博士論文
クラスタおよび広域計算環境に おける並列分散遺伝的アルゴリズム
谷 村 勇 輔
2004
年3
月iii
目次
第
1
章 序論1
1.1
研究の背景. . . . 1
1.2
研究の目的. . . . 5
1.3
本論文の構成. . . . 6
第
2
章 並列・分散計算環境7 2.1
並列計算. . . . 7
2.2
並列計算機の変遷. . . . 8
2.3
広域計算(グリッド). . . . 10
2.4
グリッド技術. . . . 13
2.5
グリッドのアプリケーション. . . . 20
第
3
章 遺伝的アルゴリズム23 3.1
進化計算による最適化. . . . 23
3.2
遺伝的アルゴリズム. . . . 24
3.3
遺伝的アルゴリズムの評価方法. . . . 28
第
4
章 並列遺伝的アルゴリズム31 4.1
分散計算モデルの分類. . . . 31
4.2
並列実行モデルの分類. . . . 33
4.3 2
個体分散遺伝的アルゴリズム(Dual DGA
). . . . 36
第
5
章PC
クラスタ型並列計算機における並列GA
の検討41
5.1
まえがき. . . . 41
5.2
従来型の並列計算モデルの比較. . . . 42
5.3 2
個体分散遺伝的アルゴリズムの並列化. . . . 49
5.4
むすび. . . . 54
第
6
章RPC
機構を利用した既存のグリッドシステムにおける並列GA
の検討67 6.1
まえがき. . . . 67
6.2
広域計算とRPC . . . . 68
6.3
ハイブリッド遺伝的アルゴリズムをもとにしたグリッド計算モデル. . . 69
6.4
むすび. . . . 84
第
7
章 マスターワーカシステム上でのグリッド計算の特性に対する並列GA
の 検討85 7.1
まえがき. . . . 85
7.2
マスターワーカのパラダイム. . . . 86
7.3 Dual DGA
をもとにしたグリッド計算モデル. . . . 88
7.4
島モデルをもとにしたグリッド計算モデル. . . . 98
7.5
マスターワーカ・システムの提案. . . 109
7.6
むすび. . . 122
第
8
章 結論125
第9
章NetSolve
のセキュリティ129 9.1
グリッド環境におけるセキュリティ. . . 129
9.2 NetSolve
とそのセキュリティ. . . 131
9.3
新しいセキュリティ機能の追加. . . 134
9.4
性能評価. . . 137
9.5
考察. . . 140
9.6
まとめ. . . 142
第
10
章EVOLVE/G
システム145 10.1
システムの概要. . . 145
10.2
システムの詳細. . . 146
目次
v
10.3
性能評価. . . 153 10.4
関連研究. . . 156 10.5
まとめ. . . 158
謝辞
159
参考文献
161
研究業績
169
vii
図目次
2.1 Example of the grid application . . . . 11
2.2 The Grid architecture . . . . 14
2.3 The Globus Toolkit architecture . . . . 16
3.1 Flow of Genetic Algorithm . . . . 25
3.2 Details of GA operators . . . . 26
3.3 2-dimensional shapes of the benchmark problems . . . . 30
4.1 Distributed computing model of Genetic Algorithm . . . . 32
4.2 Master slave model of parallel Genetic Algorithm . . . . 35
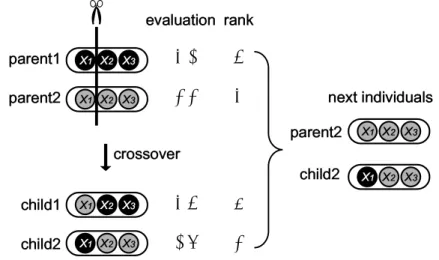
4.3 Genetic operators of Dual DGA . . . . 37
4.4 Searching reliability of Dual DGA . . . . 40
4.5 Calculation cost of Dual DGA . . . . 40
5.1 Latency of the PC cluster system . . . . 56
5.2 Throughput of the PC cluster system . . . . 57
5.3 Calculation time (Total time is normalized by 1 PE calculation time), Result of Rastrigin function . . . . 58
5.4 Calculation time (Total time is normalized by 1 PE calculation time), Result of Rosenbrock function . . . . 59
5.5 Elapsed time and fitness value : Rastrigin function . . . . 60
5.6 Elapsed time and fitness value : Rosenbrock function . . . . 60
5.7 Example of 2-dimensional truss structure . . . . 61
5.8 Total calculation time of parallel model of Simple GA . . . . 62
5.9 Total calculation time of parallel model of Island GA . . . . 62
5.10 Hierarchical migration of parallel model of Dual DGA . . . . 63
5.11 Searching capability of parallel model of Dual DGA . . . . 63
5.12 Influence on searching capability by difference of migration gap . . . 64
5.13 Parallel execution of Dual DGA . . . . 65
5.14 Estimate of the best parallel execution time of Dual DGA . . . . 66
6.1 Crossover and Selection of PSA/GAc . . . . 70
6.2 Synchronous Master-slave model of PSA/GAc . . . . 72
6.3 Difference of Synchronous MS model and Asynchronous MS model of PSA/GAc . . . . 74
6.4 Result of the minimul energy (Average of 5 trials) . . . . 79
6.5 Result of the computation time (Average of 5 trials) . . . . 79
6.6 Details of the computation time of Synchronous Master-slave model . 80 6.7 The minimul energy and computation time (Average of 5 trials) . . . 82
6.8 Comparison with the short-run SA model and the long-run SA model on the Internet environment . . . . 83
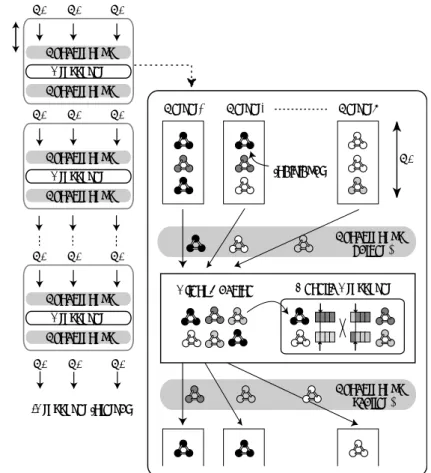
7.1 The master-worker based grid model of Dual DGA . . . . 89
7.2 Operation in the manager queue . . . . 90
7.3 Example of Scenario 3 . . . . 93
7.4 Result of Scenario 1 (One of the trials) . . . . 94
7.5 Result of Scenario 3 (One of the trials) . . . . 96
7.6 Scalability of Island model . . . 101
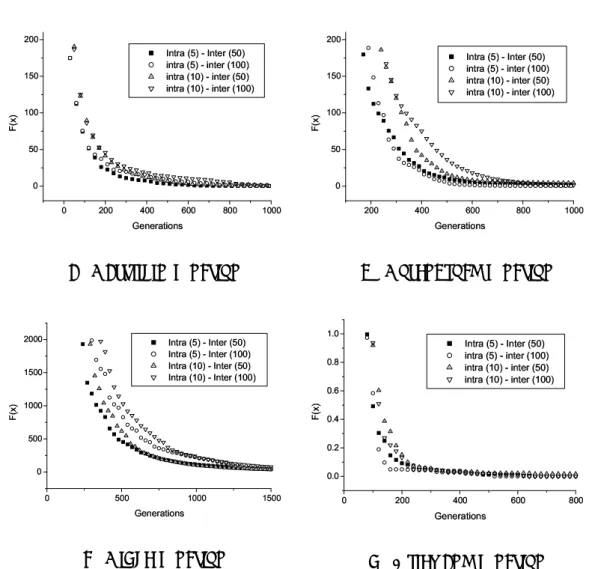
7.7 Result of the dynamic reduction (Rastrigin) . . . 102
7.8 Result of the dynamic reduction (Rosenbrock) . . . 102
7.9 Result of the dynamic reduction (Ridge) . . . 102
7.10 Implementation of Island model with the asynchronous migration us- ing EVOLVE/G System . . . 104
7.11 Evolution Speed . . . 105
図目次
ix
7.12 Comparison with Type A and Type B (Time step) . . . 106
7.13 Comparison with Type A and Type B (Search step) . . . 106
7.14 Effect of the asynchronous migration . . . 107
7.15 The basic architecture of GMWS . . . 110
7.16 Mapfile for the resource description . . . 112
7.17 Details of the GMWS communication delay . . . 116
7.18 Result of Gather communication performance . . . 117
7.19 Result of Scatter communication performance . . . 118
7.20 Result of Parallel GA with GMWS . . . 120
9.1 The NetSolve architecture . . . 132
9.2 Client authentication with Kerberos V5 on the server side . . . 133
9.3 Client authentication with Globus Security Infrastructure . . . 135
9.4 Secure communication with SSH port forwarding . . . 136
9.5 Secure Client launched communication . . . 136
9.6 Secure communication over the system . . . 137
9.7 Structure of the experimental grid environment . . . 138
9.8 Result of Blocking/Nonblocking call performance . . . 140
9.9 Result of Farming call performance (Cluster) . . . 141
9.10 Result of Farming call performance (Internet) . . . 141
10.1 The basic architecture of EVOLVE/G system . . . 147
10.2 The extended architecture of EVOLVE/G system . . . 148
10.3 The mechanism that Agent checks Workers . . . 149
10.4 A sample Agent program code using EVOLVE/G system library . . . 151
10.5 Networking of the grid used in the experiment of EVOLVE/G com- munication performance . . . 153
10.6 Details of the basic communication . . . 155
10.7 Details of the hierarchical communication . . . 156
xi
表目次
2.1 Representative grid middleware . . . . 15
3.1 List of the benchmark problems . . . . 29
3.2 Features of the benchmark problems . . . . 29
4.1 Parameters of Island model GA and Dual DGA . . . . 38
5.1 Specification of the PC cluster system used in the experiment of Par- allel GA . . . . 43
5.2 Parameters of Parallel GA . . . . 44
5.3 Waiting time equal to analizing time for the truss structure . . . . . 47
5.4 Specification of the PC cluster system used in the experiment of par- allel model of Dual DGA . . . . 51
5.5 Parameters of parallel model of Dual DGA . . . . 51
6.1 Specification of PC Cluster systems used in the experiment of PSA/GAc implemented with NetSolve . . . . 76
6.2 Specification of the Grid environment used in the experiment of PSA/GAc implemented with NetSolve . . . . 77
6.3 Throughput between Doshisha University and University of Tennessee 77 6.4 Parameters of PSA/GAc with the short-run SA . . . . 78
6.5 Parameters of PSA/GAc with the long-run SA . . . . 81
7.1 Specification of the PC cluster system used in the experiment of the
grid model of Dual DGA . . . . 92
7.2 Results of Scenario 1 and 2 . . . . 95
7.3 Result of Scenario 3 . . . . 95
7.4 Parameters of the large-scale Island model . . . 100
7.5 The heterogenious PC Cluster system used in the experiment of Island model with the asynchronous migration . . . 105
7.6 Specificaton of the Grid environment used in the experiment of GMWS115 7.7 Throughput between Master and Worker site . . . 115
9.1 Specification of the grid environment used in the experiment of the new security mechanism of NetSolve . . . 139
9.2 The discussed security mechanisms . . . 142
10.1 The EVOLVE/G Agent API . . . 150
10.2 The EVOLVE/G Worker API . . . 150
10.3 Combination of the communication pattern . . . 152
10.4 Specification of the grid used in the experiment of EVOLVE/G com- munication performance . . . 154
10.5 Result of the basic communication performance . . . 155
10.6 Result of the hiearchical communicationl performance . . . 156
1
第 1 章
序論
遺伝的アルゴリズムは,生物の進化にヒントを得た進化計算と呼ばれる優れた最適化手 法の
1
つである.本研究では,近い将来に広く利用されるであろう並列計算環境におい て,遺伝的アルゴリズムの並列・分散計算モデルを検討する.遺伝的アルゴリズムは,こ れまでにも様々な並列モデルが考えられているが,本研究では,それらについて改めて分 析を行い,黎明期から普及期に移行しつつあるPC
クラスタやグリッドのような計算環境 に適用し,そのモデルの設計や実装,実行の枠組を作ることを目標とする.これは主に最 適化手法としての解の探索性能や,計算環境を効率的に,あるいは有効に利用しているか といった観点から検討する.1.1
研究の背景1.1.1
進化計算による最適化進化とは,個々の生物がそれ自身を構築するための設計図をもち,それが子へと受け継 がれる際に変化し,生活する環境の中で様々な外的要因と戦い,より強いものだけが生き 残る過程である.このような進化論は,ダーウィンの進化論やメンデルの遺伝学を中心に,
それらから派生した多くの研究や学説をもとにしている.生物分野の研究において,ダー ウィンの進化論は必ずしも真ではないが,これにヒントを得て,コンピュータの中でそれ をシミュレートした人工生命の研究が行われるようになった.さらに,
Holland
の遺伝的 アルゴリズムが加わり,最適化手法にこれを利用しようとしたのが進化計算の始まりとい える[1]
.多くの研究者が,進化計算を用いることにより,他の手法では実現できない新しいシステムを構築できるのではないかと考え,研究を行っている.進化計算としては,
遺伝的アルゴリズム(
Genetic Algorithm
,GA
),進化プログラミング(Evolutionary Programming
,EP
),進化戦略(Evolution Strategies
,ES
),遺伝的プログラミング(
GP
),クラシファイア・システム(CS
)などが挙げられる[2][3][4]
.また,これらは ニューラルネットワーク(Artificial Neural Networks
)やファジー理論(Fuzzy Logic
) などと合わせて,コンピュータにおけるインテリジェントな手法として分類される.進化計算は現在,構造物の最適化問題,機械の制御,タンパク質の立体構造予測問題,
株式投資などの種々の戦略,知的に行動するロボット,ゲーム生物など数多くの分野に応 用され,成果を挙げている.そして,今後も広い分野に適用されていくことが予想され る.しかしながら,進化計算は解を得るまでに比較的多くの計算量を必要とする.現実の 最適化問題では,最適化する対象の解析に多くの時間を必要とし,進化計算においてさら にそれを繰り返し行うことになる.つまり,進化計算を用いて解を得ることができたとし ても,膨大な計算時間を必要としてしまうため,現実的に利用できないという問題があ る.膨大な計算量を削減する,あるいはどう高速に処理するかが課題となっている.
遺伝的アルゴリズム(
GA
)は,進化計算の中でも最もオーソドックスで,かつ広く知 られ,利用されている手法である.コンピュータの中で生物の世界をシミュレートして,親から子へと世代が進み,種が環境に適応しながら徐々に発展していくアナロジーを,最 適化の解探索にそのまま応用している.
GA
は,従来行われていた数学的に解の発見が保 証されたアルゴリズムでは解けないような複雑な問題に対して,限られた時間で優れた近 似解を提示することができる.解くべき最適化問題の規模が大きくなり,複雑化している 近年,GA
は高く注目されている.そのためGA
の研究は盛んに行われ,それは手法その ものの基礎研究だけにとどまらない.現実の問題に適用して,手法を改めて評価する応用 研究が数多く行われている.一方,他のほぼ全ての進化計算と同じく,GA
は解を得るた めの計算量が非常に大きいことも知られている.1.1.2
並列・分散計算と広域環境科学技術計算に代表される規模の大きい計算を高速に処理する研究分野として,高性能 計算(
High Performance Computing
,HPC
)分野がある.1980
年代の初め頃に並列計 算機が研究用として開発されて以来,HPC
分野では並列・分散計算を扱う計算モデルが1.1.
研究の背景3
研究されている.並列計算機は,演算ユニットとしてのプロセッサを複数もち,ある大き な計算の中のサブ計算を並列に実行する.コンピュータのプロセッサ性能はムーアの法則
[5]
に従って順調に伸びているが,その時代を卓越したスーパーコンピュータを作り,大 規模な計算を処理するためには,こうした並列処理技術が必要であった.近年の傾向として,スーパーコンピュータは大量生産できないが,中規模あるいは小規 模の入手しやすい並列計算機が普及しつつある.科学技術計算を中心に,並列計算が一般 社会においても少しずつ利用されるようになってきている.
一方,ネットワーク技術の急速な進歩により,インターネットは今や全世界的に普及し ている.そこで,インターネットを利用して,数多くのコンピュータを結びつけて大規模 計算を行おうという試みがある.例えば,
SETI@home[6]
やRC5 Cracking Contest[7]
がそうである.これらは,パーソナルコンピュータ(
PC
)のスクリーンセーバーとしてプ ログラムをインストールしておくと,使われていない間に,PC
が中央のサーバからデー タを受け取り,計算を走らせ,結果を中央のサーバに送るといった動作を行う.この仕組 みを利用して,上記のプロジェクトでは,一般にありふれたPC
や性能の良くないPC
を 数万台集めて,世界最高速のスーパーコンピュータに匹敵する,あるいはそれを越える性 能を集めている.このような形の大規模計算は,巨大な計算をあらかじめ分散して計算さ せること,インターネットに接続したPC
を利用することなどから,分散コンピューティ ングやインターネットコンピューティングと呼ばれる.あるいは,ユーザが自発的に計算 プロジェクトに自分の計算機を提供することを前提としているため,ボランティアコン ピューティングと呼ばれることもある.分散コンピューティングは,いくつかのプロジェ クトが成功を収めたこともあり,ビジネスへの応用も期待されている.HPC
分野ではなく,ネットワークを利用して,あらゆるコンピュータ機器を結びつけ て協調作業を行う試みもある.サーバやPC
などの計算機だけでなく,PDA
や各種の携 帯端末が有線,あるいは無線ネットワークで結びつき,協調しながら人間の日常活動を支 援する.いつでも,どこにおいても,簡単にコンピュータ資源にアクセスでき,その恩恵 を受けることができるというユビキタス・コンピューティングの概念に基づく研究分野で ある.しかし,個々の端末が進化して処理能力が高まるに従って,これらを大きな計算に 用いることができるようになるかもしれない.ネットワーク・コンピューティングにおいては,
P2P
に基づく計算モデルがある.P2P
(
Peer-to-Peer
)は,ICQ[8]
などのメッセージング・ツールにおいて用いられ,その後,Napster[9]
やGnutella[10]
などの音楽ソフトウェアを共有するためのネットワーク・ト ポロジのモデルとして注目を集めている.P2P
に基づくモデルでは,2
台のPC
の1
対1
の接続を基本として拡大し,大規模なネットワークを作る.これは,各個人やPC
が自然 に結びつき,何らかのコラボレーションを行いながら計算・検索・データおよび情報の共 有を実現し,大きなコミュニティへと進化する可能性をもっている.P2P
のモデルを利用 して,並列・分散計算を行うことも検討されている.このような広域ネットワーク環境を利用した並列・分散計算はまとめて,グリッド・コ ンピューティングと呼ばれ,それを実行する環境はグリッド環境と呼ばれる.グリッドは,
次世代の社会や産業の基盤となる情報システムのインフラストラクチャを構築する概念で あり,インターネットが進化すべき方向性と考えることもできる.グリッド・コンピュー ティングの本質は,ネットワーク上に存在する計算資源,ネットワーク資源,ストレージ 資源,ソフトウェア資源,データ資源,人的資源などの各種リソースを利用して,仮想的 に大規模計算を行うことである.計算資源としては,超高性能な計算機から
PC
や携帯端 末も含めて考えることができる.グリッド・コンピューティングでは,
2
章で述べる複数の理由から,これまでの並列処 理技術をそのまま適用することが難しい.また,インターネットで培われたセキュリティ やネットワーク技術も十分ではないため,複数の既存の技術を統合したり,新しい技術の 開発が必要である.これまでのグリッド技術の研究では,そうした基盤システムの開発に 焦点がおかれ,その成果として,いくつもの試験環境が構築されるようになった.近年は,その構築した環境を利用してアプリケーションを実行したり,アプリケーションの計算モ デルを考えるといった研究や,その他の実用のための研究が期待されている.
1.1.3
並列・分散計算に対応した最適化システム汎用的な最適化問題を解くことのできる最適化システム,あるいはある問題に特化した 専用の最適化システムに関する研究は数多く行われ,高い性能をもつ商用のソフトウェア も提供されている.
近年の最適化システムの課題は,進化計算のようなヒューリスティックな手法を取り入 れることと,並列計算環境やインターネットなどのネットワークに接続されたコンピュー
1.2.
研究の目的5
タを利用することのできる仕組みを取り入れることである.さらには,グリッド環境を利 用して,従来よりずっと大規模な最適化問題において良好な解を発見したり,結果を他の 研究者と共有したりすることなどが期待されている.
これまでに開発されている最適化システムは,従来的な並列計算機における実装も十 分でない.現実の最適化問題を高速に解くためには並列計算が必要であり,その実用化が 切望されている.並列計算を行うことで,解発見の速度向上だけでなく,同じ計算時間を 使ってより大規模な問題を解くことも可能となる.近年のコンピュータネットワークの発 達とともに,並列計算,および並列アルゴリズムの研究が多数行われるようになってきて いる.そして,グリッド・コンピューティングの分野においても,全探索による解の探索 問題を広域に存在する数千台のコンピュータを用いて解くことができたという事例が示さ れた
[11]
.しかし,遺伝的アルゴリズムなどの進化計算に適用された例は少なく,解探索 のモデルと高速実行のためのモデルを両方検討した研究はあまり行われていない.1.2
研究の目的進化計算の目標は,従来の手法では解くことが困難である大規模で複雑な最適化問題 において,最適解あるいはそれに近く,ユーザを満足させる解を迅速に発見することであ る.しかし,進化計算には計算量の問題があり,それを解決することが必要である.有力 な解決方法として考えられているのが,並列・分散計算を用いた高速処理である.本研究 では,近年高く注目されている並列計算環境として,
PC
クラスタ型並列計算機とグリッ ド計算環境に着目し,これらの環境における進化計算の並列・分散計算モデルを検討す る.本研究では,代表的な進化計算である遺伝的アルゴリズムを利用してこれを行う.こ れらの検討は,遺伝的アルゴリズムの分野だけでなく,グリッド計算の分野において,ど のようなアプリケーションのどういう計算モデルが,グリッド計算環境に適しているのか を提示する事例研究にもなると考える.指針としては,まず遺伝的アルゴリズムの既存の並列モデルについて調査し,
PC
クラ スタ型並列計算機を利用した実験により,基本的な問題を明らかにすることに取り組む.これによって得られた知見をもとに,遺伝的アルゴリズムのグリッド計算モデルについて 考える.グリッド計算の実行では,最初に既存のシステムの利用を考える.
RPC
機構を 利用したグリッドシステムを利用して,シミュレーテッドアニーリングとのハイブリッドGA
のマスタースレーブモデルを実装し,グリッド環境での特徴と合わせて検討を行う.次に,アプリケーションのレベルでグリッド環境の特徴を吸収できるグリッド計算モデル を検討する.これは一般に用いられる
GA
だけでなく,本研究で提案しているGA
をも とにした検討も行う.最後に,実際に検討したGA
のグリッド計算モデルを実行するシス テムとして,マスターワーカ型のシステムを提案する.提案システムを利用して,今後はGA
の多くの研究者がGA
のレベルからグリッド計算のモデルを考えて実行できることを 目指す.もちろん,提案システムはGA
以外のアプリケーションにも使えることを目指し て開発する.このような取り組みを通して,グリッド計算環境において新しい
GA
,および進化計算 を開発し,検討を行っていくことのできる枠組や手法についての知見が得られるのではな いかと考える.そして,将来的な最適化システムやGA
などの進化計算を実装するグリッ ド最適化システムの基本的な研究成果が得られるのではないかと考える.1.3
本論文の構成本章では本研究の背景を述べ,それに基づいた研究の目的と方針について述べた.
2
章 では並列処理環境として,PC
クラスタ型の並列計算機とグリッド環境について述べる.3
章では,進化計算の代表的な手法の1
つである遺伝的アルゴリズムについて説明する.4
章では遺伝的アルゴリズムの並列手法について,解探索アルゴリズムとしての分散計算 モデルと時間短縮のための並列実行モデルとを分けて説明する.同時に,本研究で提案し ている2
個体分散遺伝的アルゴリズムについて述べる.5
章では,遺伝的アルゴリズム の並列手法をPC
クラスタ型並列計算機で検討する.6
章では,既存のグリッドシステム を用いて,ハイブリッド遺伝的アルゴリズムをマスタースレーブモデルで実装し,評価実 験を行う.7
章では,グリッド環境の特徴を考慮した遺伝的アルゴリズムのグリッド計算 モデルを検討し,それを実際のグリッド環境で実行するためのシステムを提案する.最後 に,8
章において本論文で述べた研究成果をまとめる.7
第 2 章
並列・分散計算環境
コンピュータ分野において,並列計算(
Parallel Computing
),あるいは並列処理(
Parallel Processing
)は,ひとまとまりの計算や処理を複数のCPU
を用いて行うこと である.計算機の高速化の要求には終わりがなく,大規模な計算を高速に処理する方法と して並列計算に期待が集まっている.本研究では,最適化手法の1
つである遺伝的アルゴ リズムを高速に実行するために並列計算環境を利用する.そして,新しい並列計算環境と して注目を浴びているPC
クラスタ型並列計算機,およびグリッドと呼ばれる広域計算環 境の利用を考える.本章では,これらの並列計算の基本的な技術や特徴,研究動向につい て述べる.2.1
並列計算1950
年頃より始まったノイマン型デジタルコンピュータは目覚しい進歩を遂げ,現在の 科学技術の研究に必要不可欠のものとなっている.科学技術計算分野の多くは,大規模な 数値解析や数値シミュレーションを行うために高性能なコンピュータを必要としている.そのため,その時代を卓越した性能をもつスーパーコンピュータと呼ばれるコンピュータ が多く用いられてきている.コンピュータの計算性能は
CPU
を中心としたチップセット で決定されるため,その時代を卓越した性能を得るためには,1
つのCPU
では限界があ る.そこで複数のCPU
を用意し,これらを用いて1
つの仕事を分割し,並列に処理する 技術が早い段階から着目されてきた.現在,数多くの並列計算機が最先端のスーパーコン ピュータとして活躍している.2.2
並列計算機の変遷並列計算機は,専用のハードウェアや専用のソフトウェアを用いた従来型の並列計算機 から,一般に広く利用されているコンピュータと同じ汎用のハードウェアとソフトウェア を用いたクラスタ型の並列計算機へと移行しつつある.特に,個人や家庭用のパーソナル コンピュータを利用したクラスタ型の並列計算機は,
PC
クラスタと呼ばれて注目を集め ている.2.2.1
従来型の並列計算機専用のハードウェアを駆使した並列計算機の研究は
1970
年代初頭に始まり,1980
年 代前半までに研究用の並列計算機が多数開発された.この時に,プロセッサ毎にメモリを 配置した分散メモリ型並列計算機や,プロセッサとは独立に共有で利用できるメモリを集 中配置し,その共有メモリを介して通信を行う共有メモリ型並列計算機が登場した.その 後,並列プログラムの記述性を考慮して,プログラマに対しては共有メモリ環境を提供 し,実際のメモリは各プロセッサ毎に配置する分散共有メモリ型並列計算機が登場した.1990
年前後には多くの並列計算機ベンダが登場し,数千から数万台のCPU
を搭載する 超並列計算機(Massively Parallel Processor
)の研究が始まった.一方で,並列計算機にはスカラ型のプロセッサを並列にするスカラ並列と,ベクトル型 のプロセッサを並列にするベクトル並列がある.スカラ型のプロセッサではプロセッサ内 の唯一の演算器が
1
つずつ処理を行っていく.それに対して,ベクトル型のプロセッサで は,パイプライン処理などを用い,ベクトル(配列)演算を1
つの命令で高速処理するこ とができる.従来のスーパーコンピュータでは,主にベクトル並列が主流であった.従来型の並列計算機は,ハードウェアだけでなくソフトウェアも専用であることが多く,
並列計算機そのものの開発に膨大なコストを必要とした.そのため,一部の大きな研究機 関や企業にしか導入することができず,手軽に並列計算を行うことは不可能であった.
2.2.
並列計算機の変遷9
2.2.2
クラスタ型の並列計算機の登場1995
年頃より,UNIX
ワークステーションや一般のパーソナルコンピュータ(以下PC
)を用いて自前で分散メモリ型の並列計算機を作ろうという動きが始まった.前者を 用いたクラスタはNOW
(Network of Workstations
)と呼ばれ,後者を用いたクラスタ はPC
クラスタと呼ばれた.[12][13][14]
.PC
クラスタの研究については,NASA
のBeowulf
プロジェクト[15]
が先駆けといえる.
Beowulf
プロジェクトでは,以下に示すようないくつかの思想をもとに構築されるクラスタを
Beowulf
クラスタと呼んでいる.•
ハードウェアとしてはCOTS
(Commodity off the shelf
)を用いる.すなわち,一 般市場で入手できる汎用製品を用いる.•
ソフトウェアとしてはフリーでオープンなものを用いる.•
クラスタを構成するプロセッサやネットワークが変わったとしても,プログラミン グモデルが決して変わらないような並列計算機である.Beowulf
クラスタは専用のハードウェアやソフトウェアを一切使わず,手作りで構築されるため非常にコストパフォーマンスが良かった.また,従来型の並列計算機と異なり,
プログラマが特定のベンダが作るシステムの特性を学ぶ必要がないことから広く受け入れ られた.
2.2.3 PC
クラスタの発展Beowulf
に始まったPC
クラスタは広く普及することになり,スーパーコンピュータを凌駕するシステムもいくつか作られた
[16][17]
.このようなPC
クラスタが普及してきた 背景としては,次のようなことが挙げられる.ハードウェアの分野では
COTS
産業が確立し,マスマーケットでの競争が各パーツの 価格を下げ,より性能が良く信頼できるものを作れるようになった.その結果として,PC
の性能が飛躍的に向上した.同時に,ネットワーク技術が進歩し,比較的安価に高性能な ネットワークを構築できるようになった.ソフトウェアの分野では,
Linux
やGNU
コンパイラ,さらにはPVM[18]
やMPI[19]
などのメッセージパッシングライブラリがフリーでオープンなツールとして普及した.こ れにより,ソフトウェアとハードウェアの開発を切り離すことも可能になり,別々に市場 に供給されるようにもなった.プログラマにとっては,使い勝手の良い開発環境が提供さ れ,並列プログラムの記述性や移植性が著しく改善された.
こうして,並列計算の敷居が一段と低くなり,並列計算の普及にもつながり,大きな機 関でなくても,自前で並列計算機を持つことができるようになった.
近年は,多くの商用ベンダが
PC
クラスタに着目し,商用のPC
クラスタやクラスタ リングソフトウェアを提供している[20]
.Beowulf
クラスタの範囲を越えたものでは,Myrinet[21]
などの専用の高速ネットワークやSCore[22]
などの専用のクラスタリングソ フトウェアを導入して,より性能の良いPC
クラスタを構築する研究も行われている.2.3
広域計算(グリッド)PC
クラスタなどの普及により,比較的多くの機関が大規模に計算を行えるようになっ た.しかし,大規模計算の要求は尽きることがなく,次世代の大規模計算環境として広域 計算が注目を浴びている.このような広域計算を実現する基盤が,グリッド(Grid
)である
[23][24]
.グリッド技術は,広い地域に配置された計算資源やデータを格納するためのストレージ資源,あるいはデータベースなどに集められた情報資源などを利用して,広域 的に並列・分散計算を行うことを可能にする.そして,共通の目的をもつコミュニティで これらを効率的に使用する仕組みを提供する.
2.3.1
グリッドの背景と目的グリッドの語源は
Power Grid
(電力網)である.電力網が現在の社会的・産業的基盤 を形成しているのと同じようにコンピュータ資源ネットワークが近い将来の産業的基盤に なるだろう,あるいはなってほしいという願いが込められている.グリッドという言葉は 本来,アメリカのプロジェクト的名称であるため,情報ネットワークを電力網のアナロジ として捉えた場合にInformation Grid
(iGrid
)と呼ばれることもある.グリッドの利用は図
2.1
に示すように多岐にわたる.例えば,グリッド技術はネット ワークに接続された資源を,誰もがいつでもどこからでも利用可能にする仕組みや,遊休 資源を使う仕組みを提供する.現在は,そうした遊休資源を集めて巨大な計算を行うメガ2.3.
広域計算(グリッド)11
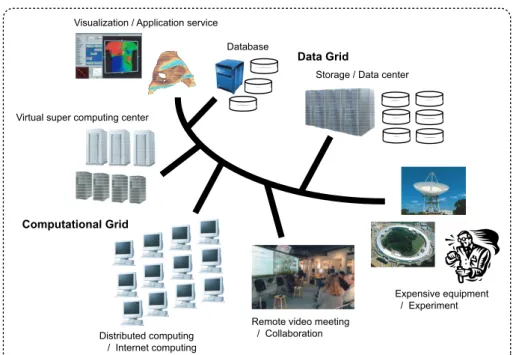
図2.1 Example of the grid application
コンピューティングに焦点が当てられることが多いが,将来的には小型のコンピュータも ネットワークにつながることでグリッドの資源となりうる.メガコンピューティング以外 では,グリッドを利用して稀少な実験機器を遠隔操作したり,リモートセンシングを行っ たりするシステムの構築や,多地点間で遠隔ビデオ会議を行うことなどが考えられてい る.これらの利用形態が普及すると,ネットワーク上に研究機関や企業などの仮想組織を 作ることができる.あるいは,グリッドを利用することで,いつでも必要なスペックのコ ンピュータを手にいれることができ,あえて高価なコンピュータを買う必要がなくなる可 能性もある.
このようなグリッドが提案され,受け入れられるようになった背景には次のようなこと が挙げられる.
•
各分野が多様化し,何らかの仕事を行ったり,問題解決を図ったりするモデルが変 化した.そして,遠隔地の研究者がチームを組んだり,コラボレーションを図った りする必要性が高まっている.•
インターネットの普及により,全世界的なネットワークが構築され,多くの高性能計算機がネットワーク上に存在している.これらは時には遊休であり,有効活用す るための仕組みが必要である.
•
近年は計算機性能に比べて,ネットワーク性能が劇的に向上している.2001
年か ら2010
年までに計算機性能は60
倍向上するのに対し,ネットワーク性能は4000
倍向上するといわれている[25]
.2.3.2
グリッド環境の特徴と要請グリッド環境を並列・分散計算環境として利用する場合,特にこれをグリッド計算環境 と呼ぶ.グリッド計算環境は,従来の並列計算環境と比べて次のような特徴がある.
•
多数の組織から,様々なタイプのリソースが提供されて構築されるヘテロ環境であ り,かつその構成は動的に変化する.•
計算は常にネットワークを介して行われるが,外乱の多いネットワークでつながれ ている可能性が高い.•
クラスタなどの並列計算機に比べると,手にできる計算リソースの規模が格段に大 きい.しかし,それを利用するためにはスケーラビリティの検討が重要である.•
ある定まった環境において,どれだけ高速に計算を終えるかというHPC
(High Performance Computing
)を追求するだけではない.ある限られた時間の中で,利用できる資源を全て利用してどれだけの計算を行えるかという
HTC
(High Throughput Computing
)も重要である[26]
.これらの特徴を踏まえた上で,グリッド計算環境を実現し,利用するために次のような 要請に応えていくことが必要である.
•
特定の機関が権限を握っていてはならない.•
どこからでも安全にアクセスでき,安全に利用できなければならない.•
計算機やネットワークの負荷に応じて,適切に資源をスケジュールできなければな らない.•
リモートにある資源でジョブを実行する場合には,そのジョブに関連するデータを 転送できる仕組みが必要である.2.4.
グリッド技術13
2.4
グリッド技術前節で述べたように,グリッド計算環境は従来の並列計算環境と異なるため,従来の並 列計算の技術がそのまま適用できない.例えば,非同期通信やヘテロ環境下での計算モデ ルに関する技術は,
HPC
のみを考えた場合,考える必要が小さかった技術である.以下 に,グリッド計算環境を実現するための技術を列挙する.•
計算機やネットワークの耐故障性と復旧•
セキュリティ•
資源の管理,およびスケジューリング•
資源へのアクセス•
情報サービスやディレクトリサービスの提供•
ユーザやサービスの認証・証明•
データベース,およびデータ転送•
パフォーマンスの測定・予測•
通信•
プログラムのポータビリティ•
アプリケーションのプログラミングモデルこのようなグリッド技術は,図
2.2
に示すような階層においてGrid Architecture Component
に相当する.Grid Architecture Component
を利用して,アプリケーショ ン に とって 使 い や す い イ ン タ フェー ス や ラ イ ブ ラ リ な ど のApplication Component
Architecture
の部分が構築され,さらに,それらを利用して分野別のグリッドシステムが構築されることになる.
表
2.1
は,1990
年頃より研究開発が行われてきた代表的なグリッドのミドルウェアの一 覧である.各ミドルウェアは,図2.2
のGrid Architecture Component
やApplication
Component Architecture
に分類される.本節では,これらのミドルウェアのうち代表的 なものについて,その目的やアーキテクチャを詳しく述べる.最初に,Globus Toolkit
に ついて述べ,Grid RPC
に基づくシステム,スケジューリングを考慮したマスターワーカ システム,そしてWeb Portal
を構築するためのツールを紹介する.本論文では以降の章図2.2 The Grid architecture
において,
Globus Toolkit
あるいはNetSolve
を利用して,遺伝的アルゴリズムの並列モ デルを実装し,グリッドの試験環境で実験を行った結果を示す.2.4.1 Globus Metacomputing Toolkit
Globus Metacomputing Toolkit
(以下,Globus Toolkit
)[27]
は,グリッドのシステ ムを構築するのに必要な基本的なサービスの集まりであり,その点において事実上の標準 ソフトウェアとして認知されていることも多い.Globus Toolkit
は,1996
年にIan Foster
やCarl Kesseleman
らによって始められたGlobus Project
,現在のGlobus Alliance
により開発されている.Globus Alliance
(旧Globus Project
)は,グリッドを科学計算,工学計算に適用するための研究開発プロジェクトとして始まり,
Argonne National Laboratory
やUniversity of Chicago
などのいく つかの大学・研究機関が参加している.グリッドの研究においては,研究成果を実際の環 境で試すことが重要であるのに対し,当時は各プロジェクトが独自にシステムを開発して いた.そのため,システム間に互換性がなく,実際的な実験環境を構築する妨げとなって いた.これを解決するべく,グリッドの基本的なサービスを集めたのがGlobus Toolkit
といえる.これにより,各システムはGlobus Toolkit
を用いて構築できるため,基本サー2.4.
グリッド技術15
表2.1 Representative grid middleware
AppLeS It provides a dynamically scheduling mechanism for applications on the computational grid.
Condor It provides a method to develp, implement, deploy and evaluate ap- plications of the High Throughput Computing on a large collection of resources over a wide area network.
Globus Toolkit It includes a fundamental technology for the grid. It is popular to use for building their own grid.
Legion It is an object-based meta-systems software that enables users to ac- cess remote resources from the destop PCs or the workstations.
NetSolve It is a client-server system to solve the complex and large scientific problems on remotes. The system allows users to access both hard- ware and software computationl resources distributed over the net- work.
Ninf / Ninf-G Ninf and Ninf-G provide an environment to access many kinds of resources such as hardware, software and scientific data on the grid with an easy-to-use interface. Ninf-G is a reference implementation of the Grid RPC based system with Globus.
UNICORE It provides a mechanism to deliver an application software and submit job on remotes easily.
ビスとは切り離して独自のシステムを研究・開発することが可能となった.
Globus Toolkit
の詳細Globus Toolkit
はグリッドのツール,サービス,アプリケーションを開発する上で標準的なグリッドプロトコル,
API
を定めて実装が行われている.これが実現すれば,グ リッド間のプロトコルを吸収し,互換性のあるグリッド環境を構築することができる.Globus Toolkit
は,2003
年10
月の段階でリリースされているバージョン2.4
において,C
とPerl
で書かれたソフトウェア開発キット(SDK
)である.ただし,OGSA
(Open
Grid Service Architecture
)をもとに再設計されたバージョン3.0
は,Java
で書かれたSDK
である.OGSA
とバージョン3.0
については後で述べる.Globus Toolkit
はオープ ンソースであり,試験環境やアプリケーションの開発などを通じて随時改善がなされて図2.3 The Globus Toolkit architecture
いる.
Globus Toolkit
の主なサービスは,以下の4
つが挙げられる.そして,これらのサービスをもとに,
Globus Toolkit
は図2.3
のようなアーキテクチャをとる.セキュリティ:
GSI
(Globus Security Infrastructure
)GSI
は公開鍵暗号を用いたセキュリティ技術であり,1
度どこかの計算機上で認 証を受ければ,どの計算機においてもプログラムを実行できるというSingle-Sign on
の機能を実現する.Globus Toolkit
では,以下に記す資源管理,情報サービス,データ管理のサービスもこの
GSI
を基盤としている.資源管理:
GRAM
(Grid Resource Allocation Management
)GRAM
は,ジョブの実行に際して計算資源やデータ資源を発見し,分析し,予約 する.その後,ジョブを実際に割り当て,結果を回収するという手順を実行する.GRAM
は資源管理に関する基本的な機構を提供し,複数の資源を同時に確保するDUROC
(Dynamically Updated Request Online Co-allocator
)やリモートサイ ト上で動作するローカルなジョブマネージャとの連係を行うこともできる.情報サービス:
MDS
(Monitoring and Discovery Service
)グリッドシステムを構成する要素に関して,静的・動的な情報の管理やアクセス手 段を提供する.これは,ヘテロで動的に変化する環境を利用するための基盤とな る.特定のリソースに関する情報を提供する
GRIS
(Grid Resource Information
Service
)と,複数のGRIS
サーバで集めた情報を提供するGIIS
(Grid Index
2.4.
グリッド技術17
Information Service
)からなる.データ管理:
Grid FTP
(Grid File Transfer Protocol
),Data Replic Management
データ・ストレージを基盤としたグリッド(Data Grid
)を構築するための基本的 な仕組みを提供する.データ転送やデータアクセスのサービスとレプリカ管理の サービスの2
つに大きく分けられる.Globus Toolkit
は,グリッドに必要なごく基本的なサービスの集まりである.各モジュールが独立しているため,必要なサービスだけを利用してインクリメンタルにシステ ムを開発することが可能になる.しかしながら,抽象度が低く,低レベルなインタフェー スしか提供していないという問題もある.
Glous Toolkit
を直接利用して,実際的なアプ リケーションを作る場合にはアプリケーション・プログラマに大きな負担がかかる.そこで,
Globus Toolkit
を利用して,アプリケーションを開発したり,その実行を支援したりするミドルウェアの構築が必要となる.
その他の問題としては,
Globus
には,資源を配分するためのメタスケジューラが含ま れていないこと,Firewall
やプライベートアドレスの利用などによるネットワークセキュ リティがあまり考慮されていないことが挙げられる.さらに,
Globus
はPC
クラスタのような計算機からなるグリッド環境について,十分に考慮していない.
PC
クラスタは,しばしばノード間を内部ネットワークで構成する.内部のノードに
Globus Toolkit
をインストールする場合は,Globus Toolkit
のインス トールされた外部のノードからクラスタの内部ノードを見ることができないため,利用が 難しくなる.一方で,外部に接続されているノードにのみGlobus Toolkit
をインストー ル場合は,外部のノードからの計算要求を受け,それを内部のノードにリダイレクトする ような機構が必要となる.このように,クラスタ型の計算機を階層的な形でグリッド環境 に組み込む仕組みは,Hyper Cluster
あるいはCluster of Cluster
と呼ばれる.Cluster
of Cluster
に関する研究はいくつかなされているが[28]
,広く使われているツールはまだ存在していない.
Globus Toolkit
は既存のHTTP
やFTP
,LDAP
などの各種プロトコルを拡張したも のを集めたツール群である.先に述べた資源管理はHTTP
をもとにし,情報サービスはLDAP
をもとにし,データ管理はFTP
をもとにしている.そのため,各サービスを統 合したシステムを作ったり,新しいサービスを追加したりすることを考えた場合,下位のプロトコルから互換性を構築する必要があり,その作業が大変であった.この問題を解決 するために,下位レイヤに汎用性の高いプロトコルを作り,その上に従来のサービスを作 り直すことを目指して,策定されたのが
OGSA
(Open Grid Service Architecture
)で ある.■
Open Grid Services Architecture
(OGSA
)OGSA[29]
では,Web Service
を拡張して 設計されたGrid Service
を利用して,グリッドを構築するための上位のサービスを提供 する.これは,Grid Architecture Component
の中の上位層に相当する.一方,OGSA
はその下位層にOGSI
(Open Grid Service Infrastructure
)[30]
を利用する.OGSI
はWeb Service
の仕組みを拡張し,Grid Service
を定義している.Web Service
では,WSDL
(Web Services Description Language
)を用いてサービスを記述し,SOAP
を利用してそれを呼び出したり,サービス同士が連係したりすることができる.すなわ ち,OGSA
ではWSDL
やSOAP
といったWeb Service
の枠組を統一的なプロトコルと して利用する.Web Service
からGrid Service
への大きな拡張としては,サービス・コ ンポーネントが状態を持つことができるようになったことである.OGSA
およびOGSI
をもとに,Globus Alliance
ではGlobus Toolkit
のバージョン3
を開発している.これにより,これまで科学技術計算分野を中心に注目されていたグリッ ド技術が,ビジネス分野のWeb Service
アプリケーションと結びつき,商業的にも高く 注目されることとなっている.2.4.2 Grid RPC
に基づくシステムグリッドのアプリケーションを開発するためのミドルウェアとしては,
Grid RPC [31]
に基づくシステムが代表的である.
Grid RPC
に基づくシステムでは,アプリケーショ ン開発者がサーバ側にあらかじめ数値計算ライブラリやデータベースなどを用意して おき,アプリケーション利用者がクライアント・ツールを利用して,容易にそのアプリ ケーションを利用できる仕組みを提供する.これらを実装したシステムとしては,産業 技術総合研究所や東京工業大学などによって開発されたNinf[32]
,UTK
(University of
Tennessee
,Knoxville
)によって開発されたNetSolve[33]
がある.一方で,Ninf
の下位 レイヤをGlobus
を利用して実装し直したNinf-G
も開発されている.2.4.
グリッド技術19
2.4.3
スケジューリングに焦点を当てたシステムスケジューリングを考慮したシステムとしては,
AppLeS
とCondor
が挙げられる.AppLeS
(Application-Level Scheduling on the Computational Grid
)はUCSD
(Uni- versity of California
,San Diego
)で開発されているシステムでり,アプリケーションレ ベルのスケジューリングを可能にする[34]
.AppLeS
のユーザは,スケジューリングを 行ってくれるAppLeS agent
に実行ジョブの情報(計算量や必要メモリ量,データ転送量 など)を提供する.一方,AppLeS agent
は,グリッド上の計算資源の情報やネットワー ク情報を解析し,必要に応じて予測も行う.AppLeS agent
は,このシステム情報とユー ザから与えられたジョブの情報とを合わせて,最適なサーバを選択してジョブを実行する.Condor
はUniversity of Wisconsin
の研究グループで開発されているシステムであり,アイドル状態にある計算資源を有効活用することを目的としている
[35, 36]
.Condor
では,
Condor Pool
に計算資源を登録しておき,ユーザの要求に従って,アイドル状態の計算資源を
Condor Pool
から探し出してジョブを投入する.その際,計算資源の提供者と利用者の間で
ClassAd Matchmaking
を行い,お互いに満足できるような形でジョブを 実行する仕組みを備えている.Condor
はもともとLAN
環境で接続された計算資源を有 効活用するものであった.しかし,Condor-G
を用いることでGlobus Toolkit
と連係し,グリッド上の計算資源を
Condor Pool
に登録し,グリッド上でのスケジューラとしても 利用可能である.2.4.4 Web Portal
構築ツールグリッドでは,