第
1
章 統計学とは何か
自然現象、社会現象は多数の要因が複雑にからみあい、さまざまな出来事が生じている.私 たちは、これらの現象を客観的に理解するために、いろいろなデータを収集し分析している. この授業では、データ分析の方法を身につけ,統計学の基礎を理解し,実際に分析を.各自の 研究でデータ分析ができるようになることを目標とする。まずデータの基礎的な分析法(代表 値、ばらつき、散布図、回帰分析)を学び(4,5月)、次に確率および確率変数を学ぶ(6,7月). その後(9月以降)確率に基礎とした統計的分析を学ぶ。
1.1
データの種類
1.1.1
測定の尺度による分類
測定の尺度は、Stevens による4つの分類が良く知られている.この分類は、名義尺度、順 序尺度、間隔尺度、比尺度1である。
名義尺度は、性別「男、女」や、産業の分類「第一次、第二次、第三次産業」などのように 複数カテゴリーに分割されるが、本来、数値的意味はない尺度である。
順序尺度は成績の「不可、可、良、優」のように順序に意味のあるような尺度である.満足度 などのアンケート調査で「とても不満、不満、どちらとも言えない、満足、とても満足」のよう に5段階で評価することがあるが、これも順序尺度の例である.順序尺度に対して、「1,2,3,4,5」 のような数値を割り当てることもあるが、便宜的なものであり、使い方には注意が必要である.
間隔尺度は、ある対象が他よりある単位によって∼だけ多い(少ない)といえる尺度.間隔 のみが意味を持つ.摂氏、華氏などの温度が間隔尺度の例である.
比率尺度とは、ある対象が他の何倍である、といえる尺度である.長さ、重さ、広さ、金額 などのような量を測る尺度は比率尺度である.
1.1.2
データの計測形態に着目する分類
データを構成する要素(数値やカテゴリー)一つ一つに時点が付与されているデータを時系 列データという.ある一時点において複数の個体について数値などが得られているようなデー タをクロスセクションデータという.同じ複数の個体のセットについての複数年分のデータを パネルデータという.
時系列データの例 : 気温,株価,為替レート
クロスセクションデータの例 : GDP,各国の人口,各県の離婚率 パネルデータ:ある中学校の学生全員の成績三年分
1英語では
第
2
章
1
変数データ分析
この章では,1変数データの分析手法を学ぶ.データの分布状況を見る手段であるヒストグ
ラム,データの代表値,データの散らばりの尺度,の順に説明する.ここで学ぶ方法は統計学 の中でも最も基本的である.
2.1
ヒストグラム
1変数データの分析で最も基本的なのが,データの分布の状況を見ることである.図 2.1は,
2010年7月−2011年2月の日経平均株価の収益率1のヒストグラムである.
ヒストグラムの描き方: まずデータが含まれる範囲を複数の区間に分ける。この各区間のこ とを階級といい、各区間の長さを階級幅という。次に各区間に含まれるデータの個数(度数と いう)を数える。横軸の各階級を底辺とし度数が面積に比例するように柱を描いた図がヒスト グラムである。日経平均収益率の分布がおおよそ左右対称であることがわかる.
Histogram of Nikkei$return
Nikkei$return
Frequency
−0.04 −0.03 −0.02 −0.01 0.00 0.01 0.02 0.03
0
5
10
15
20
25
30
図 2.1: 日経平均収益率のヒストグラム
経済・経営データでは,分布が左右対称でないものも多い.図 2.2は,平成22年の23区住 居地域の公示価格データ(単位は円/m2)のヒストグラムである.20−80万円の範囲に多く
のデータがあるが,100万円を超えるデータもそれなりにあり,右側に伸びている.このよう
1株価の収益率
な分布は右に歪んだ分布という.経済データでは分布が右に歪んでいることがよくある(所得, 貯蓄など).逆に左側にすそが伸びている場合,左に歪んだ分布という.
Histogram of kouji_23ku$kakaku
kouji_23ku$kakaku
Frequency
0 500000 1000000 2000000 3000000
0
50
100
150
200
250
図 2.2: 23区住居地域の公示価格データのヒストグラム
準備:シグマ記号について
数列の和を意味するシグマ記号の定義を説明する.
x1, x2, . . . , xnを数列とする.統計学では,これらは数値データを意味する.
定義
✓ ✏
n
∑
i=1
xi =x1+x2+· · ·+xn
✒ ✑
つまり
n
∑
i=1
xiはiが1,2, . . . , nと変わるときの xiの和を意味する.
また,数aに対して
n
∑
i=1
a=a+a+· · ·+a
| {z }
n個
=na
シグマ記号の性質
✓ ✏
(1)
n
∑
i=1
(xi +yi) = n
∑
i=1
xi+ n
∑
i=1
yi
(2)
n
∑
i=1
axi =a n
∑
i=1
xi
✒ ✑
以下の問題を解き,ノートに書きなさい.
問題1 シグマ記号の定義をノートに書きなさい. 問題2 シグマ記号の性質(1),(2)の証明をしなさい.
問題3 以下の等式が成り立つことを証明しなさい.
n
∑
i=1
(axi+byi) = a n
∑
i=1
xi+b n
∑
i=1
yi
2.2
データの代表値−平均,
メディアン,
モード−
ヒストグラムよりもさらにデータを要約して,データの特徴を表すいくつかの数値を求める ことも多い.まず,1つの数値でデータを代表させようとする場合,これをデータの代表値と いう.まず,データを
x1, x2. . . . , xn
で表そう.
2.2.1
平均
データx1, x2. . . . , xnの平均は,
¯
x= 1
n
n
∑
i=1
xi
平均の性質1
n
∑
i=1
(xi−x¯) = 0
次のような思考実験を考えてみる. ものさしの形の板があり、目盛が記入されている。この板
のx1, x2. . . . , xnの各位置に同じ重さのおもりを一つずつ置く。平均の性質1から、平均x¯の位
置に支点をおけば、この板はちょうど釣り合うことがわかる。つまり、x¯の位置は重心になっ ていることがわかる。このことを知っていると、平均の位置の見当がつくことがある。
平均の性質2 平均は外れ値に引っ張られやすい.
ただし,外れ値とは他のデータの値からかけ離れて大きい値,あるいは小さい値のことをいう.
例 2.1. 以下の数値はある会社の従業員の年間所得(万円)が以下であるとする.
330,280,230,240,390,290,340,1580
このときx¯= 460(万円)と計算できる.この会社の従業員8人のうち7人は所得が平均460
万円よりも小さい.平均が1つの大きな値1580万円に引っ張られてしまっていることがわかる.
2.2.2
メディアン
メディアン(中央値)は,データを小さいものから大きいものへ順番に並べた時に中央に位置 する値である.大きさの順に並べたデータを
x(1) < x(2) <· · ·< x(n)
で表す.メディアンは
M d=
{
x(n+1
2 ) nが奇数の場合, 1
2
{
x(n/2)+x(n/2+1)
}
nが偶数の場合.
で定義される.メディアンは外れ値に影響を受けにくい特徴がある.たとえば, データ5,10,2
のメディアンは5であり,データ2,6,9,12のメディアンは7.5である。例2.1では、年間所得の メディアンは290万円である. メディアンが外れ値の影響を受けにくいことを、メディアンは ロバスト(頑健)であるということがある.
2.2.3
モード
2.3
モード,メディアン,平均の関係
ヒストグラムを描くことによってデータの分布の形を知ることができる.峰が一つの分布を 単峰型の分布という.また,峰が二つの分布を双峰型の分布という.
単峰型で,右に歪んだ分布ではモード<メディアン<平均,の関係がある2.左に歪んだ分
布では,平均<メディアン<モード,の順番になる.
図 2.3は平成23年度の世帯所得の相対度数のヒストグラムである.世帯所得の分布は単峰型 で,右に歪んだ分布であることがわかる.図の上に示されているように,モードは350万,メ ディアンは427万,平均は528万である.
図 2.3: 平成23年度の世帯所得のヒストグラム(厚生労働省HPより転載)
2.4
四分位数
データの分布の特徴をとらえるのに四分位数が使われることがある.データを大きさの順番 に並べ,メディアンを境にデータを2つの部分に分ける.2つに分けたうち,小さい値の方の データのメディアンを第1四分位数という.2つに分けたうち,大きい値の方のデータのメディ アンを第3四分位数という.データのメディアンを第2四分位数ともいう.これらを四分位数
という.つまり, 第1四分位数以下のデータの数は全体の1/4, 第2四分位数以下のデータの数 は全体の1/2,第3四分位数以下のデータの数は全体の3/4である。
2.5
箱ひげ図
四分位数と最小値、最大値を用いた図2.4を箱ひげ図(box-and-whisker plot)という. 箱ひげ
図により分布の様子を大ざっぱにみることができる。特に、複数の分布を比較するときに便利 である(図2.5).
図 2.4: 賃貸マンションの家賃の箱ひげ図
sapporo
naha
toky
o
−10 0 10 20 30
図 2.5: 東京,那覇,札幌の気温の箱ひげ図
2.6
データのばらつきの尺度
データの特徴を把握する時に,代表値とともに重要なのがばらつきの尺度(散らばりの尺度)
である.
2.6.1
範囲,四分位範囲
データの最大値と最小値の差を範囲(レンジ)という.範囲は意味がわかりやすいが,外れ 値に影響を受けやすい.
外れ値の影響を受けにくい尺度として四分位範囲がある.四分位範囲は以下で定義される.
2.6.2
分散,標準偏差
平均は代表値の一つであった.個々の観測値の平均からの差を偏差という.
偏差=観測値−平均=xi−x¯
偏差を用いてばらつきの程度を測ることが可能である. ばらつきの尺度として用いられるのが分散で、
Sx2 =1
n
{
(x1−x¯)2+ (x2−x¯)2+· · ·+ (xn−x¯)2
}
= 1
n
n
∑
i=1
(xi−x¯)2 (2.1)
で定義される.(xi−x¯)2は,観測値xiが平均x¯から離れている程度を測っている.分散は,観
測値が平均的にどの程度離れているかを求めた値である. 分散の正の平方根
Sx =
√
S2
x
を標準偏差という.標準偏差の単位は元のデータの単位と同じであり,使いやすい.
2.7
一次式と平均、分散の性質
a, bを定数とする。統計学では、データx1, x2, . . . , xnにbを乗じてaを加えて得られるデー
タbx1+a, bx2+a, . . . , bxn+aがよく現れる。このデータに対して以下の性質がある。
(1) x1+a, x2+a, . . . , xn+aの平均はx¯+aである。
(2) bx1, bx2, . . . , bxnの平均はbx¯である。
(3) bx1 +a, bx2+a, . . . , bxn+aの平均はbx¯+aである。
分散と標準偏差については以下の性質がある。
(1) x1+a, x2+a, . . . , xn+a の分散はSx2,標準偏差はSxである。
(2) bx1, bx2, . . . , bxn の分散はb2Sx2,標準偏差は|b|Sxである。
(3) bx1 +a, bx2+a, . . . , bxn+a の分散はb2Sx2,標準偏差は|b|Sxである。
これらの性質は以下のようにまとめられる。
✓ ✏
データx1, x2, . . . , xnをa+bxi,i= 1,2, . . . , nのように一次式で変換することを考える.デー
タa+bx1, a+bx2, . . . , a+bxnの平均,分散,標準偏差はそれぞれ以下のようになる.
平均: a+bx¯
分散: b2Sx2
標準偏差: |b|Sx
である。
データの一次式による変換で特に有用なのが以下の変換である. データの標準化
✓ ✏
zi =
xi−x¯
Sx
i= 1,2, . . . , n (2.2)
この変換を標準化あるいは基準化という.標準化された値を標準化得点ということもある。
✒ ✑
標準化されたデータz1, z2, . . . , znの平均,分散,標準偏差をそれぞれz¯, Sz2,Szで表せば,z¯=
0, S2
z = 1, Sz = 1 となる. 標準化されたデータは,各観測値の全体における位置を知りたいと
きに便利である.
問題
2
問題 2.7.1.
以下は、あるたい焼き屋さんのたい焼き5つの重量である。100,105,110,115,120
平均、分散、標準偏差を求めなさい。
問題 2.7.2.
5人の学生から構成されるクラスの英語の試験の点数は以下であった。
A君 B君 C君 D君 E君
英語 85, 86, 87, 88, 89
英語の点の標準偏差を求めなさい.また英語の点数の標準化したデータを求めなさい.
参考:偏差値
標準化された観測値に10をかけ50を足した値を偏差値と呼んでいる(統計学の用語ではな
い).すなわち
xi の偏差値= 50 + 10×
xi−x¯
Sx
第
3
章
2
変数データの分析
3.1
散布図
複数の個体(たとえば,企業,個人、都道府県)について2つの変数のデータが観測されて
いる時,二つの変数の関係を見るために散布図とよばれる図を描く.2つの変数間に原因−結 果の関係が考えられる時には,値の変化が原因となると考えられる変数を横軸にとるのが普通 である(たとえば,緯度と平均気温など).
20 40 60 80 100 120
5
10
15
20
25
area
yachin
図 3.1: 家賃と専有面積の散布図 図 3.2: 19都市の緯度と平均気温
図3.1は,池袋周辺の賃貸マンション・アパート203件分の家賃と専有面積の散布図である。 家賃と専有面積は右上がりの直線に近い関係がある。このような関係を正の相関関係という。
図3.2は、日本に19都市の緯度と平均気温の散布図である.はっきりとした右下がりの直線
に近い関係がある。このような関係を負の相関関係という。正の相関も負の相関もないとき, 無相関あるいは相関がないという.
3.2
2
変数データの直線的関係の尺度−共分散,相関係数−
二つの変数の直線的関係の方向と程度を測る尺度として共分散がある. 共分散
✓ ✏
二つの変量xとyのデータが(x1, y1), . . . ,(xn, yn) で与えられている時,x と y の共分散は
Sxy =
1
n{(x1−x¯)(y1−y¯) +· · ·+ (xn−x¯)(yn−y¯)}=
1
n
n
∑
i=1
(xi−x¯)(yi−y¯) (3.1)
で定義される.
✒ ✑
+
− +
−
図 3.3: 偏差の積の正負(正の相関)
+
− +
−
図 3.4: 偏差の積の正負(負の相関)
共分散は単位やデータの散らばりの大きさに依存する(散らばりが大きいと共分散は大きく なる)ので,値を解釈することが難しい.
相関係数
✓ ✏
共分散をx, yそれぞれの標準偏差で割った値
r= Sxy
SxSy
(3.2)
をデータxとyの相関係数(correlation coefficient)と呼ぶ.
✒ ✑
相関係数rは
r=
n
∑
i=1
(xi−x¯)(yi−y¯)
v u u t
n
∑
i=1
(xi−x¯)2 n
∑
i=1
(yi−y¯)2
(3.3)
とも書ける.rを手計算で求めるときは,(3.3)式を用いる方が計算が簡単になる.前述の,家 賃と専有面積の相関係数は0.859 である.また,緯度と平均気温の相関係数は−0.973 である.
相関係数は二つの変数の直線的関係の向きと強さを測る尺度である.相関係数には以下の性 質がある(重要).
相関係数の性質
✓ ✏
(i)どのようなデータにたいしても−1≤r≤1であるa
.
(ii)二つの変数間に正の相関関係があるときに,rは正の値をとる. 正の相関関係で,直線的程度が強いほどrの値は1に近い.
(iii)二つの変数間に負の相関関係があるときに,rは負の値をとる. 負の相関関係で,直線的程度が強いほどrの値は−1に近い.
(iv)二つの変数間は無相関であるときには,rは0に近い.
a証明は「統計学入門」東京大学出版会,
49ページを見よ.
問題.以下のデータは,ある中学のクラスの5人の(1週間の)数学の勉強時間(時間)と数学 の点数である.
勉強時間(xi) 数学の点数(yi) (xi−x¯) (yi−y¯) (xi−x¯)(yi−y¯)
11 71 12 73 13 72 14 74 15 75
和
(1)表を完成させて,勉強時間と数学の点の共分散を求めなさい。(式も書く)
(2)勉強時間と数学の点の相関係数を求めなさい。(式も書く)
参考:図3.5から3.9に、2変量データと相関係数の関係が示されている。
−2 −1 0 1 2
−2
−1
0
1
図 3.5: r=−0.90
−3 −2 −1 0 1 2 3
−3
−2
−1
0
1
2
図 3.6: r=−0.50
−2 −1 0 1 2
−2
−1
0
1
2
3
図 3.7: r = 0.12
−2 −1 0 1 2
−2
−1
0
1
2
図 3.8: r = 0.50
−3 −2 −1 0 1 2
−3
−2
−1
0
1
2
図 3.9: r= 0.92
3.3
見かけ上の相関
図 3.10は,47都道府県の理容・美容所数と交通事故件数の散布図である.正の相関が見ら
れる.
図 3.10: 47都道府県の理容・美容所数と交通事故件数の散布図
しかし,理容・美容所数が増えると交通事故件数が増える,と考えるのは明らかに誤ってい る.このような相関関係を見かけ上の相関という.この場合は,人口の多い都道府県では,理 容・美容所数,交通事故件数,の両方が多いことが見かけ上の相関を生んでいる.実際,理容・ 美容所数,交通事故件数のどちらも人口で割った変数の散布図を描くと,図3.11になり,二つ の変数はほぼ無相関であることがわかる.
3.4
回帰直線
相関係数を用いて2変数のデータを分析するときは、二つの変数を対称的に扱った。ある変
数の動きを他の変数の一次式で説明する分析手法を回帰分析という。
専有面積が広くなれば家賃は高くなるという関係があり,また図3.13から、専有面積と家賃 の間には近似的に直線的な関係があることがわかる。家賃を y で、専有面積を x で表すとす
る。このときy と x の近似的な関係を表す一次関数
y=a+bx (3.4)
を求めることができれば便利である。
一般に、値を説明される方の変数を被説明変数、説明する方の変数を説明変数という。今、 変数xの値を与えたときの変数yの変動を分析したいとする。
通常は、最小2乗法と呼ばれる方法によって、2変数データ(xi, yi), i= 1,2, . . . , n に最も当
てはまる直線を求める。
最小
2
乗法
( x
i
, y
i
)
a + b x
x
i
y
i
x y
a+bx
i
図 3.12: 最小2乗法の考え方
今、x−y平面上の任意の直線y=a+bxを考えてみる。a, bは定数である。観測値(xi, yi)から
垂直に下ろした線が直線y=a+bxと交わる点は(xi, a+bxi)である。この2点の差の2乗(yi−
a−bxi)2 のすべての観測値についての和は直線y=a+bxがデータ(x1, y1),(x2, y2), . . . ,(xn, yn)
からどの程度「乖離」しているかを測る尺度と考えられる。つまり
S(a, b) =
n
∑
i=1
(yi−a−bxi)2
を直線 y =a+bxのデータからの「乖離」の尺度と考える。S(a, b) を最小にする a, b の値を
求める方法を最小2乗法という。
S(a, b) を最小にするa, b の値は以下の公式を用いて求められる1。
1この公式の導出は
b =
n
∑
i=1
(xi−x¯)(yi−y¯)
n
∑
i=1
(xi−x¯)2
(3.5)
a = ¯y−bx¯ (3.6)
上式で与えられるa, bを回帰係数という. 式(3.5)式,(3.6)式で求めたa, bを用いた一次関数 y=a+bxを回帰式という.また、回帰式が表す直線を回帰直線という. 式(3.6)から、回帰直 線は点(x, y)を通ることがわかる。
回帰式を書くときは,yにハットを付けて
ˆ
y=a+bx
で表すことが多い.
賃貸アパート・マンションの例で、回帰式を求めると
ˆ
y= 3.1553 + 0.2118×x (3.7)
となる。次に、求めた回帰式を散布図上に描いてみよう。
20 40 60 80 100 120
5
10
15
20
25
area
yachin
図 3.13: 回帰直線
例題
下の表は,ある5日間の最高気温と自動販売機によるスポーツドリンク販売本数のデータ(架 空)である2.
xi 最高気温 yi 本数
24 17 25 19 26 20 27 21 28 23
a, b を計算して見よう。以下のような表を作って計算してもよい。
xi yi (xi−x¯) (yi−y¯) (xi−x¯)2 (xi−x¯)(yi−y¯)
24 17 -2 -3 4 6 25 19 -1 -1 1 1 26 20 0 0 0 0 27 21 1 1 1 1 28 23 2 3 4 6
和 0 0 10 14
結果は以下のようになる。
¯
x=26, y¯= 20
b =14
10 = 1.4, a= 20−1.4×26 =−16.4
得られた a, b を使った式
ˆ
y=a+bx
は回帰式あるいは回帰直線とよばれる. 上の例では
ˆ
y=−16.4 + 1.4x
が回帰式である.回帰式の上では,最高気温が1度上がれば,この自動販売機でのスポーツド
リンク販売本数が1.4本増えることがわかる.
決定係数
最小2乗法によって得られた回帰式を
y=a+bx (3.8)
と書こう。この回帰式を用いて、 xi の値から計算される y の値をyˆi と表す。すなわち
ˆ
yi =a+bxi, ı = 1,2, . . . , n.
2計算しやすいように標本の大きさ
(観測値の個数)を小さくした.実際に回帰分析を行うときには,標本の大
である。yˆi を yi に対する回帰値という。当然、実際の観測値yi と回帰値yˆi は一致するとは限
らない。yi と yˆi の差
ei =yi−yˆi, i= 1,2, . . . , n (3.9)
を残差という。(3.9)式を変形すると
yi = ˆyi+ei (3.10)
と書ける。この式から、yˆi は yi の値のうち回帰モデルで説明できる部分、ei は回帰モデルで
説明できない部分である。まず、(3.10)式の両辺から y¯を引く。
yi−y¯= (ˆyi−y¯) +ei (3.11)
(3.11)式の両辺を2乗してすべての i について合計すると
n
∑
i=1
(yi−y¯)2
| {z }
yiの変動
=
n
∑
i=1
(ˆyi−y¯)2
| {z }
ˆ
yiの変動
+
n
∑
i=1
e2i
| {z }
残差の変動
(3.12)
が成り立つことを証明できる.(3.12)式は、y1, y2, . . . , ynの変動が回帰モデルで説明できる部分
と説明できない部分とに分解できることを意味している。yiの変動 に占めるyˆiの変動 の割合が
大きければ大きいほど、求めた回帰式のデータに対する当てはまりがいいことを意味する.こ の割合を
R2 =
n
∑
i=1
(ˆyi−y¯)2
n
∑
i=1
(yi−y¯)2
(3.13)
と書き、R2 を回帰式の決定係数という.決定係数は,被説明変数y
iの変動のうち回帰値yˆiの
変動が占める割合である.言い換えれば,決定係数は,被説明変数yiの変動のうち回帰式で説
明できる割合を意味している.(3.12)式のすべての項は正だから、
0≦R2 ≦1
が成立する。したがって、R2 が1に近ければ回帰式の当てはまりが良く,0に近ければ回帰式
3
章の付録
S(a, b)を最小にする a, bの値は以下のように求められる。S(a, b)はa, bの2次関数で最小値
を持つ。S(a, b) をa, bそれぞれで偏微分して0とおくと
∂
∂aS(a, b) =−2
n
∑
i=1
(yi−a−bxi) = 0,
∂
∂bS(a, b) =−2
n
∑
i=1
(yi−a−bxi)xi = 0
が得られる。これらを整理すると以下の連立方程式が得られる。
an+b
n
∑
i=1
xi = n
∑
i=1
yi (3.14)
a
n
∑
i=1
xi+b n ∑ i=1 x2 i = n ∑ i=1
xiyi (3.15)
この連立方程式を正規方程式という。(3.15)にnをかけて式から(3.14)に∑n
i=1xiをかけた式
を引くと次式が得られる。
b =
n
∑
i=1
xiyi−nx¯y¯
n
∑
i=1
x2i −nx¯2
a= ¯y−bx¯
次に、公式
n
∑
i=1
(xi−x¯)(yi−y¯) = n
∑
i=1
xiyi−nx¯y¯ および n
∑
i=1
(xi−x¯)2 = n
∑
i=1
x2i −nx¯2を用い
れば、以下の公式が得られる。
b =
n
∑
i=1
(xi−x¯)(yi−y¯)
n
∑
i=1
(xi−x¯)2
3.5
重回帰式
3.4節では、賃貸マンションの家賃をその専有面積で説明する回帰式を求めた。現実には、物
件の面積以外の特性も家賃に影響与えるだろう。たとえば、古いマンションの部屋の家賃は相 対的に安いだろうと考えられる。つまり,専有面積(x)と築年数(z)は家賃(y)に影響を与える と考えられる.このような関係を分析する最も基本的な方法は、yとx, zの関係を近似するx,
zの一次関数
y=a+bx+cz (3.16)
をデータから求めることである。このような関数をデータに当てはめて,分析を行うことを重 回帰分析という.一方,説明変数が1つの場合の回帰分析を単回帰分析ということがある.xと
z は説明する方の変数で説明変数とよばれる。yは説明される変数で、被説明変数とよばれる。 a, b, cは回帰係数とよばれる。重回帰分析の場合も最小2乗法によってデータから回帰係数
a, b, cの値を求める。データ(yi, xi, zi),i= 1, . . . , nがあるとき
S(a, b, c) =
n
∑
i=1
(yi−a−bxi−czi)2
を考える。これは点(xi, zi, yi)から平面y=a+bx+czへの垂直方向の距離の2乗をすべて足
した値である。S(a, b, c)を最小にするa, b, c の値を 求める方法を最小2乗法という。決定係数 は単回帰分析と同じように定義でき,回帰式の当てはまりの良さを表す.
3.5.1
2
変数の
1
次関数
(3.16)式は、変数 y が2変数 x, z の1次関数になっていることを意味する。ここで2変数の
1次関数について簡単に説明する。(3.16)式の1次関数を考えよう。2変数の1次関数のグラフ
はx−z−y 空間の中の平面になることがわかっている。
0
0.5
1
1.5
2
0 0.5 1 1.5 2 0 1 2 3 4 5 6 7 8
x z
y
図 3.14: 2変数の1次関数 y= 1 +x+ 2z のグラフ 上図は2変数の1次関数
のグラフである3。2変数の1次関数(3.17)で、右側第1項は 1 である。これは原点(x = 0,
z = 0)におけるグラフの高さが 1であること意味する。また、x の係数は 1 である。これは、 点が x−z 平面を x 軸と平行な方向に移動するときのグラフの傾きが 1 であることを意味す る。z の係数は 2である。これは、点がx−z 平面をz 軸と平行な方向に移動するときのグラ
フの傾きが 2であることを意味する(図3.14を参照).
重回帰式のあてはめ
下の図は賃貸マンションの面積,築年数,(駅からの)時間距離の3次元散布図である.また
次の図は,同じ3次元散布図で,各点から面積−築年数の平面への垂線を付けた.上の3次元
図 3.15: 池袋駅周辺の賃貸マンションの面積、築年数、家賃の3次元散布図
図 3.16: 池袋駅周辺の賃貸マンションの面積、築年数、家賃の3次元散布図(垂線付き)
散布図からわかるように,面積、築年数、家賃のデータはおおよそある平面の回りにばらつい ている.つまり,家賃は面積と築年数の1次関数で近似できると考えられる.重回帰分析はエ
3数学では横軸を
x,縦軸をy,垂直軸をzで表すことも多いので注意すること.平面上の格子はグラフを見や
クセルでも簡単に実行できる.家賃を被説明変数,面積と築年数を説明変数として重回帰分析 を行うと,重回帰式
家賃 = 4.352 + 0.213専有面積−0.11築年数 (3.18)
が得られる(家賃の単位は1万円,面積の単位は1m2,築年数の単位は1年).決定係数は0.797
である.回帰平面の上では,専有面積が1m2増えれば家賃は2100円増え,築年数が1年増えれ
ば家賃は1100円減少することがわかる.図3.17は回帰平面を描きこんだ3次元散布図である.
回帰分析の名前の由来
イギリスの学者Francis Galton (1822-1911)が回帰(regression)という言葉を用いた.図3.18
のように楕円状に分布しているデータを考えてみる。横軸の変数を説明変数,縦軸の変数を被 説明変数として最小2乗法によって回帰直線を求めると,図のようになる.この直線は楕円の 主軸よりも傾きが小さい.これは2変量データが楕円状に分布するときに成り立つ性質である.
Galton は,両親の平均身長と子供の身長のデータがこの図のように楕円状に分布しているこ とを示した。両親の身長が大きい場合、その子供の身長も大きい傾向がある。また、もし両親 の平均身長が全体の平均より1cm大きい場合,その子供の平均身長の全体の平均との差は1cm
より小さい.このような現象をGaltonは回帰(regression)とよんだのである.このような経緯 で、最小2乗法で求めた直線は回帰直線とよばれるようになった。
150 155 160 165 170
150
155
160
165
170
twodimrn$x
tw
odimr
n$y
ダミー変数を用いた回帰式
図3.19は2003年5月から10月の東京電力日量(発電量,単位は1000kwh)と東京の最高気温
(単位は℃)の散布図である。(横軸が東京の最高気温,縦軸が東京電力日量. )
図 3.19:
×のマーカーは平日,〇のマーカーは土日および祝日である.平日のデータとそれ以外のデー タは直線で近似すると平行に近いように見える.「平日」と「それ以外」のような質的違いの影 響をを回帰式に取り入れるときには、ある状態のときには1,それ以外のときには0をとる変数
を定義する。このような変数をダミー変数という。 上の例で、以下のようにダミー変数を定義する.
平日ダミー変数=zi =
{
1 i番目の観測値が平日の観測値の場合,
0 i番目の観測値が平日以外の観測値の場合.
電力日量を被説明変数とし,平日ダミー変数と最高気温を説明変数とする回帰式を考えると 以下のようになる.
電力日量=a+c平日ダミー変数+b最高気温
=
{
a+c+b最高気温 i番目の観測値が平日の観測値の場合, a +b最高気温 i番目の観測値が平日以外の観測値の場合.
したがって、この回帰式における平日ダミー変数の回帰係数cは, 平日のときに増加する電力
日量を意味している.
第
4
章 確率
確率は自然科学,社会科学の両方で広く用いられている.社会科学や人間の行動を分析の対 象とする科学において様々な理論やモデルがあるが,どのようなモデルを用いても現象をぴった りと完全に説明することはできない.実際の現象の不確実性は確率の概念を用いることによっ て説明される.
本章では,確率を本格的に定義する.本章の内容は,確率変数というより発展した内容(次 章で扱う)の基礎となる.大学で学ぶ確率と確率変数を用いれば,様々な現象を説明すること が可能になる.
4.1
準備:順列と組合せ
例 4.1. 大学の授業でいっしょになったa君,b君,c君,d君の4人が自己紹介を行うことに なった.自己紹介を行う順番は,最初が4通り,2番目が残りの3通り,3番目の人が残りの2
通りであるから4×3×2 = 24と計算でき,24通りであることがわかる.
例 4.2. ある授業を履修しているa君,b君,c君,d君のうち2人が授業で発表を行うことに なった.発表の順番を考慮すると,最初が4通り,2番目が残りの3通りであるから,4×3 = 12
と計算でき,12通りであることがわかる.
一般に,異なるn個のものからr個を取り出して1列に並べたものをn個からr個取る順列
といい,その場合の数をnPrで表す.nPrは
nPr =n(n−1)· · ·(n−r+ 1) =
n!
(n−r)! (4.1)
で与えられる.ただしn!はn! = n(n−1)· · ·2·1で定義され,nの階乗という.
例 4.3. 上の例では,発表の異なる順番を区別した.順番は区別せず,どの2人が発表するか だけに注目すると2人の選び方は
ab, ac, ad, bc, bd, cd
の6通りある.これは(4×3)/2 = 6と計算できる.
一般に,異なるn個のものからr個を取り出したものをn個からr個取る組合せといい,そ の場合の数をnCrで表す.n個からr個取る順列の場合の数はnPrであった.順列の個数を数
えるのに,取り出された1組のr個について,r!通りの並べ方を数えているので,組合せの場
合の数はnPrをr!で割って求められる.したがってnCrは
nCr= n
Pr
r! =
n!
(n−r)! r! (4.2)
4.2
標本空間と事象
確率は不確実性を表す数学的道具であるから,まず確率を与える対象を明確に定める必要が ある.
さいころを投げたりするような、同じ条件のもとでくり返し行うことができる実験や観測を 試行という.
1個のさいころを投げる試行を考える.出る目に着目し,可能な結果全体をΩ(オメガ)で表 す.この場合
Ω ={1,2,3,4,5,6}
である.数字は出る目を意味するとする.
このように,ある試行を行うときの可能な結果全体を標本空間といい,Ωで表す.標本空間
の部分集合を事象(event)という.
たとえばA ={1,2}は「1か2の目が出る」という事象である.また,{1,2}, {2,4,6} はそ れぞれ「1の目が出る」,「偶数の目が出る」という事象を表す.Ωの一つ一つの要素からなる
集合
{1}, {2}, {3}, {4}, {5}, {6}
はそれぞれこれ以上細かく分けることができない.これらの事象を根元事象という。また、空 集合∅ で表される事象も考える。これは「何も起こらない」という事象で、空事象という
例 4.4. :2つのコインを投げる実験を考える. このとき
標本空間: Ω = {(H, H), (H, T), (T, H), (T, T)}
ここで, たとえば(H, T) は1つ目のコインが表(Head)で, 2つ目のコインが裏(Tail)である結 果を表す.基本事象:{(H, H)}, {(H, T)}, {(T, H)}, {(T, T)}
事象:{(H, H)}, {(H, H),(H, T)} など
問題 4.2.1. 例4.4で、事象 {(H, H)}, {(H, H),(H, T)} はそれぞれ言葉で表現するとどのよ
うな事象か?
事象は集合だから, 通常の集合の演算が使用される.
和事象A∪B:A または B が起こる事象
積事象A∩B:A かつB が起こる事象
余事象Ac:事象Aの補集合.事象A が起こらないという事象
4.3
確率
確率は事象の起こりやすさを0以上1以下の数値で表したものである. つまり、事象一つ一
つに0以上1以下の数値を付与している. では,どのように各事象の確率を決めればいいだろ うか。以下の2つがよく使われる方法である.
等可能性の原理による確率の定義
起りうる結果が有限個で, それぞれが起る可能性が同様に確からしいとき, 事象 A の確率 P(A) を
P(A) = #A #Ω
で定める。ただし, #A は集合 A に含まれる要素の数を意味する. 例:均等なコイン、均等な サイコロ.
頻度に基づく確率の定義
世の中には等可能性の原理を適用できない現象がたくさんある. たとえば画びょうを投げる
とき,結果は針が上にくる場合と下にくる場合の2種類がある.この場合,2つの結果の起こ る可能性が同じであるとは言えないであろう.この場合,画びょうを多数回投げてみて、その 相対頻度を確率の近似値とすることが考えられる1.このように,試行を多数回繰り返してあ
る事象が起こった相対頻度を確率の近似値とみなす考え方を確率の頻度説という.
以上のどちらの方法を使って確率の値を決めても、確率P(·)は次の3つの性質を持つことが わかる。
確率の公理
✓ ✏
(C1) 任意の事象 A に対して 0≤P(A)≤1
(C2) 標本空間Ω に対して P(Ω) = 1,空事象 ∅に対して P(∅) = 0 (C3) A と B が互いに排反ならば P(A∪B) =P(A) +P(B)
✒ ✑
この3つの条件 (C1),(C2),(C3) を確率の公理という. 現代の数学では、確率の公理を満たせ
ば, P(·) は確率であると定義する.
4.4
確率の性質
確率の公理から,確率がもつさまざまな性質, たとえばつぎのような性質を導くことができる.
1著者が
確率の性質
✓ ✏
(a)P(Ac) = 1−P(A)
(b) A⊂B ならばP(A)≤P(B)
(c) 任意の事象 A, B に対して P(A∪B) =P(A) +P(B)−P(A∩B)
(d)A1, A2,· · · , An が 互いに排反ならば,
P(A1∪A2∪ · · · ∪An) =P(A1) +P(A2) +· · ·+P(An).
✒ ✑
問題
問題 4.4.1. 2個のさいころを投げるとき、目の和が 4 になる確率を求めよ。
問題 4.4.2.
トランプのスペードのカード13枚から無作為にに5枚を取り出す.ただし,ここで「無作為 に」とはどの5枚が取り出される可能性も同じであることを意味するとする.
このとき
(1) 1, 2, 3, 4, 5 のカードが取り出される確率
(2) 取り出される5枚に13が含まれている確率
を求めよ. 解答
(1)
1
13C5
= 5!8! 13! =
5·4·3·2·1 13·12·11·10·9 =
1 13·11·9
(2)
12C4 13C5
= 12! 4!8! ·
5!8! 13! =
5 13
4.5
条件付き確率と乗法定理
4.5.1
条件付き確率
赤球2個と白球1個が入っている袋から、1個ずつ2回球を取り出す試行を考えるこの試行に
おいて、1回目に赤球がでるという事象を A, 2回目に赤球が出るという事象を B とする。た だし、取り出した球は、もとに戻さないものとする。
このとき、Aが起こるという条件のもとで、Bが起こる確率を考えてみよう.Aが起こった
時には,袋には赤球が1個,白球が1個あるので,Bが起こる確率は1/2 である.このような 値を,Aを条件とするときのBの条件付き確率という.
これは以下のようにも求められる.Aが起こるという条件なので,事象Aを標本空間のよう
に考えてよい.その中で事象Bが起こることを考えるので,積事象A∩Bを考え,P(A∩B)
のP(A)に対する比として計算する.上の例では,P(A) = 2/3, P(A∩B) = 1/3であるから
P(A∩B)
P(A) = 1/3 2/3 =
となり,最初に求めた値と一致する.以上から,条件付き確率を以下のように定義する.
✓ ✏
定義 4.1. A,Bは事象で,P(A)>0であるとする.
P(B|A)を
P(B|A) = P(A∩B)
P(A) (4.3)
で定義する.P(B|A)を事象Aを条件とするときの事象Bの条件付き確率とよぶa
.
a事象
Aが与えられたときの事象Bの条件付き確率、とよぶ場合もある.
✒ ✑
4.5.2
乗法公式
条件付き確率の定義を変形すると以下の定理が得られる.
✓ ✏
乗法公式
P(A∩B) = P(A)×P(B |A) (4.4)
となる.
✒ ✑
以下の事象についての関係もよく使われる.
A, Bを事象とする.このとき
A ={A∩B} ∪ {A∩Bc} (4.5)
が成り立つ.二つの事象{A∩B}と{A∩Bc}は互いに排反である.
この性質と乗法公式を用いて,以下の問題を解くことができる.
問題 4.5.1 (くじの確率). 2本の当たりくじがはいっている10本のくじを、太郎君と一郎君の
2 人が1本ずつ引く.一郎君がくじを引いた後に太郎君が引くとする.ただし,引いたくじは 元に戻さない.このとき、一郎君が当たりくじを引く確率と太郎君が当たりくじを引く確率を 求めよ.
解答 : 太郎君が当たりくじを引くという事象を A, 一郎君が当たりくじを引くという事象を
B とする。一郎君が当たりくじを引く確率は 102 である。
太郎君が当たりくじを引く確率を求める。一郎君、太郎君二人ともあたりくじを引く確率 は P(A ∩ B) = P(B)P(A|B) = 2
10 ×
1
9 である。一郎君がはずれ、太郎君が当たる確率は
P(A∩Bc) = P(Bc)P(A|Bc) = 8
10 ×
2
9 である。この2つの事象は互いに排反で、和事象は B
だから
P(A) = P(A∩B) +P(A∩Bc)
= 2 10 ×
1 9 +
8 10 ×
2 9
= 2 90 +
16 90 =
18 90 =
2 10
4.6
独立性
✓ ✏
定義 4.2. 事象の独立性
2つの事象 A, B について
P(A∩B) = P(A)P(B)
が成り立つとき, AとBは独立であるという.
✒ ✑
事象AとBが独立で,P(A)>0 であれば,
P(B|A) =P(B) (4.6)
が成り立つ. (4.6)式は, 事象A が起こったという条件を加えても、事象 B の確率が変わらな いことを意味している. つまり A と B が独立であるとは, A, B の一方が起こるかどうかが他 方の起こる確率に影響を与えないことを意味する.
3つの事象 A, B, C について P(A∩B) = P(A)P(B), P(A∩C) =P(A)P(C), P(B ∩C) =
P(B)P(C),P(A∩B∩C) =P(A)P(B)P(C)のすべてが成り立つとき, A, B, C は独立である という. 4つ以上の事象の独立性も同様に定義する.
問題 4.6.1.
1つのさいころを投げるとする.事象A, B, Cを以下のように定義する.
A=出る目が2の倍数, B =出る目が2の倍数, C=出る目が4の倍数. (1) AとBは独立か?
(2) AとCは独立か?
モンティ・ホール問題
アメリカのTV番組 Let’s make a dealで行われていたゲーム.
三つのドアのうちどれかの向こう側に新車がある.あなたは、どのドアの向こうに新車があ るかを知らない.あなたはまずドアの一つ(たとえばドア1)を選ぶ.すると司会者は別のド アを(たとえばドア3)を開けてみせるが、車はない。ここであなたにチャンスが与えられる. 最初に選んだドアのままでもいいし、まだ開いていないドア(ドア2)に変えてもいい。もし
最終的に選んだドアの向こうに車があれば、それはあなたのものになる.マリリン・サブアン トはドアを変えたほうが勝てる確率が高いと主張した.あなたはどう思いますか?
参考にした本
モンティ・ホール問題の解答。ドアを変えない戦略を使うとき、新車のあるドアを選ぶ確率 は1/3である。次に、司会者が開かなかったドアに変更する戦略を使うことを考えよう。最初 の選択で新車が置いてあるドアを選ぶ事象をAとする。変更後のドアの向うに新車がある事象
をB とする。B = (A∩B)∪(Ac ∩B)だから
P(B) =P(A∩B) +P(Ac∩B)
= 1 3×0 +
2 3×1 =
2 3.
したがって、開かなかったドアに変更する戦略の方が新車を得る確率が大きい。
問題 4.6.2.
総当たり戦で優勝する確率: あるスポーツをする3つのチームa, b, cが総当たり戦を行う。つ まり、a対b, a対c, b対cという3つの試合を行うとする。問題を簡単化するために、引き分
けはないものとする。a対b, a対c, b対cの試合結果(勝敗)は独立であり、それぞれの試合 における勝敗の確率は以下であると仮定する。
P(a対bでaが勝つ) =0.6
P(a対cでaが勝つ) =0.6
P(b対cでbが勝つ) =0.75.
3つの試合の結果、勝ち試合数が最大のチームが優勝となる。ただし、勝ち試合数が同数の場合 は、優勝チームなしという決まりであるとする。このとき、aチームが優勝する確率を求めよ。 解答:aチームが優勝するのは、aチームが2勝する場合のみである。つまり、a対b, a対c, b
対cの各試合で、(aが勝つ、aが勝つ、bが勝つ) (aが勝つ、aが勝つ、cが勝つ)の2通りで ある。それぞれが起こる確率は0.6×0.6×0.75 = 0.27, 0.6×0.6×0.25 = 0.09であるから、
P(チームaが優勝する) = 0.27 + 0.09 = 0.36
学期末試験について
試験時間:90分。電卓と筆記用具のみ持ち込み可能。関数電卓やプログラム機能を持つ電卓は
持ち込み不可。
第
5
章 確率変数
確率変数とは,とる値と各区間に入る確率が定まっている変数のことを言う。確率変数の応 用範囲は広く,自然科学,社会科学のほとんどの分野で利用されている。確率変数には,とびと びの値をとる離散型確率変数と連続的な値をとる連続型確率変数がある。
5.1
離散型の確率変数と確率分布
一つのさいころを投げる試行を考え,出る目をXで表せばX は 1から 6の値をとり,それ ぞれの値が出る確率は1/6である。 これを表にすれば以下のようになる。
X 1 2 3 4 5 6
確率 1 6
1 6
1 6
1 6
1 6
1 6
一般に,変数 X のとり得る値が
x1, x2, . . . , xk
であり,Xがこれらの値をとる確率が, それぞれ
p1, p2, . . . , pk
と定まっているとき,X を離散型確率変数(random variable)という。すなわちpi =P(X =xi),
(i= 1,2, . . . , k) である。x1, x2, . . . , xk と p1, p2, . . . , pk の対応関係を, 確率変数 X の確率分布
という。当然p1+p2+· · ·+pk= 1 が成り立っている。
2つのさいころを投げたときの目の和を Z で表そう。Z も離散型の確率変数である。Z の確
率分布は以下のようになる。
Z 2 3 4 5 6 7 8 9 10 11 12
確率 1 36
2 36
3 36
4 36
5 36
6 36
5 36
4 36
3 36
2 36
1 36
説明:Z = 2 となるのは(1,1) の場合のみ(つまり最初の目が1で二番目の目が1)であり,
すべての可能な結果は36通りであるから確率は 1
36 である。Z = 3 となるのは(1,2), (2,1)の
二通りであるから確率は 2
36 である。他の確率も同様に求められる。
1 2 3 4 5 6 1/6
図5.1 さいころの目の確率分布
2 3 4 5 6 7 8 9 10 11 12 1/36
離散型確率変数とその確率分布の例を考えてみよう。一方の面に0,他方の面に1と書いてあ るカードが4枚あるとする。カードを投げてどちらの面が表になる確率も1/2である。表にな る面の数字に着目すれば,この試行の結果は(0,0,0,0),(0,0,0,1), . . . ,などで表され全部で16通
りある。これら16通りの結果の確率はすべて同じ, すなわち1/16と考えよう。4枚のカードを 投げたときに表の面の数字の和をXで表せば, Xは確率変数で, Xの確率分布は以下のように なる。
X 0 1 2 3 4
確率 1/16 4/16 6/16 4/16 1/16
Xの確率分布を以下ように線分を用いて表すと理解しやすい。
0 1 2 3 4
1 16
2 16
4 16
6 16
図 5.1: Xの確率分布
期待値
,
分散
,
標準偏差
X は離散型確率変数とし, とりうる値が x1, x2, . . . , xk であるとする。また pi =P(X = xi)
とする。このとき
E[X] =
k
∑
i=1
xipi (5.1)
を X の期待値(expected value)またはXの確率分布の平均という。期待値はX の確率分布の 中心を表す値であり, 確率分布のグラフの重心になっている.
例 5.1. 上で定義した4枚のカードの数字の和Xの期待値を計算すると
E[X] = 0× 1
16 + 1× 4
16+ 2× 6
16 + 3× 4
16+ 4× 1
16 = (0 + 4 + 12 + 12 + 4)/16 = 2
となる。
X が離散型の確率変数であれば,関数gで変換したg(X)も離散型の確率変数である。E[g(X)]
を求めるには以下の公式が便利である(証明は省略)。
E[g(X)] =
k
∑
i=1
期待値の性質
✓ ✏
X は確率変数,a, bは定数であるとする。
(a) E[aX+b] =aE[X] +b
(b) 二つの確率変数X, Y に対して E[X+Y] = E[X] + E[Y]
✒ ✑
証明(a)の証明は容易。(b)の証明は本章後半に行なう。
確率変数がどのくらいばらつくのかを測る特性値として,確率変数の分散がよく使われる.確 率変数X の分散(variance)は
V[X] = E[(X−E[X])2]
で定義される。g(x) = (x−E[X])2 とおいて公式(5.2)を用いれば,
V[X] =
k
∑
i=1
(xi−E[X])2pi = (x1−E[X])2p1+· · ·+ (xk−E[X])2pk
さらに,期待値の性質(d)を使えば,次式が成り立つこともわかる。
定理 5.1. 確率変数Xの分散について以下が成り立つ.
V[X] = E[X2]− {E[X]}2 (5.3)
証明:
V[X] =E[(X−E[X])2]
=E[X2−2E[X]X+ E[X]2] =E[X2]−2E[X]E[X] + E[X]2 =E[X2]−E[X]2 ✷
分散のプラスの平方根を標準偏差という
分散の性質
✓ ✏
a と b は定数であるとする。
(a) V[a] = 0
(b) V[aX+b] = a2V[X]
✒ ✑
証明:(a) E[a] =a だから
V[a] = E[(a−E[a])2] = 0定数の分散は0
(b) E[aX+b] = aE[X] +b だから
例題 5.1. 一つのさいころを投げて出る目を X とする。 このとき以下の問に答えなさい。
(1) E[X] を求めよ。 (2) E[X2] を求めよ。
正解:(1) 期待値の定義を用いて以下のように計算できる。
E[X] = 1× 1 6 + 2×
1 6+ 3×
1 6 + 4×
1 6 + 5×
1 6+ 6×
1 6 = 3.5
(2) 公式(5.2)を使って以下のように計算できる。
E[X2] =12× 1
6+ 2
2×1
6 + 3
2 ×1
6 + 4
2× 1
6 + 5
2× 1
6+ 6
2× 1
6 =1
6(1 + 4 + 9 + 16 + 25 + 36) = 15.17 小数点第2位で四捨五入した
代表的な離散型確率分布
離散型一様分布
(5.4)で与えられる確率分布を離散型一様分布という. つまり有限個の値を等しい確率でとる 分布が離散型一様分布である.
✓ ✏
離散型一様分布
P(X =i) = 1
k (i= 1,2, . . . , k) (5.4)
平均 k+1
2 , 分散
(k−1)(k+1) 12
✒ ✑
二項分布
試行をn回繰り返すことを考える. 各試行の結果は2つだけである(便宜上「成功」, 「失
敗」と呼ぶ)とする. さらに, n回の試行は独立であるとする. このような試行の繰り返しをn
回のベルヌーイ試行という.
今, n回のベルヌーイ試行を行い, 成功が起こる回数をXで表せばXは1,2, . . . , nの値をと
る離散型確率変数である.Xの確率分布は以下の式で与えられる.
P(X =k) = nCkpk(1−p)n−k (k= 0,1, . . . , n)
この分布は二項分布と呼ばれ,B(n, p)と表す.Xの確率分布が二項分布B(n, p)であるときに,
XはB(n, p)にしたがうといい,X ∼B(n, p)と書く.
✓ ✏
二項分布 B(n, p)
P(X =k) = nCkpk(1−p)n−k (k = 0,1, . . . , n)
平均: np, 分散: np(1−p)
✒ ✑
以下に, n = 5で, 異なるpの二項分布を図示した. 二項分布のnとpのように確率分布を定め
0.1 0.2 0.3 0.4
0 1 2 3 4 5
B(5,0.2)
0.1 0.2 0.3 0.4
0 1 2 3 4 5
B(5,0.5)
0.1 0.2 0.3 0.4
0 1 2 3 4 5
B(5,0.8)
問題
問題 5.1.1. 確率0.005で当たり(100万円がもらえる), 確率0.995ではずれの宝くじがあると
する. この宝くじを買うとき, 受け取る金額の期待値を求めよ.
問題 5.1.2. サッカーのリーグ戦では試合の結果に応じて勝ち点が得られる. 勝ち点は, 負けの
とき0点, 引き分けのとき1点, 勝ちのとき3点である. AチームがBチームと試合をするとき, Aチームが負ける, 引き分ける, 勝つ確率はそれぞれ0.2, 0.3, 0.5である. Aチームがこの試合 で得る勝ち点Xの期待値を求めよ.
問題 5.1.3. あるバスケットボールの選手がフリースローを行うときの成功確率は0.8であると
する. この選手が10回フリースローを行うときの成功回数をXとする. Xの確率分布は何か. また, Xの期待値を求めよ.
5.2
連続型確率変数
連続した値をとる確率変数を連続型確率変数という(例:身長,体重,気温, 為替レート, GNP,
など). 連続型確率変数はとる値が連続的であるから,各値毎に確率を定めることができない.
図 5.2は2002年度のJリーグ所属選手の身長の相対ヒストグラムである.
図 5.2: Jリーグの選手(846人)身長の相対ヒストグラム
このヒストグラムの柱の上の部分を見ると, なめらかな曲線で近似できるように見える. 試行 の数がどんどん大きくなるとき, 相対度数はおおよそ身長がその区間はいる確率に近いと考え
連続型確率変数 X に対しては, ある関数 f(x) ≥ 0 を定め, 任意の区間 [a, b] に対して a ≤ X ≤bとなる確率を f(x)のグラフ,直線x=a,x=b とx軸で囲まれる部分の面積で表す. こ のようなf(x)を X の確率密度関数(probability density function, 略してpdf)という. つまり
確率変数 X の確率密度関数とは,すべてのx についてf(x)≥ 0であり,またすべての a < b
に対して
P(a≤X ≤b) =
∫ b
a
f(x)dx (5.5)
が成り立つような関数fのことである.
0 2 4 6 8 10 12 14 16 18 0
0.02 0.04 0.06 0.08 0.1 0.12 0.14 0.16 0.18
a b
f(x)
∫
a b
f(x) dx
P(a≤ X≤ b)
=
図 5.3: 確率密度関数と確率の関係
✓ ✏
確率密度関数の定義
Xは確率変数であるとする. 関数f(x)が以下の性質を持つとき, 関数f(x)をXの確率密 度関数という.
(1) f(x)≥0
(2) x軸と曲線y =f(x)の間の面積は1
(3) 確率P(a≤X ≤b)が上図の斜線部分の面積に等しい.
✒ ✑
連続型確率変数の期待値
連続型確率変数の期待値は以下のように定義される.
期待値の定義: 連続型確率変数の場合
✓ ✏
Xは連続型確率変数であり,その確率密度関数はf(x)であるとする.Xの期待値E[X]は
E[X] =
∫ ∞
−∞
xf(x)dx (5.6)
で定義される. 期待値は確率分布の平均ともいう.
✒ ✑
期待値は確率密度関数の重心になっている. Xが連続型確率変数のとき,Xの関数g(X)の期待 値については
E[g(X)] =
∫ ∞
−∞
g(x)f(x)dx (5.7)
が成り立つ.
連続型確率変数Xの分散は
V[X] =E[(X−E[X])2] =
∫ ∞
−∞
で定義される.確率変数の分散は,確率変数のばらつきの大きさの尺度である.
連続型確率変数の場合も以下の公式が成り立つ.
✓ ✏
V[X] = E[X2]− {E[X]}2
✒ ✑
代表的な連続型確率分布
一様分布
a, bは実数で a < bであるとする連続型確率変数Xの確率密度関数が(5.9)で与えられると
き, Xの確率分布を[a, b]上の一様分布と呼ばれる.
✓ ✏
一様分布
f(x) =
{ 1
b−a a ≤x≤bのとき
0 それ以外 (5.9)
平均: a+b
2 , 分散:
(b−a)2
12
✒ ✑
a b
1
b−a
図 5.4: 一様分布の確率密度関数
例 5.2. 円の中心に針が止めてあり, 自由に回転できるようになっている(時計の針が自由に動 くと考えて下さい). この道具を水平に置き, 針をでたらめに回転させ, 針が止まったときの針 の角度(ラジアン)をXで表す. Xのとる値は0以上2π未満であり, 確率分布は[0, 2π]上の一
正規分布
統計学の中でもっとも重要な連続型の確率分布は正規分布である.
✓ ✏
正規分布の定義 確率密度関数f(x)が
f
(
x
) =
√
1
2
πσ
e
−1 2
(
x−µ σ
)
2
(5.10)
で与えられるような確率分布を, 正規分布(normal distribution)といい, N(µ, σ2)で表す.
✒ ✑
図5.2は正規分布N(µ, σ2)の確率密度関数のグラフである。
N
(
µ, σ
2)
µ µ + σ µ +2 σ µ +3 σ
µ − σ µ −2 σ
µ −3 σ 1 2π σ
図 5.5: 正規分布 N(µ, σ2) の確率密度関数
X の確率密度関数が(5.10)式であるとき,
E[X] = µ (5.11) V[X] = σ2 (5.12)
であることを示すことができる1から,正規分布 N(µ, σ2)は, 平均 µ,分散 σ2 の正規分布とよ
ばれる. X の確率密度関数が(5.10)式であるとき,「X は平均 µ,分散 σ2 の正規分布に従う」
といい, X ∼N(µ, σ2) と表す. 特に, 平均 0, 分散 1 の正規分布N(0,1)は標準正規分布とよば
れる.標準正規分布の確率密度関数は
f(x) = √1
2πe
−12x 2
(5.13)
である2.
1この計算はこの章の付録を見よ
2関数
正規分布N(µ, σ2) の確率密度関数 f(x) の性質
✓ ✏
(i)f(x) のグラフは µ を中心とするベル型. 左右対称.
(ii) 2つの点 (µ−σ, f(µ−σ)) と (µ+σ, f(µ+σ))が変曲点になっている. (iii) 区間[µ−3σ, µ+ 3σ] にほとんどの確率がある. くわしくは, 次が成り立つ.
P(µ−σ ≦X≦µ+σ) = 0.683
P(µ−2σ≦X ≦µ+ 2σ) = 0.955
P(µ−3σ≦X ≦µ+ 3σ) = 0.997
(iv)f(x)は x=µで最大値 √1
2πσ をとる.
✒ ✑
図5.2には、異なる平均と分散を持つ正規分布の確率密度関数のグラフを図示した。
-7 -6 -5 -4 -3 -2 -1 0 1 2 3 4 5 6 7 8
0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 0.4 0.45 0.5
N(0, 1) N(4, 1)
N(0, 4)
図 5.6: 異なる平均と分散を持つ正規分布の確率密度関数
正規分布は,統計学でもっともひんぱんに使われる確率分布である. それは次の理由からであ る.
(1) 近似的に正規分布に従うと考えられる確率変数が多くあること.
例:身長, 胸囲など. 測定誤差. 観測誤差. 大規模試験の点の分布.株価の収益率(分布の中心 部分で正規分布に近いが,分布の端でずれがある. )
(2) データを生成している確率分布が正規分布のときには, 統計分析の理論的な結果が簡潔な形 で得られる.
正規分布にしたがう確率変数を一次式で変換したものも正規分布にしたがう. つまり,次が成 り立つ.
✓ ✏
定理 5.2 (正規分布の性質1). a, b は定数であるとする.
X ∼N(µ, σ2)
であるとき
aX+b∼N(aµ+b, a2σ2)
が成り立つ. 特に,
X−µ
σ ∼N(0,1)
である.
✒ ✑
正規分布についての確率計算
確率変数 X がある値uより大きくなる確率
P(X > u) (5.14)
を求めることがよくある。(5.14)のような値を上側確率という.特に標準正規分布の上側確率
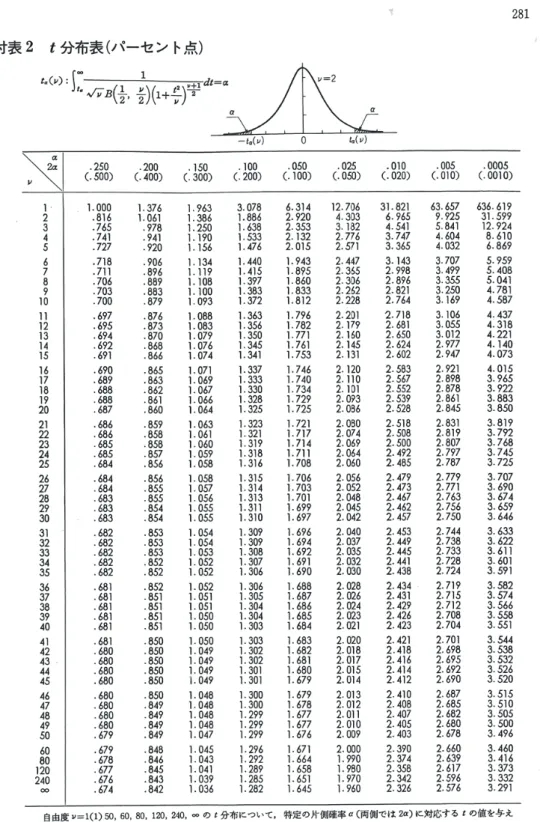
は重要なので,付表1にまとめられている.付表1には,左の縦一列(u と書いてある場所の 下)に,uの小数点第一位の値までが与えられ,上の横一行に uの小数点第二位の値が与えら れているので,たとえば u= 0.55のときには, .5 に対応する行と .05に対応する列が交差する
場所の数値 0.291 が上側確率になる. つまり,Z が標準正規分布N(0,1)にしたがうとき
P(Z >0.55) = 0.291 (5.15)
であることがわかる.
付表1を使って,標準正規分布のいろいろな確率を求めてみよう.
例題 5.2. Z ∼N(0,1) とする. このとき以下の確率を求めなさい. (1) P(Z >1)
(2) P(Z >1.96) (3) P(Z ≦1)
解答:
(1) 付表1から u= 1.00 の場所を見つけ, P(Z >1) = 0.159 (小数点第四位で四捨五入). (2) P(Z >1.96) = 0.025(小数点第四位で四捨五入).
正規分布N(µ, σ2)のしたがう確率変数Xについての確率を求めるときには、標準化を使っ
て求める. (定理5.2)
例題 5.3. X ∼N(50,100) とする. このとき以下の確率を求めなさい.
(1) P(X >60) (2) P(X ≦60)
解答:
(1)
P(X >60) =P
(
X−50 10 >
60−50 10
)
=P
(
X−50 10 >1
)
= 0.159