1
経時データのモデリング
(1)
第
10回BioS継続勉強会
本日の内容
• G.Verbeke, and G.Molenberghs.著 “Linear
Mixed Models for Longitudinal Data”(Springer, 以下「テキスト」と呼びます) の3・6・9章のうち、モデ リングに関する部分をまとめます。 • 最後の方を除いて、誤差は独立と仮定しています。 誤差の系列相関は、次回扱います。 • 参考文献は、今回と次回の内容を合わせたもので す。
3
本日の内容
1. はじめに
(データの紹介・モデリングの基礎)
2. 3章の内容
3. 6章の内容
4. 9章の内容
5. まとめと参考文献
注意
• テキストは、記号の使い方等が結構いい加減です (確率変数とその実現値の使い分け、など)。 • 数理的な部分で、たまに間違い(誤植と呼ぶには大 きいもの)もあります。 • 本資料ではテキストより記号等を変更しています。 大抵は意図的に「修正」していますので、大体はこっ ちの方が正しいです(が、誤植は結構あるはずで す)。• LMMは線形混合効果モデル(Linear Mixed Model) の略です。
5
1. はじめに
はじめに
症例 の 個の時点 のデータが
1症例の経時変化
7
本書を通して大事なこと
• 目的は
探索解析
– 本当のモデルは分からないので、探索しましょう。 – 「使える」モデルをみつけるための「試行錯誤」の方 法論を考えましょう。Essentially, all models are wrong,
統計で最も重要なこと(私見)
• 全てのtoolは不完全である。 – プロットして目視・尤度比検定・情報量規準など、どれも 「決定的」な知識はくれない。 – 「これさえしておけば絶対大丈夫」という人は信用しては いけません。 • しかし、「不完全だからいい加減でよい」わけではな い。むしろ「不完全なので、一層注意深く観察・検討 しよう」という態度が重要。 – 最終モデルに対しても、「もしかしたら不完全かも」と思う こと。ただし、「現在の知識・情報・技術ではここが限界」と9
モデリングとは(私見)
• 「全く分からない」から入って、 「少しは分かったかも
」で終わるもの。 • 「完全に分かる」=「真のモデルが分かる」は(人間の 力では)あり得ない。 • 情報がさらに蓄積すれば、構築されるモデルは変わ りうる。 • あまり自信のない判断をせざるを得なくなるときもあ るが、その時は「ここで微妙な判断をした」ということ を忘れないことが重要。 → 自分のモデルを冷静に評価すること経時データのモデリング
• 決めなければいけないものがたくさんある
( ・ は9章までのテーマ) 平均構造 変量効果の 分散構造 どの要因を選ぶか? (3.8)11
今回のモデルの
固定効果、変量効果、誤差
固定効果: → に依存しない。 → 全症例・投与群など、複数の個人に 共通の部分。 変量効果: → に依存する。 → 被験者特有の部分。被験者内変動。 誤差 : → 固定効果・変量効果で説明できない データのばらつき。被験者間変動。症例は固定効果か変量効果か?
• どちらでも解析することは可能
– 症例内のデータの相関を考慮した解析を行うため 、変量効果を用いることが多い。 – テキストでも、変量効果として扱う。 – 「投与群」の固定効果を入れて、「投与群全員に共 通の値からのずれ」という形で扱う。13
モデリングで決めなければいけないこと
• どの変数が入るか?
– 時間、性別、・・・etc• どういう風に入るか?
– 時間の1次関数?2次関数? – 変数はそのままでOK? 変換してから入れる? – 誤差は独立?相関あり? – 変量効果同士の相関は?本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
• 詳しくは2.3.1節参照 • 前立腺癌は、アメリカでは男性の癌による死亡の2番 目の原因。治療にお金もかかる。 – 早期発見が重要。• PSA (prostate-specific antigen) がマーカーになる。 • PSAは正常細胞にも癌性前立腺細胞にも含まれる
15
本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
• BPH(benign prostatic hyperplasia, 良性前立腺過形成) でもPSAが大きくなる。
• Pearson et al. (1991)によると、 PSAの値だけで判断し た場合、最大60%のBPH患者が前立腺癌と誤診される。 → 現状では、PSAは前立腺癌のマーカーとして不十分。
前立腺癌だけを 検出する判断基準を導けるような モデルを作りたい(目的)。
Prostate Data 個人ごとのデータの推移(図2.3)
(横軸は診断前の時間:
右が過去
)
これを 区別する モデリングを したい17
本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
【仮説】
PSAの変化率を見れば、前立腺癌の早期発見ができるの ではないか? → PSAの数値だけではなくて経時変化の仕方まで よく見れば、よりよい前立腺癌のマーカーに なるのでは? → 時間に依存した部分に注目 単位時間あたりの変化:正しい意味での「率」本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
BLSA (Baltimore Longitudinal Study of Aging)のデータ → Pearson et al. (1994)参照。 • デザイン – 後ろ向きCase-Control研究。 – 凍結させた血清サンプルを使用 • 被験者の内訳は – 前立腺癌:18例 • 局所浸潤性癌(L/R Cancer):14例 • 転移性癌(Metastaic Cancer):4例
19
本章であつかう実データの紹介
(
Prostate Data:前立腺癌のデータ)
【選択基準】 1. 泌尿器科医によって、前立腺癌、BPHによる単純前立 腺摘出術、前立腺の病気はない、と診断されるまでに7 年以上の追跡調査のデータがある。 2. 病理学的診断により確認されている 3. 診断の前に前立腺の手術がないデザインの詳細
• 診断時の年齢、追跡期間は対照群、BPH群、前立 腺癌群でマッチングした。 • 50歳以上ではBPHの罹患率が高すぎるため、対照 群を見つけるのが難しかった。 – 対照群は、BPH群に比べて、初回来院や診断時の年齢 がだいぶ若い。 • 局所浸潤性癌と転移性癌を分けて考えた。 • PSAは指数関数的に増加するので、対数を考え、0 に近い値であることも考慮して、21
Prostate Data
人口統計学的データなど(表
2.3)
テキスト12P
国立がんセンターの
Webページ
(http://ganjoho.jp/public/cancer/data/prostate.html)
より
23
Prostate Data 個人ごとのデータの推移(図2.3)
(横軸は診断前の時間:
右が過去
)(再掲)
これを 区別する モデリングを したい テキスト13P より引用25
誤差とは?
• 誤差
というからには、
独立同分布
が基本で
は? 少なくとも独立性は欲しい。
– 「誤差が相関する」というのは不思議な表現。 – 「モデリングが不十分」と解釈するべきでは? • 誤差が相関がある場合、その要因を取り出して、 「変量効果によるモデリング」+「(独立同分布の)誤差」 となるまでモデリングを続けたい(理想)探索:モデルを段々複雑にしていく
(1)固定効果のみのモデル(固定効果以外は全て誤差) (2)変量効果をいくつか入れたモデル 相関構造が複雑 → 別の要因の影響では? を分解27
系列相関
(Serial Correlation)とは
• いくつかの変量効果を入れた後、
– 個人のデータの経時推移による相関が に 残っているか? – 残っているなら、その部分を「時間依存する要因」 として取り出したい。 – 逆に、とりあえず取り出して見て、「相関が無視で きるか」を考えてみては? 誤差 時間に依存する部分(変量効果) この部分の相関が 十分大きいかどうかをみるモデルの一般形
誤差:独立同分布 時点ごとの相関 → 系列相関 (10.1) 独立29
3章の内容
• 「手当たり次第に変数を入れたモデルで解析する」章 • 3章では、基本的なモデル構築と推定方法である「2段 階解析(2-stage analysis)」「LMMの解析」がテーマ。 – どの要因を固定効果にして、平均構造をどうするか、等は9 章に回す。 – とりあえず、変数は多めに入れる(本書は、「足りないよりは、 多すぎる方がいい」というスタンス)。31
3章の内容
(モデル選択の基本戦略
1)
2段階解析(3.2節) 1st step 個人ごとに異なる。 固定効果と思って推定。 を求める。 代入 1st stepの「固定効果」が2nd step では「変量効果」 になるので、厳密に言うと「変」。 → 推定せずに代入して一括で推定を行うのがLMM (3.1) 2nd step 全員に共通したパラメータ (3.2) 個人ごとの変動今回のモデルで用いる説明変数
• 時間 → グラフより時間依存は明らか。
• 群
→ 入れないと意味がない。
• 年齢 → 背景の偏りがあったため入れる。
• 時間と群・年齢の交互作用
本書では、これだけを入れている。
→ 本当に十分?
→ それでいて「変数は多めに入れましょう」
33
記号
被験者 の年齢: 群を表すダミー変数(その群のとき1, それ以外0) 対照群 : BPH群 : 局浸潤性癌群 : 転移性癌群 :Prostate Data 個人ごとのデータの推移(図2.3)
(横軸は診断前の時間:
右が過去
)
時間の
2次関数として
3章の復習:Prostate Dataの例
(
2段階解析)
1st step (3.5) 1人1人別々のパラメータ 2nd step (3.6) :全症例に共通の固定効果 :変量効果 → 変量効果は、1st stepの要因全ての内のみに存在353章の解析2:Prostate Dataの例
LMM(2nd stepに1st stepを代入)
(3.10)
変量効果はここだけ
37
行列で表現してみる
1症例の1時点分
行列で表現してみる
1症例分
とおくと、 1症例の全体をまとめたベクトル・行列表示は となる。ここで、分布の仮定を 誤差は独立同分布 9・10章ではここを 変える39
3章:手当たり次第に変数を入れたモデル
(誤差分布は独立同分布)
Proc mixed data = prostate covtest; class id group;
model lnpsa = group age group*time age*time
group* time2 age*time2 / noint solution; random intercept time time2 / type = un subject = id g; run; 変量効果の分散共分散行列には制限をつけない repeated statement 不要 時間の2乗:データセットで作る パラメータ6個
出力
1:固定効果(表5.1)
左がmodel based 右がrobust 不要? 下から 順に 検討 基本的な 固定効果は 残す41
出力
2:分散成分(表5.1)
◎ covtest オプションの検定はあまり信頼できない → 変量効果が必要かどうかの検定は6章で扱う テキスト49P より引用43
6章の内容
• 「不要な変数を減らす」章 • 3章では、手当たり次第変数を入れた。 – 6章で、不要な変数かどうかを判断する検定を考える。 • Wald検定 • F検定Overall の帰無仮説
(表
5.1の結果からあたりをつける)
(6.7) まとめて判断する。 → Wald検定とF検定の 2つを示す。45
6章の解析
余分な変数を減らすための検定(
2種類)
(6.5) (6.6) Overall の帰無仮説に対する検定統計量 自由度: 分子の自由度: , 分母の自由度:何種類かある不要な固定効果を消すための検定
Proc mixed data = prostate covtest; class id group;
model lnpsa = group age group*time age*time
group* time2 age*time2 F検定の分母の自由度
Satterthwaiteの方法
/ noint ddfm=satterth chisq solution; random intercept time time2 / type = un subject = id g; contrast ‘Final model’ age*time 1,
group*time 1 0 0 0, age*time2 1, group*time2 1 0 0 0, group*time2 0 1 0 0, group*time2 0 0 1 -1 / chisq; 不要な固定効果を 消すための検定
47
SASの出力
テキスト113P より引用 分子の自由度 F分布の分母の自由度 (Satterthwaite) 統計量間の関係 どちらも有意差なし判断の根拠と私見
• 帰無仮説が棄却されなかった場合、「減らす」
– 本当にこれでOK? 例数や入れる変数の数に依存す ると思うけど…。今回は例数も少ないですし…。 – 「有意差なし」=「帰無仮説が正しい」という解釈が、 臨床統計家としては大変心苦しかったり。 – では、「こうすれば大丈夫」という対案があるかと言 われると、困る。情報量規準等も、あくまで参考値。 – なので、「不十分な方法」ということを認識して、先に 進みましょう。最終モデルも「多分 True Model では49
6章の解析:Prostate Data
(3.10)式から検定で減らした結果
(6.8)
行列で表現してみる
1症例の1時点分
とおくと、(6.8)は以下のように書ける。 投与群 ⇒ ダミー変数 投与群ごとに違う 時間の1次関数 時間の2次関数51
行列で表現してみる
1症例分
とおくと、 1症例の全体をまとめたベクトル・行列表示は となる。ここで、分布の仮定を とする。 誤差は独立同分布 9・10章ではここを 変える (3章と見た目は全く同じ)6章:変数を絞ったモデル
(誤差分散は独立同分布)
Proc mixed data = prostate covtest; class id group;
model lnpsa = group age bph*time loccanc*time
metcanc*time2 cancer*time2 / noint solution; random intercept time time2 / type = un subject = id g;
run;
群を表す ダミー変数
前立腺癌の2群を併合した群を 表すダミー変数
53
表
6.1
seの 4倍以上 テキスト59P より引用55
変数を減らしたモデルで、
群ごとの違いをみる
BPH群と、局所浸潤性癌群の比較 (1)5年時点の の値の比較 表6.1の推定値を代入 局所浸潤性癌 BPH :10年(2)5年時点の の変化率の比較 時間に対する 変化が知りたい 「局所浸潤性癌群の方が、 右に行くほど減少が大きい」 ⇒ 右が過去なので、
57
表
6.2 SASの出力
テキスト61P より引用 ◎ PSAの経時変化は群間差がありそう。 → 継続的にデータ収集して変化をみるべき変量効果が必要かどうかの判断
【大問題】
帰無仮説が、パラメータ空間の端点 → 通常の漸近論が使えない。 → Wald統計量や尤度比検定統計量が、 帰無仮説のもとで漸近的に 分布に従わない。 変量効果の分散パラメータ に対して、 として検定を行う。59
【解決策】
尤度比検定統計量
の漸近的に従う分布を考える(MLはREMLでも可)。 → 分布の混合分布になることが多い。
(Self and Liang(1987), Stram and Lee (1994,1995) 参照)。
Prostate Data
パラメータ3つ。 → 通常なら自由度3の 分布 切片 の影響範囲 より、「時間の2乗の項が必要かどうか」をみる検定の 帰無仮説は61
Prostate Data(表6.5)
◎高次の項から考える。 「時間の2乗が必要か?」が知りたい → Model1 と Model2 の比較。 テキスト72P より引用自由度2と3の 分布を 1:1で混合した混合分布 かなり大きい。 明らかに帰無仮説は棄却。 → 時間の2乗の変量効果は必要。 テキスト73P より引用
63
結論
• 帰無仮説が棄却された • → 時間の2乗の項も必要っぽい。 (やっぱり少し心苦しい。ただ、棄却されたので、 そこまで大きな問題はなさそう?例数も少ないので、 「臨床的に意味がないほど小さい差」が検出された 可能性は低そう) → 変量効果は「切片項」「時間」「時間の2乗」 の3つが必要そう。これまでのまとめ
• 3章:手当たり次第要因を入れてモデルを構築 – 2段階解析 – LMM(誤差は独立) • 6章:不要っぽい変数を減らした – 固定効果:Wald検定・F検定の使用 – Overallの帰無仮説を使用して、「帰無仮説が棄却されな い」=「帰無仮説を採択」という方針 • 固定効果はだいぶ減った – 変量効果:尤度比検定 – ただし、通常の漸近論は使えず。検定統計量の漸近分布65
9章の内容
• モデル構築の一般論の章
• 9章では、
– 平均構造が正しそうかどうかはどうやって判断し たらよいか? – 変量効果はどのように選べばよいか? – 系列相関が必要かどうかの判断がテーマ。
67
方針
• Altham(1984)「変数が少なすぎると、モデルの仮定 が正しくないときに推測が正しくなくなる。一方、変 数が多すぎると、推定効率が下がり、標準誤差が大 きくなるだけである」 → 本書は「少なすぎるより多すぎる方がよい」 というスタンス。9章の仮定など
(モデル選択の基本戦略
2)
• モデル選択の基本戦略
固定効果は 平均構造に影響 仮定 しばらくの間は69
基本的なモデル構築の手順(図
9.1)
Prostate Dataでは 1周半 テキスト122P より引用固定効果と変量効果
• 相関構造のモデリングは、平均構造で説明しき
れない部分に対して行われる
– 用いる平均構造が変わると、相関構造のモデリン グも影響を受ける。
71
平均構造(固定効果)の検討
• 効果を多めに入れて「正しいモデリング」より
も「間違った場合の影響が少ないモデリング」
をする。
– 次に分散構造を検討し、その後変数を減らす、と いう方針。• 平均構造が「間違っていそうかどうか」は
残差
プロット
で検討する
誤差と残差の関係
y -1 0 1 2 3 4 5 6 7 8 9 x -2 -1 0 1 2 3 4 5 6 y -1 0 1 2 3 4 5 6 7 8 9 x -2 -1 0 1 2 3 4 5 6 真のモデル 推定したモデル 誤差 残差73 73
誤差と残差の関係
• 「誤差」と「残差」は違います。
– 誤差:真のモデルに入っているもの。未知。 – 残差:モデルを当てはめた後、データと推定値 (や予測値)とのズレ。既知。• 「残差は誤差の予測値」
と考えることができます。
– 誤差 の性質を検討して、「誤差は未知だから、代わ りに残差 でその性質を満たすかどうか検討する。 大体性質同じでしょ?」という論法が、本章でよく用い られます。(準備)平均構造の特定を正しくした場合と
誤った場合の残差プロット
無理矢理1次関数をあてはめる y -30 -20 -10 0 10 x 0 1 2 3 4 5 6 7 8 9 10 y -30 -20 -10 0 10 x 0 1 2 3 4 5 6 7 8 9 1075 誤って1次関数を当てはめた残差 → 0との大小に傾向がある x の値によらず、0 の周りに均等にばらついていれば、 平均構造の特定は大きく間違ってはいないかも。 残差 -20 -10 0 10 20 x 0 1 2 3 4 5 6 7 8 9 10 正しく2次関数を当てはめた残差 → xによらず均等にばらつく 残差 -4 -3 -2 -1 0 1 2 3 4 5 6 x 0 1 2 3 4 5 6 7 8 9 10
残差プロット
平均構造の検討:
Prostate Data
(図
9.2:図9.1の矢印1週目左)
77 確率変動する部分 = 平均構造以外の部分 = データから平均構造を 除いた部分 平均構造の特定が 正しければ不偏推定量 のプロットには、 分散構造の情報があるのでは? 推定
「平均構造の特定がおかしそう」
なことは、どうすれば分かる?
平均構造の特定が 正しくなければ、0の 不偏推定量でない プロットしてみて、時点ごとの残差の平均が 0 から大きく離れていれば、平均構造の79
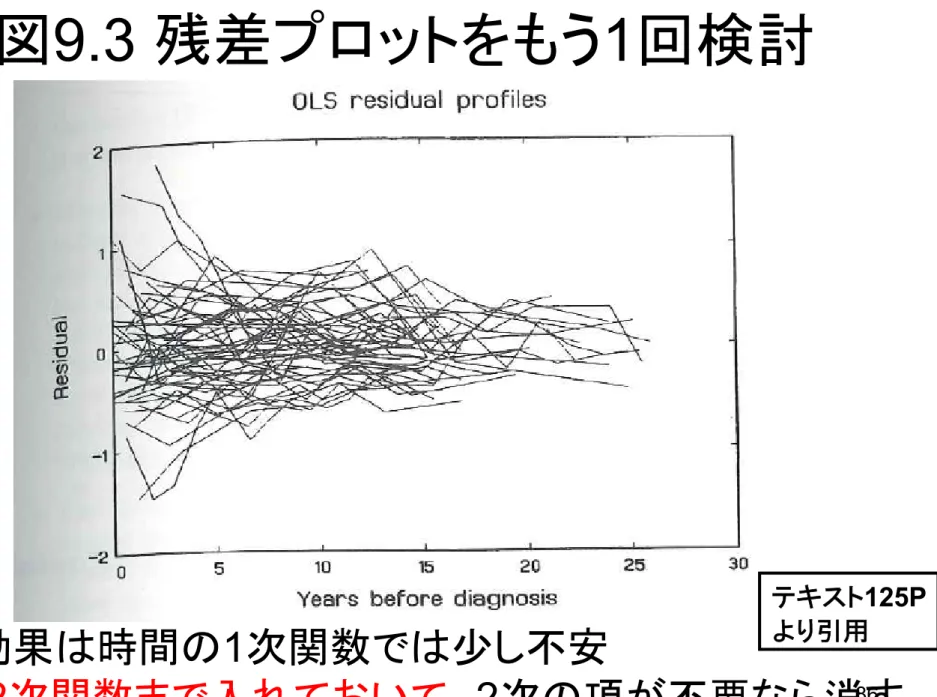
平均構造決定 ⇒
OLSで推定
⇒ 残差プロット
( の成分 )
どの時点でも残差が0を中心に均等 ⇒ 平均構造の特定は悪くないかも 個人差 → 変量切片 で減らせる 図9.3 テキスト125P より引用変量効果の検討
• 変量切片 – 個人のばらつきに対応 • 時間依存する変量効果 – 時点ごとの分散の変化に対応 ◎ばらつきの個人差・時間変化を検討する81
「分散が時間依存する」とは?
例)変量効果が時間の1次関数(のみ)の場合 とすると、 → 分散は時間の2次関数 → 時間に変量効果を入れれば、分散は 時間依存する。 時間の1次関数変量効果検討の際の
ガイドライン
(1)
①個人ごとの残差のプロファイルの回帰モデルを作る → 例)残差プロットが個人ごとに直線っぽいなら、 切片と傾きに変量効果を入れる。 ② を仮定するなら、変量効果は 「固定効果からのずれ」を表す。 → の各列は、 の列の1次結合で 表されることが必要。 → 2段階解析でモデルを作れば、この条件は83
変量効果検討の際の
ガイドライン
(2)
③Morrell, Pearson, and Brant (1997)によると、 には下意の項が全て入ったときのみ、上位の 項も入れるようにする。 → 2次の項を入れる場合は、切片と1次の項 は必ず入れる。 ④変量効果を入れる場合、理想は しかし、確認(推定した分散関数とSmoothingの 結果の比較)は必要。 誤差は 独立同分布
変量効果の検討
85
残差の
2乗( の各成分の2乗 )のプロット
と
Smoothing
残差の2乗が時間依存している → 時間依存する変量効果が必要では? 分散の次元 テキスト126P より引用図
9.3 残差プロットをもう1回検討
1次関数では少し不安
テキスト125P
87 分散の経時変化を 変量効果として取り出したい。 「誤差」は「時間によらず 等分散」が望ましい 今回のプロットからは、変量効果の追加を検討 → ガイドライン①より、時間の2次関数まで含める。 → ガイドライン③より、1次の項、切片項も含める。
分散関数の推定
(
3章のモデルをあてはめる)
とおくと、(3.10)のモデルは、
と書けた。これより、
89
3章のモデルの解析結果(表5.1)をもとにして、
図
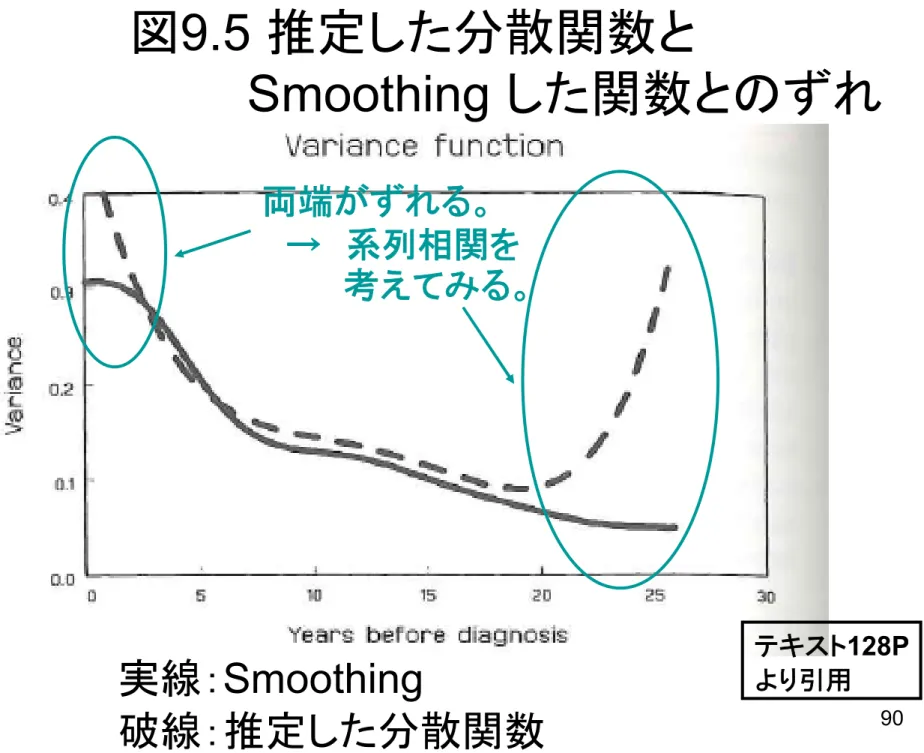
9.5 推定した分散関数と
Smoothing した関数とのずれ
両端がずれる。 → 系列相関を 考えてみる。 Smoothing テキスト128P91
両端のずれをどうにかしたい
⇒系列相関の追加
として、 を仮定し、 をモデリングする。 → 詳しくは10章。とりあえず、Gaussianを仮定。 誤差 系列相関 対角成分は1 検討済み まだ。 ⇒ ここを変更。 という仮定を 変えてみる。3章の手当たり次第に変数を入れたモデル
+系列相関をGaussianに指定(p129)
Proc mixed data = prostate covtest; class id group timeclss;
model lnpsa = group age group*time age*time
group*time2 age*time2 / noint solution; random intercept time time2 / type = un subject = id g; repeated timeclss / type = sp(gau)(time) local subject = id; run; 系列相関をGaussianに。 repeated statement で指定 カテゴリ変数 (中身は time と 誤差に も入れる
93
出力(表
9.1 :変量効果・誤差部分のみ)
REML推定
テキスト130P
分散関数の推定
(
3章のモデル+系列相関のモデルをあてはめる)
とおくと、(3.10)のモデルは、
と書けた。これより、
95
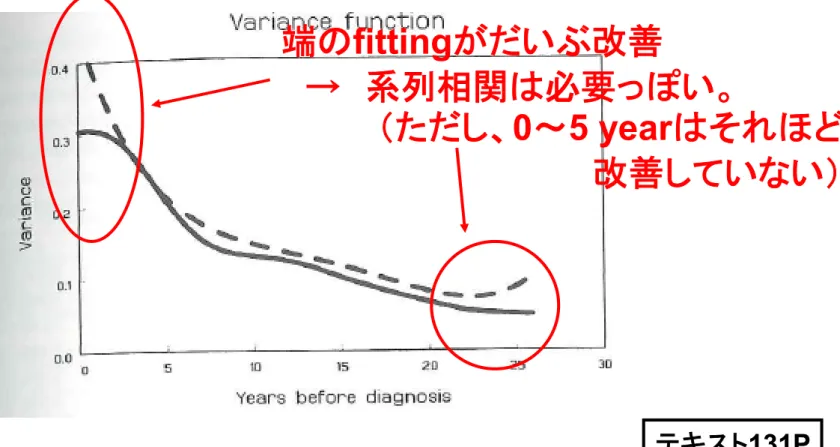
図
9.6 推定した分散関数とSmoothingとのずれ
Smoothing テキスト131P 端のfittingがだいぶ改善 → 系列相関は必要っぽい。 (ただし、0~5 yearはそれほど 改善していない)97
変数を絞る
(図
9.1の矢印2週目)
• 6章で検討した方法を用いて、減らすべき要因を減 らす。 • 本書ではきちんと書かれていない。が、 – SASの出力をみて、減らせそうなパラメータの目星をつけ る → Wald 検定か F 検定で検討。 – 平均構造が変わると、分散構造も影響を受けるので、もう 1回残差プロットをして、妥当性を検討する、などが必要。9章:変数を絞ったモデル
+ 系列相関をGaussianに指定(p133)
Proc mixed data = prostate covtest; class id group timeclss;
model lnpsa = group age bph*time loccanc*time
metcanc*time2 cancer*time2 / noint solution; random intercept time time2 / type = un subject = id g;
repeated timeclss / type = sp(gau)(time) local subject = id; run;
99
出力
1:固定効果(表9.3)
テキスト134P
出力
2:分散成分など(表9.3)
101
最終モデルで、
群ごとの違いをみる
BPH群と、局所浸潤性癌群の比較 (1)5年時点の の値の比較 表9.3の推定値を代入 局所浸潤性癌 BPH :10年(2)5年時点の の変化率の比較 時間に対する 変化が知りたい 「局所浸潤性癌群の方が、 右に行くほど減少が大きい」 ⇒ 右が過去なので、
103
9章のまとめ
• モデル構築の一般論。
– 固定効果構築 → 変量効果構築 → 減らすかどうかの検討の順番。
• テキストの記載は、最後の「詰め」が甘いです
(ただし、著者らは本書に記載していない解析を大量にしている はずです。甘いのはあくまで「記載」だけだと思います)。
105
本日のまとめ
• 3章
– 2段階解析とLMMを用いて、とりあえず解析して みた。• 6章
– 固定効果・変量効果をF検定・Wald検定・尤度比 検定で減らす方法を検討した。• 9章
– モデル選択の指針、固定効果・変量効果・系列相 関のモデリングの方法を検討した(系列相関は 「さわり」だけ。詳しくは10章で)。今回のモデル構築で微妙な点
• 固定効果・変量効果が少なすぎるのでは? – 「最低限必要なもの」しか加えていないように見える。 – 本書のスタンスは「少ないよりは多い方がよい」なので、主張 と行動が一貫していない? • 「変数を減らす」ことを検定で判断した – 「帰無仮説が棄却できない」=「帰無仮説が正しい」と判断した – 帰無仮説が棄却されるかどうかは例数に依存する – 帰無仮説の選び方が比較的恣意的 • 「だからおかしい」ではなくて、 – この点を忘れないように気をつけながら使いましょう。107
テキストの参考文献
(1)
Altham,P.M.E. (1984) Improving the precision of estimation by
fitting a model. Journal of the Royal Statistical Society, Series
B, 46, 118-119.
Diggle,P.J. (1988) An approach to the analysis of repeated measures. Biometrics, 44, 959-971.
Diggle,P.J., Liang,K.-Y., and Zeger,S.L. (1994) Analysis of
Longitudinal Data. Cxford Science Publications. Oxford:
Clarendon Press.
Lesaffre,E., Asefa,M., and Verbeke,G. (1999) Assessing the
goodness-of-fit of the Laird and Ware model: an example: the Jimma Infant Survival Differential Longitudinal Study. Statistics
in Medicine, 18, 835-854.
Morrell, C.H., Pearson,J.D., and Brant,L.J. (1997) Linear
transformations of linear mixed-effects models. The American
テキストの参考文献
(2)
Pearson,J.D., Kaminski,P., Metter, E.J., Fozard, J.L., Brant,L.J.,
Morrell,C.H., and Carter,H.B. (1999) Modeling longitudinal rates of change in prostate specific antigen during aging. Proceedings
of the Social Statistics Section of the American Statistical Association, Washington, DC, pp.580-585.
Pearson,J.D., Morrell, C.H., Landis,P.K., Carter,H.B., and Brant,L.J. (1994) Mixed-effects regression models for studying the natural history of prostate disease. Statistics in Medicine, 13, 587-601 Royston,P. and Altman,D.G. (1994) Regression using fractional
polynomials of continuous covariates: parsimonious parametric modelling. Applied Statistics, 43, 429-468.
Self,S.G. and Liang,K.Y.(1987) Asymptotic properties of maximum likelihood estimatiors and likelihood ratio tests under
109
原著の参考文献
(3)
Stram,D.O and Lee,J.W. (1994) Variance components testing in the longitudinal mixed effects model. Biometrics, 50, 1171-1177.
Stram,D.O and Lee,J.W. (1995) Correction to: Variance components testing in the longitudinal mixed effects model. Biometrics, 51, 1196.
Verbeke,G., Lesaffre,E, and Brant,L.J. (1998) The detection of residual serial correlation in linear mixed models. Statistics in
追加の参考文献
Box,G.E.P (1976). Science and Statistics. Journal of American
Statistical Association, 71, 791-799.
Box,G.E.P (1979). Robustness in the Strategy of Scientific Model
Building. Robustness in Statistics:Proceedings of a Workshop(1979)
edited by R.L.Launer and G.N.Wilkinson. 201-236.
Box,G.E.P. and Draper,N.R.(1987). Empirical Model-Building and
Response Surfaces. Wiley.
土居正明, 横道洋司, 青山淑子, 五百路徹也, 中村竜児, 吉田和生, 白岩健, 松下勲, 西山毅, 井上永介, 上原秀昭, 山口亨, 酒井美良 訳(2011). 線形モデルとその拡張-一般化線形モデル、混合効果モ デル、経時データのためのモデル-, 株式会社シーエーシー.
(McCulloch,C.E., Searle,S.R, and Neuhaus, J.M. (2008)
Generalized, Linear, and Mixed Models 2nd edition. Wiley.)
松山裕, 山口拓洋編訳(2001). 医学統計のための線形混合モデル-SAS によるアプローチ, サイエンティスト社. (Verbeke,G. and