筑波大学大学院博士課程
システム情報工学研究科修士論文
CRMのための
バラエティシーキングに着目した
顧客セグメンテーション
黒田
哲平
(社会システム工学専攻)
指導教員
香田正人
2008年3月
論文要旨
顧客が商品を選択するとき、前回購入した商品と同じ商品を慣性的に購入することがあ る。また、バラエティを求め、前回購入した商品とは異なる商品を非慣性的に購入するこ ともある。この様な慣性/非慣性による購買行動は、飲料や菓子の様な低関与に位置する商 品カテゴリーにおいて頻繁に見受けられる。低関与に位置する商品カテゴリーを購入する とき、顧客は情報探索の過程を省き経験や慣性・雰囲気に基づいて商品選択を行うことで、 時間的なコストを節約する傾向がある。また、近年では、マーケティング戦略立案におい て、顧客異質性を把握することが重要となっており、慣性/非慣性に着目した研究では、カ テゴリー属性の視点を加えることが増えている。 本研究では、階層ベイズ手法による混合正規多項ロジットモデルを使用し、日本茶と中 国茶に対する慣性/非慣性傾向を顧客ごとに推定できるモデルを構築した。 まず、潜在クラスモデルと階層ベイズモデルとの比較を行い、階層ベイズモデルを使用 することで、的中率が増加していることを確認した。次に、慣性/非慣性変数を使用しない モデルとの比較を行い、慣性/非慣性変数を使用することで、DIC が減少していることを確 認した。また、Bawa が提案した慣性/非慣性変数に購買間隔の影響を加え、モデルの拡張 を行った。このモデルによって、Bawa のモデルより DIC を減少させることができ、ブラ ンドスイッチのタイミングを予測できる顧客が存在することを確認した。分析結果から、 顧客は日本茶と中国茶では異なる慣性/非慣性傾向を持つことが分かった。 最後に、CRM に繋がる戦略提案として、効用の時間的変化からブランドスイッチしても らうために必要な割引率を計算することで、効果的なプロモーションを実施することや、 効用の減少からブランドスイッチしやすいタイミングを予測することで、それに合わせて 自社のブランドを紹介することを挙げた。−目次−
第1章 序論
... 1
1.1 研究の背景と目的 ... 1 1.2 論文の構成 ... 2第2章 分析データ
... 3
第3章 分析モデル
... 4
3.1 多項ロジットモデル ... 4 3.2 説明変数 ... 5 3.2.1 説明変数 ... 5 3.2.2 慣性/非慣性傾向の判断基準 ... 7 3.2.2.1 慣性/非慣性傾向の判断に使用するパラメータ... 7 3.2.2.2 パラメータから見る慣性/非慣性傾向... 8 3.2.2.3 慣性/非慣性傾向に購買間隔の影響を加える効果... 9 3.3 潜在クラスモデル ... 10 3.4 階層ベイズ手法 ... 11 3.5 階層ベイズ手法による混合正規分布多項ロジットモデル ... 12 3.6 パラメータの推定方法 ... 133.6.1 MCMC(Mrakov Chain Monte Carlo)法 ... 13
3.6.2 Gibbs Sampling ... 13 3.6.3 Metropolis-Hastings(MH)アルゴリズム ... 14 3.7 モデル評価基準 ... 15 3.8 収束判定方法 ... 16
第4章 潜在クラスモデルと階層ベイズモデルの比較
... 17
4.1 潜在クラスモデルのための分析データ ... 17 4.2 潜在クラスモデルの分析結果 ... 17 4.3 階層ベイズモデルの分析結果 ... 18 4.4 潜在クラスモデルと階層ベイズモデルの比較 ... 19第5章 Bawa モデルと提案モデルの比較
... 22
5.1 全データによる分析結果 ... 22 5.2 グループ毎の分析結果 ... 23 5.2.1 分析データ ... 235.2.2 ヘビーユーザーの分析結果 ... 23 5.2.3 ミディアムユーザーの分析結果 ... 26
第6章 まとめと今後の課題
... 28
参考文献
... 30
添付資料1
... 33
添付資料2
... 35
−表目次−
表2-1 分析に用いる商品選択集合...3 表4-1 潜在クラスモデルによる情報量基準...18 表4-2 階層ベイズモデルによる DIC と的中率...18 表4-3 潜在クラスモデルと階層ベイズモデルの DIC と的中率 ...19 表4-4 混合正規分布によるセグメント毎のパラメータ ...20 表5-1 Bawa モデル、提案モデルA∼Cの DIC と的中率...22 表5-2 グループ毎の購買間隔の平均 ...23 表5-3 ヘビーユーザーの各モデルの DIC と的中率...23 表5-4 各カテゴリーに対する慣性/非慣性傾向を持つ顧客の割合 ...25 表5-5 慣性/非慣性傾向の違いによるプロモーションに対する反応...26 表5-6 ミディアムユーザーの各モデルの DIC と的中率...27 表5-7 各カテゴリーに対する慣性/非慣性傾向を持つ顧客の割合 ...27−図目次−
図3-1 連続購買回数がもたらす効用の変化...9 図3-2 購買間隔に伴う Z の変化 ...10 図5-1 提案モデル B から得られた効用の変化...24 図5-2 比較モデルから得られた効用の変化...24第1章 序論
1.1 研究の背景と目的 成熟した市場に向けたマーケティング戦略では、顧客一人ひとりの異質性を把握し、 それに合わせた販売戦略をとることが重要である。情報技術の発達により、顧客一人ひ とりのデータを収集し保存することが可能になった現在では、ますますその手段は重要 となっている。 また、市場には多種多様な商品カテゴリーが存在し、商品カテゴリーの種類によって 顧客の購買行動が異なることから、様々な切り口から商品カテゴリーの分類が行われて いる。その切り口の1つとして、関与がある(Assael 1992,青木 1989、Dick and Basu 1994,Peter and Olson 1999)。高関与のアイテムは、じっくり商品を吟味して商品選択 される傾向が強く、大橋・梅津(2002)の調査によると、代表的なものとして自動車やパ ソコンが挙げられる。一方、低関与のアイテムは、慣性または、非慣性的に商品選択さ れる傾向が強く、その例として飲料・菓子・タバコが挙げられる。特に飲料は、非慣性 的に購買されることが多いアイテムとされている。しかしながら、全員が非慣性的に購 買するのではなく、慣性的に購買する顧客も存在するであろう。 低関与のアイテムにおいては、商品そのものの魅力度向上やプロモーションだけでな く、慣性/非慣性を利用した販売戦略も可能ではないかと考えられる。例えば、顧客の 慣性/非慣性傾向を把握し、ブランドスイッチのタイミングを知ることができれば、そ れに合わせたプロモーション戦略も可能になる。また、慣性的に購入する顧客を獲得す ることが出来れば、顧客との長期的な関係を構築することも可能になる。このことから、 低関与のアイテムにおいて、顧客の慣性/非慣性傾向を知ることは、CRMの実現に役 立つと考えられる。 慣性/非慣性傾向を推定するモデルに関する代表的な研究として、Givon(1984) , Lattin and McAlister(1985) ,Bawa(1990), Trivedi, Bass and Inmann(1994)がある。 Givon(1984) , Lattin and McAlister (1985)の研究は、この視点からの研究において、 比較的初期のモデルであり、慣性傾向と非慣性傾向の2つが同一個人内に存在する場合 が考慮されていない。これに対し、Trivedi, Bass and Inmann (1994)は、Lattin and McAlister (1985)のモデルを改良し、慣性/非慣性傾向が同一個人内に確率的に存在する としてモデル化を行った。Bawa(1990)は、慣性的顧客・非慣性的顧客だけでなく、同 一個人内で時間的に慣性/非慣性傾向が移り変わる顧客(ハイブリッド的顧客)を考慮 したセグメンテーションを可能にした。これにより、数回は同一ブランドを意識的に購 入し、飽きてきたところで、ブランドスイッチする(ハイブリッド行動の1例)などの 顧客を識別することが可能になった。上記の様に、商品カテゴリー内での、慣性/非慣性傾向による顧客異質性を明らかにするための研究がなされてきた。 しかし、近年、慣性/非慣性傾向に着目した研究では、商品カテゴリー内のグループ を考慮し、属性レベルでの研究が主流となりつつある(小川(2005))。川端・近藤(2004) は、属性に対する嗜好から顧客セグメンテーションを行っている。具体的には、飲料2 属性(日本茶・中国茶)のスキャンパネルデータを使用し、バラエティシーカーを属性 に拘りのないスイッチャー・日本茶に拘りを持つ日本茶ロイヤラー・中国茶に拘りを持 つ中国茶ロイヤラーにセグメンテーションしている。Inman(2001)は、ガムのデータを 用いて、属性によって、顧客の慣性/非慣性傾向が異なることを示した。 本研究では、Bawa(1990)のモデルを購買間隔の影響を加えたモデルに拡張し、顧客 異質性をモデル化できるベイズ手法を用いることで、顧客ごとに慣性/非慣性傾向を推 定できるモデルを構築する。その際に、顧客は属性によって異なる慣性/非慣性傾向を 持つと仮定し、属性毎に慣性/非慣性傾向を推定できるモデルを構築することを目的と する。また、セグメンテーション手法として普及している潜在クラスモデルと比較する ことで、本研究での提案モデルの有効性を示す。最後に、CRM を実現するための効果 的なマーケティング戦略を提案することを目的とする。 1.2 論文の構成 本研究の構成は、第1章の序論において、研究の背景と目的、慣性/非慣性傾向に関 する先行研究について論じ、第2章では、分析に用いたデータについて述べる。第3章 では、本研究で用いる潜在クラスモデルと階層ベイズによる混合正規分布を使用した多 項ロジットモデルについて述べる。第4章では、潜在クラスモデルと階層ベイズモデル の比較、第5章では、階層ベイズモデルにおけるBawa モデルと提案モデルとの比較に 関する分析結果について述べ、結果を考察する。最後に、第6章では、本研究のまとめ と今後の課題について述べる。
第2章 分析データ
飲料2 カテゴリー(日本茶・中国茶)の 2000.1.1∼2001.5.31 間の東京近郊のスーパー マーケット及び大型総合スーパーマーケット 5 店舗における日次スキャンパネルデー タを分析対象データとして用いた。スキャンパネルデータとは、小売店のレジに設置さ れているスキャナーから得られた顧客ID付きのデータであり、いつ、誰が、どの店舗 で、何を、いくらで、何個購入したかを蓄積したデータのことである。まず、全パネル 数 13238 から 7000 の顧客サンプルをランダムサンプリングによって抽出した。この 7000 サンプルの中から、以下の 3 つの条件でスクリーニングを行った。 ①同時購買されていない購買機会を抽出 ②同時購買でない購買回数が8回以下の顧客を除く ③全購買期間を3 つに分割し、以下の 3 期間すべてにおいて同時購買でない購買回数 が1 回以上の顧客を対象とする。 1 期:2000.1.1∼2000.6.30 【2000 年上半期】 2 期:2000.7.1∼2000.12.31 【2000 年下半期】 3 期:2001.1.1∼2001.5.31 【2001 年上半期】 ①のスクリーニング条件を使用する理由は、本研究で使用するモデルには効用最大化 の理論を適用しており、同時に2 種類以上の商品選択が行われた場合を扱えないからで ある。同時購買されていない購買が行われる確率は、90.1%である。 この条件をいずれも満たすサンプルは、681(購買回数 12901 回)となった。日本茶 の購買回数は、5728 回、中国茶の購買回数は 7173 回となっている。 なお、分析対象ブランド・サイズは、売上数上位7ブランド・サイズとその他のブラ ンド・サイズである。本研究では、Guadagni and Little(1983)と同様に、同一ブラン ドでもサイズが異なる場合、異なる商品として取り扱う。その他のブランドは、売上数 上位7ブランド以外の全てのブランドから構成される。なお、上位7ブランドにおける 売上数のシェアの合計は、78.09%である。また、分析対象期間中に販売されたブラン ド数は、日本茶が127、中国茶が 104 である。 表2-1 分析に用いる商品選択集合 購買回数 売上シェア サントリ―ウ―ロン茶 2L 4093 31.73% 伊藤園おーいお茶 2L 2685 20.81% 伊藤園金のウーロン茶 2L 1332 10.32% キリン生茶 500ml 547 4.24% キリン生茶 2L 479 3.71% 伊藤園おーいお茶 500ml 523 4.05% サントリ―ウ―ロン茶 500ml 415 3.22% その他 2827 21.91% 計 12901 100.00%第3章 分析モデル
本研究では、比較対象モデルとして潜在クラスモデル、提案モデルとして階層ベイズ 手法による混合正規分布多項ロジットモデルを使用する。本章では、最初に両モデルの 基礎となる多項ロジットモデルを説明し、その後に潜在クラスモデルの説明を行う。次 に提案モデルの基となる階層ベイズ手法について説明し、最後に、階層ベイズ手法によ る混合正規分布多項ロジットモデルの説明を行う。 3.1 多項ロジットモデル 多項ロジットモデルは、人々のある1 つの選択集合において 1 つの要素を選択すると いう行動を表すモデルである。マーケティングでは、各購買機会にある顧客が商品に対 して感じる効用(魅力度)を確率変数とみなし、その購買機会に選択集合の中で最大の効 用値をもった商品をその顧客が選択すると仮定する。スキャンパネルデータを用いた初 期の分析には、Guadagni and Little(1983)がある。t
期における顧客i
の商品j
に対する効用Uijtを、確定部分vijtと確率部分 ijtの和とし、 以下のように表す。Uijt vijt ijt (1)
このとき、個人iが
t
期に選択集合C
itの中から商品j
を選択する確率は、効用最大化 の理論を適用することで、以下のように表される。 j l Cit lu
u
ijt ilt ijt P Pr( ) , (2) また、効用の確率部分 ijtが2重指数分布に従うと仮定することで、個人iがt
期にブ ランドj
を選択する確率 ijtP
は、以下の(3)式で表される。なお、顧客iのt
期におけるブランド
j
の選択をyijt 1、非選択をyijt 0、説明変数をXijt、それに対するパラメータを iとする。
)
3
(
C l it ilt ijt ijt v v
e
e
P
プロモーション要素 非慣性要素 慣性 / 2 1ijt v ijt v X vijt ijt i (4) 本研究で扱わない約 10%の2種類以上の同時購買は、多変量ロジットモデルで分析 することも考えられる。 3.2 説明変数 本研究で使用する説明変数について説明する。慣性/非慣性行動は内発的動機付けに よって起こる行動であり、割引を始めとするプロモーション変数等の外発的動機付けに よ る 行 動 と は 区 別 す べ き と さ れ て い る (Hoer and Ridgway 1984,Lattin 1987, McAlister and Pessemier 1982, Raju 1981,1984, Van Trijp,Hoyer,and Inman 1996)。 そこで、本研究では、Bawa(1990)が使用した慣性/非慣性傾向を推定するための慣性/ 非慣性変数に加えて、プロモーション変数を使用する。 3.2.1 説明変数 (1)慣性/非慣性変数 a.連続購買回数 Bawa(1990) によって考えられた連続購買回数を参考にし、連続購買回数rijt とその2乗 2 ijt r を用いる。最近のブランドスイッチ時点をs 期とすると、以下の ように示される。 1 t s ij ijt
y
r
(5) 例えば、ブランドの購買履歴がAABBCCC の場合、s=5 となり t=8 におけ るrij8は、r
iC83
、r
ik80
(
k
ブランドC
以外のブランド
)
となる。b.連続購買回数×
Z
t 上記の連続購買回数rijtとその2乗 2 ijt r に購買間隔を含んだ関数を掛け合わせた 変数である。 ただし、1
exp
1
exp
a
t
a
t
Z
t期における購買間隔
期における購買間隔
(6) 購買間隔とは、前回の購買から今回の購買までの期間を日数で表したもので ある。Z を掛け合わせる理由は、本節の次項にて説明する。a の値は、10、15、 20、25 の4通りを使用した。 上記の5通りの慣性/非慣性変数は、それぞれ別のモデルで使用する。今後、連続 購買回数のみを使用したモデルをBawa モデルと呼ぶ。また、連続購買回数×Z の4 通りの説明変数において、a を 10 としたモデルを提案モデルA、a を 15 としたモデ ルを提案モデルB、a を 20 としたモデルを提案モデルC、a を 25 としたモデルを提 案モデルDと呼ぶ。 なお、この変数から推定されるパラメータ i1と i2から、慣性/非慣性傾向を4パ ターンに分類する。分類方法は、次項にて説明する。 (2)プロモーション変数 各店舗のプロモーション変数には割引率、特別陳列、自店チラシの3 変数を用いた。 a.割引率 割引率xj3tは、各店舗における商品j
の通常価格Pjから各店舗のt
期におけ る商品j
の売価pjt を差し引き、通常価格で割ったものである。 j jt t jP
p
x
31
(7) 川端・近藤(2004)は、通常価格が何度か変更された商品に関しては、通常価 格の細かい変動を顧客が即座に認識するとは考え難いため、データ期間中にお ける通常価格の最大値を各商品の通常価格としている。しかしながら、本研究 にて試用する分析データには、最大値となる価格での販売日数が極端に少ないブランドが存在している。仮に、川端と同様の通常価格の設定方法を採用した 場合、1年半の分析データの内、ほとんど毎日割引が行われていることになる。 顧客の意識としては、最大値よりも最頻値を通常価格として捉える方が現実に 即していると考えられるため、本研究では最大値ではなく最頻値を通常価格と して使用する。 b.特別陳列 特別陳列xj4tは、特別陳列実施なしの通常陳列の場合に0、中通路の端など への通常の特別陳列・平台に山積みになっているような大々的な特別陳列の場 合に1、という値をもつインディケーター変数である。
なかった場合
の特別陳列が実施され
期に商品
合
別陳列が実施された場
の大規模陳列または特
期に商品
j
t
j
t
x
j t0
1
4 c.自店チラシ 自店チラシxj5tは、t
期に商品j
が自店チラシに掲載されていない場合に 0、 自店チラシに掲載されている場合に 1 の値をもつインディケーター変数であ る。れなかった場合
が自店チラシに掲載さ
期に商品
れた場合
が自店チラシに掲載さ
期に商品
j
t
j
t
x
j t0
1
5 (3)切片 ブランド固有の魅力度を表す。 3.2.2 慣性/非慣性傾向の判断基準 本節では、Bawa(1990)によって定義された慣性/非慣性傾向の判断基準について説明 する。 3.2.2.1 慣性/非慣性傾向の判断に使用するパラメータ 慣性/非慣性傾向の判断は本節の第1項で説明した慣性/非慣性変数を使用する。そこ に記載されているように、慣性/非慣性変数は連続購買回数のみの変数と、それに購買間隔を考慮した4種類の変数からなる計5通りの変数で分析している。ここでは、その 中でも最も単純なモデルである連続購買回数のみの変数を用いて、慣性/非慣性傾向の 判断基準について説明する。 ブランド
j
がrijt回連続購買されているときに、連続購買回数とその2乗が影響を及ぼ す顧客iのt
期におけるブランドj
に対する確定的効用の慣性/非慣性要素v1ijtは、 2 2 1 1 r rijt vijt i ijt i となる。この様に、連続購買回数を基に効用を2次関数で表現することで慣性/非慣性 傾向をモデル化している。本研究では、Bawa(1990)と同様に推定されたパラメータ i1 と i2を慣性/非慣性傾向の判断に使用し、慣性/非慣性傾向を4パターンに分類した。 3.2.2.2 パラメータから見る慣性/非慣性傾向 本節では、 i1と i2の2つのパラメータから顧客の慣性/非慣性傾向を判断する方法 を述べる。Bawa(1990)は、推定されたパラメータ i1と i2の符号から慣性/非慣性傾向 を4パターンに分類・定義している。 ① i1 i20
の場合
はZero-order と定義する。 前回の購買が今回の購買行動に影響を及ぼさない顧客である。また、分析対象店 舗以外での日本茶・中国茶の購入が多い顧客も、慣性/非慣性傾向の推定が難しく なるため、このセグメントに属すると考えられる。そのため、図 3-1 のように、 連続購買回数に影響されず常に0 の値を取る。 ② i10
,
i20
または、
i10
,
i20
または、
i10
,
i20
の場合
は Inertia と 定義する。 前回のブランド選択が次回の購買機会における同一ブランドの選択確率を増加 させる顧客である。これを購買履歴の特徴から見ると、AAAAAAAAAA という 具合に、同一ブランドA を連続して購入する傾向を持つ顧客である。そのため、 図3-1 のように、連続購買回数が増加するに従い、連続購買しているブランドに 対する効用が増加する。 ③ i10
,
i20
または、
i10
,
i20
または、
i10
,
i20
の場合
はVS (Variety seeking)と定義する。前回のブランド選択が次回の購買機会における同一ブランドの選択確率を減少 させる顧客である。これを購買履歴の特徴から見ると、ACFDEADA という具合 に、頻繁にブランドスイッチを行う傾向を持つ顧客である。そのため、図3-1 の ように、連続購買回数が増加するに従い、連続購買しているブランドに対する効 用が減少する。 ④ i1
0
,
i20
の場合
はHybrid と定義する。 ブランドスイッチ後、最初は Inertia 行動をとり、後に、VS 行動をとる傾向を 持つ顧客である。これを購買履歴の特徴から見ると、AAABBBCCC という具合 に、複数回同一ブランドを購入し続けた後に、ブランドスイッチを行う傾向を持 つ顧客である。そのため、図3-1 のように、上に凸の2次曲線で表される。 図3-1 連続購買回数がもたらす効用の変化 なお、 i10
,
i20
のパラメータを持つ顧客は一人も推定されなかったため、説明 を省く。 3.2.2.3 慣性/非慣性傾向に購買間隔の影響を加える効果 上記の様に慣性/非慣性傾向に関して連続購買回数のみを使用した説明変数では、購 買間隔の大小に関わらず、連続購買回数が今期の慣性/非慣性傾向に伴う効用を決定す る。実際は、最近の購買活動が1日前の場合と1ヶ月前の場合とでは、慣性/非慣性傾 向が与えるブランド選択への影響は異なると考えられる。つまり、前回の購買機会が1 日前の場合、連続購買回数の影響を大きく残し、前回の購買機会が1 ヶ月前の場合、連 0 1 2 3連続購買回数
(日)効用
Inertia Hybrid VS Zero-order続購買回数の影響を小さくするべきであろう。そこで、本研究では、Bawa(1990)のモ デルを改良し、
1
exp
1
exp
a
t
a
t
Z
t期における購買間隔
期における購買間隔
を連続購買回数rijtとその2 乗 2 ijt r に掛け合わせた説明変数を考えた。なお、本節の第1項で説明した様に、本研究 では、a の値を 10、15、20、25 の 4 通りで分析を行った。この 4 通りの値を用いた場 合のZ の値は、購買間隔の変化によって、以下の表の様に変化する。 図3-2 購買間隔に伴う Z の変化 Z が取り得る値は 0 から 1 であり、Z は、購買間隔が小さい場合には 1 に近い値を取 り、購買間隔が大きい場合には、0 に近い値を取る。これを Bawa(1990)が使用した連 続購買回数に掛け合わせることにより、購買間隔が大きく空いた場合には、慣性/非慣 性傾向が与える効用への影響を減少させるモデルとなっている。 3.3 潜在クラスモデル本研究で使用するLCA(Latent Class Analysis)では、パラメータ sとセグメントサ
イズ sをデータから推定する。 セグメントs への所属確率を s、セグメントs に所属した場合のブランド
j
の選択確 率をP
itj
|
s とすると、顧客iのt
期におけるブランドj
の選択確率P
itj
|
,
は以下 のように表される。 S s s it s it jp
jp
1 ) | ( ) , | ( π (8) ただし、 ss
S
S s s S SL
L
L
,
,
,
,
1
0
,
1
,
1 , 1 , 1 0 0.2 0.4 0.6 0.8 1 1.2 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 購買間隔 (日) ZS s i i s s s s i i i
y
f
y
f
p
s 1 ) | ( ) | ( ) ( (9) T C y j s t itj s it s i i it jp
y
f
1 ) | ( ) | ( (10) =y
itj 0・・・それ以外の場合 を選択した場合 ンド 回目の購買機会にブラ が 1・・・顧客i t j 潜在クラスモデルでは、多項ロジットモデルのパラメータβsとセグメントサイズπs を最尤法によって推定するが、解を求めるには、EM アルゴリズムによってπsとβsを 交互に探索する。 3.4 階層ベイズ手法 ベイズ統計では、パラメータをβ、データを y、データ発生モデル分布をp
y
|
、 事前分布をp
とすると、事後分布p
|
y
は以下の式で表される。y
p
p
y
p
y
p
|
|
(11) ここで、p
y
|
をy が既知でβの関数と見なすとき、p
y
|
はβの尤度を示す尤 度関数となり、l
y
|
と表す。y を既知とし、βに関係ない項を除くと、p
y
l
y
p
|
|
(12) の様に、事後分布∝尤度×事前分布の形で表される。この時、βの事前分布p
が、 平均 、分散 で分布していると仮定した場合、 と をハイパーパラメータと 呼ぶ。このハイパーパラメータがさらに分布していると仮定したものが階層ベイズ手法 である。3.5 階層ベイズ手法による混合正規分布多項ロジットモデル
Rossi, Allenby and McCulloch(2005)により紹介された階層ベイズ手法による混合正 規分布多項ロジットモデルでは、顧客毎にパラメータを推定できる。 説明変数をXitj 、パラメータを i
とすると、顧客iの
t
期におけるブランドj
の選択 確率Pit j|Xitj, i は、選択肢データYitj の多項ロジットモデルとして以下の式で表され る。 ∼ it itj i itj MNLP j X Y | , (13) また、推定されるパラメータ iが平均 i ind 、分散 indiを持つ正規分布に従うと仮定 した場合、以下のように表される。
)
,
(
i i ind indN
i
∼
(14) さらに、 iの平均および分散共分散行列は、多項分布に従う変数
ind
iに依存し、以 下の 2 式でind
iの分布を表すことにより、 iの分布を混合正規分布として表現できる 柔軟なモデルとなっている。なお、Kは混合正規分布の数であり、K=1 の場合は 1 つ の正規分布を意味する。1 つの曲線に沿って近接する複数の正規分布を配置することに より、複数の峰を持つ同時分布を作り出すことができ、1 つの峰を 1 つのセグメントと みなし、各セグメントの特徴を捉えることが可能である。
)
( pvec
l
Multinomia
ind
i∼
K (15))
(
Dirichelt
pvec∼
(16)i のハイパーパラメータである indiと indiは、以下の様に表される。 1
,
a
N
k k∼
(17)V
v
IW
k∼
,
(18) つまり、 i ind は平均μ
の回りに分布すると仮定している。なお、初期値はv 20、 JI
V
20
(J:パラメータ数)、 01,L,0J '、a 1 0.005、(
5
1,
L
,
5
K)
とした。3.6 パラメータの推定方法
階層ベイズ手法による混合正規分布多項ロジットモデルでは、パラメータの推定に MCMC 法を使用している。以下に、その方法を示す。
3.6.1 MCMC(Mrakov Chain Monte Carlo)法
パラメータが複数存在する場合、その事後分布も多変量分布になる。しかし、個々 のパラメータの推論を行う際には、そのパラメータの周辺事後分布を用いるので、周辺 確率密度関数を求めるために多変量確率密度関数の多重積分を解く必要がある。 MCMC 法は、この多重積分をシミュレーションによって解く方法であり、不変分布が 目標分布になるようにマルコフ連鎖を構成し、イタレーションから得られる標本が目標 分布からの確率標本であると考える。MCMC 法を用いる理由は、反復を繰り返すこと で、パラメータの不変分布への収束を計算できる点にある。収束しているならば、最終 的に事後分布が得られることになる。 不変分布が目標分布になるようにマルコフ連鎖を構成する代表的な方法として、 Gibbs Sampling と Metropolis-Hastings(MH)アルゴリズムが挙げられる。なお、本研 究では、Gibbs Sampling を使用できるパラメータには Gibbs Sampling を使用し、他
のパラメータにはMH アルゴリズムを使用する Hybrid Mrakov Chain Monte Carlo 法
を使用している。 3.6.2 Gibbs Sampling Gibbs Sampling は、p 個の条件付共役事後分布π( j | j,y),j 1,L,pからサンプ リングができることが必要である。Gibbs Sampling は、以下の手順で実行される。 1.初期値 (0) (0) 1 ,L, p を決める。 2.イタレーションi=1,2,…に対して次を繰り返す。 から発生する。 を から発生する。 を から発生する。 を y y y i p i p i p i j i j i i j i p i i i , , , | , , , , , | , , , , | ) ( 1 ) 1 ( 1 1 ) ( ) 1 ( ) 1 ( 1 ) ( 1 ) ( 1 1 ) ( ) 1 ( ) 1 ( 2 ) 1 ( 1 1 ) ( 1 L M L M L 3.十分大きなN に対して (i)
,
i
N
,
N
1
…を記録する。3.6.3 Metropolis-Hastings(MH)アルゴリズム Gibbs Sampling は、p 個の条件付共役事後分布π( j | j,y),j 1,L,pからのサン プリングができることが必要であったが、Metropolis-Hastings(MH)アルゴリズムは、 Gibbs Sampling のように条件付共役事後分布からのサンプリングだけでなく、多変量 事後分布
(
|
y
)
からのサンプリングにも用いることができる。候補点θと前回の反復 で発生された (i 1)との比較を行い、対数尤度が向上していればθを採用するが、悪化 している場合は悪化の度合いに応じて確率的にθを採用する。MH アルゴリズムは、以 下の手順で実行される。 1.初期値 (0) (0) 1 ,L, p を決める。 2.イタレーションi=1,2,…に対して次を繰り返す。 (a)新しい候補点 (i 1)を、θが与えられたときの条件付分布(提案分布)を用いて 提案する。 新しい候補点θを発生させるには、θ= (i 1)+d のように前回の値 (i 1)にラン ダムなジャンプスペクトルd を加える。D はθの事前分布の不確実性に基づいて、 確率的に正規分布d
∼
N
0
,
kV
から発生させる。k はジャンプの距離を調整する パラメータで、採用と棄却の割合に影響を与え、アルゴリズムの収束の速さをコ ントロールする。 (b)次式を計算する。 ,1 | , | | , | min | , ( 1) ( 1) ) 1 ( ) 1 ( y q y y q y y i i i i (19) ただし、 (i 1)|
y
q
(i 1),
|
y
0
のときは (i 1),
|
y
1
とする。 (c)u∼Unif(0,1)を発生させ、 (i)を次のように決定する。 その他の場合 の場合 ) 1 ( ) 1 ( ) ( , | i i i u y 3.十分大きなN に対して (i),
i
N
,
N
1
…を記録する。y
y
i|
|
( 1) ならデータのフィット(対数尤度)が向上しているため必ずθ を採用し、そうでなければ確率y
y
i|
|
) 1 ( で採用することになる。3.7 モデル評価基準 本研究では、以下の5つの基準を用いてモデルの評価を行う。 ①AIC=−2×(最大対数尤度)+2×(パラメータ数) 上式のパラメータ数は期待対数尤度を計算するためのバイアス補正項として算 出されたものである。データが無限にあることを仮定した上で導出されているため、 データ数が少ない場合には、偏りが生じる場合がある。(Akaike(1973)) ②BIC=−2×(最大対数尤度)+log(n)×(パラメータ数) (n …サンプル数) ベイズモデルを前提としたモデルの評価基準である。データ数を十分大きくした もとで、モデルの事後確率に対応する周辺尤度を積分のラプラス法によって近似す ることで得られる。(Schwartz(1978)) ③CAIC=−2×(最大対数尤度)+(log(n)+1)×(パラメータ数) データ数が少ない場合の偏りを減少させるために、AIC を改良した情報量基準で ある。(Bozdogan(1987)) ④DIC =Dbar+(Dbar-Dhat) ベイズモデルの場合は BIC を使用すれば良いが、階層ベイズモデルの場合パラ メータ数が明示的に表されないため、AIC の考え方をベイズモデルに適用して算出 された情報量基準である。パラメータ数を修正する方向にAIC を一般化している。 Dbar:MCMC 法のイタレーションの最後に計算される対数尤度×(-2)の平均値 Dhat:パラメータの事後平均を使用して計算した対数尤度×(-2) (Spiegelhalter et al(2002)) ⑤的中率 推定されたパラメータを用いて算出された予測値と実測値から計算する。パラメ ータの推定方法が異なる場合、上記の情報量基準では比較できないため、的中率を 使用する。ホールドアウトサンプルのデータ期間は、Bawa(1990)と同様に、購買 機会の最後の4 回とした。 なお、潜在クラスモデル間の比較には AIC,BIC,CAIC を、階層ベイズモデル間の比 較には DIC を使用する。また、潜在クラスモデルと階層ベイズモデルとの比較には、 的中率を使用する。
3.8 収束判定方法 階層ベイズモデルによるパラメータ推定にはMCMC 法を使用しているため、パラメ ータが定常分布に収束しているかを判定する必要がある。本研究では、イタレーション 40000 回中最初の 35000 回を burn-in とし、その後の 5000 回が定常分布に収束してい るかを、グラフ上での目視とGeweke(1992)の判定方法を用いて判定した。Geweke の 判定方法は以下の通りである。 ある。) の下での変更も可能で とする。 と同様に を計算する。( を発生させ、 ① ) ( 5 . 0 , 1 . 0 1 , 1 , , 2 , 1 2 1 ) ( 2 ) ( 1 ) ( 1 2 2 1 1 1 A R s R s geweke g s g g s g R r s sr r s Rr s r r L から計算している。 いるピリオドグラム ウィンドウを使用して の は幅 でのスペクトラル密度 ただし、周波数 が無限大に近づく時 であれば を固定し、 および ② ) ( 3 . 0 , 2 ) 0 ( 0 ) ( 1 , 0 ) 0 ( ) 0 ( ) ( 1 2 1 2 1 2 1 2 1 r g Daniell R M M S w A N s S s S g g Z R R R s s R s R s g g g s s
|
Z
|
z
/2なら収束していると判定する。|
Z
|
z
/2なら「収束していると は言えない」と判定する。第4章 潜在クラスモデルと階層ベイズモデルの比較
本章では、潜在クラスモデルと階層ベイズ手法による混合正規分布多項ロジットモデ ルの比較を行う。 4.1 潜在クラスモデルのための分析データ 潜在クラスモデルを使用するにあたって、2章で説明したスクリーニング条件に、以 下の3つの条件を加えた。 ①ホールドアウトサンプル(3 期)における購買回数が 3 回以下の顧客を除く。 ②ブランドスイッチ回数が1 回以下の顧客を除く。 ③単品購買回数が23 回以下の顧客を除く。 ①のスクリーニング条件を加えた理由は、川端・近藤(2004)によって使用された潜在 クラスモデルとBawa(1990)のモデルの両スクリーニング条件を満たす顧客を抽出する ためである。潜在クラスモデルでは、川端と同様に、ホールドアウトサンプルを3 期の データとしている。また、Bawa(1990)は、ホールドアウトサンプルデータに 4 回の購 買回数を充てている。 ②のスクリーニング条件を加えた理由は、極端な購買履歴を持つ顧客を除くためであ る。 ③のスクリーニング条件を加えた理由は、ヘビーユーザーを抽出するためである。 また、分析ツールの容量制限のため、更にランダムサンプリングを行い、使用する 63 パネル(購買回数 2046 回)を決定した。 説明変数として使用する慣性/非慣性変数には、Bawa(1990)によって使用された連続 購買回数のみを考慮した変数を使用した。 4.2 潜在クラスモデルの分析結果 大橋・梅津(2002)の調査によると、飲料は非慣性(VS)的に購買を行う顧客が多い とされている。しかしながら、慣性(Inertia)的に購買する顧客や、Bawa(1990)によ って定義されたHybrid 的に行動する顧客も存在すると考えられる。そこで、潜在クラ スモデルを使用し、上記の様な行動をする顧客でセグメンテーションするために、セグメント数を1∼3に設定し分析を行った。以下に、セグメント毎の情報量基準をまとめ た。 表4-1 潜在クラスモデルによる情報量基準 表4-1 の様に、AICは 1 セグメントの場合が3892.91、2 セグメントの場合が3910.15、 3 セグメントの場合が 3925.08 であり、BIC は 1 セグメントの場合が 3988.52、2 セグ メントの場合が4106.97、3 セグメントの場合が 4223.13 であり、CAIC は 1 セグメン トの場合が 3988.52、2 セグメントの場合が 4106.99、3 セグメントの場合が 4223.16 となった。全ての情報量基準において、セグメント1の場合が最小になり、有効なセグ メンテーションを行うことは出来なかった。これは、川端・近藤(2004)と同様の結果に なった。そのため、川端・近藤(2004)では、連続購買回数を用いてクラスター分析を行 った後に、潜在クラスモデルにより3セグメントにセグメンテーションを行っている。 セグメント2や3の場合のパラメータを見ても、セグメント間に大きな違いは見られ なかった。セグメント数1∼3によって推定されたパラメータの値は添付資料1に載せ る。 4.3 階層ベイズモデルの分析結果 階層ベイズ手法による混合正規分布多項ロジットモデルでは、パラメータ i
の正規 分布の峰の数を任意に変更できる柔軟なモデルとなっている。本研究では、正規分布の 峰の数を 1 から 4 に設定し、分析を行った。また、慣性/非慣性変数は、Bawa(1990) によって使用された連続購買回数を使用した。以下に、正規分布の数毎の対数尤度、 DIC、周辺尤度、的中率1、的中率2を纏めた。的中率1は、インサンプルデータによ る的中率であり、的中率2はホールドアウトサンプルによる的中率である。 表4-2 階層ベイズモデルによる DIC と的中率
AIC BIC CAIC
1セグメント 3892.91 3988.52 3988.52 2セグメント 3910.15 4106.97 4106.99 3セグメント 3925.08 4223.13 4223.16 混合正規分布の数 対数尤度 DIC 周辺尤度 的中率1 的中率2 1 -958 5425 -1008 0.798 0.734 2 -952 5391 -995 0.810 0.766 3 -942 5333 -997 0.811 0.778 4 -943 5340 -984 0.803 0.750
表4-2 の様に、DIC が正規分布の数が 1 の場合が 5425、2 の場合が 5391、3 の場合 が 5333、4 の場合が 5340 であり、的中率1は正規分布の数が 1 の場合が 79.8%、2 の場合が 81.0%、3 の場合が 81.1%、4 の場合が 80.3%であり、的中率2は正規分布 の数が1 の場合が 73.4%、2 の場合が 76.6%、3 の場合が 77.8%、4 の場合が 75.0% となった。DIC、的中率1、的中率2全てにおいて、3 つの正規分布を混合した場合が 最良となっている。 4.4 潜在クラスモデルと階層ベイズモデルの比較 潜在クラスモデルではセグメント1を仮定したモデルが、階層ベイズモデルでは i
の分布に3 つの正規分布を混合したモデルが採択された。下表には、比較のために、上 記の 2 モデルに加えて、 i
の分布に正規分布を使用した階層ベイズモデルの結果も載 せる。なお、潜在クラスモデルと混合正規分布を使用した階層ベイズモデルとの比較に は、インサンプルデータを用いた的中率1、アウトサンプルデータを用いた的中率2を 使用する。また、正規分布を使用した階層ベイズモデルと3 つの正規分布を混合した階 層ベイズモデルとの比較には、DIC、的中率1、的中率2を使用する。 表4-3 潜在クラスモデルと階層ベイズモデルの DIC と的中率 表4-3 の様に、潜在クラスモデルの的中率1は 74.9%、正規分布を使用した階層ベイ ズモデルの的中率1は 79.8%であり、潜在クラスモデルの的中率2は 62.4%、正規分 布を使用した階層ベイズモデルの的中率2は 68.0%であり、正規分布を使用した階層 ベイズモデルの方が高い値を示している。潜在クラスモデルと3つの正規分布を混合し た階層ベイズモデルとの比較も同様の結果である。よって、顧客全員に対して同じパラ メータを推定した潜在クラスモデルではなく、顧客一人ひとりに対して異なるパラメー タを推定できる階層ベイズモデルがより良いモデルであることが分かった。 また、正規分布を使用した階層ベイズモデルのDIC は 5425、3つの正規分布を混合 した階層ベイズモデルのDIC は 5333 であり、正規分布を使用した階層ベイズモデルの 的中率1は 79.8%、3つの正規分布を混合した階層ベイズモデルの的中率1は 81.1% であり、正規分布を使用した階層ベイズモデルの的中率2は 68.0%、3つの正規分布 を混合した階層ベイズモデルの的中率2は 73.4%であり、3つの正規分布を混合した 階層ベイズモデルの方が、DIC・的中率全てにおいて、良い値を示している。 モデル 対数尤度 DIC 的中率1 的中率2 潜在クラスモデル --- --- 0.749 0.624 階層ベイズモデル(正規分布) -958 5425 0.798 0.680 階層ベイモデルズ(3つの正規分布) -942 5333 0.811 0.734
階層ベイズモデルでは、顧客毎のパラメータを推定することが可能であるため、混合 正規分布の峰ごとの平均をとることで、セグメント毎の特徴を見る。以下の表は、混合 正規分布によるセグメント毎のパラメータの中央値をまとめたものである。 表4-4 混合正規分布によるセグメント毎のパラメータ (j-:日本茶、c-:中国茶、r1:連続購買回数の1乗、r2:連続購買回数の2乗) 表 4-4 より、セグメント1を見ると、日本茶の連続購買回数にかかるパラメータが -2.66 と負の値をとり、日本茶の連続購買回数の2乗にかかるパラメータも-17.85 と負 の値をとっている。また、日本茶の割引にかかるパラメータが 1.29、中国茶の割引に かかるパラメータが 0.47 である様に、比較的小さな値を示している。この事から、セ グメント1に属する顧客の特徴は、日本茶に対してVS 行動をとり、割引には他のセグ メントと比較して反応しにくいと言える。 セグメント2を見ると、日本茶の連続購買回数にかかるパラメータが1.30 と正の値 をとり、日本茶の連続購買回数の2乗にかかるパラメータが-0.14 と負の値をとってい る。同様に、中国茶の連続購買回数にかかるパラメータが 1.60 と正の値をとり、中国 茶の連続購買回数の2乗にかかるパラメータが-0.45 と負の値をとっている。また、日 本茶の割引にかかるパラメータが4.39、中国茶の割引にかかるパラメータが 9.39 であ る様に、他セグメントの比較して中程度の値を示している。この事から、セグメント2 に属する顧客の特徴は、日本茶・中国茶共にHybrid 行動をとり、割引にはある程度反 応すると言える。 最後にセグメント3を見ると、日本茶の連続購買回数にかかるパラメータが 1.39 と 正の値をとり、日本茶の連続購買回数の2乗にかかるパラメータが-0.01 と負の値をと っている。一方、中国茶の連続購買回数にかかるパラメータが 1.06 と正の値をとり、 中国茶の連続購買回数の2乗にかかるパラメータが0.18 と正の値をとっている。また、 日本茶の割引にかかるパラメータが 25.30、中国茶の割引にかかるパラメータが 13.77 である様に、他セグメントの比較して大きな値を示している。この事から、セグメント 3に属する顧客の特徴は、日本茶に対してはセグメント2と同様にHybrid 行動をとる が、連続購買回数の2乗にかかるパラメータが-0.01 と 0 に近い値を示していることか ら、日本茶に対してInertia 行動をとる傾向があると言える。また、中国茶に対しては Inertia 行動をとり、割引に対しては、敏感に反応すると言える。 なお、3 つの正規分布を混合した場合が、対数尤度、DIC が最小であったことと、混 j-r1 j-r2 c-r1 c-r2 j-割引率 j-エンド j-チラシ c-割引率 c-エンド c-チラシ 人数 [1,] -2.66 -17.85 1.19 0.08 1.29 -2.12 -3.62 0.47 -2.14 2.17 4人 [2,] 1.30 -0.14 1.60 -0.45 4.39 -1.37 0.90 9.39 0.99 0.10 36人 [3,] 1.39 -0.01 1.06 0.18 25.30 2.76 -0.50 13.77 2.24 1.24 23人
合正規分布の数を増やした場合データ容量制限の関係で分析不可能になることの 2 点
から、今後、正規分布の数を3 に固定して分析を行う。また、ヘビーユーザーに関する
第5章 Bawa モデルと提案モデルの比較
本章では、Bawa(1990)の提案した連続購買回数のみを慣性/非慣性変数として扱う Bawa モデルと、それに購買間隔の影響を加えた変数を慣性/非慣性変数として扱う提案 モデルとの比較を行う。 5.1 全データによる分析結果 681 パネル(購買回数 12897 回)を用いて、階層ベイズ手法による混合正規分布多 項ロジットモデルで分析を行った。以下の表は、Bawa モデル、提案モデルA,B,C の DIC とインサンプルデータから求めた的中率1、およびアウトサンプルデータから 求めた的中率2をまとめたものである。 表5-1 Bawa モデル、提案モデルA∼Cの DIC と的中率 DIC は Bawa モデルが 35922、提案モデルAが 35964、提案モデルBが 35756、提 案モデルC が 35876 であり、提案モデルBが最小となっている。しかし、インサンプ ルデータから求めた的中率1は、Bawa モデルが 0.771、提案モデルAが 0.771、提案 モデルBが0.768、提案モデル C が 0.77 であり、Bawa モデルと提案モデルAが高い 値を示している。また、アウトサンプルデータから求めた的中率2は、Bawa モデルが 0.579、提案モデルAが 0.587、提案モデルBが 0.577、提案モデル C が 0.570 であり、 提案モデルAが高い値を示しており、DIC から選択したベストモデルと的中率から選 択したベストモデルは一致しなかった。 上記の全てのモデルにおいて的中率2は、57∼59%と少ない。また、Bawa モデルの 様に購買間隔を考慮しない場合、頻繁に分析対象商品を購入する顧客の分析に適さず、 購買間隔によって慣性/非慣性傾向をすぐに逓減させた場合、分析対象商品をあまり購 入しない顧客の分析に適さないと考えられる。そこで、次節では、この様な顧客を分け て分析する。 対数尤度 DIC 周辺尤度 的中率1 的中率2 Bawaモデル -6415 35922 -6568 0.771 0.579 提案モデルA -6391 35964 -6514 0.771 0.587 提案モデルB -6359 35756 -6455 0.768 0.577 提案モデルC -6387 35876 -6529 0.770 0.5705.2 グループ毎の分析結果 本節では、全パネルをヘビーユーザー・ミディアムユーザー・ライトユーザーの3グ ループに分けて、混合正規分布を使用した階層ベイズモデルで分析を行い、Bawa モデ ルと提案モデルとの比較を行う。なお、ライトユーザーに関しては、添付資料に載せる。 5.2.1 分析データ 前節で使用した全パネル681(購買回数 12897 回)を、購買回数が 14 回以上、14∼ 23 回、9∼13 回という条件で、ヘビーユーザー・ミディアムユーザー・ライトユーザ ーに分割し、グループ毎に分析を行った。ヘビーユーザーが 129 サンプル(購買回数 5537 回)、ミディアムユーザーが 213 サンプル(購買回数 3753 回)、ライトユーザー が339 サンプル(購買回数 3607 回)となっており、これを購買間隔の平均で見ると、 以下のようになっている。 表5-2 グループ毎の購買間隔の平均 5.2.2 ヘビーユーザーの分析結果 Bawa モデルと提案モデルA∼Cで分析を行った。以下の表は、DIC とインサンプル データから求めた的中率1、およびアウトサンプルデータから求めた的中率2をまとめ たものである。また、慣性/非慣性変数を使用する効果を確認するため、慣性/非慣性変 数を使用しなかった場合の結果を、比較モデルとして載せている。 表5-3 ヘビーユーザーの各モデルの DIC と的中率
Bawa モデルと提案モデル A∼C の4モデルを比較すると、DIC は、Bawa モデルの 12251 から提案モデルBの 12223 へ 28 ポイント減少し、提案モデルBが最良となって 購買間隔の平均(日数) ヘビーユーザー 10.331 ミディアムユーザー 21.132 ライトユーザー 31.880 対数尤度 DIC 周辺尤度 的中率1 的中率2 Bawaモデル -2147 12251 -2210 0.856 0.713 提案モデルA -2151 12287 -2227 0.860 0.756 提案モデルB -2139 12223 -2206 0.863 0.750 提案モデルC -2145 12230 -2210 0.860 0.736 比較モデル -2443 14199 -2491 0.840 0.736
いる。また、的中率1は、Bawa モデルの 85.6%から、提案モデルBの 86.3%へ 0.7% 上昇し、提案モデルBが最良となっている。この事から、購買間隔を考慮しないBawa モデルよりも、購買間隔を考慮した提案モデルの方が良いことが分かった。さらに、慣 性/非慣性傾向の購買間隔に伴う逓減スピードは、15 日程度で半分になり 30 日程度で ゼロになる傾向があることが分かる。 また、慣性/非慣性変数を使用しない比較モデルと比較すると、DIC、的中率共に提 案モデル B の方が良い結果が得られた。以下に、提案モデル B と比較モデルにおける Hybrid 行動をとる顧客の効用の確定項の変化を示す。なお、簡便化のため、この顧客の 購買シェア上位2ブランド(以下、J,K と表す)、12 回の購買のみを示す。この期間に おける実際の購買履歴は、表のx 軸に示した様に KKKKJJJJKKKK である。 図5-1 提案モデル B から得られた効用の確定項の変化 図5-2 比較モデルから得られた効用の確定項の変化 提案モデル B では、ブランドスイッチのタイミングを効用の減少によって比較的 上手く捉えられている。しかし、比較モデルでは、実測値との的中率も悪く、このモデ 提案モデルB 0 2 4 6 8 10 12 14 K K K K J J J J K K K K 購買履歴 効用 ブランドJ ブランドK 比較モデル 0 2 4 6 8 10 12 14 K K K K J J J J K K K K 購買履歴 効用 ブランドJ ブランドK
ルでは、Hybrid 行動をとる顧客を捉えることが困難である。Hybrid 行動をとる顧客の ブランド選択を予測するためにも、慣性/非慣性を考慮する必要があると考えられる。 以下の表は、日本茶と中国茶に対する慣性/非慣性傾向の観点から人数をまとめたも のである。 表5-4 各カテゴリーに対する慣性/非慣性傾向を持つ顧客の割合 日本茶に対して Inertia 行動をとる顧客は全体の 31.78%であり、中国茶に対して Inertia 行動をとる顧客は全体の 32.6%であることから、Inertia 傾向の人数に関して、 大きな差は見受けられなかった。VS 傾向に関しては、日本茶に対して VS 行動をとる 顧客は全体の 7.75%であり、中国茶に対して VS 行動をとる顧客は全体の 2.33%であ ることから、このセグメントに属する顧客は少ないが、日本茶の方がVS 行動をとる顧 客が多いようである。Hybrid 傾向に関しては、日本茶に対して Hybrid 行動をとる顧 客は全体の20.16%であり、中国茶に対して Hybrid 行動をとる顧客は全体の 36.4%で あった。以上のことから、中国茶は慣性的に購買される傾向が強いことが分かる。この 原因として、中国茶の方が販売されているブランド数が少なく、かつ、購買回数が多い ことが考えられる。 Zero-order 行動をとらない顧客の割合を見ると、日本茶が 59.69%(Inertia 行 動:31.78%;VS 行 動 :7.75%;Hybrid 行 動 :20.16%) 、 中 国 茶 が 71.3 % (Inertia 行 動:32.60%;VS 行動:2.33%;Hybrid 行動:36.43%)であり、スーパーマーケットで頻繁に 日本茶や中国茶を購入する顧客の多くは、慣性/非慣性傾向を持っていることが分かる。 日本茶、中国茶に対して異なる慣性/非慣性傾向を持つ顧客は、全体の 68.15%存在す る。慣性/非慣性傾向を推定するにあたって、カテゴリーを分けて顧客の反応を分析す ることは正しかったと言える。 次に、各慣性/非慣性傾向を持った顧客を獲得するためのプロモーション戦略を見る。 以下の表は、各慣性/非慣性傾向を持つ顧客別に、プロモーションに関するパラメータ の平均を計算したものである。 中国茶
Inertia VS Hybrid Zero-order total 日本茶 Inertia 10.90 0.00 13.95 6.98 31.78
VS 3.10 1.55 2.33 0.78 7.75
Hybrid 6.20 0.00 6.20 7.75 20.16
Zero-order 12.40 0.78 13.95 13.18 40.31 total 32.60 2.33 36.43 28.68 100.00
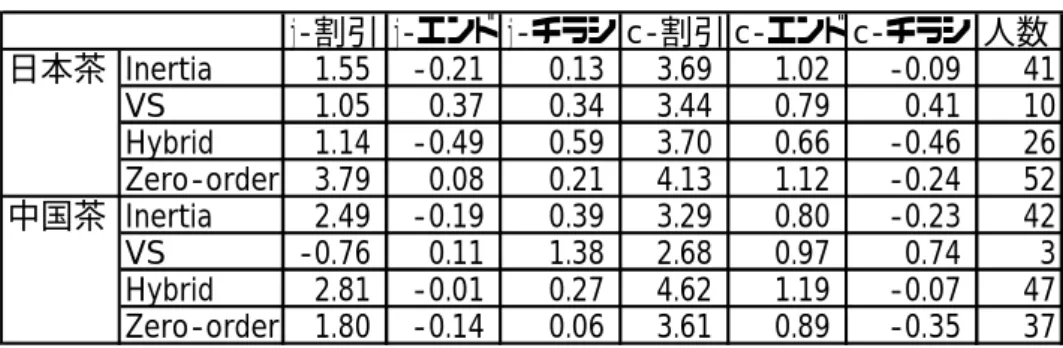
表5-5 慣性/非慣性傾向の違いによるプロモーションに対する反応 (j-:日本茶、c-中国茶) 日本茶に対して Zero-order 行動をとる顧客の日本茶の割引に対するパラメータは、 3.79 であり、Inertia 行動をとる顧客のパラメータが 1.55、VS 行動をとる顧客のパラ メータが1.05、Hybrid 行動をとる顧客のパラメータが 1.14 であるのに対し、高い値を 示しており、Zero-order 行動をとる顧客は割引に反応しやすいと言える。逆に、Inertia 行動・VS 行動・Hybrid 行動をとる顧客は、割引に反応しにくいと言える。VS 行動を とる顧客は割引に敏感に反応すると想定していたが、あまり反応しないようである。こ の原因として、前々回に選択したブランドに割引があってもそのブランドを購入しない ため、割引に対するパラメータの値が小さな値を示したと考えられる。VS 行動をとる 顧客には、前回選択したブランドを把握するだけでなく、それより前に選択したブラン ドも把握した上で、割引を実施することが必要であろう。 一方、中国茶に対してInertia 行動をとる顧客の中国茶の割引に対するパラメータは 3.29、VS行動をとる顧客のパラメータは 2.68、Hybrid 行動をとる顧客のパラメータ は 4.62 、Zero-order 行動をとる顧客のパラメータは 3.61 である。日本茶の場合と同 様に、Zero-order 行動をとる顧客のパラメータは大きく、VS 行動をとる顧客のパラメ ータは小さいが、Inertia 行動と Hybrid 行動をとる顧客のパラメータは、日本茶の場 合と異なり大きな値を示している。この原因として、スーパーマーケットに通うヘビー ユーザーにとって中国茶は頻繁に購入するカテゴリーであり、家計に影響しやすいから こそ、割引に反応する傾向が強いのではないかと考えられる。 5.2.3 ミディアムユーザーの分析結果 Bawa モデルと提案モデルA∼Dで分析を行った。以下の表は、DIC とインサンプル データから求めた的中率1、およびアウトサンプルデータから求めた的中率2をまとめ たものである。 j-割引 j-エンド j-チラシ c-割引 c-エンド c-チラシ 人数 日本茶 Inertia 1.55 -0.21 0.13 3.69 1.02 -0.09 41 VS 1.05 0.37 0.34 3.44 0.79 0.41 10 Hybrid 1.14 -0.49 0.59 3.70 0.66 -0.46 26 Zero-order 3.79 0.08 0.21 4.13 1.12 -0.24 52 中国茶 Inertia 2.49 -0.19 0.39 3.29 0.80 -0.23 42 VS -0.76 0.11 1.38 2.68 0.97 0.74 3 Hybrid 2.81 -0.01 0.27 4.62 1.19 -0.07 47 Zero-order 1.80 -0.14 0.06 3.61 0.89 -0.35 37
表5-6 ミディアムユーザーの各モデルの DIC と的中率 提案モデルCのDIC が 11617 であり、的中率2でも 59.3%と提案モデルCが最良と なっている。ヘビーユーザーにおけるベストモデルはa が 15 の提案モデルBであった のに対し、ミディアムユーザーは、a が 20 の提案モデルCのベストモデルとなった。 このことから、購買回数によって、購買間隔に伴う慣性/非慣性傾向の逓減スピードが 異なるという仮説は正しかったように思える。 以下の表は、日本茶と中国茶に対する慣性/非慣性傾向の観点から人数をまとめたも のである。 表5-7 各カテゴリーに対する慣性/非慣性傾向を持つ顧客の割合 日本茶・中国茶共に Zero-order 行動をとる顧客の割合をヘビーユーザーのそれと比 較すると、ヘビーユーザーが13.2%で合ったのに対し、ミディアムユーザーは 57.75% と4 倍以上増加している。また、日本茶に対して Zero-order 行動をとる顧客の割合は、 ヘビーユーザーの場合が40.31%であるのに対し、ミディアムユーザーの場合は 68.73% と、1.5 倍以上増加している。中国茶に対して Zero-order 行動をとる顧客の割合は、ヘ ビーユーザーの場合が28.7%であるのに対し、ミディアムユーザーの場合は 81.22%と、 2.8 倍以上増加している。この原因として、日本茶や中国茶の購買頻度が少ない顧客は 慣性/非慣性傾向をあまり持っていないことと、他店舗でも購入している顧客がデータ に増え、慣性/非慣性を推定することが難しくなったことの2通りが主に考えられる。 しかしながら、分析データが日本茶と中国茶であることから、後者の原因が大きいと考 えられ、ミディアムユーザーの慣性/非慣性傾向を推定することは困難である。ミディ アムユーザー以上に他店舗でも購入している顧客が増加すると考えられるライトユー ザーの分析結果は、添付資料2に載せる。 中国茶
Inertia VS Hybrid Zero-order total 日本茶 Inertia 5.16 0.47 1.41 13.15 20.19 VS 0.47 0.47 0.47 5.16 6.57 Hybrid 1.41 0.00 0.94 5.16 7.51 Zero-order 3.76 1.88 2.35 57.75 65.73 total 10.80 2.82 5.16 81.22 100.00 対数尤度 DIC 周辺尤度 的中率1 的中率2 Bawaモデル -2083 11625 -2154 0.710 0.575 提案モデルA -2117 11876 -2202 0.718 0.589 提案モデルB -2102 11761 -2179 0.713 0.585 提案モデルC -2080 11617 -2154 0.706 0.593 提案モデルD -2086 11626 -2189 0.713 0.567