特集●ネットワーク技術
DNS
グラフ上でのグラフ分析と脅威スコア伝搬による
悪性ドメイン特定
風戸 雄太 福田 健介 菅原 俊治
本研究では,DNS (Domain Name System) のクエリ回答結果から作成したドメイン名・IP アドレスをノードと する 2 部グラフ (DNS グラフ) を用いて,グラフ内に存在する未知の悪性ノードを検出する手法を提案する.キー となるアイディアは,事前に与えられた良性・悪性ドメインを含むグラフコンポーネントにおいて脅威確率伝搬 (Probabilistic Threat Propagation) を用いることで,良性・悪性ノードに「近い」ノードをそれぞれ良性・悪性と 推定する点にある.大規模バックボーンネットワークで得られた DNS クエリデータを用いた DNS グラフでは全 ノードの約 69%が 1 つの部分グラフ (コンポーネント) から構成されることがわかった.また,この DNS グラフに 提案手法を適用したところ,低い誤分類率で悪性なドメインを検出でき,オリジナルの脅威確率伝搬手法と比較して 9%,既存の他の手法と比較して 40%の精度向上を実現した.さらに,DNS グラフ上の未知のノードを提案手法で 推定したところ,危険性の高い未知なドメインを新たに 2,170 個検出することができ,DNS グラフを可視化するこ とで推定した悪性なノードが関わるグラフ構造を明らかにした.
This paper proposes a method to estimate malicious domain names from a large scale DNS query response dataset. The key idea of the work is to leverage the use of DNS graph that is a bipartite graph consisting of domain names and corresponding IP addresses. We apply a concept of Probabilistic Threat Propagation (PTP) on the graph with a set of predefined benign and malicious node to a DNS graph obtained from DNS queries at a backbone link. The performance of our proposed method (EPTP) outperformed that of an original PTP method (9% improved) and that of a traditional method using N-gram (40% improved) in an ROC analysis. We finally estimated 2,170 of new malicious domain names with EPTP.
1 はじめに
Domain Name System (DNS)は名前(ホスト名や
ドメイン名)とIPアドレスの変換を行うインターネッ ト上の基本サービスである.そのため,ほとんどのア プリケーションはDNSを用いて人間が識別可能な名 前からIPアドレスを得ることで通信の宛先を知る. これらのアプリケーションは正しくDNSを使用する が,悪意のあるアプリケーションもまたDNSを使用 する.例えば,悪意のあるユーザが正しいドメイン名
Detecting Malicious Domains with Probabilistic Threat Propagation on DNS Graph.
Yuta Kazato, Toshiharu Sugawara, 早 稲 田 大 学, Waseda University.
Kensuke Fukuda, 国立情報学研究所 / 総合研究大学院大 学, National Institute of Informatics / Sokendai. コンピュータソフトウェア, Vol.33, No.3 (2016), pp.16–28. [研究論文] 2015 年 8 月 20 日受付. に似た悪意のあるドメインを取得することで,他の ユーザを悪意のあるドメインへ誘導することが可能 となる.同様に,IPアドレスは変更せずにランダム に生成されたドメイン名を短期間で切り替える方法 や,ドメイン名は固定でIPアドレスを時間と共に変 化させることで,ボットネットのC&Cサーバとボッ ト間の通信を検出されにくくすることもできる. このようにドメイン名およびそのマッピングされる IPアドレスを注意深く観測することで,正常なサー ビスに関係するドメイン名と悪性なサービスに関わ るような異常な振る舞いを示すドメイン名を識別す ることができる.しかしながら,DNSクエリには無 効なクエリ(例えばタイプミスや規則違反の問い合わ せなど)が数多く含まれることから,これらのノイズ のあるデータから効率良く識別を行うことは簡単で はない. 本研究では,これらの良性なドメインおよび悪
benign.com IP 1 benign.net IP 2 unknown.com IP 3 malicious.com 図 1 DNS グラフ: 悪性なドメイン (malicious), 良性なドメイン (benign), 未知なドメイン (un-known) 性なドメインを脅威確率伝搬(Probabilistic Threat Propagation; PTP)のアイディアを用いて精度良く 検出する手法を提案する.キーとなるアイディアは, バックボーントラフィック中のDNSクエリに着目し, その中に含まれるドメイン名およびIPアドレスの マッピングから,それぞれをノードとする2部グラ フ(DNSグラフ)を構成し(図1),既知の良性・悪性 ドメイン名に対応するノードから対象ノード(ドメイ ン名もしくはIPアドレス)がグラフ上においてどの 程度「近い」かによって良性・悪性を判断する.提 案手法の妥当性を国内バックボーントラフィックで約 3週間収集されたDNSクエリを用いて評価したとこ ろ,既存のPTPを用いた手法に比べて提案手法であ るEPTP (Extended PTP)は9%の精度改善,およ び既存のドメイン名の文字列出現頻度に着目した手 法(N-gram手法)と比較して約40%の精度改善をは かることができた. 本研究の寄与は以下の2点である.(1)既存手法の PTPでは悪性ノードのみを考慮しているが,EPTP では良性ノードおよび悪性ノードを入力とすること で,さらなる性能向上を実現した.(2)大規模バック ボーンDNSトラフィックから得られるDNSグラフに 関する統計的な性質を解析し,良性ノード・悪性ノー ドのグラフ上での振る舞いについて明らかにした.
2 関連研究
2. 1 DNSトラフィック分析 DNSはインターネット上の重要なサービスの1つ であり,DNSに関する様々な測定・解析が行われてい る.測定は,権威サーバを用いるもの,エッジネット ワークに位置するキャッシュリゾルバを用いるものと が知られている.権威サーバは階層型分散データベー スであり,ルートサーバと呼ばれる階層のトップか ら,Top Level Domain (TLD) (例えば.jp),Second Level Domain (SLD) (例えば, co.jp)等を経て,最終的に名前とIPアドレスをマッピングするデータ (ゾーン情報)を持つ権威サーバと分散管理されてい る.キャッシュリゾルバは,クライアントからのクエ リを権威サーバに問い合わせるサーバであり,クライ アントからの問い合わせに対して実際の名前解決を 行っている. 権威サーバでの測定の多くは,ルートサーバや gTLDサーバ(.com, .net),ccTLDサーバ(.cn, .jp) で行われている.とりわけ,ルートサーバでのトラ フィックを解析した研究では,60–85%のクエリが同 じキャッシュリゾルバからの無効な繰り返しクエリ であり,クエリトラフィックにはノイズが多く含まれ ることを示している [8] [10] [24].また,バックボー ンでの測定では同様に,ルートサーバへのクエリの 50%が間違ったTLDを問い合わせているとの報告 がある[12].gTLDである.comや.net [20],ccTLD である.cn[25]のトラフィック解析においても,総ト ラフィックの90%が少数のキャッシュリゾルバからの クエリで占められていることを示している.さらに, gTLDのゾーン情報とDNSクエリの解析では,悪性 なドメインが登録1日後にトラフィック量が急増し, 早期に攻撃利用されることを明らかにしている[13]. ルートサーバやTLDサーバでは,世界中からのク エリデータが得られるため,その空間的なカバー率は 大きいが,ノイズが多いことから,悪性のドメイン名 は埋もれやすい傾向にある. 2. 2 悪性ドメインの特定 2. 2. 1 クエリパターンによる検出 ボットネットによるDDoS(分散サービス不能攻撃) やスパムボットなどの悪性な攻撃に利用されるドメイ ンを発見する研究として,ドメインの複数の特徴情 報を組み合わせて判別するExposure[7],Kopis[3], Notos[2]等が知られている.Exposure[7]では時系 列,回答情報,time to live (TTL)の値,ドメインの 文字列から15種類の特徴を利用してドメインを判別 し,その結果として未知の悪性なドメインを3,000個
18 以上検出した.Kopis[3]では,クエリの統計的性質 を利用して,権威サーバでの悪性なドメインやDDoS に関連するボットネットを特定した.Notos[2]は,所 属ネットワークの特徴,ゾーン情報の特徴,エビデン ス情報の特徴からドメインのスコアを計算し,キャッ シュリゾルバで悪性なドメインを特定するシステムを 提案している.また,文献[14]では,DNSトラフィッ クが集中しているヘビーユーザからのクエリの挙動 に注目し,階層型エントロピー手法とSVMを利用す ることで,ヘビーユーザからの問い合わせの分類と悪 性なドメインを判別している. 2. 2. 2 ドメイン名に含まれる文字列特徴による 検出 文献[26]では,ランダムな文字列から構成される
Domain Generation Algorithm (DGA) ドメインに 注目し,良性なドメイン名と悪性なドメイン名の文 字列パターンの出現分布(N-gram)の差異をK-Lダ イバージェンスによって計算し,悪性なDGAドメイ ンを特定する手法を提案している.文献[15]は,ボッ トネットに感染したホストから送信されるブラックリ スト登録済みのドメインをJaccard indexを用いて スコア計算し,ネットワークから未知な悪性ドメイン と未知な感染ホストを発見した. また,既知な悪性ドメインだけでなく,ボットネッ トのC&Cサーバへのアクセスの際に発生するNX ドメイン(存在しないドメイン名)を基に,ドメイン を分類する研究もある.文献[27]と[4]はNXドメ インに含まれるDGAの特徴を利用することで,ボッ トネットのドメイン検出速度と精度を向上させ,文 献[23]では未知のDGAドメインクラスタの発見シ ステムへ貢献している. 2. 2. 3 DNSグラフによる検出 文献[28]は,悪性ドメインの特定のために,ドメ イン名と名前解決を行なったホスト名によるDNSク エリグラフを用いて,ボットネットの挙動に合わせた ドメインのスコア計算を実現している.文献[22]で は,Fast-fluxを利用するボットネットなどの悪性な サービスをDNSグラフ中のIPアドレスの集合でグ ループ化し,悪性なサービスと正規のFluxサービス (CDN等) に判別するシステムを考案した.さらに, 文献[16],[6]では,NXドメインエラーのドメインと 問い合わせ元のホストの繋がりをDNS failure graph で表現し,ボットネットなどの悪性な攻撃との関係性 を調べた.その結果,ボットネットやスパムに関連す る特徴的なグラフ構造[16]や,3Gネットワーク上で のスパムクラスタを発見している. 本研究に密接に関連する技術として,確率伝搬法を 応用したネットワーク上の悪性ノードの特定をする 研究が知られている[19] [11] [9].このうち, Manad-hataら[19]はHTTPとDNSのイベントログからグ ラフを作成し, 事前情報である悪性なドメインノー ドと良性なドメインノードから確率伝搬を行うこと で,未知なドメインノードの悪性判別を可能とした. Polonium [11]は,MachineとFileの大規模2部グ ラフにおいて,確率伝搬法を用いてスコアを計算す
ることで,マルウェアを検出している.Probability
Threat Propagation (PTP)[9]は,企業ネットワー ク内web proxyデータのIPアドレス情報とURL情 報からグラフを作成し,既知の悪性ドメインのノー ドから確率伝搬法と同じように脅威確率を繰り返し 伝搬することで,他ノードの脅威確率を推定できる. この推定結果から閾値を設定し,未知な悪性ドメイン ノードの特定やIPアドレスとの関係性を明らかにし た.しかし,PTP手法では悪性ドメインのノードの みに事前脅威確率を設定しており,良性なノードが大 部分を占める場合を考慮していない. 本研究と先行研究の大きな違いは,クエリ数等の 統計的な手法や,ドメインの文字列に着目するので はなく,確率伝搬法に基づくPTP[9]に対して良性・ 悪性両方の事前情報を与えるよう拡張し,バックボー ンで得られた大規模DNSトラフィックに適用するこ とで,DNSグラフ上での悪性ドメインノードの推定 を行う点にある.さらに,先行研究では,前提となる (DNS)グラフの性質についてはほとんど述べられて いない.
3 提案手法
3. 1 DNSグラフの構築 本研究では,DNSクエリデータからAレコードの 問い合わせドメイン名とその回答である対応するIPアドレスを用いて,2部グラフであるDNSグラフを 作成する(図1).無向グラフGを,ノードの集合X, エッジの集合Eを用いて,G = (X, E)と表現する. ドメインはドメインノード,IPアドレスはIPノード と定義し,ドメインの名前解決の結果としてIPアド レスが存在する場合に,そのノード間にはエッジが 存在する.すなわち,ドメインiの名前解決結果が IPアドレスjであった場合,ドメインノードiとIP ノードj間のエッジが存在する(eij ∈ E).また,1 つのドメインノードと複数のIPノード間にエッジが 存在する場合,1つのドメインに対する回答のIPが 複数存在する(例えばCDN).同様に,1つのIPノー ドと複数のドメインノード間にエッジが存在する場 合,複数のドメインに対する回答が1つのIPである (例えばホスティングサービス). DNSグラフの構築に際して,プライベートネット アドレス,リンクローカルアドレス,自分自身を示 すループバックアドレス,ドキュメント用の例示用ア ドレス[5]などグローバルネットワークで使用不可な IPアドレスはデータセット及びグラフのノードから 除外する. 3. 2 EPTP 既存手法であるPTP[9]は,事前情報である悪性 ドメインのノードから“脅威確率”をグラフ全体に伝 搬することで,未知なノードの悪性の判別を可能にす る.すなわち,悪性なドメインの事前情報データセッ トから悪性なドメインノード(Maliciousノード)の 集合{malicious}を設定し,各悪性ノードの脅威確 率をP (x∈ malicious) = γと設定する.PTP手法 における各ノードの脅威確率は,隣接ノードの脅威確 率にエッジの重みを乗積した値の合計と等しいので, グラフG上のあるノードxiにおける脅威確率の計算 は式1で表すことができる. P (xi; G) =
∑
j∈N(xi) wijP (xj|xi= 0; G) (1) 式1において,N (xi)はあるノードxiに隣接する ノードの集合,wijはノードiとノードj間のエッジ の重みである.また,P (xj|xi= 0; G)はノードxiの 脅威確率を0として計算した場合の隣接ノードxjの 脅威確率を示す.式1は,グラフが木構造かつノード 数が少ない場合において厳密解を求めることが可能 である.一方で確率伝搬法と同じように,大規模グラ フや複雑なネットワークでは厳密解を求めるための計 算量がO(N2)であることと,ループが存在するグラ フ構造では近似値でも収束しない場合があることか ら厳密計算は不可能である.式1の効率的な近似計 算として,ノードの周辺確率の重みありの合計値と, 1回前の脅威確率伝搬の計算結果を利用することで計 算する.k回目の繰り返しにおける脅威確率伝搬の計 算を式2に示す. Pk(xi) =∑
j∈N(xi) wij(Pk−1(xj)− Ck−1(xi, xj)) (2) Pk(xi)はk回目の繰り返し計算におけるノードxi の確率,Pk−1(xj)はk− 1回目のノードxiの隣接 ノードxjの脅威確率,Ck−1(xi, xj)はk− 1回目の ノードxiからノードxjへの脅威確率寄与度である. 脅威確率の寄与度Cは,k− 1回目でのノードxiか らノードxjへの伝搬結果に依存するk回目でのノー ドxjからノードxiへの脅威確率のフィードバック であり,この寄与度を用いることで脅威確率の減少を 防ぐことと計算量の低下に有効である.また,式2の k回目の繰り返し計算における寄与度Ck−1は式3と 表すことができる. Ck−1(xi, xj) = wji(Pk−2(xi)) (3) エッジの重みwijを式4と定義する. wij=
1 |N(xi)| eij∈ E 0 eij̸∈ E (4) 既存手法であるPTPでは,事前情報として悪性ド メインノードのみを使用していた.そこで,本研究で は新たな事前情報としてAlexa[1]のトップドメイン ランキングに含まれる良性ドメインを追加し,DNS グラフ上で脅威確率を伝搬することで,未知なノード が悪性であるか良性であるかを判別する.このAlexa トップランキングの良性ドメインの集合を{benign},20
Require: W,{malicious}, {benign}, γ, β
1: P ← αN, P (malicious)← γ, P (benign) ← β, C ← 0N×N 2: repeat 3: T← W × diag(P ) 4: C← T − W ◦ CT 5: P←< C, 1 > 6: C(malicious,·) ← 0, C(benign, ·) ← 0 7: P (malicious)← γ, P (benign) ← β 8: until P has converged
9: return P
図 2 Extended Probability Threat Propagation
{benign}に属するドメインノードをBenignノードと し,Maliciousノードと同じように初期状態で脅威確 率を設定する†1.既存のPTPでは,Maliciousノー ドの脅威確率をγを[0,1]の範囲で設定し,それ以外の ノードの脅威確率を0としているが,EPTPでは,事 前情報である良性なドメインと悪性ドメインに初期値 として脅威スコアをそれぞれ設定する.事前情報で良 性なドメインノードの脅威スコアをβ > 0,事前情報 で悪性なドメインノードの脅威スコアをγ < 0,脅威 スコア伝搬前の未知なドメインノードの脅威スコアを α = γ+β2 と表現することで,脅威スコア伝搬後の未 知ノードの脅威スコアP (x)について,γ≤ P (x) < α であればP (x)がγに近いほど悪性なドメインの可能 性が高く,α < P (x)≤ βであればP (x)がβに近い ほど良性なドメインの可能性が高いとそれぞれ推定で きる.今回は対称性に基づき各脅威スコアのパラメー タをBenignノードの脅威スコアβ = 1,Malicious ノードの脅威スコアγ =−β = −1,未知なノード の脅威スコアα = γ+β2 = 0に設定し,脅威スコア伝 搬を計算する. 脅威スコアの伝搬(式2)を計算する場合,グラフ を行列で表現することで,各ノードのスコア計算が可 能である.EPTPのアルゴリズムを図2に示す. ノード数をNとすると,脅威スコアベクトルをP∈ RN(P (i) = P (x i)),エッジ重み行列をW ∈ RN×N, 伝搬行列をT ∈ RN×N (T (i, j) = W (i, j)∗ P (j)), 寄与度行列をC∈ RN×N, C = T− W ◦ CT とそれ ぞれ定義できる.ここで,A◦ Bは行列の成分同士の †1 EPTP での脅威確率は厳密には確率ではなくスコア であるため,本論文では今後,脅威スコアと表現する.
乗算である(A(i, j)∗B(i, j)).{malicious}に属する
ノードの脅威スコアP (malicious)をγ,{benign}に 属するノードの脅威スコアP (benign)をβ,それ以外 の未知なノードの脅威スコアを0,寄与度行列を0で それぞれ初期化する.繰り返しフェーズにおいて,伝 搬行列T はWとdiag(P )を乗積し(diag(P )はベク トルPを対角要素とするN×Nの行列),寄与度行 列はTからW◦CTを減算する.これは,式2での寄 与度Cの減算に相当する.そして,新しく計算したC の要素の合計から脅威スコアP =< C, 1 >を求める ことができる(<·, · >は内積,1は要素数がN個の1 であるベクトルをそれぞれ示す).この繰り返しフェー ズはPが収束するまで繰り返し,繰り返しフェーズ中 の最後には事前情報ノード{malicious}と{benign} に関わるPとCの値を初期化する.事前情報ノード の脅威スコアを初期化することで,最終的に脅威スコ アの伝搬するノードxはx̸∈ {malicious}, {benign} に限定される.また,EPTP手法の収束条件は1回 前の試行と比較して,脅威スコアベクトルP の各成 分のスコア変化の差が0.001以下であるとき収束と する.そして,最終的な脅威スコアPの結果から未 知のノードxkが悪性かどうか判別可能である.PTP 手法を利用する利点として,事前情報から脅威スコ アを設定し伝搬することで未知な悪性なドメインの 特定に有効であること,グラフ理論の“同類親和性” から悪性なドメインノードの集団を特定しやすいこ と,脅威スコアを伝搬したノードからの脅威スコアの フィードバックを防止し,脅威スコアの伝搬の効率が 良いことが挙げられる.例えば,本研究の結果では, 100万ノードを超えるグラフでも伝搬計算の繰り返し 回数は50回以内で収束することを確認している.
4 データセット
4. 1 DNSトラフィックデータ収集 DNSトラフィックのデータセットは,日本の学術 情報ネットワーク内のバックボーントランジットリン クの1つで収集したDNSクエリトラフィックデータ である.トラフィックデータは“tcpdump”を使用し てUDP port 53であるパケットをパッシブ計測した ものであり,測定期間は2013年11月5日–28日の-200 0 200 400 600 800 1000 1200 1400 11/05 11/12 11/19 11/26 Total Number (x1000) Time (JST 2013) IN domains OUT domains KEEP domains (a) 全ドメイン -2 0 2 4 6 8 10 12 14 11/05 11/12 11/19 11/26 Total Number (x1000) Time (JST 2013) IN domains OUT domains KEEP domains (b) Benign -0.5 0 0.5 1 1.5 11/05 11/12 11/19 11/26 Total Number (x1000) Time (JST 2013) IN domains OUT domains KEEP domains (c) Malicious -0.2 0 0.2 0.4 0.6 0.8 1 1.2 11/11 11/18 11/25 Total Number (x1000) Time (JST 2013) IN domains OUT domains KEEP domains (d) Suspicious 図 3 IN ドメイン数,KEEP ドメイン数,OU T ドメイン数の変化 24日間である.DNSの正引き名前解決(Aレコード 問い合わせ)では,キャッシュリゾルバと権威サーバ の間でドメイン名の問い合わせとその応答が複数回繰 り返し,最終的な回答としてIPアドレスを得ること ができる.データセットに含まれる双方向のDNSク エリのうち,本研究では測定ネットワーク内のキャッ シュリゾルバからのドメイン問い合わせに対して,外 部ネットワークに存在する権威サーバからの最終回答 情報を分析対象とする.得られた全ドメインノードは 1,348,547個, IPノードは2,417,727個,エッジ数は 3,917,402本である. 4. 2 良性・悪性ドメインデータ さらに本研究では,DNSトラフィックの分析対象 であるドメインについて,事前情報として悪性 (Ma-licious)ドメインの事前情報データセットを “mal-waredomains.com” [18]と“uribl.com” [21] (Mali-ciousデータセット),良性(Benign)ドメインの事 前情報データセットをAlexa[1]のトップランキング ドメイン(Alexaデータセット)からそれぞれ使用す る.良性ドメイン数は30,000個,悪性ドメイン数は 30,653個である. それぞれのデータセットに含まれるドメインの特徴 は次のとおりである.良性ドメインデータはドメイン へのユーザのアクセス数をAlexaが収集したランキ ング上位のドメインであり,多くのユーザが一般的に 利用している良性なドメインであると言える.一方 で,悪性ドメインデータはマルウェアに関わるドメイ ンが含まれており,このドメインの中には一部DGA ドメインも含まれている.
5 DNS グラフの性質
本節では,構築したDNSグラフの統計的な性質に ついて述べる. 5. 1 ドメインの出現頻度 まず,DNSグラフを構築する前に,データセット 中のドメインノードの出現頻度について調査する.こ こでの興味は,良性・悪性ドメインともに毎日出現 するものなのか悪性ドメインはデータセット中で稀 にしか現れないのかを知ることにある.事前情報ド メインについて,1日ごとのDNSデータセット内で の出現数を計測し,k日目のデータセットを基準と して,k− 1日目のデータセットにも出現したドメイ ンをKEEP,k− 1日目は出現したがk日目は出現 しなかったドメインをOU T,k− 1日目は出現しな かったがk日目は出現したドメインをINとそれぞ れカウントし,出現傾向を調査する.対象のドメイ ンはDNSトラフィックデータ中の全ドメイン(All), 事前情報である悪性ドメイン(Malicious)と良性ドメ イン(Benign)の3種類である.これら3種類につい て1日ごとのDNSデータセット内でのINドメイン 数,KEEP ドメイン数,OU T ドメイン数の結果を 図3の(a)–(c)に示す.この際,事前情報である良性 ドメイン30,000個,悪性ドメイン30,653個を分類対 象のドメインとして使用した.KEEP,IN,OU T ドメインの平均割合を表1に示す.全ドメインでは, 平均約65%のドメインがKEEP ドメインであった. 一方,全ドメインに比べて,良性ドメインはKEEP ドメインの割合が高く(平均71.8%),悪性ドメイン はINとOU Tの割合が高い(平均51.4%)ことがわ かる.22
表 1 KEEP ,IN ,OU T ドメインの平均割合
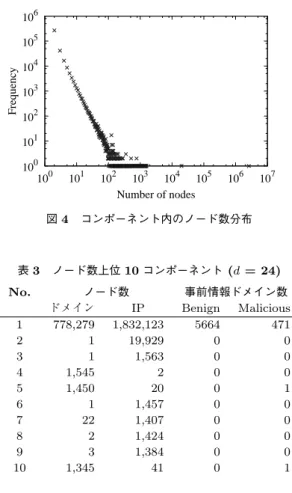
KEEP IN OU T ALL 65.9% 17.1% 17.1% Benign 71.8% 14.1% 14.1% Malicious 48.6% 25.8% 25.6% Suspicious 65.3% 17.4% 17.2% 表 2 DNS グラフの性質 d = 1 d = 24 全ノード数 1,271,975 3,766,274 ドメインノード 668,266 1,348,547 IPノード 603,709 2,417,727 エッジ数 1,199,612 3,917,402 平均次数 1.88 2.08 コンポーネント数 203,670 356,676 5. 2 DNSグラフの概要 測定初日である2013/11/05の1日分のデータ(d = 1)と,全測定期間2013/11/05–28日の24日分の データ(d = 24)から作成したグラフのノード数,エッ ジ数,コンポーネント数の解析結果を表2に示す.こ こでコンポーネントとはDNSグラフ内の連結性分で ある部分グラフを示し,コンポーネント数はこの部分 グラフの総数である. d=1のDNS問い合わせの結果から約127万ノー ド,120万エッジ,20万コンポーネントを含むDNS グラフを作成できた.そしてd = 24では,d=1の DNSグラフの結果と比較して,全ノード数2.96倍, ドメインノード数2倍,IPノード数4倍,エッジ数 3.27倍,コンポーネント数1.75倍のDNSグラフと なった. 次に,d= 24で作成したDNSグラフ内のコンポー ネント数とコンポーネントあたりの構成ノード数を プロットしたものを図4に示す.コンポーネントと ノード数の分布は冪乗則であり,グラフ内のコンポー ネントの約75%は,ドメインとIPアドレスのノード が1つずつ,すなわちドメインの問い合わせに対す る回答が1つである組み合わせのコンポーネントで ある.一方,全ノード数に対する各コンポーネント のノード数の合計について,d=24では最大コンポー ネントに属するノードの割合が全ノードの約70%を 100 101 102 103 104 105 106 100 101 102 103 104 105 106 107 Frequency Number of nodes 図 4 コンポーネント内のノード数分布 表 3 ノード数上位 10 コンポーネント (d = 24) No. ノード数 事前情報ドメイン数 ドメイン IP Benign Malicious 1 778,279 1,832,123 5664 471 2 1 19,929 0 0 3 1 1,563 0 0 4 1,545 2 0 0 5 1,450 20 0 1 6 1 1,457 0 0 7 22 1,407 0 0 8 2 1,424 0 0 9 3 1,384 0 0 10 1,345 41 0 1 占めており,全ノードの90%以上が最大コンポーネ ントまたはノード数が6以下のコンポーネントに属 する.コンポーネントに含まれるノード数について, ノード数が上位10個であるコンポーネントのノード 数,およびコンポーネントが含む事前情報ドメイン数 を表3 (d=24)に示す. ノード数が上位のコンポーネントのうち最大コン ポーネント以外は,1つまたは少数のドメインノー ドに対して多数のIPノードが存在する場合と,複数 のドメインノードに対して少数のIPノードが存在す る場合の2種類のパターンであった.前者の場合の 特徴として,“spmode.ne.jp”や“pandaworld.ne.jp” のような日本国内の携帯プロバイダが提供するスマー トフォン向けの接続サービスに関連するドメインが コンポーネントに含まれており,国内トラフィックの 特徴の1つであると言える.また,事前情報である ドメインが含まれる割合も非常に少ない.最大コン ポーネントでは他のノード数上位コンポーネントと
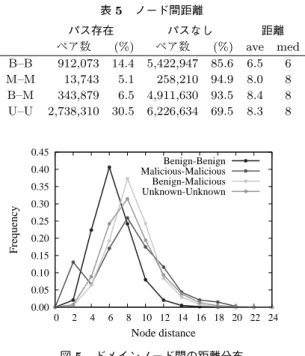
表 4 最大コンポーネントの性質 d=1 d=24 全ノード数 567,663 2,610,402 ドメインノード 349,581 778,279 IP ノード 218,082 1,832,123 エッジ数 688,706 3,095,916 平均次数 1.88 2.37 直径 28 26 比較して,ドメインノード数とIPノード数が非常に 多く,また事前情報で既知であるドメインの割合が悪 性ドメイン,良性ドメインともに多く,グラフの性質 が異なると言える. 次に,最大コンポーネントの統計的性質を表4に 示す.ただし,DNSグラフ上の全てのノード間の距 離を測定することは困難であるため,20万回ランダ ムに抽出したコンポーネント内の2ドメインのノー ド間最短経路の最大値をコンポーネントの直径とし た.d=24での最大コンポーネントはd=1のそれに 比べてグラフ全体のノード数4.6倍,エッジ数4.5倍 に増加しており,DNSグラフ全体の結果(d=1の結 果に対して全ノード数2.96倍,エッジ数3.27倍)と 比較すると最大コンポーネントの方が増加率が高い. また,表3より既知な良性,悪性ドメインも多く含ん でいることがわかる.しかし,直径はd=1とd=24 でほとんど変化せず,直径が2減少した理由としてラ ンダム抽出手法による測定に起因することが考えら れる.したがって最大コンポーネント内のネットワー クの距離は測定期間を通して大きく増加していない と言える. 5. 3 良性・悪性ノード間の距離 事前情報のあるドメインノード間の距離をd=1の グラフで測定した.Benignデータセット,Malicious データセット,および事前情報のないランダムに抽出 したUnknownドメインセットでのパスの存在有無お よび距離測定の結果を表5に示す.また, それぞれを 組み合わせたノード間の距離分布を図5に示す.図表 中のB–B, M–M, B–M, U–UはBenignノード同士, Maliciousノード同士,BenignノードとMalicious
ノードのペア,ランダムに抽出したUnknownドメイ ンノードのペアである. 表 5 ノード間距離 パス存在 パスなし 距離 ペア数 (%) ペア数 (%) ave med B–B 912,073 14.4 5,422,947 85.6 6.5 6 M–M 13,743 5.1 258,210 94.9 8.0 8 B–M 343,879 6.5 4,911,630 93.5 8.4 8 U–U 2,738,310 30.5 6,226,634 69.5 8.3 8 0.00 0.05 0.10 0.15 0.20 0.25 0.30 0.35 0.40 0.45 0 2 4 6 8 10 12 14 16 18 20 22 24 Frequency Node distance Benign-Benign Malicious-Malicious Benign-Malicious Unknown-Unknown 図 5 ドメインノード間の距離分布 表より良性ドメイン同士のペア(B–B)はノード間 平均距離が6.5であり,4種類のドメインの距離比較 ではノード間距離が最も短い.また,ノード間平均距 離では良性ドメインと悪性なドメイン(B–M)が8.4 と一番遠かったが,悪性ドメイン同士(M–M)も距離 は8.0と平均ではノード間距離が8離れている.し かし,図5を見ると,ノード間の距離分布はシング ルピークの分布となるが,悪性ドメイン同士の場合, 距離が2である頻度が15%であり,他の結果と比べ て非常に高いと言える.つまり,データセット中でこ れらの悪性ドメイン同士はIPアドレスを共有してい る.また,良性ドメイン同士(B–B)の距離は,良性– 悪性ドメイン(B–M)の距離よりも短いことから,同 種のノードの親和性が高いことを示唆している.他 方,Unknownドメイン同士のペア(U–U)では各種 ドメインが混在しているためか,ノード間の距離分布 はB–Mに近い結果となった.
6 EPTP の性能評価
本節では,はじめに事前情報データセットを用い て,EPTPおよび既存手法であるPTP, N-gramに 基づく検出手法の性能評価を行う.次に,EPTPを DNSグラフに適用した際に検出された悪性ドメイン24 0.0 0.2 0.4 0.6 0.8 1.0 -1.0 -0.5 0.0 0.5 1.0 Ratio Threshold TPR FPR 図 6 閾値依存性 について調査する. 6. 1 性能評価 はじめに,事前情報データセットを正解データと して,EPTPの検出能力を調査する.事前情報デー タセットとして,良性ドメイン2,000個,悪性ドメイ
ン1,973個を用いて,k-fold cross validation (CV) (k = 5, 10)を行った.また, 評価に利用する悪性ド
メインはDNSグラフ上で1つ以上エッジが存在する
ドメインを使用した.
はじめに,10-fold CVでのテストデータ時の悪性
ドメインと良性ドメインの脅威スコアP (x)について,
閾値の変化によるTPR (True Positive Rate)とFPR
(False Positive Rate)の結果を図6に示す.TPRの
値は−0.5と0を境に大きく上昇し,τ = 0ではTPR
が90%であった.一方,FPRはτ = 0まで変化がほ
とんどなかったがそれ以降はFPRの値も上昇してお
り,良性ドメインの脅威スコアの値が0以上である
ことがわかる.また閾値が−0.5の時,ドメインの
TLDがbiz,net,infoであり,SLD部分にランダム
な文字列を含むDGAドメインが多数含まれている
ことを確認した.
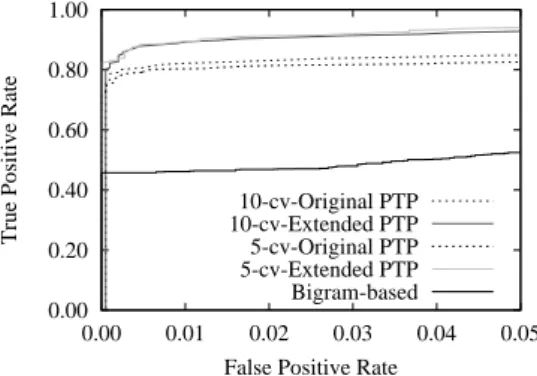
次 に ,Receiver Operatorating Characteristic (ROC) カーブによる,提案手法 (EPTP),既存手 法(PTP),N-gramを用いた既存手法[17] [26]の性 能評価結果を図7に示す.10-fold CVのROCカー ブでは,EPTP手法では良性ドメインの事前情報を利 用することで誤分類率が低くなり,FPRが0.016の とき分類率は,PTPのTPRが0.827であったのに 0.00 0.20 0.40 0.60 0.80 1.00 0.00 0.01 0.02 0.03 0.04 0.05
True Positive Rate
False Positive Rate 10-cv-Original PTP 10-cv-Extended PTP 5-cv-Original PTP 5-cv-Extended PTP Bigram-based
図 7 ROC 曲線 (k-fold cross validation)
10-1 100 101 102 103 104 103 104 105 106
Time (s) / Memory (MiB)
Number of nodes Memory (MiB) Time (s) 図 8 EPTP 手法のメモリ使用量と計算時間 対して,EPTPのTPRが0.904と,提案手法の優位 性を示している.また,5-fold CVと10-fold CVの ROCカーブを比較すると,既存手法は10-fold CV の分類率が高いが,提案手法では分類率が同程度と なった.N-gramを用いた既存手法と比較しても提案 手法は約40%ほど性能が高く提案手法が有効である ことがわかる. さらに,ノード数をランダムに1,000ノード,10,000 ノード,100,000ノード,1,000,000ノード選択して 計測したEPTP手法のメモリ使用量および計算時間 を図8に示す.測定にはコモディティハードウェア
(CPU: Intel Xeon X5675 3.07GHz; Memory 32GB)
を使用した.図よりノード数が10万を超えてもメモ
リサイズの増加は限定的であるが,計算時間が大きく なることが確認できる.
表 6 推定悪性ドメイン例とその脅威スコア ドメイン名 スコア 4c4brcwmg.biz -0.978 info-ezweb-ne-jp.info -0.75 poohpoohhany.info -0.680 bvncm-kdkdkgree.jp -0.538 nomoguz.su -0.344 kisjehmbga.jp -0.241 google-play.jp -0.2 図 9 推定悪性ノードの可視化 (黒: ドメインノード, 白: IP ノード,灰色: 事前情報の悪性ドメイン ノード) 6. 2 未知の悪性ノードの推定 最後に,DNSグラフに含まれる未知の悪性ノード の推定を行う.d=24のDNSグラフに対してEPTP 手法を適用した各ノードの脅威スコアについて,図6 より,FPRが0である境界をもとに閾値をτ =−0.1 と設定して事前情報のない未知のノードを検出する. このとき,ノードの脅威スコアが−0.1以下である 場合は,そのノードを危険性の高いドメインまたは 危険性の高いIPアドレスであると判別してカウント した.その結果,危険性の高いドメインの数は2,170 個,危険性の高いIPアドレスの数は12,884個であっ た.危険性の高いドメインとその脅威スコアの例を表 6に示す. また,EPTP手法(τ =−0.1)で推定した悪性ノー ドを含むコンポーネントの可視化結果の例を図9に 示す.ただし,最大コンポーネントは可視化が困難 であるため図中には含まれない.図9上で,黒点は ドメインノード,白点はIPノード,灰色の点は事前 情報で悪性なドメインであるノードをそれぞれ表す. EPTP手法で推定した悪性ノードを含むコンポーネ ントでは,複数の名前解決関係と事前情報のあるノー ドから,複数の未知なIPアドレスノードおよびドメ インノードへの脅威スコアの伝播を実現している.こ のようなコンポーネントの構造的特徴として,1つの IPノードから複数のドメインノードに対してエッジ が存在する場合や,少数のドメインノードから多数 のIPノードに対してエッジが存在し,かつ一部のIP ノードを共有する場合など,スター型のコンポーネン ト構造が複数存在する.
7 考察
7. 1 既知な良性・悪性ドメインの違い IN ドメイン,KEEP ドメイン,OU Tドメイン を新たに定義することで,悪性ドメインではデータ セットでのドメインの出現頻度の変化が大きく,稀に しか出現しないことがわかった.一方で良性ドメイ ンはデータセット内に一定以上出現することがわか り,既知な良性・悪性ドメインでの違いが明らかで ある.また,6. 2章においてEPTP手法で未知の悪 性ノードとして推定したドメインSuspiciousのIN ドメイン数,KEEP ドメイン数,OU T ドメイン数 の結果(図3 (d),表1)から,Suspiciousドメイン はALLドメインとINドメイン,KEEPドメイン, OU Tドメインの割合が近く,INドメイン,KEEP ドメイン,OU Tドメインの平均割合の特徴のみでは, Suspiciousドメインが悪性ドメインに近いか判別は 困難であると言える.これは,M aliciousドメイン にはDGAドメインが多いのに対して,表6で示され るように,Suspiciousドメインには必ずしもDGA ドメインでないドメインが含まれていることが予想 される.次に,DNSグラフ上で事前情報であるドメ イン同士のノード間距離を測定することで表5およ び 図5に示したノード間距離分布を得た.この結果 から, 良性ドメイン同士の距離,悪性ドメインの距 離2の割合が高いことは同種親和性の仮定が成り立っ26 ていると言え,提案手法のベースとなるPTPの考え 方が有効であることを示唆している.ドメイン同士 の距離について,ノード間距離4以上では悪性なド メインと良性なドメインを距離のみで判別すること は各ペアの割合が一定以上であるため困難であるが, 各ノードの脅威スコアを計算をすれば,未知なノード を判別することが可能となる. 7. 2 DNSグラフと最大コンポーネント DNSのドメイン問い合わせとその回答であるIPア ドレスからDNSグラフを作成すると, d=24のデータ セットでは約377万ノード,392万エッジから構成さ れる巨大なDNSグラフが得られた.得られたDNS グラフの中には日本のネットワークの特徴を表してい るコンポーネントが複数含まれていた.しかし,DNS グラフには非常に偏りが存在し,全ノードの69%は 1つの最大コンポーネントを構築していた.最大コン ポーネントでは多数のドメインとその回答であるIP ノードが含まれているグラフとなっており,このよう な複雑なグラフ構造の場合でも事前情報のノードが 複数含まれていれば,脅威スコアを伝搬することで悪 性なノードの判別に有効である.さらに時系列変化を 観測すると最大コンポーネントの直径がほとんど増 加していないことから,最大コンポーネントは様々な ドメインノードやIPノードを含むが,ランダムにコ ンポーネント内のネットワークサイズが増大するの ではなく,コンポーネント内のリンクがより密になる と考えられる.逆に,既知の良性・悪性ノードが含ま れないコンポーネント内のノードの悪性・良性推定は 原理的に不可能となる.そのため,事前情報として与 える良性・悪性ノードは素性のことなる多種のデータ セットから構成される方が効果的であると言える. 7. 3 EPTP手法の性能評価 先行研究[9]の既存手法であるPTPに,本研究で は良性ドメインの事前情報としてAlexaのトップラン キングのデータセットを使用することで,10-fold CV での判別性能の評価において,同じFPR (=0.016) で既存手法と比較して分類性能が8%向上し,悪性ド メインの分類率は90.4%となった(図7) .この性能 評価では,事前情報として良性なドメインノードを 追加したことで閾値を変化した際の誤分類が減少し, EPTP手法の分類性能が高くなったことがわかる.ま た,図6から閾値τ = 0を境に悪性なドメインと良 性なドメインを分離することができる. さらに,脅威スコアをDNSグラフ上のノードで伝 搬させることで,ドメインの問い合わせと回答結果 だけでは明らかでないノードからノードへの脅威ス コアの伝搬と各ノードの脅威スコアを効率的に計算 し,危険性の高いドメインの警告をするアラートシ ステムとしての運用が可能である.しかし,事前情報 が正しくないと脅威スコアの伝搬結果において誤判 別する可能性があり,それを防ぐためには信頼できる 事前情報データセットを利用することが重要である. また,図8より,ノード数が10万ノードを超えると 計算時間が急激に増加するため,今後の課題として, DNSグラフのスパースな部分グラフを分解すること で計算時間を減少させる等の改善が必要である. 5-fold CVと10-fold CVの結果から,事前情報で あるデータセットの一部が欠如した場合でも,残りの 事前情報のみで欠如した部分のドメインを特定でき, 与えられた事前情報から未知なる悪性なドメインの 特定が可能であると言える.今回は図6より,閾値τ を−0.1と設定することで危険性の高いドメインを新 たに2,170個発見した.これらのドメイン (表6)に ついて,全体的な傾向としてランダムな文字列で構 成されたDGAドメインの数が多く,スパムメールや ボットネットと関連するドメインが含まれていた.し かし,“google-play.jp”のような文字列は良性なドメ インのように見えるが実際はスパムメールに利用さ れているドメインである場合など,N-gramによる判 別手法では判別できないドメインも,EPTPでは判 別可能である. また,悪性なノードを含むコンポーネントの可視化 結果(図9)では,スター型などの特徴的なグラフ構 造がスパムメールやボットネットの悪性な攻撃と関連 しており,例えば,スター型の中心であるIPアドレ スは悪意のある攻撃者が用意したサーバのIPアドレ スであり,多数のドメインノードは攻撃用に取得した ドメインを表していると言える.このような攻撃をリ
アルタイムで可視化することで,ネットワーク管理者 は悪性な攻撃に関わるコンポーネントを早期に発見, 対処することができる.
8 結論と今後の課題
本研究では,バックボーンDNSトラフィックデー タ中のAレコードのドメイン問い合わせとその回答 結果に注目し,事前情報となる悪性ドメインと良性ド メインを用いたPTPに基づく悪性ドメインの検出手 法の提案と評価を行った. その結果,悪性ドメインと良性ドメインではドメ インの出現頻度,ノード間距離,脅威スコアに特徴的 な違いがあり,DNSグラフは巨大な1つのコンポー ネントとそれ以外の多量の小さなコンポーネントか ら構築されることがわかった.また,提案手法であ るEPTP手法をDNSグラフに適用することで,既 存手法と比べて低い誤分類率で,悪性なドメインを 90.4%分類可能であり,新たに危険性の高いドメイン 2,170個を発見することができた. 今後の課題としては,Maliciousデータセット以外 の悪性ドメインデータセットを追加することで,異な るタイプの悪性ドメインを検出することや,Alaxaド メイン以外の良性ドメインデータを構築することで, 精度の向上,特に孤立したコンポーネントへの推定精 度向上を目指す.謝辞
本研究は,科研費(15H02699),および,総務省 戦 略的国際連携型研究開発推進事業及び欧州連合(EU) FP7からの助成(助成番号608533:NECOMA)によ り得られた成果である. 参 考 文 献[ 1 ] Alexa: Alexa [Online], http://www.alexa.com/ topsites/.
[ 2 ] Antonakakis, M., Perdisci, R., Dagon, D., Lee, W. and Feamster, N.: Building a Dynamic Repu-tation System for DNS, in Proceedings of USENIX security symposium, 2010, pp. 273–290.
[ 3 ] Antonakakis, M., Perdisci, R., Lee, W., Vasiloglou II, N. and Dagon, D.: Detecting Mal-ware Domains at the Upper DNS Hierarchy, in Proceedings of USENIX Security Symposium, 2011,
pp. 411–426.
[ 4 ] Antonakakis, M., Perdisci, R., Nadji, Y., Vasiloglou II, N., Abu-Nimeh, S., Lee, W. and Dagon, D.: From Throw-Away Traffic to Bots: De-tecting the Rise of DGA-Based Malware, in Pro-ceedings of USENIX Security Symposium, 2012, pp. 491–506.
[ 5 ] Arkko, J., Cotton, M. and Vegoda, L.: IPv4 Address Blocks Reserved for Documentation, RFC 5737, January 2010.
[ 6 ] Bar, A., Paciello, A. and Romirer-Maierhofer, P.: Trapping botnets by DNS failure graphs: valida-tion, extension and application to a 3G network, in Proceedings of TMA’13, IEEE, 2013, pp. 393–398. [ 7 ] Bilge, L., Sen, S., Balzarotti, D., Kirda, E. and
Kruegel, C.: EXPOSURE: a passive DNS analy-sis service to detect and report malicious domains, ACM Transactions on Information and System Se-curity (TISSEC), Vol. 16, No. 4(2014), p. 14. [ 8 ] Brownlee, N., Claffy, K. and Nemeth, E.: DNS
measurements at a root server, in Proceedings of GLOBECOM’01, Vol. 3, IEEE, 2001, pp. 1672– 1676.
[ 9 ] Carter, K. M., Idika, N. and Streilein, W. W.: Probabilistic threat propagation for malicious activ-ity detection, in Proceedings of ICASSP’13, IEEE, 2013, pp. 2940–2944.
[10] Castro, S., Wessels, D., Fomenkov, M. and Claffy, K.: A Day at the Root of the Internet, ACM SIGCOMM Computer Communication Re-view, Vol. 38, No. 5(2008), pp. 41–46.
[11] Chau, D., Nachenberg, C., Wilhelm, J., Wright, A. and Faloutsos, C.: Polonium: Tera-scale graph mining and inference for malware detection, in Pro-ceedings of SIAM International Conference on Data Mining, Vol. 2, 2011.
[12] Gao, H., Yegneswaran, V., Chen, Y., Porras, P., Ghosh, S., Jiang, J. and Duan, H.: An empirical re-examination of global DNS behavior, in Proceedings of SIGCOMM’13, ACM, 2013, pp. 267–278. [13] Hao, S., Feamster, N. and Pandrangi, R.:
Mon-itoring the initial DNS behavior of malicious do-mains, in Proceedings of IMC’11, ACM, 2011, pp. 269–278.
[14] Ishibashi, K. and Sato, K.: Classifying DNS Heavy User Traffic by using Hierarchical Aggregate Entropy, in Proceedings of World Telecommunica-tions Congress (WTC’12), 2012, pp. 1–6.
[15] Ishibashi, K., Toyono, T., Hasegawa, H. and Yoshino, H.: Extending black domain name list by using co-occurrence relation between DNS queries, IEICE Transactions on Communications, Vol. 95, No. 3(2012), pp. 794–802.
[16] Jiang, N., Cao, J., Jin, Y., Li, L. E. and Zhang, Z.-L.: Identifying suspicious activities through DNS failure graph analysis, in Proceedings of ICNP’10, IEEE, 2010, pp. 144–153.
To-28
wards classification of DNS erroneous queries, in Proceedings of AINTEC’13, ACM, 2013, pp. 25–32. [18] Malware Domain Blocklist: DNS-BH Malware Domain Blocklist, http://www.malwaredomains. com/.
[19] Manadhata, P. K., Yadav, S., Rao, P. and Horne, W.: Detecting Malicious Domains via Graph In-ference, in Proceedings of ESORICS’14, Springer, 2014, pp. 1–18.
[20] Osterweil, E., McPherson, D., DiBenedetto, S., Papadopoulos, C. and Massey, D.: Behavior of DNS’Top Talkers, a. com/. net View, in Proceedings of PAM’12, Springer, 2012, pp. 211–220.
[21] P. Vixie: Traltime URI Blacklist, http://uribl. com/.
[22] Perdisci, R., Corona, I., Dagon, D. and Lee, W.: Detecting malicious flux service networks through passive analysis of recursive DNS traces, in Proceed-ings of ACSAC’09, IEEE, 2009, pp. 311–320. [23] Schiavoni, S., Maggi, F., Cavallaro, L. and
Zanero, S.: Phoenix: DGA-based botnet track-ing and intelligence, in Proceedtrack-ings of DIMVA’14, Springer, 2014, pp. 192–211.
[24] Wessels, D. and Fomenkov, M.: Wow, that’s a lot of packets, in Proceedings of PAM’03, 2003. [25] Xuebiao, Y., Xin, W., Xiaodong, L. and
Baop-ing, Y.: DNS measurements at the .CN TLD servers, in Proceedings of FSKD’09, Vol. 7, 2009, pp. 540–545.
[26] Yadav, S., Reddy, A., Reddy, A. and Ranjan, S.: Detecting algorithmically generated malicious do-main names, in Proceedings of IMC’10, ACM, 2010, pp. 48–61.
[27] Yadav, S. and Reddy, A. N.: Winning with DNS failures: Strategies for faster botnet detection, in Proceedings of SecureCom’12, Springer, 2012, pp. 446–459. [28] 石橋圭介, 豊野剛, 佐藤一道, 岩村誠: DNS クエリ グラフを用いた悪性ドメイン名リスト評価, 情報処理学 会研究報告. IOT, No. 21(2009), pp. 19–24. 風 戸 雄 太 2015年早稲田大学大学院基幹理工学 研究科情報理工学専攻修士課程修了. 同年,日本電信電話株式会社入社.イ ンターネットトラフィック解析,ネッ トワークセキュリティに興味を持つ. 福 田 健 介 1999年,慶應義塾大学大学院理工学 研究科計算機科学専攻後期博士課程修 了(博士(工学)).1999–2005年,日 本電信電話株式会社.2006年より国 立情報学研究所アーキテクチャ科学研究系准教授.こ の間,ボストン大学訪問研究員(2002),科学技術振興 機構 さきがけ研究員(2008–2012;兼任),南カリフォ ルニア大学/情報科学研究所訪問研究員(2014–2015). インターネットトラフィック測定・解析およびイン ターネット科学に関する研究に従事. 菅 原 俊 治 1982年早稲田大学大学院理工学研 究科数学専攻修士課程修了. 同年,日 本電信電話公社武蔵野電気通信研究 所基礎研究部入所. 1992–1993年,マ サチューセッツ大学アマースト校客員研究員. 現在, 早稲田大学理工学術院基幹理工学研究科情報理工・情 報通信専攻教授. 知識表現,学習,分散人工知能,マル チエージェントシステム,インターネットなどの研究 に従事. 博士(工学). 情報処理学会,日本ソフトウエ ア科学会, 電子情報通信学会,人工知能学会, ISOC,