マルチコアにおけるソフトウェア:2.マルチコアにおけるプログラミング
7
0
0
全文
(2) 特. 集 マルチコアにおけるソフトウェア. ことができる.. PC クラスタシステムは一種の分散メモリ型マルチプロ. 共有メモリ型マルチプロセッサではすべてのプロセッ. セッサシステムであるため,近年の安価な PC クラスタ. サがデータを共有している.すなわち,共有メモリ型マ. システムの普及により分散メモリ型のプログラミングモ. ルチプロセッサで並列化プログラムを書く場合,プログ. デルを利用するユーザも増えている.. ラマはプログラムの並列化そのものに着目すればよいこ. 分散メモリ型マルチプロセッサで科学技術計算のプロ. とになる.ただし,通常の共有メモリ型マルチプロセッ. グラムを開発する場合,現在 Message Passing Interface. サでは,各プロセッサが持つキャッシュ間およびメモリ. (MPI)が事実上の標準となっている.MPI はその名が示. との間でデータの一貫性を維持する必要があり,ハード. すとおりプロセッサ間のメッセージ交換(データ転送). ウェアが暗黙のうちに各プロセッサのキャッシュやメモ. を行うためのライブラリを規定しており,これらのライ. リの間でデータ転送を行うことになる.データ転送が頻. ブラリは OpenMP と同様に C や Fortran から使用するこ. 発すると通常のプログラム実行が阻害され並列処理の効. とができる.本稿では,分散メモリ型のプログラミング. 果が得られない.結局,性能を追求する場合には,共有. モデル用 API の例として MPI を取り上げる.. メモリ型マルチプロセッサの場合においてもプロセッサ 間のデータの流れを把握した上で使用するデータをメモ リ上に配置する必要がある. 共有メモリ型のプログラミングモデルは,その簡便. 代表的な 2 つの API によるプログラミ ングモデルの比較. さからこれまでにもすでに広く利用されており,POSIX. こ こ で, 図 -1 に 示 す 正 方 行 列 A と B の 行 列 積 を. thread library や Java によるマルチスレッドプログラミ. 計算し結果を行列 C に格納するプログラムを用いて. ングはこの共有メモリ型のプログラミングモデルを前提. OpenMP と MPI の特徴を紹介する. にしている.本稿では,多くのコンパイラベンダがサポ. グラムでは説明のため,行列データの作成等の並列処理. ートしており,科学技術分野でのユーザが多い OpenMP. とは関係のない処理を省略している.. を取り上げる.OpenMP は C,C++ および Fortran に対. 図 -2 に OpenMP を用いて図 -1 のプログラムを並列. する並列処理記述用 API であり,コンパイラ指示文,ラ. 化した例を示す.図 -1 と図 -2 を比較すると, 「#pragma. ンタイムライブラリ,および環境変数から構成されてい. omp」で始まる行が 1 行追加されただけであることが分. る.プログラマは通常の逐次プログラム中の並列化した. かる.OpenMP により C のプログラムを並列化する場. い部分にコンパイラ指示文を挿入してプログラムの並列. 合は,このように「#pragma omp」で始まるコンパイ. 化を行う.並列化に際してプログラムの大幅な書き換え. ラ指示文を挿入することになる. 「#pragma omp」の次. を必要としないので,プログラマは漸進的に並列化とチ. の for は,その指示文に続く for ループを並列化するこ. ューニングを行うことができる.また前述のように多く. とを意味する.すなわち,コンパイラは並列化指定され. のコンパイラベンダがすでに OpenMP をサポートして. たループを元のループの部分ループを実行するスレッド. いるので,並列化されたプログラムのポータビリティは. として切り出し,実行時に複数のプロセッサで処理でき. 非常に高い.. るようなコードを生成する.なお,図 -2 のプログラム. 一方,分散メモリ型マルチプロセッサでは各プロセッ. では private 指定によりループカウンタの i, j, k と一時変. サが持つローカルメモリは独立なものであり,ハードウ. 数の r をスレッドローカルの変数としている.OpenMP. ェアが暗黙のうちに相互にデータ転送を行うようなこと. ではループカウンタは private 指定がなくとも標準でス. はない.すなわち,プログラマはプログラムの並列化に. レッドローカル化されるが,図では説明のため明示的に. 加えて,並列化した後の各プロセッサのメモリ管理とプ. private 指定した.OpenMP ではこれ以外にも,各スレ. ロセッサ間のデータ転送を記述する必要がある.一般に,. ッドの同期をとるための指示文,ループにかかわらず任. このようなメモリ管理とデータ転送の管理は難易度の高. 意の領域を並列化するための指示文等が用意されている.. い作業である.. またランタイムライブラリとして,実行時のスレッドの. ☆1. .なお,このプロ. このように分散メモリ型マルチプロセッサにおけるプ ログラミングは難易度が高いが,ある程度以上の規模の マルチプロセッサシステムは共有メモリ型で構築するこ とが難しく,大型のマルチプロセッサシステムでは分散 メモリ型のプログラミングモデルが必須となる.また,. 18. 47 巻 1 号 情報処理 2006 年 1 月. ☆1. 現在の共有メモリ型マルチプロセッサ用自動並列化コンパイラ はこの程度のプログラムは容易に並列化できるが,ここでは分 散メモリ型マルチプロセッサとの比較のためこの行列積をサン プルとして用いる..
(3) 2.マルチコアにおけるプログラミング. 図 -1 サンプルプログラム(行列積). 図 -2 OpenMP により並列化した例. 情報を取得するためのライブラリコールや実行時環境を. より並列化された図 -3 のプログラムの流れを説明する.. 操作するためのライブラリコールも用意されている.. 説明中,プロセッサとローカルメモリの組をノードと表. 次に,図 -3 に MPI を使って並列化した例を示す.簡. 現する.. 単のため,このプログラムでは行列サイズがプロセッサ. 図 -4 は行列積の計算を 4 ノードを使って並列化した. 数で割り切れることを仮定している.図 -1 のオリジナ. 様子を表している.並列化は,行列 A を行方向で分割. ルのプログラムと比較すると,コードが大幅に追加さ. し,A の各部分行列と行列 B の積を各ノードで計算する. れていることが分かる.ここで図 -4 を使って,MPI に. という方針で行っている.まず,ノード 0 が各ノード. 図 -3 MPI により並列化した例. IPSJ Magazine Vol.47 No.1 Jan. 2006. 19.
(4) 特. 集 マルチコアにおけるソフトウェア 行列B. 行列A. ノード0用 ノード1用 ノード2用 ノード3用. ノード0から 各ノードに 部分行列を転送 CPU + キャッシュ. =. ノード2. ノード1. ノード0. メモリ. CPU + キャッシュ. 部分行列の 計算. =. ×. =. 各ノードから ノード0が 部分行列を収集. ノード0用 ノード1用 ノード2用 ノード3用. ノード3. CPU + キャッシュ. メモリ. メモリ. ×. ノード0から 各ノードに 行列全体を転送. CPU + キャッシュ. メモリ. =. ×. ×. 行列C. 図 -4 MPI による並列処理のイメージ. における計算に必要な行列 A の部分行列と行列 B 全体. モリ型それぞれのプログラミングを見てきたが,メモリ. をノード 1 ∼ 3 に転送する.各ノードでは転送された. 管理とデータ転送の記述の有無が 2 つのプログラミン. データを使って行列積の計算を行う.各ノードは計算後,. グモデルの大きな違いであることが分かる.. 計算結果である行列 C の部分行列をノード 0 に転送し, 計算が終了となる. それでは図 -3 の実際のプログラムの記述を見てみる.. 並列処理プログラミングで注意すべき点. まずこのプログラムでは MPI_Init() による実行環境の初. 先に紹介した OpenMP や MPI のような並列化 API を. 期化を行い,MPI_Comm_rank() と MPI_Comm_size() で. 用いることにより,並列化プログラムを書くことができ. ノード番号(myrank)と総ノード数(nprocs)をそれ. る.ここで,並列化プログラムを書く際に注意すべき基. ぞれ取得している.MPI の実行環境では,計算に参加す. 本的な事項をいくつか挙げる.いずれも,プログラムの. る全ノードで同一のプログラムが実行される.そのた. 設計時に深く検討する必要がある事項である.. め,各ノードが各々の担当部分を決定するため,このよ うにノード番号を取得する必要がある.次に,ノード 0. タスクの粒度. は MPI_Send() によってノード 1 ∼ 3 に行列 A の部分行. 一般に,並列処理の単位をタスク,その大きさを粒度. 列と行列 B を転送する.ノード 1 ∼ 3 は転送されたデ. という.並列処理を行う場合には,プログラムからタス. ータを MPI_Recv() により受信する.その後,各ノード. クを切り出して,それらのタスクを静的あるいは動的に. は受信したデータを使い担当部分の計算を行う.最外側. プロセッサに割り当てて実行する.このとき,タスクの. の for ループの回転範囲が 0 から isize までとなってい. 粒度がまちまちであったり,プロセッサに割り当てられ. ることに注意されたい.OpenMP ではこのような部分ル. たタスクの実行時間の総量が不均衡であったりすると,. ープの切り出しをコンパイラが自動的に行う.計算終了. たとえあるプロセッサが必要な仕事を早く終えたとして. 後,ノード 1 ∼ 3 は MPI_Send() により計算結果をノー. もプログラムの実行時間は一番遅くまで処理を行ってい. ド 0 に転送し,ノード 0 は MPI_Recv() により転送され. たプロセッサの実行時間となってしまう(負荷の不均. たデータを受信し,行列 C 全体を構築する.. 衡).このような場合,タスクの粒度や割り当て状況を. このように MPI では,データ転送のライブラリコー. 改善し,負荷を均衡化することで性能の改善を図ること. ルを挿入することでプログラムの並列化を行う.もちろ. ができる.. ん,図 -3 のプログラムで追加されたコードのほとんど. また並列処理を行う場合,共有メモリ型ではスレッド. すべてはデータ転送のためのコードである.. の制御オーバーヘッドが,分散メモリ型ではデータ転送. 本章で OpenMP と MPI を使い共有メモリ型と分散メ. のオーバーヘッドがかかってしまい,タスクの粒度が小. 20. 47 巻 1 号 情報処理 2006 年 1 月.
(5) 2.マルチコアにおけるプログラミング. プロセッサA (生産側). プロセッサB (消費側). FIFOキュー (共有データ) 図 -5 複数のプロセッサでデータを共有する例. さい場合は並列処理によって得られる効果よりもこれら. 要な同期やロックを省略するとプログラムの結果が保証. のオーバーヘッドが上回ってしまう.並列処理を行う際. できなくなる.このような本来必要な同期やロックの省. のオーバーヘッドを考慮した上でタスクの粒度を決定す. 略は,プログラム実行時のタイミングによっては正当な. る必要がある.. 結果を得られてしまうこともあり再現性に乏しいバグと. 同期・ロック 複数のタスクで計算された結果を集計する場合や,タ スク A の後にタスク B を実行するといったようなタス. なり得る.プログラムの設計段階から慎重に検討すべき 事項である.. データの配置. ク間で実行順序をつける場合,それらのタスクの間で同. 分散メモリ型では,プログラマが各プロセッサのデー. 期をとる必要がある.同期はプロセッサ間の通信によっ. タの管理とデータ転送をすべて自分で行う必要がある.. て実現される. ☆2. ため,並列処理におけるオーバーヘッ. 共有メモリ型マルチプロセッサシステムでは,各プロセ. ドとなる.. ッサの持つキャッシュ上のデータの一貫性をハードウェ. また,共有メモリ型では並列処理時に複数のプロセッ. アで保証しており,このハードウェアが暗黙のうちにデ. サで 1 つのデータを共有するような場合がよく存在す. ータ転送を行うので,プログラマはデータ転送の管理を. る.たとえば,図 -5 のようにあるプロセッサが生成し. 行う必要はない.しかしながら,現在のコンピュータシ. たデータを別のプロセッサが使用し,これらのプロセッ. ステムではプロセッサ内外のメモリアクセスコストの差. サ間のデータのやりとりを FIFO バッファを介して行う. が非常に大きく,その有効利用を行うことがプログラム. 場合を考える.このとき,2 つのプロセッサは FIFO バ. の性能向上の鍵となる.そのためには,プログラムを実. ッファを共有している.もし,生産側プロセッサの新し. 行するマルチプロセッサシステムのキャッシュの特性を. いデータの投入と消費側プロセッサのデータの取出しが. 理解し,プロセッサ間,あるいはメモリとの不要なデー. 同時に起こってしまった場合,FIFO キューの投入ポイ. タ転送が生じないようにデータの配置を決定する必要が. ンタ等の管理データが不正に書き換わってしまう可能性. ある.逆に,不用意にデータの配置を行うと並列処理に. がある.このような場合,FIFO キューの操作権を意味. よりかえって性能が落ちてしまうことになる.. するロック変数を用意して,あるプロセッサが FIFO キ. 筆者らは,自動並列化コンパイラによるコンパイル時. ューを操作したい場合はこのロック変数により操作権. のプログラム全体にわたる解析の結果を用いたデータ. (ロック)を獲得し各々のプロセッサが排他的に FIFO キ. 分割配置と,分割後のデータの有効利用を考慮したタ. ューを操作する必要がある.当然,排他操作をしている. スクの割り当て(スケジューリング)によりデータロ. 間は並列処理を行うことはできない.. ーカリティを抽出し,キャッシュあるいはローカルメ. 同期やロックは並列処理のオーバーヘッドとなるため,. モリの有効利用を行う技術を開発した.この技術を Sun. なるべく少なくするべきである.しかしながら,本来必. Microsystems の共有メモリ型マルチプロセッサである Ultra80 上で評価した結果,科学技術計算のベンチマー クである SPEC CFP95 において Sun の自動並列化コンパ. ☆2. 共有メモリ型ではメモリ上に同期用のフラグ変数を用意して同 期を行うが,結局はハードウェアがプロセッサ間通信として処 理する.. イラ Forte6 に対して 1.1 倍から 5.1 倍の性能を得ること ができた .この成果は筆者らが開発している自動並列 3). 化コンパイラにより得られたものであるが,手動で並列 IPSJ Magazine Vol.47 No.1 Jan. 2006. 21.
(6) 特. 集 マルチコアにおけるソフトウェア. 取り消し実行をやり直す.図 -6 の例では,atomic 以降 の「sum:=sum+a[i]」が 1 つのトランザクションとなる.. 文献 4)より引用. 従来の共有メモリ型のモデルでは sum の参照や代入は 図 -6 Fortress におけるループの例. 各スレッドが排他的に行う必要があるが,その場合ロッ クによる排他制御のオーバーヘッドや sum への書き込 みが並列に行えないため,並列処理の効果が得られない.. 化プログラムを開発する場合でもデータの配置を改善す. 一方,Transactional memory model では,スレッド末尾. ることにより大きな性能向上を得ることができる.. のコミットの順番さえ保証できればよいので,それ以前 の処理は並列に行うことができる.なお,Fortress の言. マルチコアプログラミングの今後. 語仕様では,このループでスレッド固有の一時変数が暗. 本稿では,これまでに共有メモリ型マルチプロセッサ. 返しによる部分和が計算される.その後,部分和を共有. と分散メモリ型マルチプロセッサにおけるプログラミン. メモリにコミットしそれらを総和して sum が求められ. グを,それぞれの構成における既存の代表的な API であ. るため,このループの並列性を最大限利用することがで. る OpenMP と MPI を用いて説明してきた.. きる.. OpenMP や MPI 以 外 に も, こ れ ま で に さ ま ざ ま な. 次に X10 を紹介する.X10 は Fortress と同様にオブ. 並 列 化 API や 並 列 化 言 語 が 提 案 さ れ て き た. 近 年 も. ジェクト指向をサポートしている.言語仕様は Java を. マルチコアやマルチプロセッサシステムの普及によ. 手本としているが,新規のプログラミング言語である.. り,いくつかの並列化言語が提案されている.本章で. X10 は分散メモリ型マルチプロセッサ上のプログラムの. は,それらの言語から米国 DARPA の High Productivity. 記述を想定しており,そのメモリモデルとして複数のロ. Computer System(HPCS)プロジェクトの一環として. ーカルアドレスペースに区切られたグローバルアドレス. 並列プログラム生産性向上のために提案されている Sun. スペースを持つ,分散共有型のメモリモデルを採用して. Microsystems Fortress,IBM X10,Cray Chapel の 3 つの並. いる(Partitioned Global Address Space: PGAS).各ロー. 列言語のうち,Fortress と X10 を紹介する.. カルアドレススペースが分散メモリ型マルチプロセッ. Fortress はオブジェクト指向の並列化言語であり特徴. サの各ノードに対応する.また配列を各ローカルアド. としては,基本型以外の型や演算はライブラリとして. レススペースにどのように配置するか指定することも. 提供し性能のチューニングはこのライブラリの段階で. できる.X10 でも並列ループを指定することができるが,. 行うこと,また演算子に Unicode を利用することで数. Fortress のような Transactional memory model は想定し. 式を自然な方法で記述できることが挙げられる. 黙のうちに確保され,その変数にいくつかのループ繰り. ☆3. .並. ていない.. 列処理のモデルとしては,共有メモリ型のモデルを採. Fortress と X10 のいずれも,ターゲットとしているの. 用している.並列化に関する Fortress の大きな特徴とし. はハイパフォーマンスコンピューティングの分野であ. ては,ループ処理が標準で並列実行を行うこと,およ. り,組み込み系でこれらに類するようなものは見られな. び Transactional memory model. を採用していることで. い.組み込み系の Cell や FR1000 のようなマルチコアプ. あ る.Transactional memory model を 用 い た Fortress の. ロセッサのように,共有主記憶と各プロセッサコア上の. ループの例を図 -6 に示す.Transactional memory model. ローカルメモリを持ったり,ローカルメモリが各プロセ. ではスレッドを 1 つのトランザクションと扱い,ある. ッサからアクセスできる分散共有メモリとしても利用で. スレッドで書き換えられたデータはスレッド固有のバッ. きる OSCAR タイプ. ファに一時的に保存され,スレッドの末尾のコミットに. り,1 コア上に汎用コアと DSP(Digital Signal Processor). よって共有メモリ上に書き込まれる.複数のスレッド間. や DRP(Dynamic Reconfigurable Processor)等の異なる. で,コミットの際にその順番がオリジナルの逐次プログ. コアを集積したヘテロジニアスなコア構成を考えると,. ラムの順番を違反したことが判明したとき,違反した. OpenMP,MPI,Fortress,および X10 のいずれも十分と. スレッドはコミットを行わずバッファ中の一時記憶を. はいえない.これらのプロセッサの能力を十分に引き出. 5). 7) ,8). のマルチプロセッサであった. し,ソフトウェアの生産性を向上させ,並列化,メモリ ☆3. 22. ASCII のみでプログラムを記述することも可能である.. 47 巻 1 号 情報処理 2006 年 1 月. 管理,クロック周波数・電圧・電源遮断制御などをサポ ートする新たな API の開発が望まれるとともに,このよ.
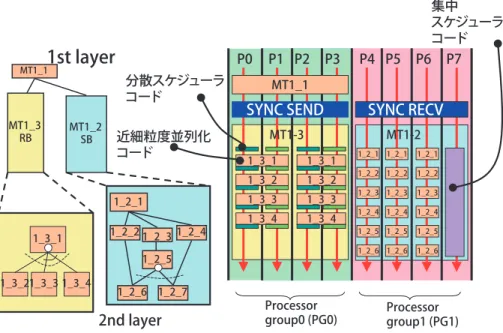
(7) 2.マルチコアにおけるプログラミング. 集中 スケジューラ コード. 1st layer. MT1_1. MT1_3 RB. P0 分散スケジューラ コード. MT1_2 SB. 近細粒度並列化 コード. 1_2_2 1_2_3 1_2_4. P3. SYNC SEND. 1_2_6. 1_2_7. P7. MT1-2. 1_3_1. 1_3_1. 1_3_2. 1_3_2. 1_3_4. 1_3_3 1_3_4. Processor group0 (PG0). 2nd layer. P6. SYNC RECV. MT1-3. 1_2_5 1_3_21_3_3 1_3_4. P4 P5. MT1_1. 1_3_3. 1_2_1 1_3_1. P1 P2. 1_2_1. 1_2_1. 1_2_1. 1_2_2. 1_2_2. 1_2_2. 1_2_3. 1_2_3. 1_2_3. 1_2_4. 1_2_4. 1_2_4. 1_2_5. 1_2_5. 1_2_5. 1_2_6. 1_2_6. 1_2_6. Processor group1 (PG1). 図 -7 MPMD(Multiple Program Multiple Data)方式. うな API で並列化されたプログラムを自動生成するよう. 型チップマルチプロセッサ技術”,NEDO“先進ヘテロ. な並列化コンパイラの開発が,大きな市場シェアを獲得. ジニアスマルチプロセッサ”プロジェクト,NEDO“リ. できるマルチコアプロセッサの必須条件になるであろう.. アルタイム情報家電用マルチコア”プロジェクトメンバ. また,プログラミングスタイルも従来の SPMD(Single. の皆様に厚く御礼申し上げます.. Program Multiple Data)方式だけでなく,タスクがスタ ティックにプロセッサに割り当てられる組み込み系アプ リケーションでは,従来自動並列化コンパイラ. 9). が生. 成していたような,各プロセッサに必要なタスクコード だけを生成しプログラムサイズを小さく抑えるとともに, 実効効率を高めることができる図 -7 の例に示すような MPMD(Multiple Program Multiple Data)方式の導入が 必要になると考えられる. 謝辞 本稿の技術的展開に有益なご議論をいただきま した,STARC プログラム研究“並列化コンパイラ協調. 参考文献 1)http://www.openmp.org/ 2)http://www-unix.mcs.anl.gov/mpi/ 3)石坂一久 他 : 配列間パディングを用いた粗粒度タスク間キャッシュ最 適化 , 情報処理学会論文誌 , Vol.45, No.4 (Apr. 2004). 4)Allen, E. et al.: The Fortress Specification, Sun Microsystems (July 2005). 5)Harris, T. et al.: Language Support for Lightweight Transactions, OOPSLA'03 (Oct. 2003). 6)Charles, P. et al.: X10: An Object-Oriented Approach to Non-Uniform Cluster Computing, OOPLSA'05 (Oct. 2005). 7)笠原博徳 他 : OSCAR(Optimally Scheduled Advanced Multiprocessor) のアーキテクチャ , 電子情報通信学会論文誌 , Vol.J71-D, No.8 (Aug. 1988). 8)木村啓二 他 : シングルチップマルチプロセッサ上での近細粒度並列 処理 , 情報処理学会論文誌 , Vol.40, No.5 (May. 1999). 9)笠原博徳 : 最先端の自動並列化コンパイラ技術 , 情報処理学会誌 , Vol.44, No.4, pp.384-392 (Apr. 2003). (平成 17 年 12 月 12 日受付). IPSJ Magazine Vol.47 No.1 Jan. 2006. 23.
(8)
図
関連したドキュメント
このように、このWの姿を捉えることを通して、「子どもが生き、自ら願いを形成し実現しよう
えて リア 会を設 したのです そして、 リア で 会を開 して、そこに 者を 込 ような仕 けをしました そして 会を必 開 して、オブザーバーにも必 の けをし ます
だけでなく, 「家賃だけでなくいろいろな面 に気をつけることが大切」など「生活全体を 考えて住居を選ぶ」ということに気づいた生
子どもたちが自由に遊ぶことのでき るエリア。UNOICHIを通して、大人 だけでなく子どもにも宇野港の魅力
以上の基準を仮に想定し得るが︑おそらくこの基準によっても︑小売市場事件は合憲と考えることができよう︒
今日のセミナーは、人生の最終ステージまで芸術の力 でイキイキと生き抜くことができる社会をどのようにつ
小・中学校における環境教育を通して、子供 たちに省エネなど環境に配慮した行動の実践 をさせることにより、CO 2
小学校における環境教育の中で、子供たちに家庭 における省エネなど環境に配慮した行動の実践を させることにより、CO 2
