2019 年度 修士論文
コンテクスト検索エンジンにおける タグを活用した知見共有に関する研究
Study on Knowledge Sharing Using Tags for Context Search Engine
2020 年 2 月 21 日 提出
指導教員 高間 康史 教授
首都大学東京大学院 システムデザイン研究科
システムデザイン専攻 情報科学域
学籍番号 18860624
岡久 太一
目次
1. はじめに ... 1
2. 関連研究 ... 3
2.1.
次世代検索エンジンに関する研究 ... 3
2.1.1.
次世代検索エンジン ... 3
2.1.2.
コンテクスト検索エンジン ... 6
2.2.
データ利活用に関する研究 ... 12
2.2.1.
ビッグデータとオープンデータ ... 12
2.2.2.
データ共有 ... 14
2.2.3.
ソーシャルブックマーク ... 16
2.2.4.
アウェアネス支援 ... 18
3. コンテクスト検索エンジンのインタフェース拡張 ... 19
3.1.
従来システム
V2の構成 ... 20
3.1.1.
ローカルデータ・公開データの統合検索機能 ... 20
3.1.2.
コンテクスト検索エンジンにおける
Data Jacket ... 293.1.3.
季節変動・傾向変動・バースト的変動のスコア導入 ... 44
3.2.
知見タグの導入とタグ・クエリの拡張 ... 52
3.3.
アウェアネスの導入 ... 60
4. 実験結果 ... 64
4.1.
知見タグの導入とタグ・クエリの拡張に関する実験 ... 65
4.1.1.
予備実験... 65
4.1.2.
評価実験... 72
4.2.
アウェアネスの導入に関する実験 ... 82
4.2.1.
評価実験... 82
5. おわりに ... 96
謝辞 ... 97
参考文献 ... 98
発表文献 ... 101
1
1. はじめに
本論文ではコンテクスト検索エンジンにおけるタグを活用した知見共有を提案する.近 年,Web 上の情報は膨大な量となっているが,一般的な検索エンジンはキーワードベース の単純な検索機能にとどまっているために,検索エンジンの基本検索機能と,利用者の多様 化する情報要求との乖離が大きくなっていることが指摘されている [1].この問題に対し,
「動向情報に関する問い」というタスクに限定することで,ドメインに依存せず高度な検索 機能を提供することが可能なコンテクスト検索エンジンが提案されている [2].時系列デー タの特徴的な変動に着目することで,その要因など関係のあるアイテムを発見するタスク において有効性が確認されている [3].
従来のコンテクスト検索エンジンは,Web 上に公開されているデータをサーバに集約し たものを検索対象としているが,ユーザはプライバシー保護などの問題 [4] [5]で外部に公 開できないようなデータを所持している場合も多い.そのようなローカルデータを公開デ ータと組み合わせ,統合して利用可能にすることで,データからの新たな価値創造などにつ ながると考える.そこで,データの概要情報のみを記載した
Data Jacket [6]を導入し,データの代わりにこれを共有可能にする手法をこれまでに提案している [7].Data Jacket
Store [8]の研究では,データ利用者が出した要求に対して提案されたソリューションを再利用することで,自分の要求するデータがどこにあるのか,ソリューションはどのデータを 利用することで実現するのかを知ることができるという考えに基づき, 「あるソリューショ ンはあるデータを用いている」 「あるソリューションはある要求を満たす」の二つをデータ 利活用知識の最小単位と定義している. 「要求」 「ソリューション」 「Data Jacket」を連結し,
これらを格納したデータベースに対して検索を行うことで,
Data Jacketを検索可能として いる.コンテクスト検索エンジンにおいては,動向情報の特徴的変動に関して発見した知見 を共有することで,新たな知見の発見につながるという考えに基づき, 「ある知見が,ある 動向情報の特徴的変動から発見された」, 「ある動向情報の特徴的変動が,ある
Data Jacketに記載されている動向情報から獲得された」の二つをデータ利活用知識の最小単位と定義 し, 「知見」 「特徴的変動」 「Data Jacket」を連結している.コンテクスト検索エンジンに導
入した
Data Jacket検索システムによって,ローカルデータ自体を公開することなく,デ
ータの利用価値の検討が可能となることを評価実験によって示している [7].
しかし,これまでに開発したシステムでは知見を文章として入力するため,その共有方法 が煩雑でありユーザにとって負担になるという問題があった.そこで,本論文ではソーシャ ルブックマークの考えに基づき,知見をタグとして付与し,共有可能なシステムを提案する.
WebTagger [9]の研究では,ブックマークしたURL
にタグを関連付けることで,
URLを複
数のカテゴリに分類し,効率的な情報共有を可能にしている.タグ型分類は,複数人の利用 者が自由にタグを付与することができるため,直感的な情報共有と柔軟な分類が可能とな
る
[10] [11] [12].コンテクスト検索エンジンにおいても知見をタグ化することで,情報共
2
有の促進が期待できる.しかし,ユーザは知見タグを自由に付与することができるため,キ ーワードによる
Data Jacketの検索を行うユーザは,どのようなキーワードで知見タグが 登録されているかを知ることができない.クエリのキーワードが少しでも異なる場合,キー ワードに関連する知見を取得できない可能性があるため,
Data Jacket検索システムの検索 性能にも課題があった.そこで,
Word2Vec1によってクエリと知見タグを拡張する手法を提 案する.付与した知見タグから
Word2Vecによって類義語を取得し,拡張タグとして付与 する.さらに,検索結果が存在しなかった場合,入力したクエリから
Word2Vecで取得し た類義語を拡張クエリとして再検索を可能とする.
知見を共有する場合,他のユーザと協調してシステムを利用する状況が考えられる.従来 システムでは,あらかじめ共有された知見情報を検索対象としていたため,システムを同時 に利用している他者の知見などは見ることができない.リアルタイムで情報を共有するこ とは,シームレスな知識継承と議論の活性化が期待でき,アイデアが洗練されることが指摘 されている [13] [14].作業環境において周囲にいる人たちやその間のやりとり,発生して いる出来事に対する意識はアウェアネス [15]と呼ばれ,共同作業において重要であること が指摘されている.中川ら [14]は
WWWにアウェアネスを導入することで,同一ページの 参照状況や画面のスクロール情報,テキスト入力情報などをリアルタイムに確認すること を可能とし,WWW におけるコラボレーションを実現した.提案手法においても,リアル タイムで知見タグを共有し,共有された他ユーザの知見情報を検索・参考にすることで,円 滑な知識共有と知見発見の促進が期待できる.
提案システムの有効性を検証するために,タグ・クエリの拡張の有効性,アウェアネスの 有効性の二つの観点から評価実験を行った.前者の評価実験では,拡張タグ・拡張クエリを 導入したコンテクスト検索エンジンと従来のコンテクスト検索エンジンで比較実験を行い,
関係あるアイテム対の発見個数,検索結果件数,アンケート結果から有効性を検証する.後 者の実験では,アウェアネスを導入したコンテクスト検索エンジンと従来のコンテクスト 検索エンジンで比較実験を行い,関係あるアイテム対の発見個数,検索ログ,アンケート結 果および,実際に共有された知見を比較することで有効性を検証する.
本論文は全
5章から構成される.第
1章では,研究背景及び研究目的について述べる.
第
2章では,関連研究について述べる.検索エンジンに関する関連研究として,既存検索エ ンジンの問題点に対する解決策として研究されている次世代検索エンジンについて述べる.
データ利活用に関する関連研究として,オープンデータ・データ共有について述べた後,ソ ーシャルブックマーク・アウェアネス支援について述べる.第
3章では,本研究で用いるデ ータや提案手法の構成について述べる.第
4章では,タグ・クエリの拡張に関する評価実験 と,アウェアネスに関する評価実験の結果を示し,提案手法の有効性について考察する.第
5章では,提案手法とその評価についてまとめ,今後の展望について述べる.
1 https://code.google.com/archive/p/word2vec/
3
2. 関連研究
2.1. 次世代検索エンジンに関する研究
2.1.1. 次世代検索エンジン
近年,Twitter
2や
Instagram3など
SNSの普及により,リアルタイムの情報 が多くのユーザによって
Web上に投稿されるようになっている.そのため,
Web上に膨大 な量の情報が蓄積され,ユーザが必要な情報を的確に検索することが困難となっている.
Google5
や
Yahoo!6などの一般的な検索エンジンはキーワードベースの検索であり,クエリ
のキーワードが含まれる
Webページを検索結果として出力するというシンプルな基本検索 機能であるため,汎用的に利用されている.しかし,Web 上の情報が多様化し,ユーザの 検索要求も多様化する一方で,既存検索エンジンの基本検索機能は単純なものにとどまっ ているために,ユーザの情報要求と検索エンジンの基本検索機能との乖離が大きくなって いることが指摘されている [1].このギャップを埋めるために,様々な次世代検索エンジン の研究がされている.次世代検索エンジンのアプローチとして,自然言語によるアプローチ
[16] [17],ドメインを限定するアプローチ [18] [19],ドメインを限定しないアプローチ [20][2]があげられる.
ユーザの自然言語による入力に対して応答するアプローチとして
Appleの
Siri7,
Googleの
Google Now8,Microsoft の
Cortana9などのサービスが実用化されている.また,通常
の情報検索システムのように漠然とした文書を返答するのではなく,システムが持つ知識 を利用して,ユーザの質問に対し直接的な返答をする
QAシステムが提案されている [16].
しかし,このシステムは「どのように~なのか」といった
how型や「なぜ~なのか」とい った
why型のような複雑な質問に対して回答するのは現状では困難である.
伊藤ら [17]は,
QAシステムに近い音声対話システムとして,協調的応答を備えた音声対 話システムを提案している.通常
QAシステムは,質問文以外の発話文に対する処理や協調 的な応答ができないという問題に対し,言語処理部で利用する単語辞書や意味表現ルール データベースにデータを追加することで,疑問文以外の願望や依頼といった発話や副詞・形 容詞を含む文も理解できるようにしている.また,知識データベースを検索した際にデータ が見つからない場合や,逆に大量の検索結果が出力された場合,ユーザがタスクを達成する ために発話数が必要以上に多くなってしまうという問題に対し,ユーザの発話の意図を抽 出し,システムがユーザに対して協調的な応答を行い,代替案を提案することで,有益な情
2 https://twitter.com/
3 https://www.instagram.com/
4 https://www.facebook.com/
5 https://www.google.co.jp/
6 https://www.yahoo.co.jp/
7 https://www.apple.com/jp/ios/siri/
8 https://www.google.com/intl/ja/landing/now/
9 https://support.microsoft.com/ja-jp/help/17214/windows-10-what-is
4
報を得るために費やす労力を軽減させている.
より高度な検索を行うために,検索対象のドメインを限定するアプローチがあげられる.
検索対象のドメインを特定の分野に特化することで,そのドメインにおいてより効率的な 検索を可能としている.
McCallum
ら [18]は,機械学習を利用してトピック階層を生成し,トピック関係の情報
抽出を自動化することで,ドメインを限定した検索エンジンの生成と保守を効率化する手 法を提案している. コンピュータサイエンス分野の論文に特化した検索エンジンの
Coraは,
すべてのページをインデックスして幅優先探索を行う汎用検索エンジンと異なり,小さな サブセットのみにインデックスすることによって,Web ページ全領域の探索を避け,効率 的な検索を実現する.Cora はコンピュータサイエンス部門の
Webページのクローリング を行い,追記文書へのリンクを収集してドキュメントをテキストに変換する.研究論文であ ると判別された場合,さらに要旨や引用などの処理を行う.タイトルや著者などの重要な識 別情報は,ヘッダや参考文献から抽出する.抽出された結果は,互いに同様の論文を引用し ているといった引用のグループ化や引用グラフの構築に利用される.Cora で検索を行うこ とで,トピック階層や引用文献の著者,タイトル,要旨が検索結果として出力される.
小久保ら [19]は,ユーザが入力したクエリに対して「検索隠し味」を用いることで,検 索結果をレシピに関するドメインに限定する手法を提案している.ドメインに特化したフ ィルタを,汎用検索エンジンから取得した検索結果に適用し,不要なページを削除するのと は対照的に,この手法はユーザが入力したクエリとドメインフィルタの連言をとってクエ リを修正し,クエリを含みかつドメインに属したページのみを取得することで,無関係なペ ージを汎用検索エンジンで取得してからフィルタにかけるという無駄な処理を省くことが できる.ドメインフィルタをフィルタとして用いずこのように利用する場合, 「検索隠し味」
と呼ぶ.
専門的な検索を行う上でドメインを限定することは有効であるが,汎用的に利用するこ とは難しい.既存検索エンジンが汎用的に利用される要因として,ドメインを限定しないこ とがあげられる.そこで,ドメインを限定しないことを重視したアプローチが提案されてい る.
既存検索エンジンはユーザが問い合わせた言語と同一言語の文書が検索対象であるため,
外国語文書に対して検索を行う場合は利用者自身が翻訳しなければならないという負担が
ある.この問題に対し,木村ら [20]は
Yahoo!のような複数の言語で類似の構造を持つWebディレクトリを利用して
Web情報の言語横断検索を行う手法を提案している.言語横断検
索にドメイン毎のコーパスを利用する手法は,学習に用いるコーパスのドメインに対する
依存が大きく,それ以外のドメインに対する検索精度が低くなるため,木村らは
Yahoo!のような複数の言語版が存在する
Webディレクトリに登録された文書群をコーパスとして用
いている.カテゴリごとに属する
Web文書から特徴語を抽出し,これを比較することで対
応する異言語のカテゴリを決定する.検索を行う際,ユーザが入力したクエリに適合する同
5
言語のカテゴリを選択し,選択されたカテゴリに対応する異言語のカテゴリの特徴語を用 いて翻訳することで,訳語の曖昧性解消を行う.得られた翻訳後の問い合わせを利用して,
目的の文書群を対象に検索を行う.この手法はほとんどのドメインに対応したコーパスを 利用しているためドメインに依存せず,Web 文書のように広範囲のドメインを対象とした 検索において有効であると考えられる.
高間ら [2]は「動向に対する問い」というタスクを対象に特化することで,幅広いドメイ
ンに対応したコンテクスト検索エンジンを提案している.ドメインを限定せずタスクを限
定することで,高度な基本検索機能が提供可能となる.次節では,このコンテクスト検索エ
ンジンについて詳しく説明する.
6
2.1.2. コンテクスト検索エンジン
コンテクスト検索エンジン [2]とは,「動向情報に関する問い」というドメインに依存し ないタスクに特化した検索エンジンである.動向に関する問いとは, 「東日本大震災が起き た時期に注目を集めたアイテムは?」や「夏に流行するアイテムは?」のような検索タスク を指す.これらのタスクはドメインに依存しないため,幅広い領域において利用可能である という特徴がある.
高間ら [2]が提案するコンテクスト検索エンジンのシステム構成を図 2.1 に示す.以降,
このコンテクスト検索エンジンを従来システム
V1とする.Web 上に公開されている動向 情報を収集し,特徴的変動を抽出してデータベースに格納する.特徴的変動とは,コンテク スト検索エンジンにおいて定義されている表 2.1 に示す
9つの変動を指し,これをクエリ として入力して検索を行うことで動向情報の流行などを検索することができる.特徴的変 動は,動向を直感的に把握するために松下ら [21]が提案した,統計量の時間的変化を概略 化した図形であるグラフプリミティブを参考にしており,変動幅の閾値は [22]を参考に定 義している.また,コンテクスト検索エンジンでは,各アイテムの価格や販売量などの統計 データのような,各企業や組織・団体によりコンテンツとして公開されている動向情報を
「Web コンテンツとしての動向データ」,各アイテムをキーワードとして既存検索エンジン で検索した際のヒット数やブログの記事数のように,Web 上でのユーザ活動により発生す る動向情報を「Web 利用としての動向データ」と定義し,それぞれについて
Web上に公開 されているデータを収集している [23].従来システム
V1で検索可能な動向情報を表 2.2 に示す.2018 年
2月時点で検索可能なアイテムは
1,366,220件であり,粒度の基本単位は
1ヵ月である.
図
2.1:従来システム
V1のシステム構成(文献
[2]を基に作成)
動向情報
クライアント
Web
サーバ
DB特徴的変動抽出
Web7
表 2.1:各特徴的変動に対応するグラフ概形とその抽出条件(文献 [24]を基に作成)
特徴的変動 グラフ概形 抽出条件 最大値
(MAX)
各動向情報が最大の期間
最小値
(MIN)
各動向情報が最少の期間
急上昇
(SI)
3ヶ月以内に、変動幅の20%以上の増加
急下降
(SD)
3ヶ月以内に、変動幅の20%以上の減少
ピーク
(PEAK)
変動幅の10%以上の増加後、減少に転じ
た山の頂点
底
(BOTTOM)
変動幅の10%以上の減少後、増加に転じ
た谷の頂点
安定
(NONE)
変動幅が月に1.5%を超えない3ヶ月以 上の期間
基準値以上
(UP)
指定した基準値以上の値をとる期間
基準値以下
(LOW)
指定した基準値以下の値をとる期間
8
表 2.2:従来システム
V1で検索可能な動向情報
統計データ名 取得期間 粒度 アイテム数
販売量 2002/01 ~ 2015/12 1 ヶ月 13 件
価格 2005/01 ~ 2014/12 1 ヶ月 171 件 生産量 1958/01 ~ 2011/12 12 ヶ月 3 件 消費量 1986/01 ~ 2011/12 12 ヶ月 1 件
増減率 2000/10 ~ 2013/12 1 ヶ月 49 件
消費者物価指数 2008/01 ~ 2010/11 1 ヶ月 1 件
卸価格 2000/07 ~ 2011/03 1 ヶ月 47 件
数 1953/01 ~ 2013/08 1 ヶ月 4 件
Yahoo!
急上昇ワードランキング 2007/11 ~ 2012/08 1 ヶ月 24512 件 きざしランキング 2006/04 ~ 2012/07 1 ヶ月 2576 件 ついっぷるトレンド
HOT ワード 2010/03 ~ 2012/07 1 ヶ月 399 件 景気ウォッチャー 2000/10 ~ 2013/04 1 ヶ月 22 件
内閣政党支持率 1998/04 ~ 2013/07 1 ヶ月 45 件
Wikipedia Page View 2008/01 ~ 2014/12 1 ヶ月 1338377 件
9
従来システム
V1のクエリ入力フォームを図 2.2 に示す.桑折ら [3]は,実験協力者に指 定した画像の場所を既存検索エンジンのみを用いて特定してもらうという予備実験を行い,
得られた検索行動を元に検索意図を分析した結果から,以下の
3タイプの基本検索機能を 実装している.
[Type1]
指定したアイテムに関する動向が特徴的変動を示した期間の検索
[Type2]
指定した期間に特徴的変動を示したアイテム・動向の検索
[Type3]
指定したアイテムに関する動向が特徴的変動を示した期間に[同様の/対照的な]
変動を示したアイテム・動向の検索
コンテクスト検索エンジンでは,特徴的変動とこれらの基本検索機能を多様に組み合わ せることで高度な検索が可能となる.
Type1
は,クエリの「アイテム名」 「特徴的変動」を指定し,出力タイプを「@Period」に
することで,指定したアイテムに関する動向が指定した特徴的変動を示す期間を検索結果 として返す.
Type2は,クエリの「期間」 「特徴的変動」を指定し,出力タイプを「@Item」
にすることで,指定した期間で指定した特徴的変動を示すアイテムを検索結果として返す.
Type3
は,クエリの「アイテム名」 「特徴的変動」を指定し,出力タイプを「@Item」にす
ることで,指定したアイテムが指定した特徴的変動を示す期間に,同様の変動を示すアイテ ムを検索結果として返す.また,
Type3で出力タイプを「@Item opposite」にすることで,
指定したアイテムが指定した特徴的変動を示す期間に,SI に対する
SDのような,対照的 な変動を示すアイテムを検索結果として返す.
図 2.2:従来システム
V1のクエリ入力フォーム
検索期間アイテム名
単位
統計データ名 UP/LOWの閾値 特徴的変動
出力タイプ 検索
10
従来システム
V1の検索結果画面の例を図 2.3 に示す.ここでは期間を「2011 年
1月~
2011
年
3月」 ,特徴的変動を「SI」,出力タイプを「@Item」として
Type2の検索を行って おり,2011 年
1月~2011 年
3月の間で急上昇したアイテムが検索結果として表示されて いる.図中の
Sparkline10とは,文章中などに縮小したグラフを表示することが可能な情報 可視化技術であり,検索結果画面で容易にグラフを比較可能にしている.なお,グラフ中の オレンジ色で示された部分が特徴的変動を示した期間である.アイテム名をクリックする とグラフの詳細を確認できる.また,Google 検索ボタンをクリックすることで,アイテム 名をクエリ,特徴的変動を示した期間を検索対象期間として
Google検索を行うことができ る.お気に入りボタンをクリックすると,その動向情報がお気に入りに登録され,グラフ詳 細画面で閲覧することができる.
図 2.3:従来システム
V1の検索結果画面の例
10 https://omnipotent.net/jquery.sparkline/#s-about アイテム名
単位
統計データ名
特徴的変動
特徴的変動を 示した期間
特徴的変動を 示した時の値
Sparkline
該当地域
Google検索 お気に入り
ボタン
11
従来システム
V1は,Web 上に公開されているデータをサーバに集約したものを検索対 象としているが,ユーザはプライバシー保護などの問題で外部に公開できないようなデー タを所持している場合も多い.著者は,ローカルデータを公開データと組み合わせ,統合し て利用可能にし,データの概要情報のみを記載した
Data Jacketと共に,動向情報の特徴 的変動に関して発見した知見を共有することで,ローカルデータ自体を公開することなく,
データの利用価値を検討可能にする手法をこれまでに提案している [7].以降,この手法を
導入したコンテクスト検索エンジンを従来システム
V2とする.従来システム
V2の構成に
ついては
3.1節で説明する.
12
2.2. データ利活用に関する研究
2.2.1. ビッグデータとオープンデータ
2013
年に合意されたオープンデータ憲章
11によって,政府データを中心としたデータの オープン化が世界中で行われるようになった [25].オープンデータハンドブック
12では,
「自由に使えて再利用もでき,かつ誰でも再配布できるようなデータ」をオープンデータ と定義しており,以下の
3つを満たす必要がある.
① 利用できる,そしてアクセスできる
② 再利用と再配布ができる
③ 誰でも使える
個人で大量のデータを収集・整備する場合,多くの資金と労力を必要とするため,その データを必要とする研究や開発を行うことが困難となる.オープン化されたデータは誰で も無償で入手して利用することが可能であるため,このような研究や開発に必要なデータ として活用することが可能となる [26].また,データが増加するにつれ,そのデータを整 備する労力が大きくなるため人為的なミスが生じてしまい,修正後のデータの再配布も困 難となる可能性がある.しかし,データをオープン化することで,多くの人がそのデータ の整理に関わることが可能となるため,データチェックによるミスの発見や修正,修正後 のデータの再配布を迅速に行うことができるようになり,データ自体の価値の向上にもつ ながるという利点がある.
オープン化されたデータを活用した研究として,村上ら [27]は災害などが発生した際に 位置情報を把握するために,SNS などの発言に含まれる地理的情報からマッピングを行う ための言語リソース生成を提案している.SNS の文章に含まれる地名や施設名からジオコ ーディングを行い地理情報に変換する際に,国土地理協会
13や
GeoNLP14で公開されてい る建物名や施設名に対応する地理座標を利用している.
この研究のようにオープンデータの活用が期待されている一方で,プライバシー保護の 問題が指摘されている [4] [5].プライバシー保護の観点から,あるサービスの利用者情報 の取り扱いにおいて,データの匿名化や利用者の同意が重要であることが指摘されている
[4].近年ではパーソナルデータが様々な用途で活用される一方,プライバシー意識が高まっているため,事業者が個人情報保護法に従ってデータを利用したとしても批判を受ける ことがあると指摘されている [5].また,パーソナルデータの法制度は国によって異な り,匿名化の手法や個人情報の適用範囲,個人情報の取り扱いなどの問題に関して議論さ
11 http://www.mofa.go.jp/mofaj/gaiko/page23_000044.html
12 http://opendatahandbook.org/guide/ja/
13 http://www.kokudo.or.jp/
14 https://geonlp.ex.nii.ac.jp/
13
れている [28] [29] [30].以上から,データのオープン化において,プライバシー保護の問
題を考慮する必要がある.
14 2.2.2. データ共有
データを共有する方法として,データ自体を公開するアプローチ [31]と,公開しないア プローチ [8]があげられる.
データ自体を公開するアプローチとして,
Linked Open Data(LOD)があげられる.
LODとは2.2.1 節で述べたオープンデータの一種であり,
RDFのように連結されたデータを
Web上に公開することで,様々なデータとの連携を可能にするシステムである [32] [33].松村 ら [31]は,博物館情報の
LODと地域情報の
LODを連携したアプリケーションを提案して いる.博物館情報の
LODからは博物館の名前や位置情報を取得し,連携されている地域情 報の
LODからは会館時間やアクセス方法を取得することが可能となるため,単独の
LODでは得られないような情報を提供可能にしている.
データ自体を公開しないアプローチとして,Data Jacket [6]があげられる.Data Jacket はデータの概要情報のみを記載したものであり,プライバシー保護の問題で公開できない データに関して,データ自体を公開せずこれを共有することでローカルデータの利用価値 を検討可能にする.早矢仕ら [8]は,過去に考案されたデータの利活用方法から,新たなデ ータの利活用方法を検討可能とするためにデータ利活用知識モデルを提案し,データ利活 用方法の検討を支援する検索システム
Data Jacket Storeを開発している.
データ市場における「保有者」 「利用者」 「提案者」の立場から議論を行い,解決策を導く ゲーム型ワークショップ
Innovators Marketplace on Data Jacket(IMDJ)によって「要求」 「ソリューション」 「データ」を創出する.IMDJ では,データの「保有者」は自身のデ ータを公開することなく活用方法を知ることができる.ここで,データ市場において,保有 者は「データ」,利用者は「要求」 ,提案者は「ソリューション」を提供すると考えると,デ ータ利活用知識は以下の
2つのように定義できる.
(1) あるソリューションはあるデータを用いている
(2) あるソリューションはある要求を満たす
(1)を表す述語(combine) , (2)を表す述語(satisfy)を定義し,モデル化する.この
2つのモデルを図式化したものを図 2.4 に示す.データ利活用知識モデルの実装には
RDFを利用し,これらのモデルを組み合わせ, 「要求」 「ソリューション」 「データ」を連結する.
なお,ここでの「データ」は
Data Jacketとしてデータベースに格納されるため,以降「デ ータ」ではなく「Data Jacket」と表現する.例えば, 「要求」へクエリを発行すると,該当 する要求を満たすソリューション及びそのソリューションに用いた
Data Jacketを発見す ることが可能となる.また, 「Data Jacket」へクエリを発行することで,過去にその
DataJacket
を用いたソリューションを得ることが可能となる.よって,過去のデータ利活用知
識から有用な
Data Jacketを得ることができるようになる.
15
図 2.4:データ利活用知識モデルの図式化(文献 [8]を基に作成)
Data Jacket Store
では,ユーザがクエリとして入力した文章からキーワードを抽出し,
それらのキーワードの
OR結合と, 「要求」 「ソリューション」 「Data Jacket」それぞれのデ ータベースを照合する.抽出したキーワードを
1つ以上含む
Data Jacketの集合を
𝐷𝐽𝑑𝑗, 抽出したキーワードを
1つ以上含むソリューションから取得された
Data Jacketの集合を
𝐷𝐽𝑠𝑜𝑙,抽出したキーワードを
1つ以上含む要求から取得された
Data Jacketの集合を
𝐷𝐽𝑟𝑒𝑞とする.以上から取得した
Data Jacketを
OR結合したもの(
𝐷𝐽𝑑𝑗∪ 𝐷𝐽𝑠𝑜𝑙∪ 𝐷𝐽𝑟𝑒𝑞)が,関
連する
Data Jacketの集合となる. 「要求」「ソリューション」「Data Jacket」を連結した
概念図を図 2.5 に示す.図中の赤矢印は,ユーザが入力したクエリをそれぞれのデータベ ースに発行した際に,クエリを満たすデータを示した例である.右側の論理式は,クエリを 満たすデータからそれぞれの
Data Jacketを取得する際に,どのデータベースから発見さ れるかを示した例である.
図
2.5:要求・ソリューション・
Data Jacketを連結した概念図(文献
[8]を基に作成)
ソリューション
(solution) 利用
(combine)
充足 (satisfy)
ソリューション
(solution)
データ
(data)
要求
(requirement)
データ利活用知識(1) combine(solution,data)
データ利活用知識(2) satisfy(solution,requirement)
req:1 sol:1
sol:2
dj:1
dj:2
dj:3 要求 ソリューション Data Jacket
𝐷𝐽𝑟𝑒𝑞 𝐷𝐽𝑠𝑜𝑙 𝐷𝐽𝑑𝑗
それぞれのデータベースにクエリを発行
𝐷𝐽𝑟𝑒𝑞 𝐷𝐽𝑠𝑜𝑙 𝐷𝐽𝑑𝑗
𝐷𝐽𝑟𝑒𝑞 𝐷𝐽𝑠𝑜𝑙 𝐷𝐽𝑑𝑗 要求のみから発見可能
要求とソリューションから発見可能
Data Jacketのみから発見可能
combine satisfy
dj:4
dj:5
𝐷𝐽𝑟𝑒𝑞 𝐷𝐽𝑠𝑜𝑙 𝐷𝐽𝑑𝑗 要求とData Jacketから発見可能
𝐷𝐽𝑟𝑒𝑞 𝐷𝐽𝑠𝑜𝑙 𝐷𝐽𝑑𝑗
ソリューションとData Jacketから発見可能
16
2.2.3. ソーシャルブックマーク
はてなブックマーク
15や楽天ソーシャルニュース
16などのサービスはソーシャルブックマ ークサービスと呼ばれる.ソーシャルブックマークとは,自分がブックマークした
Webペ ージを他のユーザに公開し,共有可能なシステムである [10].ブックマークしたページに タグ付けをして分類することで,他のユーザが有益な情報を得やすくなるという利点があ る.
ソーシャルブックマークを活用した研究として,WebTagger [9]は,ブックマークした
URLにタグを関連付けることで,
URLを複数のカテゴリに分類し,効率的な情報共有を可 能にしている.従来のブックマークとソーシャルブックマークの比較を図 2.6 に示す.従 来のブックマークはフォルダによる階層型分類を行うことが一般的であり,ある
URLは単 一のカテゴリに分けられるが,様々な状況で利用できるようにする場合,複数のカテゴリに 分類することが望ましい.タグ型分類は,利用者が自由に複数のタグを付与することができ る た め , 直 感 的 な 情 報 共 有 と 柔 軟 な 分 類 が 可 能 と な る . こ の よ う な タ グ 型 分 類 を
Folksonomyという.
図 2.6:従来のブックマークとソーシャルブックマークの比較(文献 [10]を基に作成)
高橋ら [34]は,ソーシャルブックマークにおいて過去にブックマークされたページは長 期間削除されずに残っている場合が多く,現在においても価値のあるものとは言えないと いう問題に対し,過去のブックマークの時系列パターンから活性度を評価することでラン
15 https://b.hatena.ne.jp/
16 https://socialnews.rakuten.co.jp/
A
B C
D E F
URL
A B C
URL1 URL2
従来のブックマーク ソーシャルブックマーク
17
キングを行う手法を提案している.ユーザがブックマークしたページは, 「役に立つ」 「おも しろい」などの価値のあるものとして判断したと考えることができる.また,一時的に閲覧 されたページよりも長期間持続的に閲覧されたページの方が,価値があると考えることが できる.ブックマーク日時のデータを対象に隠れマルコフモデルを用いてモデル化を行い,
活性度を求めてランキングする.
畑中ら [35]は,ソーシャルブックマークにおけるスパムによって,ユーザにとって不要
なページが表示されてしまうという問題に対し,ブックマーク類似度によってブラックリ
ストを作成する手法を提案している.ソーシャルブックマークを商用目的で利用すること
をソーシャルブックマークスパムといい,それによってランキングが汚染されることをソ
ーシャルブックマーク汚染と呼ぶ.その原因となるユーザはお互いブックマークする
Webページが似た傾向となるため,ユーザ間のブックマーク類似度を求めてブラックリストを
作成し,ブックマーク数を低減させることで不要なページがランキング上位に表示されに
くくなる.
18
2.2.4. アウェアネス支援
リアルタイムで情報を共有することは,シームレスな知識継承と議論の活性化が期待で き,アイデアが洗練されることが指摘されている [13] [14].作業環境において周囲にいる 人たちやその間のやりとり,発生している出来事に対する意識はアウェアネス [15]と呼ば れ,共同作業において重要であることが指摘されている.Paul [15]らは,アウェアネス支 援を行うシステムを導入することで,コミュニティへのアクセスやコミュニティの構築が 促進され,相互作用につながることを示している.
中川ら [14]は,WWW にアウェアネスを導入することで,同一ページの参照状況や画面 のスクロール情報,テキスト入力情報などをリアルタイムに確認することを可能とし,
WWW
におけるコラボレーションを実現した.WWW は非同期にデータを参照するシステ ムであるため,クライアント間で協調した作業を行うことができないという問題があった.
これに対し中川らは,アプリケーションを通してお互いの操作を確認しながら会話を行う ことが可能なシステムを導入することで,議論を活性化し協調的な作業を行えるようにし た.
緒方ら [36]は,議論の誘発を目的とした
Knowledge Awareness(KA)を提案している.
緒方らの提案する
Sharlokは共有知識空間を持つシステムであり,学習領域ごとに知識を 蓄積することができる.また,知識の訂正などが自由にでき,意見交換や議論を行うことが できる.この協調学習が可能なオープンな学習環境において,他の学習者が同じ知識にアク セスした際に,自身がその知識を参照していることや,議論をしていること,知識を追加し ていることなどの情報を知らせることで存在を気づかせ議論を誘発する.これにより,他の 学習者が関心のある知識が何かがわかったり,問題点に気づいたりすることができ,議論に よって間違いを修正することも可能となる.また,KA では学習者が参照している知識,行 動時間それぞれの相違の
2軸から考えることで,自身が知らない知識の存在に気づいたり,
リアルタイムの議論がしやすくなったりする.このように議論を促すことによって,能動的
な学習を促進することが可能となることを示した.
19
3. コンテクスト検索エンジンのインタフェース拡張
本論文では,コンテクスト検索エンジンにおいてタグを利用した知見共有が可能なシス テムを提案する.
2.1.2
項で説明した,従来システム
V2では知見を文章として入力するため,その共有方
法が煩雑でありユーザにとって負担になるという問題があった.そこで本論文ではソーシ ャルブックマークの考えに基づき,知見をタグとして付与し,共有可能とする.しかし,ク エリのキーワードがタグで用いられたものと少しでも異なる場合,キーワードに関連する 知見であっても取得できないため,Word2Vec によってクエリと知見タグを拡張する.
また,知見を共有する場合,他のユーザと協調してシステムを利用する状況が考えられる.
従来システム
V2では,事前に共有された知見情報を検索対象としていたため,システムを 同時に利用している他者の知見などは見ることができない.本論文では,アウェアネスを導 入することでリアルタイムに知見タグを共有し,検索・参考にすることを可能とする.
3.1
節で従来システム
V2の構成,3.2 節で知見タグの導入とタグ・クエリの拡張,3.3 節
でアウェアネスの導入について説明する.
20
3.1. 従来システムV2の構成
3.1.1. ローカルデータ・公開データの統合検索機能
本項では,2.1.2 項で紹介した,コンテクスト検索エンジンにおいてローカルデータ・公 開データの統合検索を可能にするシステム(従来システム
V2)について説明する.提案システムはこのシステムを拡張して実装している.公開されている時系列データと同様に,ユ ーザがローカルに所持している時系列データから特徴的変動を抽出し,データベースに格 納することで,コンテクスト検索エンジンにおいて検索可能とする.
一般的に,時系列データは
HTML,XML,PDF,Excel,CSVなどの形式で保存されて いるが,CSV 形式以外の時系列データを
CSV形式に変換することは一般に容易であるた め,CSV 形式を対象としている.オープンデータは様々な書式で記述されているが,単体 のアイテムに関するデータ,もしくは複数のアイテムに関するデータがまとめて記述され ている可能性が考えられる.また,集計期間は
1年ごと,もしくは
1ヵ月ごとで記述され ている場合がある.これらを考慮して,このシステムでは以下の
3タイプが解析可能であ る.それぞれのタイプの
CSVファイルの記述例を図 3.1,図 3.2,図 3.3 に示す.
1.
単体のアイテムに関して記載したもの(行:年,列:月)
2.
複数のアイテムに関して,1 年ごとに記載したもの(行:アイテム,列:月)
3.
複数のアイテムに関して記載したもの(行:年月,列:アイテム)
図 3.1:CSV ファイルの記述タイプ
1 title,統計データ名,,,,,,,,,,,target,該当地域,,,,,,,,,,, unit,単位,,,,,,,,,,, item,アイテム名,,,,,,,,,,, ,,,,,,,,,,,,
,1月,2月,3月,4月,5月,6月,7月,8月,9月,10月,11月,12月 2016年,66,44,88,40,98,8,22,3,27,32,70,78
2015年,60,32,35,97,24,35,73,36,10,44,70,24 2014年,93,14,4,5,81,84,86,38,82,29,13,77 2013年,89,94,29,76,36,34,45,37,10,81,40,27 2012年,77,48,89,7,84,3,58,29,41,5,58,54 2011年,17,45,63,13,86,66,17,4,60,23,95,4 2010年,41,70,79,74,88,64,84,15,48,10,57,40 2009年,42,6,61,80,70,13,73,24,48,87,63,5 2008年,59,37,22,67,12,86,8,48,41,35,54,97 2007年,22,23,26,24,19,2,17,31,82,50,53,23 2006年,5,44,53,81,91,45,62,84,59,86,83,36 2005年,25,1,77,49,28,47,67,86,92,62,67,30
21
図 3.2:CSV ファイルの記述タイプ
2図 3.3:CSV ファイルの記述タイプ
3 title,統計データ名,,,,,,,,,,,target,該当地域,,,,,,,,,,, unit,単位,,,,,,,,,,, item,,,,,,,,,,,, ,,,,,,,,,,,,
2016年,1月,2月,3月,4月,5月,6月,7月,8月,9月,10月,11月,12月 アイテムA,73,62,15,79,85,32,8,88,26,53,48,15
アイテムB,45,24,33,27,21,95,22,24,15,14,83,56 アイテムC,71,40,17,93,92,15,17,100,84,42,54,66 アイテムD,65,67,72,95,70,57,66,95,80,18,6,74 アイテムE,52,28,73,64,19,78,33,54,93,87,77,47 ,,,,,,,,,,,,
2015年,1月,2月,3月,4月,5月,6月,7月,8月,9月,10月,11月,12月 アイテムA,85,79,69,57,12,14,67,85,68,37,40,39
アイテムB,89,31,6,5,42,3,5,85,33,40,52,91 アイテムC,72,30,56,78,68,17,26,9,43,78,95,80 アイテムD,37,32,24,14,61,80,49,45,71,77,46,51 アイテムE,97,3,53,58,41,20,14,6,43,18,57,90
title,統計データ名,,,, target,該当地域,,,, unit,単位,,,, item,,,,, ,,,,,
,アイテムA,アイテムB,アイテムC,アイテムD,アイテムE
2017年12月,63,40,8,64,68 2017年11月,31,72,70,85,26 2017年10月,80,38,91,24,48 2017年9月,44,7,27,36,96 2017年8月,64,91,83,90,71 2017年7月,49,28,99,48,50 2017年6月,34,9,38,76,82 2017年5月,41,88,83,77,12 2017年4月,16,1,48,98,2 2017年3月,69,5,87,13,17 2017年2月,36,61,95,35,18 2017年1月,80,21,76,52,36 2016年12月,38,33,21,8,30 2016年11月,23,53,53,83,82 2016年10月,58,38,5,86,75
22
ローカルデータの管理画面を図 3.4 に示す.ここでは,CSV ファイルを解析し,コンテ クスト検索エンジンで利用可能な形式でインポート・削除することが可能である. 「Browse」
ボタンでファイルを選択し, 「CSV インポート」ボタンを押すと自動的に記述タイプを判別 し,インポートされる.過去にアップロードしたデータは, 「Delete」ボタンで削除するこ とができる.
図 3.4:ローカルデータ管理画面
従来システム
V2の構成を図 3.5 に示す.コンテクスト検索エンジンには
API機能が提 供されており,各パラメータを指定してリクエストを送信すると,検索結果を
XML形式で 取得できる.これを利用して,外部コンテクスト検索エンジンのサーバに登録されている公 開データを取得し,検索結果として出力する.
ユーザがローカルコンテクスト検索エンジンの検索フォームにクエリを入力して検索を
行うと,外部コンテクスト検索エンジンへのリクエスト
URLが作成される.外部コンテク
スト検索エンジンはリクエストを受信すると外部データベースを検索し,検索結果を
XML形式で出力する.ローカルコンテクスト検索エンジンは外部データベースの検索結果を取
得し,Ruby のライブラリ「nokogiri」を利用してパースを行い,クライアントへ出力可能
な形式に変換する.統合検索の場合はローカルデータベースの検索結果と統合し,ランキン
グスコア [37]を基準にソートする.最後に検索結果をクライアントへ送信し,画面に表示
させる.
23
図 3.5:従来システム
V2の構成
コンテクスト検索エンジンの
APIについて,リクエストパラメータを表 3.1,レスポン スパラメータを表 3.2 に,検索結果の
XML出力画面を図 3.6 に示す.
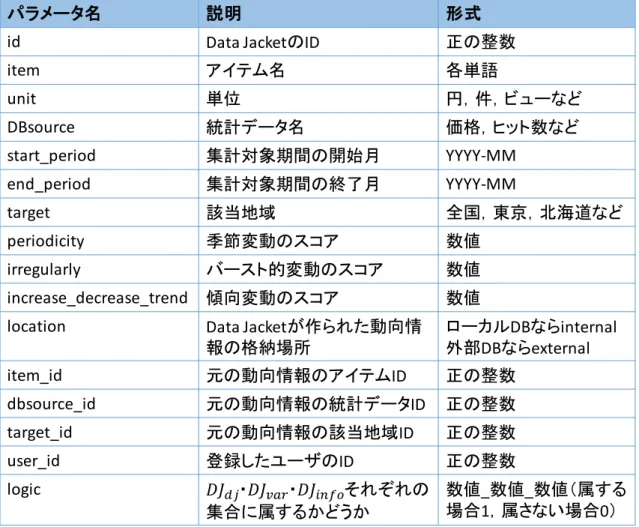
例えば
page=3とすると,1 ページを
20件として取得するので
41件目~60 件目を取得
することができる.page=0 とすると,1 件目~200 件目を取得することができる.また,
完全一致検索だけでなく,アイテム名の表記ゆれに対応するために部分一致検索が可能で あり,matchType でどちらを利用するかを指定する.レスポンスパラメータの
sparkline-period
は動向情報の集計期間のうち,値が存在する年月のリストを示しており,
sparkline-value
は
sparkline- periodに対応する値のリストを示している.i-d-t は動向情報のアイテ
ム
ID,統計データID,該当地域IDを示している.図 3.6 の
XMLは,アイテムを「iPod」 ,
出力タイプを「period」として検索を行い,1 ページ目を指定して検索結果を出力した例で
ある.
objectタグごとに検索結果
1件分の情報が記載されており,
objectタグに囲まれたそ
れぞれの要素名がレスポンスパラメータに対応している.また,
queryタグには入力したク エリ,totalResults タグには検索件数が記載されている.
外部DB
(公開データ)
外部Webサーバ
クライアント ローカルWebサーバ
ローカルコンテクスト検索エンジン 外部コンテクスト検索エンジン
APIへ リクエスト送信
検索結果 取得・統合 クエリ送信
検索結果取得
ローカルDB
24
表 3.1:API のリクエストパラメータ
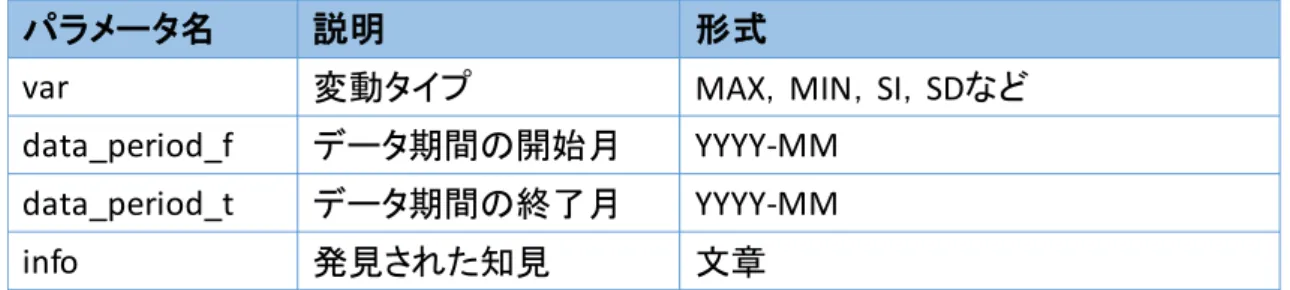
表 3.2:API のレスポンスパラメータ
パラメータ名 説明 形式
id API 使用者の登録 ID 英数字
item アイテム名 各単語
period 検索期間の開始と終了 YYYY/MM-YYYY/MM
target 該当地域 全国,東京,北海道など
var 変動タイプ MAX , MIN , SI , SD など
th 閾値( UP/LOW の場合) 数値( AVG で平均値を指定)
opposite 指定した変動タイプと反対の変
動タイプを持つアイテムを検索
yes または no
db 統計データ名 価格,ヒット数など
unit 単位 円,件,ビューなど
output 出力タイプ period または item
page 取得ページ( 1 ページ 20 件) 0 以上の整数( 0 の場合は上位 200 件を取得)
matchType 完全一致検索・部分一致検索 exact または partial
パラメータ名 説明 形式
item アイテム名 各単語
unit 単位 円,件,ビューなど
DBsource 統計データ名 価格,ヒット数など
target 該当地域 全国,東京,北海道など
varType 変動タイプ MAX , MIN , SI , SD など
data-period-f データ期間の開始月 YYYY-MM
data-period-t データ期間の終了月 YYYY-MM
value 値 数値
ranking-score ランキングのスコア 数値
sparkline-period 集計期間のうち値が存 在する年月のリスト
YYYY-MM-DD,YYYY-MM-DD, ・・・
sparkline-value sparkline-periodに対応 する値のリスト
数値,数値,数値,・・・
i-d-t 取得データに関する ID アイテム ID- 統計データ ID- 該当地域 ID
25
図 3.6:API の検索結果の
XML出力画面
また,個々のアイテムに関するデータを取得する
APIについて,リクエストパラメータ を表 3.3,レスポンスパラメータを表 3.4,XML 出力画面を図 3.7 に示す.外部データベ ースのアイテム
ID・統計データID・該当地域IDをリクエストパラメータで指定すること で個々の動向情報を取得できる.表 3.1 の
item・db・targetそれぞれに対応する
IDが,
表 3.3 の
item_id・dbsource_id・target_idである.図 3.7 の
XMLは,アイテム
IDを
「1346578」 ,統計データ
IDを「17」 ,該当地域
IDを「62」として検索を行い,検索結果 を出力した例である.object タグに囲まれたそれぞれの要素名がレスポンスパラメータに 対応しており,
queryタグには入力したクエリが記載されている.これを見ると,指定した
IDに対応したアイテムは
Ipod,統計データはWikipedia pageviewであることがわかる.
なお,データによっては該当地域に関する情報を持たない場合があり,その場合
target_idは無視される.この検索結果も該当地域に関する情報を持たないため,空白が出力されてい
る.
26
表 3.3:アイテムに関するデータを取得する
APIのリクエストパラメータ
表 3.4:アイテムに関するデータを取得する
APIのレスポンスパラメータ
図 3.7:アイテムに関するデータを取得する
APIの
XML出力画面
パラメータ名 説明 形式
id API 使用者の登録 ID 英数字
item_id アイテム ID 正の整数
dbsource_id 統計データ ID 正の整数
target_id 該当地域 ID 正の整数
パラメータ名 説明 形式
item アイテム名 各単語
unit 単位 円,件,ビューなど
DBsource 統計データ名 価格,ヒット数など
target 該当地域 全国,東京,北海道など
sparkline-period 集計期間のうち値が存 在する年月のリスト
YYYY-MM-DD,YYYY-MM-DD, ・・・
sparkline-value sparkline-period に対応 する値のリスト
数値 , 数値 , 数値 , ・・・
i-d-t 取得データに関するID アイテムID-統計データID-該当地域ID
27
従来システム
V2のクエリ入力フォームを図 3.8 に示す. 「検索対象」を追加することで,
メタサーチエンジン [38] [39]のようにローカルデータ・公開データどちらかを検索,もし くは統合して検索可能である. 「Internal」でローカルデータを検索, 「External」で公開デ ータを検索, 「Integrate」で統合検索が可能となっている.統合検索では処理速度短縮のた め,ローカルデータ・公開データそれぞれの検索結果上位
200件のみを統合して出力する.
ここで,検索結果のソートには手塚ら [37]が提案したランキングスコアを採用している.
「完全一致/部分一致検索」については, 「Exact」で完全一致, 「Partial」で部分一致検索が 可能となっている. 「変動によるソート」については
3.1.3項で説明する.
統合検索の検索結果画面を図 3.9 に示す.これは, 「北海道」というアイテムが
1950/1-2015/12
の間で最大値をとった期間を検索した結果であり,ローカルデータのアイテム名は
青色,公開データのアイテム名は紫色で表示されている.
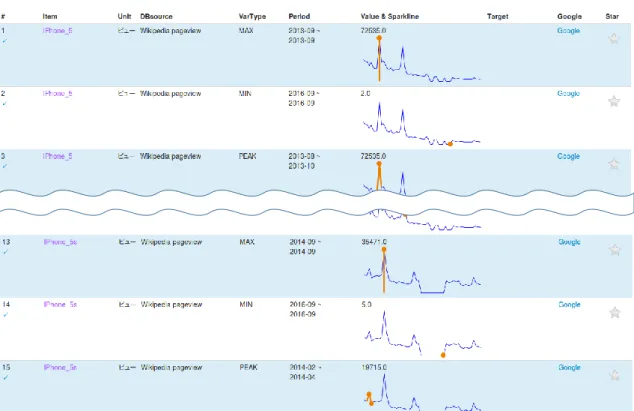
部分一致検索の検索結果画面を図 3.10 に示す.ここでは, 「iPhone」というキーワード を含むアイテムが何らかの特徴的変動を示している期間を検索している.完全一致検索の 場合, 「iPhone_5」や「iPhone_5s」として登録されているアイテムは検索結果に出力され ない.しかし,部分一致検索を利用することで,これらのアイテムも取得可能となるため,
類似アイテムの発見につながると考える.
図 3.8:クエリ入力フォーム
完全一致/部分一致検索 変動によるソート
検索対象
28
図 3.9:統合検索の結果
図 3.10:部分一致検索の結果
29
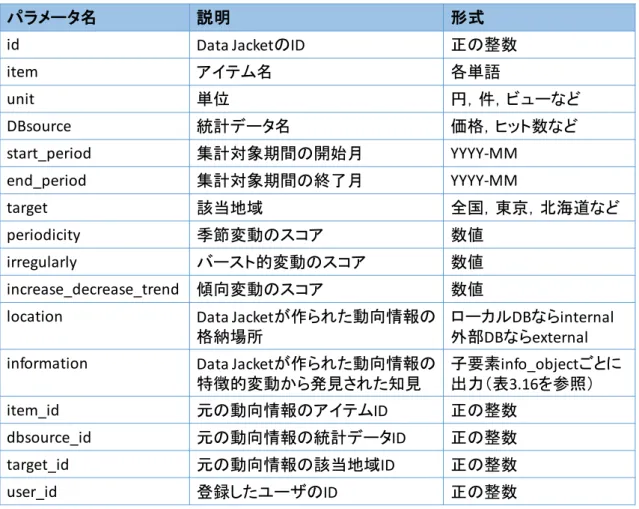
3.1.2. コンテクスト検索エンジンにおけるData Jacket
本項では,コンテクスト検索エンジンにおける
Data Jacketについて説明する.Data
Jacket
はデータの概要情報のみを記載したものである.プライバシー保護の問題で公開で
きないデータに関して,データ自体を公開せずこれを共有することでローカルデータの利 用価値が検討可能となる.
Data Jacketに記載する情報はコンテクスト検索エンジンに登録 されている情報を利用し,自動的に作成することでユーザへの負担を軽減している.コンテ クスト検索エンジンにおける
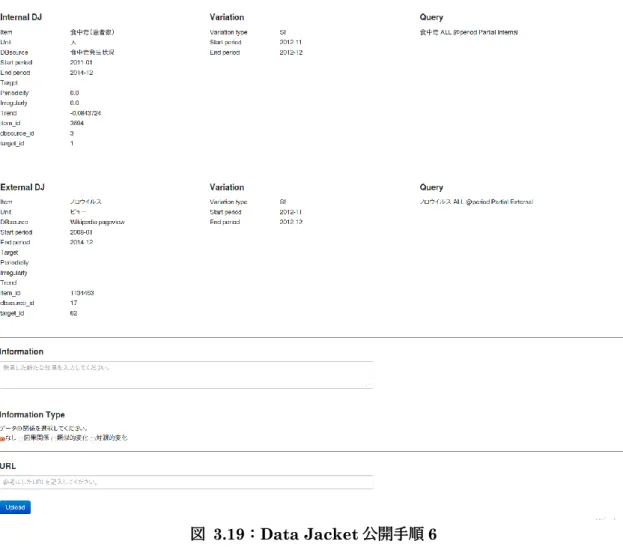
Data Jacketの例を表 3.5 に示す.この動向情報は,1 世帯 当たりのチョコレート(菓子)に対する支出金額に関する動向情報から作成された
DataJacket
である.それぞれの変動スコアについては
3.1.3項で説明する.
表 3.5:コンテクスト検索エンジンにおける
Data Jacketの例
アイテム名 チョコレート
単位 円
統計データ名 1世帯当たりの菓子支出金額 集計対象期間 2008-01 ~ 2014-12
該当地域 全国
季節変動のスコア 1.0 バースト的変動のスコア 0.0
傾向変動のスコア 0.0100977
30
従来システム
V2では,2.2.2 項で説明したデータ利活用知識によるアプローチを採用し ている.コンテクスト検索エンジンにおいては,動向情報の特徴的変動に関して発見した知 見を共有することで,新たな知見の発見につながるという考えに基づき, (1) 「ある知見が,
ある動向情報の特徴的変動から発見された」 , (2) 「ある動向情報の特徴的変動が,ある
DataJacket
に記載されている動向情報から獲得された」の二つをデータ利活用知識の最小単位
と定義し, 「知見」 「特徴的変動」 「Data Jacket」を連結している.知識(1)を表す述語(discover)
及び,知識(2)を表す述語(get)を定義し,モデル化したものを図 3.11 に示す.この時,
Data Jacket
に記載されている動向情報を取得する際にコンテクスト検索エンジンに入力
した「クエリ」をプロパティとして定義し, 「特徴的変動」と「Data Jacket」の連結部に付 与している.二つのデータ利活用知識を組み合わせて連結することで,複雑なデータ利活用 知識を構造的に記述することができる.
図 3.11:データ利活用知識モデルの図式化
特徴的変動
(variation) 発見
(discover)
獲得 (get)
クエリ
(query)
Data Jacket
(data)
知見
(information)
特徴的変動
(variation)
データ利活用知識(1) discover(variation,information)
データ利活用知識(2)
get(data,variation)
31
データ利活用知識モデルを組み合わせた例を図 3.12,図 3.13 に示す.図中のノードは,
info
は知見,var は特徴的変動,dj は
Data Jacketを表している.
図 3.12 は, 「食中毒(患者数) 」の
Data Jacketが作成された動向情報が「2012 年
11月
~2012 年
12月に
SI(急上昇)となった」という情報と,「ノロウイルス」の
Data Jacketが作成された動向情報が「2012 年
11月~2012 年
12月に
SIとなった」という二つの情報 から, 「広島で
1000人以上のノロウイルス感染者が出たことが,食中毒患者が増加した原 因である」という知見が発見されていることを表している.
図 3.13 は, 「チョコレート」の
Data Jacketが作成された動向情報が「2008 年
1月~
2008
年
3月に
PEAKとなった」という一つの情報から, 「毎月
2月にピークを迎えている」
という知見が発見されていることを表している.例えばこの情報から, 「バレンタインによ ってチョコレートを購入する人が増加するため, 毎年
2月に急上昇しているのではないか」
という他のユーザによる新たな知見によって,関係のあるアイテムとして「バレンタイン」
が発見されることが期待できる.
図 3.12:データ利活用知識モデルを連結した例1
図 3.13:データ利活用知識モデルを連結した例2
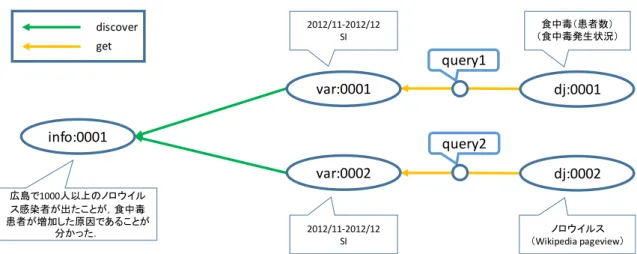
info:0001dj:0001 var:0001
dj:0002 var:0002
query1
query2
広島で1000人以上のノロウイル ス感染者が出たことが,食中毒 患者が増加した原因であることが
分かった. 2012/11-2012/12
SI 2012/11-2012/12
SI
食中毒(患者数)
(食中毒発生状況)
ノロウイルス
(Wikipedia pageview) discover
get
info:0001 var:0001 dj:0001
query1
毎年2月にピークを迎えている. 2008/01-2008/03 PEAK
チョコレート
(1世帯当たりの菓子支出金額)
discover get
![図 2.4:データ利活用知識モデルの図式化(文献 [8]を基に作成)](https://thumb-ap.123doks.com/thumbv2/123deta/10131534.1965422/17.892.163.744.155.310/図24データ利活用知識モデルの図式化文献8を基に作成.webp)