グループテストにもとづく 事後確率の近似計算アルゴリズム
2008 年度
上原 啓明
目次
概要
iii
第
1
章 グループテスト1
1.1
グループテストの歴史. . . . 1
1.1.1
グループテストとDNA
ライブラリスクリーニング2 1.1.2 DNA
ライブラリスクリーニングのためのプーリン グデザインと2
段階グループテスト. . . . 5
1.1.3
グループテストの結果にもとづく決定論的なスク リーニング. . . . 7
1.2
グループテストの結果にもとづく確率論的なスクリーニング9 1.2.1
プーリング実験の確率モデル. . . . 10
1.2.2
陽性反応の事後確率. . . . 12
1.2.3
スクリーニング. . . . 14
第
2
章BNPD
アルゴリズムとCCPD
アルゴリズム15 2.1
事後確率計算アルゴリズムMCPD . . . . 15
2.2
ベイジアンネットワークと確率伝播法. . . . 19
2.2.1
ベイジアンネットワーク. . . . 19
2.2.2
確率伝播法. . . . 20
2.2.3 LDPC
符号と確率伝播法. . . . 22
2.3 BNPD
アルゴリズム. . . . 25
2.3.1
例題. . . . 26
2.3.2 BNPD
アルゴリズム. . . . 29
2.3.3 BNPD
アルゴリズムの動作. . . . 31
2.3.4 BNPD
アルゴリズムの計算例. . . . 32
2.3.5
計算量. . . . 35
2.3.6 BNPD
と通常の確率伝播法との比較. . . . 37
2.3.7 BNPD
とLDPC
符号のアルゴリズムの比較. . . . 38
2.4 CCPD
アルゴリズム. . . . 38
2.4.1 CCCP
アルゴリズム. . . . 39
2.4.2
プーリング実験のBethe
自由エネルギー. . . . 42
2.4.3 CCPD
アルゴリズムの導出. . . . 46
2.5 BNPD
とCCPD
によって求めた周辺事後確率の偏りの指標52 2.5.1
情報幾何による周辺事後確率の偏りの指標. . . . . 52
2.5.2 BNPD
とCCPD
の偏りの指標. . . . 53
第
3
章 シミュレーション62 3.1
シミュレーションの方法. . . . 62
3.2
収束性の比較. . . . 65
3.3
評価関数R(κ, A)
によるスクリーニング能力の比較. . . . 68
3.3.1
クローン数がn = 1298
の場合. . . . 70
3.3.2
クローン数がn = 10121
の場合. . . . 73
3.4
評価関数N (ρ, A)
によるスクリーニング能力の比較. . . . 75
3.4.1
クローン数がn = 1298
個の場合. . . . 76
3.4.2
クローン数がn = 6371, 10121
の場合. . . . 77
3.4.3
タナーグラフに長さ4
の閉路がある場合. . . . 83
3.5
計算時間の比較. . . . 84
3.6
プーリングデザインとスクリーニング能力. . . . 89
3.6.1
繰り返し数によるスクリーニング能力の差. . . . . 89
3.6.2
プーリングデザインの比較. . . . 89
3.7 CCPD
によって求めた周辺事後確率の偏りの指標. . . . . 92
第
4
章 結論98
付録
A
定理1
の証明102
参考文献
105
謝辞
113
概要
1940
年代にDorfman
は,多数の検体から少数の陽性反応を示す検体を効率よく選び出すには,グループテストを用いることが有効であるこ とを示した.グループテストでは,すべての検体を個々に検査するのでは なく,複数の検体をまとめていくつかのグループを作り,各グループに対 して検査を行う.検査結果に誤りがないと仮定すると,あるグループに対 する検査で陽性反応が検出されない場合は,
1
回のテストでそのグループ に含まれる検体がすべて陰性であると判断できる.一方,陽性反応が検出 された場合にはそのグループに含まれる検体のうち少なくとも1
個の検 体が陽性(
ポジティブ)
であることがわかる.また,背景の同じ検体が複 数のグループに属するようにグループを作り,各グループに対する検査結 果から陽性である可能性が高い,つまり,事後確率の高い検体に対して2
次検査で個々に陽性反応を示すかどうかを検査し,ポジティブである検体 を識別する.すなわち,グループテストは実行するテストの回数を少なく することにより実験にかかるコストを減らし,かつポジティブである検体 をできるだけ多く確実に発見することを目的として行われる.特に陽性の 検体の割合が非常に少ない場合に大幅にテストの回数を減らすことがで きる.しかし実際には,テストの結果に誤りが生じることも少なくない.また,各検体が陽性である事後確率を正確に求めるには検体の数に対して 計算量が指数関数的に増加する.したがって,グループテストの結果に偽 ポジティブ・偽ネガティブの誤りが生じる場合に検査結果からポジティブ である可能性の高い検体を効率良く識別するアルゴリズムの研究が重要で ある.さらに,複数のグループが成す集合族の組合せ構造によって,ポジ ティブの識別能力および選別
(
スクリーニング)
能力が異なり,そのため の最適な組合せ構造の研究も必要である.グループテストは情報科学や生命科学などの分野などにも広く応用され
ており,
DNA
の塩基配列(A
,T
,G
,C
の配列)
を特定するDNA
ライ ブラリスクリーニングにも応用されている(Sham
ら(2002))
.DNA
ラ イブラリスクリーニングの分野では,各検体をクローンと呼び,グルー プをプールと呼ぶ.また,さまざまなプールの集まりをプーリングデザ インと呼んでいる.Knill
ら(1996)
はDNA
ライブラリスクリーニング で必要となる,陽性である事後確率を効率的に求める1
つの方法としてMarkov chain pool result decoder (MCPD)
と称すアルゴリズムを提案し ている.さらに,グループテストはDNA
マッピングにも用いられている(Du
ら(2000))
.近年では,DNA
チップやマイクロアレイによる試験に も応用されている(Schliep
ら(2003)
,Manoli
ら(2006))
.本論文では,グループテストの結果にもとづいて高速かつ高精度に各検 体がポジティブである事後確率を計算する
2
つのアルゴリズムを提案し,その能力を
MCPD
と比較する.第
1
章では,グループテストに関連する研究の歴史や動向について概 説し,特にDNA
ライブラリスクリーニングに関して概説し,グループテ ストとその背景にある確率モデルについて述べる.第
2
章では,まずPearl (1988)
により提案されたベイジアンネットワー クの確率伝播アルゴリズムにもとづき考案したBayesian network pool re-
sult decoder (BNPD)
アルゴリズムを提案する(Uehara and Jimbo (2007))
. 確率伝播法は確率変数間の依存関係を表すグラフ上でいくつかの頂点での 実現値が与えられたもとでの事後確率を効率良く計算するアルゴリズムで ある.グループテストのグループと検体の結合関係はタナーグラフと呼ば れる2
部グラフで表される.タナーグラフに閉路がない,つまり木である 場合には,BNPD
は正確な事後確率を計算することができるが,タナーグ ラフに閉路が存在しても短い閉路が多数存在しない場合にはアルゴリズム は収束し事後確率の近似値を得ることができる.しかし,閉路が存在する 場合にはBNPD
により求めた周辺事後確率と真の値との間には偏りが存 在する.さらに,短い閉路が多数存在する場合にはアルゴリズムが収束しな い恐れがある.この収束性に関する欠点を補うためにconcave-convex pro-
cedure (CCCP)
にもとづき考案したCCCP pool result decoder (CCPD)
アルゴリズムを提案する(Uehara and Jimbo (2008))
.CCCP
では,統計力学における
Bethe
自由エネルギーをある制約条件のもとでラグラン ジュの未定乗数法を用いて最小化する問題として定式化することにより,事後確率の推定値を求めている.タナーグラフに短い閉路が多数存在す る場合でも
CCPD
は収束が保証されているアルゴリズムである.しか し,CCPD
はBNPD
に比べて計算時間が長くなる.また,BNPD
と同 様にCCPD
により求めた周辺事後確率には偏りが存在する.BNPD
お よびCCPD
の欠点である求めた周辺事後確率の偏りについては,その偏 りに関する1
つの指標を導き,その結果を用いてタナーグラフに長さ4
の閉路が存在しない場合にはその2
次項が0
になり,偏りが小さくなる ことを理論的に示す.そして,第
3
章ではBNPD
およびCCPD
とMCPD
とをさまざま な検体の数に対するタナーグラフのもとでシミュレーションにより比較 し,BNPD
,CCPD
の高速性とスクリーニング効率を実証する.タナー グラフに長さ4
の閉路が存在しない,つまり,どの2
つの検体も同時に 高々1
個のグループにしか含まれないという条件を満たすとき,unique collinearity condition
を満たすという.unique collinearity condition
を 満たす場合に,BNPD
のスクリーニング効率の良さに言及する.また,unique collinearity condition
を満たさない場合には,BNPD
が収束し ないことが多いためにその代替アルゴリズムとしてのCCPD
とMCPD
のスクリーニング効率を比較する.次に,検体数とグループ数,および タナーグラフの辺の数を固定したとき,タナーグラフが正則かつunique collinearity condition
を満たす場合,ランダムにタナーグラフを生成する 場合よりスクリーニング能力が高くなることを実証する.さらに,unique collinearity condition
を満たさない場合にCCPD
により求めた周辺事後 確率の偏り補正の効果を検証する.最後の第
4
章は,結論として,タナーグラフがunique collinearity con-
dition
を満たすか否かによって,BNPD
,CCPD
,MCPD
を使い分ける ことが有用であることを述べる.第 1 章
グループテスト
本章では,まずグループテストの歴史や研究の動向およびその確率モデ ルなどについて述べる.グループテストは多数の検体から少数の目的物を 効率良く識別するためにさまざまな分野で用いられているが,本論文で はグループテストの応用例として,
DNA
ライブラリスクリーニングを挙 げ,その選別(
スクリーニング)
効率を高めるためのグループテストを中 心に述べる.グループテストのためのアルゴリズムには組合せ論的なアル ゴリズムと確率論的なアルゴリズムがある.ここでは主に本論文で扱う確 率論的な事後確率計算アルゴリズムのための確率モデルについて述べる.1.1 グループテストの歴史
グループテストは
1940
年代にRobert Dorfman [15]
により血液検査 にかかるコストを低く抑える目的で考案された方法である.グループテ ストを用いることにより実験や検査に要する費用や時間,作業量を削減 することができる.特に陽性の検体の割合が非常に少ない場合に大幅に コストを減らすことができる.例えば,グループテストは罹患率の推定(Thompson [62]
,Sobel
ら[57]
,Tu
ら[63]
,Brookmeyer [9])
や患者対照 研究における病原体や毒素の汚染の評価(Weinberg
ら[67])
のために用い られてきた.また,HIV
の検査の際に匿名性を守るためにも用いられて きた(Gastwirth
ら[25]
,Gastwirth
ら[26])
.遺伝学の分野では,グルー プテストはI
型(
インスリン依存型)
糖尿病の研究で初めて用いられた(Arnheim
ら[2])
.その後,植物の連鎖研究(Michelmore
ら[45])
や近交集団の劣性疾患の同型接合性マッピング
(Sheffield
ら[55]
,Carmi
ら[12]
,Nystuen
ら[49]
,Scott
ら[53])
や変異検出(Amos
ら[1])
に用いられて いる.近年ではヒトゲノム計画の成功に見られるように,グループテスト はDNA
ライブラリスクリーニングのような分野での新しい応用が見出 されている.1.1.1 グループテストと DNA ライブラリスクリーニング
本論文では,グループテストの例として
DNA
ライブラリスクリーニ ングを取り上げる.まず,DNA
ライブラリスクリーニングの実験の概要 とそこにグループテストがどのように用いられるのかを説明する.DNA
はA (Adenine)
,T (Thymine)
,G (Guanine)
,C (Cytosine)
の4
種類 の塩基から構成されている.DNA
の塩基列の断片の複製をクローンと呼 ぶ.DNA
ライブラリとはある特定の生物のDNA
を短い塩基列の断片に 切り,各塩基列ごとにクローンのプールを作って得られる単一種のクロー ンのプールの集合である.例えば,
Knill
ら[35]
がグループテストによるスクリーニングを行ったCla I
ライブラリと呼ばれるDNA
ライブラリはヒトの第16
染色体から生成され,
1298
種のクローンからなる(McCormick
ら[43])
.DNA
の 列の長さは98 Mbp (Mega base pair)
で複数のDNA
の列をショットガ ンなどの方法で短いランダムな長さの塩基列に細分し,それらの塩基列 をバクテリアに組み込んで増殖させ,単一種のクローンのコロニーを作 る.それぞれの種のクローンをmicrotiter plate
の1
つのwell
に保存す る.このような過程を経て,Cla I
ライブラリの1298
種のクローンが得 られているが各クローンの平均長は195 kbp (kilo base pair)
程度である(Morton [46])
.複数のDNA
の列を細分してクローンが作られているた めDNA
の同じ部位が複数種のクローンに重複して存在する.その平均重 複度はこの場合には195 kbp × 1298 / 98 Mbp = 2.6
程度である.これら のクローンに含まれる遺伝子などの塩基列を特定するためにPCR
法など を用いて目的のクローンのみを増幅させ反応試験を行う.この際にプロー ブと呼ばれる目的の塩基列に蛍光物質を添付しておき,プローブと相補関係にあるクローンと次々にハイブリダイズと分離を繰り返すことにより,
目的のクローンのみがコピーされる.これにより目的のクローンがプール に含まれている場合にはプールが強い蛍光を発する.この蛍光の強さを測 定することにより,目的のクローンの有無を識別することができる.
遺伝子機能の研究が非常に重要な研究分野に発展したことにより,高品 質な遺伝子のライブラリが必要とされている.
DNA
ライブラリのクロー ンに含まれる遺伝子などを識別し,そのタグを付けてタグ付きのDNA
ラ イブラリが得られる.これらのライブラリは実験を行う研究施設などに保 存されマイクロアレイの解析のような多くの遺伝子情報解析のために繰り 返し利用される.したがって,誤りのないタグが付いた品質の良いライブ ラリ生成への要求は強く,そのための高い識別能力を持つ効率の良いスク リーニング手法の開発は非常に重要である.スクリーニング実験ではクローンがある特定の
DNA
の塩基列を含ん でいるか否かを判定する.クローンがある特定のDNA
の配列を含んでい るときそのクローンはポジティブであるといい,そうでないときネガティ ブであるという.また,ポジティブクローンを単にポジティブと呼ぶこと もある.DNA
ライブラリスクリーニングの目的は大量のクローンの中か らポジティブクローンを識別すること,つまり,クローンのライブラリが ある特定の塩基列を含むか否かを識別することである.その際に時間とコ ストを削減することが必要であり,そのためにグループテストを用いるこ とが有効である.複数種のクローンからなるグループをプールと呼び,こ のプールに対して試験を行う.さまざまなクローンの組合せからなるプー ルの集まりをプーリングデザインと呼ぶ.もし各プールに対する試験結果 に誤りがないとすると,あるプールに対する試験結果がネガティブならば,そのプールに含まれるすべてのクローンがネガティブであることが一回の 検査で判定でき,個々のクローンに対して試験するより実験回数を減らす ことができる.一方,もしプールの検査結果がポジティブならそのプール に少なくとも一つのポジティブクローンが含まれていることがわかる.同 じ断片から複製されたクローンが複数のプールに属するようにプールを作 り,各プールに対して検査を行う方法をグループテストと呼ぶ.グループ テストの結果からポジティブクローンを特定するスクリーニングを行う.
上記のようなグループテストはポジティブクローンの割合が非常に小さ い場合にはプールに対する試験結果がネガティブとなる確率が高く,実験 回数を減らすことが可能となる.グループテストの効率の良さは
Barillot
ら[5]
,Berger
ら[6], Bruno
ら[10]
,Du
ら[16, 17, 18]
,およびSham
ら[54]
で述べられている.グループテストの分類の仕方のひとつに
adaptive
とnon-adaptive
と いう分類がある.adaptive
なグループテストでは,それまでのグループ テストの観測値の情報を得てから次のプールを作成することができる.つ まり,試験の結果の観測値によってプールを順次作成することができる.したがって,試験とプールの作成という手順を繰り返すことによってポジ ティブクローンを識別する.一方,
non-adaptive
なグループテストでは,実験を行う前にすべてのプールを決定しておく.つまり,試験の結果の観 測値によってプールを順次作成することができない.このグループテスト の方法ではすべての試験を同時に行い,プールに対する観測値を解析しポ ジティブクローンを識別する.この
2
つの方法のうちどちらを用いるかは 状況による.adaptive
なグループテストはnon-adaptive
なグループテス トに比べてプールを作成するための情報が多いので,一般にテストの回数 を少なくすることができる.一方,実験と解析が異なる人や組織によって 行われるときはadaptive
な方法を用いることが難しく,同時にすべての テストを行うnon-adaptive
な方法を用いる.本論文では,non-adaptive
な場合を考える.通常,観測値には偽ポジティブや偽ネガティブのような誤りが起こるこ とは避けられない.偽ポジティブとはネガティブなクローンあるいはプー ルがポジティブと判断される誤りであり,偽ネガティブとはポジティブな クローンあるいはプールがネガティブと判断される誤りである.このよう な試験結果の観測値の誤りが無視できない状況のもとで多量のクローン の中からポジティブクローンを識別するための効率の良いスクリーニング アルゴリズムの開発とプーリングデザインの計画が重要である.本論文で は,プーリング実験において高い精度でポジティブクローンを識別するた めに次の
2
つの問題に焦点をあわせる.(i)
効率的なポジティブ識別アルゴリズムクローン
プール
c
1c
2c
3c
4c
5c
6· · ·
c
nG
1G
2· · ·
G
m図
1.1:
プーリングデザイン および(ii)
効率的なプーリングデザインの組合せ論的な性質.なお,効率の良いプーリングデザインの組合せ論的な性質は識別アルゴリ ズムに依存する可能性があることに注意する必要がある.
1.1.2 DNA ライブラリスクリーニングのためのプーリングデザ インと 2 段階グループテスト
C
をn
個のクローンの集合,G
をm
個のプールの族とし,クローン をc ∈ C
でプールをG ∈ G
で表すことにする.このとき,組(C, G )
を プーリングデザインと呼ぶ.プーリングデザインはm × n { 0, 1 } -
行列ま たは図1.1
のような2
部グラフで表すことができる.H = (h
ij)
を2
元m × n
行列とする.H
の各行はm
個のプールに対応 しており,H
の各列はn
個のクローンに対応している.H
の各成分h
ijを
h
ij=
1, c
j∈ G
i のとき,0, c
j∈ / G
i のとき.c
1c
2c
3c
4c
5c
6c
7c
8c
9G
1G
2G
3G
4G
5G
6図
1.2:
式(1.1)
の結合行列H
に対するタナーグラフと定義する.このとき,
H
をプーリングデザイン(C, G )
の結合行列また はテスト行列と呼ぶ.E = { (c, G) | c ∈ C, G ∈ G
かつc ∈ G }
とすると,E
は2
部グラフ(C, G ; E)
の辺の集合とみなすことができる.このよう な2
部グラフをタナーグラフ(Tanner graph)
と呼ぶ.この「タナーグラ フ」という用語は符号理論の分野で用いられている.ここでは,次章で説 明するBNPD
アルゴリズムと「low density parity check
」(LDPC)
の 復号アルゴリズムを対応させるために同じ用語を用いることにする.例えば
c
1c
2c
3c
4c
5c
6c
7c
8c
9H =
G
1
0 1 1 0 0 1 1 0 0
G
20 0 0 1 0 0 0 1 1
G
30 0 0 0 1 0 1 0 0
G
40 1 0 0 0 0 1 1 0
G
51 0 1 0 1 0 0 0 1
G
61 0 0 1 0 1 0 1 0
(1.1)
とする.この場合,プール
G
1 は4
個のクローンc
2, c
3, c
6, c
7 を含み,G
5 は4
個のクローンc
1, c
3, c
5, c
9を含んでいる.式(1.1)
の結合行列H
に対応するタナーグラフは図1.2
で表される.通常,グループテストでは
2
段階グループテストあるいは多段階グルー プテストが行われることが多い.2
段階グループテストでは図1.3
のようグループテスト実験
c
1c
2c
3· · · c
nG
1s
1G
2s
2· · ·
· · ·
G
ms
mプーリング デザイン
スクリーニングアルゴリズム アルゴリズム
個別テスト
観測値
s = (s
1, . . . , s
m)
を出力ポジティブクローンの候補を出力
図
1.3:
グループテストの流れにまず各プール
G
i に対して反応試験が行われ,その観測値s
i が得られ る.得られた観測値s
1, . . . , s
m からスクリーニングアルゴリズムにより,ポジティブの確率が高いクローンを抽出し,第
2
段階の個別テストに渡 す.個別テストでは各クローンごとに反応試験を行い,最終的にポジティ ブクローンを識別する.本論文では,主にスクリーニングのための事後確 率計算アルゴリズムに焦点をあてて効率の良い事後確率計算アルゴリズム を開発する.また,事後確率計算アルゴリズムに適したプーリングデザイ ンにも注目し,効率の良いプーリングデザインの組合せ的性質を明らかに する.1.1.3 グループテストの結果にもとづく決定論的なスクリーニング
組合せ論的グループテストでは
n
種のクローンのうちポジティブの数が 事前に固定されているかある固定された正整数d
以下であるという仮定が なされており,決定論的なモデルが用いられる.さらに観測値に誤りがある 場合には,誤りの最大数が与えられている.組合せ論的グループテストの主な問題は,ポジティブの最大数を仮定したもとでポジティブクローンとネガ ティブクローンを識別できるように効率的なプーリングデザインを構成す ることである.組合せ論的グループテストでは以下のような「
d-disjunct
」 な行列がよく用いられる.{ 0, 1 } -
行列をH = (h
1, . . . , h
n)
とし,その添え 字の集合をI = { 1, . . . , n }
とする.このとき,任意のD ⊂ I
,| D | ≤ d
と 任意のj / ∈ D
に対して∨
i∈D
h
i≯ h
j となるとき,行列H
はd-disjunct
であるという.ただし,2
つの{ 0, 1 } -
ベクトルh = (h
1, . . . , h
m)
⊤,h
′= (h
′1, . . . , h
′m)
⊤ に対して,h ∨ h
′= (h
1∨ h
′1, . . . , h
m∨ h
′m)
⊤ であり,任 意のj
に対してh
j> h
′j のときh > h
′ と書く.d-disjunct
な行列はd
個までのポジティブクローンを識別できるだけでなくその識別アルゴリズ ムも単純である.すなわち,あるクローンがポジティブであるのはそのク ローンを含むすべてのプールがポジティブであるときまたそのときに限 るということである。したがって,試験結果の観測値に誤りがないときはd-disjunct
な行列に対するポジティブクローンの識別アルゴリズムでは,各クローン
c ∈ C
に対して{ G ∈ G : G ∋ c }
のプールがすべてポジティ ブのときc
はポジティブであり,ひとつでもネガティブなプールがあればc
はネガティブである.d-disjunct
な行列はKautz
ら[33]
が提案した強さd
の「superimposed code
」の結合行列と同値である.極値集合論の分野では「d-cover-free fam- ily
」という名前でErd˝ os
ら[21]
により研究された.さらに,
d-disjunct
な行列H
のどのd
列の成分ごとの論理和ベクトル もほかのどの列の少なくともe + 1
個の1
をcover
しないとき,H
はd
e-disjunct
であるという.d
e-disjunct
な行列はMacula [40]
により導 入された.d-disjunct
な行列はd
0-disjunct
である.d
e-disjunct
な行列 はe − 1
個の偽ポジティブや偽ネガティブの誤りを検出することができ,⌊ e/2 ⌋
個の誤りを訂正することができる.d
e-disjunct
な行列は強さd
,距 離e + 1
のsuperimposed code
の結合行列である.D’yachkov
ら[19]
とD’yachkov
ら[20]
はd
e-disjunct
な行列の構成法を提案している.これまで組合せ論的グループテストは多くの研究者により研究されてき た.
Sobel
ら[58]
は多くの工業分野への応用を紹介し,Li [37]
は組合せ 論的なグループテストを導入した.Bush
ら[11]
とHwang
ら[29]
により
non-adaptive
なグループテストに関連した結果が得られている.Vakil
ら[66]
はポジティブが2
個の場合のグループテストのためのプーリング デザインを提案し,Chang
ら[13]
はポジティブが2
個および3
個の場 合を扱った.Wolf [68]
は通信へのグループテストの応用について述べた.Hwang [27]
が初めてグループテストの組合せ論的スクリーニングアルゴリズムのひとつを提案し,
Bonis
ら[7]
は2
段階グループテストのアル ゴリズムについて述べた.また,Balding
ら[4]
は誤り訂正可能なプーリ ングデザインを提案し,Macula [41]
とNgo
ら[48]
はDNA
ライブラリ スクリーニングのための組合せ論的グループテストについて述べ,Bonis
ら[8]
やHwang
ら[28]
は阻害物質と呼ばれる物質がある場合のアルゴリ ズムやプーリングデザインを扱った.さらに,Thierry-Mieg [61]
はプー リングデザインのためのshifted transversal design
の有効性に言及して おり,Wu
ら[69]
はプーリングデザインの分子生物学の分野への応用を 見出している.M´ ezard
ら[44]
は誤りが存在するときに組合せ論的グルー プテストの確率論的な解析を与えた.組合せ論的グループテストでは主に効率の良いプーリングデザインの構 成法に主眼が置かれている.
1.2 グループテストの結果にもとづく確率論的なスク リーニング
図
1.3
の手順において観測値からポジティブクローンを識別するには 観測値s
を用いてポジティブクローンを識別する良いスクリーニングア ルゴリズムが必要不可欠であるが,偽ポジティブ・偽ネガティブの確率が 高く,ポジティブの数が想定した数を上まわることが頻繁にあるような場 合には組合せ論的グループテストに対するアルゴリズムだけではポジティ ブクローンをスクリーニングすることが困難である.確率論的グループテストでは,ポジティブクローンが事前確率に従って 確率的に現れるという仮定のもとで,確率論的なモデルが設定される.偽 ポジティブや偽ネガティブのような誤りも確率的に発生すると仮定する.
確率論的アルゴリズムでは,これらの確率モデルに従ってポジティブク
ローンをスクリーニングする.確率論的な手法は
Bruno
ら[10]
やKnill
ら[35]
により開発された.Knill
ら[35]
はMarkov Chain Monte Carlo
(MCMC)
と呼ばれるシミュレーションの方法を利用してポジティブである事後確率を求めるアルゴリズムを提案した.この方法では,プーリング デザインに
d-disjunct
な行列を用いた際にポジティブの数がプーリング デザインで定められたポジティブの最大数d
を超えていてもそれ以上の ポジティブを高い確率で識別することができる可能性がある.通常,組合せ論的グループテストはポジティブクローンの最大数や誤り の最大数が事前に与えられているという条件のもとで行われるので,組 合せ論的方法はこれらの条件を満たしている限り効率が良い.しかし,多 くの組合せ論的なグループテストは偽ポジティブや偽ネガティブの数が少 ない場合にしか適用できない.また,組合せ論的グループテストはプール の観測値が
2
値の場合にしか適用できない.観測値が多値や連続値をと る場合に組合せ論的グループテストを適用するためには観測値をポジティ ブとネガティブの2
値に変換する必要があり実験の情報が失われてしま う.一方,確率論的な方法はポジティブである確率や誤りの確率が事前に 与えられていれば,多値や連続した値をとる場合にも適用することが可能 である.さらに,組合せ論的グループテストはクローンがポジティブかネ ガティブかという2
値の判定しかできないが,確率論的な方法はポジティ ブである事後確率の大小でポジティブであるか否かを判定する.したがっ て,誤り確率が大きいときに高い確率ですべてのポジティブを見つけたい ときには組合せ論的なスクリーニングアルゴリズムは適切ではないかもし れない.しかし,組合せ論的なプーリングデザインと確率論的な事後確率 計算アルゴリズムを組み合わせることにより,効率的な識別アルゴリズム を開発することが可能であることを本論文を通して主張したい.1.2.1 プーリング実験の確率モデル
本節ではプーリング実験の確率モデルについて述べる.
X
c をX
c=
0,
クローンc
がネガティブのとき,1,
クローンc
がポジティブのとき,となる確率変数とする.通常,各クローンがポジティブである事前確率
P (X
c= 1)
は小さく,例えば,P(X
c= 1) = 0.0001, 0.001
などの値をと る.1.1
節で述べたCla I
ライブラリの場合にはP (X
c= 1) ≈ 2.6/1298 ≈ 0.002
である.さらに,Z
G をZ
G= ∨
c∈G
X
cで定義される確率変数とする.ただし,
∨
は
G
に属するすべてのクロー ンに対するX
c の論理和である.プールG
がネガティブなクローンしか 含まないとき,Z
G= 0
となり,G
が 少なくとも一つのポジティブクロー ンを含むとき,Z
G= 1
となる.S
G をプールG
に対する観測値を表す 確率変数とする.スクリーニングの実験結果の観測値は蛍光の強さなどに より測定され,以下の4
つの値で表されることがある.(Knill
ら[35]
に よる.)
S
G=
0,
プールG
がネガティブのとき,1,
プールG
が弱ポジティブのとき,2,
プールG
が中ポジティブのとき,3,
プールG
が強ポジティブのとき.このとき,誤り確率は
P (S
G= s | Z
G= z)
で表すことができる.つま り,P (S
G= 1, 2, 3 | Z
G= 0)
が偽ポジティブで,P(S
G= 0 | Z
G= 1)
が 偽ネガティブである.ここで,各
X
c は互いに独立で観測値S
G はZ
G にのみ依存し,S
G は すべてのZ
G が知られているという条件のもとで独立であると仮定する.仮定
:
プールG
1, . . . , G
m∈ G
に対してP (S
G1= s
G1, . . . , S
Gm= s
Gm| Z
G1= z
G1, . . . , Z
Gm= z
Gm)
= P (S
G1= s
G1| Z
G1= z
G1) × · · · × P(S
Gm= s
Gm| Z
Gm= z
Gm), (1.2)
およびP (S
G= s
G| Z
G= z
G, X
c1= x
c1, . . . , X
cn= x
cn)
= P(S
G= s
G| Z
G= z
G)
(1.3)
が成り立つ.
つまり,
Z
G が既知のとき,式(1.2)
はそれぞれのS
G がZ
G にのみ依 存することを示しており,式(1.3)
はZ
G が既知のもとでS
G がX
c と独 立であることを示している.1.2.2 陽性反応の事後確率
プーリング実験の確率モデルの陽性反応の事後確率について述べる.
X = (X
c1, . . . , X
cn)
とS = (S
G1, . . . , S
Gm)
を確率ベクトルとする.S
が測定されたときの事後確率はP(X = x | S = s) = P(X = x, S = s) P (S = s)
= KP (X = x, S = s)
= KP (X = x)P(S = s | X = x)
= K ∏
c∈C
P (X
c= x
c) ∏
G∈G
P (S
G= s
G| Z
G= z
G) (1.4)
と書くことができる.ただし,K = P (S = s)
−1は定数で,z
G= ∨
c∈G
x
cである.
したがって,
X
c の条件付周辺事後確率はP (X
c= x | S = s)
= ∑
x∈{0,1}n s.t.xc=x
P (X = x | S = s)
= K ∑
x∈{0,1}n s.t.xc=x
( ∏
c′∈C
P (X
c′= x
c′) ∏
G∈G
P (S
G= s
G| Z
G= z
G) )
,
(1.5)
となる.ただし,
∑
x∈{0,1}ns.t.xc=x は
x
c= x
を満たすすべてのx = (x
c1, . . . , x
cn) ∈ { 0, 1 }
n についての和を意味している.さらに,P (S
G= s
G| Z
G= z
G)
の値は事前の実験から経験的に知られていると仮定する.D ⊂ C
をクローンの部分集合とし,集合D
を「D
に属するクローン がポジティブでC \ D
に属するクローンがネガティブである事象」と同 一視する.すべてのプールの観測値ベクトルs
が与えられたもとでのD
の事後確率はP (D | S = s) = P (D)P (S = s | D) P (S = s)
となる.ただし,
S = (S
G1, . . . , S
Gm)
である.また,D
の生起確率はP (D) = ∏
c∈D
P(X
c= 1) ∏
c∈C\D
P (X
c= 0)
である.さらに,プール
G
の観測値S
GはプールG
がポジティブクロー ンを含むか否かにのみ依存すると仮定すればP (S = s | D) = ∏
G∈G
P (S
G= s
G| D) = ∏
G∈G
P (S
G= s
G| G ∩ D)
が成り立つ.ただし,
G ∩ D
はG ∩ D ̸ = ∅
のときZ
G= 1
,G ∩ D = ∅
のときZ
G= 0
である.したがって,観測値が得られたときの事後確率はP (D | S = s)
= KP (D)P(S = s | D)
= K ∏
c∈D
P (X
c= 1) ∏
c∈C\D
P (X
c= 0) ∏
G∈G
P (S
G= s
G| G ∩ D)
となる.
1.2.3 スクリーニング
式
(1.5)
のP (X
c= 1 | S = s)
は観測値s = (s
G1, . . . , s
Gm)
が与えら れたもとでクローンc
がポジティブである事後確率である.観測値がs
のときの事後確率P (X
c= 1 | S = s)
が大きいとき,クローンc
はポジ ティブである確率が高いとみなすことができる.第2
段階の実験では,事 後確率が高い順に一定数のクローンを抽出し,ポジティブクローンを決定 するためにそれらを個別にテストする.しかし,式
(1.5)
から事後確率P (X
c= x | S = s)
を計算するために は2
n−1 回の和が必要である.したがって,クローンの数n
が増加する と,計算量は指数関数的に増加する.そのため,この値を計算するための 効率的なアルゴリズムが必要である.1996
年にKnill
ら[35]
がMarkov
Chain Monte Carlo (MCMC)
法にもとづく確率論的な事後確率計算アル ゴリズムを提案した.次章では,Knill
ら[35]
によるアルゴリズムについ て概説し,この従来のアルゴリズムの欠点を補うために考案したアルゴリ ズムを提案する.第 2 章
BNPD アルゴリズムと CCPD アル ゴリズム
本章では,まず従来の
Markov Chain Monte Carlo (MCMC)
法を用いた 事後確率計算アルゴリズムMarkov chain pool result decoder (MCPD)
に ついて概説し,その上で新しい事後確率計算アルゴリズムであるBayesian network pool result decoder (BNPD)
,およびCCCP pool result decoder
(CCPD)
を提案する.さらに,BNPD
あるいはCCPD
で求まる周辺事後確率の偏りに関する
1
つの指標を導く.2.1 事後確率計算アルゴリズム MCPD
Markov Chain Monte Carlo (MCMC)
法にはさまざまな手法があるが,本節ではギブスサンプリングという基本的な手法による周辺事後確率の 計算について述べる
(Gamerman [23]
,Geman [24])
.本手法を用いた事 後確率計算アルゴリズムはKnill
ら[35]
により導入され,Markov chain pool result decoder (MCPD)
と呼ばれている.マルコフ連鎖の定常確率を利用してモンテカルロシミュレーションを行 う方法を
MCMC
法という.まず,事後確率P(X = x | S = s)
を定常 確率として持つマルコフ連鎖を次のようにして構成する.x = (x
1, . . . , x
n) ∈ { 0, 1 }
n としp(x) = P (X = x | S = s)
とおく.{0, 1}
n 上のマルコフ連鎖を考え,x
′ からx
への推移確率をp(x | x
′) =
∏
n j=1p(x
j| x
1, . . . , x
j−1, x
′j+1, . . . , x
′n)
とする.このマルコフ連鎖は既約であり,非周期的である.実際
p(x
j| x
1, . . . , x
j−1, x
′j+1, . . . , x
′n)
= P (X = (x
1, . . . , x
j−1, x
j, x
′j+1, . . . , x
′n) | S = s)
∑
x′j
P (X = (x
1, . . . , x
j−1, x
′j, x
′j+1, . . . , x
′n) | S = s)
であるので,
P (X
j= x
j) > 0
,j = 1, . . . , n
に注意すればP (X = x | S = s) > 0
となることより,p(x | x
′) > 0
.またp(x | x) > 0
も明らか である.さらに∑
x′
p(x | x
′)p(x
′)
= ∑
(x′1,...,x′n)
∏
n j=1p(x
j| x
1, . . . , x
j−1, x
′j+1, . . . , x
′n)p(x
′1, . . . , x
′n)
= ∑
(x′2,...,x′n)
∏
n j=2p(x
j| x
1, . . . , x
j−1, x
′j+1, . . . , x
′n)p(x
1, x
′2, . . . , x
′n)
= ∑
(x′3,...,x′n)
∏
n j=3p(x
j| x
1, . . . , x
j−1, x
′j+1, . . . , x
′n)p(x
1, x
2, x
′3, . . . , x
′n)
· · ·
= ∑
x′n
p(x
n| x
1, , . . . , x
n−1)p(x
1, . . . , x
n−1, x
′n)
= p(x
1, . . . , x
n)
= p(x).
が成り立つことより
p(x)
はこのマルコフ連鎖の定常確率になり,このマ ルコフ連鎖が既約かつ非周期的であることからp(x)
はこのマルコフ連鎖 の極限分布になる.このことを利用した計算法がギブスサンプリングであり,アルゴリズム は次のようになる.
1.
初期値として{ 0, 1 } -
ベクトルx
(0)= (x
(0)1, x
(0)2, . . . , x
(0)n)
を発生さ せる.2. x
(τ)= (x
(τ)1, x
(τ)2, . . . , x
(τ)n)
が与えられたもとで(a) x
(τ+1)1 をp(x
1| x
(τ)2, . . . , x
(τ)n)
から発生させる.(b) x
(τ+1)2 をp(x
2| x
(τ+1)1, x
(τ)3, . . . , x
(τ)n)
から発生させる.(c) x
(τ+1)3 をp(x
3| x
(τ+1)1, x
(τ+1)2, x
(τ)4, . . . , x
(τ)n)
から発生させる.同様に
x
(τ+1)4, . . . , x
(τ+1)n を順次発生させていく.という手順により,
x
(τ+1)= (x
(τ+1)1, x
(τ+1)2, . . . , x
(τ+1)n)
を得る.この操作を
τ = 1, 2, 3, . . .
と繰り返してx
(0), x
(1), x
(2), . . .
が得られる.この発生のさせ方から
x
(0), x
(1), x
(2), . . .
はマルコフ連鎖に従う乱数であ るとみなせる.したがって,lim
t→∞(1/t) ∑
tτ=0
I
(x(τ)=x)= p(x)
が成り 立つ.ただし,I
(x=x′) はx = x
′ のとき1
,x ̸= x
′ のとき0
である.X = (X
1, . . . , X
n)
にポジティブであるクローンの集合D = {c
j∈ C : X
j= 1}
を対応させれば,マルコフ連鎖X
(0), X
(1), X
(2), . . .
をクローン 集合の列D
(0), D
(1), D
(2), . . .
に対応させることができる.ギブスサンプリングのアルゴリズムにおいて
c
j∈ D
(τ) であるとする.すなわち
X
j(τ)= 1
であると仮定する.このときc
j∈ / D
(τ+1) となる確 率はp(0 | x
(τ+1)1, . . . , x
(τ+1)j−1, x
(τ)j+1, . . . , x
(τn))
= P(X = (x
(τ+1)1, . . . , x
(τ+1)j−1, 0, x
(τ)j+1, . . . , x
(τ)n) | S = s)
∑
xj
P(X = (x
(τ+1)1, . . . , x
(τ+1)j−1, x
j, x
(τ)j+1, . . . , x
(τ)n) | S = s)
= P(D \ { c
j} | S = s)
P (D \ {c
j} | S = s) + P (D | S = s)
となる.同様に
c
j∈ / D
(τ) であるとすると,c
j∈ D
(τ+1) となる確率はp(1 | x
(τ+1)1, . . . , x
(τ+1)j−1, x
(τ)j+1, . . . , x
(τ)n)
= P(D ∪ { c
j} | S = s)
P(D ∪ { c
j} | S = s) + P (D | S = s)
となる.ここで
D △ { c } =
D \ { c } , c ∈ D
のとき, D ∪ { c } , c / ∈ D
のとき,
の記号を導入すれば,
c ∈ D
(τ) のときc / ∈ D
(τ+1) となる確率とc / ∈ D
(τ)のとき
c ∈ D
(τ+1) となる確率はまとめて次のようになる.P (D △ { c } | S = s)
P (D △ { c } | S = s) + P (D | S = s)
= 1
1 + P (D | S = s)/P (D △ { c } | S = s)
(2.1)
ただし,
A △ B
は集合A
とB
の対称差,つまり,A △ B = (A \ B) ∪ (B \ A)
である.MCPD
アルゴリズムではD
(0), D
(1), D
(2), . . .
を以下のように発生さ せる.すべてのクローンc ∈ C
の対してD
(τ) にc
を追加するか削除 するかを式(2.1)
の確率でランダムに決めることによりD
(τ+1) を生成する.
D
(τ) からD
(τ+1) を生成することをt
回繰り返したとき,クローンc
を含むD
(τ) の数をt
で割ることによりc
がポジティブである事後確率P (X
c= 1 | S = s)
を推定する.したがって,Knill
ら[35]
によるMCPD
アルゴリズムは以下のようになる.MCPD
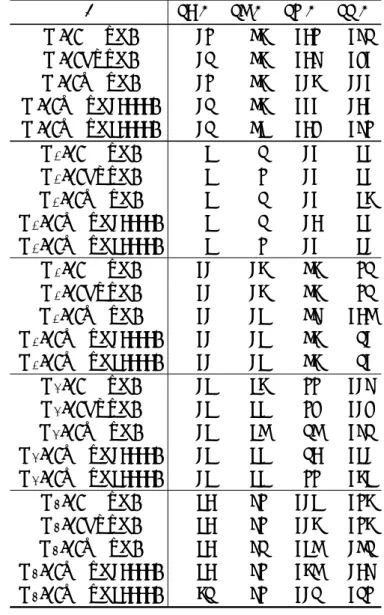
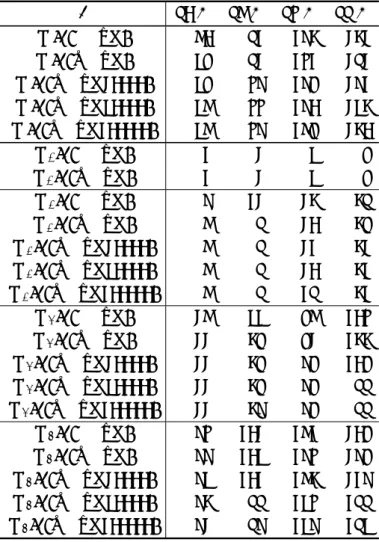
アルゴリズムステップ
1 (
初期化): D
(0)= ∅
と初期化する.t
を反復回数,t
0 をウォー ムアップの反復回数とし,τ = 1
とする.ステップ
2 (D
(τ) の初期化): D
(τ)= D
(τ−1) とする.ステップ
3 (D
(τ) の更新):
各クローンc ∈ C
に対して,乱数を発生さ せることにより式(2.1)
の確率でD
(τ)= D
(τ)△ { c }
とする.ステップ
4 (
反復): τ < t + t
0 ならτ = τ + 1
としステップ2
に戻る.τ = t + t
0 ならステップ5
へ進む.ステップ
5 (
周辺事後確率の計算):
各c ∈ C
に対して,c
がポジティブである周辺事後確率の推定値として
Q
c(1) = # { D
(τ)∋ c | τ = t
0+ 1, . . . , t
0+ t } t
を出力する.
MCPD
によって求めた事後確率の推定値Q
c(1)
が高い順に一定数のク ローンを第2
段階の個別テストにかける.MCPD
はシミュレーションに より周辺事後確率を計算するアルゴリズムのため,繰り返し乱数を生成す る必要があり,小さい確率を精度良く推定するためには反復回数t
を多く する必要があるので実行時間が長くなる.これらの問題点を解決するため に以下でベイジアンネットワーク上の確率伝播アルゴリズムにもとづいて 考案したアルゴリズムを提案する.2.2 ベイジアンネットワークと確率伝播法
本節では,ベイジアンネットワークの定義およびその上での確率伝播法 について述べる.ベイジアンネットワークは確率変数間の依存関係を表すグ ラフィカルモデルである
(Jensen [32]
,Lauritzen
ら[36]
,Neapolitan [47]
, およびPearl [51])
.2.2.1 ベイジアンネットワーク
ベイジアンネットワークは以下のように定義される.離散確率変数の集 合
U = { U
1, U
2, . . . , U
n}
とこれらの変数上で定義される同時分布P( · )
か らなる確率モデルを考える.同時分布が
P (U = u) =
∏
n i=1P (U
i= u
i| V
i= v
i)
と分解されているとする.ただし,