著者
轟 奨太
学位授与機関
Tohoku University
ZDD
に対する質問学習に関する研究
東北大学大学院 情報科学研究科
システム情報科学専攻 篠原研究室
博士課程前期二年の課程
轟 奨太
2016
年
2
月
17
日
目次
第 1 章 序論 1 1.1 はじめに . . . . 1 1.2 論文の構成 . . . . 2 第 2 章 準備 3 2.1 二分決定木 . . . . 32.2 BDD (Binary Desicion Diagram) . . . . 3
2.3 ZDD (Zero-suppressed binary Decision Diagram) . . . . 4
2.4 質問学習 . . . . 7 2.5 記号・用語の定義 . . . . 8 2.6 関連研究 . . . . 10 2.6.1 DFAに対する質問学習アルゴリズム . . . . 10 2.6.2 OBDDに対する質問学習アルゴリズム . . . . 11 第 3 章 データ構造 12 3.1 ZDDAS (ZDD with Access Strings) . . . . 12
3.2 分類木 . . . . 13 3.3 ZDDと ZDDAS,分類木の間に成り立つ性質 . . . . 15 第 4 章 ZDD に対する質問学習アルゴリズム 19 4.1 アルゴリズムの概略 . . . . 19 4.2 初期仮説の構築 . . . . 20 4.3 仮説の更新 . . . . 21 4.3.1 EdgeSplit . . . . 23 4.3.2 NodeSplit . . . . 24
4.3.3 仮説更新の具体例 . . . . 28 第 5 章 アルゴリズムの正当性と質問回数 30 5.1 アルゴリズムの正当性 . . . . 30 5.2 必要な質問回数 . . . . 34 第 6 章 まとめ 37 参考文献 38
第
1
章
序論
1.1
はじめに
ビッグデータと呼ばれる大量かつ多様なデータを処理し,その中に潜在している情報 を取り出すことの重要性が高まっている.例えば,コンビニエンスストアでは,日々大 量に集まる顧客の購買データを解析し,ある商品はどの商品と同時に購入されているか という組み合わせデータを活用して商品管理を行うことなどに注目が集まっている. 大規模なデータを短時間で処理するためには,ハードディスクや CPU などの計算機 ハードウェアの進化だけでなく,データを効率よく処理するアルゴリズムを開発するこ とが重要となる.大規模な組み合わせデータを効率よく圧縮して表現することができる ゼロサプレス型二分決定グラフ (Zero-suppressed binary Desicion Diagram; ZDD) [9] が 注目を集めている.ZDD にはデータを効率よく圧縮できるという利点だけでなく,ZDD 同士の演算により,組み合わせデータに対する演算を高速に(圧縮されたデータ量にほ ぼ比例する時間で)実行することができるという利点もある.すなわち,ZDD を用いる ことでデータを圧縮した状態で高速に演算処理を行い,その結果を取得することができ る.このような特徴に注目が集まり,データマイニング [10] や経路探索 [14] などの分野 での応用がなされている. 計算機を用いて問題を解く場合,問題によって計算が難しいものもあれば容易なもの もある.なぜその問題が難しいのかという原因を説明することは簡単なことではない.質 問学習 (query learning) という学習モデルを用いて,そのアルゴリズムに対する数学的な 解析を行うことで,問題の難しさの本質を突き止めようとする研究が行われている [1].質問学習の対象を正規言語やブール関数などとし,それに対する学習アルゴリズムの開 発・解析をする研究が行われている [2, 6, 5, 11]. 本論文では,質問学習の対象として,近年注目が集まっている ZDD を扱う.先行研究 がなされている他の学習対象と同様に,ZDD に対する質問学習のアルゴリズムを提案す る.少ない質問回数で ZDD を学習するためのデータ構造を提案し,そのデータ構造を用 いた質問学習アルゴリズムの正当性を示す.また,アルゴリズムにおいて必要な質問回 数を解析することで,ZDD に対して効率のよい学習が行えるかどうかを考察する.
1.2
論文の構成
本論文の構成は次のとおりである.第 2 章では,本論文で用いる ZDD や質問学習,関 連研究について述べる.第 3 章では,ZDD の質問学習のために必要なデータ構造につい て説明する.第 4 章では,ZDD の質問学習アルゴリズムを提案する.第 5 章では,質問 学習アルゴリズムの正当性を述べる.最後に第 6 章で,本論文のまとめと今後の課題を 述べる.第
2
章
準備
2.1
二分決定木
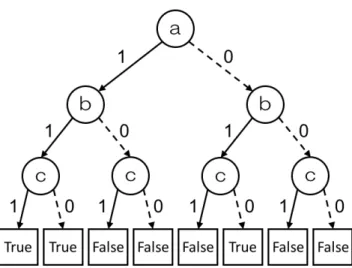
二分決定木 (Binary Decision Tree; BDT) [13] は,論理関数を木構造によって表現した ものである.論理関数 abc∨ ab¯c ∨ ¯ab¯c を表現する二分決定木の例を図 2.1 に示す.二分 決定木の内部頂点はふたつの出力辺をもつ.各頂点にはラベル xiが与えられており,2 本の出力辺によってその要素 xiに対応する真偽値を表現する.要素が真であることを表 す出力辺(実線)を 1-枝と呼び,要素が偽であることを表す出力辺(破線)を 0- 枝と呼 ぶ.また,葉と呼ばれる出力辺をもたない頂点が存在している.葉にはそれぞれ True と Falseのラベルが与えられており,二分決定木の出力と対応している. 各要素を表す変数について,真を表すときに 1 を,偽を表すときに 0 を割り当てるこ ととする.各変数に真偽値を割り当てたときの二分決定木の出力は,頂点がもっている ラベルの変数の値が 1 のときには 1-枝 を,変数の値が 0 のときには 0-枝 をたどっていき, 最終的にたどりつく葉のラベルとなる.例えば,図 2.1 において,a = 1, b = 1, c = 0 を割り当てたとき,根 ⃝ から 1-枝,次の頂点a ⃝(左側)の 1-枝,次の頂点b ⃝(左端)c の 0-枝 をたどって左から 2 番目の葉に到達する.したがって,このときの出力は True と なる.
2.2
BDD (Binary Desicion Diagram)
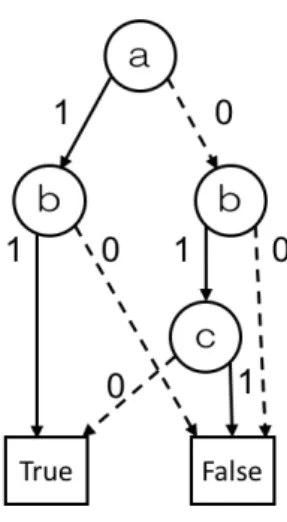
二分決定グラフ (Binary Decision Diagram; BDD) [8] は二分決定木を簡約することで 得られるデータ構造である.論理関数 abc∨ ab¯c ∨ ¯ab¯c を表現する BDD を図 2.2 に示す.
図 2.1: 論理関数 abc∨ ab¯c ∨ ¯ab¯c を表現する二分決定木 BDDの簡約規則は次の通りである. (1) 0-枝 と 1-枝 が同じ頂点を指している頂点を省略する (2) 等価な頂点を共有する この規則を図 2.3 に示す.簡約できる部分がなくなるまで上記規則を繰り返し適用する. 図 2.1 に対して,図 2.3 の簡約規則を適用することで図 2.2 の BDD が得られる. 各変数に真偽値を割り当てたときの BDD の出力は,二分決定木と同様である.根を始 点とし,各頂点がもつラベルの変数の値が 1 のときには 1-枝 を,変数の値が 0 のときに は 0-枝 をたどり,最終的にたどりつく葉のラベルが出力となる. BDDのうち,変数 x1, x2, . . . , xm間に x1 ≺ x2 ≺ · · · ≺ xmという全順序関係があるも
のを順序付き二分決定グラフ (Ordered Binary Decision Diagram; OBDD) [4] と呼ぶ. すなわち,OBDD は,根から葉までたどるすべての経路において,通過する頂点のラベ ルの順序が全順序関係に矛盾しないという性質を持つ.
2.3
ZDD (Zero-suppressed binary Decision Diagram)
ZDD [9]は,組み合わせ集合データの処理に特化した二分決定グラフである.組み合わ せ集合とは,n 個の要素から k 個の要素を選ぶ組み合わせを要素としてもつ集合のこと
図 2.2: 論理関数 abc∨ ab¯c ∨ ¯ab¯c を表現する BDD 図 2.3: BDD の簡約規則 である.ただし,0≤ k ≤ n であり,同じ要素を複数回選ばない.例えば,a,b,c という 3つの要素に対して,{{a,b,c},{a,b},{b}}, {{b,c},λ}, ∅ はそれぞれ組み合わせ集合の 例である.ここで,λ は要素を何も選ばないという組み合わせを表し,∅ は空集合を表す. 以下では,表記の簡略化のため,組み合わせ集合{{a,b,c},{a,b},{b}} を {abc,ab,b} と表記する.ZDD はグラフ中のパスを列挙する問題 [14] や電力網の配置問題 [15] などに 応用されている. 論理関数における変数に対する真偽値の割り当てを,組み合わせ集合において要素を選ぶ ことに対応させることで,組み合わせ集合を表現することができる.例えば,abc∨ ab¯c ∨ ¯ab¯c という論理関数は,{abc,ab,b}という組み合わせ集合と対応する.組み合わせ集合{abc,ab,b} を表現する ZDD を図 2.4 に示す.
図 2.4: 組み合わせ集合 {abc,ab,b} を表現する ZDD 図 2.5: ZDD の簡約規則 ZDDは次の規則によって二分決定木を簡約して得られる. (1) 1-枝 が False 葉を直接指している頂点を省略する (2) 等価な頂点を共有する この規則を図 2.5 に示す.簡約できる部分がなくなるまで上記規則を繰り返し適用する. 図 2.1 の二分決定木に対して,図 2.5 の簡約規則を適用することで図 2.4 の ZDD が得ら れる. ZDDでは,組み合わせを表現する要素 x1, x2, . . . , xm間に x1 ≺ x2 ≺ · · · ≺ xmという 全順序関係が成り立っていると仮定する.組み合わせ集合を表す要素の個数およびその 順序関係が固定されている場合,図 2.5 の規則によって簡約された ZDD の表現の一意性
は保たれる [9].
論理関数における真偽値の割り当てに対応させ,組み合わせ集合において,組み合わせ に要素 xiが含まれることを xi = 1,含まれないことを xi = 0と割り当てることで表す.す
なわち,a = 1, b = 1, c = 1 という割り当ては組み合わせ abc を表し,a = 1, b = 1, c = 0 という割り当ては組み合わせ ab を表す.ZDD で表現される組み合わせ集合にある組み 合わせが含まれているとき,その組み合わせに対する ZDD の出力は True であり,含ま れていないとき False である.出力の求め方は基本的に二分決定木と同様である.ただ し,上の簡約規則 (1) の影響で注意するべき特徴がある.それは,組み合わせ集合に含 まれるすべての組み合わせは,それを構成するすべての要素が順番に ZDD の頂点を通 過する必要があるというものである.例えば,図 2.4 において,組み合わせ bc に対する 出力は False となる.その理由は次のとおりである.根 ⃝ の 0-枝,次に頂点a ⃝(右側)b の 1-枝 をたどってラベル True をもつ葉に到達する.一見,ZDD の出力が True になるよ うに思えるが,頂点 ⃝ をスキップしてラベル True をもつ葉に到達しており,要素 c をc 表す頂点を通過していない.これは,頂点 ⃝ が簡約規則 (1) によって省略されたためでc ある.すなわち,簡約前の二分決定木において頂点 ⃝ の 1-枝 をたどった場合,ラベルc Falseをもつ葉に到達することを意味している.したがって,組み合わせ bc に対する出 力は False となる.
2.4
質問学習
質問学習という学習のモデルは Angluin によって提案されたものである [2].この学習 モデルでは,学習者が能動的に質問をすることで知識を獲得し,目標関数 f を同定する ことを目標とする.用いる質問は,等価性質問と所属性質問という 2 種類の質問である. 等価性質問とは,学習者がもつ仮説関数 h と f が等しいかどうかを尋ねるものである.等 しい場合には YES が,等しくない場合には NO およびその根拠となる反例が返答となる. 所属性質問とは,入力に対する目標関数の出力を尋ねる質問である.すなわち,入力 X に対する目標関数の出力 f (X) が返答となる. 目標関数 f についてよく知っている人を教師と呼ぶ.学習者は教師に対して,上記の 2種類の質問を投げかける.教師は質問に対して,f に矛盾しない必要最低限の答えを返す.学習者は質問に対する返答に無矛盾な仮説関数 h を構築する.出来る限り少ない質 問回数で,f と等価な h を構築することを目標とする. 質問学習における学習の流れは次のとおりである. (1) 学習者は等価性質問と所属性質問を用いて教師に質問を行い,仮説関数 h を構築 する (2) 構築した h に対して目標関数 f との等価性質問を行う (3) 等価性質問の返答が YES であれば,h を出力して学習を終了する.そうでなけれ ば (4) へ進む (4) 等価性質問により得られた反例および所属性質問を用いて h を更新し,(2) に戻る 反例や所属性質問を用いて仮説関数を更新し,目標関数と仮説関数との等価性質問を行 うという一連の流れを繰り返し,目標関数を同定することを目指す. 問題設定によっては,学習者は仮説更新の補助となるようなデータ構造を用いること がある.その例として,観察表や分類木などが挙げられる.これらの使用目的について, 2.6節で簡単に説明する.
2.5
記号・用語の定義
本節では,本論文中で扱う用語・記号についての定義を行う. 定義 1 文字列 X = x1x2· · · xmに対して,文字列 X の長さ i の接頭辞 pre(X, i),文字列 X の長さ i の接尾辞 suf (X, i),文字列 X の i 番目から j 番目までの部分文字列 X[i : j] を次のように定義する.ただし,1≤ i ≤ j ≤ m である.
pre(X, i) := x1x2· · · xi
suf (X, i) := xm−i+1xm−i+2· · · xm X[i : j] := xixi+1· · · xj
例えば,文字列 X = 01101 に対して,pre(X, 3) = 011,suf (X, 3) = 101,X[2 : 4] = 110 である.また,i = j となるとき,X[i : i] を X[i] と簡略して表記する.
定義 2 根付き有向グラフ G において,頂点のアクセス文字列を,根を開始地点とし,そ こから文字列 v を読み込んで辺をたどったときに,その頂点に到達できる文字列 v と定 義する. 例えば,図 2.4 の ZDD における頂点⃝には 11 という文字列を読み込むことで到達するc ことができる.そのため,頂点⃝のアクセス文字列は 11 である.グラフ上の頂点がもつc アクセス文字列を用いて頂点を表す.例えば,11 という表記によって頂点⃝を指す.頂c 点には複数のアクセス文字列が存在する場合がある.また,G におけるアクセス文字列 の集合を nodes(G) と表記する. 定義 3 グラフ G におけるアクセス文字列の集合 nodes(G) 上の関係=Gを次のように定義 する. u, v ∈ nodes(G) に対して, u= vG ⇐⇒ G 上で u と v が同じ頂点に到達するdef uと v が異なる頂点に到達するときは,u G ̸= v と表す.例えば,図 2.4 の ZDD において, 文字列 111 と 010 はどちらもラベル True をもつ葉に到達する.このとき,図 2.4 の ZDD を Z と表すこととすると,111= 010Z である. 定義 4 グラフ G に対して,グラフ上の頂点 u と頂点 v をつなぐ辺を (u, v) と表し, 辺 (u, v) のラベルを l(u, v) と表す. 例えば,図 2.4 において,辺 (1, 11) とは頂点 1 と頂点 11 をつなぐ辺を表し,l(1, 11) = 1 である.また,G における辺の集合を edges(G) と表記する. 定義 5 質問学習において,目標関数を f ,仮説関数を h とする.また,関数への入力を Xとする.このとき,f と h に対する等価性質問の返答と X に対する所属性質問の返答 を次のように表す. EQ (h) : f と h に対する等価性質問の返答 MQ (X) : 入力 X に対する所属性質問の返答
等価性質問は f と h が等価であるかを尋ねるため,それを表すために EQ (f, h) のように 表記するべきである.しかし,質問学習では質問の対象が f であることが明らかである ため,表記を簡略して EQ (h) と表記する.同様に,所属性質問は X に対する目標関数 f の出力を尋ねるものであるため,MQf(X)のように表記するべきである.しかし,質問 の対象の関数が f であることが明らかであるため,表記を簡略して MQ (X) と表す.
2.6
関連研究
質問学習のアルゴリズムに関する先行研究には,学習対象を決定性有限オートマト ン (Deterministic Finite Automata; DFA) [7] としたものと OBDD としたものなどが ある. 2.6.1 DFAに対する質問学習アルゴリズム DFAの質問学習アルゴリズム L∗は Anguin によって提案された [2].このアルゴリズ ムでは,仮説の更新中に得られた反例や所属性質問の結果を観察表と呼ばれるデータ構 造に保存し,観察表に無矛盾な DFA を構築する.L∗アルゴリズムにおいて目標 DFA を 構築するために必要な質問の回数は,等価性質問が n− 1 回,所属性質問が O(kmn2)回 である.ここで,n は目標 DFA の状態数,m は最長の反例の長さ,k はアルファベットサ イズ|Σ| である.L∗アルゴリズムは,Rivest と Schapire によって,必要な質問の回数を 削減する改良がなされた [12].改良版の L∗アルゴリズムでは,反例を扱う際にバイナリ サーチなどを用いて効率化を実現している.改良版 L∗アルゴリズムにおいて目標 DFA を 構築するために必要な質問の回数は,等価性質問が n 回,所属性質問が O(kn2+ n log m) 回である.また,DFA に対する質問学習アルゴリズムとして,Gavald`aと Guijarro が提案した Learn-Automaton [6]というアルゴリズムがある.このアルゴリズムは L∗アルゴリズム で用いられている観察表の代わりに分類木というデータ構造を用いたものである.分類 木は観察表と同様に,質問学習における反例および所属性質問の結果の保存および DFA の状態の区別に用いられる.観察表に比べ分類木には,所属性質問によりオートマトン の各状態を区別できる文字列を効率的に探すことができるという利点がある.また,観
察表を用いる場合は,観察表の更新のたびに仮説を一から構築する必要があるが,分類 木を用いる場合は,今の仮説を保持しながらそこに更新を加えることができ,必要な計 算を減らすことができる.Learn-Automaton アルゴリズムにおいて,目標 DFA を構築す るために必要な質問の回数は,等価性質問が n 回,所属性質問が O(kn3+ nm)回である. Learn-Automatonにおいて,仮説を更新するために反例を活用する部分に改良を加えた アルゴリズムが提案されている [3].改良版 Learn-Automaton において必要な質問の回 数は,等価性質問が n 回,所属性質問が O(kn2+ n log m)回である. 2.6.2 OBDDに対する質問学習アルゴリズム 改良版 L∗アルゴリズムを拡張した,OBDD の質問学習アルゴリズムが提案されてい る [5].論理関数を表現できるように DFA を拡張し,目標の OBDD と等価な DFA を学 習する.このアルゴリズムにおいて,必要な質問の回数は,等価性質問が n 回,所属性 質問が O(mn2 + mn log m)回である.ここで,n は目標 OBDD の頂点数,m は OBDD
で表現されるブール関数における変数の個数である.
また,Learn-Automaton アルゴリズムをベースとする OBDD の質問学習アルゴリズム として,QLearn-π-OBDD アルゴリズム [11] が提案されている.このアルゴリズムでは, OBDDAS (OBDD with Access Strings)というデータ構造および Learn-Automaton で用 いられている分類木を改良したものを用いることで,Gavald`aと Guijarro のアルゴリズ ムに比べて効率的な質問回数による OBDD の学習を実現している.必要な質問回数は等 価性質問が n 回,所属性質問が O(n2+ n log m)回である.
第
3
章
データ構造
本章では,ZDD の質問学習のために用いるデータ構造について説明する.以下では,あ る組み合わせをバイナリ文字列 X = x1x2· · · xm ただし xi ∈ {0, 1} で表現する.バイナ リ文字列の各文字と組み合わせを構成する各要素が対応しており,対応する要素が組み 合わせに含まれることを 1,含まれていないことを 0 を用いて表す.例えば,a,b,c の 3 つの要素に対して,組み合わせ abc を 111,組み合わせ c を 001 と表す.また,組み合わ せ集合を,組み合わせを表すバイナリ文字列の集合として表す.例えば,組み合わせ集 合{abc, ab, c} を {111, 110, 001} と表す.3.1
ZDDAS (ZDD with Access Strings)
組み合わせを構成する要素を x1, x2, . . . , xmとする.2.3 節で説明した ZDD に次のよう
なデータを付与した ZDDAS というデータ構造を用いる.
• 根のラベルが常に x1である.この頂点の出力辺の本数が 1 本のみの場合,この頂
点はダミー頂点である
• 辺 (u, v) のラベル l(u, v) を長さ |v| − |u| のバイナリ文字列とする • 各頂点にひとつのアクセス文字列を付与する
同じ頂点から出ている 2 本の辺のラベルの先頭ビットは必ず異なっている.また,辺の ラベルの 2 文字目以降は必ず 0 である.各頂点において複数個のアクセス文字列が存在 する場合,そのうちいずれかひとつのアクセス文字列を選び,その頂点のアクセス文字
図 3.1: 組み合わせ集合{0111, 0110, 0010}に対するZDDAS H, ZDD Z(H), 分類木 T2, T4 列とする.組み合わせ集合{0111, 0110, 0010} を表現する ZDDAS を図 3.1(1) に示す. 図 3.1(1) に示す ZDDAS H において,根から辺が 1 本しか出ていないため,この頂点は ダミー頂点である.また,各頂点の隣にある下線付き文字列はその頂点のアクセス文字 列を表している. ZDDASに次の処理を施すことで,同じ組み合わせ集合を表現する ZDD に変換するこ とができる. • 根がダミー頂点である場合,ダミー頂点とその出力辺を削除する • すべての頂点のアクセス文字列を削除する • すべての辺のラベルの先頭ビットを残し,2 文字目以降を削除する ZDDAS Hに対するこの変換をZ(H) と表記する.図 3.1(1) の ZDDAS に変換 Z を適用 して得られる ZDD を図 3.1(2) に示す.
3.2
分類木
反例の保存および ZDDAS 上における頂点の区別の効率化のために,Kearns と Vazirani が提案した分類木 [6] に対して,次のような変更を加えたものを使用する.m 個の分類 木を用いる.分類木 Ti(1 ≤ i < m)は ZDDAS におけるラベル xi+1をもつ内部頂点に
single-test頂点と multi-test 頂点と呼ぶ.分類木 Ti(1 ≤ i < m)にはバイナリ文字列の ラベルをもつ葉に加えて,ラベル µ をもつ葉がある.分類木の例を図 3.1(3) に示す.T2 はふたつの multi-test 頂点をもち,T4はひとつの single-test 頂点をもつ. 入力文字列 s に対する分類木 Tiの出力 Ti(s)は,根から辺をたどっていったときに,最 終的に到達する葉のラベルである.内部頂点は 1-枝 と 0-枝 の 2 本の出力辺をもってい るが,辺のたどり方が頂点の種類によって異なる.分類木の内部頂点のラベルを r とす る.single-test 頂点では,s と r を連結させたバイナリ文字列 s· r に対して MQ(s · r) を 求める.MQ (s· r) = True のとき 1-枝 をたどり,MQ(s · r) = False のとき 0-枝 をたど る.multi-test 頂点では,s· r に対する所属性質問に加えて,s にバイナリ文字列を連結 させた文字列に対する所属性質問を複数回行う.¯rを r の先頭ビットを反転させたバイナ リ文字列とする.どのようなバイナリ文字列を連結させた文字列に対して所属性質問を 行うかについて,Algorithm 1 に示す.Algorithm 1 に示す所属性質問を行い,すべての 条件が満たされたときに限り 1-枝 をたどり,それ以外のときは 0-枝 をたどる.分類木を 用いることで,過去に得られた反例を保存するだけでなく,ZDDAS 上の頂点の等価性を 評価することができ,目標 ZDD に存在しない頂点を ZDDAS に作成してしまうことを防 ぐことができる. ZDDASのアクセス文字列と分類木の葉のラベルには次のような対応関係がある.分類 木 Tiの葉のラベルと,ZDDAS において xi+1のラベルをもつ頂点のアクセス文字列が一 致する.ただし,ラベル µ は例外であり,ZDDAS において対応するアクセス文字列をも つ頂点は存在しない.例えば,図 3.1 において,T2にはラベル 01 と 00 をもつ葉がある ことに対して,H において x3のラベルをもつ頂点がふたつ存在し,それぞれのアクセス 文字列が 01,00 となっている. 2.3節で,ZDD において入力 X = x1x2· · · xmに対する出力を評価するときに,ラベ ル xiをもつ頂点において,組み合わせが要素 xiを含んでいるときに 1-枝 を,含まない ときに 0-枝 を選択してたどることを説明した.ZDDAS では,辺のラベルを長さ 1 以上 のバイナリ文字列に変更したことによって,辺をたどる条件が変化する.頂点 u につい て,辺 (u, v0)と (u, v1)という 2 本の出力辺をもっているとする.ただし,l(u, v0)[1] = 0
と X[|u| + 1 : |v0|] が一致したときに限り (u, v0)をたどることができる.x|u|+1 = 1であ
る場合,(u, v1)のラベルと X[|u| + 1 : |v1|] が一致したときに限り (u, v1)をたどることが
できる.いずれの場合でもラベルと X の部分文字列が一致しない場合には辺をたどるこ とができない.以降,この特徴のことを葉までたどることができないと表現する.入力 Xに対して,ZDDAS の葉までたどることができない場合,X に対する ZDDAS の出力 は False となる.図 3.1 の ZDDAS H において,葉までたどることができない例として X = 0011が挙げられる.0011 は頂点 ϵ の辺 (ϵ, 0),頂点 0 の辺 (0, 00) をたどって頂点 00 に到達するが,X[3 : 4] = 11 と辺 (00, 0110) のラベル 10 が一致しないため辺 (00, 0110) をたどることができない.このため,入力例 X に対する H の出力は False となる.この 条件により ZDDAS と ZDD の間で出力が変化することはない.
3.3
ZDD
と
ZDDAS
,分類木の間に成り立つ性質
目標 ZDD を Z,仮説 ZDDAS を H とする.H における長さ i のアクセス文字列の集合 を nodesi(H)とする.H のアクセス文字列の集合を nodes(H) = ∪i=m i=0 nodesi(H)と表記 する.また,集合 Nodes(Z) を Z のアクセス文字列の集合とする.すなわち,Nodes(Z) は,空文字列および文字列 a1a2. . . ak (1≤ k ≤ m) の集合である.ここで a1a2. . . ak と は, Z 上で頂点 xk+1に到達するような, x1 = a1, x2 = a2, . . . , xk = akという代入に よって得られるバイナリ文字列のことである.ここで注意するべきことは,|Nodes(Z)| と Z の頂点数は一致しないということである.それは,Z においてバイナリ文字列 u, v が同じ頂点に到達する場合,u ∈ Nodes(Z) かつ v ∈ Nodes(Z) が成り立つ.しかし,到 達する頂点は Z 上では同一の頂点であるので,|Nodes(Z)| の方が Z の頂点数よりも大き くなることがあるためである.v ∈ Nodes(Z) となるような文字列 v は次の性質 1 の (1) または (2) のいずれかを満たす. 性質 1 ZDD Z におけるアクセス文字列 v ∈ Nodes(Z) は, (1) |v| = m (2) 長さ m− |v| の文字列 r に対して, MQ (v· r) = True かつ r[1] = 1 を満たす文字列 r が存在するのいずれかの条件を満たす. Algorithm 1のように出力を定義した分類木 Tiは次の性質 2 を満たす. 性質 2 任意の v1, v2 ∈ Nodes(Z) ただし,|v1| = |v2| = i に対して, v1 Z = v2 =⇒ Ti(v1) = Ti(v2) が成り立つ. 本論文で提案するアルゴリズムにおいて,ZDDAS H と ZDD Z,分類木は次の補題 1 を満たす.バイナリ文字列 X に対する H,Z の出力をそれぞれ H(X),Z(X) と表す. 補題 1 目標 ZDD Z ,ZDDAS H および 分類木 Ti(1≤ i ≤ m)が次の性質 C1, C2, C3 を 満たしていると仮定する.このとき,H の頂点数と Z の頂点数が一致すれば,Z(H) = Z が成り立つ. C1 (1) nodes(H) ⊆ Nodes(Z) (2) ∀v ∈ nodesm(H)に対して,H(v) = Z(v) (3) ∀v1,∀v2 ∈ nodes(H) に対して,v1 ̸= v2 =⇒ v1 Z ̸= v2 C2 (1) ∀v ∈ nodes(H) に対して,T|v|(v) = v
(2) ∀i ∈ {1, . . . , m}, ∀a = {0, 1}iに対して,a /∈ Nodes(Z) =⇒ T
i(a) = µ
C3 ∀(u, v) ∈ edges(H) について, (1) T|v|(u· l(u, v)) = v
(2) |u| < ∀j < |v| に対して,Tj(u· pre(l(u, v), j − |u|)) = µ
証明 1 C1 (1) より,nodes(H) から Z の頂点への写像 N が定義できる.すなわち,v ∈
nodes(H)に対して,N (v) は Z 上で v に対応する頂点である.最終的に|nodes(H)| と Z の頂点数が等しくなることから,N が全単射であるといえる.|v| ̸= m であるとき,v の ラベルと Z における N (v) のラベルはどちらも x|v|+1となる.|v| = m であるときでも, C1 (2)より葉のラベルは一致する.したがって, Z (H) = Z を示すためには,任意の
v1, v2 ∈ nodes(H) に対して,Z においてラベルが b である辺 (N (v1) , N (v2))が存在する ときに,(v1, v2)∈ edges(H) であり,ラベル l (v1, v2)の先頭ビットが b であることを示せ ばよい. 任意の v1, v2 ∈ nodes(H) に対して,Z において辺 (N (v1) , N (v2))が存在し,その ラベルが l (N (v1) , N (v2)) = bであると仮定する.また,H 上の頂点 (v1, v)に対して, l (v1, v) [1] = bであるとする.すなわち,l (v1, v) = b· {0}|v|−|v1|−1である. |v| < |v2| であると仮定する.このとき, |v1 · l (v1, v)| = |v| < |N (v2)| であるから (v1 · l (v1, v)) /∈ Nodes(Z) である.C2 (2) より T|v|(v1· l (v1, v)) = µが成り立つ.したがっ て,C3 (1) より (v1, v) /∈ edges(H) といえる.これは (v1, v) ∈ edges(H) という仮定と矛 盾している.よって,|v| ≥ |v2| である. 次に,|v| > |v2| であると仮定する.|v| > |v2| であるから,pre(l (v1, v),|v2| − |v1|) = b· {0}|v2|−|v1|−1である.したがって,v 1· pre(l (v1, v),|v2| − |v1|) = v1· b · {0}|v2|−|v1|−1 Z= v2が成り立つ.よって,T|v2|(v1· pre(l (v1, v),|v2| − |v1|)) = T|v2|(v2) = v2 である.こ れは C3 (2) において, j = |v2| としたときの条件に当てはまる.すなわち,T|v2|(v1 · pre(l(v1, v),|v2| − |v1|)) = µ である.v2 ̸= µ であるから,この結果は矛盾している.よっ て,|v| = |v2| であることがわかる. |v| = |v2| として考える.l (v1, v) = b · {0}|v|−|v1|−1 である.|v| = |v2| であるから, v1· l (v1, v) Z = v2である.性質 2 より,T|v2|(v1· l (v1, v)) = T|v2|(v2) = v2である.一方, C3 (1)より T|v2|(v1· l (v1, v)) = vが成り立つ.したがって,v = v2が成り立つ. 以上より, Z にラベル l (N (v1) , N (v2))をもつ辺 (N (v1) , N (v2))が存在するとき, (v1, v2)∈ edges(H) であり,l (v1, v2)の先頭ビットが b であることが示された. 2
Algorithm 1: Ti(s) Input: バイナリ文字列: s Output: 葉のラベル: r 1 if |s| ̸= i then return µ; 2 n := (根頂点); 3 while (nが内部頂点) do 4 r, t := (nのラベル), (n の 1-枝の先の頂点のラベル); 5 r := (r¯ の先頭 1 ビットを反転させたバイナリ文字列); 6 if (nが single-test 頂点) then 7 if MQ (s· r) = True then n := (n の 1-枝の先の頂点) ; 8 else n := (nの 0-枝の先の頂点) ;
9 else if (nが multi-test 頂点) then 10 n′ := (nの 1-枝の先の頂点); 11 for i ← 1 to m − |s| do 12 if MQ (s· r) ̸= MQ(t · r) or MQ(s · ¯r) ̸= MQ(t · ¯r) or MQ (s· {1}i· {0}m−|s|−1−i)̸= MQ(t · {1}i· {0}m−|s|−1−i) or MQ (s· {0}i· {1}m−|s|−1−i)̸= MQ(t · {0}i· {1}m−|s|−1−i) or MQ (s· {0}i−|s|−1· 1 · {0}m−i)̸= MQ(t · {0}i−|s|−1· 1 · {0}m−i) or MQ (s· {1}i−|s|−1· 0 · {1}m−i)̸= MQ(t · {1}i−|s|−1· 0 · {1}m−i) then
13 n′ := (nの 0-枝の先の頂点);
14 break;
15 n := n′;
第
4
章
ZDD
に対する質問学習アルゴリズム
本章では,ZDD に対する質問学習アルゴリズムを提案する. 本論文で扱う ZDD に対する質問学習とは,質問学習のモデルにおいて目標関数として ZDDを扱う問題である.2.3 節で述べたように,ZDD は,{0, 1}mから{True, False} へ の写像を表す関数とみなすことができる.ここで,m は組み合わせを構成する要素(変 数)の個数である.このとき,より少ない質問回数で効率よく目標 ZDD を構築すること が目的である. 本問題において,効率よく学習を行うために前章で説明した ZDDAS と分類木を用い て仮説を構築する.また,等価性質問を行う際には,変換Z によって ZDDAS H を ZDD に変換したZ(H) を用いる.4.1
アルゴリズムの概略
ZDDの質問学習アルゴリズムは,OBDD の学習アルゴリズムである QLearn-π-OBDD アルゴリズム [11] をベースとしている.ZDD の質問学習アルゴリズムを Algorithm 2 に 示す.アルゴリズムの概略は,次のとおりである.等価性質問の返答が YES となるまで ステップ (2)∼ステップ (4) を繰り返し,仮説の更新を行う. (1) 初期仮説 ZDDAS H0, 初期分類木 T0 1, T20, . . . , Tm0 を作成する(詳細は 4.2 節) (2) 仮説 H をZ(H) に変換する.Z(H) に対して目標 ZDD Z との等価性質問を行う (3) 等価性質問の返答が YES であれば Z(H) を出力し,アルゴリズムを終了する.そ うでなければ (4) へAlgorithm 2: wholeAlgorithm(m) Input: m :=変数の個数 Output: 変換後の仮説 ZDD:Z(H) 1 mqλ := MQ (λ); 2 if mqλ = True then 3 Hλ :={λ}; 4 else 5 Hλ :=∅; 6 ans, e1 := EQ (Hλ);
7 if ans = YES then return Hλ;
8 ans, e0 := EQ (1);
9 if ans = YES then return 1;
10 (H, T1, T2, . . . , Tm) :=Initial-Hypothesis(e0, e1); 11 ans, e := EQ (Z(H)); 12 while ans = NO do 13 (H, T1, T2, . . . , Tm) :=Update-Hypothesis(H, T1, T2, . . . , Tm, e); 14 ans, e := EQ (Z(H)); 15 return Z(H); (4) 等価性質問により得られた反例 e をもとに仮説 H, 分類木 T1, T2, . . . , Tm を更新す る(詳細は 4.3 節).(2) へ戻る Algorithm 2において,ステップ 3 の{λ} は要素を何も選ばない組み合わせのみを含む ZDDを表し,ステップ 5 の∅ は組み合わせを何も含まない ZDD,ステップ 8 の 1 はあ らゆる組み合わせを含む ZDD を表す.
4.2
初期仮説の構築
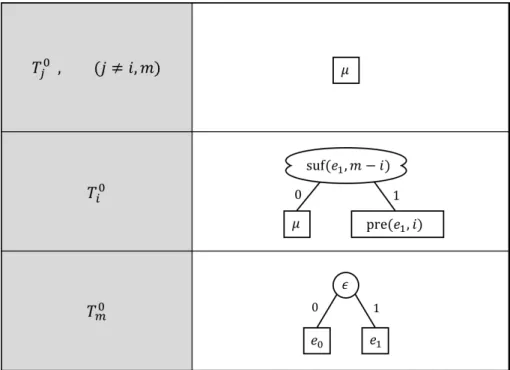
初期仮説は Algorithm 2 のステップ 8 までに得られた,ふたつの反例をもとに構築す る.構築アルゴリズムを Algorithm 3 に示す.Algorithm 3: Init-Hypothesis(e0, e1, mqλ) Input: 仮説に対する反例: e0, e1, 空集合に対する所属性質問の出力: mqλ Output: 初期仮説 ZDDAS: H0, 分類木: T10, T20, . . . , Tm0 1 i :=(e1[i] = 1となるような最小のインデックス); 2 e′1 := pre(e1, i)· {0}m−i; 3 mqe′ 1 := MQ (e ′ 1); 4 mqλと mqe′ 1 の値により初期仮説 H 0を作成する(図 4.1 参照); 5 初期分類木 T10, T20, . . . , Tm0 を作成する(図 4.2 参照); 6 return H0, T10, T20, . . . , Tm0; はじめに,葉ひとつのみで構成される ZDD に対して等価性質問をする.ここで,葉 ひとつのみで構成される ZDD は,∅ と {λ} の 2 種類がある.どちらの ZDD に対して等 価性質問をするかを,空集合に対する所属性質問の結果 mqλ( = MQ (λ))にて決定する. mqλ = Trueであれば{λ} に対して,mqλ = Falseであれば ∅ に対して等価性質問を行う. これにより,反例 e1を得る.次に,1 に対して等価性質問を行い,反例 e0 を得る.ここ までに行った等価性質問において,返答が YES であった場合には,その時点で等価性質 問に用いた ZDD を出力してアルゴリズムは停止する.そうでなければ,得られた反例 e0 と e1を用いて,初期仮説 ZDDAS および分類木を作成する.ここで,e0 と e1は先の等価 性質問で得られた,MQ (e0) = False, MQ (e1) = Trueとなるような反例である.反例 e1 を用いて i および e′1を求める.ここで, i は反例 e1において,e1[i] = 1となるような
最小のインデックスであり, 1≤ i ≤ m である.また,e′1 = pre(e1, i)· {0}m−iとなる文
字列である.e′1 に対する所属性質問の結果 mqe′1 を得る.mqλ および mqe′1 の値により, 図 4.1 の対応した部分の初期仮説および図 4.2 の分類木を構築する.
4.3
仮説の更新
等価性質問により得られた反例を利用して,仮説 ZDDAS および分類木を更新する.仮 説更新アルゴリズムを Algorithm 4 に示す.反例をもとに,仮説を次の 2 種類の方法のう ちどちらかの方法で更新する.図 4.1: 初期仮説 • EdgeSplit(4.3.1 節) • NodeSplit(4.3.2 節) どちらの方法によって仮説の更新を行うかを次のように決定する.仮説 ZDDAS H の 根をスタート地点とし,等価性質問より得られる反例 e を先頭から読み込み,辺をたどっ ていく.このとき, e が反例であることから,H 上で根から葉までをたどる際に次に挙 げるものが起こる. (1) 葉に到達する前に,辺をたどることができない (2) たどることができる頂点のいずれかに対して,頂点のラベルを xi,アクセス文字列
を v とすると, MQ (v· suf (e, m − |v|)) ̸= MQ(e) が成り立つ
(1)と (2) のうち,(1) を先に満たした場合,xi = 1となる要素で 1-枝 をたどることがで
きるように,新たな頂点を作成する EdgeSplit(4.3.1 節)という方法で更新を行う.(2) を先に満たした場合,(2) の条件より等価ではない頂点を等価であるとみなしていたこと がわかる.そのため,反例に対する H の出力が矛盾しなくなるように,ラベル xiをもつ
図 4.2: 初期分類木
4.3.1 EdgeSplit
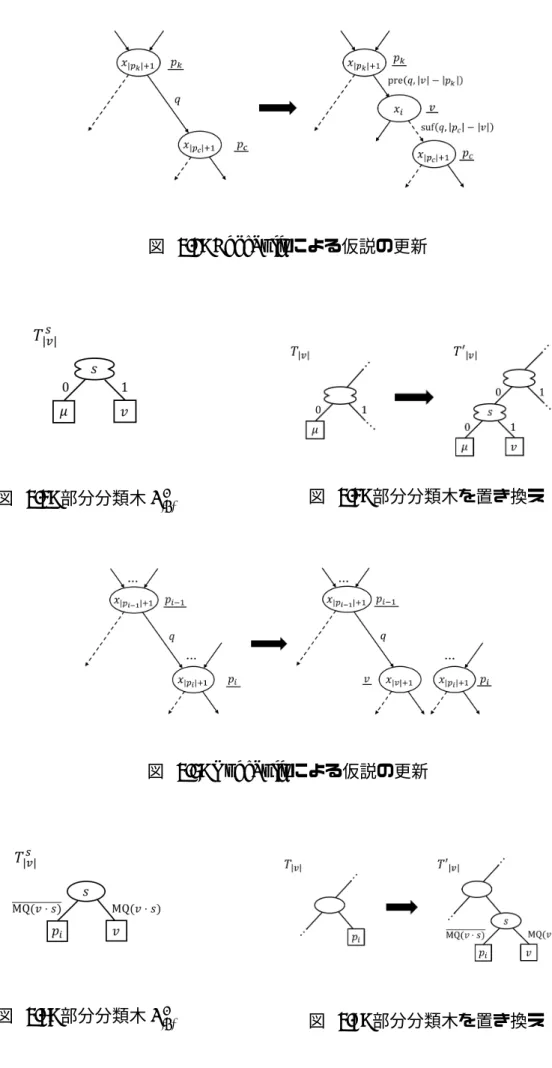
詳細なアルゴリズムを Algorithm 5 に示す.図 4.3 に,EdgeSplit による仮説 ZDDAS の更新の様子を示す. このアルゴリズムでは,xi に対応する頂点を作成し,反例に対して葉までたどること ができるように仮説を更新する.反例がたどることができていた頂点のうち,最も根か ら遠いものを親頂点と呼び,親頂点とラベル q をもつ辺でつながっている頂点を子頂点 と呼ぶ.ここで,ラベル q をもつ辺とは,反例をたどることができなかった辺のことで ある.親頂点と子頂点をつなぐ辺を削除し,親頂点と新規頂点をラベル pre(q,|v| − |pk|) をもつ辺でつなぐ.次に,新規頂点と子頂点をラベル suf (q,|pc| − |v|) をもつ辺でつなぐ. 新規頂点からのラベルの先頭ビットが 1 となる辺について,分類木 Tj(i + 1≤ j ≤ m) を用いて辺の接続先を決める.このとき,分類木 Tjの出力が µ 以外のバイナリ文字列で ある場合に,そのアクセス文字列をもつ頂点に対して辺を作成する.また,図 4.4 に示 すように,新たに作成する頂点に対応した部分分類木 T|v|s を作成する.図 4.5 に示すよう に,T|v|において,ラベル µ がついた頂点を T|v|s と置き換え,分類木の更新を行う.
Algorithm 4: Update-Hypothesis(H, T1, T2, . . . , Tm, e) Input: 仮説 ZDDAS: H, 分類木: T1, T2, . . . , Tm, 反例: e Output: 更新後仮説 ZDDAS: H′, 分類木: T1′, T2′, . . . , Tm′ 1 (p1, p2, . . . , pk) := (Hにおいて,反例 e がたどる頂点のアクセス文字列の系列); 2 for j ← 1 to k do 3 if j = k and |pk| ̸= m then 4 i := (|pk| より大きい自然数のうち,e[i] = 1 となるような最小の自然数); 5 pc:= (アクセス文字列 pkをもつ頂点の辺のうち,先頭ビットが e[|pk| + 1] で ある辺が指す頂点のアクセス文字列); 6 (H′, T1′, T2′, . . . , Tm′ ) := EdgeSplit(H, T1, T2, . . . , Tm, e, pk, pc, i); 7 break;
8 else if MQ (pj · suf (e, m − |pj|)) ̸= MQ(e) then 9 i := j;
10 (H′, T1′, T2′, . . . , Tm′ ) := NodeSplit(H, T1, T2, . . . , Tm, e, pi−1, pi); 11 break;
12 return H′, T1′, T2′, . . . , Tm′ ;
4.3.2 NodeSplit
詳細なアルゴリズムを Algorithm 6 に示す.図 4.6 に,NodeSplit による仮説 ZDDAS の更新の様子を示す. このアルゴリズムでは,xi に対応する頂点を作成し,反例に対する出力が矛盾しなく なるように仮説を更新する.条件 (2) を満たした頂点とその親頂点をつないでおり,ラベ ルの先頭ビットが e[i− 1] である辺を削除する.親頂点と新規頂点を先頭ビットが e[i − 1] である辺でつなぐ.新規頂点からの 0-枝,1-枝 については,分類木 Tj(i + 1≤ j ≤ m) を用いて辺の接続先を決める.このとき,分類木 Tjの出力が µ 以外のバイナリ文字列で ある場合にそのアクセス文字列をもつ頂点に対して辺を作成する.また,図 4.7 に示す ように,新規頂点に対応した部分分類木 T|v|s を作成する.図 4.8 に示すように,T|v|にお いて,ラベル piをもつ頂点を T|v|s に置き換え,分類木の更新を行う.
図 4.3: EdgeSplit による仮説の更新
図 4.4: 部分分類木 T|v|s 図 4.5: 部分分類木を置き換え
図 4.6: NodeSplit による仮説の更新
Algorithm 5: EdgeSplit(H, T1, T2, . . . , Tm, e, pk, pc, i) Input: 仮説 ZDDAS: H, 分類木: T1, T2, . . . , Tm, 反例: e, アクセス文字列: pk, pc, 作 成頂点のインデックス: i Output: 更新後仮説 ZDDAS: H′, 分類木: T1′, T2′, . . . , Tm′ 1 q := l(pk, pc); 2 v := pk· pre(q, i − |pk|); 3 if i ̸= 1 then 4 Hにアクセス文字列 v,ラベル xiをもつ頂点とラベル pre(q,|v| − |pk|) をもつ辺 (pk, v),ラベル suf (q,|q| − |v|) = {0}|q|−|v|をもつ辺 (v, pc)を作成する; 5 Hからラベル q をもつ辺 (pk, pc)を削除する; 6 else 7 何もしない (x1がダミー頂点として既にあるため,頂点を新たに作成しない); 8 s := suf (e, m− |v|); 9 部分分類木 T|v|s を作成する.ラベル s をもつ multi-test 頂点と,それからラベル 0 と 1 をもつ辺でつながったラベル µ と v をもつふたつの子頂点を作成する (図 4.4 参照); 10 分類木のラベル µ をもつ頂点を部分分類木で置き換える (図 4.5 参照); 11 Hにラベル 1· {0}j−1をもつ辺 (v, T|v|+j(v· 1 · {0}j−1))を作成する.ここで,j は T|v|+j(v· 1 · {0}j−1)̸= µ を満たす最小の自然数である; 12 |v1| < |v| < |v2| を満たす辺 (v1, v2)∈ edges(H) に対して,T|v|s (v1· g) を求める.ここ で,g = pre(l(v1, v2),|v| − |v1|) である.その出力が v であれば,辺 (v1, v2)を削除し, ラベル g をもつ辺 (v1, v)を作成する; 13 return H′, T1′, T2′, . . . , Tm′ ;
Algorithm 6: NodeSplit(H, T1, T2, . . . , Tm, e, pi−1, pi) Input: 仮説 ZDDS: H, 分類木:T1, T2, . . . , Tm,反例: e, アクセス文字列: pi−1, pi Output: 更新後仮説 ZDDS: H′,分類木: T1′, T2′, . . . , Tm′ 1 q := l(pi−1, pi); 2 v := pre(e,|pi−1|) · q; 3 Hにアクセス文字列 v,ラベル x|v|+1をもつ頂点とラベル q をもつ辺 (pi−1, v)を作成 する; 4 Hからラベル q をもつ辺 (pi−1, pi)を削除する; 5 s := suf (e, m− |v|); 6 部分分類木 T|v|s を作成する.ラベル s をもつ single-test 頂点と,それから辺でつな がったラベル v,piをもつふたつの子頂点を作成する (図 4.7 参照).このとき, MQ (v· s) は MQ(v · s) の出力を反転させたものである; 7 T|v|において,ラベル piをもつ頂点を部分分類木で置き換える (図 4.8 参照); 8 Hにラベル 1· {0}j1−1をもつ辺 (v, T|v|+j1(v· 1 · {0}j1−1))と,ラベル{0}j2 をもつ辺 (v, T|v|+j2(v· {0}j2))を作成する.ここで,j 1および j2は T|v|+j1(v· 1 · {0} j1−1)̸= µ お よび T|v|+j2(v· {0} j2)̸= µ を満たす最小の自然数である; 9 (v1, pi)∈ edges(H) に対して,T|v|s (v1· l(v1, pi))を求める.その出力が v であれば,辺 (v1, pi)を削除し,ラベル l(v1, pi)をもつ辺 (v1, v)を作成する; 10 return H′, T1′, T2′, . . . , Tm′ ;
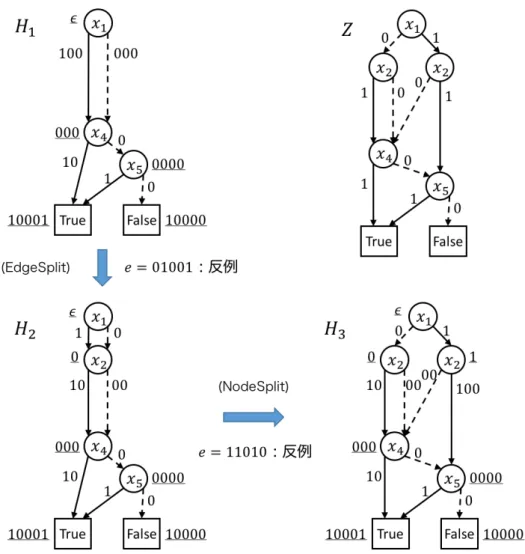
4.3.3 仮説更新の具体例 Algorithm 4を適用し,仮説 ZDDAS を更新する例を図 4.9 に示す.図 4.9 の右上の Z が目標 ZDD である.Z において,変数は x1, x2, x3, x4, x5の 5 つである.H1は,次の反 例を順に得て,これらを用いて初期仮説の生成,ZDDAS の更新を行うことで得られる: 10001,01101,00010,00001. Z(H1)に対して等価性質問を行ったときに,反例として 01001 が得られたとする.この とき,反例が H1上をたどったときに得られるアクセス文字列の系列は p1 = ϵである.こ れは,途中で辺をたどれなくなったためである.Algorithm 4 のステップ 3 の条件を満た すことから,EdgeSplit(Algorithm 5)を適用する.このとき,i = 2,pk= ϵ,pc= 000 である.Algorithm 5 によってラベル x2,アクセス文字列 0 をもつ頂点が作成され,H2 を得る. 次に,Z(H2)に対して等価性質問を行ったときに,反例として 11010 が得られたとする. このとき,反例が H2上をたどったときに得られるアクセス文字列の系列は,p1 = ϵ,p2 =
0,p3 = 000,p4 = 10001である.p = p2 = 0のとき,MQ (p· suf (e, m − |p|)) ̸= MQ(e)
より,Algorithm 4 のステップ 8 の条件を満たすことから,NodeSplit(Algorithm 6)を 適用する.このとき,pi−1 = ϵ,pi = 0である.Algorithm 6 によってラベル x2,アクセ
第
5
章
アルゴリズムの正当性と質問回数
本章では,前章のアルゴリズムの正当性およびアルゴリズム中で必要な質問の回数につ いて説明する.5.1
アルゴリズムの正当性
仮説 ZDDAS H,分類木 T1, T2, . . . , Tmに対して,Algorithm 4 を適用してそれぞれを 更新したとき,更新後の ZDDAS H′と分類木 T1′, T2′, . . . , Tm′ が次の補題 2 を満たす. 補題 2 目標 ZDD Z に対して,ZDDAS H および分類木 T1, T2, . . . , Tmが性質 C1, C2, C3 を満たし,H がふたつの葉をもっているとする.このとき,更新後の H′, T1′, T2′, . . . , Tm′ は性質 C1, C2, C3 を満たし,かつ|nodes(H′)| = |nodes(H)| + 1 である. 証明 2 更新前の H, T1, T2, . . . , Tmが性質 C1, C2, C3 を満たしているとする.また,H に 対する反例を e とする.2 種類の仮説更新方法それぞれについて,更新後の H′ および T1′, T2′, . . . , Tm′ が補題 2 を満たすことを示す. EdgeSplitのとき Algorithm 5において,ステップ 4 で仮説 H にひとつの内部頂点 v を追加する.この 他に頂点の追加を行わない.したがって,|nodes(H′)| = |nodes(H)| + 1 が成り立つ. はじめに,H′が C1 を満たすことを示す.v は内部頂点なので nodesm(H′) = nodesm(H) が成り立つ.仮定より H が C1(2) を満たしているので,H′ も C1(2) を満たす.∃u ∈および C2(1) より T|v|(v) = uが成り立つ.ここで,v = pk· pre(l(pk, pc),|v| − |pk|) であ ることと C3(2) より,T|v|(v) = T|v|(pk· pre(l(pk, pc),|v| − |pk|)) = µ が成り立つ.これは, T|v|(v) = uに矛盾するので,u Z ̸= v である.したがって H′は C1(3) を満たす.EdgeSplit アルゴリズムで更新を行う条件|pk| ̸= m と e が反例であることより,MQ(e) = True で ある.ZDD の出力が True である場合,その組み合わせの各要素に対応する頂点を通過 する必要がある.e を用いて H 上を葉までたどれないということは,|v| + 1 番目の要素 に対応する頂点が存在していないということである.MQ (e) = True であることと,性 質 1 より,v ∈ Nodes(Z) が成り立つ.したがって H′は C1(1) を満たす.以上より,H′ は C1 を満たす. 次に,H′, T1′, T2′, . . . Tm′ が C2 を満たすことを示す.アルゴリズム中で変更を加える分 類木は T|v|だけであるので,∀j ∈ ({1, 2, . . . , m} − {|v|}) に対して Tj = Tj′ が成り立つ. よって,T|v|′ のみについて考えればよい.T|v|′ は,T|v|のラベル µ をもつ頂点を,内部頂点 sとふたつの葉 v と µ で構成されている部分分類木 T|v|s で置き換えたものである.よって, 更新前に分類木 T|v|(u) = u(ただし u̸= µ)を満たす文字列 u に対して,T|v|′ (u) = uが成 り立つ.したがって,|u| = |v| を満たすような u ∈ nodes(H) に対して,T|v|′ (u) = uとな る.また,v = pk· pre(l(pk, pc),|v| − |pk|) であることと C3(2) より,T|v|(v) = µとなる.
分類木の更新方法より,T|v|(v) = µを満たす v に対して,T|v|′ (v) = T|v|s (v)である.T|v|s の定義より,T|v|′ (v) = vが成り立つ.したがって,T|v|′ は C2(1) を満たす.a /∈ Nodes(Z) となるような a∈ {0, 1}|v|について考える.C2(2) より T|v|(a) = µである.よって,a は
T|v|′ において T|v|s の部分に到達する.a /∈ Nodes(Z) であるから MQ(a · s) = False である. そのため,MQ (e) = MQ (v· s) ̸= MQ(a · s) が成り立つ.T|v|s の定義より,T|v|s (a) = µで ある.すなわち,T|v|′ (a) = µである.したがって,T|v|′ は C2(2) を満たす. 最後に,H′, T1′, T2′, . . . Tm′ が C3 を満たすことを示す. まず,ステップ 4 で作成する辺 (pk, v)と (v, pc)について考える.これらの辺につい て,T|v|′ (pk · l(pk, v)) = T|v|′ (v) = v であり,T|p′c|(v · l(v, pc)) = T|p′c|(pc) = pcである. したがって,これらの辺は C3(1) を満たす.|pk| < j1 < |v| < j2 < |pc| としたと き,Tj′1(pk· pre(l(pk, v), j1− |pk|)) = Tj1(pk· pre(l(pk, v), j1− |pk|)) = µ であり,Tj′2(v·
µである.したがって,これらの辺は C3(2) を満たす. 次に,ステップ 11 で作成する辺 (v, T|v|+j(v· 1 · {0}j−1))について考える.このとき, C3を満たしている分類木 T|v|+j を用いて辺の先の頂点を決めているので,この辺は C3 を満たしている. 次に,ステップ 12 で作成する辺 (v1, v)について考える.C3(2) より, T|v|(v1 · pre(l(v1, v2),|v| − |v1|)) = T|v|(v1 · l(v1, v)) = µである.更新後の T|v|′ において, 頂点 µ が Ts |v|に置き換わるので,T|v|′ (v1 · pre(l(v1, v2),|v| − |v1|)) = T|v|′ (v1 · l(v1, v)) = Ts |v|(v1· l(v1, v)) = vである.したがって,C3(1) を満たす.|v1| < j < |v| を満たす j に対 して,Tj′(v1· pre(l(v1, v), j− |v1|)) = Tj(v1· pre(l(v1, v), j− |v1|)) = µ である.したがっ て,C3(2) を満たす. 最後に,edges(H)∩ edges(H′)を満たす辺について考える.これらの辺は,H′の辺の うち,アルゴリズム中で追加した辺を除く辺のことである.T|a|(a) ̸= µ または |a| ̸= |v| を満たすようなアクセス文字列 a について,T|a|′ (a) = T|a|(a)であるから,T1′, T2′, . . . , Tm′
に対して C3(1) は明らかに成り立つ.T1′, T2′, . . . , Tm′ において,C3(2) を満たさないよう
な辺 (v1, v2)は|v1| < |v| < |v2| かつ T|v|′ (v1 · pre(l(v1, v2),|v| − |v1|)) = v を満たすよう
な辺である.しかし,これらの辺はステップ 5 およびステップ 12 で削除しているため,
nodes(H)∩ nodes(H′)には含まれない.そのため,nodes(H)∩ nodes(H′)を満たすすべ ての辺は C3(2) を満たす.以上より,H′, T1′, T2′, . . . Tm′ は C3 を満たす. NodeSplitのとき Algorithm 6において,ステップ 3 で仮説 H にひとつの内部頂点 v を追加する.この 他に頂点の追加を行わない.したがって,|nodes(H′)| = |nodes(H)| + 1 である. はじめに,H′が C1 を満たすことを示す.C3(1) より,T|v|(v) = T|v|(pi−1·l(pi−1, pi)) = pi が成り立つ.このことと C2(2) より,v ∈ Nodes(Z) である.したがって,H′は C1(1) を 満たす.∃u ∈ (nodes|pi|(H)− {pi}) に対して,v Z = uであると仮定する.C2(1) より, T|pi|(v) = T|pi|(u) = uが成り立つ.C3(1) より,T|pi|(v) = T|pi|(pi−1· l(pi−1, pi)) = piであ る.仮定より u̸= piであるから,上の 2 式は矛盾している.したがって,v Z = uであり,
ゴリズムの実行条件より,MQ (pi· s) ̸= MQ(v · s) が成り立つ.ZDD の簡約規則 (2) よ り,v Z ̸= piである.したがって H′は C1(3) を満たす.仮定より,H はふたつの葉をもっ ている.H′が C1(1) と C1(3) を満たしているとき,v が葉になりえないので,|v| ̸= m で ある.よって,nodesm(H′) = nodesm(H)である.したがって,H′は C1(2) を満たす.以 上より,H′は C1 を満たす. 次に,H′, T1′, T2′, . . . Tm′ が C2 を満たすことを示す.アルゴリズム中で分類木を更新す るのは T|v|だけなので,∀j ∈ ({1, 2, . . . , m} − {|v|}) に対して,Tj′ = Tj となることは明 らかである.したがって,以下では T|v|′ についてのみ考える.u ∈ (nodes|v|(H)− {pi}) とする.T|v|(u) = uであることと,T|v|′ は頂点 piを T|v|s で置き換えたものであることよ り,T|v|′ (u) = uが成り立つ.C3(1) より,T|pi|(v) = T|pi|(pi−1 · l(pi−1, pi)) = piである. よって,v は T|v|′ において T|v|s に到達する.このとき,部分分類木 T|v|s の作成方法より, T|v|′ (v) = T|v|s (v) = v,T|v|′ (pi) = T|v|s (pi) = piとなる.したがって,H′は C2(1) を満たす. a∈ {0, 1}|v| ただし,a /∈ Nodes(Z) とする.C2(2) より,T|v|(a) = µである.T|v|′ におい て,ラベル µ をもつ頂点に対しては操作を加えていないため,更新操作の前後で出力が 変化しない.よって,T|v|′ (a) = µが成り立つ.したがって,H′において C2(2) が成り立 つ.以上より,H′, T1′, T2′, . . . Tm′ は C2 を満たす. 最後に,H′, T1′, T2′, . . . Tm′ が C3 を満たすことを示す. まず,ステップ 3 で作成する辺 (pi−1, v)について考える.C2(2) より,T|v|′ (pi−1·l(pi−1, v)) = T|v|′ (v) = vであるから,C3(1) を満たす.|pi−1| < j < |v| を満たす j に対して, Tj′(pi−1· pre(l(pi−1, v), j− |pi−1|)) = Tj′(pi−1· pre(l(pi−1, pi), j− |pi−1|))
= Tj(pi−1· pre(l(pi−1, pi), j− |pi−1|)) = µ が成り立つ.したがって,この辺 (pi−1, v)は
C3(2)を満たす. 次に,ステップ 8 で作成する辺 (v, T|v|+j1(v· 1 · {0} j1−1))および (v, T |v|+j2(v· {0} j2))に ついて考える.これらの辺は分類木の出力によって辺の接続先を決めている.T|v|+j1 お よび T|v|+j2 は仮定より C3 を満たしているので,これらの辺は C3 を満たす. 次に,ステップ 9 で作成される辺 (v1, v)について考える.更新前の時点では v Z = piと 評価されていたので,性質 2 より,T|v|(v1 · l(v1, v)) = piが成り立つ.そのため,更新 後の T|v|′ において,v1 · l(v1, pi)は部分分類木 T|v|s に到達する.ステップ 9 にて T|v|s (v1 ·
l(v1, v)) = vが成り立っていることから,T|v|′ (v1· l(v1, v)) = vが成り立つ.したがって,
辺 (v1, v)は C3(1) を満たす.|v1| < j < |v| に対して,Tj には変更を加えていないので, Tj′(v1 · pre(l(v1, v), j− |v1|)) = Tj(v1 · pre(l(v1, v2), j− |v1|)) = µ が成り立つ.したがっ
て,辺 (v1, v)は C3(2) を満たす.
最後に,edges(H)∩edges(H′)を満たす辺について考える.更新前に T|a|(a)̸= piを満た
している文字列 a については,分類木の到達する葉に変化はないので T|a|′ (a) = T|a|(a)が成 り立つ.そのため,更新前に出力が µ であった文字列に対する出力は変化せず,C3(2) を満 たす.C3(1) を満たさない辺 (v1, v2)は v2 = piかつ T|v|′ (v1·l(v1, pi)) = T|v|s (v1·l(v1, pi)) = v
を満たすような辺である.しかし,この条件を満たす辺はステップ 3 およびステップ 9 で削 除しているため,nodes(H)∩nodes(H′)には含まれない.したがって,edges(H)∩edges(H′) を満たす辺は C3(1) を満たす.以上より,H′, T1′, T2′, . . . Tm′ は C3 を満たす. 以上より,本アルゴリズムにおいて,更新後の仮説および分類木は性質 C1, C2, C3 を 満たし,かつ|nodes(H′)| = |nodes(H)| + 1 となる. 2 補題 1 および補題 2 より,Algorithm 2 を用いて仮説 ZDDAS H の更新を繰り返し行 い,H の頂点数と目標 ZDD Z の頂点数が一致したとき,Z(H) と Z が等価となる.