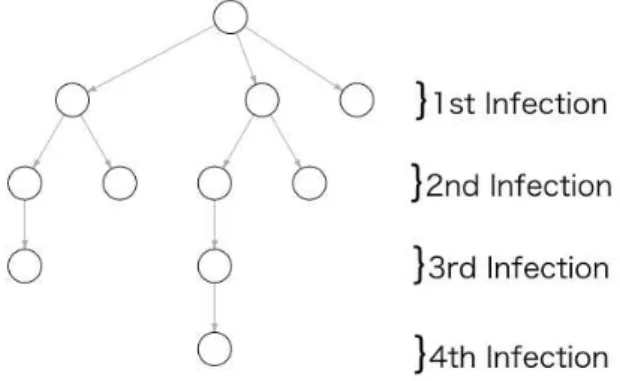
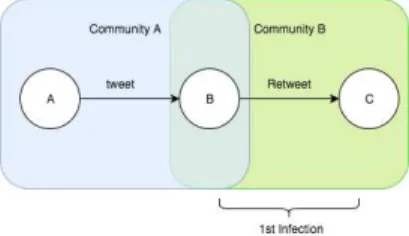
ネットワークの構造と
Retweet
の関係
早稲田大学大学院
基幹理工学研究科 数学応用数理専攻
福島 達也
目次
第1章 Introduction 3
1.1 はじめに . . . 3
第2章 Twitterデータ解析プラットフォーム構築について 4 2.1 使用したソフトウェア . . . 4
2.2 データ収集について . . . 4
第3章 Degreed Based Mean Field Theoryについて 6 3.1 SIS model . . . 6
3.2 Degreed Based Mean Field Theory . . . 7
第4章 ツイートデータとネットワーク構造解析 8 4.1 解析方法 . . . 8
4.2 フォロー数とRetweetについての検証結果 . . . 12
第5章 Networkを考慮した次数とRetweetの関係性 14 5.1 Networkを考慮する理由. . . 14
5.2 拡散ルート特定アルゴリズム . . . 16
5.3 アルゴリズムの検証結果 . . . 20
5.4 Retweetの拡散度、影響度について . . . 22
5.5 Retweetの拡散度、影響度の計算 . . . 25
5.6 TwitterネットワークにDBMFは適用できるか . . . 29
第6章 研究成果、今後について 30
第
1
章
Introduction
1.1
はじめに
今日、TwitterをはじめとするSNSは人々の生活に強く浸透し、一つの情報媒体としてその立場を確
立しつつある。その影響を受け、多くの企業もSNSでの自社製品やキャンペーンの広告宣伝へ力を入れ
始めている。本研究はその数あるSNSの中でもTwitterにおける情報拡散に注目し、Twitterでの情報 拡散にどのような特徴があるのか検証した。これまでにおけるTwitterに関する研究や統計は、主に何人 のユーザーが特定のツイートをRetweetしたかのなど最終的な拡散状況に注目されていてた[1][2][3]。例
を挙げると、ツイートには写真、URL、ハッシュタグを添付することができ、それらの要素ごとにどれほ
ど最終的な拡散が行われたかの研究[1]、災害やテロなどの緊急情報の内容が含まれた場合のリツイート
数の違いについての研究[2]、ツイート内容が主観的であるか、客観的であるかの違いによるリツイート
数の違いについての研究[3]などがある。つまり、Twitterのネットワーク構造例えば、ユーザーが何人 のユーザーをフォローしているかである次数にはあまり触れられてこなかった。一般的にはフォロワー が多いユーザーほどRetweet数が増える[4]とされていて、それはDegreed Based Mean Field (以下
第
2
章
データ解析プラットフォーム構築
について
2.1
使用したソフトウェア
本研究では、まずTwitter API[9]を用いることで10000以上に及ぶツイートデータを取得し、それを 統計処理ソフトR[10]を用いて解析した。その際に使用したソフトウェアを羅列する。
• R version 3.4.2
• RStudio version 1.1.383
2.2
データ収集について
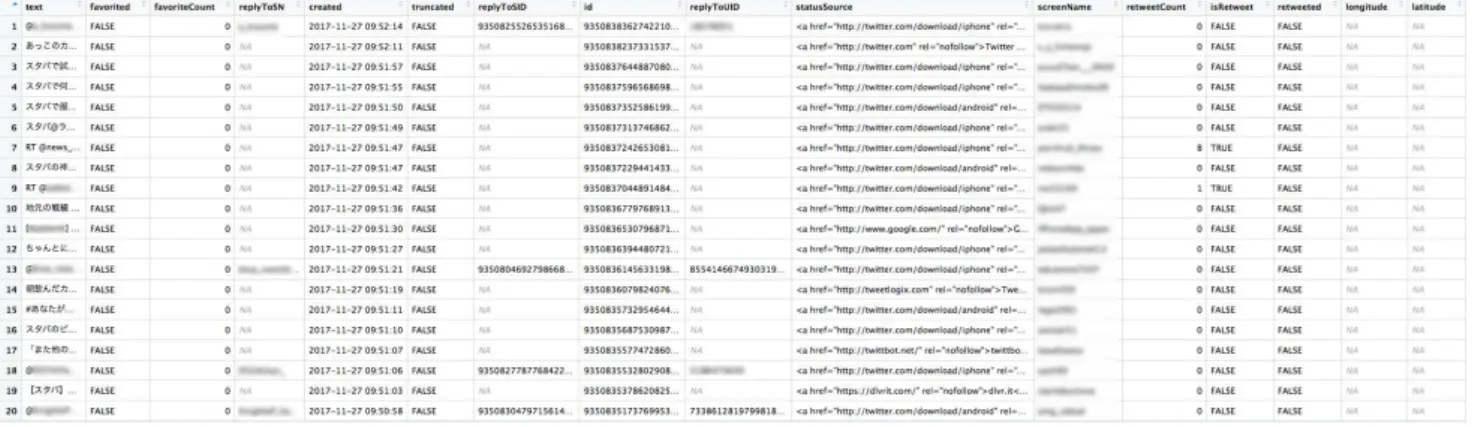
RにはTwitter APIにアクセスできる”rtweet”[7]と”twitteR”[8]というpackageがあり、これらを用 いることでツイートの様々な情報を取得することができる。実際に取得したデータサンプルのスクリーン
ショットが図2.1である。尚、プライバシーの観点から一部データにはモザイクをかけている。
図2.1 Screenshot of tweet data
意した。今回の解析で使う要素については赤文字で表記してある。 取得できる要素
✓ ✏
text
具体的なツイートの内容。@AAAはユーザー名が AAA の人へのリプライ(返信)、RT @AAAはユーザー名がAAAのユーザーのツイートをリツイートしたことを示す。
favorited
そのツイートが他ユーザーにlike(お気に入り)されたかをTRUEかFALSEで示している。
favoriteCount
そのツイートが他ユーザーにlike(お気に入り)された回数を示している。
replyToSN
そのツイートのリプライ(返信)先のユーザー名。
created
そのツイートがされた時刻をYYYY-MM-DD HH:mm:ssで示される。
truncated
replyToSID
そのツイートのリプライ(返信)先の元のツイートのID。
id
そのツイートのID。
replyToUID
そのツイートのリプライ(返信)先のユーザーのID。
statusSource
そのツイートがされたクライアント名
screenName
そのツイートをしたユーザー名
retweetCount
そのツイートが何回リツイートされたを示す。
isretweeted
そのツイートがリツイートされたをTRUEかFALSEで示している。
longitude
そのツイートがされた位置情報のうちの経度。
latitude
そのツイートがされた位置情報のうちの緯度。
第
3
章
Degreed Based Mean Field Theory
について
3.1
SIS model
今回Twitterでの情報拡散はSIS model であると仮定する。SIS model とは伝染病の伝搬を表す確 率モデルの内の1つである。SはSusceptible、 IはInfectedの頭文字を取ったもので、伝染病の流行 過程を表した2式による微分方程式でモデル化[5]される。病原菌を持っているInfected状態である人 I(t)が、病原菌を受け取りうるSuspectible状態である人S(t)に、病原菌を伝搬させInfected 状態に させる(S(t)→I(t))。また、Infectedである状態の人は一定確率で病気を治癒(I(t)→S(t))し、再び
Suspectible状態になる。これがSIS modelの基本的な考え方である。
dI
dt =βS(t)I(t)−µI(t) (3.1) dS
dt =−βS(t)I(t) +µI(t) (3.2)
βは感染率、µは治癒率を表す。(3.1)式、(3.2)式は時刻tにおけるS(t)とI(t)の時間変化について 表している。SIS modelは治癒(I(t)→S(t))しても再び感染する可能性があるのでノードは状態Sと状 態I間で状態遷移を繰り返す可能性がある(図3.1)。
図3.1 SIS model
アすることで、更に多くのユーザーにその投稿の閲覧を可能にするこれが繰り返されることで投稿が拡 散されていく様子がSIS modelと酷似していると言われている。Twitterの場合、投稿機能はツイート、 シェア機能はRetweetであり、S(t)はあるツイートを見ていないユーザー、I(t)はツイートをRetweet
したユーザーと今回仮定する。
3.2
Degreed Based Mean Field Theory
SIS modelは2変数のみで与えられる方程式で必ず定常状態に達する。同じ特徴を持ち、SIS modelを より発展させ、詳細に伝染病の伝搬を表すモデルが複数提唱されており、その中でもMean-Field Theory
で近似したものの1つが、Degreed Based Mean Field[5]であり、
dρI k(t) dt =−ρ
I
k(t) +λk[1−ρIk(t)] ∑
k′
P(k′|k)ρI
k′(t) (3.3)
と表される。このとき、ρIk(t)は時刻tにおいて、次数kで状態がInfectedであるノードの割合を表し ている。右式第1項の−ρI
k(t)は治癒(I(t)→S(t))した次数kのノードの個数を示す。第2項は新しく
Infectedになるノードについての項で、k[1−ρI
k(t)]は次数kで状態がSuspectibleであるノードの総数 を表し、P(k′|k)は次数kのノードが次数k′と繋がっている確率、ρI
k′は次数k′で状態がInfectedであ
るノードの個数を示している。つまり、第二項は次数kのノードが感染元になりうる次数k′のノードと 繋がっているか、k′がInfectedであるかを明確にし、その後感染率λで次数kのノードは状態S(t)から I(t)になることを表している。
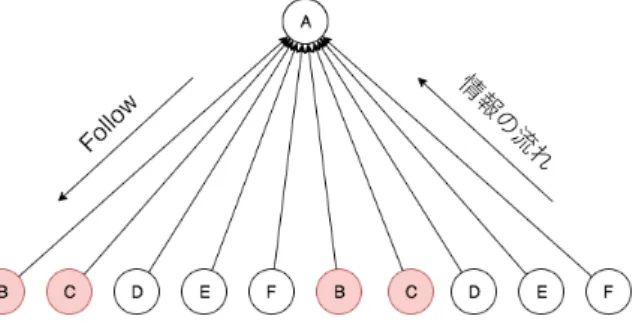
これをTwitterに当てはめる時、次数はユーザーのフォロワー数であると本論文では仮定する。図3.2、 図3.3おいて次数が異なる2つのノードの図に注目すると次数kのノードをA、次数k′のノードをA以 外のノードとする。Aが情報を受け取るためには、B∼Jの内誰かが情報を持っている必要があり、B∼J
が情報を持っている確率は一定なので、情報を仕入れる先が多い、図3.3のAの方が情報を受け取る確率 が高いと言える。
第
4
章
ツイートデータとネットワーク構造解析
集めたツイートデータを基にフォロワー数とRetweet の関係性を、実際のデータをもとに検証する。
具体的には、ツイートした人をA、Retweetしたユーザー全てをBとすると、Bの平均フォロー数(何人 のユーザーから情報を得られる状態か)とAをフォローしているのに、Retweetしなかったユーザーの平 均フォロー数を比較する。
4.1
解析方法
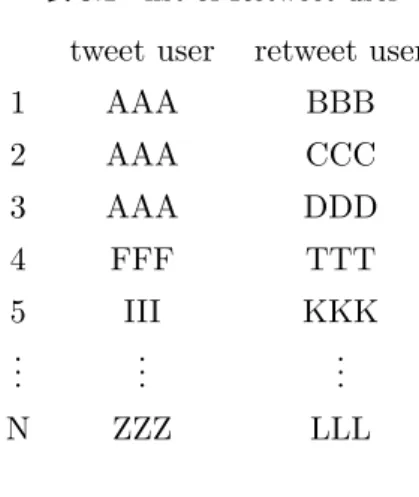
はじめにどのユーザーが誰のツイートをRetweetしたか特定する。収集したツイートのtext欄が RT @AAAでscreennameがBBBである場合、BBBがAAAのツイートをRetweetしたことを示してい る。よって、この2つを抜き出し、listを作成する(表4.1のlist)。
tweet user retweet user
AAA BBB
分析したツイートのうちRetweetがN個だとすると、どのユーザーが誰のツイートをRetweetしたか のlistをN個入手できる。
表4.1 list of Retweet user
tweet user retweet user 1 AAA BBB
2 AAA CCC 3 AAA DDD 4 FFF TTT 5 III KKK
..
. ... ... N ZZZ LLL
名をNodeとし、linkの向きをtweet userからretweet userに設定すると図4.1、図4.2のようなネット ワーク図が作成できる。今回は”スタバ”の含むツイートを集め解析した。スターバックスコーヒーはト レンドに入っていなくても、人々の話題になっていて、新商品が発表されるとすぐにトレンドになり、プ レリリース後とそれ以外での情報拡散の違いについて比較しやすいからである。図4.1は2017年12月
1日13:00ごろに”スタバ”が含まれるツイートを5000件抽出した内の500ツイートについてのRetweet
状況についてプロットしたものであり、図4.2は2017年12月13日21:00ごろに”スタバ”が含まれるツ イートを5000件抽出した内の500ツイートについてのRetweet状況についてプロットしたものだが、プ ライパシーの観点からユーザー名をアルファベット表記にしてある。また、各ユーザーがRetweetされ た回数についてまとめたのが、図4.3と図4.4である。
図4.1 View of Retweets of 500 tweets in December 1st
アルファベットは発信者のユーザー名、矢印の先にあるノードがRetweetしたユーザーを表す。
図4.2 View of Retweets of 500 tweets in December 13th
アルファベットは発信者のユーザー名、矢印の先にあるノードがRetweetしたユーザーを表す。
4.1と図4.2の中の各ユーザーが何回Retweetされたかをまとめたのが、図4.3と図4.4である。
図4.3 Number of Retweets of December 1st
それぞれのノード(アルファベット)のツイートが何回Retweetされたかを表している。
図4.4 Number of Retweets of December 13th
図4.1、図4.2の矢印は、ユーザーの名前から放射状に描画されいて、ツイートの拡散の向きを表す。 つまり、矢印の始点に位置するユーザーのツイートを矢印が向く方向に位置するユーザーがRetweetし たことを意味する。図4.1の下部分に注目してみると、AGの周りから多くの矢印(41本)が放射状に出 ているので、これは周りの矢印の先にいるユーザーがAGのツイートをRetweetしたことを表している。 更に図4.3、図4.4に注目すると、1回しかRetweetされていないものばかりで、多くRetweetされた
ツイートをしたユーザーの数は限りなく少ないことが分かる。ここで、具体的にフォロー数とRetweet
の関係性について注目する。Aに注目してみると26人のユーザーにツイートをRetweetされているが、 その一方で、そのツイートを見ながらもRetweetしなかったユーザーも存在している。それがAをフォ ローしているが、Retweetしなかったユーザー達である(図4.5)。
図4.5 Followers of A
Retweet したユーザーのフォロー数とそのツイートの発信者をフォローしているユーザーの中で、
Retweetしなかったユーザーのフォロー数を比較する。つまり図4.5においては、Aのフォロワーの中で
4.2
フォロー数と
Retweet
についての検証結果
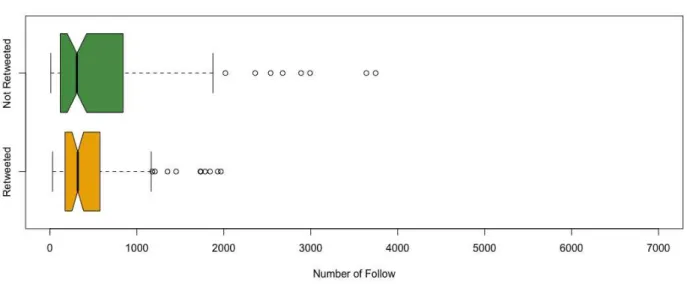
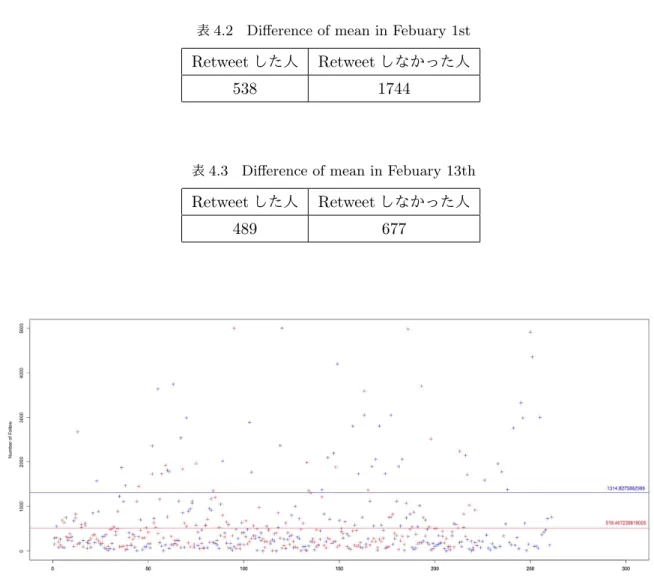
Retweetの有無とユーザーのフォロー数の違いを表した箱ひげ図と平均値をまとめた表を作成した。12
月1日のデータについてのものが図4.6と表4.2であり、12月1日のデータについてのものが図4.7と 表4.3である。
図4.6 Difference of the Follow between Retweeted user or not in Febuary 1st
表4.2 Difference of mean in Febuary 1st
Retweetした人 Retweetしなかった人
538 1744
表4.3 Difference of mean in Febuary 13th
Retweetした人 Retweetしなかった人
489 677
図4.8 Difference of the Follow between Retweeted user or not
赤がRetweetしたユーザーのfollow数、青がRetweetしていないユーザーのfollow数を示す。 赤線がRetweetしたユーザーの平均follow数、青線がRetweetしていないユーザーの平均follow数 である。
第
5
章
Network
を考慮した次数と
Retweet
の関
係性
5.1
Network
を考慮する理由
第4章で、今回収集したデータではTwitterネットワークにDBMFは適用できないことが分かった
が、これはRetweet をしたユーザーとそうでないユーザーのフォロー数を単純に比較して得られた結
果である。一方で、Twitterネットワークにおいて情報をどのようなルートを通じて得、そしてそれを
Retweetで拡散したかは、情報の拡散過程を知る上で1つの大きな要素になりうる。例えば図5.1、図5.2
に注目してみると同じRetweet数が10でもその拡散過程は全く違うものである。
図5.1 Network of 10 Retweets by First
一次拡散と複数拡散による大きな拡散状況の違いは、最終的に情報が拡散するコミュニティの種類に大 きい影響を与える可能性がある。
図5.3 Spread of First Infection Only
図5.4 Spread of Multi-Infection
5.2
拡散ルート特定アルゴリズム
収集したTwitterデータでは、どのユーザーのツイートをRetweetしたかは特定できるが、どのユー ザーから情報を受け取ったかは分からない。つまり、収集したデータではRetweetが一次拡散、二次拡
散、あるいはそれ以降の拡散なのかを特定できない。そこで、拡散ルートを特定するためのにRetweet
したユーザーAAAのフォロワーに、Retweetした他ユーザーBBBがいたとするとBBBはAAAから 情報を取得したものとする仮定のもと、プログラムを組んだ。発信者とRetweetした人のフォロー関係 を調べ、まず一次拡散かを特定する。その後、一次拡散に該当するユーザーのフォロワーに他のRetweet
したユーザーがいないかを調査し、二次拡散かを特定する。これを繰り返し行っていく。以下が特定する ために作成したプログラムのアルゴリズムの詳細である。
1. 4.1の検証方法と同様にツイートをまずRetweetされたものを抽出し、どのユーザーが誰のツイー トをRetweetしたかのlistを作成する(表5.1)。
表5.1 list of Retweet user
tweet user retweet user
1 AAA BBB 2 AAA CCC 3 AAA DDD 4 FFF TTT 5 III KKK
..
. ... ... N ZZZ LLL
2. 特定のツイートのRetweetした人のみのlistを新しく作成する。つまり表5.1においてtweet user
がAAAのみのlistを新しく作成する(表5.2)。
表5.2 list of user who retweeted AAA’s tweet
retweet user 1 BBB 2 CCC 3 DDD 4 ZZZ .. . ...
folllowerlistを作成する。Retweetしたユーザーがfollowerlistにいる場合、そのユーザーをFirst
RetweeterI1とし、残りのユーザーをnth Retweeterとする。
図5.5 Defining the First Retweeter
上図だとBBBとCCC がfollowerlistに入っているのでfirst RetweeterはBBBとCCC、nth
Retweeterはそれ以外のユーザーとなる。この段階で拡散ルートを特定できたものでネットワーク 図を作成したものが図5.6である。
図5.6 3.で特定したネットワーク
4. 次に、first Retweeter のフォロワーを全て取得し、followerlistをユーザー毎に作成する (今回 の例ではBBBと CCC のfollowerlistを作成する必要がある)。n’s Retweeter のユーザーがこ の followerlist にいる場合、そのユーザーをSecond RetweeterI2 とし、残りのユーザーをn’s
Retweeter とする。今回は、どのユーザーから情報を得てRetweet したかを分別する(BBBの
図5.7 Defining the Second Retweeter
この段階で拡散ルートを特定できたものでネットワーク図を作成したものが図5.8である。
図5.8 4.で特定したネットワーク
6. 4.の試行を繰り返すと、どのユーザーのfollowerlistにもなく、nth Retweeterに残っているユー ザーがいる場合がある。これは、Retweetを繰り返し自分のフォロワーから情報を取得し、Retweet
したわけではなく、Twitterの検索機能などを用いネットワーク外から自ら情報を取得し、その取 得した情報をRetweetとしたユーザーであり、これをI0とする。最終的にn次拡散まで起こり、
全Retweet数をI とすると、
I =I1+I2+I3+...+In+I0 (5.1)
が成り立つ。情報拡散ルートを全て特定し、作成できる図が図5.9である。
5.3
アルゴリズムの検証結果
今回は例として2種類のデータを用いる。5.2のアルゴリズムを用い、ツイートを誰から受け取り拡散 されたかを特定したものが、表5.3表5.4である。尚、実際に収集したデータを用いているが、プライ バシーの観点からユーザー名をアルファベット表記にしてある。senderがRetweet、あるいは最初にツ イートしたことにより、情報を発信したユーザーであり、情報を受け取り、再びRetweetしたユーザーが
recieverである。
表5.3 listA
sender reciever 1 AAA BBB
2 AAA CCC 3 AAA DDD 4 BBB EEE 5 DDD FFF 6 EEE GGG
表5.4 listB
sender reciever
1 ABA ABB 2 ABA ABC 3 ABA ABD 4 ABA ABE 5 ABA ABF 6 ABA ABG
7 ABA ABH 8 ABA ABI 9 ABA ABJ 10 ABA ABK 11 ABA ABL
12 ABA ABM 13 ABA ABN 14 ABA ABO 15 ABB ABP 16 ABC ABQ 17 ABC ABR
18 ABD ABT 19 ABE ABS 20 ABK ABT 21 ABL ABU 22 ABN ABV
表5.3において、Retweetしたユーザー周辺のみで構成されるNetwork図を作成したものが図5.10で
ある。図5.10ではノードがユーザーでエッジがユーザーが誰にフォローされているかを示している。最
も大きい赤いノードが発信者、その次に大きいピンクのノードがFirst Retweeter、紫色ノードがSecond Retweeterであり、 赤いエッジが一次拡散、ピンク色のエッジが二次拡散を表す。
図5.10 listAに含まれるユーザーのフォロワーネットワーク
図5.10ではツイートの流れが理解しにくいので、今回はRetweetしたユーザーのみをノードとし、ネッ トワーク図を作成したlistAから作成したものが図5.11で、listBから作成したものが図5.12である。
図5.11と図5.12は1つ1つのノードがRetweetしたユーザーを表していて、拡散の状況が分かりやす いようにツリー状にプロットされている。最も上にあるノードがそのツイートの発信者であり、下に位置 するノードほど複数Retweetを経由し、拡散したユーザー達を表す。図5.12の二次拡散において、二人 から情報を受け取ってるユーザーがいるがこれは、今回のアルゴリズムではどちらから情報を受け取った か判定が不可能なのでこのようなネットワーク図になっている。図5.11、図5.12に注目すると、少ない
Retweet数だとしてもその中に二次拡散、三次拡散...が含まれていることが分かった。このネットワーク 図を元に、再び次数とRetweetの関係について検証する。そのために、Retweetの影響度を導入する。
5.4
Retweet
の拡散度、影響度について
第4章では、Twitterネットワークではユーザーのフォロー数が少ないユーザーがRetweetすること が多いことが分かった。しかし、先行研究においてフォロワー数が多いほどRetweetされやすいという 結果が出ている[4]。そこで、フォロー数とフォロワー数両方を踏まえ、あるユーザーのRetweetに対し、 そのRetweetがどれだけ影響を与えているかの指数を導入する。
5.4.1
Retweet
の拡散度の導入
A1をA2がフォローしていて、A1のツイートをA2がRetweetしたと仮定する。このとき、 A1の
フォロワー数をA1# とし、A2のフォロー数を#A2とする。この時、A1#人に情報が行き渡り、A2は
#A2人から情報を受け取れる状況である(図5.13、図5.14)。
図5.13 Af ollower 図5.14 Bf riends
一次拡散する確率をP1、二次拡散する確率をP2とすると、A2がA1のツイートをRetweet(一次拡
散)する確率P1(A2)は、
P1(A2) =A2がA1のツイートを見る確率×A2がRetweetする確率 (5.2)
である。A2は常にTwitterを閲覧しているわけではないので、入手する全てのツイートを見ることは不
可能だと仮定すると、A2がA1の記事を見る確率は、
A1のツイート総数
A2が入手するツイートの総数
(5.3)
で表せる。ここで、A2 のツイートを受け取る先を 2a1,2a2,2a3, ...,2ai(i =# A2) とし、それぞれが
2α1,2α2,2α3, ...,2αi(i=#A2)回ツイートするとおく。A2が見るツイートの総数は、
A∑2#
i=1
であり、A1のツイート総数は2αA1なので、A2がA1の記事を見る確率は、
2αA1
∑A2#
i=1 2αi
(5.5)
である。A2がRetweetする確率をβ(A2)とすると、A2がA1のツイートをRetweetする確率P(A2)
は、
P1(A2) = 2
αA1
∑A2#
i=1 2αi
β(A2) (5.6)
である。次に、A1→A2→A3の二次拡散の場合を考える。A3がA2のツイートをRetweet(一次拡散)す
る確率P1(A3)は(5.6)式と同様に、
P1(A3) = 3
αA2
∑A3#
i=1 3αi
β(A3) (5.7)
である。A3はA1をフォローしていないので、A2がA1のツイートをRetweetしなければ、情報を得
られない。A3がA2のツイートをRetweet(一次拡散)する確率とA2がA1のツイートをRetweet(一次
拡散)する確率は独立であるとして、A3 がA2がA1のツイートをRetweetしたことで情報を入手し、
Retweet(二次拡散)する確率P2(A3)は、
P2(A3) =P1(A2)×P1(A3) (5.8)
= 2αA1
∑A2#
i=1 2αi
β(A2)×
3αA2
∑A3#
i=1 3αi
β(A3) (5.9)
である。一般に、A1のツイートがAn+1にRetweet(n次拡散)される確率は、
Pn(An+1) =
n ∏
j=1
P1(Aj) (5.10)
=
n ∏
j=1
jαAj−1
∑Aj#
i=1 jαi
β(Aj) (5.11)
である。次に、A1のツイートのRetweetによる拡散度を定義する。拡散度は最終的に何人のユーザー
がツイートを見る可能性があったのかの潜在性を数値化したものである。A1がツイートすると、A1の
フォロワーであるA1# 人がそのツイートを見る。A2がA1のツイートをRetweet(一次拡散)する確率
P1(A2)であり、そのRetweet(一次拡散)により新たにA2のフォロワーであるA2#人、A1のツイート
を見れるユーザーが増えるので、A1のツイートにおけるA2の拡散度SA1(A2)は、
SA1(A2) =P1(A2)×A2# (5.12)
である。一般に、A1のツイートがAnにRetweet(n次拡散)された時のAnの拡散度は、
SA1(An) =P1(An)An# (5.13)
である。同次拡散が複数存在した場合、どちらがより高い拡散度であったかを比較する場合を考える。n
次拡散した2人のユーザーIn1とIn2(In =In1+In2+In3...)がA1のツイートをRetweetとした場合
SA1(In1) =P n(In1)In1# (5.14)
SA1(In2) =P n(In2)In2# (5.15)
である。この値を比較することで、同時拡散同士であっても拡散度を比較することができる。
5.4.2
Retweet
の影響度の導入
A1の最終的な拡散度は、A1のツイートをRetweetしたユーザーの拡散度の総和であり、これをA1の
影響度と定義する。全Retweet数はI =I1+I2+I3+...+IN +I0であり、n次拡散したユーザーが
N(n)人いた場合、In=In1+In2+In3...+InN(n) とすると、n次拡散時でのA1のツイートにおける拡
散度SA1(n)は、
SA1(n) =
N∑(n)
i=1
P1(Ini)×Ini# (5.16)
である。A1の影響度はn次拡散時毎の拡散度の総和に、A1のフォロワー数A1#を足したものなので、
A1の影響度E(A1)は、
E(A1) =S(1) +S(2) +...+S(n) +A1# (5.17)
=
N∑(1)
i=1
Pn(I1i)×I1i#+
N∑(2)
i=1
Pn(I2i)×I2i#...+
N∑(n)
i=1
Pn(Ini)×Ini#+A1# (5.18)
=
n ∑
j=1
N∑(j)
i=1
Pn(Ini)×Ini#+A1# (5.19)
5.5
Retweet
の拡散度、影響度の計算
5.5.1
計算条件について
5.4で定義したRetweetの拡散度と影響度を取得済みであるデータを用いて計算する場合を考える。今 回、特定のユーザーが入手するツイートの総数や、各ユーザーがツイートする回数を取得していない。 よって今回は、各ユーザーは1回ツイートするものとし、フォロワー全てのツイートを見れるものとす る。つまり、A2が#A2人フォローしているとき、A1のツイートを見る確率は、#1A2 である。また、各
ユーザーがRetweetする確率も測定していないので、全ユーザーのRetweet確率は同じとし、(5.2)式の
Retweetする確率を今回は無視できるものとする。つまり、A2がA1のツイートをRetweet(一次拡散)
する確率P1(A2)は、
P1(A2) =
1
#A2
(5.20)
である。
各ユーザーのフォロー数がどのようになっているか着目するために、図5.11、図5.12に各ユーザーの フォロー数によってエッジの太さを変え(太いほどフォロー数が低い=情報を受け取りにくい)、フォロ ワー数をノードにした図が図5.15、図5.16である。図5.16にフォロワー数が記載されていないノードが あるが、これはそのユーザーのフォロー数フォロワー数を取得しようとした際、そのユーザーアカウント が凍結、あるいは既に削除されていて情報を入手できなかったものである。
28261614815771029468194332418422372686 4876
344 112 3695 3695 312320 1742
223397 545
757
6911
539 821 84 288 795 423 78 236 420 333 589 562 801 2003
1423 129 4831 338 235 1626
931 386 240
303
5.5.2
拡散度の計算
5.4.1で定義した拡散度を図5.15のデータを用いて算出する。まず、図5.15のネットワークのノード に番号をつける。(図5.17)
図5.17 図5.15におけるノード名の割り当て
図5.17において、AのツイートをBがRetweet(一次拡散)する確率は(5.20)式より、
P1(B) =
1
#B
= 1 2864
である。EがBのツイートをRetweet(一次拡散)する確率は(5.20)式より、
P1(E) =
1
#E
= 1 184
である。よって、EがAのツイートをRetweet(二次拡散)する確率P2(E)は(5.8)式より、
P2(E) =P1(B)×P1(E)
= 1 2864×
1
184 = 0.0000019
である。このように全てのノードがAのツイートをRetweetする確率を(5.8)式と(5.20)式を用い求め ると、P1(B) = 0.00035、P1(C) = 0.00287、P1(D) = 0.00043、P2(E) = 0.0000019、P2(F) = 0.000010、
次に、EとFどちらの拡散度が高いかを検証する。Eの拡散度SE(A)は(5.13)式より、
SE(A) =P2(E)×E#
= 396×0.0000019 = 0.0007524
であり、Fの拡散度SF(A′)は(5.13)式より、
SF(A) =P2(F)×F#
= 2138×0.000010 = 0.02138
であり、0.0000019<0.02138であるので、拡散度はFの方が高いことが分かる。
5.5.3
影響度の計算
5.4.2で定義した式を用い、最終的なAのツイートの影響度を算出する。(5.19)式より、二次拡散まで されたAの影響度E(A)は、
E(A) =
2
∑
j=1
N∑(j)
i=1
Pn(Ini)×Ini#+A1#
= 1.0878 + 4.18446 + 1.19712 + 0.0003002 + 0.00396 + 0.00072692 + 3051 = 3057.47437
5.6
ネットワークに
DBMF
は適用できるか
図5.16についてn次拡散毎に平均フォロー数とフォロワー数を表にまとめたのが、表5.5である。
表5.5 Mean of follow and follower of 25 Retweets Network
平均フォロワー数 平均フォロー数
全体 1013 750
1次拡散 569 683
2次拡散 1430 1087
3次拡散 519 388
4次拡散 303 757
図5.16に注目すると、一次拡散を表すエッジの中でも、細いエッジとつながっているノードから二次
拡散が多く発生しているのが分かる。そして、三次拡散が発生している直前の二次拡散を表すエッジに注 目すると、エッジが細くなっているのが分かる。エッジの太さは、情報が受け取りやすい方が細いので、 今回解析したデータでは、フォロー数が高いユーザーが一次拡散をするとその後も拡散が続くことが予想 できる。図5.16と表5.5、一次拡散の平均フォロー数683に対し、一次拡散したユーザーの中でその後も 拡散が続いたユーザーのフォロー数は616、4876、577であるが、フォロー数4876は1つ値が飛び抜け ているため、フォロー数4876抜いて平均値を再び計算すると、一次拡散の平均フォロー数は335であり、 フォロー数616、4876、577は平均より大きい値を取っている。
次に、フォロワー数について考える。一次拡散したユーザーの中でその後も拡散が続いたユーザーの フォロワー数は821、288、801、2003と一次拡散したユーザーの平均フォロワー数である569を超える ものが多い。二次拡散したユーザーの中でその後も拡散(三、四次拡散)が続いたユーザーのフォロワー 数は1423、1626と大きい値を取っている。つまり、フォロワー数が高いユーザーが拡散に大きく影響を 与えるのが分かる。
第
6
章
研究成果、今後について
今回解析したツイートの実データからは、Retweetが複数回されることでできたネットワーク構造を把 握したTwitterネットワークではDBMFは適用できると分かったが、これは全てのユーザーのRetweet
する確率、Twitter内での活動度(ユーザーが全フォロワーの中から特定のユーザーのツイートを見る確 率)を一定にした場合に限る。また、Retweetの影響度を求めることで、同次拡散が複数存在した場合で も、その中での希少性を評価することができ、最終的なRetweet数以外にも、Twitterネットワークでの 情報の拡散による最終的な影響度を評価することができるようになった。今後の研究では、
• 解析するデータに含まれるユーザーのTwitter内での活動度の算出
• 解析するデータに含まれるユーザーのRetweetする確率の算出
を行い、再びDBMFがTwitterネットワークに適用できるか検証する必要がある。
謝辞
参考文献
[1] 福島達也.『拡散しやすいツイートとその形態』早稲田大学基幹理工学部応用数理学科, 2016
[2] Sutton J, Gibson CB, Phillips NE, Spiro ES, League C, Johnson B, Fitzhugh SM, Butts CT, A cross-hazard analysis of terse message retransmission on Twitter, 14794, December 1,2015 [3] 小池達也,高木友博,主観表現と客観表現を用いた Twitter における有益なツイートの推定, DEIM
Forum 2015 A8-1
[4] Dan Zarrella, The Science of ReTweet Report,
http://danzarrella.com/the-science-of-retweets-report/, 2009
[5] Romualdo Pastor-Satorras, Claudio Castellano,Piet Van Mieghem,Alessandro Vespignani『 Epi-demic processes in complex networks』2015
[6] 豊泉洋,ソーシャルメディア上の口コミによるマーケティングの疫学的伝搬モデル
[7] https://cran.r-project.org/web/packages/rtweet/rtweet.pdf , 2017 [8] https://cran.r-project.org/web/packages/twitteR/twitteR.pdf, 2016