DOI: http://doi.org/10.14947/psychono.38.5
強化学習における認知バイアスと固執性
―選択行動を決めているのは過去の“選択の結果”か“選択そのもの”か?―
菅 原 通 代・片 平 健 太 郎*
名古屋大学Cognitive biases and perseverance in reinforcement learning:
Does your current choice behavior depend on past
“choice outcome” or
“choice per se” ?
Michiyo Sugawara and Kentaro Katahira
Nagoya University
Reinforcement learning models, which update the value related to a specific behaviour according to a reward prediction error, have been used to model the choice behaviour in organisms. Recently, the magnitude of the learning rate has been reported to be biased depending on the sign of the reward prediction error. A previous study concluded that these asymmetric learning rates reflect positivity and confirmation biases. However, another study reported that the tendency to repeat the same choice (perseverance) leads to pseudo asymmetric learning rates. Therefore, this study aimed to clarify whether asymmetric learning rates are the result of cognitive bias or perseverance by reanalys-ing the open data that the previous study obtained from two different types of learnreanalys-ing tasks. To accomplish this, we evaluated multiple reinforcement learning models, including asymmetric learning rate models, perseverance models and hybrid models. The results showed that the choice data associated with positivity bias were also explained by the perseverance model with symmetric learning rates. Meanwhile, the data associated with confirmation bias were not explained by the perseverance model. These results suggest the possibility that either cognitive bias or perseverance could explain asymmetric learning rates depending on the contextual information of learning task.
Keywords: reinforcement learning, asymmetric learning rates, confirmation bias, positivity bias, perseverance
問題と目的 心理学や神経科学における多くの基礎研究において, ヒトやそれ以外の動物の行動データに対する様々な解析 が行われてきた。従来の行動データ分析は,反応に関す る平均値などの要約統計量を参加者ごとに求め,それを 群間で比較する,あるいは個人特性との相関を調べる, といった方法が主流であった。しかしながらこのような 解析では,個人内で変動する要素についての情報は失わ れてしまう。特に時々刻々と変動していく学習プロセス においては,その変動が重要な情報となり得る。 そこで近年,変動するプロセスの成分を定量的なモデ ルで表現する計算論モデリングが注目されている (Far-rell & Lewandowsky, 2018)。例えば個人の選択は,過去の 選択に応じて変化していく。このような行動の変動性を 定式化し,変動の原因を説明するモデルの1つに強化学 習モデルがある。強化学習モデルは生体の行動選択をモ デル化するために,心理学,行動経済学,神経科学と いった様々な領域で広く用いられている (Daw, Gersh-man, Seymour, Dayan, & Dolan, 2011; KahneGersh-man, 2003; Re-dish & Johnson, 2008; Schultz, 1998)。標準的な強化学習ア ルゴリズムでは,試行錯誤により得られた結果から,行 為と結果の関連性を行為の価値として学習する (Barto, 1997)。行為の価値は,実際に得た報酬と,次にどのく らいの報酬が得られるかを表す期待報酬の差である報酬 予測誤差に従って更新されていく (Rescorla & Wagner, 1972; Sutton & Barto, 1998)。更新時に報酬予測誤差をど Copyright 2019. The Japanese Psychonomic Society. All rights reserved. * Corresponding author. Department of Cognitive and
Psychological Sciences, Graduate School of Informatics, Nagoya University, Furo-cho, Chikusa-ku, Nagoya, Aichi 464–8601, Japan. E-mail: [email protected]. nagoya-u.ac.jp
の程度反映させるか決めるパラメータは,学習率と呼ば れる重要なパラメータの1つである。
標準的な強化学習において学習率は固定のパラメータ として設定されるが,その変動性に注目した研究も多く 存在する (Nassar, Bruckner, Gold, Li, Heekeren, & Eppinger, 2016; Gershman, 2015)。例えば,成功から学ぶ程度と失 敗から学ぶ程度の差は,報酬予測誤差の符号に応じた学 習率の違いで説明される。最近の研究では,ポジティビ ティ・バイアス (良い結果に重点を置く傾向; Lefebvre, Lebreton, Meyniel, Bourgeois-Gironde, & Palminteri, 2017) や,確証バイアス (自らの信念にあった情報ばかりを集 め,反証情報に注目しない傾向; Palminteri, Lefebvre, Kilford, & Blakemore, 2017) といった認知バイアスが,学 習率の非対称性に表れることが示されている。Lefebvre et al. (2017) は,自ら選択した選択肢に対する結果に基 づく学習 (factual learning) において,報酬予測誤差が正 だった場合の学習率が,負だった場合の学習率に比べて 大きくなる傾向があることを示し,これが人間の持つポ ジティビティ・バイアスを反映すると結論づけた。その 後Palminteri et al. (2017) は,選択されなかった選択肢の 結果もフィードバックとして与えることで反実仮想学習 (counterfactual learning) のプロセスを検討した。この学 習プロセスでは,選択した選択肢における正の報酬予測 誤差に対する学習率に加え,選択しなかった選択肢にお ける負の報酬予測誤差に対する学習率も高くなることが 示された。つまり,自分の信念に沿った結果を更新に多 く取り入れ,反対に信念に沿わない結果を少ししか取り 入れないという方略が,選択肢と非選択肢の間で共通し ていた。この結果から彼らは,factual learningとcounter-factual learningの結果が,同じ学習システムによって処 理されたものであると考察した。言い換えれば,今まで 論じられていたポジティビティ・バイアスが,counter-factual learningのもとでは確証バイアスの一側面として 論じることが可能であることを示唆したのである。 しかしながら,Palminteri et al. (2017) のパラメータの 推定結果は,彼らが主張するように学習率の非対称性の みを反映しているであろうか。Katahira (2018) は,結果 とは無関係に同じ選択肢を選び続ける傾向である固執性 (perseverance) によって,見かけ上の学習率の非対称性 が引き起こされることを指摘した。先に述べたように報 酬予測誤差が正だった場合の学習率が負だった場合の学 習率よりも大きくなるという非対称性は,ポジティビ ティ・バイアスを表している (Lefebvre et al., 2017)。こ の場合,正の学習率を大きくすることで報酬の価値更新 を多くした結果,その選択肢が選ばれやすくなっている と言える。一方で負の学習率を小さくすることは,報酬 が得られなかった場合の価値の減少を少なくし,結果と して選択に対する切り替えを弱める。これらの現象から 学習率の非対称性は,結果として同じ選択肢を選び続け る固執性の結果とも考えられる。この疑問に答えるべく Katahira (2018) は,学習率は固定だが固執性を持つモデ ルから生成したシミュレーション・データに対し,学習 率の非対称を許容するモデルを適用することで,擬似的 な学習率の非対称性が生じることを明らかにした。つま り学習率の非対称性は,データの持つ自己相関を反映し た見せかけの特徴である可能性がある。 本研究では,認知バイアスを結果の認知に対するバイ アスであると考え,固執性 (Perseverance) を結果とは無 関係に同じ選択肢を選び続ける傾向であると考える。ポ ジティビティ・バイアスや確証バイアスのような認知バ イアスと固執性は,見た目上は類似した行動をもたらす が,本研究では質的に異なるプロセスであると考える。 異なるプロセスに由来していても目に見える行動が同じ である場合,これらの背景プロセスを区別することは通 常困難であるが,過去の選択や結果の履歴の影響に関す る統計的な性質が異なるため,強化学習モデルを用いる ことでそれらの区別が可能となる (Katahira, 2018)。本 研究では,擬似的な学習率の非対称性を生じさせる可能 性をもつ自己相関因子を考慮したうえでデータを再解析 し,Palminteri et al. (2017) の主張を再検討することを目 的とした。固執性を組み込んだうえで学習率の非対称性 が失われるならば,Palminteri et al. (2017) の認知バイア スは擬似的なバイアスであるといえる。一方で非対称性 が残存するならば,認知バイアスの存在を証することと なる。 これらの可能性を検証するため本研究では,Palmin-teri et al. (2017) の公開データを使用した。Palminこれらの可能性を検証するため本研究では,Palmin-teri et al. (2017) は,2つの実験から構成されている。実験1で はLefebvre et al. (2017) の追試を行い,factual learningに おけるポジティビティ・バイアスの存在を確認した。実 験 2では,実験1で行った課題を拡張し,counterfactual learningにおける確証バイアスの存在を確認した。本研 究ではこのデータに対して,学習率の非対称性を仮定す るモデルに加えて,固執性を組み込んだモデルをフィッ ティングした。最初に,複数の候補となるモデルを周辺 尤度により比較し,どのモデルがデータを最も良く説明 するかを検討した。その後,各モデルにおける学習率の 非対称性を検討した。
方 法 データ 本研究では,Palminteri et al. (2017) の公開データ1を 用いた。ここでは実験参加者と行動課題について簡単に 説明する。Palminteri et al. (2017) では,行動選択後の結 果フィードバック情報の異なる2つの実験が行われた。 各実験とも神経学的・精神医学的な疾患を持たない 18 歳以上の男女20名 (実験1: 男性7名,女性13名,平均年 齢 23.9±0.7歳; 実験2: 男性4名,女性16名,平均年齢 22.8±0.7歳) により実施された。 行動課題は,確率的な道具的学習課題である二腕バン ディット課題が用いられた。バンディット課題とは,報 酬が得られる確率である報酬確率の異なる複数のアーム (選択肢) から最適な選択を逐次的に学習する課題であ り,得られる報酬を最大化することが求められる。この 課題では選択肢刺激として,抽象的な文字刺激である “Agathodaimon” フォントを用いた (例:r)。課題中参加 者は画面に呈示される2つの選択肢のどちらかをキーを 押すことで選択し,その直後に報酬の有無についての フィードバックが得られた。報酬は+1ポイントか−1 ポイントのいずれかであった。課題は2ブロックあり, 各ブロック96試行の計192試行から構成されていた。こ のとき画面に呈示される2つの選択肢の組み合わせは固 定で,各ブロックで4種類の選択肢対が用意され,それ らがランダムに提示された。4つのうち3つの選択肢対 は報酬確率がセッションの最初から最後まで固定であ り,残りの一つは途中で確率が逆転する選択肢対であっ た。 実験 1 では,参加者の選んだ選択肢の結果だけが フィードバックされた (factual learning)。参加者は自身 が選んだ選択肢の結果のみから選択肢の価値を更新し, 次の選択肢を決定するように求められた。実験2では, 選んだ選択肢の結果に加え,選ばなかった選択肢の結果 もフィードバックされた (counterfactual learning)。この 条件が加わることで参加者は,自身が選んだ選択肢の結 果に加えて選ばなかった選択肢の結果も考慮したうえで 選択することができた。 モデル 実験 1では Palminteri et al. (2017) で使用されていた One モ デ ル (Q モ デ ル) と Valence モ デ ル (VQ モ デ ル) に,固執性を表現可能な Perseveranceモデル (Q–Pモデ ル) とValence with Perseveranceモデル (VQ–Pモデル) を 加えた4つのモデルを用いた。 Qモデルは標準的なQ学習モデルであり,各選択肢の 報酬期待値 (Q値) が,選択結果に基づいて試行ごとに更 新されていくものとする。Q値の初期値は0とし,第2ブ ロックの開始時点では選択肢に用いられた刺激が別のも のに変わるため再びQ値は0に戻る。第t試行で与えられ た結果 (ポイント) をR(t) とし,報酬期待値Q(t) との差 を,報酬予測誤差δ(t) とする。第t試行で選択された選 択肢に対応するQ値は以下の更新式により更新する。 δ(t)=R(t)−Q(t) Q(t+1)=Q(t)+αδ(t) ここで,学習率αは報酬予測誤差に基づくQ値更新の量を 決めるフリーパラメータとする。実験1では,すべての モデルにおいて,選択されなかったQ値および呈示され なかった選択肢のQ値は,更新しないものとする。2つの 選択肢に対して推定されたQ値の差を用いて,選択確率 P(t) を以下のソフトマックス関数によって評価する。c
( )
(
(
( )
( )
)
)
c u P t Q t Q t c 1 1 exp = + -β - Qcは選択した選択肢に対する Q値,Quは選択しなかっ た選択肢に対するQ値であり,Q値の差に対する感受性 を定める逆温度βを設定する。 VQモデルは,報酬予測誤差の符号による学習率の非対 称性を考慮するようにQモデルを拡張するモデルとした。(
)
Q t( )
( )
( )
( )
t if( )
( )
t Q t Q t t if t 0 1 0 ≥ < + - + + = + α δ δ α δ δ Q–PモデルではQ値の更新式はQモデルと同一である一 方,選択確率の計算時に過去の選択の影響を組み込む ため,各試行における選択履歴を反映する選択トレース (C(t)) を定義する(Akaishi, Umeda, Nagase, & Sakai, 2014)。i選択トレースとは,試行tにおいてそれまで選択肢iが選 択されてきた程度を表す変数である。 Ci(t+1)=Ci(t)+τ(I(a(t)=i)−Ci(t)) ここで,I(a(t)=i) は指示関数であり,中身の式が真で あれば1, そうでなければ 0 をとることとする。つまり C(t) は,選択肢iを選ぶと増加し,選ばなければ減少すi る。この更新式においてτは選択履歴の重みを定義する 1 https://figshare.com/articles/Confirmation_bias_in_human_ reinforcement_learning_evidence_from_counterfactual_ feedback_processing/5220619
パラメータであり,1に近いほど直近の選択の影響を強 める。Q値とは異なり選択トレースは,選択されなかっ た場合には減少し,呈示されなかった場合は更新しない ものとする。選択トレースを選択確率に反映させるた め,ソフトマックス関数は以下のように変更する。
c u c u P tc Q t Q t C t C t 1 =1 exp+ - - - - ここでのパラメータφは,正の値であれば過去の選択と 同じ選択を選びやすく,負の値であるほど今までとは異 なる選択を選びやすいことを意味する。 VQ–PモデルはVQモデルによるQ値の更新式と,Q– Pモデルで用いられた選択トレースの両方を組み合わせ たモデルとして用いた (Table 1)。 実験2では,Palminteri et al. (2017) で使用されていた One モ デ ル (Q モ デ ル),Valence×Information モ デ ル (VIQ モ デ ル),Confirmation モ デ ル (CQ モ デ ル) に, Perseverance モデル (Q–P モデル),Valence×Information with Perseverance モ デ ル (VIQ–P モ デ ル),Confirmation with Perseveranceモデル (CQ–Pモデル) を加えた 6つの モデルを用いた。これらのモデルのうち,Qモデルと Q–Pモデルは実験1と全く同じものを使用した。実験1 と同様に,すべてのモデルにおいてQ値の初期値は0と する。呈示されなかった選択肢のQ値は更新しないもの とするが,選択されなかったQ値は更新されるものとす る。 VIQ モデルでは,予測誤差の符号による違い (va-lence) に加えて,選択結果に基づく更新 (factuallearn-ing) と非選択結果からの更新 (counterfactual learnlearn-ing) に対する違い (information) に対しても異なる学習率 (αc+, αc−, αu+, αu−) を設定する。 factual learning: δc (t)=Rc (t)−Qc (t)
(
)
c( )
( )
c c( )
( )
c( )
( )
c c c c c Q t t if t Q t Q t t if t 0 1 0 ≥ < + - + + = + α δ δ α δ δ counterfactual learning: δu(t)=Ru(t)−Qu(t)(
)
u( )
( )
u u( )
( )
u( )
( )
u u u u u Q t t if t Q t Q t t if t 0 1 0 ≥ < + - + + = + α δ δ α δ δ 一方で CQモデルでは,VIQモデルで用いた4つの学習 率を自分の信念を肯定する結果か否か (Confirmation) と いう点から2つに縮約する (αcon=α+c=αu−, αdis=α−c=αu+)。 最後の 2 つのモデル (VIQ–P モデル,CQ–P モデル) は,VIQ モデルおよび CQ モデルによる Q 値の更新式 と,Q–Pモデルで用いられた選択トレースの両方を組み 合わせたモデルとして用いた (Table 1)。 パラメータ推定 実際のデータからパラメータを推定する方法として, 本研究では最大事後確率 (Maximum a posteriori; MAP) 推定を用いた。MAP推定は,ベイズの公式により得ら れる事後分布の密度が最も高くなるパラメータ値を推定 値として用いる方法である。事前分布を設定して推定を 行うMAP推定には,最尤推定で生じやすいパラメータ Table 1.The list of models and model selection results.
Model Learning rates temperatureInverse Perseverance parameter# of free Log marginal likelihood
Experiment 1 Q α β ̶ 2 −99.22 (5.39) VQ α+c, αc− β ̶ 3 −90.20 (5.84) Q–P α β τ, φ 4 −88.88 (6.01) VQ–P α+c, αc− β τ, φ 5 −89.49 (5.91) Experiment 2 Q α β ̶ 2 −89.17 (5.80) VIQ α+c, αc−, αu+, αu− β ̶ 5 −76.14 (6.67) CQ αcon, αdis β ̶ 3 −75.66 (6.61) Q–P α β τ, φ 4 −78.13 (6.28) VIQ–P α+c, αc−, αu+, αu− β τ, φ 7 −77.28 (6.69) CQ–P αcon, αdis β τ, φ 5 −76.51 (6.59)
Note. The log marginal likelihood values indicate the mean (standard deviation of mean) across participants. Experiment Q indicates the standard Q learning model, P represents perseverance, and V represents the valence of the learning rate (posi-tive/negative). In Experiment 2, I represents the task information (factual/counterfactual).
が極端な値を取ってしまうリスクを防ぐメリットがある (Katahira, 2016)。 推定に使用する事前分布と制約条件はPalminteri et al. (2017) に従い,すべての学習率は,ベータ分布 Beta (1.1, 1.1) の下で0 ≤ α ≤1の範囲とし,逆温度は形状パラ メータ1.2, 尺度パラメータ5のガンマ分布の下でβ≥0と した。固執性モデルのフリーパメータについては,τは ベータ分布Beta (1, 1),φは平均0,標準偏差5の正規分 布を事前分布とした。これらの制約条件下で非線形最適 化により事後確率密度を最大にするパラメータを求める た め,Rsolnp パッケージ (Ghalanos & Maintainer, 2015) に含まれるsolnp関数を使用した。
モデル比較
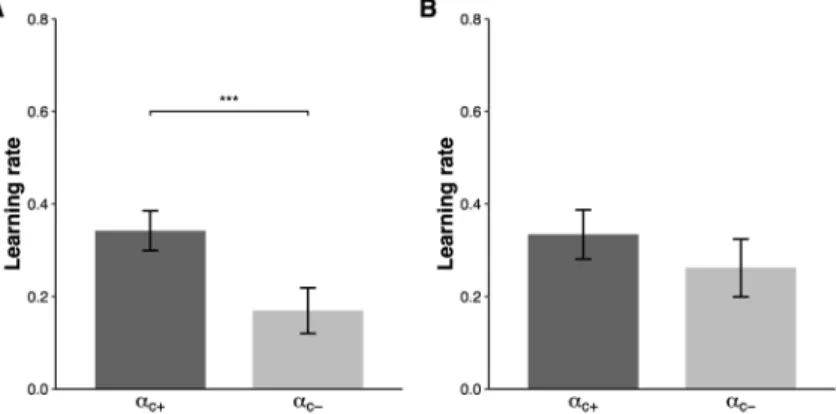
モデルの当てはまりの良さを比較する指標として,本 研究ではラプラス近似 (事後確率密度をガウス関数で近 似するもの) により得られた周辺尤度 (marginal hood) の対数を取った対数周辺尤度 (log marginal likeli-hood) を採用した (Daw, 2011)。一般的に周辺尤度はモ デルの事後確率に対応するため,周辺尤度が高いほどよ いモデルであると言える。 統計解析 各モデルの適合度を統計的に比較するため,対数周辺 尤度に対して一要因の反復測定分散分析を行った。その 際,球面性仮定からの逸脱を補正するためGreenhouse– Geisserのイプシロンによる自由度調整を行った。その 後の検定として,Shafferの方法に基づく多重比較補正を 実施した。 また実験 1 における VQ モデルと,実験 2 における VIQモデルに対して推定された各学習率間の比較を行っ た。VQモデルはそれぞれ2つの学習率を持つため,対 応のあるt検定によって比較を行った。VIQモデルでは, 4つの学習率 (α+c, α−c, αu+, αu−) に対して2要因反復測定分 散分析を行なった後,Greenhouse–Geisserの自由度調整 を行った。また各対間の比較を Shafferの方法に基づく 多重比較補正により実施した。すべてのデータ解析はR version 3.5.1 で行い,統計解析には anovakun version4.8.2 を使用した。 結 果 実験1 Palminteri et al. (2017) の実験1のデータに対し対数周 辺尤度を用いて,モデルの説明力を比較した結果,Q–P モデルが最もデータを説明することが示された。また, 4つのモデルに対する対数周辺尤度を反復測定分散分析 で比較したところ (Table 1),モデル間で有意な差がある ことが示された (F(3, 57)=6.51, p=.018)。その後の検定 により,有意傾向ではあるがQモデルとすべてのモデル 間に差が示された (.076<p<.083)。Qモデルを除くモデ ル間に有意な違いは示されなかった (p>.129)。Qモデ ル以外のモデル間に差がないことは,先行研究において Valenceモデルで説明されていた行動の特徴が,固執性 をもつモデルからも説明可能であることを示唆する。 次に,学習率における非対称性がモデルに依存してど う変化するか確認するためにVQモデルにおける2つの 学習率 (α+cとα−c) を比較したところ,α+cはα−cと比べて有 意に大きかった (t(19)=2.36, p=.029; Figure 1A)。一方 で,選択履歴の効果を追加したVQ–Pモデルでは,α+cと αc−に有意な差は認められなかった (t(19)=.78, p=.44; Figure 1B)。さらにそれぞれのモデルで,学習率の非対 称性の大きさを,α+cとα−cの差分により求め,2つのモデ
Figure 1. Learning rates for the VQ model (A) and the VQ–P model (B). The error bars represent the standard error of the mean. *p<.05, two-tailed paired t-test.
ル間で比較した。その結果,VQ モデル (M±SE=.17 ±.07) に比べてVQ–Pモデル (.05±.07) では非対称性が 有意に小さいことが示された (t(19)=3.95, p=8.62× 10−4)。これらの結果は,データの持つ固執性を考慮す ることによって,ポジティビティ・バイアスが消滅した ことを示す。 実験2 実験 2で使用した6つのモデルを実験1と同様に比較 したところ,CQモデルが最も高い対数周辺尤度を与え たモデルであった。また分散分析の結果から,モデル間 に有 意 な 差 が あ る こ と が 示 さ れ た (F(5, 95)=30.09, p<.001)。その後の検定により,Qモデルとすべてのモ デル間に差が示された (p<.001)。他のモデル間では, CQモデルはQ–PモデルとVIQ–Pモデルよりも周辺尤度 が高いことが示され (p=.022, p=.04),これ以外のモデ ル間に有意な差は認められなかった (p>.054)。これは データの固執性を加味してもなお,CQモデルが最も データをよく説明することを示す。 次に,VIQモデルにおける4つの学習率 (αc+, α−c, αu+, αu−) を比較したところ,valence及びinformationの有意な主 効 果 は 認 め ら れ な か っ た が (F(1, 19)=.04, p=.837; F(1, 19)=6.0×10− 4, p=.981), valence と information の 交 互作用が示された (F(1, 19)=124.88, p<.001; Figure 2A)。 そ の後 の 検 定 で,α+c はα−cと比 べ て 有 意 に 大 き く (p<.001), αu+はαu−と比べて有意に小さいことが示された (p<.001)。また,α+cはαu+と比べて有意に大きく(p<.001), αc−はαu−よりも有意に小さかった (p<.001)。一方でVIQ– Pモデルでは,valenceの主効果およびinformationの主効 果は認められなかったが (F(1, 19)=5.0×10− 4, p=.982; F(1, 19)=.30, p=.594), valence と information の交互作用 が示された (F(1,19)=37.95, p<.001; Figure 2B)。学習率 の非対称性は先のVIQモデルの結果と同様で,α+cはα−cに 比べて有意に大きく (p=4.0×10−4), α u +はα u −と比べて有 意に小さかった (p=.014)。また,αc+はαu+と比べて有 意に大きく (p<.001), α−cはαu−よりも有意に小さかった (p<.001)。2つのモデルの非対称性の大きさ (α+c+αu−)− (αc−+αu+) の比較では,VIQモデル (M±SE=.67±.06) と VIQ–Pモデル (.57±.09) の間に有意な違いは認められな かった (t(19)=1.24, p=.23)。これらの結果からも,Pal-minteri et al. (2017) が示した確証バイアスの存在が示唆 される。 考 察 本研究は,学習率の非対称性を確証バイアスとして解 釈したPalminteri et al. (2017) の研究を,固執性という確 証バイアスと関係のない性質によって擬似的な学習率の 非対称性が生じることを主張したKatahira (2018) の視点 から,再検討する目的で行われた。 実験 1における各モデル間の対数周辺尤度の比較か ら,同じ選択肢を選び続ける固執性を反映したQ–Pモ デルが最もデータを説明するモデルであることが示唆さ れた。注目すべきはVQモデルとVQ–Pモデルに差が認 められなかったという点である。この結果は,固執性を 反映したモデルも学習率の非対称性を反映したモデルと 同様の説明力を持っていることを示している。そこで, 本研究の興味の対象である学習率の非対称性を両方のモ デルで比較した。先行研究の非対称強化学習モデルに固 執性を組み込んだモデルを適用したうえでなお学習率の 非対称性が残存するならば,そこで表現される学習率の 非対称性は固執性に依存しない認知バイアス (ポジティ ビティ・バイアス) であるという結論が強められるだろ Figure 2. Learning rates for the VIQ model (A) and the VIQ–P model (B) *** p<.001, * p<.05. Post hoc analyses used the
う。逆も同様で,もし固執性を組み込んだモデルを フィットさせることによって学習率の非対称性に差が出 ないならば,先行研究で示された非対称性は固執性に よって生じた可能性が強まることとなる。本研究におい て,VQモデルでポジティビティ・バイアスを反映する とされていた学習率の非対称性は,固執性を組み込んだ VQ–Pモデルでは認められなかった。これらの結果は, ポジティビティ・バイアスを反映すると考えられる学習 率の非対称性が,見せかけのバイアスである可能性を示 している (Katahira, 2018)。 一方,実験2のモデル選択の結果から,確証バイアス を反映した学習率の非対称性を有するが固執性は含まな いCQモデルが最もデータをよく説明するモデルである ことが示された。実験1と同様に,学習率の非対称性を VIQ モデルと VIQ–P モデルで比較したところ,学習率 の非対称性はどちらのモデルでも強く示された。これら の結果から,選択していない結果を考慮した学習場面に おける学習率の非対称性は,固執性のみでは説明でき ず,Palminteri et al. (2017) の主張通り,確証バイアスを 反映することが示唆される。 本研究の結果は新たな疑問を生じさせる。選択した結 果のみを用いて学習する場合 (factual learning) に生じる 学習率の非対称性は固執性でも説明できるが,選択して いない結果を利用可能にする (counterfactual learning) こ とで固執性では説明不可能な非対称性が生じるのはなぜ か。選択していない結果を利用することで,選択行動に ど の よ う な影 響 が 与 え ら れ る の か。Palminteri et al. (2017) は,counterfactual learning を 検 証 す る こ と で, factual learningでポジティビティ・バイアスとして見え ていた現象が,実際には確証バイアスの一側面であると いう可能性を示唆した。この主張が正しいならば,fac-tual learning におけるα+cとα−cの非対称性と counterfactual
learningにおけるα+cとα−cの非対称性は,同じ学習システ ムを反映していると考えられる。しかし,本研究の結果 は固執性を組み込むことによる非対称への影響が実験1 と実験2で異なるため,そこには何らかの交絡要因が存 在する可能性が考えられる。 もし確証バイアスという認知バイアスが学習条件によ らない共通した心理過程であると仮定するならば,fac-tual learningとcounterfacらない共通した心理過程であると仮定するならば,fac-tual learningの違いは情報量の多 寡に依存する可能性が考えられる。Factual learningにお ける選択した結果のみに基づく文脈では,選ばなかった 選択肢に対する結果は不確実なままである。このような 曖昧性はその選択肢の選択確率を低下させることが知ら れており (Hsu, Bhatt, Adolphs, Tranel, & Camerer, 2005),
期待値とは独立して同じ選択を続けるように方向づける 可能性がある。つまり曖昧性を回避する傾向は,反復的 行動選択を引き起こす要因となり得る。この観点で考え れば,選択していない結果も呈示される counterfactual learningにおいては,情報量が増えたことにより曖昧性 が低減し,曖昧性に伴う固執性も減少した結果,行動に 反映される認知バイアスの効果が相対的に大きくなった と考えられる。 本研究における検証の結果として,学習率の非対称性 が固執性によって説明可能であるか否かは状況依存的で あるが,認知バイアスを反映する学習率の非対称性が存 在することが示された。これらの結果から,認知バイア スと固執性はどちらも選択行動を説明する重要な要素で あり,どちらが優勢になるかは利用可能な情報によって 決まるという可能性が示唆された。特に,情報が限定的 である場合には固執性の影響が相対的に強まり,完全な 情報が得られる場合には確証バイアスが優勢になると考 えられる。 本研究の結果は,設定された強化学習モデルの詳細に 依存するものであることには注意する必要がある。学習 率の非対称性とデータのもつ固執性を,特定の強化学習 モデルを仮定せずに区別する方法の1つとして,Katahi-ra (2018) は報酬履歴が現在の選択に及ぼす効果の交互 作用に注目した分析手法を提案している。ただし,その 方法を適用するためには,現在のサンプルサイズでは不 十分であり,新たに多数のデータを用いた検証を行うこ とが今後の課題である。 計算論モデルが心理学に取り入れられるようになり, 今までブラックボックスとされていた認知プロセスが行 動の結果から推定可能となっている。モデルのパラメー タや構造は自由に設定することが可能であるがゆえ,パ ラメータに対する概念的な解釈がなされる場合も多い。 しかし本研究の結果が示すように,全く異なる概念で解 釈されるパラメータが,一見類似した効果をもたらすよ うな可能性があることは留意する必要があるだろう。 引用文献
Akaishi, R., Umeda, K., Nagase, A., & Sakai, K. (2014). Auton-omous mechanism of internal choice estimate underlies de-cision inertia. Neuron, 81, 195–206.
Barto, A. G. (1997). In O. M. Omidvar & D. L. Elliott (Eds.), Neural systems for control (pp. 7–30). Cambridge: Academic Press.
Daw, N. D. (2011). Trial-by-trial data analysis using computa-tional models. In M. R. Delgado, E. A. Phelps, & T. W. Rob-bins (Eds.).Decision making, affect, and learning: Attention
and performance XXIII (pp. 3–38). Oxford: Oxford
Universi-ty Press.
Daw, N. D., Gershman, S. J., Seymour, B., Dayan, P., & Dolan, R. J. (2011). Model-based influences on humans’ choices and striatal prediction errors. Neuron, 69, 1204–1215. Farrell, S., & Lewandowsky, S. (2018). Computational modeling
of cognition and behavior. Cambridge: Cambridge
Universi-ty Press.
Gershman, S. J. (2015). Do learning rates adapt to the distribu-tion of rewards? Psychonomic Bulletin and Review, 22, 1320–1327.
Ghalanos, A., & Maintainer, S. T. (2015). Rsolnp: General
non-linear optimization using augmented Lagrange multiplier method. R package version 1.16. Retrieved from https://rdrr.
io/cran/Rsolnp/
Hsu, M., Bhatt, M., Adolphs, R., Tranel, D., & Camerer, C. F. (2005). Neural systems responding to degrees of uncertainty in human decision-making. Science, 310, 1680–1683. https://doi.org/10.1126/science.1115327
Kahneman, D. (2003). A perspective on judgment and choice mapping bounded rationality. American Psychologist, 58, 697–720.
Katahira, K. (2016). How hierarchical models improve point estimates of model parameters at the individual level.
Jour-nal of Mathematical Psychology, 73, 37–58.
Katahira, K. (2018). The statistical structures of reinforcement learning with asymmetric value updates. Journal of
Mathe-matical Psychology, 87, 31–45.
Lefebvre, G., Lebreton, M., Meyniel, F., Bourgeois-Gironde, S., & Palminteri, S. (2017). Behavioural and neural character-ization of optimistic reinforcement learning. Nature Human
Behaviour, 1, 1–9.
Nassar, M. R., Bruckner, R., Gold, J. I., Li, S.-C., Heekeren, H. R., & Eppinger, B. (2016). Age differences in learning emerge from an insufficient representation of uncertainty in older adults. Nature Communications, 7, 1–13.
Palminteri, S., Lefebvre, G., Kilford, E. J., & Blakemore, S.-J. (2017). Confirmation bias in human reinforcement learn-ing: Evidence from counterfactual feedback processing.
PLoS Computational Biology, 13, e1005684.
Redish, A. D., & Johnson, A. (2008). A unified framework for addiction: Vulnerabilities in the decision process.
Behavior-al Brain Science, 31, 415–487.
Rescorla, R. A., & Wagner, A. R. (1972). A theory of Pavlovian conditioning: Variations in the effectiveness of reinforce-ment and nonreinforcereinforce-ment. In A. H. Black & W. F. Prokasy (Eds.), Classical conditioning II: current research and theo-ry (pp. 64–99). New York: Appleton-Centutheo-ry-Crofts. Schultz, W. (1998). Predictive reward signal of dopamine
neu-rons. Journal of Neurophysiology, 80, 1–27.
Sutton, R. S., & Barto., A. G. (1998). Reinforcement learning: An introduction. Cambridge: MIT Press.