Abstract
Lacking of speech resources with adequate labeling information is a main obstruction on speech and prosody research in Thai. This paper proposes an initiative development of Thai speech corpus with plenty prosodic and linguistic information to provide an essential resource for extending knowledge in speech and prosody research area. In this paper, we focus on an enhancement of prosodic labeling by using multi-level prosodic information. The design and the construction of this corpus are also described. After construction, preliminary analyses of this corpus are given to provide overview characteristics of the corpus. Furthermore, the problems and suggestions on the speech construction and prosodic labeling are discussed.
1
IntroductionProsody is a complicated component in speech communication. To analyze and model prosody clearly, a well-designed speech corpus is minimally required. Not only speech data themselves, labeling information is another essential data for further deep analysis. Concerning a new language, different languages contain different linguistic information and prosodic characteristics.
Especially in tonal languages, they extensively use prosodic components for communication compared to non-tonal languages. Among tonal languages, Thai is a tonal language that has complication on both prosody characteristics and text analyses. Furthermore, no Thai speech corpus with prosodic description is presently existed. Thus, this paper focuses on speech corpus with plenty prosodic and linguistic labeling for analyzing and modeling prosody.
In a speech corpus, tagging of both linguistic and prosodic information are required. Usually, tagging step takes longer time than collecting speech contents. Corpus tagging is a language-dependent work, which requires experts to accomplish, especially, to label prosodic information. For major world-languages used by numerous numbers of users such as English, Chinese, Japanese, a
number of efforts on defining and standardizing of tagging methodologies have been proposed. By using standard procedures and criteria, a new speech corpus can be quickly constructed to extend the size and the varieties of contents for wider and more efficient applications. In contrast, minor world-languages with either small number of users or less influence in the worldwide communication, such as Thai, rarely have those kinds of standards, especially, prosodic- related ones. To analyze and model prosodic characteristics, a proper collection of sufficient speech samples with adequate labeling information is necessary. This kind of corpus is still lacked for Thai.
Thus, this paper aims at a pioneer development of Thai speech corpus with plenty prosodic and linguistic information for Thai prosodic studies. The contents of this paper are organized in the following orders. Section 2 reviews the existing and ongoing Thai speech corpora and prosodic labeling. Related issues on Thai speech corpus development are discussed in Section 3. To deal with the development issues, Section 4 mentions the details of this Thai prosodically enriched speech corpus. In Section 5, preliminary analyses of the speech corpus are performed to evaluate the corpus. Section 6 describes the problems and related issues in this development. Finally, conclusions and future works are described in Section 7.
2
A review on Thai Speech corporaIn the past decades of Thai speech research, only few of speech corpora have been available and published.
Furthermore, available prosodic-labeled corpora could be rarely found. Primitively, ThaiARC [1-3], the first published and on-line speech database, simply collected a wide range of Thai speech data for linguistic research including Thai regional dialects, Thai regional folktales, Thai poetries, and Speech styles. However, the speech database contained only parallel text transcriptions, but, no other detail information and segmentation. In the meantime, a number of speech databases were also mentioned in
A development of Thai prosodically enriched speech corpus Chatchawarn Hansakunbuntheung
†and Yoshinori Sagisaka
†† GITI/Language and Speech Science Research Laboratories, Waseda University, Japan [email protected], [email protected]
3-1
査読論文Refereed Papers
published works i.e. Thai digit speech database for speaker identification [4, 5]. Nevertheless, these databases were available with only common tagging i.e. word labels.
Since the significances and the requirements of speech research increase, several large speech corpora with a number of speakers have been introduced e.g. NECTEC- ATR [6], LOTUS [7], NECTEC-TRUE [8], Thai telephone speech (GlobalPhone) [9]. With the advantages of Automatic Speech Recognition (ASR) framework [10] and Machine Learning technologies [11], they provided faster and automatic methods for speech segmentation and information labeling. By using these sophisticated tools, phone labels and parts of speech (POS) were automatically assigned for the previous mention corpora [6-9], then, they were manually checked by human for more precise results.
Nevertheless, no prosodic and detailed linguistic information were labeled in these corpora.
Because of time-consuming problem in construction, only phonetic transcription and some board linguistic information were labeled in most existing corpora. Only a few works made an effort to include prosodic information in their corpora. An early-stage speech data with prosodic information then were described in the studies of Thai intonation analysis [12]. However, the speech data only contained stress and tone labels. Afterward, “TSynC-1”, the first Thai speech corpus with prosodic information, was formally published and distributed [13]. It was designed for speech synthesis purpose using Thai prosodic and linguistic information, lexical phone and tone variations as considering criteria. For labeling information, not only phonetic transcriptions were tagged in this corpus.
Acoustically prosodic information such as F0 contour and duration was also included. Nonetheless, no detailed prosodic information was concerned. The later versions of TSynC-1 focused on optimizing the text and speech selection methods to reduce the size of the corpus efficiently [14, 15]. In another word, the later visions of the corpus did not incorporate any additional prosodic i n f o r m a t i o n a n y m o r e . T h u s , t h e d e v e l o p m e n t o f prosodically labeled Thai speech corpus is still an open topic to proceed.
3
Issues on speech corpus development 3.1 Problems on Thai text and speechresources
In Thai speech research, most researchers commonly face the same difficulties from lacks of available text and speech resources. The main problem is the lack of large and public text database caused by rare contribution from copyrighted materials. At the present, there is an on-going National Thai text corpus development project that designed to collect a large public Thai text corpus of 80 million
words [16]. However, it is just at the early state of collection. Since this paper focuses on the rich labeling information, we are interested to find an available text and speech data for initiative setting up a speech corpus. In this case, TSynC-1 speech corpus is an interesting choice because of its public sharing for research and its preliminary design for Thai linguistic and prosodic coverage. Finally, we adopted the TSynC-1 corpus as an initial text and speech resources for building the proposed corpus. However, this speech corpus still misses some rare phone-pairs caused by the lack of available texts.
3.2 Problems in linguistic and prosodic labeling
In term of prosody, Thai is obviously categorized as a Tonal language by its utilization of tone to distinguish lexical meaning of a word. Furthermore, it is defined as a stress-timed language by its timing patterns in syllabic level [12]. With the combination of both tonal and stress-timed language, Thai shows more complicated prosodic characteristics than general tonal or stress-timed languages.
Therefore, Thai tends to have more difficulties in labeling prosodic information. To prepare adequate labeling information for future research, this work proposes to label detailed information in various prosodic and linguistic levels.
Another issue to consider is inexplicit boundary in Thai writing system. In English, it uses a space to mark word boundary, and, a full-stop mark to indicate the end of sentence. In contrast, Thai writing system has no explicit boundary marks, such as word-break space or full stop, for specifying word or phrase boundaries. In Thai, we can easily indicate phone and syllable boundaries. However, a lexical word in Thai can be formed from several words stringed together as a very long compound noun without space for separation. More interestingly, any long compound noun may be pronounced with prosodically pauses in the middles. To label any information at a specific speech section, we need to know tangible boundary locations in speech signal of the section. Thus, this development proposes to take prosodic boundaries into consideration.
4
A Thai prosodically enriched speech corpusThis speech corpus is designed to provide various levels of information covering acoustic, linguistic and prosodic levels. To build the corpus, Fig. 1 shows an overview of dataflow for preparing and building the corpus.
In the first step, we select text sentences from the resources for building the corpus. From the speech resources, corresponding speech data and phone labels of the candidate sentences are used for labeling higher-level
linguistic boundaries, i.e. syllable, word, stress groups (SG) and breathe groups (BG), on speech data. In the meantime, acoustic information, i.e. fundamental frequency (F0) and energy curves are extracted from speech data. Using linguistic labels and F0 data, tone group (TG) and intonation phrase (IP) are determined.
4.1 Text and speech resources
The content of the “TSynC-1” speech corpus contains narrative and writing style text from a standard Thai text corpus, namely ORCHID [17]. Its contents cover various topics from Thai Encyclopedias and academic reports. The text data were transcribed phonetic transcription by automatic probabilistic generalized left-to-right (PGLR) parser [11], then, manually corrected by linguists. All speech utterances from TSynC-1 were fluently read by an announcer-experienced female speaker. The recording environment was established using a dynamic microphone (SONY F-720) at sampling rate 44.1 kHz with 16 bits/
sample in quiet room condition. The phonetic transcription was aligned to the utterances by an automatic Hidden- Markov-Model (HMM) based phone aligner [10], then, were manually adjusted.
4.2 Data selection
To set up this development quickly for further research, we started with a size-optimized data set that covers all available phones and tones. Thus, we selected the suitable sentences by considering the minimum sentence set that covers all phones, tones, phone pairs, and tone pairs in the TSynC-1 corpus. Two scoring criteria i.e. Phone-pair
and Tone-pair scores were calculated for each sentence. In each sentence, a Phone-pair score provides a priority weight for a sentence by considering probabilities of constituent phone pairs of the sentence, and, a Tone-pair score gives a priority weight for a sentence by considering probabilities of constituent tone pairs of the sentence:
, ,
( , , , ) ( )
= PhPair Diff Phpair TPair Diff TPair
Cand f S N S N 1
(
,)
log ( )
=
= −
∑
M PhPair mPhPair m
P S
1
2
(
,)
log ( )
=
= −
∑
N TPair nTPair n
P S
1
3
Where Cand represents candidate sentence, SPhPair and STPair r e p r e s e n t P h o n e - p a i r e d a n d To n e - p a i r e d s c o r e s , respectively, PPhPair, m and PTPair, n are probabilities of the mth phone pair and the nth Tone pair that occur in the considering sentence, respectively, their probabilities are based on the total phone pairs and total tone pairs in the whole TSynC-1 speech corpus, NDiff, PhPair and NDiff, TPair are Fig. 1 Overview of the speech corpus development.
Text data
Speech data Phone
labels
Sentence selection
Syllable, Word, Breath group
labeling Lexical stress
assignment
F0 extraction
Tone group labeling
Stress group labeling
Intonation phrase labeling Text and speech
resources
Initial calculation
NDiff ,PhPair
,
SPhPair,
NDiff ,TPair,
STPair{ } (
PhPair)
c
S c =
argmax
{ } (
TPair)
c
S c =argmax
New phone pairs ?
{ } (
Diff PhPair)
c
N c =
argmax
,{ } (
DiffTPair)
c
N c =argmax ,
Candidate list (Cand)
End {
c} >1?
{
c} >1?
New tone pairs ? Y
N Y
Y N
N
N
Y
Fig. 2 Dataflow of the selection function (.).
the number of distinct phone pairs and the number of distinct tone pairs in the considering sentence, f (.) is a heuristic function for selecting sentence containing the best score.
Fig. 2 shows the dataflow of the sentence selecting function f (.), where {c} represents the temporary set of candidate sentences during calculation. The selection starts from calculating NDiff, PhPair, SPhPair, NDiff, TPair and STPair of all sentences. Due to the number of possible phone pairs larger than the number of possible tone pairs, the selection function f (.) gives a priority order that ranging from the highest to the lowest priorities to NDiff, PhPair, SPhPair, NDiff, TPair
and STPair measures, respectively. In other word, all phone pairs will be obtained first, then, the missing tone pairs were selected in the following step. By including all phone- pairs, all phones were definitely included. We used the same criteria for including tones and tone pairs. The selection will continue until there is no new phone pair and tone pair found. Then, it recursively searches all sentences to selects the sentence with the highest value of the measures in priority order in each cycle.
4.3 Acoustic data extraction
Before labeling prosodic information such as tone group, we required actual acoustic values of the prosodic information to map relationship between abstract labels and actual speech signal. This work included two acoustic information into consideration i.e. fundamental frequency (F0) and speech energy. The sentences selected from Section 4.2 were extracted acoustic information using
shifting windows to sample speech data every 10 ms.
4.4 Prosodic information labeling
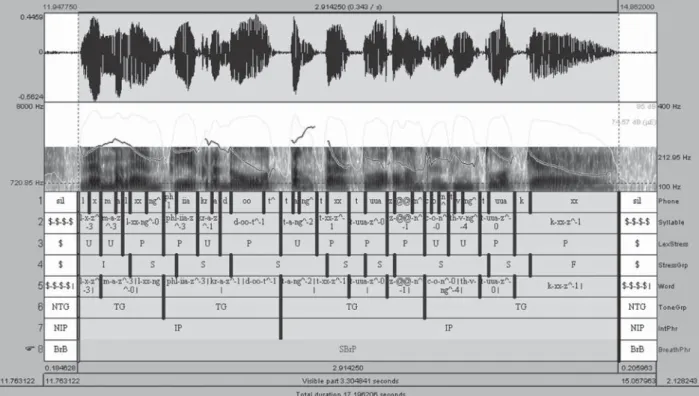
Rather than general lexical labeling information such as phone segment, word segment, this work also provided more informative labeling of multi-level prosodic information using acoustic information to describe prosodic grouping and characteristics of speech data. As mentioned in Section 3.2, we included this prosodic grouping information to provide an alternative way for describing speech grouping. Three kinds of prosodic labeling were considered in this work that are breath group, intonation phrase and tone group. Fig. 3 shows a snapshot of speech data with multi-level prosodic and linguistic labeling. The prosodic and linguistic labels were tagged in separated layers sorted from the smallest segment (phone) to the largest segment (breath group).
4.4.1 Tone group
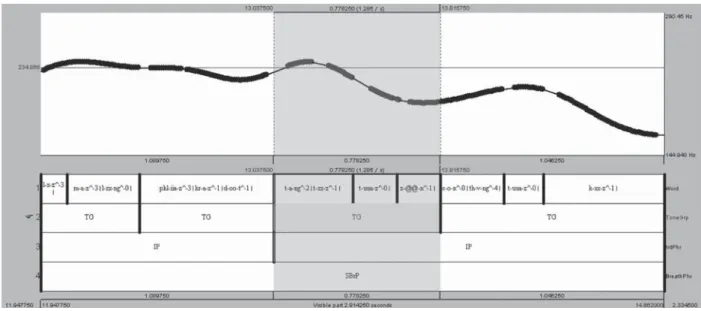
Tone group (TG) was defined as a minor F0 contour group of speech that normally corresponded with prosodic words, however, it needed not to correspond with lexical words. In some case, boundaries of the unit could occur in the mid of the words. The marking points were considered from F0 reset points that started from the current reset point to the next reset point of minor F0 contours. Fig. 4 shows an example of marking a tone group. To detect the speech unit, first, speech rate in syllable per second was estimated by the mean duration of the entire syllables in corpus. Then, extracted F0 contour was filtered by a low-passed filter
Fig. 3 An example of speech data with linguistic and prosodic labels.
using cut-off frequency of 1/4 of the estimated speech rate to filter out underlying fine prosodic structure and noise. As the result, we obtained only major F0 contour. To simplify the contour, the filtered F0 contours were stylized using Praat [18] to remove any less insignificant point that distances from the connecting line between its two adjacent F0 points less than 1 semitone. Peaks of stylized contours were considered as pitch accent at F0 reset points. Then, speech unit boundaries were marked at the boundaries of discontinuity points of the nearest primary stressed syllable, usually valley points, of the stylized F0 contour.
4.4.2 Intonation phrase
Intonation phrase (IP) here was defined as a major F0 contour group of speech that normally corresponded with noun or verb phrase, grammatical phrase, or breathe group, and always occurred in the same breath group. The marking points were considered from F0 reset points that started from the current reset point to the next reset point of major F0 contours. Another characteristic that normally found at the last syllable of the intonation phrase was very long period syllable with large F0 declining. Fig. 5 shows an example of intonation marking and its declining F0 characteristic at the end of intonation phrase. To mark the speech units, first, the low-passed F0 contours of tone group from section 4.4.1 were adopted as base contour. The F0 reset points were automatically detected at the positive transition from valley to the highest local peak. Another criterion was detecting the valley of the filtered F0 contours to find the syllable that longer than statistic outlier of syllable duration. Then, the nearest tone group boundaries of the points were selected as phrase boundaries.
4.4.3 Breath group
Breath group (BG) is a speech segment uttered in a
single expiration of a breath without in-segment pause.
Leading and following silent pauses were used to detect breath groups. On marking step, the boundaries of speech units were automatically taken from boundaries of the phones at the initial and final positions of the breath group.
4.5 Linguistic information labeling
To cover all levels of speech segments ranging from phone level to breath-group level, we also provided linguistic labels of smaller speech segments i.e. phone, syllable, stress group and lexical word boundary information. Since the phone, syllable and lexical word boundaries could be directly observed by their definitions, only stress group marking was briefly mentioned.
Stress group was defined as a syllable group that contained only one stressed syllable. Linguistically, Thai is defined as left-heading type which stressed syllable located at the leftmost position. On marking step, stress group boundaries were automatically taken from boundaries of Fig. 4 Tone group and Intonation phrase labeling.
Fig. 5 An example of marking intonation phrase.
the initial phones of a stressed syllable and the final phone of the syllable before the next stressed syllable. In addition, marking boundaries sometimes might occur in the mid of lexical word because of Thai has no explicit definition of word and several words could be merged to form a long compound word.
5
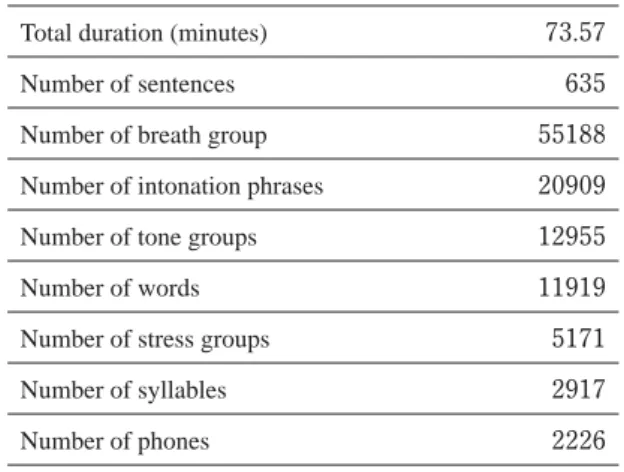
Corpus analysisAfter sentence selection, 635 phonetically balanced sentences were selected from TSynC-1 corpus. Table 1 shows a statistical overview of the corpus. From the preliminary analysis, we found 11 missing rare phone caused by insufficient text resources, thus, this corpus contained 78 Thai phones of the total 89 Thai phones. Fig.
6 shows tone distribution in this corpus and it shows that all tones were stored in this corpus. The figure shows that the highest occurrence of Thai tones in this corpus was the mid tone which has flat and less movement in F0 contours.
To observe the timing differences between stressed and unstressed syllables, histogram analyses of phone and syllable durations between stressed and unstressed syllables were evaluated. Fig. 7 obviously shows the distinction between two syllable-duration distributions of stressed and unstressed syllables. In Fig. 8, the similar results of the distinction between two distributions of phone duration in stressed and unstressed syllables have been also found. The results in these two figures confirmed the stress characteristic in Thai speech. Another Thai stress characteristic that we expected to be found was that any syllables at phrase-final positions were always stressed.
When considering Fig 7 in detail, we also found a small sub-distribution of syllable duration that only found in the distribution of stressed syllables. This sub-distribution corresponded to the syllables at phrase-final positions. Also, this sub-distribution was found in case of the phones in stressed syllables as shown in Fig. 8.
Table 2 shows timing statistics, i.e. mean and standard deviation (SD), of all speech groups. These results present
that the lengths of acoustic-based speech groups, i.e. tone group and intonation phrase, tend to be longer than those of lexical-based speech groups, such as word and stress group.
Table 3 and Table 4 show that the maximum number of phones and syllable in a word group are more than those of a tone group. These results supported that words might contain more than one tone group. In another word, a lexical word might contain more than one prosodic word.
These results supported the use of prosodic groups to label speech, instead of using lexical boundary.
6
DiscussionsFrom the developing of this corpus, we found the following issues should be considered for the future works i.e. the effort in data preparation, labeling problems, the number of speaker. Concerning to time and efforts spent in developing, TSynC-1 speech corpus, which was the base corpus of this work, took more than two years to finish including speech collecting segmentation and labeling. It quite consumed time and efforts to accomplish the whole corpus. Instead of spending efforts on manual construction, we spent most time and efforts on preparing automatic methods on speech analysis, segmentation and labeling to establish this speech corpus as a pilot corpus for further development and research. By focusing on fast and automatic establishment, we spent about six months for analyzing speech data and developing automatic methods for speech segmentation and labeling, but, we spent less than a week for segmentation and labeling a corpus. Thus, this establishment can rapidly provide a pilot corpus for further fine tuning, expanding the corpus, and more sophisticated development in the future.
Considering the labeling problems, we found some variations in inter-sentence speech rates, and, some contextual phones and tones could cause some misaligning on prosodic groups provided by the automatic labeling method. Thus, these effects should be taken into account in the future development.
Concerning the effects of the number of speakers in this corpus, an appropriate number of speakers depends on the purpose of each work. As mentioned in the Section 1, this corpus development provided a pilot of Thai prosodic- labeling speech corpus, and, automatic schemes for the development of a prosodic-labeling speech corpus. By supporting the aims, this work can applies to prosodic- related research in two aspects. The first aspect is providing a speech corpus for speaker-dependent prosodic- characteristic research such as speaker-mimic speech synthesis, individual speaking-characteristic analysis and speech verification system using speaker-dependent prosodic features for security application. These kinds of research use speaker-dependent data as a main resource.
Table 1 General summary of the speech corpus.
Total duration (minutes) 73.57
Number of sentences 635
Number of breath group 55188
Number of intonation phrases 20909
Number of tone groups 12955
Number of words 11919
Number of stress groups 5171
Number of syllables 2917
Number of phones 2226
Table 2 Timing statistics of speech groups.
Speech group Mean duration (s) SD of group duration (s)
Phone 0.080 0.055
Syllable 0.211 0.110
Stress group 0.341 0.128
Word 0.370 0.283
Tone group 0.854 0.307
Intonation phrase 1.513 0.819
Breath group 1.983 1.052 0-2 0 2 4 6
200 400 600 800 1000
Syllable duration (Z-score)
Frequency
All syllables Stressed syllables Unstressed syllables
Fig. 7 The histogram of syllable duration.
Mid Low Falling High Rising 0
0.5 1 1.5
2x 104
Tone
Frequency
Fig. 6 The histogram of tone distribution.
-2 0 2 4 6 8 10
0 1000 2000 3000 4000 5000
Phone duration (Z-score)
Frequency
All phones Stressed phones Unstressed phones
Fig. 8 The histogram of phone duration.
Table 3 Number of phones in speech groups.
Syllable SG Word TG IP BG
Minimum number of phones 1 2 2 2 2 2
Maximum number of phones 4 16 51 34 84 94
Mean number of phones 2.64 4.26 4.63 10.67 18.92 24.79
SD number of syllable 0.48 1.96 3.33 4.79 12.40 15.20
Table 4 Number of syllables in speech groups.
Unit in syllable SG Word TG IP BG
Minimum number of syllable 1 1 1 1 1
Maximum number of syllable 6 20 14 34 38
Mean number of syllables 1.61 1.75 4.04 7.17 9.39
SD number of syllables 0.75 1.31 1.82 4.72 5.77
Thus, individual speech and statistic data, such as the results in Fig. 7-8 and Table 1-4, of one speaker in this corpus is adequate for this aspect. For the statistic data extracted from text such as the data in Fig. 6, this statistic data depends on the contents of text resources used for speech recording. To improve the quality of the text resource, we require extending the contents of the text resources without concerning the number of speakers.
The second aspect is to support speaker-generalization prosodic research, such as speaker-independent speech recognition for tonal languages, and, speaker-generalized analysis of Thai prosody and timing, by providing the automatic bootstrapping schemes in Section 4 for further collecting additional speech data from multiple speakers. In this case, the statistical data extracted from speech data, such as the results in Fig. 7-8 and Table 1-4, are dependent on individual speakers. Thus, we need to further collecting a number of speakers. By supporting the automatic scheme, it can reduce time-consuming and efforts from fully-manual construction to cope with numerous data of multiple speakers in the future works.
7
Conclusions and future worksThis paper proposed an initiative development of Thai speech corpus with plenty prosodic and linguistic labeling information. The pilot corpus covered most of the Thai phones and all Thai tones. The size of this initiative speech corpus was enough for providing adequate data for general prosody analysis and speaker-dependent prosodic research.
This work also provided automatic schemes for labeling the multi-level prosodic and linguistic information to support the corpus development in the future works.
To extend the goodness of this work, the future plans will focus on the following issues. First, additional data collection for multiple speakers is required for supporting speaker-generalization prosodic research. The main target group will be standard Thai-accent speakers, and, the number of speakers should be approximately tens of speakers for speaker-generalization research. The next issue is to improve the accuracy of the automatic labeling schemes by coping speech rate variation in the corpus.
8
AcknowledgementWe would like to thank the Human Language Technology Laboratory (HLT) at National Electronics and Computer Technology Center (NECTEC), Thailand, for kindly collecting the “TSynC-1” Thai speech corpus. This work was supported in part by the Waseda University RISE research project entitled “Analysis and modeling of human mechanism in speech and language processing” and a Grant-in-Aid for Scientific Research B, No. 20300069, of JSPS.
9
References[1] Y. Hoonchamlong, S. Koraksawet and R. Janevarakul, Thai Language Audio Resource Center (ThaiARC) Project Phase II. (in Thai), NECTEC Technical Report, 2002.
[2] Y. Hoonchamlong, S. Koraksawet and R. Janevarakul, Thai Language Audio Resource Center Project: Thai Speech Database and Application in Web-Based L a n g u a g e Te a c h i n g ( i n T h a i ) , P ro c . A n n u a l Conference of NECTEC, 2002.
[3] Y. Hoonchamlong, S. Koraksawet and R. Janevarakul, Thai Language Audio Resource Center Project: Thai Speech Database and Application in Web-Based L a n g u a g e Te a c h i n g , 1 3 t h A n n u a l m e e t i n g o f Southeast Asian Linguistic Society, Soichi (eds.).
Tempe: Program in Southeast Asian Studies, 2003.
[4] N. Thubthong and B. Kijsirikul, Syllable-Based connected Thai digit speech recognition using neural network and duration modeling, Proc. IEEE ISPACS, 785-788, 1999.
[5] A. Deemagarn and A. Kawtrakul, Thai connected digit speech recognition using Hidden Markov models, Proc. SPECOM, 731-735, 2004.
[6] C. Wutiwiwatchai, P. Cotsomrong, S. Suebvisai and S.
Kanokphara, Phonetically distributed continuous speech corpus for Thai language, Proc. Language Resources and Evaluation (LREC), 869-872, 2002.
[7] S. Kasuriya, V. Sornlertlamvanich, P. Cotsomrong, T.
Jitsuhiro, G. Kikui and Y. Sagisaka, NECTEC-ATR Thai speech corpus, Proc. O-COCOSDA, 2003. [8] P. Cotsomrong, K. Saykham, C. Wutiwiwatchai, S.
Sreratanaprapahd, and K. Songwattana, A Thai Spontaneous Telephone Speech Corpus and its A p p l i c a t i o n s t o S p e e c h R e c o g n i t i o n , P ro c . O-COCOSDA, 2007.
[9] S. Suebvisai, P. Charoenpornsawat, A. W. Black, M.
Woszczyna, and, T. Schultz, Thai Automatic Speech Recognition, Proc. ICASSP, 2005.
[10] S. Kanokphara, V. Tesprasit, R. and Thongprasirt, Pronunciation Variation Speech Recognition without Dictionary Modification on Sparse Database, Proc.
ICASSP, 2003.
[11] P. Tarsaku, V. Sornlertlamvanich and R. Thongpresirt, Thai Grapheme-to-Phoneme Using Probabilistic GLR Parser, Proc. Eurospeech, vol. 2, 1057-1060, 2001.
[12] S. Luksaneeyanawin, Intonation in Thai, Ph.D.
Dissertation, Edinburgh, 1983.
[13] C . H a n s a k u n b u n t h e u n g , V. Te s p r a s i t a n d V.
Sornlertlamvanich, Thai Tagged Speech Corpus for Speech Synthesis, Proc. O-COCOSDA 2003, 97-104,
2003.
[14] C. Hansakunbuntheung, A. Rugchatjaroen and C.
Wutiwiwatchai, Space Reduction of Speech Corpus Based on Quality Perception for Unit Selection Speech Synthesis, Proc. SNLP, 2005.
[15] C. Wutiwiwatchai, S. Saychum and A. Rugchatjaroen, An intensive design of a Thai speech synthesis corpus, Proc. SNLP 2007, 201-206, 2007.
[16] National Thai Text Corpus Development Project, Chulalongkorn University, Online: http://www.arts.
chula.ac.th/~ling/TNC/index.html.
[17] V. Sornlertlamvanich, T. Charoenporn and H. Isahara, ORCHID: Thai Part-of-Speech Tagged Corpus, NECTEC Technical Report, 5-19, 1997.
[18] P. Boersma and D. Weenink, Praat: doing phonetics by computer (Version 4.4.27), Online: http://www.
fon.hum.uva.nl/praat/, 2006.