DEIM Forum 2016 C2-5
学術論文からの参考文献文字列抽出の一手法
内田 裕太
†太田
学
††高須 淳宏
†††安達
淳
††††
岡山大学工学部情報系学科 〒 700–8530 岡山県岡山市北区津島中 3–1–1
††
岡山大学大学院自然科学研究科 〒 700–8530 岡山県岡山市北区津島中 3–1–1
†††
国立情報学研究所 〒 101–8430 東京都千代田区一ツ橋 2–1–2
E-mail:
†
[email protected],
††
[email protected]
†††{
takasu, adachi
}
@nii.ac.jp
あらまし
学術論文の参考文献文字列は,参考文献のタイトルや著者名などの書誌情報を含んでいる.これは,膨
大な論文を収録する電子図書館において有益な情報となる.石本らは,PDF 形式の論文から Conditional Random
Field(CRF) を用いて参考文献文字列を自動抽出する方法を提案した.しかし,参考文献領域を分断したり,参考文献
領域の後に続いたりする表や図などを参考文献文字列として誤抽出するなどの問題があった.そこで本研究では,参
考文献欄の領域検出方法と,CRF による参考文献文字列抽出方法の改良を図った.
キーワード
情報抽出,CRF,電子図書館,参考文献
1.
は じ め に
書誌情報は電子図書館において有益な情報である.特に,学 術論文の参考文献文字列は,参考文献のタイトルや著者名など の書誌情報を含んでいる.そこで,低コストで書誌情報のデー タベースを構築するため,参考文献欄から参考文献文字列のみ を自動抽出する研究が行われている. 個々の参考文献文字列を抽出する研究として,石本ら[8]や 赤澤ら[9]の研究がある.石本らは,PDF形式の論文から,自 然処理言語など様々な分野で利用されている識別モデルの一つ であるConditional Random Field(CRF) [1]を用いて文字列(行)に対してラベルを付与し,参考文献文字列を抽出した.し かし,参考文献領域を分断する,あるいは参考文献領域の後に 続く表や図を参考文献文字列として誤抽出する問題が残った. 赤澤らはこれらの課題を解決するため,ラベル付与対象の行の 素性だけでなく,その前後の行の素性情報を利用してラベル付 与を行った.しかし,1行のみからなる参考文献文字列が連続 する場合に,ラベル付与が失敗するといった新たな問題が発生 した.そこで本研究では,参考文献欄の領域検出方法と,CRF による参考文献文字列抽出方法を改良する. 本稿の構成は次の通りである.まず,2.節で本研究の関連研 究を紹介する.3.節では参考文献文字列の自動抽出方法を説明 する.4.節で実験と評価について述べる.最後に,5.節で本稿 をまとめる.
2.
関 連 研 究
電子図書館に収録されている論文は膨大であるため,論文か ら機械学習により書誌情報を抽出する研究が行われている.阿 辺川ら[7]は,Support Vector Marchine(SVM) [2]やHidden Markov Model(HMM) [3]を用いて,電子化された学術論文か ら書誌情報を抽出する手法を提案した.阿辺川らが使用した データは,日本語及び英語で書かれたPostScriptファイルと PDFファイルの論文945件であり,それぞれの論文のタイト ルページ及び参考文献欄から書誌情報を抽出した.書誌情報抽 出の結果は,書誌情報を全て正しく抽出した論文を正解として, 論文のタイトルページは正解率が69.2%であった.また,参考 文献欄からの書誌情報抽出は,日本語と英語に分けて行った. 正解率は最も高いもので,日本語で74.8%,英語で81.6%で あった. Pengら[4]は,英語のタイトルページや参考文献欄からの書 誌情報抽出の際にCRFを用いた.Pengらはまた比較対象と してHMMを利用した.タイトルページからは著者名や所属な ど13項目の書誌情報を抽出し,平均のF値がHMMで0.756, CRFで0.939であった.一方,参考文献欄では,著者名やタイ トルなど13項目の書誌情報を抽出し,平均のF値がHMMで 0.776,CRFで0.915であった. Councillら[5]は,CRFを用いて参考文献欄の書誌情報を抽 出するオープンソースのツールParsCitを開発した.ParsCit では前処理として参考文献領域の検出を行う.彼らは評価のた め,Coraデータセット[6]の参考文献文字列200件を対象に, 著者名やタイトルなど13項目の書誌情報を抽出した.書誌情 報の抽出結果は,平均の適合率,再現率が共に0.957,平均の F値は0.950であった. 石本ら[8]は,学術論文から個々の参考文献文字列を自動抽 出する方法を提案した.その提案手法は,PDF形式の論文か ら参考文献領域の開始位置を検出し,それ以降の文字列に対し てCRFを用いて参考文献文字列と他を区別するためのラベル 付けを行うものである.第5回データ工学と情報マネジメント に関するフォーラム(DEIM2013)の論文139件に対して行っ た実験では,参考文献領域の開始位置の検出には全て成功した. 個々の参考文献文字列を抽出するための4種類からなるラベ ルの付与実験では,全てのラベル付けが成功した論文の割合が 90%以上だった.しかし,参考文献領域を分断する表や図など を参考文献文字列として誤抽出するなどの問題があった. 赤澤ら[9]は石本らの問題を解決するため,CRFを用いてラ ベルを付与する際に,ラベル付与対象の行の素性のほかに,その前後2つまでの行の素性情報を利用した.また,実験対象 のデータセットとして,石本らの使用したDEIM2013の論文
139件に加えて国立情報学研究所主催の第9回NTCIRワーク ショップ(NTCIR-9)の論文91件,情報処理学会(IPSJ)の論 文誌Vol.53のNo.1からNo.3の論文127件,合計357件の論 文を使用した.実験の結果,論文の正解率は論文誌の種類に よって92%から96%であった.しかし,IPSJの論文では,1 行のみからなる参考文献文字列が連続する場合,個々の参考文 献文字列を正しく抽出できない問題があった.さらに,“[1]” や“[2]”といった番号のない参考文献文字列も正しく抽出でき ないことがあった.また,参考文献領域の開始位置の検出に, 失敗する論文が1件あった.
3.
参考文献文字列の自動抽出
3. 1 概 要 ここでは参考文献文字列の自動抽出の手順を説明する.なお, この手順は石本らの方法[8]を採用している.まず,3. 2節で 説明する方法でPDF形式の論文をXMLファイルに変換する. 次に,3. 3節で説明する方法で参考文献領域の開始位置と終了 位置を検出する.最後に,3. 4節の方法で,検出した領域内の 全ての行に対し,CRFを用いてラベル付けを行い,個々の参 考文献文字列を抽出する.本稿では,石本らの参考文献文字列 の抽出法の改良を3. 3節及び3. 4節に示す. 3. 2 論文PDFファイルから論文XMLファイルへの変換 まず初めに,論文のPDFファイルをpdf2xml(注1)により変 換し,図1のようなXMLファイル(以下,論文XMLファイ ル)を出力する.pdf2xmlはPDFファイルの本文や表,注釈や ページ番号などに対してTOKEN,TEXT,BLOCKタグを付 与する.また,図に対しては通常IMAGEタグを付与する.し かし,図中のテキストに対してはTOKEN,TEXT,BLOCKタグを付与する場合がある. これらのタグのうち,TEXTタグは通常,論文中の一行に 対して付与される.しかし,Microsoft Word等で作成された PDFファイルの場合,1単語に対してTEXTを付与すること もある.本研究では石本ら[8]と同様に,3. 4節で説明する方 法でTEXTを対象にラベルを付与し,参考文献文字列を抽出 する. 3. 3 キーワードによる参考文献領域検出 3. 2節の方法で変換した論文XMLファイルから参考文献領 域を検出する.まず,3. 3. 1節で参考文献領域の開始位置の検 出,次に3. 3. 2節で参考文献領域の終了位置の検出について述 べる.本研究では,開始位置以降かつ終了位置直前までの領域 を参考文献領域とする. 3. 3. 1 参考文献領域開始位置検出 本研究では,参考文献領域の開始位置を,“ 参考文献 ”や “ 文献 ”,“Reference”,“References”,“REFERENCE”, “REFERENCES”の文字列を手がかりに検出する.石本ら[8] は,行がそれらの文字列のみ,あるいは節番号とそれらの文字 (注1):http://sourceforge.net/projects/pdf2xml/ 図 1 論文 XML ファイルの例 列のみの場合,参考文献領域の開始位置とした.ただし,この方 法では,参考文献領域開始位置以外のの本文中に“Reference” という文字列が出現する場合に,開始位置を誤検出する場合が あった. そこで,“Reference”等のキーワードのあるTEXTのx座 標とy座標を抽出し,そのy座標との差が5以内かつx座標と の差が200以内のTEXTが存在しない場合,参考文献領域の 開始位置とするようにした.ここで,x座標の条件は,3. 2節で のXMLファイルへの変換により,二段組の論文を一段組とし て変換する場合があるために導入した.また,y座標の条件は, 本文中や表中の“Reference”の誤検出を防ぐために導入した. また,論文によっては“REFERECE”などの綴り誤りもあ るため,“Reference”の1文字目のR以外での綴り誤りが1文 字以内のものもキーワードとする. 3. 3. 2 参考文献領域終了位置検出 石本ら[8]は,参考文献領域の開始位置のみを検出した.し かし,参考文献領域の後の付録の一部を参考文献文字列とし て誤抽出する問題があった.そのため本稿では,“ 付録 ”や “Appendix”,“APPENDIX”のキーワードを手がかりに参考 文献領域の終了位置を検出する.開始位置検出とは異なり,単 純にこれらのキーワードを含む行を終了位置として検出する. ただし,キーワードがない場合は,論文XMLファイルの末尾 を終了位置とする. 3. 4 CRFによる参考文献文字列の自動抽出 3. 3節の方法で参考文献領域の開始位置と終了位置を検出し た後,参考文献領域内のTEXTに対してCRF++0.58(注 2)を 用いてラベル付けを行い,参考文献文字列を抽出する.
3. 4. 1 Conditional Random Field
本研究では,標準的なチェーンモデルのCRFの定義を用い て,参考文献文字列を自動抽出する.参考文献領域のTEXTの 列に対して4種類のラベルを付与し,参考文献文字列と他を区 別する.すなわち,入力系列x1,...,xnが与えられたとき,出 力ラベル系列がy1,...,ynとなる条件付き確率を以下のように 与える. (注2):http://taku910.github.io/crfpp/
表 1 石本らの素性 (tpl ishimoto) 種類 素性 TEXTの内容 Unigram number(0) 識別番号 (視覚的素性) x(0) X座標 y(0) Y座標 w(0) 幅 h(0) 高さ gapx(0) 前のTEXTとのX方向の間隔 gapy(0) 前のTEXTとのY方向の間隔 Unigram c(0) 文字数 (言語的素性) ec(0) TEXT内の英字の割合 nc(0) TEXT内の数字の割合 kc(0) TEXT内の漢字の割合 jc(0) TEXT内の平仮名・片仮名の割合 sc(0) TEXT内の記号の割合 ekw(0) 参考文献以外に特徴的な文字列の種類 skw(0) 参考文献に特徴的な文字列の種類 Bigram y(−1),y(0) ラベルの遷移 表 2 tpl ishimoto による特徴的な文字列の例 素性 種類 予想される論文構成要素 特徴的な文字列の例
ekw(0) FG 図,図キャプション 図,Figure,Fig.
TB 表,表キャプション 表,Table AP 付録 付録,Appendix FT 注釈 注 skw(0) SR 参考文献文字列の始まり [1],[2] 参考文献文字列中に現れる特徴的な シンポジウム,Conf 文字列 -論文誌,Journal ブック,Handbook (編),編集,Ed -社,-出版 RE Volume,Vol. No. pp.,p. January,Jan. www,http 研究報告,大学 P (y|x) = 1 Zx exp
(
∑
n i=1∑
k λkfk(yi−1, yi, x))
(1) ただし,Zxは,全てのラベル系列を考慮したときに確率の和 が1となるための正規化項で, Zx=∑
y′∈Y (x) exp(
∑
n i=1∑
k λkfk(y′i−1, y′i, x))
(2) である.fk(yi−1,yi,x)は,(i-1)番目とi番目の出力ラベルと 入力系列xに依存する任意の素性関数である.λkは素性関数 fkの重みを表すパラメータで学習により定める.また,Y (x) は入力系列xに対する出力ラベル系列の集合である.そして, 入力系列xに対する最適な出力ラベル系列y∗は次式で与えら れる. y∗= arg max y∈Y (x) P (y|x) (3) 本研究では,石本らと同様に,ラベル付与の対象となる入 力xiは,論文XMLファイルのTEXTである.ラベルyiは, “SRef”,“NRef”,“Page”,“ETC”の4種類である.この表 3 赤澤らが利用した前後の TEXT の素性 (tpl akazawa1)
種類 素性 TEXTの内容
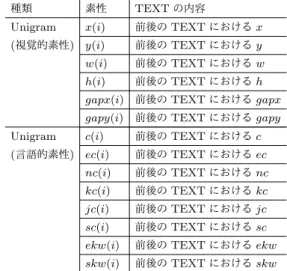
Unigram x(i) 前後のTEXTにおけるx
(視覚的素性) y(i) 前後のTEXTにおけるy w(i) 前後のTEXTにおけるw h(i) 前後のTEXTにおけるh gapx(i) 前後のTEXTにおけるgapx gapy(i) 前後のTEXTにおけるgapy
Unigram c(i) 前後のTEXTにおけるc
(言語的素性) ec(i) 前後のTEXTにおけるec nc(i) 前後のTEXTにおけるnc kc(i) 前後のTEXTにおけるkc jc(i) 前後のTEXTにおけるjc sc(i) 前後のTEXTにおけるsc ekw(i) 前後のTEXTにおけるekw skw(i) 前後のTEXTにおけるskw
表 4 赤 澤 ら が 利 用 し た 前 後 の TEXT と の 組 み 合 わ せ の 素 性 (tpl akazawa2)
種類 素性 TEXTの内容
Unigram x(0),x(i) x(0)とx(i)の組み合わせ
(視覚的素性) y(0),y(i) y(0)とy(i)の組み合わせ
w(0),w(i) w(0)とw(i)の組み合わせ
h(0),h(i) h(0)とh(i)の組み合わせ
gapx(0),gapx(i) gapx(0)とgapx(i)の組み合わせ
gapy(0),gapy(i) gapy(0)とgapy(i)の組み合わせ
Unigram c(0),c(i) c(0)とc(i)の組み合わせ
(言語的素性) ec(0),ec(i) ec(0)とec(i)の組み合わせ
nc(0),nc(i) nc(0)とnc(i)の組み合わせ
kc(0),kc(i) kc(0)とkc(i)の組み合わせ
jc(0),jc(i) jc(0)とjc(i)の組み合わせ
sc(0),sc(i) sc(0)とsc(i)の組み合わせ
ekw(0),ekw(i) ekw(0)とekw(i)の組み合わせ
skw(0),skw(i) skw(0)とskw(i)の組み合わせ
内,“SRef”は参考文献文字列の開始行のTEXT,“NRef”は 参考文献文字列の2行目以降の行のTEXTに付与する.すな わち,“SRef”とそれにつづく“NRef”が一つの参考文献文字 列となる.また,“Page”はページ番号を表すTEXT,“ETC” はその他の文字列を表すTEXTに付与する.本研究では石本 らと同様に,“SRef”とそれにつづく“NRef”を一つの参考文 献文字列として抽出する.
3. 4. 2 CRFで利用する素性
石本らは参考文献文字列の抽出に表1の素性テンプレート
(以下,tpl ishimoto)を使用した.tpl ishimotoのうち,ekw,
skwは表2のような特徴的な文字列の種類を示す素性である. 赤澤ら[9]は,石本らが利用したテンプレートtpl ishimotoに加 えて,表3のようにラベル付与対象のTEXTの前後のTEXT の素性を反映したテンプレート(以下,tpl akazawa1)と,そ れら前後のTEXTとの組み合わせの素性テンプレート(以下, tpl akazawa2)を用いた(i =−2,− 1,1,2).その結果,表や 図などを参考文献文字列として誤抽出する問題が改善された. しかし,1行のみからなる参考文献文字列が連続している部分 で,“SRef”ではなく“NRef”を付与する問題が発生した. そこで本研究では,tpl ishimotoの一部を変更した表5(以下,
表 5 提案する素性 (tpl uchida) 種類 素性 TEXTの内容 Unigram number(0) 識別番号 (視覚的素性) x(0) X座標 y(0) Y座標 w(0) 幅 h(0) 高さ gapx(0) 前のTEXTとのX方向の間隔 gapy(0) 前のTEXTとのY方向の間隔 Unigram c(0) 文字数 (言語的素性) ec(0) TEXT内の英字の割合 nc(0) TEXT内の数字の割合 kc(0) TEXT内の漢字の割合 jc(0) TEXT内の平仮名・片仮名の割合 sc(0) TEXT内の記号の割合 Unigram ek(0) 参考文献文字列以外に特徴的な情報 (特徴素性) sk(0) 参考文献文字列に特徴的な情報 Bigram y(−1),y(0) ラベルの遷移 表 6 特 徴 素 性 素性 種類 TEXTの満たすべき条件 ek(0) FG “ 図 ”領域のTEXT TB “ 表 ”領域のTEXT FT “ 注釈 ”領域のTEXT NS 文字列の構成が数字や記号のみの場合 (但し,ピリオドで終わる場合を除く) sk(0) SR [1],[2]等の番号がある行 “ 参考文献欄 ”領域の1行目 “ 参考文献欄 ”領域で検出した文字列の幅の最大値 と等しい行 “ 参考文献欄 ”領域の1行目の行とのx座標の差が 5以内の行 “ 参考文献欄 ”領域で検出した文字列の幅が最大の 行とのx座標の差が5以内の行 RE “ 参考文献欄 ”領域かつ特徴的な文字列を含むTEXT tpl uchida)の素性テンプレートを提案する.石本らの素性テ ンプレートとの違いは,tpl ishimotoでは表2のように特徴的 な文字列の種類を示す素性を,tpl uchidaでは本研究で提案す る特徴素性をそれぞれ利用する点である. tpl uchida及びtpl ishimotoで利用する素性は以下の4種類 に分類される. a ) 視覚的素性 視覚的素性は,TEXTのレイアウト情報を素性としたもので ある.具体的には,x座標やy座標といったTEXTの位置や 前のTEXTとの間隔,TEXTを構成する文字列の幅や高さと いった数値である.これらの数値はXMLファイルからTEXT の属性値として得られる.ただし,その数値は小数のため,適 当な値に丸める.すなわち,TEXTの高さを表す数値は小数点 以下を切り捨て,それ以外の数値は一の位を切り捨てた数値を 素性として用いる.この素性は,tpl uchida及びtpl ishimoto で共通である. b ) 言語的素性 言語的素性は,TEXTの文字列の中身を解析して得られる情 報を素性としたものである.具体的には,TEXT内の文字数や 表 7 領域の開始条件 領域 領域の開始条件 “ 参考文献欄 ” [1],[2] 等の番号の検出 参考文献領域内の TEXT の 1 つ目の検出 “ 参考文献欄 ”領域で検出した文字列の幅が 最大の行と幅が等しい行の検出 “ 図 ” “ 図 ”,“ Figure ”等のキーワードの検出 TEXT の幅の値が“ 参考文献欄 ”領域で抽出 した文字列の幅が最大の行の 1/10 より小さく, その値が等しい行を連続で検出した場合 “ 表 ” 表,Table 等のキーワードの検出 y の値が等しい TEXT が連続になっており, それらの幅の和が“ 参考文献欄 ”領域で検出 した文字列の幅の最大値と異なる場合 “ 注釈 ” 行頭が“ 注 (+番号) ”や“ * ”等の場合 “ その他 ” ページ番号が変わった場合 二段組の論文で左側から右側に移った場合 連続する TEXT の間隔が一定以上だった場合 文字列の種類,表2のような特徴的な文字列の種類を示す素性 である.ただし,TEXT内の文字数は一の位を切り捨てた数値 を素性とする.なお,特徴的な文字列の種類は石本らや赤澤ら の素性では使用するが,提案手法では後述する特徴素性を定め るために使用する. c ) 特 徴 素 性 石本らや赤澤らが使用した素性テンプレート(tpl ishimoto) では,言語的素性として特徴的な文字列の種類を使用した.し かしこの素性は,番号の無い参考文献文字列の開始行にNRef が付与される問題や,表のセル内の文字列やグラフ内の文字列 を参考文献文字列として誤抽出する問題には,必ずしも有効と はいえなかった.そこで本研究では,特徴的な文字列の種類の みでなく,レイアウト情報もあわせて考慮した特徴素性を提案 する.具体的には,特徴素性として,参考文献文字列以外に特 徴的な性質(ek)と,参考文献文字列に特徴的な性質(sk)の2 種類を導入する.特徴素性を与える条件を表6に示す.また, 表6の領域については後述する. ekのうちTBやFG,FTはそれぞれ“ 表 ”,“ 図 ”,“ 注釈 ” 領域の全てのTEXTに素性の値としてセットされる.また, NSは記号や数字のみで構成されているTEXTの素性の値とな る.また,“ 表 ”,“ 図 ”,“ 注釈 ”領域のTEXTの場合,NSで はなく,それぞれTB,FG,FTを素性の値とする. 一方,skのうちSRは,参考文献文字列の開始行に特徴的な 性質を持つTEXTの素性の値となる.具体的には,“[1]”など 特徴的な文字列や他のTEXTとのx座標の差を利用する.こ こで,x座標の差を利用する理由は参考文献文字列の開始行と 2行目以降でx座標が異なることが多いためである.また,RE は,“ 参考文献欄 ”にあり,かつ表2のREと同様の特徴的な文 字列を含むTEXTの素性の値となる.これにより,例えば表 の中に表2のREと同様の特徴的な文字列が現れたとしても, そのTEXTの素性値はREとはならない.また,ekもskも 表6のそれぞれのいずれの条件も満たさなければNNとする.
ここで,表6の各領域について説明する.この領域は,ルー ルにより参考文献領域の全TEXTを“ 参考文献欄 ”,“ 表 ”, “ 図 ”,“ 注釈 ”,“ その他 ”の5つに分類したもので,ルールに よる推定区分といえる. まず初めに,“ 参考文献欄 ”領域の検出について説明する.参 考文献領域の開始位置の直後は参考文献文字列の開始行と考え, “ 参考文献欄 ”領域の開始位置とする.正しい“ 参考文献欄 ” では,個々の文字列の内,開始行が最も行の幅の値が大きいた め,その幅を最大値として保存する.番号“[1]”などで始まる TEXTや保存した幅の最大値と一致するTEXTを抽出した場 合,直前が他の領域のTEXTであれば“ 参考文献欄 ”領域の 開始位置となる. 次に,“ 表 ”及び“ 図 ”,“ 注釈 ”領域の検出について説明す る.“ 表1”や“Table”等の特徴的な文字列を抽出した場合, あるいはyの値が等しいTEXTが連続し,それらの幅の和が 既出の“ 参考文献欄 ”領域で保存したTEXTの幅の最大値と 異なる場合,“ 表 ”領域とする.yの値が等しいTEXTが連続 している場合,それらは表のセルである場合が多い.“ 図 ”や “Figure”等の特徴的な文字列がある場合,あるいはTEXTの 幅が“ 参考文献欄 ”領域の文字列の幅の最大値の1/10よりも 小さく,その値が等しい行を連続で抽出した場合,“ 図 ”領域 とする.これらの文字列は図の中のグラフの値を表している場 合が多い.“ 注1”や“*”等の文字列で始まるTEXTを抽出し た場合は“ 注釈 ”領域とする. また,“ その他 ”領域は,ページ番号が変わった場合や二段 組の論文で左側から右側に移った場合,また連続するTEXT の間隔が一定以上だった場合で,かつ他の領域と判定されな い場合,そこが開始位置となる.ここで,TEXTの間隔とは,
tpl uchida やtpl ishimoto で利用されているgapy(0)のこと である. d ) Bigram素性 付与されるラベルの前後の連接に関する情報の素性である Bigram素性を使用する.これにより,ラベルの出現順に関す る制約を考慮する.この素性は,tpl uchida及びtpl ishimoto で共通である.
4.
評 価 実 験
4. 1 実験データ 本研究では,論文のPDFファイルをpdf2xmlで変換した論 文XMLファイルを使用する.国立情報学研究所主催の第10回 NTCIRワークショップ(NTCIR-10)の論文PDFファイルは 104件のうち2件で,XMLファイル変換した際に“ 参考文献 ” や“Reference”等の手がかり語に変換誤りが発生した.そのた め実験には,これら2件を除いた102件の論文と,第5回デー タ工学と情報マネジメントに関するフォーラム(DEIM2013)の 論文139件,第9回NTCIRワークショップ(NTCIR-9)の論 文91件,情報処理学会(IPSJ)の論文誌Vol.53のNo.1からNo.3の論文127件,合計459件を使用する.なお,DEIM2013 の論文は石本ら[8]や赤澤ら[9]が実験に用いた論文と同一のも のであり,NTCIR-9とIPSJは赤澤ら[9]が実験に用いた論文 表 8 tpl ishimoto によるラベル付与結果 (DEIM2013,参考文献領域終了位置検出無) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 1,668 1,670 1,668 0.9988 1.0000 0.9994 NRef 3,840 4,017 3,832 0.9581 0.9978 0.9763 Page 18 18 18 1.0000 1.0000 1.0000 ETC 2,347 2,168 2,160 0.9963 0.9432 0.9667 合計 7,873 7,873 7,678 0.9775 0.9775 0.9775 表 9 tpl ishimoto によるラベル付与結果 (DEIM2013) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 1,668 1,670 1,668 0.9988 1.0000 0.9994 NRef 3,840 4,027 3,832 0.9557 0.9978 0.9750 Page 18 18 18 1.0000 1.0000 1.0000 ETC 2,177 1,988 1,980 0.9962 0.9384 0.9642 合計 7,703 7,703 7,498 0.9763 0.9763 0.9763 表 10 tpl uchida によるラベル付与結果 (DEIM2013) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 1,668 1,670 1,668 0.9988 1.0000 0.9994 NRef 3,840 3,842 3,839 0.9992 0.9997 0.9994 Page 18 18 18 1.0000 1.0000 1.0000 ETC 2,177 2,173 2,172 0.9995 0.9967 0.9981 合計 7,703 7,703 7,697 0.9992 0.9992 0.9992 と同一のものである. 4. 2 参考文献領域検出実験 ここでは3. 3節で説明した,参考文献領域開始位置,終了位 置検出手法の評価を行う.4. 1節で説明した459件の論文では 3. 3. 1節の方法により,459件全ての論文の参考文献領域の開 始位置を正しく検出できた. 終了位置については,以下のようであった.459件の論文の うち,参考文献領域の後に“ 付録 ”や“Appendix”がある論 文は,DEIM2013で2件,IPSJで10件,NTCIR-9で1件,
NTCIR-10で2件,合計15件であった.3. 3. 2節の方法によ り,それら15件全ての“ 付録 ”や“Appendix”等のキーワー ドを正しく検出した.そのため,459件全ての論文の参考文献 領域の終了位置を正しく検出できた. 4. 3 参考文献文字列自動抽出実験 参考文献領域検出を行った後,全ての論文に対して,表5の 提案素性により“SRef”,“NRef”,“Page”,“ETC”の4種 類のラベル付与を行った.5分割交差検定によりTEXTに対す るラベル付与の適合率と再現率,およびF値等を求める.それ ぞれの定義を以下に示す. 適合率(P ) = CRFによるラベル付与の正解数 CRFが付与したラベルの数 (4) 再現率(R) =CRFによるラベル付与の正解数 正解データにおけるラベルの数 (5) F値=2・P・R P + R (6) また,ラベル付与結果をもとに論文正解率も求める.ここで 論文正解率とは,1論文中の参考文献領域の全TEXTに過不
表 11 tpl ishimoto によるラベル付与結果 (IPSJ,参考文献領域終了位置検出無) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 2,369 2,370 2,369 0.9996 1.0000 0.9998 NRef 6,805 6,864 6,804 0.9922 0.9998 0.9959 Page 208 208 208 1.0000 1.0000 1.0000 ETC 5,634 5,574 5,573 0.9998 0.9900 0.9948 合計 15,016 15,016 14,954 0.9962 0.9962 0.9962 表 12 tpl ishimoto によるラベル付与結果 (IPSJ) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 2,369 2,370 2,369 0.9996 1.0000 0.9998 NRef 6,805 6,807 6,805 0.9997 1.0000 0.9998 Page 192 192 192 1.0000 1.0000 1.0000 ETC 4,627 4,624 4,624 1.0000 0.9993 0.9996 合計 13,993 13,993 13,990 0.9997 0.9997 0.9997 表 13 tpl uchida によるラベル付与結果 (IPSJ) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 2,369 2,370 2,369 0.9996 1.0000 0.9998 NRef 6,805 6,807 6,805 0.9997 1.0000 0.9998 Page 192 192 192 1.0000 1.0000 1.0000 ETC 4,627 4,624 4,624 1.0000 0.9993 0.9996 合計 13,993 13,993 13,990 0.9997 0.9997 0.9997 表 14 tpl ishimoto によるラベル付与結果 (NTCIR,参考文献領域終了位置検出無) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 2,226 2,184 2,178 0.9971 0.9792 0.9878 NRef 6,858 6,966 6,803 0.9759 0.9918 0.9836 Page 203 202 202 1.0000 0.9945 0.9972 ETC 4,512 4,447 4,377 0.9824 0.9614 0.9707 合計 13,799 13,799 13,560 0.9815 0.9815 0.9815 表 15 tpl ishimoto によるラベル付与結果 (NTCIR) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 2,226 2,182 2,180 0.9991 0.9800 0.9893 NRef 6,858 6,921 6,801 0.9832 0.9917 0.9874 Page 201 200 200 1.0000 0.9942 0.9971 ETC 4,177 4,159 4,093 0.9823 0.9782 0.9802 合計 13,462 13,462 13,274 0.9865 0.9865 0.9865 表 16 tpl uchida によるラベル付与結果 (NTCIR) TEXT数 ラベル付与数 正解数 適合率 再現率 F値 SRef 2,226 2,224 2,224 1.0000 0.9991 0.9995 NRef 6,858 6,869 6,850 0.9971 0.9988 0.9979 Page 201 200 200 1.0000 0.9942 0.9971 ETC 4,177 4,169 4,160 0.9972 0.9942 0.9957 合計 13,462 13,462 13,434 0.9977 0.9977 0.9977 足なく正しいラベルを付与した論文を正解として,全論文に対 する正解した論文数の割合を求めたもので,式(4.4)で定義す る.また,ここで言う参考文献領域は,4. 2節の検出実験の結 果得られたものである. 論文正解率=過不足なく正しいラベルを付与した論文数 全論文数 (7) 表 17 tpl ishimoto によるラベル付与結果の論文正解率 (参考文献領域終了位置検出無) 論文数 論文の正解数 論文の不正解数 論文正解率 (%) DEIM2013 139 128 11 92.09 IPSJ 127 123 4 96.86 NTCIR 193 170 23 88.06 表 18 tpl ishimoto によるラベル付与結果の論文正解率 論文数 論文の正解数 論文の不正解数 論文正解率 (%) DEIM2013 139 128 11 92.09 IPSJ 127 126 1 99.23 NTCIR 193 168 25 87.04 表 19 tpl uchida によるラベル付与結果の論文正解率 論文数 論文の正解数 論文の不正解数 論文正解率 (%) DEIM2013 139 134 5 96.43 IPSJ 127 126 1 99.23 NTCIR 163 184 9 95.32 表 20 tpl uchida に前後の TEXT(i =−2,− 1,1,2) の素性 を加えた場合の論文正解率 論文数 論文の正解数 論文の不正解数 論文正解率 (%) DEIM2013 139 131 8 94.26 IPSJ 127 123 4 96.86 NTCIR 193 183 10 94.83 表 21 tpl uchida に前後の TEXT(i =−2,− 1,1,2) の 素性との組み合わせ素性を加えた場合の論文正解率 論文数 論文の正解数 論文の不正解数 論文正解率 (%) DEIM2013 139 132 7 94.94 IPSJ 127 124 3 97.63 NTCIR 193 187 6 96.85 表 22 tpl uchida に前後の TEXT(i =−2,− 1,1,2) の素性と 組み合わせ素性を加えた場合の論文正解率 論文数 論文の正解数 論文の不正解数 論文正解率 (%) DEIM2013 139 130 9 93.51 IPSJ 127 124 3 97.63 NTCIR 193 185 8 95.84 本研究では,提案するtpl uchida と,石本らが利用した tpl ishimotoとの比較実験を行う.tpl ishimotoでは,CRFに よるラベル付与を,[8]と同様に参考文献領域の終了位置を検 出せずに行った場合と,tpl uchidaと同様に3. 3. 2節の方法 により参考文献領域の終了位置を検出してから行った場合の 2通りで実験する.また,データセットはDEIM2013,IPSJ, NTCIR(NTCIR-9とNTCIR-10をあわせたもの)の3種類に 分ける. 石 本 ら と 同 様 に 参 考 文 献 領 域 終 了 位 置 検 出 を 行 わ ず に tpl ishimotoを利用したラベル付与結果を,DEIM2013は表8, IPSJは表11,NTCIRは表14,また論文正解率は表17に示す. 次に参考文献領域終了位置検出を行った場合にtpl ishimotoを 利用したラベル付与結果を,DEIM2013は表9,IPSJは表12, NTCIRは表15,また論文正解率は表18に示す.そして,本 研究の提案であるtpl uchidaを利用した場合のラベル付与結果 を,DEIM2013は表10,IPSJは表13,NTCIRは表16,ま
図 2 参考文献文字列の幅が 1 行ごとに異なる論文 [10] 図 3 論文 PDF と論文 XML ファイルの文字列の順序が異なる例 (論文 PDF) [11] 図 4 論文 PDF と論文 XML ファイルの文字列の順序が異なる例 (論文 XML ファイル) [11] た論文正解率は表19に示す. 表11と表12を比べると,参考文献領域の終了位置を検出し たことにより,IPSJではETCのF値が上がったことがわか る.実験に用いたIPSJの論文は,論文フォーマットが比較的 整っており,参考文献領域を分断する表や図が無かった.また, 付録のある論文が他のデータセットよりも多かったため,参考 文献領域の終了位置検出によりETCを付与すべきTEXT数が 大きく減った.しかし,参考文献領域を分断する注釈が1件あ り,提案したtpl uchidaを用いてもその注釈を参考文献文字列 として誤抽出した.DEIM2013では,表8と表9を比べると, 参考文献領域の終了位置検出を行った場合ではF値が下がった ことがわかる.また,NTCIRでは,表14と表15のF値,及 び表17と表18の論文正解率を比べると,参考文献領域の終了 位置検出を行った場合ではF値が上がるが,論文正解率が下が ることがわかる.主に,表や図からの誤抽出や,1行が複数の TEXTに分割されている参考文献文字列に対するETCラベル 付与数の増加といった問題が発生した.これらは,終了位置検 出を行い,正解ラベルがETCであるTEXTの学習データ量 が減少したため,参考文献文字列とその他の区別が失敗したと 考えられる. また,表9,表15の石本らの方法に比べて,表10,表16の 提案素性は,DEIM2013,NTCIRの論文での実験でF値が高 かった.これらのデータセットでは,参考文献領域を分断する 表や図などを参考文献文字列として誤抽出する問題が改善した. ただし,参考文献領域を分断する表や図の境界部分でラベル付 与が正しく出来ない論文があった. また,表10,表13,表16より,“SRef”の再現率はDEIM2013 とIPSJでは1だったが,NTCIRでは1にならなかった. NT-CIRでは,参考文献文字列の開始行に,“SRef”ではなく“NRef” を付与することが2件あった.この内の1件は図2のように参 考文献文字列の幅が1行ごとに異なっていた. 本研究では,赤澤ら[9]と同様にラベル付与対象のTEXTの 前後のTEXTの情報を素性テンプレートtpl uchidaに加えた 実験も行った.具体的には,tpl akazawa1と同様にtpl uchida のUnigramのうちnumber(0)を除く全ての素性についてiを 加えた素性テンプレートを用意した.それによる論文正解率を 表20に示す.また,tpl akazawa2と同様にtpl uchidaとそれ ぞれのiとの組み合わせ素性を加えた素性テンプレート用意し た.それによる論文正解率を表21に示す.最後に,それら両方 の素性を加えた場合の論文正解率を表22に示す.表21,表22 を表19と比較すると,DEIM2013及びIPSJで論文正解率が 下がったが,NTCIRでは上がった.表21,表22では,IPSJ は,1行のみの参考文献文字列が連続する場合,個々の参考文 献文字列を区別できなかった.またDEIM2013では表7の領 域推定を誤った論文に対して正しくラベルが付与されなかった. また,ページ番号にETCラベルが付与された論文もあった. NTCIRの論文では,pdf2xmlが図3の論文PDFを,図4の ような論文XMLに変換した.この例では,図3の左段と右段 の文字列が,図4のXMLにおいて順序が入れ替わっている. このような場合,領域推定が誤ることがあった.そのため表19 では,それらの論文に対するラベル付与は失敗している.
5.
ま
と
め
本稿では,学術論文からの参考文献領域の検出方法の改良と, CRFを用いた参考文献文字列の抽出方法の改良を提案した.本研究ではまず,論文XMLファイルから“ 文献 ”や“Reference” 等のキーワードにより参考文献領域の開始位置を検出し,“ 付 録 ”等のキーワードにより参考文献領域の終了位置を検出する. 次に,検出した領域からCRFにより参考文献文字列を自動抽 出する.CRFによる参考文献文字列抽出では,特徴的な文字 列やレイアウトを考慮した特徴素性を提案した.実験では参考 文献領域検出は全て成功し,参考文献文字列抽出実験の論文正 解率は論文誌の種類により95%から99%となることを確認し た.本研究では,参考文献領域を分断する表や図からの誤抽出 が改善した.
謝
辞
本 研 究 の 一 部 は ,科 学 研 究 費 補 助 金 基 盤 研 究 (B)(課 題 番号15H02789),科学研究費補助金基盤研究(C)(課題番号 25530384),および国立情報学研究所公募型共同研究の援助に よる.ここに記して深謝する. 文 献[1] J. Lafferty,A. McCallum,and F. Pereira:Conditional Ran-dom Fields:Probabilistic Models for Segmenting and label-ing Sequence Data,In Proc. of 18th International Confer-ence on Machine Learning,pp. 282-289 (2001).
[2] C. Cortes, and V. Vapnik: Support-Vector Networks,Ma-chine Learning,Vol. 20,No. 3,pp. 273-297 (1995). [3] K. Seymore,A. McCallum,and R. Rosenfeld: Learning
Hidden Markov Model Structure for Information Extrac-tion,In AAAI 99 Workshop on Machine Learning for In-formation Extraction (1999).
[4] F. Peng,A. McCallum: Automating the Extraction from Research Papers using Conditional Random Fields,HLT-NAACL 2004,pp. 329-336 (2004).
[5] I.G. Councill,C.L. Giles and M.Y. Kan:ParsCit:An open-source CRF reference string parsing package,In the Pro-ceedings of Language Resources and Evaluation Conference, pp. 1-8 (2008).
[6] A. McCallum,K. Nigam,J. Rennie,and K. Seymore: Au-tomating the Construction of Internet Portals with Machine Learning,Information Retrieval,Vol. 3,No. 2,pp. 127-163 (2000). [7] 阿辺川武,難波英嗣,高村大地,奥村学: 機械学習による科学 技術論文からの書誌情報の自動抽出,情報処理学会研究報告, 2003-FI-72/2003-NL-157,pp.83-90 (2003). [8] 石本茜,太田学,高須淳宏,安達淳: CRF による学術論文から の参考文献文字列の抽出,第 6 回データ工学と情報マネジメン トに関するフォーラム (DEIM2014),C5-3 (2014). [9] 赤澤琢朗,太田学,高須淳宏,安達淳: CRF による様々な種類 の学術論文からの参考文献文字列の自動抽出,第 7 回データ工 学と情報マネジメントに関するフォーラム (DEIM2015),E8-1 (2015).
[10] H. Isozaki: OkaPU’s Japanese-to-English Translator for NTCIR-10 PatentMT,In the Proceedings of NTCIR-10 Conference,pp. 348-349 (2013).
[11] C.W. Shih, C.W. Lee, T.H. Yang, W.L. Hsu: IASL RITE System at NTCIR-9,In the Proceedings of NTCIR-9 Wprk-shop Meeting,pp. 379-385 (2011).


![図 2 参考文献文字列の幅が 1 行ごとに異なる論文 [10] 図 3 論文 PDF と論文 XML ファイルの文字列の順序が異なる例 (論文 PDF) [11] 図 4 論文 PDF と論文 XML ファイルの文字列の順序が異なる例 (論文 XML ファイル) [11] た論文正解率は表 19 に示す. 表 11 と表 12 を比べると,参考文献領域の終了位置を検出し たことにより, IPSJ では ETC の F 値が上がったことがわか る.実験に用いた IPSJ の論文は,論文フォーマットが比較的 整](https://thumb-ap.123doks.com/thumbv2/123deta/8188594.1276778/7.892.82.412.64.449/行ごと異なるファイル異なるファイル異なるファイルフォーマット.webp)
