統計学講義メモ(1)
:記述統計
高木真吾, 北海道大学
目 次
1 データの全体像を見る 1 1.1 全体像を把握する:ヒストグラム . . . 1 1.2 分布状態を比較する:ローレンツ曲線 . . . 3 2 データを要約する 8 2.1 データを代表する尺度:代表値 . . . 8 2.2 データの散らばりを示す尺度 . . . 9 2.2.1 データの基準化と応用例 . . . 11 2.3 ヒストグラムからの要約 . . . 12 3 二つの変数の間の関係を探る 13 3.1 共分散・相関係数 . . . 13 3.2 順位相関係数 . . . 141
データの全体像を見る
• データ:何らかの概念に対応する量的・質的表現 • 記述統計学:データを正しく効率的に読む方法論(データの要約・整理)1.1
全体像を把握する:ヒストグラム
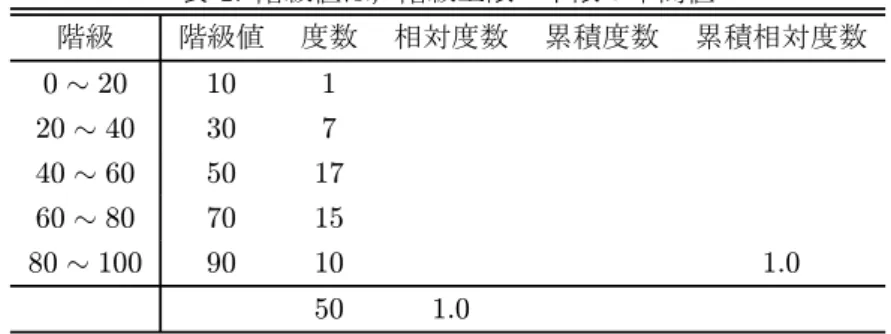
度数分布表・ヒストグラム, • 階級数・階級幅・階級値の決定 • 階級幅の異なるヒストグラムの描写 • オープンエンドとなっている上端・下端の処理 ローレンツ曲線・ジニ係数 • 同一概念に基づく二つのデータの分布状態の比較 • データの分布状態/集中の程度• データセット(標本の大きさ n): X1, X2, X3, . . . , Xn 1. 度数分布表の作成 (a) 階級数と階級幅(観測値のとりうる値を複数のクラスに分類する)の決定 方法1.目算で作成 方法2.自動で決定:スタージェス (Sturjes) の公式(標本数に応じて階級数 k を自動的に決める)1 k = 1 + log2n (b) A. 度数のカウント・B. 相対度数の計算 A. 各階級に属する観測値の個数を数える B. 標本の大きさが異なるケースでも比較可能なように標本の大きさで割る(全体で1になる) (c) 階級値の決定 方法1.各階級の上限と下限の中間値 方法2.階級内のデータの標本平均値 2. ヒストグラムの作成 • 度数分布表をグラフ化する • 階級幅が異なるときには注意が必要 • グラフの高さは,相対度数と階級幅から決まる. 注意点(1):各階級の相対度数はその階級が全体に対してどの程度貢献しているかを示している.各階級のヒ ストグラムの棒の面積も相対度数に比例する形で描写されなければならない.したがって階級幅が他の部分の 異なるときは棒の高さを調整してヒストグラムを描写しなければならない. 注意点(2):オープンエンドとなっている右端と左端の階級の扱い • 左端について,金額などのときは0を下限にすることが多い • 階級内の平均値が分かっているとき,それを利用する(以下の例を参照) • 適当に定める 例1:50 人の点数分布 • 階級数を 5,階級幅を 20 点 例2:30 人の年俸分布 • 階級は表のように定め,度数分布表を作成した. 1ほかにも多くの方法が知られている.例えば,標本標準偏差 s を用いて,k = 3.49 · ·n−1/3と決める方法や k ≥ (2n)1/3なる最小 の k を階級数とする方法もある.Sturjes の公式は,階級数 k で各階級に含まれる標本数が二項係数で近似できるような分布であるとき, 標本数と階級数の間に n = kX−1 i=0 ³k − 1 i ´ = 2k−1 ここから両辺の対数をとることで log2n = k− 1 となり公式を得る.
オープンエンドの処理方法としては, • 表 2 の例では,下限は0と分かっているのでその情報を用いる • 階級の中央の値が階級値になるように処理する,つまり次の関係を満たす x を求める. 5000 + x 2 = 16280 ⇒ x = 27560 例3:50 人の成績分布スタージェスの公式から 1 + log250≈ 6.6438 つまり階級数は6とすることが示唆されており,階級幅を6点刻みで設定した(上端はオープンエンド).階 級値は 35 と分かっているので上の例と同じように定めればよい.
1.2
分布状態を比較する:ローレンツ曲線
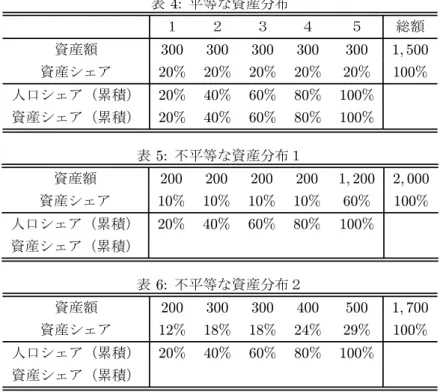
ローレンツ曲線は,各観測点が全体に対してどの程度貢献するかを求めることでそのデータの分布状態 (集中状態)を描写する. • データ:W1, W2, W3, . . . , Wn • これらは小さい方から並べられているものとする:W1≤ W2≤ W3≤ · · · ≤ Wn ローレンツ曲線は次のような手順で作成する. 1. 観測点について,全体が n 個あり,各個体が占めているシェアは Si = 1/n である.これを観測点シェ アと呼ぶことにする. 2. データの数値について みると,全体の大きさは W =Pni=1Wi であり,各観測点のシェアは Vi= Wi/W である.これをデータ値シェアと呼ぶことにする. 3. 最後にそれぞれのシェアの累積和を定義する. Xi= i X j=1 Sj,Yi= i X j=1 Vj i = 1, 2, . . . , n これらをそれぞれ観測点シェア累積和,およびデータ値シェア累積和と呼ぶことにする. 以上ふたつの累積和 {(Xi, Yi)}ni=1 を X − Y グラフにしたものがローレンツ曲線である.表 4, 5, 6 の資産分 布を例にこの曲線の意味を考える.ローレンツ曲線の考え方としては • 均等にデータが分布しているとき,「観測点シェア累積和」と「データ値シェア累積和」と等しく増加し ていくと考えられる. • 不均等に分布しているとき,最初は小さい貢献(シェア)しかしない観測点が並んでいるので,「観測点 シェア累積和」にくらべ「データ値シェア累積和」は緩やかにしか増加しない.逆に最後の方には貢献 の大きい(シェアが大きい)観測点が残っているので後者の方が急激に増加すると考えられる. 以上の結果より,ローレンツ曲線は分布状況が完全に均等なとき 45 度線になる(どの階層の人も等しい資産 総額に対する貢献しか持たないことを示している). ローレンツ曲線をグラフ化すると,表 1: 階級値は,階級上限・下限の中間値 階級 階級値 度数 相対度数 累積度数 累積相対度数 0∼ 20 10 1 20∼ 40 30 7 40∼ 60 50 17 60∼ 80 70 15 80∼ 100 90 10 1.0 50 1.0 ただし 0 ∼ 20 は 0 より大きく 20 以下と読むことにする. 表 2: 階級値は,階級内平均値 階級 階級値 度数 相対度数 累積度数 累積相対度数 1000 万円以下 (0∼ 1000) 625 6 2000 万円以下 (1000∼ 2000) 1550 10 3000 万円以下 (2000∼ 3000) 2633.3 3 4000 万円以下 (3000∼ 4000) 3500 1 5000 万円以下 (4000∼ 5000) 4540 5 5000 万円から上 (5000∼ x) 16280 5 1.0 30 1.0 表 3: 上端の階級値は階級内平均値 階級 階級値 度数 相対度数 累積度数 累積相対度数 0-5 2.5 10 6-11 8.5 20 12-17 14.5 9 18-23 20.5 5 24-29 26.5 4 30-x 35 2 1.0 50 1.0
表 4: 平等な資産分布 1 2 3 4 5 総額 資産額 300 300 300 300 300 1, 500 資産シェア 20% 20% 20% 20% 20% 100% 人口シェア(累積) 20% 40% 60% 80% 100% 資産シェア(累積) 20% 40% 60% 80% 100% 表 5: 不平等な資産分布1 資産額 200 200 200 200 1, 200 2, 000 資産シェア 10% 10% 10% 10% 60% 100% 人口シェア(累積) 20% 40% 60% 80% 100% 資産シェア(累積) 表 6: 不平等な資産分布2 資産額 200 300 300 400 500 1, 700 資産シェア 12% 18% 18% 24% 29% 100% 人口シェア(累積) 20% 40% 60% 80% 100% 資産シェア(累積) • 均等に保有している場合には 45 度線となり, • 一人に富が集中している場合には曲線が外に広がっている ことが分かる. ローレンツ曲線のひとつの問題点として,曲線が交差してしまうとき分布状態の比較ができない.例とし て,世界銀行の World Development Indicators には,表 1.2 のようなデータが掲載されている.この表を用い て国別ローレンツ曲線を描くと図 1 のようになる. 表 7: 所得階層別人口シェアと各階層が全体に占める所得シェア 人口シェア ∼ 10% 10%∼ 20% 20%∼ 40% 40%∼ 60% 60%∼ 80% 80%∼ 90% 90%∼ 100% India 0.035 0.046 0.116 0.150 0.193 0.126 0.335 Japan 0.048 0.058 0.142 0.176 0.220 0.140 0.217 China 0.024 0.035 0.102 0.151 0.222 0.162 0.304 U.S. 0.018 0.034 0.105 0.156 0.224 0.159 0.305 この例ではインドのローレンツ曲線と中国・アメリカのそれが交差しているので不平等の程度が判定でき ない.その場合の判定方法のひとつとしてジニ係数と呼ばれるひとつの尺度がある.この尺度はどの程度ロー レンツ曲線が 45 度線から乖離しているかを計測する.具体的には 45 度線とローレンツ曲線で囲む面積(の2 倍)として定義される.この定義から明らかなように,ジニ係数の性質として • 完全に平等=ローレンツ曲線が 45 度線=面積が0=ジニ係数が0
図 1: 国別ローレンツ曲線 • 不平等度大=ローレンツ曲線が 45 度線から乖離=面積が大=ジニ係数が0より大 • 完全に不平等2=ローレンツ曲線が 90 度線(軸に一致)=面積が1=ジニ係数が1 つまり,ジニ係数は0から1の間の値を取り,1に近いほど不平等の程度が大きい状態を指し示している. ジニ係数を求める一般的な公式を次の表のような形でデータが与えられている場合について考える.こ れらはローレンツ曲線を描く上で必要なものである.目的とする部分の面積は,45 度線で囲まれる三角形から 表 8: 所得階層別人口シェアと各階層が全体に占める所得シェア 観測点シェア S1 S2 · · · Sn データ値シェア V1 V2 · · · Vn データ値シェア累積和 Y1 Y2 · · · Yn ローレンツ曲線の外側の台形の総和を差し引いたものを2倍したものである.ローレンツ曲線の下部分にでき る台形の面積はそれぞれ (Yk−1+ Yk) 2 · Sk と与えられるので,ジニ係数は G = 2· ( 1 2 − n X k=1 (Yk−1+ Yk) 2 · Sk ) = 1− n X k=1 (Yk−1+ Yk)· Sk, Y0= 0. (1) と与えられる. 個別データが与えられている(あるいは観測点シェアが等しい間隔もほぼ同様の方法で計算できる)場合 には計算上便利な別の計算公式が存在している.元データを小さい順に W1≤ · · · ≤ Wn と並べ, Vk = Wk Pn i=1Wi = Wk n· ¯W, ¯ W = 1 n n X i=1 Wi 2完全に不平等という意味合いは十分たくさんの人がいて一人だけがすべての富を所有している状態を指している.
として各観測値のシェアを定義する.目的とする部分の面積は,45 度線で囲まれる三角形からローレンツ曲線 の外側の台形の総和を差し引いたものを2倍したものである.台形部分の面積の総和は n X k=1 {(n − k) + (n − k + 1)} 2 Vk である3のでジニ係数は以下のように表現できる. G = 2· ( 1 2− n X k=1 {(n − k) + (n − k + 1)} 2 Vk ) =n + 1 n − 2 n n X k=1 {n − k + 1} · Vk (2) = n + 1 n − 2 n· ¯W n X k=1 n− k + 1 n · Wk = 2 n2· ¯W n X k=1 k· Wk− n + 1 n (3) 他にも同値な表現は多く知られている4 表 4 について,式 (1) を用いてジニ係数を計算すると G = 1− {(0 + 0.2) · 0.2 + (0.2 + 0.4) · 0.2 + (0.4 + 0.6) · 0.2 + (0.6 + 0.8) · 0.2 + (0.8 + 1.0) · 0.2} = 1− (0.04 + 0.12 + 0.2 + 0.28 + 0.36) = 0 同様に計算すると表 5・表 6 についてそれぞれ約 0.400,0.165 となる(各自で確認してください).(3) 式を 用いて, 表 6 についてジニ係数を計算してみる.小さい方から順に 200, 300, 300, 400, 500 となっており,こ れらの平均は 340 なので G = 5 + 1 5 − 2 5· 340 µ 5 5· 200 + 4 5 · 300 + 3 5· 300 + 2 5 · 400 + 1 5· 500 ¶ = 0.16471· · · となり,上の結果と一致している(他の結果についても確認してください). 表 1.2 についても式 (1) から計算することができる.例えばインド (India ) について, G = 1− (0 + 0.035) · 0.10 − (0.035 + 0.081) · 0.10 −(0.081 + 0.197) · 0.20 − (0.197 + 0.347) · 0.20 − (0.347 + 0.540) · 0.20 −(0.540 + 0.666) · 0.10 − (0.666 + 1.00) · 0.10 = 0.3559
その他の国についても同様に Japan: 0.2398,China: 0.3889,U.S.: 0.3925 となる.先ほどの図でインド のローレンツ曲線と中国・アメリカの曲線が交差していたが,ジニ係数で見る限り,インドのそれの方が小さ い値をとっていることがわかる. 3シェアが均等に 1/n ずつ増加していくという性質を用いている. 4(3) 式と同値な表現として, G = 2¯ WCov(Wk, k/n) が計算機で利用しやすいものとして知られている.ただし,Cov は二次元データ {Wk, k/n}nk=1に関して標本共分散を計算したもので ある. また G = 1 n2W¯ n X i=1 n X j=1 | Wi− Wj| という表現も知られている.
2
データを要約する
データの要約 • データセットの代表値 — 各種の平均(算術平均,幾何平均,調和平均),分位点(パーセント点),最頻値(モード) — 「散らばりの尺度」(分散・レンジ) • データセットの散らばりの尺度 — 分散(標準偏差),レンジ(四分位レンジ)2.1
データを代表する尺度:代表値
大きさ n のデータセット {X1, X2, X3,· · · , Xn−1, Xn} が与えられている.このデータセットを『代表的 な値』で要約するとき,どのような尺度が考えられるであろうか.ひとつの考え方として, • データセットの代表=中心部分に関する情報を取り出すと考える. データセットの「中心」としては以下のようなものが考えられる. 標本平均(算術平均) 標本平均(算術平均)は最もよく知られた中心を示す尺度であり,非常に多くの理論的 利点5を持ち,以下のような状況では中心を示すのに適していることが多い. • 比較的均質で極端な値をとる観測点が存在していない • 異なる層が混じっていない 逆にこれらが満たされないときは中心の尺度として適切ではないことが多い. ¯ X = 1 n n X i=1 Xi (4) 幾何平均 比率に意味のある数値で,連続した時点間での伸び率(成長率)のデータなどに利用6. ¯ XG= n p X1· X2· X3· · · Xn−1· Xn= n v u u tYn i=1 Xi (5) 調和平均 逆数に意味のあるデータに利用.時速・仕事量などに利用. ¯ XH = à 1 n n X i=1 1 Xi !−1 (6) 5詳しくは標本理論のところで学ぶ. 6相加・相乗平均の関係より 1 n n X i=1 Xi≥ n v u u tYn i=1 Xi つまり算術平均は幾何平均を上回るか等しくなる.中央値(メディアン:median) 全体を小さい方の値から並べ,ちょうど50%のところにくる観測点の値7 最頻値(モード:mode) 最も高い頻度で観測される値9 例1.8人の年間所得がそれぞれ 210, 230, 250, 260, 290, 320, 340, 360 万円,平均所得は? ¯ x = 210 + 230 + 250 + 260 + 290 + 320 + 340 + 360 8 = 282.5 例2.8人の年間所得がそれぞれ 210, 230, 250, 290, 320, 340, 360, 1580 万円,平均所得は? ¯ x = 210 + 230 + 250 + 290 + 320 + 340 + 360 + 1580 8 = 447.5 例3.8人の年間所得がそれぞれ 210, 230, 250, 320, 360, 1290, 1340, 1580 万円,平均所得は? ¯ x = 210 + 230 + 250 + 320 + 360 + 1290 + 1340 + 1580 8 = 697.5 例4.人口について年率増加率が 1990 年から 2% 3% 4% 5% 1% であるとき,平均年率物価上昇率は? ¯ xG= 5 p (1.01)· (1.02) · (1.03) · (1.04) · (1.05) 例5.ある地点から目的地まで行き 60km/h,帰りが 40km/h で運転すると,行き帰りの平均時速は? ¯ xH = ½ 1 2 µ 1 60+ 1 40 ¶¾−1 例2や例3のように少数の異常な値が存在するときなどは,平均はデータセットの代表値としてあまり適切で はない. そこで「中央値」を中心の尺度と考えたとき,定義式から,少数の異常な値は全体的な傾向として中央値 に影響を与えることは少ないことが予想される. 先ほどの例2は,例1のデータをひとつだけ置き換えただけ であるが,平均が大きく変化するのに対して(282.5 7→ 447.5),中央値の変化は比較的小さい(255 7→ 285).
2.2
データの散らばりを示す尺度
データが対称に分布しているとき,中心を示す尺度(平均,中央値,モードなど)が比較的近い値を示す 傾向がある.しかし三つのデータセット(平均=中央値=最頻値=5) • {0, 3, 3, 5, 5, 5, 5, 7, 7, 10} • {0, 1, 2, 3, 5, 5, 7, 8, 9, 10} 7まずデータセットを小さい順に並べ替え Y (1)≤ Y(2)≤ Y(3)≤ · · · ≤ Y(n−1)≤ Y(n),この中心の値をとる8.つまり • n が奇数のとき M = Y((n+1)/2) • n が偶数のとき M =Y(n/2)+ Y(n/2+1) 2 とすることが多い. 9典型的な観測値という意味で,最頻値(モード:mode):観測値の中で最も頻度が高い値を利用することがある.容易に想像できる ようにこの尺度は比較的大きなデータセットでない限りあまり意味を持たない.• {3, 4, 4, 5, 5, 5, 5, 6, 6, 7} は明らかに異なる分布状態を示している.違いを見るためにデータの「散らばり」に注目する.データの散ら ばりを示す尺度としては, • 分散 • 範囲(レンジ),4分位レンジ などが知られている. どの程度散らばっているかを確認するには, • 各観測点に関して平均点=中心(重心)からの偏差に注目する. • 観測値 Yiの偏差:Yi− ¯Y この偏差の累積がどの程度の大きさになるかが散らばりの尺度になりそうであるが,偏差の総和は0になる10の であまり参考にならない.しかしながら • 2乗偏差:|Yi− ¯Y|2 • 絶対偏差:|Yi− ¯Y| について総和をとることが尺度になり得るが,ここでは平均との理論的関連性や数学的扱いやすさの観点から 2乗偏差に焦点を当てる. 分散 各観測点の2乗偏差の平均値:平均的にどの程度中心から離れているかを測る尺度11. 定義式12: S2= 1 n n X i=1 (Yi− ¯Y )2 (7) 標準偏差 分散の平方根 S =√S2 (注意点)作成方法からも明らかであるが,分散(標準偏差)はある種の平均であるから,平均が意味を持た ない場合には同様に意味を持たないし,少数の極端な値に非常に敏感に反応してしまう欠点を持つ.上の例で 分散の値を計算するとそれぞれ 6.6,10.8,1.2 となる13. より直接的なデータの散らばりの尺度として • 範囲(レンジ:range):データに含まれている最大値と最小値の差 • 4分位範囲(4分位レンジ)とは, 25% 点と 75% 点の間のレンジ 10各自で確認してください. 11偏差の2乗をとっていることによって,絶対偏差が1よりも小さいときにはより小さく,1より大きいときにはより大きく乖離の程 度を評価している.つまり近い部分と遠い部分について1を基準にして,メリハリをつけ,より強調した形に変換している. 12この定義式は n で除しているが n − 1 で割ると定義することもある.これは後に学ぶ推測統計での考え方からすると自然な調整であ るが,ここでは2乗偏差の平均値という見方を強調するため n で除しておく. 13直接公式通りに計算することもできるが S2=1 n n X i=1 (Yi− ¯Y )2= 1 n n X i=1 Yi2− ¯Y2 つまり[二乗の平均]-[平均の二乗]としても計算可能.
が用いられることがある.中央値と同様に4分位範囲(4分位レンジ)は少数の異常値が含まれていても大き く変動することがない(異常値に対して頑健/ロバストである).したがって「頑健な標準偏差」として 標準偏差 = 4分位範囲 1.35 を用いることもある14. 2.2.1 データの基準化と応用例 • データセットの「中心」と「散らばり」を統一することで複数のデータセットを比較することができる 複数のデータセットを比較する手段として,ローレンツ曲線やジニ係数による比較について先述したが,デー タセットの特性値である平均や分散を用いて,同一の「中心」と「散らばり」持つようにデータセットを変換 するという方法も考えられる. 命題 2.1 (データの基準化). データセット Y1, Y2,· · · , Yn の標本平均,標本分散を ¯Y ,SY2(標準偏差 SY) とする.数値 μ,σ を用いて Xi= μ + σ· Yi− ¯Y SY , i = 1, 2, . . . , n とすると,変換されたデータセット X1, X2,· · · , Xn の標本平均 ¯X,標本分散 SX2 は以下の通り. ¯ X = μ, SX2 = σ2 証明は容易なので省略する15. 例としては,二回行った学力考査で問題の難易度が異なるため,受験者の学力の分布状態自体はそれほど 変化していないはずなのに点数の分布状況が大きく異なることがありうる.そのとき素点を用いるのではなく, 中心位置と散らばりの程度で調整した基準得点を用いることがある.つまりデータが Y1, Y2,· · · , Yn となって いるとき,上記の μ = 50,σ = 10 としたものが偏差値と呼ばれるものである. このような操作の含意は,対象となっている集団の点数化できる学力がほぼ正規分布16といわれる分布に 近いとき,偏差値20から80の間でほとんどすべての人をカバーする.また 14この関係は標準正規分布に関する議論から導いたものである. 15以下のように確認できる. ¯ X = 1 n n X i=1 Xi= μ + 1 n n X i=1 σ·Yi− ¯Y SY = μ + 1 SY σ· à 1 n n X i=1 Yi− 1 n n X i=1 ¯ Y ! = μ + σ· 1 SY ¡¯ Y − ¯Y¢= μ また ¯X = μ の結果を用いると, SX2 = 1 n n X i=1 (Xi− ¯X)2= 1 n n X i=1 µ σ·Yi− ¯Y SY − μ ¶2 = σ 2 S2 Y à 1 n n X i=1 (Yi− ¯Y )2 ! = σ 2 S2 Y S2Y = σ2 16これについては後述.
• 偏差値 65 以上(35 以下)は,ほぼ7% • 偏差値 55 から 65(35 から 45)(35 以下)は,ほぼ24% • 偏差値 45 から 55 は,ほぼ38% となることも計算できる.これらの数値は偶然の結果ではなく,相対評価の成績と関連している.通常5段階 評価での相対評価を行うときには成績1(5):7%,成績2(4):24%,成績3:38%という割合にな るよう設定されることが多い. ここでの議論は点数化できる学力が正規分布に近いことを前提にしているので,実際に検査を実施した ときその分布が極端に正規分布から離れているとき,偏差値が100を超えたり負の値になることも原理的に は起こりうる. ウェクスラーにより考案された知能指数(偏差値知能指数:DIQ)も基準化の応用例である.同年代の人 たちにある種の検査を実施し,その結果から平均( ¯Y )・分散(S2 Y)を得たとき,各個人のスコアを DIQ = 100 + 15·Yi− ¯Y SY つまり偏差値とは異なり,中心が 100,散らばりの程度が 152となるように調整されている.これによって 79 から 130 の間に約 95% の人が含まれる(ただし知能指数にはさまざまな定義がある).
2.3
ヒストグラムからの要約
あるデータセット {Xi}ni=1 から作成した度数分布表が次のような形で与えられているものとする.この 表 9: 度数分布表 階級 階級値 度数 相対度数17 A1 a1 n1 r1 A2 a2 n2 r2 A3 a3 n3 r3 .. . ... ... ... AK−1 aK−1 nK−1 rK−1 AK aK nK rK n =PKk=1nk 1.0 =PKk=1rk とき平均・分散などはこの度数分布表から(近似的に)計算することができる.平均は ¯ X = 1 n n X i=1 Xi ˆ X = 1 n n X k=1 ak· nk= n X k=1 ak· rk ただし,代表値が階級内の平均値となっているときには二つの目近似的に等しいというところが厳密に等しく なる( ¯X = ˆX).同様に考えて分散については S2X= 1 n n X k=1 (ak− ˆX)2· nk= n X k=1 (ak− ˆX)2· rkこれは必ずしも元のデータから計算したものと等しくはならない.また中央値や最頻値についても同様に考え ることができる.
3
二つの変数の間の関係を探る
3.1
共分散・相関係数
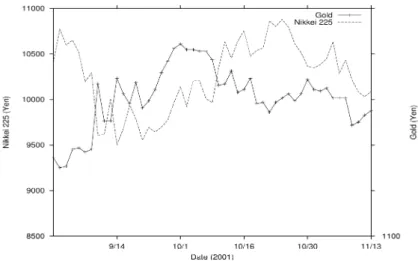
変数間の関係を示す尺度 • 二つの変数の散らばりの傾向とその大きさの程度を示す尺度:共分散 • 二つの変数の散らばりの傾向を示す尺度: — 量的データ:相関係数・偏相関係数 — 質的データ:順位相関係数 二つの変数を含むデータセット(二次元データ)が与えられているものとする. {X1, X2, X3,· · · , Xn−1, Xn} {Y1, Y2, Y3,· · · , Yn−1, Yn} 二つの変数に関するデータの散らばり (X − Y 平面に描いた散布図上での点の散らばり方) の大きさと関係の 方向性を示す尺度として,共分散を定義することができる. SXY = 1 n n X i=1 (Xi− ¯X)(Yi− ¯Y ) = 1 n n X i=1 XiYi− ¯X ¯Y (8) 共分散は,その符合と大きさで評価される.X を基準にして考えると, • 共分散が正の値:X と Y が右肩上がりの関係を持つ • 共分散が負の値:X と Y が右肩下がりの関係を持つ また大きさについては分散と同様に散らばりの程度を示している.この大きさを基準化し,二つの変数の関係 だけに注目した尺度として相関係数がある.相関係数は二つの変数の関連の強さを示し,特に正の値を持つと き,二つの変数が右肩上がりの直線に沿って散布している関係にあり,負の値を持つとき,二つの変数が右肩 下がりの直線に沿って散布している状態にあることを示す尺度となっている.その定義式は R = pSXY S2 X· SY2 (9) である.相関係数は常に-1と1の間の値を取り,0に近い状態は無関係に分布していることを示す. 例として図のような金価格と日経平均株価の時系列データ(2001 年 9 月 1 日から 11 月 14 日までの観測 値 50)を考える.『有事の金』というように,世界経済全体に影響を持つであろう 9 月 11 日のニューヨークで の大規模な事件の後,株価の下落と金価格の急上昇が観測された.これら二つの系列について相関係数を求め たところ,−0.294 という値になり,あまり大きくはないものの負の相関関係が観測される.図 2: 金価格と日経平均株価の関係 表 10: 二つのデータセットにおける各観測点の順位 データセット A RA 1 RA2 · · · RAn−1 RAn データセット B RB 1 RB2 · · · RBn−1 RBn