クラウドソーシングにおける
統計的品質管理理⼿手法の研究動向
⾺馬場 雪乃
国⽴立立情報学研究所・ERATO河原林林巨⼤大グラフプロジェクト
2014
年年7⽉月4⽇日
(情報処理理学会 第217回⾃自然⾔言語処理理研究会)
2
⾃自⼰己紹介|
国⽴立立情報学研究所でデータマイニングや
ヒューマンコンピュテーションの研究をしています
⾺馬場 雪乃
●
略略歴
2012
年年 東京⼤大学 情報理理⼯工学系研究科博⼠士課程修了了
2012
年年〜~2014年年 東京⼤大学 情報理理⼯工学系研究科
数理理情報学専攻 特任研究員
2014
年年〜~ 国⽴立立情報学研究所 および
JST, ERATO,
河原林林巨⼤大グラフプロジェクト 特任助教
●
研究
データマイニング、ヒューマンコンピュテーション
3
概要|
クラウドソーシング研究における重要トピック
「統計的品質管理理⼿手法」を(広く浅く)紹介
●
⾃自然⾔言語処理理研究においてもクラウドソーシング
が活⽤用されるようになってきた
●
クラウドソーシングの利利便便性向上のための研究も
様々⾏行行われている
●
クラウドソーシングにおける重要トピック
「統計的品質管理理⼿手法」を紹介
⾊色々な種類のタスクに適⽤用するため
研究が進められている
1.
⾃自然⾔言語処理理研究における
クラウドソーシング利利⽤用の動向
データ収集・⼈人を組み込んだアプリケーション構築
2.
クラウドソーシングにおける
統計的品質管理理⼿手法の研究動向
定型出⼒力力タスク・⾮非定型出⼒力力タスクでの品質管理理
3.
クラウドソーシング上の品質管理理に関する
発展的な話題
タスク割り当て・フローチャート制御
1.
⾃自然⾔言語処理理研究における
クラウドソーシング利利⽤用の動向
データ収集・⼈人を組み込んだアプリケーション構築
2.
クラウドソーシングにおける
統計的品質管理理⼿手法の研究動向
定型出⼒力力タスク・⾮非定型出⼒力力タスクでの品質管理理
3.
クラウドソーシング上の品質管理理に関する
発展的な話題
タスク割り当て・フローチャート制御
6
クラウドソーシングは
、
インターネット上で不不特定多
数の⼈人々に仕事を発注する仕組み
クラウド
ソーシング
サービス
リクエスタ
ワーカ
仕事を発注
仕事を割り当て
成果物を提出
報酬⽀支払い
を依頼
●
クラウドソーシングは
「インターネット上で不不特定多数の⼈人々に
仕事を発注する仕組み」
例例:Amazon Mechanical Turk (MTurk)
●
インターネット上で取引が完結するため
7
⾃自然⾔言語処理理研究では
まずはクラウドソーシングの実⽤用性確認が⾏行行われた
●
2008
年年頃から⾃自然⾔言語処理理分野における
クラウドソーシングの実⽤用性が確認され始める
アノテーションの質
[Snow et al., ’08]
o
複数⼈人のアノテーションを統合すると専⾨門家に匹敵
翻訳評価の質
[
Callison-‐‑‒Burch, ʻ‘09]
機械翻訳・⾳音声認識識⽤用コーパス構築における
8
2010年年
、
クラウドソーシングによるデータ収集を対象
にしたワークショップがNAACL併設で開催
●
“Creating Speech and Language Data With
Amazon’s Mechanical Turk”
参加者に$100分のMTurk利利⽤用権を提供し
⾳音声・⾔言語に関するデータセット構築を依頼
構築されたデータセットの例例:
o
ツイート中の固有表現
o
アラビア語の⼈人名ニックネーム
o
英⽂文⾳音声のなまりの強さ
9
データ収集でも広く活⽤用されている
(データの拡充・特殊なデータセットの構築)
●
さまざまな種類のデータを集めるのに
クラウドソーシングが使われるようになってきた
データの拡充
o
パラフレージングデータセット [Chen et al., ‘11]
»
動画を複数ワーカに⾒見見せ⼀一⽂文で内容を書かせる
o
含意関係コーパス [Negri et al., ‘11]
»
⾮非専⾨門家が作業できるようタスクを分割
特殊なデータセットの構築
10
データ収集でも広く活⽤用されている
(テキスト分類のための特徴獲得)
●
⼈人間の認知能⼒力力を利利⽤用した特徴の獲得
テキスト分類のための特徴
[
Søgaard et al., ʻ‘13]
o
あるクラスの⽂文章を特徴づける、とびとびの単語列列
(例例:“been.*more.*flavorful”)を獲得したい
o
ワーカに⽂文中の重要語をマークさせ重要語間
を”.*”で埋める
“been.*more.*flavorful”
“Not too impressed with the chicken curry either; could've been less watery and more flavorful if you ask me.”
(*) http://www.yelp.com/biz/oc-poultry-and-rotisserie-market-anaheim? hrid=maVYL0k79UVCstQAleTcdA (© Frank S.)
11
データ収集でも広く活⽤用されている
(エンティティ推定のための単語重みづけ)
●
⼈人間の認知能⼒力力を利利⽤用した特徴の獲得(続き)
エンティティ推定のための単語重みづけ
[Boyd-Graber et al., ‘13]
o
例例:「⼤大学卒業後この作家はジャズ喫茶茶を経営し…」
という⽂文が「村上春樹」を表すと推定したい
o
クイズを設計:
⽂文章を頭から読ませ「ピンポン」を押し回答させる
o
各単語付近でピンポンが押された回数を重みとする
not equivalent to missing features, which have beenstudied at training time (Cesa-Bianchi et al., 2011), test time (Saar-Tsechansky and Provost, 2007), and in an online setting (Rostamizadeh et al., 2011). In contrast, incremental classification allows the learner to decide whether to acquire additional features.
A common paradigm for incremental classification is to view the problem as a Markov decision process (MDP) (Zubek and Dietterich, 2002). The incremen-tal classifier can either request an additional feature or render a classification decision (Chai et al., 2004; Ji and Carin, 2007; Melville et al., 2005), choosing its actions to minimize a known cost function. Here, we assume that the environment chooses a feature
in contrast to a learner, as in some active learning settings (Settles, 2011). In Section 5, we use a MDP to decide whether additional features need to be pro-cessed in our application of incremental classification to a trivia game.
2.1 Trivia as Incremental Classification
A real-life setting where humans classify documents incrementally is quiz bowl, an academic competition between schools in English-speaking countries; hun-dreds of teams compete in dozens of tournaments each year (Jennings, 2006). Note the distinction be-tween quiz bowl and Jeopardy, a recent application area (Ferrucci et al., 2010). While Jeopardy also uses signaling devices, these are only usable after a ques-tion is completed (interrupting Jeopardy’s quesques-tions would make for bad television). Thus, Jeopardy is rapacious classification followed by a race to see— among those who know the answer—who can punch a button first. Moreover, buzzes before the question’s end are penalized.
Two teams listen to the same question.3 In this context, a question is a series of clues (features) re-ferring to the same entity (for an example question, see Figure 1). We assume a fixed feature ordering for a test sequence (i.e., you cannot request specific features). Teams interrupt the question at any point by “buzzing in”; if the answer is correct, the team gets points and the next question is read. Otherwise, the team loses points and the other team can answer.
3Called a “starter” (UK) or “tossup” (US) in the lingo, as it often is followed by a “bonus” given to the team that answers the starter; here we only concern ourselves with tossups answerable by both teams.
After losing a race for the Senate, this politician edited the Om-aha World-Herald. This man resigned from one of his posts when the President sent a letter to Germany protesting the Lusi-tania sinking, and he advocated coining silver at a 16
to 1 rate compared to gold. He was the three-time Democratic Party nominee for President but
lost to McKinley twice and then Taft, although he served as
Secretary of State under Woodrow Wilson, and he later argued against Clarence Darrow in the Scopes Monkey Trial. For ten points, name this man who famously declared that “we shall not be crucified on a Cross of Gold”.
Figure 1: Quiz bowl question on William Jennings Bryan, a late nineteenth century American politician; obscure clues are at the beginning while more accessible clues are at the end. Words (excluding stop words) are shaded based on the number of times the word triggered a buzz from any player who answered the question (darker means more buzzes; buzzes contribute to the shading of the previous five words). Diamonds ( ) indicate buzz positions.
The answers to quiz bowl questions are well-known entities (e.g., scientific laws, people, battles, books, characters, etc.), so the answer space is rel-atively limited; there are no open-ended questions of the form “why is the sky blue?” However, there are no multiple choice questions—as there are in Who Wants to Be a Millionaire (Lam et al., 2003)—
or structural constraints—as there are in crossword puzzles (Littman et al., 2002).
Now that we introduced the concepts of questions, answers, and buzzes, we pause briefly to define them more formally and explicitly connect to machine learning. In the sequel, we will refer to: questions, sequences of words (tokens) associated with a single answer; features, inputs used for decisions (derived from the tokens in a question); labels, a question’s correct response; answers, the responses (either cor-rect or incorcor-rect) provided; and buzzes, positions in a question where users halted the stream of features and gave an answer.
Quiz bowl is not a typical problem domain for natu-ral language processing; why should we care about it? First, it is a real-world instance of incremental classi-fication that happens hundreds of thousands of times most weekends. Second, it is a classification problem intricately intertwined with core computational lin-guistics problems such as anaphora resolution, online sentence processing, and semantic priming. Finally, quiz bowl’s inherent fun makes it easy to acquire human responses, as we describe in the next section. 1291
12
クラウドソーシングを組み込んだアプリケーションも
提案されている(リアルタイム⽂文書校正)
●
クラウドソーシングによるリアルタイム校正を導
⼊入したエディタ:Soylent
[Bernstein et al., ‘10]
Find-Fix-Verify
の3段階で校正
o
Find:
問題がある箇所の検出
o
Fix:
校正
o
Verify:
校正誤りの検出
When the crowd is finished, Soylent calls out the edited sections with a purple dashed underline. If the user clicks on the error, a drop-down menu explains the problem and offers a list of alternatives. By clicking on the desired alter-native, the user replaces the incorrect text with an option of his or her choice. If the user hovers over the Error Descrip-tions menu item, the popout menu suggests additional second-opinions of why the error was called out.
The Human Macro: Natural Language Crowd Scripting
Embedding crowd workers in an interface allows us to re-consider designs for short end-user programming tasks. Typically, users need to translate their intentions into algo-rithmic thinking explicitly via a scripting language or im-plicitly through learned activity [6]. But tasks conveyed to humans can be written in a much more natural way. While natural language command interfaces continue to struggle with unconstrained input over a large search space, humans are good at understanding written instructions.
The Human Macro is Soylent’s natural language command interface. Soylent users can use it to request arbitrary work quickly in human language. Launching the Human Macro opens a request form (Figure 3). The design challenge here is to ensure that the user creates tasks that are scoped cor-rectly for a Mechanical Turk worker. We wish to prevent the user from spending money on a buggy command.
The form dialog is split in two mirrored pieces: a task entry form on the left, and a preview of what the Turker will see on the right. The preview contextualizes the user’s request, reminding the user he is writing something akin to a Help Wanted or Craigslist advertisement. The form suggests that the user provide an example input and output, which is an effective way to clarify the task requirements to workers. If the user selected text before opening the dialog, he has the option to split the task by each sentence or paragraph, so (for example) the task might be parallelized across all en-tries on a list. The user then chooses how many separate Turkers he would like to complete the task. The Human Macro helps debug the task by allowing a test run on one sentence or paragraph.
The user chooses whether the Turkers’ work should replace the existing text or just annotate it. If the user chooses to replace, the Human Macro underlines the text in purple and enables drop-down substitution like the Crowdproof inter-face. If the user chooses to annotate, the feedback populates
comment bubbles anchored on the selected text by utilizing Word’s reviewing comments interface.
TECHNIQUES FOR PROGRAMMING CROWDS
This section characterizes the challenges of leveraging crowd labor for open-ended document editing tasks. We introduce the Find-Fix-Verify pattern to improve output quality in the face of uncertain worker quality. Over the past year, we have performed and documented dozens of experiments on Mechanical Turk.5
Challenges in Programming with Crowd Workers
For this project alone, we have interacted with 8809 Turkers across 2256 different tasks. We draw on this experience in the sections to follow. We are primarily concerned with tasks where workers di-rectly edit a user’s data in an open-ended manner. These tasks include shortening, proofreading, and user-requested changes such as address formatting. In our experiments, it is evident that many of the raw results that Turkers produce on such tasks are unsatisfactory. As a rule-of-thumb, rough-ly 30% of the results from open-ended tasks are poor. This “30% rule” is supported by the experimental section of this paper as well. Clearly, a 30% error rate is unacceptable to the end user. To address the problem, it is important to un-derstand the nature of unsatisfactory responses.
High Variance of Effort
Turkers exhibit high variance in the amount of effort they invest in a task. We might characterize two useful personas at the ends of the effort spectrum, the Lazy Turker and the
Eager Beaver. The Lazy Turker does as little work as
ne-cessary to get paid. For example, when asked to proofread the following error-filled paragraph from a high school essay site,6
A first challenge is thus to discourage or prevent workers from such behavior. Kittur et al. attacked the problem of a Lazy Turker inserted only a single character to correct a spelling mistake. The change is highlighted:
The theme of loneliness features throughout many scenes in Of Mice and Men and is often the dominant theme of sections during this story. This theme occurs during many circumstances but is not present from start to finish. In my mind for a theme to be pervasive is must be present during every element of the story. There are many themes that are present most of the way through such as sacrifice, friendship and comradeship. But in my opinion there is only one theme that is present from beginning to end, this theme is pursuit of dreams.
5 http://groups.csail.mit.edu/uid/deneme/
6 http://www.essay.org/school/english/ofmiceandmen.txt
Figure 3. The Human Macro is an end-user programming interface for automating document manipulations. The left half is the user’s authoring interface; the right half is a pre-view of what the Turker will see.
Figure 2. Crowdproof is a human-augmented proofreader. The drop-down explains the problem (blue title) and suggests fixes (gold selection).
316
13
クラウドソーシングを組み込んだアプリケーションも
提案されている(翻訳)
●
クラウドソーシング翻訳システムがいくつか提案
されている
「良良い翻訳」のモデルを学習、
複数の訳⽂文から適切切なものを選択 [Zaidan et al., ‘11]
翻訳→編集の⼆二段階化、複数の訳⽂文・編集案の中から
適切切なものを選択 [Yan et al., ’14]
弱バイリンガルとモノリンガルを段階的に活⽤用
[Ambati et al., ‘12]
1.
⾃自然⾔言語処理理研究における
クラウドソーシング利利⽤用の動向
データ収集・⼈人を組み込んだアプリケーション構築
2.
クラウドソーシングにおける
統計的品質管理理⼿手法の研究動向
定型出⼒力力タスク・⾮非定型出⼒力力タスクでの品質管理理
3.
クラウドソーシング上の品質管理理に関する
発展的な話題
タスク割り当て・フローチャート制御
15
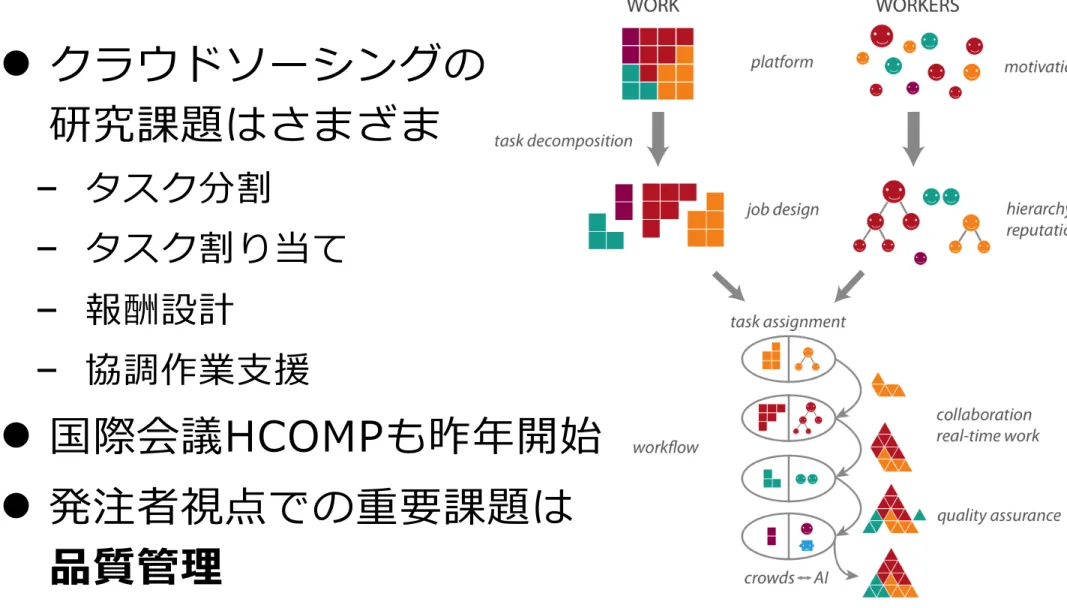
クラウドソーシングには解決すべき課題が多数あるが
(現状での)重要課題は品質管理理
●
クラウドソーシングの
研究課題はさまざま
タスク分割
タスク割り当て
報酬設計
協調作業⽀支援
●
国際会議HCOMPも昨年年開始
●
発注者視点での重要課題は
品質管理理
sections can be written. These same requirements exist in distributed computing, in which tasks need to be scheduled so that they can be completed in the correct sequence and in a timely manner, with data being transferred between computing elements appropriately. Deciding how to divide a task into subtasks and managing those subtasks is also a challenging problem, especially for complex and interdependent tasks [61,89]. This is true whether a manager in an organization is trying to plan a large project or a programmer is trying to parallelize a complex task. Furthermore, top-down approaches in which a single person (e.g., the task creator) specifies all subtasks a priori may not be possible, or subtasks may change as the task evolves.
Crowd-Specific Factors
Unlike traditional organizations in which workers possess job security and managers can closely supervise and appropriately reward or sanction workers, or distributed computing systems in which processors are usually highly reliable, crowd work poses unique challenges for both workers and requesters ranging from job satisfaction to direction-setting, coordination, and quality control. For example, organizations can maintain high quality work through management, worker incentives, and sanctions. While some of these methods are available in crowd work (e.g., how much to reward workers, whether to reject their work, or impose a reputation penalty) their power is attenuated due to factors such as lack of direct supervision and visibility into their work behavior, lack of nuanced and individualized rewards, and the difficulty of imposing stringent and lasting sanctions (since workers can leave
with fewer repercussions than in traditional organizations, such as to reference letters or work histories). The worker’s power is also limited: requesters do not make a long-term commitment to the worker, and endure few penalties if they renege on their agreement to pay for quality work. In distributed computing systems, by contrast, requesters (programmers) have fewer problems with motivating and directing their workers (computers). However, machines cannot match the complexity, creativity, and flexibility that human intelligence manifests. Combining ideas from human and computer organization theories may thus provide complementary benefits and address complementary weaknesses over using either alone.
Framework
Figure 2 presents a framework that integrates the challenges posed by managing shared resources (such as assigning workers to appropriate tasks), managing producer-consumer relationships (such as decomposing tasks and assembling them into a workflow), and crowd-specific factors (such as motivation, rewards, and quality assurance). Many of its elements combine insights from organizational behavior and distributed computing: for example the task decomposition and task assignment functions use both human and computational processes.
The goal of this framework is to envision a future of crowd work that can support more complex, creative, and highly valued work. At the highest level, a platform is needed for managing pools of tasks and workers. Complex tasks must be decomposed into smaller subtasks, each designed with particular needs and characteristics which must be assigned to appropriate groups of workers who themselves must be properly motivated, selected (e.g., through reputation), and organized (e.g., through hierarchy). Tasks may be structured through multi-stage workflows in which workers may collaborate either synchronously or asynchronously. As part of this, AI may guide (and be guided by) crowd workers. Finally, quality assurance is needed to ensure each worker’s output is of high quality and fits together. Because we are concerned with issues of design – the technical and organizational mechanisms surrounding crowd work – we highlight in the process model twelve specific research foci (Figure 2) that we suggest are necessary for realizing such a future of crowd work. These foci are grouped into three key dimensions: foci relevant to the work process; the computation guiding, guided by, and underlying the work; and the workers themselves. Our 12 foci overlap each other in places. However, in total they provide a wide-ranging multidisciplinary view that covers current and prospective crowd work processes. For example, workflow techniques may be useful for handling the flow of documents through a set of tasks [111], but the effectiveness of these techniques can be amplified through clever job design that divides tasks and allocates incentives in a way that benefits both workers and requesters (cf. [62]).
Figure 2: Proposed framework for future crowd work processes to support complex and interdependent work.
16
クラウドソーシングの品質管理理⼿手法
ワーカの事前選択・作業中選択
、
発注の冗⻑⾧長化
●
モチベーション:
検品せずに「⾼高品質の成果物」を獲得したい
●
⼤大きく3種類の⼿手法
作業開始前にワーカを選択
o
属性でのフィルタリング、事前テスト実施
作業結果に応じてワーカを選択
o
正解がわかっている問題を混ぜ成績を測る
発注の冗⻑⾧長化
o
同じタスクを複数⼈人に発注し多数決等で統合
17
統計的品質管理理⼿手法
同じタスクでの複数ワーカの回答から「正解」を推定
●
多数決よりも「賢く」回答を統合するのが
統計的品質管理理⼿手法
●
複数の回答から「正解」を推定する問題として
定式化。ポイントは能⼒力力のモデル化
「写真に⿃鳥が
写っているか?」
FALSE
TRUE
TRUE
正解は?
TRUE?
FALSE?
18
真偽型出⼒力力タスクに対する品質管理理⼿手法
(1)
ワーカーの能⼒力力を考慮し正解推定
●
ワーカが複数タスクに回答することを利利⽤用して
能⼒力力を推定、正解推定に利利⽤用
[Dawid&Skene, ‘79]
TRUE TRUE TRUE
FALSE
TRUE
TRUE
TRUE
FALSE
TRUE
ワーカ
?
?
?
タスク
「写真に⿃鳥が
写っているか?」
正解
能⼒力力を考慮19
真偽型出⼒力力タスクに対する品質管理理⼿手法
(1)
ワーカーの能⼒力力を考慮し正解推定
●
各ワーカの能⼒力力(回答傾向)を2つのパラメータ
でモデル化
●
正解がわかれば能⼒力力が推定できる、
能⼒力力がわかれば正解を推定できる
→正解を潜在変数としたEMアルゴリズムで
交互に推定
TRUE FALSE TRUE FALSE正解
回答
:正解がTRUEの時の正答確率率率
:正解がFALSEの時の正答確率率率
(0) j (1) j (1) j (0) j20
真偽型出⼒力力タスクに対する品質管理理⼿手法
(2)
ワーカーの能⼒力力とタスクの難易易度度を考慮し正解推定
●
タスクに正解する確率率率が
「ワーカの能⼒力力」「タスクの難易易度度」
に依存するモデルを提案
[Whitehill et al., ‘09]
タスク
ワーカ
難易易度度も考慮?
?
?
能⼒力力を考慮TRUE TRUE TRUE
TRUE
FALSE
FALSE
TRUE
FALSE
TRUE
21
真偽型出⼒力力タスクに対する品質管理理⼿手法
(2)
ワーカーの能⼒力力とタスクの難易易度度を考慮し正解推定
●
ワーカとタスクのパラメータを導⼊入
各ワーカの能⼒力力:
各タスクの簡単さ:
●
ワーカがタスクに正答する確率率率をモデル化:
w
j
(
, + )
能⼒力力が0 and/or タスクの簡単さが0だと正答確率率率0.5、
能⼒力力・簡単さが⼤大きいほど正答確率率率が1に近づく
x
i
[0, + )
1
1 + exp ( w
j
x
i
)
22
真偽型出⼒力力タスクに対する品質管理理⼿手法
(3)
ワーカーとタスクの相性を考慮し正解推定
●
ワーカによってタスクの難易易度度は異異なるはず
→ワーカとタスクの相性を考慮
[Welinder et al., ʼ’10]
●
正解に応じて決まるタスクの潜在特徴 と
各ワーカの判断傾向 を考慮し
回答⾏行行動をモデル化:
w
j
閾値
w
j
x
i
>
j
x
i
ならワーカは
TRUE
と回答
23
●
確信度度の回答も正解推定に利利⽤用
[Oyama et al., ‘13]
⾃自信過⼩小・過剰度度合いを表す確信パラメータを
Dawid&Skene
のモデルに追加
真偽型出⼒力力タスクに対する品質管理理⼿手法
(4)
ワーカーに聞いた「確信度度」を利利⽤用
TRUE TRUE TRUE
TRUE FALSE FALSE
TRUE FALSE TRUE
TRUE FALSE TRUE
FALSE FALSE TRUE
TRUE TRUE TRUE
回答
確信度度
TRUE FALSE TRUE FALSE正解
回答
(j) 00 (j) 01 (j) 11 (j) 10 (j) 10:正解がTRUE、
回答がFALSEのときに
「確信がある」確率率率(=⾃自信過剰)
24
さまざまな出⼒力力⽅方式のタスクに対して
統計的品質管理理⼿手法が提案されている
●
真偽型出⼒力力以外のタスクについても
統計的品質管理理⼿手法が提案されている
成果物の
種類
定型
⾮非定型
真偽型
系列列型
順序型 数値型
⾃自由回答
成果物の
統合⽅方法
統合が容易易
統合が
困難
多数決
平均
タスク例例
写真中の
特定物の
有無判定
時系列列に
並んだ写真中の
特定物有無判定
写真の
並び
替え
写真中の
特定物の
数え上げ
デザイン
・
⽂文章作成
25
系列列型出⼒力力タスクに対する品質管理理⼿手法
ワーカの能⼒力力モデルを導⼊入し
CRF
を拡張
●
系列列型に対する回答モデルを提案
[Wu et al., ‘12]
ワーカの能⼒力力:Dawid&Skene と同じく
正解に応じた回答確率率率(アイテム間の関係は考えない)
正解を決めるモデル:CRF(アイテム間の関係を考慮)
(*) (*) https://www.youtube.com/watch?v=b31CAYF2fIA (© JCVdude)TRUE TRUE FALSE TRUE
TRUE FALSE FALSE TRUE TRUE FALSE TRUE FALSE
? ? ? ? ワーカ タスク1 タスク2 … 正解 「各フレームに⿃鳥が 写っているか?」 アイテム
26
順序型出⼒力力タスクに対する品質管理理⼿手法
⼀一対⽐比較時のワーカの能⼒力力をモデル化
●
⼀一対⽐比較時の回答モデルを提案
[Chen et al., ’13]
ワーカの能⼒力力:正しく⼀一対⽐比較を⾏行行う確率率率
ワーカが「A>B」と答える確率率率:
A>B
B<D
A
B
C
D
E
0.76 0.25 0.91 0.64 0.37 … 2位 5位 1位 3位 4位各アイテムのスコアを推定
順序を得る
⼀一対⽐比較
j
jPr [A
B] + (1
j) Pr [B
A]
s: アイテムのスコア
正しくA>Bと回答 誤ってA>Bと回答Pr [A
B] = e
sA/ (e
sA+ e
sB)
27
数値型出⼒力力タスクに対する品質管理理⼿手法
誤答傾向を
Chinese Restaurant Process
で表現
●
数値型は回答候補が無限
→間違え⽅方の偏りをChinese Restaurant Process
で表現 [Lin et al., ‘12]
●
3種類の回答⾏行行動をそれぞれモデル化
(1)
正答, (2)既出の誤答を選択, (3) 未出の誤答をする
タスク例例:
“What is the largest odd
number that is a factor of 860?”
86043 … 誤答ワーカー
Chinese Restaurant Process:
「⼈人が多いテーブルに⼈人が集ま
りやすい傾向」をモデル化
43 215 215 5 860
860 860 215 215 215
215
正解28
⾮非定型出⼒力力のタスクでは成果物の統合が困難
●
デザイン・⽂文章作成の⾮非定型出⼒力力の成果物では
統合が難しいため別の⽅方針の品質管理理⼿手法が必要
成果物の
種類
定型
⾮非定型
真偽型
系列列型
順序型 数値型
⾃自由回答
成果物の
統合⽅方法
統合が容易易
統合が
困難
多数決
平均
タスク例例
写真中の
特定物の
有無判定
時系列列に
並んだ写真中の
特定物有無判定
写真の
並び
替え
写真中の
特定物の
数え上げ
デザイン
・
⽂文章作成
29
⾮非定型出⼒力力タスクでの品質管理理
[
Baba&Kashima, ‘13]
品質を推定できれば「良良い成果物」を選べる
「写真の説明⽂文 を英語で書いて ください」
“A silver tabby cat is howling with his mouth wide open’’
“A sleeping cat’’
“Dreaming of becoming a lion’’
4.7
1.2
2.6
推定品質
猫の写真の出典: http://flic.kr/p/dtT32R (© Selnadeem)
(*) http://flic.kr/p/dtT32R (© Selnadeem) (*)30
品質推定のアプローチ
●
ロゴや翻訳⽂文等の品質の統計的推定⼿手法を提案
?
31
品質推定のアプローチ
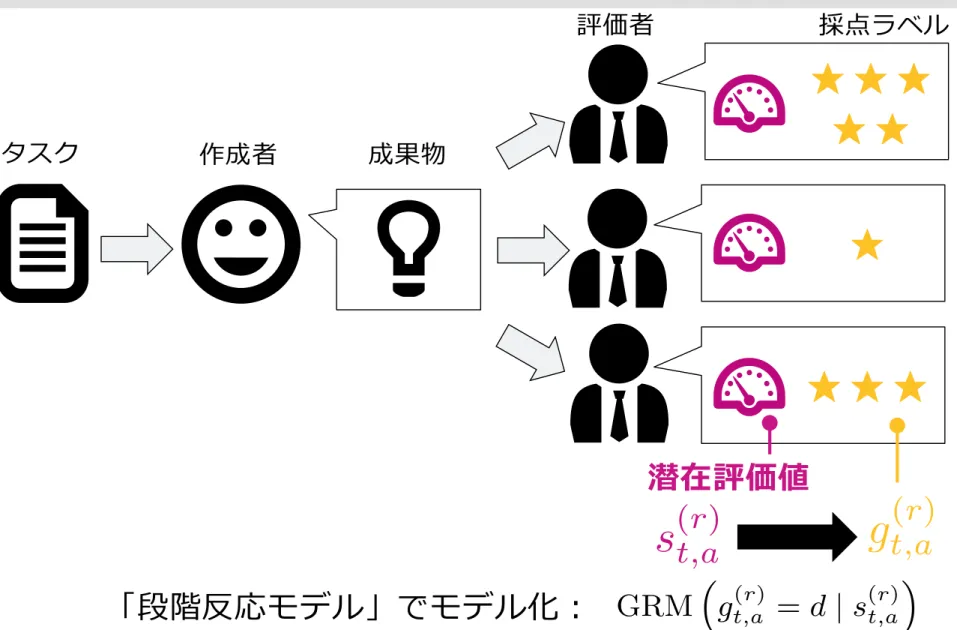
「評価」もクラウドソーシングで発注する
●
ロゴや翻訳⽂文等の品質の統計的推定⼿手法を提案
●
クラウドソーシングで成果物を評価するプロセス
を追加し評価結果を利利⽤用して品質を推定
●
成果物作成者と評価者の能⼒力力パラメータを導⼊入、
品質推定に利利⽤用
★★★★★
★★★★
★★★★★
4.7
成果物
評価者
品質
32
問題設定
採点ラベル集合を使って成果物の品質を推定する
20 “A?silver?tabby?cat? is?howling?with?his? mouth?wide?open’’? “A?sleeping?cat’’? “Dreaming?of? becoming?a?lion’’?33
成果物作成者と評価者の能⼒力力を考慮したモデルを構築
●
成果物作成者 (author)のパラメータ
基本能⼒力力 :平均的に発揮する能⼒力力
分散 :得意不不得意などによる、能⼒力力の分散
●
評価者 (reviewer)のパラメータ
バイアス :
ゼロに近いほど正確、正だと評価が⽢甘め
分散 :好き嫌いなどによる評価の分散
µ
a
a
r
r
2段階⽣生成モデル
(1) ある品質の成果物が⽣生成される過程をモデル化
24?v
t,a
q
t,a
= µ
a
+ v
t,a
µ
a
v
t,aN (v
t,a| 0, 1/
a)
342段階⽣生成モデル
(2) 採点ラベルの⽣生成過程をモデル化
25r
w
t,a
(r)
q
t,a
s
(r)
t,a
=
q
t,a
+
r
+ w
t,a
(r)
w
t,a(r)N w
t,a(r)| 0, 1/
r 352段階⽣生成モデル
(2) 採点ラベルの⽣生成過程をモデル化
26?s
(r)
t,a
g
t,a
(r)
Author parameters Reviewer parametersCreation stage Review stage
Decision thresholds
True quality Score Grade
Score
Figure 2: Graphical model of our proposed two-stage model. µa ∈ R denotes the ability of the author
a ∈ A, and 1/λa ∈ R+ denotes the variance of the
artifact-specific noise vt,a ∈ R for the pair of the task
t ∈ T , and the author a. The true quality qt,a of the
output is given as the sum of µa and vt,a. ηr ∈ R
de-notes the evaluation bias of the reviewer r ∈ R, and 1/κr ∈ R+ denotes a variance of the contextual
pref-erence wt,a(r) ∈ R for the artifact created by the author a for the task t. The quality score s(r)t,a is the sum of ηr, w(r)t,a, and the true quality qt,a, which results in the
observed grade gt,a(r) ∈ {1, 2, . . . , n} through the graded response model with threshold parameters {bd}d. k
and θ are hyper-parameters.
output. However, we assume that we can exclude such work-ers with some identifiwork-ers; in other words, the sets of authors and reviewers are distinct.
3. TWO-STAGE MODELING OF
GEN-ERAL CROWDSOURCING TASKS
To estimate the true quality qt,a of the artifact created
by author a for task t, we introduce a two-stage generative model, where the first stage models the generation of the artifact of quality qt,a, and the second stage models the
gen-eration of the grade label gt,a(r) given by reviewer r to the artifact. Figure 2 shows the graphical model of our grade label generation process.
3.1 Creation Stage
We assume that an author with a higher ability creates higher-quality artifacts on average; hence, each author a ∈ has ability µa ∈ R. We also assume that the performance
of an author on each task varies according to the type and instance of the task. Considering language translation tasks as an example, even an author with a low general translation skill might sometimes produce high quality translations for sentences related to information technologies, if he is knowl-edgeable about information technologies. We model such variety depending on the combination of task t and author a as the noise vt,a ∈ R. We assume that the noise vt,a
fol-lows a Gaussian distribution with zero mean and a variance
of 1/λa (i.e., a precision of λa); that is,
vt,a ∼ N (vt,a | 0, 1/λa) = r λa 2π exp „ −λav 2 t,a 2 « . (1) Note that each author a has their own λa.
At the end of the creation stage, the quality of the artifact qt,a ∈ R is given as the sum of the general ability and the
artifact-specific variation, namely,
qt,a = µa + vt,a.
3.2 Review Stage
In the review stage, we assume that each reviewer r has a base bias ηr ∈ R, assuming that a reviewer with a lower
bias tends to give lower grades to the given artifacts, and one with a higher bias gives higher grades. We also incorporate the contextual preferences of reviewers, for example, some reviewers might prefer short sentences to long sentences. We model such preferences as the noise depending on a pair of output and a reviewer denoted by wt,a(r) ∈ R. We assume that wt,a(r) follows a Gaussian distribution with zero mean and a variance of 1/κr (i.e., a precision of κr); that is,
wt,a(r) ∼ N “wt,a(r) | 0, 1/κr
”
. (2)
Note that each reviewer r has their own κr. When reviewer
r ∈ Rt,a evaluates the output of author a for task t, the
reviewer first estimates the (latent) quality score s(r)t,a ∈ R of the output, which is given as the sum of the true quality of an artifact, qt,a, the reviewer’s bias ηr, and contextual
preference wt,a(r), namely,
s(r)t,a = qt,q + ηr + w(r)t,a. (3)
Finally, since the final grade label gt,a(r) is a discrete value depending on the quality score, we apply Pr[gt,a(r) = d | s(r)t,a], which is the conditional probability of selecting d ∈ D given the quality score s(r)t,a. For modeling Pr[gt,a(r) = d | s(r)t,a], we adopt the graded response model (GRM) [16] (Fig. 3), which is a standard model of the graded responses of subjects in the item response theory (IRT) [20]. In the GRM, the con-ditional probability of a graded response is decomposed by using n − 1 binary response models, namely,
GRM “gt,a(r) = d | s(r)t,a” = Pr[gt,a(r) = d | s(r)t,a]
= Pr[gt,a(r) > d − 1 | s(r)t,a] − Pr[gt,a(r) > d | s(r)t,a], where Pr[gt,a(r) > 0 | s(r)t,a] = 1 and Pr[gt,a(r) > n | s(r)t,a] = 0. There are several possible choices for the binary response models, and we adopt the Rasch model [14], which is one of the simplest models, given as
Pr[gt,a(r) > d | s(r)t,a] = σ “s(r)t,a − bd
”
= 1
1 + exp“−(s(r)t,a − bd)
” , where σ is the sigmoid function, and {bd}d are threshold
parameters. Finally, our grade label generation model is GRM“gt,a(r) = d | s(r)t,a” = σ(s(r)t,a − bd−1) − σ(s(r)t,a − bd).
For simplicity, we set the thresholds (b1, b2,· · · , bn−1) =
(1, 2,· · · , n − 1) in our implementation, because it had no significant effect on the performance.
1.
⾃自然⾔言語処理理研究における
クラウドソーシング利利⽤用の動向
データ収集・⼈人を組み込んだアプリケーション構築
2.
クラウドソーシングにおける
統計的品質管理理⼿手法の研究動向
定型出⼒力力タスク・⾮非定型出⼒力力タスクでの品質管理理
3.
クラウドソーシング上の品質管理理に関する
発展的な話題
タスク割り当て・フローチャート制御
38
発展的な話題
発注回数を減らすためのタスク割り当て・フロー制御
●
クラウドソーシングでは発注の度度お⾦金金が掛かる
●
これまで⾒見見てきた統計的品質管理理⼿手法は
発注費⽤用を考慮していない
●
費⽤用と品質のバランスを取るための
発注ワークフローが必要
タスク割り当て:
発注先ワーカを決めて費⽤用を有効活⽤用
フロー制御:追加発注すべきか決める
39
タスク割り当て
良良いワーカの「探索索」と「活⽤用」のバランスを取る
●
良良いワーカ集団を早い段階で⾒見見つけ、
その⼈人達だけに発注したい
●
その際、探索索と活⽤用のバランスを取りたい
●
タスク正答率率率の信頼区間の上限が⾼高いワーカだけ
に発注する⼿手法 IEThresh
[Donmez et al., ’09]
⾒見見積もった正答率率率 0% 100% ワーカA ワーカB ワーカC
ワーカA, Cに優先的に発注
A: 探索索が⼗十分⾏行行われ
「良良いワーカ」だと判明→活⽤用
C: 探索索が不不⼗十分なワーカ→探索索
40
タスク割り当て
(2)
「難しいタスク」を「良良いワーカ」に割り当てる
●
ラベル付けにクラウドソーシングを使う能動学習、
サンプルとワーカ両⽅方を選択する
[Yan et al., 11]
⼆二値分類器構築が⽬目的
能動学習:不不確実性の⾼高いサンプルに
ラベル追加、分類器更更新
「そのサンプルでの正答確率率率が⾼高いワーカ」に
発注。正答確率率率:
1
1 + exp ( w
j
x
i
)
ワーカの判断傾向 サンプルの特徴量量41
フロー制御
ある成果物をさらに改善するべきか判断
●
直列列ワークフロー:
あるワーカの成果物を別のワーカが改善する
●
直列列ワークフローの⾃自動制御⼿手法
TURKONTROL
[Dai et al., ‘10]
状態を「改善前後の品質」、⾏行行動を「評価⽤用投票追加」
「改善」「完了了」とした部分マルコフ決定過程
品質と費⽤用からなる効⽤用関数に従って⾏行行動を決定
改善前 改善後 ⾏行行動1. どちらが良良いか決めるため投票を追加 ⾏行行動2. 質が⾼高い⽅方をさらに改善 ⾏行行動3. 質が⾼高い⽅方を採⽤用をして完了了42