1. はじめに
進化的計算とは,遺伝的アルゴリズム(Genetic Algorithm: GA)[1]や粒子群最適化(Particle Swarm Optimization: PSO)[2]などに代表されるような, 多数の解候補(ノード)の情報交換によって関数 の近似解を探索する手法である.GA は最も歴史 のある進化的計算の手法で,交叉や突然変異, 自然淘汰といった生物の進化のメカニズムを最 適化に応用したアルゴリズムである.PSO は比 較的新しい手法で,魚や昆虫が群れをなすこと によって効率的に餌を探索する様子から着想を 得た手法である. これらの手法は,(1)NP 困難な問題に対して近 似解を得られること,(2)評価関数の知識(微分性 など)がなくても近似解を求められること,(3)実 装が容易であることといった強力な長所をもっ ている. これらの最適化手法において,解候補の多様性 を保つことは,探索が局所最適解に陥ることを 防ぐために極めて重要な課題である.系の多様 性を保ち最適化の効率を上げるために,例えば 焼きなまし法(Simulated Annealing: SA)[3]のアイ デアを GA に組み込んだ熱力学的遺伝的アルゴ リ ズ ム (Thermodynamic Genetic Algorithm: TDGA)[4]や,解の再探索を抑えるために考案さ れた免疫アルゴリズム(Immune Algorithm: IA)[5] など,現在まで様々な手法が提案されてきてい る. しかし,これらの手法をはじめとする進化的計 算はいずれも解同士の情報交換によって近似解 を探索するアルゴリズムであるにもかかわらず, 解同士のつながり方と最適化手法の性能との関 係性についてはあまり議論されてきていない. 関連のある研究分野として分散遺伝的アルゴリ ズム(Distributed Genetic Algorithm: DGA)[6,7]が あるが,これは解の探索を複数の島と呼ばれる サーバで処理を分散させることにより,スルー プットの向上と解の多様性の保持の両面で従来 法より効率的な解の探索ができることが確認さ れているが,DGA の研究では一般的なグラフ構 造と最適化性能の関係性に関する議論はほとん どなされてきていない.また,ネットワーク構 造と PSO の性能に関する研究[8]もあるが,いく つかの決められたトポロジー関して性能比較を 行ったのみで,ネットワークの疎密度を変えて 得られる関数の最適値と収束速度のトレードオ フをとるなどの一般性の高い研究は行われてい ない. 本研究は,近年盛んに研究されている複雑ネッ トワーク[9,10]と最適化アルゴリズムを組み合 わせた研究である.この研究の目的は大きく分 けて 2 つある. (1) グラフ構造の導入による系の多様性の保 持,および最適化性能の向上. (2) ネットワーク環境での分散最適化におけ る,最適化に適したトポロジーの発見. 本論文では主に(1)を研究の対象とする.ノー ド同士の情報交換をあらかじめ与えたグラフ構
進化的計算におけるグラフ構造と最適化性能の関係性
須山 敦志
*1,本位田 真一
*2Relationship
between
Graph
Structure
and
Optimization
Performance on Evolutionary Algorithm
Atsushi Suyama
*1,Shinichi Honiden
*2Abstract: 進化的計算(Evolutionary Algorithm: EA)は多数の解候補の情報交換により関数の近 似解を探索する手法である.本研究では解候補同士のつながり方(トポロジー,グラフ構造)と 最適化性能の関係性について調べる.実験の結果,グラフ構造で情報交換を制限することにより, 系全体の解の多様性が増し,最適化の性能が向上することを確認した. Keywords: 進化的計算,最適化,複雑ネットワーク
JAWS 2010
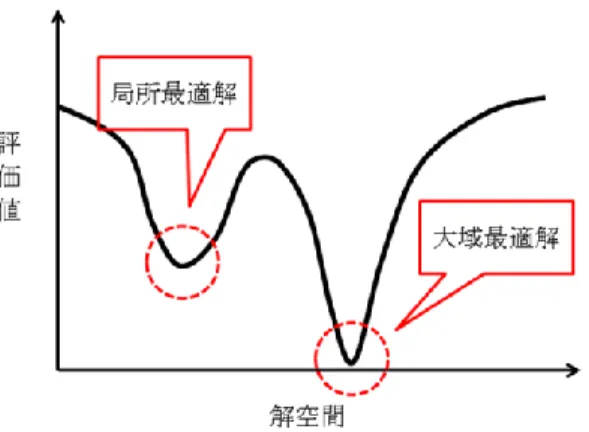
*1東京大学大学院情報理工学系研究科,〒113-8656 東京都文京区本郷7-3-1 E-mail: [email protected]図 1 局所最適解と大域最適解 造に制限することにより,系全体の多様性をコ ントロールする手法を提案する.それぞれ異な る性質をもつテスト関数を用いて実験を行った 結果,すべての関数において,グラフ構造を導 入しない場合と比べて解候補の多様性が増し, さらに最適化性能も向上することを示した. 2. 注意点 本研究で取り扱う最適化問題はすべてテスト 関数を用いた最小値探索問題である.したがっ てノード n を評価する関数を eval(n)とすると, eval(ni) < eval(nj)のとき,ノード niの方が良い解 となる.第 7 章で実験とその結果を示すが,す べてのテスト関数の最適値は eval(n) = 0 である. 3. 初期収束問題 進化的計算の効率性を妨げる原因の一つとし て,初期収束問題がある.進化的計算を用いて 探索する最適化問題は,図 1 のように局所最適 解と大域最適解をもつ複雑な多峰性の関数であ る場合が多い.最適化アルゴリズムは,良い評 価値が得られる近傍に個体群が集まるように設 計されている.これは大域最適解が存在すると 思われる近傍により多くの個体を配備すること によって効率的に探索を行うためである.しか し局所最適解に個体が集中した場合,より評価 値の良い大域最適解が解空間に存在するにもか かわらず探索が止まってしまう. 本論文では,初期収束問題を回避する新たな手 法として,解候補のインタラクション(情報交 換)をあらかじめ設定したトポロジーによって 制限する事により解の多様性を保つ手法を提案 する.
4. Memetic Network Algorithm
解同士のつながりを構成するトポロジーと最 適化の性能の関係性を調べるために,本研究で は Araujo らが提案している Memetic Network Algorithm (MNA)[11]と呼ばれる最適化アルゴリ ズムを用いる.MNA は GA と同様,多数のノー ドのインタラクションを用いて近似解を探索す るアルゴリズムである.GA と異なるのは,一般 的な GA がノードの交叉が 1 対 1 であることを基 本としているのに対して,MNA は複数のノード との情報共有によって次世代のノードの値を決 定する点である. MNA のアルゴリズムを説明する.MNA は (n1,n2,…,nN)の N 個のノードから構成される.
MNA の動作は,connection rule,aggregation rule, appropriation rule からなる.すべてのノードの組 み合わせに対して上の 3 つのルールを適用し, 解を更新する.このループを 1 世代として,世 代数があらかじめ設定した一定数を超えるか, 基準をみたす近似解が見つかるまで繰り返す.3 つのルールは以下のように定義される. ・Connection rule eval(ni) < eval(nj)のとき,niから njに向かって接 続する. ・Aggregation rule C(ni)を niが接続しているノードの集合とする. C(ni)∪{ni}から,各々のビットに対して多数決 を適用し,niのビットを更新する. ・Appropriation rule 各々のビットに対して,一定の変異確率 pmで 値を 0 か 1 に等確率で置き換える. Aggregation rule を詳しく説明する.niのビット を更新する際に,各々のビットに対して C(ni)と {ni}の中でもっとも共通する値を選ぶ.同数の場 合は,等確率で 1 か 0 か選択する.例えば,t 世 代目において, ni (t) = (0,1,1,1,0,1) C(ni (t)) = {(1,1,0,0,0,1) , (1,1,0,1,0,0)} のようなビット列であったとすると,t+1 世代目 の niはそれぞれのビットにおいて多数決をとり,
ni (t+1) = (1,1,0,1,0,1) となる. オリジナルの MNA は Simple GA と同程度の最 適化性能であることが Araujo らによって示され ているが,各々の世代において最適値を持つノ ードの影響力が非常に大きいため,局所最適解 に陥りやすいという欠点をもっている. 本論文の実験で GA の代わりに MNA を用いた 理由は,対複数交叉であり,進化的計算として 一般性が高いからである.MNA におけるコネク ション数を 1 に制限すれば,GA と同等の動作が 期待できる.また最近研究が盛んに行われてい る PSO も MNA と同様に複数のノードとのイン タラクションによって解を探索する手法である が,アルゴリズムのシンプルさから今回は MNA を選択した. 5. 実験で用いるグラフ構造 グラフ理論における「グラフ」とは,ノード(頂 点)とエッジ(枝)の集合である.本研究では,グ ラフ上のひとつのノードがひとつの解候補を表 現し,ノード同士をつなぐエッジは,ふたつの ノードが情報交換可能な状態にあることを示し ている.またノードの数に対してエッジが尐な いグラフを疎なグラフ,逆にエッジが多いグラ フを密なグラフと呼ぶ.特にグラフのエッジ数 が最大の時,すなわちノード数を N とするとき エッジ数が N(N-1)/2 であるとき,そのグラフを 完全グラフと呼ぶ.(図 2(a)) また注意点として,MNA で構成される接続関 係 と 区 別 す る た め に , こ こ で の グ ラ フ を underlying graph と呼ぶことにする.今回の実験 では underlying graph として,古典的なトポロジ ーであるランダムグラフと拡張サイクルを用い る. 5.1 ランダムグラフ ある一定の確率 p によってエッジを生成する グラフをランダムグラフと呼ぶ.ランダムグラ フにはいくつかの定義が存在するが,本研究で は以下のアルゴリズムに従ってグラフを生成す る定義を用いる. (1) ノード数 N と確率 0 < p < 1 を設定する. (2) 各ノードの組に確率 p でエッジを張る. (a) (b) (c) (d) 図 2 実験で用いたグラフ構造の例 (a)完全グラフ (b)ランダムグラフ(p = 0.40) (c)サイクル (d)拡張サイクル(k = 4) 定義から明らかであるように,p が 1 に近づく ほど,ランダムグラフは密になっていく.p = 1 の場合,すべての可能なエッジが生成されるの で,完全グラフが構成される.また図 2(b)のノー ド v のように,ランダムグラフではどのノードと も隣接していない孤立点が形成される可能性が ある. 5.2 拡張サイクル 図 2(c)のようなリング状のトポロジーをサイ クルと呼ぶ.さらに図 2(d)のように,すべての頂 点の次数が k になるようにサイクルにエッジを 追加したグラフを拡張サイクルと呼ぶ.ランダ ムグラフと同様に,k の値が大きいほどグラフは 密になっていく. 6. グラフ構造を導入した MNA
グラフ構造(underlying graph)を考慮した MNA に関して説明する.グラフ構造と最適化の関係 性を調べるため,以下の要素をオリジナルの MNA に加えアルゴリズムを実装をする. (1) underlying graph でエッジが結ばれているノ ード同士のみ,connection rule において評価 値の比較とノードの接続を行う. (2) 評価値の一番良かったノードの突然変異確 率 pmを,その世代に限り pm = 0 とする.
(2)を導入する理由は,アルゴリズムにエリー ト保存戦略を組み込むためである.エリート保 存戦略とはその世代で一番評価値の良かった解 を次世代に保存しておくようにする手法であり, 多くの進化的計算のアルゴリズムが,効率的な 解の探索を行うために採用している.オリジナ ルの MNA にはエリート保存戦略がないが,より 実用的なアルゴリズムでテストするために,今 回はこのような実装にした. これらを導入したアルゴリズムは以下のよう になる. グラフ構造を導入した MNA 7. 実験 第 6 章のアルゴリズムを用いて,グラフ構造と最適化 の性能の関係性を調べる実験を行った.いずれの関数に おいても実験設定は同じで,N = 100, ビット長l = 48, 変異確率pm = 0.06 で行った.ビットは左右24 ビットずつ に分け,それぞれ固定小数点として x1,x2にエンコーデ ィングする.また得られた結果はアルゴリズムを 100 回 実行し平均をとったものである. ここでは(1)多様性の推移,(2)最適化過程の2 つの結果 を示す.本研究では解の多様性を測る指標として,各世 代におけるすべての解候補の組のハミング距離の平均値 を用いる.どちらの実験結果も最も評価関数値の初期収 束が早かったk = k* ( p = p*),次数k (確率p)の値が 極端に小さい場合のk = 1 (p = 0.01),完全グラフ(comp)の 3 種類の推移を比較している.完全グラフの場合は,ノ ードの接続のグラフ構造による制限がないため,アルゴ リズムはオリジナルのMNA の動作と一致する. 7.1 テスト関数 実験では最適化アルゴリズムの評価で用いられる標準 的な 4 つのテスト関数を用いた.いずれの関数も値が最 小となる解を求めることを目的とする.4 つの関数の性 質を表 1 に示す.多峰性の関数は局所最適解に陥る可能 性がある.また変数間依存のある関数は,個体の各々の ビットの理想値が他のビットに依存するため,進化的計 算では特に難しい問題とされている. Sphere 関数 2 2 2 1 2 1, ) (x x x x f
5.12,5.12
i x Rosenbrock 関数 2 1 2 2 1 2 2 1, ) 100( ) ( 1) (x x x x x f
2.048,2.048
i x Rastrigink 関数 ) 2 cos( 10 ) 2 cos( 10 20 ) , ( 1 2 2 2 2 1 2 1 x x x x x x f
5.12,5.12
i x Griewank 関数 2 cos cos ) ( 4000 1 1 ) , ( 2 1 2 2 2 1 2 1 x x x x x x f
600,600
i x 表1 テスト関数の性質 関数 多峰性 変数間依存性 Sphere × × Rosenbrock × ○ Rastrigin ○ × Griewank ○ ○ 7.2 結果 図 3 はグラフ構造としてランダムグラフを用いた場合の 実行結果である.(a1),(b1),(c1),(d1)はそれぞれSphere, Rosenbrock,Rastrigin,Griiewank の最適化における解候 補の多様性の推移を表し,縦軸はaverage hamming distance (平均ハミング距離),横軸はgeneration(世代数)を示 している.(a2),(b2),(c2),(d2)は対応する最適化過程を(a1) (b1) (a2) (b2) (c1) (d1) (c2) (d2) 図 3 ランダムグラフの実験結果 表し,縦軸は evaluated value(評価関数値),横軸は generation(世代数)を示している. 図 3(a1),(b1),(c1),(d1)を見ると,ランダムグラフを 用いたアルゴリズムでは,エッジの生成確率 p が小さけ れば小さいほど多様性を保ちやすいことがわかる.しか し今回の実験では比較的簡単な関数である(a2)では,p を 小さくし過ぎることによって局所最適解に陥ってしまう 現象が見られた.これは,エッジの数を極端に制限する ことによって他のノードと情報交換を行わない多くの孤 立点を作ってしまうことが原因である.また,総じてラ ンダムグラフを用いたアルゴリズムが次に説明する拡張 サイクルを用いたアルゴリズムより最適化性能が劣った ことも同様の理由であると考えられる. 図 4 はグラフ構造として拡張サイクルを用いた場合の 実験結果である.ランダムグラフの場合と同様,(a1),(b1), (c1),(d1)はそれぞれ Sphere,Rosenbrock,Rastrigin, Griewank の最適化における解候補の多様性の推移を表し, (a2),(b2),(c2),(d2)は対応する最適化過程を表している. それぞれの図の軸の意味は図3 と同様である. 図4(a2),(b2),(c2),(d2)のすべてのgeneration において, 初期収束の早い次数k = k*を設定したアルゴリズムは (a1) (b1) (a2) (b2) (c1) (d1) (c2) (d2) 図 4 拡張サイクルの実験結果
オリジナルの MNA(comp)よりも良い評価値を出力する 傾向があることが確認できた. またその一方で,図4(b1)を見ると,comp がおよそ300 世代,k = k*がおよそ 600 世代で多様性を失っている 様子がわかる.そのため図4(b2)では,どちらも途中で局 所最適に陥り最適化が進まなくなっていることがわかる. k = 2 は多様性を高いまま保持し続けており,最初のお よそ100 世代まではk = k*に劣っているものの,それ 以降は局所最適に陥ることなく探索を継続している.こ れは他の 3 つの関数の最適化に関しても同様であり,オ リジナルの MNA(comp)よりも疎なグラフによってノー ド同士の情報交換をある程度制限することにより,初期 収束の早いアルゴリズムを得ることができることを示し ている.さらにk を小さくしてエッジの数を制限すると, 世代数は多くかかるが多様性をほとんど失うことなく解 を探索できるアルゴリズムが得られる.したがって,k を調整することにより,近似解の性質と収束の速さの間 でトレードオフがとることが可能となる. 8. 結論と今後 本研究では,既存の進化計算アルゴリズムである
ことにより,系の多様性をコントロールする手法を提案 した.拡張サイクルを用いた実験では,適切な次数 k を 設定することにより,情報交換を制限しない場合と比べ て収束効率の良いアルゴリズムを得ることができた.ま たさらに k の値を小さくして情報交換を厳しく制限すれ ば,多様性をほとんど失うことなく大域最適解を探索す ることのできるアルゴリズムを得られることを示した. 今回は古典的グラフである拡張サイクルとランダムグ ラフを用いて最適化の性質を調べたが,無数に存在する トポロジーの中からより多様性をコントロールしやすく, かつ最適化の効率を上げるようなグラフ構造を探し出す ことが今後の重要な課題である.例えば島型トポロジー において,島の数や島内のノード数をパラメータにとる ことによって,拡張サイクルやランダムグラフのように 性質の異なるいくつかのアルゴリズムを得られる可能性 がある.また,最適なトポロジーの発見は,DGA など複 数のサーバやプロセッサを用いて最適化処理を行わせる アルゴリズムの効率化に有用であるが,より現実的なネ ットワーク環境のモデルを考慮したアルゴリズムの検討 が必要であると考えられる. 文 献
(1) D. E. Goldberg, “Genetic Algorithms in Search, Optimization, and Machine Learning”, Addison-Wesley, 1989.
(2) J. Kennedy and R.C. Eberhart, “Particle Swarm Optimization”, Proceedings of IEEE International Conference on Neural Networks, Vol. 4, pp. 1942-1948, 1995.
(3) S. Kirkpatrick, CD Gelatt and MP Vecchi, “Optimization by simulated annealing”, Science 220(4598):671?680, 1983.
(4) N. Mori and H. Kita and Y. Nishikawa, “Adaptation to a Changing Environment by Means of the Feedback Thermodynamical Genetic Algorithm”, Proc. PPSN 98, pp. 149-158, 1998.
(5) K. Mori and M. Tsukiyama and T. Fukuda, “Immune Algorithm with Searching Diversity and its Application to Resourse Allocation Problem”, The Transactions of the Institute of Electrical Engineers of Japan, 1997.
(6) R. Tanese, Proc of 3rd International Conference on Genetic Algorithms, pp. 434 - 439, 1989.
(7) Jorg Lassig and Dirk Sudholt, “The benefit of migration in parallel evolutionary algorithms”, In GECCO 2010, pp. 1105-1112. ACM Press, 2010.
(8) 松下, 西尾, ”様々なトポロジーを持つネットワ ーク構造型粒子群最適化法とその振る舞い”, 電 子情報通 信学会非線形問題研 究会技術報告 , no/NLP2009-183, pp.141-144, 2010.
(9) D. Watts, “Collective dynamics of 'small-world' networks”, Nature 393, pp. 440-442, 1998.
(10) A. L. Barabasi, “Emergence of Scaling in Random Networks”, Science 286, pp. 509-512, 1999.
(11) Ricardo M. Araujo and Luis C. Lamb, “Memetic Networks: Analyzing the Effects of Network Properties in Multi-Agent Performance”, In AAAI 2008, pp. 3-8.