ウェブサーバの
パラメータ自動設定に関する研究
杉木 章義
電気通信大学大学院電気通信学研究科 博士(工学)の学位申請論文
2007 年 3 月
ウェブサーバの
パラメータ自動設定に関する研究
博士論文審査委員会
主査 岩崎 英哉 教授
委員 野下 浩平 教授
委員 岩田 茂樹 教授
委員 尾内 理紀夫 教授
委員 多田 好克 教授
委員 河野 健二 助教授
著作権所有者 杉木 章義
2007
Automatic Parameter-Tuning of Web Servers Akiyoshi Sugiki
Abstract
Modern Internet servers are rapidly becoming large and complex. To maintain good performance and availability, the administrator must perform a huge number of time-consuming tasks, particularly tuning the server’s parameters. Performance- related parameters are especially difficult to tune manually for three reasons. First, it is not always obvious which value is best for each parameter because the value largely depends on the execution environment. Second, it is time-consuming to find the optimal values because tedious trials must be repeated. Third, the optimal value may change over time because the execution environment changes.
This dissertation proposes a method for automatically tuning performance- related parameters of web servers. The contribution of this dissertation is twofold.
First, we present the tuning mechanisms that achieve both server performance and on-line tuning. From the observation that a small number of parameters dominate the server performance, we focus on two major parameters; the keep-alive timeout and the maximum number of clients. We leveraged parameter-specific features to effectively adjust each parameter without severely lowering the server performance during the adjustment. Although the interferences between the two parameters are essentially inevitable, the proposed mechanisms reduce them by carefully choosing almost independent tuning metrics, namely the HTTP request- waiting intervals for the keep-alive timeout and the deviation in response time for the maximum number of clients.
Second, we present the implementation widely applicable to the existing servers.
It is easy to deploy because they do not require any modifications to the server software and the operating system. To incorporate the mechanisms, it is sufficient to restart a web server after defining a special environment variable.
The tuning mechanisms were implemented on Linux and runs with Apache web server. We conducted experiments with the SPECweb99 benchmark modified to
introduce client-side behavior. Experimental results demonstrated that the tuning mechanisms can adjust both the keep-alive timeout and the maximum number of clients to nearly optimal values. Moreover, the tuning mechanisms adapted to workload changes within about 12 minutes, more quickly than manual tuning.
ウェブサーバの
パラメータ自動設定に関する研究 杉木 章義
論文要旨
インターネットサーバの人手によるパラメータ設定は管理コストの増大を招く ため,自動設定が求められている.ウェブサーバでは,性能を大きく支配するパ ラメータとして持続的接続時間と最大クライアント数の2つが広く知られている.
本論文では,この2つの主要なパラメータを対象とした自動設定機構を提案す る.本機構の特徴は次の2つである.第一に,本機構は個別のパラメータに特化 した手法であり,それぞれのパラメータに対して個別に分析を行い,専用の設定 機構を作成する.対象とするパラメータに特有で,お互いの干渉が小さい観測値 を基準とするため,2つの設定機構を独立に動作させ,2つのパラメータを同時設 定することができる.
第二に,本機構の実装はサーバやオペレーティングシステム(OS)を改変しな いため,容易に利用することができる.本機構は実行時にサーバとOS間に動的に 挿入され,サーバが発行したシステムコールを横取りし,書き換えることでパラ メータ設定を実現する.
実験では,ウェブサーバの標準的なベンチマークを元にした,異なる2つのワー クロードを使用して評価を行った.パラメータ片方のみを設定した場合,両方の パラメータを同時設定した場合のいずれの場合も,手動設定で試行錯誤を繰り返 して適切な値を求めた場合に近いサーバ性能が得られている.また,ワークロー ドを大きく変化させても,ワークロードの変化に応じて自動的にパラメータを設 定することが確認された.
本論文の概要は次の通りである.第1章では,研究背景について説明している.
近年,インターネットサーバでは管理コストが大きな問題となっている.人手に よるパラメータ設定は管理者の負担が大きく,監理コストの増加を招く大きな要 因となっている.ウェブサーバでは,持続的接続時間と最大クライアント数が主 要なパラメータとして知られており,この2つを対象とした自動設定が求められ ている.
第2章では,パラメータ設定の必要性を示している.実際にウェブサーバに対 して実験を行い,持続的接続時間と最大クライアント数の値を変えながらサーバ 性能の変化を測定した.実験結果から,パラメータが適切に設定された場合とデ フォルト値の場合のスループットの差は,同じ計算機にも関わらず最大6倍程度 であることが確認された.
第3章では,持続的接続時間の設定機構について示している.ウェブサーバに接 続しているクライアントの振る舞いを分析すると,データを頻繁に送受信する期 間とデータを全く送受信しない期間の2つがある.持続的接続時間を調整し,デー タを頻繁に送受信する期間のみ接続させることでサーバに対するTCP接続の使用 率を向上させ,不必要な接続の維持によるサーバ性能の低下を防いでいる.
第4章では,最大クライアント数の設定機構について示している.サーバが過 負荷状態であるかどうかは応答時間のばらつきに現れることが多い.本設定機構 は応答時間の標準偏差を観測し,最大クライアント数を設定している.サーバの 負荷が限界付近となり,標準偏差が急に増加を始める値に最大クライアント数を 設定する.これにより,サーバの過負荷状態を防ぎつつ,サーバの性能上最大の クライアント数を処理することができる.
第5章では,2つの設定機構を結合させた場合の動作について説明している.そ れぞれの設定機構は固有の観測値を元にパラメータを設定し,独立して動作する.
ここでは設定機構間の干渉について,パラメータの特性上避けられない本質的な 相関,それ以外の干渉に分けて議論している.
第6章では,実装について説明している.本機構をLinux上で動作するApache ウェブサーバに対して実装した.Apacheの内部構造について説明しながら,シス テムコールのフックによるパラメータ設定の実現方法について述べている.
第7章では,実験結果について示している.SPECweb99を元にした2つのワー クロードで実験を行った.実験では,全数探索による手動設定の結果と比較して いる.個別のパラメータのみを設定した場合,2つのパラメータを同時設定した 場合も手動設定に近いサーバ性能が得られている.ワークロードを突然変化させ,
その変化に対する適応性を観測した場合でも,約12分程度でパラメータ設定が完 了している.
第8章では,関連研究について述べている.既存の研究をパラメータに特化し た手法,パラメータに対して汎用的な手法の2つに分類し.本研究との違いについ て議論している.また,制御理論を用いた手法との関連についても言及している.
最後に,第9章で本論文をまとめ,今後の研究の展開についても言及している.
目 次
第1章 はじめに 1
1.1 ウェブサーバの性能パラメータ . . . . 2
1.2 本論文のアプローチ . . . . 3
1.3 本論文の貢献 . . . . 4
1.4 本論文の構成 . . . . 5
第2章 パラメータ設定の必要性 6 2.1 実験環境 . . . . 6
2.2 ワークロード . . . . 7
2.3 性能パラメータがサーバ性能に与える影響 . . . . 8
第3章 持続的接続時間の自動設定 12 3.1 持続的接続時間パラメータ . . . . 12
3.2 持続的接続時間の分析 . . . . 13
3.2.1 リクエスト待機間隔と持続的接続時間 . . . . 13
3.2.2 持続期間と思考期間の判別 . . . . 15
3.2.3 実運用サーバでのリクエスト待機間隔 . . . . 16
3.2.4 RTTのゆらぎによる影響 . . . . 17
3.3 持続的接続時間の設定機構 . . . . 18
3.3.1 設定機構の概要 . . . . 18
3.3.2 最大持続間隔の計算 (最大持続間隔 ≤持続的接続時間) . . . . 20
3.3.3 最大持続間隔の計算 (最大持続間隔 >持続的接続時間) . . . . 21
3.3.4 持続的接続時間の更新 . . . . 22
第4章 最大クライアント数の自動設定 23 4.1 最大クライアント数パラメータ . . . . 23
4.2 最大クライアント数の分析 . . . . 24
4.2.1 最大クライアント数と応答時間 . . . . 24
4.2.2 持続的接続時間による影響 . . . . 26
4.2.3 サーバ資源と応答時間 . . . . 27
4.3 最大クライアント数の設定機構 . . . . 32
4.3.1 設定機構の概要 . . . . 32
4.3.2 ワークロードの変化の検出 . . . . 32
4.3.3 最大クライアント数の設定 . . . . 33
第5章 両パラメータの同時設定 36 5.1 概要 . . . . 36
5.2 設定機構の共存 . . . . 36
5.2.1 パラメータ特性に基づく相関 . . . . 37
5.2.2 その他の原因による干渉 . . . . 38
5.3 適用可能なサーバ構成 . . . . 39
第6章 実装 40 6.1 概要 . . . . 40
6.2 Apacheウェブサーバの構成 . . . . 40
6.2.1 Apacheのプロセス構成. . . . 41
6.2.2 Apache内部のプロセス数調整機構 . . . . 42
6.2.3 リクエスト処理プロセス内のリクエスト処理 . . . . 42
6.2.4 Apacheの他のリクエスト処理モデル . . . . 43
6.3 実装の詳細 . . . . 44
6.3.1 実装を構成するコンポーネント . . . . 44
6.3.2 設定機構の動作 . . . . 45
6.4 持続的接続時間の設定の実装 . . . . 45
6.5 最大クライアント数設定の実装 . . . . 47
6.5.1 応答時間・プロセス使用率の測定 . . . . 47
6.5.2 最大クライアント数に基づくプロセス数の制限 . . . . 47
6.6 実装についての議論 . . . . 49
6.6.1 本論文の実装方法とApache固有の実装方法の比較 . . . . . 49
6.6.2 他のOSへの移植 . . . . 49
6.6.3 他のウェブサーバへの適用可能性 . . . . 50
第7章 実験 51 7.1 持続的接続時間の自動設定 . . . . 52
7.1.1 SPECweb標準 . . . . 52
7.1.2 SPECweb大 . . . . 57
7.2 最大クライアント数の自動設定 . . . . 61
7.2.1 最大クライアント数とサーバ性能 . . . . 61
7.2.2 最大クライアント数と性能の時間的変化 . . . . 63
7.3 両パラメータの同時設定 . . . . 66
7.3.1 同時設定でのサーバ性能 . . . . 66
7.3.2 ワークロードの変化に対する適応 . . . . 68
第8章 関連研究 71 8.1 パラメータに特化した手法の関連研究 . . . . 71
8.1.1 持続的接続時間に特化した研究 . . . . 71
8.1.2 最大クライアント数に特化した研究 . . . . 72
8.2 パラメータに対して汎用的な手法の関連研究 . . . . 73
8.2.1 古典的探索手法を利用した設定手法 . . . . 74
8.2.2 大域探索と局所探索を組み合わせた設定手法 . . . . 74
8.2.3 汎用的なパラメータ設定手法の改善 . . . . 75
8.3 制御理論を用いた手法の関連研究 . . . . 75
8.3.1 CPU,メモリの使用率に基づくApacheのパラメータ制御 . 76 8.3.2 ウェブサーバのアドミッションコントロール . . . . 77
第9章 まとめ 79 9.1 本論文の貢献 . . . . 79
9.2 今後の展望 . . . . 80
謝辞 82
関連論文の印刷公表の方法及び時期 92
図 目 次
1.1 本論文の位置づけ . . . . 5
2.1 ワークロードが模倣するクライアントの振舞い. . . . 7
2.2 パラメータ値がサーバ性能に与える影響(SPECweb標準) . . . . 9
2.3 パラメータ値がサーバ性能に与える影響(SPECweb大) . . . . 10
3.1 サーバに接続しているクライアントの振舞い . . . . 13
3.2 リクエスト待機間隔のヒストグラム . . . . 15
3.3 実運用ウェブサーバでのリクエスト待機間隔のヒストグラム . . . . 17
3.4 リクエスト待機間隔のRTTによるゆらぎ. . . . 18
3.5 持続的接続時間の設定機構の擬似コード . . . . 19
3.6 最大持続期間の計算 . . . . 21
4.1 最大クライアント数とサーバ性能の関係 . . . . 25
4.2 持続的接続時間による応答時間への干渉 . . . . 27
4.3 サーバ資源と応答時間(CPU) . . . . 29
4.4 サーバ資源と応答時間(メモリ) . . . . 30
4.5 サーバ資源と応答時間(ディスク) . . . . 31
4.6 ワークロードの変化の検出 . . . . 32
4.7 最大クライアント数設定機構の疑似コード . . . . 34
4.8 最大クライアント数の設定 . . . . 35
5.1 ウェブサーバのパラメータ自動設定機構 . . . . 37
5.2 パラメータ間の相関 . . . . 38
6.1 実装の概要 . . . . 41
6.2 Apacheの内部構成 . . . . 42
6.3 Apacheのリクエスト処理プロセスにおける処理の流れ . . . . 43
6.4 パラメータ自動設定機構の詳細な構成 . . . . 44
6.5 持続的接続時間設定機構の実装 . . . . 46
6.6 最大クライアント数設定機構の実装 . . . . 48
7.1 リクエスト待機間隔の分布 (SPECweb標準) . . . . 52
7.2 持続的接続時間の時間的変化(SPECweb標準) . . . . 53
7.3 持続的接続時間によるサーバ性能(SPECweb標準) . . . . 54
7.4 さまざまな持続的接続時間でのサーバ性能の詳細(SPECweb標準) 56 7.5 リクエスト待機間隔の時間分布(SPECweb大) . . . . 57
7.6 持続的接続時間によるサーバ性能(SPECweb大) . . . . 58
7.7 さまざまな持続的接続時間でのサーバ性能の詳細(SPECweb大) . 60 7.8 最大クライアント数とサーバ性能 . . . . 62
7.9 最大クライアント数の時間的変化 . . . . 64
7.10 最大クライアント数によるサーバ性能の時間的変化 . . . . 65
7.11 両パラメータの同時設定結果 . . . . 67
7.12 両パラメータを同時設定した場合のパラメータ値の時間的変化 . . . 69
7.13 両パラメータを同時設定した場合のサーバ性能の時間的変化 . . . . 70
表 目 次
2.1 実験で使用するワークロード . . . . 7
第 1 章 はじめに
1990年代のインターネットの急速な普及を経て,インターネットサーバが重要 な社会基盤として広く利用されている.その社会基盤としての重要性が増すにつ れて,従来,高速化が研究の話題の中心であったのに対し,ディペンダビリティ,
セキュリティ,プライバシー,管理コストなど他の側面の重要性が指摘され,広 く研究が行われている.
特に,管理コストの問題は産業界から差し迫った問題として警鐘が鳴らされ,
Recovery Oriented Computing (ROC) [65],Autonomic Computing [33]などのコ ンセプトが提唱されている.ROCの文献[65]によれば,サーバの購入価格に対して Total Cost of Ownership (TCO)は3.6倍から18.5倍にも上る.また,Autonomic Computingの文献[33]は,データベースサーバの管理コストはTCOの60%–70%を 占めることを指摘している.また,管理上の操作ミスによる障害もハードウェア,
ソフトウェアに起因するものを上回り,障害の主要な原因となりつつある[62, 58].
文献 [62] の報告によれば,管理ミスによる障害は障害全体の19%–36%の障害を占 める.日本でも,管理ミスによる障害は2005年11月の東京証券取引所,名古屋証 券取引所,2006年8月の楽天などで発生している.管理ミスが発生しやすい一方で,
障害が発生した場合の金銭的損失は多大であることが知られている.Amazon.com で障害が発生した場合の損失は1時間あたり20万ドルにも上り,金融機関では600 万ドルにも到達する [65].
管理コストや管理ミスの主な原因は,システムが急速に大規模化,複雑化して いるにもかかわらず,多くの作業を管理者が誤りなく行うことに頼っているため である.このため,計算機を利用した管理作業の支援や,管理作業そのものの自 動化が求められている [23, 83, 2, 79, 5, 16, 17, 67, 66].
管理コストを増加させる要因はさまざまであり,多方面からの総合的な試みが 必要である.本論文では,その要因の1つであるウェブサーバの性能パラメータ を対象とし,設定作業の自動化による管理コストの削減を目指す.
1.1 ウェブサーバの性能パラメータ
ウェブサーバをはじめとするインターネットサーバでは,当初,その性能の低 さが問題とされ [46],90年代半ばから性能改善のための研究が広く行われた [63, 36, 82, 56, 78, 6, 64, 10, 11, 34, 85, 59, 37, 9].これらの成果により,性能が大幅に 改善された一方で,サーバのハードウェアやネットワークなど環境に応じて決め られなければいけない困難な部分が設定ファイル中の性能パラメータとしてサー バ本体から切り離され,管理者に任されている.
性能パラメータとは,サーバの性能に大きな影響を与えるような,数値で指 定するパラメータである.例として,ウェブサーバでは持続的接続時間や最大 クライアント数が広く知られている.Apacheウェブサーバ [74]では,それぞれ KeepAliveTimeout,MaxClientsに対応する.性能パラメータを適切に設定する ことで,同じハードウェア,ソフトウェアを使用してもサーバの性能が大きく異な り,管理者がこれらの値を適切に設定することが期待されている.
90年代のインターネットサーバの改良の結果,性能パラメータが正しく設定さ れれば適切な性能が得られるようになったものの,この作業にかかる管理コスト が大きな問題となっている [71].パラメータ設定は管理者にとって困難な仕事で ある.まず,性能パラメータの適切な値はハードウェア性能に依存し,環境ごと に設定する必要がある.また,クライアントからのワークロードにも依存し,適 切な値が時間とともに変化する.その一方で,パラメータ値とCPU性能やメモリ 容量などのハードウェア仕様の数値との間には大きな隔たりがあると指摘されて
おり[28],試行錯誤することなく具体的な値を導き出すことは難しい.
現在,性能パラメータ設定の多くは管理者によって手動で行われている.適切な パラメータ値を得るため,ワークロードを運用前に予測し,予測に基づいたワー クロードをサーバに与え,何度もテストを繰り返す[4].これは多くの時間を要す るのと同時に,予測したワークロードが実際と異なっていた場合に,目標とする 性能が得られないことがある.また,このようなテストを行うことなく管理者の 経験に基づいてパラメータを設定することも多い.この場合,サーバの環境に合 わせてパラメータ値を求めているわけでないため,期待した性能が得られないこ とがある.
このように,手動による性能パラメータ設定は経験や多くの時間を必要とし,管 理コストの増加を招く.また,人が介入することで設定ミスも招きやすい[65, 62, 58, 61, 80].さらに,性能パラメータが適切でないことは運用直後のアクセスが少
ない間はあまり問題とならず,サーバをしばらく運用して,アクセスが集中した ときに初めて露見するという意味で潜在的であるといえる.以上から,自動的な パラメータ設定を可能とする技術が求められている.
1.2 本論文のアプローチ
ウェブサーバでは,主要なパラメータとして持続的接続時間と最大クライアン ト数の2つが知られている[28, 49, 75].持続的接続時間とは,クライアント・サー バ間のTCP接続における未使用時間の上限を決めるパラメータである.最大クラ イアント数とは,サーバに対して同時に接続できるクライアント数の上限を決め るパラメータである.この2つのパラメータは一般に設定が難しいことが知られ ており,1.1節で述べた通り,適切な値はハードウェア性能やワークロードに依存 して大きく異なる.
本論文では,ウェブサーバのこの2つの主要なパラメータを対象とした設定機 構を提案する.本機構は以下の2つの特徴を持つ.
• 主要なパラメータの特性の利用: インターネットサーバでは,ごく少数のパ ラメータがサーバ性能を大きく支配する.また,主要なパラメータのみを設 定対象とすることで,設定時間の短縮や安定性の面で有利であることが指摘 されている[22, 26].本機構では,対象とするパラメータ数を絞ることで,パ ラメータに特化した手法を適用可能とする.パラメータごとに専用の設定機 構を作成し,2つの設定機構が独立に設定を行う.持続的接続時間と最大ク ライアント数は元々相関が低く,また設定機構の設計時に干渉を考慮してい るため,2つのパラメータを同時に設定することができる.
• 導入が容易: 本論文の手法は,サーバソフトウェアとオペレーティングシス テム(OS)を改変しないため,容易に導入することができる.本機構は,実 行時にサーバ・OS間に挿入される外部ライブラリとして実装されており,利 用するためには,一般的なUNIX系OSが提供している特別な環境変数に本 ライブラリを指定して,サーバを再起動するだけでよい.本ライブラリがシ ステムコールを横取りし,書き換えることでパラメータ設定を実現する.
1.3 本論文の貢献
図1.1に示すように,インターネットサーバに対する既存のパラメータ自動設定 の研究は,特定のパラメータに特化したアプローチと汎用的なアプローチの2つ の視点から行われている.
• 特定のパラメータに特化した手法:個別のパラメータに特化して,専用の設 定機構を作成する[56, 13, 49, 51].この手法ではそれぞれのパラメータの特 徴を利用できるため,最適値付近に短時間で設定を行う効率的な自動設定機 構を実現しやすい.また,サーバ性能への悪影響を最小限にすることで運用 中に実際のワークロードに基づいて設定を行うオンライン設定を実現するこ とができる.その反面,実現のためのコストが高く,多数のパラメータに適 用しづらいという欠点がある.
• パラメータに対して汎用的な手法:この手法では,パラメータ設定を最適化 問題に帰着し,ヒルクライミング法などの発見的探索手法により解を探索す
る[84, 21, 27, 22].多数のパラメータを同時に設定することができ,サーバ
全体の性能を高めやすいという利点がある反面,極小解に陥ったり,解が得 られるまで時間がかかることがある.また,パラメータの知識を利用しない ため,設定中にサーバ性能を大幅に低下させるパラメータの組合わせを試行 することがあり,オンライン設定には適用しづらいという欠点がある.
現状では,どちらのアプローチも利点と欠点があり,理想的なパラメータ設定機 構に向けた継続的な試みが求められている.
本論文の手法は,他の関連研究の中で図1.1のように位置づけることができる.
本論文の手法は,パラメータ特化による設定手法から出発し,より理想的なパラ メータ自動設定手法に近づける.まず,パラメータに特化することで,単一のパ ラメータ専用の設定機構を作成した場合と同等のオンライン性を実現する.次に,
サーバの性能に対して支配的なパラメータを対象とすることで,少数のパラメー タを設定しているにもかかわらず多数のパラメータを同時に設定した場合に近い サーバ全体効果を実現する.
ウェブサーバの持続的接続時間と最大クライアント数は非常によく知られたパ ラメータであるため,提案方式のように専用の設定機構を作成する価値は十分に ある.設定機構自身は他のパラメータに対して汎用的に適用することは難しいが,
非常に多数の管理者の設定作業が軽減される.加えて,本機構は特定のウェブサー
サーバ全体の性能効果
オンライン性
パラメータに対して 汎用的な設定手法 パラメータに特化した
設定手法
本論文の貢献
理想的な設定手法
図 1.1: 本論文の位置づけ
バの実装に依存しないパラメータに共通する性質を取り出して設定機構を作成し ており,他の実装でも利用可能であることが期待される.実際,持続的接続時間 と最大クライアント数はApacheに限らず,MicrosoftのIIS [55],Zeusウェブサー バ [85]など多くのウェブサーバに共通して現れる.
また,本手法は導入を容易としており,実装の汎用性も高めている.本方式は OSとのインターフェースが変わらなければ,サーバソフトウェアのバージョンが 上がってもサーバソフトウェアやOSを改変せず利用することができる.
1.4 本論文の構成
本論文では,まず,2章で性能パラメータ設定の必要性について説明する.3章,
4章でそれぞれ持続的接続時間の設定機構,最大クライアント数の設定機構を示 す.5章で2つのパラメータを同時設定した場合の動作について説明する.6章で 実装について説明し,7章で実験結果を示す.8章で関連研究について述べ、最後 に9章で本論文をまとめる.
第 2 章 パラメータ設定の必要性
持続的接続時間と最大クライアント数の値により,同じハードウェア・ソフト ウェアを使用していても,ウェブサーバの性能が大きく異なる.
この2つのパラメータがサーバ性能に与える影響を示すため,実験を行った.
Apacheウェブサーバ2.0.54に対して,持続的接続時間,最大クライアント数の2 つの性能パラメータの値を変えながら,サーバ性能に与える影響を調べた.ワー クロードとしては,標準的なベンチマークであるSPECweb99 [72]を基本とした2 つのワークロードを使用した.
2.1 実験環境
サーバ計算機は,CPUがPentium4 2.8GHz,主記憶512MB,SCSI接続,7200 回転のHDD,32ビット/33MHz PCIバスのPCを用いた.クライアント計算機は,
サーバ計算機と同じ構成のものを16台用いた.サーバ計算機とクライアント計算 機は,1000 Base-Tで1台のスイッチに接続されている.
ウェブサーバはApache 2.0.54を用いた.Apacheのコンパイルではデフォルト の設定であるプロセスのみを使用するprefork MPMを用いた.持続的接続時間と 最大クライアント数を除く,他の全てのパラメータはApacheの設定ファイルのデ フォルト値を用いた.OSはLinux 2.4.20を用いており,カーネルのパラメータは 全て変更していない.
この環境を利用して,1500個の仮想クライアントをクライアント計算機上に生 成し,サーバに対して負荷を与えた.SPEC社のウェブサイトで公開されている
SPECweb99の公開スコアでは,単一CPU構成で440–1943の同時クライアント数
の達成が報告されており,クライアント数1500はサーバの性能測定のために十分 な値である.
持続
期間 思考
期間
経過時間 サーバ上のリクエスト処理時間
Pareto 分布 Pareto 分布
SPECweb99 の規約に従う (最小 20 ms)
持続
期間 思考期間
図 2.1: ワークロードが模倣するクライアントの振舞い
表 2.1: 実験で使用するワークロード
名前 説明 ファイルサイズ分布 合計
≤1 KB ≤10 KB ≤100 KB ≤1 MB サイズ
(a) SPECweb標準 SPECweb99の規約に従う 35% 50% 14% 1% 3.6 GB
(b) SPECweb大 SPECweb99をファイルサイズが 1% 14% 50% 35% 3.6 GB 大きくなるよう改変
2.2 ワークロード
ワークロードとしてさまざまなものが提案されているが [7, 8, 57, 12, 76],本論
文ではSPECweb99[72]に人間の思考時間を導入したものを用いた.SPECweb99
はウェブサーバを対象とした標準的なベンチマークである.しかし,サーバの性 能測定を目的とするため,人間の思考時間などのクライアントの振舞いは考慮さ れていない.そのため,図 2.1のようにクライアントの振舞いを模倣するようにし た.図 2.1では,ウェブページ取得のためデータの送受信が連続する持続期間と,
ユーザがウェブページを閲覧しておりデータを送受信しない思考期間を交互に組 み合わせる.思考期間内のファイルを受信完了してから新しいリクエストを発行 するまでの間隔を模倣するため,Pareto分布にしたがってリクエストを生成する ようにした.一般に,人間の思考時間はPareto関数で近似するのがよいことが知 られている[12].Paretoの確率密度関数p(x)は以下のように定義される.
p(x) =αkαx−(α+1) (2.1) Pareto関数の係数は,文献[12]の値k= 1,α= 1.5を用いた.なお,持続期間で のリクエストの発行間隔はSPECweb99の規約にしたがい,20ミリ秒とした.
実験では,表 2.1 の2つのワークロードを使用する.最初の(a) SPECweb
標準は,SPECWeb99の規約で定められている標準設定である.もう一つの(b) SPECweb大は,画像を多く含むサイトなどを想定した平均ファイル・サイズの 大きいファイル分布である.今回,動的ページに対する要求は行わず,静的ペー ジに対する要求のみとした.
2.3 性能パラメータがサーバ性能に与える影響
図 2.2,図2.3 に,さまざまな持続的接続時間・最大クライアント数の値を使用
した場合のスループット・平均応答時間の測定結果を示す.図 2.2は標準的なファ イル分布を想定したSPECweb標準ワークロードでの結果,図2.3は画像を多く含 むサイトを想定した平均ファイルサイズの大きいSPECweb大ワークロードを使 用した結果である.持続的接続時間は,1秒以下のパラメータ値による変化を詳し く示すため,対数表示となっている.
この結果から,2つのことがわかる.第一に,性能パラメータの値はサーバ性能 に大きな影響を与える.Apacheのデフォルト値は持続的接続時間が15秒,最大 クライアント数が150であり,そのスループットはどちらのワークロードの場合 もかなり低い.図中の曲面では左奥の角がデフォルト値に対応し,SPECweb標準 では2.74MB/s,SPECweb大では15.45MB/sである.Apacheでは,さまざまな ハードウェア性能のサーバで安全に利用可能とするため,デフォルト値は保守的に 設定されている.この環境の場合,SPECWeb標準では,持続的接続時間を600ミ リ秒,最大クライアント数を800に設定することで,スループットを605.9%向上 させ,19.32MB/sにすることができる.SPECWeb大では,持続的接続時間を800 ミリ秒,最大クライアント数を400に設定することで,スループットが52.7%向上
し,23.6MB/sとなる.応答時間では,スループットが最大となる最大クライアン
ト数以上の値を使用すると応答時間が増加し,持続的接続時間が短い場合も同様 に応答時間が増加する傾向にある.
次に,性能パラメータで同じ値を使用していても,ワークロードが異なればや はりサーバ性能が大きく変化する.図を見ても,ワークロードごとにスループッ トや平均応答時間は全く異なる曲面を描き,スループットが最大となる地点がそ れぞれ異なる.SPECweb標準では,持続的接続時間600ミリ秒,最大クライアン ト数800でスループットが最大となるが,同じパラメータ値をSPECweb大で使用 した場合,最大の70%である16.6MB/sしか得られない.
2 4 6 8 10 12 14 16 18 20
200 400
600 800
1000 1200
サーバ接続数 1000
10000
持続的接続時間 [ms]
0 5 10 15 20 25
スループット [MB/s]
(a)スループット
200 400 600 800 1000 1200 1400 1600
200 400
600 800
1000 1200
サーバ接続数 1000
10000
持続的接続時間 [ms]
0 400 800 1200 1600
平均応答時間 [ms]
(b) 平均応答時間
図 2.2: パラメータ値がサーバ性能に与える影響(SPECweb標準)
10 12 14 16 18 20 22 24
200 400
600 800
1000 1200
サーバ接続数 1000
10000
持続的接続時間 [ms]
0 5 10 15 20 25
スループット [MB/s]
(a)スループット
0 4000 8000 12000 16000 20000
200 400
600 800
1000 1200
サーバ接続数 1000
10000
持続的接続時間 [ms]
0 4000 8000 12000 16000 20000
平均応答時間 [ms]
(b) 平均応答時間
図 2.3: パラメータ値がサーバ性能に与える影響(SPECweb大)
以上から,同じハードウェア・ソフトウェアを使用していても性能パラメータの 値によりサーバ性能が大きく異なることがわかる.また,ワークロードに応じて 適切な性能パラメータの値が変わり,クライアントからのアクセスパターンが変 わるたびに再設定する必要がある.よって,管理者による手動設定は難しく,性 能パラメータの自動設定が求められている.
第 3 章 持続的接続時間の自動設定
本論文のパラメータ設定機構は,設定対象とするパラメータの分析を行い,そ の結果に基づいて専用の設定機構を作成する.3.2節で持続的接続時間の分析を行 い,3.3節でパラメータの特性を利用した持続的接続時間の設定機構について示す.
3.1 持続的接続時間パラメータ
持続的接続時間はクライアント・サーバ間のTCP接続における最大アイドル時間 を決定するパラメータである.Apacheでは,このパラメータはKeepAliveTimeout と呼ばれている.HTTP/1.1 [31]の規格により,クライアントはウェブサーバとの 間にTCP接続を維持できることが定められており,クライアントはこの接続を利 用して複数回のHTTPリクエストの送信やファイルの受信に利用している.持続 的接続時間はこの接続の切断に関係しており,データを全く送受信しない時間が 持続的接続時間を超えた場合に切断が行われる.これはサーバ側から行われ,ク ライアント側からはほとんど切断されない.我々の実験でも,Internet Explorer,
Firefox,Operaなどの主要なウェブブラウザ(クライアント)では,応答性を向
上させるために接続切断のためのタイムアウト時間が持続的接続時間に比べて長 く設定されており(例えば,2分など),ウェブページの読み込みが完了してもク ライアントからは切断しない.
この接続の維持はネットワークの利用率向上とサーバの応答性の改善に有効で あることが知られている[60]が,適切でない持続的接続時間の設定によってサー バ性能が低下することがある.特に,その影響はTCP接続数がサーバの処理能力 の限界に近い場合に顕著に現われる.それぞれのTCP接続において,データの送 受信を行わないアイドル時間はそのTCP接続が確立されている期間の大半を占め る.一方で,サーバがTCP接続を維持するためのコストは小さくない.そのため,
TCP接続数がサーバの処理能力の限界に近い場合,多くのTCP接続がアイドルし ているにも関わらず,新規の接続がサーバに接続できないという現象が発生する.
TCP接続の 確立
TCP接続の 切断
持続
期間 思考
期間
持続的接続時間
経過時間
サーバ上のHTTPリクエスト処理時間 リクエスト待機間隔
HTTPリクエストの到着 TCP接続の
確立
持続
期間 思考期間
図 3.1: サーバに接続しているクライアントの振舞い
持続的接続時間を適切に設定することで,全体の接続数に占めるデータ送受信中 のTCP接続の割合を調節することができる.持続的接続時間を長く設定し過ぎれ ば,データ送受信中の接続の割合は低下し,アイドル中の接続の割合は増加する.
よって,サーバの性能も低下する.反対に,持続的接続時間を短く設定しすぎた場 合,データ送受信中のTCP接続も切断してしまい,頻繁な再接続のためサーバ性 能が低下する.両者の中間にある適切な値に持続的接続時間を設定すれば,データ 送受信中の接続を切断することなく,アイドル中の接続を切断することができる.
3.2 持続的接続時間の分析
3.2.1 リクエスト待機間隔と持続的接続時間
持続的接続時間の適切な値はクライアントの振舞いと関係が深い.ここではそ の振舞いの詳細な分析を行う.
図3.1に,単一のクライアントがサーバに接続している場合の典型的な振舞いを 示す.クライアントはサーバとの間にTCP接続を2度確立しており,一度の接続 で複数回のHTTPリクエストを送信し,ファイルを取得している.図 3.1に示す ように,クライアントは接続中,データの送受信を常に行っているわけではなく,
データを送受信する期間とデータを送受信しない期間の2つがある[12, 28].デー タを頻繁に送受信する期間は,同一ウェブページを構成する画像や動画などのファ イルを続けて取得する期間である.一般にウェブページは複数のファイルで構成 されるため,このようにリクエストがいくつか連続する.この期間を持続期間と 呼ぶ.一方,接続を使用しない期間は,ウェブブラウザを操作する人が次のペー ジへのリンクをクリックするまでの期間であり,思考期間と呼ぶ.
思考期間は人間がウェブページを閲覧しながら考えている時間のため,思考期
間は持続期間に比べ遥かに長い.クライアントが思考期間に入ると接続を切断し,
他の新規クライアントに接続を許すようにすれば,このデータを送受信しない期 間を利用してサーバの使用率を高めることができる.新規のクライアントは接続 の確立後,直ちに持続期間を開始する.一方,切断されたクライアントは,思考 期間の後再度接続させても,思考期間が長いため利用者の体感上ほとんど気づか ない.一方,持続期間中はTCP接続を維持することが望ましい.持続期間はリク エストが連続するため,この期間にTCP接続を切断すると頻繁な再接続を招く.
提案機構では,思考期間中はTCP接続を切断し,持続期間中は接続を維持す ることを目指す.持続的接続時間を適切に設定すれば,これを実現することがで きる.
図3.1で,あるリクエストの処理が完了した時刻と次のリクエストを受信した時 刻の間隔をリクエスト待機間隔と呼ぶ.これは持続的接続時間と関係が深い.リ クエスト待機間隔が持続的接続時間を超えると接続は切断される.反対に,リク エスト待機間隔を計測すれば,その結果から持続的接続時間の適切な値を求める ことができる.持続期間ではリクエスト待機間隔は短く,思考期間ではリクエス ト待機間隔は長い.持続期間でのリクエスト待機間隔の最大値に持続的接続時間 を設定すれば,その最大値に比べ短いリクエスト待機間隔では接続は維持された ままとなり,長ければ接続は切断される.よって,持続期間中の接続は確立され たままとなり,思考期間に入ると直ちに切断される.
ここでは簡単のため,クライアントが同一サーバに対して1つのTCP接続を 維持する場合について示したが,実際のクライアントでもほぼ同様の振舞いを示 す.HTTPの規約により,同一サーバに対する接続は最大2つと決められている が,サーバに対する多数のTCP接続にHTTPリクエストが分散し,持続期間と 思考期間が判別できないということはない.よって,それぞれの接続でリクエス ト待機間隔を測定しても,クライアントの振舞いを知ることができる.
本論文の手法では思考期間の後に再接続を必要とするため,常に接続を維持し た場合に比べ,わずかながら接続コストの増加を招く.このコストは,文献 [13]
によれば17%程度のパケット数の増加であると報告されている.しかし,サーバ
が性能上のボトルネックとなる状況では,思考期間中の切断による性能改善効果 の方が大きいと報告されており,7章で示す通り,本論文の実験でも同様の効果が 得られている.
0 5 10 15 20 25 30
0 0.5 1 1.5 2 2.5 3 3.5 4
頻度 [%]
リクエスト待機間隔 [s]
思考期間内の
リクエスト待機間隔の山 持続期間内の
リクエスト待機間隔の山
最大持続間隔
(持続期間のリクエスト待機間隔の最大値)
図 3.2: リクエスト待機間隔のヒストグラム
3.2.2 持続期間と思考期間の判別
厳密に言えば,それぞれのウェブページが何個のファイルを参照しているかと いう知識がなければ,計測したリクエスト待機間隔が持続期間のものか思考期間 のものか判別することはできない.しかし,リクエスト待機間隔のヒストグラム を描き,持続期間中のリクエスト待機間隔の最大値を求めることで,大まかな判 別を容易に行うことができる.
図3.2に,2章の実験で使用したワークロードでのリクエスト待機間隔のヒスト グラムを示す.このワークロードのクライアントの振舞いは,実際のウェブサー バを代表するような負荷を生成するSURGE [12]を元にしており,測定したリク エスト待機間隔は実際の環境に近いことが期待される.この結果は,全てのクラ イアントに対してリクエスト待機間隔を測定し,単一のヒストグラムを描いた結 果である.
図3.2から,ヒストグラムは2つの山に明確に分離することができる.左側の山 は持続期間に,右側の山は思考期間に対応する.持続期間中のリクエスト待機間 隔はリクエストが連続するため,短い方に集中する.一方,思考期間のものは人 間の思考時間が入るため遥かに長い.Round-Trip Time (RTT)は人間の思考期間 にくらべ遥かに短いため,この2つの山はほとんど重なり合わない.これについ
ては,3.2.4節で詳しく議論する.
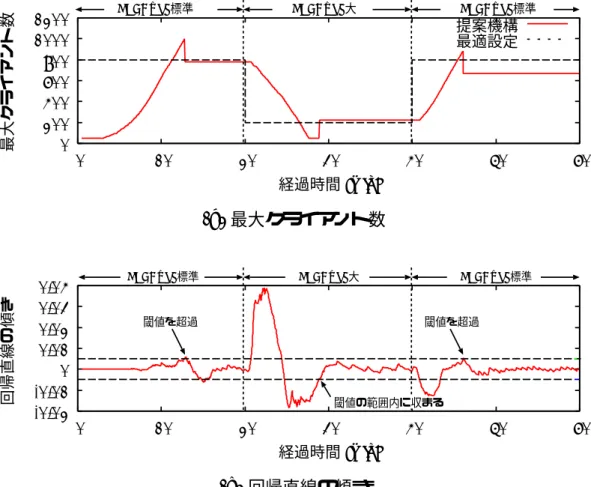
本機構では,リクエスト待機間隔を短い方から探索し,頻度が急激に減少する 場所を見つける.この地点はリクエスト待機間隔の持続期間内における最大値と 対応しており,これを最大持続間隔と呼ぶ.本機構では,持続的接続時間を最大 持続間隔の値に設定する.よって,持続期間内のTCP接続は維持され,思考期間 に入った場合,直ちに接続は切断される.
本機構では,全てのクライアントに対して単一の持続的接続時間を設定する.
Apache などの多くのウェブサーバでは,サーバで単一の持続的接続時間が性能
パラメータとして提供されており,これを設定することが期待されている.また,
ウェブサーバではクライアント・サーバ間のTCP接続が確立されている時間が短 いため,接続中にリクエスト待機間隔を測定し,その結果に応じてクライアント ごとに持続的接続時間を設定することは難しい.本論文の手法では,TCP接続の 生存期間が短い代わりに多数のクライアントから情報を集めることで自動設定を 実現する.図 3.2の最大持続間隔は,全てのクライアントでの持続期間中のリク エスト待機間隔の最大値に対応している.
3.2.3 実運用サーバでのリクエスト待機間隔
図 3.2では,ウェブサーバの代表的なベンチマークを元に議論したが,実際の ウェブサーバでも同じような傾向が共通して観測される.この例として,実運用 のウェブサーバでの測定結果を示す.
図3.3は著者らの研究室のウェブサーバで,1週間リクエスト待機間隔を測定し た結果である.6868個のリクエストがあり,その間隔のヒストグラムを示したの が図 3.3である.学外からのアクセスが全体の91.2%であった.
図3.3を見ると,リクエスト待機間隔が500ミリ秒より小さい場合にリクエスト 待機間隔の大きな分布があることがわかる.リクエスト待機間隔が500ミリ秒よ り大きくなると,リクエスト待機間隔の頻度が急激に減少し,その後一様な分布 が見られる.これは思考期間内のリクエスト待機間隔である.
図3.3に見られるような,持続期間内のリクエスト待機間隔は短く,思考期間内 のリクエスト待機間隔が長いというヒストグラム上の傾向は,多くのウェブサー バに共通して現われる.リクエスト待機間隔が短い方から探索し,頻度が急激に 減少する場所を見つければ,そこがほぼ最大持続間隔に対応している.3.3節で説 明する設定機構はこれを利用して持続的接続時間の設定を行う.
0 5 10 30 35
0 1 2 3 4 5 6 7 8
リクエスト待機間隔 [s]
頻度 [%]
図 3.3: 実運用ウェブサーバでのリクエスト待機間隔のヒストグラム
3.2.4 RTT のゆらぎによる影響
サーバ・クライアント間のネットワーク距離はクライアントごとに異なるので,
この距離が大きいほどリクエスト待機間隔は大きくなると考えられる.しかし実 際は,距離の差が持続期間におけるリクエスト待機間隔に与える影響は小さく,遠 いクライアントに関して,持続期間におけるリクエスト待機間隔を思考期間に入っ たものと取り違える可能性はきわめて小さい.
このことを確認するために,簡単な測定を行った.ここでは,著者らの研究室の ウェブサーバに対して,ネットワーク距離の異なる3個のクライアントから,100KB のファイル10個を持続的接続を利用して100回取得した.その結果を図 3.4に示 す.横軸は左から順にホップ数2の研究室内の計算機から取得した場合,ホップ数
15,19の他大学から取得した場合,最後はホップ数17の家庭用の光ファイバー回
線上の計算機から取得した場合であることを示している.縦軸はリクエスト待機 間隔の平均値と95%信頼区間を示している.
どの場合も,ほとんどのリクエスト待機間隔が100ミリ秒以内に収まっている.
これは文献[3, 39]のクライアント・サーバ間のRTTの多くが500ミリ秒以内に収 まるという結果と一致する.
0 20 40 60 80 100
17 19
15 2
リクエスト待機間隔 [ms]
ネットワーク距離 [ホップ数]
(研究室内) (他大学) (家庭用回線)
図 3.4: リクエスト待機間隔のRTTによるゆらぎ
3.3 持続的接続時間の設定機構
3.3.1 設定機構の概要
3.2節では,リクエスト待機間隔の分析から最大持続間隔の値を持続的接続時間 に設定すれば,持続期間内の接続を維持し,思考期間に入った接続を切断できる ことを示した.以下,本節ではそのための具体的な手法を説明する.
本設定機構は,3.2節の分析をそのまま実現する.まず,全てのクライアントか らのリクエスト待機間隔を測定し,記録する.次に,その測定結果からリクエス ト待機間隔のヒストグラムを作成する.リクエスト待機間隔の短い方からヒスト グラムを探索し,最大持続間隔を見つける.最後に,この最大持続間隔を元に持 続的接続時間を更新する.
図 3.5に,設定方式全体の擬似コードを示す.関数tune_ka()はリクエスト待 機間隔を測定する度に呼び出される.tune_ka()では,まず (1) 全てのリクエス ト待機間隔を記録用配列arr に記録し(9–12行),(2) リクエスト待機間隔のヒ ストグラムhistを作成する(13–15行).histは配列であり,リクエスト待機間隔 tを添字に与えると,そのリクエスト待機間隔での頻度を返す.(3)作成したヒス トグラムをもとに,最大持続間隔tmaxを見つけ(16–28行),(4) 持続的接続時間
1: //tune_ka()– リクエスト待機間隔を測定する度に呼び出される 2: procedure tune_ka();
3: //arr: リクエスト待機間隔を記録するための配列 (大きさ N) 4: //index: 配列arrのインデックス(初期値 0)
5: //hist: リクエスト待機間隔のヒストグラム(大きさ T) 6: //KeepAliveTimeout: 持続的接続時間の現在値
7: //tmax: 最大持続間隔 8: begin
9: //リクエスト待機間隔の記録
10: arr[index] :=測定されたリクエスト待機間隔; 11: index :=index+ 1;
12: if index < N then return;
13: //ヒストグラムの作成 14: Creatinghist fromarr; 15: index := 0;
16: //最大持続間隔の計算
17: fort:= 0toT −1 do begin
18: ratio :=hist[t]/j≤thist[j]; // 式(3.1) 19: if t≥KeepAliveTimeout then begin
20: err := (ratio−target)/target; // 式(3.2) 21: tmax :=t+adj ·err;
22: break
23: end;
24: if ratio <target then begin 25: tmax :=t; //最大持続間隔の更新
26: break
27: end
28: end;
29: //KeepAliveTimeoutの更新
30: KeepAliveTimeout:=α·KeepAliveTimeout+ (1−α)·tmax // 式(3.4) 31: end.
図 3.5: 持続的接続時間の設定機構の擬似コード
KeepAliveTimeout を更新する(29–30行).以上により,持続的接続時間の設定 を実現する.
持続的接続時間の設定は定期的に行うこともできる.これは,ウェブサーバに 対する負荷の変化に応じて,適切な持続的接続時間も変化するからである.
以下,擬似コードの詳細な説明を行う.まず,ヒストグラムで求めた最大持続
間隔が現在設定されている持続的接続時間以下の場合(3.3.2節),最大持続間隔 が現在の持続的接続時間を超える場合(3.3.3節)の2つに分けて説明する.最後 に,3.3.4節で最大持続間隔を元にした持続的接続時間の更新方法を説明する.
3.3.2 最大持続間隔の計算
( 最大持続間隔 ≤ 持続的接続時間 )
最大持続間隔tmax を求める過程を図3.6(a) を用いて説明する.最大持続間隔を 求めるため,ヒストグラムhist をリクエスト待機間隔0 から順に大きい方へ調べ ていく.そして,リクエスト待機間隔の頻度が十分小さくなった地点を最大持続 間隔とする.
直感的には,リクエスト待機間隔tの頻度hist[t]がある閾値を下回ったところを 最大持続間隔とするのが自然である.しかし,その判定法では比較的頻度が小さ いリクエスト待機間隔の山の立上りに閾値を下回った場合,その地点に最大持続 間隔が誤って設定されることがある.
式 (3.1)の比率ratioを用いて判定すると,山の立上りではこの比率が相対的に
大きくなるため,最大持続間隔が誤って設定されるのを避けることができる.
ratio:=hist[t]/
j≤t
hist[j] (3.1)
このratioは,新しく加えたhist[t]がこれまでに調べたリクエスト待機間隔全体に 対してどの程度の割合を占めるかを表している.山の立ち上がりではratioの値は 大きく,開始時では1.0である.ヒストグラムを調べて行くにつれて,このratio の値は小さくなり,最終的には閾値targetを下回る.判定のための閾値 target は
現在は5%としており,比較的良好な結果が得られている.また,targetはワーク
ロードによらない値であるため容易に決めることができる.hist[t]がちょうど最大 持続間隔のあたりであれば,式 (3.1)の分母は持続期間内のリクエスト待機間隔全 体となる.持続期間のリクエスト待機間隔全体に対してどの程度小さくなったら 最大持続間隔と判定するかということに応じて,target を決めればよい.
持続期間内の山
Σ < target
頻度
リクエスト待機間隔 ヒストグラムの走査
hist[t]
hist[t]
hist[j]
hist[t]
思考期間内の山
この地点を最大持続間隔とする.
Σhist[j]
i <= t
i <= t
ならば
(a)tmax ≤KeepAliveTimeout
頻度
hist[t]
前回の時刻のKeepAliveTimeout
接続の切断のため KeepAliveTimeoutを超える リクエスト待機間隔は得られない
実際の最大持続間隔 KeepAliveTimeout を
hist[t] の大きさに応じて移動する.
(b) tmax >KeepAliveTimeout 図 3.6: 最大持続期間の計算
3.3.3 最大持続間隔の計算
( 最大持続間隔 > 持続的接続時間 )
現在すでに設定されている持続的接続時間より最大持続間隔が大きい場合,図3.6 (b) に示す通り,リクエスト待機間隔が持続的接続時間を超える接続は切断される.
よって,持続的接続時間を超えるリクエスト待機間隔の分布が得られず,最大持 続間隔を計算することができない.
本機構ではこれに対処するため,現在設定されている持続的接続時間での比率
ratioと,最大持続間隔かどうかを判定する閾値target とのずれに応じて,最大持
続間隔tmax を予測する.このずれは式(3.2)により計算する(図3.5の20行目).
err := (ratio−target)/target (3.2) 現在の持続的接続時間に誤差errに比例した値を加えたものを最大持続間隔tmax
とすることで,本当の最大持続間隔に近づける.計算は式 (3.3)により行う.
tmax :=KeepAliveT imeout+adj ·err(adj は定数) (3.3) なお,最大持続間隔を大きく調整し過ぎた場合でも,3.3.2節の最大持続間隔の 計算方式により修正されるため問題はない.この修正と最大持続間隔の予測を繰 り返すことで,本当の最大持続間隔に近づくことが期待される.
3.3.4 持続的接続時間の更新
最後に,これまで計算した最大持続間隔をもとに,持続的接続時間を更新する.
本機構では,リクエストのバーストを考慮した持続的接続時間の更新を行う.イ ンターネット・サーバでは,頻繁にリクエストのバーストが観測されることが報告 されている[41, 32, 81].一時的なバーストによって,リクエスト待機間隔が大き く変化し,誤ったヒストグラムを作成し,最大持続間隔が誤った値に設定される可 能性がある.そのため本機構では,3.3.3節までの方式で求めた最大持続間隔をた だちに持続的接続時間とするのではなく,過去の持続的接続時間を考慮して持続 的接続時間を更新する.過去の持続的接続時間を含めることで,一時的なバース トにより最大持続間隔が大きく変化しても,その影響を抑えることができる.実 現には指数移動平均法による式 (3.4)を用いる(図 3.5の30行目).
KeepAliveTimeout :=α·KeepAliveTimeout + (1−α)·tmax (3.4) tmax は図3.5 の擬似コードにより計算した最大持続間隔である.右辺のKeepAlive
Timeout は式 (3.4)で計算した一つ前の時刻の持続的接続時間であり,これを用
いて新しい持続的接続時間を計算する.αは重みであり,現在はα= 0.9としてい る.この指数移動平均法は,文献[18, 47, 14]でも使用されている.
ウェブサーバの起動時には,持続的接続時間は任意の値(例えばデフォルト値)
でよい.その後,式 (3.4)により徐々に適切な持続的接続時間へと近付けていく.
第 4 章 最大クライアント数の 自動設定
本章では,最大クライアント数の自動設定機構について説明する.4.2節で最大 クライアント数の分析を行う.4.3節で,その分析の結果に応じた最大クライアン ト数専用の設定機構を作成する.
4.1 最大クライアント数パラメータ
最大クライアント数は,クライアントからサーバに接続できる最大のTCP接続 数を決めるパラメータである.Apacheでは,このパラメータはMaxClientsとし て知られている.サーバの処理能力には限りがあるため,サーバが過負荷状態と ならないよう最大クライアント数によって最大の接続数を制限する.特に,ウェ ブサーバではリクエストのバーストやFlash Crowd現象 [41, 50]によってサーバ の処理能力を一時的に上回ることが度々あり,最大クライアント数を適切な値に 設定しておくことが重要である.
最大クライアント数はウェブサーバにとって重要なパラメータである反面,最 大クライアント数の適切な設定は難しい.その要因は,2章で述べたハードウェア 性能への依存,ワークロードへの依存の他にも,次の2つがある.
• 一定でないボトルネック個所:最大クライアント数は性能上のボトルネック となる個所の最大性能によって決まり,CPU,メモリ,ディスクなどさまざ まな個所がボトルネックとなる.また,ワークロードの変動によってボトル ネックとなる個所も変化する.
• ハードウェア性能の指標と最大クライアント数の乖離:もしボトルネックと なる個所がわかっても,その利用可能な計算機資源から最大クライアント数 の具体的な値を導き出すことは難しい.最大クライアント数の適切な値は,
CPUのクロック数やメモリのサイズなどのハードウェア性能の値から大き
な隔たりがある.サーバ性能を実際に測定して試行錯誤を繰り返すことなく 最大クライアント数の適切な値を導き出すことは難しい.
最大クライアント数の値が適切でない場合,大幅な性能低下を招く.最大クラ イアント数を大きく設定しすぎた場合,サーバの過負荷状態を招き,性能が低下 する.適切でない最大クライアント数の値は,運用直後のサーバの負荷が低い間 は問題にならず,アクセスが集中し,サーバの負荷が高くなった場合,突然問題 として表面化する.そのため,適切でない最大クライアント数の設定は潜在的な 問題となりうる.一方,最大クライアント数が小さい場合にはサーバ資源を有効 に利用することができない.最大クライアント数は,接続間でサーバの資源競合 が発生しない範囲内での最大の値に設定する必要がある.
4.2 最大クライアント数の分析
4.2.1 最大クライアント数と応答時間
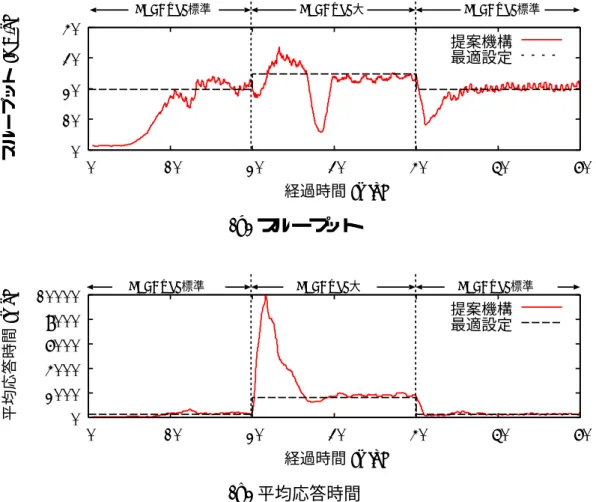
本機構では,応答時間の標準偏差を基準に最大クライアント数を設定する.サー バが過負荷となった場合,どのリソースがボトルネックとなっているかに関わら ず,応答時間にその兆候が現れることが多い.本機構では,この現象を利用して 最大クライアント数を設定する.
応答時間はさまざまに定義することが可能であるが,本論文では応答時間を単 一のHTTPリクエストを受信してからそのリクエスト結果の返信が完了するまで の時間と定義する.クライアント・サーバ間の接続にかかる時間などを極力排除 することで,サーバの負荷状態を応答時間から可能な限り読み取る.
本機構では応答時間を直接利用するのではなく,測定した応答時間から標準偏 差を計算し,利用する.小さなワークロードの変動は,標準偏差を計算する過程 で吸収される.また,サーバの負荷状態は標準偏差に現れる.サーバの負荷が高 まると,単に応答時間が増加するだけではなく,接続ごとの応答時間の幅も大き くなる.これは応答時間の標準偏差の増加に現れる.
図 4.1は,サーバの(a) スループット,(b) 平均応答時間,(c) 応答時間の標準 偏差を最大クライアント数を変えながら測定した結果である.2章でも使用した2 つのワークロードでの結果を示している.
標準偏差が急激に増加する地点は,スループットが最大となる地点と平均応答 時間が増加を始める地点にほぼ一致している.標準偏差は,SPECweb標準ワーク