自然選択による恒常性を持つ人工生命の創発
高橋 将文
情報アーキテクチャ学科 1014053
指導教員 三上貞芳
提出日 平成 30 年 1 月 29 日
Emergence of Artificial Life with Homeostasis
by Natural Selection
by
Masafumi TAKAHASHI
BA Thesis at Future University Hakodate, 2018
Advisor: Prof. Sadayoshi MIKAMI
Department of Media Architecture Future University Hakodate
The purpose as a biological agent is finite limited by symbolizing the purpose of a biological agent as an objective function. In this research, we propose a method to create artificial life that has homeostasis and can adapt to the three-dimensional environment with high dimensional visual input without using objective function. The artificial life has a neural network as a gene that determines behavior from its perceptual state and physiological state. The agent mutates genes by repeating natural selection and mutation, and adapts to the environment as a population. Finally, we evaluate the adaptability and homeostasis of the agent to the environment, and show that the agent can adapt to the environment as a population.
Keywords: Artificial Life, Homeostasis, Natural Selection, NEAT, Deep NeuroEvolution
概 要: 近年,恒常性に基づく生物学的エージェントに関する研究が行われている.また,それら の研究のほとんどでは,エージェントに対し何らかの目的関数が与えられている.しかし,生物学 的エージェントの目的を目的関数として記号化することにより,本来無限に存在する生物学的エー ジェントとしての目的を有限に制限してしまう.よって,本研究では高次元の視覚入力を伴う 3 次 元環境において,目的関数を用いることなく恒常性を持ち環境に適応可能な人工生命を創発する. 人工生命は自身の知覚状態と生理学的状態から行動を決定するニューラルネットワークを遺伝子と して持つ.エージェントは自然選択と突然変異を繰り返すことで遺伝子が変異し,個体群として環 境に適応する.最後に,エージェントの環境への適応度や恒常性を評価し,エージェントが個体群 として環境に適応可能であることを示す.
目 次
第1章 緒言 1
1.1 背景 . . . . 1
1.2 研究目的 . . . . 2
第2章 関連研究 3 2.1 Homeostatic reinforcement learning for integrating reward collection and physiological stability . . . . 3
2.2 An Adaptive Robot Motivational System . . . . 4
2.3 Homeostatic Agent for General Environment . . . . 4
第3章 関連事象 8 3.1 遺伝的アルゴリズム . . . . 8 3.1.1 選択 . . . . 8 3.1.2 交叉 . . . . 8 3.1.3 突然変異. . . . 9 3.2 自然選択 . . . . 9 3.3 ニューラルネットワーク . . . . 9 3.3.1 全結合層. . . 11 3.3.2 畳み込み層 . . . 11
3.4 NeuroEvolution of Augmenting Topologies . . . 13
3.5 Deep NeuroEvolution . . . 16
3.6 Global Average Pooling . . . 16
3.7 Unity . . . 16 3.8 Life in Silico . . . 17 第4章 提案手法 19 4.1 環境 . . . 19 4.2 エージェント . . . 19 4.3 評価方法 . . . 22 第5章 NEATを用いたエージェントによる実験 24 5.1 平地における実験 . . . 24 5.1.1 結果 . . . 24 5.1.2 考察 . . . 27 5.2 高低差がある地形における実験 . . . 27
5.2.1 結果 . . . 27 5.2.2 考察 . . . 27 5.3 草木・岩が存在する地形における実験. . . 30 5.3.1 結果 . . . 30 5.3.2 考察 . . . 30 第6章 Deep NeuroEvolutionを用いたエージェントによる実験 35 6.1 平地における実験 . . . 35 6.1.1 環境 . . . 35 6.1.2 結果 . . . 35 6.1.3 考察 . . . 35 6.2 高低差がある地形における実験 . . . 37 6.2.1 環境 . . . 37 6.2.2 結果 . . . 37 6.2.3 考察 . . . 38 6.3 草木・岩が存在する地形における実験. . . 38 6.3.1 環境 . . . 38 6.3.2 結果 . . . 38 6.3.3 考察 . . . 40 第7章 結言 41 7.1 まとめ . . . 41 7.2 今後の方針 . . . 41
第
1
章
緒言
1.1
背景
生物は,変動する外部環境に対して生体の内部状態を一定に保とうとする維持機構を備
えている[1].これは「恒常性」として知られている.近年,この恒常性に基づく生物学的
エージェントに関する研究が行われている.Ashbyは,機械の状態を動的に安定化させる
Homeostatを開発した[2].PfeiferとScheierは,古典的な人工知能における問題点として
フレーム問題や記号接地問題を説明し,完全自律エージェントと身体性認知科学の研究の 重要性を指摘した[3].銅谷らは,生存と進化的ロボット工学のための学習エージェントの 研究を目的としたサイバーローデントと呼ばれるロボットを開発した[4].サイバーロー デントは,環境中に存在するバッテリーパックを用いて充電することにより自身のバッテ リーの状態を安定に保つことが可能である.Keramatiらは,エージェントの内部状態を 考慮しない強化学習モデルの弱点は学習及び動機への統合された見解の欠如から生じると 考え,生理学的状態から動機づけ状態へのマッピングとしてドライブの仮説的概念を形式 化した[5].Yoshidaは,生存確率の対数を報酬関数とした深層強化学習を用い,視覚刺激 を含む環境において恒常性を維持し,生存可能なエージェントを開発した[6]. これらの研究のほとんどでは,設計者によってエージェントに何らかの目的関数が与え られている[4, 5, 6].しかし,生物学的エージェントの目的を目的関数としてモデル化する ことによって目的を記号化するため,本来無限に存在する生物学的エージェントとしての 目的を有限に制限してしまう.そのため,設計者が考慮していない環境では適応出来ない などの問題が発生する可能性がある.これは一般にフレーム問題と呼ばれ,生物学的エー ジェントの目的を目的関数としてモデル化する限り逃れることが出来ない問題である.こ のように,フレーム問題の影響を最小限に抑えることは,生物学的エージェントの設計に おいて重要な課題の一つである.
1.2
研究目的
本研究では,目的関数を用いることなく,自然選択と突然変異によって恒常性を持ち環 境に適応可能な人工生命を開発する.ここで,目的関数とは,最適化問題において目的を 最大化または最小化される関数として定式化したものである. 生物学的エージェントは,「食物を探す」,「食べる」,「天敵から身を守る」,「繁殖する」, 「子孫の世話をする」といった,さまざまなタスクを実行しなければならない[3].しかし, これまでの研究のほとんどでは,設計者によってエージェントに何らかの目的関数が与え られているため,本来無限に存在する生物学的エージェントとしての目的を有限に制限し てしまっていた.これは,設計者又は観測者によってエージェントの目的を目的関数とい う形でモデル化されることにより発生する問題である.よって,本研究では目的関数を用 いることなく恒常性を持ち環境に適応可能な人工生命を開発することを目的とする.第
2
章
関連研究
2.1
Homeostatic reinforcement learning for integrating
reward collection and physiological stability
Keramatiらは,各次元が1つの生理学的に調節される変数を表す多次元空間として恒 常性空間を定義し,生物学的エージェントの生理学的状態はこの空間における点として表 すことが出来ることを示した[7].また,生理学的状態の定常点からの距離としてドライブ を定義し,ドライブの時系列な偏差を強化学習における報酬関数として用いることで,生 理学的状態から動機付け状態へのマッピングを可能とした.Keramatiらが定義した恒常 性空間の例として,2次元恒常性空間のモデルを図2.1に示す. しかし,自らの生理学的状態の偏差のみを報酬として用いているため,天敵から身を守 る,繁殖する,子孫の世話をするなどといったタスクを学習することが出来ない点や,固 定的な報酬関数を用いているため,動的に変化する環境に適応出来ない可能性がある等の 課題がある. 図2.1: 2次元恒常性空間のモデル[7]
2.2
An Adaptive Robot Motivational System
KonidarisとBartoは,これまでのほとんどのモチベーションシステムにおける報酬関 数は観測者による設計や進化により固定されていることを指摘し,報酬関数に含まれる各 資源の優先度はエージェントが自ら発見した環境の特性として用いられるべきであると主 張した[8].また,その主張を基に飽和レベルσi及び優先度piを用いて資源の優先度ki を決定する優先度曲線を定義し、ステップ間の資源の差を優先度で乗算したものを報酬と した.Konidarisらが定義した優先度曲線を図2.2に示す.また,この報酬を用いた強化 学習によって資源獲得問題を解く実験を行い,優先度を用いない報酬を用いた場合と比較 し,より飽和レベルを安定化させることが可能なことを示した.Konidarisらが定義した モチベーションシステムの概要を図2.3に示す. しかし,2.1で述べた先行研究と同じように自らの資源の状態のみを報酬として用いる ため,天敵から身を守る,繁殖する,子孫の世話をするなどと行ったタスクを学習するこ とができないという問題がある. 図2.2: 優先度曲線[8]2.3
Homeostatic Agent for General Environment
Yoshidaは,報酬関数に生存確率の対数を用いて定式化を行った.また,定式化した報酬
図2.3: モチベーションシステムの概要[8] 固定的なものが用いられてきた.しかし,このような報酬や目的関数では単純な強化学習 タスクは成功するかもしれないが,複雑なタスクや生涯学習ではシステムの性能に悪影響 を及ぼす可能性があることを指摘している.そこで,Yoshidaは生存問題における報酬関 数に時間的生存確率の対数を用いて定式化を行い,生態学的ニッチ相互に依存する報酬関 数として定義した.報酬関数の基となる時間的生存確率は進化的過程を通じて得ることが 出来る.
Yoshidaは,深層強化学習の手法としてMnihらによって開発されたDeep Q-network
(DQN)を用いた.用いたニューラルネットワークの構成を図2.4に示す.入力はエージェ ントのエネルギーレベル,エージェントの視覚入力である画像の2種類であり,出力は各 行動(右回転,左回転,前進)のQ値である.視覚入力は2層の畳み込み層(3×3の8 枚のフィルタによる畳み込み層,3×3の16枚のフィルタによる畳み込み層)を伝播し, 400個のユニットを持つ全結合層へ伝播する.また,エネルギーレベルは50個のユニット を持つ全結合層へ伝播した後,視覚入力から伝播した値と加算され,出力層へ伝播する. エージェントは出力層で出力された値に対してε-greedy法を用いて行動が選択される. Yoshidaが用いた環境を図2.5に示す.フィールドは約12×12[m2]であり,芝生のテ クスチャで覆われている.また,フィールドは4つの透明な壁に囲まれ,エージェントが フィールドの外を見ることを防ぐために山に囲まれている.フィールドには赤と青の2種 類の食物が存在する.各食物はフィールド上に15個ずつランダムに配置されている.エー ジェントが食物に触れると食物の色に対応するエネルギーが0.3増加し,触れられた食物 が消去される.また,その際に消去された食物と同じ食物がフィールドにランダムな位置 に生成される.エージェントの視覚情報は,エージェントに搭載されているフロントカメ ラから32×32のRGB画像として取得される. エージェントのエネルギーレベルは0.01ずつ減少する.エネルギーレベルが[-10.0,10.0]
図 2.4: ネットワーク構成[6] の範囲を超えるとエピソードが終了する.また,次のエピソードはエージェントの各エネ ルギーレベルが0,エージェントや各食物がフィールド上にランダムな位置に配置された 状態で開始される.また,エージェントが2万ステップ生き延びた際にそのエピソードを 終了させる. Yoshidaはこの実験により,生存問題における報酬関数を生存確率の対数として定式化 を行った.また,定式化した報酬関数を用いて高次元の視覚入力を伴う3次元環境におい て深層強化学習を行い,エージェントが十分に長い時間生存可能になることを示した.し かし,自身の生存確率の対数のみを報酬関数として用いるため,他の同種の個体との協力, 子孫の世話などといったタスクを学習することが出来ないなどの問題がある.
第
3
章
関連事象
3.1
遺伝的アルゴリズム
遺伝的アルゴリズムとは,生物の進化の仕組みを参考にして考案された最適化アルゴリ
ズムであり,1975年にミシガン大学のJohn Henry Hollandによって提案された.遺伝的
アルゴリズムは,遺伝子の初期値の集合を生成した後,選択・交叉・突然変異を繰り返す ことにより最適化を行う.以下,各過程について述べる.
3.1.1
選択
選択では,適応度に基づいて各個体を評価し,次世代を生成する際に基となる個体を選 択する.適応度とは,設計者によって与えられる目的関数により求められる各個体の評価 値である.選択アルゴリズムには,ルーレット選択・ランキング選択・トーナメント選択 などがある.ルーレット選択は,個体iを選択する確率をpi,個体iの適応度をfiとした 際に,各個体の選択確率を式3.1で求める手法である.各個体を選択する確率は適応度に 比例した確率となる.ランキング選択とは,予め適応度の順位に対して選択される確率を 設定する手法である.ルーレット選択と違い,各順位間の適応度の差が選択確率に影響し ないという特徴がある.トーナメント選択は,個体群から予め設定した数の個体をランダ ムに選択し,その中で最も適応度が高い個体を選択するというプロセスを個体数分繰り返 すという手法である.ランキング選択と同様に,各順位間の適応度の差が選択確率に影響 しないという特徴がある. pi= fi ∑N k=1fk (3.1)3.1.2
交叉
交叉では,2つの個体の遺伝子を組み換えることで新しい遺伝子を生成する.交叉には, 一点交叉・多点交叉・一様交叉などがある.一点交叉は,遺伝子を切断する一点をランダ ムに選択し,その箇所で切断した遺伝子同士を繋ぎ合わせることで新しい遺伝子を生成す る手法である.多点交叉は,遺伝子の切断箇所を複数選択し,その箇所で切断した遺伝子 同士を繋ぎ合わせることで新しい遺伝子を生成する手法である.一様交叉は,遺伝子の各 要素ごと独立に1/2の確率で入れ換える手法である.3.1.3
突然変異
突然変異では,ある確率で遺伝子の一部を変化させる手法である.突然変異には,摂動・ 挿入・欠失・大変異などがある.摂動は,遺伝子の要素が実数値の際に用いられ,ある与 えられた幅の分だけ要素の値を変化させる手法である.挿入・欠失は,遺伝子に新しい要 素を挿入・削除する手法である.大変異は,一定の周期で突然変異率を高める,変化量を 大きくする手法であり,摂動などと組み合わせて利用される.主に局所解から脱出する目 的で用いられる.3.2
自然選択
自然の環境において,生まれてくるすべての個体が生き残れるわけではない.一般には, 生き残れる個体数よりもはるかに多くの個体が毎世代生まれてくる.しかし,自然界にお いて資源は有限であるため資源に対する種間競争が生じ,種全体に生存に対して選択圧が 生じる[9].また,同一集団でお互いに交配して繁殖している個体同士であっても様々な形 質の差異があり,それらの個体が皆同等に繁殖しているわけではない.このような過程に おいて,有利な変異は保存され,不利な変異は排除されることを自然選択と呼ぶ[10].自 然選択は,遺伝的アルゴリズムで用いられる選択手法と違い,設計者から目的関数は与え られない.また,自然選択は次の3つの条件さえ満たされれば必ず作動する[11].1)ある 形質が個体間で異なること,2)その変異が遺伝すること,3) その変異が原因となって繁 殖や生存に個体差が生じること.本研究では,この自然選択を用いることで目的関数を用 いずに環境に適応可能なエージェントを創発する. 図3.1: 自然選択3.3
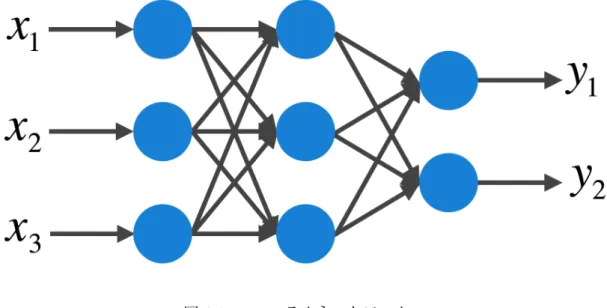
ニューラルネットワーク
ニューラルネットワークとは,生体システムにおける情報処理を数学的に表現しようと して考えられたモデルである.ニューラルネットワークは,形式ニューロンと呼ばれる素子によって構成される.形式ニューロンの例を図3.2に示す.形式ニューロンは,他の多 数の形式ニューロンi = 0, 1,...から入力信号xiを受け取る.ここで,各形式ニューロン同 士の結合の強さを表す重みとしてwiを導入する.これらを用いて,形式ニューロンへの 入力を式3.2のように定義する. u =∑ i wixi (3.2) また,形式ニューロンへの入力uは,微分可能な非線形活性化関数hを用いて式3.3の ように変換され,形式ニューロンの出力であるzとなる.非線形活性化関数hには,一般 にロジスティックシグモイド関数やtanh関数,ReLU関数などが用いられる. z = h(u) (3.3) 図3.2: 形式ニューロン ニューラルネットワークの例を図3.3に示す.ニューラルネットワークは形式ニューロ ンによって構成されている.複数の形式ニューロンを伝播することによって最終的な出力 となる. ニューラルネットワークの構成は,図3.3のように入力層,中間層,出力層の3層構造 となる.また,ニューラルネットワークには中間層がさらに細かく層で分かれているモデ ルと層で分かれていないモデルが存在する.中間層がさらに細かく層で分かれているモデ ルで主に用いられる層には,全結合層と畳み込み層が存在する.以下で全結合層と畳み込 み層について説明する.
図3.3: ニューラルネットワーク
3.3.1
全結合層
全結合層は,前の層のすべてのユニットとその次の層のすべてのユニットが接続されて いる層である.すべての層が接続されるため,非常に多くのパラメータを必要とするため, 計算コストおよびメモリ使用量の大きさ等が問題となっている.3.3.2
畳み込み層
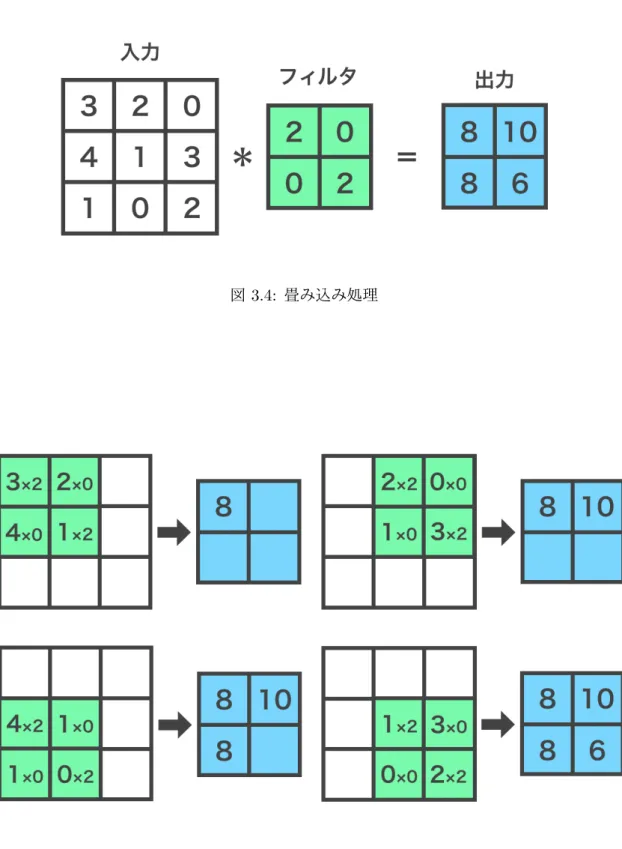
畳み込み層は行列入力に対してフィルタを用いて畳み込み処理を行う層であり,主に画 像認識や物体認識などに多く用いられる.畳み込み層における畳み込み処理の例を図3.4 に,畳み込み処理の手順を図3.5に示す.畳み込みニューラルネットワークにおける畳み 込み処理は,入力の行列に対してフィルタを作用させることで行う.フィルタは入力行列 よりも小さいサイズを持つH∗ Hの画像として用いる.また,その画素値をhpqとする. ここで,入力行列の画素をxij,出力行列の画素をyijとするとき,畳み込み処理の式は式 3.4のようになる.また,畳み込み処理の手順を可視化すると図3.5のようになる. yij = H∑−1 p,q=0 xi+p,j+qhpq (3.4) 次に,畳み込み層の例を図3.6に示す.畳み込み層では一般に入力行列と出力行列は複 数存在する.この各行列のことをチャネルと呼ぶ.ここで,入力に用いるチャネルのサイ ズがH∗ HでありK枚存在する場合,入力はH∗ H ∗ Kの画像とみなすことが出来る. ここで,入力画像の画素値をxkpqと表現する.また,出力のチャネルがM枚存在する場 合,K枚の入力チャネルに対してそれぞれM枚のフィルタを用意し,フィルタと出力画像 の画素値をそれぞれhkmpq,ymijとする.この場合,畳み込み層の処理の式は式3.5のよ うになる.また,畳み込み層での処理を可視化すると図3.6のようになる.この場合,入 力画像の各チャネルにそれぞれ対応するフィルタで畳み込み処理をしたものの総和が出力図3.4: 畳み込み処理
画像の1つの画素となる. ymij = K∑−1 k=0 H∑−1 p,q=0 xk,i+p,j+qhkmpq (3.5) 図 3.6: 畳み込み層
3.4
NeuroEvolution of Augmenting Topologies
本研究では,ニューラルネットワークにおける進化手法として, NeuroEvolution of
Argmenting Topologies (NEAT)を用いる[12].NEATとは,遺伝的アルゴリズムを用い
てニューラルネットワークのノード間の重みと構造の最適化を行う手法である.NEATに おける遺伝子型と表現型を図3.7に示す.NEATでは,遺伝子としてネットワークのノー ドと結合の情報を持つ.ノードの情報として,ノードのID,ノードが入力層,隠れ層,出 力層のどの層に属するのかの情報を持つ.結合の情報として,入力ノード,出力ノード, 重みなどの情報を持つ.これらの情報から構成されたニューラルネットワークがNEATに おける表現型となる. NEATにおける突然変異を示したものを図3.8に示す.突然変異には,ノードの突然変 異と結合の突然変異がある.ノードの突然変異では,ノードの追加・削除などがある.結 合の突然変異では,結合の追加・削除に加え,結合の有効・無効の変更,重みの変化など がある. NEATにおける交叉を示したものを図3.9に示す.交叉では,どちらか一方のみが持つ ノードや結合はすべて子に受け継がれ,両方が持つノードや結合はある確率でどちらか一 方のものが子に受け継がれる. NEATは,エージェントの毎行動ごとの評価を必要としない,行動の頻度や遅延報酬の 影響を受けない,計算量が少ない,重みだけでなく構造ごと最適化出来るなどの特徴があ るため,本研究で扱う問題において最適であると考えられる.
図3.7: NEATにおける遺伝子型と表現型[12]
3.5
Deep NeuroEvolution
本研究では,ニューラルネットワークにおける進化手法として,NEATとともにDeep
NeuroEvolutionを用いる.Deep NeuroEvolutionはDeep Neural Networkに
NeuroEvolu-tionを組み合わせた手法であり,Uber AI LabsのSuchらによって提案された[13].NEAT
と異なり,Deep NeuroEvolutionはニューラルネットワークの重みのみを遺伝子として持
ち,構造の最適化は行わずに固定的な構造を用いる.ネットワークの構造に畳み込みニュー
ラルネットワークを用いて実験を行い,Atariなどの強化学習タスクにおいて深層強化学
習アルゴリズムであるDeep Q-NetworkやAsynchronous Advantage Actor-Criticに匹敵
する学習性能があることが示されている.
3.6
Global Average Pooling
Global average poolingは,従来の畳み込みニューラルネットワークに含まれる全結合層
において問題であった過学習を抑制する手法であり,Linらによって提案された[14].従来
の畳み込みニューラルネットワークにおける全結合層とGlobal average poolingを図3.10
に示す.従来の畳み込みニューラルネットワークは,上位層において畳み込み層における
全てのチャンネルを1つのベクトルに変換することで平坦化を行い,全結合層を伝播する
ことによって特徴量を低次元のベクトルで表現していた.しかし,従来の手法は膨大な量 のパラメータを用いるため,非常に多くのメモリを必要とする,学習の処理に大きな負荷 がかかってしまう,過学習が発生する傾向があるなどの問題がある.
Global average poolingは,従来の手法を用いる代わりに畳み込み層における各チャン
ネルの全画素の平均値を求め,求めた平均値を次の層の各ユニットの値とする.これによ り,従来の手法で必要であった全結合層における膨大な量の重みのパラメータが無くなる. 図3.10の例では,3, 136∗ 128 = 401, 408個のパラメータが削減されることになる.これ により,多くのメモリが削減されるだけでなく,過学習が抑制される,学習の処理が従来 の手法に比べて少なくなるなどの効果がある.また,画像認識に用いられるデータセット であるCIFAR-10を用いて学習を行った結果,従来の全結合層を用いた手法と比較して精 度が改善されることが示されている[14].
3.7
Unity
本研究では,Unityと呼ばれるゲームエンジンを用いてシミュレーションを行った.Unity はUnity Technologiesによって2005年から開発が進められているゲームエンジンであり, ウェブプラグイン,デスクトッププラットフォーム,携帯機器向けのコンピュータゲーム, シミュレーターの開発などに用いられ,100万人以上の開発者が使用している.UnityにはNVIDIAのPhysXと呼ばれる物理エンジンが搭載されており,物理演算をCPUで行う代
わりにCUDAが使用可能なGPUで行うことで,高速な演算が可能である.また,Unity
にはアセットストアと呼ばれる,3Dモデル,テクスチャ,マテリアル,パーティクルシ
[1]全結合層
[2]Global Average Pooling
図3.10: 全結合層とGlobal Average Poolingの比較
3.8
Life in Silico
Life in Silico(LIS)とは,株式会社ドワンゴ人工知能研究所が開発したオープンソース ソフトウェアの汎用知能エージェント学習環境シミュレータである.LISの実行画面を図 3.11に示す.また,LISのアルゴリズムの概要を図3.12に示す.LISはゲームエンジンの Unityと,DQNやCNNといった機械学習開発環境をつなぎ,エージェントが自律的に学 習する枠組みを提供している.LISはエージェントが行動する環境と,学習・エージェン トの行動決定を行う部分に分かれている.エージェントにはフロントカメラや深度センサ が搭載され,それらから取得された値が学習部分に渡される.また,学習部が渡された値 からエージェントの行動を決定しUnityに渡されることで,Unityの環境上のエージェン トが行動する.エージェントが行動することによって環境から報酬を得ることが出来る. このプロセスを繰り返すことにより,エージェントはより食物を得るように学習する.第
4
章
提案手法
本研究では,目的関数を用いずに恒常性を持ち環境に適応可能なエージェントを開発す る手法として,ニューラルネットワークにおける進化手法と自然選択を組み合わせる手法 を提案する.この手法では,目的関数の代わりに,自然選択の資源に対する種間競争の過 程において有利な変異は保存され,不利な変異は排除されるという仕組みを用いる.これ により,観測者がエージェントの目的を目的関数としてモデル化することなく,環境に適 応可能なエージェントを開発することが可能となる. 以下,本研究で用いる環境とエージェントについて述べる.環境の説明では,主にエー ジェントを含めた環境に存在する資源の流れやエージェントの状態について述べる.エー ジェントの説明では,エージェントの学習や行動決定について述べる.4.1
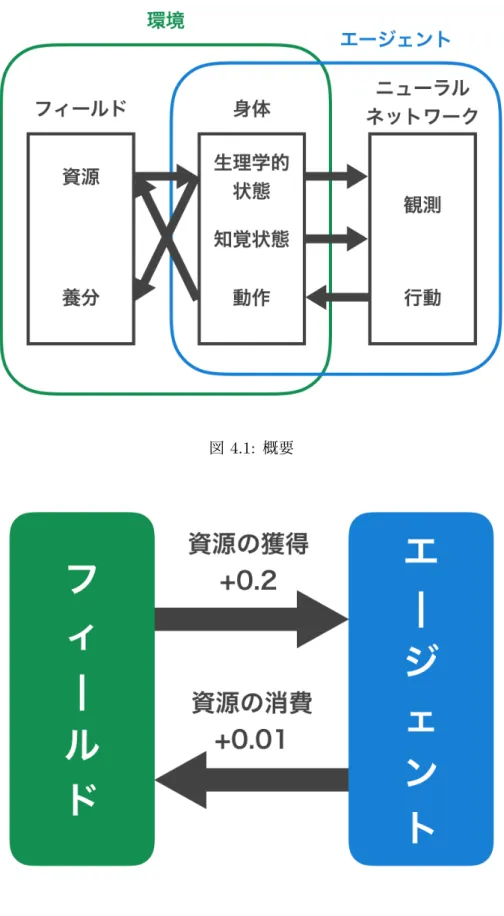
環境
本研究で用いる環境の概要を図4.1に示す.環境は,UnityのRealistic Nature
Environ-mentというアセットを用いて構築した.環境には,エージェントが生存において必要と する資源が存在する.また,資源の量が無限であることにより種間競争が起こらず自然選 択が発生しないこと,選択圧の変動により学習が不安定になることを避けるために,エー ジェントの持つ資源の量を含め環境に存在する資源の量を固定する.エージェントは,自 身の内部状態である生理学的状態と外界から取得した状態である知覚状態の2種類の状 態を持つ.生理学的状態は,内部状態として自身の持つ資源のレベルとし,エネルギーレ ベルと呼ぶ.知覚状態は外界から取得した状態として,エージェントに搭載されたカメラ でエージェントの前方を撮影した画像となる.また,この2つを組み合わせたものがエー ジェントの動機付け状態となる.エージェントは,資源に触れることで自身のエネルギー レベルを0.2増加させる.また,エージェントのエネルギーレベルが-1.0以上の時にその エージェントが生存していると定義し,エネルギーレベルが-1.0未満のエージェントは環 境から消去される.エージェントのエネルギーレベルは各ステップごとに0.01消費され る.エージェントが消費した資源は養分として環境に還元され,環境に還元された養分の 総量が0.2以上になった際に環境に資源として出現し,環境が持つ養分が0.2減少する.こ うすることでエージェントを含めた環境に存在する資源の総量を一定に保つことが可能と なる.
4.2
エージェント
エージェントを図4.3に示す.エージェントは水色でカプセルの形状をしている.エー ジェントの中心には前方を撮影するフロントカメラが搭載されている.エージェントは,遺伝子として持つニューラルネットワークにより行動を決定する.ニューラルネットワー クへの入力は,生理学的状態であるエネルギーレベルと知覚状態である画像である.また, 出力層の各ユニットはエージェントの各行動(左回転,右回転,前進)に対応しており, 最も高い値を出力したユニットに対応する行動を選択する.
図4.3: エージェント
本研究では,ニューラルネットワークにおける進化手法としてNEATとDeep
NeuroEvo-lutionを用いる.しかし,遺伝的アルゴリズムのように目的関数として適応度を用いる選 択は行わずに,自然選択を用いる.交配は,エージェント同士が触れ合った際に両エージェ ントのエネルギーレベルが0以上の場合に行われる.交配によって新しく子となる2体の エージェントが生成され,子となるエージェントは親となる2体のエージェントからエネ ルギーを1/4ずつ受け取る.交配では通常の進化手法と同じように遺伝子の交叉を行い, 新しく生まれたエージェントにその遺伝子が受け継がれる.また,新しい個体が生まれた 際に一定の確率で各進化手法に沿った突然変異が発生する.これにより,自然選択が発生 する条件である,1)ある形質が個体間で異なること,2)その変異が遺伝すること,3)そ の変異が原因となって繁殖や生存に個体差が生じることの3つの条件を満たすことが可能 となる. エージェントのコントローラの概要を図4.4に示す.エージェントのテクスチャにはLIS と同様のものを用いた.NEATを用いたエージェントによる実験では,ネットワークの構 造の初期状態として,入力層のユニットと出力層のユニットのみ用意し,すべての入力ユ ニットとすべての出力ユニットが接続されている状態とする.また,Deep NeuroEvolutio を用いるエージェントによる実験では図4.5に示すネットワークを用いる.知覚状態であ
る視覚画像は2層の畳み込み層を伝播した後,Global average poolingによって16個のユ
ニットに変換される.視覚画像は図4.6のような画像となる.また,生理学的状態である
エネルギーレベルは16個のユニットへ全結合層によって接続され,知覚状態から伝播さ
れる.また,全ての層の活性化関数にはReLU関数を用いた. 図4.4: コントローラ 図4.5: 畳み込み処理の手順
4.3
評価方法
本研究で提案する手法では,通常遺伝的アルゴリズムなどの進化計算で用いられる適応 度などの目的関数を利用しない.目的関数を利用しない理由は,フレーム問題の本質であ る無限に存在するものを記号化する際に無限に時間を要するという問題から,生物学的 エージェントとしての無限に存在する目的を記号化することは不可能であると考えたため である.そのため,本研究で用いる手法にも絶対的な評価を行うことが出来ない.しかし,図4.6: コントローラに入力される画像の例 1つ目の指標として,エージェント群として保持するエネルギーの総量を用いる.本手 法では,エージェントは自身の減少し続けるエネルギーレベルに対して環境に存在する資 源を得ることにより生存し,繁殖することが可能となる.そのため,進化によって環境に 適応することでより多くのエージェントが自身の生理学的状態を安定化させるためにより 多くのエネルギーを保持するようになると考える.よって,1つ目の指標として,エージェ ント群として保持するエネルギーの総量を用いる. 2つ目の指標として,一般に生物学において用いられる適応度を用いる.生物は,進化 を通じて生物個体が生育環境にどれくらい適応しているかを示す数値となる適応度を最大 化していると考えられている[15].今回,tステップ目におけるエージェント群の適応度 として「tからt+199ステップ目までの200ステップの間に出現したエージェントの数× 平均生存時間」を用いる.この適応度を用いて,エージェント群が生物として繁栄してい く能力の評価を行う.よって,1つ目の指標として,生物学的な適応度を用いる.
第
5
章
NEAT
を用いたエージェントによる
実験
本研究で提案する手法を用いることで,目的関数を用いることなく恒常性を持ち環境に 適応可能な人工生命が創発されることを検証するため,Unityを用いたシミュレータ上に 環境を構築し,実験を行なった. 実験では,平地における実験,高低差がある地形における実験,高低差だけでなく草木 や岩などがある地形における実験という3種類の難易度の環境において実験を行い,評価 を行なった.本章では,NEATを用いたエージェントによる実験を行う.5.1
平地における実験
平地の環境として用いる環境を図5.1,図5.2に示す.フィールドの大きさは 700× 700[m2]であり,芝生のテクスチャで覆われている.エージェントがフィールドの外に 出ることを防ぐために,フィールドの四方は透明な壁で覆われている.環境には赤色で球 状の餌が存在する.また,初期状態として1000個の資源と400体のエージェントが環境 全体にランダムな位置に配置される.また,エージェントの初期状態としてエネルギーレ ベルに0を設定する.エージェントが餌に触れることでエージェントのエネルギーレベル が0.2増加し,餌が環境から消去される.エージェントのエネルギーレベルは各ステップ ごとに0.01減少する.環境全体として持つエネルギーの量を固定するために,エージェン トが消費したエネルギーは環境に還元される.また,環境が持つエネルギーの量が0.2以 上になるごとに環境のランダムな位置に餌が配置され,環境が持つエネルギーの量は0.2 減少するされる. この環境において実験を行い,環境に存在するエネルギー量のうちエージェントが保持 するエネルギーの総量を求め,評価を行った.5.1.1
結果
実験の結果を図5.3,図??に示す.図5.3はエージェントが保持するエネルギーの総量 の時系列の変化を表している.初期はエージェントの保持するエネルギーの総量が約180 から120程度まで大幅に減少したことが分かる.また,時間の経過とともにエージェント が保持する資源の総量が160程度まで増加することが分かる.図5.4はエージェント群の 適応度の時系列の変化を表している.適応度は開始してから5度ほど約40000程度まで減 少しているが,資源の総量と同様に徐々に増加していることが分かる.図5.1: 平地として用いる環境(真上からの視点)
5.1.2
考察
図5.3から,初期にエージェントの保持するエネルギーの総量が約180から120程度ま で大幅に減少したことが分かる.また,時間の経過とともにエージェントの保持するエネ ルギーの総量が増加することが分かる.また,図??から,初期に出現したエージェントと 比較して終盤に出現したエージェントの方が適応度が高いことが分かる.これらの結果か ら,エージェントに,自身の減少し続けるエネルギーに対して餌を取得することでエネル ギーレベルを安定化させる生存能力や,十分なエネルギーを取得している状態で他のエー ジェントと触れ合い交配を行うことによる子孫を残す繁殖能力が時間の経過とともに上昇 していることが分かる.これは,時間の経過とともに突然変異と自然選択によってエージェ ントの生存能力や繁殖能力が高くなったことが考えられる.本実験では,エージェントに 報酬関数などの目的関数を与えていない.しかし,エージェントは自身の減少し続けるエ ネルギーレベルに対して,視覚情報から餌を取得することで恒常性を維持し,交配するこ とで群として成長可能なことを示せた. 以上のことから,平地の環境において,エージェントは目的関数を用いずに自然選択に よって恒常性を持ち環境に適応可能であることが示せた.5.2
高低差がある地形における実験
高低差がある地形の環境として用いる環境を図5.5,図5.6に示す.フィールドは5.1で 用いたフィールドに高低差を付けたものを用いる.5.1と同じく初期状態として1000個の 餌と400体のエージェントがフィールドにランダムに配置される.エージェントが前進す る場合,坂の角度の緩急はエージェントが進む距離には影響は無い. この環境において実験を行い,環境に存在するエネルギー量のうちエージェントが保持 するエネルギーの総量を求め,評価を行った.5.2.1
結果
実験の結果を図5.7,5.8に示す.図5.7はエージェントが群として保持するエネルギー の総量の時系列の変化を表している.初期状態から約6000ステップ目までエージェント の群として保持するエネルギーの総量が約200から90ほどまで大幅に減少していること が分かる.また,その後3回ほど約80まで大幅に減少しつつも増加を続け,約130まで 上昇し安定していることが分かる.また,図5.8はエージェント群の適応度の時系列の変 化を表している.エージェント群として徐々に適応度が上昇していることが分かる.しか し,エージェントが群として保持する資源の総量,適応度ともに5.1での実験の結果と比 較し低い値となっている.5.2.2
考察
図5.7から,初期にエージェントの保持するエネルギーの総量が約90程度まで大幅に下 がっている.これは5.1での実験の初期と比較し,30ほど低い値となっている.また,5.1図5.7: 5.2での実験におけるエージェント群が保持するエネルギーの総量の時系列な変化
での実験と比較し,エージェントの保持するエネルギーの総量の増加の速度が遅くなって いる.また,図5.8より,適応度においても5.1での実験の結果と比較して低い値となっ ている.これらは,5.1での実験と比較して適応することが困難な環境になっているため だと考えられる.今回用いた環境は5.1で用いた環境に高低差をつけた環境となるため, 自分自身よりも高い位置,もしくは低い位置にある餌も餌として認識する必要がある.ま た,認識するだけでなく,認識した位置に向かう行動を選択しなくてはいけない.また, 隆起した地形が視界を塞ぎ,近くに餌があっても認識出来なくなる場合がある.そのため, エージェントが認識しにくい窪んだ地形などに資源が集中し,その地形以外の場所の空間 に対する資源の密度が低くなることが考えられる.以上より,今回用いる環境は5.1で用 いた環境に比べ,適応しにくい地形であると考えられるため,5.1における実験と比較し てエージェント群として保持する資源の総量,適応度ともに低い値となっていると考えら れる.しかし,このような困難な環境であっても時間の経過とともにエージェントの保持 するエネルギーの総量が増加していることが分かる.よって,高低差がある環境において, エージェントは自身の減少し続けるエネルギーレベルに対して,視覚情報から餌を取得す ることで恒常性を維持し,交配することで群として成長可能なことを示せた.
5.3
草木・岩が存在する地形における実験
高低差がある地形の環境として用いる環境の全体像を図5.9,図5.10に示す.また,環 境の詳細を表す図として環境中に配置したエージェントの位置と視界の範囲を図5.11に, 各エージェントの視界の生画像を図5.12に示す.フィールドは5.2で用いたフィールドに 草木・岩を配置したものを用いる.初期状態として1000個の餌と400体のエージェント がフィールドにランダムに配置される.木や岩はエージェントの視界を遮るだけでなく, 衝突判定があるため障害物となる. この環境において実験を行い,環境に存在するエネルギー量のうちエージェントが保持 するエネルギーの総量を求め,評価を行った.5.3.1
結果
実験の結果を図5.13,図5.14に示す.図5.13はエージェントが群として保持するエネ ルギーの総量の時系列の変化を表している.初期状態から約5000ステップ目まで資源の 総量が約200から0付近まで大幅に減少していることが分かる.また,その後約50程度 まで上昇するが,その後再度減少し,18000ステップ目付近で0になり,エージェントが 絶滅していることが分かる.また,図5.14より,エージェント群の適応度もまた大幅に 減少した後上昇するが再度大幅に減少し,約18000ステップ目で0になっていることが分 かる.5.3.2
考察
図 ,図 より,エージェント群が保持する資源の総量,適応度ともに大幅に減図5.9: 草木・岩が存在する地形として用いる環境(真上からの視点)
図5.11: 各エージェントの視界
[1]1のエージェントの視点 [2]2のエージェントの視点
図5.13: 5.3での実験におけるエージェント群が保持するエネルギーの総量の時系列な変化
とが分かる.これは,5.2の環境と比較してさらに適応することが困難な環境になってい るためだと考えられる.今回用いた環境は5.2で用いた環境に草木や岩などが追加された 環境となるため,5.2で用いた環境に比べて視界を遮る物体が多くなっている.そのため, エージェントはより資源を認識することが困難になる.また,木と岩には衝突判定がある ためエージェントの障害物となっており,エージェントは木と岩を避けつつ資源を得る行 動を獲得しなければいけない.以上より,今回用いる環境は5.2で用いた環境に比べ,適 応しにくい地形であると考えられる.よって,草木・岩が存在する環境において,NEAT を用いたエージェントは環境における資源の総量を本実験で用いた量に設定した場合,環 境に適応出来ないことを示した.
第
6
章
Deep NeuroEvolution
を用いた
エージェントによる実験
6.1
平地における実験
6.1.1
環境
平地の環境として,5.1節での実験で用いた環境と同じ環境を用いる.また,初期状態 として5.1節と同様に1000個の資源と400体のエージェントが環境全体にランダムな位 置に配置されている.この環境において実験を行い,環境に存在するエネルギー量のうち エージェントが保持するエネルギーの総量,適応度として各ステップにおける産子数×生 存時間を用いて評価を行なった.6.1.2
結果
実験の結果を図6.1,図6.2に示す.図6.1はエージェント群が保持する資源の総量を示 しており,図6.2はエージェント群の適応度を示している.図6.1では,エージェント群 が保持する資源の総量が初期に130程度まで減少した後,210程度まで上昇していること が分かる.また,5.1節のNEATを用いたエージェントによる実験と比較して高い数値と なっており,エージェントの資源を得る力がNEATを用いたエージェントと比較して高い ことが分かる.6.1.3
考察
エージェント群が保持する資源の総量また適応度ともに5.1節のNEATを用いたエー ジェントによる実験と比較して最終的に高い数値となった理由として,2つの理由が考えら れる.1つ目に,NEATはネットワークの構造の初期状態として中間層が存在しないのに対 し,Deep NeuroEvolutionでは中間層にCNNという深層学習の分野でも高い精度を出す 構造を用いているため,NEATで用いた初期の構造からCNNほどの精度を出すことが可 能な構造を創発することが困難であることが考えられる.2つ目に,Deep NeuroEvolution に対してNEATは突然変異に関する重要なパラメータが多く存在するため,それらのパ ラメータの調整が失敗している可能性が考えられる.また,5.1節での実験の結果に対し て今回の実験では,エージェントの資源の総量が安定して上昇していることが挙げられ る.こちらもまた,NEATが重みだけでなく構造の最適化を同時に行うことに対してDeep NeuroEvolutionは重みのみの最適化を行うため,より安定した進化が可能となったこと が考えられる.6.2
高低差がある地形における実験
6.2.1
環境
高低差がある環境として,5.2節の実験で用いた環境と同じ環境を用いる.また,初期 状態として5.2節での実験と同様に1000個の資源と400体のエージェントが環境全体に ランダムな位置に配置されている.この環境において実験を行い,環境に存在するエネル ギー量のうちエージェントが保持するエネルギーの総量,適応度として各ステップにおけ る産子数×生存時間を用いて評価を行なった.6.2.2
結果
実験の結果を図6.3,図6.4に示す.図6.3はエージェント群が保持する資源の総量を示 しており,図6.4はエージェント群の適応度を示している.図6.3では,エージェント群 が保持する資源の総量が初期に70程度まで減少した後,160程度まで上昇していることが 分かる.また,5.2節のNEATを用いたエージェントによる実験と比較して初期は低い数 値となっているが,最終的には高い数値となっていることが分かる.また,エージェント 群として適応度についても,5.2節の実験における結果と比較して早期に高い数値を示し ていることが分かる. 図6.3: 6.2での実験におけるエージェント群が保持するエネルギーの総量の時系列な変化図6.4: 6.2での実験におけるエージェント群の適応度の時系列な変化
6.2.3
考察
6.1節での結果と同様に,5.2節のNEATを用いたエージェントによる実験の結果と比 較し,早期に高い数値を示していることが分かる.これにより,エージェントの生存,繁 殖する力がNEATを用いたエージェントと比較して高いことが分かる.6.3
草木・岩が存在する地形における実験
6.3.1
環境
平地の環境として,5.3節の実験で用いた環境と同じ環境を用いる.また,初期状態と して5.3節と同様に1000個の資源と400体のエージェントが環境全体にランダムな位置に 配置されている.この環境において実験を行い,環境に存在するエネルギー量のうちエー ジェントが保持するエネルギーの総量,適応度として各ステップにおける産子数×生存時 間を用いて評価を行なった.6.3.2
結果
実験の結果を図6.5,図6.6に示す.図6.5はエージェント群が保持する資源の総量を示 しており,図6.6はエージェント群の適応度を示している.図6.5では,エージェント群図6.5: 6.3での実験におけるエージェント群が保持するエネルギーの総量の時系列な変化
6.3.3
考察
5.3節でのNEATを用いたエージェントによる実験では絶滅してしまったが今回の実験 では絶滅せずに,エージェント群が保持するエネルギーの総量,適応度ともに初期に大幅 に減少した後大幅に上昇している.よって,草木・岩が存在する環境において,エージェ ントは自身の減少し続けるエネルギーレベルに対して,視覚情報から資源を取得すること で恒常性を維持し,交配することで群として成長可能なことを示せた.第
7
章
結言
7.1
まとめ
本研究では,生物学的エージェントの目的を目的関数として定式化することによって, 本来無限に存在する生物学的エージェントとしての目的を有限に制限してしまうという問 題に対し,自然選択によって目的関数を用いずに恒常性を持ち環境に適応可能な人工生命 を開発することを目指した.我々のエージェントが自身の減少し続けるエネルギーレベル に対して,視覚情報から餌を取得することで恒常性を維持し,交配することで群として適 応可能なことを示した.また,平地だけでなく高低差がある環境,草木や岩などが存在す る地形においてもエージェントが適応可能なことを示した.NEATとDeep NeuroEvolutionとの比較では,Deep NeuroEvolutionを用いたエージェ ントの方がより適応度またエージェントの保持する資源の総量ともに高い数値となる結果 となるだけでなく,より安定した進化が可能であることを示した.
7.2
今後の方針
本研究で用いたエージェントはカプセルの形状をしており,エージェントが選択可能な 行動は左回転,右回転,前進の3種類であった.形状と行動ともに設計者によって与えら れた固定的なものとして扱われていること,グループ化された大まかな行動であることか ら,エージェントの形状や選択可能な行動は大きく制限されている.そのため,本研究で 用いた手法を拡張し,ニューラルネットワークだけでなくエージェントの形状や選択可能 な行動をエージェントの遺伝子として持ち進化を行うことで,より環境に適応可能なエー ジェントを開発出来る可能性がある.謝辞
本研究を進めるにあたり,研究内容やその方針に関するご指導を頂いた公立はこだて未 来大学システム情報科学部複雑系知能学科三上貞芳教授に心から感謝いたします.また,
参考文献
[1] 海谷啓之,中山実,ホメオスタシスと適応,裳華房, 2016.
[2] Ashby W. R., Design for a Brain, Springer Science and Business Media., 1960. [3] Pfeifer, R., and Scheier, C., Understanding intelligence, MIT Press, 1999.
[4] Doya K., Uchibe E., The cyber rodent project: Exploration of adaptive mechanisms for self-preservation and self-reproduction, Adaptive Behavior, 13, 2, 149-160 [5] Keramati M. Gutkin B. S., A reinforcement learning theory for homeostatic
regula-tion, In Advances in neural information processing systems, 82-90, 2011.
[6] Yoshida N, Homeostatic Agent for General Environment, Journal of Artificial Gen-eral Intelligence, 8, 1, 1-22, 2017.
[7] Keramati M., Gutkin B. S., Homeostatic reinforcement learning for integrating re-ward collection and physiological stability, Elife, 3, 2014.
[8] Konidaris, G. D., An Adaptive Robot Motivational System, From Animals to Ani-mats, 9, 346-356, 2006.
[9] 嶋田正和,山村則男,粕谷英一,伊藤嘉昭,動物生態学,海游舎, 2005. [10] Darwin C.,堀伸夫(訳), 堀大才(訳),種の起源,槇書店, 1988.
[11] 日本生態学会,生態学入門,株式会社東京科学同人, 2012.
[12] Kenneth O. Stanley, Evolving Neural Networks through Augmenting Topologies, Evolutionary Computation, 10, 2, 9-127, 2002.
[13] Petroski Such, F., Madhavan, V., Conti, E., Lehman, J., Stanley, K. O., and Clune, J., Deep neuroevolution: Genetic algorithms are a competitive alternative for train-ing deep neural networks for reinforcement learntrain-ing, arXiv preprint to appear, 2017. [14] Min Lin., Qiang C., Shuicheng Y., Network In Network, Cornell University Library,
arXiv preprint to appear, 2014.
[15] 森裕司,武内ゆかり,内田佳子,動物行動学―獣医学共通テキスト編集委員会認定,イ
図 目 次
2.1 2次元恒常性空間のモデル[7] . . . . 3 2.2 優先度曲線[8] . . . . 4 2.3 モチベーションシステムの概要[8] . . . . 5 2.4 ネットワーク構成[6] . . . . 6 2.5 Yoshidaが用いた環境[6] . . . . 7 3.1 自然選択 . . . . 9 3.2 形式ニューロン . . . 10 3.3 ニューラルネットワーク . . . 11 3.4 畳み込み処理 . . . 12 3.5 畳み込み処理の手順 . . . 12 3.6 畳み込み層 . . . 13 3.7 NEATにおける遺伝子型と表現型[12] . . . 14 3.8 突然変異[12] . . . 14 3.9 交叉[12] . . . 153.10 全結合層とGlobal Average Poolingの比較 . . . 17
3.11 Life in Silico . . . 18 3.12 アルゴリズムの概要 . . . 18 4.1 概要 . . . 20 4.2 資源の循環 . . . 20 4.3 エージェント . . . 21 4.4 コントローラ . . . 22 4.5 畳み込み処理の手順 . . . 22 4.6 コントローラに入力される画像の例 . . . 23 5.1 平地として用いる環境(真上からの視点) . . . 25 5.2 平地として用いる環境(斜め上からの視点) . . . 25 5.3 5.1での実験におけるエージェント群が保持するエネルギーの総量の時系列 な変化 . . . 26 5.4 5.1での実験におけるエージェント群の適応度の時系列な変化. . . 26 5.5 高低差がある地形として用いる環境(真上からの視点) . . . 28 5.6 高低差がある地形として用いる環境(斜め上からの視点) . . . 28 5.7 5.2での実験におけるエージェント群が保持するエネルギーの総量の時系列
5.8 5.2での実験におけるエージェント群の適応度の時系列な変化. . . 29 5.9 草木・岩が存在する地形として用いる環境(真上からの視点) . . . 31 5.10 草木・岩が存在する地形として用いる環境(斜め上からの視点) . . . 31 5.11 各エージェントの視界 . . . 32 5.12 草木・岩が存在する地形として用いる環境(エージェント視点) . . . 32 5.13 5.3での実験におけるエージェント群が保持するエネルギーの総量の時系列 な変化 . . . 33 5.14 5.3での実験におけるエージェント群の適応度の時系列な変化. . . 33 6.1 6.1での実験におけるエージェント群が保持するエネルギーの総量の時系列 な変化 . . . 36 6.2 6.1での実験におけるエージェント群の適応度の時系列な変化. . . 36 6.3 6.2での実験におけるエージェント群が保持するエネルギーの総量の時系列 な変化 . . . 37 6.4 6.2での実験におけるエージェント群の適応度の時系列な変化. . . 38 6.5 6.3での実験におけるエージェント群が保持するエネルギーの総量の時系列 な変化 . . . 39 6.6 6.3での実験におけるエージェント群の適応度の時系列な変化. . . 39
![図 2.3: モチベーションシステムの概要 [8] 固定的なものが用いられてきた.しかし,このような報酬や目的関数では単純な強化学習 タスクは成功するかもしれないが,複雑なタスクや生涯学習ではシステムの性能に悪影響 を及ぼす可能性があることを指摘している.そこで, Yoshida は生存問題における報酬関 数に時間的生存確率の対数を用いて定式化を行い,生態学的ニッチ相互に依存する報酬関 数として定義した.報酬関数の基となる時間的生存確率は進化的過程を通じて得ることが 出来る.](https://thumb-ap.123doks.com/thumbv2/123deta/9903238.998685/9.892.142.761.160.492/モチベーションシステムたしかしタスクタスクシステム出来る.webp)
![図 2.4: ネットワーク構成 [6] の範囲を超えるとエピソードが終了する.また,次のエピソードはエージェントの各エネ ルギーレベルが 0 ,エージェントや各食物がフィールド上にランダムな位置に配置された 状態で開始される.また,エージェントが 2 万ステップ生き延びた際にそのエピソードを 終了させる. Yoshida はこの実験により,生存問題における報酬関数を生存確率の対数として定式化 を行った.また,定式化した報酬関数を用いて高次元の視覚入力を伴う 3 次元環境におい て深層強化学習を行い,エージェ](https://thumb-ap.123doks.com/thumbv2/123deta/9903238.998685/10.892.165.742.162.559/ネットワークエージェントルギーレベルエージェントエージェント.webp)
![図 2.5: Yoshida が用いた環境 [6]](https://thumb-ap.123doks.com/thumbv2/123deta/9903238.998685/11.892.143.767.483.749/図25Yoshidaが用いた環境6.webp)
![図 3.7: NEAT における遺伝子型と表現型 [12]](https://thumb-ap.123doks.com/thumbv2/123deta/9903238.998685/18.892.143.763.197.504/図37NEATにおける遺伝子型と表現型12.webp)
![図 3.9: 交叉 [12]](https://thumb-ap.123doks.com/thumbv2/123deta/9903238.998685/19.892.172.739.327.989/図39交叉12.webp)