関する研究
著者
星川 貴樹
学位授与機関
Tohoku University
不完全な文法情報を用いた
データ圧縮の高効率化に関する研究
東北大学大学院 情報科学研究科
システム情報科学専攻 篠原・吉仲研究室
博士課程前期二年の課程
星川 貴樹
2017
年
02
月
17
日
目次
第 1 章 序論 1 1.1 研究の背景と目的 . . . . 1 1.2 先行研究 . . . . 2 1.3 本論文の構成 . . . . 4 第 2 章 準備 5 2.1 用語の定義 . . . . 5 2.1.1 圧縮率 . . . . 5 2.1.2 文法,文法情報 . . . . 52.2 Prediction by Partial Matching . . . . 6
2.2.1 算術符号 . . . . 6 2.2.2 レンジコーダ . . . . 7 2.2.3 PPM . . . . 7 2.3 PPM を用いた構文木の符号化 . . . . 9 2.4 アーリー法 . . . . 12 第 3 章 不完全な文法情報を用いた構文木の生成と TreePPM の適用 14 3.1 エラー . . . . 14 3.2 文法のエラー許容化 . . . . 14 3.2.1 エラー許容化のアプローチ . . . . 15 3.2.2 エラー許容化のプロセス . . . . 15 3.3 抑制的エラー許容構文木の生成 . . . . 16 第 4 章 自然言語文への TreePPM の適用 21 4.1 自然言語文に対する構文木 . . . . 21
4.2 自然言語文に対する構文木の符号化 . . . . 22 4.2.1 構文木にすることによる効果 . . . . 22 4.2.2 構文木にすることによる問題点 . . . . 22 第 5 章 実験 26 5.1 エラーを含む場合の TreePPM . . . . 26 5.1.1 構文解析の速度比較 . . . . 26 5.1.2 抑制的エラー許容構文木に対する TreePPM の適用 . . . . 27 5.2 自然言語に対する TreePPM の適用 . . . . 29 5.2.1 実験 . . . . 29 5.2.2 圧縮率に有意性が見られなかった原因の考察 . . . . 30 第 6 章 まとめ 34 参考文献 35
第
1
章
序論
1.1
研究の背景と目的
情報通信のトラフィックは世界的に年々増加している.特にモバイルのトラフィックは, デバイスの高性能化に伴いコンテンツのサイズが増加したことや,世界的なモバイルデ バイスの普及により 10 年で約 4,000 倍増加した [2].その一方で,統計的に Web サイト の読み込みに 3 秒以上かかるとモバイル利用者の約 53%がそのページから離れてしまう [5] というデータがあるように,Web 業界においてデータの読み込み速度は利益に関わる 重要な指標である.トラフィックの増加に対し,通信技術の発展やネットワーク網の強化 により速度の改善が行われているが,その一方でコンテンツ制作者はコンテンツのデー タを削減することにより高速化を図っている.例えば HTTP 通信では,以前より通信内 容を圧縮することが可能であったが,近年ではデバイスの性能が向上していることも手 伝い,より圧縮率の高いアルゴリズム [4] が登場しており,コンテンツ読み込みの高速化 が期待されている. 一般にデータ圧縮と呼ばれるものにはデータの完全復元が可能な可逆圧縮と,データ の完全性は損なわれるものの同等の品質を保つ不可逆圧縮が存在する.本論文ではこれ らのうち可逆圧縮について扱う.圧縮手法の優劣の指標としては,一般的なアルゴリズ ムの優劣の指標である速度や必要メモリ量などに加え,圧縮率が用いられる.本論文で はこの圧縮率を主眼に置き,検討を行う. 可逆圧縮を用いる場面の1つとして,テキストデータの圧縮が挙げられる.テキスト データはバイナリデータと比較して同一の部分データ列が複数回出やすい傾向にあり,この特徴を活かした様々な圧縮アルゴリズムが提案されている.その中でも Prediction by Partial Matching (PPM)[10][8] はこの特徴を強く活かしたアルゴリズムであり,そし て 7zip 1など一般的に用いられているソフトウェアにも採用されている. PPM はバイナリデータに対しては他の一般に用いられる手法並,またはそれ未満の圧 縮率であるものの,テキストデータに対しては非常に高い圧縮率を誇る.更に,先行研 究の TreePPM[13] では PPM を文脈自由文法の構文木に対し適用することで,元のテキ ストに PPM を適用するよりも高い圧縮率を出すことが示されている. TreePPM を,先に述べたデータ通信に応用した場合,例えば JavaScript を構文解析し たときの構文木を圧縮し転送することで,転送速度と受信側の構文解析が必要なくなり, 高速なコンテンツ表示が可能となる可能性がある.このように,構文木を保存しつつ圧 縮率を向上させる点から,TreePPM が有効な場面は少なくないと考えられる. 本研究では,TreePPM の欠点である構文木を構築できる文字列にしか適用できない点 を修正することで,TreePPM の利用が有効となる場面を広げることを目的とする.更に, 応用として明確な文法が存在しない自然言語に対しても同様の手法を適用可能か検討す ることを目的とする. なお,文法情報が与えられたにも関わらず構文木を構築できない場合として,一般に 文字列が文法に即していない場合と,文法情報が不完全である場合が考えられるが,こ れらは文法が完全であるという立場に立っているか,それとも文字列が完全であるとい う立場に立っているかによって起こる表現上の違いで本質的には違いはないものである. これらはどちらも規則を修正することで構文木を生成することが可能である.本論文で は,説明の都合上これらの表現が混在するが,どちらも等価であるという前提で用いて いる.
1.2
先行研究
テキストデータの圧縮の中でも,ソースコードのように構造モデルを構築できるもの については,この構造を考慮して圧縮を行うとより高い圧縮率を出すことができる. 例として,文脈自由文法 G1 = ({A, B, C, X}, {i, :=, +, ∗, ), (}, P1, X) を定める.なお,本論 1http://www.7-zip.org/表 1.1: G1の生成規則集合 P1 規則 GPN LPN X→ i := A 1 1 A→ A + B 2 1 A→ B 3 2 B→ B ∗ C 4 1 B→ C 5 2 C→ (A) 6 1 C→ i 7 2 X i := A B B C i ∗ C ( A A B C i + B C i ) 図 1.1: ‘i := i∗ (i + i)’ の構文木 1 i := 3 4 5 7 i ∗ 6 ( 2 3 5 7 i + 5 7 i ) 図 1.2: GPN で表した構文木 文では文脈自由文法 Gnの定義は (非終端記号集合, 終端記号集合, 生成規則集合, 開始記号 ) の順で記す.規則集合 P1を図 1.1 に示す.生成規則に従った文字列として,i := i∗(i+i) の圧縮について考える.この文字列に対して生成した構文木は図 1.1 のようになる. 図 1.1 の規則の番号のことを GPN (Global Production Number) と呼ぶ.この木のノー ドを GPN に置き換えると,図 1.2 のように表すことができ,深さ優先探索の行き掛け順 で辿ることで 134576235757 を得る.この表現を GPN シーケンスと呼ぶ.また,非終端 記号ごとに規則に番号を割り振った場合,木を行き掛け順で辿り 121221122222 を得る. この番号を LPN (Local Production Number),表現を LPN シーケンスと呼ぶ.
これらの GPN シーケンス・LPN シーケンスは,どちらも文法定義を別に保存してお けば構文木を復元可能である.LPN シーケンスは,GPN シーケンスと比較し小さい数 字で表現が可能であるため,構文木の保存に適した表現方法と言える.また,この LPN
シーケンスに対し通常のエントロピー符号を適用すると,構造的特徴を持つ文字列であ れば,元の文字列に対してエントロピー符号を適用するよりも高い圧縮率を出すことが 知られている [1]. 本研究では,第 2 章にて詳説する,構文木の構造を考えたより性能の良いアルゴリズ ムについて,改善と応用を行う. なお,形式文法を用いた圧縮手法としてよく知られる,文法圧縮 [9] と本研究で扱う圧 縮アルゴリズムは似て非なるものであることに注意が必要である.文法圧縮では,入力 文字列だけを一意に生成する形式文法の規則を自動生成し,規則そのものが符号化後の データとなる.入力文字列を一意に生成する規則であるため,開始記号を決めておけば, 規則に従って文字列を生成していくと最終的に元の文字列となる.これに対し,本研究 で用いる手法は,文法規則自体は与えられたものを用い,LPN シーケンスを通常の圧縮 手法よりも効率的に符号化することを目的とする. また,実際の文法圧縮では,生成した規則に対して何かしらのエントロピー符号を適 用することもある.本論文では検証を行わないが,この生成した規則に対して適用する 符号として本研究で扱う手法を用いることは可能である.
1.3
本論文の構成
本論文の構成は次のとおりである.第 2 章では,先に触れた構文木の圧縮について詳 しく述べる.第 3 章では,構文木が構築できない場合について説明する.第 4 章では,自 然言語の文字列に対して適用する場合について説明する.第 5 章では,既存手法に対す る提案手法の計算時間や圧縮率の比較を行う.第 6 章では,本論文のまとめや今後の課 題点について述べる.第
2
章
準備
本章では,本論文に登場する用語と先行研究について説明する.2.1
用語の定義
2.1.1 圧縮率 データ圧縮における圧縮率とは, 圧縮後のファイルサイズ 元のファイルサイズ × 100 (%) で定義される,データ圧縮アルゴリズムの評価指標の 1 つである.圧縮率は数値が低く なるほど性能が高いと言えるが,一般に圧縮率が「高い」「低い」と言った場合は性能の 高低を指す.そのため本論文でも断りなしにこの表現を用いる. 2.1.2 文法,文法情報 本論文では,文法について「文法」,「文法情報」の 2 語を使い分ける.文法情報とは, 本論文では文法についてファイルなどで与えられる情報を指す.「文法」に誤りは存在し ないが,その文法について記した「文法情報」には時として誤りや欠損を含む可能性が ある,という違いを表現するために用いる.2.2
Prediction by Partial Matching
Prediction by Partial Matching (PPM) は,1984 年に Cleary と Witten によって
発表された可逆圧縮アルゴリズムである.このアルゴリズムはテキストデータに対して 非常に高い圧縮率を出すことで知られる.PPM はエントロピー符号を拡張したアルゴリ ズムであり,通常のエントロピー符号では文字ごとの出現頻度を基に符号化を行うのに 対し,N-gram モデル用いて符号化を行うことでテキストデータに対する圧縮率を向上 させている.PPM 内部の符号化部分は,一般にレンジコーダを用いる.本節ではレンジ コーダの基となっている算術符号 [8],レンジコーダ [11],PPM についてそれぞれ概要を 説明する. 2.2.1 算術符号 基本的な算術符号では,データ全体での出現頻度に合わせてそれぞれの文字に半開区 間を割り当て,文字の出現順に 1 字ずつ区間を選択していく.出力する符号データは最 終的な区間である. 図 2.1 に abacaabc を符号化する例を示す.出現頻度の比は a : b : c = 2 : 1 : 1 なので, 割り当てる半開区間にもその比率を用いる.1 字目は a なので,[0, 0.5) を選択,次は b な ので,[0.25, 0.375) を選択,というようにして最後の文字まで区間を選択する.この例で は最終的に [0.299560546875, 0.2998046875) が選択される. 復号は,図 2.2 に示すように,最終的に選択された [0.299560546875, 0.2998046875) が どの文字の区間に位置するかを見ていけば良い.まず [0, 0.5) に位置しているので 1 字目 は a であり,区間を [0, 0.5) に絞る.次は [0.25, 0.375) に位置するので 2 字目は b,という 流れで復号できる. この基礎的な手法の問題点は,出現頻度表を保存する必要がある点である.この問題 点を解決する方法として,適応型算術符号がある.適応型では,図 2.3 に示すように,初 めは全ての文字が均一に出現しているものとして区間を割り当てる.1字符号化する毎 に出現頻度表を更新し,以降 1 字符号化するごとに出現頻度を更新し,その出現頻度を 用いて区間を割り当てる.
0 0.5 0.75 1 0 0.25 0.375 0.5 0.375 0.3125 0.34375 0.25 0.2995… 0.2998…
a
b
c
図 2.1: 算術符号による符号化 0 0.5 0.75 1 0 0.25 0.375 0.5 0.375 0.3125 0.34375 0.25 0.2995… 0.2998… [0.2995, 0.2998)a
b
c
図 2.2: 算術符号による復号 0 1/3 2/3 1 0 1/6 1/4 1/3 1/4 1/6 1/60 7/30 1/5 157/9450 25/1512 31/1890a
b
c
図 2.3: 適応型算術符号による符号化 2.2.2 レンジコーダ レンジコーダは算術符号を基に,速度面において改善を行った符号化アルゴリズムで ある.算術符号では基本的に 0 から 1 の区間を分割していくため小数の計算になるが,レ ンジコーダでは整数の範囲に収める点が算術符号とは異なっている.ある一定の整数の 範囲で符号化を開始し,その範囲で符号化ができなくなった時点で桁を増やすことで整 数に収める. 2.2.3 PPM PPM の符号化・復号のアルゴリズムは一般に適応型の算術符号やレンジコーダが用い られる.算術符号やレンジコーダは符号化する文字のみの出現頻度を用いたが,PPM で は N-gram モデルを用い,直前に出現する文字列を考慮して符号化を行う.本論文では, N-gram モデルで用いる,符号化する文字の直前に出現する長さ N までの文字列のこと を文脈と呼ぶ. PPM は圧縮率が高い反面,レンジコーダと比較すると計算量が増えているため,速度 が比較的遅いことでも知られている.Algorithm 1: PPM
Function EncodeWithPPM(S, RangeCoder, n): Input : 文字列 S, RangeCoder, 文脈の最大長 n
Data: 文脈 context, 出現頻度表 FreqTable, エスケープを表す文字 ESC
1 FreqTable[ϵ] は ESC を除く全ての文字の出現回数を 1 で初期化;
2 for chr in S do 3 for i in 0..n do
4 context = chr の直前に出現する長さ n− i の文字列;
5 if context が FreqTable のキーとして存在していない then
6 FreqTable[context] の初期化;
7 else if FreqTable[context][chr] が存在 then
8 FreqTable[context] を基に chr を RangeCoder で符号化;
9 FreqTable[context][chr] += 1;
10 break;
11 else
12 FreqTable[context] を基に esc を RangeCoder で符号化; 13 FreqTable[context][chr] = 1; 14 FreqTable[context][ESC] += 1; また PPM では,文脈を保存するためにエスケープ (ESC) と呼ばれる新しい概念を導 入する.エスケープは,未出現の文字を表す概念である.Algorithm 1 にアルゴリズムの 概要を示す. 出現頻度情報として記録する文脈の最大の長さを n で表す.以下では bcbacbca を n = 2 で符号化する場合を例にこのアルゴリズムの流れを述べる.この文字列の中でも 5 字目 と 7 字目の c が出現する際の符号化のプロセスが特徴的であるため,これら 2 つの場合 について説明を行う. 5 字目の c の場合,最大で長さ 2 の文脈を見るので,符号化する際は ba → c, a → c, ϵ→ c の順に出現頻度を見ていく.ここで,→ は左辺の文脈の次に右辺の文字が出現す ることを表す記号である. ba → c, a → c は共に事前に出現していない.このうち前者については ba という文字 列自体初出である.左辺の文字列が初出の場合,初期化を行う.このとき,出現頻度は ESC, chr をそれぞれ 1 とする. 初出でなかった場合,レンジコーダで ESC を符号化する.ESC を含む出現頻度の符号
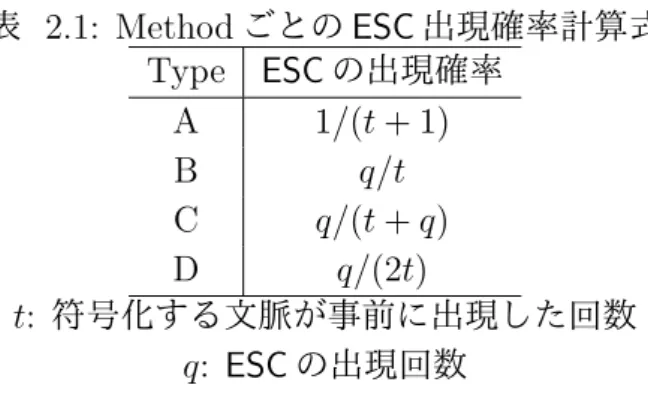
表 2.1: Method ごとの ESC 出現確率計算式 Type ESC の出現確率 A 1/(t + 1) B q/t C q/(t + q) D q/(2t) t: 符号化する文脈が事前に出現した回数 q: ESC の出現回数 化するには,事前に決められた計算式で ESC の出現率を求め,これを符号化の際に用い る.この計算式は表 2.1 に示すようにいくつかの種類が存在する.これらを Method と 呼ぶ.中でも Method C, Method D は高い圧縮率を出すことで知られている. ϵ→ c は 1 行目で初期化した際に出現していることにしているので,chr をレンジコー ダで符号化する. 7 文字目の場合,cb → c は存在しないため ESC を符号化し,b → c は存在するため chr を符号化する.この時点で chr の符号化は終了し,次の文字に移る.
2.3
PPM
を用いた構文木の符号化
構文木に PPM を適用するアルゴリズム [13] は Tarhio により 2001 年に提案された.本 論文では通常の PPM と区別する目的で TreePPM と呼ぶ.通常の PPM では符号化す る位置の直前に出現するある長さの部分文字列を文脈として使用するが,TreePPM では 符号化するノードに対し直近のある数の先祖ノードを文脈として使用する.図 1.1 の構文 木の符号化を例に,n = 2 での符号化について説明する. まず,符号化するのはノードの LPN のみで,葉や GPN などは含まない.しかし,出 現頻度については,GPN と親ノードから見た子ノードのインデックスのタプルを記録す る.例えば,非終端記号 A を生成する 3 つの文脈はそれぞれ ((0, 0), (1, 3)), ((4, 3), (6, 2)), ((6, 2), (2, 1)) である.ただし,(0, 0) はルートノードより上であることを表す.また,ノー ドの辿り方は深さ優先探索の行き掛け順で行う.これは復号を行う際に先祖のノード情 報が必要なため,根から辿る方法として採用している.この出現頻度の取得方法以外は 通常の PPM と同じ流れで符号化を行う.復号についても,符号化と同様にして出現頻度を取得する.復号される情報は LPN なので,生成規則を見ることでノードのラベル,す なわち非終端記号を復元できる. 通常の PPM と比較したときに,TreePPM を適用することで圧縮率が改善される可能 性を考える際,以下の点に着目する必要がある. 1 つ目は,規則がコンパクトであるかどうかである.例えば,各非終端記号を左辺に持 つ規則がそれぞれ多数存在するとき,場合によっては木構造を生成したことによって符 号化するには無駄な情報が増え,逆に圧縮率が悪化することもある. 2 つ目は,文字列のある位置の前後の関係だけではわからない,構造的な出現頻度の偏 りが存在するかどうかである.前後の非終端記号の並びから十分に出現頻度の偏りがわ かるような構造の場合,通常の PPM を適用するのと変わらないか,場合によっては悪化 する.例えば文中に “10 dollar” という文字列が出現する場合,そのままの文字列を PPM で符号化する場合前後の文字の出現頻度から効率的に符号化できる可能性があるのに対 し,例えば図 2.4 に示したような構造の場合,文字種の並びがわかるのみで,“dollar” と いう文字の並びのような文脈を出現頻度に含めることができない.このような規則の場 合,レンジコーダのように終端記号の出現頻度で符号化をするのとほとんど変わらず,場 合によってはレンジコーダより悪くなってしまう. 本論文ではこれらの性質を踏まえて,手法の提案・考察を行っていく. なお,本論文では,TreePPM と他のアルゴリズムの圧縮率を比較するにあたって,構 文木を符号化したときのファイルサイズだけではなく,文法の生成規則を適切な方法で 保存したときのファイルサイズも含めて圧縮後のサイズとして用いる.アルゴリズム側 に生成規則を持たせ,構文木の符号化後のサイズのみで良いという考えもあるが,この ようにした理由は 2 点ある. 1 点目は,アルゴリズムの性能比較の有効性の観点によるものである.例として,ある 文字列 Saを復号するプログラム内に Saを包含すれば,Saを復号するための符号データ は不必要であるため,Saに対する圧縮率は 0%であると言える.しかしアルゴリズムの 性能比較としては無意味なものであることは明らかである.同様の理由から,文字列 Sa を構成する単語の集合をプログラム内に包含する場合も,性能比較として公正であると は言い難い.実際,圧縮率の高さを競うコンテストとして著名な Hutter 賞 [7] では,こ
.. . CHAR CHAR CHAR CHAR CHAR CHAR CHAR CHAR CHAR CHAR .. . NUM 1 NUM 0 SPACE ⊔ LATIN d LATIN o LATIN l LATIN l LATIN a LATIN r * ⊔は空白の意 図 2.4: 非効率的な木の例 の観点から復号を行う実行ファイルまで含んだファイルサイズを用いて圧縮率を求める. 2 点目は,実用上における問題によるものである.生成規則集合を圧縮後のサイズとし て用いる場合に問題となるのは,主に章 4 で述べる自然言語文を文脈自由文法と見たと きの規則集合のように,構文木の符号化後のサイズに対して無視できないほど規則数が 多い場合である.特に自然言語文の生成規則は,同じ言語でも年代や地域,文章のジャ ンルによって様々であることが考えられる.アルゴリズム側に生成規則を持たせる場合 は,復号をする際に非終端記号の数および各非終端記号から生成される規則の数が符号 化時から変動があってはならないが,自然言語の性質から不変性を担保することは運用 上難しい. これらの理由から,TreePPM の圧縮率算出には生成規則サイズを含めたファイルサイ ズを用いた.
2.4
アーリー法
本論文では,文脈自由文法の構文解析器にアーリー法 [3][12] を用いる.アーリー法は 文脈自由文法などの構文解析器として知られ,動的計画法を用いた手法である.最悪時 間計算量は,文法の規則数を定数とすると,曖昧な文法に対し O(n3),曖昧でない文法 に対し O(n2),左再帰に書かれた曖昧でない文法に対しては O(n) となる. まず,アーリー法のアルゴリズムでは,状態と呼ばれるものを用いて構文解析の候補 を求める.状態とは,適用する規則 p,文字列に適用する際の開始位置 startIndex (0≤startIndex ≤ n),適用する規則における位置 pIndex (0 ≤ pIndex ≤ len(p)) を保存す
るものである (n は構文解析する文字列の長さ,len(p) は規則 p の長さ).
実際の構文解析の流れは Algorithm 2 に示したとおりである.正しく構文解析が可能 である場合,必ず状態の集合 S[n] には,p の左辺が開始記号で pIndex = len(p) となっ ている状態が含まれる.
アーリー法のアルゴリズムによって得られる状態の集合の配列 S を基に,構文木を構 築することが可能である.通常は,Predict, Scan, Complete の各操作において,新たな 状態を作り出す各操作でその元となった状態を記録しておくことで,S[n] に含まれる p の 左辺が開始記号で pIndex = len(p) となっている状態から順に,各状態の生成元を辿っ ていくことで,構文木を構築する.
Algorithm 2: アーリー法 Function earleyParse(V, P, Z, str): Input : 非終端記号のセット V, 生成規則のセット P, 開始記号 Z, 文字列 str Output: 各位置における状態の集合の配列 S /* 状態を表すオブジェクト State に含まれる情報: */ /* 使用する生成規則 p, 開始位置 startIndex, 生成規則の位置 pIndex */ let S = Array<Set>(length=len(str)); S[0] = Set<State>(); for p in P.get(左辺=Z) do Z から予測できる状態を S[0] に追加; for i in 0..len(str)− 1 do S[i + 1] = Set<State>(); predict(S, i ); scan(S, str, i ); complete(S, i ); return S; Function predict(S, i ): /* 状態セット S[i] の中から,位置 i から始まる非終端記号を探し,それらの非終 端記号を左辺に持つ規則から状態を生成して S[i] に追加.これを生成できる 状態がなくなるまで繰り返す. */ Function scan(S, str, i ): /* S[i] の中で,str[i + 1] に一致する終端記号を生成可能なものを探し,それらを 基に i + 1 における状態を S[i + 1] に追加. */ Function complete(S, i ): /* S[i + 1] の中で,規則の位置が末端に達した状態 s を探し,この状態の生成元 となった状態を S[i + 1] に追加.追加する状態がなくなるまで繰り返す. */ /* ここで「生成元となった状態」とは,S[s.startIndex] に含まれる状態のうち 関数 Predict にて規則 s.p の左辺の非終端記号が次に出現するとした状態の ことである. */
第
3
章
不完全な文法情報を用いた構文木の生成と
TreePPM
の適用
第 2.3 節で述べた TreePPM は,構文木を構築できない文字列を圧縮することが不可能で ある.本章では,構文木を構築することはできないものの,部分的には文法に則してい る文字列に対し符号化が可能な形で木構造を生成することについて述べる.3.1
エラー
そのままでは構文解析に失敗する文字列の一部または全部を削除するか置換をしたと きに構文解析が成功するようになるとき,その削除・置換した各部分をエラーと定義す る.なお,エラーを含む文字列に対してエラーは一意に定まらないことがある.例えば, 文法 G1では構文解析不可能な文字列 “i := (i∗ i) + i)”は,2 度出現する右括弧のうち一方 をエラーと考え削除することで,構文解析に成功するようになる.これはエラーとなる 文字の個数が最も少ない選び方であるが,他にも “+i)” の部分や,文字列全体をエラー と考えることもできる.3.2
文法のエラー許容化
エラーを含む文字列に対しても TreePPM を適用するために,元の文法情報を用い,エ ラーを含む文字列も構文解析できるようにした新たな文法を生成する手法を提案する. 本論文では,この既知の文法情報から新たな文法を生成する手法のことをエラー許容化と表記する. 3.2.1 エラー許容化のアプローチ まず初めに,エラー許容化した文法のアプローチについて述べる.エラーが存在する 文字列であっても,その文字列と編集距離が近い,文法に即した文字列が存在するとき, 多くの場合任意の非終端記号から部分的に構文木を生成可能な箇所が存在する.これら の部分的な構文木を TreePPM で符号化すると,元の文字列を通常のアルゴリズムで符号 化するよりも圧縮率が高くなることが考えられる. エラー許容化のプロセスでは,部分的に生成した構文木や構文木を生成できなかった 部分文字列を 1 つの構文木としてまとめ上げるための生成規則や非終端記号を追加する. これらの規則や非終端記号により,最終的には図 3.1 の例のような構文木を生成する.図 3.1 で薄い色で示した部分が元々の文法による部分的な木構造,濃い色で示した部分がエ ラー許容化した文法によって新たに生成可能となった部分である. 1 つの構文木にすることで,TreePPM のアルゴリズムに手を加えることなく,各部分 構文木を符号化する際に TreePPM の出現頻度を共有することが可能である.また,構文 木を生成できなかった部分も TreePPM のアルゴリズムのみで符号化における通常の文字 列に対する PPM と同等の恩恵を受けることができる. 3.2.2 エラー許容化のプロセス 以下では,エラー許容化のプロセスについて述べる.エラー許容化のアルゴリズムを, Algorithm 3 に示す. エラー許容化のプロセスでは,まず新たな非終端記号 S を定義する.また S を新たな 開始記号とする.また,空文字 ε も定義する. S からは,全ての非終端記号および全ての終端記号を左再帰的に生成可能な規則を定 義する.また,S から空文字のみを生成する規則も定義する. 例として ET(G1) にて追加する規則を図 3.1 に示す.GPN が 8∼11 の 4 つの規則が S か ら非終端記号を左再帰的に生成する規則,12∼17 が終端記号を左再帰的に生成する規則, 18 が空文字のみを生成する規則にあたる.
S S S S S ε X i := A B C i ∗ ( A A B C i + B C ( A A B C i + B C i )
図 3.1: ‘i := i∗ (i + (i + i)’ の ET(G1) の構文木
表 3.1: ET(G1) で追加する生成 規則 規則 GPN LPN S→ S X 8 1 S→ S A 9 2 S→ S B 10 3 S→ S C 11 4 S→ S i 12 5 S→ S := 13 6 S→ S ∗ 14 7 S→ S + 15 8 S→ S ( 16 9 S→ S ) 17 10 S→ ε 18 11 以上のように,エラー許容化のプロセスにより,自動的にエラーを許容化した文法を 生成可能である.
3.3
抑制的エラー許容構文木の生成
3.2 節で示したエラー許容化した文法を用いることで,エラーを含む文字列の構文解析 が可能になった.しかし,エラー許容化で追加した規則により,元の文法の曖昧性に関 係なくエラー許容化した文法は曖昧な文法となる. 一般に,曖昧な文法を用いた構文解析は,曖昧でない文法を用いた構文解析に比べ,必 要な計算量は増加する.例えば,アーリー法 [3] で構文解析器を行った場合,2.4 節で述 べたように長さ n の文字列に対して文法が曖昧でない場合の最悪時間計算量は O(n2) で あるのに対し,曖昧になった場合は O(n3) である. エラー許容化した文法での構文解析と元の文法での構文解析は対象となる文字列が異 なるため厳密な比較はできないが,例えば元の文法に即した文字列 A と,A 中の 1 文字 を他の終端記号に置き換えたエラーを含む文字列 B において,元の文法で A を,エラー 許容化した文法で B を構文解析したとき,後者の計算量は前者に比べて増加する.また, エラー許容化した文法で A を構文解析した場合も同様に増加する. これは,曖昧な文法ではある文字列に対する構文木の解釈が複数存在する可能性があAlgorithm 3: エラー許容化のプロセス Function ET(G): Input : 拡張前の文法 G = ( 非終端記号集合 V, 終端記号集合 Σ, 生成規則集合 P, 開始記号 Z ) Output: エラー許容化した文法 1 let S = createNonterminal(); /* 新たな開始記号 S を定義 */ 2 let ε = ‘’; /* 空文字 ε の定義 */
3 let V′ = cloneOf(V), Σ′ = cloneOf(Σ), P′ = cloneOf(P); 4 for X in V do /* 全ての非終端記号 X について */ 5 P′ += Production(S→ S X); /* S→ S X となる規則を追加 */ 6 for x in Σ do /* 全ての終端記号 x について */ 7 P′ += Production(S→ S x); /* S→ S x となる規則を追加 */ 8 P′ += Production(S→ ε); 9 V′ += S ; /* S を非終端記号集合に追加 */ 10 Σ′ += ε; /* ε を終端記号集合に追加 */ 11 return (V′, Σ′, P′, S); ることが原因である.しかし,本研究の目的は圧縮率を向上させることであるため,エ ラー許容化した文法に対する構文木を全て求める必要はなく,圧縮率が高くなると考え られる構文木を 1 つ求めることができればよい.そこで本論文では,元の文法による部分 構文木が大きくなるような単一のエラー許容化した文法の構文木を構築することで,計 算量を下げたアルゴリズムを提案する.このアルゴリズムを Algorithm 4 に示す.G1を 例にこのアルゴリズムの説明をする. はじめに,G1の非終端記号と規則,そして構文解析する文字列を入力とする.以下に 行ごとの関数の説明を記す. 3∼4 行目 エラー許容化のプロセスにて追加される規則のうち,右辺で S と非終端記号を生成 する規則のみを元の文法の規則集合に追加する.G1の例では,表 3.1 に示した規則 のうち GPN が 8 から 11 である 4 つの規則を追加する. 10∼27 行目 全ての構文解析が終了するまで繰り返す.以下細かい内容について記す.
11 行目 アーリー法のアルゴリズムでは,文法的に出現することがない文字が存在し た時点で構文解析を終了しその前の文字までの状態を出力させる.そのため, 最初のループの場合は文字列の先頭から,そうでない場合は前のループで構 文解析が終わっていない部分の先頭から構文解析をする.出力はこのループ で構文解析を始めた位置を 0 とし,位置 0 から構文解析できた位置まで,各位 置に複数の状態を持つ 2 次元リストである. 12∼26 行目 葉を 2 つ以上持つ構文木を生成できる場合,その木を out に追加する.構文解 析できた範囲が 0 または 1 字の場合,その部分は構文解析不可能であるとみな す. 15∼23 行目では,取得した状態のリストを末尾から見ていく.閉じている状 態が存在するならば,最も開始位置のインデックスが小さい状態を選ぶ. 21 行目, 27 行目 構文解析が終わっていない範囲を次に構文解析させるため,終わった範囲は unread から削除する. 28 行目 out は部分構文木のリストなので,エラー許容化した文法の規則に沿って 1 つ の木を生成する.GPN が 12∼17 の規則を用いている木が連続していた場合 は,1 つにまとめる.最後にこの木を出力する. 本アルゴリズムは,必ずしも元の文法で生成可能な部分構文木が最大となる構文木を 生成するとは限らない.しかし本手法が十分有効であることは,第 5 章にて示す.また, 本アルゴリズムにより生成された構文木のことを抑制的エラー許容構文木と呼ぶ. 抑制的エラー許容構文木の生成について,以下の定理が成り立つ. 定理 1 抑制的エラー構文木の生成にかかる最悪時間計算量はエラー許容化する前の文法 に依存し,文法の規則数を定数とすると,その文法に対するアーリー法の最悪時間計算 量と同等である.
証明 1 与えられた文法に対するアーリー法の最悪時間計算量を O(earley(n)) と表記す る.文法が曖昧なとき O(earley(n)) = O(n3),曖昧でないとき O(earley(n)) = O(n2),
曖昧でなく左再帰的であるとき O(earley(n)) = O(n) である.入力文字列 Str を構文解 析できる部分で区切ったときの文字列の集合を Spr ={Str1, Str2, ..., Strm} とする. 多項定理より,自然数 a の分割 a = a1+ a2+ ... + alにおいて,ak = (a1+ a2+ ... + al)k≥ ak 1 + ak2 + ... + akl は自明である.このことから,O(ak) = O((a1 + a2 + ... + al)k) ≥ O(ak 1 + ak2 + ... + akl) が成り立つため,Spr の全ての要素に対してアーリー法を適用する のに必要な最悪時間計算量は O(earley(n)) である. また,開始位置が最小の閉じた状態を見つける処理に左再帰的な文法の場合アーリー法
の性質から O(1),そうでない場合 O(n) かかるため,全ての Striの構文解析結果を out
に追加する処理に必要な最悪時間計算量は左再帰的な文法の場合 O(n),そうでない場合
O(n2) かかる.
以上から,最悪時間計算量は文法が曖昧なとき O(n3),曖昧でないとき O(n2),曖昧で
なく左再帰的であるとき O(n) となり,与えられた文法に対するアーリー法の最悪時間計 算量と同等になる.
Algorithm 4: 抑制的エラー許容構文木の生成 Function GenerateErrorTree(G, Str): Input : 拡張前の文法 G = ( 非終端記号集合 V, 終端記号集合 Σ, 生成規則集合 P, 開始記号 Z ), 拡張前の生成規則 P, 文字列 Str Output: エラー許容構文木 1 G’ = ET(G); 2 Vtmp = cloneOf(V); 3 S = createNonterminal(); 4 Vtmp += S; 5 for nonterminal in V do 6 Ptmp に Y → nonterminal となる生成規則を追加; 7 index = 0; 8 out = emptyList(); /* 生成した木を保存するためのリスト */ 9 unread = Str; 10 while len(unread) > 0 do 11 文法 Gtmp = (Vtmp, Σ, Ptmp, S) を用い,可能な範囲で unread をパースし,パース した範囲の状態リスト states を取得; 12 if len(states) > 1 then 13 tmp = 木のリスト; 14 first = true;
15 for i in len(states)− 1 downTo 0 do
16 if states[i] に開始位置が i でない閉じた状態が存在 then 17 開始位置が最小の閉じた状態を tmp に追加; 18 i に追加した状態の開始位置を代入; 19 if first then 20 first = false; 21 unread = unread の i から最後までの部分文字列; 22 else 23 文法 G’ を基に unread[i] を生成する木を tmp に追加; 24 tmp を逆順に out に追加; 25 else 26 文法 G’ を基に unread[0] を生成する木を out に追加; 27 unread = unread の先頭 1 字を削除した部分文字列; 28 return out の各部分木を結合した,文法 G’ に従った木構造;
第
4
章
自然言語文への
TreePPM
の適用
前章では構文解析できない文字列に対し,エラーの概念を導入することで構文木を生成 し TreePPM を適用できることを示した.本章では自然言語文に TreePPM を適用するこ とについて検討を行う.4.1
自然言語文に対する構文木
自然言語文に対する構文木の構築自体は既に様々な研究がなされている.本論文では, Stanford Parser[6] と呼ばれるライブラリによる英文の構文解析結果を用いて実験を行う. 以下では Stanford Parser について簡単に説明する.例として,“The quick brown fox jumped over the lazy dog.” という文の構文解析結果 を図 4.1 に示す. Stanford Parser にはいくつかの実装が含まれるが,本論文では確率文脈自由文法によ る構文解析結果を用いる.確率文脈自由文法とは,各生成規則に出現確率の情報が含ま れる文脈自由文法の拡張である.出現確率により枝刈りを行うことで,特に曖昧な文法 において構文解析速度が向上する. また,Stanford Parser では必ず木構造を生成できるように作られている.もし定義さ れていない単語が出現したり,定義されたものでも文法上間違った位置に単語が出現す る場合は “未定義” という品詞として分類される.この “未定義” は必ず生成できるよう に規則が定められているので,木を生成できないという状況には至らないようになって いる.
ROOT S NP DT The JJ quick JJ brown NN fox VP VBD jumped PP IN over NP DT the JJ lazy NN dog . . 図 4.1: 確率文脈自由文法による構文木の例
4.2
自然言語文に対する構文木の符号化
まずはじめに,自然言語に対する構文木を TreePPM で符号化した場合に,通常の PPM と比較して圧縮率が改善する可能性について検討を行う. 4.2.1 構文木にすることによる効果 自然言語文を構文木にすることによる圧縮率に表れる効果は 2 点考えられる.まず,図 4.1 を例に考えると,動詞 “jumped” の前には “The quick brown fox” に限ら ず名詞や名詞句などが来ることが多いと考えられる.このようなケースが多数存在する 場合において,構文木にすることで圧縮率が向上する可能性が考えられる.
また通常の PPM の場合,各文字ごとに符号化処理を行うのに対し,TreePPM では構 文木のノードごとに符号化処理を行う.“The quick brown fox…” の文では,単語間のス ペースを含めると 45 文字を符号化する必要があるが,構文木にすることで 16 個のノー ドを符号化するだけでよいため,符号化処理を行う回数が減り,圧縮率が向上する可能 性もある. 4.2.2 構文木にすることによる問題点 しかしながら,実際に自然言語文を構築すると,生成規則の数が膨大であることが判 明した.この問題は一般的なアルゴリズムと比較し TreePPM を採用することで逆に圧縮 率を悪化させる要因となりうることが事前に判明していた.
表 4.1: 英文ファイルと用いられている規則のサイズ(単位:KB) 英文 plrabn12 内で使用 (plrabn12) されている規則集合 元サイズ 481,859 188,677 7zip(PPMd) 適用後 133,117 63,241 表 4.2: 生成規則数とその出現回数内訳(単位:個) 全規則数 出現回数別 1 回 2 回 3 回 それ以上 19,923 12,100 2,774 1,258 3,791 例えば,約 471KB の英文 (plrabn12 1) を構文解析した場合に使用される生成規則集合 のみをファイルとして保存すると,表 4.1 のように無圧縮状態で約 184KB,圧縮をして も約 62KB であった.2.3 章で述べたように,本論文では規則集合のサイズも圧縮率に関 わる数値として扱うため,この数値を小さくすることを考える必要がある. もう 1 つの問題点は,出現回数の少ない規則がこの生成規則集合の中で大きな割合を 占めているという点である.例として,plrabn12 を構文解析したときに使用された規則 を,出現回数で分けたときの結果が表 4.2 である.また,図 4.2 には表 4.2 で示していな い出現回数も含め,出現回数ごとの規則数を座標軸上にプロットした.これらの結果か ら,1 つの英文ファイルに含まれる約 20,000 個の規則のうち,半分以上は 1 回しか使用 されず,また圧縮率を向上させるのに役に立たないと思われる回数しか利用されない規 則も多く含まれていることがわかる.出現回数の多いものでは 1 万回以上使われている 規則もある一方,約 80%の規則は出現回数が 3 回以下であり,これらの規則は生成規則 を保存したときのサイズを不必要に増加させている原因と考えられる. 本研究では,これらの改善策として,前章で用いたエラー許容構文木に変形させるこ とを提案する.前章では,効率的に構文解析を行うためにエラー許容構文木を導入した が,本章では符号化のための構造として用いる. 符号化する文字列の一部分を変形させる場合の例を図 4.3 に示す.この例では,“jumped” という単語が文字列中にあまり出現しなかった場合の変形後を表す.また,実データでは 単語の間にはスペースが含まれるため,それも符号化するために,木に含めている.生 1http://www.textfiles.com/etext/NONFICTION/plrabn12.txt
100 101 102 103 104 105 100 101 102 103 104 105 x回以上出現す る規則の数 ( 個 )
規則の出現回数x (回)
図 4.2: 出現回数別に見る規則数の分布 成規則は前章と同様,全ての非終端記号と終端記号を生成する S という非終端記号を定 めている.ただし,S→ S x (x は任意の終端記号) の形をとる規則について,x の位置に 出現する終端記号は 1 バイト文字の計 256 個のみに限定した. 次章にて,実験および考察を行う... . S S S S S S S S S S .. . NP DT ⊔The JJ ⊔quick JJ ⊔brown NN ⊔fox ⊔ j u m p e d PP IN ⊔over NP DT ⊔the JJ ⊔lazy NN ⊔dog . . 図 4.3: 確率文脈自由文法による構文木の例
第
5
章
実験
本章では本研究の成果を確認するために,他の圧縮手法との比較を行う.実験環境は, Intel(R) Core(TM) i7-4790K CPU, 32GB RAM の Windows 10 マシンを使用する.
5.1
エラーを含む場合の
TreePPM
第 3 章にて示した,エラーを含む文字列に対する構文木を生成し TreePPM を適用する 手法の比較を行った. 5.1.1 構文解析の速度比較 はじめに,提案手法のうち抑制的エラー許容構文木の生成について,通常のアーリー 法で構文解析を行った場合の時間と比較し有効性を確かめる.まず,図 5.1 に示す生成規 則集合 P2を持つ文脈自由文法 G2 = ({A, B, C, N, I, X}, {i, :=, +, ∗, ), (, 0, 1, .., 9}, P2, X) を定 義し,この G2によって生成できる文字列を,長さを変えて複数自動的に生成した.この 生成された文字列に対しエラーとして終端記号を任意の位置に 1 つ挿入したものを,実 験に使用する文字列とした.. エラーを含む文字列に対し,ET(G2) で通常のアーリー法を適用した場合と提案手法を 適用した場合,そしてエラーを挿入する前の文字列に対して G2で通常のアーリー法を適 用した場合の 3 つの場合について,速度の比較を行った. 結果を図 5.2 に示す.ただし,通常のアーリー法で ET(G2) として構文解析する場合に ついては,使用メモリ量が膨大となったために途中で打ち切った.結果より,提案手法 の構文解析速度はエラーがない場合の G2の速度と同等であることが確認できた.(1) X→ i := A (2) A→ A + B (3) A→ A − B (4) A→ B (5) B→ B ∗ C (6) B→ B / C (7) B→ C (8) C→ (A) (9) C→ N (10) C→ 0 (11) N → 1 (12) N → 2 .. . (19) N → 9 (20) N → N 0 (21) N → N 1 .. . (29) N → N 9 図 5.1: G2の生成規則集合 P2
0.1
1
10
100
1000
10000
100000
1x10
610
100
1000
10000
100000
1x10
61x10
7時間
(ms)
G
3(エラーなし)
G
3'
提案手法
⼊⼒⽂字列の⻑さ (⽂字)
図 5.2: 提案手法と G′2,エラーを除いた場合の G2との比較 ET(G2) は曖昧な文法であるため,アーリー法による構文解析の最悪時間計算量は O(n3) となると考えられるが,実際はそこまでの計算時間はかからなかった.その理由は,左 再帰的な定義となっていることと,比較的単純な文法であるためと考えられる.しかし それでも,提案手法はその 10 分の 1 程度の時間で計算ができているため,十分に有効で あると言える. 5.1.2 抑制的エラー許容構文木に対する TreePPM の適用 次に,エラーの存在する文字列から生成した抑制的エラー許容構文木に TreePPM を適 用した場合,その文字列からエラーを除き,G2の構文木を生成して TreePPM を適用し35
40
45
50
55
60
65
70
1
10
100
1000
10000
Co
mp
re
ssio
n
ra
tio
(
%
)
File size (KB)
TreePPM
PPM
7z
bz2
gz
xz
zip
図 5.3: ファイルサイズの変化による圧縮率の変動の比較 表 5.1: アルゴリズムごとの圧縮率の比較 アルゴリズム名または ファイルフォーマット名 ファイルサイズ (byte) 圧縮率 (%) (エラーを含んだ圧縮前テキスト) 1,836,603 -TreePPM(エラー除外) 742,224 40.412 TreePPM(エラーを含む) 742,310 40.417 PPM 793,258 43.191 7zip(PPMd) 786,904 42.845 gzip 893,936 48.673 bzip2 817,678 44.521 xz 837,516 45.601 zip(Deflate) 892,531 48.597 た場合を比較し,提案手法に圧縮率の著しい低下が見られないかを比較した.また一般 的に用いられる様々な圧縮手法と比較し,それらのアルゴリズムとの圧縮率の違いを実 験により調べた. 実験に用いた文字列は 5.1.1 節で用いたものと同様にして生成したものである. ファイルサイズを変えて他の圧縮アルゴリズムと比較を行ったときの圧縮率の変化の グラフを図 5.3 に示す.また,このうち最も大きなファイルサイズのテキストを各アルゴ リズムで圧縮した際の値を表 5.1 に示す. このうち,提案手法は 3 行目の太字で示したものである.また,2 行目に示した値はエ ラーを挿入していない文字列に対して TreePPM を適用したものである.この他のアルゴリズムについてはエラーを含んだデータを圧縮した際の圧縮率を示す.4 行目の PPM は,本実験で使用した TreePPM の内部で用いているものと同じ PPM のアルゴリズムを, 通常のテキストに対して適用したものである.また,7zip で用いられている PPMd は, PPM を速度面で改良したアルゴリズムである. 表から,提案手法はエラーを含まない場合と比較しても圧縮率の悪化は小さく抑える ことができることを確かめられた.また,他の手法と比較すると高い圧縮率が出ている ことも確かめられた.グラフからは,ファイルサイズが大きくなるほど TreePPM が有効 であることが読み取れる.
5.2
自然言語に対する
TreePPM
の適用
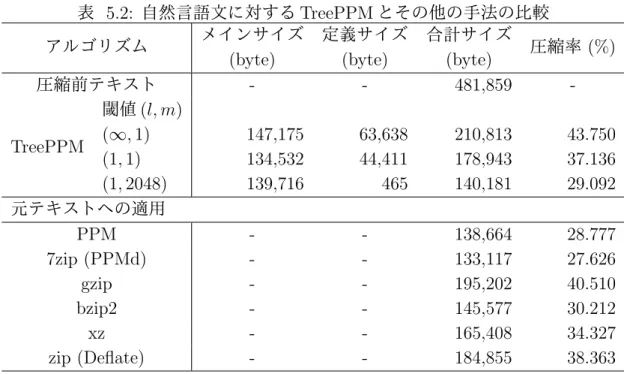
5.2.1 実験 第 4 章に示した手法が有効かどうかを確かめる.本手法での規則の削減は,閾値 l, m を設定し, 1. 各ノードにおける最も近い葉までの距離が l 以下のものに関して,各規則ごとの出 現回数を数える 2. 1. で数えた回数が m 回以上の規則のみを抽出 という 2 段階のプロセスで行う.なお,各ノードにおける最も近い葉までの距離は,図 4.1 の例では,DT や JJ などは 1,NP や VP などは 2 と数える. これらの閾値を変化させ,圧縮率がどのように変化するかを調べた結果が図 5.4 であ る.また,比較対象として同じファイルを他のアルゴリズムで圧縮したときの結果を表 5.2 に示す.なお,メインサイズとは構文木そのものを符号化したときのサイズ,定義サ イズとは生成規則の定義を符号化したときのサイズのことである. 図 5.4 の結果から,閾値を定めることにより,圧縮率が変化することが確かめられた. 図 5.4(a) では,閾値 l は∞ 固定で閾値 m を変化させた場合のメインサイズと定義サイズ を合計したサイズの比較結果である.メインサイズは,生成規則を削除したことで 1 度 圧縮後のサイズは大きくなったが,定義サイズの減少幅の方が大きいために全体サイズ表 5.2: 自然言語文に対する TreePPM とその他の手法の比較 アルゴリズム メインサイズ (byte) 定義サイズ (byte) 合計サイズ (byte) 圧縮率 (%) 圧縮前テキスト - - 481,859 -TreePPM 閾値 (l, m) (∞, 1) 147,175 63,638 210,813 43.750 (1, 1) 134,532 44,411 178,943 37.136 (1, 2048) 139,716 465 140,181 29.092 元テキストへの適用 PPM - - 138,664 28.777 7zip (PPMd) - - 133,117 27.626 gzip - - 195,202 40.510 bzip2 - - 145,577 30.212 xz - - 165,408 34.327 zip (Deflate) - - 184,855 38.363 は単調減少となっている.また,図 5.4(b) より,葉までの最小距離の最大値については, 1 に制限したとき,すなわち図 5.5 に示すような品詞から終端記号 (単語) が直接生成さ れる規則のみに制限したときが最も効果的に符号化できた,という予想と反する結果と なった. 閾値 m を増加させると,次第に圧縮後のサイズは減少していくが,m を増加させ続け ると最終的に単に文字列を PPM で符号化することと違いがなくなるため,次第に通常 の PPM の圧縮後のサイズに近づいている.予想では,最終的に PPM の圧縮後のサイズ に収束する前に一度そのサイズよりも小さくなる可能性を考えていたが,実際には単調 減少であった. また表 5.2 から,元のテキストを通常の PPM で圧縮した場合と比べると,あまり効果 的になっていないことも判明した.なお,調査した既存アルゴリズムの中では,7zip の PPMd モードが最も圧縮率が高くなった.これと比較すると圧縮率に大きな差があり,課 題が浮き彫りとなった. 5.2.2 圧縮率に有意性が見られなかった原因の考察 まず,構文木を保持することで圧縮率が悪化した原因としては,構文木にしたことで 文脈から単語そのものの情報が消えてしまったということが挙げられる.
全く文法規則を削除していない図 4.1 を例に説明すると,動詞が “jumped” のとき,主 語として用いられる名詞は限られ,“fox” や “dog” を主語とする場合はあっても,“pen” を 主語とする場合はほとんどないと考えられる.しかしながら,本手法では「“jumped” は
動詞の過去形の一種」,「その前には名詞節が来る」という出現情報のみで符号化を行って
いるため,この結びつきを完全に無視してしまっている.同様のことが主語である “fox” など他の単語にも言える.
また,本手法では “The quick brown fox” と “The brown fox” は全くの別扱いになる などの点でも,構文木にすることはむしろ効率が悪いと言える.ただし単語のみを符号 化した場合は,文の構造情報が削除されている分,ある程度圧縮率が向上したと考えら れる. 次に 7zip の PPMd に圧縮率で大きく差を開けられた原因としては,PPMd のアルゴリ ズムが深く関わっている.PPMd は PPM を改良した圧縮アルゴリズムで,高速化・省メ モリ化を実現している.この副次的な効果として,通常の PPM では実現が実質不可能 な,32 文字までの長い文脈での出現頻度情報を基に符号化が可能となっている.それだ け長い範囲で出現頻度を求めることができるのであれば,前後の単語の繋がりの情報も 符号化に反映できるため,圧縮率が非常に高くなったと考えられる.
120
140
160
180
200
220
1
10
100
1000
圧
縮
後
の
サ
イ
ズ
(KB)
規則の最⼩出現回数の閾値 (個)
全体サイズ
メインサイズのみ
(a) l =∞ で m を変化させたときのメインサイズと合計サイズ比較120
140
160
180
200
220
1
10
100
1000
圧
縮
後
の
サ
イ
ズ
(KB)
規則の最⼩出現回数の閾値 (個)
l=∞
l=2
l=1
(b) l が∞, 2, 1 の場合に m を変化させたときの合計サイズ比較 図 5.4: 自然言語文に対する TreePPM の圧縮サイズ比較.. . S S S S S S S S S S S S S S S S .. . DT ⊔The JJ ⊔quick JJ ⊔brown NN ⊔fox ⊔ j u m p e d IN ⊔over DT ⊔the JJ ⊔lazy NN ⊔dog . . 図 5.5: 葉までの最小距離 1 に制約した場合の構文木の例
第
6
章
まとめ
本研究では文脈自由言語の文字列にエラーが含まれる場合でも,構文解析器のアルゴ リズムを修正することにより高速に構文木を生成し,かつ圧縮率の低下を抑えることに 成功した.また,自然言語文に対して構文木を生成する既存研究の成果を利用して,圧 縮率を高めることが可能かどうか検討を行った. 本研究の提案手法では自然言語文に対して圧縮率を向上させることはできなかったが, 圧縮率を向上するための次のアプローチの方向性を示すことができた. 今後の課題としては,品詞以外にも意味による細かい分類を行うことや,隣接してい ないが構文木から関係が深いと考えられる単語同士の関係も文脈に含めることで圧縮率 を向上させることが挙げられる. また,多くのファイルで実験に使用していた PPM のアルゴリズムよりも 7zip などで 用いられている PPMd の方が高い圧縮率を出していることから,TreePPM にて使用す る PPM のアルゴリズムを PPMd に置き換えた実験を行うことも,今後の課題である.参考文献
[1] R.D. Cameron. Source encoding using syntactic information source models. In
IEEE Transactions on Information Theory ( Volume: 34, Issue: 4, Jul 1988 ), pp.
843–850, 1988.
[2] Cisco. Cisco visual networking index:全世界のモバイルデータトラフィックの予測、 2015 ∼ 2020 年アップデート, 2016. https://www.cisco.com/web/JP/solution/ isp/ipngn/literature/pdf/white_paper_c11-520862.pdf.
[3] Jay Earley. An efficient context-free parsing algorithm. In Communications of the
ACM, pp. 94–102, 1970.
[4] Google. Brotli. https://github.com/google/brotli.
[5] Google. The need for mobile speed — better user experiences, greater publisher rev-enue, 2016. https://storage.googleapis.com/doubleclick-prod/documents/ The_Need_for_Mobile_Speed_-_FINAL.pdf.
[6] The Stanford Natural Language Processing Group. Stanford parser. http://nlp. stanford.edu/software/lex-parser.html.
[7] Marcus Hutter. 50’000 prize for compressing human knowledge. http://prize. hutter1.net/.
[8] Timothy Clinton Bell Ian H. Witten, Alistair Moffat. Managing Gigabytes:
Com-pressing and Indexing Documents and Images, Second Edition (The Morgan Kauf-mann Series in Multimedia Information and Systems), pp. 51–65. 1999.
[9] En-Hui Yang Jean-Claude Kieffer. Grammar-based codes: a new class of universal lossless source codes. In IEEE Transactions on Information Theory, pp. 737–754, 2000.
[10] Ian H. Witten John Gerald Cleary. Data compression using adaptive coding and partial string matching. In IEEE Transactions on Communications, pp. 396–402, 1984.
[11] G. Nigel N. Martin. Range encoding: An algorithm for removing redundancy from a digitized message. In Video and Data Recording Conference, 1979.
[12] Paul Tarau. Earley parser. http://www.cse.unt.edu/~tarau/teaching/NLP/ Earley%20parser.pdf.
[13] Jorma Tarhio. On compression of parse trees. In String Processing and Information