DEIM Forum 2016 G5-3
ランダム仮説下での出現回数分布を利用した散在反復配列の発見
中村
武憲
†中村
篤祥
†工藤
峰一
††
北海道大学大学院情報科学研究科
〒 060–0814 北海道札幌市北区北 14 条西 9 丁目
E-mail:
†{
takenori,atsu,mine
}
@main.ist.hokudai.ac.jp
あらまし 生物の DNA の塩基配列には散在して現れる類似配列が多く存在し,それら散在反復配列は遺伝子の発現
制御,さらには進化における機能発現に密接に関連しているとされている.散在反復配列の発見に頻出パターンマイ
ニングを用いることは可能であるが,オカレンスの出現確率がパターン長に依存するため、最小サポートを指定する
方法では偶然では起こりえない散在反復配列のパターンを一度に抽出することはできない.本研究では,類似性をア
ライメントスコアにより測り,パターンの出現として局所最適なもののみカウントする頻出パターンマイニング手法
において,最小サポートをランダムシーケンスにおけるパターンの出現回数分布に依存して決める方法を提案し,ヒ
トゲノムのシーケンスを用いた実験により有効性を示す.
キーワード 頻出パターン, ローカルアラインメント, データマイニング, 最小サポート, ランダムウォーク
1.
は じ め に
近年,メール文書のようなテキストデータやHTML・XML のような半構造化データ,生物のゲノム配列のような大規模な データなど,様々な情報がデータとして蓄積されている.それ らのデータより有用な知識を得るための分析技術であるデータ マイニング技術も大幅に進歩しており,中でも頻出するパター ンを抽出する頻出パターンマイニングは中心的に扱われている 手法の1つである.本稿では,1つの文字列に頻出する類似し た部分文字列を発見する手法を考える. 生物のDNAの塩基配列には多くの反復配列が存在している. 反復配列には,連続した繰返しである縦列反復配列(タンデム リピート)と,レトロトランスポゾンと呼ばれる部分の転移に よっておこる散在反復配列が存在し,それらは遺伝子の発現制 御に関係し,進化における機能発現に密接に関連しているとさ れている[2]. 散在反復配列の発見手法の1つとして,指定した閾値(最小 サポート)以上出現するシーケンスパターンを列挙するマイニ ング手法を適用することが可能である[1], [6].しかし,パター ン長が増加するにつれてオカレンスの出現確率は小さくなるた め,パターン長に合った最小サポートを出現回数の閾値としな ければ,偶然では起こりえない散在反復配列をもれなく抽出す ることはできない. そこで本稿では,パターンの最小長を指定せず,また固定の 閾値としての最小サポートを利用しない方法として,類似性を アライメントスコアにより測り,パターンの出現として局所最 適なもののみカウントする頻出パターンマイニング手法[7]に おいて,最小サポートをランダムシーケンスにおけるパターン の出現回数分布に依存して決める方法を提案し,比較実験によ り有効性を示す.2.
関 連 研 究
反復配列発見手法は大きく”クラスタリングを利用する手法” と”頻出パターンマイニングを利用する手法”に分けられる. クラスタリングを利用する手法として,シーケンスに対し頻 度の高いk-mer(長さkの文字列)の切り出し,不一致やギャッ プを考慮しつなぎ合わせたものを反復配列候補とし,それら反 復配列候補をクラスタリングすることで類似する反復配列候補 をまとめて反復配列とする手法が存在する[3].この手法では, k長の切り出しをつなぎ合わせる際に経験的な知見を利用した ヒューリスティクな手法を使用することや,発見される反復配 列がクラスタリング性能に依存すること,反復配列と判断され た基準がはっきりしないなどの問題がある. 頻出パターンマイニングを利用する手法として,類似性を ハミング距離やアラインメントスコアを利用して測ることで, 類似反復配列パターンを抽出する手法が提案されている[7] [8]. しかし,反復配列パターンであると判断する上で固定の最小サ ポートを使用しているため,統計的に重要と考えられる長い反 復配列パターンが出現回数が少ないために検出されないといっ た問題がある. 頻出パターンマイニングを利用する手法で,長さの異なるラ ンダムシーケンスにおけるオカレンスの出現確率を考慮して固 定ではなく可変の最小サポートを導入した手法も存在する[6]. しかし,複数のシークエンスに対して可変最小サポートを導入 した頻出パターンマイニング法であり,本稿で提案するゲノム のような一本の長大なシークエンスに対して可変最小サポート を導入するものではない.与えられたサブシーケンスバターン に対して,1本のシーケンス内におけるオカレンスの頻度分布 の近似値を計算する方法[4]が提案されているが,頻出パター ンを探す問題への拡張はされていない.3.
準
備
3. 1 問 題 設 定
Σを有限集合とし,Σの要素を文字と呼ぶ.Σの任意の2文
字x, yに対し,以下の条件を満たすスコア関数wが定義され
ているものとする.
SF1 w(x, y) = w(y, x) for all x, y∈ Σ
SF2 w(x, x) > 0 for all x∈ Σ SF3 w(x, y) < 0 for some x, y∈ Σ 文字s[1], s[2], . . . , s[n]∈ Σに対し,その列s = s[1]s[2]· · · s[n] を文字列と呼び,nを文字列sの長さと呼ぶ.長さの等しい2 つの文字列s = s[1]s[2]· · · s[n],t = t[1]t[2]· · · t[n]に対し,2 つの文字列の類似スコアSを S(s, t) = n ∑ i=1 w(s[i], t[i]) と定義する. 文字列s[1]s[2]· · · s[n]のi(>= 1)番目からj(<= n)番目まで の部分文字列s[i]s[i + 1]· · · s[j]をs[i..j]と表記する.ただし, s[i + 1..i]は空文字列を表すものとする.文字列sから文字列 p[1..m]に似ている部分を抽出する際,本質的に同じ領域を重 ねて抽出することを少なくするために以下に定義される極小局 所最適なオカレンスのみを取り出すことを考える. [定義1]([7]のギャップを許さないバージョン) 以下の条件 を満たす文字列s[1..n]の部分文字列s[j..j + m− 1]を,文字 列p[1..m]の極小局所最適なオカレンスと呼ぶ. CS1 S(p[1..h], s[j..j + h− 1]) > 0 for all 0 < h <= m CS2 S(p[1..m], s[j..j + m− 1]) > S(p[1..h], s[j..j + h − 1]) for all 0 <= h < m 論文[7]では,以下のような頻出パターンマイニング問題を 扱っている. [問題1] 与えられた文字列s,スコア関数w,自然数σに対 し,sにおいて極小局所最適なオカレンスがσ回以上出現する sの部分文字列s[h..j]を列挙せよ. 散在反復配列は長いものは出現回数が2回でも,偶然起こっ たとは考えにくいので抽出に意味があり,逆に短いものは出現 回数が10000回でも偶然に起こる確率が高い場合には抽出する 価値はない.問題1のマイニングでは,最小サポートσを固定 するため,散在反復配列としてあまり意味のない短いものが多 く抽出されたり,意味がある出現回数がσより少ない長い配列 が抽出されないという問題がある. そこで小さな確率Pを指定して,対象文字列sと同じ長さn のランダムシーケンスにおいてℓ(p, P, n)回以上起こる確率が P 以下となるような最小サポートℓ(p, P, n)をパターンp毎に 設定する頻出パターンマイニング問題を考える.情報源S0か ら発生した長さnの文字列に対し,文字列pの極小局所最適な オカレンスがm回以上生起する確率がP 以下であるような最 小のmをσ(S0, n, p, P )と表記すると,本稿で考えるマイニン グ問題は以下のように述べることができる. [問題2] 与えられた文字列s[1..n],スコア関数w,sと同じ文 字を発生する情報源の確率モデルS0および実数P ∈ (0, 1)に対 し,sにおいて極小局所最適なオカレンスがσ(S0, n, s[h..j], P ) 回以上出現するsの部分文字列s[h..j]を列挙せよ. 本稿では,sと同じ文字を発生する情報源の確率モデルS0と して,sにおける各文字の出現割合をその文字の出現確率とす る無記憶情報源を考える.
4.
提 案 手 法
問題2において,パターン候補s[h..j]毎にσ(S0, n, s[h..j], P ) の値を正確に計算するのは難しいのでパターン長mには依存 するがパターンの出現文字には依存しない,σ(S0, n, p, P )の最 大値maxp[1..m]∈Σmσ(S0, n, p, P )の近似値σ(Sˆ 0, n, m, P )を用 いるものとする.以下の2ステップで問題2を近似的に解く. (1) パターン長m毎のσ(Sˆ 0, n, m, P )の値を計算する. (2) sにおいて極小局所最適なオカレンスがσ(Sˆ 0, n, m, P ) 回以上出現するsの部分文字列s[h..j]を列挙する. 4. 1 パターン長毎の最小サポートに使う値の計算 パターン長m毎の最小サポートに使う値σ(Sˆ 0, n, m, P )を 以下のように計算する. (1) スコア関数wとして以下のものを使う. w(x, y) = { +a (x = y : match) −b (x |= y : mismatch) (1) ただし,a, bはa < bを満たす自然数(正の整数)とする.こ のスコア関数におけるパターンp[1..m]の(極小)局所最適な オカレンスs[j..j + m− 1]は,任意の1 <= h <= mに対し, s[j..j + h− 1]がp[1..h]と,また,s[j + h− 1..j + m − 1]が p[h..m]と100× b/(a + b)%より多くの位置で一致しているこ とを保証する. (2) s[1..n]における各文字の出現割合をその文字の出現確 率とする無記憶情報源S0から発生した1文字xがパターンの ある位置の1文字yと一致する確率Pyは,yのS0における発 生確率に依存する.計算簡略化のためどの文字yに対しても一 致確率をPmax= maxy∈σPyで計算する.これを使うと,S0か ら発生した文字列tの任意の位置jからの部分列t[j..j + m− 1] が長さmのパターンの極小局所最適なオカレンスとなってい る確率の最大値PLOOMax(m)を計算できる.この計算法に関 しては次小節で詳しく説明する. (3) PLOOMax(m) を 利 用 し て σ(S0, n, p, P ) の 最 大 値 maxp[1..m]∈Σmσ(S0, n, p, P )の 近 似 値ˆσ(S0, n, m, P )を 計 算 す る .ま ず,S0 か ら 発 生 す る 長 さ n の 文 字 列 t に 対 し , j = 1, 2, . . . , n−m+1に対し部分列t[j..j + m−1]が長さmの パターンの極小局所最適なオカレンスとなる事象が独立であると 仮定すると出現回数Xは二項分布B(n− m + 1, PLOOMax(m)) に従う.mはnに比べて非常に小さい(m ≪ n)という仮 定の下にB(n− m + 1, PLOOMax(m))はB(n, PLOOMax(m)) で近似できる.更にnが大きいときにはB(n, PLOOMax(m)) は ポ ア ソ ン 分 布P o(nPLOOMax(m)) で 近 似 で き る .そ こ で X∼ P o(nPLOOMax(m))とし,ˆ σ(S0, n, m, P ) = min h∈N{h : P (X >= h | X > 0) <= P } で計算する. 図 1 最小サポートの計算 ˆ σ(S0, n, m, P )はPLOOMax(m))が小さいほど小さくなる.こ こで条件付き確率P (X >= h|X > 0)を考えたのは,パターン の候補をsの部分列に限っているため,sにおいてどの候補も 1回は出現するからである.実際のP (X >= h|X > 0)の値は P (X >= h|X > 0) =P (X >= h) P (X > 0) = e −λ 1− e−λ ∞ ∑ i=h λi i! = 1 1− e−λ ( 1− e−λ h−1 ∑ i=0 λi i! ) で 計 算 で き る .一 般 に ,パ タ ー ン 長 mが 長 く な る と 確 率 PLOOMax(m))が減少し,その結果σ(Sˆ 0, n, m, P )の値が小さ くなる.したがってσ(Sˆ 0, n, m, P ) >= 3となる最大のmまで ˆ σ(S0, n, m, P )を計算し,それより大きなmに関しては最小サ ポートを2に設定する. 4. 2 極小局所最適なオカレンスとなる確率の最大値の計算 S0から発生した文字列をtとする.文字列tの任意の位置j からの部分列t[j..j + m− 1]が長さmのパターンの極小局所 最適なオカレンスとなっている確率の最大値PLOOMax(m)を 計算する方法を示す.(1)で定義されるスコア関数wを用いる 場合,tの部分列t[j..j + m− 1]がパターンp[1..m]の極小局所 最適なオカレンスとなっているか否かは一致(t[j + h] = p[h]) する位置h∈ {1, . . . , m}のみで決まるので,t[j..j + m− 1]が p[1..m]の極小局所最適なオカレンスとなる場合の不一致位置 の集合の集合族をF(p)とすれば,t[j..j + m− 1]がパターン p[1..m]の極小局所最適なオカレンスとなる確率PLOO(S0, p) は PLOO(S0, p) = ∑ F∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F (1− Pp[h]) と書ける.このとき,以下の定理が成り立つ. [定理1] max p∈ΣmPLOO(S0, p) = m ∑ k=0 |{F ∈ F(p) | |F | = k}|Pm−k max (1− Pmax)k ただし,|{·}|は集合{·}の要素数を表すものとする. (証明)任意のp∈ Σmに対して ∑ F∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F (1− Pp[h]) < = ∑ F∈F(p) ∏ h̸∈F Pmax ∏ h∈F (1− Pmax) (2) が成り立つことを示す.Pp[1]= · · · = Pp[m] = Pmax の場合
(2)は等号で成立する.|{i : Pp[i]< Pmax}| = kを満たす任意
の文字列p[1..m]に関して不等式(2)が成立していると仮定す る.このとき,|{i : Pp[i]< Pmax}| = k + 1を満たす任意の文
字列をp[1..m]とする.Pp[i]< Pmaxを満たすi番目の文字を
Py = Pmaxを満たす文字yに置き換えた文字列をp′とする.
|{i : Pp′[i]< Pmax}| = kが成り立つので仮定より
∑ F∈F(p′) ∏ h̸∈F Pp′[h] ∏ h∈F (1− Pp′[h]) < = ∑ F∈F(p′) ∏ h̸∈F Pmax ∏ h∈F (1− Pmax) が成立する.よって ∑ F∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F (1− Pp[h]) < = ∑ F∈F(p′) ∏ h̸∈F Pp′[h] ∏ h∈F (1− Pp′[h]) (3) を証明すれば,pに関しても(2)が成り立つことが示せる.極 小局所最適なオカレンスの性質より,F∈ F(p)であればF に 含まれる任意の集合G(⊂=F )に関してG∈ F(p)が成り立つ. したがって ∑ F∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F (1− Pp[h]) = ∑ i∈F ∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F (1− Pp[h]) + ∑ i̸∈F ∈F(p),F ∪{i}∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F (1− Pp[h]) + ∑ i̸∈F ∈F(p),F ∪{i}̸∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F (1− Pp[h]) = ∑ i∈F ∈F(p) ∏ h̸∈F Pp[h] ∏ h∈F \{i} (1− Pp[h]) + ∑ i̸∈F ∈F(p),F ∪{i}̸∈F(p) Pp[i] ∏ h̸∈F ∪{i} Pp[h] ∏ h∈F (1− Pp[h]) < = ∑ i∈F ∈F(p′) ∏ h̸∈F Pp′[h] ∏ h∈F \{i} (1− Pp′[h]) + ∑ i̸∈F ∈F(p′),F∪{i}̸∈F(p′) Pp′[i] ∏ h̸∈F ∪{i} Pp′[h] ∏ h∈F (1− Pp′[h]) = ∑ i∈F ∈F(p′) ∏ h̸∈F Pp′[h] ∏ h∈F (1− Pp′[h]) + ∑ i̸∈F ∈F(p′),F∪{i}∈F(p′) ∏ h̸∈F Pp′[h] ∏ h∈F (1− Pp′[h]) + ∑ i̸∈F ∈F(p′),F∪{i}̸∈F(p′) ∏ h̸∈F Pp′[h] ∏ h∈F (1− Pp′[h]) = ∑ F∈F(p′) ∏ h̸∈F Pp′[h] ∏ h∈F (1− Pp′[h])
が成り立つ,つまり不等式(3)が示された.よって|{i : Pp[i]< Pmax}| = k + 1を満たす任意の文字列をp[1..m]に対して不 等式(2)が成り立つ.したがって数学的帰納法により任意の p∈ Σmに関して不等式(2)が成り立つことが示された. □ 定理1より PLOOMax(m) = m ∑ k=0 |{F ∈ F(p) | |F | = k}|Pmaxm−k(1−Pmax)k で計算できる.|{F ∈ F(p) | |F | = k}|の値の計算法を考える. |{F ∈ F(p) | |F | = k}|は,ある長さmの文字列t[1..m]が 文字列p[1..m]の極小局所最適なオカレンスになっている場合 の各位置iの文字t[i], p[i]の一致(C),不一致(M )のシーケ ンスパターンで不一致がちょうどk回になるものの数である. 不一致の位置の集合F∈ F(p)はそのようなシーケンスパター ンの1つの表現であるが,ここでは文字CとU の長さmの シーケンスでパターンを表現する.スコア関数(1)を使う場 合,一致・不一致のシーケンスパターンが同じで文字列t[1..m], t′[1..m]のpとの類似スコアは同じ(S(t, p) = S(t′, p))になる. 数直線上を時刻0に位置0におり,時刻i + 1に時刻iの位置 からw(p[i + 1], t[i + 1])だけ移動するウォークを考えると,時 刻iの位置は類似スコアS(p[1..i], t[1..i])と一致する.時刻iに おいては,t[i]がp[i]と一致していたら+a不一致であれば−b 移動する. 不一致の数がkのとき,最終的な類似スコアは(m−k)a−kb = ma− (a + b)kである.今,αh,i,kを現在の位置がi(<= h)のと き,残り(h− i)/a回の移動で,途中で(0, h− (a + b)k)の範 囲から出ずに(h−i)/a回目にh− (a + b)kに到達する一致・ 不一致のシーケンスパターンの数を表すものとする. このとき αma,0,k=|{F ∈ F(p) | |F | = k}| が成り立つ.αh,i,kに関して,以下の定理が成り立つ. [定理2] 以下の漸化式が成り立つ. αh,i,k= k = 0の場合 1 ((h− i)はaの倍数) 0 ((h− i)はaの非倍数) k >= 1の場合 αh,i+a,k (i <= b) αh,i+a,k+ αh−(a+b),i−b,k−1 (b + 1 <= i <= h − (a + b)k − a − 1) αh−(a+b),i−b,k−1 (i >= h − (a + b)k − a) (証明) k = 0の場合におけるαh,i,0= 1は定義より明らかで ある. k >= 1とする.i <= bのときは,次が不一致であると0以下 になってしまうためしなければ局所最適性を満たさない.よっ てαh,i,k= αh,i+a,kとなる.i = h−(a + b)k−aの場合は, 一致するとh−(a + b)kに到達してしまうため不一致しかあり 得ない. 求める場合の数は,次が不一致だと「位置i−bから 残り(h−(i + a))/a = (h− i)/a − 1回のランダムウォークで, 途中で(0, h−(a + b)k)の範囲から出ずに(h−(i + a))/a = (h− i)/a − 1回目にh−(a + b)kに到達する場合の数」と等し くなるが,これはαh−(a+b),i−b,k−1(「位置がi−bのとき,残り ((h−(a+b))−(i−b))/a = (h−i)/a−1回のランダムウォーク で,途中で(0, (h−(a+b))−(a+b)(k−1)) = (0, h−(a+b)k)
の範囲から出ずに((h−(a + b))−(i−b))/a = (h− i)/a − 1 回目に(h−(a + b))−(a + b)(k−1) = h− (a + b)kに到達 する場合の数」)に等しい.よってαh,i,k = αh−(a+b),i−b,k−1 が成り立つ. b + 1 <= i <= h − (a + b)k − a − 1の場合は,次が一致でも不 一致でも問題がないため,一致した場合の場合の数αh,i+a,kと 不一致である場合の数αh−(a+b),i−b,k−1の和となる.
よってαh,i,k= αh,i+a,k+ αh−(a+b),i−b,k−1が成り立つ. □
定理2の漸化式を用いて,以下のような動的計画法によりあ る範囲の1 <= m <= M, 0 <= k <= ma a+b に対してO(M 3)の計算量 でαma,0,kの値を求めることが可能である. Step 1 1 <= h <= M a,0 <= i <= hを満たす整数のペア(h, i)に 対しαh,i,0を定理2の漸化式を用いて設定する.k = 1とする. Step 2 (a + b)k + 1 <= h <= M a の各々のhに対し, i = h− (a + b)k − aを満たすiに対して定理2の漸化式を使って αh,i,k= αh−(a+b),i−b,k−1に設定する. Step 3 (a + b)k + 1 <= h <= M a の各々のhに対し, i = h− (a + b)k − a − 1, h − (a + b)k − a − 2, . . . , b + 1 の 各々のi に 対 し て 大 き い 方 か ら 定 理2 の 漸 化 式 を 使って
αh,i,k= αh,i+a,k+ αh−(a+b),i−b,k−1に設定する.
Step 4 (a + b)k + 1 <= h <= M a の各々のhに対し, i = b, b− 1, . . . , 0の各々のiに対して大きい方から定理2の漸化式 を使ってαh,i,k= αh,i+a,kに設定する. Step 5 k + 1 > M a a+bであれば停止.そうでなければk = k + 1 としてStep 2へとぶ. 4. 3 頻出近似パターンの列挙 与えられた文字列sにおいて,任意の長さm > 0に対し 極小局所最適なオカレンスがσ(Sˆ 0, n, m, P )回以上出現するs の部分文字列s[j..j + m− 1]を列挙する.O(n3)時間O(n2) 空間のアルゴリズムESFLOO-0G.C [7]を用いて列挙する.た だし,最小サポートは固定ではなくパターン長mに依存する ˆ σ(S0, n, m, P )を用いる.極小局所最適なオカレンスが頻出す るパターンは逆単調性をもたないが,CS1のみを満たす部分列 の数でカウントすると逆単調性をもつので,CS1を満たす部分 列の数が2以上ある場合は探索を打ち切らずより長いパターン のチェックを続けることにより,もれなくすべての頻出パター ンを列挙する.
5.
実
験
ヒトゲノムの21番染色体で本手法の有効性を検証する.以 下ではΣ ={A, C, G, T }とし,以下のスコア関数wを用いる ものとする.w(x, y) = { +1 (x = y : match) −4 (x |= y : mismatch) (4) このスコア関数において類似と判断される2つの文字列は 80%より多くの位置で文字が一致していることに注意されたい. まず,無記憶情報源から発生するシーケンスにおいて各位置 独立であるという仮定の影響について実験を行い,その後本手 法をヒトゲノムに適用した実験を行う. 5. 1 独立性の仮定の影響 提案手法では,無記憶情報源から発生するシーケンスのオカ レンスの発生が各位置で独立であるという仮定を行いさらに2 項分布をポアソン分布で近似してパターンのオカレンスの出現 頻度分布を推定するが,そのように推定した分布が実際の分布 とどのくらい異なるかを調べる. 無記憶情報源から発生する文字列の長さは10, 000, 000とす る.以下の2つの条件下で実験を行う. (1) 条件1各文字の出現確率が等確率(PA= PG= PC= PT= 0.25) (2) 条件2各文字の出現確率が21番染色体と同じ(PA= 0.29689322, PG = 0.20436933, PC = 0.20395605, PT = 0.29478140) 条件1の場合は,長さmの文字列の極小局所最適なオカレ ンスとなる確率はどの長さmの文字列に対しても同じである. そこで,4文字が等確率で発生する無記憶情報源から出力され た長さ10, 000, 000の文字列において,各位置からの長さmの 文字列(10, 000, 000− m + 1)個の各々をパターンとした場合 の,極小局所最適なオカレンスの出現回数を調べた.図2,図 3にそれぞれm = 7,m = 11の結果を示す.赤のプロットラ インは提案手法による近似値を表し,青のプロットラインは出 現割合(出現回数/(10, 000, 000− m + 1))を表す. 図 2 m=7における比較. 近似値は,実測値とほぼ一致していることがわかる. 条件2の場合は,PLOOMax(m)はAのみからなる文字列が パターンの場合の極小局所最適なオカレンスの出現確率である. そこで各文字の出現確率が条件2の無記憶情報から出力される 長さが10, 000, 000の文字列を10, 000本生成し,各文字列に おいて長さがmの連続するAをパターンとした場合の極小局 所最適なオカレンスの出現回数を調べた.図4,図5にそれぞ れm = 7,m = 11の場合の結果を示す.それぞれ赤のプロッ トラインは提案手法による近似値を表し,青のプロットライン 図 3 m=11における比較. 図 4 m=7における比較. 図 5 m=11における比較. は実測値を表す. 近似値と実測値との間に少し誤差がみられる.平均にはほと んど差がないが,実測値の方が分散が大きくなっている.これ は’A’の連続をパターンとした場合を考えているため,パター ンが連続して起こりやすくなっていることによるものと考えら れる.文字列長nに対してnPLOOMax(m)がある程度大きい場 合は中心極限定理より正規分布で近似できるため,論文[4]の ように正規分布で近似し,隣接文字列との共分散を考慮に入れ て計算した分散を用いて分布を近似することにより,より誤差 の少ない近似が可能になると考えられる. 5. 2 ヒトゲノムによる実験 ヒトゲノムの21番染色体に提案手法を適用し,リピートと して既にデータベースに登録されているものとの比較を行った. 21番染色体は約4500万塩基対からなっているが,不定を意味
する’N’が連続する領域を多く含むため,それらが繰り返し領 域として抽出されないように10回以上連続する’N’を取り除い てそこで切断して複数のシーケンスに分割し,各々のシーケン スのオカレンスカウントの合計を全体のオカレンスカウントと した. ’N’を取り除いた結果,長さの合計は約3510万塩基対に 減少した. 問題2において sを21番染色体の塩基配列とし,P = 100× 10−23に設定して,提案手法により頻出近似パターンを 列挙した. 局所最適なオカレンスに対する頻出近似マイニングは逆単 調性を満たさないことから,局所最適なオカレンスの数は,パ ターンが長くなっても増えることがあるが,左右どちらに長く しても局所最適なオカレンスの数が少ないものしか存在しない パターンを閉パターンと定義し,閉パターンのみ列挙した.左 右両方の伸張に関して同時にチェックしながら列挙は難しいた め,まずは右端を延ばしながら右伸張のチェックを行って列挙 し,列挙されたものに関して左伸張のチェックを別に行うこと により閉パターンのみに絞り込んだ.さらに,相補シーケンス も頻出パターンになっているものに関しては,頻度の多い方の み残して少ない方は削除した.その結果,4, 819, 759パターン が抽出された. 抽出されたパターンを用いて以下のように21番染色体の各 位置に情報を埋め込んだ.各位置において,そこから始まる抽 出されたパターンまたはその相補パターンのオカレンスで最長 なものでかつ,どのパターンの他のオカレンスにも包含されて いないオカレンスの,パターンIDとオカレンス長をその位置 の情報として埋め込んだ.その結果,全体の長さ約3510万の 位置のうち,2, 039, 898の位置から始まるオカレンスの情報が 埋め込まれ,それらのオカレンスに覆われている部分は全体の 60.001%であった. データベースに登録されている既知の散在反復配列として,
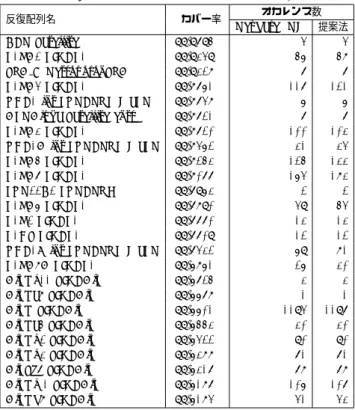
Genetic Information Research Instituteの反復配列データベー スであるRepbaseU pdate [5]に登録されている反復配列のオカ レンスをRepeat Masker (RM)を用いて抽出したものを用い た..反復配列のオカレンスにより覆われている部分は全体の 45.196%であった. 図6に詳細を示す. 図 6 提案手法のオカレンスと Repbase+RM のオカレンスの領域の 比較 21番染色体領域全体の内、提案手法のみにカバーされた領域 は27.2%,Repbaseに登録されているリピートのオカレンスで あるが提案手法によりカバーされなかった領域は12.4%, Rep-baseに登録されているリピートのオカレンス領域の内72.3%が 提案手法により検出できた. 以下図7に提案手法のみがカバーする領域に現れたパターン のサイズの分布を示す. 図 7 提案手法のみがカバーする領域に現れたパターンサイズの分布 また図8にRepbaseに反復配列として登録されている領域 で,かつ提案手法でカバーできなかった領域に現れたパターン のサイズ分布を示す. 図 8 既知の手法のみがカバーする領域に現れたパターンサイズの分布 図7より,提案手法のみがカバーした領域はパターン長の小 さいパターンが多くを占めている.一方図8より,Repbaseに 登録されている反復配列のオカレンスがカバーする領域は提案 手法のみがカバーした領域におけるパターンサイズと比べ大き なパターン長のパターンが多く検出された.これは,本稿にお いて文字列とパターン間におけるギャップを許していないこと から,パターン長が大きくなるにつれてオカレンスと判断され づらくなるためであると推測される. 次に提案手法が反復配列と判断した領域に関して考察を行う. 表1,表2に ”提案手法が反復配列と判断した領域 ”の詳細 を示す. 提案手法によって高いカバー率を得られた反復配列に関して, Repbase Updateに登録されている反復配列の出現回数と,提 案手法によるパターンの出現回数が非常に近い値になっている. これは断片的な短いパターンで網羅的にカバーしているのでは なく,データベースに登録されている反復配列のオカレンスと
表 1 領域ごとのカバー率(降順上位 25 種) 反復配列名 カバー率 オカレンス数 Repbase+RM 提案法 CER Satellite 99.9795% 4 4 L1PA2 LINEL1 99.9349% 56 58 SVA D RetroposonSVA 99.9328% 7 7 L1PA4 LINEL1 99.8761% 117 121
THE1 int LTRERVL MaLR 99.8748% 6 6 ALRAlpha Satellitecentr 99.8721% 7 7
L1PA3 LINEL1 99.8720% 100 103
THE1A int LTRERVL MaLR 99.8462% 31 34
L1PA5 LINEL1 99.8253% 125 133 L1PA7 LINEL1 99.8077% 164 183 LTR22C2 LTRERVK 99.7963% 2 2 L1PA6 LINEL1 99.7890% 49 54 L1P2 LINEL1 99.7770% 13 13 L1HS LINEL1 99.7709% 12 12
THE1B int LTRERVL MaLR 99.7432% 69 81
L1PA8A LINEL1 99.6861% 26 30 AluYk11 SINEAlu 99.6725% 3 3 AluYa8 SINEAlu 99.6678% 1 1 AluY SINEAlu 99.6601% 1194 1197 AluYa5 SINEAlu 99.6553% 30 30 AluYk2 SINEAlu 99.6422% 90 90 AluYk3 SINEAlu 99.6388% 71 71 AluSg7 SINEAlu 99.6317% 78 78 AluYm1 SINEAlu 99.6187% 106 107 AluYb8 SINEAlu 99.6184% 41 43 表 2 領域ごとのカバー率(降順下位 25 種) 反復配列名 カバー率 オカレンス数 Repbase+RM 提案法 SSU rRNA Hsa rRNA 21.6216% 2 13
LTR22A LTRERVK 21.5536% 2 17
HERVE int LTRERV1 21.2851% 1 8 MamRep488 DNAhAT Tip100 21.2329% 3 9 CR1 16 AMi LINECR1 21.0256% 1 4 MER91B DNAhAT Tip100 20.8672% 6 15
UCON28b Unknown 19.4915% 1 2
L1P3b LINEL1 19.4805% 2 3
UCON97 DNA 18.8679% 1 1
tRNA Arg AGA tRNA 18.4211% 1 2
X34 DNA DNA 18.3908% 2 5
MER68B LTRERVL 18.1992% 3 17
tRNA Met tRNA 18.1818% 1 1
UCON69 DNAhAT 17.5258% 1 2 U4 snRNA 15.4930% 1 2 Eulor6A DNA 14.2857% 1 3 MER133B DNA 13.7255% 1 1 CR1 13 AMi LINECR1 12.5786% 1 2 LTR103b Mam LTRERV1 11.3636% 1 1 Eutr2 DNA 9.3750% 1 1
tRNA Gly GGY tRNA 8.4906% 2 2
L1M3de LINEL1 0.0000% 1 0
tRNA Cys TGY tRNA 0.0000% 2 0
tRNA Lys AAG tRNA 0.0000% 1 0
ほぼ同じ領域を提案手法で見つけた反復配列のオカレンスと判 断できていることを意味している. 一方でカバー率が非常に低い反復配列領域も存在する.こ れは染色体全体でその反復配列の出現回数が非常に少ないか, もしくは1度しか出現しないような反復配列であることがカ バー率が低くなってしまった原因の1つであると考えられる. Repbase Updateに登録されている反復配列はヒトゲノム全体 における反復配列であり,他の染色体には複数回出現する反復 配列であっても21番染色体には少数,もしくは1度しか出現 しない反復配列も含まれている.そのため,反復配列領域を提 案手法では反復配列と判断できなかった可能性がある.
6.
ま と め
本稿では,極小局所最適なオカレンスとなる確率を動的計画 法を用いて効率的に計算し,その確率を用いてパターン長mに 依存する最小サポートσ(Sˆ 0, n, m, P )を設定することで,従来 の頻出パターンマイニングの問題点の改善を図った. 提案手法によって計算した最小サポートを,類似度をアライ ンメントスコアで測る従来法に適用することで,既知の反復配 列とされている領域の約72.306 %を,事前情報無しで,かつ 短い断片的なパターンで網羅的にカバーすることなく,正しく 反復配列領域であると判断した上で検出できた. 今後の課題として,文字列とパターンの間にギャップを考慮 することが挙げられる.本稿ではギャップを許していないため, 提案手法のみがカバーする領域においてパターン長の小さいパ ターンが多くを占める結果となった.ギャップを考慮した極小 局所最適なオカレンスとなる確率の最大値を導入することで, パターン長の小さいパターンのオカレンスに過敏に反応してし まうことの少ない最小サポートを設定できると考えられる.ま た,既知の反復配列領域で,かつ提案手法で反復配列として検 出できなかった領域に関して,検出できなかった理由の追求と, それらの領域に関する調査が必要である.謝
辞
本研究に関して大変有意義なコメントいただいた北海道大学 の有村博紀教授に感謝いたします.本研究の一部は,JSPS科 研費25280079の助成を受けたものです. 文 献[1] R. Agrawal and R. Srikant. Mining sequential patterns. In
Proceedings of the 11th international conference on Data Engineering (ICDE1995), pages 3–14, 1995.
[2] G. J. Faulkner et al. The regulated retrotransposon tran-scriptome of mammalian cells. Nature Genetics, 41:563– 571, 2009.
[3] M. Ghodsi, B. Liu, and M. Pop. Dnaclust: accurate and ef-ficient clustering of phylogenetic marker genes. BMC
Bioin-formatics, 12(1):1, 2011.
[4] Robert Gwadera, Mikhail J. Atallah, and Wojciech Sz-pankowski. Reliable detection of episodes in event se-quences. In Proceedings of the 3rd international conference
on Data Mining (ICDM2003), pages 67–74, 2003.
[5] J. Jurka, VV. Kapitonov, A. Pavlicek, P. Klonowski, O. Ko-hany, and J. Walichiewicz. Repbase update, a database of eu-karyotic repetitive elements. Cytogenet Genome Res., 110(1-4):462–467, 2005.
[6] C. Low-Kam, C. Raissi, M. Kaytoue, and J. Pei. Min-ing statistically significant sequential patterns. In
Proceed-ings of the 13th international conference on Data Mining (ICDM2013), pages 488–497, 2013.
[7] A. Nakamura, I. Takigawa, H. Tosaka, M. Kudo, and H. Mamitsuka. Mining approximate patterns with frequent locally optimal occurrences. Discrete Applied Mathematics, 200:123–152, 2016.
of frequent approximate sequential patterns. In
Proceed-ings of the 7th international conference on Data Mining (ICDM2007), pages 751–756, 2007.