ニューラルネットワークを用いた着順予測に基づく予想記事の
生成
Generation of Predicted Articles Based on Arrival Order Prediction
Using Neural Network
吉田 拓海
1∗横山 想一郎
2山下 倫央
2川村 秀憲
2Takumi Yoshida
1Soichiro Yokoyama
2Tomohisa Yamashita
2Hidenori Kawamura
21
北海道大学 工学部
1
School of Engineering Hokkaido University
2
北海道大学 大学院情報科学研究科
2
Graduate School of Information Science and Technology, Hokkaido University
Abstract: 競輪の 1 日当たりのレース数を考えると予想記事の作成にかかるコストは大きい.よっ て本研究では,競輪の予想記事を自動生成することを目的とする.また,新規ユーザーの獲得という 競輪業界の課題や既存記事が新規ユーザーには理解が困難であることを踏まえ,本研究では,新規 ユーザー向けの予想記事の自動生成を行う.本研究では,機械学習による着順予測の生成と,生成さ れた着順予測を解説する予想記事の生成を行った.着順予測については,予測のための入出力設定 の比較,機械学習手法の比較,入力特徴量の比較を実施し,本研究での最良の着順予測を生成した. 記事生成については,既存記事を参考に,生成する記事の満たすべき条件を設定し,その条件を満た す記事生成手法としてテンプレートによる記事生成を提案した.
1
はじめに
スポーツ競技における記事の自動生成に関する研究 は,盛んに行われている.野球においては,打者成績 からイニング速報を生成する研究 [1] や,テキスト速報 からイニングの要約文を生成する研究 [2] 等が行われて いる.また,スポーツ以外の分野においても時系列数 値データから概況テキストを自動生成する研究 [3] や, 天気予報コメントを自動生成する研究 [4] 等が行われて いる. 本研究対象である競輪は,1 日平均約 60 レース実施 されており,その各レースごとに予想記事が人手によっ て作成されている.また,翌日のレースの出走者は前 日のレース終了まで決定しないということもあり,競 輪の予想記事の作成にかかるコストは大きい.そこで 本研究では,競輪の予想記事を自動生成することを考 える.近年,競輪ではライブ配信やインターネット投 票により,新規ユーザーが気軽に参加可能な環境が整 備されている.また,ガールズ競輪やミッドナイト競 輪,モーニング競輪の開催など,新規ユーザー獲得の ための活動が行われている.このように,競輪業界で ∗連絡先: 北海道大学 工学部 〒 060-0814 札幌市北区北14条西9丁目 北海道大学 大学院情報科学研究科9階 調和系工学研究室 E-mail: [email protected] は新規ユーザーの獲得が課題となっている.その一方 で,既存の予想記事は新規ユーザーにとっては理解が 困難であるという問題点がある.以上を踏まえ,本研 究では競輪新規ユーザー向けの予想記事の自動生成を 目標とする.2
競輪について
競輪とは,選手 9 人でバンクと呼ばれる競争路を周 回し,ゴールを競う日本発祥のトラックレースであり, 競輪特有の要素としてラインと呼ばれるものがある.ラ インとは,レース中に選手が形成する縦列である.ラ インの先頭になって走る先行選手は,走るペースや勝 負を仕掛けるタイミング等を自由に組み立てることが できるが,風の抵抗を一番に受けるため,体力を消耗 する.一方で,先行選手の後ろで走る番手選手は,先 行選手を風よけとして走ることができるため,先行選 手よりも体力を消耗しない.その代わりに,他のライ ンに抜かれないように,後続選手をブロックすること で先行選手を援護する.選手は最後のゴール前の直線 に入るまで,ラインを組んでチームで走り,最後はラ イン関係なく 1 着を競う.このラインによって繰り広 げられるレース展開は,その他の競技にはない競輪特有の面白さであると言うことができる.
3
記事生成アプローチ
本研究の目的は新規ユーザー向けの予想記事の自動 生成である.そのため,予想記事の生成方法として既 存記事を学習データとして機械学習を適用するという 手法は,現実的では無いことが考えられる.よって本 研究では学習データを必要としない手法として,テン プレートによる予想記事生成を提案する.3.1
競輪における予想記事
既存記事の例を次に示す. • 磯島が駆けて番手の野木が本命.鋭さ光るのは丸 山だ.逆転の捲りに一考.目標の高鍋次第で大久 保,攻め多彩な吉田も怖い.[5] 既存記事に含まれている情報として次の 4 つが挙げら れる. • 注目選手 • 注目選手に関する情報 • ラインに関する情報 • レース展開に関する情報 レース展開については,本研究段階では取得する手段 が存在しないため,本研究では注目選手,注目選手に 関する情報,ラインに関する情報の記述を含むことを 生成記事が満たすべき条件として設定する. また,この既存記事が新規ユーザーにとって理解が 困難であると考えられる理由として次の 2 つが考えら れる. • 独特な表現 (鋭さ光る,攻め多彩な) • 複数の展開予想の記述 独特な表現は,競輪に詳しい人には理解ができるもの であることが考えられるが,新規ユーザーには理解が 困難である.また複数の展開予想の記述も,1 つの着 順を予想することが容易ではない新規ユーザーにとっ ては理解が困難である.以上のことから,記事生成に 使用するテンプレートは,ある着順について解説する というような形式にする.また,解説する着順は機械 学習によって生成する.3.2
文テンプレートの設定
本研究で設定した文テンプレートを次に示す. • < 修飾文 1>< 選手名 > が < 修飾文 2>< 予測順 位 > 着 < 修飾文 3> この文テンプレートに任意の文字列を当てはめること によって予想記事を生成する.文テンプレートに実際 に文字列を当てはめると次のようになる. • 前日は 9 着だった⃝大山が自力で決めて1着.2 – <修飾文 1> : 前日は 9 着だった – <選手名 > : ⃝大山2 – <修飾文 2> : 自力で決めて – <予測順位 > : 1 – <修飾文 3> : . このように,文テンプレートに対して,説明したい状 況に応じた < 修飾文 > を当てはめることによって,そ の状況を説明する文が生成可能である.4
着順予測
予想記事生成のための着順予測を機械学習によって 生成する.レース情報,選手情報を入力に用いて機械 学習による着順予測を生成する.機械学習の入出力の 設定,機械学習手法の選択肢,入力特徴量の選択肢と して幾つか考えられる.本研究では入出力設定の比較, 機械学習手法の比較,入力特徴量の比較実験を実施し, 本研究での最良の着順予測生成器を生成する. 以降では,次の条件を満たすレースを学習,テスト データの対象とする. • 男性レース • 競り無し • 同着無し • 欠損データのないレース – (過去 nヶ月競争得点を入力に用いる場合, 過去 nヶ月レースに出場して無い等の理由 により競争得点が取得できない選手が存在 するレースを除外する)4.1
入出力設定の比較
入出力設定の比較として次の「9 人モデル」と「2 人 モデル」の 2 種類を比較する. • 9 人モデル • 2 人モデル図 1: 多クラス分類器の入出力の概要 4.1.1 9人モデル 9人モデルでは,レースの情報と選手 9 人分の情報 を多クラス分類器に入力し,出力されるベクトルの値 から着順予測を生成する.以降では,多クラス分類器 の入出力とモデルの出力から着順予測を生成する部分 についてそれぞれ詳細を説明する. 多クラス分類器の入出力 9人モデルで使用する多ク ラス分類器の入出力の概要を図 1 に示す.多クラス分 類器の入力として,レース情報と車番 1 から車番 9 の 選手情報のベクトルを用いる.入力ベクトル x の目標 出力を t = [t1, t2, ..., t9]と表記する.ここで,車番 i が 1着の入力に対する目標出力は ti= 1, tj̸=i= 0となる. 入力 x に対する出力は y = [y1, y2, ..., y9]となり,yiを 車番 i が 1 着になる確率として扱う. 着順予測の生成 多クラス分類器の出力から着順予測 を生成する.9 人モデルの 1 着予測,2 着予測,3 着予 測をそれぞれ次のように決定する. 1着 = arg max i yi (1) 2着 = arg max j̸=1着 yj (2) 3着 = arg max k̸=1着,2 着 yk (3) 4.1.2 2人モデル レースの情報と選手 2 人の情報を二値分類器に入力 し,その出力値を 1 レース分集計する.集計した数値 から着順発生確率を近似的に計算し,着順発生確率が 最大のものを予測着順とする.以降では,二値分類器 の入出力と着順発生確率の近似計算についてそれぞれ 詳細を説明する. 二値分類器の入出力 2人モデルで使用する二値分類 器の入出力の概要を図 2 に示す.二値分類器の入力と してレース情報と車番 i,車番 j の選手情報のベクト ルを用い,xi,jと表記する.入力 xi,jの教師ラベルを ti,jと表記して,車番 i が車番 j よりも上位である場合 図 2: 二値分類器の入出力の概要
ti,j= 1, tj,i= 0とする.入力を xi,jとした時の二値分
類器の出力を yi,jと表記し,yi,jを車番 i が車番 j より
上位になる確率として扱う. 着順予測の生成 二値分類器の出力値から着順予測を 生成する.二値分類器の出力値は yi,j̸= 1 − yj,iとなっ ているため,出力集計時に式 4 のような補正を行う. yi,j(補正後) = yi,j+ (1− yj,i) 2 (4) 式 4 の補正によって yi,j= 1− yj,iが成立する.補正後 の出力値を用いて着順の発生確率を近似的に計算する. 次の 3 つの確率をそれぞれ計算し,その積によって上 位 3 着の発生確率を近似的に計算する. • 車番 a が 1 着になる確率 • 車番 a が 1 着の時,車番 b が 2 着になる確率 • 車番 a が 1 着,車番 b が 2 着の時,車番 c が 3 着 になる確率 各確率の計算式を次に示す. p(1着 = a) = ∏ j̸=aya,j ∑ i( ∏ j̸=iyi,j) (5) p(2着 = b|1 着 = a) = ∏ j̸=a,bya,j ∑ i( ∏ j̸=a,iyi,j) (6) p(3着 = c|1 着 = a, 2 着 = b) = ∏ j̸=a,b,cya,j ∑ i( ∏ j̸=a,b,iyi,j) (7) 式 5,6,7 の積を着順 a−b−c の発生確率として以降扱う. 発生確率の最も高い着順を着順予測として生成する. 4.1.3 実験目的 競輪の着順予測のための最適な入出力設定を行うた めに,入出力設定による着順予測の精度を比較する.9 人モデルと 2 人モデルを比較する. 4.1.4 実験設定 学習,テストデータとして 2013 年 6 月 1 日 2016 年 11月 1 日に実施された 67,936 レースを使用する.学習 はニューラルネットワークによって行い,67,936 レー
スの前半 33,968 レースを使用してハイパーパラメータ 探索を行う.ハイパーパラメータ探索はグリッドサー チによって行い,性能検証は 5 分割交差検証によって行 う.ニューラルネットワークの分類の精度 (accuracy) が最良のハイパーパラメータセットを最適なものとし て選択する.入力に用いた特徴量を表 1 に示す.ニュー ラルネットワークのハイパーパラメータの探索範囲を 表 2 に示す.探索によって選択されたハイパーパラメー タを以下に示す. • 9 人モデル – 最適化手法 : Adam – 中間層 :[256] • 2 人モデル – 最適化手法 : Adam – 中間層 :[256, 256] 決定したハイパーパラメータを用いて,67,936 レー スの後半の 33,968 レースに対し各機械学習手法の性 能比較を行う.性能検証は 5 分割交差検証によって行 う.評価項目として,上位 3 着の着順的中率,Top-K-accuracyを用いる.ここで,Top-K-accuracy はある順 位の選手を上位 K 着以内に予測できたレースの割合と する.top3(1-2 着) は 1 着 2 着の選手を上位 3 着以内 に予測できたレースの割合を表す. 表 1: 入力特徴量 特徴量 レース情報 先行選手の競争得点の最大値 バンク 選手情報 車番 年齢 ギヤ倍率 競争得点1 先行選手の競争得点 単騎2か否か ラインの長さ (人数) 先行選手か否か ライン内での自身の位置 4.1.5 実験結果・考察 9人モデルと 2 人モデルの比較の結果を以下に示す. 各モデルの着順予測に関する結果を表 3 に示す.実験 2レースの結果によって選手に与えられる得点 2ラインを組まず一人で走る選手 表 2: ニューラルネットワーク:ハイパーパラメータ探 索範囲 ハイパーパラメータ 探索範囲 活性化関数 ReLU 出力層 softmax(9人モデル), sigmoid(2 人モデル) バッチサイズ 256 学習率 (初期値) 0.001 ドロップアウト率 0.5 学習 epoch 数 20
最適化手法 Adagrad, Adadelta, RMSProp, Adam 中間層 [2n], [2n, 2n] (n=6,7,8) の結果から,2 人モデルが 9 人モデルよりも良い性能 であることが示された.9 人モデルは 1 着を予測する ためのモデルであるため 2 着,3 着の精度に関して大 きく差がついたものと考えられる.9 人モデルについ ては 2 着,3 着の予測精度の向上が今後の課題となる. 本研究では,2 人モデルを使用する. 表 3: 9 人モデルと 2 人モデルの比較 着順的中率 [%] 9人モデル 3.0 2人モデル 4.2
top1(1着)[%] top2(1着)[%] top3(1着)[%]
9人モデル 36.7 57.8 72.1
2人モデル 37.2 58.1 71.5
top2(1-2着)[%] top3(1-2着)[%] top3(1-3着)[%]
9人モデル 21.0 40.0 9.9 2人モデル 23.4 41.5 12.6
4.2
機械学習手法の比較
分類問題を解くための機械学習の手法は数多く存在 する.入出力設定の比較で使用したニューラルネット ワークに加え,ロジスティック回帰,ランダムフォレス トの 3 種類の機械学習手法を比較する. 4.2.1 実験目的 競輪の着順予測を生成するための,最適な機械学習 手法を調査する.ロジスティック回帰,ランダムフォレ スト,ニューラルネットワークの 3 種類の機械学習手 法に対して,それぞれ最適なハイパーパラメータを探 索した後,その性能を評価する. 4.2.2 実験設定 学習,テストデータとして 2013 年 6 月 1 日 2016 年 11 月 1 日に実施された 67,936 レースを使用する.67,936レースの前半の 33,968 レースを使用して各機械学習手 法の最適なハイパーパラメータ探索を行う.ハイパー パラメータ探索はグリッドサーチによって行い,性能 検証は 5 分割交差検証によって行う.モデルの分類の 精度 (accuracy) が最良のハイパーパラメータセットを 選択する.入力特徴量は実験 4.1 と同じものを使用し た.各機械学習手法のパラメータの探索範囲を表 4,5, 2に示す.探索によって選択されたハイパーパラメータ を以下に示す. • ロジスティック回帰 – 手法 : newton-CG 法 – C : 0.01 • ランダムフォレスト – 最小サンプル数 : 32 • ニューラルネットワーク – 最適化手法 : Adam – 中間層 : [256, 256] 決定したハイパーパラメータを用いて,67,936 レースの 後半の 33,968 レースに対し各機械学習手法の性能比較 を行う.性能検証は 5 分割交差検証によって行う.評価 項目として,上位 3 着の着順的中率,Top-K-accuracy を用いる. 表 4: ロジスティック回帰:ハイパーパラメータ探索 範囲 ハイパーパラメータ 探索範囲 ペナルティ L1, L2 (手法によって決定される) 反復回数 100 C 10n(n = 3,−2, −1, 0, 1, 2, 3) 手法 準ニュートン法,newton-CG 法,sag,saga 表 5: ランダムフォレスト:ハイパーパラメータ探索 範囲 ハイパーパラメータ 探索範囲 木の数 50 分割基準 Gini係数 選択特徴数 √d 最小サンプル数 2n(n = 0, 1, 2, 3, 4, 5, 6, 7, 8, 9) 4.2.3 実験結果・考察 各機械学習手法における交差検証結果の平均を比較 すると表 6 のようになった.全項目においてニューラ ルネットが最良の値を記録した.代表的な 3 種類の機 械学習手法の比較を行ったが,今後は本研究で比較の 対象としなかった手法についても比較を行い,最適な 機械学習手法を調査する必要が有ると考えている.以 降の実験ではニューラルネットワークを学習に用いる ものとする. 表 6: 機械学習手法の比較 着順的中率 [%] ロジスティック回帰 3.8 ランダムフォレスト 4.1 ニューラルネットワーク 4.2
top1(1着)[%] top2(1着)[%] top3(1着)[%]
ロジスティック回帰 35.4 56.8 70.7
ランダムフォレスト 37.0 57.7 71.4
ニューラルネットワーク 37.2 58.1 71.5 top2(1-2着)[%] top3(1-2着)[%] top3(1-3着)[%]
ロジスティック回帰 22.5 40.7 12.4 ランダムフォレスト 23.2 41.5 12.5 ニューラルネットワーク 23.4 41.5 12.6
4.3
入力特徴量による比較 (競争得点)
一般に機械学習において,特徴量の選択はモデルの 精度に大きな影響を与える.表 1 中の競争得点につい て,平均値を計算する対象期間についての比較を行う. 4.3.1 実験目的 競輪の着順予測を生成するための,最適な競争得点 の対象期間を調査する. 4.3.2 実験設定 入力に用いる競争得点の対象期間として次のものを 比較する. • 過去 1ヶ月の競争得点 • 過去 2ヶ月の競争得点 • 過去 3ヶ月の競争得点 • 過去 4ヶ月の競争得点 • 過去 1ヶ月,過去 2ヶ月,過去 3ヶ月,過去 4ヶ月 の競争得点 (全てを入力として使用) 競争得点以外の特徴量は,表 1 に示したものを使用す る.競争得点の対象期間によって,欠損値の発生が異 なるため,本実験では対象データを過去 1ヶ月の競争 得点を使用した場合のものに統一する.2013 年 6 月 1 日∼2016 年 11 月 1 日に実施された 64,232 レースの後半 33,968 レースに対して学習とテストを行い,モデル の性能を比較する.ハイパーパラメータ設定は機械学 習手法の比較で決定したものを使用する.性能検証は 5分割交差検証によって行う.評価項目として,上位 3 着の着順的中率,Top-K-accuracy を用いる. 4.3.3 実験結果・考察 各入力を使用したモデルの交差検証結果の平均を比 較すると表 7 のようになった.各競争得点を全て入力に 用いた時に,全評価項目において最良の結果が得られ た.競争得点については,対象期間によって着順予測の 性能に変化が見られた.有効な特徴量の調査は,今後の 課題である.以降の実験では,入力として過去 1,2,3,4ヶ 月の競争得点を全て使用する. 表 7: 入力特徴量の比較 (競争得点) 着順的中率 [%] 過去 1ヶ月 4.2 過去 2ヶ月 4.3 過去 3ヶ月 4.3 過去 4ヶ月 4.1 過去 1,2,3,4ヶ月 4.5
top1(1着)[%] top2(1着)[%] top3(1着)[%] 過去 1ヶ月 37.1 57.5 70.8 過去 2ヶ月 37.9 58.4 71.8 過去 3ヶ月 37.6 58.3 72.0 過去 4ヶ月 37.4 57.9 71.5 過去 1,2,3,4ヶ月 38.5 58.6 72.0
top2(1-2着)[%] top3(1-2着)[%] top3(1-3着)[%] 過去 1ヶ月 23.0 40.9 12.6 過去 2ヶ月 23.6 41.8 13.1 過去 3ヶ月 23.7 42.1 13.1 過去 4ヶ月 23.2 41.4 12.6 過去 1,2,3,4ヶ月 23.8 42.4 13.3
4.4
入力特徴量による比較 (ラインフラグ)
現在ラインに関する特徴量として次のものを使用し ている. • 先行選手の競争得点 • 単騎か否か • ラインの長さ • 先行選手か否か • ライン内での自身の位置 選手 2 人を比較してどちらが上位になるのかを予測す るとき,選手 2 人が同じラインである場合と選手 2 人が 異なるラインである場合とでは,考慮すべき要素が異 なるということが考えられる.現在使用しているライ ンに関する特徴量には,入力された選手 2 人が同じラ インかどうかを識別するための変数が存在しない.そ こで,2 人モデルに入力する選手が同じラインの選手 の場合に 1,違うラインの選手であった場合に 0 の値 をとるラインフラグという特徴量を新しく導入する. 4.4.1 実験目的 新しく導入した特徴量であるラインフラグの有無に よる比較を行い,ラインフラグの有効性を調査する. 4.4.2 実験設定 学習,テストデータとして 2013 年 6 月 1 日 2016 年 11 月 1 日に実施された 64,232 レースを使用する. 64,232レースの前半の 32,116 レースを使用してニュー ラルネットワークの最適なハイパーパラメータ探索を 行う.ハイパーパラメータ探索はグリッドサーチによっ て行い,性能検証は 5 分割交差検証によって行う.モデ ルの分類の精度 (accuracy) が最良のハイパーパラメー タセットを選択する.ハイパーパラメータ探索の結果, ラインフラグの有無に関わらず次のハイパーパラメー タを選択する. • ニューラルネットワーク – 活性化関数 :ReLU,sigmoid(出力層) – バッチサイズ :256 – 学習率 (初期値):0.001 – ドロップアウト率:0.5 – 学習 epoch 数 :20 – 最適化手法 : Adam – 中間層 : [256] 決定したハイパーパラメータを用いて,64,232 レー スの後半の 32,116 レースに対しラインフラグの有無 による性能比較を行う.性能検証は 5 分割交差検証に よって行う.評価項目として,上位 3 着の着順的中率, Top-K-accuracyを用いる. 4.4.3 実験結果・考察 ラインフラグの有無による比較の結果を表 8 に示す. 2人モデルの入力としてラインフラグを用いることに よって,僅かではあるが性能の向上が確認された.あま り大きな性能向上が得られなかった理由としては,既に 入力に使用していたラインに関する特徴量を比較する ことで,同じラインかどうかを識別可能であるという ことが考えられる.ラインに関する有効な特徴量の調 査は,今後の課題である.以降の記事生成においては, ラインフラグを入力に使用した着順予測を使用する.表 8: 入力特徴量の比較 (ラインフラグの有無):着順 予測
着順的中率 [%] ラインフラグ有り 4.6 ラインフラグ無し 4.5
top1(1着)[%] top2(1着)[%] top3(1着)[%] ラインフラグ有り 38.4 58.7 71.7 ラインフラグ無し 38.3 58.6 71.7
top2(1-2着)[%] top3(1-2着)[%] top3(1-3着)[%] ラインフラグ有り 24.0 42.2 13.6 ラインフラグ無し 23.8 42.0 13.3 図 3: 記事生成の概要
5
記事生成
第 4 章で生成した着順予測に基づき予想記事を生成 する.5.1
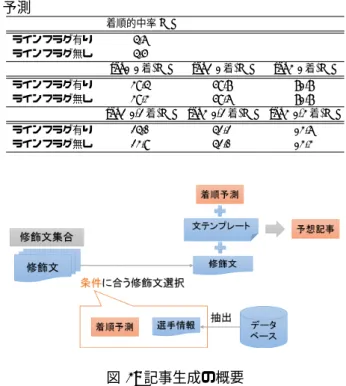
記事生成システムの説明
記事生成システムの概要を図 3 に示す.生成された 着順予測と選手情報から文テンプレートに当てはめる 修飾文を選択し,選択された修飾文を文テンプレート に当てはめることによって,予想記事を生成する.以 降では,修飾文の選択について詳細を説明する. 5.1.1 着順予測に基づく修飾文の選択 着順予測のライン構成に基づき修飾文を選択するこ とにより,着順予測のライン構成を説明する予想記事 を生成する.ライン構成は,1,2,3 着の選手の所属する ラインと 1,2,3 着の選手のラインでの位置 (単騎,先行, 番手) によって決定され,合計で 58 通り存在する. 5.1.2 選手情報に基づく修飾文の選択 選手に関する情報に基づき修飾文を選択することに よって,選手個人に注目した記述をする予想記事を生 成する.選手に関する修飾文を選択するにあたり,デー タベースから注目する選手のデータを抽出する.本研 究では次のデータを抽出の対象とする. • 前日レースの着順 • 過去 nヶ月の平均着順 (n=1,2,3,4) • 過去 4ヶ月の競争得点 • 年齢 抽出したデータに関して条件を設定し,その条件に応 じて修飾文を選択する.本研究では,以下の条件を設 定した. • 前日順位 ≦ 2 • 前日順位 ≧ 6 • 過去 nヶ月の平均着順 ≦ 3 (n=1,2,3,4) • 過去 nヶ月の平均着順 ≧ 6 (n=1,2,3,4) • 年齢 ≦ 25 • 年齢 ≧ 40 • 過去 4ヶ月の競争得点 = 最大の過去 4ヶ月の競争 得点 (レース内)5.2
生成記事結果・考察
実際に生成された記事の例を表 9,10 に示す.ライン に関する情報と注目選手個人に関する情報を含む着順 予測を解説する予想記事が生成されることが確認でき る.表 9,10 の生成記事は,1,3 着が同じラインというラ イン構成を説明している.トップ 2 独占とワンツーの ような語彙の言い換えによって,同じ内容でも異なる 記事が生成されていることが確認できる.選手個人に 関する情報については,設定した条件によって生成記 事の約 96%に選手個人の情報を含むことが可能となっ た.しかし,その種類としては前日順位について,過 去の平均着順について,年齢について,競争得点につ いての 4 種類となっている.今後は,選手個人の情報 のパターン数の増加が必要である.また,既存記事の 注目選手と生成記事の注目選手には重複が数多く見ら れたことや,1,2 着の top-3-accuracy が 42%,1,2,3 着 の top-3-accuracy が 71%ということから,生成された 予想記事の予想内容は悪くないと考えられる.表 9: 生成された記事例 1 2016年 10 月 1 日函館競輪場第 5 レース 既存記事 主導権争いとなりそうな三分戦となった が、一番の先行力を持つのは⃝宗崎で初2 日同様に好スパートを決めれば逃げ切れ るとみた。追走堅実な⃝木村が続き四国9 コンビが本線。怖いのは⃝菅原に前を任6 せる特選スタートの実力者⃝小橋だ。1 ⃝6 菅原次第ではあるが直線強襲のシーンも。 穴は一発力ある⃝臼井の一撃。[5]7 生成記事 若手の⃝宗崎が自力で決めて 1 着. 別ラ2 インから⃝小橋が 2 着.1 ⃝小橋に 2 着1 を取られるも⃝宗崎ラインの2 ⃝木村が 39 着. トップ 2 独占とはいかないが⃝宗崎2 ラインが別線より有利と予測. 表 10: 生成された記事例 2 2016年 10 月 3 日高松競輪場第 10 レー ス 既存記事 ⃝中田がパンチ力発揮して他派を封じれ7 ば番手⃝有坂が決め脚を伸ばす。カマシ2 強烈⃝永井―1 ⃝小林の突っ走りや南関勢9 の一発も要注 [5] 生成記事 過去4ヶ月競争得点が最大の⃝有坂が2 ⃝7 中田の力もあって 1 着. 別ラインから⃝1 永井が 1 着は逃すも自力で 2 着.⃝永井1 に 2 着を取られるも⃝中田が 3 着. ワン7 ツーとはいかないが⃝中田ラインが有利7 と予測.