベータ分布版を作る.必要なシートは「モデル定義」「オプション定義」「効用計算」「パ ラメータ設定」「CPT (1)」であるが,このうち作り変えるのは「CPT (1)」のみである. 20-1) 「実験1.xlsx」を開き,ファイルの名前を変えて保存で,「実験2.xlsx」として保存 する. 20-2) 「CPT (1)~(4)」と「実験結果」の5シート分を削除する. 20-3) 「モデル管理.xlsx」を開き,H 列 7 に変えてから,いったん CVS ファイルに保存 し,ファイルを閉じる(繰り返すが,エクセルファイルから直接シートをコピーするので はない). 20-4) 「実験2.xlsx」に戻り,作成し直した「CPT (1).csv」と既存の「実験結果.csv」を開 いて,「実験 2.xlsx」にシートを移動する.データのリンクを編集してリンク元を「実験 2.xlsx」に変更する. 20-5) ⑲と同様に,「CPT (1).csv」を 3 回シート複製し,「CPT (2)」「CPT (3)」「CPT (4)」 それぞれで G 列のオプションを 2,3,4 に変える.ファイル名を「実験 2.xlsx」に変えて 保存する. 20-6) 適宜分析を追加する(図参照).. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 24.
(25) 参考文献 [1] Abdellaoui M. (2000). Parameter-free elicitation of utilities and probability weighting functions. Management Science, 46(11), 1497-1512. doi: 10.1287/mnsc.46.11.1497.12080 [2] Allais, M. (1953). Le comportement de l'homme rationnel devant le risque: critique des postulats et axiomes de l'école américaine. Econometrica, 21, 503–546. doi: 10.2307/1907921 [3] Birnbaum, M. H. (2008). New paradoxes of risky decision making. Psychological Review, 115(2), 463–501. doi: 10.1037/0033-295X.115.2.463 [4] Birnbaum, M. H. (2018). Empirical evaluation of third-generation prospect theory. Theory and Decision, 84(1), 11–27. doi: 10.1007/s11238-017-9607-y [5] Bleichrodt, H., and Pinto, J. L. (2000). A parameter-free elicitation of the probability weighting function in medical decision analysis. Management Science, 46(11), 14851496. doi: 10.1287/mnsc.46.11.1485.12086 [6] Brandstätter, E., Gigerenzer, G., and Hertwig, R. (2006). The priority heuristic: making choices without trade-offs. Psychological Review, 113(2), 409–432. doi: 10.1037/0033-295X.113.2.409 [7] Camerer, C. F., & Karjalainen, R. (1994). Ambiguity-aversion and non-additive beliefs in non-cooperative games: experimental evidence. In Munier, B., and Machina M.J. (eds.), Models and experiments in risk and rationality, Dordrecht: Springer, pp. 325-358. doi: 10.1007/978-94-017-2298-8_17 [8] Chateauneuf, A. (1991). On the use of capacities in modeling uncertainty aversion and risk aversion. Journal of Mathematical Economics, 20(4), 343-369. doi: 10.1016/0304-4068(91)90036-S [9] Chew, S. H., Karni, E., and Safra, Z. (1987). Risk aversion in the theory of expected utility with rank dependent probabilities, Journal of Economic Theory, 42(2), 370381. doi: 10.1016/0022-0531(87)90093-7. ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 25.
(26) [10] Choquet, G. (1954). Theory of capacities. Annales de l'Institut Fourier, 5, 131-295. doi: 10.5802/aif.53 [11] Currim, I. S., and Sarin, R. K. (1989). Prospect versus utility. Management Science, 35(1), 22-41. doi: 10.1287/mnsc.35.1.22 [12] Einhorn, H. J., and Hogarth, R. M. (1985). Ambiguity and uncertainty in probabilistic inference. Psychological Review, 92(4), 433–461. doi: 10.1037/0033295X.92.4.433 [13] Einhorn, H. J., and Hogarth, R. M. (1986). Decision making under ambiguity, Journal of Business, 59 (4), 30–55. http://www.jstor.org/fcgibin/jstor/listjournal.fcg/00219398/.51-.60 [14] Ellsberg, D. (1961). Risk, ambiguity, and the Savage axioms. The Quarterly Journal of Economics, 75(4), 643-669. doi: 10.2307/1884324 [15] Erev, I., Roth, A. E., Slonim, R., and Barron, G. (2002). Combining a theoretical prediction with experimental evidence. Social Science Electronic Publishing. [http://ssrn.com/abstract=1111712] doi:10.2139/ssrn.1111712 [16] Fennema, H., and Wakker, P. (1997). Original and cumulative prospect theory: A discussion of empirical differences. Journal of Behavioral Decision Making, 10(1), 53-64. doi: 10.1002/(SICI)1099-0771(199703)10:1<53::AID-BDM245>3.0.CO;2-1 [17] Grabisch, M. (2016). Set Functions, Games and Capacities in Decision Making. Springer International. doi: 10.1007/978-3-319-30690-2 [18] Gilboa, I. (1987). Expected utility with purely subjective non-additive probabilities. Journal of Mathematical Economics, 16(1), 65–88. doi: 10.1016/03044068(87)90022-X [19] Gonzalez, R., & Wu, G. (1999). On the shape of the probability weighting function. Cognitive Psychology, 38(1), 129-166. doi: 10.1006/cogp.1998.0710 [20] Grant, S., Kajii, A., & Polak, B. (2000). Decomposable choice under uncertainty. Journal of Economic Theory, 92(2), 169-197. doi:10.1006/jeth.2000.2644 [21] Halevy, Y. (2004). The possibility of speculative trade between dynamically consistent agents. Games and Economic Behavior, 46(1), 189-98. doi: 10.1016/S08998256(03)00044-7 [22] Halevy, Y. (2008). Strotz Meets Allais: Diminishing Impatience and the Certainty Effect. American Economic Review, 98(3):1145-62. doi: 10.1257/aer.98.3.1145 [23] Handa, J. (1977). Risk, Probabilities, and a New Theory of Cardinal Utility. Journal of Political Economy, 85(1), 97-122. doi: 10.1086/260547 [24] Herrnstein, R. J., D. I. Laibson, and H. Rachlin, 2000. The Matching Law: Papers in Psychology and Economics. Harvard University Press. [25] 犬童健良(2013). アレの背理における注目と注目の流れ, 行動経済学, 6, 70-73. doi:10.11167/jbef.6.70 [26] 犬童健良. (2015). ギャンブル比較における観点:投票関数によるモデル化と実験 データからの再構成. 関東学園大学経済学紀要, 40, 25-103. doi: 10.20589/kantogakueneconomics.40.0_25 ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 26.
(27) [27] 犬童健良(2018a). 共通比効果と共通結果効果を共に予測するプロスペクト理論の シミュレーション研究. 関東学園大学経済学紀要 44, 19-43. doi: 10.20589/kantogakueneconomics.44.0_19 [28] 犬童健良(2018b). プロスペクト理論のシミュレーション研究. 行動経済学会第 12 回大会ポスター発表. http://www.abef.jp/conf/2018/common/doc/poster/G11_PR0021.pdf [29] Indo, K. (2019a). Programming prospect theory in prolog. The Research Bulletin of Economics Kanto Gakuen University 45, 40-75. doi: 10.20589/kantogakueneconomics.45.0_40 [30] 犬童健良(2019b). マッチング法則からの確率ウェイト関数の近似について. 行動 経済学会第 13 回大会ポスター発表. http://www.abef.jp/conf/2019/common/doc/poster/P20_PR0060.pdf [31] 犬童健良(2020). 確率ウェイト関数とベータ分布. 行動経済学会第 14 回大会ポス ター発表. http://www.abef.jp/conf/2020_archive/common/doc/program/P13.pdf [32] Kahneman, D., and Tversky, A. (1979). Prospect theory: An analysis of decision under risk. Econometrica, 47, 263–291. doi: 10.1017/CBO9780511609220.014 [33] Karni, E., and Safra, Z. (1987). "Preference reversal" and the observability of preferences by experimental methods. Econometrica, 55(3), 675-685. doi: 10.2307/1913606 [34] Lattimore, P. K., Baker, J. R., and Witte, A. D. (1992). The influence of probability on risky choice: A parametric examination. Journal of Economic Behavior & Organization, 17(3), 377-400. doi: 10.1016/S0167-2681(95)90015-2 [35] Lévy, P. (1939). Sur certains processus stochastiques homogènes. Compositio Mathematica, 7: 283–339. doi: [36] Luce, R. Duncan and Peter C. Fishburn. (1991). Rank-and sign-dependent linear utility models for finite first-order gambles. Journal of Risk and Uncertainty, 4, 2959. doi: 10.1007/BF00057885 [37] Prelec, D., and Loewenstein, G. (1991). Decision making over time and under uncertainty: A common approach. Management Science, 37(7), 770-786. doi: 10.1287/mnsc.37.7.770 [38] Luce, R. D., and Fishburn, P. C. (1991). Rank- and sign-dependent linear utility models for finite first-order gambles. Journal of Risk and Uncertainty, 4, 29–59. doi: 10.1007/BF00057885 [39] Machina, M. (1982). "Expected Utility" Analysis without the Independence Axiom. Econometrica, 50(2), 277-323. doi:10.2307/1912631 [40] Machina, M. J., (1992). Choice under uncertainty: Problems solved and unsolved. The Journal of Economic Perspectives, 1(1), 121–154. doi: 10.1257/jep.1.1.121 [41] 蓑谷千凰彦(2010). 統計分布ハンドブック増補版. 東京:朝倉書店. Phelps, R. R. (2001). Lectures on Choquet’s Theorem. Berlin: Springer-Verlag. doi:10.1007/b76887 [42] 中村國則(2013). 確率加重関数の理論的展開. 心理学評論, 56(1), 42-64. doi: ©関東学園大学, 2021. 関東学園大学経済学紀要 第 47 集. 27.
図
+3
関連したドキュメント
成される観念であり,デカルトは感覚を最初に排除していたために,神の観念が外来的観
問についてだが︑この間いに直接に答える前に確認しなけれ
このように資本主義経済における競争の作用を二つに分けたうえで, 『資本
算処理の効率化のliM点において従来よりも優れたモデリング手法について提案した.lMil9f
2 E-LOCA を仮定した場合でも,ECCS 系による注水流量では足りないほどの原子炉冷却材の流出が考
Zeuner, Wolf-Rainer, Die Höhe des Schadensersatzes bei schuldhafter Nichtverzinsung der vom Mieter gezahlten Kaution, ZMR, 1((0,
・ 津波高さが 4.8m 以上~ 6.5m 未満 ( 津波シナリオ区分 3) において,原
炉心損傷 事故シーケンスPCV破損時期RPV圧力炉心損傷時期電源確保プラント損傷状態 後期 TW 炉心損傷前 早期 後期 長期TB 高圧電源確保 TQUX 早期 TBU
