Exemplar の生成と一般化に基づく 学習分類子システムに関する研究
松島 裕康
電気通信大学 大学院情報理工学研究科 博士 ( 工学 ) の学位申請論文
2013 年 3 月
博士論文審査委員会
主査 髙玉 圭樹 教授
委員 吉浦 裕 教授
委員 中嶋 信生 教授
委員 西野 哲朗 教授
委員 高橋 裕樹 准教授
著作権所有者
松島 裕康
2013 年
A Study of Learning Classifier System
based on Exemplar Generation and Generalization
Hiroyasu Matsushima
Abstract
In real world, there are a lot of real-value (continuous-value) problems such as the navigation task or the robot arm (manipulator) control task. To tackle these problems, many approaches were proposed, e.g., the function approximation, the direct policy search (DPS) and etc. For example, Ikeda proposed the exemplar-based direct policy search where an exemplar is represented as a correct state-action (i.e., condition-action) rule, and a set of exemplars (i.e., policy) is optimized by Genetic Algorithms (GA).
However, Ikeda’s approach requires sufficient number of exemplars to derive the appropriate DPS. For such a situation, learning classifier systems (LCS) are suit because LCS can reduce the number of rules by generalizing them. From this fact, we proposed the exemplar-based learning classifier system (ECS) which is combined the exemplar-based direct policy search with the generalization ability of LCS. Intensive simulation on the cargo layout problem has revealed that (1) Dynamic Matching Range ECS contributes to not only improving the performance but also reducing the number of the exemplars with an appropriate range of the match selection and (2) opportunities of estimation usefulness of exemplar by Roulette-Wheel Selection in exploration phase conduct growing in performance. From result of checkerboard problem, extended ECS by (3) the update range by using sigmoid function under concerning imbalance data set and (4) it is revealed that classification by using ECS is good performance from compared result of some technique using data set of UCI Machine Learning Repository.
(5)Rule generation by using DPS reveal that maintains stable performance in the
imbalance data set by generation and the extraction of a classifiable rule appropriately.
Through mountain-car problem as the multi-step problem, (6)generation of exemplars by ECS maintains performance as one by using previous knowledge. (7)The result of using ECS is better than related work and exemplar generation promote generalization of exemplars.
Exemplar の生成と一般化に基づく 学習分類子システムに関する研究
松島 裕康
概要
実数値環境の問題は離散値環境の問題と比べて現実世界の問題に多く,最適な 政策を獲得することは非常に困難である.実数値環境の問題に対するアプロー チとして,直接政策探索手法(Direct Policy Search: DPS)が提案されており,正例
の
if-thenルールとして表現される
exemplarを政策表現に適用しその集合を進化
計算法によって最適化することが試みられてきたが適切な政策を獲得するまで は多くの試行時間がかかるという問題が残っている.そこで
exemplarそのもの の有効な範囲を見積り,効率的に状態空間をカバーすることができる
exemplarを見出すために,ルールの一般化能力をもつ学習分類子システム
(LearningClassifier System: LCS)を応用する.LCS
は環境との相互作用を通じて分類子
(classifier)
と呼ばれる条件-行動ルールを学習し,一般化(generalization)されたル
ールを獲得可能だが,実数値問題を解く際は,高次元な空間や状態数の爆発的 増加により状態数分だけ価値の見積りのための計算量が増加してしまうため,
学習困難な状況となり,問題に対して適切な解を見つけることが困難となり,
一般化されたルールを獲得するのには効率が悪い.そこで本研究ではこれらの
課題に対し,
exemplar(模範,手本)に着目し,不必要なexemplar(一部重複しているなど
)を可能な限り削除することによって一般化されたルール群を効率的に構
築する
exemplarに基づく学習分類子システム
(Exemplar-based LCS: ECS)を提案
し,実問題に適用可能なシステムの構築を目指す.具体的には,
(1)問題に対し て与えられた手本のみを一般化する方法と,(2)与えられた手本を一般化しなが ら新たにルールを生成することで問題を解決する政策を直接的に見出す方法を 提案する.上記の提案システムを検証し提案手法の有効性の範囲を明確化する ためにシミュレーション実験をしたところ,シングルステップ問題の結果から
は,
(1)ECSは動的に照合範囲(Exemplar の有効範囲) を変更すると固定の照合範
囲を用いた場合と比べて少ない
exemplar数で同程度の性能を示すこと,(2)学習 時における選択手法にはルーレット選択を用いて
exemplarの有用性を見積る機 会は均一に与えた方が性能を向上させることを明らかにした.さらに,(3)デー タの偏りを考慮し,
exemplaの有効範囲の更新量を偏りに従って変化させる手法 は,多数データの
exemplarの過剰に範囲をカバーする現象を抑制し,少数デー
タの
exemplarの有効な範囲を確保できることを示し,加えて,(4)UCI Machine
Learning Repository
のデータセットを用いて様々な手法と比較したところ,提案
シ ス テム は非 常に 高い 分 類精 度を 示し た.
(5)直 接政 策探 索法を 応 用し た
exemplar
の生成・削除は従来手法と比較しても偏りの厳しい不均衡データ集合
に対しても安定的な分類成功率を示し,少数データの有効な範囲の維持に寄与 していることを明らかにした.マルチステップ問題の結果からは,(6)ECS によ
る
exemplarの一般化は事前知識と同等の性能を維持しながら
exemplarの削減に
成功し,
(7)exemplarの生成・削除を導入した
ECSは従来手法に比べ解の性能が
良く,さらに
exemplarの一般化を促進しより少ない
exemplarで問題を解くこと
が可能であることを示した.
目次
第1章 序論 1
1.1 はじめに . . . 1
1.2 研究目的 . . . 3
1.3 本論文の構成 . . . 3
第2章 直接政策探索法 5 2.1 概要. . . 5
2.2 モデルベース表現 . . . 6
2.3 ルールベースの政策表現 . . . 8
2.4 政策の一般化 . . . 10
第3章 学習分類子システム 12 3.1 概要. . . 12
3.2 正確性に基づく学習分類子システム . . . 12
3.3 実数値分類子表現型XCS . . . 17
3.4 教師あり学習に基づく学習分類子システム . . . 21
3.5 関数近似型学習分類子システム . . . 24
第4章 Exemplar-based LCS 26 4.1 概要. . . 26
4.2 メカニズム . . . 26
4.3 固定照合範囲型ECS . . . 28
4.4 動的範囲照合型ECS . . . 31
4.5 シーケンス . . . 36
4.6 不均衡データへのためのECS . . . 37
4.7 メカニズムの特徴 . . . 41
第5章 実数値問題 43
目次
5.1 実数値シングルステップ問題 . . . 44 5.2 実数値マルチステップ問題 . . . 47 第6章 計算機実験:シングルステップ問題 50 6.1 チェッカーボード問題 . . . 50 6.2 UCI リポジトリ . . . 61 第7章 計算機実験: 実数値マルチステップ問題 68 7.1 マウンテンカー問題 . . . 68
第8章 結論 85
8.1 本研究の成果 . . . 85 8.2 今後の課題 . . . 86 88
参考文献 89
A H-IIA Transfer Vehicle: HTV . . . 93 104
図目次
2.1 エージェントの政策 . . . 5
2.2 CoSyNeの概要[Gomez et al. 1989] . . . 7
2.3 NEATにおける遺伝子の表現の概要[Stanley 2002] . . . 7
2.4 インスタンスベース政策の例 . . . 9
2.5 ECSの一般化のイメージ . . . 10
3.1 XCSのアーキテクチャの概要 . . . 13
3.2 XCSのシーケンス . . . 16
4.1 ECSのアーキテクチャの概要 . . . 27
4.2 照合集合の形成 . . . 29
4.3 被覆の操作 . . . 29
4.4 照合集合での削除の操作 . . . 30
4.5 行動集合における包摂の操作 . . . 30
4.6 固定照合範囲を用いたECSによる一般化 . . . 31
4.7 動的照合範囲を用いたECSによる一般化 . . . 32
4.8 基底関数を用いた動的照合範囲 . . . 33
4.9 照合範囲の縮小 . . . 34
4.10 行動集合における包摂の操作(再掲) . . . 34
4.11 照合範囲の拡大 . . . 35
4.12 ECSのシーケンス . . . 36
4.13 不均衡データ集合に対する一般化の問題点 . . . 37
4.14 シグモイド関数 . . . 38
4.15 多数データの範囲の更新イメージ . . . 38
4.16 少数データの範囲の更新イメージ . . . 38
4.17 シングルステップ問題におけるexemplar生成の概要 . . . 40
4.18 削除の概要 . . . 40
図目次
4.19 マルチステップ問題におけるexemplar生成の概要 . . . 41
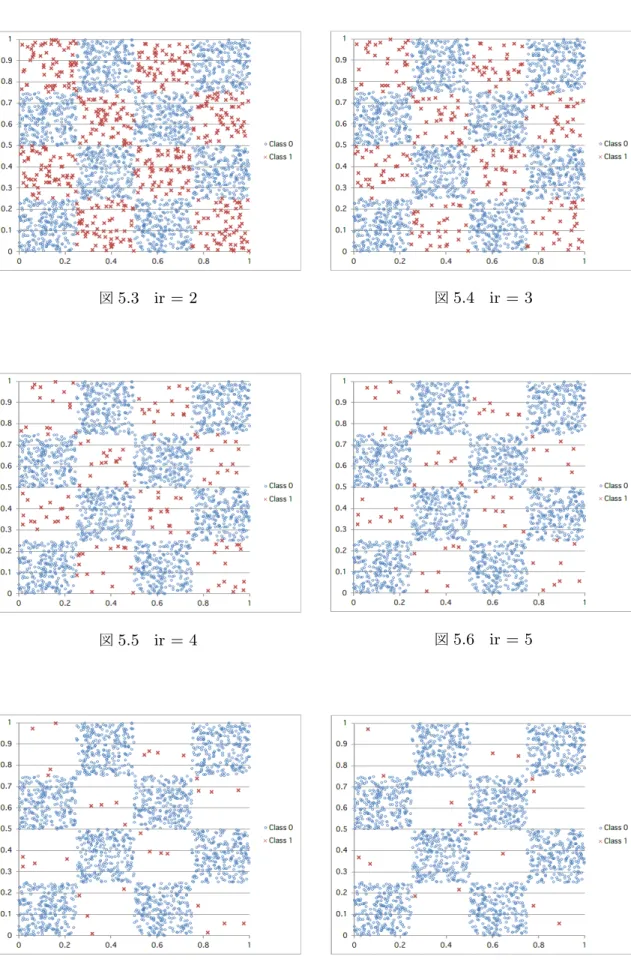
5.1 ir = 0 . . . 45
5.2 ir = 1 . . . 45
5.3 ir = 2 . . . 46
5.4 ir = 3 . . . 46
5.5 ir = 4 . . . 46
5.6 ir = 5 . . . 46
5.7 ir = 6 . . . 46
5.8 ir = 7 . . . 46
5.9 UCI Machine Learning Repositoryにあるアヤメ(iris)の分類 . . . 47
5.10 マウンテンカー問題 . . . 49
6.1 各データバランスiにおけるECS分類成功率と失敗率 . . . 51
6.2 各データバランスiにおけるECSのPopulation Sizeの推移 . . . 52
6.3 各データバランスiにおける生成・削除を導入したECS分類成功率と失 敗率 . . . 53
6.4 各データバランス iにおける生成・削除を導入したECSのPopulation Sizeの推移 . . . 54
6.5 各データバランスにおける提案システムとUCSの比較 その1 . . . 55
6.6 各データバランスにおける提案システムとUCSの比較 その2 . . . 56
6.7 各データバランスにおける提案システムとUCSの比較 その3 . . . 57
6.8 i = 7 におけるECSによるExemplarの範囲更新と一般化の様子 . . . . 59
6.9 i = 7 における生成・削除を取り入れたECSによるExemplarの範囲更 新と一般化の様子 . . . 60
6.10 UCIリポジトリのデータ集合を用いた比較(10分割交差検定) . . . 62
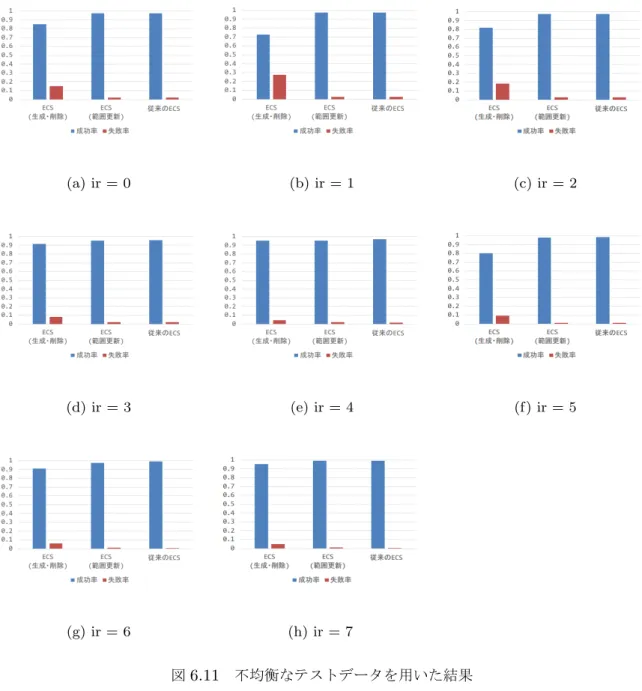
6.11 不均衡なテストデータを用いた結果 . . . 64
6.12 各ir値における少数データのみの分類精度 . . . 65
6.13 各データ集合におけるECSのP opulationsizeの平均推移 . . . 67
7.1 Q学習による最適行動マッピング . . . 69
7.2 学習した結果を用いたランダムな位置からのゴールパス . . . 69
7.3 ECSによるExemplar数とステップ数の推移(ステップ数はQ学習と比 較) . . . 71
7.4 ECSによるExemplar抽出 . . . 71
7.5 試行回数30000回後の平均獲得報酬と最大獲得報酬 . . . 72
図目次
7.6 一般化のみ ゴールパス 5 . . . 73
7.7 一般化のみ ゴールパス 4 . . . 73
7.8 一般化のみ ゴールパス 3 . . . 73
7.9 一般化のみ ゴールパス 2 . . . 74
7.10 一般化のみ ゴールパス 1 . . . 74
7.11 EBPと比較した平均獲得報酬と最大獲得報酬の推移 . . . 75
7.12 ゴールパスと設定した母集団上限数による学習後の平均獲得報酬 . . . . 76
7.13 ゴールパスと設定した母集団上限数による学習後の総exemplar数の平均 77 7.14 生成・削除を追加 初期設定: pop. size 400, ゴールパス 4 . . . 78
7.15 生成・削除を追加 初期設定: pop. size 300 ゴールパス 4 . . . 78
7.16 生成・削除を追加 初期設定: pop. size 200 ゴールパス 4 . . . 78
7.17 生成・削除を追加 初期設定: pop. size 400, ゴールパス 3 . . . 79
7.18 生成・削除を追加 初期設定: pop. size 300 ゴールパス 3 . . . 79
7.19 生成・削除を追加 初期設定: pop. size 200 ゴールパス 3 . . . 79
7.20 生成・削除を追加 初期設定: pop. size 400, ゴールパス 2 . . . 80
7.21 生成・削除を追加 初期設定: pop. size 300 ゴールパス 2 . . . 80
7.22 生成・削除を追加 初期設定: pop. size 200 ゴールパス 2 . . . 80
7.23 生成・削除を追加 初期設定: pop. size 400, ゴールパス 1 . . . 81
7.24 生成・削除を追加 初期設定: pop. size 300 ゴールパス 1 . . . 81
7.25 生成・削除を追加 初期設定: pop. size 200 ゴールパス 1 . . . 81
7.26 ECSの包摂による性能への影響 . . . 83
7.27 一般化のみのECSと生成・削除を導入したECSの比較 . . . 84
A.1 HTV内のラック . . . 93
A.2 ラック内のCTB . . . 94
A.3 2次元上に荷物配置するカーゴレイアウト問題 . . . 95
A.4 カーゴの交換手順 . . . 96
A.5 カーゴの交換手順 . . . 97
A.6 評価方法 . . . 98
A.7 Population Sizeの変動 . . . 99
A.8 実験ケース別のPopulation Sizeの変化 . . . 100
A.9 実験ケース別のPopulation Size . . . 101
A.10 実験ケース別の重心誤差の平均 . . . 102
A.11 固定照合範囲型ECSによって抽出されたexemplarの照合範囲 . . . 102
A.12 動的照合型ECSによって抽出されたexemplarの照合範囲 . . . 103
表目次 ix
表目次
2.1 DPSの表現法の種類 . . . 6
2.2 ルールベース表現の比較 . . . 9
2.3 本研究の位置づけ . . . 11
4.1 XCS(LCS)とECSの比較 . . . 42
5.1 UCIリポジトリのデータ集合 . . . 48
6.1 各データバランスiにおけるECS分類成功率と失敗率 . . . 52
6.2 各データバランスiにおけるECS分類成功率と失敗率 . . . 53
6.3 UCIリポジトリのデータ集合を用いた比較(10分割交差検定) . . . 62
7.1 ゴールパスと設定した母集団上限数による学習後の平均獲得報酬 . . . . 76
7.2 ゴールパスと設定した母集団上限数による学習後の総exemplar数の平均 77 7.3 ECSによるマウンテンカー問題におけるランダムスタートからの獲得報 酬の平均(P opulation size = 200) . . . 84
A.1 最適化問題のクラス . . . 95
A.2 固定照合範囲と動的照合範囲による重心誤差 . . . 98
第 1. 序論 1
第 1 章
序論
1.1 はじめに
近年,コンピュータやネットワークの進歩によって,電子データやテキストが大量に出 回るようになってきている.こうしたデータの洪水の中では,データを分析し有用な知 識を得る事が重要であり,その手段として人工知能の分野で現在活発に研究が行われて いる機械学習(machine learning)技術が着目されている.これらの応用技術は,データ マイニング(data mining) ,テキストマイニング(text mining) などと呼ばれ,機械学 習研究と密接な連携を保ちながら発展している.例えば,ロボットの自律制御,Amazon
やGoogleなどに見られる推薦システムや検索システム,投資行動の分析や人工市場のシ
ミュレーションなどの金融分野への応用,バイオインフォマティクス(Bioinformatics) と呼ばれる遺伝子発現解析やタンパク質構造の予測などの生物学と情報学の複合研究領 域などの様々な研究分野やサービスに機械学習が応用されている.しかし実世界には実 数値 (または,連続値) を扱う問題が数多く存在する.例えば,搭載されたセンサ情報 を頼りに自走する探査車,地球シミュレータによる海流の予測,またはセンサーデータ マイニングを活用した人流計測による避難シミュレータの構築など様々な研究例が挙げ られるが,高精度なコントロールを要するロボットの制御や,より現実に近い環境をシ ミュレータで再現する際に用いる実データの中には実数値が含まれ,それを適切に扱う 必要がある.その解決手法として,システムが知覚した環境(問題空間)からの状態(入 力) に対して行動 (出力) を決定し実行することで,環境からの反応として正解や不正 解,報酬,次の状態などを受け取るインタラクションを通して,状態に対する適切な行 動の確率集合である政策(policy)を獲得するアプローチが研究されている.適切な政策 を獲得するための方法として,入力を受け取ったら出力を返すモデルのパラメータを環 境とのインタラクションから徐々に更新する学習法,またはパラメータそのものを一度 に複数生成し環境とのインタラクションから最適な政策を選択することで直接的に獲得 する手法の2つが挙げられる.パラメータを徐々に更新していく学習法は,ニューラル
1.1. はじめに 第1. 序論
ネットワークなどのモデルを用いた場合はノード間の接続重みを更新していく手法など が挙げられ,Q 学習や Sarsa のような状態と行動の組み合わせによる期待値を示した ルックアップテーブルを用いて各テーブルの期待値を徐々に更新していく方法などが古 くから研究されている.しかしながら,ルックアップテーブルを用いた手法は,マルコ
フ性 (Markov Property) が保証されている環境でなければ学習が困難となり,実数値
(連続値)の状態・行動空間を取り扱うと不完全知覚を伴い非マルコフ性を発生してしま う.また,複数回の状態を遷移し目標とする状態となることを目指すマルチステップ問 題のような場合,必要とするパラメータの更新頻度が増大してしまい計算コストが高く なる.一方,パラメータを直接求める手法である直接政策探索法(Direct Policy Search:
DPS)[Moriarty 1999, Gomez et al. 1989, Hansen 2001, Igel 2003,宮崎 2007]と呼ばれ るアプローチは,ニューラルネットワークなどで表現されたモデルのパラメータそのもの を直接的に最適化する手法であり,表形式の価値関数を持つ必要がないため,実数値(連 続値)の問題にも適用可能であり,パラメータの更新が必要ない.
直接政策探索法は近年注目されている研究であり,モデルベースの手法とルールベース の手法に分けることができる.モデルベースの手法は政策表現にニューラルネットワーク や線形の関数モデルなどを使用し,モデルに設定したパラメータを最適化する.問題に合 わせて適切なモデルを使用することで高精度な解を得ることができるが,モデルの選択 において対象とする問題に関する深い知識を必要とする点が挙げられる.一方,ルール ベースの手法は政策表現にIF-THEN ルール(状態と行動の組み合わせで表される)の集 合を使用し,その組み合わせの最適化を行う.例えば,[土屋ほか,2005]や[宮崎 2007]
らの研究では,IF-THEN で表現されたルールの集合を遺伝的アルゴリズム (Genetic
Algorithms: GA)によって最適化することを試みた.この手法の利点は,問題の解決に必
要なIF-THENルールの獲得が可能であり,さらに,対象とする問題に関する深い知識を
必要としない実装の容易さが挙げられるため,広く応用が可能である.だが,実数値問題に おいて適切な政策を獲得するまでは試行時間を非常に多く必要としてしまう.特に,進化 計算を用いたアプローチによる政策の最適化は,確率的多点探索により環境とのインタラ クションの回数が多くなる傾向にある.これに対して,[Ikeda 2005]は,手本や模範といっ た事前知識として得られる正例のIF-THENルールとして表現されるexemplarを政策表 現に適用し,exemplarの集合の最適化により,効率的に信頼性の高い政策(exemplar集 合)を獲得することを可能とした.しかしながら,事前に得られる知識であるexemplarの 数が必要な分だけ用意できるとは限らず,また,exemplarが多すぎても有用なexemplar をのみを抽出する必要がある.そこで,本研究では,学習分類子システム (Learning Classifier Systems: LCSs)のルール生成と一般化のメカニズムを応用することに着目す る.LCSは環境との相互作用を通じて分類子(classifier)と呼ばれる条件-行動ルールを 学習し,一般化(generalization)されたルールを獲得する.分類子の学習はQ-学習のと同
第1. 序論 1.2. 研究目的
様の枠組みで実行されるが,さらに遺伝的アルゴリズムを用いてシステムが保持する分類 子の集合を進化させることにより分類子の条件部を一般化する能力を実現している.例と して,実数値の状態空間条件部の一般化を可能としたXCSRやXCSIが提案されている [Butz 2001, Butz 2006,和田ほか,2004, Wilson 2000].さらに,データマイニングに特 化した教師あり学習分類子システムぼUCS[Bernad´o 2002, Bernad´o 2003, Orriols 2005]
や関数近似を取り入れ拡張した XCSF[Lanzi et al. 2005a, Lanzi 2005b, Wilson 2002]
などが提案され数多く研究されている.このLCSのルール生成と一般化を応用し,適切
なexemplarの生成と一般化による抽出により上記の問題解決を図る.
1.2 研究目的
本研究では,手本となるデータである exemplar の生成と一般化に着目し,不必要
な exemplar(一部重複しているなど) を可能な限り削除することによって一般化され
たexemplar群を効率的に構築するシステムを設計し,その有効性を検証することを目
的とする.exemplar のような事前知識として導入された手本データの集合から,有用 なexemplarを抽出を可能とするExemplar に基づく学習分類子システム(Exemplar-
based LCS: ECS) を提案する.有効性の検証方法としては,実数値環境の問題は離散値
環境の問題と比べて現実世界の問題に多く,実数値環境下で最適な政策を獲得することは 非常に困難であるため,データ・マイニングなどが例として挙げられるシングルステップ 問題と,ロボットの制御問題などが例として挙げられるマルチステップ問題と呼ばれる大 きな2つの問題クラスにおいて,それぞれ実数値を扱う問題に焦点を当て,提案システム を評価する.
1.3 本論文の構成
本論文の構成は以下の通りである.2章では直接政策探索法(DPS)について説明する.
直接政策法とは,状態や状態-行動対の価値推定に基づいて政策を導出する価値関数手法 や,政策を表すモデルのパラメータ空間を最適化する手法などを用いて直接政策を探索す る手法であることを紹介するとともに,その種類や特徴について述べる.
3章では学習分類子システムについて説明する.まず,ミシガンアプローチ(Michigan approach) とピッツアプローチ(Pittsburgh approach) という 2種類のアプローチに分 類されている.その中でもミシガンアプローチで主流となっている評価値に正確性を取り 入れた正確性に基づく学習分類子システムであるXCSを説明し,更に,実数値に拡張し たXCSRとXCSI,教師あり学習分類子システムであるUCS,そして,関数近似を取り 入れたXCSFを順に紹介してする.
4章ではexemplarの一般化に着目し提案したexemplarに基づく学習分類子システム
1.3. 本論文の構成 第1. 序論
について説明する.まず固定の照合範囲を用いたECSと動的照合範囲型ECSについて 説明し,次に,データバランスを考慮したシグモイド関数を用いた照合範囲の更新方法 と,直接政策法を用いたルールの生成を導入したECSを説明する.
5 章では実数値を扱う問題について説明する.シングルステップ問題 (single-step problems)とはある入力群x = (x1, x2,· · · , xn)に対して出力yが一意的に決まった問題 (y =f(x1, x2,· · · , xn)の様な問題)である.シングルステップ問題としては,単純カー ゴレイアウト問題と偏りのある実数値データ集合を模擬したチェッカーボード問題を紹介 する.偏りがあるデータ集合では各入力に対する出力を学習する際に,学習頻度に差が生 じてしまい,正確な出力を予測することが困難となる性質を持ち,データマイニングの研 究においても需要な課題の1つである.次に,マルチステップ問題(multi-step problems) は,報酬という特別な入力を手がかりに環境に適応する機械学習の問題の一つであり,実 数値 (連続値)の状態や行動空間を扱う場合では不完全知覚により非マルコフ性となって 学習困難となる課題が存在する.
6章ではシングルステップ問題のシミュレーション実験の結果と考察について述べる.
まず,単純カーゴレイアウト問題を通して,exemplarの政策表現として,固定の範囲に よる照合方法と動的な照合範囲の2種類の照合方法に関して検証した結果と考察をする.
次に,偏りのあるデータ集合のチェッカーボード問題上で,幾つかのデータの偏り度合い によるECSの性能の検証をする.具体的には,事前知識である exemplar集合の中から 適切に領域を被覆するexemplarを抽出できているかについて,そして,新たにルールを 生成する手法による性能の検証をする.
7章ではマルチステップ問題のシミュレーション実験に関するの結果と実験から得た結 果についてそれぞれ議論する.具体的には,マウンテンカー問題を通して,マルチステッ プ問題上でも適切にexemplarの抽出が可能であるかを検証する.
最後の8章では,本研究に関する結論をまとめる.研究の総括と今後の課題について述 べる.
第 2. 直接政策探索法 5
第 2 章
直接政策探索法
2.1 概要
強化学習手法は自律エージェントの幅広い未知の環境に対し,有望なアプローチとして 知られている.政策は状態集合から行動集合への写像であり,図2.1に示すように,エー ジェントは政策を最適化させることで自身の行動を最適化する.
図2.1 エージェントの政策
マルコフ決定過程(Markov Decision Processes: MDPs)では,学習エージェントと環 境は以下に示すやり取りを行う.
1. エージェントは時刻tにおいて状態st を観測し,
2. 政策π に従って行動を出力する.
3. 環境は行動at に応じて状態をst からst+1 に遷移し,
4. エージェントは状態遷移に応じた報酬rt を得る.
5. 時刻tをt+1に進めてステップ1へ戻る.
強化学習手法の離散空間の MDPsにおける最適な政策への収束は証明されてる一方,
それらの結果を連続空間のMDPsへ変換するのは容易ではなく,状態-行動空間が大きく なるとより困難となり実問題への適用の課題に対して課題がある.特に,問題の状態-行 動空間の価値関数を表現するための関数近似手法があるが,価値関数の最適政策を表現で
2.2. モデルベース表現 第2. 直接政策探索法
きない場合,関数近似を用いたアルゴリズムによる性能は低下する.また,適切な政策を 学習するための十分な環境とのインタラクションを必要であり,状態を広くカバーする関 数近似が望まれる.サンプリングの効率と価値関数の表現の可読性にはトレードオフが 存在し,例えば,線形近似関数などを用いた政策表現はサンプリングの効率を向上させ るが,非線形の政策表現を必要とする問題に適用できない.直接政策探索手法(Direct Policy Search: DPS,以下DPS)[Moriarty 1999]は,状態や状態-行動対の価値推定 に基づいて政策を導出する価値関数手法や,政策を表すモデルのパラメータ空間を最適化 する手法などを用いて直接政策を探索する[Sutton 1998].関数近似を用いる手法は状態- 行動空間の価値関数の複雑さに影響を受け,DPSは政策自身の複雑さに影響を受ける.
例えば,MDPにおいて,比較的単純な政策を用いて表現できても状態-行動空間の価値関 数が複雑である場合,DPSは最適な政策を獲得するためのサンプリングに関して利点が ある.一方,関数近似手法は個々の状態 → 行動 → 報酬 → 次状態といった遷移に基づ いて学習するため,マルコフ性が満たされている限りにおいて,1エピソード内で得られ る情報を効率的に活用することが可能であるといった利点や欠点が存在する.直接政策手 法は表2.1のように分類される.
表2.1 DPSの表現法の種類
モデルベース ルールベース
政策 モデル ルール集合
特徴 モデルパラメータを探索 ルール集合を探索 利点 適切なモデルを用いると高性能 必要なルールを獲得可能 欠点 モデル選定において対象問題 ルールの有効範囲が不明
に関する深い知識が必要 (近傍を使うことで暗に一般化)
2.2 モデルベース表現
2.2.1 政策表現の重みを最適化する DPS
Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES)[Hansen 2001, Igel 2003] や Cooperative Synapse Neuroevolution(CoSyNe)[Gomez et al. 1989] は ニューラルネットワークを使って政策を表現しネットワークの重みを最適化するアルゴリ ズムである.図2.2はCoSyNeの概要図である.CoSyNeはニューラルネットワークの 重みと対応する各遺伝子をもつ各母集団(図2.2では 6つの母集団)を進化計算手法によ り最適化させ,問題に対して適切に出力する重みが最適化されたニューラルネットワーク を形成することが目的となる.
第2. 直接政策探索法 2.2. モデルベース表現
図2.2 CoSyNeの概要[Gomez et al. 1989]
2.2.2 政策表現とその重みの両方を最適化する DPS
NeuroEvolution of Augmenting Topologies(NEAT)[Stanley 2002] や Evolutionary Acquisition of Neural Topologies (EANT)[Kassahun 2006]のようなニューラルネット ワークの結合と重みを学習するアルゴリズムは重みだけではなく政策表現モデルも最適化 される.例えば,NEATはニューラルネットワークのトポロジー(ノード間の接続形態) とノード間の接続の重みの両方を最適化する手法である.つまり,NEATは図2.2.2のよ うに,進化計算に適用される遺伝子はノードとノード間の接続で構成されており,その ノード接続を表す各遺伝子座に対してはノード間の接続の重みも付加された形式を取る.
図2.3 NEATにおける遺伝子の表現の概要[Stanley 2002]
Gomez らによって,幾つかの種類の関数モデルを用いた DPS(CoSyNe, CMA-ES,
NEAT)とSarsaやAdaptive Heuristic CriticのらのTD学習法[Sutton 1998]と比較検
2.3. ルールベースの政策表現 第2. 直接政策探索法
証した報告がされている[Gomez et al. 1989].それによると,ベンチマーク問題のポー ルバランス問題上では,連続値の状態-行動空間の領域が価値関数の表現を困難にしてし まいマルコフ性を侵してしまうため,TD学習法では学習が困難となり,DPSはTD学 習法に比べて有効であるという報告がされている.Heidrich-MeinsnerとIgelはDPSで あるCMA-ESとニューラルアクタークリティック(Neural Actor Critic: NAC)をノイ ズを含むマウンテンカー問題と二重倒立振子問題を通して比較検証した結果,CMA-ES はノイズや任意に設定したハイパーパラメータの調整,そして,政策の初期化の設定に対 し頑健な性能を示す一方,NACは問題に対してハイパーパラメータや初期化の設定につ いて慎重に設定する必要があると報告されている.また,CMA-ESが優れているのは,
分散して探索する適応メカニズムやランク形式による政策の評価方法を用いているためだ とも主張されている.
2.3 ルールベースの政策表現
政策の表現には,Q 値テーブルを用いた表現,ニューラルネットワークを用いた表現,
メモリーベースの表現[土屋ほか,2005]などがある.メモリーベースの表現は,状態行動 空間中の代表点の集合によって表現する方法であり,可読性の高いことが特徴である.そ のため,事前知識の直接的な導入ができる,最適化後の政策から直接的に知識を導入でき るという利点がある.さらに,モジュール性が高く,政策の構成要素を部分的に交換でき るため,進化計算を適用する場合に進化オペレータを設計しやすいという利点ができる.
メモリーベース政策表現には,Instance based,Exemplar based,Case basedなど 様々な呼び方があり,定義は研究者によって様々である.DPSは政策表現モデルの選択 が重要であり,例えば,単一のニューラルネットを使用するにはタスクごとに特別な工夫 が必要となり,政策表現モデルをタスクごとに設計する事は好ましくない.DPSの別な 政策表現モデルとして,インスタンスベース政策(Instance-Based Policy: IBP,以 下IBP)またはexemplarベース政策(Exempar-Based Policy: EBP,以下EBP)
がある [Ikeda 2005].インスタンスベース政策は,図2.4のように,点の位置が状態を,
矢印が行動を表したこの組がインスタンスに対応しており,それらの集合を政策パラメー タとみなして政策を表現する.
本稿では手本として導入される状態行動対をexemplar と呼び,その集合によって表 現される政策を exemplarベース政策と呼ぶことにする.これは,後述のように本研究 で扱う状態行動対が事前に導入される知識として信頼のあるものとしてを扱うからであ る.言い換えると、模範となる状態行動対で政策を表現するということである.政策は
exemplar 集合と行動選択器によって表現される.exemplarは任意の状態と行動からな
る状態行動対によって表され, 状態では行動を実行する という意味を持つ.行動選択
第2. 直接政策探索法 2.3. ルールベースの政策表現
器はexemplar集合から観測状態と最も近いexemplarを選択しそのexemplarの行動を 出力する.このようにして表現される政策は,状態空間を分割し,各領域に行動をラベ ル付けしたものと等価となる.ルールを用いた政策とexemplarを用いた政策を比較した 際,表2.2のように表すことができる.具体的に,ルールを用いた政策は最適化手法によ るルール群の構築により,必要なルールの獲得が可能であるが,0からルール群を構築す るため計算コストが高い.一方でexemplarを用いた政策は,既にある事前知識を手本と して活用することにより,効率的に信頼性の高い政策を獲得することが可能となり利点と して挙げられる.
表2.2 ルールベース表現の比較
政策 ルールを用いた政策の獲得 exemplar(手本)を用いた政策の獲得 rule-based policy exemplar-based policy 特徴 最適化手法によるルール群の構築 事前知識として導入可能
必要なルールを獲得可能 効率的に信頼性の高い政策の獲得 0からルール群を構築するため
計算コストが高い
図2.4 インスタンスベース政策の例
2.4. 政策の一般化 第2. 直接政策探索法
2.4 政策の一般化
直接政策探索法の現実世界の問題への適用を考慮した場合,exemplarに基づく政策表 現を用いて,図2.4のように綺麗に領域を区切ることができるとは限らない.なぜなら,
現実世界の問題の多くは実数値を扱うため,領域は実数値の桁数分だけ分割することがで き,さらには問題の制約条件によっては領域が細かく複雑になるため緻密に最適な政策の 獲得は状態爆発を起こしてしまい非常に困難である.
これに対して学習分類子システム(Learning Classifier System)の持つルールの一般化 能力を,組み合わせることで入力状態に対して正例であるexemplar[土屋ほか,2005]を
活用し各exemplarが活用できる範囲を見極めることで少ないルール数で状態数が多い問
題空間をカバーするシステムの設計を目指す.
Exemplarの一般化 図2.5はECSによる一般化のイメージ図であり,各印(○や△等)は exemplarを表し,印の違いはexemplarのもつ行動の違いを表す.図2.5の左図は 事前知識として入力されたexemplar集合であり,右図のように有用なexemplar を抽出することによって一般化する(少ないexemplarで全体をカバーする).
図2.5 ECSの一般化のイメージ
本研究で提案するシステムとDPSのクラスと比較すると,DPSと大きく異る点 として,(1)提案システムは手本データをそのまま扱い,手本データ自体の有効性 を推定し手本データと生成した政策(if-thenルール)の両方を活用しているという
点,(2)DPSは暗に一般化が進められるが,提案システムは陽に一般化が進められ
るという点がそれぞれ挙げられる.
よってDPSと比較した本研究の位置づけとしては,表2.3のように表すことがで きる.
本研究の提案システムは学習分類子システムを基本とし,一般化のメカニズムを利
第2. 直接政策探索法 2.4. 政策の一般化
表2.3 本研究の位置づけ
直接政策探索法 本研究(Exemplar-Based Classifier System)
· パラメータで表現された政策のみを活用 ·手本データと生成した政策両方を活用
· 暗に一般化 ·陽に一般化
用する設計となっているため,次の章では学習分類システムについて説明する.
第 3 章
学習分類子システム
3.1 概要
学習分類子システム [Goldberg 1989, Holland 1978] には様々な種類があり,強度 値に基づく学習分類子システム (Zeroth level Classifier System: ZCS)[Wilson 1994]
や ,現 在 主 流 と な っ て い る 分 類 子 の 適 応 度 に 正 確 さ の 概 念 を 取 り 入 れ た正 確 性 に 基 づ く 学 習 分 類 子 シ ス テ ム (accuracy based Learning Classifier System:
XCS)[Butz 2001, Butz 2006, 和田ほか,2004, Wilson 1995] な ど が あ る .XCS は 正 確 か つ 適 切 に 一 般 化 さ れ た 分 類 子 を 学 習 す る 能 力 を 持 つ こ と が 示 さ れ て い る [Kovacs 1996, Wilson 1998].また,XCSから派生した関数近似を取り入れた関数近似 型学習分類子システム(XCSF)[Lanzi et al. 2005a, Lanzi 2005b, Wilson 2002] やデー タマイニングに特化させた教師あり学習分類子システム(sUpervised Classifier System:
UCS)[Bernad´o 2002, Bernad´o 2003]などが提案されている.
なお,XCSについては今後本研究との比較を行っていく必要がある.そこで,XCSは LCSのアーキテクチャの基本的な部分を備えており,また上述にある理由からもここで はXCSを基本とした学習分類子システムについて紹介させていただく.
3.2 正確性に基づく学習分類子システム
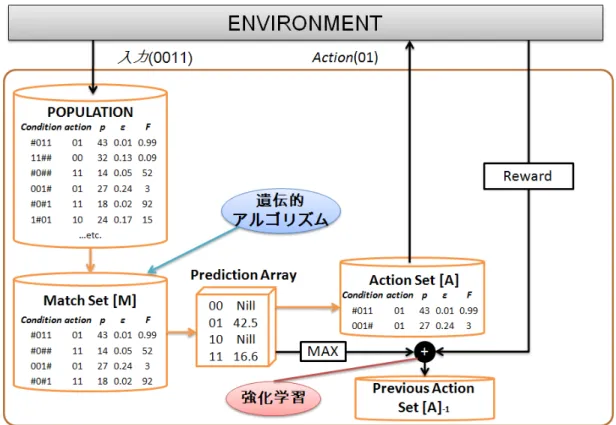
XCSは図 3.1に示すとおり,環境からの入力である状態(state)に対して適切な行動
(action) を実行することで環境から得られる報酬 (reward)の合計を増大するよう学習
する.以下,この過程を次の手順で説明する.はじめにXCS における分類子の形式を 示し,次にXCSの学習過程を構成する(1)実行部(performance component),(2)
強化部(reinforcement component),(3)発見部(discovery component)を順に説明す る.最後にXCS における分類子条件部の一般化を効率的に行うための拡張である包摂
(subsumption)について説明する.XCSではこれらの学習過程が実現される.
第3. 学習分類子システム 3.2. 正確性に基づく学習分類子システム
図3.1 XCSのアーキテクチャの概要
3.2.1 メモリ部
分類子
XCS における分類子は条件部と行動部の対に XCS 固有の属性である予測値
(prediction),誤差値(eroor),そして適応度値(fitness)の3つを加えた形式を とる.さらにXCSでは数多くの分類子を効率的に扱うために条件部と行動部とも に等しい分類子の集合をマクロ分類子(macro-classifier)として縮約する.マクロ 分類子に含まれる分類子の数を重合度(numerosity)という.XCSはパラメータN を分類子の上限として保持する.以下,分類子cliの予測値,誤差値,適応度値,重 合度をそれぞれ,pi,ϵi,Fi,numi と記す.
3.2.2 メカニズム
実行部
実行部は分類子集団を参照することで状態に対して適切な行動を選択し出力する 過程を担う.この過程を図3.1を用いて説明する.はじめに環境から状態が入力さ れると,図3.1における[P]で表される分類子集団の各分類子に対して条件部と状
3.2. 正確性に基づく学習分類子システム 第3. 学習分類子システム
態との照合(match)が実行される.照合に成功した分類子は図 3.2における[M]
で表される照合集合(match set)を形成する.なお,分類子集団に状態と照合す る分類子が存在しない場合には入力状態に照合する分類子を新たに生成する被覆
(Covering)と呼ばれる操作が実行される.照合集合中の分類子行動部には複数の
行動が含まれる場合があるので競合を解消するために候補となる各行動に対する利 益(payoff)を連ねた予測配列(prediction array)が計算される.予測配列におけ る各行動ai の予測値P(ai)は以下の式で定義される.
P(ai) =
∑
clk∈|M|aipk×Fk
∑
clk∈|M|aiFk
(3.1) 上記の式(3.1)に基づいて行動選択(action selection)が行われた後,照合集合中 で選択された行動を行動部に持つ分類子により図3.1における[A]で表される行動
集合(action set)が形成される.そして,選択された行動が実行されることによ
り実行部における一連の処理が完了する.この処理単位をステップと呼ぶ.
強化部
強化部は各ステップにおける実行部の処理が完了した後に環境から得られた報酬 に基づいて行動集合として選択された分類子の適応度を更新する(update).この 過程は図3.1において[A]−1 で表される1ステップ前の行動集合(previous action set)に含まれる各分類子 clj に対して更新規則適用することで実現される.なお,
左矢印は左辺への代入を意味する.
P ←r+γmax
a P(a) (3.2)
pj ←pj+β(P −pj) (3.3) ϵj ←ϵj+β(|P −pj| −ϵj) (3.4) ここで,P は予測値pj を更新する際の目標値であり 前ステップの報酬rと予測 配列中の最大値maxaP(a)を用いて計算される.図3.1における[A]−1 へ向かう 矢印はこの操作を図式的に表わしている.パラメータβ(0≤β ≤1),γ(0≤γ ≤1) は学習率(learning rate)および割引率(discount factor)と呼ばれ,それぞれ学 習の柔軟性と将来の報酬を考慮する度合を制御する.そして,次式に示すように更 新後の誤差値ϵj に基づき分類子の絶対的な正確さ κj と[A]−1 における相対的な 正確さκ′j が順に計算され最後に適応度Fj が更新されることで強化部における一 連の処理が完了する.ここで,Fj の計算に正確さκj を用いる点が,正確さに基づ く学習分類子システムとしてのXCSの際立った特徴である.
第3. 学習分類子システム 3.2. 正確性に基づく学習分類子システム
κj = {
1 if ϵj ≤ϵ0
α(ϵj/ϵ0)−ν otherwise (3.5)
κ′j = (κj ×numj)
∑
clk∈|A|−1(κk×numk) (3.6) Fj ←Fj+β(κ′j−Fj) (3.7) ここで,ϵ0 およびν は誤差ϵj から絶対的な正確さκj を計算する際のパラメータ であり問題に応じて適切に設定される必要がある.
発見部
発見部では,GAを用いた分類子の生成と削除を通して実行部と強化部で用い られる分類子集団[P]を進化させる.XCSにおけるGAは前ステップの行動集合 [A]−1の各分類子の前回のGA発動から経過したステップ数の平均パラメータθGA
の値を上回る場合に発動される.GAが発動すると,[A]−1の各分類子の適応度の 比率を選択確率として2つの分類子が親個体として選択される.そして,親個体に 対してGAの基本的な演算である交叉および突然変異がそれぞれパラメータχ ,µ の確率で適用される.生成された2つの子個体は分類子集団に追加され,GAの一 連の処理が完了する.なお,分類子集団中の分類子の数がパラメータN を超えた 場合はNを超えた数の分類子が削除される.
包摂
包摂とは分類子集団の中である分類子と同じ行動部を持ち,かつ,より一般化さ れた条件部をもつ分類子が存在した場合に前者を後者に統合することで分類子集団 における分類子条件部の適切な一般化を促進する操作である.2つの分類子間でど ちらの条件部がより一般化されているかの判断は一般性比較演算(is-more-general
operator)として定義され,分類子を比較する際に用いられる.マクロ分類子が条
件部と行動部が共に等しい分類子集合を束ねる表現であるのに対して包摂は本来異 なる条件部をもつ2つの分類子に対して一方の条件部を他方の条件部へと変更する 操作であり,結果として分類子集合のマクロ分類子の数の減少に寄与する.
3.2.3 シーケンス
XCSの一連のシーケンスについて図3.2を用いて説明する.
照合
環境からの入力状態に対して[P]の中から照合条件を満たすルールを探索
3.2. 正確性に基づく学習分類子システム 第3. 学習分類子システム
図3.2 XCSのシーケンス
被覆発動条件
照合条件を満たすルールで[M]を形成
照合条件を満たすルールが[P]に存在しない場合,被覆へ 行動選択
[M]にあるルールの中から行動選択手法にしたがって,行動を選択し[A]を形成 適応度更新
[A]にあるルールの適応度を獲得した報酬を用いて更新
GA発動条件
GA発動条件を満たさない場合,包摂発動条件へ
GA発動条件を満たす場合,発見部で新たなルールを生成 包摂発動条件
包摂発動条件を満たさない場合,削除発動条件へ
第3. 学習分類子システム 3.3. 実数値分類子表現型XCS
包摂発動条件を満たす場合,包摂を発動 削除発動条件
削除発動条件を満たさない場合,1ステップ終了 削除発動条件を満たす場合,削除を発動
1ステップ終了
以上がXCSの学習過程の1ステップとなる.尚,XCSでは探索段階(exploration)と評
価段階(exploitation)の2つの段階に分かれている.探索段階では行動選択にランダム
性が混じるため,均一にルールの適応度を見積もる機会が与えられる.一方,評価段階で は入力状態に対して最良と判断されるルールが選択され実行される.加えて,評価段階で は,被覆,適応度の更新,発見部,削除,そして包摂を停止する.
3.3 実数値分類子表現型 XCS
実数値分類子表現型XCSでは実数値をビット列に変換することなく直接扱うために分 類子の条件部を区間述語と呼ばれる要素の組み合わせとして表現しているため,分類子条 件部に関連する(1)被覆,(2)突然変異,(3)交叉,そして(4)包摂の4つの分類子操作に 関しても再定義される.ここではこれらの拡張部分をまとめて分類子表現と呼ぶことにす る.実数値分類子表現には,同じ区間の表現方法でもXCSRとXCSIと呼ばれる2つの 異なる表現方法を用いた手法がある.XCSR における分類子表現は後に詳述するように 区間述語が表す実数値の区間を中央値(center value)及び散布度(spread value)と呼ばれ る属性の組みを用いて指定する.一方,整数値の区間を直接扱うためにXCSIは,分類子 表現においてXCSRと同じく区間に基づく分類子条件部を採用しているにもかかわらず 区間述語の表す整数値の区間は下限値(lower value)及び上限値(upper value)と呼ばれ る属性の組で指定されており,関連する分類子の設計も異なる.このように同じ区間に基 づく分類子表現においても異なる設計指針が存在し,これらは共に実数値分類子表現とし て実現できる.この章ではXCSRとXCSIにおける分類子表現について説明する.なお,
本論文ではXCSRの分類子表現をCS表現,XCSIの分類子表現をLU表現と呼ぶ.
3.3.1 CS 表現を用いた XCSR
ここでは,CS表現の詳細を分類子条件部,被覆,突然変異,交叉,そして一般性比較 演算の順に記述する.
条件部の表現
CS表現分類子条件部は区間述語と呼ばれる要素の入力状態の次元数個から構成さ れている.ここでi番目の区間述語は中央値と散布度の組み(ci, si)からなり,数
3.3. 実数値分類子表現型XCS 第3. 学習分類子システム
直線上の区間[ci−si, ci+si)を指定する.この分類子表現においてn次元実数値 ベクトルである入力状態⃗x = (x1, x2,· · · , xn)に対する分類子の照合は次のように 定義される.全ての入力状態の要素xi について対応する区間述語(ci, si)の表す範 囲にxiが含まれているか,つまり,条件ci−si ≤xi, xi < ci+si を満たす場合に 限り,分類子は入力状態と照合する.このように入力状態の各要素の照合を判断す る区間述語の表す区間のことを照合区間と呼ぶ.ここで,(ci, si)の各値は[0,1)の 範囲に設定されるが,この制限はCS表現の必要条件ではない.
被覆
CS表現における被覆ではn次元の入力状態を⃗x= (x1, x2,· · · , xn)とすると,生 成される分類子の各区間述語がi番目の入力状態の要素および区間述語の属性の関 係を表した次式で定義される.
{
ci =xi
si =rand(s0). (3.8)
ここで,rand(a)は区間[0, a]の一様乱数を与える関数であり,s0 は分布度 si の 上限を指定するパラメータである.パラメータs0 は(0,1]の範囲に設定されるが,
この制限はCS表現の必要条件ではない.
突然変異
CS表現における突然変異では分類子の全ての区間述語の各属性値に対して,パラ メータµで指定された確率で変異が発生する.変異がi番目の区間述語の中央値 ciに発生した場合,ciに次式で定義される変量∆ci が加えられる.
∆ci =±rand(m) (3.9)
変異がi番目の区間述語の散布度si に発生した場合はsi に次式で定義される変量
∆si が加えられる.
∆si =±rand(m) (3.10)
ここで,±rand(a)は区間[−a, a]の一様乱数を与える関数であり,mは変量 ∆ci
および,∆si の絶対値の上限を指定するパラメータである.パラメータmは(0,1]
の範囲に設定されるが,この制限はCS表現の必要条件ではない.
交叉
交叉は,GAが発動された際にパラメータχで指定された確率で実行され,CS表 現では選択された各分類子対についてすべての区間述語の各属性を線上に並べて同 一の要素同士を組み替えることにより新たに2つの分類子対を生成する.この際の 要素の組み換えの仕方による様々な交叉手法が存在する.
第3. 学習分類子システム 3.3. 実数値分類子表現型XCS
一般性比較演算
CS表現では,実数値分類子表現に対応した一般性比較演算を定義する.実数値分 類子表現では区間述語が数直線上の入力と照合する区間を表す.よって,比較すべ き2つの分類子において対応する区間述語が表す区間同士の包含関係を調べること で,上述の役割を実現できる.具体的には分類子X 及びY のi番目の区間述語を (ci, si)および,(c′i, s′i)とおいた場合,全ての区間述語について(ci−si)≤(c′i−s′i) 且つ,(c′i+s′i)≤ (ci+si)が成り立つ場合に限り分類子X はY より一般的であ ると定義する.ただし,全ての区間述語について(ci =c′i)且つ,(si =s′i)の場合 は除く.
3.3.2 LU 表現を用いた XCSI
ここでは,CS表現の詳細を分類子条件部,被覆,突然変異,交叉,そして一般性比較 演算の順に記述する.
条件部の表現
LU表現の分類子条件部はCS表現と同様に入力状態の次元数と同数の区間述語に より構成されるが,その区間述語においてCS表現と異なり下限値と上限値の組み を用いる.ここで,i番目の区間述語は下限値と上限値の組(li, ui)で表され,その 照合区間は[li, ui)を指定する.分類子の照合に関してはCS表現と同様n次元の 実数値入力状態⃗x = (x1, x2,· · ·, xn)に対して,全ての要素xi が対応する区間述 語(li, ui)の照合区間に含まれる場合,すなわちli ≤xi < ui が成り立つ場合に限 り分類子は入力状態と照合する.ここで,(li, ui)の各値は[0,1]の範囲に設定され るがこの制限はLU表現の必要条件ではない.
被覆
LU表現における被覆は,n次元の入力状態⃗x= (x1, x2,· · · , xn),生成される分類 子のi番目の区間述語を(li, ui)とおくと入力状態の要素および区間述語の属性の 関係を表した次式で定義される.
{
li =xi−rand(s0)
ui =xi+rand(s0). (3.11) ここで,s0 は被覆にとって生成される分類子の下限値と上限値を設定する際に生 成される乱数の範囲を指定するパラメータである.パラメータs0 は(0,1]の範囲 に設定されるがこの制限はLU表現の必要条件ではない.また,被覆により下限値 と上限値が0≤li ≤ui ≤1で示す範囲を超える値に設定された場合は次の手順に 従って修正される.もし,li <0ならばliを0に設定し,また,1< uiならば,ui
3.3. 実数値分類子表現型XCS 第3. 学習分類子システム
を1に設定する.
突然変異
LU表現における突然変異ではCS表現の場合と同様に分類子の全ての区間述語の 各属性値に対してパラメータµで指定された確率で変異が発生する.ただし,変異 がi番目の区間述語の下限値li に発生した場合liに次式で定義される変量∆li が 加えられる.
∆li =±rand(m) (3.12)
変異がi番目の区間述語の上限値ui に発生した場合はui に次式で定義される変量
∆ui が加えられる.
∆ui =±rand(m) (3.13)
ここで,mは変量∆li および,∆ui の絶対値の上限を指定するパラメータである.
パラメータmは(0,1]の範囲に設定されるが,この制限はLU表現の必要条件で はない.この操作により変量∆li および,∆uiが加えられた結果として下限値と上 限値が0≤li ≤ui ≤1で示す範囲を超える値に設定された場合は次の手順に従っ て修正される.(1)もし変異後のliが負ならば,li を0に設定する.(2)もし変異 後のli がuiより大きいなら,liをui に設定する.(3)もし変異後のui がli より 小さいなら,ui をli に設定する.(4)もし,ui が1よりも大きいならばuiを1に 設定する.
交叉
LU表現における交叉はGAが発動された際にパラメータχで指定された確率で 実行され,区間述語の属性が中央値と散布度ではなく下限値と上限値であることを 除いてCS表現と同様に定義される.
一般性比較演算
LU表現における一般性比較演算はCS表現の場合と同様に区間述語の表す照合区 間同士の包含関係により定義される.すなわち,分類子X及びY のi番目の区間 述語を(li, ui)および,(li′, u′i)とおいた場合,全ての区間述語について li ≤ l′i 且 つ,u′i ≤ ui が成り立つ場合に限り分類子X はY より一般的であると定義する.
ただし,全ての区間述語について(li =l′i)且つ,(ui =u′i)の場合は除く.
第3. 学習分類子システム 3.4. 教師あり学習に基づく学習分類子システム
3.4 教師あり学習に基づく学習分類子システム 3.4.1 概要
教師あり学習分類子システム (sUpervised Classifier System: UCS) は XCS から 派生した学習分類子システムであり,教師あり学習問題に特化した設計となっている [Bernad´o 2002, Bernad´o 2003].
3.4.2 分類子の表現
UCS は個体の母集団 [P] を進化させる.UCS における各分類子は条件部とクラス のペアで構成され,分類子 cli には,パラメータとして正確性 (Accuracy)acci,評価 値 (Fitness)Fi,入力に照合した回数として経験値 (experience)expi,正しく分類でき た回数として正答数 (Correct Track)cti,ニッチセットサイズ (Niche Set Size)nsi, GAが最後に実行されて経過した時間であるタイムスタンプ(Time Stamp)tsi,重合度 (Numerosity)numiを加えた形式で構成されている.
3.4.3 実行部
UCS は教師あり学習の仕組みによって徐々に学習する.訓練データの中から x = (x1, x2,· · · , xn)で表される要素集合とクラスcで構成されている入力事例に照合する分 類子によって照合集合[M]を形成する.[M]からクラスcを正しく予測できた分類子らで 正例集合[C]を形成する.もし,[C]が空だった場合,被覆によって入力事例の各要素に 照合可能な新しい分類子を生成する.そして,分類子のパラメータを順々に更新し,GA が実行される.学習した分類子の性能を評価するテストでは,テストデータの中から入力 xが与えられ,UCSは関連するクラスを予測する.照合した各分類子の評価値の合計を 用いて,最も値の大きいクラスを入力xに対するクラスとして出力する.テストにおいて UCSはパラメータの更新及び,GAは実行されない.
3.4.4 パラメータの更新
照合に成功した[M]を構成する各分類子cliは,経験値expiを+1追加し,次に,入力 に対して正しいクラスを持つ分類子で構成された[C]における各分類子cli はcti を+1 追加する.そして,[M]にある各分類子cliは以下の式を用いて正確性acciを計算する.
acci = cti expi
(3.14)