機械学習を用いた量子状態異常検知
* IBM東京基礎研究所原聡
$\dagger$ Satoshi Hara IBM Research —Tokyo
概要 精緻な処理が必要となる量子情報処理において量子系の状態をあらわす密度行列の異常の 検知は重要な課題である.本稿では機械学習を用いた密度行列の異常検知手法\mathrm{E}\mathrm{D}^{3} を紹 介する.観測された密度行列は一般に統計的なゆらぎを含むが, \mathrm{E}\mathrm{D}^{3} を用いることでそ のようなゆらぎから異常な変化を抽出することができる.シミュレーション及び実データ 実験において, \mathrm{E}\mathrm{D}^{3} が平均行列を使った単純な手法よりも高い精度を達成することを確 認した. \mathrm{E}\mathrm{D}^{3} は密度行列の異常が問題となる多くの局面において有用な解決策となると 考えている.1
はじめに
精緻な処理が必要となる量子情報処理では所望の量子状態からのずれ,すなわち異常の検出 が重要な課題である.しかしながら,異常の検知は量子系が持つ本質的なゆらぎのために困難 な課題の一つでもある.通常,量子系の状態を表現する密度行列は量子トモグラフィ-[2]
を 用いて推定される.この際,実験で得られる観測の総数は限られているために推定された密度 行列には統計的なゆらぎが生じる.この統計的なゆらぎと量子系の変化とを区別することが異 常検知における技術的な課題である.本稿では機械学習を用いて密度行列の異常検知を行う方法
\mathrm{E}\mathrm{D}^{3}
(Erroneous
DeviationDetector forDensity
matrices)
[1]
を紹介する. \mathrm{E}\mathrm{D}^{3} は密度行列の各要素の絶対値が変化するような量子系の異常を検知する手法である。このような異常にはデコヒーレンスなど実用上 重要な例が数多く含まれる.量子もつれ光子対の量子トモグラフィーにおいて \mathrm{E}\mathrm{D}^{3} と単純な 手法とを比較したところ,シミュレーション・実験データの両方で異常検知性能の大きな向上 が見られた. \mathrm{E}\mathrm{D}^{3} は密度行列を扱う問題には全て適用できるため,量子光学系に限らず超伝 * 本研究はブリストル大学の小野貴史氏,京都大学の竹内繁樹氏,岡本亮氏,及び大阪大学の鷲尾隆氏との共同 研究である [1].
導回路やイオントラップを用いた系にも適用できる.このため,
\mathrm{E}\mathrm{D}^{3}
は密度行列の異常が問 題となる多くの局面において有用な解決策となると考えている.2
密度行列の異常検知手法
量子トモグラフィーにより K個の観測密度行列 \hat{p}_{1}, \hat{ $\rho$}_{2},...
,\hat{ $\rho$}_{K} が得られているとする.以
下ではk番目の観測密度行列の
(i, j)
要素の絶対値を|\hat{ $\rho$}_{k,i-}\cdot|
とし,これら絶対値を要素として 持つ観測密度行列を|\hat{ $\rho$}_{k}|
\in \mathbb{R}d\timesá と表記する.本稿では,これら K個の絶対値の観測密度行列
|\hat{ $\rho$}_{1}|, |\hat{ $\rho$}_{2}|
,...,
|\hat{ $\rho$}_{K}|
から異常な行列のインデックス集合S\subseteq\{1, 2, . . . , K\}
を探す問題を対象とする.ただし,異常行列のインデックス集合Sの補集合S^{\mathrm{c}}においては行列
|\hat{ $\rho$}_{k^{J}}|(k'\in S^{\mathrm{c}})
は全て正常であるとし,また異常行列はK個の行列のごく一部,つまり
|S|\ll K
であると仮 定する.このような問題は機械学習において異常検知や外れ値検知として知られている[3].
異常検知を最も直接的に実現する方法は,計測された密度行列を正しい密度行列と比較す ることである.量子トモグラフィー装置を物理モデルに基づいて表現することができれば,そ の物理モデルから正しい密度行列を計算することができる.そしてその 正しい密度行列 と各観測密度行列がどの程度異なるかを評価することで異常な行列を見つることができる.このためには量子トモグラフィー装置内の光路に関する正確なパラメータを用いて物理モデルを
計算する必要がある.しかし,現実的には実験装置の正確なパラメー\check{}タを知ることは困難であり、その近似値を用いざるをえない.つまり,近似的なパラメータから計算された正しい密
度行列は,量子トモグラフィーにより実際に得られる観測密度行列とは必ずしも一致しない.
そのため、以下では物理モデルを仮定せず、統計的な手法を用いて異常検知を行うことを考 える。 2.1平均行列を使う手法 (平均値法)
物理モデルを用いずに正しい密度行列を観測密度行列から近似的に表現することを考える. 最も単純な方法の一つとしてK個の観測密度行列の平均値を使う方法が考えられる.|\displaystyle \overline{p}|=\frac{1}{K}\sum_{k=1}^{K}|\hat{ $\rho$}_{k}|.
K 個の観測密度行列のうち大半は正常な行列だと仮定しているため,この平均行列は正し
い密度行列の近似値として使うことができる.そして,各行列のこの平均行列からの偏差
醸
=|\hat{ $\rho$}_{k}|-|\overline{ $\rho$}_{k}|
に基づいて,異常の度合いを評価する.ここでは量子力学的な差異を測る一般的な方法としてトレース距離
[4]
を用いる.ここで,
\Vert\cdot\Vert_{\mathrm{t}\mathrm{r}}
は行列の特異値の和をあらわしており トレースノルムと呼ばれる.計算された 亀が一定値以上大きければ,密度行列は正しい密度行列からの乖離が大きい,つまり異常だと 判定できる. 平均行列を使う方法は単純で直感的にもわかりやすいが,問題点として平均行列|\overline{ $\rho$}_{k}|
の計算 に数が少ないとは言え異常な行列が混入して偏りを生じさせていることがあげられる.この偏 りが異常検知の性能を低下させてしまう要因となる. 2.2機械学習を用いた異常検知手法 \mathrm{E}\mathrm{D}^{3}
[1]
k番目の絶対値の密度行列の真の値を|$\rho$_{k}|
とすると,これは正しい密度行列 $\theta$ とそこからの偏差 $\omega$_{k} を使って
|$\rho$_{k}|= $\theta$+$\omega$_{k}
と表現できる.また,観測密度行列|\hat{ $\rho$}_{k}|
はこの|$\rho$_{k}|
に観測に伴う統計的ゆらぎが加わったものと して解釈できる.このとき,正常な行列については正
しい密度行列 $\theta$からの偏差については $\omega$ k\approx 0 と想定できる.他方,異常な行列については
$\omega$_{k}\neq 0 となる.そのため,偏差の行列の集合
\{$\omega$_{1}, $\omega$_{2}, . . . , $\omega$_{K}\}
は多くが零行列であり,ごく一部に非零行列を含むスパースな構造を持つと仮定できる.このようにデータの背後にスパー
スな構造が隠れている場合には機械学習のスパース推定の技術が有効である
[5,
6,7].
そこで, \mathrm{E}\mathrm{D}^{3}では以下の正則化つきの最小二乗問題を解くことで,このスパースな偏差行列の集合
を推定する.
$\theta$,\displaystyle \{ $\omega$\}_{k=1}^{K}\min_{k}\frac{1}{2}\sum_{k=1}^{K}\Vert|\hat{p}_{k}|-( $\theta$+$\omega$_{k})\Vert_{\mathrm{F}}^{2}+ $\gamma$\sum_{k=1}^{K}\Vert s$\omega$_{k}\Vert_{\mathrm{F}}
.(2)
ここで
\Vert\cdot\Vert_{\mathrm{F}}
は行列のフロベニウスノルム, はアダマール積, $\gamma$は非負のパラメータである.また,行列s\in \mathbb{R}á\timesd は
s_{ij}=(\displaystyle \frac{1}{K}\sum_{k=1}^{K}\tilde{ $\omega$}_{k,ij}^{2})^{-1/2}
により定義される.式(2) の第一項はなるべく各観測密度行列
|\hat{ $\rho$}_{k}|
に近い $\theta$+$\omega$_{k} を推定す ること,第二項は行列の各要素の大きさを正規化したうえでできる限りスパースでありゼロに近い偏差行列の集合を推定することに対応する.最後に問題
(2)
を解くことによって得られる$\omega$_{k} から,式(1) と同じく トレース距離
e_{k}=\Vert$\omega$_{k\Vert \mathrm{t}\mathrm{r}}
を計算し, e_{k} が一定値以上大きければ異常と判断する.式(2)
による推定では, $\theta$ と $\omega$_{k} の同時推定により平均行列を使う場合に比べて正しい密度行列 $\theta$ の偏りが抑えられること,スパースな偏差行列を推定できることの2
点により,精度の高い異常検知が期待できる.
問題 (2) の各項は凸関数なので全体としても凸関数であり,各種凸最適化アルゴリズムに
図1 (a) 量子もつれ光子対の量子トモグラフィー装置,(b) 正常な密度行列の各要素の平
均のヒストグラム,(c) 異常な密度行列の各要素の平均のヒストグラム
(Alternating
DirectionMethodofMultipliers)
[8]
を用いた.このアルゴリズムは問題 (2) の構造を活用することで効率的に大域最適解を求めることができる.3
評価実験
\mathrm{E}\mathrm{D}^{3} と平均値法の性能比較実験を行った.実験では図1(\mathrm{a})
に概要を示した量子トモグラ フィー装置を用い,1個の観測密度行列を1000回の量子もつれ光子対入射の計数から得た. 観測を繰り返すことで,図1(\mathrm{b}) の正常な密度行列及び図1(c)
の異常な密度行列をそれぞれ複 数生成した.なお,各密度行列を計測した前後に装置のパラメータが変動していないことを可 能な限り確認して,極カ所望の密度行列が計測されるようにした.異常な密度行列では(1, 4)
及び(4, 1)
の非対角要素 (図中(HH, VV)
に相当) の値が0.421から0.339まで低下してい る.この異常状態は正常な場合よりも2光子間の量子もつれの程度が少ない状態である.本評 価実験では,実際の実験データ及び図1(\mathrm{a})
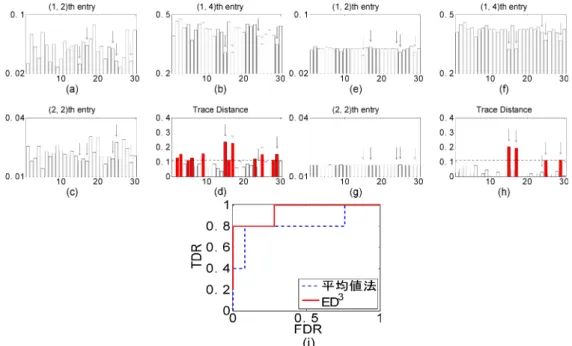
の実験系を模した計算機シミュレーションによる データの2種類を用意した.(1,2)\mathrm{t}\mathrm{h} entry O.03 (1_{2}2)\mathrm{t}\mathrm{h} entry
\downarrow 1
\downarrow 010(\mathrm{a})
20 302^{\mathrm{x}\uparrow$\sigma$^{3}}(2,2)\mathrm{t}\mathrm{h}
en 04 Taoe Distance 03\downarrow \downarrow
\downarrow \downarrow 02
0\mathrm{t}0 0 10 20 30 10 20 30 (\mathrm{c}\rangle (d) 1 0. 8
\mathrm{o}^{0.6}\mathrm{m}
\vdash 0.4 0. 20_{0}
\mathrm{J}\downarrow\downarrow 1 110(\mathrm{e})
20 302^{\mathrm{x}1$\sigma$^{3}(2_{\downarrow}2)\mathrm{t}\mathrm{h}}
entry \downarrow\downarrow\downarrow \downarrow 010(\mathrm{g})
20 30 0.5 1 FDR (i) 図2 シミュレーションデータの結果一例 : (\mathrm{a})-(\mathrm{d}) 観測行列の(1, 2), (1, 4)及び(2, 2) 要素と平均値法により計算されたトレース距離 (図中の矢印は異常行列),(\mathrm{e})-(\mathrm{h})\mathrm{E}\mathrm{D}^{3}
に より計算された行列の (1, 2), (1, 4)及び(2, 2)要素とトレース距離 (図中の矢印は異常行列 ), (i) 平均値法と \mathrm{E}\mathrm{D}^{3}のROC曲線
\mathrm{E}
ナ95%
90 85% 図3シミュレーションデータでの1000回の実験におけるAUCの分布 3.1結果 :シミュレーションデータ
シミュレーションデータでは正常な密度行列を25000個,異常な密度行列を5000個生成し た.これらを1000個の組にわけ,それぞれ正常行列25個,異常行列5個の計30個を1つの データセット (K=30) とした.これら1000個のデータセットそれぞれで平均値法と \mathrm{E}\mathrm{D}^{3}の性能を比較した.なお, \mathrm{E}\mathrm{D}^{3}のパラメータ $\gamma$は事前に10個のデータセットで複数の $\gamma$の値
図2にシミュレーションデータ及びその結果の一例を示す.図
2(\mathrm{a})-(\mathrm{c})
はある1つのデー タセットの30個の観測行列の(1, 2), (1, 4)
及び(2, 2)
要素である.また,図2(\mathrm{e})-(\mathrm{g})
は \mathrm{E}\mathrm{D}^{3} で推定された行列 $\theta$+$\omega$_{k}の(1, 2), (1, 4)
及び(2,
2)
要素である.矢印がついた項目が 5個の異常行列をあらわしている.観測行列の要素 (図2(\mathrm{a})-(\mathrm{c})
) と \mathrm{E}\mathrm{D}^{3} により推定された 値(図2(\mathrm{e})-(\mathrm{g})
) とを比較すると,元の行列にはあった統計的なゆらぎが \mathrm{E}\mathrm{D}^{3} により抑えら れ小数の変動だけが残っていることがわかる.特に(1, 4)
要素でこの傾向は顕著であり,矢印 のついた異常行列を除き, 他の正常行列では要素がほぼ一定の値になっている.つまり, \mathrm{E}\mathrm{D}^{3}により確かに期待した通りのスパースな偏差行列が得られていることがわかる.図2(d), (h)
はそれぞれ平均値法 \mathrm{E}\mathrm{D}^{3} から計算されたトレース距離である.トレース距離が0.04 (破線) を超える行列は赤で強調表示してある.図2\langle \mathrm{d})
では0.04前後の値を取っていた正常行列の多くが図2(h)
では 0になっている.他方,図2(d)
では他の行列に埋もれていた2つの異常行列が図2(h)
では埋もれずに非零のトレース距離として抽出されている.これは平均値法では検知できなかった2つの異常が\mathrm{E}\mathrm{D}^{3} ではきちんと検知できたことを示している.図
2(\mathrm{i})\ovalbox{\tt\small REJECT} $\lambda$ 2
つの手法それぞれについて ROC 曲線を描画したものである. \mathrm{E}\mathrm{D}^{3} のほうが曲線がより左上
にあり,平均値法よりも高い異常検知精度を達成できていることがわかる.
1000個のデータセットについて ROC 曲線下の面積AUC (Area Under the Curve)を
0% から100%で評価した結果が図3である.平均値法では約半数でしかAUC=95\% が達成
できなかったのに対し, \mathrm{E}\mathrm{D}^{3} では約7割でAUC=95\% が達成できた.この結果からも \mathrm{E}\mathrm{D}^{3}
の優位性が確認できる. 3.2
結果
:実験データ
実験データでは正常な密度行列を250個,異常な密度行列を50個生成した.ここから ランダムに正常な行列を25個,異常な行列を5個取り出し計30個を1つのデータセット (K=30) とした,これを1000回繰り返して1000個のデータセットを作り,それぞれで平 均値法と \mathrm{E}\mathrm{D}^{3} の性能を比較した.なお,シミュレーションデータのときと同様に \mathrm{E}\mathrm{D}^{3} のパラ メータ $\gamma$は事前に10個のデータセットで複数の $\gamma$ の値を試し,その結果が一番良かった値を 1000個のデータセット実験で使った. 図4(\mathrm{a})-(\mathrm{c})
に実験データの一例を示す.図4(\mathrm{a})-(\mathrm{c})
はある1つのデータセットの30個の 観測行列の(1, 2), (1, 4)
及び(2,
2)
要素である.シミュレーションデータ (図2(\mathrm{a})-(\mathrm{c})
) と 実験データ (図4(\mathrm{a})-(\mathrm{c})
) とを比較すると,どちらも同じ実験系を対象にしているにも関わら ず得られる密度行列が異なることがわかる.例えば,シミュレーションデータでは(2, 2)
要素 は 10^{-3} 前後と小さな値を取っているのに対し,実験データでは0.02前後の少し大きめの値 を取っている.これは実験系がシミュレーションの系とは異なること,つまり理想的な物理モ デルとは完全に一致しないことを示している.先にも述べたとおり,この結果は物理モデルを0. 4 0. 3 0. 2 0. 1 0 FDR (i) 図4 実験データの結果一例: (\mathrm{a})-(\mathrm{d}) 観測行列の (1, 2), (1, 4)及び(2, 2) 要素と平均値 法により計算されたトレース距離 (図中の矢印は異常行列),
(\mathrm{e})-(\mathrm{h})\mathrm{E}\mathrm{D}^{3}
により計算され た行列の (1, 2), (1, 4)及び(2, 2)要素とトレース距離 (図中の矢印は異常行列), (i) 平均 値法と \mathrm{E}\mathrm{D}^{3}のROC曲線\displaystyle \mathrm{E}\oint
95% 90% 85% 図5 実験データでの1000回の実験におけるAUCの分布 使った異常検知は真の実験パラメータが得られないためにうまくいかないことを示している.図
4(\mathrm{e})-(\mathrm{g})
は \mathrm{E}\mathrm{D}^{3} で推定された行列 $\theta$+$\omega$_{k}の(1, 2), (1,
4)
及び(2, 2)
要素である.図
4(\mathrm{a})-(\mathrm{c})
と比較すると,シミュレーションデータでの結果 (図2) と同様に,\mathrm{E}\mathrm{D}^{3}
により元データの統計的ゆらぎが抑えられ,異常に伴う変動が抽出できていることがわかる.図4(d),
(h)
はそれぞれ平均値法, \mathrm{E}\mathrm{D}^{3} から計算したトレース距離である.こちらもシミュレーション データの結果と同様に,平均値法では埋もれてしまっていた異常が\mathrm{E}\mathrm{D}^{3} により検知できてい ることがわかる.2つの手法の結果をROC曲線で比較したものが図4(i)
であり,ここからも \mathrm{E}\mathrm{D}^{3} の優位性がわかる.1000個のデータセットについて ROC 曲線下の面積AUC (Area Under the Curve)を
0% から100%で評価した結果が図5である.平均値法では約3割でしかAUC=95\%が達成
できなかったのに対し, \mathrm{E}\mathrm{D}^{3} では半数以上でAUC=95\% が達成できた.この結果も \mathrm{E}\mathrm{D}^{3} の
優位性を示している.
4
まとめ
本稿では機械学習を用いて密度行列の異常を検知する方法\mathrm{E}\mathrm{D}^{3}
について紹介した.\mathrm{E}\mathrm{D}^{3}
で は観測行列の偏差の集合がスパースになることに着目し,機械学習のスパース正則化の技術を 導入することで異常検知性能の向上を達成した.実際に, \mathrm{E}\mathrm{D}^{3} を使うことでシミュレーショ ンデータ,実験データの両方において平均値法よりも高い精度で異常が検知できることを確認 した. \mathrm{E}\mathrm{D}^{3} は量子情報と機械学習という異なる分野の組み合わせから生まれた新しい技術である. 今後,これらの領域の課題技術の交流が深まることでより良い・新しい技術が生み出される 可能性がある.例えば\mathrm{E}\mathrm{D}^{3} は密度行列の絶対値の変化に着目した技術であるが,これを位相 変化の検知まで広げることができればより多くの局面で異常検知が可能となる.また,密度行 列でなく物理観測系をモデル化してそこに機械学習の技術を導入することで,観測データから より直接的に異常を検知できるようになる可能性も考えられる.参考文献
[1]
Satoshi Hara, Takafumi Ono, Ryo Okamoto, TakashiWashio, and Shigeki Takeuchi.Anomaly detection inreconstructed quantum states using a machine‐learning tech‐
mque. PhysicalReview A,
89(2):022104
, 2014.[2]
Daniel FV James,PaulG Kwiat, WilliamJ Munro, and Andrew G White. Measurement ofqubits.
Physical
ReviewA,64(5):052312
, 2001.[3]
Victoria J Hodgeand JimAustin. A survey of outlierdetectionmethodologies. Arti‐ficial Intelligence Review,
22(2):85-126
, 2004.[4]
Michael A NielsenandIsaac L Chuang. Quantumcomputationandquantuminforma‐tion. Cambridgeuniversitypress, 2010.
[5]
Robert Tibshirani. Regression shrinkageand selection via the lasso. Journal oftheRoyalStatisticalSociety. Series B
(Methodological),
pages267‐288, 1996.[6]
Pradeep Ravikumar,JohnLafferty, HanLiu, andLarryWasserman. Sparse additivemodels. Journal ofthe
Royal
Statistical Society: Series B(Statistical Methodotogy),
[7]
Ah Jalali, Sujay Sanghavi, Chao Ruan, and Pradeep K Ravikumar. A dirty modelformulti‐task
learning.
In Advances in NeuralInformation ProcessingSystems,
pages964‐972, 2010.
[8]
Stephen Boyd, Neal Parikh, Eric Chu, Borja Peleato, and Jonathan Eckstein. Dis‐tributedoptimizationand statisticallearningviathealternatingdirection method of