DEIM Forum 2016 B6-4
拡散可能性を用いた流言ツイートの検出
吉田
然
†有次 正義
†††
熊本大学工学部情報電気電子工学科 〒 860–8555 熊本県熊本市中央区黒髪 2 丁目 39 番 1 号
††
熊本大学大学院自然科学研究科 〒 860–8555 熊本県熊本市中央区黒髪 2 丁目 39 番 1 号
E-mail:
†
[email protected],
††
[email protected]
あらまし
近年,誰もが容易に情報を発信できる場として SNS が注目されている.特に Twitter では投稿文字数が
140 文字以内と制限されており,利用者は気軽に情報を発信できる.しかし一方で,その気軽さから多くの流言が発
信され,利用者の混乱を招いている.流言による問題が発生するのはその情報が拡散されるためである.本研究では
流言と拡散の関係性に注目し,流言ツイートの検出手法に拡散可能性を組み合わせることで流言検出の精度向上を目
指す.この目標に向け,投稿内容の拡散可能性を考慮した流言検出手法を提案し,その有効性を検討する.
キーワード
SNS, Twitter, 流言, 情報拡散
1.
は じ め に
近年,誰もが容易に情報を発信,受信できる場としてSNS が注目されている.従来の情報発信者はテレビや新聞などのマ スメディアであったが,SNSが登場したことにより個人でも情 報発信を容易に行うことができるようになった.特にTwitter では投稿文字数を140文字以内に制限することで,より気軽に 情報を発信できる他,リアルタイムな情報の収集源としても利 用されている.2011年3月11日に発生した東日本大震災の際 も,Twitterを用いた被災者の安否確認や被害情報の収集など が行われ,被災地の最新の情報を得るための手段として広く活 用された[1]. しかし,個人が気軽に情報を発信できる一方で,Twitterを 始めとするSNS上には多くの流言が拡散されてしまっている という問題がある.同じく東日本大震災の際,炎や噴煙をあげ る工場の様子から「工場から出た有害物質が雲に付着し,雨と 一緒に降ってくる」という事実無根の内容のツイートが拡散さ れ,人々の混乱を招いたという事例がある[2].また,2013年 4月に起こったボストンマラソン爆弾テロ事件に関するツイー トでは,デマや噂の情報が全体の29%を占めていた,という研 究結果もある[3].これら事例の他にも,流言が拡散されること で多くの利用者の混乱を招くような状況はTwitter上で後を絶 たず,有志によってTwitter上の流言情報が手動でまとめられ る事態にも発展している(注1). このようにTwitter上では流言による様々な問題が発生して いるが,これらの問題が発生するのは流言が拡散されることで 多くの人の目に触れてしまうためである.本研究ではこの点に 注目し,Twitter上の流言検出に情報の拡散可能性を組み合わ せることで流言検出の精度を向上することを目的とする.本稿 ではまず,拡散されるツイートの特徴を素性とし,拡散される 可能性が高いと考えられるツイートを分類する拡散可能性分類 (注1):デ マ に 関 連 す る 1630 件 の ま と め - Togetter ま と め http://togetter.com/t/%E3%83%87%E3%83%9E 器を構築する.そしてこの拡散可能性分類器によって分類され たツイートに対して,流言訂正情報をもとに流言検出を行い, 拡散可能性を用いる有効性を検証する. 本研究の貢献を以下に示す. • 拡散する可能性の高いツイートを抽出する拡散可能性分 類器の実装 • 流言検出に拡散可能性を用いるという手法の提案 • 流言検出に拡散可能性を用いることの有効性を示した検 証結果 本論文は以下のように構成する.まず第2章では本研究と関 連のある既存研究について述べる.第3章では拡散可能性分類 器の構築と,本研究で提案する流言検出手法を説明する.第4 章では拡散可能性分類器と提案した流言検出手法の評価のため の実験内容と実験結果を述べる.第5章では実験結果に基づい た考察を述べる.最後に第6章で本論文のまとめと将来研究に ついて述べる.2.
関 連 研 究
本章では,流言情報の検出に関する先行研究と拡散するツ イートの傾向に関する先行研究について述べる. 2. 1 流言情報の検出 村山ら[4]は流言ツイートの傾向を探るための調査を行って いる.調査によって,流言ツイートには他者を騙す目的のもの, 根拠のない噂,過去の情報が最新情報として拡散されてしまっ たもの,など様々な種類が存在することが分かった.このこと から,ツイートを見ただけではその情報が正しいかどうかを判 断することは難しい可能性が高いという結論に至っている. 一方で宮部ら[5]は,流言を訂正している発言を用いて流言 ツイートの自動検出を実現するため,ツイートが本当に流言訂 正情報であるかを分類するための流言訂正情報分類器を構築し ている.しかし,流言訂正情報から自動的に流言元のツイート を検出する手法については提案されていない.本研究ではこの 流言訂正情報分類器を用いて,流言検出に必要な流言訂正情報 を抽出する.流言の自動検出を目的とした研究は他にも数多く行われてい る.Maら[6]は,災害時のツイートについて情報が広がるにつ れて起こる文脈や特徴の変化から流言を検出する手法を提案し, 最高89.6%の正解率を得た.また,鍋島ら[7]は,災害時のツ イートについて,流言訂正表現のパターンをもとに流言訂正情 報中に含まれる訂正内容を抽出し,流言元のツイートを検出す る手法を提案し,流言の約半数を検出できている.更に,須田 ら[8]は,災害時にバーストしたツイートに対して,リツイー トの深さと感情極性を用いて流言推定を行い,61%の正解率を 得ている.このように流言の自動検出実現のために様々なアプ ローチが試されているが,これらの研究で扱われているのはど れも災害時のデータである.災害時という状況は限定的である 上,平常時と災害時の流言では含まれるフレーズや広がり方に 違いがあるという研究結果[9]もあるため,幅広い流言に対応 するためには平常時の流言に対する検出手法が必要である. 平常時も含めた自動流言検出の研究として,Qazvinianら[10] の研究がある.彼らは特定の流言に関するツイートを網羅的に 自動検出し,その噂の信頼度の推定を目指した研究を行ってい る.そして実験結果として,ツイート本文の特徴量を用いた場 合にF値が0.932という高い精度で自動検出ができたことを示 した.本研究ではこの研究とは異なったアプローチとして,拡 散可能性を組み合わせた流言の自動検出手法を提案する. 2. 2 拡散するツイートの傾向 興梠ら[11]は,SNSにおいて読者を誘引する要素を定性的に 明らかにすべく調査を行っている.調査によって,理由,驚き, 得,特別感に繋がる表現が読者の関心を惹きやすいこと,画像 の有無,投稿時間,文章の先頭に【】があることなどが情報拡 散に寄与する要素であること,そして実際に拡散したツイート では,文章の先頭から【】,固有名詞,名詞の順に形態素が続 く構成が多いことなどが示されている.一方で,安田[2]は東 日本大震災時の流言を取り上げ,震災時におけるSNS上の情 報拡散の分析を行っている.その中で,拡散される流言ツイー トには「拡散希望」などという拡散を促すフレーズが入ってい る場合が多く,情報源や地名を含む傾向にあることが分かって いる. また,Nadamotoら[12]は災害時に拡散されるツイートの 傾向について調査している.震災時にリツイートが多かったツ イートについて本文内容に応じてそれらをジャンルごとに分け たところ,伝聞のツイートが全体の74.9%を占めていたことが 分かった.また,拡散を促すような表現,URL,ハッシュタグ, 数値や場所などの詳細な情報を含んでいたツイートをそれぞれ 分析したところ,どれも約9割が伝聞のツイートであったこと が分かっている.他にも,梅島ら[13]は災害時の流言ツイート とリツイートについての調査を行っている.その中で,流言は 行動を促したり,ネガティブだったり,不安を煽る内容である 場合が多いことを明らかにしている.またその上で,そのよう な内容のツイートはリツイートされやすいことを示すことで, 災害時に流言は拡散されやすいということを証明した.また一 方でGupta [3]らは,ツイートをフォロワーの多いユーザや著 名人のアカウントがリツイートしていることだけでは,そのツ 図 1 提案手法の流れ イートが正しいかどうかは判断できないことを述べている. これらのことから,投稿されるツイートの中でも拡散される ツイートは様々な特徴を有していることが分かる.紹介したこ れらの研究は,拡散するツイートを検出するための判断材料を 見極める上で参考となる.しかし,それらの特徴を用いて拡散 しそうなツイートを自動で分類するという試みは未だ行われて いない.本研究ではこれらの研究を参考とし,拡散しそうなツ イートを自動で分類する拡散可能性分類器を構築する.
3.
提 案 手 法
3. 1 概 要 本研究では2. 2節で紹介した,拡散されるツイートに見られ る様々な特徴を用いることで拡散される可能性の高い,つまり 多くの利用者の目に触れる可能性が高いツイートに的を絞り, それらの中から流言を検出する.図1で今回の提案手法の流れ を説明する.まず,投稿されるツイートの中から拡散される可 能性の高いツイートを予め拡散可能性分類器によって分類する. そして,流言訂正情報分類器によって取得した流言訂正情報ツ イートをもとにして,拡散可能性の高いツイートの中から流言 ツイートを検出する.流言検出に情報の拡散可能性を組み合わ せるという,この新たな手法で流言検出の精度向上を目指す. 3. 2 拡散可能性分類器の構築 本研究では「拡散可能性分類器」という,拡散しそうか否か でツイートを分類をする分類器を構築する. 3. 2. 1 使用データ 拡散可能性分類器の構築に用いたデータは,2015/12/17∼20 のツイートから無作為に抽出されたリツイート数100以上のツ イート15,000件と,リツイート数100未満のツイート15,000 件の計30,000件である.拡散したツイートかどうかはそのツ イートのリツイート数をもとに判断することとし,閾値につい ては今回は暫定的にリツイート数100とした. 3. 2. 2 素 性 拡散可能性分類器の構築に用いた素性は表1の通りである. 単語の有無を用いた素性では,2. 2節にて示した興梠ら[11], 安田[2],梅島ら[13]の研究を参考とし,理由を示す単語を「背 景,理由,秘密,なぜ,何故,裏側,真実,知られざる,実態, とは」,方法を示す単語を「法則,作り方,方法,秘訣」,驚き を示す単語を「すごい,凄,驚,驚き,素敵,びっくり,ビッ表 1 拡散可能性分類器の素性 素性 型 次元数 画像の添付の有無 二値 1 URL の有無 二値 1 ツイートした時間帯 二値 5 (2∼5,6∼9,10∼15,16∼19,20∼1 時) ツイートした日 (平日,休日) 二値 2 ツイートの先頭は【か 二値 1 最初の形態素は固有名詞か 二値 1 2 番目の形態素は名詞か 二値 1 場所を示す単語の有無 二値 1 ツイートの形態素数 整数 1 ツイートの感情指数(注 2) 実数 1 理由を示す単語の有無 二値 1 方法を示す単語の有無 二値 1 驚きを示す単語の有無 二値 1 特別を示す単語の有無 二値 1 拡散を促す表現の有無 二値 1 !マークの数 整数 1 ?マークの数 整数 1 クリ」,特別を示す単語を「特別,スペシャル,とっておき,だ けの,得,特,初,重大」,拡散を促す表現を「拡散,広めて, 知らせて,RT,リツイート」と定めた. 3. 2. 3 学習アルゴリズム
分類器の学習にはSVM(Support Vector Machine)を用い る.今回は,libsvm3.20を用いてデータのスケーリング,パラ メータ調整,分類器構築を行った. 3. 3 流言ツイートの検出 流言ツイートの検出は,次のアプローチで行う. (1) 流言訂正情報のツイートを形態素解析し,文章中で最 初に出てきた「デマ」という単語より前の一般名詞, 固有名詞,動詞を抽出する. (2) 検出にかけるツイートを形態素解析し,一般名詞,固 有名詞,動詞を抽出する. (3) (1)で流言訂正情報から抽出した形態素が(2)で抽出 した形態素にいくつ含まれているか数える. (4) 検出にかける各ツイートに含まれていた(1)で抽出し た形態素の平均個数以上が,ツイート中に含まれてい ればそのツイートは流言ツイートだと判断する.
4.
実
験
本論文では,2種類の実験による評価を行う. 4. 1 拡散可能性分類器の性能評価 本節では,3. 2節で構築した拡散可能性分類器の評価を行う. 4. 1. 1 実 験 内 容 3. 2節で構築した拡散可能性分類器が,どの程度正確に拡散 したツイートを分類できるかについてlibsvm3.20による10分 割交差検定を用いて評価を行う.3. 2. 1節でも説明した通り, (注2):感情指数の算出には,日本語評価極性辞書 (名詞編)ver.1.0 [14] [15] を 用いた. 表 2 使用したツイートデータと拡散可能性分類器の分類性能 ツイートデータの種類 Accuracy Precision Recall F 値30,000 ツイート 0.882 0.868 0.905 0.886 1,000 ツイート 0.868 0.843 0.904 0.873 今回は「拡散した」の基準をリツイート数100以上と暫定的に 定めることとする. 4. 1. 2 使用データ 使用するデータは次の2つである. (1) 3. 2. 1節で示した2015/12/17∼2015/12/20のツイー ト30,000件(正クラス15,000件,負クラス15,000件) (2) (1)のデータから無作為に抽出したツイート1,000件 (正クラス500件,負クラス500件) 4. 1. 3 実 験 結 果 4. 1. 2節で示した30,000件と1,000件のツイートデータを 用いて,libsvm3.20による10分割交差検定を行った結果を表 2に示す.表2に示した結果から,3. 2節で構築した拡散可能 性分類器は85%以上の正解率で拡散されるツイートとそうでな いツイートを分類できることが分かった.また,30,000件のツ イートを用いた場合と1,000件のツイートを用いた場合の比較 より,サンプル数の違いによる影響は低いとみられる.このた め,以降は1,000件の方のデータを用いて実験を行っていく. 4. 2 流言ツイート検出の評価 本節では,3. 3節で提案した流言ツイート検出方法について 評価を行う. 4. 2. 1 実 験 内 容 まず,3. 3節で説明した流言ツイートの検出方法がどの程度 正しく流言ツイートを検出できるかを検証する.流言訂正情報 であるツイートと,検出にかけるツイートのデータセットを用 意し,それらのツイートに対して提案した検出方法を用いる. 次に,ツイートの拡散可能性を用いることの有効性を検討 する.評価は,データセットの全ツイートに対して流言検出を 行った場合と,拡散可能性分類器によって拡散されると分類さ れたツイートのみに対して流言検出を行った場合の2つの実験 結果の比較により行う. 4. 2. 2 使用データ 本実験では,過去にTwitter上で実際に拡散された2つの流 言に関するデータを用いる.今回取り上げる流言は次の2つで ある. 流言1 「スマートフォンの発信画面で110を押して発信する と通信速度が速くなる」 流言2 「年金運用失敗で損失額21兆5000億円」 それぞれの流言について「拡散した流言」「拡散しなかった流 言」「流言に関連するジャンル」「その他の内容」のツイートを 含む40件のツイートデータと,5件の流言訂正情報を用意す る.表3に流言1の流言訂正情報,表4に流言2の流言訂正情 報,表5に40件のツイートデータの内訳を示す. 4. 2. 3 用いる流言の背景 4. 2. 2で示した,本実験で用いる2つの流言の内容について 詳しく説明する.
表 3 使用する流言 1 についての訂正情報 番号 ツイート本文 1 110 にかけたら通信制限解除するていうデマの情報のやつがテ レビのニュースであってた 2 「110 を入力すると通信速度が速くなる」のデマ拡散 22 府警 に影響 3 110 にかけると通信速度が向上する的なデマに騙される人って 本当にいるんだなぁと 4 実際にやってて気が付かないものなのかな。110 なんて日時 生活では入力しないのでピンとこないのか。∼ 通信制限を 解除できる裏ワザ広まる。実際は 110 番通報してしまうデマ http://…… 5 iPhone で 110って押して通話すると通信速度が速くなるって いうデマが出回ってるようだけどこれ騙される人いるのか…? 表 4 使用する流言 2 についての訂正情報 番号 ツイート本文 1 ツイッターで拡散されてた『年金損失 21 兆 5 千億円』ってデ マだった。 2 年金損失 21 兆 5 千億円デマの勢いが衰えない 3 年金損失 21 兆円のデマ、本当のところどうなってる? なぜ 拡散したの?: 私たちの公的年金に 21 兆 5000 億円の損失 が出ているという話がネットで広がっています。これはツイッ ターで拡散した人の誤解であり、... http://…… 4 去年の段階で、最悪で 21 兆 5000 億円の損失が出る恐れがある ことは分かっていたことじゃないか。それが伝言ゲームで断定 調になったらしい。 年金損失 21 兆円のデマ、本当のところど うなってる? なぜ拡散したの? — THE PAGE http://…… 5 大きな芸能ニュースの裏で 21 兆の話はデマ。短期に 7 兆マイ ナスだったことはマジ。 表 5 流言検出の実験で使用したデータの種類別件数 流言の種類 拡散流言 非拡散流言 流言関連 その他 計 流言 1 2 4 4 30 40 流言 2 3 5 4 28 40 流言1: スマートフォンの発信画面で110を押して発信する と通信速度が速くなる 2015年8月下旬にTwitter上で拡散された流言である.ス マートフォンのキーパッドで「1」を2回押した後に「0」を1 回押し,その0.5秒以内に通話ボタンを押すと通信制限が解除 される,という流言である.110番と書かずに1を2回,0を 1回と分かりにくく書いている点や,0.5秒以内に通話ボタン を押すという制約をつけ,通話前に考える隙を与えないよう工 夫されている点から,最初から他人を騙す目的をもって発信さ れた流言であると考えられる.この流言の拡散により,22府県 において110番への誤通報の増加が確認され(注3),社会的混乱 を招いた. (注3):デマで 110 番誤通報急増 22 府県、ツイッターで拡散: 日本経済新聞 http://www.nikkei.com/article/DGXLASDG26H6F W5A820C1000000/ 表 6 流言 1 における流言検出の結果 (全ツイート対象) 訂正情報番号 拡散流言 非拡散流言 流言関連 その他 1 0/2 1/4 2/4 4/30 2 1/2 2/4 2/4 4/30 3 1/2 2/4 2/4 4/30 4 1/2 0/4 2/4 7/30 5 2/2 4/4 4/4 4/30 表 7 流言 2 における流言検出の結果 (全ツイート対象) 訂正情報番号 拡散流言 非拡散流言 流言関連 その他 1 3/3 5/5 3/4 2/28 2 3/3 5/5 3/4 1/28 3 3/3 5/5 3/4 1/28 4 3/3 5/5 4/4 9/28 5 0/3 0/5 0/4 0/28 表 8 拡散可能性分類器によって流言 1 のデータセットから省かれた ツイート数とその種類別件数 ツイート種類 拡散流言 非拡散流言 流言関連 その他 全ツイート (40 件) 2 4 4 30 抽出後 (23 件) 2 1 3 18 省かれたツイート数 0 3 1 12 省いた拡散ツイート数 - 0 0 3 省いた非拡散ツイート数 - 3 1 9 正解率 - 1.0 1.0 0.75 表 9 拡散可能性分類器によって流言 2 のデータセットから省かれた ツイート数とその種類別件数 ツイート種類 拡散流言 非拡散流言 流言関連 その他 全ツイート (40 件) 3 5 4 28 抽出後 (22 件) 2 5 2 13 省かれたツイート数 1 0 2 15 省いた拡散ツイート数 1 - 1 0 省いた非拡散ツイート数 0 - 1 15 正解率 0.0 - 0.50 1.0 流言2: 年金運用失敗で損失額21兆5000億円 2016年1月下旬にTwitter上で拡散された流言である.国 が年金資金の運用を失敗してしまい21兆5000億円の損失が 出てしまった,という流言である.事実は,年金資金運用失敗 により想定される「最大損失額」が21兆5000億円になるとい うものであった(注 4).流言を最初に発信した人がニュース中の 「最大損失額」を実際に損失した額だと誤解してTwitter上に 投稿してしまったことで,21兆5000億円の損失が出てしまっ たという流言が拡散されることになってしまったと考えられる. この流言の発端となった投稿者は既に当該ツイートを削除し, Twitter上で謝罪している. 4. 2. 4 実 験 結 果 提案手法を用いて,4. 2. 1節に示した流言検出の実験を行っ た結果を表6,表7に示す.次に,40件のツイートデータに対 (注4):年金損失 21 兆円のデマ、本当のところどうなってる? なぜ拡散し たの?—THE PAGE(ザ・ページ) http://thepage.jp/detail/20160121-00000001-wordleaf
表 10 流言 1 における流言検出の結果 (拡散すると思われるツイート のみ対象) 訂正情報 No 拡散流言 非拡散流言 流言関連 その他 1 0/2 (± 0) 0/4 (-1) 1/4 (-1) 1/30 (-3) 2 1/2 (± 0) 1/4 (-1) 0/4 (-2) 1/30 (-3) 3 1/2 (± 0) 0/4 (-2) 1/4 (-1) 1/30 (-3) 4 1/2 (± 0) 0/4 (± 0) 2/4 (± 0) 7/30 (± 0) 5 2/2 (± 0) 1/4 (-3) 3/4 (-1) 1/30 (-3) 表 11 流言 2 における流言検出の結果 (拡散すると思われるツイート のみ対象) 訂正情報 No 拡散流言 非拡散流言 流言関連 その他 1 2/3 (-1) 5/5 (± 0) 2/4 (-2) 1/28 (-1) 2 2/3 (-1) 5/5 (± 0) 2/4 (-2) 1/28 (± 0) 3 2/3 (-1) 5/5 (± 0) 2/4 (-2) 0/28 (-1) 4 2/3 (-1) 5/5 (± 0) 2/4 (-2) 5/28 (-4) 5 0/3 (± 0) 0/5 (± 0) 0/4 (± 0) 0/28 (± 0) して3. 2節で構築した拡散可能性分類器を用い,拡散すると思 われるツイートを抽出した結果とその内訳を示したのが表8, 表9である.そして,拡散可能性分類器によって抽出された, 拡散すると思われるツイートに対して流言検出の実験を行った 結果を表10,表11に示す.表中,括弧内に記されている数字 は表6,表7にて示した全ツイートを対象とした結果からの検 出数の変化である. 表8,表9から分かる通り,拡散可能性を用いることで拡散 されていないツイートの一部を検出対象から省くことができた. 表10,表11を見ると拡散可能性分類器によってツイートを省 いた分,誤検出の数を抑えることができていることが分かる. この結果から,誤検出を抑えるという観点において,流言検出 に拡散可能性を用いることは有効であると考えられる.しかし ながら流言2については,拡散している流言のうち1つが拡散 可能性分類器によって省かれてしまったために検出できていな い.この点については課題が残る. 一方,提案手法が正しく流言ツイートを抽出できるかにつ いては,まだまだ改良の必要があると考える.表6,表7の結 果からも分かる通り,用いる訂正情報によっては検出すべきで ある拡散した流言ツイートが検出できなかった.今回提案した 手法は本文の単純なマッチングのみで構成されていたが,それ では判断材料として不十分であったことが窺える.検出できな かったツイートについては次章の考察にて述べる.
5.
考
察
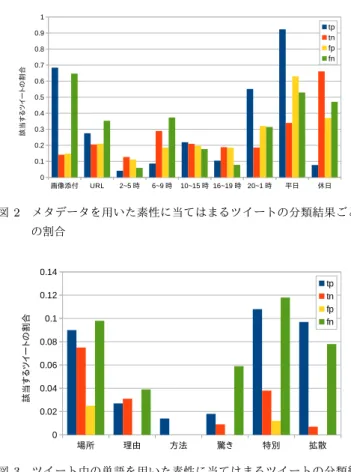
5. 1 拡散可能性分類器による分類結果 5. 1. 1 ツイートのメタデータをもとにした素性の有効性 ツイートのメタデータをもとにした素性(画像の添付,URL の有無,投稿時間帯,投稿日は平日か休日か)に当てはまるツ イートの割合を分類結果ごとにまとめたグラフを図2に示す. 図2より,分類結果がtp,fnのツイートに多く画像が添付さ れていることが分かるので,画像の有無はツイートが拡散する かどうかに大きく関わっているといえる.これは興梠ら[11]の 図 2 メタデータを用いた素性に当てはまるツイートの分類結果ごと の割合 図 3 ツイート中の単語を用いた素性に当てはまるツイートの分類結 果ごとの割合 研究結果に矛盾していない.一方で,URLの有無については画 像添付ほどの傾向は見られなかった.また,ツイートの投稿時 間帯については,20∼1時に投稿されたツイートに拡散された ツイートが多く含まれており,他の時間帯と比較してもfnに含 まれるツイート数と比べてtpに含まれるツイート数が多いこ とから,20∼1時に投稿されたツイートは比較的高い割合で拡 散したツイートを分類できていることが分かる.しかし,6∼9 時に投稿されたツイートについては,tpに含まれるツイート 数に比べてfnに含まれるツイート数が圧倒的に多いことから, 拡散したツイートをあまり分類できていないことが分かる.こ のことから,時間帯によって拡散するツイートの傾向は変化し ている可能性がある.このため,拡散したツイートをうまく捉 えられていなかった朝の時間帯のツイートについて更に調査を 行い,その傾向を究明する必要がある.投稿日が平日か休日か についても時間帯と同じことが言える.平日のツイートについ ては拡散したツイートを比較的よく分類できているが,休日の ツイートについては拡散したツイートを捉えられていない.平 日か休日かによっても拡散する要因は変化している可能性があ ることが窺える. 5. 1. 2 ツイートに含まれる単語をもとにした素性の有効性 次に,ツイート中で使用されている単語を用いた素性に当て はまるツイートの割合を分類結果ごとにまとめたグラフを図3 に示す. 図3より,まずどの素性についても当てはまるツイートの数 が少なかったことが分かる.理由,方法,驚き,特別,拡散を 示す単語については3. 2. 2節でも説明したように,こちらで用表 12 分類結果ごとのツイートの形態素数平均値 tp tn fp fn 43.23 21.62 23.19 38.02 意したいくらかの単語に当てはまる単語があるかで判断を行っ たため,類義語を取りこぼしてしまっている可能性もある.同 じような意味を示す単語でよく使われている単語が他に有るか, また拡散に大きく寄与するような表現などが他にもないか,調 査する必要がある.しかし,中でも拡散を促す表現については, その表現が入っているツイートが非常に高い可能性で拡散され ていることが分かった.このことから拡散を促す表現について はツイートの拡散に大きく寄与していることが分かるので,分 類の際にこの素性に重みをつけるなどすると更に拡散されるツ イートを的確に分類することができると考える. 5. 1. 3 分類を誤ったツイート まず,分類結果ごとのツイートの形態素数の平均値を表12 に示す.表12より,拡散されているツイート(tp,fn)は形態素 数が比較的多い傾向にあることが分かる.しかし,fnのツイー トを確認すると画像付きで文章が短いツイートが多く見つかっ た.このように,分類を誤ったツイートの中には,短文で拡散 していたツイートが存在していた.形態素数20個以下の拡散 されていたツイートは,今回用いたデータの中で拡散されてい るツイート500件中,81件であった.また,形態素数20個以 下の拡散されていたツイートの中で画像が添付されていないも のは81件のうち14件のみであった.これより,短文で拡散さ れたツイートのほとんどには画像が添付されていたことになる. 図2にて確認した,画像の添付がツイートの拡散に寄与してい ることがこの結果からも分かる.このことから,画像の添付は ツイートの拡散可能性を見極める重要な要素であることが窺え る.そのような拡散可能性に大きく寄与する素性とそうでない 素性に対してそれぞれ適切な重み付けを行なうことで誤検出を 更に抑えられる可能性があると考えられる. また,画像添付無しの短文にも関わらず拡散されていたツ イートの投稿主はほとんどが著名人や企業の公式アカウント であった.このことから,投稿ユーザによって拡散の規模が変 わってくることが確認できる.ユーザ間の拡散の規模の違いに 大きく関わっていると考えられるのは投稿主とリツイートした ユーザのフォロワー数である.フォロワーの数が多いほど,そ の人のツイートやリツイートを見る人の母数は大きくなる.安 田[2]の研究では,解析したデータセットにおいて20回以上リ ツイートされているツイートは全て拡散されていく過程で500 人以上のフォロワーを持つユーザにリツイートされていたとい う調査結果がある.これより,投稿主やリツイートしたユーザ のフォロワー数を新たに判断材料として取り入れることでより 良い分類ができるようになると考えられる. 5. 2 提案手法による検出結果 5. 2. 1 拡散可能性を用いたことによる流言検出結果の変化 まず,拡散可能性を用いることによる誤検出数の変化を見る. 表10,表11より,流言1については訂正情報1,2,3,5,流言2 については訂正情報1,2,3,4において拡散可能性を用いること で誤検出数を抑えることができている.この結果から流言検出 に拡散可能性を用いることは誤検出抑制の観点から有効である と考える. 一方,拡散可能性を用いることによる正しい流言検出数の 変化を見る.表10,表11に示す拡散した流言の検出数につい て,流言1については変化は見られないものの,流言2につい ては減少してしまっていることが分かる.これは表9からも分 かる通り,拡散可能性分類器が拡散した流言を誤って省いたこ とが原因である.これは拡散可能性を用いる欠点といえる.拡 散可能性分類器の分類精度は4. 1. 3節より,1,000件のツイー トを用いた場合で86.8%の正解率であり,90.4%の再現率であ る.より取りこぼしの少ない正しい流言検出を実現するために は,拡散可能性分類器の性能において再現率を向上させる必要 がある. 5. 2. 2 検出できなかったツイートの分析 今回の実験での流言検出結果において検出できなかったツ イートについて考察する.流言1における流言検出について, 表6に示す結果からは,用いる訂正情報によっては流言ツイー トが検出できていない場合があったことが分かる.今回用意し た,流言1に関する拡散した流言ツイート2件のうちの片方 は「書き直した笑iPhoneの人めっちゃいいやん」という本文 で,添付されている画像に流言の内容が明記されていたもので あった.訂正情報1,2,3,4はこのツイートを検出できていなかっ た.この結果より,本文のみの解析では流言検出手法としては 不十分であることが窺える.この例の他にも,画像だけではな く本文中のURLなどに流言情報が含まれている場合やリプラ イを使ってリプライ先の流言情報を訂正している場合なども考 えられる.また,社会情勢の様々な変化や流行の移り変わり, Twitter上のトレンドの変化など,流言かどうかを判断するた めに活用できそうな要素は多く存在する.このことから,更に 正確な分類を実現するためには,検出に用いる判断材料を増や すことで幅広い流言ツイートに対して対応できるよう改良する 必要がある. また,流言2における流言検出について,表7に示す結果か らは,訂正情報5が1つもツイートを検出できていないことが 分かる.流言ツイートを全く検出できなかった原因として,訂 正情報5中に抽出の対象となる流言関連の情報が存在しなかっ たことが挙げられる.訂正情報5は表4にも示す通り「大きな 芸能ニュースの裏で21兆の話はデマ。短期に7兆マイナスだっ たことはマジ。」というものであった.提案手法では「デマ」と いう単語以前の一般名詞,固有名詞,動詞のみを抽出するため, この訂正情報5から抽出される単語は「芸能ニュース,裏」の みであった.数詞は抽出単語に含めていないため「21,兆」は これに含まれていない.これをもとにして検出を行っていたた めにどのツイートともマッチしなかったのだと考えられる. この考察に基づけば,数詞を抽出単語に加えればこのような ツイートも検出できそうであるが,新たな問題が発生した.数 詞を抽出対象に加えて全ツイートを対象に流言2のデータセッ トに対して行った流言検出結果を表13に示す.数詞を抽出対 象に加えた場合,流言ツイートは取りこぼしなく検出できたが,
表 13 流言 2 における数詞を加味した場合の流言検出の結果 (全ツ イート対象) 訂正情報 No 拡散流言 非拡散流言 流言関連 その他 1 3/3 5/5 4/4 4/28 2 3/3 5/5 4/4 1/28 3 3/3 5/5 4/4 1/28 4 3/3 5/5 4/4 9/28 5 3/3 5/5 4/4 0/28 その一方で流言に関係したことを述べているツイートについて も,流言ではないのに全て流言であると誤検出されてしまう結 果となった.また,数詞は様々な場面で用いられる一般的な単 語であるため,関係のないツイートを多く検出してしまう危険 性も増える.このため,数詞を抽出する単語に追加するという 手段とは違った方法によって解決する必要があると考える. 5. 2. 3 誤検出してしまったツイートの分析 次に,今回の実験での流言検出結果において誤検出してし まったツイートの傾向について考察する.誤検出の中で傾向と して目立っていたのが,表6中の訂正情報1,2,3,5において,そ れぞれその他のツイートから4件が誤検出されてしまっている ことである.これら4件はどれも同じツイートを誤検出してし まっており,それらのツイートには共通して「する」という単 語が含まれていた.一方で,流言訂正情報1,2,3,5についても 「デマ」という単語より前の本文中,つまり提案手法によって抽 出の対象となった文章中にも「する」という単語が含まれてい た.これが訂正情報1,2,3,5という多くの訂正情報で共通のツ イートが誤検出されてしまった理由と考えられる.本来,流言 情報を特定するための単語が入っているべきところに一般的な 単語が入ってしまっていたことが,このような誤検出を引き起 こしてしまった.このような事態を防ぐためには,訂正情報か ら抽出した形態素に含まれる一般的な単語を省く必要がある. 5. 2. 4 流言の種類ごとの検出率の違い 最後に,拡散された流言ツイートの検出率について流言の種 類ごとに比較する.表6,表7より,流言であるツイートにつ いては流言1よりも流言2の方が正しく検出できていることが 分かる.この検出率の違いは,文字数の違いによるものである と考える.流言自体を短い言葉で表しやすい内容であった流言 2に比べて,手順を踏んで説明しなければならない流言1は流 言自体の文字数が比較的多かった. これに関連する結果として,表6,表7中の訂正情報4によ る検出結果がある.流言1,2の訂正情報4は,表3,表4から 分かる通り,「デマ」という単語がツイートの後ろの方にあると いう特徴を持つ.そして流言1,2共に訂正情報4を用いた検出 において,その他のツイートの誤検出が他の訂正情報による検 出よりも多いことが分かる.「デマ」という単語が後ろの方にあ ることは,抽出対象の文字数がそれだけ多くなることを意味す る.抽出対象が長い分,流言と直接関係ない単語もより抽出さ れてしまい,その影響でその他ツイートの誤検出が増えたと考 えられる. これらのことから今回提案した検出手法では,抽出対象の文 字数が多い訂正情報を用いた検出を苦手とすることが分かった. そしてこの弱点より,長い文中から的確に訂正情報を抽出する 性能がまだ不足していることが窺える.今回の提案手法の改善 すべき点の一つとして,文脈の情報を用いるなどして,流言訂 正情報が何を訂正しているのかを更に正確に抽出できるように 改良する必要があるという点が挙げられる.
6.
ま と
め
本論文では,誰もが情報を発信できることで現在注目を集め ているSNSからTwitterを取り上げ,Twitter内で投稿され た流言ツイートが利用者の混乱を招いているという問題に目を 向けた.SNS上で発生する流言による問題は情報が拡散されて 初めて発生するものであり,拡散されない流言については被害 が少ない分,大きな問題とはならない.本研究ではこの点から 流言と拡散の関係性に注目し,流言検出の精度向上のために, 流言検出と拡散可能性を組み合わせて用いるという新たな手法 を提案した.今回提案した手法は,拡散される可能性が高いと 判断されたツイートの中から,流言訂正情報に基づいて流言ツ イートを検出するというものであった.そして提案手法の実現 のために拡散可能性分類器を構築し,流言訂正情報を用いた流 言ツイート検出がどの程度できるか実験を行った. 拡散可能性分類器については,ツイート30,000件を用いて訓 練させた時に88.2%の正解率,90.5%の再現率を得ることがで きた.また,ツイートの投稿時間帯や,投稿日が平日か休日か によって分類結果に差がみられた.このことから投稿時間帯や 投稿日に応じて拡散に寄与する要因は異なっている可能性があ ることが分かった.他にも,画像添付の有無や形態素数といっ た複数の素性において,拡散されたツイートとされていないツ イートの間にはっきりとした関係性が見られた. 流言ツイート検出の手法については,現段階では検出のため の判断材料が本文しかなかったため正確な検出を行う上ではま だ不十分であったと考える.しかし,拡散可能性を用いること については,拡散可能性分類器によって拡散しないと思われる ツイートを対象から省くことにより,誤検出数を抑えることが できるという点で有効性を見出すことができた. これらの実験結果を踏まえた上で,本研究の貢献を以下に 示す. • 拡散する可能性の高いツイートを抽出する拡散可能性分 類器の実装 • 流言検出に拡散可能性を用いるという手法の提案 • 流言検出に拡散可能性を用いることの有効性を示した検 証結果 流言検出に拡散可能性を組み合わせるという新たな観点から の流言検出が有効であることを示すことができたため,流言が 引き起こすSNS上での実際の問題を解決することに貢献できた と考える.しかしながら,検出精度については従来の研究以上 の結果は出せていないため,より正確な自動検出という点にお いては課題が残っていると言える.一方で,今回実装した拡散 可能性分類器は,拡散するツイートを9割弱の正解率で抽出で きたため,この分類器は流言検出に留まらず,様々なTwitter上の問題を解決する際に活用できると期待している. 今後は,情報拡散分類器と流言ツイート検出手法の実験結果 から得られた傾向や問題点をもとにしてそれぞれに改良を加え ることで,より正確な流言の自動検出の実現を目指す.また, 平常時と災害時の違いを始めとし,社会情勢の変化や,愉快犯, 特定人物への嫌がらせ,ビジネス,誤報などといった流言を投 稿する目的の違いなどによって流言ツイート自体の特徴や傾向 も変化すると考えられる.今回取り扱った2つの流言について も,4. 2. 3節で述べたように流言が投稿された目的はそれぞれ 異なっていた.幅広い内容の流言に対応するためにも,そのよ うな特徴や傾向を究明し,それに応じた検出法を考案すること も必要であると考える. 文 献 [1] 吉次由美:東日本大震災に見る大災害時のソーシャルメディアの 役割,放送研究と調査 2011 年 7 月号,NHK 放送文化研究所, 2011. [2] 安田雪:ソーシャルメディア上の情報拡散の特性−東日本大震災 時のデマの事例とハブの役割,関西大学『社会学部紀要』第 45 巻第 1 号,pp.33-46,2013
[3] Aditi Gupta, Hemank Lamba, and Ponnurangam Ku-maraguru: $1.00 per RT #BostonMarathon #PrayFor-Boston: Analyzing Fake Content on Twitter, eCrime Re-searchers Summit (eCRS), pp.1-12, 2013.
[4] 村山優子,向井未来,西岡大,齊藤義仰:緊急時の Twitter に おけるデマ情報拡散を考慮したリツイートの意思決定モデル の提案,マルチメディア、分散、協調とモバイルシンポジウム (DICOMO2013),pp.873-879,2013 [5] 宮部真衣,梅島彩奈,灘本明代,荒牧英治:流言情報クラウド: 人間の発信した訂正情報の抽出による流言収集,言語処理学会 第 18 回年次大会,pp.891-894,2012
[6] Jing Ma, Wei Gao, Zhongyu Wei, Yueming Lu, and Kam-Fai Wong: Detect Rumors Using Time Series of Social Con-text Information on Microblogging Websites, the 24th ACM International on Conference on Information and Knowledge Management (CIKM ’15), pp.1751-1754, 2015. [7] 鍋島啓太,水野淳太,岡崎直観,乾健太郎:訂正パターンに基づく 誤情報の抽出と集約,情報処理学会第 75 回全国大会,pp.2-179 - 2-180,2013. [8] 須田剛裕,小嶋和徳,伊藤慶明,石亀昌明,鳥海不二夫:震災時 におけるツイッターのトレンドワードと拡散情報を利用したデマ 推定の一考察,第 75 回全国大会講演論文集,pp.99-101,2013. [9] 宮部真衣,梅島彩奈,灘本明代,荒牧英治:マイクロブログに おける流言の特徴分析,情報処理学会論文誌,Vol.54,No.1, pp.223-236,2013.
[10] Vahed Qazvinian, Emily Rosengren, Dragomir R.Radev, and Qiaozhu Mei: Rumor has it: Identifying Misinforma-tion in Microblogs, the 2011 Conference on Empirical Meth-ods in Natural Language Processing, pp.1589-1599, 2011.
[11] 興梠紗和,木村昭悟,藤代裕之,西川仁:SNS 上での拡散を誘
発する web ニュース説明文の調査と自動選択,第 7 回データ工 学と情報マネジメントに関するフォーラム,2015
[12] Akiyo Nadamoto, Mai Miyabe, and Eiji Aramaki: Analy-sis of Microblog Rumors and Correction Texts for Disaster Situations, the 15th International Conference on Informa-tion IntegraInforma-tion and Web-based ApplicaInforma-tions & Services (ii-WAS2013), pp.44-52, 2013. [13] 梅島彩奈,宮部真衣,荒牧英治,灘本明代:災害時 Twitter にお けるデマとデマ訂正 RT の傾向,情報処理学会研究報告,研究報 告 データベースシステム,Vol.2011-DBS-152,No.4,pp.1-6, 2011 [14] 小林のぞみ,乾健太郎,松本裕治,立石健二,福島俊一. 意見 抽出のための評価表現の収集. 自然言語処理,Vol.12, No.3, pp.203-222, 2005 [15] 東山昌彦, 乾健太郎, 松本裕治, 述語の選択選好性に着目した 名詞評価極性の獲得, 言語処理学会第 14 回年次大会論文集, pp.584-587, 2008