JMP によるオッズ比、ハザード比(リスク比)の算出方法と注意点
SAS Institute Japan 株式会社 JMP ジャパン事業部
1.はじめに
医学研究では、イベント発生のリスクを要約、評価する指標としてオッズ比が用いられます。また、生存時間分析で生存時間を 評価する指標としてハザード比が用いられます。オッズ比を求める際、調整因子があればロジスティック回帰を用いて求めます。 一方、ハザード比は比例ハザードモデルによって求めます。JMP ではいずれの分析も行うことができますが、説明変数としてカテ ゴリ変数(名義尺度、順序尺度)を用いたとき、オッズ比、ハザード比(JMP ではリスク比と表示されるため、以後リスク比と表記) の求め方には注意が必要になります。本文章は、JMP でのオッズ比、リスク比の算出方法、算出に関しての注意点、理論的な背 景を述べたものです。 この後の2章(p.1-p.8)では、オッズ比、リスク比を求めるためのデータテーブルの作成、分析のための操作方法を示します。3 章(p.8-p.11)では、名義尺度が 2 カテゴリのときの分析法、カテゴリ変数が順序尺度のときの分析法を説明します。4章(p.12-p.15) では JMP でオッズ比、リスク比を求めるときの理論的な背景を説明します。とりあえず JMP でオッズ比、リスク比を算出したいとい う目的であれば、2章のみをご参照ください。さらなる詳細、理論的な説明が必要な場合は、併せて3章、4章もご参照下さい。2.オッズ比、リスク比の算出方法
この章では、サンプルデータを用いて、JMP でのオッズ比、リスク比の算出方法をご説明します。2.1 使用するデータ
■ロジスティック回帰(オッズ比) ・データファイル:「odd1.jmp」・出典:SAS/STAT LOGISTIC Procedure Example 42.2 のデータから一部の変数を抜粋 ・変数の詳細
変数名(列名) 尺度 詳細
Pain 名義 目的変数、アウトカム(No, Yes)
Treatment 名義 治療法(A, B, P)
Age 連続 調整因子
Duration 連続 調整因子
■比例ハザードモデル(リスク比) ・データファイル:「risk1.jmp」 ・出典:JMP のサンプルデータ「ラット.jmp」に対して、一部の変数を抜粋、修正、データを追加 ・変数の詳細 変数名(列名) 尺度 詳細 生存日数 連続 イベントまでの時間 打ち切りの有無 連続 打ち切りの変数 (打ち切りあり=1、打ち切りなし=0) グループ 名義 グループ(G1, G2, G3, G4) ・データテーブル(一部) この章では、名義尺度の説明変数を、ダミー変数とういう変数に変換し、この変数を用いる分析方法を示します。名義尺度のカ テゴリ数が 2 の場合は、ダミー変数を作成せず、直接モデル効果に名義尺度の変数を指定することによって求められます。詳細 は3章をご参照下さい。
2.2 ロジスティック回帰によるオッズ比の算出
分析内容
データファイル「odd1.jmp」を用いて、疾患(Pain)の発生(Yes)に対し、「Age」、「Duration」 を調整因子として、治療法 P に対する 治療法 A(カテゴリ P→A に変化)のオッズ比、治療法 P に対する治療法 B(カテゴリ P→B に変化)のオッズ比を算出する。 例えば、治療法 P はプラセボを投与、治療法 A はアウトカムとなる疾患に効果があると思われる薬剤を 10mg 投与、治療法 B は治療法 A と同様の薬剤を 20mg 投与したとします。このときのプラセボに対する治療薬 A,のオッズ比、プラセボに対する治療薬 B のオッズ比を求めると考えることができます。JMP での分析法
(多重)ロジスティック回帰は、メニューにある [分析] > [モデルのあてはめ] で行います。モデルの指定画面で、[Y] に名義尺 度の列を指定すると、自動的に右上に表示される(あてはめの)手法が名義ロジスティック回帰に変更されます。そのため、目的 変数はあらかじめ名義尺度に変更しておく必要があります。 分析メニューを実行する前の準備として、あらかじめデータテーブルに対し、以下の a、b を行います。a. 目的変数のカテゴリの順番を確認 名義尺度に指定した変数には、カテゴリに順番があります。順番を確認するには、該当の列を選択(青く反転)し、メニューから [列] > [値のチェック] > [リストチェック] を選択します。図 2.1 はリストチェックの画面ですが、カテゴリの順番は、No, Yes の順です。 これでは、最初のカテゴリである「No」、すなわち疾患がないという事象のオッズ比を求めることになります。目的は、疾患があると いう事象のオッズ比を求めたいため、リストの順番を変更します。 図 2.1 リストチェックのウィンドウ: No, Yes の順番になっている リストチックのウィンドウで、「No」をクリックし、[下に移動] ボタンを押すことによって順番を変更することができます。 順番を変更すると、データテーブルの列名の後ろの下向きの矢印マークが追加されます。(図 2.2) 図 2.2 リストチェックのウィンドウ: Yes, No の順番に変更 順番を変更すると列名の右側に矢印が表示される b. 名義尺度の説明変数に対して、ダミー変数を作成 ロジスティック回帰を行う際、説明変数「Treatment」は名義尺度のため、これをダミー変数に変換します。ここでのダミー変数と は、名義尺度の変数を条件ごとに”0” または ”1”の 2 値に変換した変数のことで、「Treatment」の各カテゴリに対し、3 つのダミ ー変数を表 2.1 のルールで作成します。
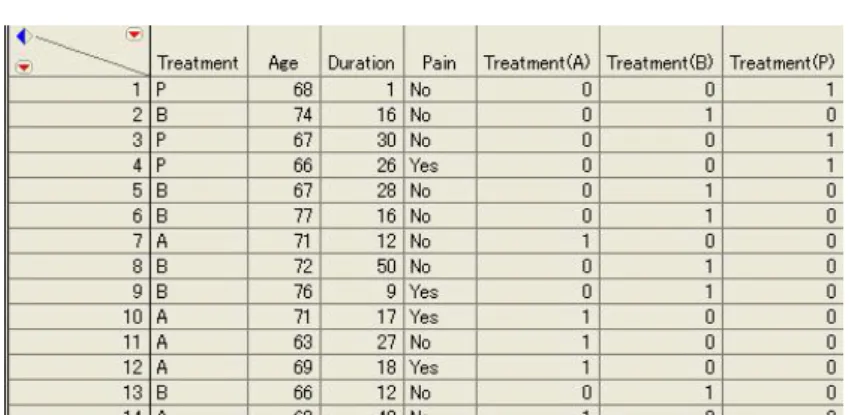
ダミー変数 ルール 「Treatment(A)」 「Treatment」の値が"A"であれば「1」、そうでなければ「0」 「Treatment(B)」 「Treatment」の値が"B"であれば「1」、そうでなければ「0」 「Treatment(P)」 「Treatment」の値が"P"であれば「1」、そうでなければ「0」 表 2.1 ダミー変数の作成ルール JMP では、計算式エディタを用いて以下の方法で作成します。 計算式エディタでの操作方法 --- 1. メニューより、[列] > [新規作成] を選びます。列名を「Treatment(A)」に変更します。その後、列プロパティのボタンをク リックし、計算式を選択します。 2. 計算式パレットが開きますので、次の順序で計算式を入力します。(図 2.3 参照) ・関数から、条件付き > If を選択 ・テーブル列から「Treatment」を選択 ・関数から、比較 > a==b を選択 ・赤い太枠に “A” と入力。( ” も入力する) ・then 節の枠をクリックして赤い枠を移動し、1 と入力 ・else 節の枠をクリックして赤い枠を移動し、0 と入力 ・ [OK] ボタンを押す 3. 列の新規作成ウィンドウを [OK] ボタンを押して閉じます。これより、データテーブルに新しい列が作成されます。 --- 図 2.3 計算式の入力画面 以下、ダミー変数「Treatment(B)」、「Treatment(P)」 も同様に作成します。図 2.4 はダミー変数作成後のデータテーブルになり
図 2.4 ダミー変数作成後のデータ データテーブル「odd2.jmp」 は a.目的変数のカテゴリの順序の変更と b.ダミー変数の作成 を行った後のデータテーブルになり ます。 上記の操作でダミー変数を作成できますが、名義尺度のカテゴリ数が多い場合、作成には手間がかかります。弊社ではダミー 変数を自動的に作成する JMP のスクリプトをサンプルとして提供しております。このスクリプトを用いると、ダミー変数を作成する 名義変数を選択するだけで自動的にダミー変数を作成することができます。以下の Web ページにある「日本語のサンプルスクリ プト 1」 または「日本語のサンプルスクリプト 2」にある「0/1 のダミー変数作成」が該当するスクリプトになります。 https://www3.sas.com/jmp/japan/includes/scripts_lib_sysdep_j.html 注意:このスクリプトは、JMP のユーザ登録をされている方のみがリクエストすることができます。 目的変数のカテゴリ順序の確認、ダミー変数の作成を行った後、メニューより [分析] > [モデルのあてはめ] を選び、列を図 2.5 のように指定します。 図 2.5 モデルの指定(名義ロジスティック) この分析例では、治療法 P を基準にしているので、ダミー変数「Treatment(P)」 をモデルに含めず、残りのダミー変数をモデル の効果に追加します。
ウィンドウ右上の[モデルの実行] ボタンを押すと、「名義ロジスティックのあてはめ」の結果レポート画面が表示されます。「パ ラメータ推定値」のレポートの下に「推定値は次の対数オッズに対するものです: Yes/No」と表示されます。これは、No に対する Yes のオッズ比を対数変換した値が(パラメータ)推定値になることを意味します。先ほど a.で行った、目的変数のカテゴリ順序の 変換で変更したカテゴリ順が反映されています。もし、事前にカテゴリ順序を変更しなかった場合は No/Yes と表示されます。そ のため、この表示からでも正しいカテゴリ順序になっているかどうかをチェックすることができます。 名義ロジスティック回帰のレポート画面の左上にある赤い三角ボタンから、[範囲オッズ比]または[単位オッズ比] (JMP 6 以前 のバージョンでは[オッズ比])を選択するとオッズ比が出力されます。さらにオッズ比の信頼区間を出力する際は、赤い三角ボタン から[信頼区間] を選択し、信頼水準(デフォルトはα=0.05)を入力することにより表示されます。(図 2.6) 図 2.6 オッズ比、信頼区間の表示 図 2.6 より、疾患の発生を事象としたときの治療法 P に対する治療法 A、治療法 B それぞれのオッズ比、オッズ比の 95%信頼 区間は、表 2.2 のようにまとめられます。 治療法 オッズ比 95%信頼区間 A 0.069 [0.010 , 0.337] B 0.039 [0.004 , 0.237] 表 2.2 治療法 P をリファレンスとしたときの、治療法 A、治療法 B のオッズ比とその 95%信頼区間
2.3 比例ハザードのあてはめによるリスク比の算出
分析内容
データファイル「risk1.jmp」を用いて、グループ間の死亡リスクの比較、リスク比を用いて行う。比較は、G1 を比較の対照(リファレ ンス)として、G2 ,G3 ,G4 の死亡リスクがどのぐらい高まるかをみる。 例えば、変数「グループ」の値 G1, G2, G3, G4 を癌のステージ(ステージⅠからステージⅣ)と想定すると、ステージⅠに対して、 ステージ Ⅱ、Ⅲ、Ⅳ それぞれの死亡リスクをリスク比で評価すると考えることができます。JMP での分析法
ロジスティック回帰のときと同様に、変数「グループ」に対するダミー変数を作成することになります。ダミー変数「グループ(G1)」、 「グループ(G2)」、「グループ(G3)」、「グループ(G4)」 を追加したテーブル図 2.7 に示します。図 2.7 データテーブルにダミー変数を追加 データテーブル「risk2.jmp」は、ダミー変数作成後のデータテーブルになります。 ダミー変数の作成を行った後、メニューより、[分析] > [生存時間もしくは信頼性分析] > [比例ハザードのあてはめ] を選び、列 を次のように指定します。(図 2.8) 図 2.8 モデルの指定(比例ハザード) この分析例では、グループ G1 を基準(リファレンス)にしているので、ダミー変数「グループ(G1)」 をモデルに含めず、残りのダ ミー変数をモデルの効果に追加します。 ウィンドウ右上の[モデルの実行] ボタンを押すと、「比例ハザードのあてはめ」の結果レポート画面が表示されます。(図 2.9) 結果のレポート画面にはデフォルトでリスク比の推定値、95%信頼区間が表示されます。JMP の出力では、それぞれ「リスク比」、 「(下側、上側)信頼限界」と表示されます。
図 2.9 リスク比、(両側 95%)信頼区間の表示 図 2.9 より、グループ G1 に対する、グループ G2、G3、G4 それぞれのリスク比、リスク比の 95%信頼区間は、表.2.3 のようにま とめることができます。 グループ リスク比 95%信頼区間 G2 1.875 [0.945 , 3.707] G3 1.025 [0.517 , 2.029] G4 3.435 [1.690 , 7.002] 表 2.3 グループ G1 をリファレンスとしたときの、グループ G2、G3、G4 のリスク比とその 95%信頼区間
3.更なるトピック
2章で説明しましたように、ロジスティック回帰でオッズ比を算出するときと比例ハザードでリスク比を算出するときとで、ダミー 変数の作成方法、ダミー変数をモデルの効果に指定する方法は同じです。そのため、以下ではロジスティック回帰でオッズ比を算 出する方法で説明します。3.1 名義尺度の変数が2カテゴリのとき
2章で用いたデータ「odds1.jmp」で、モデルの効果に指定した名義尺度「Treatment」は 3 つのカテゴリ(P ,A ,B)があります。同 様に「risk1.jmp」では、名義尺度「グループ」は 4 つのカテゴリ(G1, G2, G3, G4)があります。カテゴリ数が 3 つ以上であれば、2章 のように分析を行いますが、カテゴリ数が 2 つであれば、ダミー変数を用いることなく、モデル効果に 2 カテゴリの名義尺度を追加 することによって、オッズ比、リスク比を求めることができます。 ここでは例として、データ 「odds1.jmp」 で、Treatment=A のデータを除外し、P と B の 2 つのカテゴリのデータにしたときについ て説明します。JMP では、対象となる行を選択し、右クリックのメニューから [除外する/除外しない] を選ぶことにより、データの 一時的な除外を簡単に行うことができます。(図 3.1) また一時的な除外ではなく、Treatment=B または P のデータのみ新しいデ ータテーブルに抽出する方法は、文末の付録 1 をご参照下さい。図 3.1 データの除外:除外されたデータ行にはマークが表示される メニュー[モデルのあてはめ] で、列を以下のように選択します。 [Y]:「Pain」 [モデル効果の構成]:「Treatment」、「Age」、「Duration」 図 3.2 は、[範囲オッズ比](JMP 6 以前のバージョンでは[オッズ比])と[信頼区間](α = 0.05 に設定) を選択した後の出力レ ポートになります。Treatment[B] の行に記されている「オッズ比」、「オッズ下側」、「オッズ上側」 が治療 P に対する治療 B のオッ ズ比、95%信頼区間になります。 図 3.2 治療 P に対する 治療 B のオッズ比とその 95%信頼区間
3.2 順序尺度の活用
JMP にはカテゴリを表す尺度として、名義尺度のほかに順序尺度があります。この章では、ダミー変数を用いず、順序尺度を用 いてオッズ比、リスク比を算出する方法を説明します。データは2章で用いた「odds1.jmp」 を用います。ここではオッズ比の例で 説明しますが、リスク比の操作方法も同様です。 「odds1.jmp」の変数「Treatment」は名義尺度に設定されていますが、これを順序尺度に変更します。(データテーブル左中央に ある列欄の列アイコンをクリックし変更) さらにリストチェックを用い、値の順序を A, B, P から P, A, B の順に変更します。(図 3.3 参照) 図 3.3 リストチェック値の順序を変更後、[分析] > [モデルのあてはめ] で、図 3.4 のように列を選択します。 図 3.4 モデルのあてはめ:順序尺度の「Treatment」を「モデル効果の構成」に含める 図 3.5 は、モデルのあてはめの結果レポートで、左上の赤い三角ボタンから、[範囲オッズ比] と [信頼区間] を選択したとき の表示になります。 図 3.5 名義ロジスティックのあてはめ : リスト順 P, A, B 図 3.5 でパラメータ推定値の項に表示される「Treatment[A-P]」の行のオッズ比は、P に対する A のオッズ比を表し、 「Treatment[B-A]」の行のオッズ比は、A に対する B のオッズ比を表します。このように順序尺度に対しては、”1 番目のカテゴリ” に対する”2 番目のカテゴリ”のオッズ比、”2 番目のカテゴリ”に対する”3 番目のカテゴリ”のオッズ比、・・・が出力されます。リスト チェックと結果レポートのパラメータ推定値に表示される項目との関係は、図 3.6 のようになります。図 3.5 の項 Treatment[A-P] のオッズ比、信頼区間は、図 2.6 の項 Treatment(A) のオッズ比、信頼区間と一致します。 図 3.6 リストの順番と項目の表示との関係
さらに、P に対する B のオッズは、 P に対する B のオッズ比 = (P に対する A のオッズ比) × (A に対する B のオッズ比) で求められることから、(Treatment[A-P] のオッズ比: 0.06869689) × (Treatment[B-A] のオッズ比: 0.57225218) = 0.039 に なります。この値は、図 2.6 の Treatment(B) のオッズ比の値に一致することがわかります。ただし、オッズ比の信頼区間は、同様 に掛算することによって求めることはできません。 自動的に P に対する B のオッズ比を求めたいのであれば、リストチェックを用いて、リストの順番を P, B, A と変更することによ り、前述と同様の操作で求めることができます。図 3.7 は、そのときの結果のレポートになります。 図 3.7 の項 Treatment[B-P] の行の値は、図 2.6 の Treatment(B) の値に一致します。 図 3.7 名義ロジスティックのあてはめ : リスト順 P, B, A 3.1 節では、名義尺度で 2 カテゴリの説明変数について、オッズ比を求めましたが、ここでは、名義尺度を順序尺度に変更して、 同様にオッズ比を求めてみます。図 3.1 で示したデータ、すなわち、Treatment = A を除外したものを用います。分析の流れは以 下の通りです。 1. 列「Treatment」 を名義尺度から順序尺度に変更する。 2. リストチェックで、カテゴリの順序が、P, B, A の順に変更する。(実際、A のデータは除外しているため、A の位置は任意で構 いません) 3. [モデルのあてはめ] で、列を以下のように選択する。 [Y]:「Pain」 [モデル効果の構成]:「Treatment」、「Age」、「Duration」 4. 結果のレポートで、[範囲オッズ比]、[信頼区間] を選択する。 図 3.8 は、上記の方法で求めた結果になります。項 Treatment[B-P] のオッズ比とその信頼区間の値は、図 3.2 の項 Treatment[B]のものと一致します。ただし、パラメータの推定値、標準誤差は一致していません。この理由は4章で説明します。 図 3.8 治療 P に対する 治療 B のオッズ比とその 95%信頼区間:順序尺度を使用
4.理論的な背景
3 章では、以下のことを説明しました。 A. 名義尺度が 2 カテゴリのときは、ダミー変数を作成せず、直接、名義尺度の列をモデルの効果に含めることによってオッズ比を 求められる。 B. 2 カテゴリの名義尺度を順序尺度に変更しても、カテゴリの順序を正しく変更すると A と同様にオッズ比を求めることができる。 ただし、パラメータ推定値とその信頼区間は、名義尺度と順序尺度にした場合とで値が異なる。 C. 3 カテゴリの場合、名義尺度と順序尺度では、出力されるオッズ比が異なる。 JMP では、2 章で説明したデータのように説明変数として 3 カテゴリ以上の名義尺度の変数を用いるとき、ダミー変数を用いて 分析することをお勧めしております。この章では、上記の内容(A, B, C)も含め、なぜ直接、カテゴリ変数(名義尺度、順序尺度)を モデルの効果に含めてオッズ比を求めることができず、ダミー変数を作成してから分析を行う必要があるかを説明します。4.1 ダミー変数について
通常、名義尺度を説明変数に含めてロジスティック回帰や重回帰分析を行うとき、名義尺度の説明変数はダミー変数に変換し ます。そして、このダミー変数を説明変数に加えてパラメータの推定を行います。JMP でもモデル効果に名義尺度を指定したとき は、内部的に名義尺度の変数をダミー変数にしてパラメータ推定値を計算します。 しかし、一般にダミー変数への変換方法は複 数ありまして、2章で説明したダミー変数への変換方法と JMP で内部的に行っているダミー変数への変換方法は異なります。この 節では、これらの違いについて説明します。 2カテゴリのとき まずは、簡単のため2カテゴリの場合について説明します。そのためにデータテーブル 「odds1.jmp」 で Treatment = B または P のみを抽出したデータを用いて説明します。JMP でこのようなデータを抽出する方法を、文末の付録 1 に記します。名義尺度 「Treatment」 のリスト順は B, P です。ここでは JMP で、モデル効果に指定した名義尺度の変数、順序尺度の変数それぞれをダ ミー変数に変換する際の変換ルール(JMP の内部的な変換法でして、ダミー変数の列が作られるわけではありません)、2 章で行 ったダミー変数への変換方法を表 4.1 にまとめておきます。例えば①の場合、値が B のデータは ”1” に、値が P のデータ は”-1” に変換されることを示します。カテゴリ
①JMP
名義尺度
②JMP
順序尺度
③2 章で作成し
たダミー変数
B
1
0
1
P
-1
1
0
表 4.1 ダミー変数への変換ルール(2カテゴリ) 図 4.1 は、①、②、③の方法で求めた、パラメータ推定値、(範囲)オッズ比を JMP のテーブルにまとめたものです。図 4.1 それぞれの方法のパラメータ推定値、(範囲)オッズ比 表 4.1 と 図 4.1 を参照し、以下の疑問(Q1, Q2)に答えます。 Q1. ①と③ではパラメータ推定値が異なるのに、オッズ比が等しいのはなぜか? A1. JMP では、名義尺度の変数で複数のカテゴリがあるとき、最後のカテゴリのパラメータ推定に関する情報は結果のレポートに 表示されません。最後のカテゴリ(P)のパラメータ推定値は、表 4.1 の①のダミー変数の指定方法より、最初のカテゴリ(B)のパ ラメータ推定値を-1 倍したものになります。一方③では、最後のカテゴリ(P)のパラメータ推定値は 0 になります。 表 4.2 にこれらの値をまとめます。これより、①、③双方でパラメータ推定値は異なりますが、値の範囲は双方で等しく、 (P の推定値)-(B の推定値) = 2.728 となります。そのため、説明変数の値が最小値から最大値へ変化したときのオッズ比 が何倍になるかを示す「範囲オッズ比」では、①と③双方でのオッズ比が等しくなります。範囲オッズ比と単位オッズ比の違い については、文末の付録 B に記します。 ①の範囲オッズ比: Exp((-1.364)-1.364) = Exp(-2.728) = 0.065 ③の範囲オッズ比: Exp((-2.728)-0) = Exp(-2.728) = 0.065
カテゴリ
①JMP
名義尺度
③2 章で作成し
たダミー変数
B
-1.364
-2.728
P
1.364
0
表 4.2 変数「Treatment」 のパラメータ推定値 Q2. ②と③でのパラメータ推定値、オッズ比が異なる理由は? A2. パラメータ推定値は、符号の違いになります。これは表 4.1 より、②では B → 0, P → 1 となっているものが、③では B → 1、P → 0 となっていることによります。②のときのオッズ比は、B に対する P のオッズ比を示すため、②のオッズ比の逆数 = 1/15.31063 = 0.065 (=③のオッズ比) になります。②で①、③のように P に対する B のオッズ比に変更するのであれば、3.2 節で説明したように、順序尺度のリスト順を変更(P, B の順)する必要があります。 3カテゴリのとき 3カテゴリの変数のとき、パラメータ推定に用いるダミー変数は、2 つのダミー変数 D1, D2 を用いて、表 4.3 のように示されま す。①JMP
名義尺度
②JMP
順序尺度
③2 章で作成し
たダミー変数
カテゴリ
D1
D2
D1
D2
D1
D2
A
1
0
0
0
1
0
B
0
1
1
0
0
1
P
-1
-1
1
1
0
0
表 4.3 ダミー変数への変換方法(3カテゴリ) ③の D1, D2 はそれぞれ、2 章で作成したダミー変数 「Treatment(A)」、「Treatment(B)」 に該当します。(図 2.4 参照) 図 4.2 は、①、③の方法で求めたパラメータ推定値、(範囲)オッズ比を JMP のテーブルにまとめたものです。 (②は、3.2 節で説明したため省略します。) 図 4.2 それぞれの方法のパラメータ推定値、(範囲)オッズ比 ①について、「名義ロジスティックのあてはめ」 のレポートの左上の赤い三角ボタンから、[確率の計算式の保存] を選択すると、 データテーブルにいくつかの列が追加されます。その中の列 「線形[Yes]」 の計算式を参照しますと、「Treatment」 のカテゴ リ”A”, “B” , ”P” のパラメータ推定値を確認することができます。(図 4.3) 名義尺度に対する JMP のパラメータ推定値は、すべ てのカテゴリの推定値を合計すると 0 になるよう設計されております。 A B P (-0.7066) + (-1.2648) + 1.9714 = 0 図 4.3 線形[Yes] の計算式:列名の「+」ボタンをクリックすることにより表示できる①で求めたパラメータ推定値(図 4.2 参照)を用いて、P に対する A のオッズ比、P に対する B のオッズ比を求めるには、以 下のような計算を行います。ここで、β(A) は カテゴリ A のパラメータ推定値を示します。 β(A) + β(B) + β(C) = 0 より、 ・P に対する A のオッズ比 Exp{β(A)-β(P)} = Exp[β(A)-{-(β(A)+β(B))}] = Exp{2×β(A) + β(B)} = Exp{(2×(-0.7066) + (-1.2648)} = Exp(-2.678) = 0.069 ・P に対する B のオッズ比 Exp{β(B)-β(P)} = Exp[βB)-{-(β(A)+β(B))}] = Exp{β(A) + 2×β(B)} = Exp({(-0.7066)+ 2×(-1.2648)} = Exp(-3.2362) = 0.039 これらは、③で求めたオッズ比の値に一致します。 このように、ダミー変数を作成せずに 3 カテゴリの名義尺度を用いて、あるカテゴリを基準(リファレンス) としたオッズ比を求め る場合は、上記のような計算が必要になります。そのため、JMP では 2 章で説明したように、ダミー変数を作成して分析する方法 をお勧めしております。この方法であれば、4 カテゴリ以上のカテゴリ変数でも適用することができます。
付録A.部分的にデータを抽出する方法
ここでは、JMP である条件のデータを抽出する方法を説明します。例として、データテーブル「odd1.jmp」で、Treatment= B また は P のデータのみを新しいデータテーブルに抽出することを考えます。 操作方法 1. メニューより、[分析] > [一変量の分布] を選択し、列「Treatment」 を[Y] に選択します。 2. レポートに出力される棒グラフ(ヒストグラム)に対し、P と B のヒストグラムを複数選択します。複数選択するには、一方のカ テゴリを選択後、Shift キーを押しながら、もう一方のカテゴリを選択することによって行えます。(図 A1 参照) 3. データテーブルにもグラフで選択した箇所がリンクされるので、データテーブルでも Treatment=P または B のデータが選択さ れています。データテーブルをアクティブにし、メニューより、[テーブル] > [抽出(サブセット)] を選択します。表示されるウィ ンドウ(図 A2 参照)でそのまま[O.K] ボタンを押します。新しいテーブルが作成され、このテーブルは、Treatment = B または P が抽出されたものになります。 図 A1 一変量の分布で P と B のカテゴリを選択 図 A2 抽出(サブセット) の画面付録B 範囲オッズ比と単位オッズ比の違い
JMP 6 では、オッズ比の選択項目として、「範囲オッズ比」と「単位オッズ比」 があります。ここでは、これらのオッズ比の違いに ついて説明します。 範囲オッズ比 説明変数(X)の値が、最小値(Xmin)から最大値(Xmax)へ変化したときにオッズ比が何倍になるかを示した値です。 たとえば、説明変数 X として年齢という変数を取り上げ、その変数の値の範囲は、15(歳) から 35(歳)だとします。このとき、範 囲オッズ比は、年齢が 15 歳から 35 歳に上がったときに、Y のオッズ比が何倍になるかということが求まります。パラメータ推定値 をβとしたとき、連続尺度のオッズ比は、Exp{β×(Xmax-Xmin)} で計算します。本文で説明した通り、JMP で名義尺度の場合は、パラメータ推定値を求める際に、”-1”と”1” にコード化されます。このことから、 名義尺度のオッズ比は、Exp{β×(1-(-1))} = Exp(2β) で計算されます。順序尺度の場合は、”0”と”1” にコード化されますので、 順序尺度のオッズ比は、Exp(β) になります。 単位オッズ比 説明変数(X)が 1 単位変化したときのオッズ比の変化を示します。例えば、年齢であれば、年齢が 1 歳年を取ったときの Y のオッ ズ比が何倍になるかということが求まります。このため、単位オッズ比に場合は、連続尺度、名義尺度、順序尺度ともに Exp(β) で計算されます。 範囲オッズ比、単位オッズ比の計算式をまとめたものが表 B になります。
![図 2.7 データテーブルにダミー変数を追加 データテーブル「risk2.jmp」は、ダミー変数作成後のデータテーブルになります。 ダミー変数の作成を行った後、メニューより、[分析] > [生存時間もしくは信頼性分析] > [比例ハザードのあてはめ] を選び、列 を次のように指定します。(図 2.8) 図 2.8 モデルの指定(比例ハザード) この分析例では、グループ G1 を基準(リファレンス)にしているので、ダミー変数「グループ(G1)」 をモデルに含めず、残りのダ ミ](https://thumb-ap.123doks.com/thumbv2/123deta/7010574.781928/7.892.87.539.116.322/データテーブルデータテーブルデータテーブルリファレンス.webp)
![図 2.9 リスク比、(両側 95%)信頼区間の表示 図 2.9 より、グループ G1 に対する、グループ G2、G3、G4 それぞれのリスク比、リスク比の 95%信頼区間は、表.2.3 のようにま とめることができます。 グループ リスク比 95%信頼区間 G2 1.875 [0.945 , 3.707] G3 1.025 [0.517 , 2.029] G4 3.435 [1.690 , 7.002] 表 2.3 グループ G1 をリファレンスとしたときの、グルー](https://thumb-ap.123doks.com/thumbv2/123deta/7010574.781928/8.892.87.400.136.370/グループに対するグループそれぞれグループグループリファレンス.webp)
![図 3.1 データの除外:除外されたデータ行にはマークが表示される メニュー[モデルのあてはめ] で、列を以下のように選択します。 [Y]:「Pain」 [モデル効果の構成]:「Treatment」、「Age」、「Duration」 図 3.2 は、[範囲オッズ比](JMP 6 以前のバージョンでは[オッズ比])と[信頼区間](α = 0.05 に設定) を選択した後の出力レ ポートになります。Treatment[B] の行に記されている「オッズ比」、「オッズ下側」、「オッズ上側](https://thumb-ap.123doks.com/thumbv2/123deta/7010574.781928/9.892.85.421.124.331/データマークメニューモデルモデルオッズバージョンオッズポート.webp)

