✞ ✝
☎ ✆
原著論文
Original Paper
☞☞日本語学習者の作文自動誤り訂正のための語学学
習
SNS
の添削ログからの知識獲得
Mining Revision Log of Language Learning SNS for Automated Japanese Error
Correction
水本
智也
Tomoya Mizumoto
奈良先端科学技術大学院大学 Nara Institute of Science and Technology
[email protected], http://cl.naist.jp/∼tomoya-m/
小町
守
∗1Mamoru Komachi
奈良先端科学技術大学院大学 Nara Institute of Science and Technology
[email protected], http://cl.naist.jp/∼komachi/
永田
昌明
Masaaki Nagata
NTTコミュニケーション科学基礎研究所
NTT Communication Science Laboratories
[email protected], http://www.kecl.ntt.co.jp/icl/lirg/members/nagata/index-j.html
松本
裕治
Yuji Matsumoto
奈良先端科学技術大学院大学 Nara Institute of Science and Technology
[email protected], http://cl.naist.jp/staff/matsu/home.html
keywords:Japanese error correction, mining revision log, language learning SNS, second language learning
Summary
Recently, natural language processing research has begun to pay attention to second language learning. How-ever, it is not easy to acquire a large-scale learners’ corpus, which is important for a research for second language learning by natural language processing. We present an attempt to extract a large-scale Japanese learners’ corpus from the revision log of a language learning social network service. This corpus is easy to obtain in large-scale, covers a wide variety of topics and styles, and can be a great source of knowledge for both language learners and instructors.
We also demonstrate that the extracted learners’ corpus of Japanese as a second language can be used as training data for learners’ error correction using a statistical machine translation approach. We evaluate different granularities of tokenization to alleviate the problem of word segmentation errors caused by erroneous input from language learners. We propose a character-based SMT approach to alleviate the problem of erroneous input from language learners. Experimental results show that the character-based model outperforms the word-based model when corpus size is small and test data is written by the learners whose L1 is English.
1.
は
じ
め
に
「外務省の広報文化外交(海外広報・文化交流)」∗1に
よると,2009年時点で海外133の国・地域で約365万
人が日本語を学習しており,学習者の数は30年で30倍
に増加している.しかしながら,海外で日本語を教えて
いる教師の数はおよそ5万人に留まり,日本語第2言語
学習者に対する教師の需要が高まっている.
近年,自然言語処理による第2言語学習支援に関する
研 究 が 注 目 を 集 め て い る[Park 11, Rozovskaya 11, Liu
11, Oyama 10, Xue 10]が,多くの研究では学習者の犯す
誤りを限定している.たとえば,日本語学習者の作文誤
り訂正に関する研究では,[Oyama 10,南保07,今枝03]
が助詞の誤り訂正を行なっている.図1にNAIST誤用
†1 現在,首都大学東京に勤務.[email protected]. ∗1 http://www.mofa.go.jp/mofaj/gaiko/culture/
koryu/edu/index.html
コーパス[大山09] ∗2から調べた,日本語学習者の誤り
傾向を示す∗3.助詞が25%を占めており,日本語学習者
の誤りやすい箇所だとわかるが,残りの75%は語彙選択
や表記など助詞以外の誤りであるため,これらの誤りの
検出や訂正も重要であることがわかる.
[Park 11]はEMアルゴリズムを使った教師なしの手法
を用いて,誤りをひとつに限定することなく,複数の誤
りの訂正を行なったが,雑音のある通信路モデル(noisy
channel model)のパラメータ学習のためにあらかじめ誤
りのタイプを決めておく必要がある.
学習者の誤りを限定しない誤り訂正の手法として,
[Brock-ett 06]の統計的機械翻訳を用いた自動誤り訂正がある.
統計的機械翻訳を用いる利点としては,専門的な知識を
∗2 NAIST誤用コーパスは2·1節 で示す作文対訳DBに対して 誤りタイプを付与したものである.
必要としないことが挙げられる.統計的機械翻訳を用い
る手法では,学習者の文とその添削の対応がとれた大規
模な学習者コーパスから訂正モデルを学習する.しかし
ながら,大規模な学習者コーパスを手に入れることは容
易ではない.実際,[Brockett 06]は正規表現を用いて,ネ
イティブのコーパスから自動で英語の加算・不加算名詞
の誤りを含むコーパスを作成して訂正モデルの学習を行
なったが,全ての種類の誤りに対してこのように人工的
にデータが作成できるわけではない.従って,[Brockett
06]の手法は誤りを限定しないものの,コーパスによっ
て訂正できる誤りの制限を受けるため,特定の誤りの実
験結果しか報告していない.
この問題を解決するため,本研究は語学学習SNSの添
削ログから大規模な学習者コーパスの構築を行なう方法
を提案する.語学学習SNSの添削ログを使うことには主
に4つの利点がある.(1)多数のネイティブスピーカー
による添削結果を活用できる.(2)大規模な実コーパスを
構築できる.(3)幅広いトピック・スタイルをカバーでき
る.(4)言語学習者のみでなく,教師にとっても有益な情
報を得ることができる.
本研究では,構築した大規模な学習者コーパスを使い,
統計的機械翻訳の手法による誤りの種類を限定しない日
本語学習者の作文の誤り訂正を行なった.
[Brockett 06]が行なった英語を対象とした誤り訂正と
異なり,日本語を対象とした場合特有の問題が存在する.
英語の場合,単語は空白で区切られているが,日本語の
場合は単語に区切られていないため,最初に単語単位に
分割する処理を行なうことが多い.しかしながら,日本
語学習者の書いた文には誤りが含まれていたり,単語が
ひらがなで書かれることがある.そのため,学習者の書
いた文を既存の形態素解析器で解析すると単語分割に失
敗することが多く,誤り訂正を行なう際に影響を及ぼす
と考えられる.そこで,単語分割誤りの影響を軽減する
ため,本研究では文字分割を用いた誤り訂正を提案する.
以下2章で語学学習SNSから日本語学習者コーパス
を作る方法について述べる.3章でフレーズベースの統
計的機械翻訳を使った日本語誤り訂正手法について説明
を行ない,4章では2章で構築したコーパスと統計的機
械翻訳の手法を用いた誤り訂正の実験とその結果を示し,
5章で考察について述べる.
2.
語学学習
SNS
の添削ログから作る大規模日
本語学習者コーパス
Webの急速な発展によって場所や時間を気にすること
な く イ ン タ ー ネット を 使 う こ と が で き る ように なった .
ソーシャルネットワーキングサービス(SNS)が注目を
集めるようになり,最近では語学学習SNSも誕生した.
特に代表的な語学学習SNSとして,Livemocha∗4,
Lang-∗4 http://www.livemocha.com/
図1 日本語学習者の作文誤り傾向
図2 Lang-8での学習言語別ユーザ数
8∗5
がある.以下,2つの語学学習SNSについて簡単に
説明を行なう.
Livemochaは文法の勉強に加えてライティング,スピー
キングの練習をするためのコースを備えた語学学習SNS
サイトである.Livemochaは38の言語に対して教材を
提供している.ユーザは課題に沿った作文を書いて提出
したり,学習言語を母語とする他のユーザからのフィー
ドバックを受けることができる.Livemochaのフィード
バックの情報は添削とは限らず,コメントであることが
多い.また,学習者の文とフィードバック文が1文対1
文対応になっていない.
Lang-8は相互添削型SNSとも言われており,学習者が
学習している言語で日記を書くとその言語を母語とする
ユーザから添削を受けることができ,また学習者も自分
の母語で書かれた日記を添削するよう促される.Lang-8
では2010年12月(2011年10月)の時点で77の言語を
サポートしており,214,170人(同317,307人)のユー
ザが登録している.Lang-8は,ユーザインタフェースに
よって,1文に対して1つの添削を行なうようになって
いるため,学習者の文とその添削文の1対1対応がとれ
たものを獲得することができる.本研究で使用したい形
式は学習者の文と添削文で1対1対応がとれたものであ
るため,本研究ではLang-8のみ使用する.
2·1 日本語学習者コーパス
もっとも有名な日本語学習者コーパスの一つに,「寺村
誤用データ」∗6がある.このコーパスの大部分は1986年
に収集され,主にアジアの学生からデータが取得されて
いる.自由作文・穴埋め問題・パターン作文などいろい
ろなスタイルの作文からなっている.寺村誤用データと
異なり,Lang-8は世界中の日本語学習者が作文(日記)
を書いている.Lang-8では,学習者が自由にいろいろな
種類の作文を書いており,データのサイズもLang-8の
データ(448MB)は寺村誤用データ(420KB)よりも3 桁大きい.また,寺村誤用データはエラーの種類がタグ
付けされているが,正しい単語やフレーズは付けられて
いないため,学習者の作文の自動誤り訂正に利用するこ
とは難しい.
一方,大曽による「日本語学習者の作文コーパス」∗7も
広く用いられている.こちらはエラーの種類だけでなく,
訂正後の文字列も含めてタグ付けされているので,誤り
検出だけではなく,誤り訂正にも用いることができる.し
かしながら,大曽らのコーパスは4つの作文データから
集めたものであり,寺村誤用データと同様に多くのトピッ
クをカバーできておらず,データサイズも限られている
(756ファイル,平均ファイルサイズ:2KB).
また,最近になり国立国語研究所で「作文対訳DBコー
パス」∗8という日本語学習者コーパスが作成された.こ
のコーパスの特徴は,学習者が自分の書きたかった意図
を自分が使いやすい言語で説明する対訳文になっている
ことである.第三者が誤りを訂正しようとすると学習者
の意図が分からない,といったことがしばしば起こるが,
学習者の意図と実際に書く文のズレについての分析が行
なえるようになっている.このコーパスは日本語学習者
が手で書いた1,754作文を電子化しており,そのうちの
およそ250作文に日本語教師もしくは一般人が添削を行
なったものである.しかしながら,作文対訳DBコーパ
スもサイズが限られている.そこで,我々は上記に挙げ
た3つのコーパスと違い,日本語教師を必要とせず,多
数のネイティブスピーカーによる添削を用いることで大
規模な学習者コーパスを作成した.
2·2 Lang-8のデータの分析
Lang-8の添削ログから作成した大規模学習者コーパス
の特徴について分析する.図2を見ると,およそ75,000
人のユーザが日本語を学習していることがわかる∗9.表
1 にLang-8から作成したコーパス中で文数の多い言語
∗6 http://teramuradb.ninjal.ac.jp
∗7 https://kaken.nii.ac.jp/ja/p/08558020
∗8 http://jpforlife.jp/taiyakudb.html
∗9 ユーザのプロフィール情報をもとに計算を行なった.ユーザ
の中には,2つもしくはそれ以上の学習言語を登録している場
合がある.
トップ7を示す.英語学習者の文が最も多く1,069,549
文であり,日本語学習者の文は925,588文である∗10.本
研究では日本語学習者コーパスを作成したが,抽出方法
は言語に依存しないため2·4·1節,2·4·2節で示す方法
で他の言語の学習者コーパスを作成することも可能であ
る.日本語学習者の書いた925,588文のうち93.4%にあ
たる763,971文に人手による添削がついている.Lang-8
では,学習者の書いた文は異なるユーザによって2つも
しくはそれ以上の添削がつくことがある∗11.添削され
た後の文の総数を数えると,1,288,934文となっており,
1文に対して平均で1.69の添削がついていることがわか
る.また,Lang-8は多くの人が自由に作文を書いていて,
作文のトピックは多様なものになっており,スタイルも
通常の学習者コーパスに現れにくいものが含まれている.
Lang-8のトピックが多いことを確かめるために,作文
対訳DBとLang-8で使われている単語のドメインの調 査を行なった.ドメインの調査を行なうため,形態素解
析器JUMAN∗12及び,JUMANに用いられているドメイ
ン付きの辞書を利用した.JUMANの辞書は大きく分け
ると12のドメインに分かれているが,単語によっては
複数ドメインを持つものがある.例えば,JUMANの辞
書では「研究」は“科学・技術”に,「資源」は“科学・技
術;ビジネス;政治”に分類される.複数ドメインにまた
がるものを1つのドメインとして数えると,JUMANの
辞書に含まれているドメインの細分類数は124であった.
JUMANを使用して調べたLang-8,対訳DBに出現する
ドメインの細分類数はそれぞれ116 (94%),62 (50%)で
あった.このことから,Lang-8では,幅広い話題に対し
て作文が書かれていることがわかる.
作文スタイルに関しても作文対訳DBとLang-8コー
パスで比較を行なった.ここではスタイルを“敬体”,“常
体”,“くだけた会話体”の3つとする.“くだけた会話体”
は顔文字が含まれていたり,文末が長音(∼,ー)で終
わっている場合とする.作文対訳DB,Lang-8コーパス
からそれぞれ100記事ランダムにサンプリングしてきて
分類した結果,作文対訳DBでは敬体:75記事,常体:
25記事なのに対して,Lang-8コーパスでは,敬体:43
記事,常体:24記事,くだけた会話体:33記事となって
おり,Lang-8コーパスには,通常の学習者コーパスには 出てこないスタイルがあることがわかる.
2·3 Lang-8のデータの特徴
Lang-8から得られたデータにはいくつかの特徴がある.
ここで挙げる1,2,3番目の特徴は,どのような添削が
されているか,どのようなことを言いたいときに誤った
∗10 作文ごとにどの言語で書いているかユーザが指定しており,
それをもとに計算を行なった.
∗11 新しい添削はそれより前に他のユーザによってされた添削に
影響を受けることがある.
表1 Lang-8内での学習言語ごとの文数
言語 英語 日本語 中国語 韓国語 スペイン語 フランス語 ドイツ語
文数 1,069,549 925,588 136,203 93,955 51,829 58,918 37,886
表2 Lang-8内での学習者の母語による日本語作文の文数
母語 英語 中国語 韓国語 ロシア語 スペイン語
文数 509,924 265,340 48,406 19,499 17,133
表現を使ってしまうか,母語によってどこを間違えやす
いかを知ることができるため,学習者はもちろん教師に
とっても有益な情報となる.
1つ目はLang-8が語学学習SNSであるため,学習者
の作文とその添削の文のペアを簡単に手に入れることが
できる点である.このデータを使うことで,学習者の誤
りを集めることが可能になる.この章の後半でLang-8の
添削ログからの学習者コーパスの作り方について説明を
行なう.
2つ目の特徴はLang-8のユーザ情報から学習者の母語
情報を獲得することができることである.表2はLang-8
内の日本語学習者の作文を母語ごとに分類した場合の文
数を示している.[Rozovskaya 10]は英語学習者の誤り
を分析しており,母語によって誤り方の傾向が異なるこ
とを示した.[Rozovskaya 11]は母語による誤りの傾向
をモデルに組み込むことで,誤り訂正の精度が向上する
ことを示した.このコーパスを用いることで,日本語学
習者の誤りの傾向を分析することができ,誤り訂正に用
いる際にも母語ごとの誤りの傾向を大規模なデータから
学習して用いることができる.
3つ目の特徴は,Lang-8で添削を行なうユーザが学習
者の文に添削するだけではなく,文に対してコメントを
書くことがあるという点である.多くの場合,コメント
であることを示すために括弧で閉じられているが,そう
でない場合もある.添削者は,作文を書いた学習者の母
語に応じて,学習言語,もしくは学習者の母語でコメン
トをいれる.このコメント情報は学習者がよく犯す誤り
について誤りの理由等の説明を加えたものであり,言語
学習に対する有益な情報である.
4つ目の特徴はLang-8のデータでは1つの文に対して
複数の添削がついていることである.この特徴を利用す
ることで,[Barzilay 01]と同じような手法を用いて言い
換え表現を獲得することができる.表3に1文に対して
複数の添削がつく例を示す.2人の添削者が学習者の書
いた同じ文に対して添削をしており,この例では,“なり
の表現で”と“なりに”が互いに言い換え表現であると推
測することができる.
5つ目の特徴は対訳コーパスを獲得することができる
点である.図3にLang-8で学習者の書いた文が対訳に
なっている例を示す.この例では,日本語学習者は2つの
文を日本語で書いており,それぞれの文に対して何が言
いたいのかを英語で書いている.学習言語で書かれた文
図3 Lang-8で他言語が対になっている文の例
は誤りを含んでいることがあるが,英語で書かれた文か
ら正しい日本語の文へ対応をつけることができる.SNS
の添削ログから作られた対訳コーパスはブログやSNSと
いったCGMの翻訳に対する口語表現の重要な情報源と
なる.
2·4 Lang-8コーパスの作成
最 初 に コ ー パ ス を 作 る に あ たって 必 要 であ るLang-8
コーパスのHTML構造とデータの統計について説明する.
§1 Lang-8のHTML構造
Lang-8では,全ての添削はWebの訂正エディタのイ
ンタフェースから編集が行なわれており,添削者は文字
列の削除,挿入,置換によって添削を行なうことができ
る.表4はLang-8の訂正エディタから作られるHTML の例である.<span class="sline">タグはタグの
間の文字列を削除することを表している.色のタグ<span
class="red">と<span class="f blue">は添削
者が任意で強調したい場合などに用いられる.一般的に,
色のタグは正しい文字列を示すために使用される.表4
では,添削者が1つ目の誤り“してなかった”を削除タグ
で消して,挿入した部分“せずに”を赤色タグで強調して
示しおり,また青色タグで文末の挿入“だった”を示して
いる.
§2 編集距離によるデータの統計
実際の添削では学習者の書いたオリジナルの文を添削
者が全て書き直すのではなく,多くの文字列は学習者の
書いたままであると考えられる.そこで,Lang-8のデー
タの学習者の書いた文と添削後の文との編集距離(添削
ログ中の文字列の削除数と挿入数)の分析によって定量
的な分布を調べた.
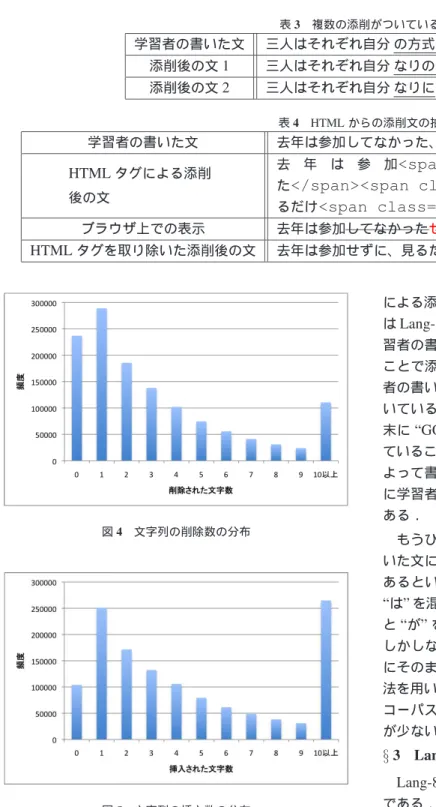
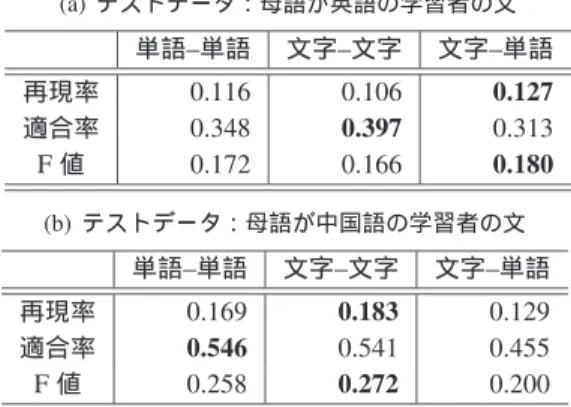
図4と図5に1文あたりの文字列の削除・挿入数の分
布を示す.削除・挿入数を数えるにあたり,文字列の置換
の場合は削除・挿入ともにカウントを行なった.削除数の
表3 複数の添削がついている例
学習者の書いた文 三人はそれぞれ自分 の方式で 感情を表 れ ます。
添削後の文1 三人はそれぞれ自分 なりの表現で 感情を表 し ます。
添削後の文2 三人はそれぞれ自分 なりに 感情を表 し ます。
表4 HTMLからの添削文の抽出
学習者の書いた文 去年は参加してなかった、見るだけ。
HTMLタグによる添削
後の文
去 年 は 参 加
<span class="sline">
し て な かった
</span><span class="red">
せ ず に</span>
、見るだけ
<span class="f_blue">
だった</span>
。ブラウザ上での表示 去年は参加してなかったせずに、見るだけだった。
HTMLタグを取り除いた添削後の文 去年は参加せずに、見るだけだった。
図4 文字列の削除数の分布
図5 文字列の挿入数の分布
で削除数と挿入数の分布で異なる点も存在している.例
えば,削除数が0である頻度は約230,000であるが,挿
入数が0である頻度は約100,000であり,削除数0の場
合の方が多い.また,挿入数が10以上である頻度が約
250,000,削除数が10以上である頻度は約100,000であ
り,挿入数と削除数を比べると差がある.これは,Lang-8
ではコメントを付けて添削することが多く,また添削者
が学習者の書いた文をなるべく残すように文字を多く削
除しないという傾向が現れているためである.
Lang-8の作文,添削文の観察から,添削は2つのタイ
プに分けることができる:(1)文字列の挿入・削除・置換
による添削,(2)コメントの挿入による添削である.表5
はLang-8内での添削の例である.1つ目の例は日本語学 習者の書いた文に誤りが含まれており,文字を挿入する
ことで添削を行なっている例である.2つ目の例は学習
者の書いた文は正しいが,添削者が文末にコメントを書
いている例である.学習者の書いた文が正しければ,文
末に“GOOD”や“OK”とだけコメントを付け加えられ
ていることもある∗13.この場合,学習者の文は添削者に
よって書き換えられておらず,挿入されたコメントは単
に学習者に書いた文に誤りがないことを知らせるだけで
ある.
もうひとつの重要な問題として,添削者が学習者の書
いた文に含まれる誤りの全てを訂正していない可能性が
あるということがある.表6は日本語学習者が“が”と
“は”を混同して書いて誤った例である.この例では,“は”
と“が”をそれぞれ“が”と“は”に訂正する必要がある.
しかしながら,添削者は2つ目の助詞“は”は訂正せず
にそのまま残している.本研究では統計的機械翻訳の手
法を用いており,数が少ないものは確率が低くなるため,
コーパスを作成するにあたり,このようなケースは影響
が少ないと考え,この問題は無視して扱った.
§3 Lang-8コーパスの作成手順
Lang-8コーパスの作成手順は大きく分けて次の2つ
である.(1) HTMLタグを取り除き添削文を抽出,(2)添 削文のコメントを取り除く.以下それぞれについて説明
する.
i. HTML構造からの添削文の抽出
HTMLタグの付き方から,単純なヒューリスティックス
を用いることでLang-8から添削後の文を抽出することが
できることがわかる.まず最初に全ての<span class=
"sline">とタグに挟まれている文字列を削除する.そ
の後,他のタグを削除し,タグに挟まれている文字列は
そのまま置いておく.このルールを用いたあと得られる
添削後の文は表4の一番下の行のようになる.
表5 Lang-8内の添削の例
学習者の書いた文 ビデオゲームをやました
添削後の文 ビデオゲームをや り ました
学習者の書いた文 銭湯に行った。
添削後の文(コメント付き) 銭湯に行った。 いつ行ったかがある方がいい
表6 Lang-8内での添削が全て正しく行なわれていない問題
学習者の書いた文 この4つ が 僕 は 少年のころに発売されて
添削後の文(誤りを含む) この4つ は 僕 は 少年のころに発売されて
正しい文 この4つ は 僕 が 少年のころに発売されて
ii. コメント除去のためのフィルタリング
2·4·2節で説明したコメントを処理するために,以下の
3つの前処理を行なった.(1)もし,添削後の文が“GOOD”
もしくは“OK”のみの場合,その文のペアをコーパスに含
めない,(2)もし学習者の文と添削後の文の間の削除数・挿
入数がともに5よりも大きい場合は,その文のペアはコー
パスには含めない,(3)もし添削後の文の文末が“GOOD”
もしくは“OK”で終わっている場合は,“GOOD”,“OK”
の文字を削除してその文のペアはコーパスに含める.こ
の処理を行なった結果,およそ34%の文が除去され,学
習者の書いた文と添削後の文の対応がとれた849,894文
対の学習者コーパスになった.
3.
フレーズベース統計的機械翻訳を使った日
本語学習者の作文誤り訂正
本研究ではフレーズベースの統計的機械翻訳[Koehn
03]を用いて日本語学習者の作文誤り訂正を行う.
ˆ
e=arg max
e P(e|f) =arg maxe M
∑
m=1λ
mhm(e,f)(1)式(1)は対数線形モデルを使った統計的機械翻訳の式であ
る.ここでeはターゲット側(翻訳後の言語)であり,f
がソース側(翻訳前の言語)である.hm(e,f)はM個の
素性関数であり,
λ
mが各素性関数に対する重みである.ソース側の文f に対して,素性関数の重み付き線形和を
最大化するターゲット側の文eを探せばいいことを意味
している.素性関数には,翻訳モデルや言語モデルなど
が用いられる.翻訳モデルは一般にP(f|e)という条件付
き確率の形で表される.この翻訳モデルP(f|e)はフレー
ズ間の対訳確率に分解して定義される.言語モデルは一
般にP(e)という確率の形で表され,n-gram言語モデル
が広く用いられている.また,翻訳モデルは文単位で1
対1対応のとれた対訳コーパスから学習し,言語モデル
はターゲット側言語から学習することができる.
これを誤り訂正に適応した場合,fは学習者の書いた添
削前の文となり,eは添削された後の文となる.また,翻
訳モデルは添削前後の文で1対1対応のとれた添削コー
パスからフレーズを抽出して学習し,言語モデルは誤り
を含まない文(添削後の学習者の文やネイティブが書い
た文など)から学習したものになる.こうすることで統
計的機械翻訳を使って,誤りを含む文を正しい文に変換
することができる.
統計的機械翻訳を誤り訂正に用いることには,以下の
4つのメリットがある.(1)言語教育に関する特別な知識
を必要としない.(2)統計的機械翻訳のツールを誤り訂正
タスクに対してそのまま利用することができる.(3)統
計的機械翻訳の手法が改善されれば,統計的機械翻訳を
使った誤り訂正も恩恵を受けることができる.(4)言語モ
デルの学習にはネイティブの書いた文からなる大規模な
生コーパスを用いることができる.
フレーズベース統計的機械翻訳を使った誤り訂正の関
連研究には,[Brockett 06]が英語を対象として行なった
ものがある.[Brockett 06]は統計的機械翻訳を使った加
算・不加算名詞の誤り訂正を提案し,自動で作り出した
346,000文の中から45,000文をランダムに抽出して学習
に用いた.我々の研究は,(1)誤り訂正の対象とする誤り
のタイプを加算・不加算名詞のみのように限定しない,(2)
大規模な実際の学習者の書いた文を用いる点で[Brockett
06]と異なる.
3·1 フレーズ抽出方法
フレーズの抽出は単語対応が付与された対訳コーパスか
ら統計的機械翻訳で一般的なヒューリスティックス(
grow-diag-final)[Och 03b]を用いて行なう.ここでは単語対応
の例を用いて説明を行なう.フレーズ抽出を行なう前処
理として,はじめに“学習者の書いた文から添削後の文”
と“添削後の文から学習者の書いた文”の両方向の単語の
対応をとる.学習者の書いた文から添削後の文への単語
対応の結果を図6(a)に,添削後の文から学習者の文への
単語対応の結果を図6(b)に示す.フレーズ抽出のヒュー
リスティックスgrow-diag-finalでは,両者の積集合を求 めその積集合の対応点を起点とし,両者の和集合の中の
対応点から既にある対応点に隣接する点を加えていく.
図6(c)の黒の部分が積集合の点で,灰色の部分が新たに
加えられた点である.その後,対応点が内部に閉じてい
るようなフレーズの対応を取り出す.赤の線で囲んであ
(a) 学習者の文から添削後の文への単語対応 (b)添削後の文から学習者の文への単語対応 (c)フレーズ抽出
図6 単語対応からのフレーズ抽出
“私は”に,“画工行きます”を“学校に行く”に,“行きま
すつもり”を“行くつもり”に対応させるフレーズを抽出
することができる.
3·2 文字–文字対応を用いたフレーズ抽出
一般的に機械翻訳で日本語から他の言語へ変換する場
合,単語に分割してから行うが,学習者の書いた文は新
聞記事などの日本語母語話者の書いた編集済みのコーパ
スから学習された形態素解析器では,単語にうまく分割
することができない.たとえば,
でもじよずしやありむせん
といった学習者の書いた文があるとすると∗14,これを辞
書としてUniDic 1.3.12∗15を用いたMeCab ∗16 で分か ち書きを行うと,
で もじ よ ずし や あり むせん
と分割されてしまう.一方,実際に人が添削した後の文
をMeCabで分かち書きすると,
で も じょうず じゃ あり ませ ん
のようになる.この2つを見ると,学習者の文には解析誤
りが含まれており,添削後の文と対応を取ることができ
ないため,図6のように適切なフレーズをとることが難
しく,単純に統計的機械翻訳で用いられている手法を適
用してフレーズ抽出することは困難であると予想される.
そこで,この問題を解決するために,単語よりも細か
い文字の単位に分割することを提案する.文字分割にす
ることにより形態素解析器の誤りの影響を受けないため,
頑健な解析が可能であると考える.実際に上記の学習者
の例と正解の例を文字に分割し,対応をとった結果が図
7のようになる.フレーズベースの手法を用いることで,
「じよず」と「じょうず」との対応を学習でき,単語分割
した場合と比べると頑健な誤り訂正が期待できる.
3·3 文字–単語対応を用いたフレーズ抽出
文字–文字対応では,学習者の文も添削後の文の両方と
も文字分割を行なっているため,単語の情報が失われて
∗14 説明のために,著者が作例したものである.
∗15 http://www.tokuteicorpus.jp/dist/
∗16 http://mecab.sourceforge.net/
図7 文字–文字対応の例
図8 文字–単語対応の例
しまっている.学習者の文は単語分割に失敗することが
あるが,添削後の文は正しく単語分割できる可能性が高
いにもかかわらず,文字-文字対応を用いた手法では学習
者の文も添削後の文も文字分割してしまい,単語の情報
を十分に活用することができない∗17.
そ こ で ,学 習 者 の 文 は 文 字 分 割 ,正 し い 文 は 単 語 分
割にした“文字–単語対応”を用いたフレーズ抽出手法を
提案する.図8は文字–単語対応の例である.“じよず”
か ら “じょうず”へ の 変 換 を 学 習 で き る の は も ち ろ ん ,
“じ よ ず し や”から“じょうず じゃ”への変換を学習す
ることができる.学習者の文は文字に分割することで未
知語の問題を軽減し,添削後の文は単語に分割すること
で品詞などのリッチな情報を活用することができる.こ
れにより学習者の文も正しい文に対しても文字分割を行
なった場合よりも,正しく訂正できると考えられる.
4.
大規模学習者コーパスと統計的機械翻訳を
使った誤り訂正の比較実験
以下の3つのことを確かめるためにLang-8コーパス
の一部をテストとして用いて実験を行なった.(1) 3章で
提案した単語,文字対応の粒度を変えた分割モデルによ
る性能の違い,(2)コーパスのサイズによる影響,(3)母
語の違いによる影響.また,(a)本研究で構築したコーパ
スの有効性および,(b)誤りタイプごとに訂正性能を見る
ためにNAIST誤用コーパスを用いた実験を行なった.実
∗17 学習者コーパスに辞書のエントリを加えるなど,辞書の情報
験にはMoses 2010-08-13∗18をデコーダ,GIZA++ 1.0.5
(HMMとIBMモデル1∼5を使用)∗19を対応づけ
のツールとして利用した.Mosesで使用されている素性
は,並べ替えの重み∗20,翻訳モデルの重み,言語モデル
の重み,目的言語の長さのペナルティ,並べ替えの制限
範囲である.また,単語分割にはUniDic 1.3.12を辞書
として用いたMeCab 0.97を利用した.
ベースラインとして単語–単語対応モデルを用い,提
案手法として文字–文字対応モデル,文字–単語対応モデ
ルの2種類を準備した.単語–単語対応モデルおよび文
字–単語対応モデルの言語モデルには単語N-gramを使用
し,文字–文字対応モデルの言語モデルには文字N-gram
を使用した.言語モデルのトレーニングには,Lang-8の
添削後の文を全て使うことができるため,単語ベースの
言語モデルで十分な性能が出ることが予測できる.しか
しながら,文字-文字モデルの場合は,デコードの際単語
ベースの言語モデルを用いると単語境界をまたぐフレー
ズが使われる可能性がある.そのため文字-文字モデルに
対しては文字ベースの言語モデルを用いた.言語モデル
のNは予備実験により決定し ,単語言語モデルに対して
は3-gram,文字言語モデルに対しては5-gramを使用し
た.全てのモデルに対して,BLEU [Papineni 02]を最大
化するようにminimum error rate training (MERT) [Och
03a]を行なった.
4·1 実 験 デ ー タ
実験には,Lang-8コーパスおよびNAIST誤用コーパ
スを用いた.Lang-8コーパスはクローリングによって獲
得した2010年12月までの作文データである.文が長く
なると対応づけの精度が下がり,誤り訂正の精度が下が
ると考えたため,2·4·2節で作成した849,894文の学習
者コーパスからさらに添削後の文字数が50以下のもの
だけ抽出し,796,956文を実験に使用した.また,母語
による誤りの影響を見るために,英語・中国語の2つの
母語を用意して実験を行なった.796,956文のうち,英
語を母語とする学習者の作文は298,359文であり,中国
語を母語とする学習者の作文は166,688文であった.テ
ストおよびデベロップメントデータには,トレーニング
データとは別に,英語,中国語を母語とする学習者が書
いた作文をそれぞれ500文を用意して∗21,人手で再添
削を行なったものを使用した.500文のうち200文をテ
スト,残りの300文をデベロップメントデータとして利
用した.NAIST誤用コーパスで実験に用いたデータは ∗18 http://http://www.statmt.org/moses/
∗19 http://code.google.com/p/giza-pp/
∗20 並べ替えには語彙並べ替えモデル(msd-bidirectional-fe)を使 用した.
∗21 クローリングして集めたLang-8のデータには学習言語が明
記されていない作文がある.その作文はLang-8コーパスを作
成した際に削除した.用意した500文はここで除外した作文で
あり,訓練データには含まれていない.また,学習言語は人手
で判断した.
図9 文字単位の誤り訂正の再現率・適合率の評価
6,433文で,そのうちランダムで500文抽出し,テスト
に200文,デベロップメントに300文を使用し,残りの
5,933文をトレーニングデータとして利用した.
4·2 評 価 尺 度
評価尺度として,文字単位による再現率,適合率およ
びF値を用いた.再現率,適合率,F値は以下のように
定義する.
再現率=
t p
t p+f n, 適合率= t p t p+f p, F値=
2×再現率×適合率
再現率+適合率
t p(true positive)はシステムが訂正を行ない正解だった箇
所,f p(false positive)はシステムが訂正を行なったが訂
正する必要がなかった箇所,f n(false negative)はシステ
ムは訂正を行なわなかったが訂正が必要だった箇所であ
る.また,F値は再現率と適合率の調和平均である.図9
の例を用いて説明を行なう.図9中のtnはシステムが訂
正を行なわず正解だった箇所である.t pの数は1,f pの
数は1,f nの数は2である.したがって,再現率は1/3
となり,適合率は1/2となる.
NAIST誤用コーパスを用いた実験では,コーパスに付
与された誤りタイプを用いた評価を行なった.誤りタイ
プごとの評価は,NAIST誤用コーパスで誤りタグがつけ
られた箇所を対象に,誤りタイプごとに正しく訂正でき
た数を数え,同じ誤りタイプがついた誤りの総数で割る
再現率を用いた.再現率のみで評価する理由は,訂正す
る必要がなかった箇所(学習者が正しく書いていた箇所)
をシステムが訂正してしまった場合,提案手法では誤り
タイプが何であるかわからないので,適合率に反映させ
ることが難しいためである.
4·3 Lang-8コーパスをテストデータとした場合の実験
結果
全ての実験はコーパスから10回ランダムで翻訳モデ
ルの学習用のデータを抽出して,それぞれのデータでモ
デルの学習を行なった.そのそれぞれのモデルでテスト
した出力に対する再現率,適合率,F値の平均で評価を
行なった.言語モデルの学習は全ての実験でテスト,デ
ベロップメントデータを除いた学習者コーパスの添削後
表7 分割モデルによる性能比較
(a)テストデータ:母語が英語の学習者の文
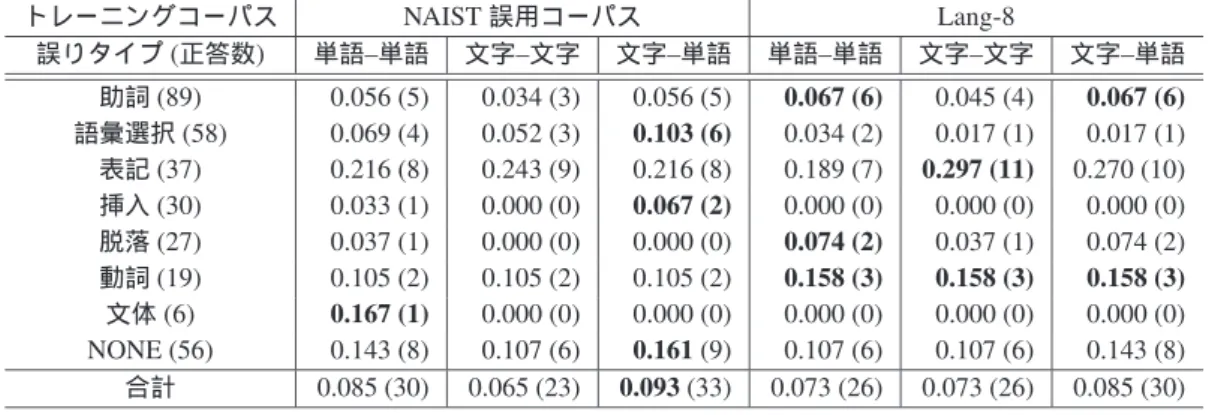
単語–単語 文字–文字 文字–単語 再現率 0.116 0.106 0.127 適合率 0.348 0.397 0.313 F値 0.172 0.166 0.180
(b)テストデータ:母語が中国語の学習者の文
単語–単語 文字–文字 文字–単語 再現率 0.169 0.183 0.129 適合率 0.546 0.541 0.455 F値 0.258 0.272 0.200
iii. 分割単位の違いによる性能評価
3章で提案した分割モデルの有効性を確かめるために
比較実験を行なった.表7に分割モデルごとの実験結果
を示す.翻訳モデルの学習には79万文を用いた.テスト
データが英語母語話者の文の場合では,F値,再現率は
文字–単語モデルが最も高く,適合率は文字–文字モデル
が最も高かった.中国語母語話者の文の場合では,F値,
再現率は文字–文字モデルが最も高く,適合率は単語–単
語モデルが最も高かった.
iv. 学習に用いるコーパスサイズの影響
2章で作成した大規模学習者コーパスの有用性を確か
めるため,翻訳モデルのトレーニングに使用するコーパ
スサイズを増減した場合(5万文,10万文,15万文,30
万文,50万文,79万文)の結果の変化を見る.図10,図
11,図12に学習に使用するコーパスのサイズを変化を
させた場合の単語–単語モデル,文字–文字モデル,文字–
単語モデルの実験結果を示す.テストコーパスが英語母
語,中国語母語の場合の単語–単語モデルおよび,テスト
コーパスが英語母語の場合の文字–文字モデルにおいて
は,コーパスのサイズが大きくなるとF値が高くなって
いる.
v. 学習に用いるコーパスの母語による影響
作成したコーパスと提案した手法を用いた場合,母語
を考慮することで精度に変化があるのか確かめるために,
トレーニングデータとテストデータの母語を変えて実験
を行なった.表8にトレーニング,テストに用いるコー
パスの母語を変化させた場合の実験結果を示す.翻訳モ
デルのトレーニングに用いるコーパスサイズは全て15万
文に固定して実験を行なった.母語が英語の学習者の文
をテストデータに用いた場合は母語が英語の学習者の文
でトレーニングした文字–文字モデルが最もF値が高く,
母語が中国語の学習者の文をテストデータに用いた場合
は母語が中国語の学習者の文でトレーニングした単語–
単語モデルが最もF値が高かった.
4·4 NAIST誤用コーパスをテストデータとした場合の
実験結果
(a)日本語教師によって誤りが訂正されたコーパスと
Lang-8コーパスのようなWebで訂正されたコーパスと
の性能差を比較するため,および,(b)誤りタイプごとの
訂正性能を見るために実験を行なった.上記2点を満た
すコーパスとして,教師によって訂正が行なわれ,誤り
タイプがついているNAIST誤用コーパスを用いて実験
を行なった.実験はそれぞれNAIST誤用コーパス5,933
文,Lang-8コーパス796,956文を用いて学習を行なった.
言語モデルの学習には,両方の場合で,Lang-8コーパス
の796,956文を用いた.
表9にタイプごとの再現率と正答数,表10に文字単位
による再現率,適合率,F値を示す.表9を見ると,ト
レーニングコーパスによる誤りタイプごとの訂正性能を
比較すると大きな差はないが∗22,語彙選択に関しては
NAIST誤用コーパスで学習した場合の方が訂正性能が高
くなっている.また,再現率は低いが複数の種類の誤り
も訂正できていることがわかる.表10の文字単位による
F値を見ると,単語–単語モデルではトレーニングコーパ
スによって差はないが,文字–文字,文字–単語モデルに
おいてはLang-8コーパスで学習した場合の方が高くなっ ている.
5.
考
察
2章で述べたようにLang-8から作成したコーパスの
添削後の文にはコメントが含まれている文もあるが,4
章で行なった日本語誤り訂正の実験での大きな影響はな
かった.統計的機械翻訳の手法を用いたシステムのアウ
トプットのチェックを行なったが,コメントが原因とな
る誤り訂正エラーはなかった.以下,4章で行なった実
験に合わせて考察を行なう.
5·1 分割モデルの違いによる考察
各分割モデルによる訂正結果の違いの例を示しながら
考察を行なう.本研究では,3つの手法を比べたが,それ
ぞれ異なるタイプの誤りを訂正できる傾向があった.表
11に実際の出力例を示す.表11(a)にどのモデルを用い
た場合でも訂正できた例を示す.最初の例では,発音と
表記が異なる助詞の“は”を同じ発音の“わ”に間違える
という誤りは学習者が間違えやすい誤りの典型であるた
め,どのモデルでも訂正できたと考えられる.また,イ
形容詞の「かわいい」をナ形容詞(形容動詞)だと誤っ
て「だ」を挿入してしまう“おいしいだね”も学習者が間
違いやすい誤りであり,どのモデルのフレーズテーブル
でも“おいしいだね”から“おいしいね”への変換の対応
が存在していた.このように,学習者が犯しやすい誤り
(a) テストデータ:母語が英語の学習者の文
(b)テストデータ:母語が中国語の学習者の文
図10 学習に用いるデータサイズによる
性能の比較(単語–単語)
(a)テストデータ:母語が英語の学習者の文
(b)テストデータ:母語が中国語の学習者の文
図11 学習に用いるデータサイズによる
性能比較(文字-文字)
(a)テストデータ:母語が英語の学習者の文
(b)テストデータ:母語が中国語の学習者の文
図12 学習に用いるデータサイズによる
性能比較(文字–単語)
表8 学習データの母語の違いによる性能比較.1列目の言語はトレーニングに用いるコーパスの学習者の母語
である.
(a)テストデータ:母語が英語の学習者の文
手法
単語–単語 文字–文字 文字–単語
英語
再現率 0.010 0.128 0.136 適合率 0.326 0.383 0.271 F値 0.151 0.190 0.181
中国語
再現率 0.051 0.089 0.097 適合率 0.248 0.266 0.189 F値 0.084 0.132 0.126
全言語
再現率 0.105 0.107 0.146 適合率 0.324 0.378 0.246 F値 0.158 0.167 0.181
(b)テストデータ:母語が中国語の学習者の文
手法
単語–単語 文字–文字 文字–単語
英語
再現率 0.170 0.151 0.171 適合率 0.457 0.494 0.354 F値 0.245 0.229 0.231
中国語
再現率 0.183 0.116 0.124 適合率 0.457 0.474 0.389 F値 0.260 0.185 0.187
全言語
再現率 0.155 0.132 0.119 適合率 0.478 0.476 0.373 F値 0.232 0.205 0.180
は,どの分割モデルでも十分な数出現するため,どのモ
デルでも訂正できたと考えられる.
以下,それぞれの分割モデルについて例を示しながら
考察を行なう.
vi. 単語–単語モデル
表11(b)は単語–単語モデルの出力結果の例である.表 に示しているような例で,学習者の文で誤りを含む場合
でも単語分割ができる場合は,単語の対応をとることが
できるため訂正できた.人手による正解データと比べると
“協会”を“教会”に変換しているが,“勉強”と“続けたく
て”の間に“を”を挿入できなかった.これは“協会”を“教
会”に変換するものがフレーズテーブルに存在しており,
“協会に行く”は言語モデルにないが“教会に行く”は存在
したためであると考える.一方,“勉強”と“続けたくて”
の間に“を”を挿入できなかった.これは,“勉強続き”を
“勉強を続け”に変換するようなフレーズはコーパスにな
く抽出できなかったためである.このように,格助詞の
挿入と動詞の活用誤りが同時に起きているような複合的
な誤りは出現数が少なく,訂正が困難である.これを解
決するひとつの策は,コーパスサイズを大きくして“勉
強続き”を“勉強を続け”が変換する対がコーパスに含ま
れるようにすることである.また,コーパスサイズの拡
充の他にも,“勉強続き”を“勉強を続け”に1度で変換で
きるフレーズはないが,“勉強続き”を“勉強続け”,“勉
強続け”を“勉強を続け”に変換するフレーズは存在して
いるため,2つのフレーズを合わせる,2度訂正を行なう
ことで訂正できると考える.
vii. 文字–文字モデル
文字–文字モデルの出力例を表11(c)に示す.文字–文
字アライメントモデルでは,日本語学習者にとって習得
が難しい長音の誤りである“アバイン”を“アーバイン”,
“インタネット”を“インターネット”に訂正することが
可能であったほか,キーボードのタイプミスと考えられ
る“けだ”を“だけ”に訂正するなど,単語のスペル誤り
を訂正できた.このように文字–文字アライメントモデ
表9 NAIST誤用コーパスをテストデータとした場合の誤りタイプ別再現率と正答数
トレーニングコーパス NAIST誤用コーパス Lang-8
誤りタイプ(正答数) 単語–単語 文字–文字 文字–単語 単語–単語 文字–文字 文字–単語 助詞(89) 0.056 (5) 0.034 (3) 0.056 (5) 0.067 (6) 0.045 (4) 0.067 (6) 語彙選択(58) 0.069 (4) 0.052 (3) 0.103 (6) 0.034 (2) 0.017 (1) 0.017 (1) 表記(37) 0.216 (8) 0.243 (9) 0.216 (8) 0.189 (7) 0.297 (11) 0.270 (10) 挿入(30) 0.033 (1) 0.000 (0) 0.067 (2) 0.000 (0) 0.000 (0) 0.000 (0) 脱落(27) 0.037 (1) 0.000 (0) 0.000 (0) 0.074 (2) 0.037 (1) 0.074 (2) 動詞(19) 0.105 (2) 0.105 (2) 0.105 (2) 0.158 (3) 0.158 (3) 0.158 (3) 文体(6) 0.167 (1) 0.000 (0) 0.000 (0) 0.000 (0) 0.000 (0) 0.000 (0) NONE (56) 0.143 (8) 0.107 (6) 0.161(9) 0.107 (6) 0.107 (6) 0.143 (8) 合計 0.085 (30) 0.065 (23) 0.093(33) 0.073 (26) 0.073 (26) 0.085 (30)
表10 NAIST誤用コーパスをテストデータとした場合の文字単位による再現率・適合率・F値
トレーニングコーパス NAIST誤用コーパス Lang-8
単語–単語 文字–文字 文字–単語 単語–単語 文字–文字 文字–単語 再現率 0.080 0.048 0.112 0.081 0.072 0.130 適合率 0.222 0.231 0.131 0.190 0.295 0.236 F値 0.118 0.080 0.121 0.113 0.116 0.167
正に強い.その理由としては,文字という細かい単位を
利用することで,フレーズテーブルに単語として存在し
ない場合でも訂正が可能であるからだと考えられる.例
えば,“アバイン”を“アーバイン”に変換するようなも
のはどのモデルでも抽出したフレーズには存在していな
かった.しかしながら,文字–文字モデルの抽出されたフ
レーズを見ると,“のア”を“のアー”の対応は存在して
おり,訂正する際にこれと言語モデルを用いることで訂
正できたと推測される.
viii. 文字–単語モデル
文字–単語アライメントモデルで訂正できた文を見る
と,単語–単語アライメントモデルと同じものが多く,文
字–文字アライメントモデルで訂正できたものも一部訂
正できており,両方のモデルのよいところを持っている.
実際,表11(b)に示した2つの例や,表11(c)で示した
“けだ”を“だけ”に直すものは文字–単語アライメントモ
デルで訂正できた.
5·2 分割モデルとコーパスサイズの違いによる考察
4章のコーパスサイズを変えた場合の実験結果,図10,
図11,図12について考察を行なう.テストコーパスが
英語母語,中国語母語両方の場合ともコーパスサイズが
小さい時は文字–文字モデルが最もF値が高い.5·1節の
文字–文字モデルで説明したような長母音の挿入など単語
中の1文字の変換といった訂正はフレーズが完全に一致
していなくても訂正できるため,コーパスサイズが小さ
くても比較的高いF値になると考える.テストコーパス
が英語母語の場合は,文字–文字モデルではコーパスサイ
ズを大きくしてもあまり効果はなかった.これは1文字
の変換がある特定のひらがなに限られており,コーパス
サイズが小さい場合でもすでに大部分が出現しているた
めだと考えられる.テストコーパスが中国語母語の場合
では,日本語にはない中国語で使われる簡体字を誤って
使用する場合があるため,コーパスサイズを大きくする
ことでこのような誤りに対応できるようになるため,文
字–文字モデルでもコーパスサイズを大きくしてF値が
改善すると考える.
単語–単語モデルでは,テストコーパスが英語母語,中
国語母語の場合でもコーパスサイズを大きくすることで
F値が改善する.これは,コーパスサイズを大きくするこ
とで訂正に利用できるフレーズの数が増えるためである.
文字–単語モデルでは,テストコーパスが英語の場合は
79万文の時にF値が下がったが,50万文まではF値は向
上している.テストコーパスが中国語母語の場合,コー
パスサイズを大きくしてもF値は上がらなかった.テス
トコーパスが中国母語の文字–単語モデルの実際の出力を
見ると関係ない文字列が挿入されていることが他の2つ
のモデルと比べると多いことから,文字–単語アライメン
トに失敗していることが考えられる.文字–文字や単語–
単語アライメントの場合,多くの場合同じ文字が対応し
ているのでアライメントをとるのは容易である.文字–単
語アライメントの場合でも,多く出現するフレーズのア
ライメントはとることができる.しかしながら,中国語
母語の学習者が使う簡体字の漢字は出現頻度も低いため
アライメントに失敗し,結果的に訂正の性能にも影響し
ていると考える.
5·3 トレーニングコーパスの母語の違いによる考察
トレーニングコーパスの母語とテストコーパスの母語
を同じにした場合,最も高いF値は,図10,図11,図
12の同じデータサイズ15万文の結果よりも高い.この
ことから,統計的機械翻訳の手法による誤り訂正におい
てもトレーニングコーパスの母語とテストコーパスの母
英語母語の場合と中国語母語の場合で,最も高いF値 を達成したモデルが違う.これは英語母語の学習者の文
はひらがなで書かれていることが多く,単語分割に失敗
することがあるため文字–文字モデルの精度がよくなる
が,中国語母語の学習者の文は漢字が多用されており,単
語分割の失敗が少ないため単語–単語モデルの精度がよ
くなるためである.
5·4 誤りタイプによる考察
4·4節で行なったNAIST誤用コーパスを用いて行なっ
た実験に関する考察を行なう.4·4節でも触れたが,語彙
選択に関してはトレーニングデータにLang-8コーパス
を用いた場合よりも,NAIST誤用コーパスを用いた場合
の方が再現率が高かった.これはトレーニングデータと
テストデータでドメインが一致していたためだと考えら
れる.例えば以下の例は,NAIST誤用コーパスでトレー
ニングした場合に訂正できた文である.
Original:自治州の 人民 におめでとうと言う
Correct:自治州の 人々 におめでとうと言う
これは「あなたの国の行事/料理/歴史の出来事」といっ
た作文のテーマがあり,その中で“人民”が多く使われ,
また添削者によって“人々”に訂正されていたからである.
これを訂正する方法の一つはコーパスの量を増やすこと
である.他には,誤りやすい傾向をモデル化して,その
モデルから誤りを予想するといったことが考えられる.
また,NAIST誤用コーパスが手書きテキストを電子化 したデータであるため,初めからキーボードで入力され
たLang-8のデータにはないタイプの誤りもあり,その誤
りに関してはLang-8でトレーニングした場合は訂正で
きない.例えば,“他”を“地”に間違える,“与”を“写”
に間違えるといった似た漢字の書き間違いの誤りである.
誤りタイプごとの再現率を見ると,助詞に関しては先
行研究と比べ非常に低い値になった.この原因としては,
フレーズベース統計的機械翻訳では遠くの依存関係を捉
えることができず,訂正できないためである.
Original:すぐ近く から たばこの煙を吸う
Correct:すぐ近く で たばこの煙を吸う
この例で助詞“から”を“で”に訂正するためには,“近
く”と“から”と“吸う”に依存関係があるということが
分かる必要がある.しかしながら,実験に用いたフレー
ズベース統計的機械翻訳の手法ではこのような長距離の
関係を扱うことができない.この問題は,構文情報を扱
うことのできるstring-to-dependencyのようにソース側
が単語列でターゲット側が係り受け構造になっている機
械翻訳の手法を用いることで解決できると考える.
表11 各モデルの出力例
(a)全てのモデルで訂正できた例
学習者の作文 TRUTHわ 美しいです
人手による添削 TRUTHは 美しいです
学習者の作文 おいしい だ ね
人手による添削 おいしい ね
(b)単語–単語モデルの出力例
学習者の文 私は協会に行 きます つもりです
システムの出力 私は教会に行 く つもりです
人手による添削 私は協会に行 く つもりです
学習者の文 勉強続 き たくて
システムの出力 勉強続けたくて
人手による添削 勉強 を 続けたくて
(c)文字–文字モデル出力例
学習者の文 カルフォルニアのアバイン大学
システムの出力 カルフォルニアのア ー バイン大学
人手による添削 カルフォルニア大学のア ー バイン校
学習者の文 インタネットを壊した
システムの出力 インタ ー ネットを壊した
人手による添削 インタ ー ネットを壊した
学習者の文 いつも英語 けだ を話したくない
システムの出力 いつも英語 だけ を話したくない
人手による添削 いつも英語 だけ を話したくない
6.
お
わ
り
に
本研究では,語学学習SNSの添削ログから大規模な学
習者コーパスを作成する方法を提案した.この作成した
コーパスは簡単に大規模に手に入れることができ,幅広
いトピック,スタイルをカバーしており,学習者・教師
両方にとって有益な情報源である.また,本研究では統
計的機械翻訳の手法と作成した大規模な学習者コーパス
を用いて実際に学習者の書いた文に対する誤り訂正を行
なった.日本語学習者の誤りを含む文を処理する際に生
じる単語分割の問題に対して,文字分割を用いることで
対処した.実験の結果,基本的には,提案手法である文
字–文字モデル,文字–単語モデルの方が単語–単語モデ
ルのF値よりも高くなった.学習に用いるデータを多く
すると,多くの場合でF値が高くなった.また,母語の
情報を用いることでより高いF値を達成することができ
ることも確かめた.
本研究では大規模なコーパスを用いて誤り訂正を行なっ
たが,実用化できるまでの精度には至らなかった.今後,
性能を改善するための課題としては,Lang-8の2011年
以降のデータの使用や他の言語学習SNSからデータを抽
出することで学習に使用するコーパスのサイズをさらに
ルの作成が考えられる.本研究では,単語–単語モデル,
文字–単語モデルには単語言語モデルを使用し,文字–文
字モデルに対しては文字言語モデルを使用したが,文字–
文字モデルに対して単語言語モデルを利用することで性
能が改善すると考えられるため,言語モデルの粒度に関
しても今後の課題である.また,学習者コーパスに出現
しないような誤りにも対応するためには,誤り訂正候補
の自動生成[Dahlmeier 12]などを行なっていく必要があ
る.さらに,現在はフレーズベース統計的機械翻訳を使っ
て訂正を行なっているが,構文情報を用いた統計的機械
翻訳の手法を使うことで性能を改善できると考える.
謝 辞
Lang-8のデータ使用に際して,快諾してくださった株
式会社Lang-8社長喜洋洋氏に感謝申し上げます.また, 匿名で査読してくださり,有益な助言,コメントをくだ
さった3名の方に感謝申し上げます.
♦
参
考
文
献
♦
[Barzilay 01] Barzilay, R. and McKeown, K. R.: Extracting Para-phrases from a Parallel Corpus, inProceedings of the 39th Annual Meeting of the Association for Computational Linguistics, pp. 50–57 (2001)
[Brockett 06] Brockett, C., Dolan, W. B., and Gamon, M.: Correct-ing ESL Errors UsCorrect-ing Phrasal SMT Techniques, inProceedings of the 21st International Conference on Computational Linguistics and 44th Annual Meeting of the Association for Computational Linguis-tics, pp. 249–256 (2006)
[Dahlmeier 12] Dahlmeier, D. and Ng, H. T.: A Beam-Search De-coder for Grammatical Error Correction, inProceedings of the Con-ference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, pp. 568–578 (2012) [今枝03] 今枝恒治,河合敦夫,石川裕司,永田亮,桝井文人:日本
語学習者の作文における格助詞の誤り検出と訂正,情報処理学会
研究報告 コンピュータと教育研究会報告, pp. 39–46 (2003)
[Koehn 03] Koehn, P., Och, F. J., and Marcu, D.: Statistical Phrase-Based Translation, inProceedings of the 2003 Human Language Technology Conference of the North American Chapter of the As-sociation for Computational Linguistics, pp. 48–54 (2003) [Liu 11] Liu, X., Han, B., and Zhou, M.: Correcting Verb Selection
Errors for ESL with the Perceptron, inProceedings of the 12th In-ternational Conference on Computational Linguistics and Intelligent Text Processing and Computational Linguistics, pp. 411–423 (2011) [南保07] 南保亮太,乙武北斗,荒木健治:文節内の特徴を用いた
日本語助詞誤りの自動検出・校正,情報処理学会研究報告 自然
言語処理研究報告, pp. 107–112,情報処理学会(2007)
[Och 03a] Och, F. J.: Minimum Error Rate Training in Statistical Ma-chine Translation, inProceedings of the 41st Annual Meeting of the Association for Computational Linguistics, pp. 160–167 (2003) [Och 03b] Och, F. J. and Ney, H.: A Systematic Comparison of
Various Statistical Alignment Models, Computational Linguistics, Vol. 29, No. 1, pp. 19–51 (2003)
[大山09] 大山浩美:日本語学習者コーパスのための誤用タグ構築
について,熊本県立大学日本語日本文学会,第54巻, pp. 102–114
(2009)
[Oyama 10] Oyama, H. and Matsumoto, Y.: Automatic Error Detec-tion Method for Japanese Case Particles in Japanese Language Learn-ers, inCorpus, ICT, and Language Education, pp. 235–245 (2010) [Papineni 02] Papineni, K., Roukos, S., Ward, T., and Zhu, W.-J.:
BLEU: A Method for Automatic Evaluation of Machine Translation, inProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, pp. 311–318 (2002)
[Park 11] Park, Y. A. and Levy, R.: Automated Whole Sentence Grammar Correction Using a Noisy Channel Model, inProceedings of the 49th Annual Meeting of the Association for Computational Lin-guistics: Human Language Technologies, pp. 934–944 (2011) [Rozovskaya 10] Rozovskaya, A. and Roth, D.: Annotating ESL
Er-rors: Challenges and Rewards, inProceedings of the Human Lan-guage Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics Fifth Workshop on Innovative Use of NLP for Building Educational Applications, pp. 28–36 (2010)
[Rozovskaya 11] Rozovskaya, A. and Roth, D.: Algorithm Selection and Model Adaptation for ESL Correction Tasks, inProceedings of the 49th Annual Meeting of the Association for Computational Lin-guistics: Human Language Technologies, pp. 924–933 (2011) [Xue 10] Xue, H. and Hwa, R.: Syntax-Driven Machine Translation
as a Model of ESL Revision, inProceedings of the 23rd International Conference on Computational Linguistics, pp. 1373–1381 (2010)
〔担当委員:濱崎 雅弘〕
2012年7月18日 受理
著 者 紹 介
水本 智也(学生会員)
2010年甲南大学理工学部情報システム工学科卒業.2012
年奈良先端科学技術大学院大学情報科学研究科博士前期課 程修了.現在,同大学院大学情報科学研究科博士後期課程 在学中.日本学術振興会特別研究員(DC2).自然言語処理 の研究に従事.ACL会員.
小町 守(正会員)
2005年東京大学教養学部基礎科学科科学史・科学哲学分
科卒.2010年奈良先端科学技術大学院大学情報科学研究 科博士後期課程修了.博士(工学).同年より同研究科助 教を経て,2013年より首都大学東京システムデザイン学 部准教授.専門は自然言語処理.大規模なコーパスを用い た意味解析および統計的自然言語処理に関心がある.情報 処理学会,言語処理学会,ACL各会員.
永田 昌明(正会員)
1987年京都大学大学院工学研究科修士課程修了.同年,日
本電信電話株式会社入社.現在,コミュニケーション科学 基礎研究所 主幹研究員.工学博士.統計的自然言語処理の 研究に従事.電子情報通信学会,情報処理学会,言語処理 学会,ACL各会員.
松本 裕治(正会員)
1977年京都大学工学部情報工学科卒業.1979年同大学工