筑波大学大学院博士課程
システム情報工学研究科修士論文
インタラクティブな
ビジョンシステムに関する研究
竹村 浩司
(知能機能システム 専攻)
指導教官 谷江 和雄
2005 年 1 月
概要
近年,ロボット技術の向上に伴い,ロボットは工場のような整備された環境だけでは なく,日常生活空間への進出が期待されている.また同時に,ユビキタス社会の到来に よりユビキタス的な情報環境に適合したロボットが求められている. このような人間生活環境で活躍するロボットを実現するためには,画像等による物体 認識能力が必要である.従来の物体認識手法は,環境に存在する物体の情報をあらかじ めロボット内のデータベースに登録しておき,その情報を用いることで物体認識を実現 してきた.しかし工場や実験室のように,存在する物体がある程度特定できる環境下に おいては有効であるが,われわれの生活する環境には多種多様な物体や環境が存在して いるため,扱うべき情報が無限に存在し,かつ変動するため,現実的にはこのままの適 用は困難であると考えられる. 本論文では,従来の物体認識手法におけるビジョンシステムにおいて,人間・ロボッ ト・環境・物体との関係について論じ,それぞれについて一般環境下において,物体認 識の持つ問題点の考察を行い,その問題点の多くは,従来型のビジョンシステムが受動 的であることに着目する.次にそれらの関係を解決するために,他の要素とのインタラ クションを利用する インタラクティブなビジョンシステム の提案と考察を行うこと で問題の解決手法を示す.さらに,一般環境下において実現するために本論文では,そ の例として特に物とビジョンシステムのインタラクションを利用した,知識分散型タグ ベーストビジョンシステムの提案を行う.知識分散型タグベーストビジョンシステムは, ユビキタスコンピューティング技術を応用し,IC タグを用いて物体とビジョンシステ ムの間で知識のインタラクションを行うことで,効率のよい物体認識の実現を可能とす る.さらに,物体生産者が知識記述に参加する枠組みを提供することで,従来手法にお ける誰が知識生成を行うかという問題点の解決を試みる.ここでは,一般生活環境下の 例として,ロボットによる食卓における食器類の後片付けをタスクとした実験システム を構築し,提案手法の有効性を確認する.目次
第 1 章 序論... 1 1.1 研究背景... 1 1.1.1 従来のロボットビジョンシステム... 1 1.1.2 従来のビジョンシステムにおける物体認識手法の分類... 1 1.2 従来のロボットビジョンシステムとインタラクティブなビジョンシステム... 5 1.2.1 受動的なビジョンシステムの問題点... 5 1.2.2 インタラクティブなビジョンシステム... 5 1.3 本論文の構成... 7 第 2 章 インタラクティブなビジョンシステム... 8 2.1 従来型ビジョンシステム ... 8 2.1.1 従来型ビジョンシステムと人間との関係... 10 2.1.2 従来型ビジョンシステムとロボットとの関係... 11 2.1.3 従来型ビジョンシステムと環境条件との関係... 13 2.1.4 従来型ビジョンシステムと物体との関係... 13 2.2 インタラクティブなビジョンシステム... 16 2.2.1 人間に対する働きかけ... 19 2.2.2 ロボットに対する働きかけ... 21 2.2.3 空間に対する働きかけ... 23 2.2.4 物体に対する働きかけ... 25 2.3 インタラクティブなビジョンシステムに関する議論... 30 2.4 まとめ... 32 第 3 章 知識分散型タグベーストビジョンシステム... 33 3.1 従来手法の問題点... 33 3.2 知識分散型タグベースト手法... 41 3.2.1 知識分散型ロボット制御手法... 41 3.2.2 知識分散型タグベーストビジョンシステム... 46 3.3 実験システム構成... 49 3.3.1 位置検出手法... 61 3.3.2 キャリブレーション... 65 3.4 実験結果... 73 3.5 まとめ... 76 第 4 章 結論... 77謝辞... 78 参考文献... 79
図目次
図 1. 1:インタラクティブなビジョンシステムのイメージ ... 6 図 2. 1:従来型のビジョンシステム... 9 図 2. 2:従来型ビジョンシステムとロボットの関係... 12 図 2. 3:二次元タグを利用したビジョンシステム ... 15 図 2. 4:ビジョンによる働きかけ ... 18 図 2. 5:インタラクティブなビジョンシステムの概念図... 18 図 2. 6:インタラクティブなビジョンシステムから人への働きかけ... 20 図 2. 7:インタラクティブなビジョンシステムとロボットの関係 ... 22 図 2. 8:インタラクティブなビジョンシステムから環境への働きかけ ... 24 図 2. 9:位置情報の提示を用いたインタラクティブなビジョンシステムから ... 27 図 2. 10:物体情報の提示を用いたインタラクティブなビジョンシステムから ... 28 図 2. 11:物体情報の提示を用いたインタラクティブなビジョンシステムから ... 29 図 2. 12:タグシステム... 29 図 2. 13:ビジョンシステムにおける要素の関係 ... 31 図 3. 1:モデルベースト手法概念図... 35 図 3. 2:モデルベースト手法のプロセス... 35 図 3. 3:モデルベースト手法... 36 図 3. 4:タグベースト手法概念図 ... 38 図 3. 5:タグベースト手法 ... 39 図 3. 6:処理速度の向上... 39 図 3. 7:タグベースト手法の問題点... 40 図 3. 8:知識分散型ロボット制御手法を用いた食器片付けロボットシステム ... 43 図 3. 9:知識分散型ロボット制御手法概念図 ... 44 図 3. 10:従来の知識の作成 ... 45 図 3. 11:知識分散型ロボット制御手法における知識の作成 ... 45 図 3. 12:知識分散型タグベーストビジョンシステム概念図 ... 47 図 3. 13:知識分散型タグベースト手法 ... 47 図 3. 14:提案手法のプロセス... 48 図 3. 15:非接触通信型ICタグシステム概念図... 50 図 3. 16:ICタグ ... 51 図 3. 17:オブジェクト例(浅皿) ... 52 図 3. 18:実験系外観 ... 53図 3. 19:実験系イメージ ... 54 図 3. 20:Webサーバを構築したPC... 56 図 3. 21:情報の流れ ... 57 図 3. 22:情報の流れ ... 58 図 3. 23:アンテナを埋め込んだ実験テーブル... 59 図 3. 24:外部接続図 ... 63 図 3. 25:濃淡画像テンプレート例... 64 図 3. 26:位置検出... 64 図 3. 27:座標変換... 66 図 3. 28:ロボット座標取得イメージ ... 67 図 3. 29:画像座標取得イメージ ... 68 図 3. 30:計算結果... 69 図 3. 31:物体高さに応じた測定誤差 ... 69 図 3. 32:物体高さを考慮した位置検出 ... 71 図 3. 33:補正後結果 ... 71 図 3. 34:高さを考慮した補正結果... 72 図 3. 35:実験画像... 74 図 3. 36:実験結果外観... 75 iv
表目次
表 1. 1:モデルベース物体認識とアピアランスベース物体認識の特徴 ... 4 表 3. 1:ICタグ諸元表... 51 表 3. 2:対象物体諸元表... 52 表 3. 3:PA-10 諸元表 ... 55 表 3. 4:ICタグリーダー諸元表 ... 60 表 3. 5:IP7000BD諸元表... 62 表 3. 6:高さを考慮した補正結果 ... 72第1章
序論
1.1
研究背景
1.1.1
従来のロボットビジョンシステム
近年,ロボットは人間生活環境などの環境が非整備の場所での利用が期待されており, 様々な物体に対応するためにセンサ等による物体の認識率の向上が必要とされている. 従来のロボットシステムで多く用いられているセンサは,画像を用いたものが多く, そのため,画像を用いた物体認識の向上が必須とされている.しかしながら,多くの場 合,これらのロボットシステムにおける画像処理に関する研究は,画像が最適な状態で 得られた後の,画像から何らかの特徴を抽出し,それらの特徴量と,ロボットが持つ物 体のモデルとの照合を行うことで,物体認識を行っている. 現在まで物体認識手法は多く報告されているが, 画像処理技術は多くの場合,照明 などの環境条件や,認識しようとする対象物の特徴などに大きく依存することがよく知 られている[1][2][3].1.1.2
従来のビジョンシステムにおける物体認識手法
の分類
ロボットの視覚を担うロボットビジョンを実現するためには,カメラから得られた画 像の中に何の物体が写っているのか認識出来ることが必要である.このような物体認識 では,学習によって与えられた知識との照合によって実現される.照合する知識の種類 で物体認識法を分類すると,以下の 2 つになる. (1) 二次元照合による方法(アピアランスベース) (2) 三次元照合による方法(モデルベース) 1二次元照合による方法は,画像をそのまま知識として持ち,テンプレートマッチング に代表されるような単純な相関演算により物体認識を行う手法である.この方法では, すべての画像を記憶しておかなければならないため膨大な情報量となってしまうとい う問題があったが,学習に用いる画像をそのまま記憶して物体認識に用いるのではなく, それらの画像から特徴量を求めておき,これらの特徴量により照合を行う方法が考えら れた.これらの手法を“アピアランスベース認識手法”と呼ぶ. 三次元照合による方法は,物体の幾何モデルや CAD モデルのような幾何学的に表現 された対象物体の特徴点と,取得した画像から抽出した特徴点との対応関係により物体 認識や姿勢検出を行う手法である.これらの手法は,人間が初めて見た物体を理解する 際の認識工程を計算機に応用した解析手法である.このような手法を“モデルベース物 体認識手法”と呼ぶ. ・ 二次元照合による方法(アピアランスベース) モデルベース物体認識手法において物体の絶対的な三次元形状を利用していたのに 対して,アピアランスベース物体認識手法では,物体の見え方(Appearance)だけを学 習しておけば十分ではないかという考えに基づき,物体を多方向から観測した二次元画 像の集まりとして記述する方法である. この手法では,認識対象となる物体の画像をすべて学習する必要がある.濃淡画像を 用いた場合,照明条件による画像の変化や物体の姿勢による画像の変化など考慮するこ とが多く,学習サンプル数は膨大になる.このことから,記憶容量,照合時間の点で困 難とされてきたが,その後固有空間を用いた画像照合法が提案され,少ない記憶容量で 学習画像を記憶し,固有空間上で照合することで高速に照合を行うことが可能となった. 近年,この手法を応用して,物体の認識,姿勢検出を行うパラメトリック固有空間法 が提案され,複雑背景における物体の位置検出,動画像認識,視覚サーボ,照明計画, Shape from shading,距離画像への適用,局所領域への適用,などさまざまなところで応 用されている. このようなアピアランスベース物体認識においては,次に示す三次元照合による方法 で述べるような特徴モデルを用意する必要がなく,幾何学的に複雑な形状の物体の認識 や,顔認識などにも用いることが出来る.しかし,画像照合を基本とするため,以下の 問題点がある. (1) 認識対象の移動,照明の変化などに対応する多数の学習サンプルを用意しなけ ればならない (2) 微妙な位置ずれや回転,見た目の大きさ変化などにより誤認識を生じやすい
三次元照合による方法(モデルベース) モデルベース物体認識のプロセスは,ボトムアップ解析による解析的な認識手法が例 に挙げられる.ボトムアップ解析は,まず与えられた入力画像に対し,第 1 段階として 線や領域といった画像特徴を抽出する.しかし,このようなプリミティブな線や領域と いった特徴量は照合において記述レベルが低く,扱いづらい.そこで,第 2 段階として これらの特徴量を組み合わせて構造化(グループ化)する.さらに第 3 段階では,構造 化された線や領域といった二次元特徴量をエッジや面などの三次元情報に変換する.そ して,あらかじめ知識として与えられたモデルと照合を行い,物体を認識したり,姿勢 を求めたりする. このようなモデルベースの認識手法の問題点として,以下の 3 点が挙げられる. (1) モデルが複雑になると計算コストが膨大になる (2) 幾何学的に複雑な認識対象のモデル記述は困難である (3) 画像から特徴量を安定に抽出することが困難である しかし,認識対象の見た目の大きさ,位置,姿勢の変化に対して柔軟に対応すること が出来るという利点がある. 以上より,モデルベース物体認識とアピアランスベース物体認識,それぞれの利点と 欠点を表 1.1 にまとめる. 3
表 1. 1:モデルベース物体認識とアピアランスベース物体認識の特徴 利点 位置,姿勢,見た目の大きさの変化に対して柔軟に対応 出来る. モデルベース 欠点 幾何学的に複雑なものはモデルの記述が困難である. 特徴量を安定して抽出するのは困難である. 利点 幾何学的に複雑な形状の物体も容易に認識可能である. ヒューリスティックな特徴検出は不要である. アピアランス ベース 欠点 膨大な学習サンプルが必要である. 位置ずれや見た目の大きさの変化に弱い.
1.2 従来のロボットビジョンシステムとインタラク
ティブなビジョンシステム
1.2.1
受動的なビジョンシステムの問題点
現在,ロボットを一般生活環境下といった非整備環境での使用することが期待されて おり,如何に環境に存在する多種多様な物体を認識するかが大きな問題となっている. しかし,前節で述べたように,従来型のビジョンシステムによる物体認識手法において は,それぞれに長所と短所を併せ持つため,非整備環境における汎用性の高いビジョン システムの実現はされていない.ここで,従来型のロボットビジョンシステムは,ロボ ット側からの要求に対して応答するという“受動的”な動作をするものであると考えら れる.そのため,照明条件など常にビジョンに合わせた環境を作らなければならず,限 られた環境でしか使用することが出来なかった.特に,固定型のカメラでは視点位置が 固定されてしまうため,与えられた画像のみから必要な全ての情報を得なければならな かったが,視野内に必要な情報が全て含まれているとは限らない.また,知能ロボット の視覚システムの構築で重要視されてきたモデルベース物体認識手法では,データベー スの中に類似した形状のモデルが存在する場合,認識出来ないことがあった.また視点 位置が固定されてしまうために,与えられた画像のみを用いて必要な情報をすべて獲得 しなくてはならなかった. このように従来のビジョンシステムが有する“受動的”な性質が,ビジョンシステムを 複雑な人間生活でロボットを用いる上での問題点であると考える.1.2.2
インタラクティブなビジョンシステム
そこで本論文では,環境からの情報を利用してビジョンシステムが能動的に指令を出 し,他の機能が応答する,すなわちビジョンシステムとその他の機能がインタラクティ ブな関係を持つシステムモデルを提案する.ここでは,図 1.1 に示すように従来のビジ ョンシステムが今まで有していなかった新たな働きかけを環境や物体,ロボットなどに 行うことで,従来のビジョンシステムが抱えている問題に対する解決への筋道を示すこ とが期待出来る.インタラクティブなビジョンシステムについての詳細は第 2 章に述べ る. 5電気をつけて ください! 電気をつけて ください! コップは どこですか? コップは どこですか? コップが見づらい ので移動します! コップが見づらい ので移動します! 図 1. 1:インタラクティブなビジョンシステムのイメージ
1.3 本論文の構成
本論文では,これらの従来型のビジョンシステムの問題点を考察しながら,従来型の ビジョンシステムの問題をその受動性にあるとし,空間に存在する他の機能(人間,ロ ボット,環境,物体)に対してインタラクティブなビジョンシステムを提案し,その中 で特にビジョンシステムからロボット,ビジョンシステムから物体へのインタラクショ ンを通して,物体認識を効率よく行うシステムの研究開発を行う. 本章では,本論文の研究背景について述べた.従来のビジョンシステムにおける物体 認識手法について示し,従来型の受動的なビジョンシステムとは異なる,インタラクテ ィブなビジョンシステムを位置づけた. 第 2 章では,本論文の基礎となるインタラクティブなビジョンシステムの概念につい てビジョンシステムと人,ロボット,環境,物体とのそれぞれとの関係を上げながら議 論を行い,その中で特に人間および物体との関係が,ビジョンシステムにとって直接的 であり,重要であることを議論する. 第 3 章では,第 2 章で議論した,インタラクティブなビジョンシステムにおいて重要 とされる,特にビジョンシステムと物体との関係について議論を行い,知識分散型タグ ベースト手法を提案する. ここでは,インタラクティブなビジョンシステムを一般環境下で実用するための例と して,タグベーストビジョンシステムを用いることで物体の位置検出システムを実現す る.まず,従来型のビジョンシステムと,インタラクティブなビジョンシステムである タグベーストビジョンシステムの違いを論じる.次に,一般環境下におけるタグベース トビジョンシステムの未解決点としてフレーム問題を指摘し,解決手法として知識分散 型タグベーストビジョンシステムを提案し,知識分散型ロボット制御システムを用いな がら,実証を行う. 最後に第 4 章で本論文の総括をする. 7第2章
インタラクティブなビジョンシステム
本論文では,従来型の画像を取り込み,処理し,結果を表示するビジョンシステムを “受動的”なシステムと位置づけ,ユビキタスコンピューティング技術を用いることで, ビジョンが主導権を持ち,必要に応じて人間・ロボット・環境・物体へ作用しながら画 像を取り込み・処理・表示する新しい形のビジョンシステムを, “インタラクティブな ビジョンシステム”として提案を行なう.ここでいうインタラクティブとは,ビジョン システムが他の機能に対する振る舞いについて述べている. 本章では,“インタラクティブなビジョンシステム”について示す前に,従来型ビジョ ンがなぜ“受動的”であるのかについて論じ,“受動的”であることの問題点について議論 しながら,ビジョンシステムがインタラクティブ性を持つことによる有効性を示す.2.1 従来型ビジョンシステム
ここでは従来型のビジョンシステムの例として,人間,ロボット,環境,物体とのか かわり方について事例を挙げ,議論を行う. 従来型のビジョンシステムでは,環境における照明条件やロボットによる視点位置な どといった制約を受けつつ,検出対象の画像を撮像し,処理を行う.ここではこれを画 像手段と定義する.次に,得られた画像とデータベース内のモデルとのマッチング処理 を行うことで,物体認識・位置姿勢検出を行う(図 2.1).画像手段 画像手段
ビジョン
人間
画像の取得 画像の取得データベース
検出目的: 物体認識 位置姿勢検出環境
(照明など)
ロボット
(視点位置など)
物体
図 2. 1:従来型のビジョンシステム 92.1.1
従来型ビジョンシステムと人間との関係
ロボットは,人間のように物事を理解して,人間の代わりに作業をしてくれる存在で あることが理想である.しかし,現在のロボットはそのような理想からはかけ離れてお り,行なえる作業も非常に少ない.ビジョンシステムも同様であり,世の中のすべての ものを人間と同じように認識することは不可能である.われわれの生活する環境におい て実用的なレベルでの物体認識を行なわせる場合,さまざまな問題があるが,一番は物 体認識に必要なモデルデータをどのように用意するか,ということにあると考える. 従来型のインタラクティブメディアシステムでは,ビジョンシステム自体には多くの 機能を持たせることはせずに,人が音声と画像情報を用いて,マルチモーダル的にビジ ョンシステムにインタラクションすることによって,ジェスチャーなどの認識を容易に 行なおうとしている[20][21].これは,人からビジョンシステムに対して“一方的に対話” し,その“一方的な対話”に応答してビジョンシステムは処理を行い,システム自体がそ の“一方的な対話”に対する答えを提示している.この場合,人とメディアとの関係とし ているインタラクティブなシステムということが可能である.しかし,ビジョンシステ ムの立場では,人からの“一方的な対話”に対して処理を行い,その結果をシステム自体 に送信しているのみで,ここに“双方向の対話”は存在しない.よって,このシステムで は,人とビジョンシステムが“対話”しているとはいえない.このように従来の人とシス テムとのインタラクションを実現するために用いられているインタラクティブメディ アシステムは,われわれの定義するインタラクティブなビジョンシステムに対して狭い 意味で使われているといえる. 本論文で示す,インタラクティブなビジョンシステムでは, ・ 人からの“対話”に対する応答 ・ ビジョンシステムから人に向けての“対話” とビジョンシステムが真の意味での“対話”を行なうことを提案する.2.1.2
従来型ビジョンシステムとロボットとの関係
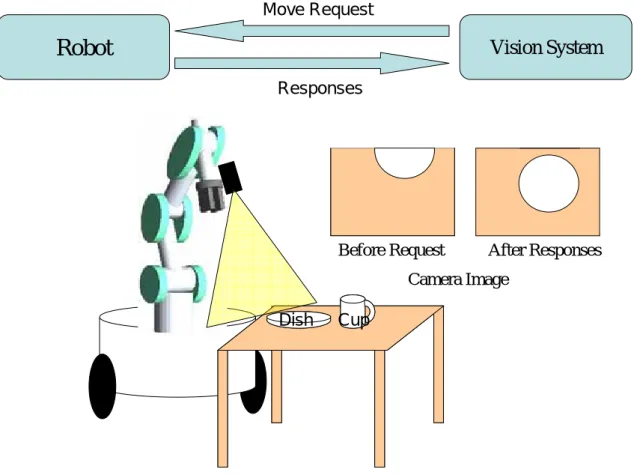
現在行なわれているロボットビジョンの研究において,ビジョンシステムはロボット のセンサとして,ロボットの求めるデータを獲得し,その情報をもとにロボットの制御 を行う.工場等で,すでに実用化されているシステムでは,ビジョンシステムはあらか じめプログラマによって作成されたモデルデータを元にして,対象物の位置,姿勢を検 出し,ロボットの作業に貢献している[9].従来は単眼カメラによる,二次元的な画像 においてモデルとのマッチングを行ない物体の位置,姿勢を導出する手法がとられてい たが,ステレオビジョンの研究が進むに連れ,三次元的なモデルデータを用いたモデル マッチングも一般的になってきている[10].また,より実用的な利用では,マニピュレ ータの先端にビジョンセンサを取り付け,マニピュレータが作業を行なう際に正確性を 増すためにビジョンセンサは用いられている[11][12].さらに,環境認識という点では, ロボットの周りの情報を獲得するためにステレオビジョンによってえられた奥行き画 像を元に環境マップを生成するような研究も行なわれている[13]. このように画像情報を元にして,ロボットが外界の情報を認識するために,ビジョン システムは非常に重要な役割を果たしている.しかし,これらのシステムにおいて,ビ ジョンシステムは,ロボットが作業するためにロボットからの要求を受け,それに対し て動作するシステムとなっており,いわゆる“受動的”なシステムであるということが出 来る.具体的には図 2.2 に示すようにロボットからの「テーブルの上にある物体の位置 を教えてください」(図 2.2(a))という要求に対して,「Cup は(x1,y1),Dish(x2,y2)」(図 2.2(b))という形で返答する形のシステムであった. ビジョンシステムが“受動的”であるということは,ビジョンシステム自体は処理をし て,その結果をロボットへ返すという形をとればよいことになり,システム構成として はシンプルな形であるが,その結果ロボット側での判断が多く求められることとなる. ここで,ビジョンシステムがインタラクティブに関わることで,ロボットにて行なわれ ていた判断をビジョンシステム自身で行なうことが出来ると同時に,最適な作業計画も ビジョンシステム自身が立てることが可能となり,一見複雑に見えるが,結果として作 業の効率化につながるものと考えられる. このようなインタラクティブ性を考慮したビジョンシステムの例としては,レンジセ ンサの様に,受動的なビジョンシステムに加えて能動的なレーザーなどの機能を追加す ることで,受動的なビジョンシステムだけでは得られない情報を獲得する,一部“イン タラクティブ”なビジョンシステムはある[14].しかしこの一部の“能動性”は固定である ことが多く,インタラクションを実現しているとは言いがたい. 11Please detect object positions on the
table
Request
Responses
Robot Vision System
Dish Cup
Please detect object positions on the
table
Request
Responses
Robot Vision System
Dish Cup (a) ロボットシステムからビジョンシステムへの要求 Cup: (x1,y1) Dish(x2,y2) Request Responses
Robot Vision System
Dish Cup
Cup: (x1,y1) Dish(x2,y2) Request
Responses
Robot Vision System
Dish Cup
(b) ビジョンシステムからロボットシステムに対する応答
2.1.3
従来型ビジョンシステムと環境条件との関係
一般的にビジョンシステムを用いるとき,その照明条件などの撮像環境は非常に重要 である.例えば,われわれが生活する室内で用いられている蛍光灯は 50~60Hz の周期 で点灯しており,人間には気にならないものの,ビジョンシステムで画像を取得すると きには,この明滅が大きな影響を及ぼす場合もある.この影響を軽減するために,蛍光 灯をインバータタイプのものに切り替えて使用している例も多く見られる.また,室内 に入り込んでくる太陽光も大きく影響してくる.そのために,ビジョンシステムを用い る部屋では暗幕などを用い,外からの光が入射しないようにする必要も出てくる. われわれの生活する環境には上記のようなビジョンシステムにとって不都合な条件 がそろっており,ビジョンシステムを運用する場合は,環境の整備が不可欠となる.こ のとき環境を整備するのは人に依存することとなる.現状環境の変化にビジョンシステ ムが左右されやすいのは,ビジョンシステム自身は,環境の状態をありのままにしか受 け入れることが出来ない“受動的”なシステムだからである.つまり,ビジョンシステム から環境に働きかけ,撮像環境をコントロール出来るような インタラクティブな 機 能を有していれば,上記のような問題は解決出来るものと考える. 従来型のビジョンシステムの中で,このような環境への“インタラクティブ性”を積極 的に用いたものとしては,いわゆる“Shape from Shading”のように,照明の位置と物体表 面の傾きによって物体の三次元形状を復元する方法があるが,一般的には実験環境など において多数の照明が事前に既知な位置に置かれた特殊空間を必要とする[15].2.1.4
従来型ビジョンシステムと物体との関係
従来,物体認識における課題として,物体のモデルデータの生成は重要な要素となっ ている.このモデルデータとして,元の物体を忠実に再現したデータを用いることは理 想であるが,物体を認識する際には計算量が増加すること,またモデルデータサイズが 大きくなってしまい,モデルデータのライブラリのサイズ自体も大規模になるために, 現在多く用いられている方法は,対象物のモデルデータをエッジデータのような,特徴 量を用いたデータとする手法が主である.モデルデータを用いた物体認識では,多くの 研究が行なわれてきており,工場などでは,実用レベルで採用されている. また最近では,われわれの生活する環境での利用を考慮に入れ,物体自身に QR コー ドや光学タグなどを添付し,それらのタグから物体の情報を取得し,情報を利用するこ とで物体認識と位置姿勢検出を行なう手法が多く提案されている[16][17][18](図 2.3). しかし,われわれの生活する環境では,物体が多数存在し,物体の位置関係もさまざま なケースが考えられることなどから,このような画像手段のみを用いた情報取得だけで 13は,十分であるとは言えず,このような手法は実用的なレベルにはいたっているとは言 いがたい. 一方,環境における物体の在り方の議論としては,人工知能における物体認識の研究 において,物体の属性が物体自身をどのように扱ったらよいかについてメッセージを発 するという“アフォーダンス”の概念が存在する[29].しかし,この手法に至っても実用 的なレベルを満たしていない. ここで考えられる物体認識の問題として,現在研究されている事例を考慮に入れ,以 下のことが挙げられる. ・ 生活環境に存在する全ての物体のモデル生成の問題 ・ 物体同士の位置関係によって生じるオクルージョンの問題 ・ 同一物体が存在する可能性があることから生じる誤認識の問題 実験室環境であれば,存在する物体は有限個であり,そのモデルを生成することはあ る程度可能であると考えるが,一般的な環境においては環境に存在するすべての物体の モデルデータを作成することが困難である.よって,このモデルデータの生成に関する 問題は非常に重要であると考える. 続いて,われわれの生活環境では,物体同士は不規則に配置されている.そのために ある視点から物を観測したときに,注目対象がほかのものの影に隠れて見えない(オク ルージョン)というケースが多く生じる.このような場合にどのように対応していくか ということも必要となる[19]. 最後に,見た目が同一な物体が視界に入ったときに,どのようにしてこの物体を厳密 に区別するかということも重要となる.人間の場合,見た目が同じ場合には,手に取り, 様々な方向から見ることや,過去の経験に基づくことで,見た目に同じ物体の区別を行 なっている.従来の受動的なビジョンシステムにこのような人間と同様の機能を実装す ることは実質不可能であるといえる. これらの問題は,ビジョンシステムが他の機能に対して“受動的”であるがために生じ ているものと考えられる.物体認識において,ビジョンシステムが“インタラクティブ” になることにより,これらの問題点の解決策を提案出来るものと考える.
画像手段 画像手段
画像の取得
画像の取得
人間
画像の取得
データベース
ビジョン
検出目的:
物体認識
位置姿勢検出
知識
QRコード、光学タグと いった二次元タグ知識
知識
QRコード、光学タグと いった二次元タグ QRコード QRコード環境
(照明など)
ロボット
(視点位置など)
物体
図 2. 3:二次元タグを利用したビジョンシステム 152.2
インタラクティブなビジョンシステム
従来型のビジョンシステムは他の要素(人・ロボット・環境・物体)に対して“受動 的”であるために,以下のような問題点を有していた. ・ 視点位置が固定されている ・ 撮像条件に強い影響を受ける ・ 持っている物体情報だけで物体認識をしなければならない これらは,ビジョンシステムがタスクはもっているものの,他の要素に働きかけるた めの機能を持っていないことに起因すると考える. 現在注目を集めている,ユビキタスコンピューティング技術では,空間に存在するコ ンピュータはそれぞれが処理能力を有しており,また他のコンピュータと情報をやり取 りすることが可能となるようなプラットホーム作りを目指している.このような世界で は,ビジョンシステムもロボットもさらに環境も人もさまざまな情報を容易に獲得し, やり取りすることが可能となる[7].このようなユビキタスコンピューティング技術を 積極的にビジョンシステムに利用することにより,ビジョンシステムから人間・ロボッ ト・環境・物体に対して,情報の獲得,または動作の要求を出すことも可能となる.つ まり,“インタラクティブなビジョンシステム”では,下記の条件が前提として存在して いる. ・ 空間に存在する物体は,それぞれが大小のコンピュータを内蔵しており,このコン ピュータの中にその物体に関する情報が格納されている 本論文では,図 2.4 に示すようにビジョンシステムは画像以外の手段を通して他の要 素に能動的に働きかけを行うことで,従来の 受動的 な画像手段による問題の解決を 図り,図 2.5 に示すようなビジョンシステムを中心に,主導権を持つ統合システムを, インタラクティブなビジョンシステム と定義する.本システムは,従来のビジョン システムに比較し,より積極的なビジョンシステムを構築するのに有効なシステムモデ ルであると考えられる. ここで示すインタラクティブなビジョンシステムとは,先に示したような,人間とシ ステムのインターフェースとしてのインタラクティブ性は有するものの,人とビジョン システムとは “人からビジョンシステムへの一方的な対話”であるシステムとは異なり, ビジョンシステムが画像処理を行う際に必要となる情報を人へ要求し,それに対して人が応答するような,双方向の応答を実現するモデルとして定義する. ここまで述べてきた,インタラクティブなビジョンシステムの機能を分解し,以下の ような4つの関係によって構成されるものとする. (a) 人間に対して働きかけるもの (b) ロボットに対して働きかけるもの (c) 空間(環境)に対して働きかけるもの (d) 物体に対して働きかけるもの ここでは,前記したインタラクティブなビジョンシステムに対する具体的な例につい て議論する. 17
画像以外の手段 画像以外の手段 画像手段 画像手段 人間 画像の取得 データベース 要求 要求 能動的な動作 ビジョン 検出目的: 物体認識 位置姿勢検出 環境 (照明など) ロボット (視点位置など) 物体 図 2. 4:ビジョンによる働きかけ
Vision System
Robot Environment Human Objects Requests Responses Requests Responses Responses Requests Requests Responses 図 2. 5:インタラクティブなビジョンシステムの概念図2.2.1
人間に対する働きかけ
物体に対してビジョンシステムが働きかけ,何かの動作を行なわせることにより,人 に働きかけることも可能となる.従来のビジョンシステムにおいて,お皿の上にティー カップが載せられている状態を認識するのは非常に困難であった.このようなとき,人 に働きかけることによって,問題を容易にすることが出来る.図 2.6 に示すように,ビ ジョンシステムがコップの下のお皿の検出を行ないたい場合において,コップが載せら れているために,正確に位置検出を行なうことを妨げられているとき,人にコップを除 いてもらうようにビジョンシステムから働きかけ,このケースではコップの LED を点 灯するなどして,ビジョンシステム自身が検出を行ないやすい環境を作り上げる.今回 の例は,実用的な面で考えると考えにくいケースであるが,間接的にでも,ビジョンシ ステムが人に働きかけることによって従来解決出来なかった問題へアプローチ出来る ものと考える. 19Human Vision System Request Responses Dish Cup Please
Clear Off the Cup
Dish
Human
Human Vision System
Request
Responses
Dish Cup Please
Clear Off the Cup
Dish
Human
(a) ビジョンシステムから,人に対する指令
Human Vision System
Request
Responses
Dish Cup Dish
Human Vision System
Request Dish Cup Responses Dish (b)人によるビジョンシステムからの指令に対する応答 図 2. 6:インタラクティブなビジョンシステムから人への働きかけ
2.2.2
ロボットに対する働きかけ
ロボットに対してビジョンシステムから働きかけるシステムとしては,従来から研究 が行われているハンドアイシステムがあげられる.ハンドアイシステムは,マニピュレ ータ先端にビジョンセンサが取り付けられ,対象物までの動作計画,およびハンドリン グ時のビジュアルサーボによる補正など,全体としてロボットが作業を行ううえでの補 佐的な役割をなす. ハンドアイシステムを用いることによって,ある一視点からの画像を処理し,その画 像から対象物体を検出しなくてはならなかったのに対し,視点を変えながら,しかも単 眼のカメラでさまざまな位置からの画像情報を取得することが可能であることから,擬 似的なステレオ視を可能とするなど,多くの利点を有する. 従来のハンドアイシステムでは,ロボットが周りの環境情報や自分が物体を操作する ために必要な情報を,マニピュレータを移動させながら撮影した画像を用い,そこの中 から獲得していた.一般環境で考える場合,ロボットまたビジョンシステム自身は空間 に存在する物体の情報はモデルデータしか有していない状況で,さらに自分の周りにそ の物体があるかないかもわからない状況で画像情報を元に物体を探索しなくてはなら ず,非常に非効率である. このようなときに“インタラクティブなビジョンシステム”では,インタラクティブ に空間の情報を取得し, ・ 作業空間の構造 ・ 現在の自分の位置と,その物体までの相対関係 等の情報を利用しながら,マニピュレータの動作計画をハンドアイシステムの中で行な うことが可能になる.よって,従来のシステムではマニピュレータからビジョンシステ ムに指令を出す形であったが,ビジョンシステムからマニピュレータを動かすことが出 来,対象の認識に適した視点から,物体認識を行なうことが可能となる.図 2.7 に示す ように,ビジョンシステムは空間にお皿があることは認識している状況では,画面内に お皿が少し見えるような場合,マニピュレータを動かして,別の視点に移動し,そこか ら観測を行なうことが可能となる. 固定視点における画像を用いて物体認識を行なう場合は,モデルデータにある程度の 分解能が求められる.これはモデルとマッチングさせるための参照画像が 1 枚しか取得 出来ないためである.しかしハンドアイシステムでは分解能の低いモデルデータにおい ても,視点を移動しながら取得した画像とモデルデータとの相関値を取りながら認識を 行なうことが出来,結果としてモデルデータベースの小型化を図ることが可能となる. 21Robot
Vision System
Camera Image
Before Request After Responses
Move Request
Responses
Dish Cup
2.2.3
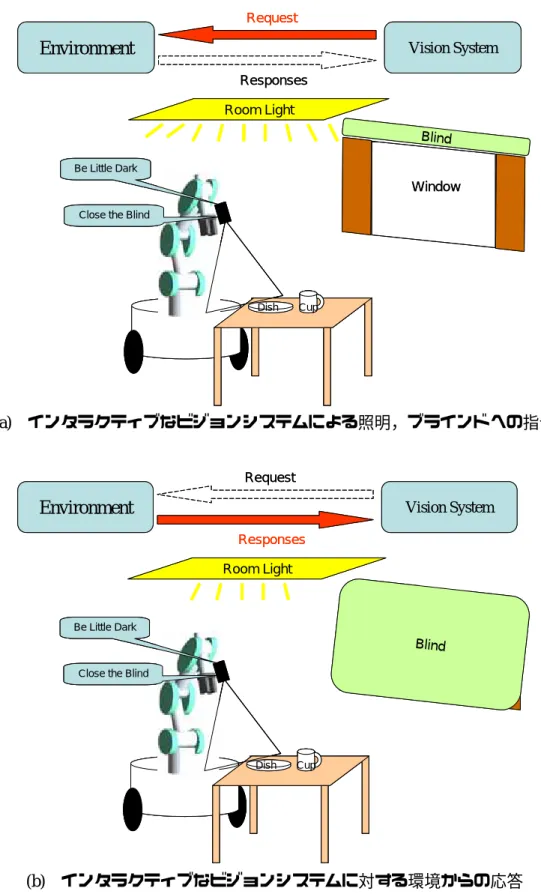
空間に対する働きかけ
前節では,ビジョンシステムの問題点として,照明条件や対象物の位置関係に対して 大きな影響を受けるということを挙げた.従来のビジョンシステムでは,自分の存在す る環境の情報に対して,無知で受身であった.しかし,“インタラクティブなビジョン システム”では,従来の問題点のある環境の問題を,環境に働きかけることで克服する ことを可能とする. 例えば,インタラクティブなビジョンシステムは,空間に対して,“現在の部屋の照 度”などについて問い合わせ,その情報を用いることでカメラパラメータを変更するな どして,画像の撮像に適した状態にカメラを設定することが出来る.また,カメラパラ メータを変更するのではなく,照明などの環境にユビキタスコンピューティング技術を 持たせることで,環境そのもののパラメータを変化させることも可能となる.図 2.8 に 示すように,ビジョンシステムは,現在の照明条件が適していないとき,自分が最適だ と思われる照度になるように,照明に働きかけることが出来,また外からの日光などが 強く影響しているとき,ブラインドを締めるなどを空間に対して要求し,それを実行さ せることも可能となる. このようにビジョンシステムが環境空間に対してインタラクティブ性を持たせるこ とにより,従来の問題点の克服を考えることが可能となる. 23Environment
Vision System Request Responses Blind Window Room Light Dish Cup Be Little DarkClose the Blind
Environment
Vision SystemRequest Responses Blind Window Room Light Dish Cup Be Little Dark
Close the Blind
Dish Cup Be Little Dark
Close the Blind
(a) インタラクティブなビジョンシステムによる照明,ブラインドへの指令
Environment Vision System
Request Responses Blind Room Light Dish Cup Be Little Dark
Close the Blind
Environment Vision System
Request Responses Blind Room Light Dish Cup Be Little Dark
Close the Blind
Dish Cup Be Little Dark
Close the Blind
(b) インタラクティブなビジョンシステムに対する環境からの応答
2.2.4
物体に対する働きかけ
われわれの生活する空間には多くの物体が存在する.このことはビジョンシステムに おける物体認識に対して,大きな壁となっている.しかし,環境に存在する物体に関す る情報をビジョンシステムが何らかの方法で取得することが出来,その情報が仮に物体 のモデルデータである場合,従来のモデルベーストビジョンで問題視されていたフレー ム問題に対する解決策を示すことが可能となる.物体に対する働きかけとしていくつか のケースが考えられるが,ここでは以下の位置情報と物体情報の 2 点にしぼって議論を 行う. (A) 位置情報の提示 ここでいう位置情報の提示とは,物体自身が自分の存在位置をアピールすることを意 味する.具体的には,図 2.9 に示すように,物体に LED などの位置提示装置を持たせ, もしある物体を限定して認識を行ないたいとき,その物体に対してビジョンシステムは 指令を出し,物体はその応答として,LED を点灯させる[22].このようにすることで, ビジョンシステム自体では判別が難しい見た目が同一物体の分別などを行なうことが 可能となる. (B) 物体情報の提示 図 2.10,2.11 に示すように各物体に自分がどのような形状なのか,どのような色なの か,などの物体固有の情報を持っている場合には,ビジョンシステムは各物体に対して 情報を要求することにより,その物体の位置,姿勢を検出するために必要な情報を取得 することが可能となる.このような物体固有の情報を,物体自身に付随させることは, IC タグなどのユビキタスシステムにおいて初めて実現可能となるものであり,ビジョ ンシステムの人,ロボット,環境,物体への働きかけの中でも,最もユビキタス的な要 素を必要とするものである. 最近,物体に対する働きかけを利用した手法として画像手段を用いないインタラクテ ィブなセンサシステムである,タグシステムが提案されている(図 2.12).これは物体に IC タグを対象に貼付し,センサ側が働きかけることで物体の知識を取得し,物体の認 識を行う.このシステムでは未だに物体の位置姿勢検出は実現していないが,画像手段 を用いないため,これまで挙げてきた画像手段による問題を回避することができる.こ のような手法において位置検出のためにビジョンシステムを用いたシステムとしてタ グベーストビジョンシステムが提案されている[23][24].この手法では,前記したよう にビジョンシステムが物体認識を行なうために必要な情報をネットワーク上に存在す るデータベースから獲得し,物体認識を行なう.すなわち,ビジョンシステムは「取得 25画像情報」からではなく「タグから得られる情報」をもとにインタラクションを行う. そのため,画像手段のみを利用する手法に比べ高い物体認識精度を利用することが出来 る.ここでは,これまで述べてきたインタラクティブなビジョンシステムとはインタラ クションのアプローチが異なり,物体がビジョンにおける取得画像を通した,すなわち 画像手段を用いたインタラクションではなく,画像以外の手段を用いたインタラクショ ンと言える.このタグベーストビジョンシステムについては第 3 章で詳しく述べる. このような画像以外の手段を用いたインタラクションにおいても,物体とビジョンシ ステムの関係という観点においては,前述(A)では,ビジョンシステムが物体に対して 「物体の位置」の要求がなされ,それに対して物体が画像手段を用いて自分の位置を明 示するシステムであった. それに対し(B)では,「物体の認識」というビジョンシステムからの要求に対し,画像 手段による情報提示ではなく,IC タグからの画像以外の手段による「認識のための情 報」を物体から応答として返している,ということになる.このことから,ビジョンシ ステムと他の機能との広い意味でのインタラクションがとられたと考えられる.本論文 では,このような画像以外の手段を用いたインタラクションもインタラクティブなビジ ョンシステムとして定義することとする.
Object Vision System Request Responses Dish1 Cup Light the Dish1’s LED LED Dish2
Object Vision System
Request Responses Dish1 Cup Light the Dish1’s LED LED Dish2 (a) ビジョンシステムから物体への指令
Object Vision System
Request
Responses
Dish Cup
Light LED
Dish
Object Vision System
Request Dish Cup Responses Light LED Dish (b) 物体からビジョンシステムへの LED 点灯による応答 図 2. 9:位置情報の提示を用いたインタラクティブなビジョンシステムから 物体への働きかけ 27
Object Vision System Request Responses Dish Cup What kind of object exists? TAG (a) ビジョンシステムから物体への指令
Object Vision System
Dish Cup Request Responses Name : Dish Weight : ・・・ ・ ・ ・ Name : Cup Weight : ・・・ ・ ・ ・ (b) 物体からビジョンシステムへの物体情報の応答 図 2. 10:物体情報の提示を用いたインタラクティブなビジョンシステムから 物体への働きかけ
Object Vision System Dish Cup Request Responses Dish Cup Localization (c) 物体情報を用いた物体認識 図 2. 11:物体情報の提示を用いたインタラクティブなビジョンシステムから 物体への働きかけ 画像以外の手段 画像以外の手段 画像手段 画像手段
人間
データベース
要求
要求
知識 知識センサ
検出目的: 物体認識 ICタグ ICタグ環境
(照明など)
ロボット
(視点位置など)
物体
図 2. 12:タグシステム 292.3
インタラクティブなビジョンシステムに関す
る議論
インタラクティブなビジョンシステムにおけるビジョンシステムと各要素間の関係 を図 2.13 に示す.従来手法におけるビジョンシステムでは,その本来持つ「画像の取 得」の機能を主に利用することで物体の認識を行ってきた.それに対し,インタラクテ ィブなビジョンシステムは得られた画像情報をもとに他の要素に認識のための働きか けを行い,物体の認識効率を高めることが可能となる.さらにタグベースト手法におい ては物体から直接的にモデル情報を取得することが可能であり,性質の異なるインタラ クションを行っている.つまり本論文では,このような画像以外の手段を用いたインタ ラクションも広義の意味でのインタラクティブなビジョンシステムとして定義するこ ととする. また,一般的にビジョンシステムは物体や人間などを対象に物体認識や位置検出を行 うことが目的とされる.また,検出対象としての人間は物体と同様に扱うことが出来る ため,ここでは物体と同義として論じる.本章では,インタラクティブなビジョンシス テムとして,ビジョンシステムと,人間,ロボット,空間,物体それぞれとの関係を例 に挙げて議論を行ってきたが,ビジョンシステムの最終的な目的を考慮に入れると,イ ンタラクティブなビジョンシステムにおいては,人間やロボット,空間への働きかけは 「物体の認識と位置検出」の手段であることがいえる. そういう意味では,ビジョンシステムの物体への働きかけは,検出対象への直接的な 働きかけである,ということが出来,ロボットや空間への働きかけは,物体認識や位置 検出を行う目標を達成するための,間接的な働きかけであるということが出来る. 以上のことからも,ビジョンシステムの物体への働きかけは,検出対象への直接的な 働きかけであり,画像手段とそれ以外の手段を用いて,目的である物体認識や位置検出 を行えることから,ビジョンシステムにとって非常に重要な機能であるということが出 来る. 第3章では,本章での議論をもとに,ビジョンシステムと物体のインタラクションを 行うための新しい枠組みとして,タグシステムを用いた知識分散型タグベーストビジョ ンシステムについて論じる.ビジョン ロボット 環境 検出手段 検出目的: 物体認識 位置姿勢検出 物 人間 検出対象 画像の取得 知識 画像手段 画像以外の手段 データベース (a) 従来のビジョンシステム ビジョン ロボット 環境 検出手段 要求 知識 撮像条件の設定 物 人間 検出対象 画像の取得 知識 画像手段 画像以外の手段 検出目的: 物体認識 位置姿勢検出 データベース (b) インタラクティブなビジョンシステム 図 2. 13:ビジョンシステムにおける要素の関係 31
2.4
まとめ
本章では,従来の受動的な動作を行なっていたビジョンシステムに対して,ユビキタ スコンピューティング技術を導入し,空間に存在するすべての物体がコンピュータを内 蔵し,ビジョンシステム自身がインタラクティブに他の要素に働きかけることで物体認 識のための情報を取得することを可能とするシステムモデルである “インタラクティ ブなビジョンシステム”について提案を行い,その詳細を示した. インタラクティブなビジョンシステムでは,人間,ロボット,環境,物体に対し働き かけることで自分に適した環境などを能動的に構築し,高い物体認識精度の実現が期待 出来る.また物体情報をインタラクティブに取得することによって,物体認識における 負荷を軽減するなど,従来ビジョンシステムが抱えてきている問題に対して,多くの解 決策を示すことが可能となると考える. 次章では,インタラクティブなビジョンシステムの実証例として,2.3 節で述べたよ うに物体による物体情報の提示を利用した手法が物体認識において有効であると考え, 一般環境下における導入を試みる.また,その際に生じる問題点としてフレーム問題に 注目し,提案手法による問題の解決を行う.第3章
知識分散型タグベーストビジョンシス
テム
本章では第 2 章で議論したインタラクティブなビジョンシステムの一般環境下への 導入を試みる.ここではその一例として,ビジョンシステムから直接的に物体に働きか けることで,物体から必要な情報を獲得する有効な物体認識手法としてタグベースト手 法を紹介し,その問題点を論じながら,一般環境において物体認識を実現する“知識分 散型タグベーストビジョンシステム”の提案を行う. 3.1 節では,従来型の物体認識手法とタグベースト手法において,家庭やオフィスと いった一般生活環境下における物体認識,位置検出の際の問題点とフレーム問題につい て論じる. 3.2 節では,それらの問題点を解消し,一般生活環境下においても適用出来る知識分 散型タグベースト手法を提案し,知識の分散配置,分散生成の有効性について述べると 同時に,インタラクションにより得られる物体知識を積極的に扱うことで実現するキャ リブレーション手法と位置補正手法について述べる. 3.3 節では 3.2 節で提案した知識分散型タグベースト手法を実際に実験システムに実 証した知識分散型ロボット制御システムを構築し,一般環境下における提案手法の有効 性の検証を行う.3.1 従来手法の問題点
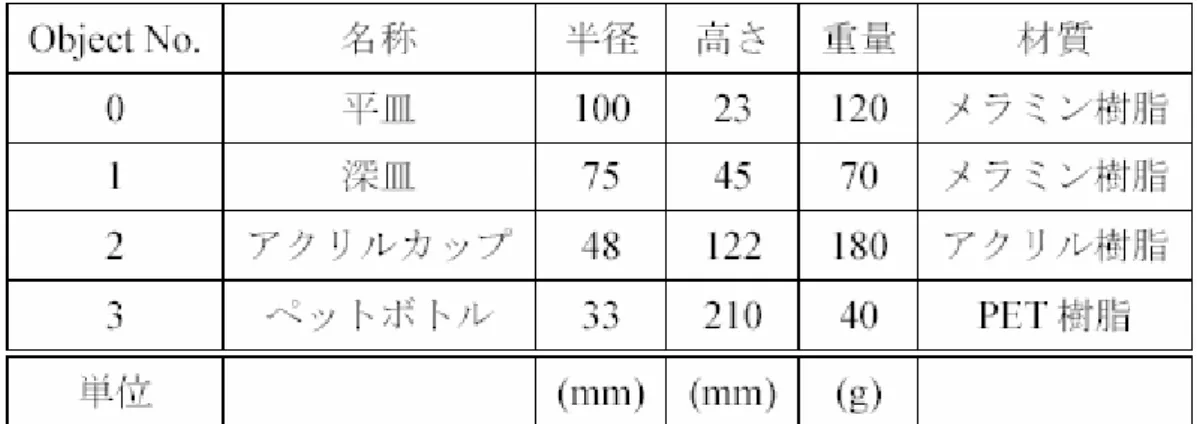
センサとしてのビジョンシステムは,主に物体認識と位置姿勢検出の機能が求められて いる.多くの場合,対象とする物体の二次元もしくは三次元のモデルを事前に作成し, そのモデルを用いて物体の認識を行い,三次元空間中での位置姿勢を検出する二次元な いし三次元モデルベースト物体認識手法は,ロボットなどのための視覚センサとして欠 くことの出来ない重要な機能とされてきた.ここでは,これらの従来型のビジョンシス テムの物体認識および位置姿勢検出アルゴリズムについて議論を行う. (1)モデルベースト手法 図 3.1,図 3.2 にモデルベースト手法を用いた物体認識,位置検出のプロセスを示す. 33従来のモデルベースト手法による物体認識は整備された環境において,以下に示す前提 条件が必要である. ・ 存在する物体が既知である ・ 事前に物体のモデルの記述が必要 したがって,対象物の種類が少ない場合には,事前に用意するモデルデータの数が少 なくすませることが出来,モデルデータの生成にはある程度負荷がかかるものの,工場 などの整備環境では有効に利用されてきた.しかし,家庭やオフィスといった実際の非 整備環境においては,環境内に存在する対象物体が無数に存在し,かつ変動するために, あらかじめ大量のモデルデータが必要になること,新たに環境に導入された物体につい てはモデルデータを新規に作成してなくてはならないなどの問題がある.また様々な環 境条件が想定されるため,保持するモデルと対象物の照合を正確に取ることが難しいこ とがあることが指摘されている. さらに,環境において存在すると想定される物体のデータベース全てに対して一つ一 つ検索をかけながらモデルとの認証を行う必要があり(図 3.3),その検索に必要な計算 時間は,存在すると思われる物体の個数が非常に大きくなると,実用的な範囲を超えて しまうという問題が指摘されている.同時にデータベースと検索テーブルが大きくなる ことで,それだけ見た目の似通った物体の存在する可能性が高くなるため,誤認識率を 上げてしまう可能性が考えられる.また位置姿勢検出においても同様に,作成されたモ デルが非整備環境においては照明などの環境状況が一定でないため,高精度な位置情報 が得にくいという問題点がある.
画像手段 画像手段 ビジョン 人間 画像の取得 画像の取得 データベース 検出目的: 物体認識 位置姿勢検出 環境 (照明など) ロボット (視点位置など) 物体 図 3. 1:モデルベースト手法概念図
モデル作成
形状データ
形状モデル
物体認識
位置姿勢検出
入力画像
Off-Line
On-Line
図 3. 2:モデルベースト手法のプロセス 35Robot database
Objects
Environments
Model
matching
Vision system
図 3. 3:モデルベースト手法(2)タグベースト手法 前述のモデルベースト手法では,事前のモデルの生成の負荷と,モデルとの認証過程 における検索の負荷が問題とされてきた.そこで,安藤らによって提案されている,IC タグを環境に存在する全ての物体に貼り付け,その中に物体認識に必要な情報を書き込 むことで,物体認識の負荷を減らすことを可能とするタグベースト物体認識手法は,一 般環境下での物体認識において有効な手法として考えられる[8].このタグベースト手 法は,環境に付けられた IC タグリーダーが,それぞれの物体に付けられた IC タグの情 報を読むことにより,従来の物体認識手法と比べ,インタラクティブ性を持つと言える (図 3.4,図 3.5).また,環境に存在する物体の認識が容易に実現出来るため,ビジョン システムは物体の位置,姿勢を検出することだけが求められるため,従来のモデルベー スト手法に比べて,計算コストの削減を図ることが出来る(図 3.6). ここで,タグベーストビジョンシステムが解決していない課題として,フレーム問題 が挙げられる.ここで言うフレーム問題とは,以下の 2 つである. 1)一般環境下においては数限りない検出対象物体の存在が考えられるため,物体の 知識を全てシステム提供者が記述することは困難である 2)記述した情報も数限りないものとなるため,配置場所に関する問題が考えられる すなわち,タグベーストビジョンシステムを用いても,環境内に新たに追加された物 体がデータベースに存在しないものであった場合,新たにシステム提供者が物体モデル の作成及しデータベースに追加する必要があり(図 3.7),また先に述べた様に実際の環 境においては無数の対象物体が想定されるため,解決するためには莫大なデータベース と,そのデータベース更新のためにシステム提供者への負担が必要であり,実際の人間 生活環境において実現は困難である.すなわち,以下に挙げる枠組みの実現が求められ る. ・ 物体モデル記述者の負担の軽減 ・ データベースに物体モデルを追加する仕組み ・ データベースの縮小 37
画像以外の手段 画像以外の手段 画像手段 画像手段
人間
データベース
ビジョン
検出目的: 物体認識 位置姿勢検出環境
(照明など)
ロボット
(視点位置など)
要求
要求
知識 知識 画像の取得 画像の取得物体
図 3. 4:タグベースト手法概念図Vision system IC tag Information IC tag Information Objects Environments Robot database IC tag 図 3. 5:タグベースト手法
タグベーストビジョンシステム
従来のモデルベーストビジョンシステム
n
データベースの情報量 m
処理時間
タグベーストビジョンシステム
従来のモデルベーストビジョンシステム
タグベーストビジョンシステム
従来のモデルベーストビジョンシステム
n
データベースの情報量 m
処理時間
処理の高速化
処理の高速化
図 3. 6:処理速度の向上 39Vision system
New Object
New Object
IC tag Information
Objects
Environments
Robot
database
New Model
Should be
installed
New Model
New Model
New Model
Should be
installed
図 3. 7:タグベースト手法の問題点3.2
知識分散型タグベースト手法
ここでは,インタラクティブなビジョンシステムの例として,物体とのインタラクシ ョンに用いる IC タグとネットワーク技術を利用することで先に述べたタグベースト手 法における問題点としてフレーム問題を解消し,一般環境下において物体の認識を実現 する知識分散型タグベースト手法を提案する.また,提案手法における情報のインタラ クションと,ユビキタスコンピューティング技術を利用することによる利点を議論する.3.2.1
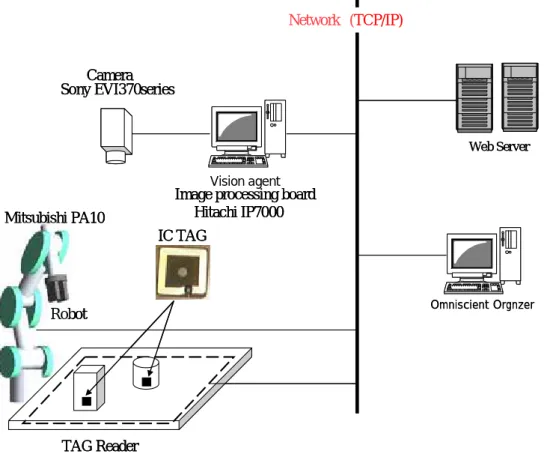
知識分散型ロボット制御手法
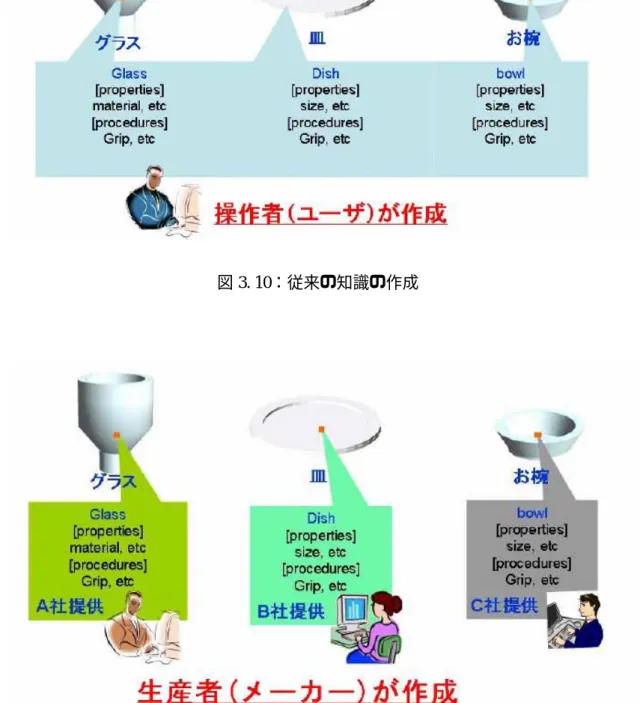
まず,知識分散型タグベーストビジョン手法のプラットホームである知識分散型ロボ ット制御手法について述べる[4][5][6].知識分散型ロボット制御手法は人間が生活を行 う非整備環境において,先に述べたビジョンシステムなどの実用的な問題点を解決し, 実用的にロボットが人間にサービスを行うことを目標とする(図 3.8)[25]. 従来,家庭やオフィスのような環境下において多種の作業を自律的に実行出来るロボ ットシステムの実現を可能とする手法として,モデルベースト手法に関する研究が数多 くなされてきた.しかし,モデルベースト手法には 3.1 節で触れたように,作業空間が 複雑になると膨大な量の知識をユーザが記述する必要になる性質があり(図 3.10),それ と同時にロボットデータベースにおいては莫大な容量が要求されることが考えられる. そのため,実際にシステムを実現するためには困難であると考えられる.すなわち,そ れらをどこに記録し,また,誰が記述するのかに関して現実的な解が求められている. 我々は,前節のタグベースト手法の問題点である,環境に存在可能な物体の物体モデ ルをどのように効率よく生成するか,また,物体モデルの情報をどうやって効率よく分 散配置するかについての議論を行い,知識分散型ロボット制御手法を提案している.図 3.9 に知識分散型ロボット制御手法の概念図を示す. この知識分散型ロボット制御手法の特徴は,以下の二つである. ・ 知識の分散生成 (物体製造者) ・ 知識の分散配置 (IC タグ,ネットワーク上のデータベース) この知識の分散生成と分散配置とは,前節で議論した,物体モデルを逐次作る手間を 省くため,本来,製品を製造する際に製造者が作った CAD データなどの物体モデルを, インターネットなどで分散的に提供してもらうことにより実現する.IC タグの中には, 製造者の持つデータへのリンクアドレスが書かれている. 41つまり,知識分散型ロボット制御手法ではユビキタスコンピューティング技術を利用 し,ロボットが動作するために必要な知識の分散配置を行い,物体操作のための知識は 物体の提供者が記述を行い(図 3.11),それぞれ提供者の保有するネットワーク上のデー タサーバに配置される.これによってストレージを分散することにより知識量の集中に よる負担を解決し,モデルベースト手法を用いた実用的なロボットシステムを実現する. すなわち,ロボットの提供者は,必要な物体操作データを物体に埋め込まれた情報を介 して読み出すソフトを作成し,それを制御プログラムに取り込むだけで,目的とするロ ボットシステムの構築が可能であり,また,我々が生活する煩雑な環境下において動作 するために必要な知識を必要に応じてロボットは取得が可能であることで,従来実用さ れてきた工場のような環境下に近い運用の実現が可能となる.
図 3. 8:知識分散型ロボット制御手法を用いた食器片付けロボットシステム
・・・
タグリーダ
ネットワーク
ICタグ
ロボット制御
プログラム
物体知識
物体知識
ビジョンロボットアーム
製造者
製造者
物体知識
物体知識
・・・
タグリーダ
ネットワーク
ICタグ
ロボット制御
プログラム
物体知識
物体知識
ビジョン ビジョンロボットアーム
製造者
製造者
物体知識
物体知識
図 3. 9:知識分散型ロボット制御手法概念図図 3. 10:従来の知識の作成
図 3. 11:知識分散型ロボット制御手法における知識の作成