音声言語の研究と今後の展開
奈良先端科学技術大学院大学
データ駆動型サイエンス創造センター長
先端科学技術研究科 教授
(RIKEN AIP 観光情報解析チーム)
中村
哲
with
須藤克仁、Sakriani Sakti、吉野幸一郎、田中宏季、Graham Neubig,
Do Quoc Truong, 叶
高朋、Andros Tjandra, 帖佐克己
話し言葉とコミュニケーション
o 書き言葉
o 記録、保存、時代を超えた伝承が目的
o 時間をかけて推敲し文を作成
o 高圧縮、文法的
o 時間をかけて読解
o わかるまで読み返す
o 話し言葉
o その場でのコミュニケーション、意図伝達が目的
o リアルタイムで発話を生成
o 低圧縮、非文法的、文脈依存、冗長語、不完全
o マルチモーダル、パラ言語(韻律、個人性、強調、感情)
o リアルタイムに発話を理解
o 文脈、パラ言語、マルチモーダル情報の利用
o Mutual Grounding の構築と利用
奈良先端大における研究
C
要素技術を統合し、コミュニケーション
支援技術について研究
音声同時通訳
ニューラル機械翻訳
脳計測音声対話
マルチモーダル対話
中村研に 入りませんか? 研究室を探し ています?知識獲得
QAシステム
マルチモーダル
多言語音声認識
音声合成
Deep Speech Chain
ディープニューラル
ネットワーク
アフェクティブコンピューティング
感情、パラ言語処理
認知症早期検出
コミュニケーション支援対話
コミュニケーション
支援技術の研究
話し言葉の音声・言語処理
WEB
情報処理
目的指向対話
チャット対話
違和感検出
感情検出
内容
1. 音声認識、音声合成と統合最適化
2. 音声翻訳の統合最適化
3. 音声翻訳の同時性
4. パラ言語の取り扱い
1.
音声翻訳
2.
音声表現とテキスト表現の等価性
3.
発話顔 音声画像翻訳
5. 課題と今後の展開
6. まとめ
内容
1. 音声認識、音声合成と統合最適化
2. 音声翻訳の統合最適化
3. 音声翻訳の同時性
4. パラ言語の取り扱い
1.
音声翻訳
2.
音声表現とテキスト表現の等価性
3.
発話顔 音声画像翻訳
5. 課題と今後の展開
6. まとめ
最近の音声認識の進歩
o これまでの経緯
o テンプレートマッチング、動的計画法 [Sakoe 71]
o 隠れマルコフモデル、N-Gramモデル [Mercer 83, etc]
o ニューラルネットワーク、TDNN[Waibel 89], LSTM [Hochreiter 97]
o Weighted Finite State Transducer [Mohri 2006]
o 大量のデータの収集、試行サービスによるデータ収集
o 深層学習による最近の進化
o DNN-HMM [Hinton 2012]
o DNN により状態の事後確率を直接推定する
o Connectionist Temporal Classification [Graves 2013]
o フレーム毎に音素ラベルを出力する
o Listen, Attend, and Spell [Chan 2016]
最近の音声合成の進歩
o フォルマント合成、素片合成
o 確率モデルベース音声合成:HTS
o HMMフレームワークによる音声合成
o Tokuda, et al., “Speech parameter generation algorithms for HMM-based speech synthesis”, ICASSP
2000
o WaveNet
o 時系列信号に対し、畳み込みを行うNNにより波形生成
o van den Oord et al., “WAVENET: A GENERATIVE MODEL FOR RAW AUDIO”,
arXiv:1609.03499v2 [cs.SD] 19 Sep 2016
o Tacotron
o 文字入力でスペクトログラムを生成、その後、Griffin-Lim法で波形生成
o Wang, et al., “TACOTRON: TOWARDS END-TO-END SPEECH SYNTHESIS”,
arXiv:1703.10135v2 [cs.CL] 6 Apr 2017
①Machine speech chain の構成
a. Machine speech chain の構成
b. ASR から TTS
c. TTSからASR
A.Tjandra,et al., “Listening while Speaking: Speech Chain by Deep Learning“ , arXiv:1707.04879, 2017
Accepted for IEEE ASRU 2017
ASRの基本構造
TTSの基本構造
Reference : Chan et al (2015), Listen Attend Spell
Reference : Wang et al (2017), Tacotron
Encoder with BiLSTM & sequence subsampling
Decoder with LSTM & attention module
Modified Tacotron with additional speaker
embedding + frame ending binary prediction
①Speech Chain のアルゴリズム
o Speech とTextのペアデータと、Speech only, Text onlyのペアでないデータを用意
o Supervised training :
o それぞれ、ASRとTTSの生成誤差をペアデータで計算
o Unsupervised training :
o ペアでないデータに対し、ASRに関してはTTSを用いて音声を生成、TTSに対してはASRを用いてテ
キストを生成
o 生成誤差(音声の誤差、テキストの誤差)を計算
o 2種類の生成誤差を組み合わせ、ASRとTTSのパラメータの勾配計算
機械翻訳の進歩
o ルールベース:
言語学者、言語学の知識のある作業者がルールを注意して作成
o コーパスベース:
o 用例ベース (Example-Based)ルールを自動的にコーパスから抽出
[M.Nagao84, Sato et al.,89, Sumita et al., 91 ]
o 統計ベース翻訳 (Statistical Machine Translation) さらに、ルールが頻出するかの確率を学習。Noisy
Channel Model [P.F.Brown, et al. 93]
o Phrase-base SMT
単語レベルでなくフレーズという単位を導入。
o Tree-to-string
o 構文構造の関係を学習する統計的機械翻訳
o Neural Machine Translation
o LSTMによるEncoder と Decoderを組み合わせ、翻訳文を生成する
o Attention NMT
o 原言語の単語列のEncoder出力に重みを加えてDecoderにいれることでアライメントをImplicitに学習する
内容
1. 音声認識、音声合成と統合最適化
2. 音声翻訳の統合最適化
3. 音声翻訳の同時性
4. パラ言語の取り扱い
1.
音声翻訳
2.
音声表現とテキスト表現の等価性
3.
発話顔 音声画像翻訳
5. 課題と今後の展開
6. まとめ
(おまけ)我が国の音声翻訳プロジェクトの流れ
情報処理学会 NL研 Copyright@2019 中村 哲@NAIST読み上げ文を
音声翻訳
• 文法的な表現 • 明瞭な発声 国際会議申込み」日常の話し言葉
を音声翻訳
• 標準的な表現 • 明瞭な発声 • 限定された話題 「ホテル予約」広い話題に適応
• 広い話題での表現 (日常旅行会話) • 雑音を含む音声 • 日英+日中1986
1992
2000
2006
要素技術
ルールベース
人手作業
大規模コーパス
+ 機械学習
2008
A-STAR
内閣府社会
還元加速PJ
• 8アジア言語 •ネットワーク型音声翻訳2010
C-STAR
• 音声翻訳国際共同研究コンソーシアムIWSLT
• 音声翻訳性能評価ワークショップ2011
VoiceTra
NAIST
2014
U-STAR
NICT
GC PJ
NICT
ATR
・2007年 11月開始Deep Learningによる直接音声翻訳
o 音声入力、翻訳出力をEnd-to-endで学習できないか?
o Attention LSTMを用いたEnd-to-end 音声翻訳*
Bi-directional
LSTM Encoder
Attention
LSTM decoder
Acoustic
features
Target
words
*Alexandre Berard et. al “Listen and Translate: A Proof of Concept for End-to-End Speech-to-Text Translation” ,
NIPS workshop 2016
Curriculum Learningを用いたEnd-to-end 音声翻訳
Phase 1
ASR
Bi-LSTM Encoder LSTM Decoder AttentionMT
LSTM Decoder Attention Bi-LSTM EncoderASR + MT
Bi-LSTM Encoder LSTM Decoder AttentionPhase 2
ASR
Bi-LSTM Encoder LSTM Transcoder Attention Bi-LSTM EncoderPhase 3
LSTM Transcoder Attention LSTM DecoderASR + MT
Slow track
Fast
track
Attentional-based LSTMをASR,MT用に学習しておき、逐次End-to-end音声翻訳
にカリキュラム学習する
叶 高朋,サクリアニ サクティ,中村 哲, “カリキュラムラーニングを用いた日英直接翻訳システ
ムの提案”、音響講論 2-10-5
Curriculum Learningによる音声翻訳結果
コミュニケーションとしての音声翻訳を考えよう
入力
テキスト
音声
画像
ジェスチャ
音声⇒テキスト 音声認識同時
翻訳
変換
対話制御
言語情報
非言語情報 感情・スタイル 声質・韻律 ジェスチャ言語情報
非言語情報 感情・スタイル 声質・韻律 ジェスチャ出力
テキスト
音声
画像
ジェスチャ
原言語 目的言語 音声信号 “to o kyo e i ku”機械翻訳結果 /I/go/to/Tokyo/ 音声合成結果 “ai go tu tokyo/ 声質、韻律 声質、韻律
談話構造
文脈
ドメイン知識
オントロジ
テキスト 画像⇒テキスト 画像認識 テキスト テキスト⇒音声 音声合成 テキスト⇒画像 画像合成電子情報通信学会誌2015,改
End-to-end で学習
コミュニケーションにおける
① 逐次性,同時性
② パラ言語情報
内容
1. 音声認識、音声合成と統合最適化
2. 音声翻訳の統合最適化
3. 音声翻訳の同時性
4. パラ言語の取り扱い
1.
音声翻訳
2.
音声表現とテキスト表現の等価性
3.
発話顔 音声画像翻訳
5. 課題と今後の展開
6. まとめ
①同時性
o 同時通訳:
o 音声認識と平行に文解析,並び替えを考慮ながら翻訳,音声合成する.このた
めには,音声処理と言語処理の密結合が必要.
o 対話制御:
o 音声認識と平行に文解析,情報抽出し,適切なタイミングで割り込み,確認対話,
合成音出力,情報出力を行う.このためには,音声処理と言語処理の密結合が
必要.
o 講演の要約:
o 講演のような長い発話を音声認識しリアルタイムで要約する.このためには,音
声処理と要約の密結合が必要.
簡単な例
o TED Talksの講演(書き起こしと字幕)
I wanted to talk to you today
about creative confidence.
I'm going to start way back in the third grade
at Oakdale School in Barberton, Ohio.
I remember one day my best friend Brian was
working on a project.
He was making a horse out of the clay
that our teacher kept under the sink.
今日はクリエイティビティに対する
自信についてお話しします
オハイオ州バーバートンの小学3年生だった頃の
昔の話から始めましょう
親友のブライアンが 創作に取り組んだ時のことを 今でもよく覚えています
先生が洗面台の下に置いていた粘土を使って
馬を作ろうとしていました
同時通訳者の訳出
o 逐次的な訳出のための工夫がある
I wanted to talk to you today
about creative confidence.
I'm going to start way back in the third grade
at Oakdale School in Barberton, Ohio.
I remember one day my best friend Brian was
working on a project.
He was making a horse out of the clay
that our teacher kept under the sink.
今日皆さんに
お話するの
は
クリエイティブな自信、
創造性の自信
についてです。
まず
三年生のところから
バービカン、オハイオ州のオークデールスクールのことです。
私の親友のブライアンがプロジェクトをしていました。
馬を作っていたんです
、粘土で。
えー先生の棚から
粘土を持ってきて、馬を作っていました
。
今日はクリエイティビティに対する
自信についてお話しします
オハイオ州バーバートンの小学3年生だった頃の
昔の話から始めましょう
親友のブライアンが 創作に取り組んだ時のことを 今でもよく覚えています
先生が洗面台の下に置いていた粘土を使って
馬を作ろうとしていました
人間の同時通訳モデル
[水野2016]
英日通訳の場合の例
(1) The relief workers (2) say (3)
they don’t have
(4)
enough food, water, shelter,
and medical supplies
(5)
to deal with
(6)
the gigantic wave of refugees
(7)
who are
ransacking the countryside
(8)
in search of the basics
(9)
to stay alive
.
(1) 救援担当者は (9)
生きるための
(8)
食料を求め
て
(7)
村を荒らし回っている
(6)
大量の難民達の
(5)
世話をするための
(4)
十分な食料や水,宿泊施設,
医療品が
(3)
無いと
(2) 言っています.
必要短期記憶>3!
(1) 救援担当者達の (2) 話では (4)
食料,水,宿泊施
設,医薬品が,
(3)
足りず
(6)
大量の難民達の
(5)
世話が出来ない
とのことです.(7)
難民達は今村々
を荒らし回って,
(9)
生きるための
(8)
食料を求めて
いるのです
.
必要短期記憶<3!
記憶チャンク数
同時通訳への挑戦 (InterSpeech 2013)
o 課題:従来法は文末を待つ
o 提案法:文末を待たず、フレーズ毎に翻訳
発話
音声認識
翻訳
音声合成
時間
発話
音声認識
翻訳
音声合成
翻訳
音声合成
翻訳
音声合成
時間
音声翻訳で実現するには?
分割:
いつ翻訳を開始するか?
予測:
次の発話をどう予測するか?
言い換え:
同時通訳用に言い換えることが出来るか?
評価:
どの通訳結果が良いかどう評価するか?
4つの課題:
分割してみよう
(Fujita, et al., Interspeech 2013)
統計的機械翻訳で用いられる翻訳モデルに着目
+データから自動構築可能
+言語情報を利用
+翻訳と同じ情報を利用するため相性が良い
具体的には
「
フレーズ
」と呼ばれる、翻訳に用いる単語列の区切りで翻訳開始
「
並べ替え確率(右確率)
」で同時性と精度のバランスを調整
「
言語モデル適応
」を行い、精度の低下を防ぐ
フレーズベース統計的機械翻訳(SMT)
o
文を翻訳可能な小さい塊(フレーズ)に分けて並べ替える
Today I will give a lecture on machine translation .
Today
今日は、
I will give
を行います
a lecture on
の講義
machine translation
機械翻訳
.
。
Today
今日は、
I will give
を行います
a lecture on
の講義
machine translation
機械翻訳
.
。
今日は、機械翻訳の講義を行います。
翻訳モデル(フレーズテーブル)・並べ替えモデル・
言語モデル
をテキストから統計的に学習
フレーズ抽出
アライメントに基づいてフレーズを列挙
the
hotel
front
desk
ホ
テ
受
ルの付
ホテル の
→ hotel
ホテル の
→ the hotel
受付
→ front desk
ホテルの受付
→ hotel front desk
並べ替えモデル
フレーズの並べ替え方を確率的に表し精度向上
現在のフレーズ
と
次のフレーズ
の順番を4種類に分類:
「順」と「不連続(右)」の確率の和は「
右確率
」
背 の 高い 男
the tall man
順:
順番は同じ
太郎 を 訪問 した
visited Taro
逆順:
順番は逆
私 は 太郎 を 訪問した
I visited Taro
不連続(右):
不連続(左):
背 の 高い 男 を 訪問 した
visited the tall man
右確率を用いた訳出タイミングの調整
まず、手法1を用いて訳出タイミングを仮確定
フレーズの
右確率
が閾値を上回った場合のみ本確定
閾値が1.0の場合は文ごと、0.0の場合はフレーズごと
例(閾値= 0.8):
hello
where is the station
“hello”
モデルに存在
↓
保留
“hello where”
存在しない
↓
“hello”を選択
↓
右確率 0.9 > 0.8
↓
出力 “
hello”
“where is”
モデルに存在
↓
保留
“where is the”
存在しない
↓
“where is”を選択
↓
右確率0.6 < 0.8
↓
出力しない
“the station”
発話終了
↓
出力
“where is
the station”
本確定
仮確定
本確定
仮確定
評価設定
4通りの実験的評価:
英日旅行対話文 (en-ja)
日英旅行対話文 (ja-en)
日英11単語以上の旅行対話文 (ja-en 11+)
仏英ニュース文 (fr-en)
2通りの評価項目:
精度:BLEU (参照はja-en,en-jaで14文, fr-enで1文)
遅延:秒
右確率は様々な閾値を調査
16.2万文で学習
4.4万文で学習
機械翻訳
遅延
結果1:各設定の精度・遅延
全ての設定において
遅延が減少
実験 (IWSLT2013)
o 対象データ: TED Talk(英語⇒日本語)
- 翻訳(キャプション)
vs. 通訳
o 異なるスキルの通訳者
スキルのレベル
# 経験年数
S
15 年
A
4 年
B
1 年
結果
38 40 42 44 46 48 50 0 1 2 3 4 5 6 R IBE S Dealy (Sec) LM+Tu A rank B rankA ランク:4 年経験
B ランク:1 年経験
Fast
Ac
curat
e
フレーズ終了時翻訳
発話終了時翻訳
B ランク(経験 1 年)
A ランク(経験 4 年)
≒
経験年数1年のB ランク通訳者と同等
統語要素予測に基づく訳出開始判定
o 未観測の統語要素(ラベル)を予測
o 既観測部を構文解析
o 素性抽出&要素予測
o 翻訳途中に統語要素ラベルが現れたら「待機」
o 句の並べ替えの有無に
よって訳出タイミング
を変更する
Oda, Yusuke et al., Syntax-based Simultaneous Translation through Prediction of Unseen Syntactic Constituents, Proc. of ACL-IJCNLP 2015.
Syntax Prediction Process
10/16/2016 Invited Talk ©Satoshi Nakamura, NAIST 46
I minutes 18 next the in
Input translation unit PP NP IN NP NN NP NNS CD JJ DT
1. Parse the input as-is
Word:R1=I POS:R1=NN Word:R1-2=I,minutes POS:R1-2=NN,NNS ... ROOT=PP ROOT-L=IN ROOT-R=NP ... 2. Extract features VP ... 0.65 NP ... 0.28 nil ... 0.04 ...
3. Predict the next tag (linear SVM)
VP
4. Append to sequence
nil 5. Repeat until nil
タグ推定後の
入力文
in the next 18 minutes
i 'm going to take
[NP]
(待機)i 'm going to take
you on a journey
翻訳結果
18 分 で あ る
[NP]
を 行 っ て い ま す
NMTと同時通訳
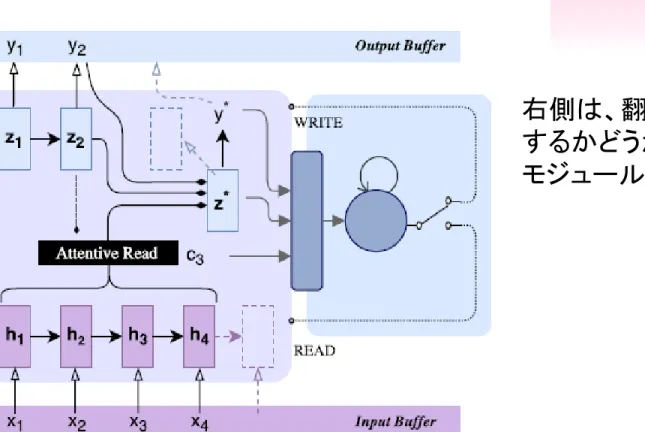
Figure 2: Illustration of the proposed framework: at each step, the NMT
environment (left) computes a candidate translation. The recurrent agent
(right) will the observation including the candidates and send back decisions–
READ or WRITE
左側は、NMT
右側は、翻訳を出力
するかどうかの判定
モジュール
Jiatao Gu, Graham Neubig, Kyunghyun Cho, Victor O.K. Li. “
Learning to Translate in Real-time with Neural Machine
ブッシュ
大統領
は
プーチン
と
会談
する
President
Bush
meets
with
Putin
Wait K tokens
Controllable!
Prediction!
原文
ブッシュ
大統領
は
プーチン
と
会談
する
従来法
President
Bush
meets with Putin
提案法
President
Bush
meets with
Putin
Prediction!
delay
delay
delay
Controllable!
予測と遅延制御による翻訳制御
翻訳例
Source
The analysis was carried out using fluorescence correlation spectroscopy and laser
scanning type fluorescence microscope.
Reference
蛍光相関分光法及び,レーザ走査型蛍光顕微鏡を用いて解析を行った。
Attention EncDec
蛍光相関分光法とレーザ走査型蛍光顕微鏡を用いて解析を行った。
“Wait-k” model
その解析を蛍光相関分光法とレーザ走査型蛍光顕微鏡を用いて行った。
39
• 参照訳、Atten EncDec訳では、フレーズの順番が変わっている。
• Wait-k アルゴリズムでは、フレーズの順番がある程度保存される。
帖佐克己, 須藤克仁, 中村哲, “英日同時通訳におけるニューラル機械翻訳の検討”, 言語処理学会全国大会 2019
コミュニケーションとしての音声翻訳を考えよう
入力
テキスト
音声
画像
ジェスチャ
音声⇒テキスト 音声認識同時
翻訳
変換
対話制御
言語情報
非言語情報 感情・スタイル 声質・韻律 ジェスチャ言語情報
非言語情報 感情・スタイル 声質・韻律 ジェスチャ出力
テキスト
音声
画像
ジェスチャ
原言語 目的言語 音声信号 “to o kyo e i ku”機械翻訳結果 /I/go/to/Tokyo/ 音声合成結果 “ai go tu tokyo/ 声質、韻律 声質、韻律
談話構造
文脈
ドメイン知識
オントロジ
テキスト 画像⇒テキスト 画像認識 テキスト テキスト⇒音声 音声合成 テキスト⇒画像 画像合成電子情報通信学会誌2015,改
End-to-end で学習
コミュニケーションにおける
① 逐次性,同時性
② パラ言語情報
内容
1. 音声認識、音声合成と統合最適化
2. 音声翻訳の統合最適化
3. 音声翻訳の同時性
4. パラ言語の取り扱い
1.
音声翻訳
2.
音声表現とテキスト表現の等価性
3.
発話顔 音声画像翻訳
5. 課題と今後の展開
6. まとめ
(INTERSPEECH2015)
海賊王
に俺は
なる
!
I am going to
become
the king of pirates!
パラ言語情報
o パラ言語情報:
o 個人性:声質に個人性が含まれる
o 強調,感情:
o 意図,話題の焦点が含まれる.
o F0周波数パターンの変化や,ポーズ,強勢の違いに現れる.
o 文構造,Phrase boundaryの影響を受ける.
o 音響情報の言語情報の組み合わせで表現される.
⇒ 音声処理と言語処理をさらに融合する必要.
How_0.1
are_0.9
you_0.2?
強調の推定
強調の翻訳
お_0.1
元気_0.8
です_0.2 か_0.1?
パラ言語情報を伝える音声翻訳
音声認識
機械翻訳
音声合成
o 入力話者の強調、感情などのパラ言語情報を翻訳出力に付加できないか?
元の英語音声
従来の音声翻訳 (強調の翻訳なし)
強調を含んだ音声翻訳法(CRF)
強調を含んだ音声翻訳法(LSTM)
日本語の自然音声
D.Q.Truong, S.Sakti, G.Neubig, S.Nakamura, ”Transferring Emphasis in Speech Translation
Using Hard-Attentional Neural Network Models“, INTERSPEECH 2016
Deep Learningによるパラ言語音声翻訳
D.Q.Truong, S.Sakti, G.Neubig, S.Nakamura, ”Joint Translation of Words and Emphasis in Speech-to-spee
ch Translation using Sequence-to-sequence models”, 音響講論2-10-4
内容
1. 音声認識、音声合成と統合最適化
2. 音声翻訳の統合最適化
3. 音声翻訳の同時性
4. パラ言語の取り扱い
1.
音声翻訳
2.
音声表現とテキスト表現の等価性
3.
発話顔 音声画像翻訳
5. 課題と今後の展開
6. まとめ
テキストと音声における強調等価性
48
●
テキストと音声からなるコーパスを作成:
○
テキスト
■
標準的表現のテキストを4つの異なる強調様式をもつ文
章にアノテータに変換してもらう
■
アノテータは同時にその困難さを記録する
○
音声
■
発話者は標準的表現のテキストを強調を有する文章を
読む感覚で読み上げてもらう
○
1050文の標準的表現の日英テキストを読み上げる
Quoc Truong Do, Sakriani Sakti, Satoshi Nakamura, “TOWARD MULTI-FEATURES EMPHASIS SPEECH TRANSLATION:
コーパスの内容
49
○
英語 5250文
●
This overcoat is incredibly short for me .
●
This overcoat is so short for me .
●
This overcoat is relatively short for me .
●
This overcoat is a bit short for me .
●
This overcoat is short for me .
■
アノテータは1名、発話者は2名
Emphasis levels
Difficulty levels
Doubtful
14.64
Somewhat strong
10.68
Strong
8.92
クラウドソーシングで評価
50
●
タスク1: 音声による強調度の評価
○
被験者に音声だけを提示
クラウドソース評価
51
●
タスク2: テキストによる強調度の評価
●
被験者にテキストだけを提示
クラウドソース評価
52
●
タスク3: 音声とテキストの等価性についての評価
○
被験者に音声とテキストを提示
内容
1. 音声認識、音声合成と統合最適化
2. 音声翻訳の統合最適化
3. 音声翻訳の同時性
4. パラ言語の取り扱い
1.
音声翻訳
2.
音声表現とテキスト表現の等価性
3.
発話顔 音声画像翻訳
5. 課題と今後の展開
6. まとめ
課題と研究課題
o 同時音声翻訳、パラ言語情報の取り扱い、全体最適化
o 高速化、高精度化、大語彙化、多言語化、未知言語対応
o 持続的なデータ自動収集と教師無し学習
o 方言・アクセント対応
o 雑音・残響対応、遠隔認識
o 韻律利用、パラ言語・非言語制御
o 対話構造・談話構造の考慮
o 主語省略への対応、照応への対応
o 知識表現、意味表現とその利用
o クロスカルチャー対応
コミュニケーション研究の課題
Symbol Grounding
再帰的に相手 を想定 共通の概念接地 を想定 発話単位レベル 発話内容,韻律,(発話理解) ジェスチャ 対話,発話単位レベル 発話理解,Dialog State Tracking,対話制御,文生成,発話交代 辞書, オントロジ 知識グラフ 大規模対話 データ 音声, テキスト 物理レベル タイミング,相づち, 頷き,視線,韻律 意図レベル 意図,目的 談話レベル 談話構造,相互信念, 焦点,注意,主導権 談話構造 コーパス 再帰的に相手 を想定 Web 知識