博士論文
プログラムの実行挙動に基づく
投機的並列実行方式に関する研究
指導教員 横田 隆史 教授
宇都宮大学大学院 工学研究科
システム創成工学専攻
十鳥 弘泰
2014
年
3
月
プログラムの実行挙動に基づく
投機的並列実行方式に関する研究
十鳥 弘泰
内容梗概
近年,クロック周波数の増加によるプロセッサコアの性能向上は頭打ちになっ ており,複数のプロセッサコアを単一のチップ上に搭載したマルチコアプロセッサ が注目されている.プログラムを高速に実行する必要がある場合,プログラムを 並列化し,マルチコアプロセッサコア上で並列に動作するようにプログラミング する必要があるが,プログラムの並列化においては高度な並列プログラミング技 術の習得が課題となる.この課題に対して,プログラムの自動並列化の研究が盛 んに行われている.自動並列化は単純な構造のプログラムに対しては非常に高い 有効性を示すが,複雑な依存関係を持つプログラムについては,静的に依存関係 を解析することが困難であるため,並列化を行えない場合もある.複雑な依存関 係を持つプログラムとしては,記号処理等を行う非数値処理系プログラムが挙げ られる.このプログラムを並列化する場合,プログラムの整合性を保つための同 期制御や排他制御を頻繁に行わなければならない.このため,同時並列に実行さ れる処理が少なくなり速度向上を達成することが困難であるといった問題がある. 本論文では,この問題を解決するため,投機的並列実行に着目する.投機的並 列実行は,次に実行される処理を予測し先行して並列実行する方式である.先行 して実行した処理の予測が正しければ性能向上を達成することができる.予測が 誤っていた場合には実行を破棄し,再度実行し直す必要があるため,高性能な投 機的並列実行を実現するためには精度の高い予測手法が重要となる.また,予測 や実行の破棄・再開を迅速に行うためには,ハードウェアによるサポートが必要 不可欠である.本論文では,複雑な依存関係のため並列化による性能向上が困難 であるプログラムに対して有効な投機的並列実行方式として,プログラムの実行 挙動の偏りを利用した実行方式を開発する. まず,投機成功率の高い投機実行を実現するため,ループにおける実行経路(パス)の実行割合に着目する.2 パス限定投機方式は,プログラム実行全体における 実行割合上位 2 本のパスを投機対象とする投機的並列実行方式であり,トレース ベースの性能評価実験により高い有効性が期待されている.そこで,2 パス限定投 機方式の性能を最大限引き出すためのマルチコアプロセッサアーキテクチャであ る 2 パス限定投機システムの設計を行う.また,2 パス限定投機システム上で実行 するプログラムの最適化について検討し,最適化を施したプログラムをクロック サイクル精度のシミュレータ上で実行することにより,システムの性能評価を行 う.その結果,依存関係を持つループに対して,プロセッサ 4 台の場合に逐次実行 に比べ 1.55 倍の性能向上を達成できることを示す. 次に,複数のパスを予測の対象とすることで,パス予測性能を向上させる手法 について検討する.プログラム全体を通した実行割合のうち,上位 2 本以外のパス を投機対象とする手法について,多くの追加ハードウェアを必要としない,新た なパスの予測メカニズムを提案する.1 ビットであった実行パスの履歴情報を,2 ビット,3 ビットと拡張して扱うことにより,投機対象となるパスの種類数を増大 させる手法を検討し,拡張した履歴情報を扱うことのできる新しいパス予測メカ ニズムを提案する.1 ビットの実行パス履歴情報を利用するパス予測機構に対し, 同程度の計算資源で複数パスの予測を実現でき,予測性能を 7.6 %向上できること を示す. 最後に,プログラムの実行挙動の追従して動的に予測対象を変更することで,パ ス予測性能を向上させる手法について検討する.あるループの実行に突入してか らループを抜けるまでの区間におけるパス実行割合の遷移の観測結果を示し,直 前のループ区間の実行割合上位 2 本のパスを予測対象とした動的選択方式につい て提案する.動的な選択を行った場合の予測成功率についての性能評価を行い,従 来の静的な予測手法に比べ,予測性能を 33%向上できることを示す. 本論文の成果は,(1) 2 パス限定投機システムにより,2 本のパスが高い実行割 合を占めるループの性能向上を実現できること,(2) 複数のパスが存在するループ については,実行パス履歴情報の拡張により高い予測性能を達成できること,(3) 複数のパスが複雑に実行されるループについては,実行挙動に動的に追従した投 機実行を実現することにより高い予測性能を達成できること,の 3 点を明らかに したことである.
A Study on Methods for Speculative Parallel
Execution based on Behavior of Programs
Hiroyoshi Jutori
Abstract
Recently, performance improvement of a single processor core by increasing clock frequency has reached a ceiling. Therefore, a multi-core processor which has sev-eral processor cores becomes widely used. Multi-core processor systems require effective parallel execution methods for performance improvement of program exe-cution time. However, manual parallelization for effective utilization of multi-core processor is a very hard task, especially for non-numerical programs which have complicated structures. An auto-parallelization system can ease parallelization of programs which have simple code structures. Meanwhile, a non-numerical pro-gram which has complicated code structures is difficult to improve performance by previous parallelization approaches. To parallelize programs which have compli-cated code structures, it is necessary to perform frequently data synchronization and exclusive control to engage the consistency of program execution. For this reason, there is a problem that the processes which executed simultaneously in parallel are decreasing.
To solve this problem, this paper focuses on ‘speculative parallel execution method’. This method predicts the next operations, and the processor executes these operations speculatively and in parallel. If the speculative execution is suc-cessful, the system can gain performance improvement. If the speculative execution is fail, the system needs to perform a recovery process to engage the consistency of program that becomes an overhead of parallel execution. Therefore, to realize a high performance speculative execution system, it is necessary to implement a prediction mechanism with highly accuracy. This paper studies new speculative parallel execution methods which use behavior of program execution to improve
programs which have complicated code structures.
Firstly, this paper focuses on the frequently executed paths in a loop. Two-path limited speculation method is a speculative parallel execution method that speculates the two most frequently executed paths in a whole program execution. Performance improvement of the method is exhibited by trace-based simulation. This paper shows a novel multi-core processor architecture, called PALS (PAth Limited Speculation system), in which the method is implemented by realistic hardware resources. The paper shows hardware mechanisms and code schedul-ing method for inter-thread dependency. Furthermore, this paper evaluates these mechanisms by using SPEC CINT2000 benchmark programs. As a result, in the case of four processors, the system achieves to improve the performance of 1.55 times compared to the sequential execution by one processor core.
Prediction mechanism is a key to achieve high performance by using methods of speculative parallel execution. High prediction accuracy expected to improve the effectiveness of speculative execution. To realize highly accuracy prediction, this paper introduces an extensive history information to identify and predict the multiple paths in loops. An N-bit history information represents 2N−1 paths, and
the predictor selects a path for the next thread from these paths. This paper shows that the proposed path prediction mechanism increases the prediction accuracy by up to 7.6 percent compared to the previous prediction mechanism using 1-bit history information.
To maximize the performance of the method, this paper discusses ‘phased be-haviors’ in program execution. This paper shows actual behaviors in program exe-cution in terms of exeexe-cution paths. Then, this paper introduces practical methods of dynamic selection of speculation paths. Preliminary results show that the opti-mal dynamic method increases the speed by 1.8 times at maximum and also that the practical dynamic method can increase the speculation success ratio by up to 33 percent compared with the previous static method.
The main contributions of this paper are following: (1) two-path limited spec-ulation systems can improve performance of loops that have two most frequently executed paths, (2) path predictor with extended path history information can
improve prediction accuracy of loops that have multiple paths, and, (3) dynamic selection method of speculation paths can follow the complicated execution be-haviors of loops, and realizes a highly accurate path prediction.
目 次
第 1 章 序論 1 第 2 章 関連研究 5 2.1 投機的並列実行 . . . . 5 2.2 投機的並列実行を実現するプロセッサ・アーキテクチャ . . . . 6 2.2.1 Multiscalar . . . . 6 2.2.2 Superthreaded Architecture . . . . 7 2.3 投機的並列実行におけるプログラム最適化 . . . 10 第 3 章 2 パス限定投機システム 12 3.1 プログラムの実行パスに基づく投機的並列実行 . . . 12 3.1.1 ループパス . . . 13 3.1.2 パスの実行割合の偏り . . . 17 3.1.3 2 レベル分岐予測を応用したパス予測機構 . . . . 18 3.1.4 投機スレッドコードと投機実行の成否判定 . . . 20 3.1.5 投機実行モデル . . . 22 3.2 2 パス限定投機システムのハードウェア設計 . . . . 26 3.2.1 設計方針 . . . 26 3.2.2 投機的並列実行制御にかかるオーバヘッド . . . 28 3.2.3 投機失敗時の回復処理にかかるオーバヘッド . . . 31 3.2.4 PALS のハードウェア構成 . . . . 33 3.2.5 マルチスレッド制御機構 TMU . . . 34 3.2.6 スレッド実行機構 TU . . . 37 3.2.7 メモリアクセス機構 MAU . . . 40 3.3 システムシミュレータの開発 . . . . 44 3.3.1 ソフトウェアシミュレータの開発 . . . 453.3.2 SimpleScalar . . . . 45 3.3.3 ISIS . . . . 46 3.3.4 ISIS-SimpleScalar . . . . 46 3.3.5 PALS シミュレータの実装方法 . . . . 46 3.3.6 システムシミュレータを中心とした評価環境 . . . 48 3.4 SPEC ベンチマークを用いた性能評価 . . . . 50 3.4.1 評価結果 . . . 51 3.5 結論 . . . 53 第 4 章 投機対象パスの複数化 55 4.1 概要 . . . 55 4.2 細粒度のプログラム実行挙動解析 . . . 56 4.3 パス履歴情報の詳細化 . . . 59 4.3.1 GAg 分岐予測ベースのパス予測器 . . . . 60 4.3.2 Gshare ベースのパス予測器 . . . . 62 4.3.3 ハッシュによる PHT へのアクセス . . . 63 4.4 予測成功率の評価 . . . 64 4.4.1 評価環境 . . . 65 4.4.2 評価結果 . . . 65 4.5 結論 . . . 66 第 5 章 投機対象パスの動的変更 70 5.1 概要 . . . 70 5.2 動的パス変更の適用可能性 . . . 71 5.3 動的な投機対象パスの変更 . . . 72 5.3.1 理想的な動的パス変更を行った場合の性能見積もり . . . 72 5.3.2 性能見積もり評価 . . . 73 5.4 現実的な動的パス変更手法の提案 . . . 75 5.5 予測/投機成功率の評価 . . . 78 5.5.1 評価方法 . . . 79 5.5.2 評価結果 . . . 79 5.6 結論 . . . 81
第 6 章 結論 83 参考文献 86 付 録 A 命令セット 93 A.1 制御命令 . . . . 94 A.2 ロード/ストア命令 . . . . 95 A.3 整数演算命令 . . . . 97 A.4 浮動小数点演算命令 . . . . 99 A.5 補助命令 . . . 101 A.6 PALS 用追加命令 . . . 102 A.6.1 実行モード制御命令 . . . 102 A.6.2 assert 命令 . . . 102 付 録 B 動的パス変更手法における評価の詳細グラフ 104
図 目 次
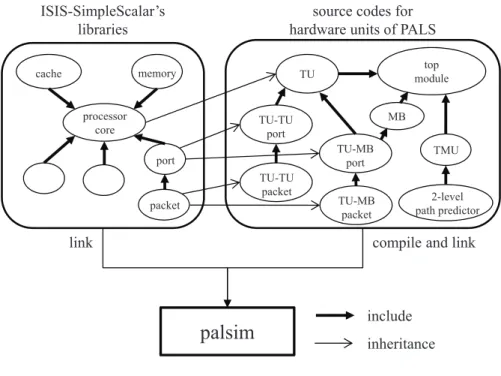
2.1 Multiscalar の構成 . . . . 7 2.2 Superthreaded Architecture の構成 . . . . 8 2.3 スレッドパイプライニングモデルによる投機的マルチスレッド実行 の様子 . . . 10 3.1 ループとパスの関係 . . . . 16 3.2 SPEC CINT95 におけるパスの実行割合 . . . . 17 3.3 SPEC CINT2000 におけるパスの実行割合 . . . . 18 3.4 PHT における 2 ビット飽和カウンタの状態遷移 . . . . 19 3.5 2 レベルパス予測器の構成 . . . . 20 3.6 投機スレッドコードにおける assert 命令の例および概念 . . . 22 3.7 Double Speculation 方式の 2 パス限定投機方式による実行 . . . . 25 3.8 パス予測器の配置 . . . 31 3.9 PALS のハードウェア構成 . . . . 35 3.10 TMU のハードウェア構成図 . . . . 36 3.11 PALS におけるプログラム実行の概念図 . . . . 383.12 forward bit と wait bit mask register を用いた TU 間のレジスタデー タ転送 . . . 41 3.13 メモリ依存違反検出時の実行の様子 . . . . 43 3.14 MAU のハードウェア接続関係 . . . . 44 3.15 MB と LS におけるエントリのフォーマット . . . . 45 3.16 シミュレータの構成 . . . . 47 3.17 プログラムを palsim で実行するまでの流れ . . . . 49 3.18 並列実行によるプログラムの速度向上比 . . . . 52 3.19 投機実行における予測成功率 . . . . 53
4.1 ループ区間の定義 . . . 56 4.2 関数 table pointer() のループ区間ごとのパス実行割合 . . . 57 4.3 関数 Grp DeleteRgn() のループ区間ごとのパス実行割合 . . . 58 4.4 パス履歴レジスタの更新の様子 . . . 60 4.5 GAg ベースのパス予測器 . . . . 61 4.6 #1 パスが実行されたときのパス PHT の更新 . . . . 62 4.7 #1 パスのパス PHT における 2 ビット飽和カウンタの状態遷移 . . . 62 4.8 Gshare ベースのパス予測器によるパス PHT へのアクセス . . . . . 63 4.9 ハッシュインデックスを用いた PHT へのアクセス . . . 64 4.10 SPEC CINT2000 ベンチマークプログラムにおけるパス予測成功率 68 4.11 全てのプログラムにおけるパス予測成功率の幾何平均 . . . . 69 4.12 ハッシュインデックス法を実装した場合のパス予測成功率 . . . . . 69 5.1 理想的な動的パス変更を行った場合の性能見積もり方法 . . . 74 5.2 性能見積もり結果 . . . 75 5.3 直前のループ区間におけるパスの実行割合に基づく動的パス変更手法 77 5.4 予測/投機成功率の評価 . . . 80
B.1 164.gzip の関数 longest match() における予測/投機成功率 . . . 104
B.2 164.gzip の関数 scan tree() における予測/投機成功率 . . . 105
B.3 175.vpr-place の関数 get bb from scratch() における予測/投機成功率 105 B.4 181.mcf の関数 primal bea mpp() における予測/投機成功率 . . . 105
B.5 186.crafty の関数 NextMove() における予測/投機成功率 . . . 105
B.6 186.crafty の関数 InitialZeroMasks() における予測/投機成功率 . . . 106
B.7 197.parser の関数 table pointer() における予測/投機成功率 . . . 106
B.8 254.gap の関数 ProdFFEVecFFE() における予測/投機成功率 . . . . 106
B.9 255.vortex の関数 Grp DeleteRgn() における予測/投機成功率 . . . . 107
B.10 300.twolf の関数 new dbox a() における予測/投機成功率 . . . 107
表 目 次
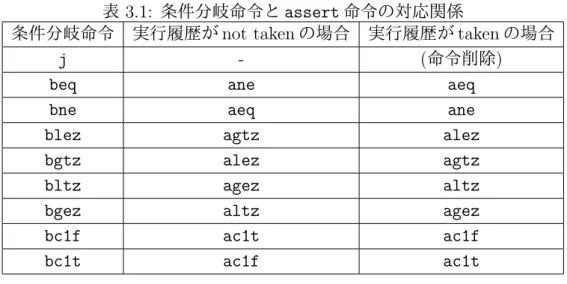
3.1 条件分岐命令と assert 命令の対応関係 . . . 21
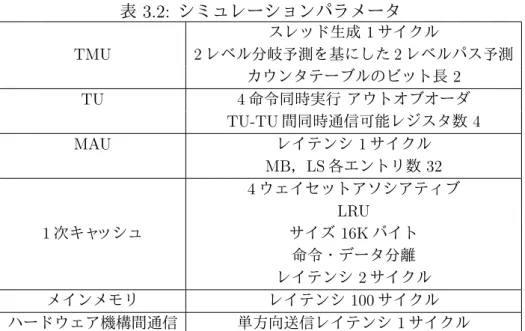
3.2 シミュレーションパラメータ . . . . 50
4.1 プログラム全体の実行を通したパスの実行割合 . . . 57
第
1
章 序論
近年の半導体集積技術の向上により,計算機に必要なプロセッサコアやキャッ シュといったハードウェアの微細化が進んだ.これにより,それらの豊富なハード ウェア資源を 1 個のチップ上に搭載したマルチコアプロセッサの普及が進んでい る.一方で,動作周波数の向上によるプロセッサコア単独の性能向上は,消費電 力や発熱量の増大等の問題を抱えており,限界を迎えている [1][2].このため,プ ログラム単独の実行を高速化するためには,プログラムの並列化を行い,マルチ コアプロセッサ上で並列実行することが求められる. 並列化の方法として,プログラムコードをいくつかのかたまり (以下,スレッド と呼ぶ) に分け,それぞれを複数のプロセッサ上で並列に実行することにより,プ ログラムに対してスレッドレベル並列性の抽出を行うマルチスレッド化がある.マ ルチスレッド化の効果が期待できるプログラムとしては,データ局所性の高い行 列計算等の数値処理系プログラムが考えられる. 文献 [3] では,配列をあつかう数値処理系プログラムについて,以下のような性 質があるとしている. • 配列を取り扱うコードは,並列化が可能なループを数多く含む場合が多い. • 並列性を有するループの場合,実行順序の並び替えによって,データ局所性 を大幅に向上させることができる. 一方,非数値処理系のプログラムに対しては,スレッドレベル並列性を高める ことが困難であった.非数値処理系プログラムとは,記号処理や自然言語処理等 を行うプログラムであり,複雑な制御構造やポインタを多用したデータ依存を含 んでいるものが多い.粒度の高いデータ並列性を抽出することが難しい非数値処 理系プログラムに対して,実行が確定されるよりも先行し,複数の制御フローを 並列に実行するマルチスレッド実行手法の開発が必要となった. Lam らの研究 [4] では,非数値処理系プログラムに対しては,基本ブロックレベルでのプログラムの制御依存解析を行い,複数の制御フローを細粒度のスレッド として抽出した後,実際に実行されるよりも早くそれらの制御フローを投機的に マルチスレッド実行していくことでスレッドレベル並列性の抽出が可能になると している.このとき実行は投機状態であるため,投機が成功した場合のみ実行結 果を採用する.そうでなかった場合はそのスレッドの実行結果を破棄し,元々の 制御フローに従い実行をやり直す必要がある.このため,投機実行の対象とする スレッドの選択,および,投機実行するスレッドを選択するための予測メカニズ ムが性能向上に大きな影響をあたえる.投機が失敗した場合には,それらの実行 がオーバヘッドとなってしまい,逐次実行に比べて速度低下を引き起こす可能性 すらある.以上のように,投機的並列実行方式における予測メカニズムは重要な 研究トピックであり,これまでに様々な研究が行われている [5][6][7][8]. 本研究では,非数値処理系のプログラムに対して有効な投機的マルチスレッド実 行を実現するため,プログラムにおいて頻繁に実行されるループのうち,特に頻繁 に実行される実行経路 (以下,パスと呼ぶ) に着目する.ループの 1 イタレーショ ンをスレッドの対象として,複数のイタレーションを並列実行することが,ルー プを高速化するにあたって効果的であると考えられる.ここで,1 イタレーション においてどのようなパスを通ったか等の,挙動の解析 (以下,プロファイリングと 呼ぶ) を行い,頻繁に実行されているパスを特定する. 複雑な制御構造を持つ非数値処理系プログラムにおいて,ループには多数の条 件分岐によって複数のパスが存在する.実行されうるパスの本数は,条件分岐の 数に応じて指数関数的に増加するため,すべてのパスを予測の対象とすることは 難しい.これに対して,従来研究における調査により,複数の条件分岐によって 多数のパスが存在するループであっても,実行割合の上位を占めるのは高々2 本で あることが多いことが明らかとなっている [9].この従来研究 [9] では,投機実行の 対象とするパスを,実行割合の高い 2 本のパスに限定することで高い投機成功率 を引き出すことができることを明らかにした.また,それら 2 本のパスにおいて 実行されないループ中の無用命令を削除することにより,命令スケジューリング 等によるスレッドコードの最適化を最大限に行うことができることを示した. 横田らの提案した 2 パス限定投機方式 [9][10] では,プログラムのプロファイリ ング結果を利用して,ループの実行の大部分を占める割合の高い上位 2 本のパス を抽出し,これらのパスに対して,投機的マルチスレッド実行に特化したコード
(以下,投機スレッドコードと呼ぶ) を作成する.ループ 1 周 (以下,ループイタ レーションと呼ぶ) をスレッドの単位として,投機スレッドコードをマルチコアプ ロセッサ上で投機的にマルチスレッド実行することで,ループの高速化を達成す ることができる. 2 パス限定投機方式は,トレースベースのシミュレーションによりその有効性を 確認した [9].一方,このシミュレーションは理想的な構成に基づいたものであり, 現実的なプロセッサ・アーキテクチャにおいて同方式を実現した場合の性能評価 は行われていない.また,広範なプログラムに対するクロックレベルでの同方式 の詳細な評価を行うためには,同方式を実現するアーキテクチャを設計し,クロッ クレベルで動作を模擬するシミュレータを構築する必要がある. 次章以降の本論文の内容は以下のとおりである. 2 章 関連研究 投機的並列実行方式による依存関係が複雑なプログラムの並列化について述べ, これまでにされた手法について詳説した上でそれらの問題点を示し,新しい投機 的並列実行方式の必要性について述べる.コンパイラによる静的な並列化手法の 問題点について述べ,プログラムの実行挙動の性質を反映した投機的並列実行に ついて述べる. 3 章 2 パス限定投機システム 投機成功率の高い投機実行を実現するため,非数値処理系プログラムに対して 実行パスの解析を行い,実行パスの割合に偏りがあることから,実行挙動の解析 情報を基に適切な投機対象を選択することの重要性について示す.プログラム実 行全体を通した実行経路(パス)の実行割合に着目した 2 パス限定投機方式につ いて述べ,2 パス限定投機方式の性能を最大限引き出すためのマルチコアプロセッ サ・アーキテクチャである 2 パス限定投機システムを提案する.そして,2 パス限 定投機システム上で実行するプログラムの最適化について検討し,最適化を施し たプログラムをシミュレータ上で実行することにより,システムの性能評価を行 う.その結果,依存関係を持つループに対して,プロセッサ 4 台の場合に逐次実行 に比べ 1.45 倍の性能を向上できることを示す.
4 章 投機対象パスの複数化 プログラム全体を通した実行割合のうち,上位 3 位以下のパスを予測の対象と した,予測性能を向上させる手法について検討する.1 ビットであった実行パスの 履歴情報を,2 ビット,3 ビットと拡張することにより,投機対象となるパスの種 類数を増大させる手法を検討し,少量の追加ハードウェアで実現可能な,新たな パスの予測メカニズムを提案する.1 ビットの実行パス履歴情報を用いるパス予測 ハードウェアに対し,同程度の計算資源で複数パスの予測を実現でき,予測性能 を 7.6 %向上できることを示す. 5 章 投機対象パスの動的選択 プログラム実行中に予測対象とする実行パスを動的に変更する手法について検 討する.あるループの実行に突入してからループを抜けるまでの区間におけるパ ス実行割合の遷移の様子から,直前のループ区間での実行割合上位 2 本のパスを予 測対象とした動的選択方式を提案する.次に,動的な選択を行った場合の予測成功 率についての性能評価を行い,従来の静的な予測手法に比べ,予測性能を 33%向 上できることを示す. 6 章 結論 本研究で得られた成果をまとめ,今後の展望について述べる.
第
2
章 関連研究
本章では,本研究における背景として重要な関連研究について述べる.まず,本 研究の核となる投機的並列実行方式について説明する.次に,投機的並列実行を 実現するプロセッサ・アーキテクチャの代表例について説明する.最後に,投機 的並列実行におけるプログラム最適化について説明する.2.1
投機的並列実行
非数値処理系プログラムは,一般に並列化による性能向上を達成することが難 しいとされている.中島はこの原因として,非数値処理系のプログラムに対して, 並列性を抽出するために個別のアルゴリズム設計や実装を行うことが困難である ことを挙げている [11]. これに対して,非数値処理系に個別に対応した並列化手法を検討するのではな く,プログラムから並列性を抽出するアプローチが考えられる.Lam らの研究で は,基本ブロックレベルでプログラムの制御依存関係を解析し,複数の制御フロー を同時に実行することで高い並列性を抽出することができるとしている [4]. このアプローチのひとつとして,次に実行されるであろう制御フローをスレッ ドとし,実際に実行されるよりも早く投機的にマルチスレッド実行をすることで, 高いスレッドレベル並列性を抽出することができる,投機的並列実行がある. 投機実行とは,将来実行される可能性が高いコードを,実行されることが確定 する前に予測し,先行して実行することである.これにより,制御の依存関係や データの依存関係を無視してコードを並列実行することができ,複雑な依存関係 が多数存在する非数値処理系プログラムの性能向上に有効であると考えられる.2.2
投機的並列実行を実現するプロセッサ・アーキテク
チャ
投機的並列実行を実現する代表的なプロセッサ・アーキテクチャとして,Multiscalar[12] と Superthreaded Architecture[13] がある.本節では,それぞれの並列実行モデル およびアーキテクチャについて説明する.2.2.1
Multiscalar
Sohi らによる Multiscalar[12] は,プログラム全体から基本ブロックやループイ タレーション,サブルーチンコール等をマルチスレッド化の対象とした投機的マ ルチスレッドアーキテクチャである.図 2.1 に Multiscalar の構成を示す.リング 状ネットワークで接続されたプロセッサに対して,スレッドを順次割り当てなが ら並列実行を行う.隣接するプロセッサ間では単方向のデータ転送を行うことが できる. 投機実行されるスレッドは専用の Sequencer と呼ばれるハードウェアによって集 中的に管理される.最も先行するスレッドは先頭スレッド (head thread) と呼ば れ,投機を行わず,逐次実行と同様の実行 (非投機実行と呼ぶ) となる.したがっ て,先頭スレッドの実行が破棄されることはない.そして,先頭スレッド以外の 後続スレッドはすべて投機実行となる.また,Multiscalar ではデータ投機も実現 しており,メモリ依存違反を検出することでプログラムの整合性を保証する. Multiscalar ではコンパイラによってプログラム全体を対象としたマルチスレッ ド化を行うが,スレッド間の依存関係についての最適化効果は限定的となる.特 に,ループイタレーションをマルチスレッド化の対象とした場合に,スレッド間の 依存関係となる変数 (誘導変数) が算術的に計算可能でなければ,並列実行のオー バラップが得られない可能性が高くなる.このため,複雑な制御構造を持つ非数 値処理系のプログラムに対する速度向上率は,それ以外のプログラムに比べると 低い傾向にあることが分かっている [12].Processing Unit Interconnect hardware communication icache processing element register file
Processing Unit Processing Unit
uni-directional ring
Data Bank
arb dcache
Data Bank Data Bank
Sequencer
図 2.1: Multiscalar の構成
2.2.2
Superthreaded Architecture
Tsai らによる Superthreaded Architecture[13] は,Multiscalar に似た構成の投機 的マルチスレッドアーキテクチャである.Multiscalar と同様に,プログラムの並 列化はコンパイラによって静的に行われる.本アーキテクチャは,スレッド実行の 制御を独自の機械命令をスレッドコードに埋めこむことによって行う.このため, 各スレッドは次のスレッドの実行開始位置を指定することができる.Multiscalar とは異なり,本アーキテクチャではスレッド間でのレジスタデータ通信はできな い.スレッド間でのデータ通信は,メモリを介すことによって実現する.
図 2.2 に,Superthreaded Architecture を示す.スレッドを実行する Thread Pro-cessing Unit は単方向のリングネットワークで接続されている.Thread ProPro-cessing Unit は,以下の 4 つの機構により構成される.
Thread Processing Unit Thread Processing Unit Thread Processing Unit L1 Data Cache hardware communication Communication Unit L1 Instruction Cache Execution Unit Memory Buffer Write-back Unit Communication Unit Execution Unit Memory Buffer Write-back Unit Communication Unit Execution Unit Memory Buffer Write-back Unit 図 2.2: Superthreaded Architecture の構成 汎用プロセッサコアに相当し,スレッドコードを実行する. • Communication Unit
Thread Processing Unit 間での通信を担う.スレッドコードに埋め込まれた 命令により,スレッド開始およびスレッド終了の通信や,スレッド間におけ る同期を行うためのスレッド停止の通信を行う. • Memory Buffer 投機的なストアデータの格納および管理を行う. • Write-back Unit 実行が終了したスレッドの Memory Buffer に格納されたストアデータをメモ リ上に書き戻す. Superthreaded Architecture では,スレッドパイプライニングモデルと呼ばれる 並列実行モデルに従い投機的マルチスレッド実行する.図 2.3 に,スレッドパイプ ライニングモデルによる投機的マルチスレッド実行の様子を示す.Multiscalar と
同様にスレッドパイプライニングモデルにおいても,先頭スレッドは投機を行わ ず,逐次実行と同様の非投機実行となる.各スレッドは図 2.2 に示したリングネッ トワークの Thread Processing Unit に対して順に割り当てる.
スレッドパイプライニングモデルにおけるスレッドは,以下の 4 つのステージ により構成される. • Continuation ステージ 次のスレッドの実行を開始するために必要な計算を行うステージである.ルー プの誘導変数などの,静的に求めることが可能なスレッド間での依存となる 変数の値の計算を行う.そして,スレッド実行開始命令によって,計算した 値を次の Thread Processing Unit に送信し,次のスレッドの実行を開始する. • TSAG (Target Store Address Generation) ステージ
スレッド間におけるデータ依存となる可能性があるメモリ上の変数について, そのアドレスを計算し Memory Buffer に登録するステージである.Memory Buffer は登録されたアドレスへのメモリアクセスを監視する.後述する Com-putation ステージにおいて,スレッド実行時に登録されたアドレスに対して のロードが行われた場合,先行するスレッドにおいて当該アドレスに対する ストアが行われるまでスレッドの実行を待たせる.これにより,メモリデー タについての同期通信を実現しており,メモリ依存違反は発生しない. • Computation ステージ スレッドとして割り当てられた計算処理の本体を実行するステージである. 本ステージにおいて実行されたストアデータは,すべて Memory Buffer に格 納する. • Write-back ステージ Memory Buffer に格納されたストアデータをメモリに書き戻すステージであ る.書き戻しが完了した後,スレッド終了命令によってスレッドの実行がす べて終了したことが次のスレッドに通信される.メモリデータの整合性を保 証するため,先行スレッドの Write-back ステージが終了するまで,他のス レッドは Write-back ステージを実行することができない. Superthreaded Architecture では,投機スレッドに関する制御は専用の命令に よってソフトウェアで行う.また,データ投機は行わず,メモリ上の依存関係とな
Thread #i-1 Continuation TSAG Computation Writeback Continuation TSAG Computation Writeback Thread #i fork TSAG done data transfer commit fork TSAG done data transfer commit Continuation TSAG Computation Writeback time Thread #i+1 stage control notification data transfer 図 2.3: スレッドパイプライニングモデルによる投機的マルチスレッド実行の様子 りうるメモリアドレスをスレッドごとにあらかじめ計算しておき同期を取る.こ のため,スレッド間に複雑な依存関係が存在する場合,依存関係の計算および同 期待ちによって性能向上が達成できない可能性が高くなる.
2.3
投機的並列実行におけるプログラム最適化
コンパイラによる依存関係の静的な解析だけでなく,プログラムをあらかじめ 実行することで,実行挙動に関する解析情報を得ることができる.これにより,投 機実行の対象とする処理を限定することができ,その部分のコードに対して最大 限の命令最適化を施すことが可能になる. 無用な命令コードの削除と最適なスケジューリングを行う研究事例としては, Mandriles らによる Mitosis[14] が挙げられる.Mitosis においても,ループの実行 経路の挙動に関する情報は活用していない.また,ループを対象とした投機的並列実行によるプログラム高速化の研究には,Gao らによる Loop Recreation[15] が ある.Loop Recreation では,コンパイルの際にループに存在するデータ依存関係 の解析を行い,この依存関係を緩和するようにループを再構築し,投機的に並列 実行する. プロファイリング情報を用いることで投機実行するパスを限定し,無用な命令 コードの削除を行い,最適な命令スケジューリングを実現することにより,データ 依存が緩和される可能性が高くなる.以降の章では,プログラムの実行挙動に着 目し,プロファイリング情報を活用した投機的並列実行方式について検討を行う.
第
3
章
2
パス限定投機システム
本章では,本研究において設計・開発を行う 2 パス限定投機システムについて述 べる.まず,本システムが実現する投機的並列実行方式として,ループ中におけ る実行割合上位 2 本のパスを投機実行対象とする,2 パス限定投機方式について説 明する.次に,2 パス限定投機方式による並列実行の性能を引き出すためのハード ウェアサポートについて検討し,マイクロアーキテクチャ全体の設計を行う.そ して,設計したアーキテクチャをクロックサイクル精度で模擬するシミュレータ の実装について述べ,ベンチマークプログラムを用いた性能評価を行う.3.1
プログラムの実行パスに基づく投機的並列実行
プログラムを並列化する際には,並列処理の単位となる処理の大きさが重要と なる.この処理の大きさを粒度と呼ぶ.粒度は,命令を単位とする細粒度,繰り 返し処理 (以下,ループと呼ぶ) を単位とする中粒度,サブルーチンを単位とする 粗粒度などに分類される.粒度を細かくすることによって並列度は大きくなるが, 分けた処理の間での通信や同期などによるオーバヘッドの影響が大きくなる.マ ルチコアプロセッサによる並列実行を考えた場合,プロセッサコア間での通信に 時間がかかることを考慮すると細粒度の並列化は難しい.このため,マルチコア プロセッサを利用した上で,様々なプログラムに対して汎用性のある並列化の対 象としては,中粒度であるループが適していると言える.プログラムにおいて頻 繁に実行されるループを高速化することにより,プログラム全体の性能向上に大 きく寄与することができる. ループから細かい粒度のスレッドレベル並列性 (TLP: Thread-Level Parallelism) を抽出することを考えた場合,ループの最小単位であるループイタレーション (ルー プの繰り返し 1 回分) をスレッドとすることが理想的である.さらに,ループイタ レーションにおいて実行されるプログラム上の経路 (実行経路: 以下,パスと呼ぶ)を特定することが可能ならば,そのパスを並列実行に特化したコードを作成し,そ のコードをスレッドとして実行することで効果的な並列実行が可能になると考え られる.スレッドとして実行する命令コードをスレッドコードと呼ぶ.パスを特 定することは,ループに含まれる条件分岐命令の結果が明らかになることであり, スレッドコードの作成において,そのパスの実行に関係のない命令を削除するこ とが可能となる.また,削除した命令と依存関係にある命令はその依存関係から 解放され,命令の移動 (コードスケジューリング) の自由度が増す.そこで本研究 では,まずループイタレーションにおけるパスの特定について議論を行う.
3.1.1
ループパス
プログラムにおけるパスは,制御フロー上の分岐によって決定される.プログ ラム中に存在する分岐は以下の 5 種類である. 1. 前方分岐 (forward branch) 2. 後方分岐 (backward branch) 3. レジスタ間接分岐 (indirect branch) 4. サブルーチンコール (subroutine call) 5. サブルーチンリターン (subroutine return) 前方分岐はプログラムカウンタ (PC: Program Counter) を増加させる分岐であり, 後方分岐は PC を減少させる分岐である.レジスタ間接分岐は,レジスタに格納さ れたアドレスを次の PC とする分岐である.また,サブルーチンコールはジャンプ 命令の次の命令のアドレスを戻り先アドレスとして記録してジャンプする分岐で あり,サブルーチンリターンは,サブルーチンコールによって記録された戻り先 アドレスへジャンプする分岐である. これらの分岐を利用してパスの開始点および終了点を規定することにより,扱 うパスの形を規定することができる.パスを区別するにあたっての境界となるの は,(1) 後方分岐によるループイタレーション境界,(2) レジスタ間接分岐による 間接分岐境界,(3) サブルーチンコールによる関数コール境界,(4) サブルーチン リターンによる関数リターン境界,の 4 種類である.パスに関する重要な関連研究として,Ball らによる Efficient Path Profiling (EPP) がある [16].文献 [16] において定義されたパスは,著者の名前をとって Ball-Larus path (BL path) と呼ばれる.BL path の開始条件および終端条件の定義は以下の とおりである. • 開始条件は以下のいずれかの命令が実行されたときである. – サブルーチンコール先 (関数コール境界後の最初の命令) – 後方分岐先 (ループイタレーション境界後の最初の命令) – 間接分岐先 (間接分岐境界後の最初の命令) • 終了条件は以下のいずれかの命令が実行されたときである. – サブルーチンリターン点 (関数リターン境界となる命令) – 後方分岐点 (ループイタレーション境界となる命令) – 間接分岐点 (間接分岐境界となる命令)
BL path は関数内における非巡回パス (acyclic path) と定義することができる. EPP では,BL path の開始条件を満たす命令にプログラムが到達するとパスの トレーシングを開始する.関数コール境界は終了条件ではないため,サブルーチ ンコールが実行された場合にはパスのトレーシングを中断し,関数コール先で新 たにパスのトレーシングを開始する.その後,サブルーチンリターンによって戻っ てきたときに,中断していたトレーシングを再開する.EPP では,プログラムの 各基本ブロックにパスの実行回数をカウントするための命令を挿入することによっ て,パスの実行回数を実行時に調べることを可能としている [16]. BL path の定義により,関数内のパスの振る舞いを正確に把握することができ る.一方,ループを並列化するための情報として BL path を利用する場合,ルー プ部分以外の命令が多く含まれることになる.そこで,BL path のうちループに 関する定義のみを利用した,ループパスを以下に定義する. • 開始条件は後方分岐先の命令が実行されたときとする. • 終了条件は開始条件となった後方分岐先へ分岐する後方分岐命令が実行され たときとする.
同じ後方分岐先を開始条件とするループパスによって,1 つのループが構成され る.異なる後方分岐先となるループパスは,異なるループに属すことになる.従っ て,ループパスは常に最も内側のループ (最内ループ) を対象としており,本研究 においても多重ループ構造そのものは並列化対象として扱わず,常に最内ループ に限った並列化について議論を行う. 図 3.1 にループと BL path,および,本研究で定義するループパスの関係を示す. 図中の丸はプログラムの基本ブロックを表しており,矢印は基本ブロックから基 本ブロックへの制御フローを表している.図 3.1 (a) は関数の制御構造の例を示し ており,基本ブロック E から基本ブロック B への後方分岐により,基本ブロック B,C,D,E がループを構成する.
図 3.1 (b) は,(a) の関数から抽出できる BL path を示している.BL path の開 始条件を満たす基本ブロックは A および B であり,終了条件を満たす基本ブロッ クは E および F である.この間に存在する基本ブロックにより BL path は構成さ れる.また,図 3.1 (c) は,(a) の関数から抽出できるループパスを示しており,そ れは (i) BCE,(ii) BDE の 2 つのパスである.
以降,本論文においては,特に断りのない限り “ループ” は最内ループを指し,“ パス” はループパスを指す. 一般にループ中には複数の条件分岐が存在するため,イタレーションにおいて実 行される可能性のあるパスは条件分岐の数に応じて指数関数的に増大する.ルー プパスの定義により,最内ループにおけるすべてのパスを区別することが可能と なるが,実際にそれら全てのループパスを対象として投機実行する際にかかる,予 測の時間的コストおよびハードウェア資源的コストについては検討する必要があ る.また,投機が失敗した場合,プログラムの整合性を保証するため,レジスタ やメモリを投機スレッドを実行する以前の状態に戻す必要があるが,この回復処 理は実行性能の向上を阻害するオーバヘッドとなる可能性がある.このため,パ スを対象とした投機的マルチスレッド実行の実現においては,以下の 3 点が要件 となる. • 投機対象とするパスに対して最大限のコード最適化を行うことができる. • パスの予測を高い確率で成功することができる. • 最小限の時間でパスの予測を行うことができる.
A B C D E F basic block control flow (a) !"#$%&"'
(b) (a) !"#$%&BL path A B C F E A B D F E A B C E A B D E B C F E B D F E B C E B D E (1) (2) (3) (4) (5) (6) (7) (8) B C E B D E (i) (ii) (c) (a) !"#$%&'()*+ loop back edge 図 3.1: ループとパスの関係
#1-path #2-path other paths compress() sweep() forward_DCT() killtime() 22.4% 54.5% 48.2% 80.7% 97.0% 42.2% 19.3% 3.0% 図 3.2: SPEC CINT95 におけるパスの実行割合
3.1.2
パスの実行割合の偏り
ここで,実際に実行されるパスの実行割合の偏りに着目する.プログラム全体 を通して全てのパスが満遍なく実行されているならば,全てのパスを予測の対象 としなければならないが,実行されるパスに偏りがあるならば,実行割合の高い パスを中心に予測を行えばよい.そこで横田らは,プログラムを実際に実行した 際のパスの履歴情報を解析し,ループにおけるパスの実行割合を調査した [9].こ の調査により,多くのループにおいて高々2 本のパスが実行割合の大部分を占めて いるという特徴を発見した.これらのパスを,実行頻度の高い順に#1 パス,#2 パスと呼ぶ.図 3.2 に横田らの調査による SPEC CINT95 ベンチマーク (以下,単に CINT95 と呼ぶ) におけるパスの実行割合を示す [9].CINT95 は,CPU の性能を比較す るためのベンチマークである SPEC CPU95 のうち,整数演算処理性能のベンチ マークテストを行うプログラムである.調査対象は 129.compress の compress(), 132.ijpeg の forward DCT(),130.li の sweep(),124.m88ksim の killtime(),以 上 4 プログラムの関数中に存在するループである.入力データセットは train で ある. 図 3.2 から,ループの実行割合全体の約 8 割以上を#1 パスと#2 パスが占めてお り,その他のパスは実行頻度が低い.このことから,上位 2 本のパスのみを投機 の対象とすることが,高速化の期待できるマルチスレッド化において十分である と考えた.横田らが提案している 2 パス限定投機方式は,パスプロファイラから 得られるループ中のパスの実行割合をもとに,実行割合の上位 2 本のパスをマル チスレッド化の対象として投機的にマルチスレッド実行することでループの高速 化を達成する手法である [9].
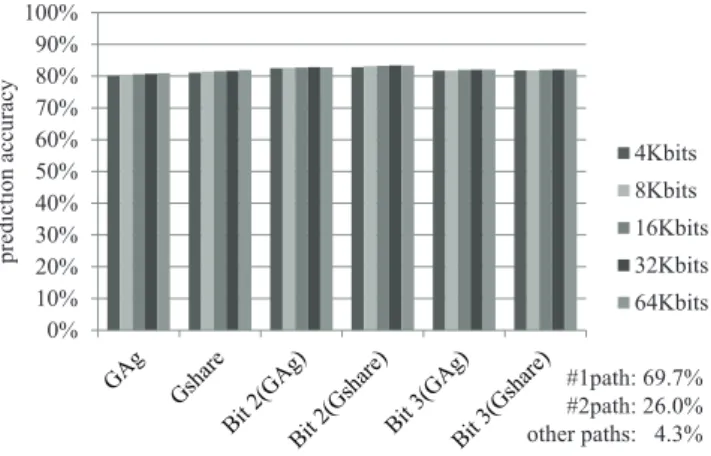
#1-path #2-path other paths longest_match() new_dbox_a() primal_bea_mpp() match() 10.2% 86.0% 59.0% 61.4% 77.1% 28.6% 38.6% 22.9% 図 3.3: SPEC CINT2000 におけるパスの実行割合 投機の対象を#1 パスおよび#2 パスに限定することにより,次のイタレーショ ンで#1 パスが実行されるか,#2 パスが実行されるかという二通りの予測をする だけでよく,予測アルゴリズムを単純に実現することができる.また,2 本のパス では実行しない無用な命令コードを削除することで,当該パスのコードに対する 命令スケジューリングをはじめとした最適化の効果を最大化することができ,イ タレーションの実行が効率化される. SPEC ベンチマークプログラムは,普及しているプロセッサの性能等を考慮し て数年ごとに新しいバージョンがリリースされている.そこで,本研究では SPEC CINT95 に比べてプログラムの規模も大きくなっている SPEC CINT2000 ベンチ マークプログラムにおけるパスの実行割合を追加調査した [23].SPEC CINT2000 におけるパスの実行割合を図 3.3 に示す.
調査対象としたベンチマークプログラムは,181.mcf の primal bea mpp(),164.gzip の longest match(),300.twolf の new dbox a(),179.art の match(),以上 4 プロ グラムの関数中に存在するループである.入力データセットは train であり,プ ログラム全体を通して頻繁に実行されるループを選択した.図 3.3 より,#1 パス と#2 パスの実行割合の合計が全体の約 9 割以上を占めていることが分かる.この ことから,SPEC CINT2000 に対しても 2 パス限定投機方式による性能向上が期 待できる.
3.1.3
2
レベル分岐予測を応用したパス予測機構
横田らの文献 [9] では,プロセッサにおける 2 レベル分岐予測機構 [24] を参考に し,パスの実行履歴とカウンタテーブルを用いて次に実行されるパスの予測を行っ ている.2 レベル分岐予測機構では,分岐命令の実行履歴を記録する履歴レジスstrongly taken / 11 weakly taken / 10 weakly not taken / 01 strongly not taken / 00
taken taken taken
taken not taken not taken not taken not taken 図 3.4: PHT における 2 ビット飽和カウンタの状態遷移 タ (History Register: 以下,HR と呼ぶ) と,ある実行履歴の場合の分岐の確率を 記録するパターン履歴テーブル (Pattern History Table: 以下,PHT と呼ぶ) によ り次の分岐命令の結果を予測する.図 3.4 に,PHT が 2 ビット飽和カウンタによ り構成された場合の状態遷移を示す.‘taken’ は分岐が行われる場合であり,‘not taken’ は分岐が行われない場合である.分岐命令において,分岐が続けて taken と なった場合には状態が ‘strongly taken’ に遷移し,当該分岐命令が taken の結果と なる可能性が高いことを示す.状態が ‘strongly taken’ および ‘weakly taken’ であ る場合には,予測器は ‘taken’ であると予測し,逆の場合には ‘not taken’ であると 予測する. 図 3.5 に 2 レベルパス予測器の構成を示す.2 レベルパス予測器では,イタレー ションごとに#1 パスが実行されたか否かを#1 パス履歴レジスタ (以下,#1 パス HR) に記録し,#1 パス HR に表れるビットパターンを#1 パスパターン履歴テー ブル (以下,#1 パス PHT) を参照する際のインデックスとして扱う.#1 パス PHT のエントリ数は#1 パス HR のビット数に対応する.図 3.5 では,#1 パス HR が 4 ビットであるため,#1 パス PHT は 2 進表現で 0000 から 1111 までの計 16 エント リを持つ. パスを予測する場合,ループイタレーション実行前に#1 パス HR のビットパター ンに対応する#1 パス PHT のエントリから値を読み出し,その値を閾値 X と比べ る.読み出した値が閾値以上ならば予測結果は#1 パスとなり,そうでなければ予 測結果はその他のパスとなる.閾値 X はカウンタビット数を n としたとき 2n−1 (す なわち,最上位ビットのみ 1) とする.これにより,比較は#1 パス PHT のエント リの最上位ビットが 1 か 0 を判断するだけでよく,簡素なハードウェアとして実現
v0 v13 v14 v15 15 14 13 0 #1-path pattern history table #1-path
history register
threshold
predicts #1-path (speculates #1-path)
predicts other paths (speculates #2-path) v T v < T 図 3.5: 2 レベルパス予測器の構成 することができる. 実際に#1 パスが実行された場合,その時点での#1 パス HR のビットパターン に対応する#1 パス PHT のエントリのカウンタ値を 1 インクリメントする.その 他のパスが実行された場合,エントリのカウンタ値を 1 デクリメントする.その 後,#1 パス HR を 1 ビット左シフトし,#1 パスが実行された場合は最下位ビッ トに 1 をセットし,そうでなければ 0 をセットする.
3.1.4
投機スレッドコードと投機実行の成否判定
2 パス限定投機方式では,パスプロファイラ上でプログラムを実行することで得 られるプロファイリング情報をもとに,ループ中の投機の対象とする#1 パスおよ び#2 パスを決定し,それぞれのパスに沿って基本ブロックコードの抽出を行う. プロファイリング情報には,(1) パスの開始アドレス,(2) 分岐命令の実行履歴, (3) 継続アドレス,(4) パズ属性情報,(5) パスの命令数,(6) パスの実行回数が含 まれる.そして,抽出した基本ブロックコードに対して,無用な命令の削除,命令 のスケジューリングといったコード最適化を施し,投機的マルチスレッド実行に 特化したコード (以下,投機スレッドコードと呼ぶ) を作成する.この投機スレッ ドコードをマルチコアプロセッサ上で並列にマルチスレッド実行することによっ て速度向上を達成する. 投機実行の際には,何らかの方法で投機の成否判定を行わなければならない.そ表 3.1: 条件分岐命令と assert 命令の対応関係
条件分岐命令 実行履歴が not taken の場合 実行履歴が taken の場合
j - (命令削除)
beq ane aeq
bne aeq ane
blez agtz alez
bgtz alez agtz
bltz agez altz
bgez altz agez
bc1f ac1t ac1f
bc1t ac1f ac1t
こで 2 パス限定方式の投機スレッドコードでは,オリジナルのコードに含まれる 条件分岐命令を対応する assert 命令に置き換える.パスにおける条件分岐命令の 分岐履歴 (taken/not taken) によって,異なる assert 命令に置き換わることにな る.表 3.1 に,条件分岐命令と assert 命令の対応関係を示す.また,それぞれの assert 命令の仕様については,付録 A.6.2 節に記載している.assert 命令の実行 結果が偽であった場合は投機失敗とし,投機スレッドコードに含まれるすべての assert 命令の実行結果が真であれば投機成功となる. 図 3.6 に,条件分岐命令を assert 命令に置き換える際の例を示す.図 3.6 (a) は, 投機スレッドコードに変換する前のオリジナルのプログラムコードであり,PISA のアセンブリコードおよびラベルにより表される.条件分岐命令である beq 命令 は,オペランドに指定された 2 つのレジスタの値が等しかった場合に,指定され たアドレスにジャンプする条件分岐命令である.図 3.6 (a) のプログラムコードに おいて,beq 命令の実行時に 3 番レジスタと 0 番レジスタの値が等しかったとす る ($+数字はレジスタであることを示す).このとき,beq 命令の結果は真 (実行 履歴は taken) となり,$L2 ($+L+数字はラベルであることを示す) にジャンプす る.図 3.6 (b) は,図 3.6 (a) を制御フローグラフとして表したものであり,丸は 基本ブロック,矢印は制御フローを表す.beq 命令により基本ブロックの境界が規 定され,図 3.6 (a) には 3 つの基本ブロックが存在することになる. 図 3.6 (b) における AC のパスの投機スレッドコードを作成する場合,オリジナ ルコードから beq 命令を取り出し,assert 命令への変換を行う.この場合,実行
beq
$L2:
lw aeq
(a) !"#$%&' (c) !"#$%&'()*+)
$3, $0, $L2 $2, $20 (fp) $3, $0 addu $2, $2, 1 addu $2, $2, 1 B A C $L2 (b) (a) !"#$%&'# $L1: $L0: $Lno1path: $L0 $L1 basic block control flow 図 3.6: 投機スレッドコードにおける assert 命令の例および概念
履歴は taken であるため,当該命令を aeq 命令に置き換える (表 3.1 を参照).aeq 命令は,オペランドに指定された 2 つのレジスタの値が等しくなかった場合に実 行結果が偽となり,投機実行が失敗したと判定される.続いて,分岐先である$L2 以降の命令を投機スレッドコードとして追加していく.
3.1.5
投機実行モデル
投機的並列実行においては,投機実行したパスが誤りであった場合 (以下,投機 失敗と呼ぶ) に,投機を諦めプログラムのオリジナルコードを逐次実行する方法 と,異なるパスを再度投機実行する方法の 2 つの選択肢が考えられる.文献 [9] で は,1 度のみ投機実行する Single Speculation 方式と,投機失敗時に投機対象とし た 2 本のパスのうち,投機実行していないもう一方のパスも投機実行する Double Speculation 方式の性能を比較した.その結果,Double Speculation 方式が高い性 能を示すことを明らかにした.これは,投機スレッドコード中に含まれる assert 命令によって,投機実行開始後の早期に投機失敗を判定できたことによる. 図 3.7 に,Double Speculation 方式である 2 パス限定投機方式の実行を示す.図 3.7 (a) は,3 つのプロセッサコアに対して,3 つの投機スレッドを割り当て,それ らのすべてのスレッドが投機成功した場合の実行である.また,図 3.7 (b) は,2 スレッド目において投機失敗,すなわち assert 命令の結果が偽となった場合の実 行であり,図 3.7 (c) は,2 スレッド目において投機失敗が二度起こった場合の実 行である.図では,上から下へ時間が経過するものとしている.図中の四角はプロセッサコ ア上での処理を表しており,縦につながっているものは同一のプロセッサコアで実 行されることを意味する.(a) における sequential execution は,単独のプロセッサ コアによる逐次実行を示しており,speculative multithread execution は,マルチコ アプロセッサによる 2 パス限定投機方式の投機的並列実行を示している.#1-path code,#2-path code は,投機対象としたループから抽出した 2 本のパスの投機ス レッドコードであり,各プロセッサコアに割り当てられ,並列に投機実行される. original loop code は,投機が失敗したときに実行するスレッドコードであり,元々 のループのコードそのものである.recovery は,あるスレッドで投機失敗が起こっ た場合に,当該スレッドの実行前の状態にプロセッサコアを戻すための回復処理 である.具体的には,レジスタやメモリの内容を,投機実行開始時に保存した内 容へロールバックする処理が行われる.図中の実線矢印は,投機スレッド生成の 指示を表している.投機スレッド生成の指示によりスレッドを割り当てられたプ ロセッサコアは,投機スレッドを割り当てられていない別のプロセッサコアに対 して,次の投機スレッドの生成を指示する.図中の破線矢印は,あるスレッドに おいて投機が失敗した際に,当該スレッド以降のスレッドを破棄する流れを表し ている.投機スレッド生成と同様に,投機スレッド破棄を指示されたスレッドは, 次のスレッドに対して破棄を指示する. 図 3.7 (a) では,3 イタレーションを逐次実行した場合と,すべてのスレッドが 投機成功した場合を比較している.この場合,理想的には 2 回分の投機スレッド 生成の指示にかかる時間と,3 イタレーション目のパスの実行にかかる時間の合計 が実行時間となる.このため,逐次実行に比べて大幅な速度向上を達成すること ができる.実際には,イタレーション間 (スレッド間) に存在する依存関係により 生じる同期待ち時間により,実行時間が増大する可能性がある. 図 3.7 (b) および (c) は,2 つ目のプロセッサコア上での投機スレッド実行が 1 度または 2 度の投機失敗を起こした場合の状況を示している.2 イタレーション目 は実際とは異なる#1 パスが投機実行されていたため,投機スレッドコード内に含 まれる assert 命令によりパスの予測失敗が検出される.当該スレッドを実行して いるプロセッサコアは,後続スレッドを実行しているプロセッサコアに投機スレッ ドの破棄を指示し,自身は回復処理を行い投機スレッド実行前の状態に戻る.そ して,もう一方のパス (図の場合は#1 パスコード) の投機実行を開始する.後続
スレッドを投機実行していたプロセッサコアは,あらためてパスの予測結果に基 づいて投機実行を開始することとなる. 図 3.7 (c) は,2 イタレーション目で実際に#1 パスと#2 パスのどちらでもない パスが実行される場合の状況を示している.2 イタレーション目を実行しているプ ロセッサコアは,まずパスの予測結果にもとづいて 1 度目の投機実行を開始する (図の場合は#2 パスコード).その後,assert 命令よりパスの予測失敗が検出さ れ,(b) の場合と同様に自身およびその後続の投機スレッド実行を破棄し,回復処 理を行う.そして,次はもう一方の投機スレッドコード (図の場合は#1 パスコー ド) を実行するが,再び assert 命令によりパスの予測失敗を検出され,自身およ びその後続の投機スレッドの破棄と回復処理を行う.2 度目の投機失敗となった場 合は,オリジナルのループコードを実行する.これにより,プロセッサコアは逐 次実行することで正しい実行結果を得る.
time
time
time
recovery
generate speculative thread #1-path code
#2-path code original loop code
squash next thread
performance improvement sequential execution speculative parallel execution iter. 1 iter. 2 iter. 3 iter. 1 iter. 2 iter. 3 (b) 1 !"#$%&'()*+,!-. (c) 2 !"#$%&'()*+,!-. assert failure (a) !"#$%&'()*+ 図 3.7: Double Speculation 方式の 2 パス限定投機方式による実行
3.2
2
パス限定投機システムのハードウェア設計
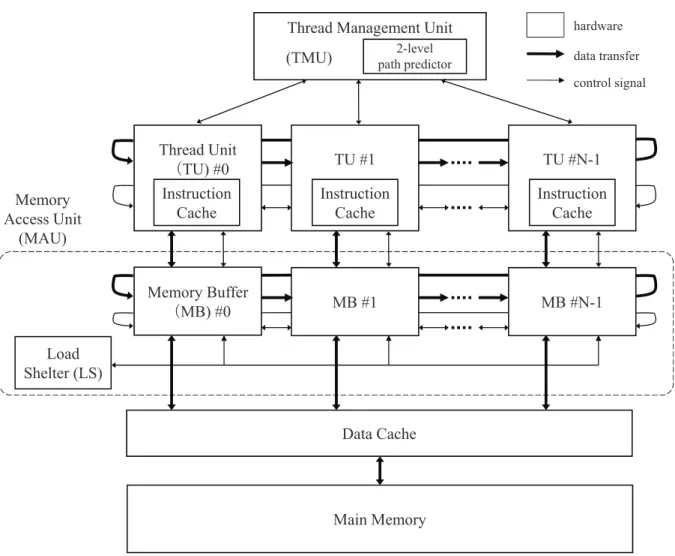
3.1 節では,複雑な制御構造を持つ非数値処理系プログラムのループに対して有 効な投機的マルチスレッド実行方式として,ループの実行経路 (パス) の実行の偏 りに着目した投機を行う 2 パス限定投機方式について述べた.本節では,この方 式を実現するためのハードウェア機構を備えたアーキテクチャである 2 パス限定 投機システム PALS (PAth Limited Speculation) について述べる [17][18].そし て,PALS でのプログラム実行をクロックサイクルレベルで模擬するシステムシ ミュレータについて述べる. ここまでに,複雑な制御構造を持つループに対する有効なマルチスレッド実行方 式として,ループ中で頻繁に実行される経路 (パス) に着目した 2 パス限定投機方 式について述べた.横田らの研究では,同方式の評価としてマルチスレッド化の対 象であるループの実行トレース情報を用いた実験を行った.その結果,CINT95 に おける 130.li の sweep() 関数に含まれるループに対して,プロセッサ 4 台で 2.886 倍の性能向上が達成できることを明らかにした [9]. 横田らの研究では,トレースベースのシミュレーションによって 2 パス限定投機 方式の有効性を示したが,広範なプログラムに対する同方式の詳細な評価を行う ためには,現実的なハードウェア構成を想定したマルチコアプロセッサアーキテ クチャの設計が必要となる.本節では,文献 [18] で提案した実現アーキテクチャ である 2 パス限定投機システム PALS の設計について述べる.まず,PALS の設 計方針について述べ,ハードウェア構成の全体像を示す.そして,PALS を構成す る,(1) マルチスレッド制御機構,(2) スレッド実行機構,(3) メモリアクセス機 構といった 3 つのハードウェア機構について詳細に説明する.
3.2.1
設計方針
投機的並列実行の実現のためには,投機実行をサポートする機構を備えたマル チコアプロセッサシステムを設計する必要がある.多くの投機的並列実行システ ムでは,プロセッサコア間のレジスタ・データ通信等のハードウェアサポートによ り,効率的な投機的並列実行を実現している.本研究では,ハードウェアサポー トにより 2 パス限定投機方式を実現するマルチコアプロセッサを設計し,同方式 の実現に特化した投機的並列実行システムを提案する.2 パス限定投機方式は,ループにおける 1 イタレーション (ループ 1 周分の実行) を 1 つのスレッドとして投機的にマルチスレッド実行することを基本としている. 同方式において,投機的並列実行を実現するために必要な機能として,以下のも のが考えられる. • 投機対象とする 2 本のパスのどちらが実行されるかを予測する機構 • 投機実行の成否を判断する機構 • 投機失敗時にプログラムの整合性を保証する回復処理を行う機構 予測機構として,文献 [9] におけるパス予測機構である,2 レベル分岐予測をベー スとしたパス予測器をハードウェアとして実装する.プロセッサコアはパス予測 器から受け取った予測結果に従い,投機スレッドコードを実行することとなる.投 機スレッドを割り当てる方法としては,(1) 静的に割り当てる方法,(2) 動的に割 り当てる方法といった 2 つの方法が考えられる.(1) は,隣り合うプロセッサコア に対して順番にスレッドを割り当てていく方法であり,(2) はプロセッサコアの位 置関係は考慮せず,スレッドの実行が終わった順に新しいスレッドを割り当てる 方法である.3.1.5 節で示した 2 パス限定投機方式を実現するためには,隣り合う プロセッサコアに対して順番にスレッドを割り当てる構造となる (1) の方法が自 然である.一般に,ループではループの実行回数を示すループカウンタを始めと して,イタレーション間において変数の依存関係が存在する.連続して実行され るループイタレーションを投機スレッドとして順番にプロセッサコアに割り当て ることにより,プロセッサコア間の接続関係が静的に決まりネットワークを単純 化できるため,プロセッサコア間のデータ通信の制御が簡単化できる. 2 パス限定投機方式では,すべてのスレッドは投機実行されるため,先頭スレッ ドを実行するプロセッサコアにおいても投機失敗が起こりうる.投機が失敗した スレッドによって後続のスレッドに通信されたデータは誤りである可能性があり, その誤ったデータを計算に使用した後続スレッドの実行もまた誤りとなる.従っ て,投機が失敗した場合,投機失敗となったスレッドおよび,その後続のすべて のスレッドの実行を破棄し,回復処理を行うことでプログラム実行の整合性を保 証することができる.この場合,破棄された後続スレッドに対しては,予測情報 を更新した後,再度予測を行いスレッドを起動する.これは,投機失敗となった スレッドによって,後続スレッドのパスの予測に用いた履歴レジスタの内容が更

![図 3.2 に横田らの調査による SPEC CINT95 ベンチマーク ( 以下,単に CINT95 と呼ぶ ) におけるパスの実行割合を示す [9] . CINT95 は, CPU の性能を比較す るためのベンチマークである SPEC CPU95 のうち,整数演算処理性能のベンチ マークテストを行うプログラムである.調査対象は 129.compress の compress() , 132.ijpeg の forward DCT() , 130.li の sweep() , 124.m88ksim の k](https://thumb-ap.123doks.com/thumbv2/123deta/8154788.1270894/29.892.185.714.164.301/横田らベンチマークにおけるベンチマークマークテストプログラム.webp)