3 次元点群を用いた車両の自己位置推定のための圧縮地図表現
松 康平
†a)柳原 広昌
†b)Compressed Map Representation for Vehicle Localization Using 3D Point Cloud Kohei MATSUZAKI†a) and Hiromasa YANAGIHARA
†b)
あらまし 自動走行車両の自己位置を推定する方法の一つに,あらかじめ生成された環境地図と現在位置から センサで計測した3次元点群を照合するスキャンマッチングがある.大規模な環境を表現する3次元点群はデー タ量が大きいため,ディスク容量や通信帯域の制限に対処するためにはコンパクトな地図表現に変換する必要が ある.本論文では,3次元点群を一部の空間に対応するベクトルデータの集合として表現する地図生成手法及び 自己位置推定手法を提案する.提案手法は,3次元点群をボクセルグリッドを用いてモデル化した後に,ボクセ ルデータの集合をベクトルとして表現する.そして,ベクトル量子化によって圧縮されたデータを効率的に格納 することによって地図データ量を削減する.自己位置推定を行う際には,ベクトル間の類似度に基づいて二つの データを照合する.提案手法は,従来手法であるnormal distributions transformアルゴリズムに基づく地図の データ量と比べて100倍以上コンパクトである47 [kB/km]の地図データを生成可能であることを示した.ま た,その地図データを用いて高精度な自己位置推定をリアルタイムに実現可能であることを実証した.
キーワード 自己位置推定,スキャンマッチング,地図生成,3次元点群,ベクトル量子化
1.
ま え が き自己位置推定は,車両の自動運転を実現するため の基礎的要件の一つである.商用の
GNSS (Global Navigation Satellite System)
は建築物による電波の 反射や遮断等に起因して車線レベルでの高精度な自己 位置推定の実現は困難である[1]
.そのため,車両に搭 載されたセンサと事前に作成された環境地図を用いた 高精度な自己位置推定手法が検討されている.自己位置推定課題の解法に対しては,車両の自動走 行を実現するための高い精度と計算効率性が要求され る.走行中の車線と自車を対応付けるためには,誤差
1 m
未満の位置精度が必要である[2]
.また,走行中に 逐次的に自己位置推定を行うために,リアルタイム処 理が求められる.環境地図を用いた自己位置推定手法は地図データの 表現形式に適するように設計されるため,自己位置推 定を検討する上では地図をどのように表現するかも重
†(株)KDDI総合研究所,ふじみ野市
KDDI Research, Inc., 2–1–15 Ohara, Fujimino-shi, 356–8502 Japan
a) E-mail: [email protected] b) E-mail: [email protected]
DOI:10.14923/transinfj.2018JDP7011
要となる.環境地図の表現形式の一つに,道路上の特 定の物体のみで地図を構成する手法がある.例えば文 献
[3]
では,正射投影された航空画像から白線や道路標 識のような物体を抽出し,それらをモデル化したデー タを地図とみなす.自己位置推定を行う際には車載の センサで同種の物体を抽出し,その位置合わせを行う ことで自己位置を推定する[2]
.しかしながら,このよ うな表現形式による自己位置推定は地図側とセンサ側 の両方で物体が抽出される場合にしか実現できない.例えば,地図側に対象となる物体が存在しない場合や,
センサ側で遮蔽等の外乱に起因して物体を検出できな い場合には推定が困難となる.また,物体検出手法を 用いて地図を生成する場合には未検出や誤検出の問題 が不可避的に発生する
[4]
〜[9]
.したがって,誤りのな い地図を作るためには少なからず手動での処理を要す るため,地図生成を完全に自動化することが難しい.一方で,物体抽出を伴わずに環境地図を生成する手 法も存在する.代表的なアプローチとして,
3D Li-
DAR (Light Detection and Ranging)
センサで計測 した3
次元点群を環境地図とする方法がある.このア プローチでは,環境地図と現在位置からセンサで計測 した3
次元点群の位置合わせを行うスキャンマッチン グと呼ばれる手法によって自己位置を推定する[10]
〜[15]
.物体抽出に基づく手法とは異なり,この手法は 特定の物体に依存せずに頑健に自己位置推定を実現す ることができる.また,LiDAR
センサは放射光を利 用するため,この手法は照明環境に関して独立という 利点をもつ.しかしながら,
3
次元点群で表現される環境地図は データ量が大きいという課題がある.特に,車両の自 動運転のように大規模な環境地図を要する場合にお いては,そのデータ量は膨大となり得る.車両で地図 データを利用するためには,二つの方法が考えられる.一つ目は,例えば国家規模のような大規模な地図デー タをあらかじめストレージに保持する方法である.こ の方法では単位長当たりのデータ量が大きい場合,ス トレージの空き容量(例えば
100 GB
)に収まらない 恐れがある.二つ目は,地図データを通信モジュール を介して車両へストリーミング配信する方法である.この方法では電波の乱れ等により通信帯域が狭くなっ た場合でも遅延なく配信する必要があるため,コンパ クトな地図データが求められる.したがって,いずれ の方法に対しても可能な限りデータ量は小さいことが 望ましい.
そこで本論文では,スキャンマッチングに基づく自 己位置推定において車両の自動運転に要求される精度,
計算効率性を実現しつつ,可能な限り環境地図のデー タ量を削減することを目的とする.この目的のために,
LiDAR
に基づく新たな地図生成手法及び自己位置推定手法を提案する.提案地図生成手法は,物体抽出を 行わずに全ての計測データをモデル化,及び圧縮す る.具体的には,ボクセルグリッドを用いて
3
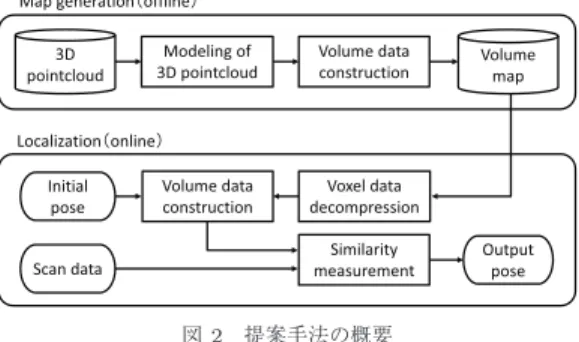
次元点 群をモデル化した後に,それらのデータを量子化する ことによって地図データを圧縮する.また,更にデー タ量を削減するために,図1
に示すようなボリュー ム地図を構築する.提案自己位置推定手法は,同一体 積の空間に対応するデータの類似性に基づいてスキャ ンマッチングを行う.ここでは,地図データが含む量 子化インデックスを復号することにより,各ボクセル 内のモデルを復元する.提案手法は,地図データとス キャンデータをボクセル単位で照合することにより,デシメートル精度の自己位置推定を実現する.高速な 照合のために,有限の空間を表現するベクトル間の類 似度計算,及び粗密探索法に基づく位置姿勢パラメー タの探索を行う.
以降本論文では,
2.
にて関連研究について述べた 後,3.
及び4.
で新たな地図生成手法及び自己位置推図1 ボリューム地図の概要図.緑色,青色の立方体はそ れぞれボリューム,サブボリュームを表す.灰色の 立方体は占有ボクセルを表し,非占有ボクセルは図 示しない.
Fig. 1 Illustration of the proposed volume map. The green cubes and blue cubes represent the vol- umes and the subvolumes respectively. The gray cubes represent occupied voxels, but un- occupied voxels are not shown.
定手法を提案する.そして,
5.
にて地図データ量及び 自己位置推定性能についての評価実験結果を示し,6.
でまとめと今後の課題を述べる.
2.
関 連 研 究3
次元点群に基づくスキャンマッチングに対して,多 くの手法が提案されている.最も一般的な手法は,ICP (Iterative Closest Point) [10]
とその変形[11], [12]
で ある.これらの手法では,3
次元点群を地図データと みなす.スキャンマッチングの実行時には,地図デー タとスキャンデータ(3
次元点群)の間で最近傍点の 対応付けと位置姿勢変換を交互に反復する.そして,全ての対応点間の距離の総和を最小化する位置姿勢を 求めることにより,高精度な自己位置推定を実現でき る.一方で,これらの手法は地図のデータ量が非常に 大きい.近年の
LiDAR
センサは1
秒間に数十万点以 上の3
次元点を計測するため,構築される3
次元点群 のデータ量は経路1 km
あたり数百MB
から数GB
の オーダーとなり得る.点群に対するデータ圧縮は,地図データ量削減の課 題に対する解決策の一つである.
Sim
ら[16]
はQS-
plat
法[17]
によって表現された点群を対象に,個々の 点データに対して線形量子化を適用することでデータ量を削減する.文献
[18]
では,線形量子化の代わりに ベクトル量子化を利用することによって,点群データ をより効率的に圧縮する.ベクトル量子化とは,ある ベクトルの集合を事前に用意された代表ベクトルの集 合(
コードブック)
を用いて近似するデータ圧縮手法で ある.Golla
ら[19]
は八分木ボクセルを用いて3
次元 空間を再帰的に分割し,各ボクセルに含まれる点群を 画素値を量子化した高さ地図画像及び占有地図画像で 表現することによって点群データを圧縮する.これら の手法は点群の詳細を保持しつつデータ量を削減する ことを目指している.すなわち,点群の局所的な密度 や表面形状の曲率等の諸量が損なわれないようにデー タを圧縮する.そのため,スキャンマッチングの精度 を維持しつつ地図データ量を削減するという本研究の 目的に対して必ずしも最適な方法とは言えず,十分な 削減率が得られない可能性がある.3
次元点群を特定の近似表現に変換することによって 地図データ量を削減する手法も提案されている.Mag- nusson
ら[13]
は,3D NDT (Normal Distributions Transform)
アルゴリズムを提案した.この手法は,ボ クセルごとの3
次元点群を3
変量正規分布モデルで表 現する.これにより,元々の3
次元点群と比べて地図 データ量を大きく削減することができる.また,最近 傍点の対応付けを行わず,スキャンデータをボクセル へ割り当てることによって点と正規分布モデルを対応 付けるため,ICP
と比べて計算量が小さいという利点 をもつ.Stoyanov
ら[14]
は,地図側の3
次元点群だ けでなく,現在位置で計測されたスキャンデータも正 規分布モデルで表現することによって,標準的な3D NDT
より高速なスキャンマッチングを実現している.このような近似表現を用いた地図のデータ量は,経路
1 km
あたり数MB
から数十MB
のオーダーとなる.国家規模の地図を想定する場合,道路の総延長は数十 万
km
から数百万km
に及ぶため,単純に換算した場 合の地図データ量は数TB
から数百TB
のオーダーと なる.車両に搭載されたストレージに格納する目的に 対して,この値は小さいとは言い難い.したがって,大規模な範囲を表す地図データのコンパクト表現には 依然として課題が残っていると言える.
本論文では,
3
次元点群を近似表現に変換した上で,ベクトル量子化を用いて地図データを圧縮する手法を 提案する.この手法は点データを個別に量子化する代 わりに,有限空間内での点群の形状を表すベクトルを 量子化することにより,効率的にデータ量を削減する.
3.
ボリューム地図自動運転に要求される精度と計算効率性を達成しつ つ,地図データ量を削減するための新たな地図生成 手法を提案する.図
2
の上段に提案する地図生成手 法の概要を示す.提案手法は,SLAM (Simultaneous Localization and Mapping)
技術や位置姿勢計測セン サの利用によって生成された3
次元点群地図が入力と して与えられることを前提とする.提案手法は,初めに空間をボクセルグリッドで分割 し,各ボクセル内のデータをモデル化する.その後,
指定した大きさのボリューム内のボクセルの集合をベ クトル表現に変換する.地図データ量を削減するため に,このベクトルをあらかじめ作成したコードブック を用いて代表ベクトルに置き換える量子化処理を行 う.この際,サイズの小さいコードブックを用いて効 率的にベクトルを表現するために,サブボリュームご とにベクトルの計算と量子化を行う.更に,各サブボ リュームの絶対位置をボリューム内の相対位置で表現 することによって,位置情報に関するデータ量を削減 する.
3. 1 3
次元点群のモデル化3
次元点群が与えられた場合,初めに一辺の長さがr
のボクセルグリッドを用いて空間を分割する.そし て,ボクセルの占有・非占有を二値で表現する二値占 有モデルを用いて所与の3
次元点群をモデル化する.得られたボクセルデータは,有限個のボクセルで構 成されるボリュームデータとしてモデル化する.この 際,後述のベクトル表現における次元数を削減すると ともに,非占有ボクセルのみで構成される一部の空間 を効率的に格納するために,ボリュームデータのサブ セットであるサブボリュームを用いて階層的にモデル
図2 提案手法の概要
Fig. 2 Overview of the proposed method.
化する.すなわち,初めに
x
,y
,z
方向にそれぞれm
個,合計M = m
3個のボクセルを一つのサブボリュー ムとしてモデル化する.その後,同様に一方向にn
個,合計
N = n
3個のサブボリュームから一つのボリュー ムを形成する.パラメータr
,m
,n
はx
,y
,z
方向 のそれぞれに対して独立に設定することが可能だが,本論文では特筆のない限り全ての方向に対して同じ値 に設定するものとする.そして,サブボリューム内の ボクセルの集合を単一のベクトルとして表現する.す なわち,サブボリューム内で
( x, y, z )
方向に0
から数 えて( u, v, w )
番目に位置するボクセルに対して,次式 のインデックスを与える.i = u + vm + wm
2+ 1 . (1)
このインデックス
i
を次元,ボクセルのもつ二値表現 を要素としたベクトルを用いてサブボリュームを表現 する.その後,地図データ量を削減するために,各サ ブボリュームのもつベクトルをベクトル量子化する.コードブックは,訓練用の
3
次元点群から計算された サブボクセルを表現するベクトル群をK
個にクラスタ リングし,各クラスタの代表を求めることで作成する.そして,各サブボリュームを,それが割り当てられた 代表ベクトルのインデックス
k ∈ { 1 , . . . , K}
で表現す る.全てのボクセルが非占有であるサブボリュームに 対してはこの処理をスキップし,N/A(not available)
と表現する.図
1
は,提案手法によって生成されるボリューム地 図の概要を示している.提案手法においては,最終的 に得られたボリュームデータの集合を地図データとする.図
3 (a)
はある入力ベクトルで表現されたサブボリュームの例を,図
3 (b)
はコードブックを用いて代 表ベクトルへ置き換えられたサブボリュームを模式的 に表現している.代表ベクトルは量子化誤差に相当す る形状的な誤差を含むものの,入力ベクトルに近似し図3 ベクトル量子化の例 Fig. 3 Example of the vector quantization.
た形状を表現することができる.
3. 2
ボリュームデータの構築各ボリュームデータは,
3
通りの情報で構成される:ボリュームの中心座標,
N/A
ではないサブボリューム の相対位置を表すビット列B
P,N/A
ではないサブボ リュームを表現する代表ベクトルのインデックスで構 成されたビット列B
I.地図データ量を削減するために,各サブボリューム の位置情報を絶対位置として表現する代わりに,ボ リューム内での相対位置のインデックスとして表現す る.初めに,ボリューム内で
( x, y, z )
方向に( u, v, w )
番目に位置するサブボリュームに対して,数式(1)
と 同様の様式でインデックスj
を与える.そして,j
番 目の要素に対して,サブボリュームが一つ以上の占有 ボクセルを含めば‘1’
,そうでなければ‘0’
が割り当て られるビット列B
P を生成する.サブボリュームを表現する代表ベクトルのインデッ クス
k
は,コードブックのサイズK
を表現可能な最 短(
すなわち,長さceil (log
2( K )))
のビット列b
jに変 換される.その後,対応するj
の小さい順にb
jを並べ たビット列B
Iを生成する.このビット列には,N/A
のサブボリュームに対応するb
jは含まない.4.
自己位置推定地図データとスキャンデータの間の類似度に基づく 自己位置推定手法を提案する.図
2
の下段に示すよう に,提案手法への入力は地図側の座標系における位置 姿勢を表す回転行列R
及び並進ベクトルt
の初期値ξ
0= [ R|t ]
,3.
に記載のボリューム地図,LiDAR
セ ンサによって計測されたスキャンデータである.提案手法は文献
[15]
と同様にサンプリングに基づく 探索によって,初期値の誤差を補正する位置姿勢変換 パラメータを求める.前述のICP
やNDT
は勾配法 に基づいて変換パラメータを探索するため,適切な初 期値を設定しない場合には局所解に陥ることが知られ ている.それに対し,サンプリングに基づく手法はあ らかじめ設定した離散的な変換パラメータを全探索す ることによって,局所解の問題を回避することができ る.したがって,提案手法は勾配法に基づく手法に比 べて得られる結果が離散的ではあるものの,探索範囲 内での最適性を保証する利点をもつと言える.具体的には,初めにコードブックを用いて量子化イ ンデックス
b
jを復号することにより,ボリューム地 図からボクセルデータを復元する.その後,復元されたデータから初期値に基づく自己位置を中心としたボ リュームデータを生成する.この処理は,復元された ボクセルデータに対して数式
(1)
のインデックスを再 計算するのみで実現される.また,様々な位置姿勢変 換を施されたセンサ側の3
次元点群からボリューム データを生成する.そして,地図側のボリュームデー タと最も類似するセンサ側のボリュームデータを検索 し,それに対応する位置姿勢変換パラメータを求める.なお,我々の地図データは
3
次元点群地図に基づく 既存の自己位置推定手法でも利用可能である.しかし,本論文では前述の最適性と計算効率性を実現するため に,新たな自己位置推定手法を提案する.
4. 1
定 式 化自己位置推定問題を,地図側とセンサ側における同 一体積の空間を表現するベクトル間の類似検索問題 として定式化する.初期値の位置成分
t
を地図側のボ リュームデータの中心座標C
とする.地図側の3
次 元点群P
から生成され,パラメータΘ = {C, r, m, n}
を用いて構築されたボリュームデータを次式で表す.
V ( P, Θ) = {p
1, . . . , p
N}, (2)
ここで,
p
j= {p
j,1, . . . , p
j,M} ( j = 1 , . . . , N )
はボ リューム内のj
番目のサブボリュームを表現するベク トルである.N/A
のサブボリュームに対しては,p
jを全ての要素が
0
のベクトルとみなす.センサ座標 系の原点を,センサ側のボリュームデータの中心座 標C
とする.初期値が誤差を含まない場合,C
とC
は実世界の同一位置を表す.しかしながら,一般的に 初期値は誤差を含むため,必ずしもそうなるとは限 らない.初期値の誤差を補正するために,パラメー タη = ( t
x, t
y, t
z, θ
roll, θ
pitch, θ
yaw) ∈ SE (3)
を用い てセンサ側の3
次元点群P
に様々な位置姿勢変換を 施す.その後,3. 1
に記載された様式でパラメータΘ
= {C
, r, m, n}
を用いてボリュームデータを生成 する.ただし,ここではデータ量を削減する必要がな いため,サブボリュームを表すベクトルは代表ベクト ルには置き換えない.V
( T ( P
, η ) , Θ
) = {q
1, . . . , q
N}, (3)
ここで,
T
は位置姿勢変換関数である.Θ
内のr
,m
,n
は,常にΘ
のものと同一になるように設定する.提案手法は,ボリュームデータに含まれるボクセル の内,ボリューム内での相対位置が一致し,かつ同一
の表現をもつボクセルのペアに対して類似度スコアを 与える.効率的な計算のために,サブボリュームを表 す二値ベクトルの
Hamming
距離を非類似度尺度とし て利用する.したがって,初期値の誤差を最も良く補 正する変換パラメータη
を求める問題を,次式で表さ れる非類似度関数の最小化問題として定式化する.argmin
η
d ( η ) =
M i=1 N j=1|p
i,j− q
i,j|
⊕, (4)
ここで,
|p
i,j− q
i,j|
⊕は二つの二値表現の間のHam- ming
距離である.4. 2
ボリュームデータ間の類似度計算初期値の誤差を補正するために,位置姿勢変換パラ メータをサンプリングする.初めに,様々な位置姿勢 変換を施されたセンサ側の
3
次元点群からボリューム データを生成し,地図側のからのボリュームデータと 最も類似するセンサ側のボリュームデータを求める.そして,そのボリュームデータに対応する変換パラ メータを用いて初期値を補正し,自己位置を推定する.
4. 2. 1
回 転 変 換初めに,回転に関してのみセンサ側の座標系を地図 側の座標系に一致させるために,初期値
R
を用いて スキャンデータP
を回転変換する.その後,初期値 の誤差を補正するために,R
を基準とした回転オフ セットo
θを用いてP
を更に変換する.回転オフセッ トo
θ は,回転パラメータに関するサンプリングの範 囲[ −θ , θ ]
内で等間隔に位置する指定個数の回転角度 である.以降の処理は,異なるオフセットで変換され たセンサ側の3
次元点群ごとに独立に行う.4. 2. 2
スライディングによる並進変換初期値の並進誤差を補正するために,並進オフセッ ト
o
tを用いて並進変換された3
次元点群からボリュー ムデータを生成する.ただし,並進変換を効率的に計 算するために,実際に3
次元点群を並進変換する代わ りに,求めるサブボリューム及びボリュームと同じ大 きさの3
次元ウィンドウをスライディングさせること によってボリュームデータを計算する.具体的には,初めに
3. 1
と同じ様式でボクセル群を 構築する.その後,サブボリュームと同じ大きさの3
次元ウィンドウを各方向にボクセル単位でスライディ ングさせることによってサブボリューム群を構築する.すなわち,サブボリュームを構築する際には,各サブ ボリューム内でのボクセルの相対位置を表すインデッ クス
i
のみを計算する.したがって,同一のボクセルであっても,異なるサブボリュームにおいては異なる
i
が割り当てられる.同様にして,ボリュームと同じ 大きさの3
次元ウィンドウをサブボリューム単位でス ライディングさせることによってボリューム群を構築 する.並進オフセットo
tは,各サブボリューム及び各 ボリュームを構築する際のスライディング回数の組み 合わせから計算できる.4. 2. 3
初期値の補正センサ側の
3
次元点群から生成された全てのボリュー ムデータの中から,数式(4)
の非類似度を最小化する ものを求める.その後,得られたボリュームデータに 対応する姿勢変換パラメータη ˆ
は,上述のオフセットo
θ及びo
tから計算できる.最後に,η ˆ
を用いて初期 値を補正することによって,自己の位置姿勢を得る.4. 3
探索の効率化効率的な探索のために,粗密戦略を利用する.すな わち,徐々に細かくなるオフセットを用いて段階的に 位置姿勢変換パラメータを求める.この処理は一つの 地図データしか利用せず,追加のデータを要求しない.
最初の段階においては,初期値
ξ
0と最も粗いオフ セットo
θ,1及びo
t,1を用いて,指定された範囲を徹 底的に探索する.結果として,推定された位置姿勢ξ
1を得る.次の段階においては,より細かいオフセット
o
θ,2及びo
t,2を用いて,より狭い範囲のみを探索する.ここでは,
ξ
1を初期値とみなす.結果として,推定さ れた位置姿勢ξ
2を得る.これ以降の段階においても,同様にオフセットを細かくしながらより狭い範囲を探 索する.
5.
評 価 実 験本章では,提案した地図生成手法及び自己位置推定 手法の性能を評価する.提案手法は従来手法と比べて 遥かにデータ量が小さい地図を用いて,車両の自己位 置推定に対して妥当な性能を実現することを示す.
5. 1
実 験 設 定様々な環境下で計測された
3
次元点群を用いて提案 手法の性能を評価するために,公開データセットであ るKITTI Vision Benchmark Suite [20]
を利用する.このデータセットは,
LiDAR
センサ,GNSS/INS
を 搭載した車両を用いて市街地で計測したデータを含む.実験では,初めに所与の
GNSS/INS
データを用いて 複数のスキャンデータを統合することにより3
次元点 群地図を構築した.その後,提案した地図生成手法を 用いて地図データを作成した.本実験において,単位長当たりの地図データ量はこの
3
次元点群を構築す る際に使用したGNSS/INS
データの軌跡の総延長で 地図データ量を除算することによって求める.コード ブックは,M´ alaga Urban Dataset [21]
から訓練用の3
次元点群を構築し,k-medoids
法を用いて作成した.提案手法では,求める位置姿勢の並進成分はボクセ ル単位での探索によって決定される.そのため,ボク セルの一辺の長さ
r
が大きいほど並進成分の誤差が大 きくなり,一方で計算量が削減される.本論文の実験 においては許容可能な並進成分の誤差量を1 m
までと 想定し,それより十分に小さい並進誤差を達成しつつ 計算量を削減する為にr = 25 cm
に設定した.また,提案手法ではボリュームの一辺の長さが大き いほど,
3. 2
に記載のビット列B
P のデータ量が大き くなる.一方で,小さいほどボリューム内でのN/A
で はないサブボリュームの割合が平均的に高くなり,結 果として全データに対するビット列B
Iのデータ量の 割合が大きくなる.我々は地図データ量をおよそ最小 にする値を調査し,ボリュームの大きさを24 m × 24 m × 24 m
に設定した.提案手法による自己位置推定で は,実行時に構築するボリュームが大きいほど利用可 能な地図データ及びスキャンデータの範囲が広くなる が,一方で処理時間が増加する.処理時間を抑えつつ 広範囲のデータを利用するために,地図側とセンサ側 の両方でボリュームの大きさを96 m × 96 m × 24 m
に 設定した.提案手法における位置姿勢変換パラメータ
η
の探索 範囲については,LiDAR
センサの計測を入力として リアルタイム処理を行う前提で設定した.すなわち,KITTI
データセットで使用されたLiDAR
センサの 反復率である10 Hz
の周期で逐次的に自己位置推定 を行う場合に,初期値の誤差のとり得る範囲をカバー するように探索範囲を設定した.また,本実験では文 献[15], [22]
と同様に車両に対するロール角及びピッチ 角は微小な値であると想定し,探索範囲に含めないも のとした.具体的には,x
方向及びy
方向にそれぞれ[−3 m, 3 m]
,z
方向に[−0.5 m, 0.5 m]
,そしてヨー 角に対して[ − 5
◦, 5
◦]
を探索範囲とした.また,本実 験では粗密戦略に基づき2
段階の探索を行った.1
段 目は上述の範囲に対してx
方向,y
方向,z
方向にそ れぞれ0.5 m
刻みで探索するo
t,1を,ヨー角には1
◦ 刻みで探索するo
θ,1を設定した.2
段目ではx
方向及 びy
方向にそれぞれ[ − 1 m, 1 m]
,z
方向に[ − 0.25
m, 0.25 m]
の範囲を0.25 m
刻みで探索するo
t,2 を,図4 異なるパラメータを用いた際の提案手法の性能評価
Fig. 4 Performance evaluation of the proposed method with different parameters.
ヨー角には
[ − 1
◦, 1
◦]
の範囲を0 . 5
◦刻みで探索するo
θ,2を設定した.2
段目のオフセットには,1
段目で 誤った場合にも正しい推定を可能とするために,冗長 性をもたせる設定とした.全ての実験は,
3.4 GHz Intel Core i7-6800K CPU
と32GB
のRAM
を搭載するPC
上で実行した.提 案手法については,類似度計算を変換パラメータご とに独立に処理可能である.そこで,高速化のためにOpenMP
(注1)によるCPU
での並列処理技術によって 実装し,6
コア12
スレッドを用いて並列に処理した.5. 2
サブボリューム及びベクトル量子化の影響 提案手法で使用されるパラメータであるサブボリュー ムの1
辺の長さL (= rm )
及びコードブックのサイズK
について,性能への依存性を検証する.初めに100
通りのスキャンデータをランダムに選択し,真値か ら離れるような変換を施した位置姿勢を初期値とし て地図データに対する自己位置推定を行う.ここで は,初期値の誤差を模擬する目的で5. 1
に記載の探 索範囲内でのランダムな変換を使用した.各スキャン データに対してそれぞれ100
回の試行を行い,RMSE (Root Mean Square Error)
を計算した.更に,参考 のために地図データがベクトル量子化の前後でどの 程度劣化したかを,3
次元点群に対するPSNR (Peak Signal-to-Noise Ratio)
を用いて定量的に示す.この(注1):https://www.openmp.org
PSNR
は,地図データを占有ボクセルの中心位置を座 標とする3
次元点群とみなすことによって,文献[19]
に記載の計算式から求められる.また,経路
1 km
当 たりの地図データ量及び処理時間も計測した.検証するパラメータには,メートル単位の
L ∈ { 1 , 2 , 3 }
及びK ∈ { 2
1, 2
2, . . . , 2
20}
を用いた.各L
に対して,ボリュームの大きさが同一になるようにサ ブボリューム数を設定した.また,L
は,地図生成時 と自己位置推時に共通の値を用いた.更に,ベクト ル量子化の有無が性能へ及ぼす影響を検証するため に,地図生成においてベクトル量子化を行わない場合 のRMSE
も合わせて測定した.全ての結果を図4
に 示す.図
4 (a)
より,K
が等しい場合はL
が小さいほど自 己位置推定の精度が向上する傾向があることがわかる.また,同一の
L
を用いた場合はK
が大きいほど自己 位置推定の精度が改善する.これらは,サブボリュー ムの体積に対してK
が大きくなるほど,量子化誤差 が減少するためである.各L
において,ベクトル量子 化を行わない場合の精度と比較した場合,L = 1
,2
,3
のそれぞれに対してK = 2
6,2
12,2
20の時点でほ ぼ同等の精度を達成した.すなわち,これらの値以上 のサイズをもつコードブックを用いた場合には,自己 位置推定の精度への悪影響を抑えつつ地図データ量を 削減できる.図
4 (b)
はベクトル量子化の前後のPSNR
を示しており,縦軸の値が大きいほど地図データの損失が少な いことを表す.図
4 (a)
と合わせて見ることで,自己 位置推定の精度と地図データの損失は対応する傾向が あることが分かる.すなわち,K
が等しい場合はL
が小さいほどPSNR
が大きく,各L
においてK
の増 加がPSNR
を改善する.これは,前述した理由によっ て量子化誤差が減少するためである.したがって,各L
においてK
の増加が地図データの損失を低減させ,それによって自己位置推定の精度が改善したと考えら れる.
地図データ量に関しては,図
4 (c)
よりL
に大きく 依存することがわかる.これは,同一の体積の空間に 含まれるサブボリュームの個数がL
の三乗に反比例 するためである.一方で,K
への依存性は小さい.こ れば,サブボリュームを表現するベクトル量子化イン デックスのサイズがlog
2( K )
であり,K
の増加量に対 してインデックスサイズの増加量が緩やかであるため である.したがって,地図データ量を削減するために はL
を増加させることが効果的であることがわかる.ただし,
L
の増加はサブボリュームを表現するベクト ルの次元を増加させるため,いわゆる次元の呪いに起 因して適切なコードブックのサイズK
を指数関数的 に増加させる.それにより,いずれはK
の増加に伴 う地図データの増加量が,L
の増加に伴う削減量を上 回ることが予想される.ここで,
3
次元データの圧縮に広く利用される八分 木を用いてサブボリュームを表現する場合との比較を 検討する.例えばr = 25 cm
,L = 2 m
の場合,提案 手法は一つのサブボリュームを最小12 bits
で表現で きる.一方,八分木を用いた場合はこのサブボリュー ムは3
レベルの八分木構造で表現される.データ量の 最小値は各レベルで一つのノードのみが子ノードもつ 場合の8 + 8 + 8 = 24 bits
,最大値は全てのノード が子ノードをもつ場合の8 + 8
2+ 8
3= 584 bits
とな る.したがって常に提案手法の方がデータ量が小さく なる.ただし,提案手法は非可逆圧縮手法であるのに 対し,二値占有モデルへの八分木表現は可逆圧縮手法 である.図
4 (d)
は,異なるL
及びK
に対する平均処理時 間を示している.この図より,L
が大きくなるほど処 理時間が増加する傾向があることがわかる.これは,L
が大きくなるほどN/A
のサブボリュームが減少し ていくことに起因する.我々の実装では,地図側とセ ンサ側のサブボリュームが両方ともN/A
であった場合,それらのサブボリュームを表現するベクトル間の
Hamming
距離を0
とみなして計算をスキップする.本実験では,異なる
L
に対してボリュームの大きさを 共通にしているため,入力点群が同一であればL
が 大きいほどサブボリュームがN/A
となる割合が減少 する.したがって,L
が大きいほどビット演算の回数 が増加し,処理時間が大きくなる.ただし,L
が小さ いほどボリューム内のサブボリューム数が増えるため,N/A
であるか否かの判定に要する処理時間が増加し ていく.そのため,必ずしもL
が小さいほど高速化で きるとは限らない.一方で,処理時間はK
には影響 を受けないことがわかる.これは,ビット演算を行う 回数がK
に依存しないためである.高精度な自己位置推定を実現しつつ地図データ量を 削減するために,地図生成時に利用するパラメータ として
{L
,K} = {3
,2
20}
を選択する.これらのパ ラメータに対応するコードブックのデータ量は226.5 MB
であり,自己位置推定時に利用するために地図 データとともに追加的に格納される.図5
にこれら のパラメータを用いて生成した地図データとスキャン データの間の非類似度関数d (η)
の値の例を示す.こ こでは,スキャンデータに対して真値を基準にx
方向 及びy
方向に変位を与えた.量子化された地図データ であっても真値において非類似度が最小となるため,高精度な自己位置推定が可能であることが確認できる.
また,図における右斜め方向への変位に対しては,地 図データの形状的な変化が少ないために非類似度の変 化が緩やかであることがわかる.
提案手法では,地図生成時に量子化したボクセル データを自己位置推定時に復元する.その後,復元さ れたボクセルデータから再度サブボリュームを構築す る.そのため,地図生成時と自己位置推定時に必ずし も共通の
L
を利用する必要はない.したがって高速化 のために,自己位置推定時に利用するパラメータにはL = 1
を選択した.以降の実験では,これらのパラメータを使用する.
5. 3
自己位置推定性能及び地図データ量の評価 連続的に計測されたスキャンデータを用いて,提案 した自己位置推定手法の性能を検証する.また,自己 位置推定に利用された地図のデータ量も測定する.こ の実験では,KITTI
データセットに含まれる都市内の
3.7 km
の経路に渡って計測されたスキャンデータを用いて地図データに対する自己位置推定を行う.地 図データは,図
6
に示す3
次元点群地図を入力として図5 非類似度関数の可視化
Fig. 5 Visualization of the dissimilarity function.
図6 3次元点群地図
Fig. 6 Three-dimensional pointcloud map.
生成する.ここでは,入力フレームより前のフレーム の推定結果を用いて線形予測した位置姿勢を初期値と して利用する.推定誤差を計算する際には,各スキャ ンデータに対応する
GNSS/INS
データを真値とみな す.また,地図データがコンパクトであり,最も広く 利用されるスキャンマッチング手法の一つである3D NDT
との比較も行う.3D NDT
の実装には,オープ ンソースソフトウェア(注2)を利用した.3D NDT
に対 するボクセルの1
辺の長さは,Stoyanov
ら[23]
の調 査において最良の精度を達成した1.6 m
に設定した.3D NDT
に対しては,処理の高速化のためにスキャンデータに
1
辺が1.6 m
のボクセルグリッドフィル タ[24]
を適用した.評価指標として,進行方向への位置誤差
(Longitudi- nal error)
,その横方向への位置誤差(Lateral error)
, 進行方向に対する方向誤差(Orientation error)
,処理 時間(Computational time)
を用いる.図7
に横軸を フレーム番号としたグラフを,表1
にこれらの平均絶 対値及び地図データ量を示す.提案手法については,(注2):https://github.com/OrebroUniversity/perception oru- release
表1 自己位置推定性能及び地図データ量の比較 Table 1 Comparison of localization performance and
map data size.
3D NDT Proposed method Longitudinal error 9.36 [cm] 12.60 [cm]
Lateral error 10.78 [cm] 14.38 [cm]
Orientation error 0.31 [◦] 0.27 [◦] Computational time 0.17 [s] 0.077 [s]
Map data size 8.06 [MB/km] 0.047 [MB/km]
参考のために図
7 (a)
の1,500
フレーム付近に見られ る大きな位置誤差の例,図7 (c)
の3,000
フレーム付 近に見られる大きな方向誤差の例を図8
に示す.図8
では,直交する矢印が進行方向及び横方向を表し,青 と赤の色がそれぞれ真値と推定値に対応する.進行方向及び横方向への位置誤差に関して,提案手
法は
3D NDT
と類似した傾向を示すが,わずかに大きな誤差をもつことが示された.これは,提案手法が ボクセル単位の離散的な探索を行うために,ボクセル を形成する際の空間の離散化誤差の影響を受けるこ とに起因する.しかしながら,提案手法の位置に関す る平均誤差は
15 cm
未満であり,車線レベルの位置 推定を実現可能と考えられる.どちらの手法において も,道路脇に建物の壁面のような表面が平坦な構造物 が並ぶ環境においては大きな誤差をもつことがあった(図
8 (a)
参照).これは,どちらも物体の3
次元形状 を手掛かりとする手法であり,形状的な変化に乏しい 環境では正確な推定が困難なためである.方向誤差に 関しても,両手法で類似した精度を示した.どちらの 手法も角を曲がる際に大きな方向誤差をもつ場合も あった(図8 (b)
参照)が,その後のフレームにおい ては精度良く推定された.図7 3D NDT及び提案手法の自己位置推定性能
Fig. 7 Localization performance of the 3D NDT and the proposed method.
図8 提案手法によって生じた大きな誤差の例 Fig. 8 Examples of large errors in our method.
処理時間に関して,提案手法は
KITTI
データセッ トで利用されたLiDAR
センサの計測間隔である0.1 s
を安定的に下回っており,リアルタイム処理を可能と することがわかる.提案手法によって生成される地図 の経路1 km
当たりのデータ量は0.047 MB/km
であ り,3D NDT
の8.06 MB/km
に比べて171
倍コンパ クトであった.これは,ベクトル量子化に基づくデー タの圧縮,及びボリューム地図表現による効率的な格 納のためである.したがって,提案手法は3D NDT
より2
桁倍コンパクトな地図を用いて同程度の精度を 実現しており,その有効性を確認できる.提案手法によって生成される地図のデータ量に関し て,例えば日本の道路の実延長である
122
万km [25]
に対する地図データ量を単純換算すると約
57 GB
とな る.この値は車載のストレージに格納する目的に対し て妥当であり,大規模な範囲を地図化する場合であっ ても全ての地図データが車両に搭載可能であるといえ る.一方で,走行中の車両へストリーミング配信をす る場合を想定すると,例えば車両が時速100 km
で走 行する際に必要な通信帯域は約10 kbps
となる.この 値はG.729
による音声通話に要求される通信帯域(8
kbps)
に匹敵するほど小さく,従って利用可能な通信帯域が狭い場合であっても安定的にストリーミング配 信が可能であると思われる.
6.
む す び本論文では,データ量の小さい地図を用いて高速か つ高精度な自己位置推定を実現する手法を提案した.
提案手法は自己位置推定問題を同一体積の空間を表現 するベクトル間の類似度最大化問題として定式化する.
提案された地図生成手法は空間全てを地図化するため,
物体抽出の困難性を回避することができる.公開デー タセットを用いた評価実験では,提案手法は従来手法 と同程度の自己位置推定性能をもちつつ,地図データ 量を
2
桁倍削減可能であることを示した.今後はより符号化効率に優れた量子化手法の適用に よる地図データの更なるコンパクト化や,初期値が与 えられない状況への適用について検討する.
文 献
[1] L.-T. Hsu, F. Chen, and S. Kamijo, “Evaluation of multi-GNSSs and GPS with 3D map methods for pedestrian positioning in an urban canyon environ- ment,” IEICE Trans. Fundamentals, vol.E98-A, no.1, pp.284–293, Jan. 2015.
[2] A. Schindler, “Vehicle self-localization with high- precision digital maps,” Proc. IV, pp.141–146, 2013.
[3] A. Schindler, G. Maier, and F. Janda, “Genera- tion of high precision digital maps using circular arc splines,” Proc. IV, pp.246–251, 2012.
[4] G. M´attyus, S. Wang, S. Fidler, and R. Urtasun, “HD maps: Fine-grained road segmentation by parsing ground and aerial images,” Proc. CVPR, pp.3611–
3619, 2016.
[5] B. Mathibela, P. Newman, and I. Posner, “Reading the road: Road marking classification and interpreta- tion,” IEEE Trans. ITS, vol.16, no.4, pp.2072–2081, 2015.
[6] A.B. Hillel, R. Lerner, D. Levi, and G. Raz, “Recent progress in road and lane detection: A survey,” MVA, vol.25, no.3, pp.727–745, 2014.
[7] M. Cheng, H. Zhang, C. Wang, and J. Li, “Extrac- tion and classification of road markings using mobile laser scanning point clouds,” IEEE J-STARS, vol.10, no.3, pp.1182–1196, 2017.
[8] Y. Yu, J. Li, H. Guan, F. Jia, and C. Wang, “Learn- ing hierarchical features for automated extraction of road markings from 3-D mobile LiDAR point clouds,”
IEEE J-STARS, vol.8, no.2, pp.709–726, 2015.
[9] S. Gargoum and K. E.-Basyouny, “Automated ex- traction of road features using LiDAR data: A review of LiDAR applications in transportation,” Proc. IC- TIS, pp.563–574, 2017.
[10] P.J. Besl and N.D. McKay, “A method for regis- tration of 3-D shapes,” IEEE Trans. Pattern. Anal.
Mach. Intell., vol.14, no.2, pp.239–256, 1992.
[11] S. Rusinkiewicz and M. Levoy, “Efficient variants of the ICP algorithm,” Proc. 3DIM, pp.145–152, 2001.
[12] A. Segal, D. Haehnel, and S. Thrun, “Generalized- ICP,” Proc. RSS, 2009.
[13] M. Magnusson, A. Lilienthal, and T. Duckett, “Scan registration for autonomous mining vehicles using 3D-NDT,” JFR, vol.24, no.10, pp.803–827, 2007.
[14] T. Stoyanov, M. Martin, and A.J. Lilienthal, “Point set registration through minimization of the L2 distance between 3D-NDT models,” Proc. ICRA, pp.5196–5201, 2012.
[15] R.W. Wolcott and R.M. Eustice, “Robust LIDAR localization using multiresolution Gaussian mixture maps for autonomous driving,” IJRR, vol.36, no.3, pp.292–319, 2017.
[16] J.Y. Sim, C.S. Kim, and S.U. Lee, “Lossless com- pression of 3-D point data in QSplat representation,”
IEEE Trans. Multimedia, vol.7, no.6, pp.1191–1195,
2005.
[17] S. Rusinkiewicz and M. Levoy, “QSplat: A multires- olution point rendering system for large meshes,”
Proc. SIGGRAPH, pp.343–352, 2000.
[18] J.Y. Sim and S.U. Lee, “Compression of 3-D point visual data using vector quantization and rate- distortion optimization,” IEEE Trans. Multimedia, vol.10, no.3, pp.305–315, 2008.
[19] T. Golla and R. Klein, “Real-time point cloud com- pression,” Proc. ICRA, pp.5087–5092, 2015.
[20] A. Geiger, P. Lenz, and R. Urtasun, “Are we ready for autonomous driving? The KITTI Vision Bench- mark Suite,” Proc. CVPR, pp.3354–3361, 2012.
[21] J.-L. B.-Claraco, F.- ´A. M.-Due˜nas, and J. G.- Jim´enez, “The M´alaga urban dataset: High-rate stereo and LiDAR in a realistic urban scenario,”
IJRR, vol.33, no.2, pp.207–214, 2014.
[22] L. Li, M. Yang, C. Wang, and B. Wang, “Road DNA based localization for autonomous vehicles,” Proc.
IV, pp.883–888, 2016.
[23] T. Stoyanov, M. Magnusson, H. Almqvist, and A.J.
Lilienthal, “On the accuracy of the 3D normal dis- tributions transform as a tool for spatial representa- tion,” Proc ICRA, pp.4080–4085, 2011.
[24] Point Cloud Library, “Downsampling a PointCloud using a VoxelGrid filter,” [オ ン ラ イ ン].Available:
http://pointclouds.org/documentation/tutorials/
voxel grid.php
[25] 国土交通省,“道路統計年報2016,” [オンライン].Avail- able: http://www.mlit.go.jp/road/ir/ir-data/tokei- nen/2016/nenpo02.html
(平成30年2月26日受付,6月2日再受付,
7月23日早期公開)
松 康平 (正員)
2010年,東北大学工学部電気情報・物 理工学科卒業.2012年,同大学大学院修 士課程修了.同年,KDDI(株)入社.現 在,KDDI総合研究所(株)メディア認識 グループ研究員.大規模特定物体認識,画 像認識,点群処理に関する研究開発に従事.
柳原 広昌 (正員)
1990年,名古屋大学大学院電気工学研 究科博士課程前期修了.同年,国際電信電 話(株)入社.1997年より,現KDDI総 合研究所(株)にて映像の圧縮伝送・編集 変換・検索技術に関する研究開発,及び端 末プラットホームに関する技術開発に従事.
現在,メディアICT部門担当執行役員.博士(工学).